C++入门
一、基础
(〇)HelloWorld
#include<iostream>
using namespace std;
int main() {
cout << "helloworld" << endl;
return 0;
}
(一)C标准库
1. cstring
(1)strlen
计算可见字符的长度(不包括空字符\0)
char s1[] = "Em0s_Er1t";
const char *s2 = "Em0s_Er1t";
cout << s1 << endl; //输出:Em0s_Er1t
cout << s2 << endl; //输出:Em0s_Er1t
cout << strlen(s1) << endl; //输出:9
cout << sizeof(s1) << endl; //输出:10
cout << strlen(s2) << endl; //输出:9
cout << sizeof(s2) << endl; //输出:4或8。s2是个地址
(2)strcpy & strcpy_s & strncpy
/*复制 `src` 所指向的字符串(包含空终止符)到 `dest` */
char *strcpy( char *dest, const char *src );
char *strcpy( char *restrict dest, const char *restrict src );
/*复制 `src` 所指向的字符串(包含空终止符)到 `dest` ,最多复制 n/destsz 个字符*/
errno_t strcpy_s(char *restrict dest, rsize_t destsz, const char *restrict src);
char *strncpy(char *dest, const char *src, size_t n)
参数:
-
dest:指向要写入的字符数组的指针 -
src:指向要复制的空终止字节字符串的指针 -
destsz:写入的最大字符数,一般设置为src的长度+1因为
strlen()返回字符串长度,但是不包括字符串末尾的空字符,所以+1。
(3)strstr
char *strstr(const char *haystack, const char *needle)
功能:在字符串 haystack 中查找第一次出现字符串 needle 的位置,不包含终止符\0。
参数
haystack:要被检索的 C 字符串。needle:在 haystack 字符串内要搜索的小字符串。
返回值
- 该函数返回在 haystack 中第一次出现 needle 字符串的位置(needle字符串在haystack中的起始地址),如果未找到则返回 null。
#define _CRT_SECURE_NO_WARNINGS
#include<iostream>
using namespace std;
int main() {
char site[] = "https://www.cnblogs.com/Em0sEr1t/", *author = new char[9];
strncpy(author, strstr(site, "Em0sEr1t"), 8);
author[8] = '\0';
cout << author << endl;
}
/*输出:
Em0sEr1t
*/
(3)strchr
char *strchr(const char *str, int c)
功能:strchr() 用于查找字符串中的一个字符,并返回该字符在字符串中第一次出现的位置。
参数:
str:要查找的字符串。c:要查找的字符。
返回值:如果在字符串 str 中找到字符 c,则函数返回指向该字符的指针,如果未找到该字符则返回 NULL。
(4)strcat
char *strcat(char *dest, const char *src)
功能:把 src 所指向的字符串追加到 dest 所指向的字符串的结尾。
参数:
dest:指向目标数组,该数组包含了一个 C 字符串,且足够容纳追加后的字符串。src:指向要追加的字符串,该字符串不会覆盖目标字符串。
返回值:该函数返回一个指向最终的目标字符串 dest 的指针。
(5)strtok
char *strtok(char *str, const char *delim)
功能:分解字符串 str 为一组字符串,delim 为分隔符。
参数
str:要被分解的字符串。delim:包含分隔符的 C 字符串。
返回值:返回 str 的一个个被分割的串,当 str 中的字符查找到末尾时,返回NULL。如果查找不到delim中的字符时,返回当前strtok的字符串的指针。
说明:
- 当
strtok()在参数s的字符串中发现参数delim中包含的分割字符时,则会将该字符改为\0字符,在第一次调用时,strtok()必需给予参数 str 字符串,往后的调用则将参数 str 设置成NULL。每次调用成功则返回指向被分割出片段的指针。
#define _CRT_SECURE_NO_WARNINGS
#include<iostream>
#include<string>
using namespace std;
int main() {
/*打印输出用 delim 分隔 str 得到的每个小字符串*/
char str[] = "Em0s_Er1t is not a writer.";
char delim[2] = " ";
const char *p = strtok(str, delim);
cout << p << endl;
while ((p = strtok(NULL, delim)) != NULL) {
cout << p << endl;
}
return 0;
}
/*输出:
Em0s_Er1t
is
not
a
writer.
*/
(6)strcmp
int strcmp(const char *str1, const char *str2)
功能:把 str1 所指向的字符串和 str2 所指向的字符串自左向右逐个字符相比较(按 ASCII 值大小相比较),直到出现不同的字符或遇 \0 为止。
注意:
- 只能比较字符串(比较两个字符串常量,或比较数组和字符串常量),不能比较数字等其他形式的参数。
"A"<"B"、"A"<"AB"、"compare"<"computer"
参数:
str1:要进行比较的第一个字符串。str2:要进行比较的第二个字符串。
返回值:
- 如果返回值小于 0,则表示 str1 小于 str2。
- 如果返回值大于 0,则表示 str1 大于 str2。
- 如果返回值等于 0,则表示 str1 等于 str2。
例:
#define _CRT_SECURE_NO_WARNINGS
#include<iostream>
using namespace std;
int main() {
char str1[10] = {0},
str2[10] = {0};
strcpy(str1, "Em0s_Er1t");
strcpy(str2, "Em0s_er1t");
if (strcmp(str1, str2) > 0)
cout << "str1 > str2";
else if (strcmp(str1, str2) < 0)
cout << "str1 < str2";
else cout << "str1 = str2";
}
/*输出:
str1 < str2
*/
(7)memcpy
void *memcpy(void *str1, const void *str2, size_t n)
功能:从存储区 str2 复制 n 个字节到存储区 str1。
参数:
str1:指向用于存储复制内容的目标数组,类型强制转换为 void* 指针。str2:指向要复制的数据源,类型强制转换为 void* 指针。n:要被复制的字节数。
返回值:
- 该函数返回一个指向目标存储区 str1 的指针。
例:
#define _CRT_SECURE_NO_WARNINGS
#include<iostream>
using namespace std;
int main() {
char site[] = "https://www.cnblogs.com/Em0sEr1t/", *author=new char[9];
memcpy(author, site + 24, 8); //从site[24]开始复制8个字节到author
author[8] = '\0'; //封口
cout << author << endl;
delete author;
}
(8)memset
void *memset(void *str, int c, size_t n)
功能:将从 str 开始 n 个字符,每个字符替换成 c。
参数:
str:指向要填充的内存块。c:要被设置的值。该值以 int 形式传递,但是函数在填充内存块时是使用该值的无符号字符形式。n:要被设置为该值的字符数。
返回值:
- 该值返回一个指向存储区 str 的指针。
例:
#define _CRT_SECURE_NO_WARNINGS
#include<iostream>
using namespace std;
int main() {
char site[] = "https://www.cnblogs.com/Em0sEr1t/";
memset(site, '-', 8); //site开始的前8个字符每个都被替换成`-`
cout << site << endl;
}
/*输出:
--------www.cnblogs.com/Em0sEr1t/
*/
2. cstdio
(1)printf
返回所打印字符串的长度(不包括\0)
3. cmath
(1)fabs
double fabs(double x)
返回 x 的绝对值。
(2)sqrt
double sqrt(double x)
返回 x 的平方根。
(3)pow
double pow(double x, double y)
返回 x 的 y 次幂。
(4)ceil
double ceil(double x)
返回大于或等于 x 的最小的整数值。
4. cstdlib
(1)rand
int rand();
功能:rand() 会生成一个位于 0 ~ RAND_MAX 之间的随机整数。
参数:无参数
返回值:返回 0 \(\sim\) RAND_MAX 之间的随机整数
- rand()函数是将随机数表里面的随机数顺序输出,这些随机数是根据一个被称为“种子”的数值计算出来的,每次启动计算机以后,种子就是定值了,所以函数返回的结果(也就是生成的随机数)在从开机到关机这段时间内每次运行程序时都是固定的,要想每次运行程序生成不同的值需要用srand函数播种以改变“种子”。
- 对得到的随机数取模、加上偏移就得到了特定范围的随机数,如想要输出 \([min, max]\)范围内的随机数就是
rand()%(max-min+1)+min
(2)srand
void srand(unsigned int seed)
功能:重新播种以改变“种子”
参数:
-
seed:这是一个整型值,用于伪随机数生成算法播种。为了使得每次生成的随机数不同,此参数通常传入时间
返回值:不返回任何值。
例:
#include<cstdlib>
#include<ctime>
using namespace std;
/*输出n个[min,max]范围内的随机数*/
void getrand(int min, int max, int n) {
srand((unsigned)time(NULL)); //不要每次循环都播一次种,因为一次循环不到一秒,所以每次传入的种子还是一致的,这样每次生成的数就一样的。
for (int i = 0; i < n; i++) //使用for循环生成10个随机数
cout << (rand() % (max - min + 1) + min) << " ";
}
(3)abs
注意:abs() 函数只适用于整数,如果需要计算浮点数的绝对值,需要使用 fabs() 函数
int abs(int x)
返回x的绝对值
(4)转换函数
如果没有执行有效的转换,则返回一个零值。
| 原型 | 描述 |
|---|---|
double atof(const char *str) |
把参数 str 所指向的字符串转换为一个浮点数(类型为 double 型)。 |
int atoi(const char *str) |
把参数 str 所指向的字符串转换为一个整数(类型为 int 型)。 |
long int atol(const char *str) |
把参数 str 所指向的字符串转换为一个长整数(类型为 long int 型)。 |
double strtod(const char *str, char **endptr) |
把参数 str 所指向的字符串转换为一个浮点数(类型为 double 型),如果 endptr 不为空,则用于存放最后一个数字的下一个字符的位置。 |
long int strtol(const char *str, char **endptr, int base) |
把参数 str 所指向的字符串根据给定的 base 进制转换为一个长整数(类型为 long int 型),base 必须介于 2 和 36(包含)之间,或者是特殊值 0。如果 endptr 不为空,则用于存放最后一个数字的下一个字符的位置。 |
unsigned long int strtoul(const char *str, char **endptr, int base) |
把参数 str 所指向的字符串根据给定的 base 进制转换为一个无符号长整数(类型为 unsigned long int 型)。如果 endptr 不为空,则用于存放最后一个数字的下一个字符的位置。 |
例:
#include<iostream>
using namespace std;
void main() {
char str[] = "190312Em0s_Er1t";
char *tmp = new char();
long number = strtol(str, &tmp, 10); //将"1903121"解析成10进制数据190312存入number中,剩下的字符串的指针存入tmp
cout << number << " " << tmp;
}
5. cctype
C 标准库的 ctype.h 头文件提供了一些函数,可用于测试和映射字符。这些函数接受 int 作为参数,它的值必须是 EOF 或表示为一个无符号字符。
如果参数 c 满足描述的条件,则这些函数返回非零(true)。
如果参数 c 不满足描述的条件,则这些函数返回零。
int isxxxx(int)
| 函数名称 | 返回值 |
|---|---|
| isalnum() | 如果参数是字母数字,即字母或者数字,函数返回true |
| isalpha() | 如果参数是字母,函数返回true |
| iscntrl() | 如果参数是控制字符,函数返回true |
| isdigit() | 如果参数是数字(0-9),函数返回true |
| isgraph() | 如果参数是除空格之外的打印字符,函数返回true |
| islower() | 如果参数是小写字母,函数返回true |
| isprint() | 如果参数是打印字符(包括空格),函数返回true |
| ispunct() | 如果参数是标点符号,函数返回true |
| isspace() | 如果参数是标准空白字符,如空格、换行符、水平或垂直制表符,函数返回true |
| isupper() | 如果参数是大写字母,函数返回true |
| isxdigit() | 如果参数是十六进制数字,即0-9、a-f、A-F,函数返回true |
| tolower() | 如果参数是大写字符,返回其小写,否则返回该参数 |
| toupper() | 如果参数是小写字符,返回其大写,否则返回该参数 |
(二)内存分区
C/C++程序在执行时,将内存大方向划分为4个区域
-
代码区:存放函数体的二进制代码,由操作系统进行管理的;
-
全局区:存放全局变量和静态变量以及常量,属于静态分配。
- BBS(Block Started by Symbol)段:用来存放程序中未初始化的全局变量、静态局部变量、静态全局变量的一块内存区域;
- 数据段(data segment):用来存放程序中已初始化的全局变量、静态局部变量、静态全局变量的一块内存区域;
-
栈区(stack):由编译器自动分配释放,存放函数的参数值,局部变量等;
-
堆区(heap):由程序员分配和释放,若程序员不释放,程序结束时由操作系统回收;
(三)字节存储顺序
节存储顺序主要分为大端序(Big-endian)和小端序(Little-endian),区别如下
Big-endian:高位字节存入低地址,低位字节存入高地址Little-endian:低位字节存入低地址,高位字节存入高地址
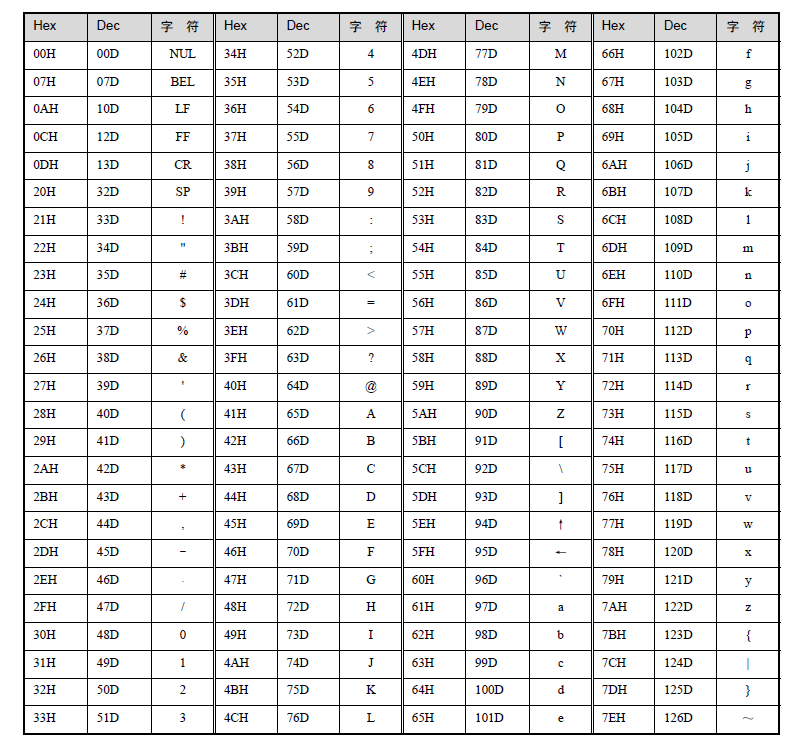
(四)ASCII码表
大写字母:65('A') \(\sim\) 90('Z')
小写字母:97('a') \(\sim\) 122('z')
二、引用(reference)
引用变量是一个别名,也就是说,它是某个已存在变量的另一个名字。一旦把引用初始化为某个变量,就可以使用该引用名称或变量名称来操作变量,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。
(〇)基本规则
-
引用必须在定义的同时初始化,并且从一而终,不能更换成另一个内存空间的引用;
引用本质上是一个指针常量
int a = 101, b = 50; int *p = &a; int &ref = *p; //创建a的引用ref p = &b; //即便p指向新的内存空间,ref仍然是a的引用 -
不能通过赋值运算设置引用;
-
不能给一个常量设置(左值)引用
const int a = 10; int &r1 = a; //错误 int &r2 = 10; //错误 -
可以用一个引用去初始化另一个引用,这样两个引用就引用同一个变量。
int a; int &r1 = a, &r2 = r1; //r1和r2都是a的引用 -
引用在定义时需要添加
&,在使用时不能添加&; -
不能建立引用的引用;
int &&r; //错误,不能建立引用的引用 -
不能建立引用数组;
int &b[3]; //错误,不能建立引用数组 -
允许给一个指针变量取别名,但不允许建立指向引用的指针;
引用即给变量取别名,这个变量当然可以是指针变量
int &*p; //错误,不能建立指向引用的指针 int *&p; //正确,允许给一个指针变量取别名 -
有空指针,但没有空引用
int &ri = NULL; //错误,有空指针,无空引用 -
没有变量或对象的类型是void,所以不可能给一个void类型的变量取别名
void &a = 3; //错误,没有变量或对象的类型是void -
存在常引用,但不存在引用常量,因为引用本身就具有不可更改所引对象的性质
(一)常引用
对const的引用称为常引用/常量引用
注意点
-
常引用可能引一个并非const的变量,此时不能通过常引用自身去更改所指向的内存空间的值,但可以用变量间接更改
#include <iostream> using namespace std; int main() { int a = 10; /*不能通过常引用的别名更改所指向的内存空间的值,但可以用变量更改*/ const int &b1 = a; //b1 = 100; //错误 a = 100; cout << b1 << endl; /*非常引用既能通过别名,也能通过变量修改内存空间的值*/ int &b2 = a; a = 1000; cout << b2 << endl; b2 = 10000; cout << b2 << endl; return 0; } -
常引用既可以引变量,也可以引常量
int &a = 10; //错误,引用必须引一块合法的内存空间 const int &b = 10; //正确,此时相当于"int tmp=10; const int &b = tmp;" b = 20; //错误,b为只读,不可修改当常引用引常量时,编译器会给该常量开辟一片内存,并将引用名作为这片内存的别名
【应用】常引用作为函数形参
当我们希望能传递常量同时也能传递变量,且变量在函数中不能被修改时可以使用常引用作为函数形参
当引用作为函数形参时,此时不能传递常量

修改成常引用后就可以在实现变量传参的同时实现常量传参。
#include<iostream>
using namespace std;
void fun(const int & a) {}
int main() {
int a = 10;
fun(1);
fun(a);
return 0;
}
(二)左值引用 & 右值引用
1. 左值与右值
在 C/C++ 语言中,一个表达式根据其使用场景不同,分为左值表达式和右值表达式。右值通常是字符串除外的字面量、(运算)表达式、函数非引用返回值。
通常情况下,判断某个表达式是左值还是右值有以下 2 种方法:
-
可位于赋值号(=)左侧的表达式就是左值;反之,只能位于赋值号右侧的表达式就是右值。值得一提的是,C++ 中的左值也可以当做右值使用
int a = 5; 5 = a; // 错误,5 不能为左值 int b = 10; // b 是一个左值 a = b; // a、b 都是左值,只不过将 b 可以当做右值使用 int c = a + b;// a+b是右值 -
有名称的、可以获取到存储地址的表达式即为左值;反之则是右值。
上面例子中,a、b、c 是变量名,且通过 &a、&b、&c 可以获得他们的存储地址,因此 a、b、c 都是左值;反之,字面量 5、10,它们既没有名称,也无法获取其存储地址(字面量通常存储在寄存器中,或者和代码存储在一起),因此 5、10 都是右值。由于 a+b 也无法取地址,因此,a+b 也是右值
/*"abc"虽然是字面量,但他是左值*/ char *p_char="abc"; cout << &("abc") << endl; //可以输出其地址
2. 左值引用
正常情况下,C++的引用是给已有(左值)变量起别名,即左值引用
int a = 10;
int &b = a; //正确
int &c = 10; //错误,10是右值
int &d = b*b; //错误,b*b乘法结果是右值
/*常量左值引用既可以绑定左值,也可以绑定右值*/
const int &e = 10;//正确,常量左值引用可以绑定右值
const int &f = a; //正确,常量左值引用可以绑定左值
int *g=NULL;
int &h = *g; //正确
3. 右值引用
实际开发中我们可能需要对右值进行修改(如实现移动语义),显然左值引用的方式是行不通的。C++11 标准新引入了另一种引用方式,称为右值引用,用 "&&" 表示。
注意:
-
右值引用也必须立即进行初始化操作,且只能使用右值进行初始化。那么给一个函数的右值引用形参传左值也自然是不允许的
int n = 10, m = 20; int && a = n; //错误,右值引用不能初始化为左值,见“1” int && a = 10; //正确 int && b = m + n;//正确,m+n是右值 -
和常量左值引用不同的是,右值引用还可以对右值进行修改
int && a = 10; cout << &a << endl;//此时a是有地址的 a = 100; //正确 cout << a << endl; //输出100 -
某函数非引用类型的返回值属于右值(当返回值为对象时,这个对象其实是临时无名对象,也属于右值)

#include<iostream>
using namespace std;
void fun(int & a) {
cout << "左值引用 a=" << a << endl;
}
void fun(int && a) {
cout << "右值引用 a=" << a << endl;
}
int main() {
int a = 10;
fun(a);
fun(10);
return 0;
}
/*输出:
左值引用 a=10
右值引用 a=10
*/
4. move
move函数实现将左值强制变成右值
int num = 10;
int && a = num; //错误,右值引用不能初始化为左值
int && a = std::move(num);//正确
5. 完美转发
完美转发指的是函数模板可以将自己的参数“完美”地转发给内部调用的其它函数。所谓完美,即不仅能准确地转发参数的值,还能保证被转发参数的左、右值属性不变。
背景
下面的例子func可以接收左值或右值,但函数内部调用f2传入的一定是左值(因为t本身在函数f1内可以取到地址,是左值),没有实现完美转发。
template<typename T>
void f1(T t) {
f2(t);
}
实现
这里介绍实现完美转发的2种方法,即函数重载、forward函数
采用函数重载的方式实现完美转发——一个函数名下设计两个函数,一个用于接受左值,一个用于接收右值
#include <iostream>
using namespace std;
void f2(int & t) { cout << "lvalue\n"; }
void f2(const int & t) { cout << "rvalue\n"; }
/*重载函数模板,分别接收左值和右值*/
//接收右值参数
template <typename T>
void f1(const T& t) { f2(t); }
//接收左值参数
template <typename T>
void f1(T& t) { f2(t); }
int main()
{
f1(5);//5 是右值
int x = 5;
f1(x);//x 是左值
return 0;
}
通常情况下右值引用形式的参数只能接收右值,不能接收左值,但对于函数模板中使用右值引用语法定义的参数来说,它不再遵守这一规定,既可以接收右值,也可以接收左值(此时的右值引用又被称为“万能引用”),所以统一用右值接收,而无需实现两个版本的函数
对于第一层函数内部调用第二层函数,给第二层函数传参要想要也保证左右值属性不变需要用forward函数。
#include <iostream>
using namespace std;
void f2(int & t) { cout << "lvalue\n"; }
void f2(const int & t) { cout << "rvalue\n"; }
template <typename T>
void f1(T && t) { f2(forward<T>(t)); }
int main() {
f1(5); //5 是右值
int x = 5;
f1(x); //x 是左值
return 0;
}
(三)引用 vs 指针
指针和引用的区别:
- 相同点:都是地址的概念; 指针指向一块内存,它的内容是所指内存的地址;引用是某块内存的别名。
- 不同点:
- 指针是一个实体,而引用仅是个别名;
- 引用使用时无需解引用(
*),指针需要解引用; - 引用只能在定义时被初始化一次,之后不可变(不能指向另一个变量);指针可变;
- 引用不能为空,指针可以为空;
sizeof(引用)得到的是所指向的变量(对象)的大小,而sizeof(指针)得到的是指针本身(所指向的变量或对象的地址)的大小;- 指针和引用的自增(
++)运算意义不一样; - 从内存分配上看,程序为指针变量分配内存区域,而引用不需要分配内存区域。
三、函数
(〇)基本概念
1. 函数调用
#include<iostream>
#include<cmath>
using namespace std;
int main() {
double number = sqrt(6.25);
return 0;
}
表达式sqrt(6.25)将调用sqrt()函数。表达式sqrt(6.25)被称为函数调用,被调用的函数叫做被调用函数(called function),包含函数调用的函数叫做调用函数(calling function)。main函数是调用函数,sqrt函数是被调用函数。
注意:实参按从左到右的顺序依次被赋给相应的形参,而不能跳过任何参数。因此,
fun(1,,2)是不允许的:
2. 函数定义 & 函数原型
函数原型语句只描述函数接口,即发送给函数的信息和返回的信息。C+ +编译器需要根据函数原型知道函数的参数类型和返回值类型(函数是返回整数、字符、小数还是别的什么?)以便解释返回值。如下便是一种函数原型
void fun(int); //函数原型
函数原型有2种提供方法:
-
在源代码文件中输入函数原型。通常把原型放到
main()定义之前,将代码放在main()的后面。#include<iostream> void fun(int); //函数原型 int main(){ ...; fun(a); ...; return 0; } //函数定义 void fun(int n){ ...; } -
包含(include)定义了原型的头文件;
函数定义中包含的是函数的代码,如计算平方根的代码。如下便是函数定义。
//函数定义
void fun(int n){
...;
}
- C和C++将库函数的原型和定义分开了。库文件中包含了函数的编译代码,而头文件中则包含了原型。
- C++不允许对函数作嵌套定义,也就是说在一个函数中不能完整地包含另一个函数。
3. 形参 & 实参
形式参数(formal parameter),简称形参,是在函数头括号内声明的,某一函数私有的局部变量,。在函数外部中同名变量不会与之冲突。每次调用函数,会对函数头内定义的形参赋值。
实际参数(actual argument),简称实参,它是主调函数(calling function)赋给被调函数(called function)的具体值。它可以是常量,变量,正确的表达式,甚至是函数。但无论如何实参必须有一个具体的值以供拷贝于形参之中。
(一)main函数
main函数有如下几种标准原型
int main();
int main(int, char *[]);
int main(int, char**);
在第2与第3个原型中,
- 第一个参数表示传递的字符串的数目;
- 第二个参数是一个指针数组,每个指针指向一个字符串(一份数据),其中保存的是从控制台输入的参数。
main()的返回值是返回给操作系统。很多操作系统都可以使用程序的返回值。例如,UNIX外壳脚本和Windows命令行批处理文件都被设计成运行程序,并测试它们的返回值(通常叫做退出值)。
——书写格式
ANSI/ISO C++标准规定,如果编译器到达main()函数末尾时没有遇到返回语句,则认为main()函数以return 0;结尾,且这条隐含的返回语句只适用于main()函数,而不适用于其他函数。

return0; //不合法
return(0); //合法
return (0); //合法
intmain(); //不合法
int main() //合法
int main ( ) //合法
int main(void) //合法
(二)带默认参数值的函数
-
默认参数不能在声明(即函数原型)和定义中同时出现
/*错误*/ void fun1(int a=10); void fun1(int a=10){ ...... } /*正确*/ void fun2(int a=10); void fun2(int a){ ...... } -
默认参数必须从函数参数的右边向左边使用
/*错误*/ void fun3(int a=5, int b, int c); void fun4(int a, int b=5, int c); /*正确*/ void fun1(int a, int b=10); void fun2(int a, int b=10, int c=20);
(三)内联函数
用关键字 inline 放在函数定义(注意是定义而非声明,下文继续讲到)的前面表明请求编译器将该函数按内联函数处理,但编译器有权忽略这个请求,所以并非用inline修饰的函数一定能作为内联函数处理。
如果一个函数是内联的,那么在编译时,编译器会把该函数的代码副本放置在每个调用该函数的地方。相比普通的函数调用运行时需要开辟栈空间等等,内联函数可以减少系统开销,加速代码运行。
特点:
-
适用于代码量小的简单函数
-
内联是以代码膨胀(复制)为代价,仅仅省去了函数调用的开销,从而提高函数的执行效率。如果执行函数体内代码的时间比函数调用的开销更大,那么效率的收获会很少。另一方面,每一处内联函数的调用都要复制代码,将使程序的总代码量增大,消耗更多的内存空间。以下情况不宜使用内联:
- 如果函数体内的代码比较长,使用内联将导致内存消耗代价较高。
- 如果函数体内出现循环,那么执行函数体内代码的时间要比函数调用的开销大。
(四)函数占位参数
通常在函数声明的形参表中不给出形参名,直接给出数据类型作为占位用,但函数调用时仍需要传递参数
占位参数可以设置默认值,此时就无需为其传递参数。
void fun(int = 10);
(五)函数重载
1. 重载规则
函数重载需要满足如下条件:
-
这些函数同一个作用域下;
如派生类中的同名函数会覆盖基类中的同名函数而不会发生重载(即便两个函数只是函数名相同,参数列表不同),因为两个函数位于不同的作用域。
-
这些函数的名称相同;
-
参数列表(又叫参数签名)不同,即这些函数参数的类型、个数、顺序的一个或者几个体现出差别;
注意!!!在调用重载的函数的时候一定要避免二义性,即编译器在编译函数调用语句时不能有多个匹配
- 函数返回值不能作为函数重载的条件。
 上面的例子中,调用这两个函数的语句都只能是
上面的例子中,调用这两个函数的语句都只能是fun();进而产生二义性 - 引用与常引用可以作为函数重载的条件,但如果单单是引用与变量不同则会出现二义性问题
- 当函数重载碰到默认参数时有时会产生二义性,通常对于重载函数不设置默认参数

- main函数不能重载。
- NULL作为参数传递有时会引起函数重载失败

- 函数返回值不能作为函数重载的条件。
例:
#include<iostream>
using namespace std;
void fun(const int& a) {
cout << "fun(const int& a)" << endl;
}
void fun(int& a) {
cout << "fun(int& a)" << endl;
}
/*//会产生冲突
void fun(int a) {
cout << "fun(int a)" << endl;
}
*/
int main() {
int a = 10;
fun(a); //输出fun(int& a)
fun(10); //输出fun(const int& a)
return 0;
}
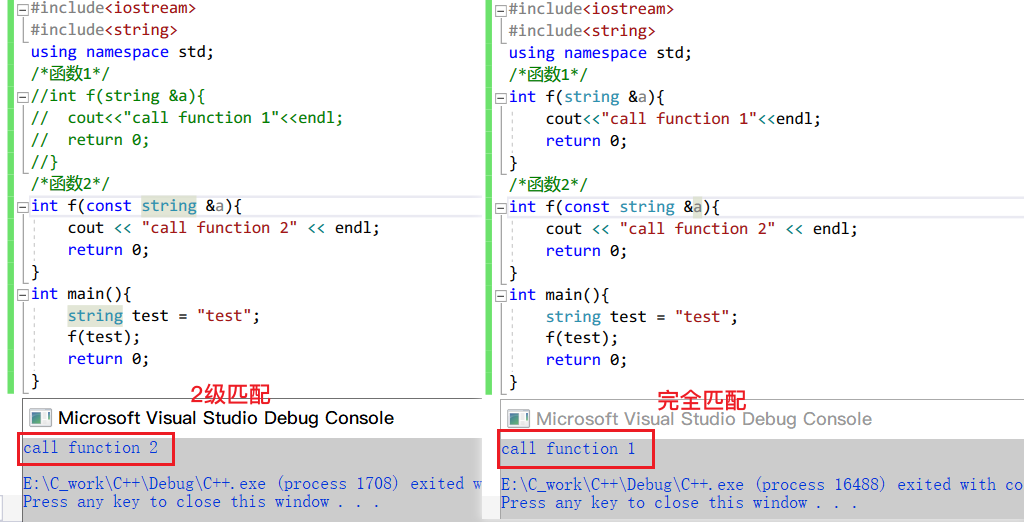
2. *匹配规则
参考:一文彻底搞懂重载函数匹配
-
确定同名函数(声明在调用点可见):将这些函数作为候选函数
-
确定可行函数:可行函数指的是本次调用传入的实参能够被同名函数使用。它要满足两个条件, 一是形参数量和实参数量相同,二是每个实参的类型和对应形参类型相同或者能够转换成形参的类型。
-
确定最佳匹配函数:最佳匹配函数是最终调用的函数,实参类型越接近,它们就越匹配,遵循最佳匹配原则。
最佳匹配原则
如下,等级越靠前代表越匹配。
- 精确匹配(包括实参类型和形参类型相同,实参从数组或函数转换成对应的指针类型,向实参添加顶层const或从实参删除顶层const)
- 通过const转换实现的匹配
- 通过类型提升实现的匹配:float提升到double;(unsigned )char、(unsigned )short提升到int。
- 通过算数类型转换实现的匹配:short、int和float、double等之间的转换,都是算术类型之间的转换
- 通过类类型转换实现的匹配
3. 原理
C++代码在编译时会根据参数列表对函数进行重命名,例如void Swap(int a, int b)会被重命名为_Swap_int_int,void Swap(float x, float y)会被重命名为_Swap_float_float。当发生函数调用时,编译器会根据传入的实参去逐个匹配,以选择对应的函数,如果匹配失败,编译器就会报错,这叫做重载决议(Overload Resolution)。
不同的编译器有不同的重命名方式,这里仅仅举例说明,实际情况可能并非如此。
从这个角度讲,函数重载仅仅是语法层面的,本质上它们还是不同的函数,占用不同的内存,入口地址也不一样。
4. 应用
函数重载可以实现完美转发
完美转发指的是函数模板可以将自己的参数“完美”地转发给内部调用的其它函数。所谓完美,即不仅能准确地转发参数的值,还能保证被转发参数的左、右值属性不变。
#include<iostream>
using namespace std;
//接收左值
void otherdef(int & t) {
cout << "lvalue\n";
}
//接收右值
void otherdef(const int & t) {
cout << "rvalue\n";
}
//接收右值
template <typename T>
void function(const T& t) {
otherdef(t); //t有const属性,所以调用的是void otherdef(const int & t)
}
//接收左值
template <typename T>
void function(T& t) {
otherdef(t); //调用的是void otherdef(int & t)
}
int main()
{
function(5); //5 是右值
int x = 1;
function(x); //x 是左值
return 0;
}
/*输出:
rvalue
lvalue
*/
(六)返回值类型后置
传统的函数声明,返回值的定义位于参数之前,若出现返回值类型依赖于参数类型的情况(泛型编程中)就不好用了,于是推出了返回值类型后置,即在函数名和参数列表后面(而不是前面)指定返回类型
#include<iostream>
using namespace std;
/*正确*/
template<class T1,class T2>
auto mul(T1 t1, T2 t2)->decltype(t1*t2) {
return t1 * t2;
}
/*错误, 默认情况下C++的返回值是前置语法,在返回值定义的时候参数变量还不存在。*/
//template<class T1,class T2>
//decltype(t1*t2) mul(T1 t1, T2 t2) {
// return t1 * t2;
//}
int main() {
cout<<mul<int, double>(12, 1.2)<<endl; //输出14.4
return 0;
}
四、控制结构
(一)基于范围的for循环
for (declaration : expression){
//循环体
}
两个参数各自的含义如下:
declaration:表示此处要定义一个变量,该变量的类型为要遍历序列中存储元素的类型。- declaration参数处定义的变量类型可以用 auto 关键字表示,该关键字可以使编译器自行推导该变量的数据类型。
- 如果需要遍历的同时修改序列中元素的值,实现方案是在 declaration 参数处定义引用形式的变量
expression:表示要遍历的序列,常见的可以为- 事先定义好的普通数组或者容器
- 用 {} 大括号初始化的序列。
#include<iostream>
using namespace std;
int main() {
char name[11] = "Em0s_Er1t";
for (const auto &e : name) {
cout << e; //输出数组的每个元素
}
return 0;
}
/*输出:
Em0s_Er1t
*/
1. 注意点
- 基于范围的for循环只会逐个遍历每个元素,不能指定遍历的范围,而传统for循环可以指定循环范围
- 如果需要在遍历序列的过程中修改器内部元素的值,declaration处就必须定义引用形式的变量;反之,建议定义
const &(常引用)形式的变量(避免了底层复制变量的过程,效率更高),也可以定义普通变量。 - 要遍历的序列必须是可以确定范围的

