vue源码阅读—05—响应式原理(二)计算属性和侦听属性;组件更新;组件更新之diff
一、计算属性
总结:
其实就做了两件事:
1.把计算属性的每个key都代理到Sub.prototype上(方便模板通过this.计算属性名访问。)
2.在initComputed阶段,给计算属性的每个key都定义一个计算watcher,(这样计算属性触发props或者data的依赖收集,就可以把自己的计算watcher添加进去。)
总结:
计算属性会给每一个key,都使用Object.definedProperty拓展到根组件实例上或者Sub构造函数.prototype上,方便后续通过vm直接访问计算属性,它的实现和props、data的代理是不一样的;
然后,当渲染watcher执行vm._render()去实例化vnode时,会触发计算属性的getter,如果浏览器环境,就是一个computedGetter具名函数;
这个函数有两个特别重要的方法, 一个是watcher.evalate(),它的作用就是调用我们自己手写的计算属性的getter,因为我们的计算属性是依赖props或者data里的数据,去订阅props或data数据的变化;所以会触发他们响应式的getter,所以,会把计算watcher添加到数据的dep实例的subs数组里,
然后evalate()方法会把求得值赋值给计算watcher的value属性上,这个value属性,就是计算属性的值;
第二个特别重要的方法,watcher.depend();计算watcher一般被调用,都是被渲染watcher或者侦听器也就是user watcher调用,所以,我们调用watcher.depend()方法,遍历计算watcher的deps数组,然后数组的每个元素也就是dep实例调用dep.depend方法,把渲染wathcer页添加剂进去;
这样,响应式数据修改后,会调用setter,然后通知计算watcher去重新求职,通过渲染watcher重新渲染,通知user watcher调用回调函数;
为什么说计算属性有缓存?
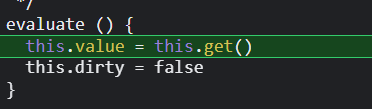
原因找到了,计算watcher在watcher.evaltoe()中会将watcher.dirty属性置为false,
表明属性不是脏的,没被修改过,下一次还可以继续用。但是如果一旦出发了计算watcher的更新,就会
把watcher.dirty置为true,所以有模板引用计算属性要重新计算了。
计算属性的依赖也必须是一个可响应式的数据;不然没有意义;不然计算属性也将不是响应式的;
- 渲染watcher的特性:看watcher实例的expression属性,这个属性是实例Watcher类时传入的expFn函数,只有渲染watcher的执行函数是
updateComponent = () =>vm._update(vm._render(), hydrating)}
- 计算watcher的特征: 1. 实例的lazy属性和dirty是true; const computedWatcherOptions = { lazy: true } ; 2.计算watcher的value属性也可能有值,因为watcher.evalate()方法后会把value赋值给watcher;
- 侦听watcher或者叫user watcher的特性:实例的user属性时true;
1.2流程:
计算属性的流程分为两大块,第一快是计算属性如何初始化、被渲染watcher依赖,本身计算watcher如果依赖props或data里的数据;
第二大块是prps或data里的数据改变了,计算属性如何变;
所以说计算属性到底是不是响应的?
我我觉不是,因为他是一种对props、data数据的封装;data数据改变后通过计算watcher重新计算,计算watche又通知依赖我的渲染watcher重新渲染;
