

数据采集与融合技术实践作业一
| 这个作业属于哪个课程 | 2024数据采集与融合技术实践 |
|---|---|
| 这个作业要求在哪里 | 作业1 |
| 这个作业的目标 | 1.爬虫设计 2.掌握requests库、BeautifulSoup库、re库 3.规范化打印输出结果 4.图片下载 |
| 学号 | 102202101 |
gitee链接:https://gitee.com/ma-xin1/data-acquisition/tree/master/作业1
作业①
o要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
o输出信息:
| 排名 | 学校名称 | 省市 | 学校类型 | 总分 |
|---|---|---|---|---|
| 1 | 清华大学 | 北京 | 综合 | 852.5 |
| 2...... |
1.实践过程
网页检查
打开指定页面,通过F12查看页面源码
找出需要爬取的内容并定位
发现需要爬取的排名信息在tbody节点下
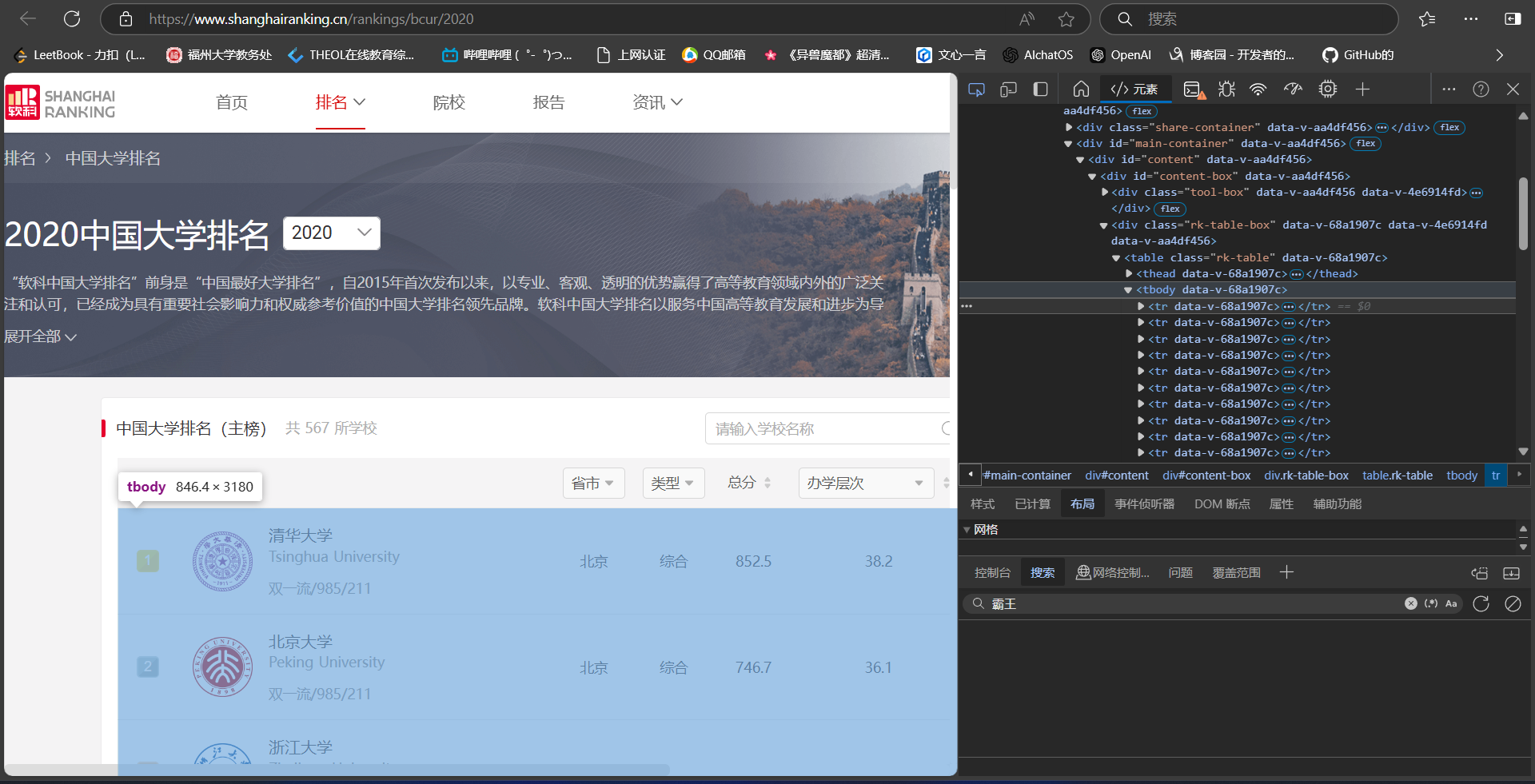
发先学校具体信息都在td标签中
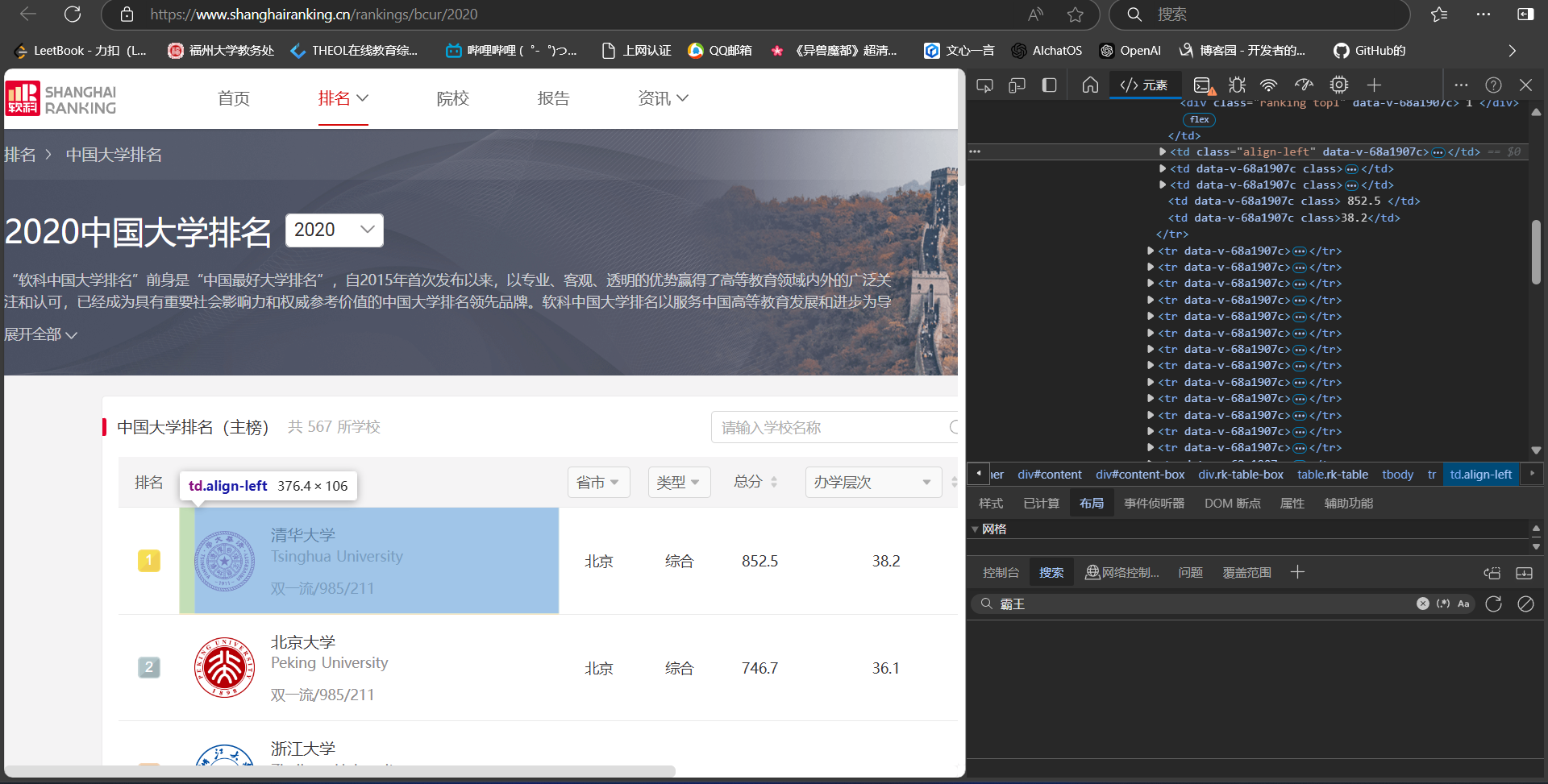
通过遍历表格中的每一行找出td标签,将td标签中的信息填入初始化的数据列表
点击查看代码
# 初始化数据列表
data = []
# 遍历表格的每一行,提取数据
for row in ranking_table.find_all('tr')[1:]:
cols = row.find_all('td')
if len(cols) >= 6: # 确保有足够的列
rank = cols[0].text.strip()
school_name = cols[1].text.strip()
province = cols[2].text.strip()
school_type = cols[3].text.strip()
total_score = cols[4].text.strip()
data.append([rank, school_name, province, school_type, total_score])
后将数据插入到表格中,并在屏幕上进行打印(此代码将数据一并储存在了数据库中,屏幕打印数据从数据库中读取)
点击查看代码
# 插入数据到表格
cursor.executemany('''
INSERT INTO ranking (rank, school_name, province, school_type, total_score)
VALUES (?, ?, ?, ?, ?)