(二)switch
- 大多数switch 结构都在每个case中使用一个 break,以在处理完该case语句后终止switch结构。 没有break语句,那么处理完case语句后,控制就不能转到switch结构的结束部分。相反,它会转去处理下一个 case 语句(包括 default )中的动作。
- case后面只能指定一个常量整型表达式(字符常量与整型常量的任意组合)
(三)if-else
C/C++语言规定,else连接到在同一层中最接近它而又没有其他else语句与之相匹配的if语句。
#include<iostream>
using namespace std;
int main()
{
int score = 100;
if (score >= 60)
if (score > 90)
cout << "A" << endl;
else //此处的else是与最近的if配对
cout << "B" << endl;
return 0;
}
/*输出:
A
*/
五、运算符
(一)优先级、结合性、计算顺序
优先级规定操作数的结合方式,但并未说明操作数的计算顺序,实际的计算顺序其实是由编译器来决定的,而结合性规定了具有相同优先级的运算符如何进行分组。
- \(单目运算符>算术运算符>移位运算符>关系运算符>\&\&>||>条件运算符>赋值运算符\)
| 符号 | 操作类型 | 结合性 |
|---|---|---|
数组下标[] 、圆括号()、成员选择.、成员选择->、++ --(后缀) |
表达式 | 从左到右 |
sizeof、取地址&、取值运算符*、+、负号-、按位取反运算符~、逻辑非!、++ --(前缀) |
一元 | 从右到左 |
| typecasts | 一元 | 从右到左 |
* / % |
乘法 | 从左到右 |
+ - |
加法 | 从左到右 |
<< >> |
按位移动 | 从左到右 |
< > <= >= |
关系 | 从左到右 |
== != |
相等 | 从左到右 |
& |
按位“与” | 从左到右 |
^ |
按位“异或” | 从左到右 |
| ` | ` | 按位“与或” |
&& |
逻辑“与” | 从左到右 |
| ` | ` | |
? : |
条件表达式 | 从右到左 |
= *= /= %= += -= <<= >>= &= ^= ` |
=` | 简单和复合赋值 2 |
, |
顺序计算 | 从左到右 |
在C/C++中规定了所有运算符的优先级以及结合性,但是并不是所有的运算符都被规定了操作数的计算次序,在C/C++中只有4个运算符被规定了操作数的计算次序,它们是逻辑运算符(&&和||)、逗号运算符/顺序运算符(,)、条件运算符(?:)、函数调用运算符。
- 逻辑运算符需要按从左至右的顺序计算操作数,同时需要遵循短路原则:
- 逻辑“与”运算符(
&&) :完全计算逻辑“与”运算符的左操作数,并在继续之前完成所有副作用。 如果左操作数的计算结果为false,则不计算另一个操作数。 - 逻辑“或”运算符(
||):完全计算逻辑“或”运算符的左操作数,并在继续之前完成所有副作用。 如果左操作数的计算结果为true(非零),则不计算另一个操作数。
- 逻辑“与”运算符(
- 逗号运算符需要按从左至右的顺序计算操作数,逗号表达式的结果是最后一个表达式的值
复杂表达式分析
分析技巧:对于复杂表达式,找到涉及到的运算符,按优先级从高到低组合操作数(用括号括起来),优先级相同的按照结合性组合,最后考虑计算顺序(① 操作数确定的可以优先计算,多个已确定则随机挑选一个计算;② 对于一些有规定计算顺序的操作符按照规定计算顺序)
(1)q && r || s--
组合:(q && r) || (s--)
计算: 由于逻辑运算符确保按从左到右的顺序计算操作数,因此 q && r 先于 s-- 被计算。 但是,如果 q && r 计算的结果为非零值,则不计算 s--,并且 s 不会减少。
(2)p == 0 ? p += 1: p += 2
组合:((p == 0) ? p += 1: p) += 2
计算: 从上面组合方式可以看出这个表达式是非法的
(3)++i || --j && ++k
组合:(++i) || ((--j) && (++k))
计算: 由于逻辑运算符确保按从左到右的顺序计算操作数,因此++i先计算,如果++i非0,则右边的不用再计算,否则计算--j和++k(二者都确定了操作数,计算顺序可颠倒),再计算二者结果的逻辑与(由于要先得到--j和++k的结果,所以计算顺序靠后)。
(4)a < b ? a : c < d ? c : d
组合:(a < b) ? a : ((c < d) ? c : d)
计算:先计算的是(c < d) ? c : d,得到结果后再计算(a < b) ? a : <结果>
(5)x+=x-=x*x
若
x=6
组合:x+=(x-=(x*x))
计算:先计算的是x*x,再计算x-=(x*x),此时x值-30,最终x值为-60。
(6)cout<<a,b+a,b+3
若
a=1,b=2
组合:((cout<<a),b+a,b+3)
说明:<<是重载后的移位运算符,由于重载不改变运算符优先级结合性,所以<<优先级大于,运算符
(二)运算符对操作数的限制
%运算符的操作数必须是整型或者字符型- 位运算符的操作数必须是整型或者字符型
(三)sizeof
sizeof() 是运算符,而不是一个函数,在编译时确定其值,用于计算类型或变量的长度(在内存中所占用的存储空间),单位为字节(byte)。
- sizeof 不能用来返回动态分配的内存空间的大小。
- sizeof 常用于计算返回值类型和静态分配的对象、结构或数组所占的空间,返回值跟对象、结构、数组所存储的内容没有关系。
- 括号内的赋值和函数, 不会被执行
sizeof(引用)等同于sizeof(引用所属的类型)
1. 基本数据类型及其变量所占内存大小
| 基本数据类型 | 32 位 | 64位 |
|---|---|---|
| char | 1 | 1 |
| (unsigned )int | 4 | 4 |
| short | 2 | 2 |
| (unsigned )long | 4 | 8 |
| long long | 8 | 8 |
| float | 4 | 4 |
| double | 8 | 8 |
| 指针 | 4 | 8 |
#include<iostream>
using namespace std;
int test1() { //此函数未被调用
cout << "test~" << endl;
return 1;
}
void test2(int arr[10]) {
cout << sizeof(arr) << endl; //当`sizeof(数组名)`中的数组是函数的形参时会将会降为指针
}
int main() {
char c = 8;
int i = 32;
int *p = NULL;
cout << sizeof(c) << endl; // 输出:1,因为char就是1字节
cout << sizeof(c + i) << endl; // 输出:4,i是4字节,运算时c值被隐式转换成int,运算值是4字节
cout << sizeof(c = c + i) << endl; // 输出:1,等同于sizeof(c),编译时,赋值不被执行
cout << sizeof(test1()) << endl; // 输出:4,等同于sizeof(char),不调用函数s
cout << sizeof(p) << endl; // 输出:4/8,若为32位则输出4,64位输出8
cout << sizeof(int &) << endl; // 输出:4,等同于sizeof(int),对一个引用取sizeof可以忽略&
/*(一维)数组*/
int arr[10] = {};
cout << sizeof(arr) << endl; // 输出:40,4×10
const char* s1 = "Em0s_Er1t";
char s2[] = "Em0s_Er1t";
cout << sizeof(s1) << endl; // 输出:4/8,s1是个指针
cout << sizeof(s2) << endl; // 输出:10,包括'\0',s2是个数组
cout << strlen(s2) << endl; // 输出:9,不包括'\0',与sizeof做区分
cout << sizeof(s2) / sizeof(s2[0]) << endl; //输出:10,获取s2数组的长度
test2(arr); // 输出:4/8,降为指针
cout << sizeof(int[3]) << endl; // 输出:12,4×3,将int[3]看作一个数据类型
/*(二维)数组*/
int arr2[][4] = { {1,2,3,4},{5},{9,10,11} };
cout << sizeof(arr2[0]) << endl; // 输出:16,即4×4,应该将arr2[i]看作一个数组
cout << sizeof(arr2) << endl; // 输出:48,arr2是个二维数组,行数为3,列数为4,于是4×3×4=48
return 0;
}
2. 自定义数据类型所占内存大小
(1)结构体
结构体所占内存大小的手算过程如下
-
若结构体为空,C++语言中规定空结构体和空类所占内存大小为1
C语言中空类和空结构体占用的大小是0。
-
结构体(struct)的第一个数据成员放的位置偏移(offset)在0的地方,以后每个数据成员的偏移为对齐单位的整数倍,\(对齐单位=min\{数据成员的默认对齐数,\ n\}\)
其中n代表预编译指令
#pragma pack(n)设置的对齐单位,n可取1、2、4、8、16-
基本类型成员的默认对齐数为该数据成员占用内存;
-
数组成员的默认对齐数为数组元素所属的类型所占内存;
-
作为成员的结构体的默认对齐数为成员结构体内部占用内存最大的成员所占内存;
注意:
- 作为成员的结构体所占的大小为其内部最大元素的整数倍,不足补齐。
- 作为成员的结构体所占内存仍要按照“2”计算。不是将该结构体的成员直接移动到所属结构体中。
-
位字段的默认对齐数就是冒号后面的数值(单位是bit,需要转换成byte)
-
静态成员不占用结构体的内存空间
-
-
结构体的总大小,也就是sizeof的结果,必须是 \(min\{占用空间最大变量所占内存,\ n\}\) 的整数倍,不足的要补齐。
案例
#pragma pack(4) //设定为4字节对齐
struct test
{
char m1;
double m4;
int m3;
};
16。无论是32位/64位机都是这个结果,首先为m1分配空间,其偏移量为0,满足我们自己设定的对齐方式(4字节对齐),m1占用1个字节。接着开始为 m4分配空间,这时其偏移量为1,需要补足3个字节,这样使偏移量满足为n=4的倍数(因为
sizeof(double)==8>n)。接着为m3分配空间,这时其偏移量为12,满足为sizeof(int)==4的倍数。这时已经为所有成员变量分配了空间,共分配了16个字节,满足为n的倍数。
struct test
{
char m1;
double m4;
int m3;
};
sizeof(Test)==24。无论是32位/64位机都是这个结果,
#pragma pack(8)
struct S1 {
char a;
long b;
};
struct S2 {
char c;
struct S1 d;
long long e;
};
#pragma pack()
sizeof(S2)==24
- S1中,成员
a是1字节默认按1字节对齐,指定对齐参数为8,这两个值中取1,a按1字节对齐;成员b是4个字节,默认是按4字节对齐,这时就按4字节对齐,所以sizeof(S1)应该为8;- S2 中,c和S1中的a一样,按1字节对齐,而d 是个结构体,它是8个字节,它按什么对齐呢?对于结构体来说,它的默认对齐方式就是它的所有成员使用的对齐参数中最大的一个,S1的就是4。所以,成员d就是按4字节对齐,成员e是8个字节,它是默认按8字节对齐,和指定的一样,所以它对到8字节的边界上,这时,已经使用了12个字节了,所以又添加了4个字节的空,从第16个字节开始放置成员e。这时,长度为24,已经可以被8(成员e按8字节对齐)整除。这样,一共使用了24个字节。
#pragma pack(4)
struct S1 {
char a;
long long b;
char c;
};
struct S2 {
char d;
struct S1 e;
long long f;
char g;
};
#pragma pack()
sizeof(S1)==16;sizeof(S2)==32;
//64位机器下
struct T {
char a;
int *d;
int b;
int c:16;
double e;
};
T *p;
sizeof(p)=8;;sizeof(*p)=32;a:本身占1个字节,字节对齐占7个字节,共8个字节
d:64位指针,占8字节
b:占32位,4个字节
c:16 :占16位,2个字节,字节对齐占2个字节,共4个字节
e:64位,8个字节 ,8 + 8 + 4 + 4 + 8 = 32
(2)类
-
C++语言中规定空结构体和空类所占内存大小为1,而C语言中空类和空结构体占用的大小是0。
空类可以实例化成不同的对象,不同的对象在内存中的地址不同,所以C++中隐含地加入一个字节来标识不同的对象。
-
当计算类的内存占用时,不仅仅需要考虑其普通数据成员所占内存,还要考虑是否含有虚表指针以及其基类的数据成员
普通成员函数与虚函数、静态成员均不占用内存
#include<iostream>
using namespace std;
struct empty_struct {};
class empty_class {};
int main() {
cout << sizeof(empty_class) << endl; //输出1
cout << sizeof(empty_struct) << endl; //输出1
return 0;
}
(3)联合类型/共用体
(四)作用域运算符::
用于标识某个成员属于哪个类。
(五)位运算
对浮点数不能进行位运算
1. 移位
(1)左移位<<
- 若
num为无符号整型(unsigned):按二进制形式把所有数字向左移动n位,高位移出(舍弃),低位的空位补0,结果相当于 \(num\times 2^n\) - 若
num为有符号整型:略
(2)右移位>>
- 若
num为无符号整型(unsigned):按二进制形式把所有数字向右移动n位,低位移出(舍弃),高位的空位补0,结果相当于 \(num/2^n\) - 若
num为有符号整型:按二进制形式把所有数字向右移动n位,低位移出(舍弃),高位的空位补符号位(正数为0、负数为1)
六、变量与数据类型
(一)标识符
所有 C++ 变量(variables)必须用唯一名称(unique names)标识(identified)。这些唯一的名称称为标识符(identifiers)。
为变量(唯一标识符)构造名称的一般规则是:
- 名称可以包含字母、数字和下划线
- 名称必须以字母或下划线 (
_) 开头 - 名称区分大小写(
myVar和myvar是不同的变量) - 名称不能包含空格或特殊字符,例如
!、#、%等。 - 保留字(如 C++ 关键字,如
int)不能用作名称
(二)单值变量的初始化
1. 列表初始化(list-initialization)
C++11使得大括号初始化器可以任何类型的初始化,可以使用等号=,也可以不使用。
/*用大括号初始化器可以对单值变量初始化*/
int a{7}; //将a初始化为7
int b = {7}; //将b初始化为7
大括号内可以不包含任何东西,在这种情况下,变量被初始化为0。
int a = {}; //将a初始化为0
int b{}; //将b初始化为0
列表初始化下的类型转换
列表初始化引发的类型转换并不允许缩窄(如不允许将浮点型转换成整型)。
在不同的整型之间转换或将整型转换为浮点型可能被允许,当且仅当编译器知道目标变量一定能够正确地存储赋给它的值(如可将long型变量初始化为int值,因为long总是至少与int一样长,相反方向转换可能被允许)。
/*非法,尽管10可以存入char型变量,但编译器看来,a是int型变量,无论存储的值是大是小都一视同仁,不被允许缩窄成char型*/
int a = 10;
char b = { a };
/*合法*/
int a = 10;
char b = a;
2. 圆括号初始化
/*也可以用小括号*/
int c(7); //将c初始化为7
int d = (7); //将d初始化为7
string s(5,'c'); //s被初始化为"ccccc"
(三)字符型
1. unsigned char & signed char
C标准规定char有符号还是无符号取决于编译环境。
- arm-linux-gcc 规定 char 为 unsigned char
- vc 编译器、x86上的 gcc 规定 char 为 signed char
缺省情况下,编译器默认数据为signed类型,但是char类型除外。
1. wchar_t
传统的字符数据类型为char,占用一个字节,存放的数据内容为ASCII编码,最多可以存放255种字符,基本的英文以及常用字符都可以涵盖,随着计算机在国际范围内普及,大量使用其它语言的计算机用户也纷纷出现,传统的ASCII编码已经无法满足人们的使用,包含更多字符的字符集随之出现,因此一种新的字符存放类型wchar_t应运而生。
wchar_t为宽字符类型或双字符类型,它占用两个字节,因此能够存放更多的字符。
- 给wchar_t类型的变量初始化或者赋值时,常量需要加上前缀
L,如果没有L,程序将会将wchar_t转换为char - 对于ASCII码能够存放的数据类型,其高位存放的数据为0x00
- char类型的字符串以
\0结尾,wchar_t类型的字符串以\0\0结尾 - cin和cout将输入和输出看作是char流,因此不适于用来处理wchar_t类型,如今已经提供了与之作用相似的工具wcin 和wcout,可用于处理wchar_t流。
(四)布尔型
布尔变量的值为true或false
- C++将非0值解释为
true,将0解释为false,任何非0值可以被隐式转换成true,0被隐式转换成false; - 字面值
true和false都可以通过提升转换为 int 类型,true 被转换为1,而false被转换为0;
int a=true; //a被初始化为1
cout << a; //输出1
int b=false; //b被初始化为0
bool c=100; //c被初始化为true
bool d=0; //d被初始化为false
(五)数组
1. 定义
数组定义的通用格式如下
类型说明符 数组名[数组大小]
- 数组大小:可以以整型常数、const值、常量表达式的形式,但不能是变量。

错误定义方法
int[] arr = { 1, 2 }; //错误
2. 初始化
数组初始化采用的是列表初始化
(1)一维数组初始化
-
只有定义数组时才能初始化,不能将一个数组赋给另一个数组。
int a[3] = { 1,2,3 }; //合法 int b[3]; //合法 b = a; //非法 -
初始化数组时提供的值可以少于数组的元素数目,若只对数组的一部分进行初始化,编译器将其它元素置为0。
#include<iostream> int main() { int a[3] = { 1 }; std::cout << a[2]; return 0; } /*输出: 0 */ -
在列出全部数组元素初值时,可以不指定数组长度,C++编译器将计算元素的个数。
#include<iostream> int main() { int a[] = { 1,2,3,4 }; //编译器将把数组a视作包含4个元素 //int a[] = {} //错误,不可以在不给定数组长度的同时不指定元素 int num = sizeof(a) / sizeof(int); //计算数组a所含元素的个数 std::cout << "the array 'a' has " << num << " elements." << std::endl; return 0; } /*输出; the array 'a' has 4 elements. */ -
用大括号初始化数组时,可以省略等号(=),且可以在大括号内不包含任何元素,此时所有元素被设置为0
#include<iostream> int main() { int a[2]{}; std::cout << a[0] << std::endl; return 0; } /*输出: 0 */ -
列表初始化引发的类型转换禁止缩窄变换。
long a[] = {25, 92, 3.0}; //非法,浮点数转整数是缩窄操作 double a[] = {25, 92, 3.0}; //合法 char b[4] { 'h', 'i', 1122011, '\0'}; //非法,1122011超出char变量的取值范围 char c[4] { 'h', 'i', 112, '\0'}; //合法
(2)二维数组初始化
-
将所有初值写在一个
{}内, 按顺序初始化static int a[3][4]={1,2,3,4,5,6,7,8,9,10,11,12}; static int a[3][4]={1,2,,,,,,,,10,11}; //非法 -
分行列出二维数组元素的初值
static int a[3][4]={{1,2,3,4},{5,6,7,8},{9,10,11,12}}; -
可以只对部分元素初始化
static int a[3][4]={{1},{0,6},{0,0,11}}; -
列出全部初始值时,第1维下标个数(行数)可以省略,第2维下标(列数)不可以省略。
如果不指定列数,系统就无法得知一行需要存放几个数值,只要知道了列数,排头放就可以知道一共能放多少行。
static int a[][4]={1,2,3,4,5,6,7,8,9,10,11,12}; static int a[][4]={{1,2,3,4},{5,6,7,8},{9,10,11,12}; -
static数组默认初始化为0
-
初始化数组时提供的值可以少于数组的元素数目,若只对数组的一部分进行初始化,编译器将其它元素置为0。
3. 对象数组
定义对象数组
类名 数组名[元素个数];
访问对象数组元素
数组名[下标].成员名
初始化(不考虑编译器优化):
-
如果给数组中某个元素提供了默认值(默认值可能是基本数据类型或对象),则调用构造函数构造一个临时对象然后再调用复制构造函数初始化数组中相应的对象元素,初始化完成后还要调用析构函数对临时对象析构;
- 默认值为基本数据类型,则类中必须有转换构造函数供调用;
- 默认值为显式调用构造函数创建的临时对象;
-
如果没有给数组中某个元素提供默认值,则只调用默认构造函数在数组元素所在位置直接构造
当数组中每一个对象被删除时,系统都要调用一次析构函数。如果给数组中某个元素提供了默认值
#include<iostream>
using namespace std;
class Sample {
public:
Sample() { cout << "Constructor_1 Called" << endl; }
Sample(int n) { cout << "Constructor_2 Called" << endl; }
Sample(const Sample &s) { cout << "Copy Constructor Called" << endl; }
~Sample() { cout << "Destructor Called" << endl; }
};
int main() {
Sample arrayl[2];
cout << "-------------" << endl;
Sample array2[2] = { 4, 5 };
cout << "-------------" << endl;
Sample array3[2] = { Sample(4), Sample(5) }; //与array2等价
cout << "-------------" << endl;
Sample array4[2] = { 3 }; //array4[0]调用转换构造函数初始化临时对象,其它元素就地调用构造函数
cout << "-------------" << endl;
Sample* array5 = new Sample[2];
delete[] array5;
cout << "-------------" << endl;
return 0;
}
/*输出:
Constructor_1 Called
Constructor_1 Called
-------------
Constructor_2 Called
Copy Constructor Called
Destructor Called
Constructor_2 Called
Copy Constructor Called
Destructor Called
-------------
Constructor_2 Called
Copy Constructor Called
Destructor Called
Constructor_2 Called
Copy Constructor Called
Destructor Called
-------------
Constructor_2 Called
Copy Constructor Called
Destructor Called
Constructor_1 Called
-------------
Constructor_1 Called
Constructor_1 Called
Destructor Called
Destructor Called
-------------
Destructor Called
Destructor Called
Destructor Called
Destructor Called
Destructor Called
Destructor Called
Destructor Called
Destructor Called
*/
4. 数组作为函数形参
把数组作为参数时,数组退化为指针,且一般不指定数组第一维的大小,即使指定也会被忽略
此外往往还需要一个形参用于传递数组的长度
5. 数组的各种表示
(1)一维数组表示
T arr[N]
-
数组名arr:数组首地址,可以看作指向数组第一个元素的指针(所指类型为T)。 -
&arr:对数组取地址,可以看作一个数组指针(所指类型为数组T[N])int arr[5] = { 1, 2, 3, 4, 5 }; int *ptr = (int *)(&arr + 1); //注:&arr步长为一个数组,加1后指向arr[4]的下一个位置 cout << *(ptr - 1) << endl; //输出5
(2)二维数组表示
二维数组是数组的数组
下面几种元素表示方法等价
a[i][j]*(*(a+i)+j)*(a[i]+j)*(&a[0][0]+i*列数+j)*(&a[i][0]+j)
#include<iostream>
using namespace std;
int main() {
const int ROW = 3;
const int COL = 4;
int a[ROW][COL] = { {1,2,3,4},{5,6,7,8},{9,10,11,12} };
/*输出元素arr[1][2]*/
cout << a[1][2] << endl; //输出:7
cout << *(*(a + 1) + 2) << endl; //输出:7
cout << *(a[1] + 2) << endl; //输出:7
cout << *(&a[0][0] + 1 * COL + 2) << endl; //输出:7
cout << *(&a[1][0] + 2) << endl; //输出:7
return 0;
}
一些说明:
-
a[i]+j与*(a+i)+j将
a[i]整体看作一个数组名,那么a[i]+j就表示元素a[i][j]的地址,又因为a[i]相当于*(a+i),于是a[i]+j等价于*(a+i)+j例:
a[i]表示元素a[i][0]的地址,相当于*(a+i) -
二维数组名
aa = &a[0],而a[0] = &a[0][0],于是a是一个二重指针a = &a[0],a[0]可看作一个数组名,于是a是指向一个一维数组的指针
-
a+i与&a[i]a是一个指向一维数组的指针,于是移动步长也是一个一维数组的长度,于是数值上a+i = &a[i] = &a[i][0];- 表示以
a[i][0]为首元素的二维数组
注意:
a[i]与&a[i]数值上相同,但含义却不相同
(六)指针
指针:内存地址,用于间接访问内存单元
指针变量:用于存放地址的变量
1. 定义与初始化
类型名 *指针变量1, *指针变量2;
//例:“int *p;”读作“定义了p这一指针变量,且p存储的地址对应的内存空间存放的是int型数据”
-
用变量地址作为初值时,该变量必须在指针初始化之前已声明过,且变量类型应与指针类型一致。
int a = 1; long *b = &a; //错误,a的类型与指针变量b的类型并不一致 -
可以用一个已有合法值的指针去初始化另一个指针变量。
-
不要用一个内部非静态变量去初始化static 指针,尽管这样是合法的。
-
允许定义或声明指向void类型的指针,该指针可以被赋予任何类型的地址。
-
不允许建立指向引用的指针
但允许给一个指针变量起别名,如
int *a;int *&ref = a;,ref是指针变量a的引用 -
当定义了一个指针,但其指向尚未明确,我们需要将其初始化为空指针。
-
指针变量与非指针的普通变量可以一起定义
-
*不能位于类型名之前
static int i;
static int *ptr = &i; //正确,见“1”(指针变量ptr中只能存储static int型变量的内存空间的地址)
*ptr = 3; //相当于 i=3;
void *general; //正确,见"4"
int &*p; //错误,见“5”(不允许建立指向引用的指针)
int *a, b, c; //正确,见“7”,此处只有 a 是指针变量,b、c 都是类型为 int 的普通变量
*int d; //错误,见“8”
/*见“6”,下面3种方法都可以初始化为空指针*/
int *p=nullptr; //C++11,nullptr专用于初始化空类型指针。
int *p=0; //C++98/03
int *p=NULL; //C++98/03
(1)野指针
“野指针”又称“悬挂指针”,指的是没有明确指向的指针。野指针往往指向那些不可用(未分配或者已经释放)的内存区域,这就意味着像操作普通指针那样使用野指针(例如 &p),极可能导致程序发生异常。
解决:实际开发中,避免产生“野指针”最有效的方法,就是
- 在定义指针的同时完成初始化操作,如果不知道将其初始化为哪个内存空间则将其初始化为空指针。
- delete释放堆区空间后及时置为空指针
/*场景①*/
int *a; //a为野指针,虽然编译器不报错,但这是不可取的
/*场景②*/
p=new int;
delete p; //p为野指针
/*修正*/
a=nullptr;
p=nullptr;
(2)空指针
传统初始化为空指针有3种做法
int *p = 0;
int *p = NULL;
int *p = nullptr;
前2种做法等价,因为NULL是一个宏,字面值就是0,但这种机制带来一定问题(如下)
#include<iostream>
using namespace std;
void fun(int a) {
cout << __LINE__ << endl; //打印当前代码行数
}
void fun(int* a) {
cout << __LINE__ << endl;
}
int main() {
fun(NULL); //输出4,但我们想要的是让fun(NULL)对应void fun(int* a),但事与愿违
fun(0); //输出4
fun(nullptr); //输出7,nullptr专用于初始化空类型指针,克服了NULL的bug
return 0;
}
注意:
- nullptr 可以被隐式转换成任意的指针类型。
- 相比 NULL 和 0,使用 nullptr 初始化空指针可以令我们编写的程序更加健壮。
- 虽然nullptr==0返回的是true,但它不能作为整型0使用(传参、初始化、……)
2. const限定的指针
(1)指向const的指针(所指向的内存空间只读)
对于指向const的指针,不能通过其改变所指变量的值,但指针本身可以改变,可以指向别的变量
/*特点:const位于*左边*/
const 数据类型 *指针变量名; //这2种定义方式等价
数据类型 const *指针变量名;
int a, b;
const int *p1 = &a; //p1是指向const的指针,等价于`int const *p1 = &a;`
const int *p2; //正确,常量指针p2可以不初始化,但此时p2是野指针
p1 = &b; //正确,p1本身的值可以改变
//*p1 = 1; //错误,不能通过p1改变所指的对象
(2)指针常量/常指针(指针本身只读)
指针常量即指针类型的常量。若声明指针常量,则指针本身的值不能被改变,但指针所指向的内存空间的值可以改变
/*特点:const位于*右边*/
数据类型 * const 指针类型的常量名
int a, b;
int* const p1 = &a; //p1是指针类型的常量(p1是常量)
//int* const p2; //错误,指针常量p2必须初始化,类似于`const int a`必须初始化
//p1 = &b; //错误,p1是指针常量,指针不能改变,只能指向a的内存空间
*p1 = 1; //正确,且相当于a=1
小结
int a;
const int * p = &a; //不能通过p改变a的数值,但可以改变p的指向
int * const p = &a; //同上
int * const p = &a; //可以通过p改变a的数值,但不能改变p的指向
int const * const p = &a; //不能通过p改变a的数值,也不能改变p的指向
const int * const p = &a; //同上
const * int p = &a; //语法错误
3. 指针的运算
(1)关系运算
指向相同类型数据的指针之间可以进行各种关系运算,如果两个相同类型的指针相等则表示这两个指针指向的是同一个内存单元或者都为空。
#include<iostream>
using namespace std;
int main() {
const char* ptr1 = "Em0s_Er1t";
const char* ptr2 = "Em0s_Er1t";
cout << boolalpha << (ptr1 == ptr2) << endl; //输出true。ptr1和ptr2指向同一个位于常量区的字符串"Em0s_Er1t"
return 0;
}
指针可以和0之间进行等于或不等于的关系运算。例如:p==0或p!=0(用于判断是否是空指针)
/*顺序输出每个元素*/
#include<iostream>
using namespace std;
int main() {
int arr[10] = { 1,2,3,4,5,6,7,8,9,0 };
int *p = arr;
for (int i = 0; p < arr+10; p++) //用指针关系运算作为判定条件
cout << *p << " ";
return 0;
}
(2)算术运算
-
移动指针的步长取决于该指针所指对象的类型(若指向一个数组变成数组指针则该指针的步长为一个数组长度)
对指针做强制类型转换变成另一种指针类型无疑会改变指针移动步长。
-
两个指针变量不可以相加,但有的时候可以相减获取偏移
4. 指针数组(元素为指针的数组)
指针数组:数组的每个元素都是指针
int* 数组名[数组大小];
指针数组比二维数组更适合行间交换,且指针数组与二维数组一样都支持对元素的随机存取

#include<iostream>
using namespace std;
int main() {
int row0[3] = { 1,0,0 },
row1[3] = { 0,1,0 },
row2[3] = { 0,0,1 };
int *arr[3] = { row0,row1,row2 };
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 3; j++)
cout << arr[i][j]<<' ';
cout << endl;
}
return 0;
}
/*输出:
1 0 0
0 1 0
0 0 1
*/
5. 数组指针(指向数组的指针)
指针所指向的对象是数组
数组元素类型 (*指针名)[数组大小];
确定指针所指对象的数据类型
当我们去掉
*指针变量名后看到的就是该指针所指向的对象所属类型,下面是区分指针数组与数组指针的方法。//*p未用括号括起来,说明[]的优先级高,p先和[]结合成数组,在被前面的*定义为一个指针类型的数组。 int* p[10];//()优先级高,首先说明p是一个指针,去掉*p后看到的是int [n],这就是它所指对象的类型,即指向一个整型的一维数组,这个一维数组的长度是n,也可以说是p的步长,即执行p++时,p要跨过n行的长度。 int (*p)[n];
(1)初始化
int arr1[4],arr2[4][4];
int(*p1)[4] = &arr1; //①用一维数组的地址初始化
int(*p2)[4] = arr2; //②用二维数组初始化
(2)应用
动态创建多维数组
/*动态创建多维数组*/
#include<iostream>
using namespace std;
const int N = 7;
int main() {
//定义
int(*p)[4][5] = new int[N][4][5];
//初始化
for (int i = 0; i < N; i++)
for (int j = 0; j < 4; j++)
for (int k = 0; k < 5; k++)
p[i][j][k] = i * 100 + j * 10 + k; //也可以写成 *(*(*(p+i)+j)+k) = i * 100 + j * 10 + k;
//输出
for (int i = 0; i < N; i++)
for (int j = 0; j < 4; j++) {
for (int k = 0; k < 5; k++)
cout << p[i][j][k]<<' ';
cout << endl;
}
return 0;
}
6. 与函数、对象相关的指针应用
(1)指针作为函数参数
适用于需要数据双向传递(引用也可以达到此效果)、传递一组数据(如数组)
『用指向常量的指针作为函数参数』
#include<iostream>
using namespace std;
const int N = 4;
void output(const int *a, int num);
int main() {
int arr[N];
for (int i = 0; i < N; i++)
cin >> arr[i];
output(arr, N);
return 0;
}
/*格式化输出*/
void output(const int *a, int num) { //这里使用指向常量的指针遵循了最小权限原则,确保a指向的内存空间中的数据不会被修改。
cout << "{" << a[0];
for (int i = 1; i < num; i++) {
cout << "," << a[i];
}
cout << "}" << endl;
}
(2)指针作为函数返回值
-
不要将非静态局部变量的地址用作函数返回值(如将子函数内定义的局部变量的地址返回给主函数),尽管可以正常编译
#include<iostream> using namespace std; int *fun(); int main() { int *p=fun(); *p = 1; //危险的访问 return 0; } int *fun(){ int i; return &i; //错误 } -
将动态分配的内存地址返回给主函数不能忘记释放
#include<iostream> using namespace std; const int N = 4; int *fun(); int main() { int *p = fun(); *p = 5; delete p; return 0; } int *fun() { int *ptr = new int(); return ptr; }
(3)函数指针
函数指针即指向函数的指针,有如下通用定义语法
数据类型 (*函数指针名) (形参表);
//- 数据类型:函数指针所指函数的返回值类型
//- 形参表:函数指针所指函数的形参表
① 函数指针的初始化
函数指针的初始化即用相同返回值类型、形参表的函数初始化
#include<iostream>
using namespace std;
int f(int a, char * b) {
return 1;
}
int main() {
int(*p1)(int a, char * b) = f; //正确,加不加&无所谓
int(*p2)(int a, char * b) = &f; //正确
//int(*p3)() = f; //错误,不同类型函数不能初始化
}
② 函数回调
函数指针即指向函数入口处的指针,函数指针最常见的应用就是实现函数回调,如将函数指针作为参数传递给一个函数,使得这个函数可以调用不同的其它函数,调用者无需关心谁是被调用者,这个被调用的函数称为回调函数(callback)
#include<iostream>
using namespace std;
const int N = 4;
int compute(int a, int b, int(*fun)(int, int));
int max(int a, int b);
int min(int a, int b);
int add(int a, int b);
int main() {
int a, b;
cout << "请输入整数a:";
cin >> a;
cout << "请输入整数b:";
cin >> b;
cout << "最大值为" << compute(a, b, &max) << endl;
cout << "最小值为" << compute(a, b, &min) << endl;
cout << "a和b的和为" << compute(a, b, &add) << endl;
return 0;
}
int compute(int a, int b, int(*fun)(int, int)) {
return fun(a, b);
}
int max(int a, int b) {
return (a > b ? a : b);
}
int min(int a, int b) {
return (a > b ? b : a);
}
int add(int a, int b) {
return a + b;
}
(4)对象指针
通过对象指针访问对象成员
/*下面两种访问方法等价*/
ptr->getx(); //对象指针名->成员名;
(*ptr).getx();
① this指针
② 互为组件类引发的问题
class B;
class A{
B b; //错误:类B的声明不完善,无法为B类分配空间
};
class B{
A a;
};
用指针可解决上述问题
class B;
class A{
B *b; //存放地址的空间是可以为编译器预分配的
};
class B{
A a;
};
(5)类成员指针
① 指向类的成员函数的指针
定义格式如下
类型 (类名::* 函数成员指针名)(参数表);
函数成员指针名 = &类名::函数成员名;
//合并如下
类型 (类名::* 函数成员指针名)(参数表) = &类名::函数成员名;
使用格式如下
(*函数成员指针名)(实参表)
② 指向类的数据成员的指针
定义格式如下
类型 类名::* 数据成员指针名;
数据成员指针名 = &类名::数据成员名;
//合并如下
类型 类名::* 数据成员指针名 = &类名::数据成员名;
若该数据成员公有,则类外访问格式如下
对象名.*数据成员指针名 //相当于`对象名.数据成员`
对象指针->*数据成员指针名 //相当于`对象指针->数据成员`
③ 测试案例
#include<iostream>
using namespace std;
class Test {
public:
int a;
void seta(int i) { a = i; }
};
int main() {
Test t;
/*
int Test::*p;
p = &Test::a;
*/
int Test::*p = &Test::a;
t.*p = 2; //相当于t.a = 2
cout << t.a << endl; //输出2
/*
void (Test::*funp)(int);
funp = &Test::seta;
*/
void (Test::*funp)(int) = &Test::seta;
(t.*funp)(3); //相当于t.seta(3)
cout << t.a << endl; //输出3
return 0;
}
7. 指向字符串常量的指针
const char *ptr = "...";
下面两行代码的底层实现并不一致,不能相提并论
char* fun() {
char *s1 = "Em0s_Er1t"; //s1指向常量区的"Em0s_Er1t",严格意义上此处应该写为`const char *s1="Em0s_Er1t";`
char s2[] = "Em0s_Er1t"; //用字符串"Em0s_Er1t"初始化数组s2
s1 = "author"; //可以更改s1的指向
//s2 = "author";//错误,不能用另一个字符串给字符数组赋值
//s1[4] = ' '; //错误,s1指向常量区,是不可以修改常量区数值的
s2[4] = ' '; //正确,修改的是存放在数组s2中的元素。
return s1; //可以返回s1,不能返回s2,因为s2是个数组,是局部变量
}
(七)自定义数据类型
C++语言常用的自定义数据类型有枚举、联合体、结构体等。
1. 枚举类型(Enum)
枚举类型的数据类型定义如下
enum <枚举类型名> {
枚举量0, 枚举量1,..., 枚举量n-1
}
-
枚举类型变量的取值范围只能是这个列表中这几个枚举量
-
默认情况下编译器会将枚举值按照他们定义时排列的先后顺序将他们分别与 \(0\sim n-1\) 的整数关联起来,也可以自定义初始化枚举量的值,但这个值必须要是整型常量(此时未被初始化的枚举量的值将设置成比前一个大1);

