

MySQL基础
一、MySQL概述
1、什么是数据库 ?
答:数据的仓库,如:在ATM的示例中我们创建了一个 db 目录,称其为数据库
2、什么是 MySQL、Oracle、SQLite、Access、MS SQL Server等 ?
答:他们均是一个软件,都有两个主要的功能:
- a. 将数据保存到文件或内存
- b. 接收特定的命令,然后对文件进行相应的操作
3、什么是SQL ?
答:MySQL等软件可以接受命令,并做出相应的操作,由于命令中可以包含删除文件、获取文件内容等众多操作,对于编写的命令就是是SQL语句。
二、MySQL安装
MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,目前属于 Oracle 旗下公司。MySQL 最流行的关系型数据库管理系统,在 WEB 应用方面MySQL是最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件之一。
想要使用MySQL来存储并操作数据,则需要做几件事情:
a. 安装MySQL服务端
b. 安装MySQL客户端
b. 【客户端】连接【服务端】
c. 【客户端】发送命令给【服务端MySQL】服务的接受命令并执行相应操作(增删改查等)
下载 http://dev.mysql.com/downloads/mysql/ 安装 windows: http://jingyan.baidu.com/article/f3ad7d0ffc061a09c3345bf0.html linux: yum install mysql-server mac: 一直点下一步
客户端连接
连接: 1、mysql管理人默认为root,没有设置密码则直接登录 mysql -h host -u root -p 不用输入密码按回车自动进入 2、如果想设置mysql密码 mysqladmin -u root password 123456 3、如果你的root现在有密码了(123456),那么修改密码为abcdef的命令是: mysqladmin -u root -p password abcdef 退出: QUIT 或者 Control+D
三、数据库基础
分为两大部分:
1、数据库和表的创建;
2、数据库和表内容的操作
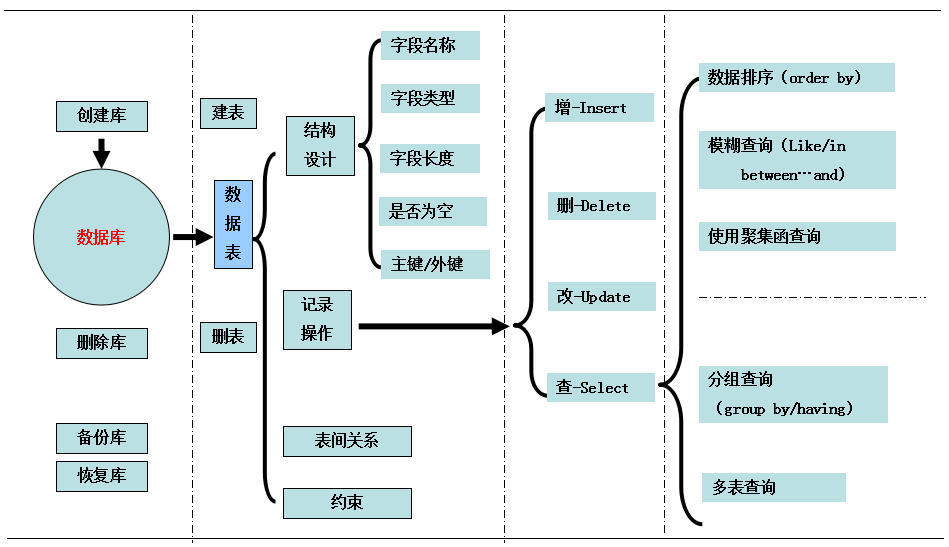
1、数据库和表的创建
(一)数据库的创建
1.1、显示数据库
SHOW DATABASES;
默认数据库:
mysql - 用户权限相关数据
test - 用于用户测试数据
information_schema - MySQL本身架构相关数据
1.2、创建数据库
# utf-8 CREATE DATABASE 数据库名称 DEFAULT CHARSET utf8 COLLATE utf8_general_ci; # gbk CREATE DATABASE 数据库名称 DEFAULT CHARACTER SET gbk COLLATE gbk_chinese_ci;
1.3、打开数据库
USE db_name; 注:每次使用数据库必须打开相应数据库
显示当前使用的数据库中所有表:SHOW TABLES;
1.4、用户管理
用户设置:
创建用户 create user '用户名'@'IP地址' identified by '密码'; 删除用户 drop user '用户名'@'IP地址'; 修改用户 rename user '用户名'@'IP地址'; to '新用户名'@'IP地址';; 修改密码 set password for '用户名'@'IP地址' = Password('新密码') PS:用户权限相关数据保存在mysql数据库的user表中,所以也可以直接对其进行操作(不建议)
用户权限设置:
show grants for '用户'@'IP地址' -- 查看权限 grant 权限 on 数据库.表 to '用户'@'IP地址' -- 授权 revoke 权限 on 数据库.表 from '用户'@'IP地址' -- 取消权限
all privileges 除grant外的所有权限 select 仅查权限 select,insert 查和插入权限 ... usage 无访问权限 alter 使用alter table alter routine 使用alter procedure和drop procedure create 使用create table create routine 使用create procedure create temporary tables 使用create temporary tables create user 使用create user、drop user、rename user和revoke all privileges create view 使用create view delete 使用delete drop 使用drop table execute 使用call和存储过程 file 使用select into outfile 和 load data infile grant option 使用grant 和 revoke index 使用index insert 使用insert lock tables 使用lock table process 使用show full processlist select 使用select show databases 使用show databases show view 使用show view update 使用update reload 使用flush shutdown 使用mysqladmin shutdown(关闭MySQL) super 使用change master、kill、logs、purge、master和set global。还允许mysqladmin调试登陆 replication client 服务器位置的访问 replication slave 由复制从属使用 对于权限设置
