数据采集与融合技术实践第二次作业
数据采集与融合技术实践第二次作业
码云地址:https://gitee.com/ma-xin1/data-acquisition/tree/master/作业2
作业①
– 要求:在中国气象网(http://www.weather.com.cn)给定城市集的 7 日天气预报,并保存在数据库。
– 输出信息:
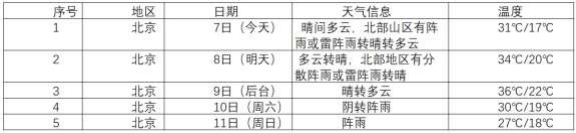
Gitee 文件夹链接:https://gitee.com/ma-xin1/data-acquisition/blob/master/作业2/task1.py
1.实践过程
打开指定页面F12查看页面源码
定位到要爬取的相关信息
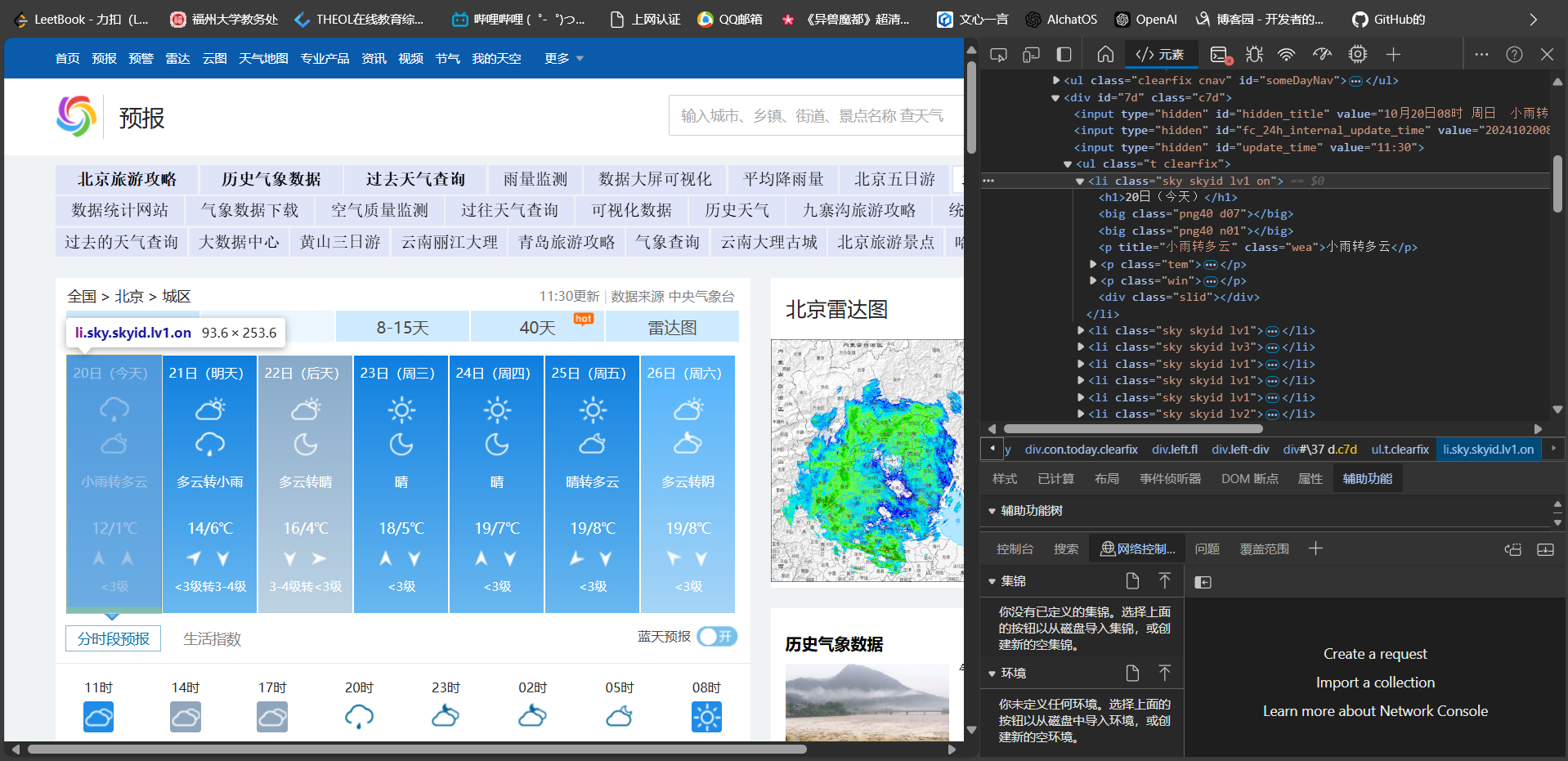
通过分析发现爬取数据都在li标签下
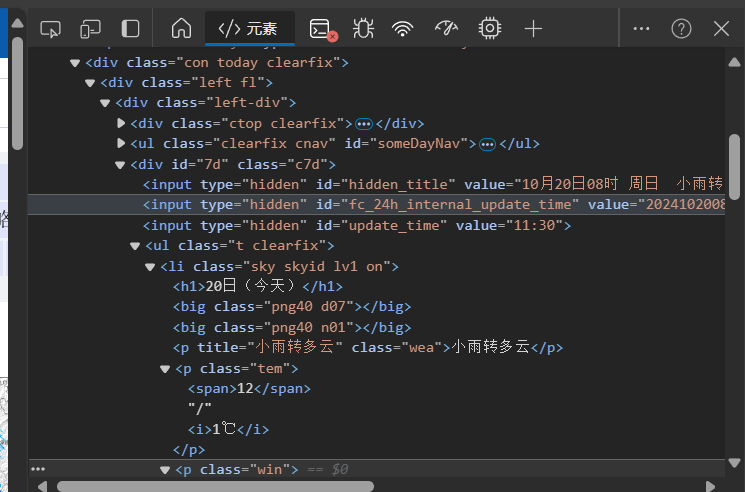
爬取定位的相关代码
点击查看代码
def forecastCity(self, city):
if city not in self.cityCode.keys():
print(city + " 找不到代码")
return
url = "http://www.weather.com.cn/weather/" + self.cityCode[city] + ".shtml"
try:
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
lis = soup.select("ul[class='t clearfix'] li")
x = 0
for li in lis:
try:
date = li.select('h1')[0].text