#include <iostream> using namespace std; enum weekdays { Monday, Tuesday, Wednesday=1, Thursday, Friday }; int main() { weekdays today; today = Monday; cout << today << endl; //输出0 today = Tuesday; cout << today << endl; //输出1 today = Wednesday; cout << today << endl; //输出1 today = Thursday; cout << today << endl; //输出2 return 0; } -
一个枚举量的底层存储依赖于系统;
-
枚举变量是全局变量的情况下, 枚举值的缺省值是0,不是枚举的第一个值。
#include <iostream> using namespace std; enum string { x1, x2, x3 = 10, } x; void main(){ cout << x << endl; //0 }
以下是利用枚举类型配合switch增强代码可读性的一个例子
#include <iostream>
using namespace std;
enum weekdays { Monday, Tuesday, Wednesday, Thursday, Friday };
int main() {
int today;
cin >> today;
switch (today) {
case Monday:
cout << "Today is Monday";
break;
case Tuesday:
cout << "Today is Tuesday";
break;
case Wednesday:
cout << "Today is Wednesday";
break;
case Thursday:
cout << "Today is Thursday";
break;
case Friday:
cout << "Today is Friday";
break;
default:
cout << "Invalid selection" << endl;
}
return 0;
}
枚举类
用
enum创建的数据类型,会产生如下同名冲突的问题enum Color{black,white,red}; //black、white、red作用域和color作用域相同 enum Color1{black,white,red}; //错误,Color和Color1的枚举量发生同名冲突 int white; //错误,white关键字已经被占用 enum Color; //错误于是枚举类应运而生。
枚举类对普通枚举类型的改进:
- 用
enum class(或者enum struct)创建的数据类型的枚举量在外部被使用需要加上作用域限定 - 枚举类变量必须使用枚举类成员(枚举量)进行初始化或赋值,不能使用整数常量直接初始化或赋值。
- C++编译器不会将枚举类变量默认转换为整数类型,但是我们可以使用强制类型转换将枚举类型变量显式地转换为整数类型。
- 可以指定枚举量的底层数据类型
enum class Color{black,white,red}; //black、white、red作用域仅在大括号内生效
int white; //正确,这个white并不是Color中的white
Color a = 1; //错误,枚举类变量必须使用枚举类成员进行初始化或赋值,不能使用整数常量直接初始化或赋值。见"2"
Color a = white; //错误,在作用域范围内没有white这个枚举量,见"1"
Color a = Color::white; //正确,见"1"
auto b = Color::white; //正确,见"1"
int c=static_cast<int>(Color::white); //正确,见"3"
enum class weekdays:char { Monday, Tuesday, Wednesday=1, Thursday, Friday };//正确,见"4"
2. 联合类型/共用体(Union)
在一个联合体内,我们可以定义多个不同类型的成员,这些成员将会共享同一块内存空间,该内存空间的大小是其最大成员的内存空间大小,因此后赋值的会将前面赋值的数据覆盖。
联合类型的数据类型定义如下
union <联合类型名> {
<成员表>
};
举个例子
#include <iostream>
using namespace std;
union author{
unsigned long birthday;
float score;
};
int main() {
author me;
me.birthday = 20010101;
cout << me.birthday << endl;
me.score = 90.5;
cout << me.birthday << endl;
cout << me.score << endl;
return 0;
}
/*输出:
20010101
1119158272
90.5
*/
例题:X定义如下,若存在
X a; a.x=0x11223344;,则a.y[1]的值可能为( )【多选】union X{ int x; char y[4]; };A. 11
B. 22
C. 33
D. 44
解析:B、C
3. 结构体(Struct)
struct 结构体名称{
公有成员
protected:
保护型成员
private:
私有成员
}
(1)初始化
#include<iostream>
#include<string>
using namespace std;
struct Person1 {
string name;
double height;
};
struct Person2 {
string name;
double height;
Person2(string n = "", double h = 1.7) :name(n), height(h) {};
};
int main() {
/*1. 顺序初始化*/
Person1 John = { "John",1.75 };
Person1 Alice = { "Alice" }; //只初始化前几个成员也是可以的
//Person Ray = { ,1.7 }; //不能跳过前面的成员初始化后面的成员
/*2. 已有结构体初始化新结构体*/
Person1 Bob = John;
/*3. 像类一样初始化(需要构造函数)*/
Person2 David("David", 1.8);
return 0;
}
(2)C++中的结构体与C语言中的结构体的区别
C中的结构体没有函数,但是C++的结构体可以有函数;这是C与C++结构体的区别。
(3)结构体与类的区别
结构体和类的唯一区别在于,结构体和类具有不同的默认访问控制属性
- 类中对于未指定访问控制属性的成员,其访问属性为私有
- 结构体中对于未指定访问控制属性的成员,其访问属性为公有
(4)结构体数组
struct 结构体名 数组名[元素个数]={ {}, {},..., {}};
-
允许声明结构体的同时定义结构体数组
struct A { int a; char b; } a1[10]; A a2[10]; //可以用在后面的结构体变量的定义中,无需再次声明
(5)结构体位字段
C/C++允许指定占用特定位数的结构体成员,这使得创建与某个硬件设备上的寄存器对应的数据结构非常方便。
成员的类型为整型或枚举,接下来是冒号,冒号后面是一个数字,它指定了使用的位数,也可以使用没有名称的字段来提供成员间的间距,这样的每个成员都被称为位字段(bit field)。
#include<iostream>
using namespace std;
struct torgle_register {
unsigned int SN : 4;
unsigned int : 4;
bool goodIn : 1;
bool goodTorgle : 1;
};
int main() {
torgle_register tr = { 14,true,false };
return 0;
}
4. 类(Class)
(八)类型推导
1. auto
auto让编译器自动推断出这个变量的类型,而不需要显式指定类型。
auto x = 5; // 正确,x是int类型
auto pi = new auto(1); // 正确,pi被推导为int*
const auto *v = &x, u = 6; // 正确,v是const int*类型,u是const int类型
static auto y = 0.0; // 正确,y是double类型
const auto *v = &x, u = 6.0;// 错误,初始化v时auto已经被替换为int型,u此时也应该用int型常量初始化
auto int r; // 错误,auto不再表示存储类型指示符
auto s; // 错误,auto无法推导出s的类型
(1)注意点
-
auto 并不能代表一个实际的类型声明,只是一个类型声明的“占位符”。使用 auto 声明的变量必须马上初始化,以让编译器推断出它的实际类型,并在编译时将 auto 占位符替换为真正的类型。
-
auto不能作为自定义类型的成员变量
-
函数形参不能为auto类型
-
模板实例化类型不能是auto类型
-
不存在auto类型的数组
-
C++11中auto不再表示存储类型指示符
-
auto类型的声明语句只能涉及一种变量类型
旧版本的auto
旧版本中auto相对于static而存在,都是存储类型指示符,如
int a;声明a是非静态变量,其实这里隐含了一个auto,即auto int a;,通常这个auto是被省略的。

(2)auto的推导规则
int x = 0;
auto * a = &x; // a -> int*,auto被推导为int
auto b = &x; // b -> int*,auto被推导为int*
auto & c = x; // c -> int&,auto被推导为int
auto d = c; // d -> int ,auto被推导为int
const auto e = x; // e -> const int
auto f = e; // f -> int
const auto& g = x; // g -> const int&
auto& h = g; // h -> const int&
通过上面的一系列示例,可以得到下面这两条规则:
- 当不声明为指针或引用时,auto 的推导结果和初始化表达式抛弃引用和 cv 限定符后类型一致。
- 当声明为指针或引用时,auto 的推导结果将保持初始化表达式的 cv 属性。
2. decltype
有时我们希望定义一个与某表达式同一类型的变量,但不希望用该表达式来初始化该变量,此时可以用decltype返回其类型
#include<iostream>
#include<vector>
using namespace std;
int main() {
int i = 10;
decltype(i) j = 11; //定义一个int型变量j,并被初始化为11
enum { Monday, Tuesday, Wednesday, Thursday, Friday } weekday1;
decltype(weekday1) weekday2; //定义一个枚举类型weekday2
return 0;
}
【应用】
场景一:在泛型编程时,有时需要通过参数运算来确定返回值类型,此时可以将类型推导与返回值类型后置(->)结合起来实现返回值类型推导
#include<iostream>
using namespace std;
template<class T1,class T2>
auto mul(T1 t1, T2 t2)->decltype(t1*t2) {
return t1 * t2;
}
int main() {
cout << mul<int, double>(12, 1.2) << endl; //输出14.4
return 0;
}
场景二:某些类型(如迭代器)的书写繁琐
#include<iostream>
#include<string>
#include<vector>
using namespace std;
class Person {
public:
int age;
string name;
Person(int a, string n) :age(a), name(n) {}
};
int main() {
vector<Person> v{
Person(19, "John"),
Person(20, "Alice"),
Person(18, "Bob"),
Person(21, "Ray")
};
/*遍历*/
for (auto i = v.begin(); i != v.end(); i++) { //用auto自动识别迭代器类型
cout << (*i).name << "'s age is " << i->age << endl;
}
return 0;
}
/*输出
John's age is 19
Alice's age is 20
Bob's age is 18
Ray's age is 21
*/
(九)register关键字
register 这个关键字请求编译器尽可能的将变量存在CPU内部寄存器,而不是通过内存寻址访问,以提高效率。注意是尽可能,不是绝对
(十)类型转换
为了获得目标类型,编译器会不择手段,综合使用内置转换规则和用户自定义转换规则, 进行多级类型转换。
类型转换包括自动类型转换(隐式转换)和强制类型转换(显式转换)
1. 基本类型的自动类型转换
C++基本类型的自动类型转换通常出现在初始化、传参、返回值、表达式运算(包括赋值)这几个场景中。
(1)表达式中的自动类型转换
算术运算符、关系运算符、逻辑运算符、位运算符、赋值运算符这些二元运算符要求操作数类型一致,如果不一致就会触发自动类型转换。
- 算术运算&关系运算:转换的原则是低类型数据转换成高类型数据(类型越高,数据的表示范围越大,精度越高),这种转换是安全的,转换过程中精度没有损失;
- 逻辑运算符:其要求参与运算的操作数必须是bool类型,如果是其它类型,编译系统会自动将其转换成bool类型(非0转换成true,0转换成flase);
- 位运算符:要求操作数必须是整数,转换原则与算术运算和关系运算的相同;
- 赋值运算符:左值与右值类型不同时,一律将右值转换成左值类型,有些情况下势必会导致精度损失;
2. 基本类型的强制类型转换
参考:
- 《C++ Primer Plus》(第6版)中文版 P.649
强制类型转换支持将表达式结果类型转换成另一种指定类型,强制类型转换传统的通用格式如下
类型名(待转换的表达式); //C++风格
(类型名)待转换的表达式; //C风格
标准C++又添加了四个适用于不同场景的强制类型转换运算符dynamic_cast、const_cast、static_cast、reinterpret_cast,使用格式如下:
强制类型转换运算符<typename>(expression)
//typename:要转换到的类型
//expression:待转换的表达式
(1)static_cast
个人理解:static_cast实现的是真正的内容转换,如int型转double型,int型的数据重新按照double型编码,此时只有被解析成double型才具有实际意义。
static_cast<typename>(expression)
static_cast 可用于如下转换
-
标准转换:所有隐式转换都可以用static_cast代替
如基本数据类型之间的转换,把int转换为char,但是不能用于两个不相关的类型转换(如不同类型的指针之间、整型和指针之间、不同类型的引用之间)
-
类层次结构中基类和派生类之间指针或引用的转换
-
上行转换/向上转换(派生类指针/引用 \(\rightarrow\) 基类指针/引用)
-
下行转换/向下转换(基类指针/引用 \(\rightarrow\) 派生类指针/引用)
虽然
static_cast支持将一个基类指针(或引用)转换成一个派生类指针(或引用),但只有在这个基类指针(或引用)指向一个派生类对象时这种转换才是安全的转换,如果基类指针(或引用)确实指向一个基类对象,则这种转换就是不安全的,所以当要执行向下转换时建议使用dynamic_cast,dynamic_cast会在基类指针指向的确实为基类对象并试图将其转换成派生类指针时发现这一错误并返回NULL。
-
-
如果对象所属的类重载了强制类型转换运算符 T(假定 T 是 int、int* 或其他类型名),则 static_cast 也能用来进行对象到 T 类型的转换;
-
把空类型指针转换成目标类型的空指针
-
把任何类型的表达式转为void类型
static_cast不能转换掉expression的const、volatile或者__unaligned属性
#include <iostream>
using namespace std;
class B {
};
class A :public B {
public:
operator int() { return 1; }
operator char*() { return NULL; }
};
int main() {
A a;
B b;
int n;
char* p;
const int d = 10;
/*见“1”*/
n = static_cast <int> (3.14); //n 的值变为 3
//n = static_cast <int> (p); //错误,static_cast不能将指针转换成整型
//p = static_cast <char*> (n); //错误,static_cast不能将整型转换成指针
/*见“2”*/
B* pb = static_cast <B*> (&a); //派生类指针可以转换成基类指针(向上转换)【安全】
A* pa = static_cast <A*> (&b); //基类指针可以转换成派生类指针(向下转换)【不安全,使用pa访问A类新增成员会报错】
/*见“3”*/
n = static_cast <int> (a); //调用 a.operator int,n 的值变为 1
p = static_cast <char*> (a); //调用 a.operator char*,p 的值变为 NULL
//int* c = static_cast<int*>(&d);//错误,static_cast不能转换掉const属性
return 0;
}
(2)reinterpret_cast
个人理解:reinterpret_cast转换的是对底层数据的解析方式,如
float*转换成int*,则对同一块内存单元存放的底层数据没有发生改变,只是原来将底层编码解析成float型,现在按照int型来解析了
reinterpret_cast<typename>(expression)
reinterpret_cast用于进行各种不同类型的指针之间、不同类型的引用之间以及指针和能容纳指针的整数类型之间的转换。转换时,执行的是逐个比特复制的操作, 从底层对数据编码进⾏重新解释。
#include<iostream>
using namespace std;
int main() {
struct dat { short a; short b; };
long value = 0xA224B118;
//dat *pd = &value; //错误,不同类型不能初始化
dat *pd = reinterpret_cast<dat *>(&value); //让pd强行指向value所在内存空间,于是通过pd解析value的数值也就按照结构体来解析了
cout << hex << pd->a << endl; //输出:b118
pd->b = 0xAAAA;
cout << hex << value << endl; //输出:aaaab118
//pd指向的就是value的内存空间,只是二者对底层数据的解析不同(下面的输出不固定)
cout << pd << endl; //输出:006FF9C4
cout << &value << endl; //输出:006FF9C4
return 0;
}
(3)const_cast
const_cast<typename>(expression)
const_cast 运算符仅用于进行去除 const 属性的转换,常用于将 const 引用(或指针)转换为同类型的非 const 引用(或指针),它也是四个强制类型转换运算符中唯一能够去除 const 属性的运算符。
注意:
- 这里去除的是expression自身的const属性,不能去除expression所指向的变量的const属性。
- typename与expression除了const和volatile不同之外,类型必须相同
#include <iostream>
using namespace std;
int main()
{
int x = 1;
const int* px = &x; //无法直接通过px修改x的值
int* newpx = const_cast<int*>(px);
*newpx = 2;
cout << x << endl; //输出2
const int y = 1;
const int* py = &y; //无法直接通过py修改y的值
int* newpy = const_cast<int*>(py);
*newpy = 2;
cout << y << endl; //输出1,newpy指向的y是常量,本身是只读的,所以修改失败
return 0;
}
(4)dynamic_cast
郑莉 C++语言程序设计 P.337
C++四种强制类型转换介绍 - 知乎 (zhihu.com)
C++四种强制类型转换运算符_c++强制类型转换运算符_程序猿编码的博客-CSDN博客
C++面试:C++ 的四种强制转换 - 知乎 (zhihu.com)
C++ Primer Plus(第6版)P.667
dynamic_cast<typename>(expression)
用 reinterpret_cast/static_cast 可以将多态基类(包含虚函数的基类)的指针强制转换为派生类的指针,但是这种转换不检查安全性,如果转换后的指针不指向一个派生类对象,则后续用这个指针访问派生类新增成员就会产生灾难性后果,而
dynamic_cast检查转换后的指针是否确实指向一个派生类对象,就可以避免这类问题。
dynamic_cast 用于不同类之间的指针或引用转换
- 上行转换(派生类指针/引用 \(\rightarrow\) 基类指针/引用):与static_cast效果相同
- 下行转换(基类指针/引用 \(\rightarrow\) 派生类指针/引用):检查基类的指针/引用是否指向派生类,如果兼容则转换,否则——执行的指针类型转换则返回空指针,执行的是引用类型转换则抛出异常。
- 不相关的类之间转换:检查待转换的指针/引用所指向/引用的对象是否兼容目标类的对象,如果兼容则转换,否则——执行的指针类型转换返回空指针,执行的引用类型转换抛出异常。
注意
- dynamic_cast只能用于多态类(即必须公有继承且有虚函数),这是因为运行时的类型检查需要运行时类型信息,而这个信息存储在类的虚函数表中,只有定义了虚函数的类才有虚函数表,没有定义虚函数的类是没有虚函数表的
dynamic_cast通常用于下行转换以及两个不相关类的指针/引用的转换(上行转换通常用static_cast)
#include<iostream>
using namespace std;
class Base1 {
public:
virtual ~Base1() {}
};
class Base2 {
public:
virtual ~Base2() {}
};
class Derived : public Base1, public Base2 {};
/*“不相关的类之间转换”(基类1指针/引用 → 基类2指针/引用)*/
void test1() {
Derived d;
Base1* pb1 = &d;
//Base2* pb2 = static_cast<Base2*>(pb1); //【编译错误】因为static_cast是编译时检查,不知道指针的具体指向,检查时单纯判断Base1*不能转Base2*,但其实这种表面上不相干的转换却是可行的
Base2* pb2 = dynamic_cast<Base2*>(pb1); //不报错也成功转换
}
/*“下行转换”(基类指针/引用 → 派生类指针/引用)*/
void test2() {
Base1 b1;
Derived *pd1 = static_cast<Derived*>(&b1); //static_cast支持这种转换,但这种转换不安全不可取,后续用pd1访问派生类成员会产生灾难性后果
cout << pd1 << endl;
cout << &b1 << endl;
Derived *pd2 = dynamic_cast<Derived*>(&b1); //此处dynamic_cast会检测到这种转换不安全,进而返回NULL给d_2
cout << pd2 << endl;
cout << &b1 << endl;
}
int main(){
test1();
test2();
return 0;
}
3. 其他类型与自定义类型间的转换
参考:《C++ Primer Plus》(第6版)中文版 P.411
其它类型与自定义类型的类型转换需要我们自己定义一些函数,定义完之后就可以像基本数据类型那样显示/隐式转换,这种转换与基本数据类型一样也是出现在初始化、传参、返回值、表达式运算(包括赋值)这几个场景中。
(1)其他类型 \(\rightarrow\) 自定义数据类型
见“转换构造函数”,定义了转换构造函数我们就可以实现其它类型显示/隐式转换成自定义数据类型。
(2)自定义数据类型 \(\rightarrow\) 其他类型
见“类型转换运算符重载”,定义了转换构造函数我们就可以实现自定义数据类型显示/隐式转换成其它类型。
(3)explicit关键字
隐式转换有时候并不好用,会出现如二义性等问题,而explicit关键字使得其他类型与自定义类型的相互转换只能显式调用。我们在类型转换时也应该尽可能多的使用显式的强制类型转换。
(十一)变量取值范围
| 类型 | 名称 | 字节数 | 范围 |
|---|---|---|---|
| signed char | 有符号字符型 | 1 | -128 ~127 |
| unsigned char | 无符号字符型 | 1 | 0 ~255 |
| 类型 | 名称 | 字节数 | 范围 |
|---|---|---|---|
| [signed] int | 有符号整型 | 4 | -2147483648 ~ 2147483647 |
| unsigned [int] | 无符号整型 | 4 | 0 ~4294967295 |
| [signed] short | 有符号短整型 | 2 | -32768 ~ 32767 |
| unsigned short [int] | 无符号短整型 | 2 | 0 ~ 65535 |
| [signed] long [int] | 有符号长整型 | 4 | -2147483648 ~ 2147483647 |
| unsigned long [int] | 无符号长整型 | 4 | 0 ~4294967295 |
| 类型 | 名称 | 字节数 | 范围 |
|---|---|---|---|
| float | 单精度型 | 4 | \(1.2e^{-38}\sim 3.4e^{38}\) |
| double | 双精度型 | 8 | \(2.2e^{-308}\sim 1.8e^{308}\) |
| long double | 长双精度型 | 8 | \(2.2e^{-308}\sim 1.8e^{308}\) |
七、常量
(〇)基本概念
1. 字面量(literal)
在计算机科学中,字面量(literal)是用于表达源代码中一个固定值的表示法(notation),不需要额外的对象来对其地址或值进行保存(通常,用户定义字面量除外)
#include <stdio.h>
int main(void)
{
int a = 10; // 10为int类型字面量
char a[] = {"Hello world!"} // "Hello world!"为字符串形式字面量
//.............
return 0;
}
2. 表达式
C++语言中的表达式可分为算术表达式、关系表达式和逻辑表达式等多种类型,但从表达式中变量所起的作用角度来看可分为两类:有副作用的表达式和无副作用的表达式。
- 一个表达式在求值过程中,对使用的变量不但引用,对它们的值还加以改变,这样的表达式称为有副作用的表达式。
- 在表达式求值过程中,需要提取这些变量的值,但并不改变这些变量的值,这样的表达式称为无副作用的表达式(传统意义上的表达式是不应该有副作用的)。
5*x; //无副作用表达式
x+y; //无副作用表达式
x++; //有副作用表达式
y-=18*2; //有副作用表达式
(一)整型常量
代码中整数的书写有3种方式
- 若从左往右第一位为 \(1\sim 9\),则这个整数是十进制数;
- 若从左往右第一位为 \(0\),
- 第二位是
x或者X,则这个整数是十六进制; - 第二位是 \(1\sim 7\),则这个整数是八进制。
- 第二位是
#include<iostream>
using namespace std;
int main() {
int a = 23, b = 0x23, c = 023;
cout << a << endl;
cout << b << endl;
cout << c << endl;
return 0;
}
/*输出:
23
35
19
*/
整型常量的类型
在不加后缀的情况下,
- 一个十进制整型常量按有符号存储,且类型为
int、long、long long中能容纳其数值的尺寸最小的那个 - 一个八进制或者十六进制整型常量的类型是能容纳其数值的
int、unsigned int、long、unsigned long、long long、unsigned long long中能容纳其数值的尺寸最小的那个
整型常量可以用后缀指定它是否带符号以及所属类型,后缀是放在数字常量后面的字母,用于表示类型。
-
整数后面的
l或L后缀表示该整数为long常量 -
u或U后缀表示unsigned int常量 -
ul(u和l顺序可互换,且大小写均可)表示unsigned long常量(由于小写1看上去像1,因此应使用大写L作后缀)。例如,在int 为16位、long 为32位的系统上,数字22022被存储为int,占16位,数字22022L被存储为long,占32位。同样,22022LU和22022UL都被存储为unsigned long。C++11 提供了用于表示类型long long的后缀II和LL,还提供了用于表示类型unsigned long long 的后缀
ull、Ull、uLL和ULL。
(二)字符常量
一些不可打印字符以转义字符的形式来表示
| 转义字符 | 意义 | ASCII码值(十进制) |
|---|---|---|
\a |
响铃(BEL) | 007 |
\b |
退格(BS) ,将光标的当前位置移到前一列 | 008 |
\f |
换页(FF),将光标当前位置移到下页开头 | 012 |
\n |
换行(LF) ,将光标当前位置移到下一行开头 | 010 |
\r |
回车(CR) ,将光标当前位置移到本行开头 | 013 |
\t |
水平制表(HT) (跳到下一个TAB位置) | 009 |
\v |
垂直制表(VT) | 011 |
\\ |
代表一个反斜线字符''' | 092 |
\' |
代表一个单引号(撇号)字符 | 039 |
\" |
代表一个双引号字符 | 034 |
\? |
代表一个问号 | 063 |
\0 |
空字符(NULL) | 000 |
\ddd |
1到3位八进制数所代表的任意字符 | |
\xhh |
1到2位十六进制所代表的任意字符 |
若某字符既有数字转义序列也有符号转义序列(如
\x8和\b),则应使用符号序列,因为数字表示与特定的编码方式(如ASCII码)相关,而符号表示适用于任何编码方式,其可读性也更强。、
#include<iostream>
using namespace std;
int main() {
int code;
cout << "\aPlease Enter The Code: ________\b\b\b\b\b\b\b\b";
cin >> code;
cout << "\aThe Code Is " << code << endl;
return 0;
}
(三)常量变量
符号常量 vs 常量变量
相同:二者都可以为常量命名,增加代码可读性,避免修改常量值带来的不一致性
不同:
- 符号常量即用符号表示的常量,通常是由
#define定义的,不占用内存空间,在预编译时就全部由符号常量代表的值替换了- 常量变量占用内存空间,有具体的数据类型,但是此变量在存在期间不能重新赋值。
const int a; a = 10; //(错误)常量a不能被修改
const float PI = 3.14; //(正确),也可以写成`float const PI = 3.14;`
int m = 10;
const int a = m; //(正确)借助一个变量来初始化一个符号常量
int b = a; //(正确)借助一个常量变量来初始化一个变量
1. const局部变量底层原理
const变量在编译期会被编译期编译成一张常量表,所有读取常量的操作都会从这个常量表里直接读取(其实是在编译时编译器用表里面的对应值替换,这就是所谓的常量折叠),但当const变量是一个局部变量时,如果对const变量使用取地址&操作赋给某个指针值或者使用extern声明,此时会在栈上被分配内存空间,并且通过指针的操作都是对栈上的空间进行操作,对常量表的内容不会有任何影响。
下面的例子中,即便用const_cast去除了const属性也不能改变a的值,因为常量是只读的,修改的只是其被分配内存单元后的副本。
#include <iostream>
using namespace std;
int main()
{
const int a = 10;
int *p = const_cast<int*>(&a); //等价于`int *p = (int *)(&a);`
*p = 20;
cout << "a = " << a << ", *p = " << *p << endl;
return 0;
}
2. const限定的变量间复制
(1)顶层const & 低层const
-
被修饰的变量本身无法改变的
const是 顶层 const(top-level const ),如const int int *const const int* const(右边的) const int**** const(右边的) //多级指针 -
通过指针或引用等间接途径来限制目标内容不可变的
const是 低层 const(low-level const),如const int* const int* const(左边的) const int&
(2)基本规则
-
对于一级指针
-
低层const一致的情况下,顶层const相同与否,不影响初始化,但对于
=赋值运算来说,顶层const当然是不允许被修改的。 -
当执行对象的复制操作(即包括初始化和赋值)时,拷入和拷出的对象必须具有相同的低层const资格,或者两个对象的数据类型必须能够转换。一般来说,非const可以转换成const,反之就不行。
原对象的可写性(可修改性)在复制过程中,不应有所扩大。
-
-
对于多级指针,上面的规则会失效,如C++不允许将
char**转换成const char**',只能转换成const char* const *,即每一层都必须是const才允许转换
/*
说明:
A → B:代表用A类型对象初始化B类型对象
A ⇒ B:代表A类型对象给B类型对象赋值
*/
#include<iostream>
using namespace std;
int main() {
int a = 10;
int &ref = a;
/*顶层const,见“1”*/
const int c = a; //int → const int
int b = c; //const int → int
b = c; //const int ⇒ int
int* const p1 = &a; //int* → int* const
int *p2 = p1; //int* const → int*
p2 = p1; //int* const ⇒ int*
const int* d = &c;
const int* const p3 = &c;//const int* → const int* const
const int* p4 = p3; //const int* const → const int*
p4 = p3; //const int* const ⇒ const int*
/*低层const,见“2”*/
const int* p5 = &a; //int* → const int*
p5 = &a; //int* ⇒ const int*
//int *f = p5; //错误,低层const只支持非常量转常量(权限降低)
//int *f; f = p5; //错误,同上
const int &r1 = ref; //int& → const int&
//int& r2 = r1; //错误,低层const只支持非常量转常量(权限降低)
/*混合*/
const int* p6 = p1; //int* const → const int*
//int* const p7 = p6; //错误,低层const只支持非常量转常量(权限降低)
}
3. constexpr
const有时会带来二义性问题,即它可以被理解为只读变量(本质上还是变量)和常量

C++ 11标准中,为了解决 const 关键字的双重语义问题,保留了 const 表示“只读”的语义,用于为修饰的变量添加“只读”属性,而 constexpr 关键字则用于指明其后是一个常量(或者常量表达式),编译器在编译程序时可以顺带将其结果计算出来,而无需等到程序运行阶段,这样的优化极大地提高了程序的执行效率。
因此 C++11 标准中,建议将 const 和 constexpr 的功能区分开,即凡是表达“只读”语义的场景都使用 const,表达“常量”语义的场景都使用 constexpr。
(1)constexpr变量
定义变量时可以用 constexpr 修饰,从而使该变量获得在编译阶段即可计算出结果的能力(编译时该“变量”被编译器解读为常量)。
constexpr int N = 100; //这里constexpr可以用const代替,因为const可以表示‘常量’语义
int arr[N] = {1,2,3}
(2)constexpr函数
constexpr函数是能用于常量表达式的函数,定义这样的函数需要满足如下条件:
-
函数体中除了可以包含typedef、using、静态断言外只能有一条语句,且为return语句
//错误,函数体中只能有一条语句 constexpr int fun1(){ constexpr int a = 1; return a; } //正确 constexpr int fun2(){ static_assert(1,"fail") return 3; } -
函数返回值不能是void型
-
对constexpr函数的定义放在constexpr函数的调用前
-
return后面跟着的不能含有非常量表达式的函数、全局数据,必须是一个常量表达式
//错误,return后面不能含有全局数据 int a = 1; constexpr int fun1(){ return a; } //错误,return后面不能含有非常量表达式的函数 int test(){return 10;} constexpr int fun2(){ return test(); } //正确 constexpr int test(){return 10;} constexpr int fun2(){ return test(); }
(4)可产生常量的自定义数据类型
当我们想自定义一个可产生常量的类型时,正确的做法是在该类型的内部添加一个常量构造函数,constexpr 修饰类的构造函数时,要求该构造函数的函数体必须为空,且采用初始化列表的方式为各个成员赋值时,必须使用常量表达式。
(四)浮点数/实型常量
浮点数常量可以采用下面2种方式表示:
-
标准小数点表示法
小数点前面若都是0,可以省略这个0
-
E表示法(科学计数法):
d.dddE+n指的是将小数点向右移n位,而d.dddE-n指的是将小数点向左移n位。之所以称为“浮点”,就是因为小数点可移动。注意:
- e/E 前面的必须是十进制的数(小数或者整数),为小数时不能只有小数点
- e/E 后面的必须是十进制整数
- e/E、e/E前面的数、e/E后面的数,这三个部分均缺一不可

例:(下面几种表示方法等价)
1.314E8
1.314e8
1.314E+8
1.314e+8
131400000.0
e3 //错误,e前面不能没有数
2e4.2 //错误,e后面必须是十进制整数
.e5 //错误,e前面不能只有小数点
-.18 //合法,即-0.18
-e3 //错误,e前面的不是数
默认情况下浮点常量属于double类型,如果希望常量为float 类型,需要使用f或F后缀。对于long double 类型,可使用l或L后缀。
有效数字
单7双16
- 单精度浮点数占32位,可表示的十进制有效位数是7位。
- 双精度浮点数占64位,可表示的十进制有效位数是16位。
(五)自定义字面量/自定义后缀操作符
C++11允许用户自定义实现一个后缀操作符,将申明了该后缀标识的字面量转化为需要的类型
后缀操作符函数的参数只能是如下几种
char const *
unsigned long long
long double
char const *, size_t
wchar_t const *, size_t
char16_t const *, size_t
char32_t const *, size_t
-
最后4个形参表对于字符串相当有用,因为第2个参数会自动推断为字符串的长度
#include <iostream> using namespace std; size_t operator"" _len(char const * str, size_t size){ return size; } int main(){ cout << "Em0s_Er1t"_len << endl; //结果为9 return 0; } -
若一个记号同时匹配用户定义字面量的语法和常规字面量的语法,则它被假定为常规字面量(即不可能重载 123LL 中的 LL)
(六)字符串常量
字符串一定是以ASCII码为0的空字符\0结尾的一系列连续字符,C++有很多处理字符串的函数,其中包括cout所使用的那些函数,它们都逐个处理字符串中的字符,直到到达空字符\0为止。如果使用cout显示如下name2这样的字符串,则将显示前9个字符,发现空字符后停止。
但是,如果使用cout显示如下的name1数组(它不是字符串,但会被视作字符串处理),cout 将打印出数组中的9个字符,并接着将内存中随后的各个字节解释为要打印的字符,直到遇到空字符为止。由于空字符(实际上是被设置为0的字节)在内存中很常见,因此这一过程将很快停止,但尽管如此,还是不应将不是字符串的字符数组当作字符串来处理。
将字符数组初始化为字符串可以用双引号将字符串括起来(如下的name3),这就隐式地包含了空字符\0。
/*区分字符串与字符数组*/
#include<iostream>
int main()
{
char name1[] = { 'E','m','0','s','_','E','r','1','t' }; //不是字符串而是字符数组
char name2[] = { 'E','m','0','s','_','E','r','1','t','\0' }; //是字符串
char name3[] = "Em0s_Er1t"; //是字符串
std::cout << name1 << std::endl;
std::cout << name2 << std::endl;
std::cout << name3 << std::endl;
return 0;
}
/*输出:
Em0s_Er1t烫烫烫?N9???Y
Em0s_Er1t
Em0s_Er1t
*/
原生字符串字面值
C++11支持所见即所得的原始字符串(如对包裹在内的“转义字符”不转义等等),格式如下
R"(原始字符串)";

