Hadoop 2.x简介
Hadoop 2.0产生背景
- Hadoop1.0中HDFS和MapReduce在高可用、扩展性等方面存在问题
- HDFS存在的问题
- NameNode单点故障,难以应用于在线场景
- NameNode压力过大,且内存受限,影响系统扩展性
- MapReduce存在的问题
- JobTracker访问压力大,影响系统扩展性
- 难以支持除MapReduce之外的计算框架,比如Spark 、Storm等
MapReduce是离线计算框架,计算时间会比较长
Spark是内存计算框架,更快
Storm是流计算框架,可实时获取计算结果
Hadoop 1.x 与Hadoop 2.x
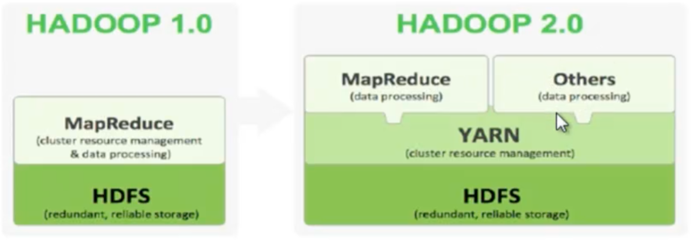
- Hadoop 2.x由HDFS、MapReduce和YARN三个分支构成
- HDFS : NN Federation、HA;
- MapReduce : 运行在YARN上的MR
- YARN : 资源管理系统(内存、CPU资源)
Federation把元数据分成两个独立的NameNode去工作。
YARN知道任何一台机器的使用情况,在执行任务的时候,首先去YARN上申请,YARN 分配到某台机器上去执行,可做到资源不浪费
HDFS存储的数据可由MapReduce进行计算,也可以由其它的计算框架计算
HDFS 2.x优点
- 解决HDFS 1.0中单点故障和内存受限问题
- 解决单点故障
- HDFS HA : 通过主备NameNode解决(只有一个NameNode正常工作,其它都是备用)
- 如果主NameNode发生故障,则切换到备NameNode上
- 解决内存受限问题
- HDFS Federation(联邦)
- 水平扩展,支持多个NameNode
- 每个NameNode分管一部分目录(相互独立)
- 所有NameNode共享所有DataNode存储资源
- 2.x仅是架构上发生了变化,使用方式不变
- 对HDFS使用者透明
- HDFS 1.X中的命令和API仍可以使用


 浙公网安备 33010602011771号
浙公网安备 33010602011771号