根组件: <script> new Vue({ el: "#app", render: h=>h(App) }); </script> 子组件即App组件: const App = { name: 'App', data() { return { useless: 0, firstName: "san", lastName: "li", }; }, computed: { name() { if (this.useless > 0) { return this.firstName + "---" + this.lastName; } }, }, template: ` <div id="dependencyDepend"> <div >{{name}}</div> <button @click="change">change</button> <button @click="changeLast">changeLast</button> </div> `, methods: { change() { this.useless++; }, changeLast() { this.lastName = "zhang"; }, }, }
1.2.1流程:第一大块
首先,到了这一步,由于根组件没有computed选项,所以,不进行initComputed;
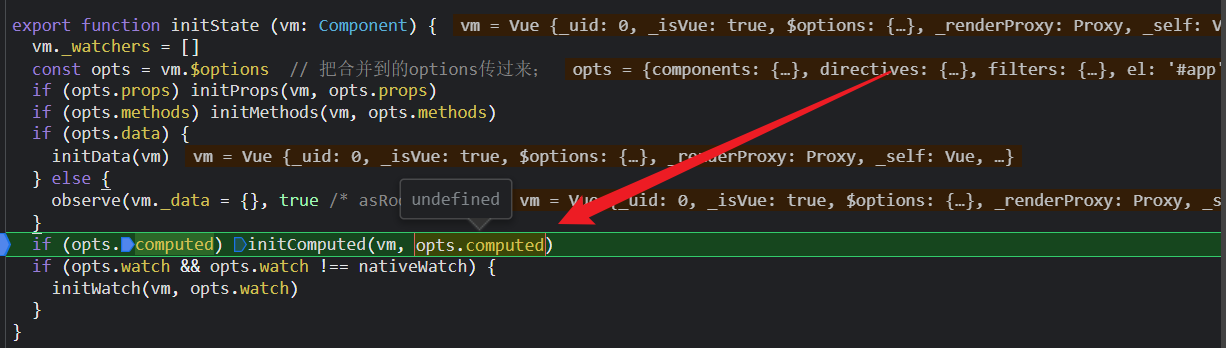
然后再是初始化组件vnode过程中,要把App组件对象转化成组件构造函数,通过合并配置,sub.options里有了我们再组件里配置的计算属性name,所以走initComputed;
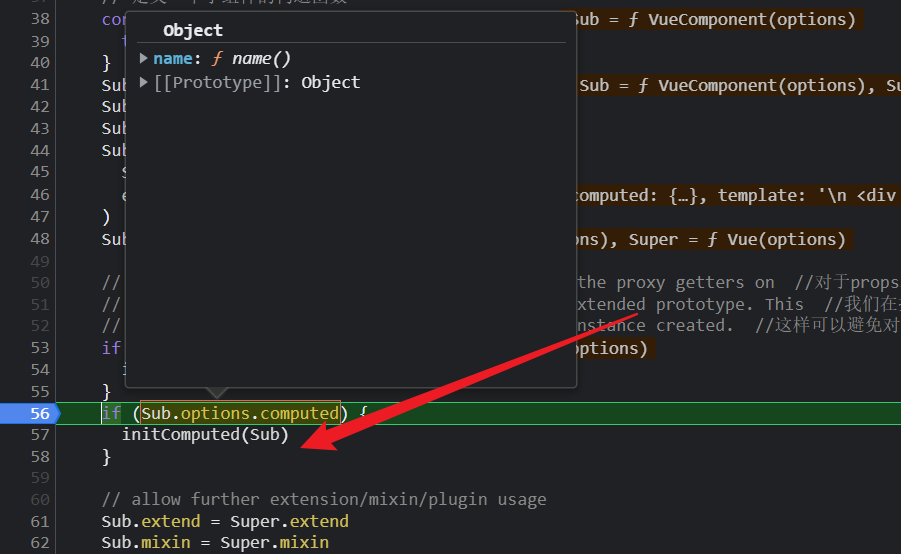
initComputed会将所有的计算属性的key都放到子组件构造函数的prototype上;所以后续我们可以通过vm.name的方式直接调用计算属性,这个原理不是props或data里的代理,而是被直接挂载到了实例上,这是区别!!!

然后defineComputed的目的是定义计算属性的getter操作,
注意,在非服务器渲染环境里,是要缓存的,所以shouldCache是true,所以会把createComputerdGetter(key)放回的函数comuptedGetter添加到Sub.prototype上。
后续render函数调用计算属性的值时就是走这个computedGetter函数,
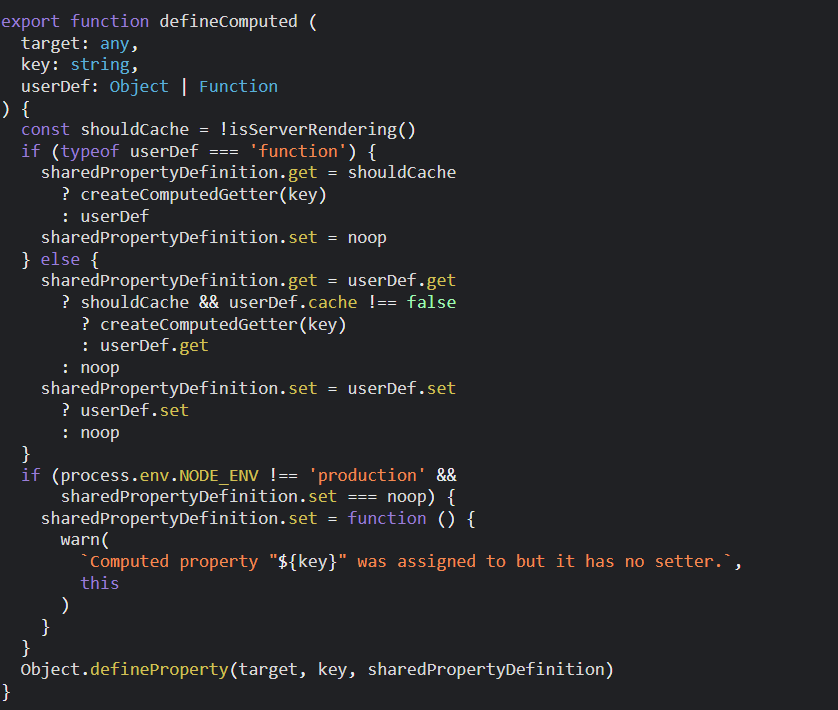
返回的具名函数叫computedGetter;
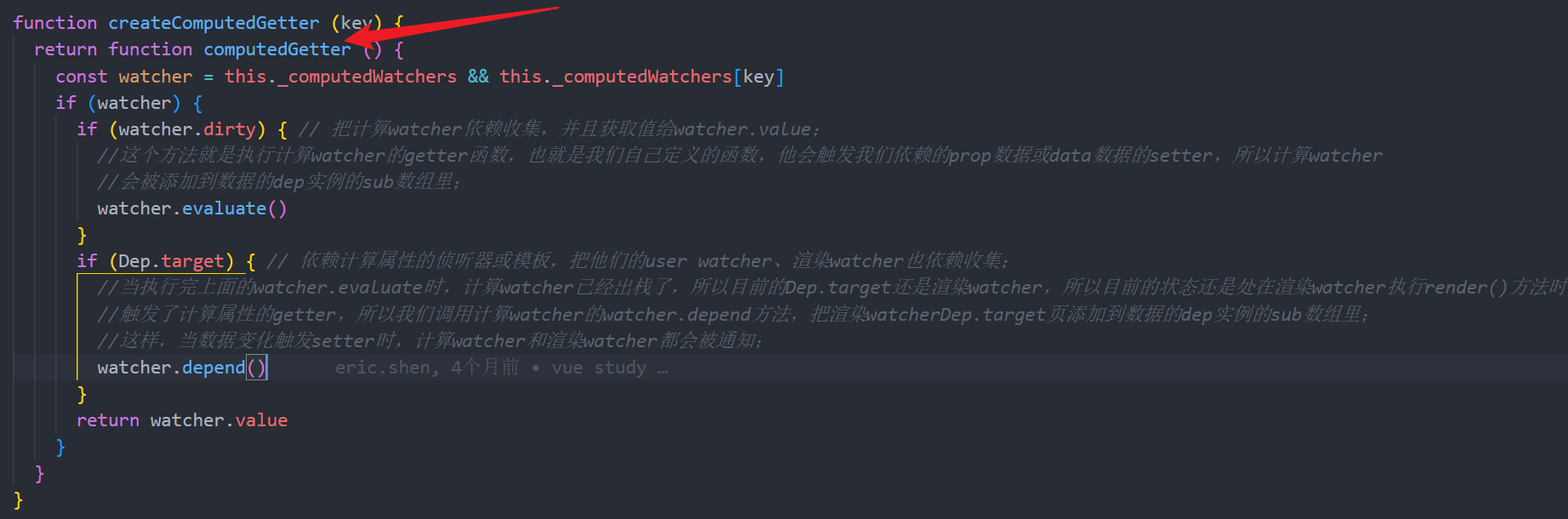
然后当组件patch时,会实例化子组件,然后子组件会走this._init(),然后子组件也会走这一步,到了这里,这一次,计算属性存在;
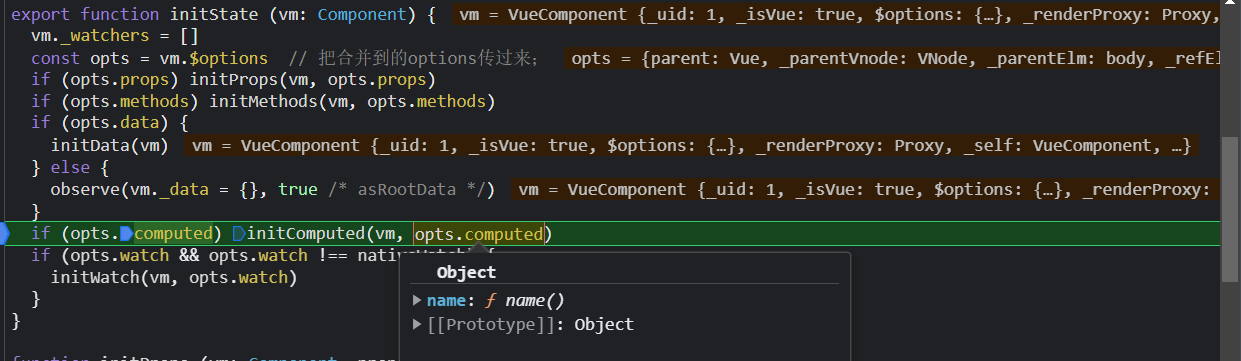
initComputed函数的主要目的是:
watchers即vm._computedWatcher,是一个对象,我们通过forin的方式+对象的数据结构,遍历了计算属性配置项所有的key,然后给每个key都新建一个watcher实例。
由于watcehrs对象保存了所有的计算watcher实例,我们可以通过key即计算属性的名字来获取他们对应的计算属性;
由于子组件实例保存了计算属性,所以if ( ! (key in vm)) {这段代码不会执行;这段代码是给根组件的计算属性绑定到根组件实例上执行的;
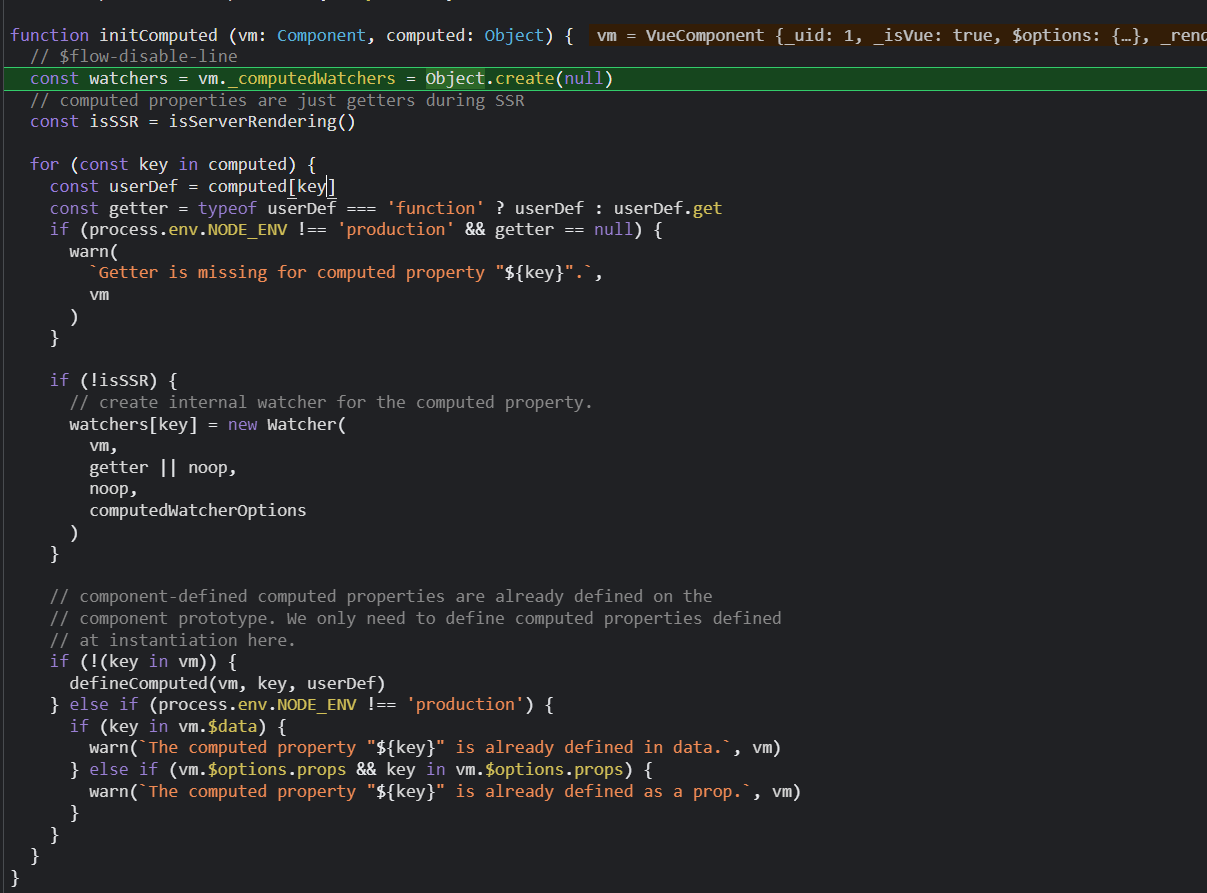
然后,render函数,调用计算属性,走计算属性的getter,也就是这个函数;
watcher变量是watchers即vm._computedWatcher对象里根据key取出的计算watcher;所以watcher.dirty肯定是true;