八、类与对象
(〇)基本概念
面向对象编程的3大特性:封装性、继承性、多态性
- 封装性:把数据和操作结合在一起
- 继承性:对于类的方法的改变和补充
- 多态性:同一个属性或行为在不同类有不同的具体实现使之呈现不同语义
类描述了一种数据类型的全部属性(包括可使用它执行的操作),对象是根据这些描述创建的实体。在不考虑静态成员的情况下,当需要使用一个类的功能时,只能通过定义一个对象才能使用。
类的描述指定了可对类对象执行的所有操作,但要对特定对象执行这些允许的操作,需要给该对象发送消息。C++提供了两种发送消息的方式:
-
使用类方法(本质上就是函数调用);
-
重新定义运算符;
cin 和cout采用的就是这种方式,
cout << "helloworld!";使用重新定义的<<运算符将要打印的消息"helloworld!"发送给cout。
(一)类的定义
类定义的通用语法形式如下:
class 类名称{
public:
公有成员(外部接口)
private:
私有成员(一些数据、起辅助作用的子功能函数)
protected:
保护型成员(继承关系相关)
}
-
公有类型成员:在关键字public后面声明,是类与外部的接口,任何外部函数都可以访问公有类型数据和函数。
-
私有类型成员:在关键字private后面声明,只允许本类中的函数访问,而类外部的任何函数都不能访问。
如果紧跟在类名称的后面声明私有成员,则关键字private可以省略。
-
保护型成员:如果希望类的某个成员既不向外暴露(类外部不能通过对象访问),还能为其派生类所用,那么只能声明为 protected。
-
对其所在类对象来说,它与private成员的性质相同,即类外不能通过对象访问
class A{ protected: int x; } int main(){ A a; a.x=5 //错误 return 0; } -
对于其所在类的派生类来说,不管什么继承方式,派生类的成员函数可直接访问基类的保护成员(就像基类的public成员一样)。
class A { protected: int x; }; /*公有继承*/ class B_pub :public A { public: void fun() { x = 5; //正确 } }; /*私有继承*/ class B_pri :private A { public: void fun() { x = 5; //正确 } }; /*保护继承*/ class B_pro :protected A { public: void fun() { x = 5; //正确 } };
-
(二)对象建立
对象建立有2种方式
- 静态建立对象:是由编译器为对象在栈空间中分配内存,是通过直接移动栈顶指针,挪出适当的空间,然后在这片内存空间上调用构造函数形成一个栈对象。使用这种方法,直接调用类的构造函数。
- 动态建立对象:使用new运算符将对象建立在堆空间中。这个过程分为两步,第一步是执行operator new()函数,在堆空间中搜索合适的内存并进行分配;第二步是调用构造函数构造对象,初始化这片内存空间。这种方法,间接调用类的构造函数。
(三)类的基本规则
-
类内的成员函数可以直接访问类的所有数据成员(类的成员函数共享类的数据成员);
-
类的成员函数可以在类内说明函数原型(函数申明),在类外给出函数体实现(需要在函数名前加上作用域限定“
类名::”);允许声明重载函数和带默认参数值的函数
-
类的成员函数也可以在类内部实现,但不推荐这种做法;
在类内部实现成员函数则默认被视作内联函数
-
类外需要使用
对象名.成员名方式访问public属性的成员,且只能访问public属性的成员; -
类的成员函数内部可以访问任何同类对象的所有成员(包括私有成员);
用友元可以打破这层约束,见“友元”
-
类内可以使用
=或{}就地初始化非静态成员变量如果在一个类中,既使用了就地初始化来初始化非静态成员变量,又在构造函数中使用了初始化列表,则执行顺序是:先执行就地初始化,然后执行初始化列表。
-
类的非静态成员变量不能作为成员函数的默认实参,但静态成员可以作为类成员函数的默认实参
-
自身类的对象不可以作为该类的成员,但自身类的对象指针可以作为该类的成员
-
类的数据成员不可以加存储类型说明(如auto、register等等)
定义类时,数据并未被分配内存,无法指定
#include<iostream>
using namespace std;
class Clock {
int hour{ 0 }, minute{ 0 }, second = 0; //见"6"
//register int hour; //错误,见"9"
//auto int minute; //错误,见"9"
public:
void setTime(int newH = 0, int newM = 0, int newS = 0); //见"2"
void showTime() { //见"3"
cout << hour << ":" << minute << ":" << second << endl; //见"1"
}
void compTime(const Clock &time);
};
void Clock::setTime(int newH, int newM, int newS) { //见"2"
hour = newH; //见"1"
minute = newM; //见"1"
second = newS; //见"1"
}
void Clock::compTime(const Clock &time) {
if (time.hour == hour && time.minute == minute && time.second == second) //见"5"
cout << "equal" << endl;
else
cout << "not equal" << endl;
}
int main() {
Clock myclock;
/*通过调用setTime函数间接完成对对象的数据成员的赋值*/
myclock.setTime(20, 15, 23); //见"4"
myclock.showTime(); //见"4"
return 0;
}
(四)类的初始化及相关问题
1. 类内初始化/就地初始化
C++11支持在类内对数据成员进行等号或者大括号版本的初始化操作。
通过使用类内初始化,可避免在构造函数中编写重复的代码,如果构造函数在成员初始化列表中提供了相应的值,则类内初始化设定默认值将被覆盖。
#include<iostream>
using namespace std;
class Clock {
int hour = 0;
int minute = 0;
int second = 0;
public:
Clock() {};
Clock(int newH) : hour(newH), minute(13), second(14) {};
void showTime() {
cout << hour << ":" << minute << ":" << second << endl;
}
};
int main() {
Clock time1;
time1.showTime(); //输出:0:0:0
Clock time2(20);
time2.showTime(); //输出:20:13:14
return 0;
}
2. 构造函数(Constructor)
(0)基本规则 & 特征
在对象被创建时自动调用构造函数使用特定的值构造对象,将对象初始化为一个特定的初始状态。构造函数有如下特征:
-
函数名与类名相同;
-
不能定义返回值类型,也不能有return语句;
-
可以有形式参数,也可以没有形式参数;
-
可以是内联函数;
-
可以重载,即一个类可以拥有多个构造函数;
重载的构造函数必须避免二义性(在形式参数的类型、个数和顺序等至少一个方面不一样)
-
可以带默认参数值。
-
通常被声明为公有,被声明为私有也是合法的。
只要定义了一个对象就势必触发构造函数的调用,每次定义类对象时,编译器会自动查找并匹配最合适的构造函数
-
如果编译器发现程序中未定义构造函数,则将自动生成一个默认构造函数/缺省构造函数(default constructor)再调用;
-
如果程序中定义了构造函数,则编译器不再生成默认构造函数,只从所有已定义的构造函数中选择合适的来调用执行,若没有合适的就报错(如下);
定义对象时没有提供实际参数则会调用无参构造函数,若此时程序中有构造函数但没有无参构造函数则会报错(如下)

此时需要重载一个无参构造函数就可以通过,或者也可以用default关键字让编译器再为我们生成。

#include<iostream>
using namespace std;
class Clock {
int hour, minute, second;
public:
Clock();
Clock(int newH, int newM, int newS);
void setTime(int newH = 0, int newM = 0, int newS = 0);
void showTime() {
cout << hour << ":" << minute << ":" << second << endl;
}
};
/*定义无参构造函数(默认构造函数)*/
//Clock::Clock() :hour(0), minute(0), second(0) {} //构造函数的实现可以采用初始化列表形式
Clock::Clock() {
hour = minute = second = 0;
}
/*定义构造函数*/
//Clock::Clock(int newH, int newM, int newS) : hour(newH), minute(newM), second(newS) {} //构造函数的实现可以采用初始化列表形式
Clock::Clock(int newH, int newM, int newS) {
hour = newH;
minute = newM;
second = newS;
}
void Clock::setTime(int newH, int newM, int newS) {
hour = newH;
minute = newM;
second = newS;
}
int main() {
Clock myclock_1, //自动调用无参构造函数
myclock_2(20,13,14); //自动调用有3个形参的构造函数
cout << "myclock_1:" << endl;
myclock_1.showTime();
cout << "myclock_2:" << endl;
myclock_2.showTime();
return 0;
}
(1)初始化列表
若构造函数体中只使用赋值语句初始化对象的数据成员,则还可以用初始化列表的方式达到同样的效果
/*一般形式*/
Clock::Clock(int newH, int newM, int newS) {
hour = newH;
minute = newM;
second = newS;
}
/*初始化列表的形式*/
Clock::Clock(int newH, int newM, int newS) : hour(newH), minute(newM), second(newS) {} //构造函数的实现可以采用初始化列表形式
(2)构造函数的调用
构造函数的调用有括号法、显示调用、隐式转换调用这几种
#include<iostream>
using namespace std;
class Clock {
int hour, minute=0, second=0;
public:
/*构造函数*/
Clock(int newH, int newM = 0, int newS = 0) :hour(newH), minute(newM), second(newS) { cout << "有参构造函数" << endl; }
/*无参构造函数*/
Clock() { cout << "无参构造函数" << endl; }
/*复制构造函数*/
Clock(const Clock &time) : hour(time.hour), minute(time.minute), second(time.second) { cout << "复制构造函数" << endl; } //参数是本类对象的常引用
/*析构函数*/
~Clock() { cout << "析构函数" << endl; }
};
int main() {
/*1. 括号法(常用)*/
Clock c_1(20, 13, 14); //调用有参构造函数
Clock c_2; //调用无参构造函数
Clock c_3(c_2); //调用复制构造函数
//Clock c_2(); //【注意:调用无参构造函数不能加括号,如果加了编译器认为这是一个函数声明,不会认为在创建对象】
/*2. 显式法*/
Clock c_4 = Clock(20, 13, 14); //调用有参构造函数
Clock c_5 = Clock(c_3); //调用复制构造函数
Clock(20, 13, 14); //调用有参构造函数创建了一个匿名对象,当前行执行完毕后系统自动回收
//Clock(c_3); //【注意:并不是调用复制构造函数初始化一个匿名对象,其实这行等价于Clock c_3,编译器认为这行是一个对象声明】
/*3. 隐式转换法*/
Clock c_6 = 20; //调用有参构造函数,相当于Clock c_6 = Clock(20);【本例中的有参构造函数也是一种转换构造函数】
Clock c_7 = c_5; //调用复制构造函数,相当于Clock c_7(c_5);
return 0;
}
(3)默认构造函数/缺省构造函数(Default Constructor)
定义:调用时不需要提供实参的构造函数是默认构造函数,也称缺省构造函数
注意:默认构造函数不是因为编译器自动生成所以称其为默认构造函数
默认构造函数有如下特征:
- 参数列表为空或者不为空但均有默认值,只负责为对象的数据成员分配空间,而不为数据成员设置初始值;
- 如果类内定义了成员的初始值,则使用类内定义的初始值;如果没有定义类内的初始值,则以默认方式初始化;
- 基本类型的数据默认初始化的值是不确定的;
- 一个类至多只能有一个默认构造函数。
以下两种形式的构造函数都是默认构造函数(两种形式不可以同时出现在一个类中,因为有二义性)
/*形式一:不带形参*/
Clock(){
}
/*形式二:已经提供了(默认)实参*/
Clock(int newH=0,int newM=0,int newS=0){
}
/*不是默认构造函数*/
Clock(int newH, int newM, int newS) {
hour = newH;
minute = newM;
second = newS;
}
例题:对于默认构造函数,下面哪一种说法是错误的?
A. 一个无参构造函数是默认构造函数
B. 只有当类中没有显式定义任何构造函数时,编译器才自动生成一个公有的默认构造函数
C. 默认构造函数一定是一个无参构造函数
D. 一个类中最多只能有一个默认构造函数
本题选C。A选项,无参构造函数一定是默认构造函数,正确。B选项,当类中没有显式定义任何构造函数时,编译器自动生成一个公有的默认构造函数。如果一个类显式地声明了任何构造函数,编译器不生成公有的默认构造函数。在这种情况下,如果程序需要一个默认构造函数,需要由类的设计者提供。正确。C选项,无参构造函数一定是默认构造函数, 而默认构造函数可能是无参构造函数,也可能是所有参数都有默认值的构造函数。因此C选项错误。D选项,一个类只能有一个默认构造函数,一般选择 testClass(); 这种形式的默认构造函数 ,因此D选项描述正确。综上,默认构造函数可能是无参构造函数(形式一),也可能是所有参数都有默认值的构造函数(形式二),因此C选项错误。本题选C。
(4)委托构造函数
即允许构造函数通过初始化列表调用同一个类的其他构造函数,目的是简化构造函数的书写,提高代码的可维护性,避免代码冗余膨胀。
举个例子
/*定义构造函数*/
Clock::Clock(int newH, int newM, int newS) : hour(newH), minute(newM), second(newS) {} //构造函数的实现可以采用初始化列表形式
/*定义无参构造函数(默认构造函数)*/
Clock::Clock() :hour(0), minute(0), second(0) {} //构造函数的实现可以采用初始化列表形式
用委托构造函数后可以将上面的写成
/*定义构造函数*/
Clock::Clock(int newH, int newM, int newS) : hour(newH), minute(newM), second(newS) {} //构造函数的实现可以采用初始化列表形式
/*委托构造函数*/
Clock::Clock() :Clock(0,0,0) {}
(5)复制构造函数(Copy Constructor)
复制构造函数是一种重载的构造函数, 其形参为本类的对象引用,可以帮助我们用一个已经存在(已被定义)的对象去初始化新的同类型对象。
/*函数原型*/
类名([const ]类名 &对象名); //参数是本类对象的(常)引用
参数:
- 参数通常采用引用方式传入,因为复制构造函数直接传对象,本身会导致无穷递归(形参参数是对象默认调用复制构造函数)。
- 参数通常设置成const,这样就可以利用一个临时无名对象进行复制构造操作,同时也可以放置被修改
- 如果有其它参数则必须为这些参数设置默认值。
下面3种情况下系统自动调用复制构造函数:
-
明确表示由一个已定义的对象初始化一个新对象;
注意:
- 这里是初始化!!并不是赋值!!
- 用几个已定义的对象初始化一个对象数组也会调用赋值构造函数。
-
如果函数的形参是类的对象(不是对象的引用),调用函数时,将调用复制构造函数用实参对象初始化形参对象,产生一个副本;
注意:
- 为了避免因形参为类的对象而调用复制构造函数造成额外开销,通常会将形参设置成对象的引用
- 如果函数形参是基类对象,传入的实参是派生类对象,同样会调用(基类的)复制构造函数
-
如果函数的返回值是类的对象,函数执行完成返回主调函数时,将调用复制构造函数使用return语句中的对象初始化一个临时无名对象, 传递给主调函数。
注意:
- 很多编译器会认为此情况多余而将其优化掉。
- 这个临时无名对象被视作常量对象(右值),不能为其取别名
- 使用移动构造函数可以避免这一无意义的复制
若程序中没有定义复制构造函数,则系统会自动隐含生成默认复制构造函数并实现对应数据成员一一复制,自定义的复制构造函数可以根据需要实现特殊的复制功能。
#include<iostream>
using namespace std;
class Clock {
int hour, minute, second;
public:
Clock(int newH = 0, int newM = 0, int newS = 0); //构造函数
Clock(const Clock &time); //复制构造函数,参数是本类对象的常引用
void showTime() { //显示时间
cout << hour << ":" << minute << ":" << second << endl;
}
~Clock();
};
/*构造函数*/
Clock::Clock(int newH, int newM, int newS) {
hour = newH;
minute = newM;
second = newS;
cout << "Constructor called." << endl;
}
/*复制构造函数*/
Clock::Clock(const Clock &time) {
hour = time.hour; //类的成员函数内部可以访问任何同类对象的私有成员
minute = time.minute;
second = time.second;
cout << "Copy Constructor called." << endl;
}
/*析构函数*/
Clock::~Clock() {
cout << "Destructor called." << endl;
}
/*普通函数,用于创建新对象并返回*/
Clock fun(Clock time) { //调用复制构造函数(情形2):实参初始化形参time
Clock newtime(time); //调用复制构造函数(情形1):time初始化newtime
return newtime; //调用复制构造函数(情形3):newtime初始化newtime的副本(临时无名对象)并返回
//【函数执行结束后time和newtime被析构】
}
int main() {
cout << "①----------------------------" << endl;
Clock(20, 13, 14); //调用普通构造函数
//【构造的是一个临时无名对象,此语句结束后该对象被析构】
cout << "②----------------------------" << endl;
Clock time1(20, 13, 14), //调用普通构造函数
time3; //调用普通构造函数
Clock time4(); //不调用构造函数【不调用任何构造函数创建对象,编译器会认为这是声明了一个函数】
Clock time5{}; //调用普通构造函数,相当于`Clock time5;`
cout << "③----------------------------" << endl;
/*这3种复制构造方法等效*/
Clock time2(time1), //调用复制构造函数(情形1)
time6 = time2; //调用复制构造函数(情形1)
cout << "④----------------------------" << endl;
Clock time7[2] = { time1,time2 }, //调用复制构造函数×2(情形1)
time8[2] = { Clock(20, 13, 14) , Clock(20, 13, 14) }, //调用普通构造函数×2(创建临时无名对象)、复制构造函数×2(一些编译器会将其优化掉)
time9[2] = { 1,1 }, //调用转换构造函数×2(隐式转换并创建临时无名对象)、复制构造函数×2
time10 = Clock(20, 13, 14) //调用普通构造函数(创建临时无名对象)、复制构造函数(一些编译器会将其优化掉)
;
cout << "⑤----------------------------" << endl;
time3 = time2; //无【对于赋值语句,由于涉及的对象都是已经初始化过的,所以不调用复制构造函数】
Clock time11 = fun(time2); //调用复制构造函数×3(情形2+1+3)【本条语句执行结束后临时无名对象被析构】
//调用复制构造函数×1(情形1)【用返回的临时无名对象初始化time9】
cout << "⑥----------------------------" << endl;
//Clock &t = fun(time2); //【返回的临时无名对象是一个常量对象,不能建立一个常量对象的引用】
time3.showTime();
cout << "⑦----------------------------" << endl;
//system("pause");
return 0;
}
/*输出:
①----------------------------
Constructor called.
Destructor called.
②----------------------------
Constructor called.
Constructor called.
Constructor called.
③----------------------------
Copy Constructor called.
Copy Constructor called.
④----------------------------
Copy Constructor called.
Copy Constructor called.
Constructor called.
Copy Constructor called.
Destructor called.
Constructor called.
Copy Constructor called.
Destructor called.
Constructor called.
Copy Constructor called.
Destructor called.
Constructor called.
Copy Constructor called.
Destructor called.
Constructor called.
Copy Constructor called.
Destructor called.
⑤----------------------------
Copy Constructor called.
Copy Constructor called.
Copy Constructor called.
Destructor called.
Copy Constructor called.
Destructor called.
Destructor called.
⑥----------------------------
20:13:14
⑦----------------------------
Destructor called.
Destructor called.
Destructor called.
Destructor called.
Destructor called.
Destructor called.
Destructor called.
Destructor called.
Destructor called.
Destructor called.
Destructor called.
Destructor called.
Destructor called.
*/
注意:赋值运算与复制构造没有任何关系,复制构造是用于初始化的
① 禁用复制构造函数
有时我们不希望对象被复制构造,除了可以将赋值构造函数设为private,还可以用delete关键字
class Clock {
int hour, minute, second;
public:
... ...
Clock(const Clock &time)=delete; //禁用复制构造函数
... ...
};
此时若再出现触发调用复制构造函数的那3种情形会报错

② 深复制与浅复制问题
这类问题存在于默认复制构造函数的调用以及赋值运算,前者需要自定义复制构造函数解决,后者需要重载赋值运算符解决。
默认复制构造函数实现的是数据成员的一一复制,这种机制有时会产生问题,如下:
由于复制构造函数的作用,m1和m2的message都是指向同一块内存空间(浅复制),之后m1和m2的析构函数被调用,对同一块动态内存空间进行了两次释放进而报错。
#include<iostream>
#include<cstring>
using namespace std;
class Message {
char *message;
public:
//注意参数类型是指向字符串常量的指针变量
Message(const char *m = "") {
message = new char[strlen(m) + 1];
strcpy_s(message, strlen(m) + 1, m);
}
~Message() {
delete[] message;
}
};
int main() {
Message m1("Em0s_Er1t");
Message m2(m1);
return 0;
}
解决此类问题有2种方法:
-
自定义复制构造函数和赋值运算符,申请一个新的内存空间让m2的message指向(深复制)
Message(const Message &m) { message = new char[strlen(m.message) + 1]; strcpy_s(message, strlen(m.message) + 1, m.message); }对于仅申请少量堆空间的临时对象来说,深复制的执行效率依旧可以接受,但如果临时对象中的指针成员申请了大量的堆空间,那么势必会影响初始化的执行效率。
-
若m1除了初始化m2之外无其他用处,则可以内置移动构造函数以及移动赋值运算符,同时方法一的弊端也可以得到解决
Message(Message &&m) noexcept{ message=m.message; m.message = nullptr; //cout << "Move Constructor called." << endl; } int main() { Message m1("Em0s_Er1t"); Message m2(move(m1)); //初始化m2时传入右值,由于m1为左值,需要move强制转换,此语句执行完毕后m1不再可访问 return 0; }
(6)移动构造函数与移动语义
思想:复制构造函数通过复制的方式构造新的对象,而很多时候被复制的对象仅作复制之用,之后便被销毁,而且当数据很多时,逐个进行复制是一项很耗资源的工作(例如给一个长度为100000的动态对象数组类进行复制构造)。此时如果可以不进行复制操作,而是直接转移该对象在内存中的“所有权”便可省去这些额外的复制工作,从而大大提升性能,移动语义便是实现这一功能的。
移动语义,指的就是以移动而非深拷贝的方式初始化含有指针成员的类对象。简单的理解,移动语义指的就是将其他对象(通常是临时对象)拥有的内存资源“移为已用”。
实现移动语义有两步,第一步是右值引用作为形参提醒编译器此处使用移动语义而非复制构造,第二步是定义移动构造函数/移动赋值运算符实现“移动”。
-
移动构造函数的参数是该类对象的右值引用,在构造中移动源对象资源,构造后源对象不再指向被移动的资源,源对象可重新赋值或者销毁
/*移动构造函数常用定义*/ 类名(类名 &&对象名) noexcept{ //参数是本类对象的引用,通常不是常引用 //1.当前对象的指针指向源对象的指针 //2.将源对象的指针成员置为空指针 }当类中同时包含拷贝构造函数和移动构造函数时,如果使用右值对象(如临时对象)初始化当前类的对象,编译器会优先调用移动构造函数来完成此操作。只有当类中没有合适的移动构造函数时,编译器才会退而求其次,调用拷贝构造函数。
-
移动赋值运算符:见“运算符重载”
① 案例1
下面的例子可以很好对比复制构造与移动构造的效率问题。
#include<iostream>
#include<cassert>
using namespace std;
class Point {
int x, y;
public:
Point(int newx = 0, int newy = 0) :x(newx), y(newy) {
cout << "Constructor of Point called." << endl;
}
Point(const Point &p) : x(p.x), y(p.y) {
cout << "Copy Constructor of Point called." << endl;
}
~Point() {
cout << "Destructor of Point called." << endl;
}
};
class ArrayOfPoint {
Point *p; //指向动态数组首地址
int size; //动态数组的大小
public:
ArrayOfPoint(int s = 1) :size(s) {
p = new Point[s]();
cout << "Constructor of ArrayOfPoint called." << endl;
}
/*复制构造函数*/
ArrayOfPoint(const ArrayOfPoint & ap) {
p = new Point[ap.size](); //有多少元素就要申请多少内存
for (int i; i < ap.size; i++) {
p[i] = ap.p[i];
}
cout << "Copy Constructor of ArrayOfPoint called." << endl;
}
/*移动构造函数*/
ArrayOfPoint(ArrayOfPoint && ap) noexcept {
p = ap.p; //1.当前对象的指针指向源对象的指针
ap.p = nullptr; //2.将源对象的指针成员置为空指针
cout << "Move Constructor of ArrayOfPoint called." << endl;
}
~ArrayOfPoint() {
delete[] p;
cout << "Destructor of ArrayOfPoint called." << endl;
}
};
ArrayOfPoint fun() {
ArrayOfPoint ap(5);
return ap;
}
int main() {
int asize;
cout << "请输入待创建的数组大小:";
cin >> asize;
cout << "--------------------" << endl;
ArrayOfPoint points_1(asize);
ArrayOfPoint points_2(move(points_1)); //调用移动构造函数(用move将points_1转换成右值,编译器识别右值后知道此处要调用移动构造函数)
cout << "--------------------" << endl;
ArrayOfPoint points_3(asize);
ArrayOfPoint points_4(points_3); //调用复制构造函数
system("pause");
return 0;
}
下面的测试可以看出,移动构造函数只需要将数组内的元素构造一次即可,而复制构造函数则需要重复构造。

② 案例2
#include<iostream>
#include<cassert>
using namespace std;
class Point {
int x, y;
public:
Point(int newx = 0, int newy = 0) :x(newx), y(newy) {
cout << "Constructor of Point called." << endl;
}
Point(const Point &p) : x(p.x), y(p.y) {
cout << "Copy Constructor of Point called." << endl;
}
~Point() {
cout << "Destructor of Point called." << endl;
}
};
class ArrayOfPoint {
Point *p; //指向动态数组首地址
int size; //动态数组的大小
public:
ArrayOfPoint(int s = 1) :size(s) {
p = new Point[s]();
cout << "Constructor of ArrayOfPoint called." << endl;
}
/*复制构造函数*/
ArrayOfPoint(const ArrayOfPoint & ap) {
p = new Point[ap.size](); //有多少元素就要申请多少内存
for (int i; i < ap.size; i++) {
p[i] = ap.p[i];
}
cout << "Copy Constructor of ArrayOfPoint called." << endl;
}
/*移动构造函数*/
ArrayOfPoint(ArrayOfPoint && ap) noexcept {
p = ap.p; //1.当前对象的指针指向源对象的指针
ap.p = nullptr; //2.将源对象的指针成员置为空指针
cout << "Move Constructor of ArrayOfPoint called." << endl;
}
~ArrayOfPoint() {
delete[] p;
cout << "Destructor of ArrayOfPoint called." << endl;
}
};
ArrayOfPoint fun() {
ArrayOfPoint ap(5);
return ap;
}
int main() {
ArrayOfPoint && poinst_1 = fun();
system("pause");
return 0;
}
当返回值为对象时,移动构造函数代替复制构造函数完成构造过程,省去了深拷贝时的创建与临时对象的析构。

③ 案例3
还有一个更简单的案例
#include <iostream>
using namespace std;
class Demo {
int *num;
public:
Demo() : num(new int(0)) {
cout << "construct!" << endl;
}
Demo(const Demo &d) : num(new int(*d.num)) {
cout << "copy construct!" << endl;
}
Demo(Demo &&d) : num(d.num) {
d.num = nullptr;
cout << "move construct!" << endl;
}
~Demo() {
cout << "class destruct!" << endl;
}
};
Demo getDemo() {
Demo d0;
return d0;
}
int main() {
Demo d = getDemo();
return 0;
}
输出结果分析如下
construct! ->构建Demo类对象d0
move construct! ->移动构造函数利用d0初始化d0的副本
class destruct! ->d0被析构
move construct! ->移动构造函数用d0的副本初始化d
class destruct! ->d0的副本被析构
class destruct! ->d被析构
④ 心得 & 见解
- 移动构造函数是基于右值引用的,右值引用是移动构造函数出现的基础
- 移动构造函数相当于将复制构造函数右值复制的功能给承担了
- 往往在类中有指针成员时,移动构造函数才能体现出它的价值
- 如果我们要处理对象数组类,内置一个移动构造函数是不错的选择
- 移动构造函数可以避免因为函数返回值是对象时导致的复制构造,提升效率
(7)转换构造函数
只需要提供一个参数就可以完成构造的构造函数称为转换构造函数,转换构造函数可以实现将其他类型隐式转换成自定义数据类型(要求自定义数据类型包含有该类型的属性),但本质上是根据其他类型的实例调用转换构造函数进行重新构造。
隐式转换在下面5种情况下会触发(假定A类定义如下,A的某个成员是B类型,C类型可以转换成B类型)
class A{
B b;
D d;
}
-
B类型实例初始化A类对象;
-
B类型实例给A类对象赋值;
-
B类型实例作为参数传递给接受A类形参的函数;
-
声明某个函数返回一个对象,但实际函数体中返回的是一个B类型的实例;
-
上述任意一种情况下,使用可以转换成B类型的C类型时;(两步转换)
两步转换需要避免二义性,即C类型只能转换成B类型,不能转换成同为成员的D类型。
① <案例1>一步隐式转换
前面四种隐式转换情形有如下案例供参考
#include<iostream>
#include<string>
using namespace std;
class Person {
public:
int age;
string name;
double height;
/*转换构造函数1*/
Person(int a) :age(a), name("He"), height(1.7) {}
/*转换构造函数2*/
Person(double h) :age(18), name("He"), height(h) {}
/*有参构造函数*/
Person(int a, string n, double h) :age(a), name(n), height(h) {}
/*无参默认构造函数*/
Person() :age(18), name("He"), height(1.7) {}
////可以将上面的4个构造函数可以合并成一个构造函数
//Person(int a = 18, string n = "He", double h = 1.7) :age(a), name(n), height(h) {}
};
void display_age(Person p) {
cout << p.name << " is " << p.age << " years old" << endl;
}
void display_height(const Person & p) {
cout << p.name << " is " << p.height << " meters." << endl;
}
Person get_a_person_who_is_20_years_old() {
return 20;
}
int main() {
/*1. 其他类型实例初始化类对象*/
Person Alice = 20; //相当于Person Alice(20);
const Person & Bob = 17; //相当于const Person & Bob = Person(17);
/*2. 其它类型实例给类对象赋值*/
Person John;
John = 18; //隐式调用转换构造函数(隐式转换)
John = (Person)1.75; //显式调用转换构造函数(显式强制类型转换)
John = Person(1.75);
/*3. 其它类型实例传递给接受对象形参的函数*/
display_age(30); //相当于display_age(Person(30));
display_height(1.8); //相当于display_height(Person(1.8));
/*4. 声明返回一个对象,但实际返回的是一个其他类型的实例*/
cout << "He is " << get_a_person_who_is_20_years_old().age << " years old." << endl;
}
/*输出:
He is 30 years old
He is 1.8 meters.
He is 20 years old.
*/
隐式转换的典型应用
实现复数的加法运算需要重载加法运算符,但为了适应实数+虚数、虚数+虚数、虚数+实数我们需要重载很多个版本,对于实数+虚数甚至必须要重载为非成员函数,但有了转换构造函数我们就可以将这些重载版本合并成一个版本(虚数+虚数)以兼容这几种加法运算形式。
② <案例2>两步隐式转换
第五种情形是两步转换,如下面的例子中我们剔除了age这一属性,于是,Person Alice=2这一初始化语句相当于先将int型字面量2转换成double型再调用转换构造函数构造出Alice这一Person实例
#include<iostream>
#include<string>
using namespace std;
class Person {
public:
//int age;
string name;
double height;
/*转换构造函数*/
Person(double h) : name("He"), height(h) {}
/*有参构造函数*/
Person(string n, double h) :name(n), height(h) {}
/*无参默认构造函数*/
Person() :name("He"), height(1.7) {}
////可以将上面的3个构造函数可以合并成一个构造函数
//Person(string n = "He", double h = 1.7) :name(n), height(h) {}
};
void display_height(const Person & p) {
cout << p.name << " is " << p.height << " meters." << endl;
}
Person get_a_person_who_is_2_meters() {
return 2;
}
int main() {
/*1. 其他类型实例初始化类对象*/
Person Alice = 2; //相当于Person Alice(2.0);
const Person & Bob = 2; //相当于const Person & Bob = Person(2.0);
/*2. 其它类型实例给类对象赋值*/
Person John;
John = 2; //隐式调用转换构造函数(隐式转换)
John = (Person)2; //显式调用转换构造函数(显式强制类型转换)
John = Person(2);
/*3. 其它类型实例传递给接受对象形参的函数*/
display_height(1); //相当于display_height(Person(1));
/*4. 声明返回一个对象,但实际返回的是一个其他类型的实例*/
cout << "He is " << get_a_person_who_is_2_meters().height << " meters." << endl;
}
/*输出:
He is 1 meters.
He is 2 meters.
*/
两步隐式转换需要避免二义性,即C类型可转换的中间类型B有多种选择时会报错,例如不剔除age属性,而是将age属性int型改为long型,则对于Person Alice=2,编译器不知道是采用Person Alice=Person(2)【\((int)2\rightarrow(long)2\rightarrow Person(2)\)】还是Person Alice=Person(2.0)【\((int)2\rightarrow(double)2.0\rightarrow Person(2)\)】
③ explicit关键字
将构造函数用作自动类型转换函数似乎是一项不错的特性。然而,这会导致意外的类型转换。因此,C++新增了关键字explicit,用于关闭这种自动特性。声明构造函数时在前面加上explicit限定,此时它只能用于显式转换,不能用于隐式转换
如下,下面的例子中在转换构造函数前面加上explicit后,所以涉及隐式转换的调用语句都报错了