对于目标数据库以及内部其他: 数据库名.* 数据库中的所有 数据库名.表 指定数据库中的某张表 数据库名.存储过程 指定数据库中的存储过程 *.* 所有数据库
用户名@IP地址 用户只能在改IP下才能访问 用户名@192.168.1.% 用户只能在改IP段下才能访问(通配符%表示任意) 用户名@% 用户可以再任意IP下访问(默认IP地址为%)
grant all privileges on db1.tb1 TO '用户名'@'IP' grant select on db1.* TO '用户名'@'IP' grant select,insert on *.* TO '用户名'@'IP' revoke select on db1.tb1 from '用户名'@'IP' 实际例子
1.4、备份库和恢复库
备份库:
MySQL备份和还原,都是利用mysqldump、mysql和source命令来完成。
1.在Windows下MySQL的备份与还原
备份 1、开始菜单 | 运行 | cmd |利用“cd /Program Files/MySQL/MySQL Server 5.0/bin”命令进入bin文件夹 2、利用“mysqldump -u 用户名 -p databasename >exportfilename”导出数据库到文件,如mysqldump -u root -p voice>voice.sql,然后输入密码即可开始导出。 还原 1、进入MySQL Command Line Client,输入密码,进入到“mysql>”。 2、输入命令"show databases;",回车,看看有些什么数据库;建立你要还原的数据库,输入"create database voice;",回车。 3、切换到刚建立的数据库,输入"use voice;",回车;导入数据,输入"source voice.sql;",回车,开始导入,再次出现"mysql>"并且没有提示错误即还原成功。
2、在linux下MySQL的备份与还原
2.1 备份(利用命令mysqldump进行备份) [root@localhost mysql]# mysqldump -u root -p voice>voice.sql,输入密码即可。 2.2 还原 方法一: [root@localhost ~]# mysql -u root -p 回车,输入密码,进入MySQL的控制台"mysql>",同1.2还原。 方法二: [root@localhost mysql]# mysql -u root -p voice<voice.sql,输入密码即可。
3、更多备份及还原命令
备份: 1.备份全部数据库的数据和结构 mysqldump -uroot -p123456 -A >F:\all.sql 2.备份全部数据库的结构(加 -d 参数) mysqldump -uroot -p123456 -A -d>F:\all_struct.sql 3.备份全部数据库的数据(加 -t 参数) mysqldump -uroot -p123456 -A -t>F:\all_data.sql 4.备份单个数据库的数据和结构(,数据库名mydb) mysqldump -uroot -p123456 mydb>F:\mydb.sql 5.备份单个数据库的结构 mysqldump -uroot -p123456 mydb -d>F:\mydb.sql 6.备份单个数据库的数据 mysqldump -uroot -p123456 mydb -t>F:\mydb.sql 7.备份多个表的数据和结构(数据,结构的单独备份方法与上同) mysqldump -uroot -p123456 mydb t1 t2 >f:\multables.sql 8.一次备份多个数据库 mysqldump -uroot -p123456 --databases db1 db2 >f:\muldbs.sql 还原: 还原部分分(1)mysql命令行source方法 和 (2)系统命令行方法 1.还原全部数据库: (1) mysql命令行:mysql>source f:\all.sql (2) 系统命令行: mysql -uroot -p123456 <f:\all.sql 2.还原单个数据库(需指定数据库) (1) mysql>use mydb mysql>source f:\mydb.sql (2) mysql -uroot -p123456 mydb <f:\mydb.sql 3.还原单个数据库的多个表(需指定数据库) (1) mysql>use mydb mysql>source f:\multables.sql (2) mysql -uroot -p123456 mydb <f:\multables.sql 4.还原多个数据库,(一个备份文件里有多个数据库的备份,此时不需要指定数据库) (1) mysql命令行:mysql>source f:\muldbs.sql (2) 系统命令行: mysql -uroot -p123456 <f:\muldbs.sql 更多备份
更多备份知识:
http://www.jb51.net/article/41570.htm
(二)数据表的创建
1.1、显示数据表
show tables;
1.2、创建数据表
create table 表名( 列名 类型 是否可以为空, 列名 类型 是否可以为空 )ENGINE=InnoDB DEFAULT CHARSET=utf8