weather = li.select('p[class="wea"]')[0].text
temp = li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text
print(city, date, weather, temp)
self.db.insert(city, date, weather, temp)
except Exception as err:
print(err)
except Exception as err:
print(err)
2.心得体会
改任务中的信息定位较为简单,数据爬取比较顺利,增加了储存到数据库中的步骤,学习了如何可视化数据库
作业②
– 要求:用 requests 和 BeautifulSoup 库方法定向爬取股票相关信息,并 存储在数据库中。
– 候选网站:东方财富网:https://www.eastmoney.com/ 新浪股票:http://finance.sina.com.cn/stock/
– 技巧:在谷歌浏览器中进入 F12 调试模式进行抓包,查找股票列表加 载使用的 url,并分析 api 返回的值,并根据所要求的参数可适当更改 api 的请求参数。根据 URL 可观察请求的参数 f1 、f2 可获取不同的数 值,根据情况可删减请求的参数。
参考链接:https://zhuanlan.zhihu.com/p/50099084
– 输出信息:
Gitee 文件夹链接:https://gitee.com/ma-xin1/data-acquisition/blob/master/作业2/task2.py
1.实践过程
打开指定页面用F12进行抓包
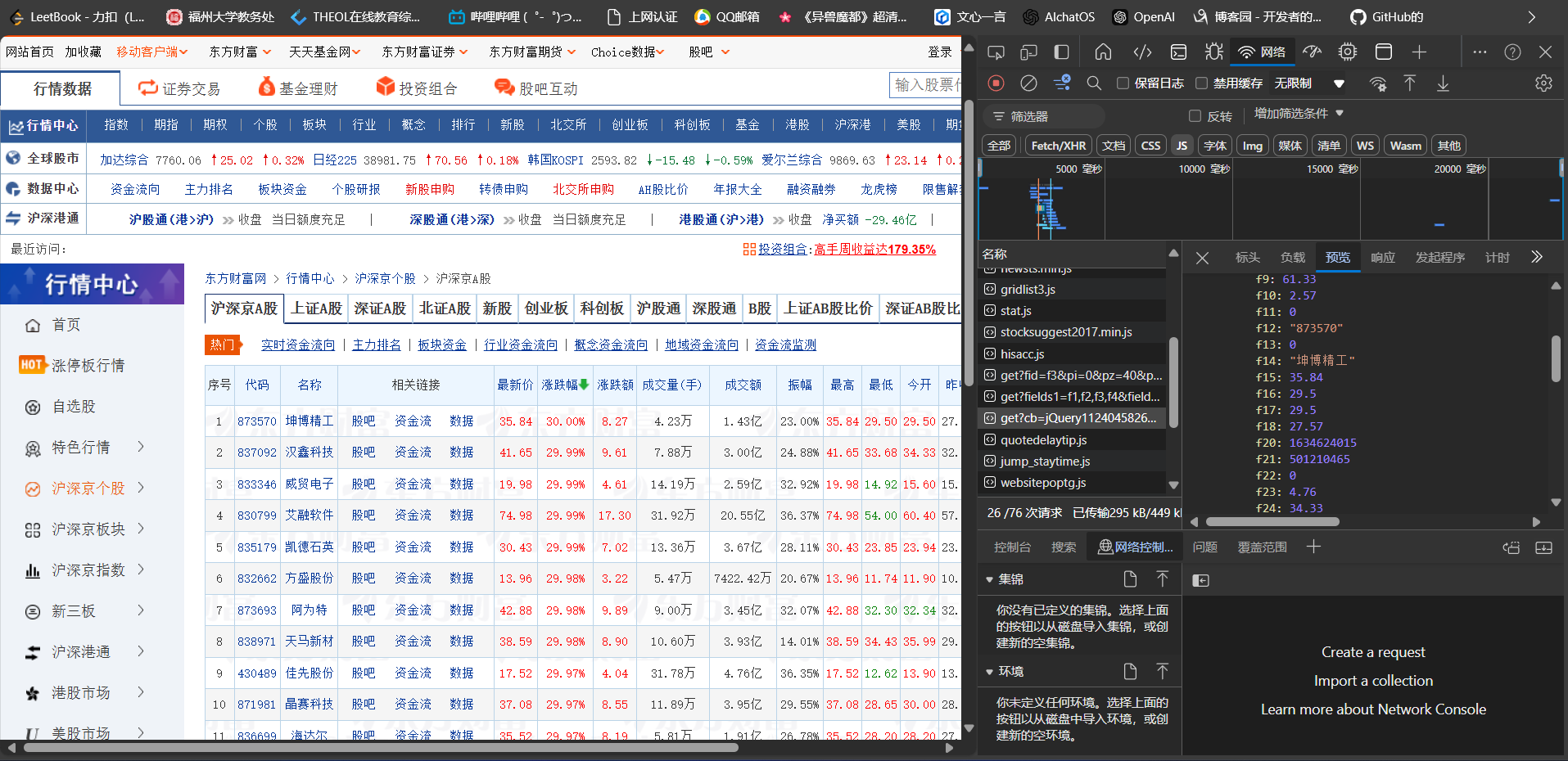
首先创建数据库,将单个页面的股票数据信息获取,再对获取信息进行筛选