3. 析构函数(Destructor)
析构函数完成对象被删除前的清理工作,当离开对象所在作用域时,该对象的析构函数被调用。在对象被撤销前执行,本身并不自动回收先前分配的内存空间
如我们为一个数据成员new一个内存空间后需要在析构函数中delete
析构函数有如下特征:
- 一个类只能有一个析构函数。
- 析构函数不能有形参和返回值。
- 析构函数与类同名,前面加
~
4. 组合类的构造函数设计
A类的一个对象作为B类的数据成员,则该对象为对象成员,B类为组合类,且构造函数的通用形式如下:
组合类名::组合类名(对象成员所需的形参,本类基本类型数据成员形参):内嵌对象1(参数),内嵌对象2(参数),....{
/*函数体其它语句*/
}
组合类的构造函数中代码执行顺序如下:
- 首先如果有就地初始化则执行就地初始化;
- 其次对构造函数初始化列表中列出的成员(包括基本类型成员和对象成员)进行初始化,初始化次序是成员在类体中定义的次序
- 对象成员的构造函数的调用顺序:按对象成员的声明顺序,先声明的先构造。
- 初始化列表中未出现的成员对象,调用用默认构造函数(即无形参的)初始化
- 处理完初始化列表之后,再执行构造函数的函数体。
/*测试初始化顺序*/
#include<iostream>
using namespace std;
class Point1 {
double x, y;
public:
Point1(double newx = 0, double newy = 0);
};
class Point2 {
double x, y;
public:
Point2(double newx = 0, double newy = 0);
};
class Line {
Point1 p1;
Point2 p2;
public:
Line(double x_1, double x_2, double y_1, double y_2);
};
Point1::Point1(double newx, double newy) :x(newx), y(newy) {
cout << "Class Point1's constructor called." << endl;
}
Point2::Point2(double newx, double newy) : x(newx), y(newy) {
cout << "Class Point2's constructor called." << endl;
}
Line::Line(double x_1, double x_2, double y_1, double y_2) :p2(x_2, y_2), p1(x_1, y_1) {
cout << "Class Line's constructor called." << endl;
}
int main() {
Line line(3, 4, 5, 6);
return 0;
}
/*输出:
Class Point1's constructor called.
Class Point2's constructor called.
Class Line's constructor called.
*/
#include<iostream>
using namespace std;
/*基类1*/
class Base1 {
int x;
public:
Base1(int newx = 0) :x(newx) {
cout << "Constructor of Base1 called." << endl;
}
Base1(const Base1 &b1) :x(b1.x) {
cout << "Copy Constructor of Base1 called." << endl;
}
~Base1() {
cout << "Destructor of Base1 called." << endl;
}
};
/*基类2*/
class Base2 {
int x;
public:
Base2(int newx = 0) :x(newx) {
cout << "Constructor of Base2 called." << endl;
}
Base2(const Base2 &b2) :x(b2.x) {
cout << "Copy Constructor of Base2 called." << endl;
}
~Base2() {
cout << "Destructor of Base2 called." << endl;
}
};
class Member {
int x;
public:
Member(int newx = 0) :x(newx) {
cout << "Constructor of Member called." << endl;
}
Member(const Member &m):x(m.x) {
cout << "Copy Constructor of Member called." << endl;
}
~Member() {
cout << "Destructor of Member called." << endl;
}
};
/*派生类*/
class Derived:public Base1, public Base2{
int x;
Member m;
public:
/*派生类构造函数*/
Derived(int newx1, int newxm, int newx2, int newx3) : //书写顺序与初始化顺序无关
x(newx1), //本类数据成员初始化
m(newxm), //本类对象成员初始化
Base2(newx2), Base1(newx1) //基类成员初始化
{
cout << "Constructor of Derived called." << endl;
}
/*派生类复制构造函数*/
Derived(const Derived &d) :m(d.m), x(d.x), Base2(d), Base1(d) {
cout << "Copy Constructor Derived called." << endl;
}
/*派生类析构函数*/
~Derived() {
cout << "Destructor of Derived called." << endl;
}
};
int main() {
Derived d1(1,2,3,4);
cout << "------------------------" << endl;
Derived d2(d1);
cout << "------------------------" << endl;
return 0;
}
/*输出:
Constructor of Base1 called.
Constructor of Base2 called.
Constructor of Member called.
Constructor of Derived called.
------------------------
Copy Constructor of Base1 called.
Copy Constructor of Base2 called.
Copy Constructor of Member called.
Copy Constructor Derived called.
------------------------
Destructor of Derived called.
Destructor of Member called.
Destructor of Base2 called.
Destructor of Base1 called.
Destructor of Derived called.
Destructor of Member called.
Destructor of Base2 called.
Destructor of Base1 called.
*/
5. 前向引用声明
C++规定类应该先声明,后使用,但如果需要在某个类的声明之前,引用该类,则应进行前向引用声明,前向引用声明只为程序引入一个标识符,但具体声明在其他地方。
举例如下:
class B; //前向引用声明
class A{
public:
void fun1(B b);
};
class B{
public:
void fun2(A a);
};
即便是使用前向引用声明,在提供一个完整的类声明之前,不能声明该类的对象,也不能在内联成员函数中使用该类的对象。
class B; //前向引用声明
class A{
B b; //错误,因为定义A类需要知道其成员的全部细节,但B的细节此时不知道
};
class B{
A a;
};
(五)this指针
当定义了一个类的若干对象,这些对象显然共享所属类的成员函数代码,当成员函数需要获取对象的数据成员时,如何精准找到这个对象的数据成员的内存空间?this指针便可以解决这个问题。
this 指针实际上是成员函数的一个形参,不是对象本身的一部分,在调用非静态成员函数时将对象的地址作为实参传递给 this(静态成员函数没有this),不过 this 这个形参是隐式的,它并不出现在代码中,而是在编译阶段由编译器默默地将它添加到参数列表中,对象调用成员函数时 this 被赋值为当前对象的地址。其实类似于Python的类方法第一个参数——self。
以下面代码为例,若程序定义了Point类对象A和B,那么A在调用showPointLoc时,它的地址便被记录在this指针中,这样函数输出x时输出的其实是this->x,即A的x,而不是B的x。
void Point::showPointLoc() {
cout << "(" << x << "," << y << ")" << endl;
}
(六)类的继承
1. 基本概念
被继承的类相对于继承其的类来说称为基类,也称父类、超类
继承于基类的类相对于基类来说称为派生类,也称子类
从一个基类派生的继承称为单继承;
从多个基类派生的继承称为多继承;
2. 派生类
派生类的定义如下
class 派生类名: 继承方式 基类名1,继承方式 基类名2,...{
派生类成员声明;
}
-
若继承方式缺省则默认为私有继承
-
基类的构造函数、析构函数、静态成员函数、赋值运算符重载函数、友元函数不能被派生类继承
但从C++11开始,推出了构造函数继承(Inheriting Constructor),使用using来声明继承基类的构造函数,使之成为派生类的构造函数。
派生类的组成
- 吸收基类成员:吸收基类成员之后,派生类实际上就包含了它的全部基类中除构造和析构函数之外的所有成员。
- 改造基类成员:如果派生类声明了一个和某基类成员同名的新成员,派生的新成员就隐藏或覆盖了外层同名成员
- 添加新的成员:派生类增加新成员使派生类在功能上有所发展
3. 继承方式
不同继承方式会影响(类内访问)派生类成员函数对基类成员的访问权限和(类外访问)通过派生类对象对基类成员的访问权限
有三种继承方式:公有继承、私有继承、保护继承
(1)公有继承
基类的public和protected成员的访问属性在派生类中保持不变,但基类的private成员不可直接访问
- 【类内访问基类成员】派生类中的成员函数可以直接访问基类中的public和protected成员,但不能直接访问基类的private成员。
- 【类外访问基类成员】通过派生类的对象只能访问从基类继承的public成员。
——向上转型/赋值兼容规则
公有派生类是兼容基类的,所以公有派生类可以当成基类用,但反之不行
- 派生类的对象可以隐含转换为基类对象,反之不可以
- 派生类的对象可以初始化基类的引用,反之不可以
- 派生类的指针可以隐含转换为基类的指针,反之不可以
注意:
- 通过基类的对象、指针、引用一般情况下只能访问基类成员,不可以通过基类的对象、指针、引用来访问派生类的新增成员
- 向上转型规则之所以成立,是因为派生类中含有基类的部分,但如果派生类的一个基类是二义基类,即派生类通过不同的继承路径得到的该基类不止一份拷贝(例如菱形继承),则此时基类指针指向该派生类对象时不知道指向其中哪一个基类子对象,调用基类成员也不知道调用哪个基类的成员。
(2)私有继承
基类的public和protected成员都以private身份出现在派生类中,但基类的private成员不可直接访问。即
- 【类内访问基类成员】派生类中的成员函数可以直接访问基类中的public和protected成员,但不能直接访问基类的private成员。
- 【类外访问基类成员】通过派生类的对象不能直接访问从基类继承的任何成员。
(3)保护继承
基类的public和protected成员都以protected身份出现在派生类中,但基类的private成员不可直接访问。即
- 【类内访问基类成员】派生类中的成员函数可以直接访问基类中的public和protected成员,但不能直接访问基类的private成员。
- 【类外访问基类成员】通过派生类的对象不能直接访问从基类继承的任何成员。
小结
-
继承方式中的 public、protected、private 是用来指明基类成员在派生类中的最高访问权限的。
-
不管继承方式如何,基类中的 private 成员在派生类中始终不能使用(不能在派生类的成员函数中直接访问或调用,通常是调用从基类继承的对其进行操作的接口来间接修改/访问这个成员)。
我们这里说的是基类的 private 成员不能在派生类中使用,并没有说基类的 private 成员不能被继承。实际上,基类的 private 成员是能够被继承的,并且(成员变量)会占用派生类对象的内存,它只是在派生类中不可见,导致无法直接使用罢了。private 成员的这种特性,能够很好的对派生类隐藏基类的实现,以体现面向对象的封装性。
-
派生类内部,派生类对象可以访问基类中的公有和保护成员;派生类外部,派生类对象只能访问基类公有继承的公有成员。即只有在派生类中才可以通过派生类对象访问基类的protected成员。
理解:基类的protected成员不管以何种方式被派生类继承都会变成派生类的成员(私有或者保护),那么派生类中访问同类对象的成员当然可以访问,由于该成员在派生类中不可能为公有,所以类外访问该成员无论如何都不能访问。
测试案例如下:
#include<iostream>
using namespace std;
class Base {
private:
int a;
public:
int b;
protected:
int c;
};
class Derived_pub :public Base {
/*
Derived_pub类中此时有
- 公有成员b
- 保护成员c
*/
void fun() {
//a = 1; //错误,基类的私有成员在派生类中不可见
b = 1; //正确
c = 1; //正确
/*类的成员函数内部可以访问任何同类对象的所有成员*/
Derived_pub d;
//d.a = 1; //错误,可以认为d中没有数据成员a
d.b = 1;
d.c = 1;
Base b;
//b.a = 1; //错误,当前类对Base类对象来说是类外,类外不能访问私有和保护成员
b.b = 1;
//b.c = 1; //错误,当前类对Base类对象来说是类外,类外不能访问私有和保护成员
}
};
class Derived_pri :private Base {
/*
Derived_pri类中此时有
- 私有成员b
- 私有成员c
*/
void fun() {
//a = 1; //错误,基类的私有成员在派生类中不可见
b = 1; //正确
c = 1; //正确
/*类的成员函数内部可以访问任何同类对象的所有成员*/
Derived_pri d;
//d.a = 1; //错误,可以认为d中没有数据成员a
d.b = 1;
d.c = 1;
Base b;
//b.a = 1; //错误,当前类对Base类对象来说是类外,类外不能访问私有和保护成员
b.b = 1;
//b.c = 1; //错误,当前类对Base类对象来说是类外,类外不能访问私有和保护成员
}
};
class Derived_pro :protected Base {
/*
Derived_pri类中此时有
- 保护成员b
- 保护成员c
*/
void fun() {
//a = 1; //错误,基类的私有成员在派生类中不可见
b = 1; //正确
c = 1; //正确
/*类的成员函数内部可以访问任何同类对象的所有成员*/
Derived_pro d;
//d.a = 1; //错误,可以认为d中没有数据成员a
d.b = 1;
d.c = 1;
Base b;
//b.a = 1; //错误,当前类对Base类对象来说是类外,类外不能访问私有和保护成员
b.b = 1;
//b.c = 1; //错误,当前类对Base类对象来说是类外,类外不能访问私有和保护成员
}
};
int main() {
Derived_pub d1;
Derived_pri d2;
Derived_pro d3;
//cout << d1.a << endl; //错误
cout << d1.b << endl; //正确,由于公有继承基类的公有成员在派生类中仍为公有,所以在类外派生类对象可以且只能访问公有继承的公有成员
//cout << d1.c << endl; //错误
//cout << d2.a << endl; //错误
//cout << d2.b << endl; //错误
//cout << d2.c << endl; //错误
//cout << d3.a << endl; //错误
//cout << d3.b << endl; //错误
//cout << d3.c << endl; //错误
return 0;
}

4. 修改基类成员在派生类中的访问权限
使用保护派生或私有派生时,基类的公有成员将成为保护成员或私有成员。假设要让基类的方法在派生类外面可用,方法之一是定义一个使用该基类方法的派生类方法。
#include<iostream>
#include<string>
using namespace std;
class Person {
string name = "Em0s_Er1t";
public:
void Print() { cout << name << endl; }
};
class Student :private Person {
public:
void Print() { Person::Print(); }
};
int main() {
Student s;
s.Print(); //输出:Em0s_Er1t
}
下面是另外两种fang'f
(1)访问声明
注:相当于不包含关键字using的using声明,此方法已被摒弃,仅作了解或满足应试需要即可。
访问声明机制可以个别调整私有派生类从基类继承下来的成员性质,从而使外界可以通过派生类的界面直接访问基类的某些成员,同时也不影响其他基类成员的访问属性。
-
数据成员也可以使用访问声明。
-
访问声明中只含不带类型和参数的函数名或者变量名。
-
访问声明不能改变成员在基类中的访问属性,也就是说,访问声明只能把原基类的保护成员调整为私有派生类的保护成员(在派生类的保护属性定义中声明),把原基类的公有成员调整为私有派生类的公有成员(在派生类的公有属性中定义)。
-
对于基类中的重载函数名,访问声明将对基类中所有同名函数起作用。这意味着对于重载函数使用访问声明时要慎重。
#include<iostream>
#include<string>
using namespace std;
class Person {
string name = "Em0s_Er1t";
public:
int age = 21;
void Print() { cout << name << endl; }
void Print(int) { cout << age << endl; }
};
class Student :private Person {
public:
Person::Print; //Print函数在基类中是公有成员,那就要派生类中的public域内进行访问声明
Person::age; //见“1”
/*见“2”*/
//Person::Print(); //错误
//void Person::Person(); //错误
//void Person::Person; //错误
};
void main() {
Student s;
s.Print(); //输出:Em0s_Er1t
s.age = 22;
/*见“4”*/
s.Print(1); //输出:22
}
(2)using声明
派生类的某访问属性定义的部分中加上using 基类名::要转换权限的基类成员;声明就可以设置基类成员在派生类中的属性
#include<iostream>
#include<string>
using namespace std;
class Person {
string name = "Em0s_Er1t";
public:
int age = 21;
void Print() { cout << name << endl; }
void Print(int) { cout << age << endl; }
};
class Student :private Person {
public:
using Person::Print;
using Person::age;
};
void main() {
Student s;
s.Print(); //输出:Em0s_Er1t
s.age = 22;
s.Print(1); //输出:22
}
5. 派生类的构造与析构
-
默认情况下基类的构造函数不被继承,派生类需要定义自己的构造函数。
-
如果基类没有默认构造函数(如基类自己定义了带形参的构造函数,编译器不为其生成默认构造函数),派生类应该自定义带形参的构造函数。
-
定义构造函数时,只需要对本类中新增成员进行初始化,对继承来的基类成员的初始化,是自动调用基类构造函数完成的(编译器编译时生成相应的调用代码),派生类的构造函数需要给基类的构造函数传递参数。
派生类中尽管继承了基类的私有成员,也无法将其初始化,需要基类自己完成
-
基类构造函数先于派生类构造函数被执行调用
(1)派生类构造函数的定义
派生类构造函数定义语法如下:
派生类名::派生类名(总形参表):基类名(参数表), 本类成员初始化列表, 对象成员初始化列表{
//其它初始化;
};
说明:
:后面的书写顺序与执行顺序无关基类名(参数表)不是调用基类构造函数,而是给基类构造函数传递什么参数的说明- 当基类中声明有默认构造函数或未声明构造函数时,派生类构造函数可以不向基类构造函数传递参数,也可以不声明构造函数。构造派生类的对象时,基类的默认构造函数将被调用。
- 当需要执行基类中带形参的构造函数来初始化基类数据时,派生类构造函数应在初始化列表中为基类构造函数提供参数。
(2)派生类的复制构造函数
-
若建立派生类对象时没有编写复制构造函数,编译器会生成一个隐含的复制构造函数,该函数先调用基类的复制构造函数,再为派生类新增的成员对象执行复制。
-
若编写派生类的复制构造函数,一般都要为基类的复制构造函数传递参数。
-
派生类的复制构造函数只能接受一个参数, 此参数不仅用来初始化派生类定义的成员,也将被传递给基类的复制构造函数。
-
基类的复制构造函数形参类型是基类对象的引用,实参可以是派生类对象的引用(向上转型)。
Derived::Derived(const Derived &derived):Base(derived){...}
(3)继承构造
在C++11之前,需要在初始化列表调用基类的构造函数,从而完成构造函数的传递,如果基类拥有多个构造函数,那么子类也需要实现多个与基类构造函数对应的构造函数。但设想如果派生类并没有添加新的成员,只是添加了一些成员函数,则此时书写多个派生类构造函数只为传递参数完成基类的初始化,这种方式会给开发人员带来麻烦,降低了编码效率。
从C++11开始,推出了构造函数继承(Inheriting Constructor),使用using来声明继承基类的构造函数,使之成为派生类的构造函数。
注意:
-
派生类只能继承基类中除了默认构造函数、复制构造函数、移动构造函数之外的构造函数;
-
继承的构造函数只能初始化基类中的成员变量,不能初始化派生类的成员变量,因而这种情况通常适用于当派生类没有新增数据成员时,如果对派生类新增的成员变量进行初始化则需要自定义构造函数;
此时如果派生类声明的构造函数与基类声明的构造函数参数列表一致,将覆盖基类构造函数的可见性,即使使用了基类构造函数声明,也无法直接通过基类构造函数构造对象
-
如果基类的构造函数被声明为私有,或者派生类是从基类中虚继承,那么不能继承构造函数;
-
一旦使用继承构造函数,编译器不会再为派生类生成默认构造函数;
#include<iostream>
using namespace std;
class Base {
int val_1;
int val_2;
public:
Base(int v1, int v2 = 0) :val_1(v1), val_2(v2) {
cout << "Constructor of Base called." << endl;
}
};
class Derived :public Base {
int val_3;
public:
using Base::Base; //继承Base的构造函数
Derived() :val_3(0) ,Base(1){
cout << "Default Constructor of Derived called." << endl;
}
Derived(int v1, int v3) :Base(v1), val_3(v3) {
cout << "Derived(int v1, int v3) of Derived called." << endl;
}
Derived(int v1, int v2, int v3) :Base(v1,v2),val_3(v3) {
cout << "Derived(int v1, int v2, int v3) of Derived called." << endl;
}
};
int main() {
Derived d1(1,2,3);
cout << "-------------------------" << endl;
Derived d2(1,2); //此时Base构造函数不可见,会调用Derived的构造函数,而非直接调用从Base继承来的构造函数
cout << "-------------------------" << endl;
Derived d3(1); //Derived没有相应的构造函数,于是直接调用从Base继承来的构造函数
cout << "-------------------------" << endl;
Derived d4;
return 0;
}
/*输出:
Constructor of Base called.
Derived(int v1, int v2, int v3) of Derived called.
-------------------------
Constructor of Base called.
Derived(int v1, int v3) of Derived called.
-------------------------
Constructor of Base called.
-------------------------
Constructor of Base called.
Default Constructor of Derived called.
*/
(4)派生类的析构函数
- 析构函数不被继承,派生类如果需要,要自行声明析构函数。
- 声明方法与一般(无继承关系时)类的析构函数相同。
- 不需要显式地调用基类的析构函数,系统会自动隐式调用。
- 析构函数的调用次序与构造函数相反。
6. 同名冲突问题
理解
派生类中要访问某个成员时,会按自底向上的顺序依次进行名字匹配:
- 如果派生类新增的成员中有该成员,则不再往上寻找。于是基类如果有同名成员,则该成员不为派生类所见。
- 如果派生类新增的成员中没有该成员,则会去上一级(直接基类)匹配,
- 如果有多个名字匹配就会报错,此时需要指定是哪个直接基类的同名成员;(这里的匹配是名字匹配!!!即便位于不同基类的同名函数有不同的参数列表也会产生二义性问题)
- 如果没有名字匹配则继续前往更高层(间接基类)匹配直至匹配成功;
(1)基类与派生类同名冲突
由于同名覆盖原则,单继承不会出现二义性问题。
当派生类数据成员名称与基类某个成员同名时,按照同名覆盖原则:
-
① 在派生类内部访问同名成员、② 通过派生类对象访问同名成员、③ 通过派生类对象的指针(或引用)访问同名成员,在未加任何特殊标识的情况下默认访问派生类中的那个成员,而基类中的同名成员会被隐藏。
如果派生类中声明了与基类成员函数同名的新函数,即便两个函数只是函数名相同,参数列表不同,此时从基类继承的同名函数的所有重载形式都会被隐藏,如果要访问被隐藏成员,需要加上
基类名::来作用域限定。 -
基类的指针指向派生类对象时,访问的是基类中的同名成员
-
基类的引用成为派生类的对象别名时,访问的是基类的同名成员
若要通过基类的指针(指向派生类对象)或者引用(成为派生类的对象别名)来访问派生类中的同名成员,需要通过虚函数实现,否则无论如何都不能访问,即便加了作用域标识符。
#include<iostream>
using namespace std;
class Base {
public:
/*f()与f(int)位于同一作用域下,此时发生了重载*/
void f() { cout << "Base::f()" << endl; }
void f(int a) { cout << "Base::f(int)" << endl; }
};
class Derived : public Base {
public:
void f() { cout << "Derived::f()" << endl; }
};
int main() {
/*见1*/
Derived d;
d.Base::f(); // 输出:Base::f()
d.f(); // 输出:Derived::f()
//d.f(1); // 错误,基类中任何与派生类某成员函数同名的函数在派生类中都不可见,如果将派生类中的f()函数去掉则可以编译通过
d.Base::f(1); // 输出:Base::f(int)
/*见2*/
Base* b1 = &d;
b1->f(); // 输出:Base::f()
//b1->Derived::f();// 错误,不能用基类指针访问派生类同名成员,作用域限定也不可以
/*见3*/
Base& b2 = d;
b2.f(); // 输出:Base::f()
//b2.Derived::f(); // 错误,不能用基类引用访问派生类同名成员,作用域限定也不可以
}
(2)多重继承中直接基类同名冲突
派生类继承了多个基类,这多个基类中有同名成员,此时在派生类中访问这些成员时在其前面指定基类名,否则将报错。
(3)共同祖先基类引发的同名冲突(菱形继承问题)
需要注意的一点是,菱形继承不仅仅引发了同名冲突,也引发了空间浪费问题
若有一个Person类,派生出Student类和Teacher类,此时有一个Assistant(助教)类,继承了Student类和Teacher类,那么Assistant类就拥有了Person类成员的两份复制,一份来自Student类对Person类的继承,另一份来自Teacher类对Person类的继承,这就产生了二义性以及空间浪费的问题,伴随而来也会导致赋值兼容规则的失效。
总之,从不同途径继承来的同一基类,会在子类中存在多份拷贝,虚继承便是解决这类问题。
//若age是Person类的一个公有成员,则普通继承下,age在Assistant中有多份拷贝
class Assistant size(8):
+---
0 | +--- (base class Teacher)
0 | | +--- (base class Person)
0 | | | age
| | +---
| +---
4 | +--- (base class Student)
4 | | +--- (base class Person)
4 | | | age
| | +---
| +---
+---
#include<iostream>
using namespace std;
class Person {
public:
int age;
};
class Teacher :public Person {};
class Student :public Person {};
class Assistant :public Teacher, public Student {};
int main() {
Assistant John;
//John.Person::age = 18; //错误,编译器无法区别是哪个age
//John.age = 18; //错误,因为John有多个age,编译器无法区别是哪个age
//Person *p = &John; //错误,因为John有多个基类子对象,基类指针不知道该指向哪个基类子对象。
John.Teacher::age = 18; //指明从Teacher继承的age
John.Student::age = 28; //指明从Student继承的age
cout << John.Teacher::age << endl; //输出18
cout << John.Student::age << endl; //输出28
return 0;
}
虚继承
虚基类是在其派生类的派生列表中使用了关键字virtual的基类
如果一个类是从多个基类直接继承而来的,那么有可能这些基类本身又共享了另一个基类。在这种情况下,中间类可以选择使用虚继承,从而声明愿意与层次中虚继承同一基类的其他类共享虚基类。用这种方法,后代派生类中将只有一个共享虚基类的副本。如下面的例子,Teacher和Student都声明虚继承Person类,那么他们的共同派生类Assistant只会拥有一份来自虚基类Person的数据成员的拷贝。
#include<iostream>
using namespace std;
class Person {
public:
int age;
};
class Teacher :virtual public Person {};
class Student :virtual public Person {};
class Assistant :public Teacher, public Student {};
int main() {
Assistant John;
John.age = 18; //正确,这三条语句操作的都是同一个age
John.Teacher::age = 18;
John.Student::age = 28;
Person *p = &John; //正确,此时派生类John中只有一份Person类子对象
cout << John.Teacher::age << endl; //输出28
cout << John.Student::age << endl; //输出28
return 0;
}
class Assistant size(12):
+---
0 | +--- (base class Teacher)
0 | | {vbptr}
| +---
4 | +--- (base class Student)
4 | | {vbptr}
| +---
+---
+--- (virtual base Person)
8 | age
+---
(七)多态性
多态分为静态多态和动态多态:
-
静态多态:函数重载和运算符重载属于静态多态,复用函数名;静态多态的函数地址早绑定——编译阶段确定函数地址
-
动态多态:派生类和虚函数实现运行时多态;动态多态的函数地址晚绑定——运行阶段确定函数地址
C++动态多态的前提:
- 需要有继承关系;
- 子类重写父类的虚函数(重载只要求函数名相同,重写需要函数名、参数表、……全部基本相同);
- 父类指针(或引用)指向子类对象
C++动态多态在开发中的应用:
- 对原始代码进行功能扩展;
1. 虚函数
我们知道,当基类的指针指向派生类对象时,访问的是基类中的同名成员;当基类的引用成为派生类的对象别名时,访问的是基类的同名成员,有没有一种方法可以让基类的指针指向派生类对象时调用派生类中的同名成员,指向基类对象时调用基类中的同名成员?有如下2种方法
- 向下转换,即需要调用派生类同名函数时将基类指针类型转换成派生类指针(如用
dynamic_cast)- 虚函数(使用虚函数就不必进行转换了,此时只需要用一个基类指针就能根据其所指向的对象所属类型动态地决定调用的是基类的还是派生类的同名函数,进而产生不同的行为)
虚函数是用virtual关键字说明的函数,是实现运行时多态性基础,经过派生之后,就可以实现运行过程中的多态。C++中的虚函数是动态绑定的函数,支持按照实际类型调用相关的函数。
包含虚函数的类称为多态类。
(1)原理
每个多态类有一个虚表(virtual table),虚表中有当前类的各个虚函数的入口地址。
每个对象有一个指向当前类的虚表的指针,称为虚指针(vptr),在构造函数中自动为对象的虚指针初始化,从而让虚指针正确指向所属类的虚表。
注意:虚表是在编译时创建的,虚指针是在运行时才初始化的
通过多态类型的指针或引用调用成员函数时,每个对象通过虚指针找到虚表,进而找到所调用的虚函数的入口地址,通过该入口地址调用虚函数。(对象在查虚表时只能查到所属类中的那个虚函数版本)

当父类定义了虚函数时,在子类进行继承的时候会将父类的虚函数表也给继承下来,如果要对父类中的虚函数进行重写时或添加虚函数,则顺序是
①先将父类的虚函数列表复制过来
②重写虚函数时是把从父类继承过来的虚函数表中对应的虚函数进行相应的替换。
③如果子类自己要添加自己的虚函数,则是把添加的虚函数加到从父类继承过来虚函数表的尾部
(2)基本规则
class 类名{
...
public:
virtual 函数类型 函数名(形参表);
}
-
若基类中用
virtual声明某成员函数为虚函数,则派生类中可以不显式地用virtual声明虚函数,满足以下条件的函数会被系统自动确定为虚函数,这时派生类的虚函数便覆盖了基类的虚函数。- 该函数与基类的被覆盖的虚函数有相同的名称、参数个数及对应参数类型、是否const、引用限定符(&或&&)、返回值类型(若返回值不同,则该函数的返回值类型必须可以隐含转换为基类被覆盖的虚函数的返回值类型)。
但一般习惯于在派生类的函数中也使用
virtual关键字, 以增加程序的可读性。 -
在名字查找时,派生类中的虚函数仍然会隐藏基类中同名函数的所有其它重载形式。
派生类中调用基类同名的非私有成员的虚函数仍要用
基类名::限定,当然这样的调用就不算是多态性了 -
并非任何函数都可以声明为虚函数,虚函数必须是一般的非静态成员函数。
-
静态成员函数不能是虚函数
静态成员函数不属于某一个对象,不具有多态性。
-
构造函数不能是虚函数
-
友元函数不能是虚函数
-
析构函数可以是虚函数,且往往声明为虚函数。
-
虚函数不可以是内联函数,但是虚函数可以声明为inline。
因为对虚函数的调用需要动态绑定,而对内联函数的处理是静态的
虚函数可以声明为inline,这只是一个建议,编译器不会展开它。
-
-
虚函数的声明只能出现在类定义的函数原型声明中,不能在成员函数实现的时候。
-
虚函数可以是私有的,私有虚函数在派生类中可以被重写
#include<iostream>
using namespace std;
class Base {
public:
int x;
Base(int newx = 0) :x(newx) {}
/*虚函数*/
virtual void display() { cout << "[Base::display] Base::x = " << x << endl; }
/*非虚函数*/
void display(int) { cout << "[overloaded Base::display] Base::x = " << x << endl; }
};
class Derived :public Base {
public:
int x;
Derived(int x1 = 0, int x2 = 0) :x(x1), Base(x2) {}
void display() { cout << "[Derived::display] Derived::x = " << x << ", Base::x = " << Base::x << endl; }
void display(int) { cout << "[overloaded Derived::display] Derived::x = " << x << ", Base::x = " << Base::x << endl; }
};
void fun(Base &rb) {
rb.display();
}
void fun(Base *pb) {
pb->display();
}
int main() {
Base b, *pb;
Derived d;
d.x = 1;
d.Base::x = 2;
d.display(); //[Derived::display] Derived::x = 1, Base::x = 2
cout << "------------------------------------" << endl;
pb = &b;
pb->display(); //[Base::display] Base::x = 0
pb->display(1); //[overloaded Base::display] Base::x = 0
//pb->Derived::display(); //错误
cout << "------------------------------------" << endl;
Derived *pd = (Derived*)pb; //【将基类指针强制转换成派生类指针(这种强制转换比较危险,当访问某虚函数时派生类中存在而基类中不存在时,就可能导致运行时出现访问错误,程序崩溃,而此时编译是正常的,因为指针的虚函数表是动态链接的。)】
pd->display(); //[Base::display] Base::x = 0
cout << "------------------------------------" << endl;
pb = &d;
pb->display(); //[Derived::display] Derived::x = 1, Base::x = 2
pb->display(1); //[overloaded Base::display] Base::x = 2
/*派生类中访问基类同名虚函数仍要用`基类名::`限定*/
pb->Base::display(); //[Base::display] Base::x = 2
cout << "------------------------------------" << endl;
fun(b); //[Base::display] Base::x = 0
fun(d); //[Derived::display] Derived::x = 1, Base::x = 2
fun(&b); //[Base::display] Base::x = 0
fun(&d); //[Derived::display] Derived::x = 1, Base::x = 2
return 0;
}
(3)虚函数的最终覆盖函数
如果继承关系很复杂,此时如何确定调用哪一个虚函数?这就需要我们确定虚函数的最终覆盖函数
每个虚函数都有最终覆盖函数,即进行虚函数调用时所(默认)执行的函数,这里不同于加限定符的非虚调用。
如果基类 Base 有虚函数 vf,除非其派生类声明或(通过多重继承)继承了覆盖 vf 的另一个函数,否则基类 Base 的虚成员函数 vf 就是最终覆盖函数。
#include<iostream>
using namespace std;
struct A {
virtual void f() { cout << "A::f()" << endl; }; // A::f 是虚函数
};
struct B : A {
void f() { cout << "B::f()" << endl; }; // B 中的 B::f 覆盖 A::f
};
struct C : virtual B {
void f() { cout << "C::f()" << endl; } // C 中的 C::f 覆盖 A::f
};
struct D : virtual B {}; // D 不引入覆盖函数,最终覆盖函数是 B::f
struct E : C, D { // E 不引入覆盖函数,最终覆盖函数是 C::f
using A::f; // 非函数声明,只为了能让 A::f 被查找到
};
int main(){
E e;
e.f(); // 虚调用 e 中的最终覆盖函数 C::f
e.E::f(); // 非虚调用,调用在 E 中可见的 A::f
e.B::f();
return 0;
}
(4)构造函数与析构函数中直接/间接调用虚函数
构造函数中直接/间接调用虚函数,虚函数表现为该类中虚函数的行为
如在父类构造函数中调用虚函数,那么虚函数的表现就是父类定义的函数的表现。原因如下:
- 假设构造函数中调用虚函数,表现为普通的虚函数调用行为,即虚函数会表现为相应的子类函数行为,并且假设子类存在一个成员变量int a;子类定义的虚函数的新的行为会操作a变量,但在子类初始化时根据构造函数调用顺序会首先调用父类构造函数,那么虚函数回去操作a,而因为a是子类成员变量,但这时a尚未初始化,这是一种危险的行为,作为一种明智的选择应该禁止这种行为。所以虚函数会被解释到基类而不是子类。
#include<iostream>
using namespace std;
struct Base{
/*构造/析构函数中间接调用虚函数*/
Base() { test(); }
~Base() { test(); }
void test() { f(); }
virtual void f() { cout << "Base::f" << endl; }
};
struct Derived: Base {
/*构造/析构函数中直接调用虚函数*/
Derived() { f(); }
~Derived() { f(); }
virtual void f() { cout << "Derived::f" << endl; }
};
int main() {
Derived d; //非多态
cout << "------------------" << endl;
Base *p = &d;
p->test(); //多态
cout << "------------------" << endl;
return 0; //非多态
}
/*输出:
Base::f
Derived::f
------------------
Derived::f
------------------
Derived::f
Base::f
*/
(5)【应用】虚析构函数
- 如果父类的析构函数不加virtual关键字:当父类的析构函数不声明成虚析构函数,且子类继承父类,父类的指针指向子类时,delete掉父类的指针会直接调动父类的析构函数,跳过对子类析构函数的调用。
- 如果父类的析构函数加virtual关键字:当父类的析构函数声明成虚析构函数,且子类继承父类,父类的指针指向子类时,delete掉父类的指针会先调动子类的析构函数,再接着调动父类的析构函数。
#include<iostream>
using namespace std;
class Base1 {
public:
Base1() {
cout << "Constructor of Base1 called." << endl;
}
~Base1() {
cout << "Destructor of Base1 called." << endl;
}
};
class Derived1 :public Base1 {
public:
Derived1() {
cout << "Constructor of Derived1 called." << endl;
}
~Derived1() {
cout << "Destructor of Derived1 called." << endl;
}
};
class Base2 {
public:
Base2() {
cout << "Constructor of Base2 called." << endl;
}
virtual ~Base2();
};
class Derived2 :public Base2 {
public:
Derived2() {
cout << "Constructor of Derived2 called." << endl;
}
virtual ~Derived2();
};
Base2::~Base2() {
cout << "Destructor of Base2 called." << endl;
}
Derived2::~Derived2() {
cout << "Destructor of Derived2 called." << endl;
}
int main() {
Base1 *b1 = new Derived1();
delete b1; //这里直接调用基类析构函数,跳过子类析构函数的调用
cout << "----------------------" << endl;
Base2 *b2 = new Derived2();
delete b2; //这里调用子类析构函数,再调用基类析构函数
return 0;
}
/*输出:
Constructor of Base1 called.
Constructor of Derived1 called.
Destructor of Base1 called.
----------------------
Constructor of Base2 called.
Constructor of Derived2 called.
Destructor of Derived2 called.
Destructor of Base2 called.
*/
(6)纯虚函数
纯虚函数是一个在基类中声明的虚函数,它在该基类中没有函数体,要求各派生类根据实际需要定义自己的版本,其本质是将指向函数体的指针定为空指针。
纯虚函数的声明格式为:
class 类名{
//其它成员...
virtual 函数类型 函数名(参数表) = 0;
}
注意:
- 纯虚函数不能被调用(无函数体)。
- 纯虚函数作用在于为派生类提供一个标准的函数原型(统一接口),最终由派生类具体实现覆盖。
(7)抽象类
包含纯虚函数的类称为抽象类,抽象类为抽象和设计的目的而声明,其将有关的数据和行为组织在一个继承层次结构中,保证派生类具有要求的行为,因而对于暂时无法实现的函数,可以声明为纯虚函数,留给派生类去实现。
注意:
-
抽象类只能作为基类来使用,但抽象类本身可以是别的类的派生类,也可以是基类进而派生出其它类
一个非抽象类也是可以派生出抽象类的
-
如果派生类中还有纯虚函数,则该派生类仍为抽象类;
子类必须重写抽象类中的纯虚函数,否则仍是抽象类
-
不能实例化抽象类的对象,但可以有抽象类的指针和引用。
抽象类不能用作参数类型、函数返回类型或显式转换的类型,但可以使用抽象类的引用和指针,以实现多态
-
抽象类中可以定义普通成员函数或虚函数

(8)override
将派生类中需要重写的虚函数用override声明,表示这个函数必须重写基类中的某个函数,编译器编译时会检查派生类中声明override的函数,在基类中是否存在可被覆盖的虚函数,若不存在,则会报错,这样可以防止书写代码不规范导致重写失败
下面例子中Base的fun和Derived的fun函数原型不同,所以无法覆盖

