DM性能优化
-
数据库主机的cpu、IO、内存如果使用率很高,是硬件性能问题,还是数据库性能问题?通过修改sql等方式解决?
-
架构是否最优?(海量数据分析应选择mpp集群;高并发事务型应选择主备)
-
参数是否优化
-
sql优化
我们的每个会话都是一个线程,一般来说,我们的每个线程最多是消耗一颗cpu的,也就是100%
只有在parallel_policy这个参数开启的情况下,才会去进行并行操作;
是否开启并行查询去加快查询速度,要先把一条sql的查询时间优化好,再去开启。
-
memory_pool是运行时内存,计算时需要消耗的内存
-
buffer是数据缓冲区,它是内存的一部分,主要存放数据页;它是磁盘数据在内存的一个副本。
当数据量比较大的话,为了避免对磁盘大量IO,需要将buffer设置的大一些。
-
buffer_pool是buffer切片;为什么需要把一个buffer分成几个片?因为buffer里有很重要的数据,会话会频繁地访问buffer,而buffer为了安全考虑,是会自动上锁的,如果只有一个buffer,大量进程竞争性访问buffer,会导致buffer上锁解锁时间过长,进程等待时间长,导致降低性能,这时分为几个不同的buffer片,大家可以访问不同的buffer片,将竞争分散进程等待时间短,有效提高性能。
可以通过select * from v$system_event观察是否有buffer_busy记录,如果有说明我们的buffer竞争很激烈,需要修改buffer_pool这个参数,增加一些buffer片数;最终分块效果通过V$buffer_pool查询
-
recycle是临时表缓冲区,和buffer一样也是内存的一部分。当我们写一些sql比如create没有commit时就会放在这块内存里,或者我们的sql里有sort、hash join、hagr时数据也会暂时存放在recycle中。如果这一块内存不大的话,那么数据就会写入TEMP.DBF文件中,但是我们知道,TEMP.DBF文件初始大小是不大的,如果数据很多,TEMP.DBF就要不停的拓展(每次拓展为1M),而拓展其实是一个系统中断的过程,很影响数据库处理性能。
-
recycle_pool:和buffer_pool一样
-
cache_pool_size: SQL缓冲区,和buffer不一样的是它存放的东西很明确,就是执行计划、sql语句、结果集、PACKAGE信息;如果这个设置的过小,可能对导致上一个sql语句被淘汰,下一个相似的sql进行缓冲区时会进行硬解析;
-
dict_buf_size:数据字典缓冲区
可以通过视图select * from v$db_cache查询,如果发现lru_discard项的值比较大,说明因为数据字典缓冲区过小淘汰了很多对象了,需要适当把缓冲区调大;
-
hj_buf_global_size:表示数据库一共可以分配多少内存进行hj操作(hj是hash join哈希连接,hagr是hash agr聚集操作)
hj_buf_size: 表示一个hash join操作,最多可使用多少内存
hj_blk_buf_size: 表示每次要内存的时候申请多少
数据库会话监控:
-