是否可空,null表示空,非字符串 not null - 不可空 null - 可空
默认值,创建列时可以指定默认值,当插入数据时如果未主动设置,则自动添加默认值 create table tb1( nid int not null defalut 2, num int not null )
自增,如果为某列设置自增列,插入数据时无需设置此列,默认将自增(表中只能有一个自增列) create table tb1( nid int not null auto_increment primary key, num int null ) 或 create table tb1( nid int not null auto_increment, num int null, index(nid) ) 注意:1、对于自增列,必须是索引(含主键)。 2、对于自增可以设置步长和起始值 show session variables like 'auto_inc%'; set session auto_increment_increment=2; set session auto_increment_offset=10; shwo global variables like 'auto_inc%'; set global auto_increment_increment=2; set global auto_increment_offset=10; 设置自增
主键,一种特殊的唯一索引,不允许有空值,如果主键使用单个列,则它的值必须唯一,如果是多列,则其组合必须唯一。 create table tb1( nid int not null auto_increment primary key, num int null ) 或 create table tb1( nid int not null, num int not null, primary key(nid,num) ) 设置主键
外键,一个特殊的索引,只能是指定内容 creat table color( nid int not null primary key, name char(16) not null ) create table fruit( nid int not null primary key, smt char(32) null , color_id int not null, constraint fk_cc foreign key (color_id) references color(nid) ) 设置外键
主键与外键关系(非常重要)
http://www.cnblogs.com/programmer-tlh/p/5782451.html
1.3删除表
drop table 表名
1.4、清空表
delete from 表名 truncate table 表名
1.5、基本数据类型
MySQL的数据类型大致分为:数值、时间和字符串
bit[(M)] 二进制位(101001),m表示二进制位的长度(1-64),默认m=1 tinyint[(m)] [unsigned] [zerofill] 小整数,数据类型用于保存一些范围的整数数值范围: 有符号: -128 ~ 127. 无符号: ~ 255 特别的: MySQL中无布尔值,使用tinyint(1)构造。 int[(m)][unsigned][zerofill] 整数,数据类型用于保存一些范围的整数数值范围: 有符号: -2147483648 ~ 2147483647 无符号: ~ 4294967295 特别的:整数类型中的m仅用于显示,对存储范围无限制。例如: int(5),当插入数据2时,select 时数据显示为: 00002 bigint[(m)][unsigned][zerofill] 大整数,数据类型用于保存一些范围的整数数值范围: 有符号: -9223372036854775808 ~ 9223372036854775807 无符号: ~ 18446744073709551615 decimal[(m[,d])] [unsigned] [zerofill] 准确的小数值,m是数字总个数(负号不算),d是小数点后个数。 m最大值为65,d最大值为30。 特别的:对于精确数值计算时需要用此类型 decaimal能够存储精确值的原因在于其内部按照字符串存储。 FLOAT[(M,D)] [UNSIGNED] [ZEROFILL] 单精度浮点数(非准确小数值),m是数字总个数,d是小数点后个数。 无符号: -3.402823466E+38 to -1.175494351E-38, 1.175494351E-38 to 3.402823466E+38 有符号: 1.175494351E-38 to 3.402823466E+38 **** 数值越大,越不准确 **** DOUBLE[(M,D)] [UNSIGNED] [ZEROFILL] 双精度浮点数(非准确小数值),m是数字总个数,d是小数点后个数。 无符号: -1.7976931348623157E+308 to -2.2250738585072014E-308 2.2250738585072014E-308 to 1.7976931348623157E+308 有符号: 2.2250738585072014E-308 to 1.7976931348623157E+308 **** 数值越大,越不准确 **** char (m) char数据类型用于表示固定长度的字符串,可以包含最多达255个字符。其中m代表字符串的长度。 PS: 即使数据小于m长度,也会占用m长度 varchar(m) varchars数据类型用于变长的字符串,可以包含最多达255个字符。