第一次个人编程作业
https://github.com/Es-war/work1
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 15 | 10 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 600 | 540 |
| · Design Spec | · 生成设计文档 | 40 | 30 |
| · Design Review | · 设计复审 | 60 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 10 |
| · Design | · 具体设计 | 300 | 600 |
| · Coding | · 具体编码 | 700 | 600 |
| · Code Review | · 代码复审 | 60 | 40 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 280 | 120 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 30 | 10 |
| · Size Measurement | · 计算工作量 | 15 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| · 合计 | 2160 | 2020 |
二、计算模块接口
(3.1)计算模块接口的设计与实现过程。设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?说明你的算法的关键(不必列出源代码),以及独到之处。(18')
设计思路:
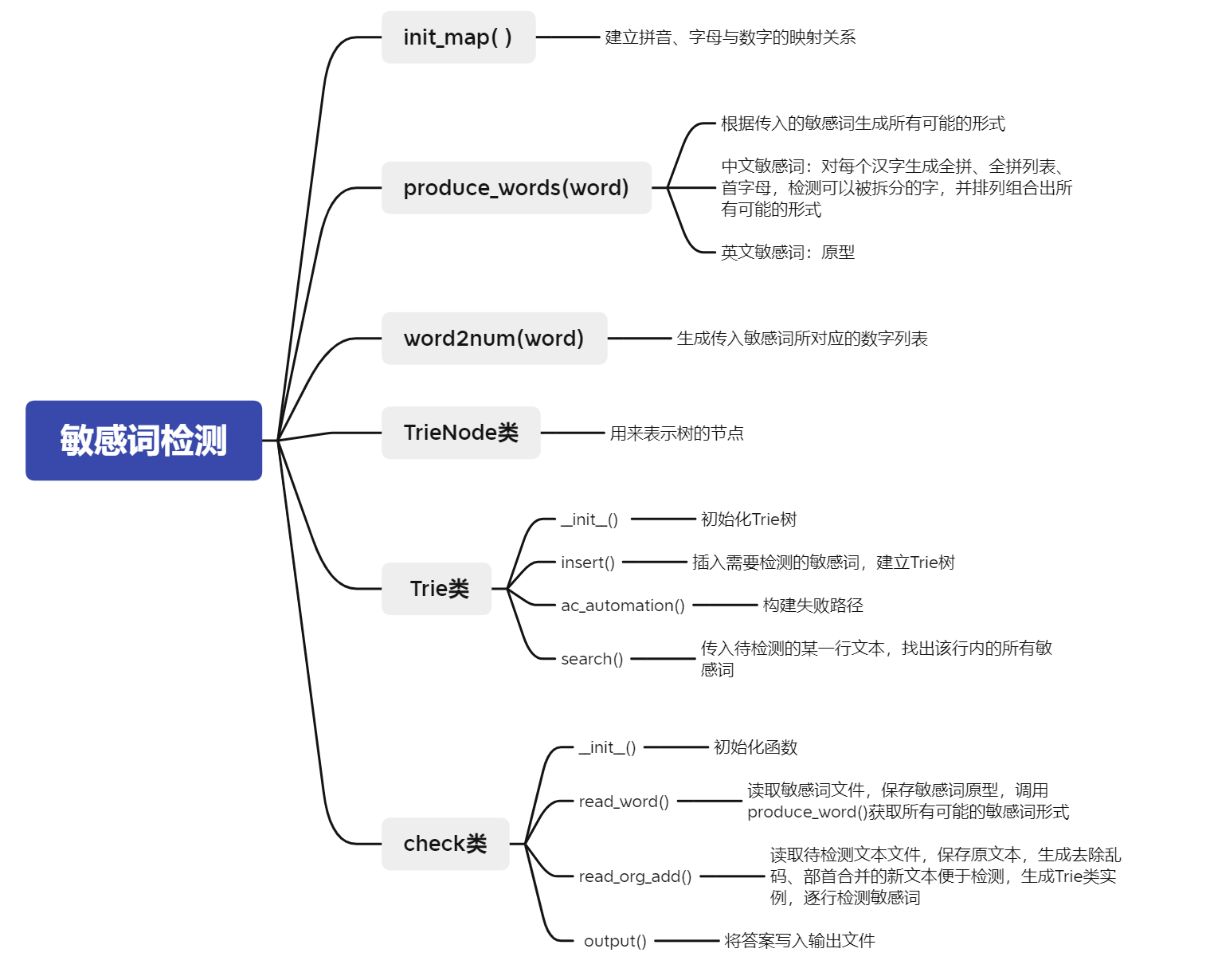
流程图:

本次作业的难点在于如何得到敏感词的各种变形,并准确找出文本中所有的敏感词。
-
先考虑对敏感词的处理,处理思路如下:
- 中文敏感词
- 每个字存在谐音替代、拼音替代、拼音首字母替代、繁体字、左右拆分的情况,可以逐字处理,谐音、繁体本质是都是同个拼音,对于左右结构可拆分的汉字,将拆分结果与原汉字形成映射关系,便于之后在待检测文本中进行处理。罗列每个字的所有可能情况(左右拆分在待检测文本中体现,这里不做组合),进而对敏感词进行组合,得到所有可能的敏感词。
- 例如,"算法":
['suan', 'fa']
['s', 'u', 'a', 'n', 'fa']
['s', 'fa']
['suan', 'f', 'a']
['s', 'u', 'a', 'n', 'f', 'a']
['s', 'f', 'a']
['suan', 'f']
['s', 'u', 'a', 'n', 'f']
['s', 'f']
- 例如,"算法":
- 将拼音、字母与数字进行映射,保证数字的唯一性
- 上例中得到的结果被映射为如下形式
[411, 17]
[428, 430, 1, 424, 17]
[428, 17]
[411, 416, 1]
[428, 430, 1, 424, 416, 1]
[428, 416, 1]
[411, 416]
[428, 430, 1, 424, 416]
[428, 416]
- 上例中得到的结果被映射为如下形式