--查询活动会话数 select count(*) from v$sessions where state='ACTIVE';
-
--已执行超过2秒的活动SQL select * from ( SELECT sess_id,sql_text,datediff(ss,last_send_time,sysdate) Y_EXETIME, SF_GET_SESSION_SQL(SESS_ID) fullsql,clnt_ip FROM V$SESSIONS WHERE STATE='ACTIVE') where Y_EXETIME>=2;
-
--锁查询 select o.name,l.* from v$lock l,sysobjects o where l.table_id=o.id and blocked=1
-
--阻塞查询
--简略版
select * from v$trxwait;(可以查询出事务A等待事务B等待了多久)
select sql_text from v$sessions where trx_id in (事务id,事务id,事务id。。。); (可以查询出这个事务id所对应的sql是什么)
--详细版
with locks as( select o.name,l.*,s.sess_id,s.sql_text,s.clnt_ip,s.last_send_time from v$lock l,sysobjects o,v$sessions s where l.table_id=o.id and l.trx_id=s.trx_id ), lock_tr as ( select trx_id wt_trxid,row_idx blk_trxid from locks where blocked=1), res as( select sysdate stattime,t1.name,t1.sess_id wt_sessid,s.wt_trxid, t2.sess_id blk_sessid,s.blk_trxid,t2.clnt_ip,SF_GET_SESSION_SQL(t1.sess_id) fulsql, datediff(ss,t1.last_send_time,sysdate) ss,t1.sql_text wt_sql from lock_tr s,locks t1,locks t2 where t1.ltype='OBJECT' and t1.table_id<>0 and t2.ltype='OBJECT' and t2.table_id<>0 and s.wt_trxid=t1.trx_id and s.blk_trxid=t2.trx_id) select distinct wt_sql,clnt_ip,ss,wt_trxid,blk_trxid from res;
sql优化
1.数据库大部分性能问题最后都还是要sql优化;sql优化的处理流程是:
-
生成日志(开启dm.ini参数中的svr_log)
-
日志入库(使用DmLog.jar工具把日志进入到自己的测试库中,产生excel表)
-
分析sql
-
优化方案