''', data)
# 提交事务
conn.commit()
# 从数据库中读取数据
cursor.execute('SELECT * FROM ranking')
rows = cursor.fetchall()
# 打印标题行和数据
headers = ["排名", "学校名称", "省市", "学校类型", "总分"]
print(tabulate(rows, headers=headers, tablefmt="grid"))
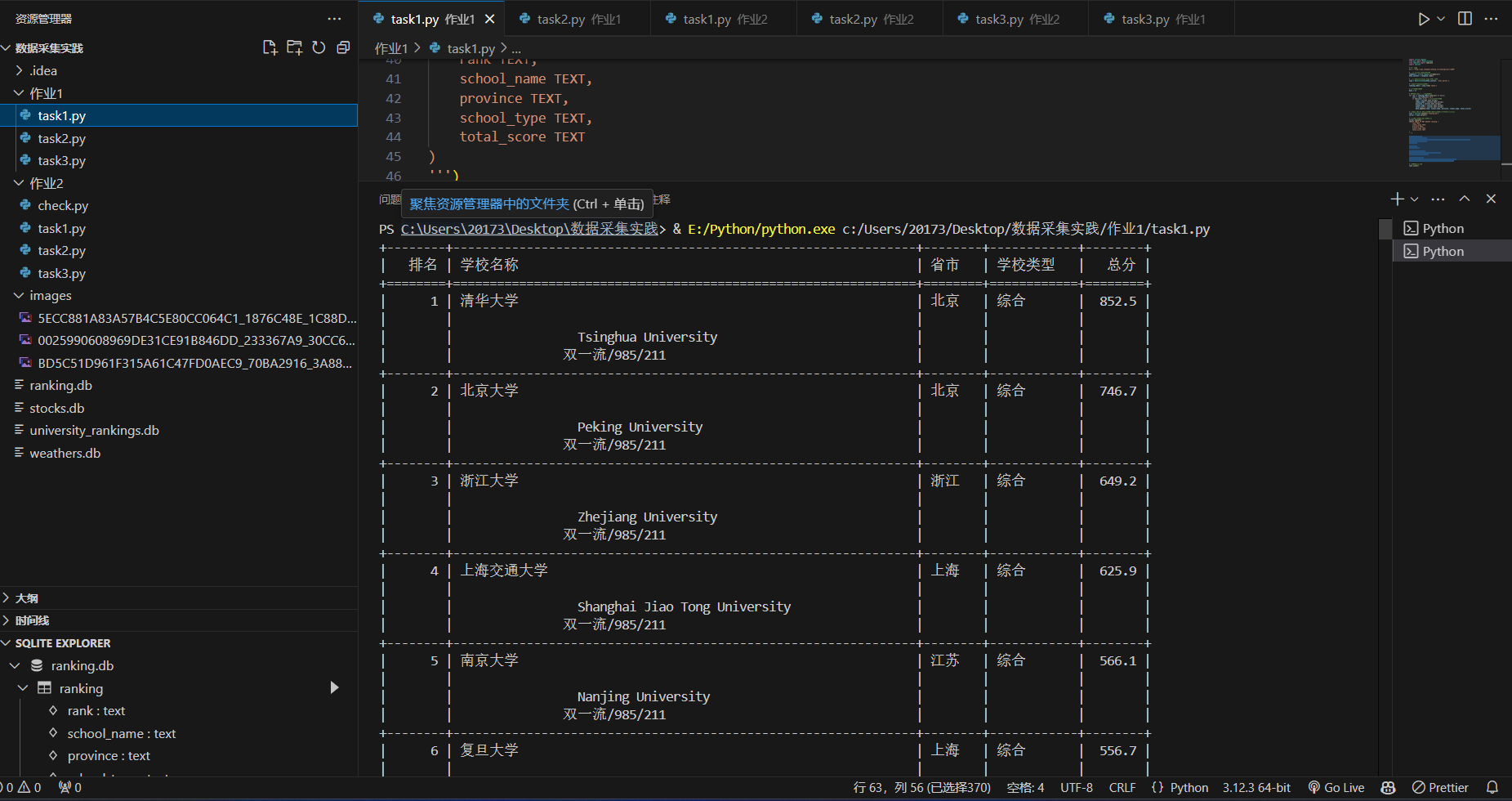
2.实践心得
数据爬取:使用 urllib.request 获取网页内容,并使用 BeautifulSoup 解析 HTML 内容。
数据解析:通过 BeautifulSoup 提取表格中的数据,直接通过查找table更加快捷,后续只需分析table中的具体数据,提取我们需要的信息。