其中m代表该数据类型所允许保存的字符串的最大长度,只要长度小于该最大值的字符串都可以被保存在该数据类型中。 注:虽然varchar使用起来较为灵活,但是从整个系统的性能角度来说,char数据类型的处理速度更快,有时甚至可以超出varchar处理速度的50%。因此,用户在设计数据库时应当综合考虑各方面的因素,以求达到最佳的平衡 text text数据类型用于保存变长的大字符串,可以组多到65535 (2**16 − 1)个字符。 mediumtext A TEXT column with a maximum length of 16,777,215 (2**24 − 1) characters. longtext A TEXT column with a maximum length of 4,294,967,295 or 4GB (2**32 − 1) characters. enum 枚举类型, An ENUM column can have a maximum of 65,535 distinct elements. (The practical limit is less than 3000.) 示例: CREATE TABLE shirts ( name VARCHAR(40), size ENUM('x-small', 'small', 'medium', 'large', 'x-large') ); INSERT INTO shirts (name, size) VALUES ('dress shirt','large'), ('t-shirt','medium'),('polo shirt','small'); set 集合类型 A SET column can have a maximum of 64 distinct members. 示例: CREATE TABLE myset (col SET('a', 'b', 'c', 'd')); INSERT INTO myset (col) VALUES ('a,d'), ('d,a'), ('a,d,a'), ('a,d,d'), ('d,a,d'); DATE YYYY-MM-DD(1000-01-01/9999-12-31) TIME HH:MM:SS('-838:59:59'/'838:59:59') YEAR YYYY(1901/2155) DATETIME YYYY-MM-DD HH:MM:SS(1000-01-01 00:00:00/9999-12-31 23:59:59 Y) TIMESTAMP YYYYMMDD HHMMSS(1970-01-01 00:00:00/2037 年某时)
1.6、修改表(alter)
添加列:alter table 表名 add 列名 类型 删除列:alter table 表名 drop column 列名 修改列: alter table 表名 modify column 列名 类型; -- 类型 alter table 表名 change 原列名 新列名 类型; -- 列名,类型 添加主键: alter table 表名 add primary key(列名); 删除主键: alter table 表名 drop primary key; alter table 表名 modify 列名 int, drop primary key; 添加外键:alter table 从表 add constraint 外键名称(形如:FK_从表_主表) foreign key 从表(外键字段) references 主表(主键字段); 删除外键:alter table 表名 drop foreign key 外键名称 修改默认值:ALTER TABLE testalter_tbl ALTER i SET DEFAULT 1000; 删除默认值:ALTER TABLE testalter_tbl ALTER i DROP DEFAULT; 修改表
更多参考:
- http://www.runoob.com/mysql/mysql-data-types.html
1.7、数据表关系
关联映射:一对多/多对一
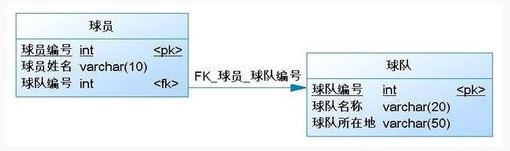
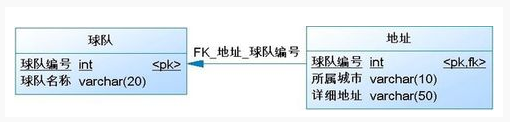

约束是一种限制,它通过对表的行或列的数据做出限制,来确保表的数据的完整性、唯一性。
MYSQL中,常用的几种约束:

===================================================
主键(PRIMARY KEY)是用于约束表中的一行,作为这一行的标识符,在一张表中通过主键就能准确定位到一行,因此主键十分重要。主键要求这一行的数据不能有重复且不能为空。
还有一种特殊的主键——复合主键。主键不仅可以是表中的一列,也可以由表中的两列或多列来共同标识
===================================================
默认值约束(DEFAULT)规定,当有DEFAULT约束的列,插入数据为空时该怎么办。
DEFAULT约束只会在使用INSERT语句(上一实验介绍过)时体现出来,INSERT语句中,如果被DEFAULT约束的位置没有值,那么这个位置将会被DEFAULT的值填充
===================================================
唯一约束(UNIQUE)比较简单,它规定一张表中指定的一列的值必须不能有重复值,即这一列每个值都是唯一的。
当INSERT语句新插入的数据和已有数据重复的时候,如果有UNIQUE约束,则INSERT失败.
