
【目标检测算法】Faster Rcnn+Cascade Rcnn+Yolo+RetinaNet+Fcos+DETR
(部分可见 https://www.cnblogs.com/EstherLjy/p/9328996.html )
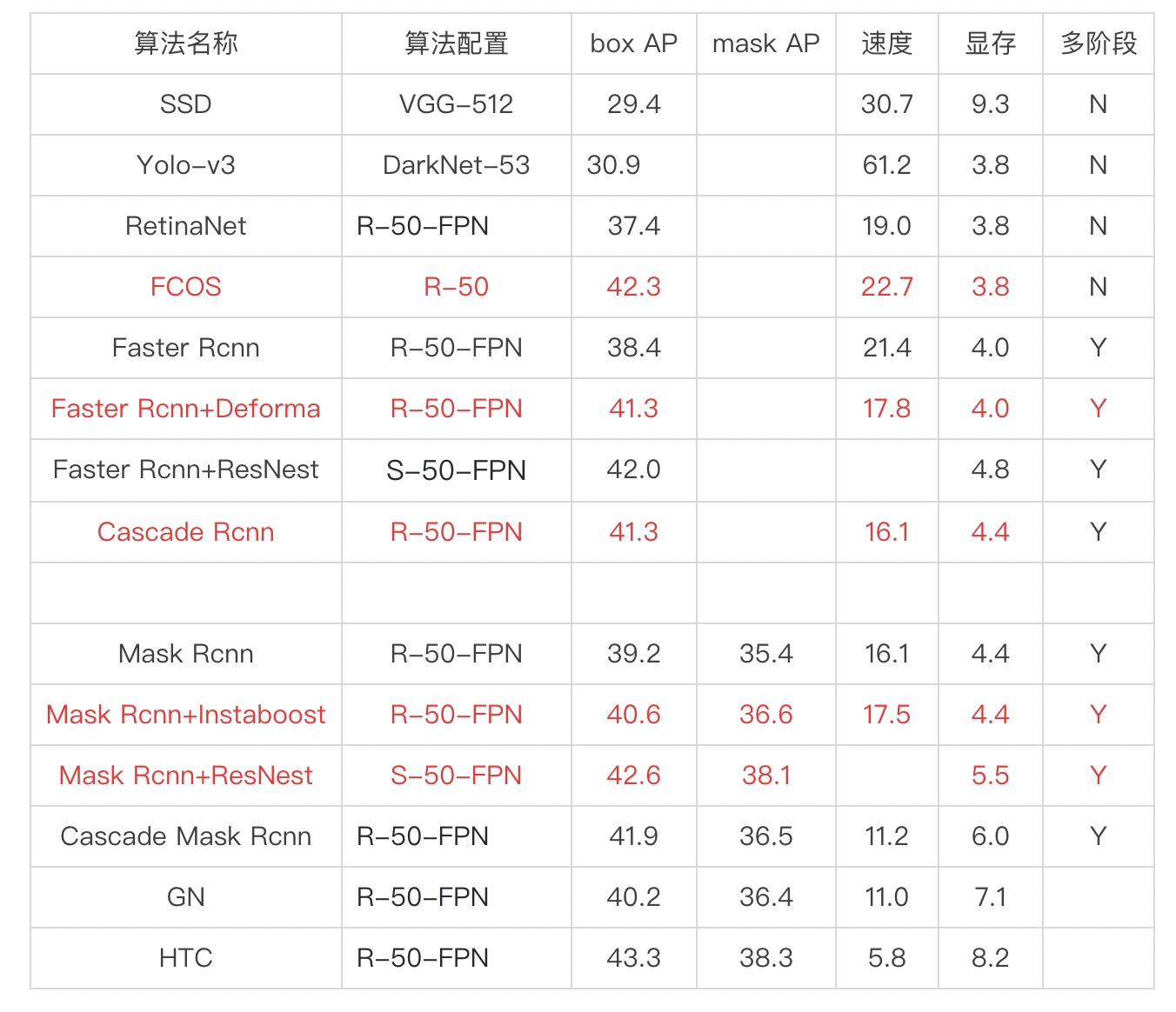
一、Faster Rcnn
1. 基本原理
1)用基础网络(VGG16)获得feature map;2)将feature map输入到RPN网络中,提取proposal,并将proposal映射到原feature上;3)将proposal的feature map用ROI pooling池化到固定长度;4)进行类别的分类和位置的回归。
2.网络结构