数据展示:使用 tabulate 库将数据以表格形式打印出来。
作业②:
o要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
o输出信息:
| 序号 | 价格 | 商品名 |
|---|---|---|
| 1 | 65.00 | xxx |
| 2...... |
1.实践过程
打开指定页面,通过右键查看页面源码
找出需要爬取的内容并定位
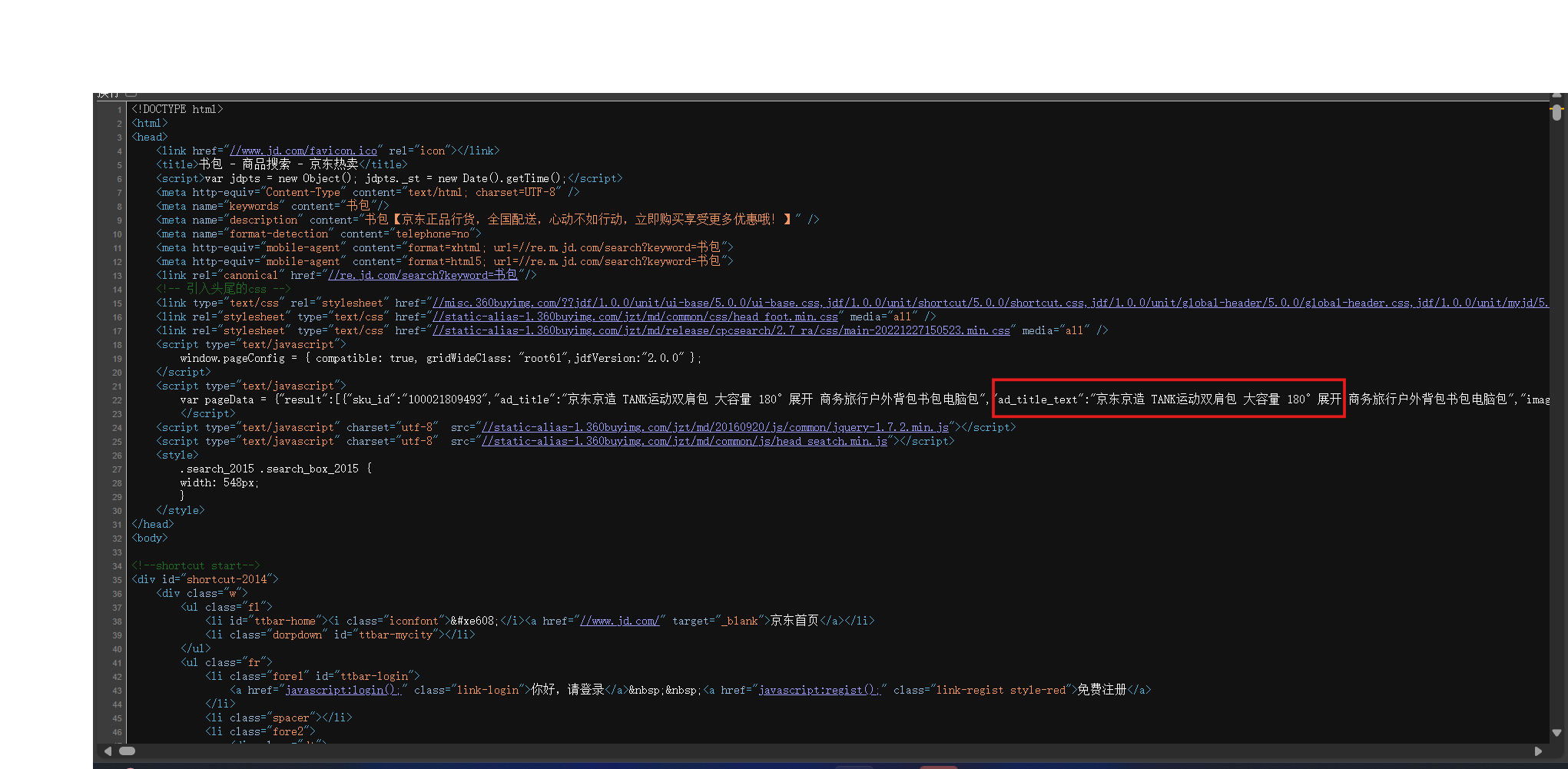
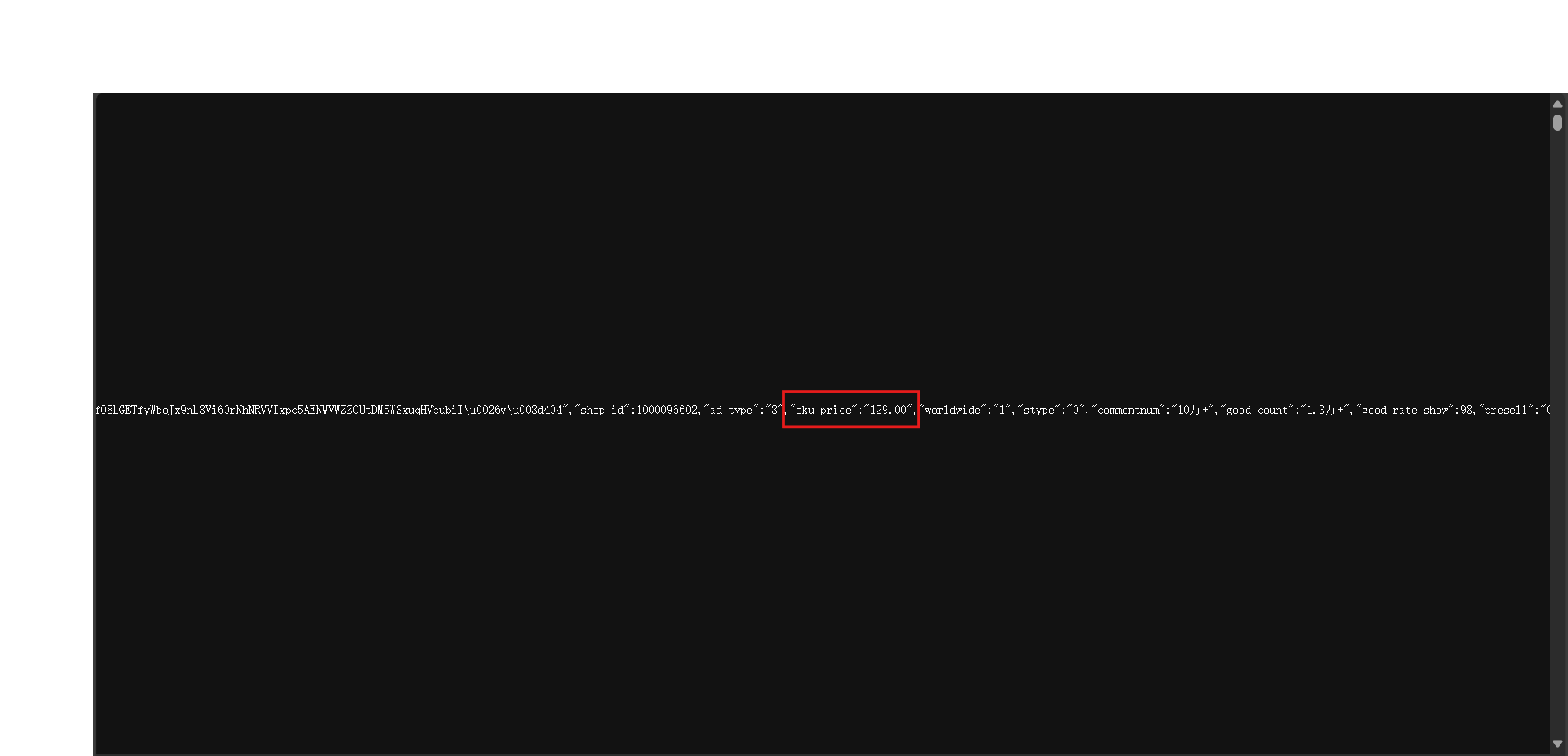
相关代码
点击查看代码
# 解析HTML内容,提取商品价格和名称
def parse_page(goods_list, html):
