AVA 源码解读-规则逻辑
做可视化决策的过程,为了节省人的工作量及提效,一个好的方案是推荐。
现有的智能可视化推荐系统分为两类: 基于规则的 和 基于机器学习的。
前者一般是根据专家经验或实验得到的可视化准则; 后者则是直接学习从数据到可视化的模型。
本文是在研究基于规则的可视化推荐的过程中,查看背后源码规则部分实现的过程后的衍生物。
一、AVA 背景介绍
AVA 是阿里出品。定义如下:
AVA (AVA logo Visual Analytics) 是为了更简便的可视分析而生的技术框架。 其名称中的第一个 A 具有多重涵义:它说明了这是一个出自阿里巴巴集团(Alibaba)技术框架,其目标是成为一个自动化(Automated)、智能驱动(AI driven)、支持增强分析(Augmented)的可视分析解决方案。
二、推荐流程

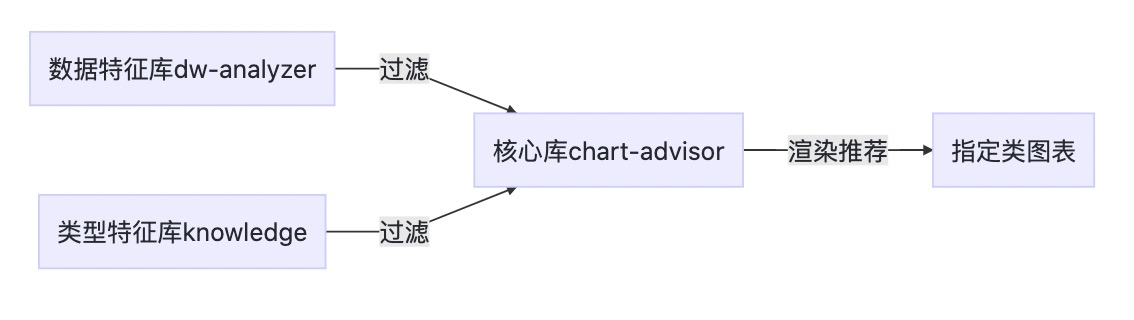
数据有特征,每一种类型也有特征。
数据特征在所有的图表类型特征中判断后,当数据高度满足某一种类型的所有特征时,那么就找到了指定的类型,渲染推荐给用户。
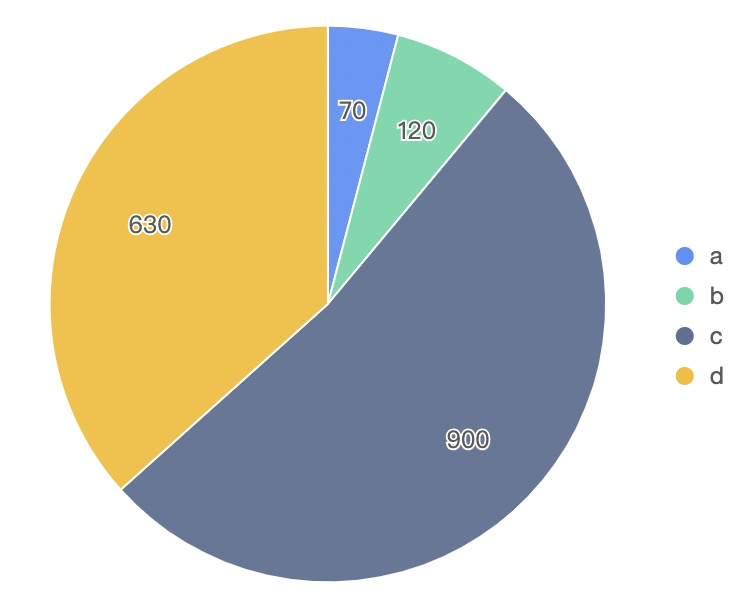
- 给定数据
[
{ f1: 'a', f2: 70 },
{ f1: 'b', f2: 120 },
{ f1: 'c', f2: 900 },
{ f1: 'd', f2: 630 },
]
- 经过 @antv/dw-analyzer 分析处理后得到的具有更多特征的数据集:
[
{
"count": 4,
"distinct": 4,
"type": "string",
"recommendation": "string",
"missing": 0,
"samples": [
"a",
"b",
"c",
"d"
],
"valueMap": {
"a": 1,
"b": 1,
"c": 1,
"d": 1
},
"maxLength": 1,
"minLength": 1,
"meanLength": 1,
"containsChars": true,
"containsDigits": false,
"containsSpace": false,
"containsNonWorlds": false,
"name": "f1",
"levelOfMeasurements": [
"Nominal"
]
},
{
"count": 4,
"distinct": 4,
"type": "integer",
"recommendation": "integer",
"missing": 0,
"samples": [
70,
120,
900,
630
],
"valueMap": {
"70": 1,
"120": 1,
"630": 1,
"900": 1
},
"minimum": 70,
"maximum": 900,
"mean": 430,
"percentile5": 70,
"percentile25": 70,
"percentile50": 120,
"percentile75": 630,
"percentile95": 900,
"sum": 1720,
"variance": 121650,
"stdev": 348.78360053190573,
"zeros": 0,
"name": "f2",
"levelOfMeasurements": [
"Interval",
"Discrete"
]
}
]
- 数据集是否是某一种图表类型,那么数据集需要符合该类图表的条件(特征)。因此知识库中定义了43中图表类型(g2plot中的图表类型)的类型知识特征 @antv/knowledge
举例 basic_pie_chart 类型:
basic_pie_chart: {
id: 'basic_pie_chart',