通过['data']['diff']标签进行定位,并将其标签中的数据根据f1~f21进行数据爬取
相关代码
点击查看代码
# 将股票信息存储到SQLite数据库
def saveToDatabase(stock_list):
conn = sqlite3.connect('stocks.db')
c = conn.cursor()
c.execute('''CREATE TABLE IF NOT EXISTS stocks
(f1 TEXT, f2 TEXT, f3 TEXT, f4 TEXT, f5 TEXT, f6 TEXT, f7 TEXT, f8 TEXT, f9 TEXT, f10 TEXT, f12 TEXT, f13 TEXT, f14 TEXT, f15 TEXT, f16 TEXT, f17 TEXT, f18 TEXT, f20 TEXT, f21 TEXT)''')
for stock in stock_list:
c.execute("INSERT INTO stocks VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)",
(stock.get('f1'), stock.get('f2'), stock.get('f3'), stock.get('f4'), stock.get('f5'), stock.get('f6'), stock.get('f7'), stock.get('f8'), stock.get('f9'), stock.get('f10'), stock.get('f12'), stock.get('f13'), stock.get('f14'), stock.get('f15'), stock.get('f16'), stock.get('f17'), stock.get('f18'), stock.get('f20'), stock.get('f21')))
conn.commit()
conn.close()
2.心得体会
在打开指定页面后,此次数据爬取的方式是以抓包的方式进行爬取,定位到数据的包花费一定时间,定位后就以数据库的方式存储数据
作业③:
– 要求:爬取中国大学 2021 主榜
(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信 息,并存储在数据库中,同时将浏览器 F12 调试分析的过程录制 Gif 加 入至博客中。
– 技巧:分析该网站的发包情况,分析获取数据的 api
– 输出信息:
| 排名 | 学校 | 省市 | 类型 | 总分 |
|---|---|---|---|---|
| 1 | 清华大学 | 北京 | 综合 | 969.2 |
Gitee 文件夹链接:https://gitee.com/ma-xin1/data-acquisition/blob/master/作业2/task3.py
1.实践过程
实践方法类似于作业一中的大学排行榜数据爬取,不同的是以抓包的形式将爬取的数据传入数据库中
通过F12进行抓包定位数据
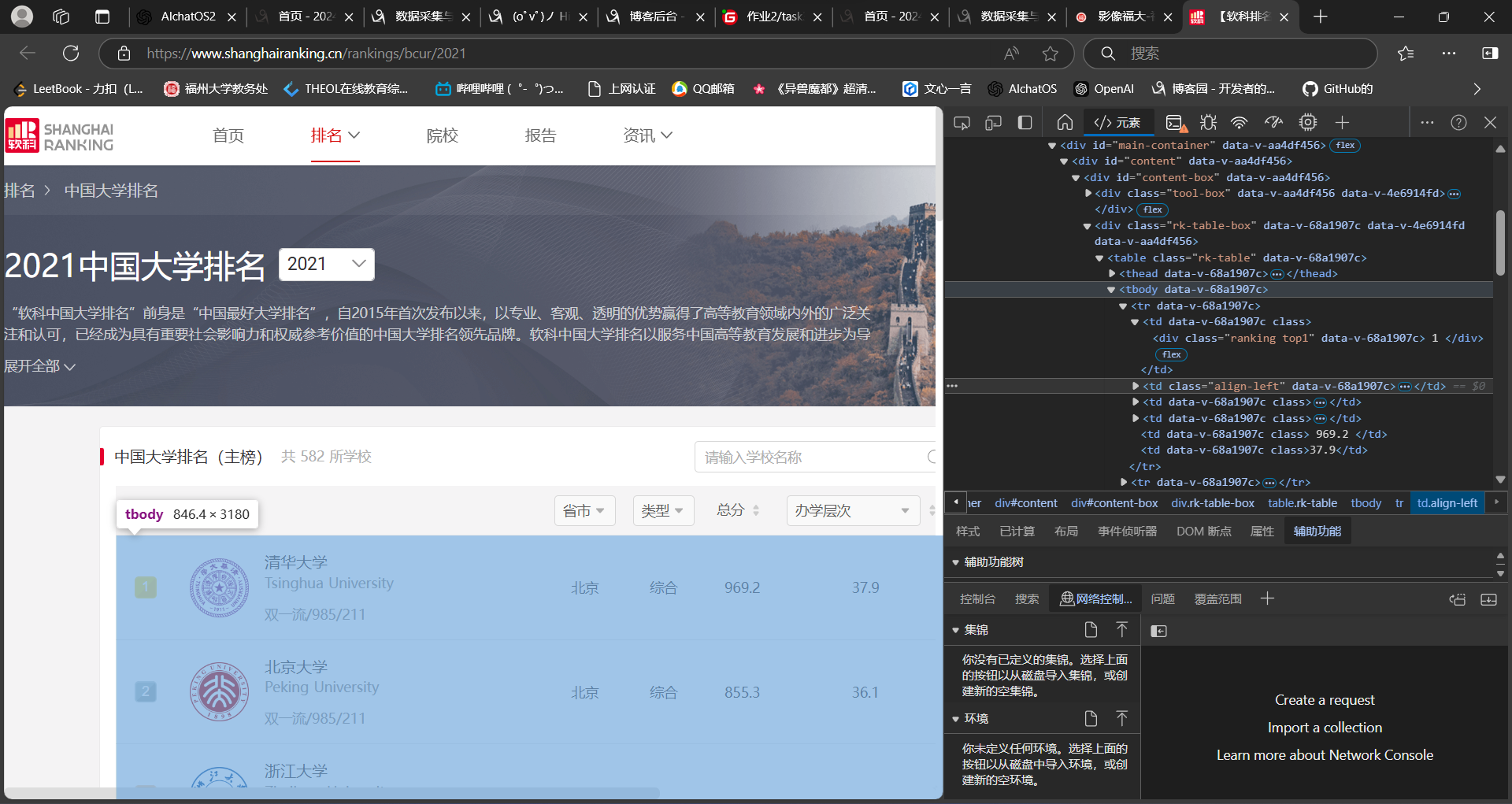
由于映射较多不好精准定位
发现数据位置在tr标签中的td标签下,通过查找td爬取每一项数据
相关代码
点击查看代码
ranking_table = soup.find('table')
# 初始化数据列表
data = []
# 遍历表格的每一行,提取数据
for row in ranking_table.find_all('tr')[1:]:
cols = row.find_all('td')