# 使用正则表达式查找所有商品价格
prices = re.findall(r'"sku_price":"([\d.]+)"', html)
# 使用正则表达式查找所有商品名称
titles = re.findall(r'"ad_title_text":"(.*?)"', html)
# 确保价格和名称的数量一致,以避免索引错误
min_length = min(len(prices), len(titles))
# 遍历所有商品,提取价格和名称,并添加到商品列表中
for i in range(min_length):
price = prices[i].replace('"', '') # 去除价格中的引号
name = titles[i].strip('"') # 去除名称中的引号
goods_list.append([len(goods_list) + 1, price, name]) # 添加到商品列表中
爬取结果
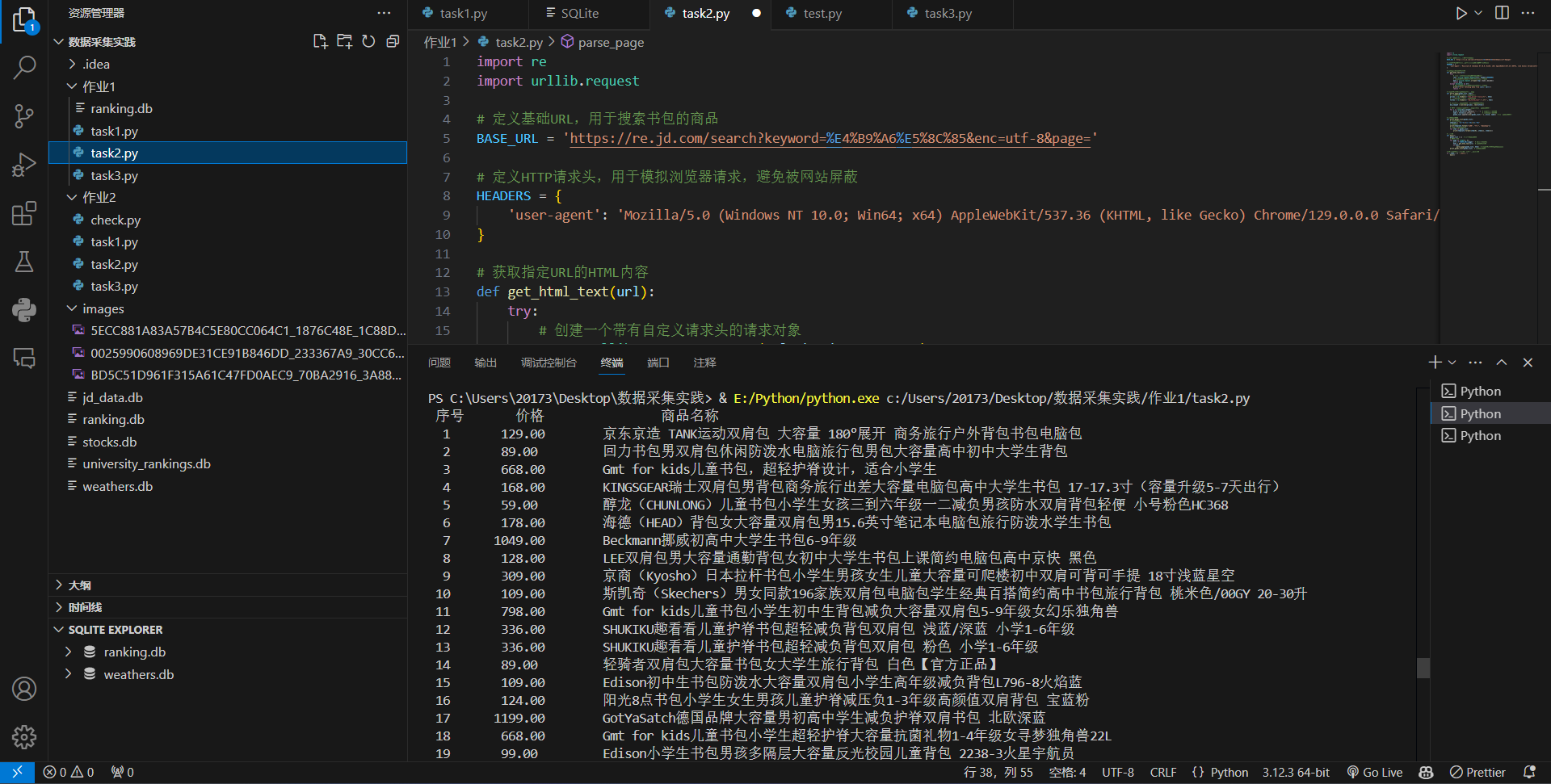
2.实践心得
通过进入页面源码寻找我们要爬取的相关信息有时要比F12更加方便(不知道为啥有时候在F12中定位的信息爬取不出来)
作业③:
o要求:爬取一个给定网页(https://news.fzu.edu.cn/yxfd.htm)或者自选网页的所有JPEG和JPG格式文件
o输出信息:将自选网页内的所有JPEG和JPG文件保存在一个文件夹中
1.实践过程
打开指定页面F12分析页面源码
源码相对简洁,一步步点开就可定位到要提取的图片
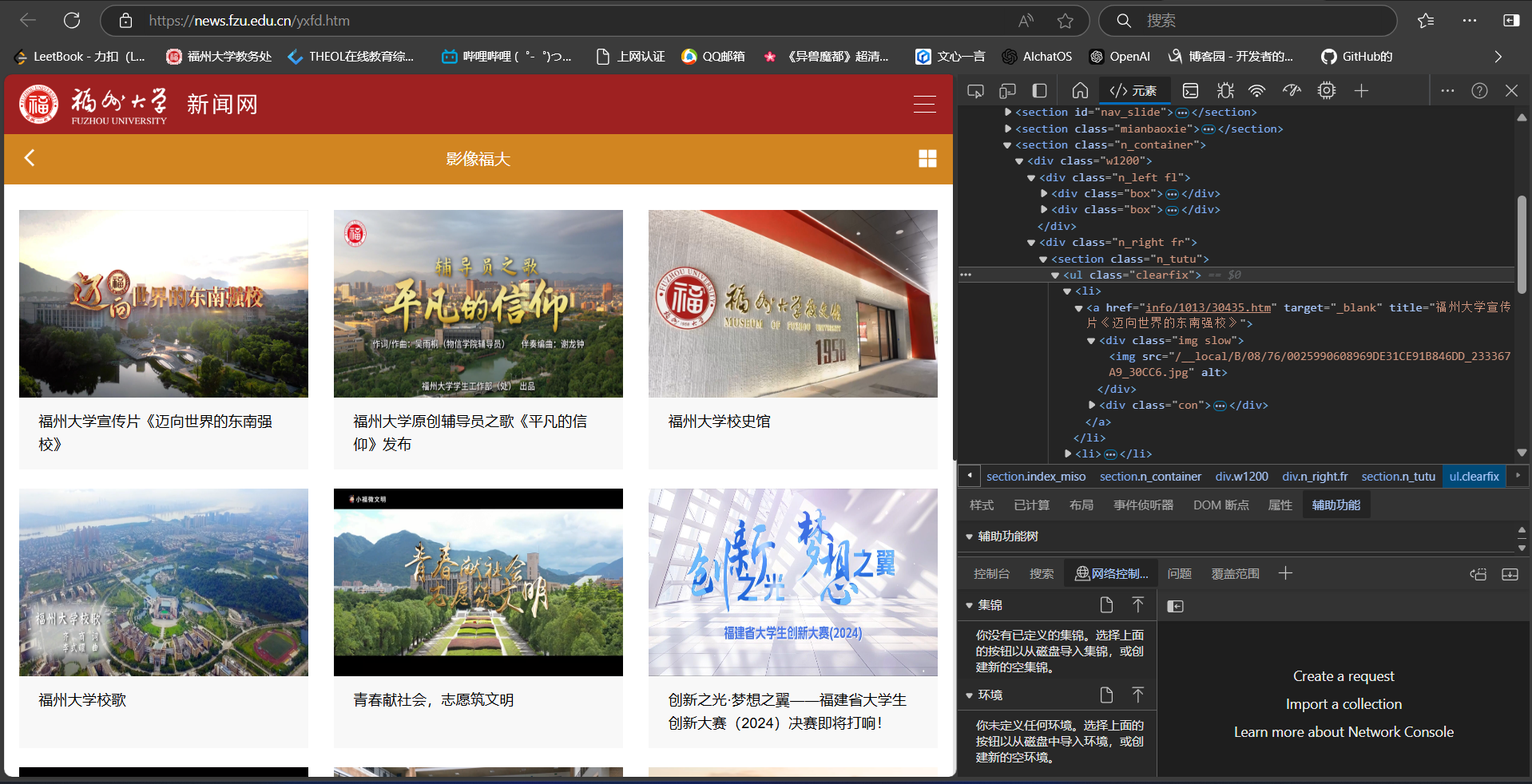
通过img进行定位,查找该标签中以‘jpg’、‘jpeg’结尾的src中的url
点击查看代码
