达梦数据库数据迁移
一、准备工作:
统计oracle基本信息和数据库对象等:
--统计页大小 select name,value from v$parameter where name ='db_block_size';
--查询编码格式 select * from v$nls_parameters a where a.PARAMETER='NLS_CHARACTERSET';
--根据指定用户统计用户下的各对象类型和数目
select object_type,count(*) from all_objects whereowner='OA8000_DM2015' group by object_type;
--创建移植辅助表,统计指定用户下所有的对象并插入到辅助表中
create table oracle_objects(obj_owner varchar(100),obj_name varchar(100),obj_type varchar(50));
insert into oracle_objects select owner,object_name,object_type from
all_objects where owner ='OA8000_DM2015';
select * from oracle_objects;
1.做oracle和达梦数据的备份
2.开启达梦数据库的COMPATIBLE_MODE参数兼容性,开启为2表示兼容oracle
3.观察Oracle的块大小和dm的页大小是否一致,观察Oracle的字符集、大小写敏感是否和dm一致
4.先在目的端创建好用户和表空间,不允许把数据迁移到system用户和main表空间下。
迁移的时候选择模式时,系统自带的不要选。
二、开始迁移
第一步先迁移序列
第二步只迁移表定义即表结构,去掉约束、索引;
如果迁移多张表,可以把左下角的"应用当前选项到其他同类对象"勾上。
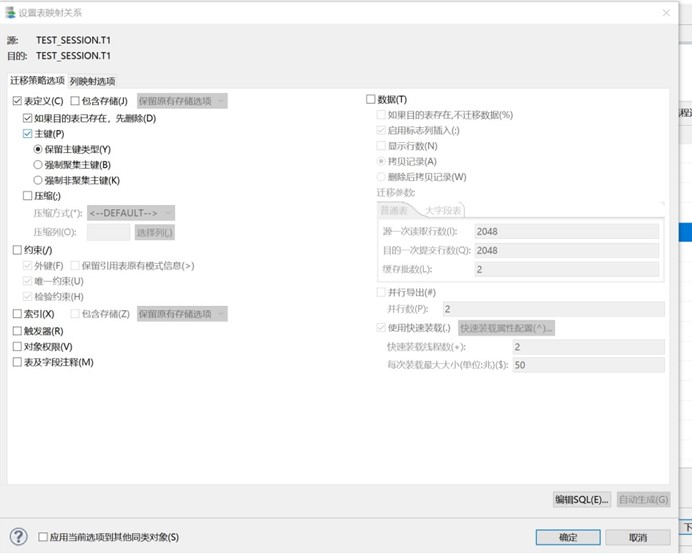
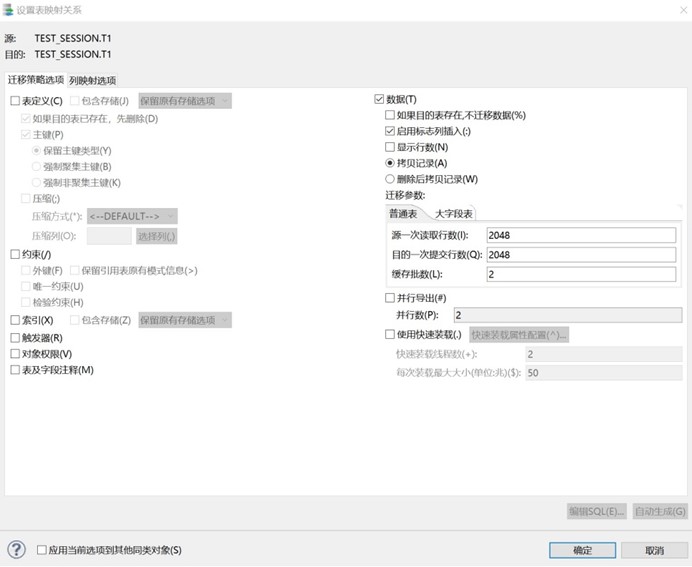
第三步只迁移数据;
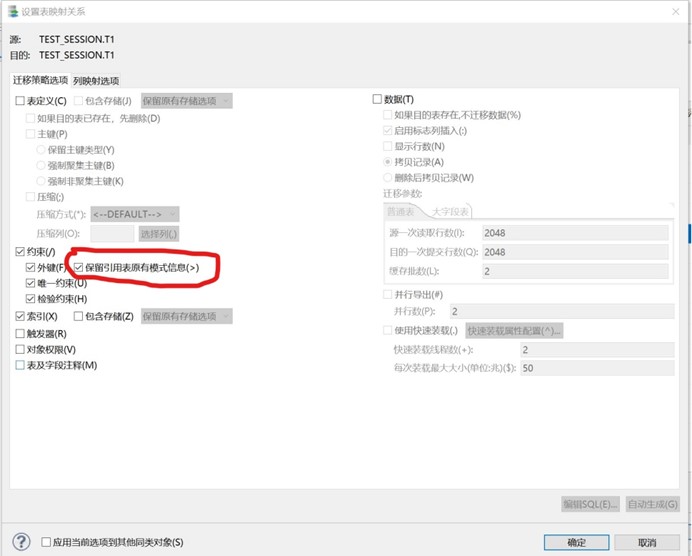
第四步只迁移约束、索引;记住勾选选项(保留引用表原有模式信息)
第五步迁移视图;
第六步迁移函数、触发器、包等,分开迁移。
注意事项:对于表比较少,数据量不大的系统,可以通过DTS采取一次性迁移,全部选中即可
对于表比较多,数据量大的系统,建议先迁移小表再进行大表的迁移,迁移时最好不用快速装载功能。
部分表数据量特别大,单独针对该表迁移,可以选择快速装载
三、比对信息
--统计页大小 select page; --通过编码格式 select unicode; --统计大小写敏感参数 select case_sensitive; --根据指定用户统计用户下的各对象类型和数目 select object_type,count(*) from all_objects where owner='OA8000_DM2015' group by object_type; --统计指定用户下所有的对象,并记录到新的记录表中 create table dm_objects(obj_owner varchar(100),obj_name varchar(100),obj_type varchar(50));
insert into dm_objects select owner,object_name,object_type from all_objects where owner='OA8000_DM2015'; --统计每个表的数据量到表数据记录表 1. create table dm_tables(tab_owner varchar(100),tab_name varchar(100),tab_count int);
2. begin for rec in (select owner,object_name from all_objects where owner='OA8000_DM2015' and object_type='TABLE') loop beginexecute immediate 'insert into dm_tables select '''|| rec.owner ||''','''|| rec.object_name ||''',count(*) from '|| rec.owner || '.' || rec.object_name; exception when others then print rec.owner || '.' || rec.object_name || 'get count error'; end; end loop; end; --对比达梦数据库中对象和 oracle 库中对象以及数据量差异 --比对对象,找出没有迁移的对象 select * from oracle_objects where (obj_owner,obj_name) not in ( select obj_owner,obj_name from dm_objects ) --and obj_type='TABLE' --比对表数据量,找出数据量不相等的表 select a.tab_owner,a.tab_name,a.tab_count-b.tab_count from oracle_tables a, dm_tables b where a.tab_owner=b.tab_owner and a.tab_name=b.tab_name and a.tab_count-b.tab_count<>0
四、收尾工作
更新统计信息 数据核对完成无问题后,应进行一次全库的统计信息更新工作。
统计信息更新脚本示例如下:
DBMS_STATS.GATHER_SCHEMA_STATS(
'HNSIMIS', --HNSIMIS 为模式名
100,
FALSE,
'FOR ALL COLUMNS SIZE AUTO'
);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号