(9)final
-
被声明为final的类不允许被继承
class 类名 final{ }
-
被声明为final的函数不允许被覆盖
class 类名{ virtual 返回值类型 函数名(形参表) final; }
2. 运算符重载
运算符重载是对已有的运算符赋予多重含义,使同一个运算符作用于不同类型的数据时导致不同的行为,本质是函数重载。针对自定义的类,可以对原有运算符进行重载。
运算符重载可以有2种方式:
-
重载为(非静态)成员函数
箭头运算符
->、下标运算符[]、函数调用运算符()、赋值运算符=、强制类型转换运算符只能被重载为成员函数。 -
重载为非成员函数(必要时可以声明为友元):非成员函数的参数具有逻辑的对称性
当左操作数不是类的对象或者是类对象但非本类对象时,只能被重载为非成员函数
(0)基本规则
-
C++几乎可以重载全部的运算符,而且只能够重载C+ +中已经有的。
不能重载的运算符:成员访问运算符(
.)、成员指针访问运算符(.*与->*)、域运算符(::)、条件运算符(?:)、长度运算符(sizeof)、预处理符号(#) -
重载之后运算符的优先级、结合性、语法结构都不会改变。
-
重载运算符的操作数需要至少有一个是自定义类型的对象。
-
运算符重载函数不能有默认的参数,否则就改变了运算符操作数的个数,这显然是错误的。
(1)重载方式
① 重载为类的(非静态)成员函数
注意:
- 若双目运算符的左操作数不是类的对象,则该运算符无法重载为类的(非静态)成员函数
//可以将 “operator 运算符” 整体看作一个函数名;
//形参个数=原操作数个数-1(后置++与后置--除外)
返回值类型 operator 运算符(形参){
/*...*/
}
-
双目运算符重载规则(以
a op b为例,要重载op为类成员函数):若a为A类对象,则op可被重载为A类成员函数,此时形参类型应该是b所属类型,重载后a op b相当于a.operator op(b)。 -
单目运算符重载规则(以
op a为例,要重载op为类成员函数):若a为A类对象,则op可被重载为A类成员函数,无形参,重载后op a相当于a.operattor op()。对于
前置++与后置++的重载,需要通过形参表来区分前置后置——前置++无形参,后置++设置一个占位形参(这个形参仅用于区分前后置,通常不需要给形参名),此时a++相当于a.operator ++(0)
② 重载为非成员函数
有些运算符不能重载为成员函数,例如二元运算符的左操作数不是对象,或者是不能由我们重载运算符的对象(如插入运算符<<和>>),这时就可以重载为非成员函数。
//函数的形参代表依自左至右次序排列的各操作数,至少应该有一个自定义类型的参数。
//形参个数=原操作数个数(后置++、后置--除外)
//如果在运算符的重载函数中需要操作某类对象的私有成员,可以将此函数声明为该类的友元。
[friend ]返回值类型 operator 运算符(形参){
/*...*/
}
-
双目运算符
op重载后a op b相当于operator op(a, b)其中插入运算符的重载比较特殊,它的左操作数是
std:ostream引用,右操作数是输出对象,返回仍是std::ostream引用,这样便可以支持级联输出,如cout<<a<<b;就相当于operator << (operator << (cout, a), b); -
前置单目运算符
op重载后op a相当于operator op(a) -
后置单目运算符
op重载后a op相当于operator op(a, 0)单目运算符
后置++和后置--的重载函数,形参列表中要增加一个int,但不必写形参名。
『选择重载为成员函数还是非成员函数』
-
全局函数的参数具有逻辑的对称性;与此相对应的,把运算符定义为成员函数能够保证在调用时对第一个(最左的)运算对象不出现类型转换(C++ 不会对调用成员函数的对象进行类型转换);
-
有一部分运算符重载既可以是成员函数也可以是全局函数,虽然没有一个必然的、不可抗拒的理由选择成员函数,但我们应该优先考虑成员函数,这样更符合运算符重载的初衷;
-
另外有一部分运算符重载必须是全局函数,这样能保证参数的对称性;除了 C++ 规定的几个特定的运算符外,暂时还没有发现必须以成员函数的形式重载的运算符;
C++规定,箭头运算符
->、下标运算符[]、函数调用运算符()、赋值运算符=、强制类型转换运算符只能被重载为成员函数。
(2)赋值运算符重载
赋值运算符=只能被重载为成员函数
类名 & operator =(const 类名 &){
//TODO...
}
- 应用:实现赋值运算的深复制、实现移动赋值运算符
<案例>深复制 & 移动赋值
/*功能:
1. 赋值运算符重载实现深复制
2. 赋值运算符重载实现移动赋值运算
*/
#include<iostream>
#include<cstring>
using namespace std;
class Message {
char *message;
public:
Message(const char *m = "") { //注意参数类型是指向字符串常量的指针变量
message = new char[strlen(m) + 1];
strcpy_s(message, strlen(m) + 1, m);
}
/*赋值运算符重载实现深拷贝*/
Message & operator=(const Message & m) {
/*一般步骤:
1. 处理自己给自己赋值的情况
2. 将本对象自身的内存(如果有的话)delete
3. 本类对象自己申请新的内存并按值拷贝
4. 返回本类对象自身(引用)
*/
if (this == &m) { //处理自身给自身赋值的操作
return *this;
}
if (message != nullptr) { //判断message是否已经指向堆区
delete message;
message = nullptr;
}
message = new char[strlen(m.message) + 1]; //申请新的动态内存
strcpy_s(message, strlen(m.message) + 1, m.message);//拷贝字符串
return *this; //基于赋值运算的特性,最后需要返回自身(必须是引用,否则返回的是副本)
}
/*赋值运算符重载实现移动赋值运算*/
Message & operator=(Message && m) noexcept {
if (message != nullptr) { //判断message是否指向堆区
delete message;
message = nullptr;
}
message = m.message;
m.message = nullptr;
cout << "Move~" << endl;
return *this;
}
~Message() {
delete[] message;
}
void ShowMessage() {
cout << message << endl;
}
};
int main() {
Message m1("Em0s_Er1t"), m2, m3;
m1 = m1; //调用深复制的赋值运算符
m1.ShowMessage();
m2 = Message("HelloWorld"); //调用移动赋值运算符
m2.ShowMessage();
m3 = m2 = m1; //调用深复制的赋值运算符(级联)
m3.ShowMessage();
return 0;
}
/*输出:
Em0s_Er1t
Move~
HelloWorld
Em0s_Er1t
*/
(3)下标运算符重载
下标运算符[]只能被重载为成员函数,有以下2种声明版本
返回类型 & operator [] (形参表); //供一般对象调用,返回值可读可写
const 返回值类型 & operator[] (形参表) const;//供常对象调用,返回值只读
注意:
一定是返回引用,这样可以保证返回值可以作为左值使用;
形参表中只有一个形参,通常是下标;
使用第一种声明方式,
[]不仅可以访问元素,还可以修改元素。使用第二种声明方式,[]只能访问而不能修改元素。在实际开发中,我们应该同时提供以上两种形式,这样做是为了适应 const 对象,因为通过 const 对象只能调用 const 成员函数,如果不提供第二种形式,那么将无法访问 const 对象的任何元素。
<案例>可变长数组
#include<iostream>
using namespace std;
template<class T>
class Array {
T* arr;
int size;
public:
Array(int s = 0);
~Array();
Array(const Array<T> &A);
Array(Array<T> &&A);
/*输出各个元素*/
void display() const;
/*赋值运算符重载*/
Array<T> & operator=(const Array & A); //实现深复制
Array<T> & operator=(Array && A); //实现赋值运算的移动语义
/*下标运算符重载*/
T & operator[](int index); //此版本的返回值可读可写
const T & operator[](int index) const; //此版本的返回值只可读,且该函数只能被长对象调用
};
template<class T>
Array<T>::Array(int s) {
try {
if (s < 0)
throw "ERROR: Creation failed.";
else {
arr = new T[s];
size = s;
}
}
catch (const char* msg) {
cout << msg << endl;
arr = nullptr;
s = 0;
}
}
template<class T>
Array<T>::~Array() {
delete[] arr;
}
template<class T>
Array<T>::Array(const Array<T> &A) {
if (arr != nullptr) {
delete arr;
arr = nullptr;
}
arr = new T[A.size];
for (int i = 0; i < A.size; i++)
arr[i] = A.arr[i];
size = A.size;
}
template<class T>
Array<T> & Array<T>::operator=(const Array & A) {
if (&A = this)
return *this;
if (arr != nullptr) {
delete arr;
arr = nullptr;
}
arr = new T[A.size];
for (int i = 0; i < A.size; i++)
arr[i] = A.arr[i];
size = A.size;
return *this;
}
template<class T>
Array<T>::Array(Array<T> &&A) {
arr = A.arr;
A.arr = nullptr;
size = A.size;
}
template<class T>
Array<T> & Array<T>::operator=(Array && A) {
arr = A.arr;
A.arr = nullptr;
size = A.size;
return *this;
}
template<class T>
T & Array<T>::operator[](int index) {
try {
if (index < 0 || index >= size)
throw "ERROR: Index failed";
//cout << "<operator[]>" << endl;
return arr[index];
}
catch (const char* msg) { cout << msg << endl; }
}
template<class T>
const T & Array<T>::operator[](int index) const {
try {
if (index < 0 || index >= size)
throw "ERROR: Index failed";
//cout << "<const operator[]>" << endl;
return arr[index];
}
catch (const char* msg) { cout << msg << endl; }
}
template<class T>
void Array<T>::display() const {
for (int i = 0; i < size; i++) {
cout << arr[i] << " ";
}
cout << endl;
}
const int SIZE = 7;
int main() {
Array<double> arr_1(SIZE);
for (int i = 0; i < SIZE; i++) {
arr_1[i] = i;
}
arr_1.display();
cout << "-----------------------" << endl;
const Array<double> arr_2(arr_1);
arr_2.display();
cout << "-----------------------" << endl;
cout << arr_2[-1] << endl;
cout << "-----------------------" << endl;
Array<double> arr_3(-1);
return 0;
}
/*输出:
0 1 2 3 4 5 6
-----------------------
0 1 2 3 4 5 6
-----------------------
ERROR: Index failed
6.51852e+91
-----------------------
ERROR: Creation failed.
*/
(4)提取与插入运算符重载
提取运算符>>和插入运算符<<只能被重载为非成员函数
istream & operator >>(istream & in, 用户类类型 & obj){
....
in >> ...;
....
return in;
}
ostream & operator <<(ostream & out, 用户类类型 & obj){ //由于提取用户的输入并存入对象,所以不要加const
....
out << ...;
....
return out;
}
注意:
- 由于第一操作数是流类对象而非本类对象,所以只能被重载为非成员函数;
- 返回值为流类对象的引用,所以可以实现级联输入输出;
<案例>复数输入输出
/*功能:重载了提取与插入运算符来实现的复数的输入输出*/
#include<iostream>
using namespace std;
class Complex {
double real;
double vir;
/*重载输出运算符*/
friend ostream & operator<<(ostream & out, const Complex & c);
/*重载输入运算符*/
friend istream & operator>>(istream & in, Complex & c);
};
ostream & operator<<(ostream & out, const Complex & c) {
out << c.real << "+" << c.vir << "i";
return out;
}
istream & operator>>(istream & in, Complex & c) {
in >> c.real >> c.vir;
return in;
}
int main() {
Complex c;
cin >> c; //相当于operator>>(cin , c);
cout << c; //相当于operator<<(cout , c);
return 0;
}
(5)关系运算符重载 & 四则运算关系符重载
四则运算符有+、-、*、/、+=、-=、*=、/=,关系运算符包括>、<、<=、>=、==、!=,当左操作数是本类对象时,可以重载为成员函数或非成员函数,否则只能重载为非成员函数(如实数+复数)。
<案例1>复数运算
/*
功能:
1. 对关系运算符和四则运算符重载实现复数(类)加减以及关系运算;
2. 对+-重载实现复数(类)加减运算;
*/
#include<iostream>
using namespace std;
class Complex {
double real;
double vir;
public:
Complex(double r, double v) :real(r), vir(v) {
//cout << "Constructor of Complex called." << endl;
}
/*--------------------重载为成员函数----------------------*/
/*重载 != 运算符(判断两个复数是否不相等)*/
bool operator!=(const Complex & c){
return !(real == c.real && vir == c.vir);
}
/*重载 += 运算符*/
Complex & operator+=(const Complex & c) {
real += c.real;
vir += c.vir;
return *this;
}
/*重载 -= 运算符*/
Complex & operator-=(const Complex & c) {
real -= c.real;
vir -= c.vir;
return *this;
}
/*--------------------重载为非成员函数----------------------*///当选择重载为非成员函数时,由于要访问传入的Complex对象的私有成员,所以需要声明友元
/*重载插入运算符(格式化输出复数)*/
friend ostream &operator <<(ostream & out, const Complex & c);
/*重载 + 运算符(实+虚)*/
friend Complex operator +(double r, const Complex & c);
/*重载 + 运算符(虚+虚)*/
friend Complex operator +(const Complex &c1, const Complex &c2);
/*重载 + 运算符(虚+实)*/
friend Complex operator +(const Complex & c, double r);
/*重载 == 运算符(判断复数是否相等)*/
friend bool operator==(Complex &c1, Complex &c2);
};
ostream &operator <<(ostream & out, const Complex & c) { //为了支持级联输出,这里返回的是对象的引用
out << c.real << "+" << c.vir << "i";
return out;
}
Complex operator +(double r, const Complex & c) {
return Complex(r + c.real, c.vir);
}
Complex operator +(const Complex &c1, const Complex &c2) {
return Complex(c1.real + c2.real, c1.vir + c2.vir);
}
Complex operator +(const Complex & c, double r) {
return Complex(c.real + r, c.vir);
}
bool operator==(Complex &c1, Complex &c2) {
return c1.real == c2.real && c1.vir == c2.vir;
}
int main() {
Complex c1(1, 2), c2(3, 4);
Complex c3 = c1 + 1; //相当于c3=c1.operator +(1)
cout << "c3=" << c3 << endl; //输出c3=2+2i
Complex c4 = c1 + c3; //相当于c4=c1.operator +(c3)
cout << "c4=" << c4 << endl; //输出c4=3+4i
Complex c5 = 2 + c3; //相当于c5=operator +(2, c3)
cout << "c5=" << c5 << endl; //输出c5=4+2i
if (c4 == c2)
cout << "c4=c2=" << c2 << endl; //输出c4=c2=3+4i
else
cout << "c4不等于c2" << endl;
return 0;
}
<案例2>复数运算.Pro
利用转换构造函数可以将上面的加法运算符重载版本缩减,但相对来说效率会下降,因为每次加法运算都需要调用一次转换构造函数,最终代码如下
/*
功能:
1. 对关系运算符和四则运算符重载实现复数(类)加减以及关系运算;
2. 对+-重载实现复数(类)加减运算;
改进:
- 在原来代码的基础上给构造函数添加了默认值使之能够转换构造;
*/
#include<iostream>
using namespace std;
class Complex {
double real;
double vir;
public:
Complex(double r = 0, double v = 0) :real(r), vir(v) {
//cout << "Constructor of Complex called." << endl;
}
/*--------------------重载为成员函数----------------------*/
/*重载 != 运算符(判断两个复数是否不相等)*/
bool operator!=(const Complex & c) {
return !(real == c.real && vir == c.vir);
}
/*重载 += 运算符*/
Complex & operator+=(const Complex & c) {
real += c.real;
vir += c.vir;
return *this;
}
/*重载 -= 运算符*/
Complex & operator-=(const Complex & c) {
real -= c.real;
vir -= c.vir;
return *this;
}
/*--------------------重载为非成员函数----------------------*///当选择重载为非成员函数时,由于要访问传入的Complex对象的私有成员,所以需要声明友元
/*重载插入运算符(格式化输出复数)*/
friend ostream &operator <<(ostream & out, const Complex & c);
/*重载 + 运算符*/
friend Complex operator +(const Complex &c1, const Complex &c2);
/*重载 == 运算符(判断复数是否相等)*/
friend bool operator==(Complex &c1, Complex &c2);
};
ostream &operator <<(ostream & out, const Complex & c) { //为了支持级联输出,这里返回的是对象的引用
out << c.real << "+" << c.vir << "i";
return out;
}
Complex operator +(const Complex &c1, const Complex &c2) {
return Complex(c1.real + c2.real, c1.vir + c2.vir);
}
bool operator==(Complex &c1, Complex &c2) {
return c1.real == c2.real && c1.vir == c2.vir;
}
int main() {
Complex c1(1, 2), c2(3, 4);
Complex c3 = c1 + 1; //相当于c3=c1.operator +(Complex(1))
cout << "c3=" << c3 << endl; //输出c3=2+2i
Complex c4 = c1 + c3; //相当于c4=c1.operator +(c3)
cout << "c4=" << c4 << endl; //输出c4=3+4i
Complex c5 = 2 + c3; //相当于c5=operator +(Complex(2), c3)
cout << "c5=" << c5 << endl; //输出c5=4+2i
if (c4 == c2)
cout << "c4=c2=" << c2 << endl; //输出c4=c2=3+4i
else
cout << "c4不等于c2" << endl;
return 0;
}
(6)类型转换运算符重载
类型转换运算符只能被重载为成员函数,同样可以有两个重载版本
operator 类型名 (){ //供一般对象调用,返回值可读可写
//TODO
return 该类型的实例;
}
operator const 类型名 () const{ //供常对象调用,返回值只读
//TODO
return 该类型的实例;
}
注意:
- 重载类型转换运算符时,由于返回值类型是确定的,就是运算符本身代表的类型,所以不需要指定返回值类型,但函数体中还是要将值返回;
- 重载类型转换运算符时,参数表为空,因为该运算符需要通过类对象来调用,从而告知函数要转换的值,因此,函数不需要参数;
- 如重载
(double)后,(double)c等价于c.operator double();- 重载类型转换运算符可以实现自定义类型显示/隐式转换成其他类型;
explicit关键字同样也适用于此函数,声明后仅支持显式调用强制类型转换函数(即禁用隐式转换,仅支持显示转换)
<案例1>
/*功能:实现double强制类型转换Person类返回height,int强制类型转换Person类返回age*/
#include<iostream>
#include<string>
using namespace std;
class Person {
public:
int age;
string name;
double height;
Person(string n = "He", int a = 18, double h = 1.7) :age(a), name(n), height(h) {}
/*类型转换运算符重载*/
operator int();
operator double();
};
Person::operator double() {
return height;
}
Person::operator int() {
return age;
}
void display(int age, double height) {
cout << "He is " << age << " years old, and his height is " << height << "." << endl;
}
int getage(Person &p) {
return p;
}
double getheight(Person &p) {
return p;
}
int main() {
Person John("John", 20, 1.75);
/*显示调用*/
cout << John.name << " is " << (int)John << " years old, and his height is " << (double)John << "." << endl;
/*隐式调用(编译器根据上下文知道要调用什么转换函数)*/
double height = John; //1. 类对象给其它类型初始化
int age;
age = John; //2. 类对象给其它类型赋值
cout << John.name << " is " << age << " years old, and his height is " << height << "." << endl;
display(John, John); //3. 类对象传参给其它类型形参
display(getage(John), getheight(John)); //4. 返回值为其它类型,但实则返回类对象
//注意:不能像下面那样隐式调用,会产生二义性错误,编译器不知道该调用哪个转换函数来完成John的类型转换
//cout << John.name << " is " << John << " years old, and his height is " << John << "." << endl;
}
/*输出
John is 20 years old, and his height is 1.75.
John is 20 years old, and his height is 1.75.
He is 20 years old, and his height is 1.75.
He is 20 years old, and his height is 1.75.
*/
<案例2>可变长数组.Pro
/*功能:对前面的可变长数组进行功能扩展使之支持强制类型转换*/
#include<iostream>
using namespace std;
template<class T>
class Array {
T* arr;
int size;
public:
Array(int s = 0);
~Array();
Array(const Array<T> &A);
Array(Array<T> &&A);
/*赋值运算符重载*/
Array<T> & operator=(const Array & A); //实现深复制
Array<T> & operator=(Array && A); //实现赋值运算的移动语义
/*下标运算符重载*/
T & operator[](int index); //此版本的返回值可读可写
const T & operator[](int index) const; //此版本的返回值只可读,且该函数只能被长对象调用
/*强制类型转换运算符*/
operator T*(); //此版本的返回值可读可写
operator const T*() const; //此版本的返回值只可读,且该函数只能被长对象调用
};
template<class T>
Array<T>::Array(int s) {
try {
if (s < 0)
throw "ERROR: Creation failed.";
else {
arr = new T[s];
size = s;
}
}
catch (const char* msg) {
cout << msg << endl;
arr = nullptr;
s = 0;
}
}
template<class T>
Array<T>::~Array() {
delete[] arr;
}
template<class T>
Array<T>::Array(const Array<T> &A) {
if (arr != nullptr) {
delete arr;
arr = nullptr;
}
arr = new T[A.size];
for (int i = 0; i < A.size; i++)
arr[i] = A.arr[i];
size = A.size;
}
template<class T>
Array<T> & Array<T>::operator=(const Array & A) {
if (&A = this)
return *this;
if (arr != nullptr) {
delete arr;
arr = nullptr;
}
arr = new T[A.size];
for (int i = 0; i < A.size; i++)
arr[i] = A.arr[i];
size = A.size;
return *this;
}
template<class T>
Array<T>::Array(Array<T> &&A) {
arr = A.arr;
A.arr = nullptr;
size = A.size;
}
template<class T>
Array<T> & Array<T>::operator=(Array && A) {
arr = A.arr;
A.arr = nullptr;
size = A.size;
return *this;
}
template<class T>
T & Array<T>::operator[](int index) {
try {
if (index < 0 || index >= size)
throw "ERROR: Index failed";
//cout << "<operator[]>" << endl;
return arr[index];
}
catch (const char* msg) { cout << msg << endl; }
}
template<class T>
const T & Array<T>::operator[](int index) const {
try {
if (index < 0 || index >= size)
throw "ERROR: Index failed";
//cout << "<const operator[]>" << endl;
return arr[index];
}
catch (const char* msg) { cout << msg << endl; }
}
template<class T>
Array<T>::operator T*() {
return arr;
}
template<class T>
Array<T>::operator const T*() const {
return arr;
}
/*输出各个元素*/
void display(int *a,int size) {
for (int i = 0; i < size; i++) {
cout << a[i] << " ";
}
cout << endl;
}
const int SIZE = 7;
int main() {
Array<int> arr_1(SIZE);
for (int i = 0; i < SIZE; i++)
arr_1[i] = i;
display(arr_1, SIZE); //此处Array型的arr_1强制类型转换成int*型
//输出0 1 2 3 4 5 6
return 0;
}
/*输出:
0 1 2 3 4 5 6
-----------------------
0 1 2 3 4 5 6
-----------------------
ERROR: Index failed
6.51852e+91
-----------------------
ERROR: Creation failed.
*/
(7)自增与自减运算符
自增与自减运算符无论是前置还是后置都可以被重载为成员函数和非成员函数
-
重载为成员函数
/*前置++*/ 类名 & operator++(){ //返回自身的引用,以便对同一个对象进行下一步操作 //TODO return *this; } /*前置--*/ 类名 & operator--(){ //返回自身的引用,以便对同一个对象进行下一步操作 //TODO return *this; } /*后置++*/ 类名 operator++(int){ //返回值而不是引用,因为不能返回局部变量的引用 //用占位参数区分前后置 /*1. 保存自增前的当前对象*/ 类名 old=*this; /*2. 对当前对象进行自定义自增操作*/ //TODO /*3. 返回自增前的当前对象*/ return old; } /*后置--*/ 类名 operator--(int){ //返回值而不是引用,因为不能返回局部变量的引用 //用占位参数区分前后置 /*1. 保存自减前的当前对象*/ 类名 old=*this; /*2. 对当前对象进行自定义自减操作*/ //TODO /*3. 返回自减前的当前对象*/ return old; } -
重载为非成员函数
/*前置++*/ 类名 & operator++(类名 & 形参对象){ //返回自身的引用,以便对同一个对象进行下一步操作 //TODO return *this; } /*前置--*/ 类名 & operator--(类名 & 形参对象){ //返回自身的引用,以便对同一个对象进行下一步操作 //TODO return *this; } /*后置++*/ 类名 operator++(类名 & 形参对象, int){ //返回值而不是引用,因为不能返回局部变量的引用 //用占位参数区分前后置 /*1. 保存自增前的当前对象*/ 类名 old=*this; /*2. 对当前对象进行自定义自增操作*/ //TODO /*3. 返回自增前的当前对象*/ return old; } /*后置--*/ 类名 operator--(类名 & 形参对象, int){ //返回值而不是引用,因为不能返回局部变量的引用 //用占位参数区分前后置 /*1. 保存自减前的当前对象*/ 类名 old=*this; /*2. 对当前对象进行自定义自减操作*/ //TODO /*3. 返回自减前的当前对象*/ return old; }
<案例>
/*功能:对时间进行前后置自增*/
#include<iostream>
#include<cassert>
using namespace std;
class Clock {
int hour, minute, second;
public:
Clock(int h, int m, int s) :hour(h), minute(m), second(s) {
assert(h >= 0 && h <= 23 && m >= 0 && m <= 59 && s >= 0 && s <= 59);
//cout << "Constructor of Clock called." << endl;
}
/*前置++*/
Clock &operator ++() {
if (second + 1 > 59) {
if (minute + 1 > 59) {
if (hour + 1 > 23) second = minute = hour = 0;
else {
hour += 1; second = minute = 0;
}
}
else {
minute += 1; second = 0;
}
}
else second += 1;
return *this; //返回的是引用,这样可以保证返回的是自增处理后的对象(而不是副本)
}
/*后置++*/
const Clock operator ++(int i) {
Clock old = *this;
++(*this); //由于前后置都是实现自增,所以这里直接调用前置++函数
return old; //这里返回的不能是引用,因为局部变量在本函数执行完毕后就会被释放,所以不能把局部变量的引用返回。
//返回值其实是一个临时对象(old的副本)
}
void Display() const {
cout << hour << ":" << minute << ":" << second << endl;
}
~Clock() {
//cout << "Destructor of Clock called." << endl;
}
};
int main() {
Clock time(23, 59, 59);
//time++相当于time.operator ++(0);
//由于后缀++返回的是自增前的对象的副本,将副本作为左值是没有意义的,所以后缀++不能作为左值
(time++).Display();
//++time相当于time.operator ++();
(++time).Display();
return 0;
}
(8)函数调用运算符重载
如果类重载了函数调用运算符
(),则我们可以像使用函数一样使用该类的对象,由于重载后使用的方式非常像函数的调用,因此称为仿函数。因为这样的类同时也能存储状态,且仿函数本身没有固定写法,所以与普通函数相比它们更加灵活。
C++重载运算:函数调用运算符_c++ 重载操作符实现 调用_Error Man的博客-CSDN博客
(9)new & delete运算符重载
重载形式既可以是类的成员函数,也可以是全局函数。
在重载 new 或 new[] 时,无论是作为成员函数还是作为全局函数,它的第一个参数必须是 size_t 类型。size_t 表示的是要分配空间的大小,对于 new[] 的重载函数而言,size_t 则表示所需要分配的所有空间的总和。
size_t 在头文件
<cstdio>中被定义为typedef unsigned int size_t;,也就是无符号整型。
-
重载为类的成员函数
void * 类名::operator new( size_t size ){ //TODO: } void 类名::operator delete( void *ptr){ //TODO: } -
重载为全局函数
void * operator new( size_t size ){ //TODO: } void operator delete( void *ptr){ //TODO: }
<案例>限制某类不允许动态创建对象
将operator new()设为私有可以禁止对象被new在堆上
#include<iostream>
using namespace std;
class A
{
private:
void* operator new(size_t t) {} // 注意函数的第一个参数和返回值都是固定的
void operator delete(void* ptr) {} // 重载了new就需要重载delete
};
int main() {
//A* ptr = new A;
A a;
}
(八)string类
string容器可以看作是元素为char的vector容器
string和char*区别:
char*是一个指针string是一个内部封装了char*的类,管理这个字符串,是一个char*型的容器。
1. 初始化
string s; //创建一个空的字符串
string s1(s2); //使用s2初始化s1
string s = "Em0s_Er1t"; //使用一个字符串初始化string对象
string s(n, c); //使用n个字符c初始化
2. 迭代器相关
v.begin() //返回指向容器中第一个元素的迭代器。
v.end() //返回指向容器最后一个元素所在位置后一个位置的迭代器,通常和 begin() 结合使用。
v.rbegin() //返回指向最后一个元素的迭代器。
v.rend() //返回指向第一个元素所在位置前一个位置的迭代器。
v.cbegin() //和begin()功能相同,只不过在其基础上,增加了 const 属性,不能用于修改元素。
v.cend() //和end()功能相同,只不过在其基础上,增加了 const 属性,不能用于修改元素。
v.crbegin() //和rbegin()功能相同,只不过在其基础上,增加了 const 属性,不能用于修改元素。
v.crend() //和rend()功能相同,只不过在其基础上,增加了 const 属性,不能用于修改元素。
3. 赋值操作
string& operator=(const string& s); // 把字符串s赋值给当前字符串
string& assign(const char* s); // 用c语言形式的字符串s赋值
string& assign(const char* s, size_t n); // 用c语言形式的字符串s前n个字符赋值
string& assign(const string& s); // 将字符串s赋值给当前字符串
string& assign(size_t n, char c); // 用n个字符c赋值给字符串
string& assign(const string& s, int start, int n); // 将字符串s中从start开始的n个字符赋值给当前字符串
string& assign(const_iterator first, const_iterator last); // 把first和last迭代器之间的部分赋值给当前字符串
例
#include<iostream>
#include<string>
using namespace std;
int main() {
string str1;
str1 = "hello world";
cout << "str1 = " << str1 << endl;
string str2;
str2 = str1;
cout << "str2 = " << str2 << endl;
string str3;
str3 = 'a';
cout << "str3 = " << str3 << endl;
string str4;
str4.assign("hello c++");
cout << "str4 = " << str4 << endl;
string str5;
str5.assign("hello c++", 5); //将前5个字符赋值给str5
cout << "str5 = " << str5 << endl;
string str6;
str6.assign(str5);
cout << "str6 = " << str6 << endl;
string str7;
str7.assign(5, 'x');
cout << "str7 = " << str7 << endl;
return 0;
}
4. 大小操作
.size(); //返回字符串长度(不包括'\0'),以字节表示。
.length(); //返回字符串长度(不包括'\0'),以字节表示。
.capacity(); //返回当前为字符串分配的存储空间的大小,以字节表示。
.max_size(); //返回字符串可以达到的最大长度。
void resize (size_t n, char c = '\0'); //重新指定容器的元素个数为n。若容器变长,则以c填充新位置;若容器变短,则末尾超出容器长度的元素被删除,但此时容量不变
.empty(); //判断是否为空子串
.shrink_to_fit(); //将容量减少到等于当前元素实际所使用的大小。
.reserve(int n); //容器预留n个元素长度,预留位置不初始化,元素不可访问。
5. 拼接
string& operator+=(const char* str); //重载+=操作符
string& operator+=(const char c); //重载+=操作符
string& operator+=(const string& str); //重载+=操作符
string& append(const char *s); //把字符串s连接到当前字符串结尾
string& append(const char *s, int n); //把字符串s的前n个字符连接到当前字符串结尾
string& append(const string &s); //同operator+=(const string& str)
string& append(const string &s, int pos, int n); //字符串s中从pos开始的n个字符连接到字符串结尾
#include<iostream>
#include<string>
using namespace std;
int main() {
string str1 = "I";
str1 += " love playing video games";
cout << "str1 = " << str1 << endl;
str1 += ':';
cout << "str1 = " << str1 << endl;
string str2 = "LOL DNF";
str1 += str2;
cout << "str1 = " << str1 << endl;
string str3 = "I";
str3.append(" love ");
str3.append("game abcde", 4);
//str3.append(str2);
str3.append(str2, 3, 4); // 从str2的下标4位置开始 ,截取3个字符,拼接到字符串末尾
cout << "str3 = " << str3 << endl;
return 0;
}
*6. 替换
string& replace(int pos, int n, const string& str); //将从pos开始的n个字符替换为字符串str
string& replace(int pos, int n, const char* s); //将从pos开始的n个字符替换为字符串s
*7. 查找
(1)find/rfind(完全匹配)
//find从左往右查找,查找失败返回string::npos,也就是-1,查找成功则返回子串第一个字符的下标
.find(const string& str, int pos = 0); //从pos位置开始查找str第一次出现的位置
.find(const char* s, int pos = 0); //从pos位置开始查找字符s第一次出现的位置
.find(const char c, int pos = 0); //从pos位置开始查找字符c第一次出现位置
.find(const char* s, int pos, int n); //从pos位置查找s的前n个字符的第一次出现位置
//rfind与find的区别只是查找方向不一样,rfind从右往左查找
.rfind(const string& str, int pos = npos); //从pos位置开始查找str最后一次出现的位置
.rfind(const char* s, int pos = npos); //从pos位置开始查找s最后一次出现的位置
.rfind(const char c, int pos = nops); //从pos位置开始查找字符c最后一次出现位置
.rfind(const char* s, int pos, int n); //从pos开始查找s的前n个字符的最后一次出现位置
(2)find_first_of/find_last_of(部分匹配)
在母串中查找和子串序列中任意字符相匹配的第一个/最后一个字符,并返回其位置
或者说在母串中查找包含在子串序列中的第一个/最后一个字符,并返回其位置
//若查找失败,则返回string::npos,也就是-1,查找成功则返回其下标
.find_first_of(const string& str, int pos = 0); //从pos位置开始查找str中任意字符第一次出现位置
.find_first_of(const char* s, int pos = 0); //从pos位置开始查找s中任意字符第一次出现位置
.find_first_of(const char c, int pos = 0); //从pos位置开始查找字符c第一次出现位置
.find_first_of(const char* s, int pos, int n); //从pos开始查找s的前n个字符中任意字符第一次出现位置
//find_last_of也只是查找方向不一样
.find_last_of(const string& str, int pos = nops);//从pos位置开始查找str中任意字符最后一次出现位置
.find_last_of(const char* s, int pos = nops); //从pos位置开始查找s中任意字符最后一次出现位置
.find_last_of(const char c, int pos = nops); //从pos位置开始查找字符c最后一次出现位置
.find_last_of(const char* s, int pos, int n); //从pos开始查找s的前n个字符中任意字符最后一次出现位置
在母串中查找第一个/最后一个与子串序列中任意字符都不匹配的字符
或者说在母串中查找不包含在子串序列中的第一个/最后一个字符,并返回其位置
//若查找失败,则返回string::npos,也就是-1,查找成功则返回其下标
.find_first_not_of(const string& str, int pos = 0); //从pos位置开始查找不匹配str中任意字符的第一个字符的出现位置
.find_first_not_of(const char* s, int pos = 0); //从pos位置开始查找不匹配s中任意字符的第一个字符的出现位置
.find_first_not_of(const char c, int pos = 0); //从pos位置开始查找不匹配字符c的第一个字符的出现位置
.find_first_not_of(const char* s, int pos, int n); //从pos开始查找不匹配s的前n个字符中任意字符的第一个字符的出现位置
//find_last_not_of也只是查找方向不一样
.find_last_not_of(const string& str, int pos = nops);//从pos位置开始查找不匹配str中任意字符的字符第一次出现位置
.find_last_not_of(const char* s, int pos = nops); //从pos位置开始查找不匹配s中任意字符的字符第一次出现位置
.find_last_not_of(const char c, int pos = nops); //从pos位置开始查找不匹配字符c的最后一个字符出现位置
.find_last_not_of(const char* s, int pos, int n); //从pos开始查找不匹配s的前n个字符的最后一个字符的出现位置
<案例>
① 查找子串所有出现的位置
/*功能:查找sub子串/字符在字符串s中出现的位置*/
template<class T=string>
void find_all(const string &s, const T &sub) {
int pos = -1;
//cout << typeid(T).name() << endl;
while ((pos = s.find(sub, pos + 1)) != -1) { //string::npos==-1
cout << pos << " ";
}
cout << endl;
}
② 判断子串在母串中是否只出现了一次
/*功能:判断sub子串/字符在字符串s是否只出现了一次*/
template<class T=string>
bool if_once(const string &s, const T &sub) {
int pos1 = s.find(sub),
pos2 = s.rfind(sub);
return pos1 == pos2;
}
③ 特定字符查找替换
/*功能:将s中包含在sub中的字符全部替换成字符串rep*/
template<class T = string>
void replace_ch(string &s, const T &sub, const string &rep) {
int pos = 0;
while ((pos = s.find_first_of(sub, pos + 1)) != -1) {
s.replace(pos, 1, rep);
}
}
8. 比较
字符串比较是按字符的ASCII码逐个进行比对,比较得出结果则不再往下比较
- 若为 = 则返回 0
- 若为 > 则返回 1
- 若为 < 则返回 -1
int compare (const string& str) const noexcept; //与字符串str比较
int compare (size_t pos, size_t len, const string& str) const; //将从pos位置开始的长度为len的字符串与str比较
int compare (size_t pos, size_t len, const string& str, size_t subpos, size_t sublen) const;//将从pos位置开始的长度为len的字符串与str从subpos位置开始的长度为sublen的字符串比较
int compare (const char* s) const; //与字符串s比较
int compare (size_t pos, size_t len, const char* s) const; //将从pos位置开始的长度为len的字符串与s比较
int compare (size_t pos, size_t len, const char* s, size_t n) const;//将从pos位置开始的长度为len的字符串与s的前n个字符比较
9. 字符存取
string中单个字符存取方式有2种
char& operator[](int n); //通过[]方式取字符
char& at(int n); //通过at方法获取字符
#include<iostream>
#include<string>
using namespace std;
int main() {
string str = "hello world";
//方法1
for (int i = 0; i < str.size(); i++)
cout << str[i] << " ";
cout << endl;
//方法2
for (int i = 0; i < str.size(); i++)
cout << str.at(i) << " ";
cout << endl;
//字符修改
str[0] = 'x';
str.at(1) = 'x';
cout << str << endl;
return 0;
}
10. 插入与删除
string& insert(int pos, const char* s); //插入字符串
string& insert(int pos, const string& str); //插入字符串
string& insert(int pos, int n, char c); //在指定位置插入n个字符c
string& erase(int pos, int n = npos); //删除从Pos开始的n个字符
#include<iostream>
#include<string>
using namespace std;
int main() {
string str = "hello";
str.insert(1, "111");
cout << str << endl; //输出h111ello
str.erase(1, 3); //擦除从下标为1的位置开始的3个字符
cout << str << endl; //输出hello
return 0;
}
11. 复制
实现将字符串的子串复制到数组中,返回实际被复制的子串长度
被复制的子串中始终不包括字符\0,如果想输出s需要在s中字符串的末尾加上\0
size_t copy (char* s, size_t len, size_t pos = 0) const; //将pos位置开始的len个字符复制到数组s中
例:
#include<iostream>
#include<string>
using namespace std;
int main() {
char buffer[20];
string name = "Em0s_Er1t is a writer?";
int len = name.copy(buffer, 100000, 5); //真正被复制的子串长度不是100000,而是17,于是返回的也是17
buffer[len] = '\0';
//cout << len << endl;
cout << buffer << endl;
return 0;
}
*12. 子串截取
string substr(int pos = 0, int n = npos) const; //返回由pos开始的n个字符组成的字符串
#include<iostream>
#include<string>
using namespace std;
int main() {
string str = "abcdefg";
cout << "subStr = " << str.substr(1, 3) << endl; //输出subStr = bcd
string email = "hello@sina.com";
int pos = email.find("@");
cout << "username: " << email.substr(0, pos) << endl;//输出username: hello
return 0;
}
*13. 转换函数
(1)数值转换
| string和数值转换 | 转换类型 |
|---|---|
| to_string(val) | 把val转换成string |
| stoi(s, p, b) | 把字符串s从p(默认是0)开始转换成b(默认是10)进制的int |
| stol(s, p, b) | 把字符串s从p(默认是0)开始转换成b(默认是10)进制的long |
| stoul(s, p, b) | 把字符串s从p(默认是0)开始转换成b(默认是10)进制的unsigned long |
| stoll(s, p, b) | 把字符串s从p(默认是0)开始转换成b(默认是10)进制的long long |
| stoull(s, p, b) | 把字符串s从p(默认是0)开始转换成b(默认是10)进制的unsigned long long |
| stof(s, p) | 把字符串s从p(默认是0)开始转换成float |
| stod(s, p) | 把字符串s从p(默认是0)开始转换成double |
| stold(s, p) | 把字符串s从p(默认是0)开始转换成long double |
(2)字符串转换
在实际编程中,有时必须要使用C风格的字符串(如一些C库函数不支持string)
c_str()函数和.data()函数能够将 string 字符串转换为C风格的字符串,并返回该字符串的 const 指针(const char*),注意:之后如果调用了会修改容器的其它成员函数,返回的指针可能会失效。通常将其转存到另一个字符数组中存储以避免指针失效
例:
string path = "D:\\demo.txt";
FILE *fp = fopen(path.c_str(), "rt");
14.输入输出
string除了重载了插入与提取运算符,但有时需要在最终得到的字符串中保留输入的空格字符,此时应该用getline函数来替代。
istream& getline(istream&& input, string & str, CharT delim ); //从输入流对象input中提取文本(遇到delim结束)写入str,此函数返回input的引用
底层实现流程如下:
- 调用
str.erase()清空str; - 从 input 提取字符并后附它们到 str,直到满足下列任一条件(按顺序检查):
- 如果没有提取到字符(不包括一开始提取到分隔符的情况),那么
getline设置failbit并返回。
(九)default & delete
1. default
若程序中定义了构造函数,则编译器不再为我们默认生成构造函数,此时我们再希望编译器为我们默认生成构造函数时可以用default关键字声明,
-
default可以指示编译器提供无参构造函数、复制构造函数、赋值运算符重载函数、析构函数等等
C++编译器通常可以提供的默认生成函数有四种:默认构造函数(无参且函数体为空)、默认析构函数(无参且函数体为空)、默认拷贝构造函数(对属性逐值拷贝)、赋值运算符operator=(对属性逐值拷贝)
-
default声明可以放在类外,放在类外此时需要加作用域限定
class A {
private:
int a;
public:
A() = default; //正确
A(const A&) = default; //正确
A & operator=(const A &) = default; //正确
~A();
//A(int a) = default; //错误,编译器无法默认生成该构造函数
};
A::~A() = default; //正确,default声明可以放在类外
2. delete
有时我们希望将类的某些功能禁用(如复制构造),delete关键字就可以实现
- delete关键字可以用于禁用任何成员函数
class Clock {
int hour, minute, second;
public:
... ...
Clock(const Clock &time)=delete; //禁用复制构造函数
... ...
};
(十)构造函数调用顺序总结
不同对象之间的构造函数调用有如下规律
- 全局对象最先被构造(多个全局变量之间按照定义顺序依次调用构造函数,析构时它们顺序相反)
- 静态类型的对象和全局对象最后析构(顺序与它们的定义顺序相反)
- 其它同一作用域内的对象遵循先构造的后析构,后构造的先析构
对涉及复杂多重继承的单个对象构造所调用的构造函数调用顺序细化如下
-
对派生列表各个分支依次检查,如果有直接或者间接的虚基类,则优先调用虚基类构造函数且整个过程只调用一次(中间基类对虚基类构造函数的调用会被忽略)
如下面的案例1中,Base是Base1和Base2的直接虚基类,是Derived的间接虚基类
-
同一层次的其它非虚基类按照派生列表中的顺序(从左向右)调用基类构造函数
-
按照初始化列表中的对象成员和基本类型成员在类中声明的顺序(不是初始化列表的顺序)对其进行初始化,对象成员初始化是自动调用对象所属类的构造函数完成的(对象所属类如果也是派生类则也要考虑构造析构顺序的问题)。
-
执行派生类的构造函数体中的内容。
-
析构函数调用执行(次序与构造函数相反)。
<案例1>
#include<iostream>
#include<string>
using namespace std;
class Sample {
string tips;
public:
Sample(string t) :tips(t) { cout << "Constructor of " << tips << " called." << endl; }
~Sample() { cout << "Destructor of " << tips << " called." << endl; }
};
Sample g1("v_Global_1");
static Sample g2("v_Global_2");
void f() {
static Sample v_sl("v_StaticLocal");
Sample v_l("v_Local_f");
}
int main() {
Sample v_lm("v_Local_main");
cout << "--------------<before f>---------------" << endl;
f();
cout << "--------------<after f>---------------" << endl;
return 0;
}
/*输出:
Constructor of v_Global_1 called.
Constructor of v_Global_2 called.
Constructor of v_Local_main called.
--------------<before f>---------------
Constructor of v_StaticLocal called.
Constructor of v_Local_f called.
Destructor of v_Local_f called. //离开作用域自动调用析构函数
--------------<after f>---------------
Destructor of v_Local_main called.
Destructor of v_StaticLocal called.
Destructor of v_Global_2 called. //全局对象最后析构
Destructor of v_Global_1 called.
*/
<案例2>
/*
功能:显示Derived类对象创建过程中构造函数与析构函数的调用顺序
*/
#include<iostream>
using namespace std;
/*Derived的祖先基类-虚基类*/
class Base {
protected:
int x;
public:
Base(int newx) :x(newx) {
cout << "Constructor of virtual Base called." << endl;
}
~Base() {
cout << "Destructor of virtual Base called." << endl;
}
};
/*Derived的直接基类1*/
class Base1 :virtual public Base {
protected:
int x;
public:
Base1(int newx = 0, int newxv = 0) :x(newx),
Base(2 * newxv) //这里对Base构造函数的调用会被忽略,但不可缺失
{
cout << "Constructor of Base1 called. {Base1::x=" << Base1::x << " Base::x=" << Base::x << "}" << endl;
}
~Base1() {
cout << "Destructor of Base1 called." << endl;
}
};
/*Derived的直接基类2*/
class Base2 :virtual public Base {
protected:
int x;
public:
Base2(int newx = 0, int newxv = 0) :x(newx),
Base(3 * newxv) //这里对Base构造函数的调用会被忽略,但不可缺失
{
cout << "Constructor of Base2 called. {Base2::x=" << Base2::x << " Base::x=" << Base::x << "}" << endl;
}
~Base2() {
cout << "Destructor of Base2 called." << endl;
}
};
class Member {
protected:
int x;
public:
Member(int newx = 0) :x(newx) {
cout << "Constructor of Member called." << endl;
}
~Member() {
cout << "Destructor of Member called." << endl;
}
};
/*Derived类*/
class Derived :public Base1, public Base2 {
int x;
Member m;
public:
/*派生类构造函数*/
Derived(int newx, int newxm, int newx1, int newx2, int newx3, int newxv) :
//下面的书写顺序与最终初始化顺序无关
x(newx), //本类数据成员初始化
m(newxm), //本类对象成员初始化
Base2(newx2, newxv), Base1(newx1, newxv), //直接基类初始化
Base(newxv) //虚基类初始化,只有此处才发挥作用
{
cout << "Constructor of Derived called." << endl;
}
~Derived() {
cout << "Destructor of Derived called." << endl;
}
};
int main() {
Derived d(1, 2, 3, 4, 5, 6);
Member m(1);
cout << "------------------------" << endl;
return 0;
}
/*输出:
Constructor of virtual Base called.
Constructor of Base1 called. {Base1::x=3 Base::x=6} //此处说明直接基类对虚基类构造函数的调用被忽略了
Constructor of Base2 called. {Base2::x=4 Base::x=6}
Constructor of Member called.
Constructor of Derived called.
Constructor of Member called.
------------------------
Destructor of Member called. //后构造的先析构,先构造的后析构
Destructor of Derived called.
Destructor of Member called.
Destructor of Base2 called.
Destructor of Base1 called.
Destructor of virtual Base called.
*/
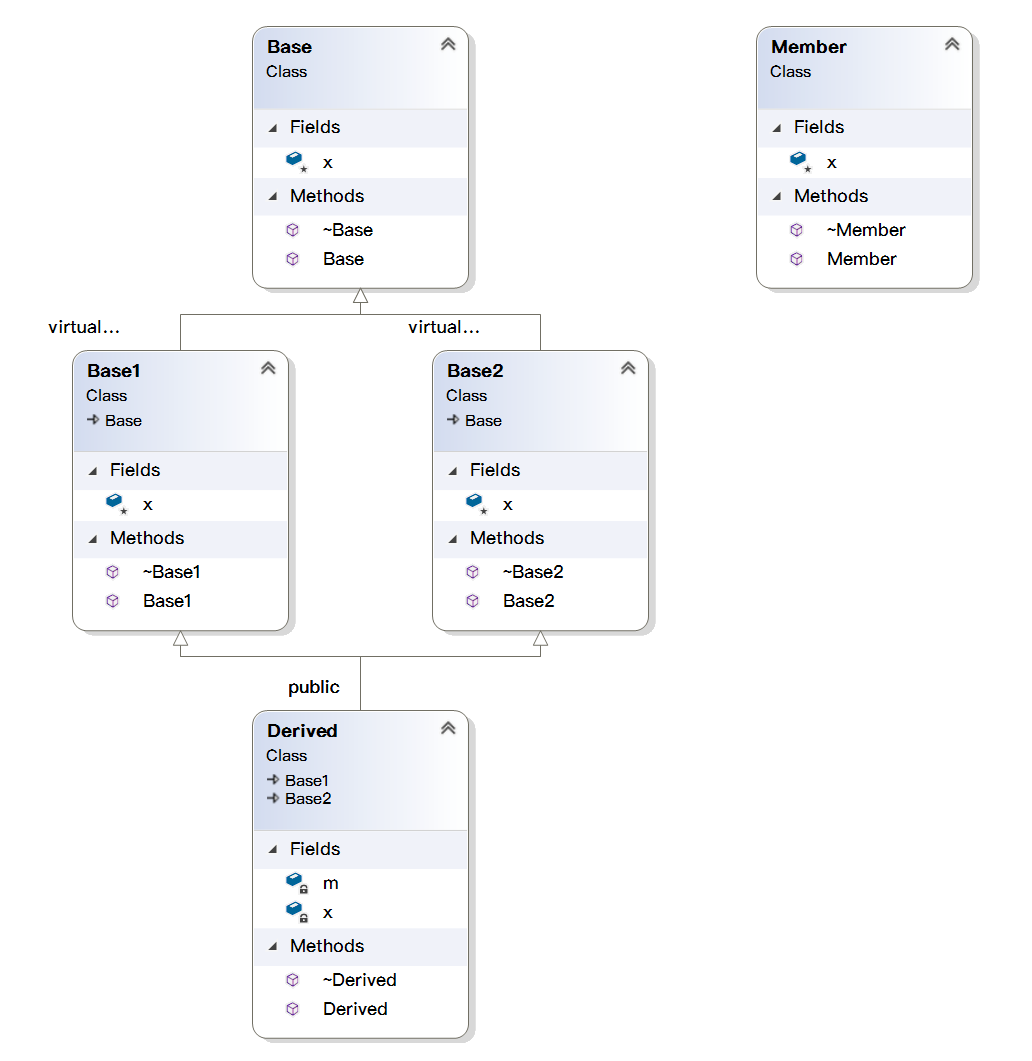
<案例3>
#include<iostream>
using namespace std;
struct ZooAnimal {
ZooAnimal() { cout << "ZooAnimal()" << endl; }
};
struct Bear :virtual ZooAnimal{
Bear() { cout << "Bear()" << endl; }
};
struct Character {
Character() { cout << "Character()" << endl; }
};
struct BookCharacter :Character {
BookCharacter() { cout << "BookCharacter()" << endl; }
};
struct ToyAnimal {
ToyAnimal() { cout << "ToyAnimal()" << endl; }
};
struct TeddyBear :virtual BookCharacter, Bear, virtual ToyAnimal {
TeddyBear() { cout << "TeddyBear()" << endl; }
};
int main() {
TeddyBear t;
return 0;
}
/*输出:
Character()
BookCharacter()
ZooAnimal()
ToyAnimal()
Bear()
TeddyBear()
*/
<案例4>
#include<iostream>
using namespace std;
struct Class {
Class() { cout << "Class()" << endl; }
};
struct Base :public Class {
Base() { cout << "Base()" << endl; }
};
struct D1 : virtual public Base {
D1() { cout << "D1" << endl; }
};
struct D2 : virtual public Base {
D2() { cout << "D2" << endl; }
};
struct MI : public D1, public D2 {
MI() { cout << "MI" << endl; }
};
struct Final : public MI, public Class {
Final() { cout << "Final()" << endl; }
};
int main() {
Final f;
return 0;
}
/*输出:
Class()
Base()
D1
D2
MI
Class()
Final()
*/
<案例5>
#include<iostream>
using namespace std;
class A {
public:
A(int i) { cout << i; }
};
class B :virtual public A {
public:
B(int i, int j = 0) :A(j) { cout << i; }
};
class C :virtual public A {
public:
C(int i, int j = 0) :A(j) { cout << i; }
};
class D :public C, public B {
C obj2;
B obj1;
public:
D(int a, int b, int c, int d) :obj1(a), obj2(b), B(c), C(d), A(a) { cout << b; }
};
int main() {
D d(1, 2, 3, 4);
return 0;
}
/*输出:
14302012
*/
九、数据共享与保护
(一)函数间数据共享
1. 变量的作用域
(1)函数原型作用域
变量:函数原型中的形参
范围:函数原型中的参数作用域始于(,终于)。
double area(double radius); //正确
double area(double); //正确,函数原型内的形参变量名称可以舍去。
(2)局部作用域
变量:函数的形参、在块中声明的标识符
范围:自声明处起,限于块中