name: 'Pie Chart',
alias: ['Circle Chart', 'Pie'], // 别名
family: ['PieCharts'], // 大类
def: // 定义
'A pie chart is a chart that the classification and proportion of data are represented by the color and arc length (angle, area) of the sector.',
purpose: ['Comparison', 'Composition', 'Proportion'], // 分析目的:对比、成分、占比
coord: ['Polar'], // 坐标系:极坐标系 - 多用于圆形的图形布局
category: ['Statistic'], // 图形类别:统计图表 - 折线图、饼图等用来表示数据的统计或聚合结果的经典图表
shape: ['Round'], // 形状:圆形 - 如:饼图、雷达图,等
dataPres: [ // 所需数据条件:下面解读为图表中有且只有 1 个 数值 或 无序名词 字段
{ minQty: 1, maxQty: 1, fieldConditions: ['Nominal'] },
{ minQty: 1, maxQty: 1, fieldConditions: ['Interval'] },
],
channel: ['Angle', 'Area', 'Color'], // 视觉通道:角度、面积、颜色
},
- 数据特征、图表类型特征有了,接着便是是特征条件契合判断。找出满足条件的。@antv/chart-advisor
最终绘制图如下:
三、规则探索
数据特征多(>10),图表类型多(43),每一种图表类型特征也多(>10),而且特征权重不同。
数据特征和图表类型特征,条件判断该怎么设计呢,才能使代码易阅读理解、易扩展呢?
条件判断, 常见方式 if-else,当判断条件较多,一般大于 3 时,采用 switch-case 实现。这儿都不适用。
庞大的条件判断,这个库给出了一种方案:规则 + 计分 实现。

1.规则过滤代码片段:过滤
const allTypes = Object.keys(Wiki) as ChartID[];
const list: Advice[] = allTypes.map((t) => {
// anaylze score
let score = 0;
let hardScore = 1;
Rules.filter((r: Rule) => r.hardOrSoft === 'HARD' && r.specChartTypes.includes(t as ChartID)).forEach(
(hr: Rule) => {
const score = hr.check({ dataProps, chartType: t, purpose, preferences });
hardScore *= score;
record[hr.id] = score;
}
);
let softScore = 0;
Rules.filter((r: Rule) => r.hardOrSoft === 'SOFT' && r.specChartTypes.includes(t as ChartID)).forEach(
(sr: Rule) => {
const score = sr.check({ dataProps, chartType: t, purpose, preferences });
softScore += score;
record[sr.id] = score;
}
);
score = hardScore * (1 + softScore);
// ....
