ELK日志系统介绍
ELK介绍
需求背景:
- 业务发展越来越庞大,服务器越来越多
- 各种访问日志、应用日志、错误日志量越来越多,导致运维人员无法很好的去管理日志
- 开发人员排查问题,需要到服务器上查日志,不方便
- 运营人员需要一些数据,需要我们运维到服务器上分析日志
为什么要用到ELK:
一般我们需要进行日志分析场景:直接在日志文件中 grep、awk 就可以获得自己想要的信息。但在规模较大也就是日志量多而复杂的场景中,此方法效率低下,面临问题包括日志量太大如何归档、文本搜索太慢怎么办、如何多维度查询。需要集中化的日志管理,所有服务器上的日志收集汇总。常见解决思路是建立集中式日志收集系统,将所有节点上的日志统一收集,管理,访问。
大型系统通常都是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。
一个完整的集中式日志系统,需要包含以下几个主要特点:
- 收集-能够采集多种来源的日志数据
- 传输-能够稳定的把日志数据传输到中央系统
- 存储-如何存储日志数据
- 分析-可以支持 UI 分析
- 警告-能够提供错误报告,监控机制
而ELK则提供了一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用。是目前主流的一种日志系统。
ELK简介:
ELK是三个开源软件的缩写,分别为:Elasticsearch 、 Logstash以及Kibana , 它们都是开源软件。不过现在还新增了一个Beats,它是一个轻量级的日志收集处理工具(Agent),Beats占用资源少,适合于在各个服务器上搜集日志后传输给Logstash,官方也推荐此工具,目前由于原本的ELK Stack成员中加入了 Beats 工具所以已改名为Elastic Stack。
Elastic Stack包含:
-
Elasticsearch是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。详细可参考Elasticsearch权威指南
-
Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
-
Kibana 也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
- Beats在这里是一个轻量级日志采集器,其实Beats家族有6个成员,早期的ELK架构中使用Logstash收集、解析日志,但是Logstash对内存、cpu、io等资源消耗比较高。相比 Logstash,Beats所占系统的CPU和内存几乎可以忽略不计
ELK Stack (5.0版本之后)--> Elastic Stack == (ELK Stack + Beats)。目前Beats包含六种工具:
- Packetbeat: 网络数据(收集网络流量数据)
- Metricbeat: 指标 (收集系统、进程和文件系统级别的 CPU 和内存使用情况等数据)
- Filebeat: 日志文件(收集文件数据)
- Winlogbeat: windows事件日志(收集 Windows 事件日志数据)
- Auditbeat:审计数据 (收集审计日志)
- Heartbeat:运行时间监控 (收集系统运行时的数据)
上面是一些官方说明,比较清晰明了,下面是一般的ELK架构:
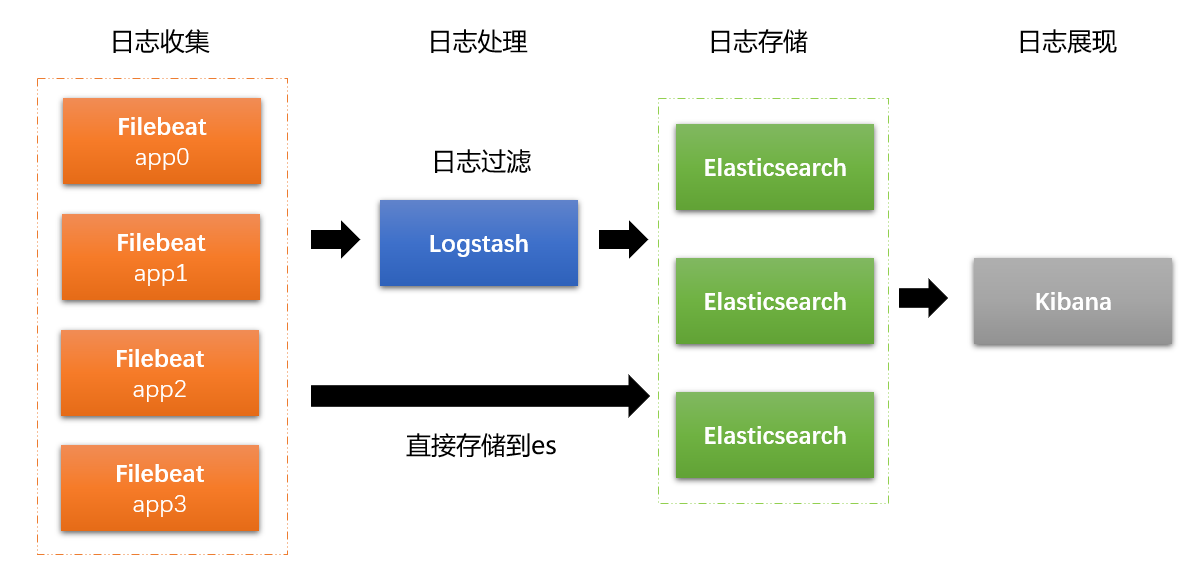
filebeat是作为客户端的日志收集器,部署在若干个产出日志的应用系统上,将数据传输到es集群和logstash服务,传递给logstash的数据会被进一步处理最终流入es集群,kibana从es中获取索引日志信息进行展现。
之后会依次详细介绍logstash、beats、kibana组件,由于在工作中elasticsearch是作为存储组件使用的,无需特别调研,就不详细介绍了,只介绍些在elk中使用到的操作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号