
mysql索引
场景介绍
现在有一个书籍表10万条数据,如下表列举出来的top7:
| 文章id | 文章标题 | 文章内容 |
|---|---|---|
| 1 | 问题比答案重要 | 问题比答案重要,喜欢答案的人很痛苦,因为他的世界在不断崩塌。 |
| 2 | 从非同凡响开始 | 从非同凡响开始,绝不做他人都在做的事 |
| 3 | 从动物到上帝 | 十万年前,地球上至少有六种不同的人但今日,世界舞台为什么只剩下了我们自己 |
| 4 | 刻意学习 | 在存在干扰的情况下,稳定地把事情完成的能力 |
| 5 | 思维模型 | 底层的思维模型往往是至简的道理 |
| 6 | 衣服 | 选择合适的服装,因为服装往往是你的一张名片 |
| 7 | 配饰 | 一个小小的配饰就能为你的整体风格增添不少效果... |
| ... | ... | ... |
现在我要查询文章中带"世界"两个字的文章,一般会是这样:
先将文章分类->在可能的类别里面进行查找,反应到数据库中的概念,即建立一个索引文件,按照索引文件的规则去查找。索引文件如下:
index | 文章id
---|---|---
1 | 1,2,4...
2 | 3, 5, ...
3 | 6, 7, ...
...|...
那么具体的查找是如何实现的呢? 先来理解一些基本概念:
什么是索引?
索引的查找算法?
具体查找过程的分析?
索引优化的建议!
什么是索引?
索引是帮助mysql高效获取数据的数据结构,索引的本质是数据结构。
数据结构
B Tree = Balance Tree(平衡树), 平衡树是一颗查找树,且所有的叶子节点位于同一层。
B+ Tree 是基于B Tree 和叶子节点顺序访问指针进行实现,它具有平衡性,并且通过顺序访问指针来提高区间查询的性能。
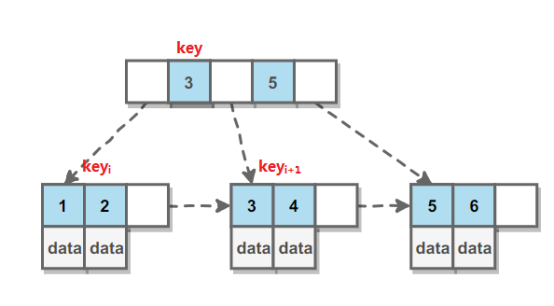
B+ Tree中如果某个指针的左右相邻 key 分别是 keyi 和 keyi+1,且不为 null,则该指针指向节点的所有 key 大于等于 keyi 且小于等于 keyi+1。
相关操作
1、查找
首先从根节点出发进行二分查找,找到一个key所在的指针,然后递归地在指针所指向的节点进行查找。知道查找到叶子节点,然后在叶子节点上进行二分查找,找出key所对应的data。

2、插入、删除
插入、删除操作会破坏平衡树的平衡性,因此,在插入删除操作之后,需要对树进行一个分裂、合并、旋转等操作来维护平衡性。
为什么不是红黑树
我们知道红黑树等平衡树也可以用来实现索引,但是为什么文件系统、数据库系统普遍采用 B+ Tree 作为索引结构呢?
原因如下:
B+树的高度要比红黑树小,有效减少了磁盘的随机访问
B+树的数据节点相互临近,能够发挥磁盘顺序读取的优势(缓存)
B+树的数据全部存于叶子结点,而其他节点产生的浪费在经济负担上能够接收,红黑树存储浪费小
红黑树常用于存储内存中的有序数据,增删很快,
b+树常用于文件系统和数据库索引,因为b树的子节点大于红黑树,
红黑树只能有2个子节点,b树子节点大于2,子节点树多这一特点保证了存储相同大小的数据,
树的高度更小,数据局部更加紧凑,而硬盘读取有局部加载的优化(把要读取数据和周围的数据一起预先读取),
b树相邻数据物理上更加紧凑这一特点符合硬盘进行io优化的特性。b+树在b树基础上进一步将数据只存在叶子节点,
非叶子节点不存值只存储值的指向,这使得单个节点能有更多子节点,除此之外将所有叶子节点(值存在叶子节点)
放入链表中,使得数据更加紧凑有序,只需要链表(叶子节点)的一次遍历就能获取所有树上的值。
b+树这些特性适合用于数据库的索引,mysql底层数据结构就是b+树。
索引万能?
索引并非万能,需要在实际的场景中去平衡它的优缺点。
优势:类似图书馆建书目索引,提高数据检索的效率,降低数据库的IO成本,通过索引列对数据进行排序,降低数据排序的成本,降低了CPU的消耗
劣势:索引实际上也是一张表,该表保存了主键与索引字段,并指向实体表的记录,索引虽然会大大提高查询速度
,同时却会降低更新表的速度,如对表进行insert,update,delete,因为表更新时,mysql不仅要保存数据,还有保
存索引文件每次更新添加了索引列的字段,都会调整因为更新所带来的键值变化后的索引信息。
索引怎么查?
索引的目的在于提高效率,可以类比字典,如果要查 Mysql,没有索引时,需要a-z查找,如果有索引,
索引可以将数据排好序,然后查找。
索引查找算法:
首先根据给定的索引值K1,在索引表上查找出索引值等于K1的索引项,以确定对应子表在主表中的开始位置和长度
,然后再根据给定的关键字K2,在对应的子表中查找出关键字等于K2的元素。
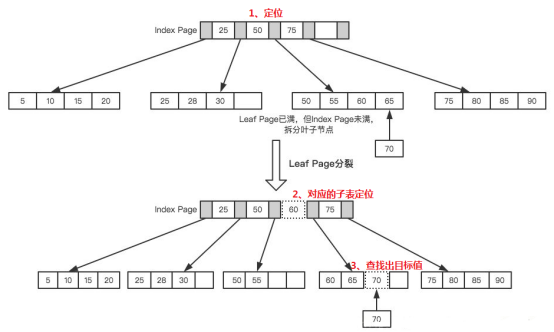
分块查找:
分块查找属于索引查找,其对应的索引表为稀疏索引,具体地说,分块查找要求主表中每个子表(又称为块)之间是
递增(或递减)有序的。即前块中最大关键字必须小于后块中的最小关键字,但块内元素的排列可无序。它还要求索
引值域为每块中的最大关键字。
索引分类
单值索引,一个索引只包含单个列,一个叫表可以有多个单列索引
唯一索引,索引列的值必须唯一,但允许空值
复合索引,一个索引包含多个列
这些需要创建索引情况
1、主键自动建立唯一索引
2、频繁作为查询条件的字段
3、查询中与其他表关联的字段,外键关系建立索引
4、频繁更新的字段不适合创建索引
5、where条件里用不到的字段不创建索引
6、高并发下倾向创建组合索引
7、查询中排序的字段,排序字段若通过索引取访问将大大提高排序速度
8、查询中统计或者分组字段
9、如果某个数据列包含许多重复的内容,建立索引就没有太大的效果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号