===================================================
外键(FOREIGN KEY)既能确保数据完整性,也能表现表之间的关系。
一个表可以有多个外键,每个外键必须REFERENCES(参考)另一个表的主键,被外键约束的列,取值必须在它参考的列中有对应值。
在INSERT时,如果被外键约束的值没有在参考列中有对应,比如以下命令,参考列(department表的dpt_name)中没有dpt3,则INSERT失败
===================================================
非空约束(NOT NULL),听名字就能理解,被非空约束的列,在插入值时必须非空。
在MySQL中违反非空约束,不会报错,只会有警告.
CREATE DATABASE mysql_shiyan; use mysql_text; CREATE TABLE department ( dpt_name CHAR(20) NOT NULL, people_num INT(10) DEFAULT '10', CONSTRAINT dpt_pk PRIMARY KEY (dpt_name) ); CREATE TABLE employee ( id INT(10) PRIMARY KEY, name CHAR(20), age INT(10), salary INT(10) NOT NULL, phone INT(12) NOT NULL, in_dpt CHAR(20) NOT NULL, UNIQUE (phone), CONSTRAINT emp_fk FOREIGN KEY (in_dpt) REFERENCES department(dpt_name) ); CREATE TABLE project ( proj_num INT(10) NOT NULL, proj_name CHAR(20) NOT NULL, start_date DATE NOT NULL, end_date DATE DEFAULT '2015-04-01', of_dpt CHAR(20) REFERENCES department(dpt_name), CONSTRAINT proj_pk PRIMARY KEY (proj_num,proj_name) ); 例子
2、数据库和表内容的操作(增、删、改、查)
2.1、增
insert into 表 (列名,列名...) values (值,值,值...) insert into 表 (列名,列名...) values (值,值,值...),(值,值,值...) insert into 表 (列名,列名...) select (列名,列名...) from 表
2.2、删
delete from 表 delete from 表 where id=1 and name='aaron'
2.3、改
update 表 set name = 'aaron' where id>1
2.4.1、普通查询
select * from 表 select * from 表 where id > 1 select nid,name,gender as gg from 表 where id > 1
a、条件 select * from 表 where id > 1 and name != 'alex' and num = 12; select * from 表 where id between 5 and 16; select * from 表 where id in (11,22,33) select * from 表 where id not in (11,22,33) select * from 表 where id in (select nid from 表) b、限制 select * from 表 limit 5; - 前5行 select * from 表 limit 4,5; - 从第4行开始的5行 select * from 表 limit 5 offset 4 - 从第4行开始的5行 更多选项查询
2.4.2、数据排序(查询)
排序 select * from 表 order by 列 asc - 根据 “列” 从小到大排列 select * from 表 order by 列 desc - 根据 “列” 从大到小排列 select * from 表 order by 列1 desc,列2 asc - 根据 “列1” 从大到小排列,如果相同则按列2从小到大排序
2.4.3、模糊查询
通配符(模糊查询) select * from 表 where name like 'ale%' - ale开头的所有(多个字符串) select * from 表 where name like 'ale_' - ale开头的所有(一个字符)
2.4.4、聚集函数查询
