深度学习 - 图片编码压缩实践
图片编码实践
对图片编码的作用有很多:
- 极大降低图片的存储空间,相当于对图片压缩;
- 方便计算图片与图片之间的计算,这方面应用就很多了,比如相关图片搜索等
非机器学习方法
非机器学习的方法有“感知哈希算法”(Perceptual hash algorithm),它的作用是对每张图片生成一个”指纹”(fingerprint)字符串,然后比较不同图片的指纹。结果越接近,就说明图片越相似。由于生成的是64为01编码,一般采用hamming距离来度量。
其中phash算法对于图片缩放无感知,一般适合找到完全相同的图片和缩略图找图,对于图片相关但是不同的图片效果比较差。
这种方法的特点是编码速度很快,但是在很多业务上效果并不理想。该方法网上资料特别多,现成代码也不少,大家可以自行翻阅,下面着重介绍下采用深度学习的一些实践。
深度学习方法
深度学习的方法有基于有监督的编码和无监督的编码,使用场景不同。
有监督标签的学习编码
如果图片是有类别分类的,可以通过分类模型,取中间的隐藏层来作为编码输出结果。
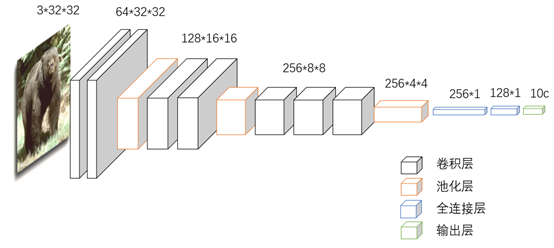
这种方法本质就是一个分类模型,输出层的分类结果越准确,编码效果也越好。
- 模型输入为cifar10的样本图片(10个类别的32*32图片);
- 图片的特征提取采用卷积层+池化层若干,这里图像是3通道的彩色图片,然后拼接两层全连接层(fc),最后通过softmax作为输出层选择分类;
- 当然也可以通过迁移学习如vgg16等模型来提升效果;
- 最后取全连接层128作为输出进行编码。
这种方法主要看分类效果,一般效果比较好。
非监督标签的学习编码
无监督编码其实是自标注编码思想,即通过编码(压缩)+解码(解压缩)的方式对图片处理,将图片作为压缩后的短编码输出,作为图片的表示。这种方法输入和输出相同,就无需人工标注,只要有图片自己学自己即可。
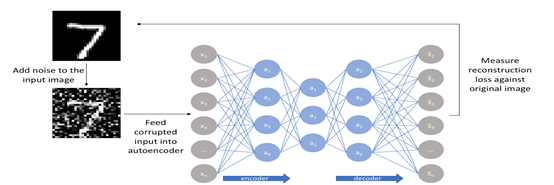
这种形式也是最普遍的先编码、再解码的形式,同样输出中间层作为编码结果。

模型结构同样是利用卷积层+池化层来提取特征,上面的模型是和有监督的方式差不多,只不过最后一层输出层和原始图片大小一致,做回归的误差计算。如果不用全连接层,采用反卷积还原图片,效果也是差不多的。
1 MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder() 2 .seed(12345) 3 .weightInit(WeightInit.XAVIER) 4 .updater(new AdaGrad(0.05)) 5 .activation(Activation.LEAKYRELU) 6 .l2(0.0001) 7 .list() 8 .layer(new ConvolutionLayer.Builder(2, 2) 9 .nIn(1) 10 .stride(1, 1) 11 .nOut(20) 12 .cudnnAlgoMode(cudnnAlgoMode) 13 .build()) 14 .layer(new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.MAX) 15 .kernelSize(2, 2) 16 .stride(2, 2) 17 .build()) 18 .layer(new ConvolutionLayer.Builder(2, 2) 19 .stride(1, 1) // nIn need not specified in later layers 20 .nOut(50) 21 .cudnnAlgoMode(cudnnAlgoMode) 22 .build()) 23 .layer(new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.AVG) 24 .kernelSize(2, 2) 25 .stride(2, 2) 26 .build()) 27 .layer(new DenseLayer.Builder().nIn(height * width).nOut(1024).dropOut(0.6) 28 .build()) 29 .layer(new DenseLayer.Builder().nIn(1024).nOut(512) 30 .build()) 31 .layer(new DenseLayer.Builder().nIn(512).nOut(128) 32 .build()) 33 .layer(new DenseLayer.Builder().nIn(128).nOut(512) 34 .build()) 35 .layer(new DenseLayer.Builder().nIn(512).nOut(1024) 36 .build()) 37 .layer(new OutputLayer.Builder().nIn(1024).nOut(height * width) 38 .lossFunction(LossFunctions.LossFunction.MSE) 39 .build()) 40 .build();
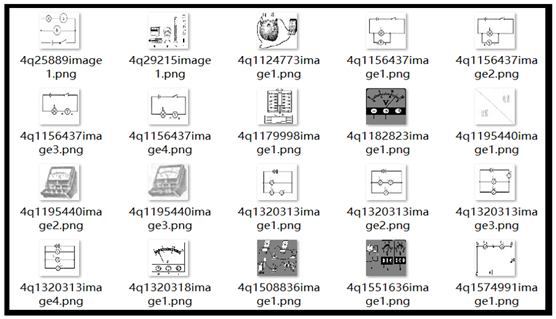
实验结果示例
挑选了一些试卷中的图片缩放到64*64,由于对颜色没有要求,就都处理成单通道黑白图片了,计算量小一些,图片如下:
根据训练学习后,编码后还原的图片如下:
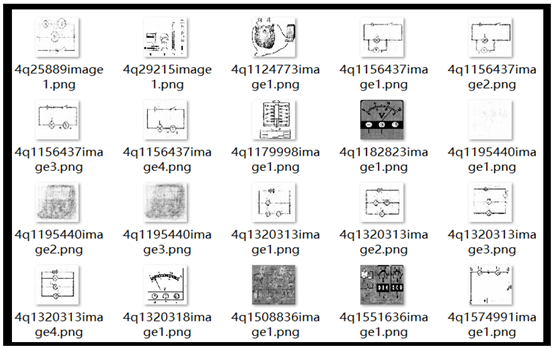
可以看出来还原的图片几乎效果已经很相近了。
【图片相似度】我们选取一张图片,通过模型取出128维编码来找出图库中相关的图片。左边为原始比较图片,右边为其他Top5相关图片:
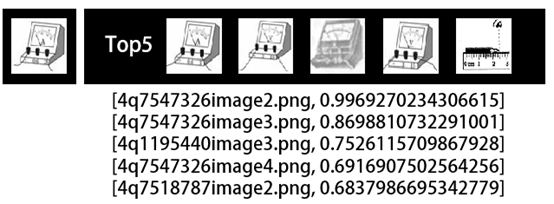

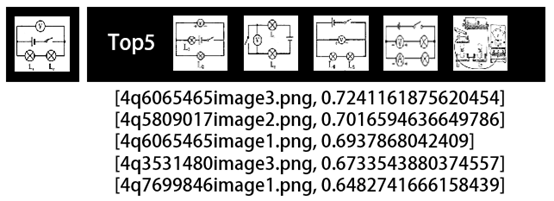
总的来说效果还行,感兴趣的同学可以进行尝试。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号