大型网络架构变迁和知识图谱
——仅供个人学习使用,如有侵犯版权,请作者联系我,立马处理。
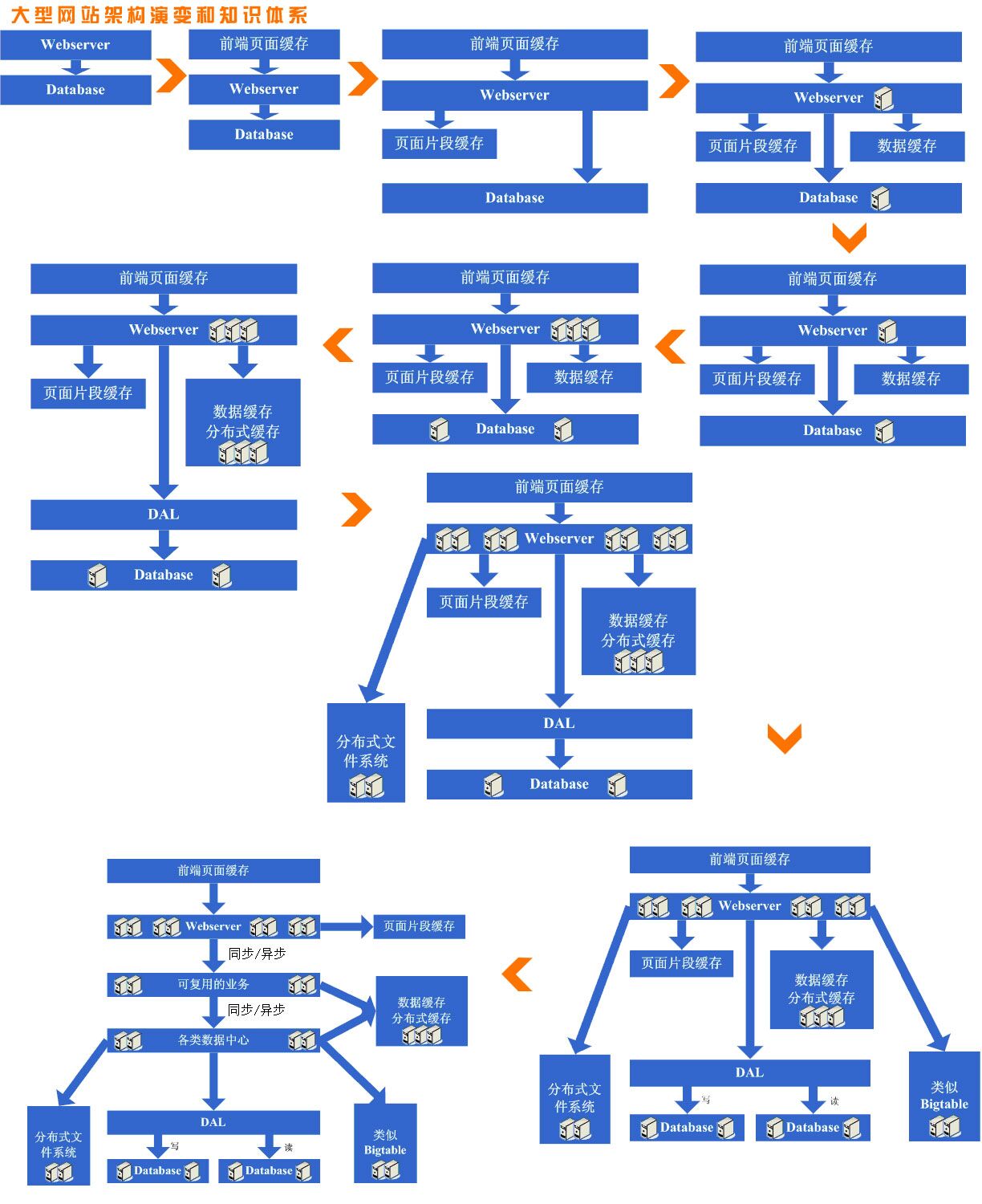
【前端页面缓存】 sessionStorage,localStorage,userData,cookie,
[sessionStorage]
h5后出现的新技术,这个生命周期短,当页面关闭后,存储资源即被释放。可存储体积也较大。对于不同的网站,数据存储于不同的区域,并且一个网站只能访问其自身的数据。注:页面刷新,或disable cache,存储资源还在,只有当页面关闭后才没有。
[localStorage]
与sessionStorage唯一区别是,存储生命周期。它是长久存储在浏览器中,没有时间限制, 不清除就会一直存在。它不是存储在浏览器中,存储在本地。它按域名存储,存储大小大概是5m缺点是兼容性中等,ie9、ie10不支持,不能跨浏览器读取的。
[userData]
这个是比较老的存储技术,有兼容问题,Ie支持
[cookie]
这个兼容性最好,应用也最广泛,现在大多登陆校验都用这个。特点是:每次向服务器发请求,请求头都会带cookie,存储大小有限制
[openDataBase]
其实就是一个本地数据库,缺点是对前端开发成本高。它存储在本地
【页面片段缓存】
场景介绍:https://www.cnblogs.com/yuyijq/archive/2011/05/07/fragment_cache_one.html
一般,页面上会分为很多部分,而不同的部分更新的频率是不一样的。如果对整个页面采用统一的缓存策略则不太合适,
而且很多系统的页面左上角都有一个该死的“Welcome XXX”。这种特定于用户的信息我们是不能缓存的。对于这些情况我们就需要使用片段缓存了。对页面不同的部分(片段)施加不同的缓存策略,而要使用片段缓存,首先就得对页面进行切分。土一点的办法可以用iframe,用iframe将页面划分为一块块的,不过我总觉得iframe是个邪恶的东西。好点的办法可以用Ajax单独的请求这个片段的内容然后再填充,看起来挺美好的。不过使用Ajax也有一些限制:
1、如果页面上有许多片段,使用太多的这种技术,会有很多请求发送到服务器,HTTP对同一个域名有连接的限制,这样会降低并发连接的效率。
2、如果说第一个不是什么问题,那么还有一点可能对用户体验不友好。比如有一个片段可能响应慢点,造成页面闪烁。不过如果前面两点都可以克服,这个方案还是可以的。可恶的是我们的客户(此处省略500字),说他们的大多数用户处于一个禁用JavaScript的环境里。好吧,这个方案也不能使用了。
成熟的页面片段缓存技术-:ESI(Edge Side Include) https://www.cnblogs.com/yuyijq/archive/2011/05/08/fragment_cache_two.html