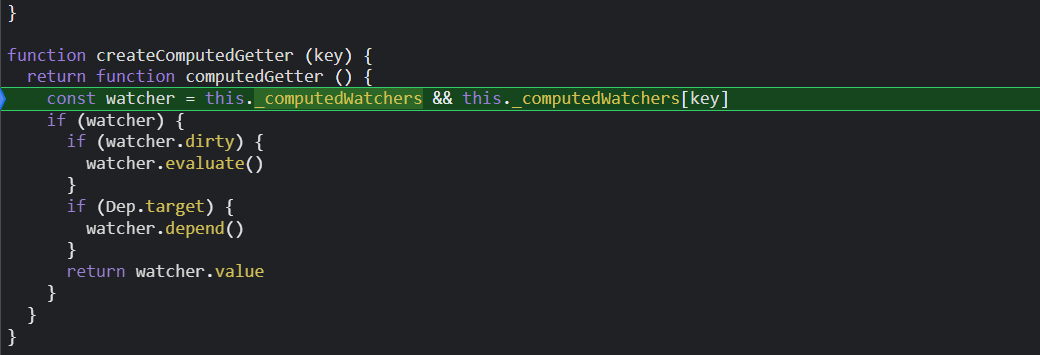
然后执行watcher.evaluate();
get主要是两个功能:
1.将计算watcher赋值给Dep.Target;
2.调用getter操作;也就是我们自己写的函数
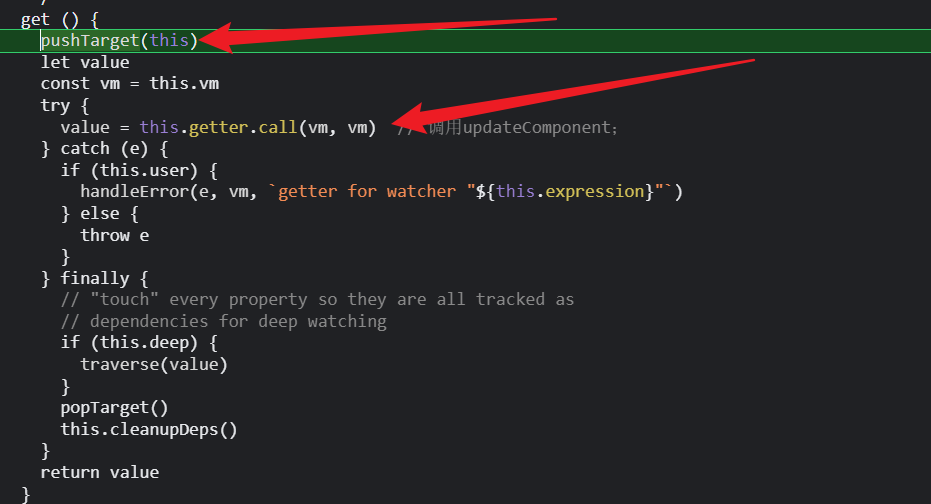

由于useless是data数据里定义的变量,所以在执行计算属性的函数时会触发userless的getter,接着把计算watcher添加到useless的dep实例的subs数组里;
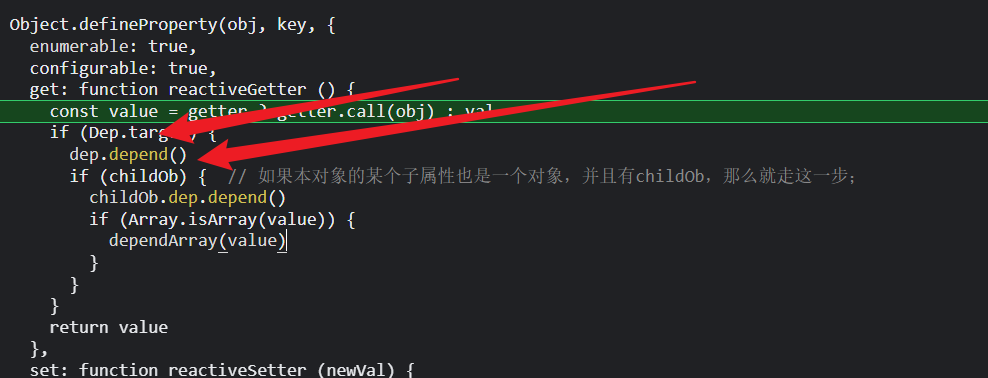
1.2.2流程:第二大快
useless的dep添加了计算watcher;
后面执行popTarget(),将Dep.Target从计算watcher出栈为渲染watcher;
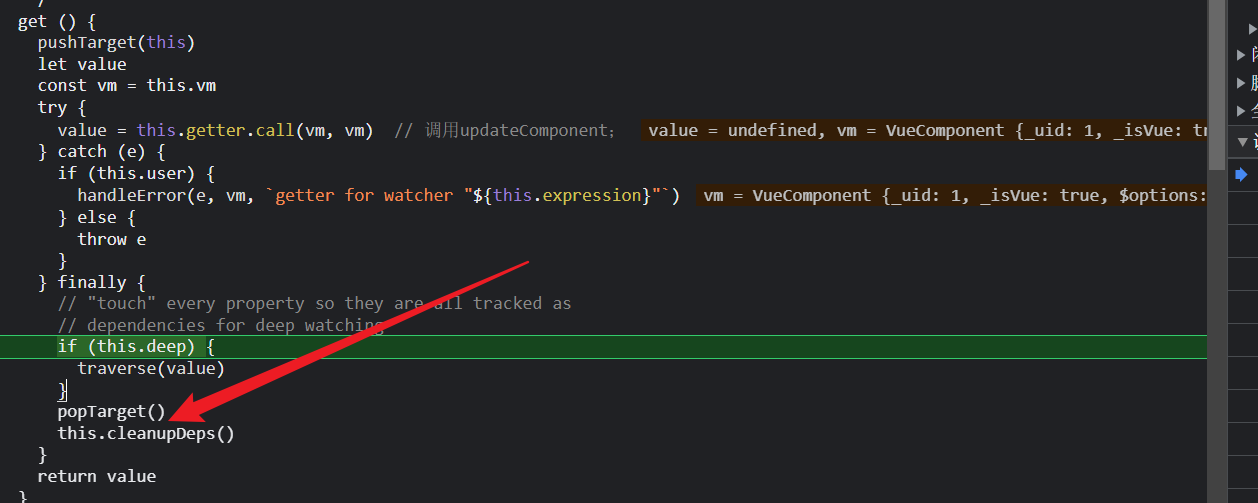
然后执行这一步,
注意这个时候watcher变量仍然是计算watcher,但是Dep.Target已经是渲染watcher了;
开始走watcher.depend();
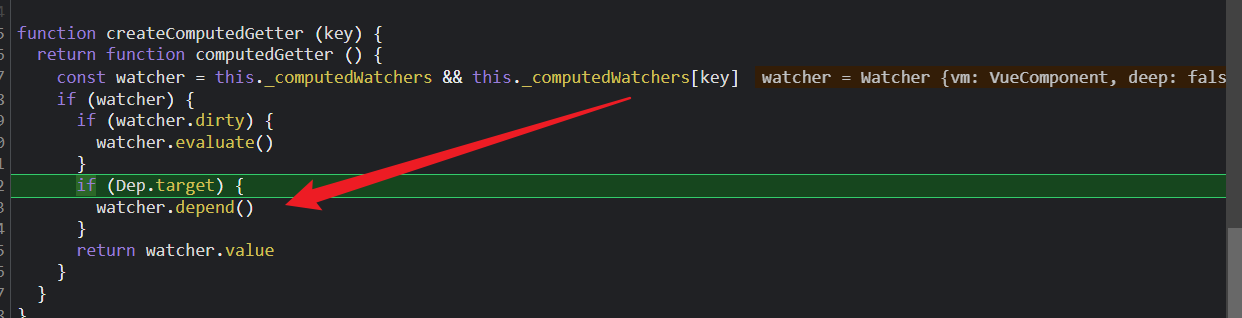
计算watcher实例的deps是什么?
这个很重要,它的deps是计算watcher依赖的dep,也就是jisuanwatcher以来的useless的dep实例!
useless的dep实例又会调用depend()方法,把渲染watcher添加到自己的subs数组里。
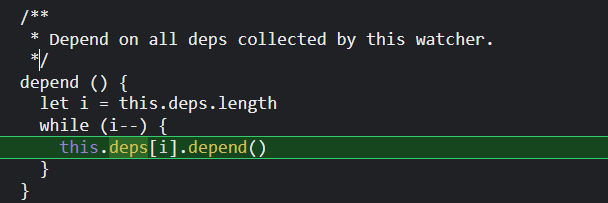
所以说,
当我们通过change按钮修改useless的值,触发setter;然后useless的deps实例会通知计算watcher和渲染watcher都去更新;
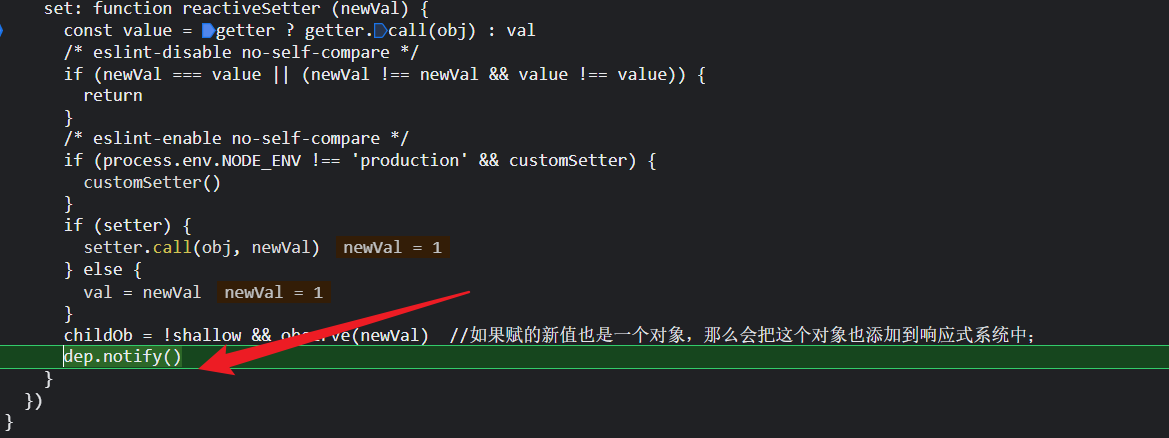
然后计算watcher会去重新计算自生的值,渲染watcher会触发自己的update(),然后调用queueWatcher(),后面就是重新渲染的操作;
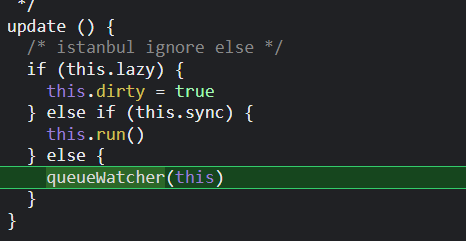
然后就会重新渲染render函数,然后模板就有新的数据了。
dep会通过dep.depend方法,通知watcher实例通过addDep()方法把dep实例添加到自己的deps数组里;
watcher的addDep方法,又会通知dep实例会通过addSub()方法,把watcher实例添加到自己的subs数组里;
所以这是一个相互调用的过程,目的是相互添加对对方的引用;
特殊:计算watcher会有一个depend方法,他会遍历自己的deps数组,然后把依赖它的渲染watcher或user watcher添加到dep实例的subs数组里;
计算属性的依赖收集,是通过render函数触发计算属性的函数,然后才触发响应式数据的getter;
侦听属性的依赖收集,是通过配置项的字符串,然后通过vm.name去触发响应式数据的getter;
那么,这两种不同的方式,会有什么不同?
目前发现的是,计算属性去依赖嵌套的属性时,不需要加deep= true,但是侦听属性需要;
计算属性主要在模板中用,因为计算watcher的依赖收集 必然伴随着渲染watcher;
侦听器主要是自己想在数据变化后做一些操作时用,因为user watcher的cb会被回调,而这个cb就是我们定义的;

二、侦听属性
总结:
先遍历watch配置项,去除我们配置的key、options、handle函数,然后本质上还是通过vm.$watch()方法去创建侦听器;
我们的key一般来说是一个字符串,表明要监听的props、data、计算属性的名字,
