
作业五:jieba分词——西游记相关的分词,出现次数最高的20个。
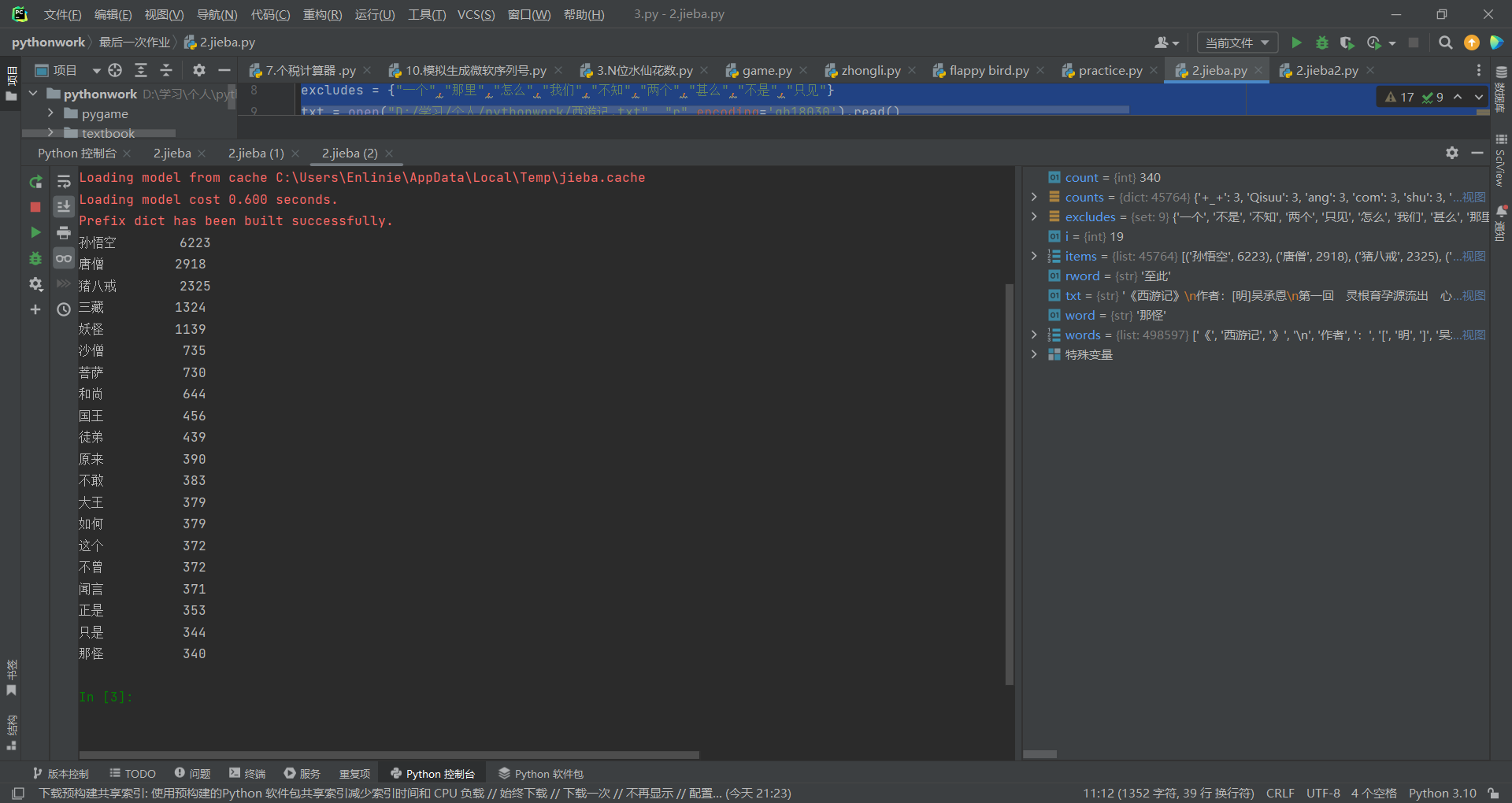
1 import jieba 2 ''' 3 f = open("D:/学习/个人/pythonwork/西游记.txt", 'r', encoding='utf-8') 4 txt =f.read() 5 if txt.startswith(u'\ufeff'): 6 content = txt.encode('utf8')[3:].decode('utf8') 7 ''' 8 excludes = {"一个","那里","怎么","我们","不知","两个","甚么","不是","只见"} 9 txt = open("D:/学习/个人/pythonwork/西游记.txt", "r",encoding='gb18030').read() 10 words = jieba.lcut(txt) 11 counts = {} 12 13 for word in words: 14 if len(word) == 1: 15 continue 16 elif word == "孙猴子" or word == "石猴" or word == "孙行者" or word == "齐天大圣" or word == "弼马温" or word == "斗战胜佛" or word == "行者" or word == "大圣" or word == "俺老孙" or word == "老孙" or word == "悟空": 17 rword = "孙悟空" 18 elif word == "江流儿" or word == "长老" or word == "师父": 19 rword = "唐僧" 20 elif word == "猪刚鬣" or word == "八戒" or word == "老猪" or word == "二师兄" or word == "呆子": 21 rword = "猪八戒" 22 elif word == "沙悟净" or word == "卷帘大将" or word == "沙河尚": 23 rword = "沙僧" 24 elif word == "妖精" or word == "妖魔" or word == "妖道": 25 rword = "妖怪" 26 elif word=="佛祖": 27 rword="如来" 28 elif word=="三太子": 29 rword="白马" 30 else: 31 rword = word 32 counts[rword] = counts.get(rword,0) + 1 33 for word in excludes: 34 del(counts[word]) 35 items = list(counts.items()) 36 items.sort(key=lambda x: x[1], reverse=True) # 根据词语出现的次数进行从大到小排序 37 38 for i in range(20): 39 word, count = items[i] 40 print("{0:<10}{1:>5}".format(word, count))
运行结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号