}
allTypes 来源于图表类型;
import { CKBJson, LevelOfMeasurement as LOM, ChartID } from '@antv/knowledge';
const Wiki = CKBJson('en-US', true);
其中dataProps就是data提取特征后的数据集:数据特征提取
export function dataToDataProps(data: any[]): FieldInfo[] {
const dataTypeInfos = DWAnalyzer.typeAll(data);
const dataProps: FieldInfo[] = [];
dataTypeInfos.forEach((info) => {
const lom = [];
if (DWAnalyzer.isNominal(info)) lom.push('Nominal');
if (DWAnalyzer.isOrdinal(info)) lom.push('Ordinal');
if (DWAnalyzer.isInterval(info)) lom.push('Interval');
if (DWAnalyzer.isDiscrete(info)) lom.push('Discrete');
if (DWAnalyzer.isContinuous(info)) lom.push('Continuous');
if (DWAnalyzer.isTime(info)) lom.push('Time');
const newInfo: FieldInfo = { ...info, levelOfMeasurements: lom as LOM[] };
dataProps.push(newInfo);
});
return dataProps;
}
每个图表类,所有规则按 hard 和 soft 分别过滤,把规则集合中符合当前图表类的规则,再遍历一遍,传递数据,调用check计算得分,最后计算综合得分。
softScore = 0;
softScore += score;
hardScore = 1;
hardScore *= score;
score = hardScore * (1 + softScore)
2.规则类定义属性和方法:规则类:定义了以下方法和属性
this._id = id;
this._hardOrSoft = hardOrSoft;
this._specChartTypes = specChartTypes;
this._weight = weight;
this.validator = validator;
在check的时候,将规则定义的权重加上
check(args: Info) {
return this.validator(args) * this._weight;
}
3.规则集合定义规则:规则集合
const ChartRules: Rule[] = [
// Data must satisfy the data prerequisites
new Rule('data-check', 'HARD', allChartTypes, 1.0, (args): number => {
let result = 0;
const { dataProps, chartType } = args;
if (dataProps && chartType && Wiki[chartType]) {
result = 1;
const dataPres = Wiki[chartType].dataPres || [];
for (const dataPre of dataPres) {
if (!verifyDataProps(dataPre, dataProps)) {
result = 0;
return result;
}
}
}
return result;
}),
// ...
// Some charts should has at most N series.
new Rule(
'series-qty-limit',
'SOFT',
['pie_chart', 'donut_chart', 'radar_chart', 'rose_chart'],
0.8,
(args): number => {
let result = 0;
const { dataProps, chartType } = args;
let limit = 6;
if (chartType === 'pie_chart' || chartType === 'donut_chart' || chartType === 'rose_chart') limit = 6;
if (chartType === 'radar_chart') limit = 8;
if (dataProps) {
const field4Series = dataProps.find((field) => hasSubset(field.levelOfMeasurements, ['Nominal']));
const seriesQty = field4Series && field4Series.count ? field4Series.count : 0;
if (seriesQty >= 2 && seriesQty <= limit) {
result = 2 / seriesQty;
}
}
return result;
}
),
// ...
]
hard 可以理解为硬性条件,weight 都为 1。
soft 理解为非硬性条件,因此 weight 视条件而定,(0,1) 直接取值。
result 可以理解为每个规则的得分。
结合规则 rule 类理解,每个规则针对特定的图表类型集合,有名称、hardorsoft、weight、得分计算规则。
一共定义了11个规则:
["data-check", "data-field-qty", "no-redundant-field", "purpose-check", "series-qty-limit", "bar-series-qty", "line-field-time-ordinal", "landscape-or-portrait", "diff-pie-sector", "nominal-enum-combinatorial", "limit-series"]
每个规则针对多个图表类型。
每个规则内部将数特征和图表类型特征所需条件进行比较判断,计算出分值。
4.代码日志
如上面的举例的data:
在遍历所有图表类型,通过所有规则后,其中 pie_chart 和 donut_chart 得分相同 1.8303440007183807,最高,因此最后渲染的是 饼图:

经过了这些规则得分:
data-check: 1 hard
data-field-qty: 1 hard
diff-pie-sector: 0.4303440007183805 soft
limit-series: 0 soft
no-redundant-field: 1 hard
nominal-enum-combinatorial: 0 soft
purpose-check: 1 hard
series-qty-limit: 0.4 soft
43中类型得分图如下:

推荐一个的话,就推荐得分最高的那个图表类型。
推荐多个的话,就推荐得分大于0或得分大于1的图表类型(看实际需求)。
总结
- 规则的代码设计逻辑可应用于分类。优点是易阅读理解、易扩展。
举例:鲜花识别
当你在花园里看到一种花,很漂亮,你想知道它叫什么名字,有什么故事,寓意着什么?
会不会也向玫瑰一样,有美丽的名字,象征着爱。
- 对于可视化的认知更深了,特别推荐仔细阅读知识库文档。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号