if len(cols) >= 6: # 确保有足够的列
rank = cols[0].text.strip()
university = cols[1].text.strip()
country = cols[2].text.strip()
score = cols[3].text.strip()
alumni = cols[4].text.strip()
award = cols[5].text.strip()
data.append((rank, university, country, score, alumni, award))
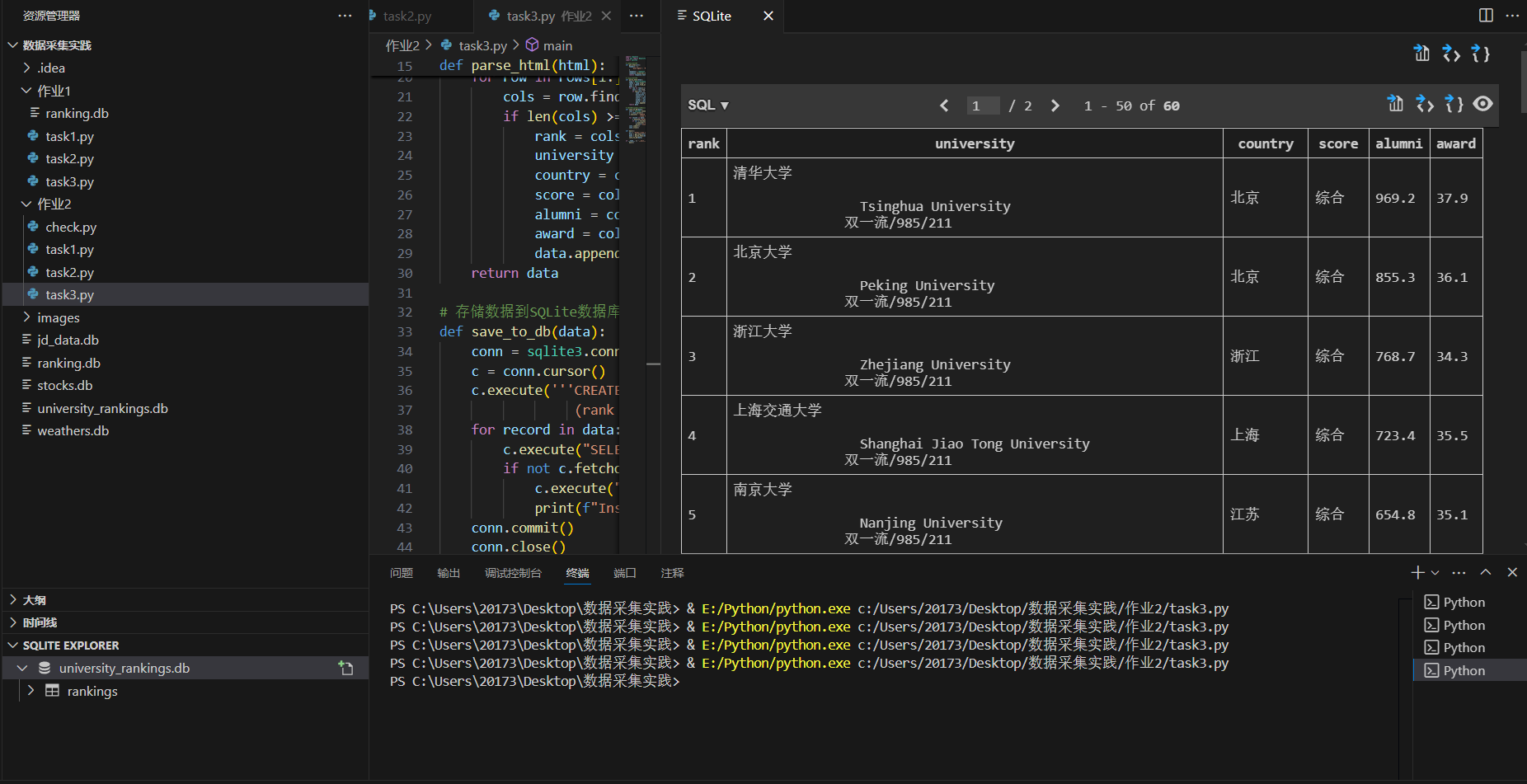
将表中数据插入数据库中
点击查看代码
# 检查数据是否已经存在,避免重复插入
for record in data:
c.execute("SELECT * FROM rankings WHERE rank=? AND university=?", (record[0], record[1]))
if not c.fetchone():
c.execute("INSERT INTO rankings VALUES (?, ?, ?, ?, ?, ?)", record)
2.心得体会
1.网络请求与数据抓取:
使用 requests 模拟浏览器请求,获取网页内容。
通过浏览器开发者工具(F12)分析网站的发包情况,找到数据API。
数据解析:
2.使用 BeautifulSoup 解析HTML内容,提取所需数据。
确保数据完整性和准确性。
数据存储:
3.使用 sqlite3 将数据存储到SQLite数据库中。
避免重复插入数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号