1)COUNT 语法:COUNT(e1) 参数:e1为一个表达式,可以是任意的数据类型 返回:返回数值型数据 作用:返回e1指定列不为空的记录总数 2)SUM, 语法:SUM(e1) 参数:e1为类型为数值型的表达式 返回:返回数值型数据 作用:对e1指定的列进行求和计算 3)MIN, MAX 语法:MIN(e1)、MAX(e1) 参数:e1为一个字符型、日期型或数值类型的表达式。 若e1为字符型,则根据ASCII码来判断最大值与最小值。 返回:根据e1参数的类型,返回对应类型的数据。 作用:MIN(e1)返回e1表达式指定的列中最小值; MAX(e1)返回e1表达式指定的列中最大值; 4)AVG 语法:AVG(e1) 参数:e1为一个数值类型的表达式 返回:返回一个数值类型数据 作用:对e1表达式指定的列,求平均值。 5)MEDIAN 语法:MEDIAN(e1) 参数:e1为一个数值或日期类型的表达式 返回:返回一个数值或日期类型的数据 作用:首先,根据e1表达式指定的列,对值进行排序; 若排序后,总记录为奇数,则返回排序队列中,位于中间的值; 若排序后,总记录为偶数,则对位于排序队列中,中间两个值进行求平均,返回这个平均值; 6)RANK 1)用法1:RANK OVER 语法: RANK( ) OVER ([ PARTITION BY column1 ] ORDER BY column2 [ASC|DESC]) 为分析函数,为每条记录产生一个序列号,并返回。 参数: column1为列名,指定按照哪一列进行分类(分组) column2为列名,指定根据哪列排序,默认为升序; 若指定了分类子句(PARTITION BY),则对每类进行排序(每个分类单独排序) 返回:返回一个数值类型数据,作为该记录的序号! 作用:为分析函数,对记录先按column1分类,再对每个分类进行排序,并为每条记录分配一个序号(每个分类单独排序) 注意:排序字段值相同的记录,分配相同的序号。存在序号不连续的情况 实例:student表记录了学生每科的成绩,要求按学科排序,并获取每科分数前两名的记录 student表如下: SQL> select * from student order by kemu; NAME ID KEMU FENSHU ---------- -------------- -------------- ---------------- Li 0113101 物理 80 Luo 0113011 物理 80 Wang 0113077 物理 70 Zhang 0113098 物理 90 Luo 0113011 高数 80 Wang 0113077 高数 70 Zhang 0113098 高数 80 Li 0113101 高数 90 rows selected 按学科分类,按成绩排序(降序) SQL> select rank() over(partition by KEMU order by FENSHU desc) as sort,student.* from student; SORT NAME ID KEMU FENSHU ---------- ---------- ---------------- ------------ ---------- Zhang 0113098 物理 90 Li 0113101 物理 80 Luo 0113011 物理 80 Wang 0113077 物理 70 Li 0113101 高数 90 Luo 0113011 高数 80 Zhang 0113098 高数 80 Wang 0113077 高数 70 由返回记录可了解,对排序列的值相同的记录,rank为其分配了相同的序号(SORT NAME列)。 并且之后的记录的序号是不连续的。 若获取每科前两名,只需对排序后的结果增加二次查询即可 select * from (select rank() over(partition by KEMU order by FENSHU desc) as sort_id,student.* from student) st where st.sort_id<=2; 2)用法2:RANK WITHIN GROUP 语法: RANK( expr1 ) WITHIN GROUP ( ORDER BY expr2 ) 为聚合函数,返回一个值。 参数:expr1为1个或多个常量表达式; expr2为如下格式的表达式: expr2的格式为'expr3 [ DESC | ASC ] [ NULLS { FIRST | LAST } ]' 其中,expr1需要与expr2相匹配, 即:expr1的常量表达式的类型、数量必须与ORDER BY子句后的expr2表达式的类型、数量相同 实际是expr1需要与expr3相匹配 如:RANK(a) WITHIN GROUP (ORDER BY b ASC NULLS FIRST); 其中,a为常量,b需要是与相同类型的表达式 RANK(a,b) WITHIN GROUP (ORDER BY c DESC NULLS LAST, d DESC NULLS LAST); 其中,a与b都为常量;c是与a类型相同的表达式、d是与b类型相同的表达式; 返回:返回数值型数据,该值为假定记录在表中的序号。 作用:确定一条假定的记录,在表中排序后的序号。 如:假定一条记录(假设为r1)的expr2指定字段值为常量expr1,则将r1插入表中后, 与原表中的记录,按照ORDER BY expr2排序后,该记录r1在表中的序号为多少,返回该序号。 注释: NULLS FIRST指定,将ORDER BY指定的排序字段为空值的记录放在前边; NULLS LAST指定,将ORDER BY指定的排序字段为空值的记录放在后边; 实例:假设一个员工的薪水为1500,求该员工的薪水在员工表中的排名为多少? 