创建user Watcher的时候,因为最后一个会调用this.getter,而user watcher的getter其实是一个访问vm上的key,那么就会触发数据的响应式,也就是setter,然后把user watcher也添加到数据的dep的subs数组里;
后续数据修改触发setter,然后就是一样的dep.notify(),然后watcher都被添加到queueWAtcher队列里,
然后再nexttick后,通过flushSchedualerQueue方法,调各个watcher的run()方法,
最后再watcher的run方法里,会调用cb回调函数,这个回调函数就是我们字节写的handle方法;
const App = { name: 'App', data () { return { useless: 0, firstName: 'san', lastName: 'li', nested:{ a:{ b:1 } } } }, computed: { name () { if (this.useless > 0) { return this.firstName + '---' + this.lastName } } }, template: ` <div id="dependencyDepend"> <div ref='msg'>{{name}}</div> <button @click="change">change</button> <button @click="changeLast">changeLast</button> </div> `, methods: { change () { this.useless++, this.nested.a.b =2 ; }, changeLast () { this.lastName = 'zhang' } }, watch:{ useless(newVal){ console.log('watch useless',newVal); }, name:{ immediate:true, handler(newVal){ console.log('watch name',newVal); } }, nested:{ deep:true, handler(newVal){ console.log('watch nested',newVal); } } } }
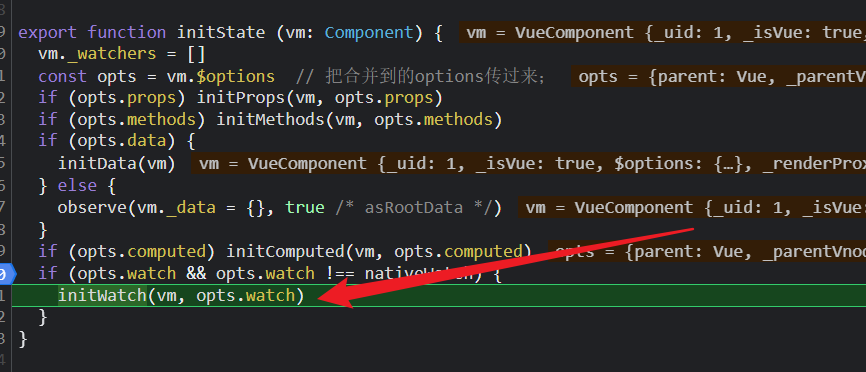
遍历watch配置项的key,然后调用cretewatcher()方法;
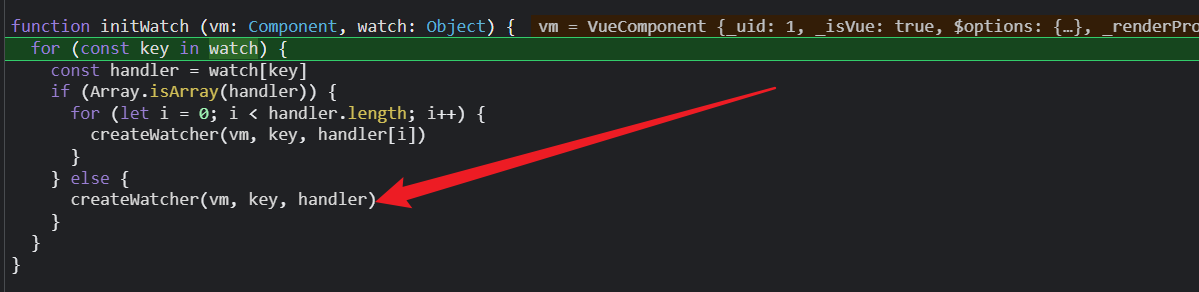
如果我们通过watch配置项的key取出的是个对象,走if (isPlainObject(handler)) {;
所以useless走第三个return vm.$watch(expOrFn, handler, options);
nama和nested先走第一个if (isPlainObject(handler)) {;再走第三个;
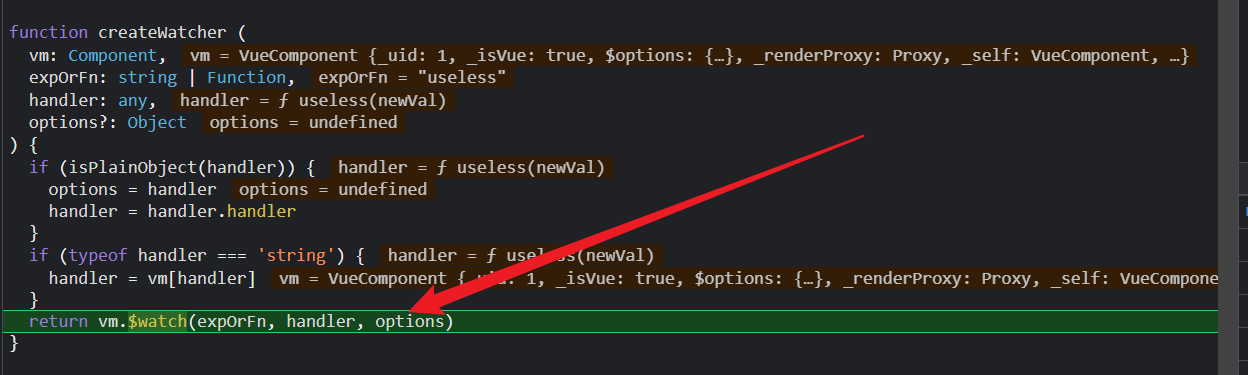
开始实例化user watcher了;注意这里的options有个属性user是true;
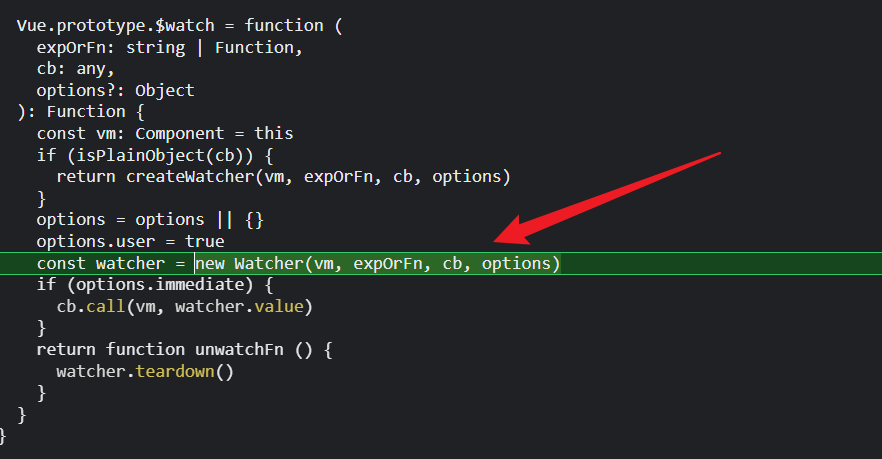
由于我们的useless是一个字符串,所以expOrFn是一个字符串,所以应该走parsePath()这一步;
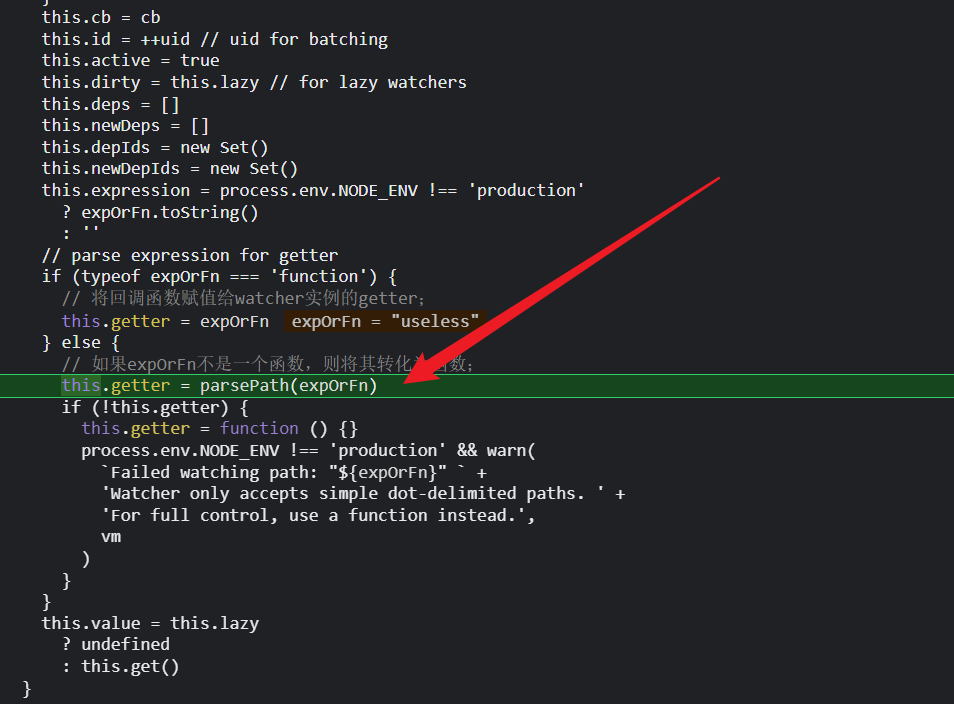
那么this.getter就是这个函数;
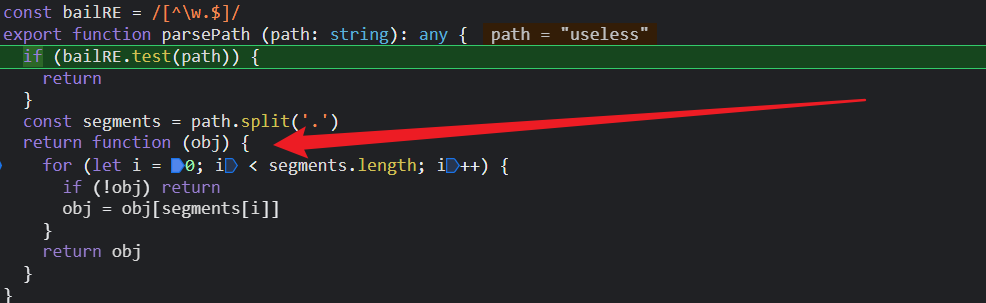
然后实例化watcher的最后一步,调用this.get();本质上就是调用刚刚赋值的getter;