3.ROI-pooling
1)目的:由于有全连接层,需要将proposal对应的feature_map转成固定长度
2)方法:ROI-pooling,ROI-align
ROI-pooling:直接量化,整个流程中有两次量化,一次是proposal对应到fature map(直接向下取整),一次是ROI-pooling,分n*n的块不能完全且分(舍弃一部分)
ROI-align:对proposal对应的feature map(非整数)切成n*n,对每个cell双线性插值获得k(一般是4)个采样点,对采样点取最大值/平均值
4.RPN
输入公共feature map,做3*3的卷积得到H*W*256的feature map,在feature map的每个cell上(真实是原图上,一个点对应原图上一个框)赋予9=3(3种size)*3(3种比例,1:1,1:2,2:1)个anchor,每个anchor需要检测该cell是不是目标(9*2=18维),以及目标的更精确的位置(9*4=36维),整个feature map得到W/4*H/4*(18+36=54)大小的feature map,接着就可以按分数取正负样本。
二、Cascade Rcnn
1.基本原理
Faster Rcnn存在的问题:1)BBox精度不够高,原因为RPN提取的proposal>0.5认为是正样本,输入到网络中进行回归;2)0.5附近这部分正样本并不太正,回归起来较难,且这种正样本输入训练出的回归器,容易把更高IOU(比如0.8)的的proposal回归的不好;3)单纯提高阈值会导致正样本比例不够,容易过拟合
优化思路: 1)单次回归不足以产生准确的信息,需要多次迭代 2)使用分类器集合,针对不同IOU层次的box进行不同回归,使得每个阶段的proposal都能较好回归 3)前面分类器回归后的proposal(IOU从0.5到0.6)可以作为后面分类器的正样本,因此高层的正样本也是够的
很难让一个在指定IOU阈值界定的训练集上训练得到的检测模型对IOU跨度较大的proposal输入都达到最佳,因此采取cascade的方式能够让每一个stage的detector都专注于检测IOU在某一范围内的proposal,因为输出IOU普遍大于输入IOU,因此检测效果会越来越好。
三、YOLO系列
1.YOLO-V1
基本思想:1)将一幅图像分成SxS个网格(grid cell),如果某个object的中心 落在这个网格中,则这个网格就负责预测这个object。每个网络需要预测B个BBox的位置信息和confidence(置信度)信息,一个BBox对应着四个位置信息和一个confidence信息。confidence代表了所预测的box中含有object的置信度和这个box预测的有多准两重信息。

缺点:由于存在全连接层输入大小需要固定;一个网格最多检测一个物体;损失是绝对值;效果不好;
2.YOLO-V2
分类和检测联合训练(类似扩充数据集并移植);放9个先验框;去除全连接层;约束学习到的边框;passthrough层;图像多尺度训练;
3. YOLO-V3
darknet53;sofmax->多个二分类;FPN;
4. Yolo-v5
数据增强(随机缩放、随机裁剪、随机排布),自适应锚框计算,自适应图片缩放
四、Fcos
1.基本原理
2019年的模型。
避免anchor设置中的各种超参数,把分割运用到检测,anchor free,对图上每个位置进行回归和分类;负样本会很多,用与目标中心点的距离抑制错误。
基本流程:
1)将feature_map的每一个cell映射回原图上成一个框,如果这个映射框处在待检测目标的范围内(有交集)则这个cell为正样本,否则为负样本
2)模糊case(真实处在多个目标框)判为面积最小的边界框,
3)确定GT后,回归与原图框的相对位移,不同层回归不同大小的目标
4)分类回归的同时学习离目标中心的距离抑制错误
2.网络结构

3.与基于anchor的方法(下面称为anchor法)不同之处
1)Fcos对feature map对应的原图框进行回归,anchor法是对anchor进行回归;
2)Fcos的gt是 如果原图框与真实框有交集就是正样本,anchor法是anchor与真实边框的iou大于一定阈值时正样本;
3)Fcos训练C个二元分类器,anchor法回归一个多元分类器。
4)FCOS通过直接限定不同特征级别的边界框的回归范围来解决模糊case。
5)FCOS添加Center-ness分支,用于抑制低质量的预测边界框。
4.实践
Fcos比Faster召回高但带来大量噪声,实际可能不适用
五、RetinaNet
1.基本思想:
2018年何恺明的文章,Resnet+FPN+FCN+Focal_loss,重点在于Focal_loss,效果不如Faster Rcnn
2.网络结构

六、DETR
1.基本原理
detr是Facebook团队在2020年提出的基于Transformer的端到端的检测框架。
基本思想是去除NMS/anchor等人工先验,把目标检测作为一个集合预测问题来看待,用一个标准的transformer encoder-decoder结构生成预测集合,用二分图匹配(匈牙利算法)来配对预测和真值来构造集合损失,从而简化pipline实现端到端的目标检测。
大致过程是,先用backbone提取图像基础特征,然后转换维度变成N个序列,再加上位置encoding输入到transformer的encoder中,最后用过transformer的decoder生成预测。encoder是多头self-attention模块和FFN模块。decoder时输入的query是位置的encoder。
2.网络结构


3.其他
1)detr为什么可以不用先验?
transformer中的self-attention机制能够模型化图像上集合中元素间的交互关系,且能够捕获全部上下文间的关系,使得这个架构十分适合集合预测的特定约束(比如删除重复预测)。
2)detr为什么要二分图匹配?
输出目标中顺序的变化不应该带来损失的变化,因此需要二分图匹配。
4.参考资料
https://blog.csdn.net/baidu_36913330/article/details/120495817
https://blog.csdn.net/amusi1994/article/details/116113351
https://arxiv.org/pdf/2005.12872.pdf