已知员工表如下: SQL> select * from employees; EMP_ID EMP_NAME SALARY ---------- -------------------- --------------- ZhangSan 500 LiSi 1000 WangWu 1500 MaLiu 2000 NiuQi 2500 SQL> select rank(1500) within group (order by salary) as "rank number" from employees; rank number ----------- 由结果可知,薪水为1500的员工,在表中按升序排序,序号为3 7)FIRST、LAST 语法: agg_function(e1) KEEP (DENSE_RANK FIRST ORDER BY e2 [NULLS {FIRST|LAST}]) [OVER PARTITION BY e3 ] agg_function(e1) KEEP (DENSE_RANK LAST ORDER BY e2 [NULLS {FIRST|LAST}]) [OVER PARTITION BY e3 ] 参数: agg_function为一个聚合函数,可以为 MIN、MAX、SUM、AVG、COUNT、VARIANCE或STDDEV e2指定以哪个字段为依据,进行排序; e3指定以哪个字段为依据,进行分类(分组); 当指定OVER PARTITION BY子句后,针对分类后的每个类单独排序; DENSE_RANK为排序后的记录分配序号,并且序号为连续的。 NULLS {FIRST|LAST}指定排序字段e1的值若为空,则拍在序列前边(NULLS FIRST)或者后边(NULLS LAST) DENSE_RANK后的FIRST/LAST确定选取通过DENSE_RANK排好序后的序列中,序号最小/最大的记录。序号相同时,返回多条记录 当序号相同,返回多条记录时,agg_function(e1)聚合函数继续对这多条记录的e1字段做聚合操作。 作用: 如果agg_function为min(e1),获取排序后的FIRST或LAST的多条记录中,某字段e1的最小值 该字段不是排序关键字段e2 实例: 已知员工表有薪水字段,奖金字段。要求获取薪水最低的员工中,奖金最高的员工的记录。 已知表内容如下: SQL> select * from employees order by salary; EMP_ID EMP_NAME SALARY COMMISSION ---------- ---------------------------- ------------ ------------ ZhangSan 500 200 LiSi 500 300 WangWu 500 100 MaLiu 2000 500 NiuQi 2500 200 ShangDuo 2500 300 BaiQi 2500 400 SQL> select max(commission) keep(dense_rank first order by salary asc) as commission from employees; COMMISSION ---------- 首先,按salary排序后,获取薪水最低的记录,分别为员工10001、10002、10003三条记录。 聚合函数max(commission)对3条记录获取奖金最高的为员工10002,奖金为300。 聚集函数
2.4.5、分组查询
分组 select num from 表 group by num select num,nid from 表 group by num,nid select num,nid from 表 where nid > 10 group by num,nid order nid desc select num,nid,count(*),sum(score),max(score),min(score) from 表 group by num,nid select num from 表 group by num having max(id) > 10 特别的:group by 必须在where之后,order by之前
2.4.6多表查询
a、连表 无对应关系则不显示 select A.num, A.name, B.name from A,B Where A.nid = B.nid 无对应关系则不显示 select A.num, A.name, B.name from A inner join B on A.nid = B.nid A表所有显示,如果B中无对应关系,则值为null select A.num, A.name, B.name from A left join B on A.nid = B.nid B表所有显示,如果B中无对应关系,则值为null select A.num, A.name, B.name from A right join B on A.nid = B.nid b、组合 组合,自动处理重合 select nickname from A union select name from B 组合,不处理重合 select nickname from A union all select name from B

 浙公网安备 33010602011771号
浙公网安备 33010602011771号