- 每个字存在谐音替代、拼音替代、拼音首字母替代、繁体字、左右拆分的情况,可以逐字处理,谐音、繁体本质是都是同个拼音,对于左右结构可拆分的汉字,将拆分结果与原汉字形成映射关系,便于之后在待检测文本中进行处理。罗列每个字的所有可能情况(左右拆分在待检测文本中体现,这里不做组合),进而对敏感词进行组合,得到所有可能的敏感词。
- 英文敏感词
- 只需要考虑大小写问题,统一转化为小写进行处理。
- 由于之后的答案中需要输出原串,所有在对待检测文本进行处理之前,首先保存一份原文本,然后对待检测文本中的乱码(除汉字、字母以外的所有符号),统一转化为字符 '#',另存起来用于检测时使用,处理时忽略 '#'。
- 中文敏感词
-
再考虑用AC自动机实现对所有可能串的查找,AC自动机的原理网上已有专业介绍,这里不多赘述。主要阐述将AC自动机应用于此次编程中所需注意之处。
- 首先,由于输出中需要输出原串,所以返回值中需要有可以定位原串的数据、该敏感词对应的原敏感词数据。
- 其次,考虑最长匹配问题,因为中文敏感词在变形的过程中存在最后一个字为首字母的情况。
- 例如,此次检测的敏感词为“算法”,文本中出现了 "saunfa",若使用传统的AC自动机,那么会得到两个答案—— "suanf","suanfa",在算法匹配这块做一些改动,取最长匹配串,也就是说将 "suanfa" 保存为答案,舍弃 "suanf"。
- 最后,考虑左右拆分情况,遍历文本找出所有可能是敏感词左右拆分后的汉字进行合并,注意,这里不合并可以组合成汉字但未出现在敏感词中的汉字。对于拆分的情况,由于进行了合并操作,假设现在在修改后的文本中匹配到了 "法" 字,需要判断其原文本的同一位置是否为 "法",若不是,则将该位置的下一个位置作为该匹配串的结束位置返回。