2.优化目标为:按并发量来,先将并发非常高(就是执行的次数非常多)的优化下;再者并发一般,再者并发很少;
4.ET的使用
开启参数ENABLE_MONITOR=1; MONITOR_SQL_EXEC=1; MONITOR_TIME=1;后,方可已使用ET;
在disql中,输入ET(执行号)即可;
注意:monitor_sql_extc不要在生产环境全局打开,可以会话级打开;会话级打开命令为call sf_set_session_para_value();
5、call_set_para_value(数值,名字,数值)的使用
这个是用来修改ini文件中可动态修改的动态参数和静态参数的。
其中:
-
第一个参数可取值0、1、2;
0表示只在内存中修改,1表示在内存和文件中同时修改,2表示只在文件中修改;
-
第二个参数就是ini文件里参数的名字
-
第三个参数是你想要修改的值,比如20480;
6、阻塞与死锁
阻塞分为:
-
事务型阻塞:
比如会话A正在更新test表的某条记录 比如在执行update test set id =5 where id =3 ;执行完后,会话A未commit;
这个时候会话B执行一条update test set id =7 where id =3 ;这个时候就会发生会话B事务等待会话A事务commit的过程,这个就是阻塞;
-
系统型阻塞
调度作业由 TASK_THREAD负责 ,除此之外,task_therad线程还负责我们的PURGE 操作(DELETE 了一条数据,不是标记为不可见,而是真实的腾出物理空间) 如果此时我的调度作业很多,而且执行时间很长 TASK_THREAD是有限的,就那么几个线程全部被调度作业占据
明显的 PURGE 动作就被阻塞,这个就是系统性阻塞。
通过查询select * from V$task_queue可以查询任务队列的情况,如果waiting非常多,说明我们的task thread线程太忙了,可以修改dmini文件的taskthread参数,多增几个线程;
二、DM执行计划
1、介绍
什么是执行计划?一条SQL语句在数据库中执行过程或访问路径的描述;
举例:

- 一个执行计划由若干个计划节点组成,如上图中的1、2、3
- 每个计划节点中包含操作符(CSCN2)和它的代价([0, 1711, 396])等信息, 代价由一个三元组组成[代价,记录行数,字节数]
- 代价的单位是毫秒,记录行数表示该计划节点输出的行数,字节数表示该计划节点输出的字节数(也就是数据长度)
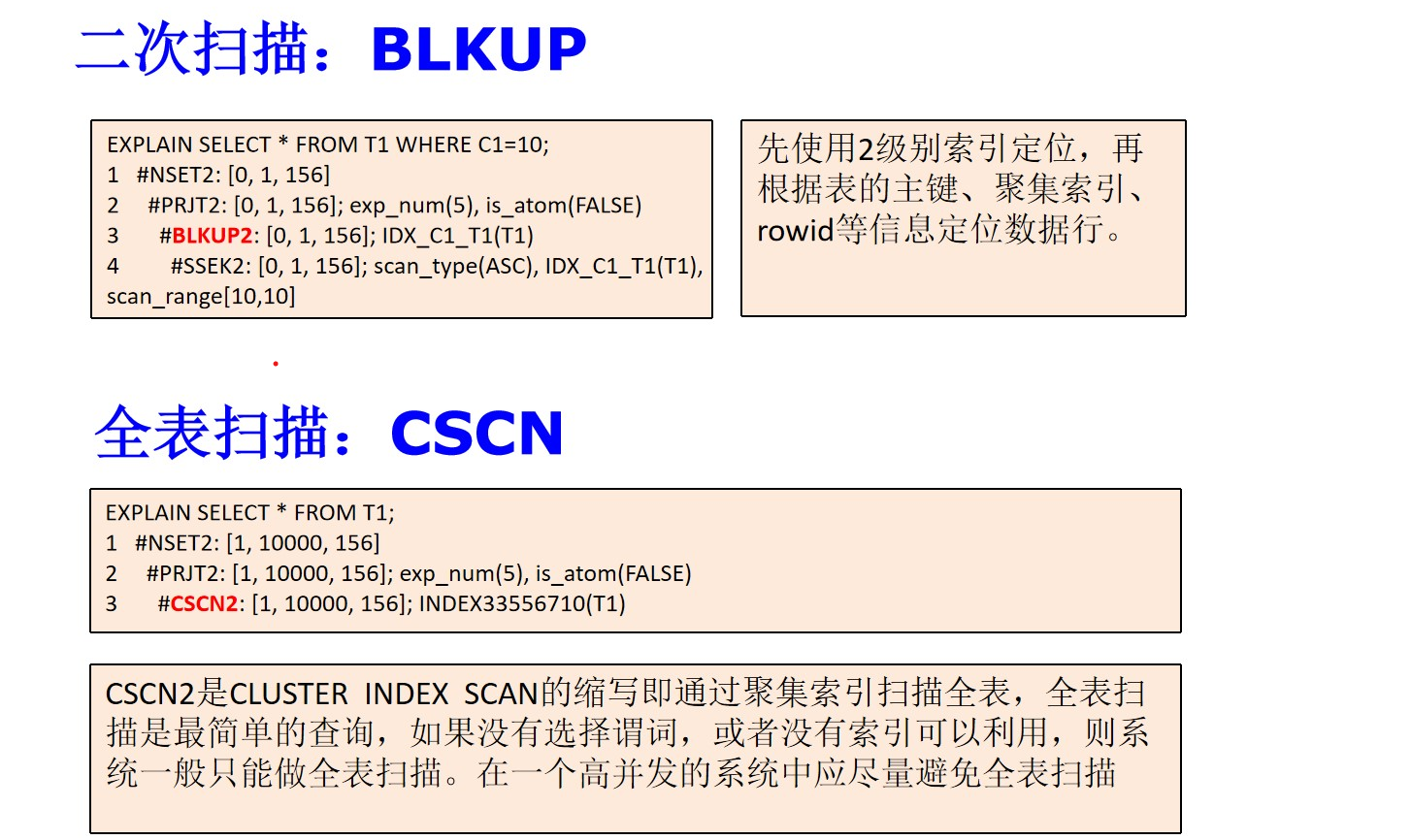
-解读一下第三个计划节点:操作符是CSCN2即全表扫描,代价估算是0ms,扫描的记录行数是1711行,输出字节数是396个
2、执行计划中的常用操作符介绍



![]()
- hagr就是hash agr;sagr就是 sort agr;只有说要么手工进行排序,要么在计划里进行排序,导致拿出来的记录是有顺序的,那么才可以走sagr;任何情况都可以走hagr;
![]()


3、连接
nest loop
nest loop with index
hash join
merge
三、统计信息和索引
1、统计信息定义
什么是统计信息?