;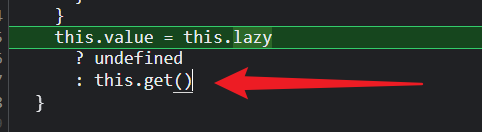
首先将user watcher赋值给Dep.Target;其次,调用getter
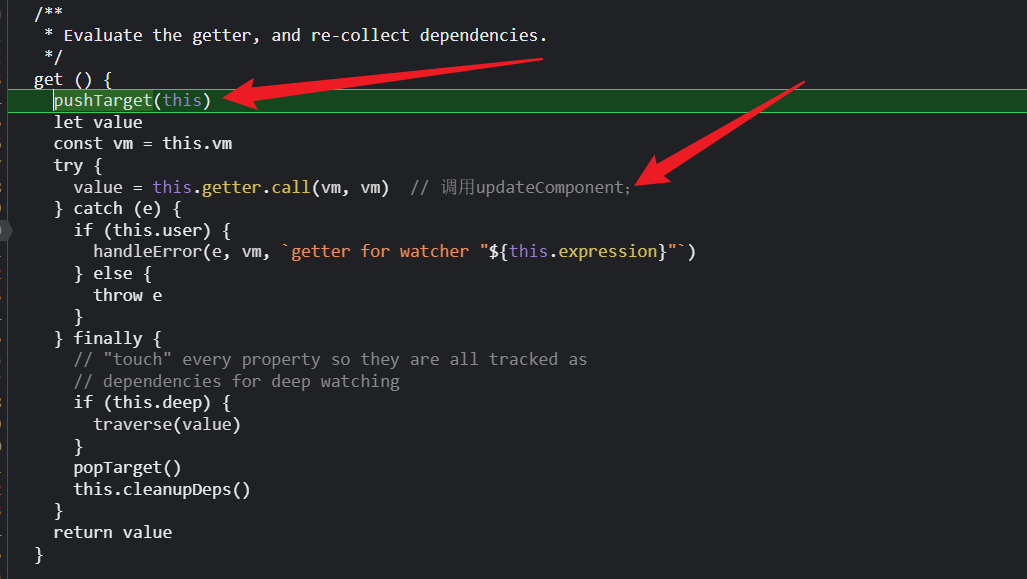
调用setter又回到了这个函数,segments就是我们的 useless经过split()后返回的数组;obj是this.getter.call(vm,vm)传递过来的vm实例;
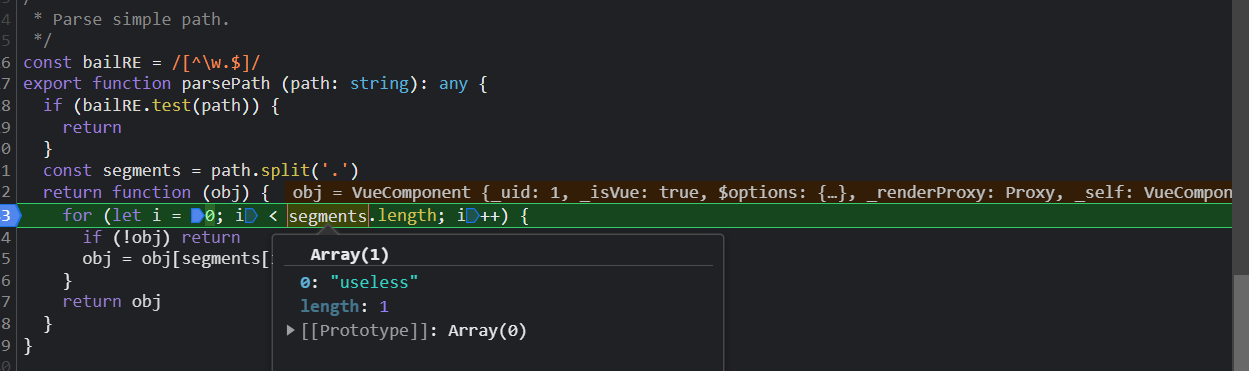
所以,到这一步,侦听属性调用我们手写的data配置项里的useless,那么会触发useless的setter,那么这个user watcher会被加入到useless的deps实例的subs数组里;具体的就不分析了,和前面的一样;
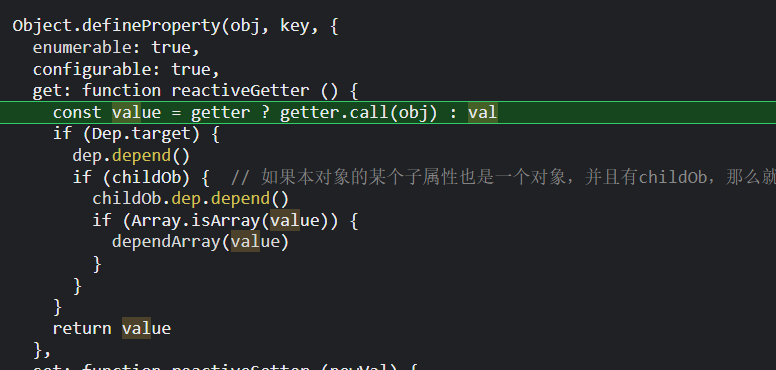
等到依赖收集后,继续执行实例化user watcher的步骤,如果我们某一个侦听属性配置的deep为true,就会执行这一步;这个时候value = this.getter.call(vm.vm),在这个例子中也就是说value等于nested对象;
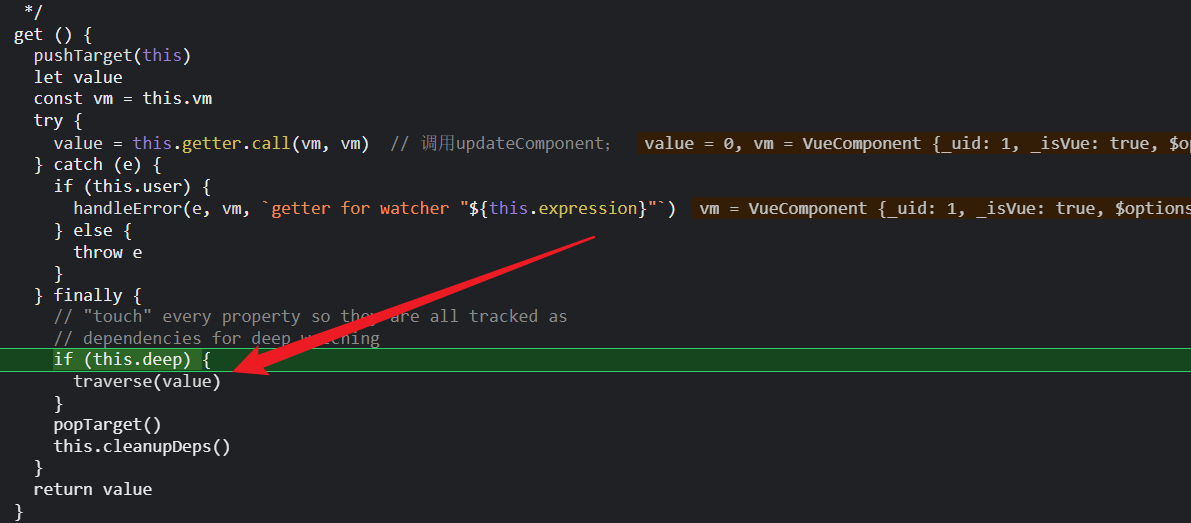
traverse是干啥的,说白了,就是递归的遍历我们的对象,遍历的过程中由于触发了val[keys[i]],所以就是说出发了nested对象的a属性的getter,那么这 user watcher也会被添加到a的实例的subs数组里;
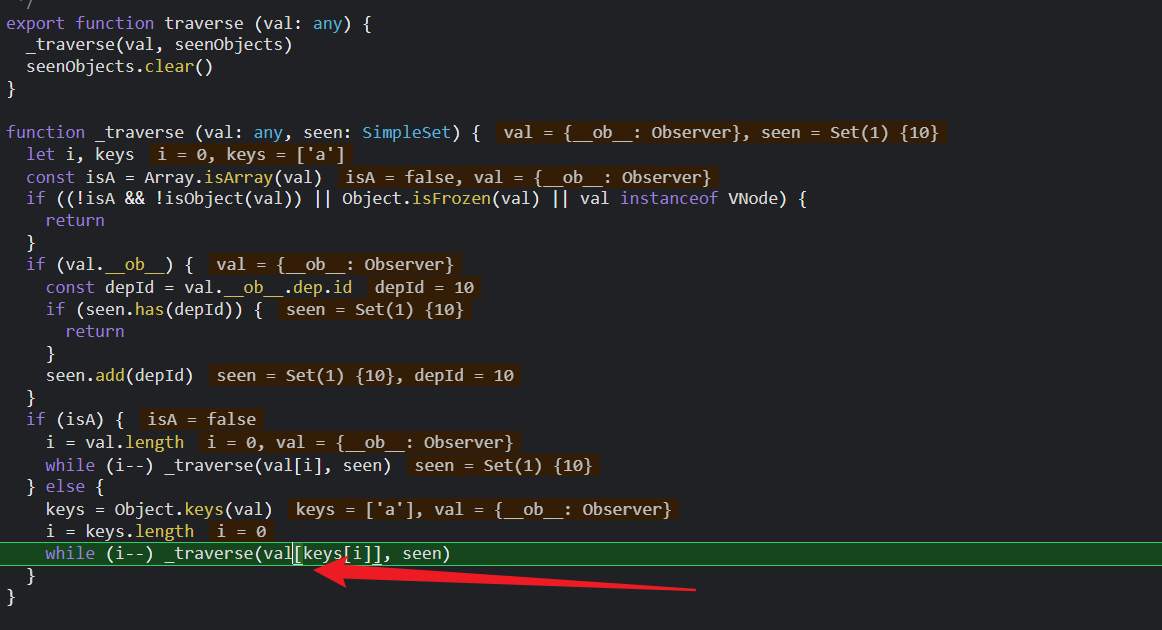
然后整个侦听属性的依赖收集部分就结束了。
第二大块,派发更新,
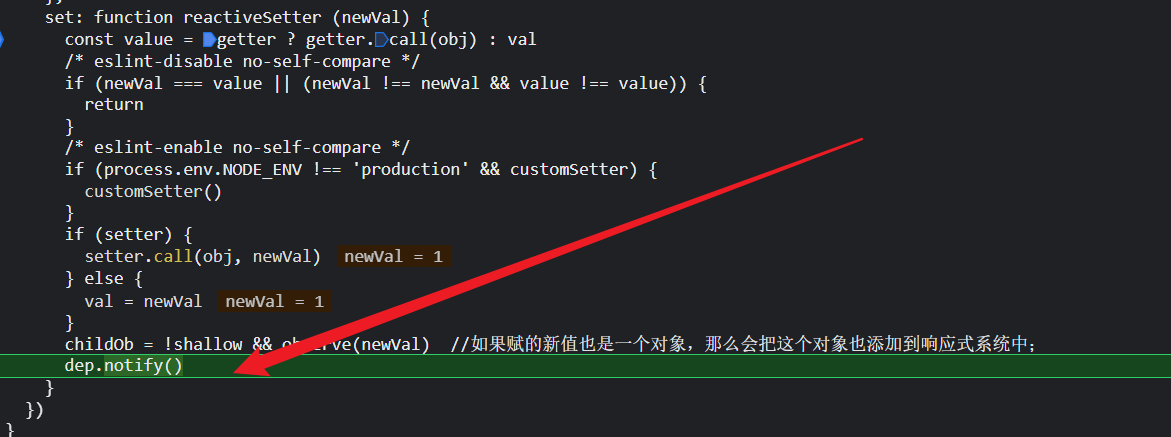
我们以useless举例,因为侦听属性依赖了useless,所以会有一个,并且是第一个;因为user watcher实在initWatch方法即初始化时就被依赖收集。
因为计算属性也依赖了useless,,计算watcher也被添加到uselss的dep实例的subs数组了,并且是第二个; 因为计算watch只有在别人调用我的时候我才会去找自己依赖的props、data,然后才会被依赖收集;
因为侦听watcher依赖了计算属性name,所以也会被添加到useless中
因为模板依赖计算属性name,所以渲染watcher也被添加到useless中,并且是第四个;
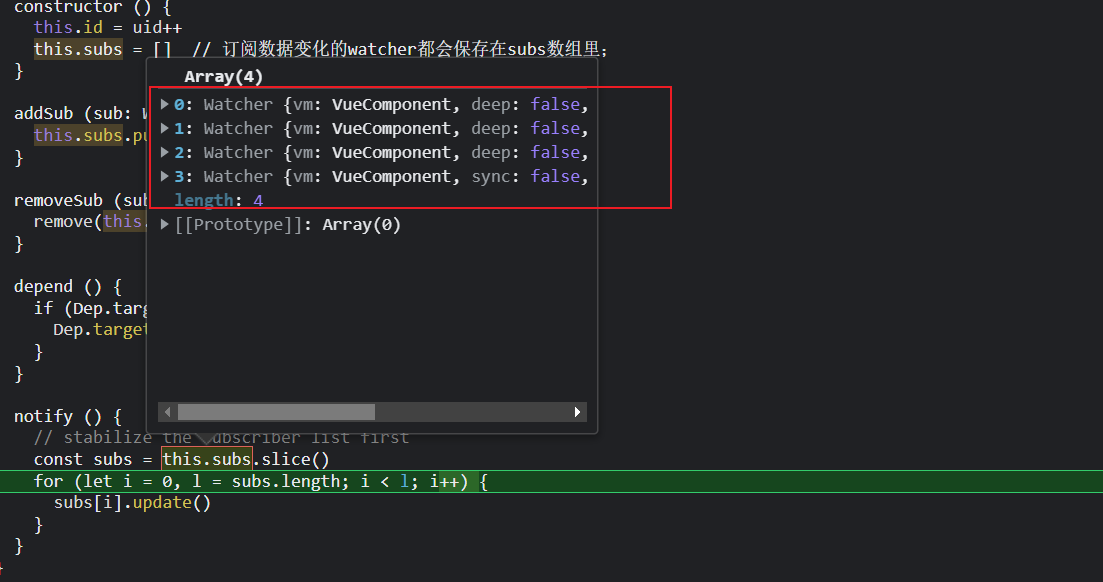
通知这些watcher去更新,然后我们知道,会先把他们添加到queueWAtcher队列里,
然后再nexttick后,通过flushSchedualerQueue方法,调各个watcher的run()方法,
cb回调函数就是侦听器传递的handle函数,会被执行;
三、组件更新
总结:
组件更新时,
会调用vm._update(vm._render())方法,vm._render()方法会重新生成新的vnode;
然后到了vm._update()过程,会重新调用patch函数
这个时候,会判断,
1.如果老vnode不是一个真实的dom节点,并且新老vnode是符合sameVnode方法的(即vnode的key、tag、data等属性一致就判断为true),就进行patch Vnode方法;
2.如果不符合,比如说老节点是一个真实的dom节点,或者新老vnode是不符合sameVnode方法的,那么会进行创建新节点的真实dom,替换老节点的原有位置,删除原有dom等操作;
一般来说,首次渲染会不符合判断;后续的组件更新,都是符合判断走patchVnode;
所以我们来看patchVnode;