# 解析HTML并提取图片URL
def parsePage(html):
soup = BeautifulSoup(html, 'html.parser')
img_urls = []
for img in soup.find_all('img'):
src = img.get('src')
if src and (src.lower().endswith('.jpg') or src.lower().endswith('.jpeg')):
img_urls.append(urljoin(URL, src))
return img_urls
将爬取的url依次进行图片下载
点击查看代码
def downloadImages(img_urls):
for img_url in img_urls:
try:
img_data = requests.get(img_url).content
img_name = os.path.join(SAVE_FOLDER, os.path.basename(img_url))
with open(img_name, 'wb') as handler:
handler.write(img_data)
print(f"成功下载图片: {img_name}")
except Exception as e:
print(f"下载图片失败: {e}")
爬取结果
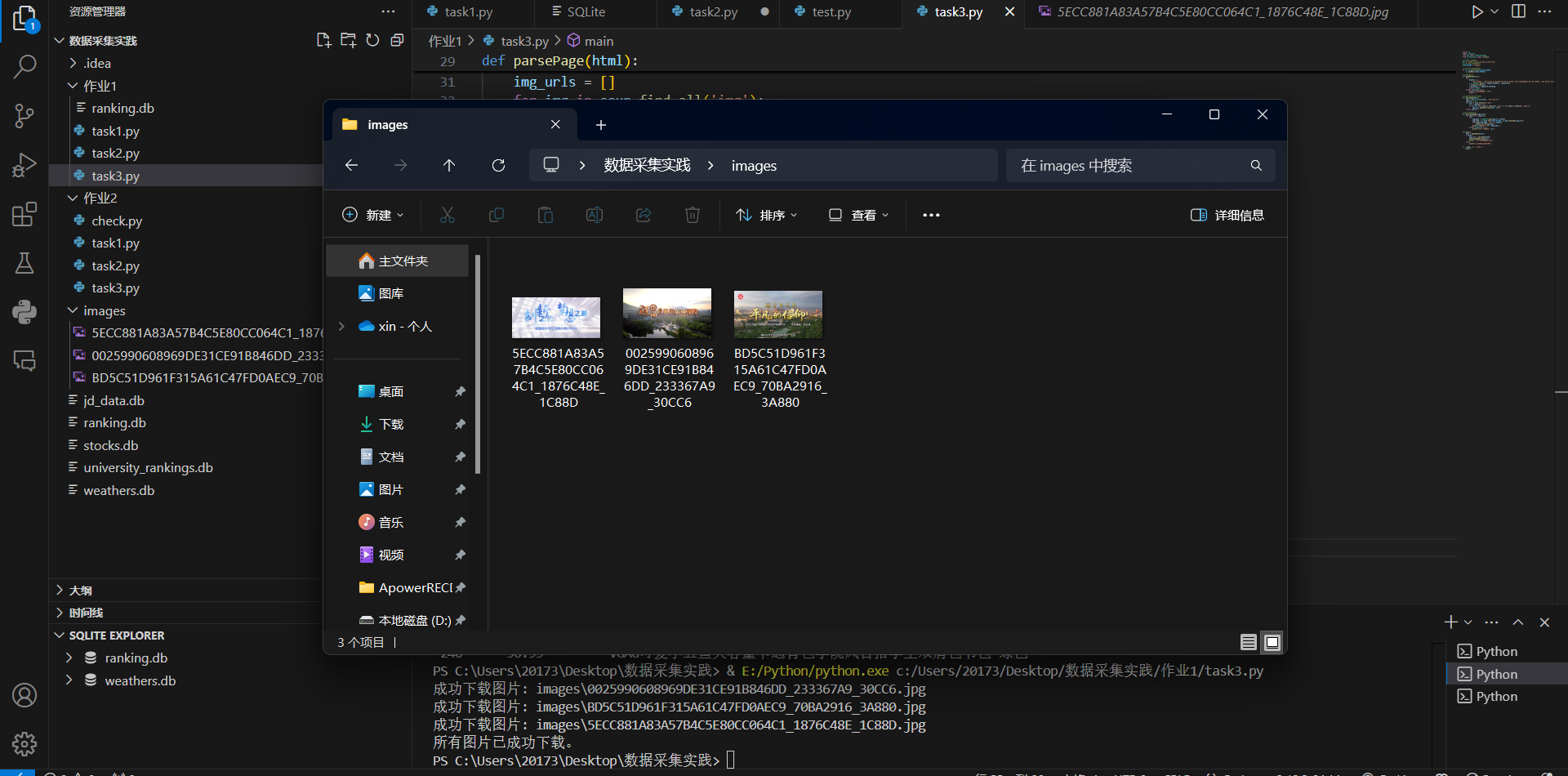
2.实践心得
此次信息定位较为简单,就是由单纯的文字数据变成了爬取图片,首先要定位图片的url,再由url进行图片下载


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了