统计信息主要是描述数据库中表,索引的大小,规模,数据分布状况等的一类信息。比如,表的行数,块数,平均每行的大小,索引的高度、叶子节点数,索引字段的行数,不同值的大小等,都属于统计信息。
2、索引存储结构
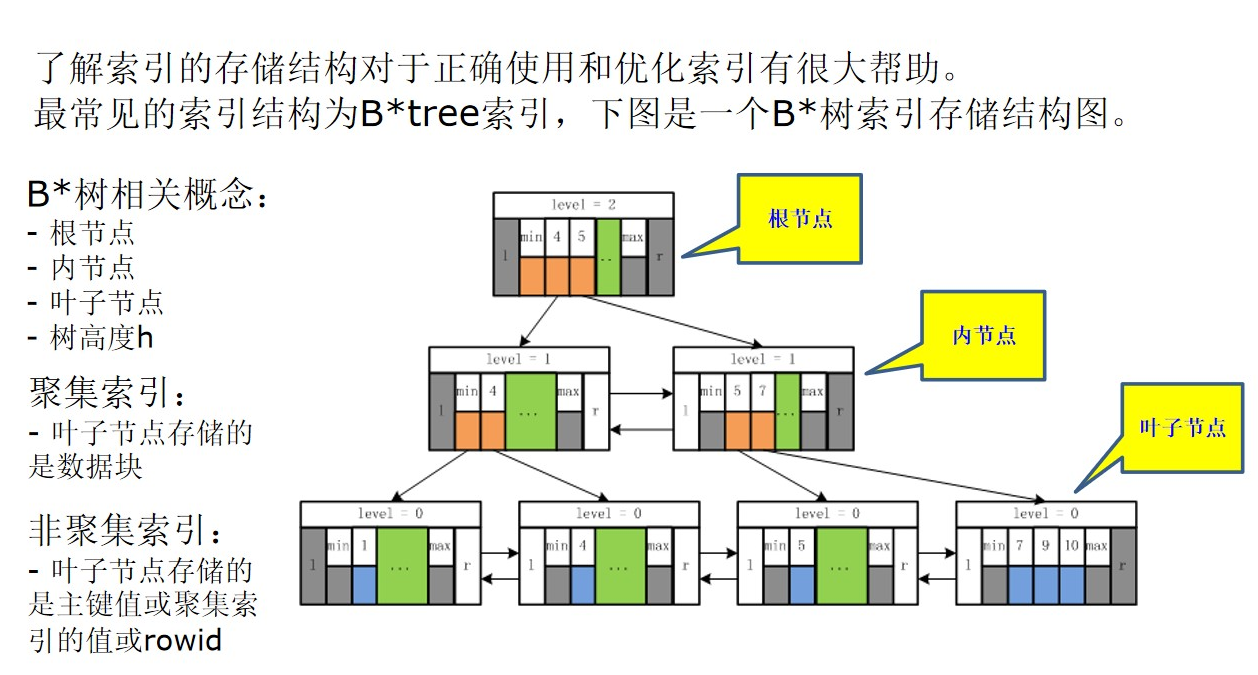
由于每个节点的大小都是占用一个数据页,我们可以通过空间的占用情况来查询节点数。

3、创建索引的原则
-
原则1:根据索引查询只返回很少一部分行
- 原则2:索引作为一个较瘦版本的表(对于一个宽列的表来说,如果只想查询其中的一两列,那么建一个只有一两列的索引是很好的,然后将索引当作一个瘦表,对索引查询)
-
原则3:组合索引列的顺序:(1)最优先把等值匹配的列放最前面,范围匹配的放后面 (2)其次把过滤性好的列放前面,过滤性差的放后面 (3)查询时组合索引只能利用一个非等值字段
注意:
1、在CREATE INDEX语句中列的排序会影响查询的性能。通常,将最常用的列放在最前面。
2、如果查询中有多个字段组合定位,则不应为每个字段单独创建索引,而应该创建一个组合索引。
3、当两个或多个字段都是等值查询时,组合索引中各个列的前后关系是无关紧要的。
但是如果是非等值查询时,要想有效利用组合索引,则应该按等值字段在前,非等值字段在后的原则创建组合索引,查询时只能利用一个非等值的字段。
4、为什么不走索引?
-
案例1:条件列不是索引的首列
-
案例2:条件列上有函数或计算
-
案例3:存在隐式类型转换
-
案例4:如果走索引会更慢
-
案例5:没有更新统计信息
5、索引对DML语句的影响


 浙公网安备 33010602011771号
浙公网安备 33010602011771号