首先,如果是一个组件vnode,会走prepatch方法,(但是显然,在我们这个例子中不是,他是App组件的渲染vnode),完成一个子组件的更新操作,会把组件占位符vnode上的内容赋值给组件的渲染vnode;;
其次,执行钩子函数;
其次,会进入patch最核心的diff逻辑,即判断新老vnode的
const HelloWorld = { name: 'HelloWorld', props:{ flag:Boolean, }, data () { return { } }, template: ` <div id="dependencyDepend"> <div v-if='flag'> wo shi helloworld</div> <ul v-else> <li>1</li> <li>2</li> </ul> </div> `, } const App = { name: 'App', data () { return { flag:true, } }, components:{ HelloWorld, }, template: ` <div id="dependencyDepend"> <HelloWorld :flag='flag'></HelloWorld> <button @click="toggle">toggle</button> </div> `, methods: { toggle () { this.flag = !this.flag; }, }, }
组件的更新
当我们点击change按钮时,先触发setter,这个时候的dep里只有App组件的渲染watcher;
所以App的渲染watcher重新渲染,那么即vm._update(vm_.render)。
然后最后一个是patch操作;
由于vnode是一个组件vnode并不是一个真实dom节点,又因为sameVnode(oldVnode, vNode)为true,所以走patchVnode这一步;
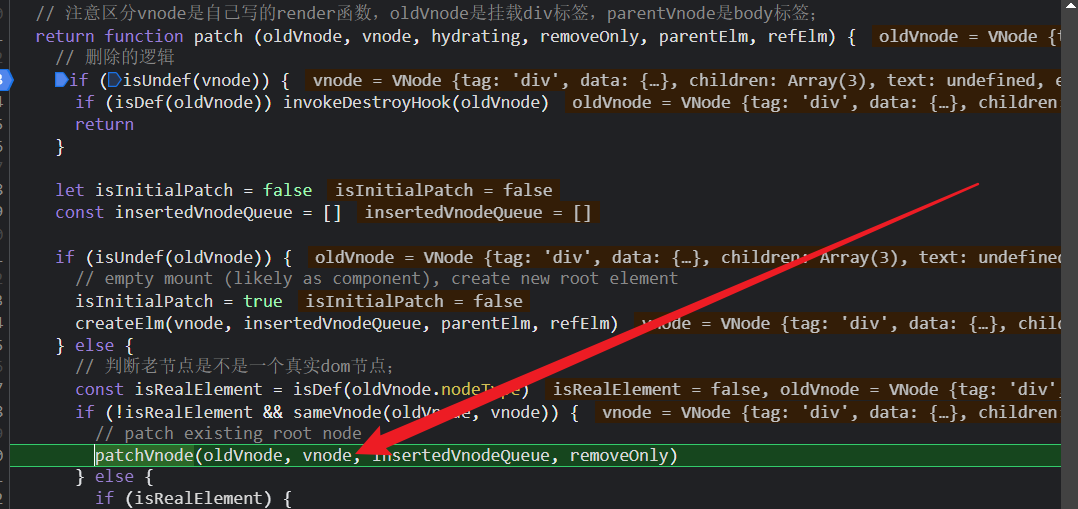
patch这一步,主要是这些操作
需要注意的是,如果vnode和oldVnode都不是文本节点,那么他们就开始比较children了。
而这一次,因为oldVnode和vnode都不是文本节点,并且oldVnode和vnode的子节点oldCh和ch都存在,所以走updateChildren这一步,这也就是diff算法;并把我们的新老节点的子组件都传递进去;
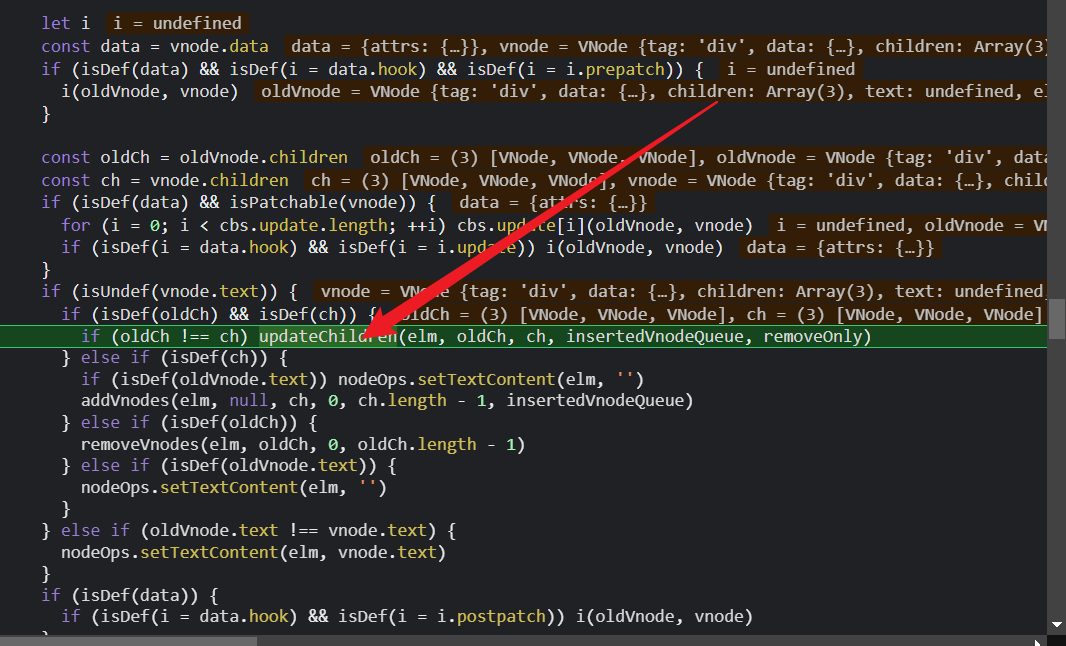
diff算法原理下一篇讲,我们在执行updateChildren时,因为新老节点的第一个子组件都是helloworld,是sameVnode判断为true,会指向这一步,继续patchVnode;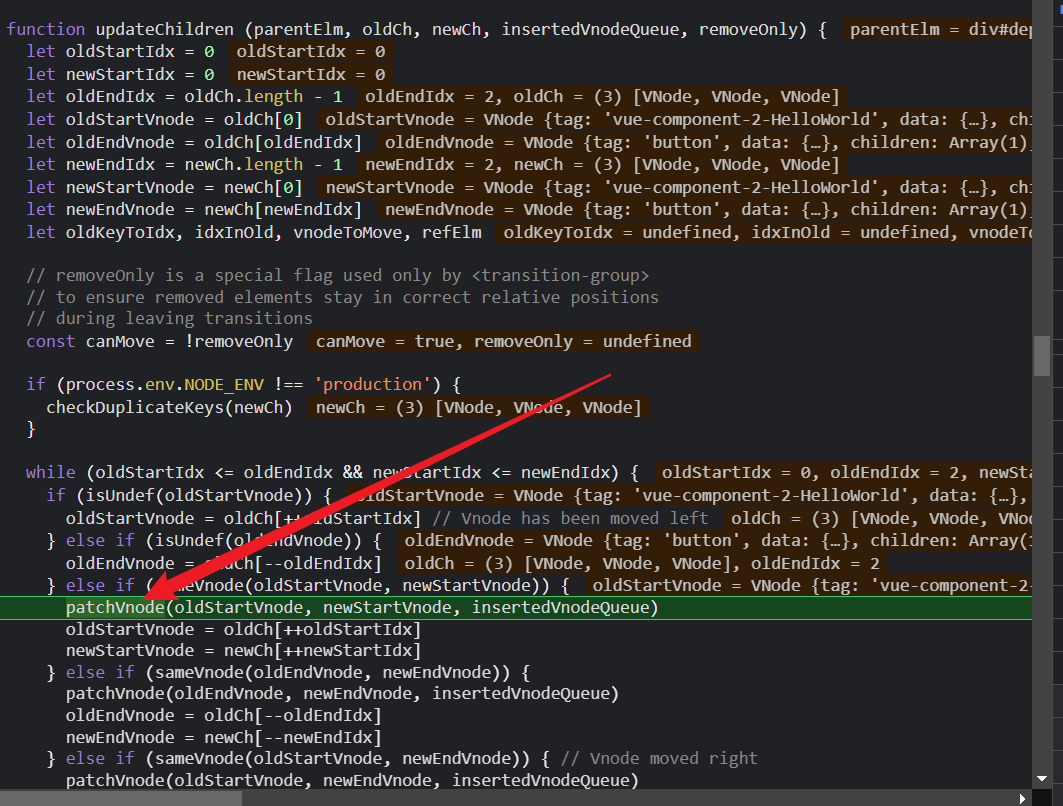
然后我们重新进入了patchVnode组件,但注意这个时候是App组件的子组件,所以就是HelloWorld组件了。
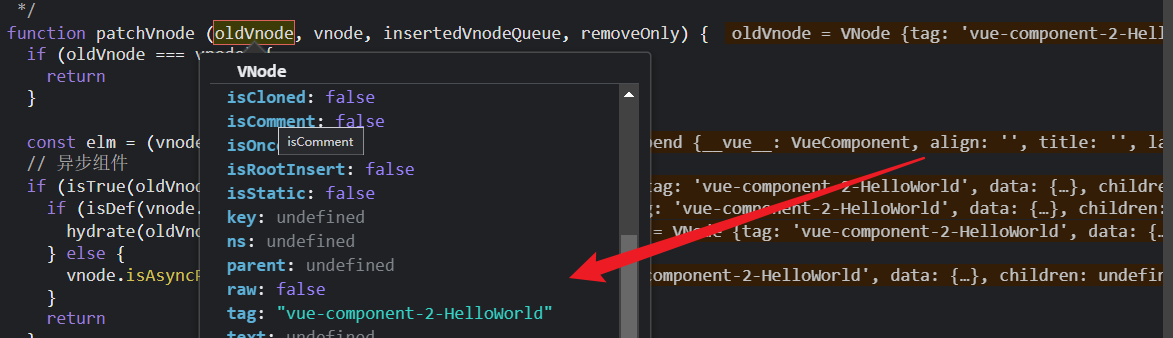
因为helloworld是一个组件占位符vnode,所以它的data拓展了componentVnodeHooks里的几个方法,所以走这一步,即执行prepatch函数

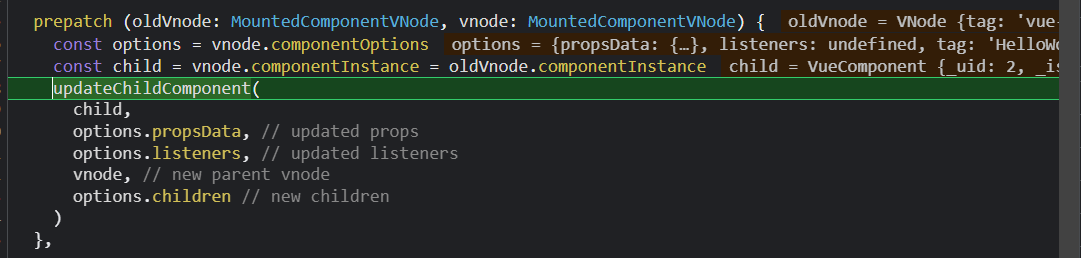
Helloworld组件有props属性,所以走这一步,由于给HelloWorld组件的flag属性赋值,所以会继续触发HelloWorld组件的flag的setter;
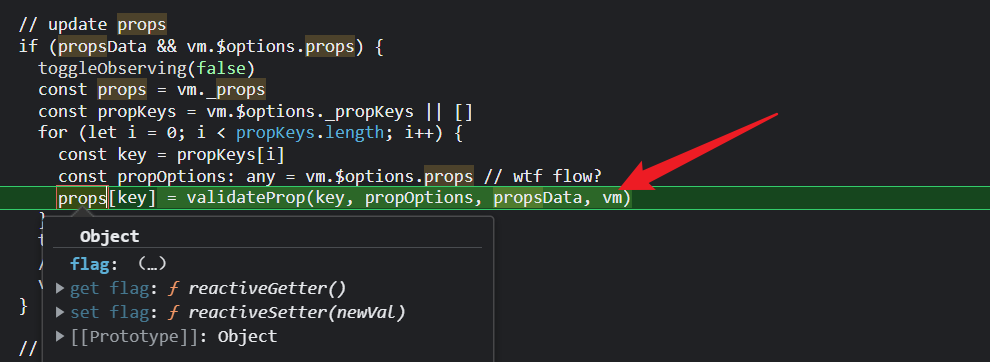
这个HelloWorld组件的dep实例有自己的渲染watcher,
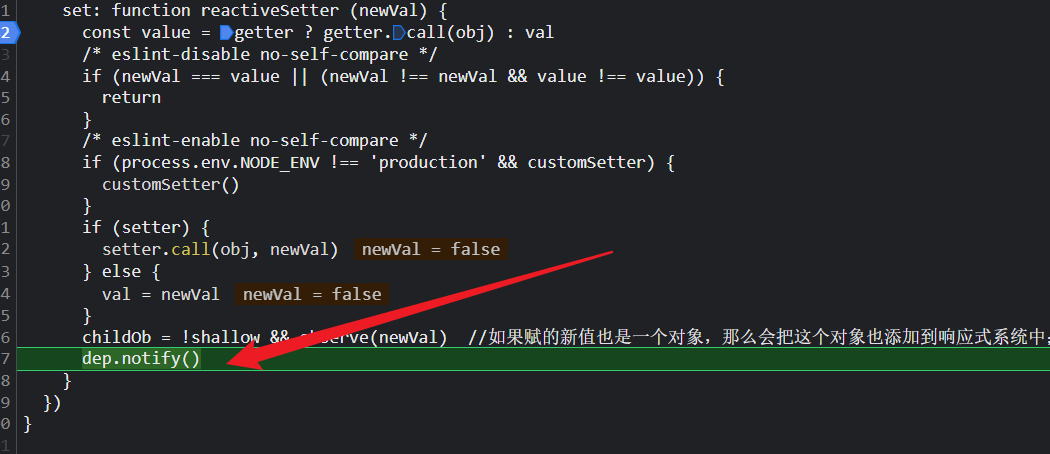
所以HelloWorld组件也会自己重新渲染;所以helloworld组件也会走自己的patch流程;但是都差不多的流程,就不介绍了。