(3)类作用域
变量:类的成员
范围:类体+非内联函数函数体
如果在类作用域以外访问类的成员,要通过类名(访问静态成员时)或者该类的对象名、对象引用、对象指针(访问非静态成员时)
(4)命名空间作用域
① 命名空间
程序访问名称空间std的方法可以有如下几种:
- 将
using namespace std;放在函数定义之前,告知编译器后续的代码将使用std命名空间中的名称。 - 将
using namespace std;放在特定的函数定义中,让该函数能够使用名称空间std中的所有元素。 - 在特定的函数中使用类似
using std::cout;这样的编译指令,而不是using namespace std;,让该函数能够使用指定的元素,如cout。 - 完全不使用编译指令
using,而在需要使用名称空间std中的元素时,使用前缀std::,如下所示std::cout << "Em0s_Er1t" << std::endl;
用户可以自定义命名空间来解决重名问题
#include <iostream>
using namespace std;
/*第1个命名空间*/
namespace first_space{
void func(){
cout << "Inside first_space" << endl;
}
}
/*第2个命名空间*/
namespace second_space{
void func(){
cout << "Inside second_space" << endl;
}
}
using namespace first_space;
int main ()
{
func(); // 调用第1个命名空间中的函数
return 0;
}
/*输出:
Inside first_space
*/
(5)枚举类作用域
见枚举类
extern关键字
修饰符extern用在变量或者函数的声明前,用来说明“此变量/函数是在别处定义的,要在此处引用”。extern声明不是定义,即不分配存储空间。
定义在文件A中的一个变量在文件B中用extern声明,则该变量的作用域扩展至B文件
2. 同名变量与可见性
可见性表示从内层作用域向外层作用域“看”时能看见什么。如果标识在某处可见,就可以在该处引用此标识符。
- 如果某个标识符在外层中声明,且在内层中没有同一标识符的声明,则该标识符在内层可见;
- 对于两个嵌套的作用域,如果在内层作用域内声明了与外层作用域中同名的标识符,则外层作用域的标识符在内层不可见。(即内层屏蔽外层同名的标识符)
#include<iostream>
using namespace std;
int i = 1;
int main() {
int i = 2;
{
int i = 3;
cout << i << endl; //输出3
cout << ::i << endl; //输出1(指定全局变量i)
}
cout << i << endl; //输出2
return 0;
}
3. 变量的生存期
生存期 :即从诞生到消失的时间段,在生存期内,对象的值保持不变,直到被改变为止。
生存期可以分为静态生存期与动态生存期
-
静态生存期与程序运行期相同,在函数内部声明静态生存期对象要冠以关键字
static,如静态局部变量全局变量具有静态生存期
-
动态生存期是在块作用域中声明的,没有用static修饰的
(1)静态(static)变量
与static变量相对应的是auto变量,所有未加 static 关键字的都默认是 auto 变量
① 初始化
- 若一个静态变量未经过初始化,则其自动被初始化为0
- 静态变量(无论是全局还是局部变量)的初始化在任何代码之前
② 静态局部变量
- 生存期:整个源程序运行期间
- 作用域:与局部变量相同,只能在定义该变量的函数内使用该变量。
③ 静态全局变量
-
生存期:整个源程序运行期间
-
作用域:全局作用域,准确来说是定义它的文件中(无论如何都不能作用到其它文件里)
即使两个不同的源文件都定义了相同名字的静态全局变量,它们也是不同的变量。
(2)全局变量/外部变量
-
初始化:若一个全局变量未经过初始化,则其自动被初始化为0
-
生存期:整个源程序运行期间
-
作用域:全局作用域,准确来说是整个工程(可以通过extern关键字在其他文件中使用)
#include<iostream>
using namespace std;
int i = 1;
void other();
int main() {
static int a;
int b = -10, c = 0;
cout << "-main-" << endl;
cout << "i:" << i << endl;
cout << "a:" << a << endl;
cout << "b:" << b << endl;
cout << "c:" << c << endl;
c += 8;
cout << "第1次调用other" << endl;
other();
cout << "第2次调用other" << endl;
i += 10;
other();
cout << "-main-" << endl;
return 0;
}
void other(){
static int a = 2, b; //第二次进入other不会再创建一个新的静态变量a
int c = 10;
a += 2;
i += 32;
c += 5;
cout << "i:" << i << endl;
cout << "a:" << a << endl;
cout << "b:" << b << endl;
cout << "c:" << c << endl;
b = a;
}
/*输出:
-main-
i:1
a:0
b:-10
c:0
第1次调用other
i:33
a:4
b:0
c:15
第2次调用other
i:75
a:6
b:4
c:15
-main-
*/
(二)对象间的数据共享
1. 同类对象间共享(静态成员)
(1)同类对象间数据共享(静态数据成员)
静态数据成员在类内用关键字static声明,存放于全局数据区,为该类的所有对象共享。
-
初始化:静态数据成员不是由构造函数初始化的,其在类外定义与初始化,且初始化要用类名限定(必须初始化!!!)
C++11支持静态常量数据成员(const或constexpr修饰)类内初始化,此时类外仍可定义该静态成员,但不可再次初始化操作。
class A{ ...... static int a; //(类内)静态数据成员声明 ...... } int A::a = 0; //(类外)静态数据成员定义与初始化 -
生存期:整个源程序运行期间(即静态数据成员具有静态生存期)
(2)同类对象间功能共享(静态函数成员)
静态函数成员不属于任何一个对象,它主要用于处理该类的静态数据成员,它实际上是“加上了访问控制的全局函数”
-
类外可以直接使用类名和作用域操作符调用静态成员函数(静态成员函数无this指针),也可以使用已定义的对象来调用。
-
静态成员函数无法直接访问非静态数据成员。
因为静态成员函数被调用时可能一个对象还没创建,自然也无法访问非静态数据成员
#include<iostream>
using namespace std;
class Point {
int x, y;
static int count; //给创建的点计数
public:
Point(int newx = 0, int newy = 0);
Point(const Point &p);
~Point();
int getx();
int gety();
static void showcount();
};
int Point::count = 0; //静态数据成员在类外定义与初始化,并用类名限定
Point::Point(int newx, int newy) :x(newx), y(newy) {
count++;
}
Point::Point(const Point &p) : x(p.x), y(p.y) {
count++;
}
Point::~Point() {
count--;
}
int Point::getx() {
return x;
}
int Point::gety() {
return y;
}
void Point::showcount() { //静态成员函数的定义前面无需加static
cout << "now you have " << count << " points." << endl;
}
int main() {
Point::showcount();
Point p(1, 2);
p.showcount(); //即便用特定的对象去调用静态成员函数也不会传入该对象的地址
return 0;
}
<说明>
-
父类的静态成员在派生类中依然可用,但是受访问性控制(比如,在父类的private域中的静态成员就不可访问)
个人理解:派生类通过继承的方式只是拥有了对父类静态成员的访问权限,并非真正的继承
#include<iostream> using namespace std; class Base { private: static int val_pri; public: static int val_pub; }; int Base::val_pri = 1; int Base::val_pub = 2; class Derived :public Base { public: void fun() { //cout << val_pri << endl; //错误,不可访问基类中私有成员(包括静态成员变量) cout << val_pub << endl; //输出2 } }; int main() { Derived d; d.fun(); cout << d.val_pub << endl; //输出2 return 0; } -
静态成员变量始终存放于全局区,不占用类和对象空间
#include<iostream> using namespace std; class A { static int a; }; int A::a = 1; int main() { cout << sizeof(A) << endl; //输出1。说明静态成员变量不占用类和对象空间 return 0; } -
类的非静态成员变量不能作为成员函数的默认实参,但静态成员可以作为类成员函数的默认实参
2. 类与外部数据共享(友元)
类的成员函数内部可以访问任何同类对象的所有成员,对于非本类对象是无法访问其私有成员的,友元可以打破这一限制。
友元可以提升程序运行效率,打破了类的封装性和隐藏性。
(1)友元类
class A{
friend class B; //声明B类是A类的友元
private:
...
public:
...
}
- 友元关系是单向的:如果声明B类是A类的友元(如下),则B类的成员函数都是A类的友元函数,可以访问A类的所有成员(包括私有和保护数据),但A类的成员函数却不能访问B类的私有、保护数据。
- 友元关系不能被继承:基类的友元对派生类没有特殊的访问权限。
- 友元关系不具有传递性:若类B是类A的友元,类C是B的友元,类C不一定是类A的友元。
(2)友元函数
class A{
friend 数据类型 C::fun1(参数表);//声明C中的成员函数fun1是A类的友元
friend 数据类型 fun2(参数表); //声明全局函数fun2是A类的友元
private:
...
public:
...
}
- 友元函数不是成员函数,不能被继承,没有this指针
- 友元声明可以放置在类内的任意位置
<案例>
#include<iostream>
#include<cmath>
using namespace std;
class Point {
friend double getdistance(Point &p1, Point &p2); //不是类的成员,只是一个声明,可以放置在大括号内的任意位置
int x, y;
public:
Point(int newx = 0, int newy = 0);
Point(const Point &p);
};
Point::Point(int newx, int newy) :x(newx), y(newy) {
}
Point::Point(const Point &p) : x(p.x), y(p.y) {
}
double getdistance(Point &p1, Point &p2);
int main() {
Point p1(3, 4), p2(1, 2);
cout << "the distance of the 2 points is " << getdistance(p1, p2) << endl;
return 0;
}
double getdistance(Point &p1, Point &p2) {
int a = p1.x - p2.x, //此时在友元函数中可以直接访问该类的私有成员
b = p1.y - p2.y;
double d = sqrt(a*a + b * b);
return d;
}
/*输出:
the distance of the 2 points is 2.82843
*/