- 例如,敏感词为“算法”、“你好”,文本为"算氵去你女生",则只需合并 '氵'、'去' 为 '法',将 '氵' 改为 '法','去' 改为 '#' ,不合并 '女'、'生'。
运行结果:
词云图:

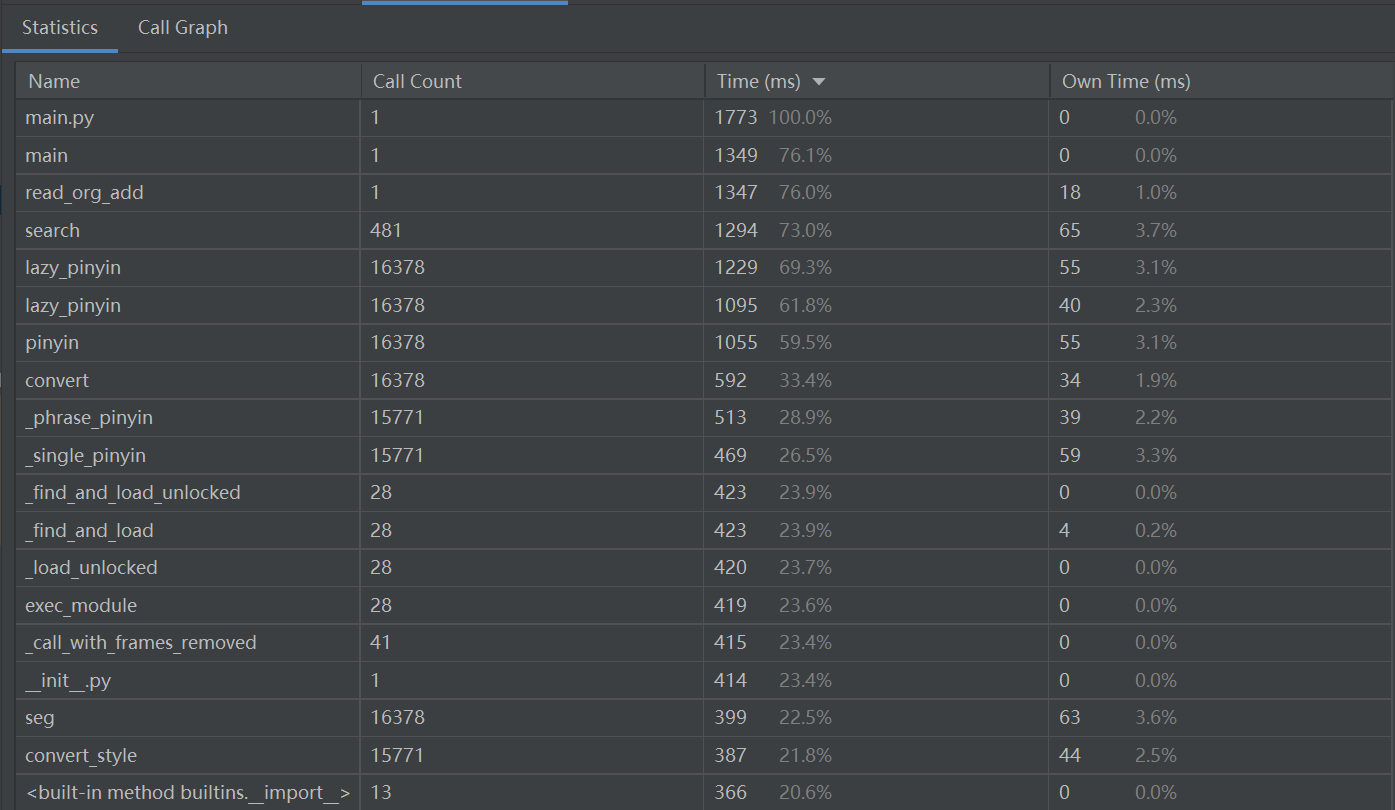
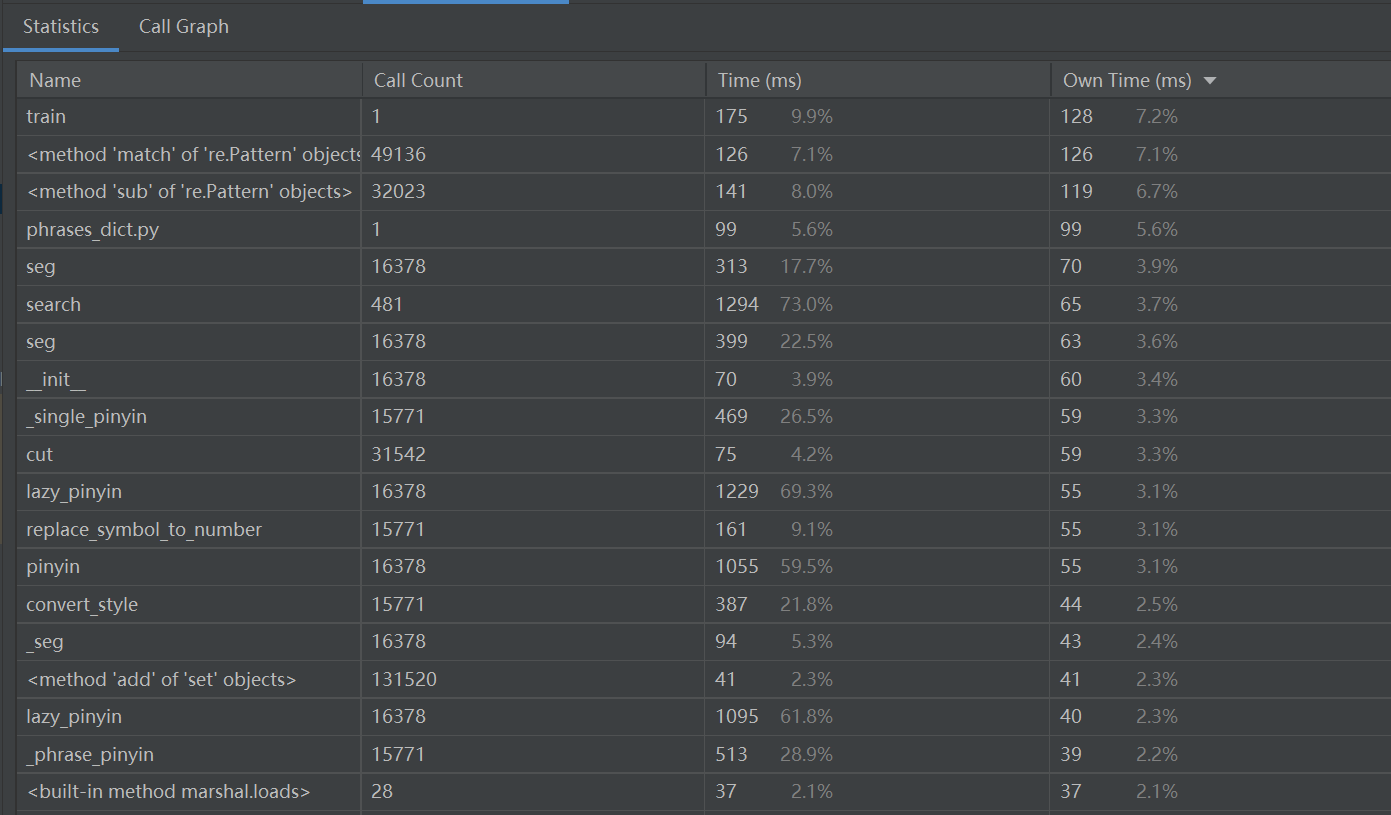
(3.2)计算模块接口部分的性能改进。记录在改进计算模块性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(由VS 2019、JProfiler或者Jetbrains系列IDE自带的Profiler的性能分析工具自动生成),并展示你程序中消耗最大的函数。(12')
-
按总时间排序:
-
按函数实际运行时间排序:
-
可以看出来,最耗时的是
search()函数以及第三方类库pypinyin中lazy_pinyin()的调用。search()函数是AC自动机中的关键算法,比起暴力检测已经优化了很多,时间复杂度是大大降低,语句已经足够精简,暂时无法对它进行剪枝修改。pypinyin可以支持简繁体中文,实现汉字到拼音的转换,这个是我目前找到最合适、最全面的拼音库,也没法替换。
(3.3)计算模块部分单元测试展示。展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路。并将单元测试得到的测试覆盖率截图,发表在博客中。(12')
待检测文本为:
刚刚在电梯间看见一小 孩儿在吃雪糕
出于关心,顺口告诉那个xiao&^$#%$)h:这么凉的天,会吃坏身体的!