总结:
组件的patch流程是什么;子组件是如何被触发重新渲染的;
四、组件更新之updateChildren
总结:
模板变成了render函数,h函数把render函数的所有内容都变成了vnode;
组件的更新,就使用vnode;
先把每个老节点vnode和新节点的vnode进行同层级比较,
如果不相同,则删除老的真实dom节点,把新的真实dom节点替换上去;
如果新老节点的vnode相同,则调用patchVnode,这个方法主要是比较节点的子节点,找出子节点的差异化。(通过方法的名字也可以看出来,给Vnode打补丁)
1.如果新节点的vnode是文本节点,如果是直接替换
2.如果新节点的vnode不是文本节点,
- 2.1:新老节点,都有子节点,则调用diff算法的核心updateChildren()方法,进行子节点的比较;
- 2.2:新老节点,新节点有子节点,老节点没有子节点,则直接创建新的子节点的真实dom添加上去;
- 2.3:新老节点,新节点没有子节点,老节点有子节点,则直接删除老的子节点的真实dom;
- 2.4:上面的条件都不满足,那说明新老节点都没有子节点,如果这个时候老节点是文本节点,则清楚老节点的内容;
那么新老节点的子节点,调用updateChildren方法进行更新,是个什么样的操作?
首先进入while循环,
通过源码我们知道,是首尾指针法:
1.先判断新老节点的子节点的首首、尾尾、首尾和尾首是否有相等的,有的话通过坐标的方式,直接改老节点的子节点的位置;
2.如果都没有,再通过搜索的方式看老节点的子节点中有没有新节点的第一个子节点即newStartVnode的元素,
- 有的话比如说它是vnodeToMove,那么不管它在哪个位置都给移到老节点的第一个子节点的位置上来,然后vnodeToMove原来在的位置赋值为undefined,然后把newStartVnode的位置加1,即原来的新节点的第二个子节点现在变成第一个了。
- 遍历了所有的老节点的子节点都没有的话,直接新建,放到老节点的第一个子节点上,然后把newStartVnode的位置加1,
3.然后继续整个while循环,直到不满足条件跳出;
https://mp.weixin.qq.com/s?src=11×tamp=1659018975&ver=3948&signature=1UyXxdAjpYm14q7oTfYGjm5AyJfHrYyzkO-rAT3f7-634Vr*WpWiYta7UX3LPDOx*Ben*WxatPjlBv*TvlRrjVY973l4PDFvsgShr7lMZ618DnRxH7IH8f8pQDJCFb4m&new=1
vnode的渲染的好处:
如果新旧节点同层级相同,那么vue会有有以下两种情况的优化:
1.或者是真实dom的位置的调换,并不是真实dom的销毁与重新创建,很节省性能,因为可以减少重排和减少创建dom等工作量; 这句话说的有问题,同层级相同,怎么会是dom位置的调换,应该是直接进行patchVnode,不会直接进行真实dom的重新删除创建;
2.dom的映射后即用js进行diff算法比对,比上真实dom的销毁与重新创建,也可以很节省性能,因为可以减少重排和减少创建dom等工作量;
这两种情况相比单纯的真实dom的销毁与重新创建都尽量减少重排和真实dom的创建;
如果新旧节点同层级不同,那么还是要真实dom的重新删除创建;
总结:使用vnode,比直接操作真实dom会减少性能损耗;
因为我们要探讨updateChildren方法,所以,同级的新老节点我们让他们的sameVnode相同;然后让他们新老节点都有子节点,例子如下:
const App = { name: 'App', data () { return { arr:['a','b','c','d'] } }, template: ` <div id="dependencyDepend"> <ul > <li v-for='item in arr' :key='item'>{{item}}</li> </ul> <button @click="smallToggle">small-toggle</button> //这个用来测试理想状态的首尾指针法 <button @click="bigToggle">big-toggle</button> //这个用来测试,非理想状态下,即新老节点的子节点没有一个相同; <button @click="addToggle">addToggle</button> //这个用来测试添加一个元素后,会如何操作; </div> `, methods: { smallToggle () { this.arr.reverse(); }, bigToggle () { this.arr=[1,2,3,4] }, addToggle () { this.arr.push('e'); }, }, }
我们点击toggle按钮,触发arr的setter,然后dep实例的subs数组保存了渲染watcher,所以会导致渲染watcher的重新渲染,那就是重新走vm_update(vm_render())函数;然后在patch的时候,由于sameVnode新老节点是一样的,都是
<div id="dependencyDepend">
所以走patchVnode;
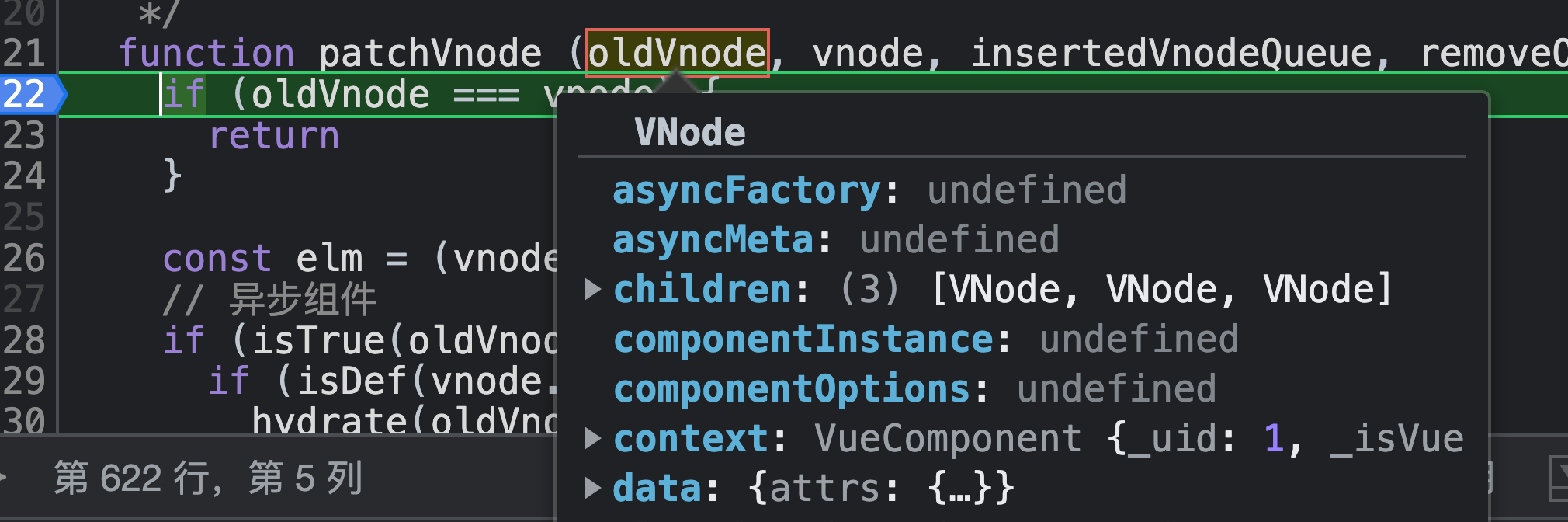
第一次的oldVnode和vnode都是 <div id="dependencyDepend">,且他们都有ul子节点、注释子节点、toggle按钮子节点,所以直接走 updateChildren;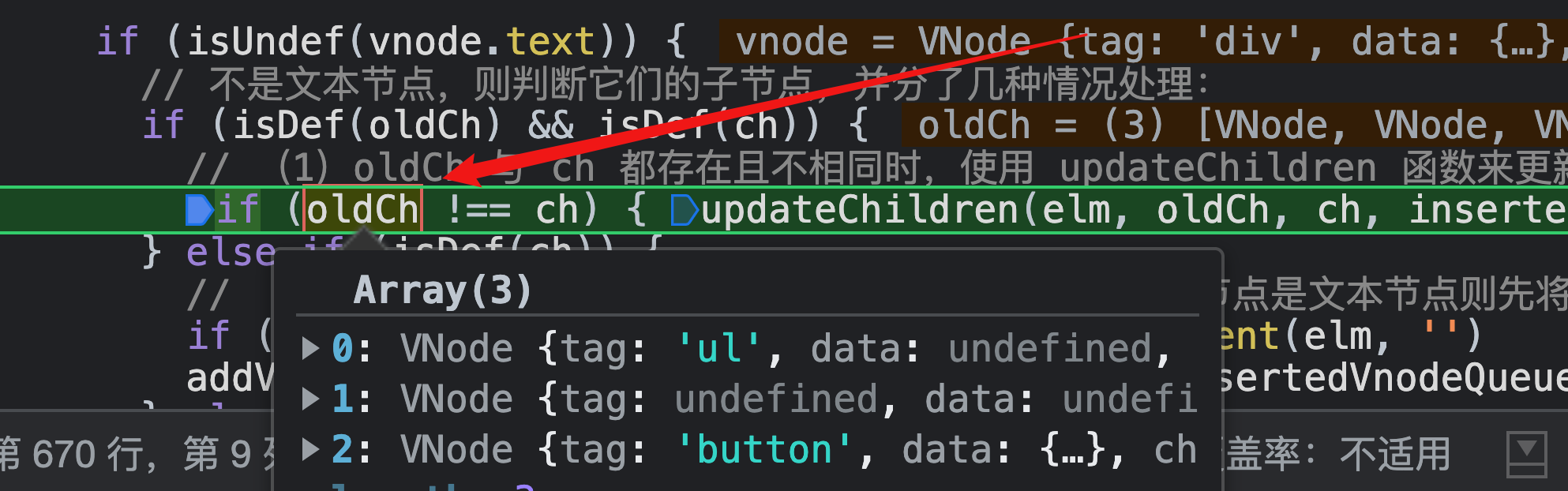
因为老节点和ul子节点和新节点的ul子节点都是第一个,且满足sameVnode,即sameVnode(oldStartVnode, newStartVnode)所以走这一步;
去比较新老ul节点的子节点,即li子节点(算是div节点的孙子节点了)的差异化;
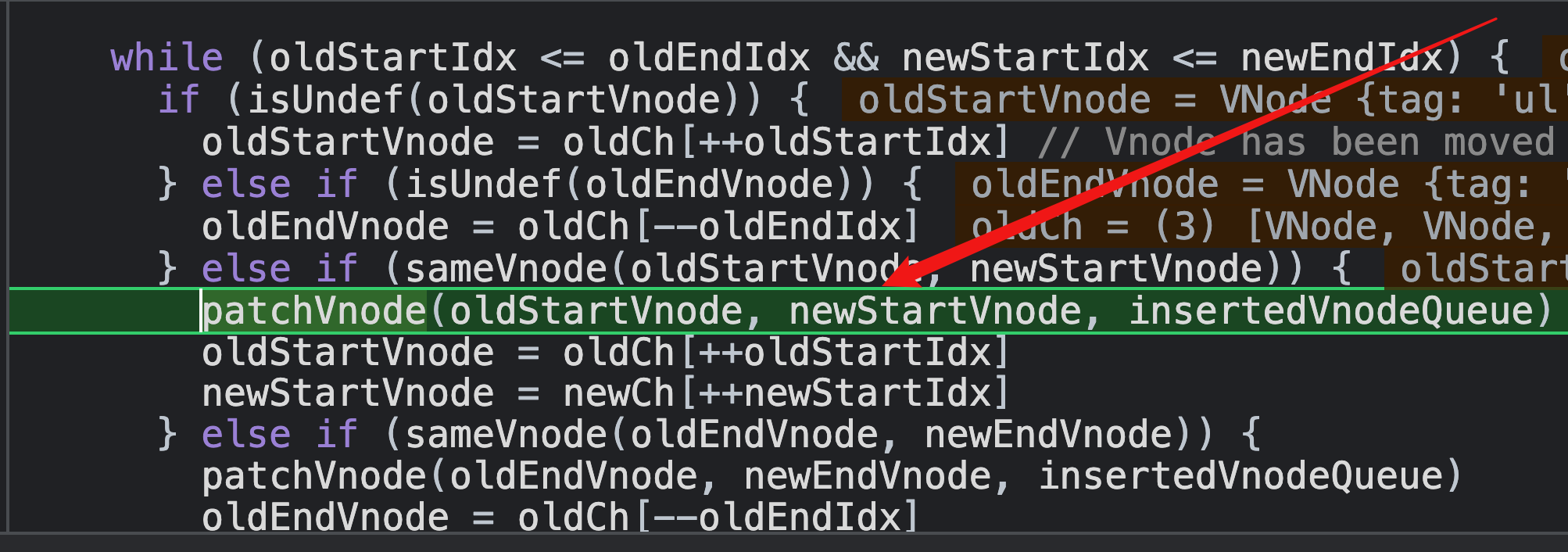
因为,新老ul节点的子节点,即li子节点都存在,一个是<li>a</li>,一个是<li>d</li>,所以继续走updateChildren方法;
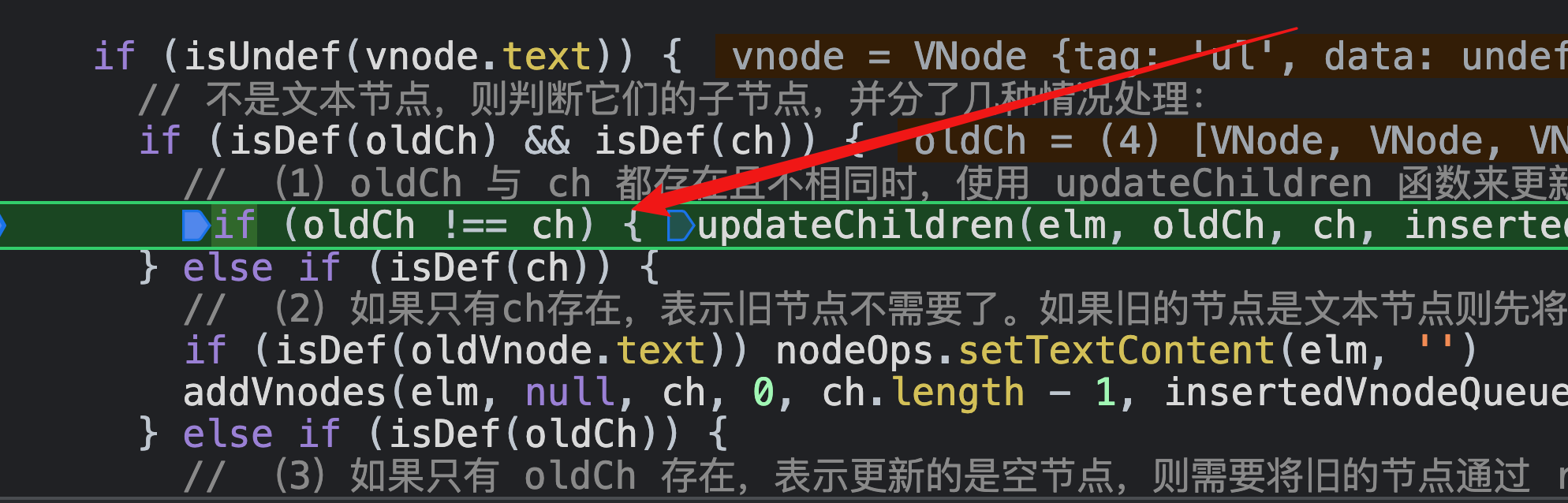
因为oldEndVnode和newStartVnode都是 <li>e</li>,所以走这个;这个patchVnode我就不进行了,它主要是比较<li>e</li>的子节点e,因为都有子节点且,所以还会走updateChildren,然后因为sameVnode(oldStartVnode, newStartVnode,所以继续走patchVnode,但这次是比较新的文本节点e和老的文本节点e的子节点,因为新的节点本老的节点都是是文本节点且值也一样,所以不做任何修改;
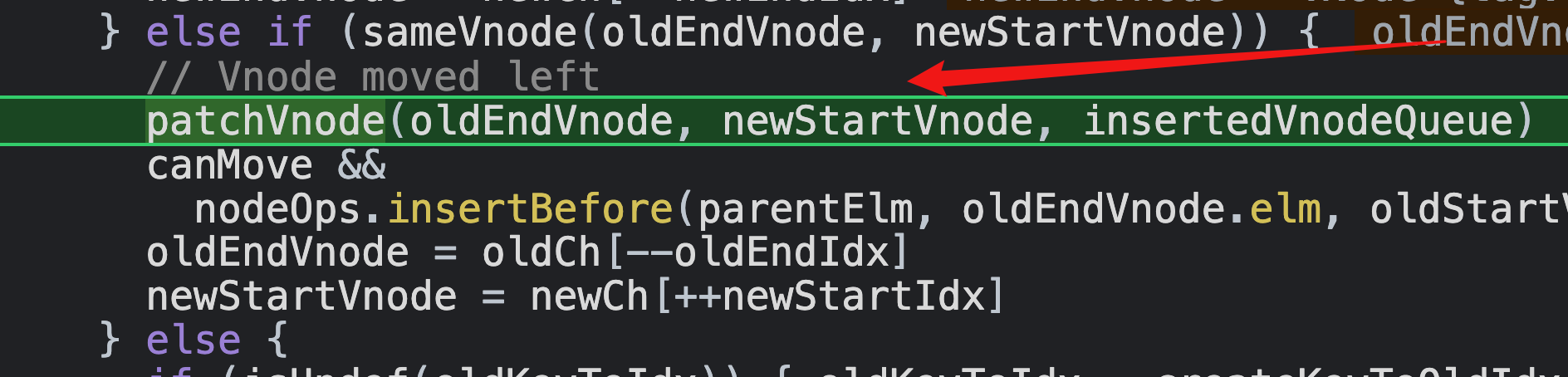
至此,第一个li子节点的即文本节点e的patchVnode结束,然后调用nodeOps.insertBefore,把老节点的最后一个子节点插入到老节点的第一个子节点位置上。这个时候我们就可以看到,他们并不涉及真实dom的销毁与创建,只是调换了下位置,所以说可以节省性能;
然后让老节点的最后一个子节点的坐标--,让新节点的第一个子节点的坐标++。(毕竟原有的第一个和最后一个都比较过了,所以废弃;)
至此,第一次循环结束,进行第二次循环,也就是比较新老ul节点的第二个子节点;
后面的循环就不讲解了,因为流程一样;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号