使用Velocity自定义标签的方案工作在应用程序这一层,这样开发人员有最大的控制权力,而且实现起来也比较简单,所使用的也都是大家都熟悉的技术,但问题是它还是由应用程序服务器来处理得,可以说它减轻了一部分应用程序服务器和数据库服务器的压力,但还有一部分压力还是需要它来承担,而且在应用程序中解决所使用的缓存必定是和应用程序所采用的缓存机制一样(当然你也可以为此独立使用一个缓存),对缓存服务器也有部分压力。
而使用ESI的方案,它需要运维团队的配置,甚至需要修改服务器配置的架构(添加了前端服务器),如果在多部门协调比较困难的项目中,这种方案还会遇到一些阻力。
但是它带来的好处确实显而易见的。首先ESI是一个W3C标准,我更倾向于采用标准的做法。而且Varnish这样的方向代理,它本来就擅长这个,它可以完全把这部分压力从应用程序服务器和缓存服务器上接管过来,而且会处理的更出色。
【数据缓存】https://mp.weixin.qq.com/s/rD6hln8bSLW07lNAgOmZ1g
[解决的问题] 缓存是分布式系统中的重要组件,主要解决高并发,大数据场景下,热点数据访问的性能问题。提供高性能的数据快速访问。
[原理]将数据写入读写更快的存储、离应用最近的位置(分布式应用、推荐系统)、离用户最近的位置(需要及时响应到客户端的服务)
[媒介]中间件: Varnish\Ngnix\Squid\Memcache\Redis\Ehcache,内容;文件、数据、对象;介质:CPU、内存、磁盘
[缓存设计] what?where?How?
what:1、热点数据 2、静态资源
Where:CDN、反向代理、分布式缓存服务器、本机
How:过期策略、固定时间、相对时间、同步机制、实时写入、异步刷新
【数据分布式缓存】大型网站分布式缓存 https://blog.csdn.net/chenxiaochan/article/details/71036497
[产生背景]
高并发环境下,大量的读写请求涌向数据库,磁盘的处理速度与内存显然不在一个量级,从减轻数据库的压力和提高系统响应速度两个角度来考虑,一般都会在数据库之前加一层缓存。由于单台机器的内存资源以及承载能力有限,并且,如果大量使用本地缓存,也会使相同的数据被不同的节点存储多份,对内存资源造成较大的浪费,因此,才催生出了分布式缓存。
[memecache原理]
【数据库中间件】数据库中间件技术概貌了解一下、数据中间件技术详解
[解决的问题]为海量前台数据提供高性能、大容量、高可用性的访问
为数据变更的消费提供准实时的保障
高效的异地数据同步
[数据库中间件的分类]
分布式数据库分表分库
数据增量订阅与消费
数据库同步(全量、增量、跨机房、复制)
跨数据库(数据源)迁移
【分布式文件系统】分布式文件系统
[主流的分布式文件系统] Hadoop生态、以spark为核心的大数据中心
[应用背景及作用]企业对数据存储的要求越来越高,而且模式各异。分布式文件系统将数据存储在物理上分散的多个存储节点上,对这些节点的资源进行统一的管理与分配,并向用户提供文件系统访问接口,其主要解决了本地文件系统在文件大小、文件数量、打开文件数等的限制问题。参见

 浙公网安备 33010602011771号
浙公网安备 33010602011771号