肖13573孩告诉我,他的nai_&^$% 女乃活了 103 岁。
我问:吃雪糕吃的?
他说:不是,我奶&……7女乃从来不管闲事!
多么深刻!现在终于知道自己为什么衰老得这么快了!
瞎扌喿&&&%……¥%心操的……
inT%%%&96ere stIn1234G
单元测试代码如下:
import unittest
import main
class MyTestCase(unittest.TestCase):
def test_something(self):
ans = """Total: 7
Line1: <小孩> 小 孩
Line2: <小孩> xiao&^$#%$*)h
Line3: <小孩> 肖13573孩
Line3: <奶奶> nai_&^$% 女乃
Line5: <奶奶> 奶&*……7女乃
Line7: <操心> 扌喿&&&%……¥%心
Line8: < interesting > inT%%%&96ere stIn1234G""" # 此处敏感词加空格是因为博客园会将不加空格的识别为html标签
org = "./org1.txt"
org_add = "./org_add1.txt"
file_ans = "./ans.txt"
main.init_map()
checker = main.Check()
checker.read_words(org)
checker.read_org_add(org_add)
self.assertEqual(checker.output(file_ans), ans) # add assertion here
if __name__ == '__main__':
unittest.main()
主要测试produce_words(),search()的正确性,由于编程的时候没有太考虑代码之间的独立性,导致很多函数的调用是嵌套调用的,要通过如上代码才可以对比结果。在测试中,构造出各种可能的敏感词来对代码进行正确性测试。
测试覆盖率如下图:

(3.4)计算模块部分异常处理说明。在博客中详细介绍每种异常的设计目标。每种异常都要选择一个单元测试样例发布在博客中,并指明错误对应的场景。(6')
- IOError:当输入文件不存在或没有权限时抛出
代码如下
def test_file_read(self):
main.init_map()
checker = main.Check()
try:
checker.read_words("./wrongpath12.txt")
except IOError:
self.assertTrue(True)
else:
self.assertTrue(False)
- 参数传递错误:参数传递错误时结束程序
# 正确输入文件路径的三个参数
if len(sys.argv) == 4:
file_word = sys.argv[1]
file_org_add = sys.argv[2]
file_ans = sys.argv[3]
else:
print("请重新输入正确参数")
exit(0)
三、心得
- (4.1)在完成本次作业过程的心得体会(3')
在完成这次作业之前,我只会 C、C++,虽然有听说过 Python 有强大的第三方类库,调用起来非常方便,但是也没想过用 Python 来完成这次作业。在网上找了不少关于简繁体转换、汉字转拼音的 C++ 的代码,撇开调用起来不方便来说,其完整性、正确性也不够高,后来决定速成 Python,各种赶进度学习 Python,以为已经快到这次作业的终点了,没想到只是起点。在设计算法这块花了不少时间,也明白了写一个项目前,分析需求、整理思路的重要性,深深体会到了柯老板的威力。在思考敏感词的各种可能形式时,没少问测评组的同学一些奇葩的样例,感谢他们的耐心解答。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号