(三)共享数据的保护:const
对于既需要共享、又需要防止改变的数据应该声明为常类型(用const进行修饰)
-
常对象:必须进行初始化,不能被更新
const 类名 对象名注意:通过常对象只能调用它的常成员函数或者静态成员函数,所以有时我们实现了一个普通成员函数的功能,要想使常对象也可以用到这个功能就需要为此函数再重载一个常成员函数。
-
常成员:用const修饰的常数据成员和常函数成员
-
常引用:被引用的对象不能被更新
const 类型名 &引用名称 -
常数组:数组元素不能被更新
类型名 const 数组名[数组大小] -
常指针:指向常量的指针
对于不改变对象状态的成员函数应该声明为常函数。
1. 常成员
(1)常成员函数
类型说明符 函数名(参数表) const;
注意:
- 常成员函数可以访问常数据成员,也可访问普通数据成员。
- 常成员函数不能更新对象的非静态数据成员(如果有此类操作则编译器编译时报错),但可以更新静态数据成员(可以理解为静态成员不严格属于类成员);
- 常成员函数不能调用非静态成员函数(如果有此类操作则编译器编译时报错),但可以调用静态成员函数(可以理解为静态成员不严格属于类成员)。
- const是函数类型的组成部分,因此在实现部分也要带const关键字
- const关键字可以用于参与对重载函数的区分
- 对于普通成员函数及其const重载版本的常成员函数,普通对象优先匹配调用普通成员函数(常成员函数也可调用),常对象只能调用常成员函数。
实际应用:通过在类中定义常成员函数,类的常对象就可以调用这些函数实现一些功能(如打印数据成员的值),否则常对象无法实现一些功能
(2)常数据成员
- 初始化:常数据成员只能通过初始化列表来获得初值
2. 常引用
如果在声明引用时用const修饰,被声明的引用就是常引用。
const 类型名 &引用名称
注意:
- 常引用所引用的对象不能被更新。
- 实际应用:用常引用做形参便不会意外地发生对实参的更改,且不会触发复制构造函数的调用。
十、动态内存分配
(〇)概念
1. 内存泄漏
内存泄漏也称作“存储渗漏”,用动态存储分配函数动态开辟的空间,在使用完毕后未释放,结果导致一直占据该内存单元。直到程序结束。(其实说白了就是该内存空间使用完毕之后未回收)即所谓内存泄漏
2. malloc/free vs new/delete
malloc/free 与 new/delete的区别如下:
-
malloc/free 是C/C++语言的标准库函数,new/delete是C++的运算符
-
new 能自动分配空间大小
-
对于用户自定义的对象而言,用malloc/free无法满足动态管理对象的要求
对象在创建的时候会自动调用构造函数,对象在消亡之前自动执行析构函数,由于malloc/free是库函数而不是运算符,不在编译器的控制范围,不能把构造函数和析构函数的任务强加于malloc/free 。于是C++需要一个能够对对象完成动态分配内存和初始化工作的运算符new,以及一个释放内存的运算符delete。
简单来说就是new/delete能完成更加详细的对内存的操作,而malloc/free不能。
(一)单个变量动态内存分配与释放
1. 分配
在程序执行期间,申请用于存放相应类型(这里记作T)的内存空间,并依初始化参数进行初始化。
new 类型名(初始化参数);
/*例:
int *p=new int; //p指向新申请的动态内存,无初值
int *p=new int(); //p指向新申请的动态内存,初值为0
int *p=new int(2);//p指向新申请的动态内存,初值为2
Person *p=new Person("John",19)
*/
-
初始化:
-
若T是基本类型:如果有初始化参数,依初始化参数进行初始化;如果没有括号和初始化参数,不进行初始化,新分配的内存中内容不确定;如果有括号但初始化参数为空,初始化为0。
-
若T是对象类型:
-
若有括号
- 有初始化参数,则以初始化参数中的值为参数调用构造函数进行初始化;
- 初始化参数为空,则以用户定义的默认构造函数初始化,如果用户未定义默认构造函数,则生成默认构造函数来调用并为对象的基本数据类型和指针类型用0赋初值(这是一个递归的过程:如果对象的对象成员没有用户自定义的默认构造函数,则同样用0赋初值)。
-
若没有括号,则仅以默认构造函数初始化。
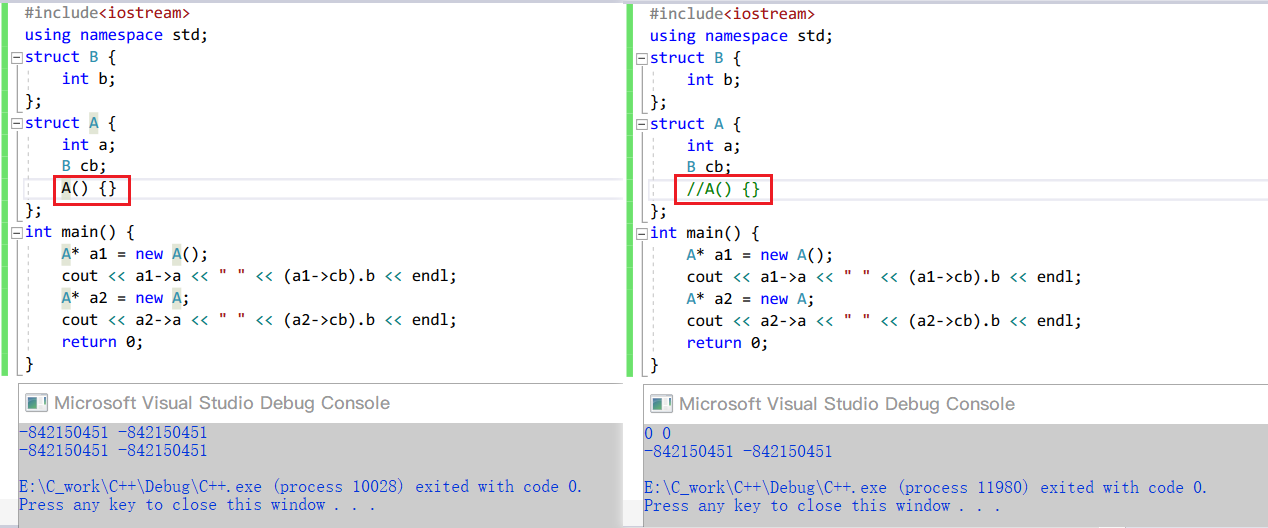
-
-
-
返回值:若成功则返回类型
T的指针,若失败则抛出异常。
2. 释放
释放p所指向的动态内存空间(p必须是new操作的返回值),若p指向一个对象类型,则自动调用析构函数
delete 指针p;
注意:
- 当free释放内存之后,指针p还指向原来的那块地址而成为野指针,此时需要我们设置 p = NULL
- 不能对一个指针重复delete
(二)数组动态内存分配、释放、封装
1. 分配
在程序执行期间,申请用于存放指定类型(这里记作T)的数组的内存空间。
new 类型名 [变量/常量表达式][常量表达式][常量表达式]....();
/*例:
int *p = new int[10]; //创建一个每个元素值随机,长度为10的数组
int *p = new int[10](); //创建一个每个元素都为0,长度为10的数组
int *p = new int[10](0); //错误!!!!
int *p = new int[10]{ 1,2,3,4,5,6,7,8,9,0 }; //C++11的列表初始化可以用于初始化动态分配的数组
*/
- 初始化:可以有
()但括号内必须为空,即动态内存分配数组不能设定初始值- 如果有
(),对每个元素的初始化与执行new T()所做进行初始化的方式相同。 - 如果没有
(),对每个元素的初始化与执行new T所做进行初始化的方式相同。
- 如果有
- 返回值:若成功则返回内存首地址,若失败则抛出异常。
2. 释放
释放指针p所指向的数组(p必须是new分配得到的数组首地址)
delete[] 指针p
/*对象的动态内存分配与释放*/
#include<iostream>
using namespace std;
class Point {
int x, y;
public:
Point();
Point(int newx, int newy);
Point(const Point &p);
~Point();
};
Point::Point() {
cout << "Default Constructor called." << endl;
}
Point::Point(int newx, int newy) :x(newx), y(newy) {
cout << "Constructor called." << endl;
}
Point::Point(const Point &p) : x(p.x), y(p.y) {
cout << "Copy Constructor called." << endl;
}
Point::~Point() {
cout << "Destructor called." << endl;
}
int main() {
Point *p1 = new Point();
delete p1;
cout << "---------------------" << endl;
Point *p2 = new Point(1, 2);
delete p2;
cout << "---------------------" << endl;
Point *pa = new Point[3];
delete[] pa; //如果去掉这一句,不会调用析构函数析构Point数值中的对象元素
return 0;
}
/*输出:
Default Constructor called.
Destructor called.
---------------------
Constructor called.
Destructor called.
---------------------
Default Constructor called.
Default Constructor called.
Default Constructor called.
Destructor called.
Destructor called.
Destructor called.
*/
3. 动态数组的封装
#include<iostream>
#include<cassert>
using namespace std;
class Point {
int x, y;
public:
Point(int newx = 0, int newy = 0);
Point(const Point &p);
~Point();
void move(int newx, int newy);
void show();
};
class ArrayOfPoint {
Point *p; //指向动态数组首地址
int size; //动态数组的大小
public:
ArrayOfPoint(int s = 1);
~ArrayOfPoint();
Point& element1(int index);
Point element2(int index);
};
Point::Point(int newx, int newy) :x(newx), y(newy) {
cout << "Constructor of Point called." << endl;
}
Point::Point(const Point &p) : x(p.x), y(p.y) {
cout << "Copy Constructor of Point called." << endl;
}
Point::~Point() {
cout << "Destructor of Point called." << endl;
}
void Point::move(int newx,int newy) {
x = newx;
y = newy;
}
void Point::show() {
cout << "(" << x << "," << y << ")" << endl;
}
ArrayOfPoint::ArrayOfPoint(int s):size(s) {
p = new Point[s]();
cout << "Constructor of ArrayOfPoint called." << endl;
}
ArrayOfPoint::~ArrayOfPoint() {
delete[] p;
p = nullptr;
cout << "Destructor of ArrayOfPoint called." << endl;
}
/*一种返回对象,一种返回对象的引用*/
Point& ArrayOfPoint::element1(int index) {
assert(index >= 0 && index < size); //若数组下标越界则报错,程序终止
return p[index]; //此处返回的是引用,则就是返回p[index]本身
}
Point ArrayOfPoint::element2(int index) {
assert(index >= 0 && index < size); //若数组下标越界则报错,程序终止
return p[index]; //此处返回的是对象,则会调用复制构造函数创建p[index]的一个副本并返回
}
int main() {
int asize;
cout << "请输入待创建的数组大小:"; //若输入小于2的数则会触发assert报错
cin >> asize;
ArrayOfPoint points(asize);
cout << "---------------------------" << endl;
//此处修改的是p[0]
points.element1(0).move(1, 2);
points.element1(0).show();
//此处打印的不是p[0],而是p[0]的副本,本语句执行完毕之后这个副本便被析构
points.element2(0).show();
cout << "---------------------------" << endl;
//此处修改的不是p[1],而是它的副本(这里记作1号副本),本语句执行完毕之后1号副本便被析构
points.element2(1).move(3, 4);
//p[1]由于未被修改,所以打印出来的为(0,0)
points.element1(1).show();
//再次创建了一个p[1]的副本,这个副本与1号副本(已被修改)不一样(这里记作2号副本),所以打印出来为(0,0),且本语句执行完毕之后2号副本也会被析构
points.element2(1).show();
cout << "---------------------------" << endl;
return 0;
}
/*输出:
请输入待创建的数组大小:3
Constructor of Point called.
Constructor of Point called.
Constructor of Point called.
Constructor of ArrayOfPoint called.
---------------------------
(1,2)
Copy Constructor of Point called.
(1,2)
Destructor of Point called.
---------------------------
Copy Constructor of Point called.
Destructor of Point called.
(0,0)
Copy Constructor of Point called.
(0,0)
Destructor of Point called.
---------------------------
Destructor of Point called.
Destructor of Point called.
Destructor of Point called.
Destructor of ArrayOfPoint called.
*/
(三)智能指针
智能指针和普通指针的用法是相似的,不同之处在于,智能指针可以在适当时机自动释放分配的内存。也就是说,使用智能指针可以很好地避免“忘记释放内存而导致内存泄漏”问题出现。
C++11 引入了 3 个智能指针类型:
std::auto_ptr已被废弃。
std::unique_ptr<T>:独占资源所有权的指针。std::shared_ptr<T>:共享资源所有权的指针。std::weak_ptr<T>:共享资源的观察者,需要和std::shared_ptr一起使用,不影响资源的生命周期。
1. shared_ptr
和 unique_ptr、weak_ptr 不同之处在于,多个 shared_ptr 智能指针可以共同使用同一块堆内存。并且,由于该类型智能指针在实现上采用的是引用计数机制,即便有一个 shared_ptr 指针放弃了堆内存的“使用权”(引用计数减 1),也不会影响其他指向同一堆内存的 shared_ptr 指针(只有引用计数为 0 时,堆内存才会被自动释放)。
(1)定义与初始化
/*创建空智能指针*/
shared_ptr<int> p1;
shared_ptr<int> p2(nullptr);
/*创建有明确指向的智能指针*/
//(下面两种方法等价)
shared_ptr<int> p3(new int(99));
shared_ptr<int> p4 = make_shared<int>(99);
//拷贝构造
shared_ptr<int> p5(p3);
//移动构造(构造完毕后p4变成空指针)
shared_ptr<int> p6(move(p4));
shared_ptr 指针默认的释放规则是不支持释放数组的,只能自定义对应的释放规则,才能正确地释放申请的堆内存。
/*采用提供的释放规则释放*/
shared_ptr<int> p6(new int[10], default_delete<int[]>());
/*采用自定义规则释放*/
//传入lambda表达式
shared_ptr<int> p7(new int[10], [](int* p) {delete[]p; });
//传入函数
shared_ptr<int> p7(new int[10], deleter);
void deleter(int *p){
delete[] p;
}
2. unique_ptr
当我们独占资源的所有权的时候,可以使用 std::unique_ptr 对资源进行管理
/*创建空智能指针*/
unique_ptr<int> p1;
unique_ptr<int> p2(nullptr);
/*创建有明确指向的智能指针*/
//(下面两种方法等价)
unique_ptr<int> p3(new int(99));
unique_ptr<int> p4 = make_unique<int>(99);
//unique_ptr<int> p5(p3); //错误!!unique不支持拷贝构造
//移动构造(构造完毕后p4变成空指针)
unique_ptr<int> p6(move(p4));
十一、模板
模板声明
Template <class 形参名, class 形参名, ......>
template //错误
template<T1,T2> //错误
template<class T1,T2> //错误
template<class T1,class T2> //正确
template<typename T1,T2> //错误
template<typename T1,typename T2> //正确
template<class T1,typename T2> //正确
<typename T1,class T2> //错误
(一)函数模板
函数模板即是一种通用函数,其函数返回值类型和形参类型可以不具体制定,用类型参数来代表。
当类型参数确定后,编译器以函数模板为样板生成一个函数,这一过程称为函数模板的实例化。
函数模板的实例化是由编译器完成的
1. 定义
template <class 类型参数1[, class 类型参数2, ...]> //用class或者typename
返回值类型 函数名(形参表){
//...
}
C++11规定,函数模板也支持默认的模板参数,需要从右往左给出
2. 模板的使用
模板使用时必须要确定具体的数据类型,可以用两种方法使用定义的模板
-
编译器根据传入的参数自动类型推导
自动类型推导的前提必须是能推导出一致的数据类型
-
显示指定类型
举个例子
#include<iostream>
using namespace std;
/*利用模板提供通用的交换函数*/
template<class T>
void mySwap(T& a, T& b) {
T temp = a;
a = b;
b = temp;
cout << "T: " << typeid(T).name() << endl; //运行时打印T的数据类型
}
// 1、自动类型推导,必须推导出一致的数据类型T,才可以使用
void test01() {
int a = 10;
int b = 20;
char c = 'c';
mySwap(a, b); // 正确,可以推导出一致的T
//mySwap(a, c); // 错误,推导不出一致的T类型
}
// 2、模板必须要确定出T的数据类型,才可以使用
template<class T>
void func() {
cout << "func 调用" << endl;
}
void test02() {
//func(); //错误,模板不能独立使用,必须确定出T的类型
func<int>(); //利用显示指定类型的方式,给T一个类型,才可以使用该模板
}
int main() {
test01();
test02();
return 0;
}
3. 函数模板与普通函数的区别
- 普通函数调用时可以发生自动类型转换(隐式类型转换)
- 如果利用自动类型推导方式调用函数模板,不会发生隐式类型转换(此时不能推导出一致的类型)
- 如果利用显示指定类型的方式,可以发生隐式类型转换
- 与普通函数不同,函数模板本身在编译时不会生成任何目标代码,只有由模板生成的实例会生成目标代码、
- 函数指针只能指向模板的实例,不能指向模板本身
#include<iostream>
using namespace std;
//普通函数
int myAdd01(int a, int b) {
return a + b;
}
//函数模板
template<class T>
T myAdd02(T a, T b) {
return a + b;
}
int main() {
int a = 10, b = 20;
char c = 'c';
cout << myAdd01(a, c) << endl; //正确,将char类型的'c'隐式转换为int类型 'c' 对应 ASCII码99
//cout << myAdd02(a, c) << endl; //报错,使用自动类型推导时,不会发生隐式类型转换
cout << myAdd02<int>(a, c) << endl;//正确,如果用显示指定类型,可以发生隐式类型转换
return 0;
}
4. 函数模板调用规则
规则如下:
-
寻找一个与参数完全匹配的普通函数,如果找到了就调用
如果函数模板和普通函数都可以调用,优先调用普通函数,此时可以通过空模板参数列表来强制调用函数模板;
-
如果查找失败则寻找一个函数模板,将其实例化产生一个匹配的模板函数,如果成功则调用
-
如果匹配失败则尝试低一级对函数的重载方法,如通过类型转换产生可以匹配的参数并调用
不存在为了调用普通函数选择放弃调用可以匹配的模板函数而进行隐式类型转换。类型转换是无可匹配的情况下进行的
-
如果无论如何都匹配不到,则这是一个错误的调用。
#include<iostream>
using namespace std;
//普通函数
void print(int a, int b) {
cout << "调用普通函数" << endl;
}
//函数模板1
template<class T>
void print(T a, T b) {
cout << "调用函数模板" << endl;
}
//函数模板2(函数重载)
template<class T>
void print(T a, T b, T c) {
cout << "调用重载的函数模板" << endl;
}
int main() {
print(1,1); //优先调用普通函数
print<>(1,1); //通过空模板参数列表强制调用函数模板1
/*如果函数模板可以产生更好的匹配,优先调用函数模板*/
print(1, 1, 1);
print('a', 'b');//见“3”。如果没有函数模板1,编译器只好进行类型转换以适配普通函数的调用
return 0;
}
/*输出:
调用普通函数
调用函数模板
调用重载的函数模板
调用函数模板
*/
5. 具体化模板
并不能为包括自定义数据类型在内的所有数据类型提供一个万能的模板,有些特殊数据类型的操作可以利用模板重载为其提供具体化的模板
#include<iostream>
#include<string>
using namespace std;
class Person {
public:
int age;
string name;
Person(string n = "", int a = 0) :age(a), name(n) {}
};
/*比较函数通用模板(不能比较自定义类)*/
template<class T>
bool mycompare(T &a, T &b) {
return a == b;
}
/*创建具体化的Person数据类型的比较函数模板,用于特殊处理这个类型*/
template<> bool mycompare(Person &p1, Person &p2) {
if (p1.age == p2.age && p1.name == p2.name)
return true;
else return false;
}
int main() {
int a = 1, b = 1;
Person John1("John", 18), John2("John", 18);
if (mycompare(John1, John2)) cout << "相等" << endl;
/*内置数据类型直接使用通用函数模板*/
if (mycompare(a, b)) cout << "相等" << endl;
return 0;
}
<案例>
(1)几种排序算法
#include<iostream>
using namespace std;
bool mygreater(int t1, int t2) {
return t1 <= t2;
}
/*直接插入排序*/
template<class T>
void Insert_Sort(T arr[], int size) {
T tmp;
for (int i = 1; i < size; i++) {
tmp = arr[i];
for (int j = i - 1; j >= 0; j--) {
if (mygreater(arr[j], tmp)) {
arr[j + 1] = arr[j];
arr[j] = tmp;
}
else break;
}
}
}
/*简单选择排序*/
template<class T>
void Select_Sort(T arr[], int size) {
int min;
T tmp;
for (int i = 0; i < size; i++) {
min = i;
for (int j = i + 1; j < size; j++) {
if (mygreater(arr[min], arr[j]))
min = j;
}
if (min != i) {
tmp = arr[i];
arr[i] = arr[min];
arr[min] = tmp;
}
}
}
/*冒泡排序1*/
template<class T>
void Bubble_Sort_1(T arr[], int size) {
T tmp;
int flag;
for (int i = size; i > 1; i--) {
flag = 1;
for (int j = 0; j < i - 1; j++) {
if (mygreater(arr[j], arr[j + 1])) {
tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
flag = 0;
}
}
if (flag)
break;
}
}
/*冒泡排序2*/
template<class T>
void Bubble_Sort_2(T arr[], int size) {
T tmp;
int flag;
for (int i = 0; i < size; i++) {
flag = 1;
for (int j = size - 1; j > i; j--) {
if (mygreater(arr[j - 1], arr[j])) {
tmp = arr[j];
arr[j] = arr[j - 1];
arr[j - 1] = tmp;
flag = 0;
}
}
if (flag) break;
}
}
/*快速排序*/
template<class T>
void Partition(T arr[], int begin, int end) {
if (begin >= end) //递归出口
return;
int i = begin, j = end;
T piviot = arr[begin];
while (begin < end) { //注意:在本程序快排算法中,mygreater(a,b)必须设计为包含a==b的情况,即要么a>=b,要么a<=b,否则当出现相同元素时会死循环
while (mygreater(arr[end], piviot) && begin < end) end--;
arr[begin] = arr[end]; //当begin==end后就是自己给自己赋值,不会对排序造成影响。
while (mygreater(piviot, arr[begin]) && begin < end) begin++;
arr[end] = arr[begin];
}
arr[begin] = piviot; //循环结束后可以确定枢轴元素最终要存放的位置,即当前下标为begin(也就是end)的位置
Partition(arr, i, begin - 1);
Partition(arr, begin + 1, j);
}
template<class T>
void Quick_Sort(T arr[], int size) {
Partition(arr, 0, size - 1);
}
int main() {
const int SIZE = 8;
int arr[] = { 49,38,65,97,76,13,27,49 };
//Insert_Sort<int>(arr, SIZE);
//Select_Sort<int>(arr, SIZE);
//Bubble_Sort_1<int>(arr, SIZE);
//Bubble_Sort_2<int>(arr, SIZE);
Quick_Sort<int>(arr, SIZE);
for (int i = 0; i < SIZE; i++)
cout << arr[i] << ' '; //13 27 38 49 49 65 76 97
return 0;
}
待补充:堆排序、归并排序、顺序查找
(2)折半查找算法
递归
#include<iostream>
using namespace std;
bool mygreater(int t1, int t2) {
return t1 > t2;
}
/*二分查找(递归算法)*/
template<class T>
int Search(T arr[], int begin, int end, const T & key) {
if (begin > end) { //查找失败
return -1;
}
int mid = (begin + end) / 2;
if (mygreater(key, arr[mid])) {
return Search(arr, mid + 1, end, key);
}
else if (mygreater(arr[mid], key)) {
return Search(arr, begin, mid - 1, key);
}
else {
return mid; //查找成功
}
}
template<class T>
int Binary_Search(T arr[], int size, const T & key) {
int pos = Search<T>(arr, 0, size - 1, key);
return pos;
}
int main() {
const int SIZE = 8;
int arr[] = { 13, 27, 38, 49, 49, 65, 76, 97 };
cout << Binary_Search<int>(arr, SIZE, 20) << endl;
cout << Binary_Search<int>(arr, SIZE, 97) << endl;
}
非递归
#include<iostream>
using namespace std;
bool mygreater(int t1, int t2) {
return t1 > t2;
}
/*二分查找(非递归算法)*/
template<class T>
int Binary_Search(T arr[], int size, const T & key) {
int low = 0, high = size - 1, mid;
while (low <= high) { //注意:这里是小于等于,不是小于
mid = (low + high) / 2;
if (mygreater(key, arr[mid]))
low = mid + 1;
else if (mygreater(arr[mid], key))
high = mid - 1;
else
return mid; //查找成功
}
return -1; //查找失败
}
int main() {
const int SIZE = 8;
int arr[] = { 13, 27, 38, 49, 49, 65, 76, 97 };
cout << Binary_Search<int>(arr, SIZE, 20) << endl;
cout << Binary_Search<int>(arr, SIZE, 97) << endl;
}
(二)类模板
使用类模板使用户可以为类声明一种模式,使得类中的某些数据成员、某些成员函数的参数、某些成员函数的返回值,能取“任意”类型(包括基本类型的和用户自定义类型)。
1. 定义
定义形式如下
template <class 类型参数1[, class 类型参数2, ...]> //类型参数可以有默认实参
class 类名{
//TODO
}
在类模板以外定义其成员函数要采用下面形式
template <class 类型参数1[, class 类型参数2, ...]>
类型名 类名<模板参数标识符列表>::函数名(参数表){
//TODO
}
- 类型参数可以有默认实参(从右往左给出)
2. 类模板别名
typedef只支持为一个类型取别名,而using超出了这一限制,using可以为一个模板取别名。
类模板(不是一种类型)实例化后是模板类(可以看作一种类型),using支持为类模板以及模板类取别名,但typedef只支持实例化(即具体化)得到的模板类取别名
举个例子
#include<iostream>
using namespace std;
template<class T1=double,class T2=double> //类模板在模板参数列表中可以有默认参数,但需要从右往左给出
class Point {
T1 x;
T2 y;
public:
Point(T1 newx = 0, T2 newy = 0);
};
/*类外实现构造函数*/
template<class T1, class T2>
Point<T1,T2>::Point(T1 newx, T2 newy) :x(newx), y(newy) {
cout << "Constructor of Point called." << endl;
}
template<class T1,class T2>
using TypePoint=Point<double,T2> //为一个模板取别名(这个模板往往是部分类型参数实例化后的模板)
int main() {
//using intPoint = Point<int,int>; //给实例化的类模板取别名
typedef Point<int,int> intPoint;
intPoint p1; //即 Point<int,int> p1;
Point<> p2; //即 Point<double,double> p2;
TypePoint<double> p3; //即 Point<double,double> p3;
return 0;
}
3. 类模板与函数模板的区别
-
类模板没有自动类型推导的使用方式,但函数模板可以根据实参自动推导类型
-
如今类模板与函数模板都支持默认的模板参数,但需要从右往左给出
C++11中解除了函数模板不能有默认参数的限制
4. 类模板与普通类的区别
普通类中的成员函数一开始就可以创建
类模板只有在被其它代码引用时才根据需要创建生成具体的类
5. 类模板对象作函数参数
有三种传入方式
- 显示指定实例化后的模板类
- 将形参的类型参数模板化来构建一个函数模板
- 将整个形参类模板化来构建一个函数模板
#include<iostream>
#include<string>
using namespace std;
template<class T1=int,class T2=string>
class Person {
public:
T1 age;
T2 name;
Person(T1 a, T2 n) :age(a), name(n) {}
~Person() {}
};
/*1.显示指定实例化后的模板类*/
void print_1(Person<int, string> p) {
cout << p.name << "'s age is " << p.age << endl;
}
void print_2(Person<> p) { //指定默认类型
cout << p.name << "'s age is " << p.age << endl;
}
/*2.参数模板化来构建一个函数模板*/
template<class T1, class T2>
void print_3(Person<T1, T2> &p) {
cout << p.name << "'s age is " << p.age << endl;
}
/*3.整个类模板化来构建一个函数模板*/
template<class T>
void print_4(T &p) {
cout << p.name << "'s age is " << p.age << endl;
}
int main() {
Person<int, string> John(18, "John");
/*四种方式输出结果相同*/
print_1(John); //输出:John's age is 18
print_2(John);
print_3(John);
print_4(John);
return 0;
}
6. 类模板的继承
模板类是类模板的实例化,模板类是具体,类模板是抽象
-
类模板可以继承:模板类、普通类、类模板;
类模板只能派生出类模板,无法派生出一个具体的类(如模板类/普通类)
-
普通类可以继承:模板类、普通类;
7. 类模板与友元
(1)友元函数
类模板的友元函数可以在类内实现,也可以在类外实现
#include<iostream>
#include<string>
using namespace std;
/*3. 友元函数模板的类外实现*/
template<class T1, class T2>
class Person; //为print_3设立前向引用声明
template<class T1, class T2>
void print_3(const Person<T1, T2> &p) { //此外,也可以在前面声明,在后面实现
cout << p.name << "'s age is " << p.age << endl;
}
template<class T1 = int, class T2 = string>
class Person {
T1 age;
T2 name;
public:
Person(T1 a, T2 n) :age(a), name(n) {}
~Person() {}
/*1. 友元函数类内声明与实现*/
friend void print_1(const Person<T1, T2> &p) {
cout << p.name << "'s age is " << p.age << endl;
}
/*2. 指定类型友元函数的类内声明*/
friend void print_2(const Person<> &pm); //由于参数类型确定,所以此时友元函数相当于一个普通函数
/*3. 友元函数模板的类内声明*/
friend void print_3<>(const Person<T1, T2> &p);//由于参数类型不确定,所以此时友元函数是一个函数模板
};
/*2. 指定类型友元函数的类外实现*/
void print_2(const Person<> &p) {
cout << p.name << "'s age is " << p.age << endl;
}
int main() {
Person<int, string> John(18, "John");
/*四种方式输出结果相同*/
print_1(John); //输出:John's age is 18
print_2(John);
print_3(John);
return 0;
}
8. 类模板与静态数据成员
类模板每个实例化的模板类都有自己的类模板静态数据成员,该模板类的所有对象共享一个静态数据成员。
和普通类的静态数据成员一样, 模板类的静态数据成员也应在文件范围内初始化。每个模板类都有其类模板的静态成员函数的副本。
<案例>
(1)数组类模板
#include<iostream>
#include<cassert>
using namespace std;
template <typename T>
class CArray {
T* arr;
int capacity;
int size;
public:
CArray(int c = 0) :capacity(c),size(0) {
arr = new T[c];
assert(c >= 0);
//cout << "Constructor of CArray called." << endl;
}
/*自定义复制构造函数实现深复制*/
CArray(const CArray<T> &ca) :capacity(ca.capacity), size(ca.size) {
arr = new T[ca.capacity];
for (int i = 0; i < ca.size; i++) {
arr[i] = ca.arr[i];
}
}
~CArray() {
delete[] arr;
arr = nullptr;
//cout << "Destructor of CArray called." << endl;
}
int getcapacity() const { return capacity; } /*获取数组容量*/
int getsize() const { return size; } /*获取数组大小*/
void recapacity(int c); /*修改数组容量*/
bool push_back(const T &val); /*尾插*/
bool pop_back(); /*尾删*/
T &operator [](int index); /*重载运算符[]使得可以像访问数组那样访问私有成员arr(但常对象无法调用这个函数)*/
const T &operator [](int index) const; /*常对象只能调用常成员函数,所以需要专门为其重载运算符[]使得可以像访问数组那样访问私有成员arr*/
CArray<T>& operator =(const CArray<T> &ca); /*重载赋值运算符实现深层复制*/
operator T*(); /*重载指针转换运算符,使得CArray类对象可以转换成T类型*/
operator const T*() const;/*重载指针转换运算符,使得CArray常对象可以转换成不可修改的T类型*/
};
template<typename T>
void CArray<T>::recapacity(int c) {
assert(c >= 0); //检查c是否非负
if (c == capacity) return;
T* newarr = new T[c];
size = (c > size) ? size : c;
for (int i = 0; i < size; i++) { //数组逐元素复制
newarr[i] = arr[i];
}
delete[] arr; //先释放arr所指向的旧的动态内存空间
arr = newarr; //让arr指向新的动态内存空间
capacity = c; //更新数组容量
}
template<typename T>
T & CArray<T>::operator [](int index) {
assert(index >= 0 && index < size);
return arr[index]; //由于返回的是引用,于是当返回值作为左值被修改时则切切实实修改的是arr[index]
}
template<typename T>
const T & CArray<T>::operator [](int index) const { //即使是实现中const也不能省略
assert(index >= 0 && index < size);
return arr[index]; //作为常引用返回,确保不能成为左值
}
template<typename T>
CArray<T> &CArray<T>::operator =(const CArray<T> &ca) {
if (&ca != this) {
if (ca.capacity != capacity) {
delete[] arr;
capacity = ca.capacity;
arr = new T[ca.capacity];
}
for (int i = 0; i < ca.size; i++) //元素复制
arr[i] = ca.arr[i];
size = ca.size; //更新大小
}
return *this; //仍然要返回引用,避免返回副本,这样才符合赋值运算的规则
}
template<typename T>
CArray<T>::operator T*() {
return arr;
}
template<typename T>
CArray<T>::operator const T*() const {
return arr;
}
template<typename T>
bool CArray<T>::push_back(const T& val) {
if (size == capacity)
return false;
arr[size] = val;
size++;
return true;
}
template<typename T>
bool CArray<T>::pop_back() {
if (size == 0)
return false;
size--;
return true;
}
void print_arr(int *a, int size) {
for (int i = 0; i < size; i++)
cout << a[i] << " ";
cout << endl;
}
int main() {
using IntArray = CArray<int>; //起别名
cout << "----------------------------" << endl;
const int capacity = 10;
IntArray arr1(capacity);
cout << "arr1的容量为" << arr1.getcapacity() << endl;
cout << "arr1的大小为" << arr1.getsize() << endl;
/*插入数据*/
for (int i = 0; i < capacity; i++)
arr1.push_back(i);
print_arr(arr1, 10);
cout << "arr1的容量为" << arr1.getcapacity() << endl;
cout << "arr1的大小为" << arr1.getsize() << endl;
cout << "----------------------------" << endl;
IntArray arr2(arr1); //调用复制构造函数
print_arr(arr2, 10);
/*删除数据*/
arr2.pop_back();
cout << "arr2的容量为" << arr2.getcapacity() << endl;
cout << "arr2的大小为" << arr2.getsize() << endl;
cout << "----------------------------" << endl;
IntArray arr3;
arr3 = arr1;
arr3.recapacity(5); //容量更改
print_arr(arr3, 5);
cout << "arr3的容量为" << arr3.getcapacity() << endl;
cout << "arr3的大小为" << arr3.getsize() << endl;
arr3.recapacity(8);
cout << "arr3的容量为" << arr3.getcapacity() << endl;
cout << "arr3的大小为" << arr3.getsize() << endl;
return 0;
}
(2)链表类模板
(三)可变参数模板
在C++11之前,类模板和函数模板只能含有固定数量的模板参数。C++11增强了模板功能,允许模板定义中包含0到任意个模板参数,这就是可变参数模板。
十二、泛型程序设计 & STL基础
泛型程序设计:编写不依赖于具体数据类型的程序将算法从特定的数据结构中抽象出来,成为通用的C++的模板
概念:用于界定具备一定功能的数据类型。通常用概念作为模板的类型参数
例如:
- 将“可以比大小的所有数据类型(有比较运算符)”这一概念记为
Comparable。- 将“具有公有的复制构造函数并可以用
=赋值的数据类型”这一概念记为Assignable。- 将“可以比大小、具有公有的复制构造函数并可以用
=赋值的所有数据类型”这个概念记作Sortable。
子概念:对于两个不同的概念A和B,如果概念A所需求的所有功能也是概念B所需求的功能,那么就说概念B是概念A的子概念。
例如:
Sortable既是Comparable的子概念,也是Assignable的子概念。
模型(model): 符合一个概念的数据类型称为该概念的模型。
例如:
int型是Comparable概念的模型。静态数组类型不是Assignable概念的模型(无法用“=" 给整个静态数组赋值)。
标准模板库(Standard Template Library,简称STL)定义了一套概念体系,STL中的各个类模板、函数模板的参数都是用这个体系中的概念来规定的
使用STL的模板时,类型参数既可以是C+ +标准库中已有的类型,也可以是自定义的类型——只要这些类型是所要求概念的模型。
STL包含容器、迭代器、函数对象、算法这四个基本组件

(一)容器(container)
容器:容纳、包含一组元素的对象。使用容器需要包含相应的头文件。
容器可以按如下方式分类:
-
基于容器中元素的组织方式:顺序容器、关联容器(有序+无序)、容器适配器;
-
顺序容器/序列式容器:表示线性数据结构,每个元素先后顺序与物理上存储顺序一致
如
array(数组)、vector(向量)、deque(双端队列)、forward_list(单链表)、list(列表); -
关联容器:二叉树结构,没有严格物理上顺序关系
-
(有序)关联容器:
如
set(集合)、multiset(多重集合)、map(映射)、multimap(多重映射) -
无序关联容器:
如
unordered_set(无序集合)、unordered_multiset(无序多重集合)、unordered_map(无序映射)、unorder_multimap(无序多重映射)
-
-
容器适配器:
如
stack(栈)、queue(队列)、priority_queue(优先队列)
-
-
按照与容器所关联的迭代器类型划分:可逆容器(包括随机访问容器……)、……;
1. 容器的通用功能
通用功能如下
- 用默认构造函数构造空容器
- 支持关系运算符:
==、!=、<、<=、>、>= begin()、end():获得容器首、尾迭代器cbegin()、cend():获取容器首、尾常迭代器,不需要改变容器时更加安全clear():将容器清空empty():判断容器是否为空size():得到容器元素个数s1.swap(s2):将s1和s2两容器内容交换
当创建某特定容器的迭代器时,需要用到相关迭代器数据类型(S表示容器类型):
S::iterator:指向容器元素的迭代器类型S::const_iterator:常迭代器类型
访问可逆容器
STL为每个可逆容器都提供了逆向迭代器,逆向迭代器可以通过下面的成员函数得到:
rbegin():指向容器尾的逆向迭代器rend():指向容器首的逆向迭代器
逆向迭代器的类型名的表示方式如下(S表示容器类型):
S::reverse_iterator:逆向迭代器类型S::const_reverse_iterator:逆向常迭代器类型
2. 顺序容器
顺序容器包括有array(数组——大小固定不可变)、vector(向量——大小可变)、deque(双端队列)、forward_list(单链表——增删操作特殊)、list(列表);
有如下特点:
- 元素线性排列,可以随时在指定位置插入元素和删除元素。
- 符合
Assignable这一概念(即具有公有的复制构造函数并可以用=赋值) array对象的大小固定,forward_list有特殊的添加和删除操作。
除了容器公有的通用功能外,顺序容器有自己独有的功能,以下功能不包含数组和单向链表
-
默认构造函数:初始化
S s(n, t);构造一个由n个t元素构成的容器实例s;S s(n);构造一个有n个元素的容器实例s, 每个元素都是T();S s(q1, q2);使用将 \([q1, q2)\) 区间内的数据作为s的元素构造,其中q1和q2都是迭代器;
-
赋值函数assign:将指定的元素赋给顺序容器,顺序容器中原先的元素会被清除
s.assign(n, t)赋值后的容器由n个元素构成;s.assign(n)赋值后的容器是有n个元素的容器实例s,每个元素都是T();s.assign(q1, q2)赋值后的容器中的元素为 \([q1, q2)\) 区间内的数据;
赋值函数的三种形式与构造函数一一对应。
-
插入函数:可以一次插入一个或多个指定元素,也可以将一个迭代器区间中的序列插入,通过一个指向当前容器元素的迭代器来指示插入位置,返回值为指向新插入的元素中第一个元素的迭代器。
s.insert(p1, t)在s容器中p1所指向的位置插入一个t的复制(插入后的元素夹在原p1和p1 - 1所指向的元素之间)。s.insert(p1, n, t)在s容器中p1所指向的位置插入n个t的复制(插入后的元素夹在原p1和p1 - 1所指向的元素之间)。s.insert(p1, q1, q2)将[q1, q2)区间内的元素顺序复制插入到s容器中p1位置(新元素夹在原p1和p1 - 1所指向的元素之间)。s.emplace(p1, args)将参数args传递给T的构造函数构造新元素t,在s容器中p1所指向的位置插入t(插入后的元素夹在原p1和p1 - 1所指向的元素之间)。
-
其它函数:
- 删除函数:
erase、clear、pop_front(只对list和deque)、pop_back - 首尾元素的直接访问:
front,back - 改变大小:
resize
- 删除函数:
(二)迭代器(iterator)
迭代器:迭代器是泛化的指针(指针也具有同样的特性,因此指针本身就是一种迭代器),提供了顺序访问容器中每个元素的方法
- 迭代器使得容器与算法能无缝衔接。
- 使用独立于STL容器的迭代器,需要包含头文件
<iterator>。
0. 基本操作方法
- 可以使用
++运算符来获得指向下一个元素的迭代器; - 可以使用
*运算符访问一个迭代器所指向的元素,如果元素类型是类或结构体,还可以使用->运算符直接访问该元素的成员; - 有些迭代器还支持通过
--运算符获得指向上一个元素的迭代器;
相关函数模板(需要包含头文件 algorithm):
advance(p, n):对p执行n次自增操作distance(first, last):计算两个迭代器first和last的距离,即对first执行多少次++操作后人
能够使得first == last
1. 迭代器的分类
(1)按功能分类
常用的迭代器按功能强弱分为输入、输出、正向、双向、随机访问五种,这里只介绍常用的三种。
-
正/反向迭代器:假设 p 是一个正/反向迭代器,则 p 支持以下操作:++p,p++,*p。此外,两个正向迭代器可以互相赋值,还可以用
==和!=运算符进行比较。正向迭代器与反向迭代器的自增操作移动方向相反
-
双向迭代器:双向迭代器具有正向迭代器(或者反向迭代器)的全部功能。除此之外,若 p 是一个双向迭代器,则除了
p++、++p之外--p和p--都是有定义的。--p使得 p 朝着与++p相反的方向移动。 -
随机访问迭代器:随机访问迭代器具有双向迭代器的全部功能。若 p 是一个随机访问迭代器,i 是一个整型变量或常量,则 p 还支持以下操作:
-
p+=i:使得 p 往后移动 i 个元素。 -
p-=i:使得 p 往前移动 i 个元素。 -
p+i:返回 p 后面第 i 个元素的迭代器。 -
p-i:返回 p 前面第 i 个元素的迭代器。 -
p[i]:返回 p 后面第 i 个元素的引用。
-
不同容器的迭代器的功能如下
| 容器 | 迭代器功能 |
|---|---|
| vector | 随机访问 |
| deque | 随机访问 |
| list | 双向 |
| set / multiset | 双向 |
| map / multimap | 双向 |
| stack | 不支持迭代器 |
| queue | 不支持迭代器 |
| priority_queue | 不支持迭代器 |
(2)按定义分类
迭代器按照定义方式分成以下四种。
-
正向迭代器:
容器类名::iterator 迭代器名; -
常量正向迭代器:
容器类名::const_iterator 迭代器名; -
反向迭代器:
容器类名::reverse_iterator 迭代器名; -
常量反向迭代器:
容器类名::const_reverse_iterator 迭代器名;
注意
- 对于只读的容器必须设置常量迭代器(只读迭代器)来对其进行访问,否则会报错
- 对常量迭代器指向的元素进行修改会报错


2. 输入/输出流迭代器
- 输入流迭代器
istream iterator<T>:以输入流(如cin)为参数构造, 可用*(p++)获得下一个输入的元素; - 输出流迭代器
ostream iterator<T>:构造时需要提供输出流(如cout), 可用(*p++) = x将x输出到输出流。
二者都属于适配器,适配器是用来为已有对象提供新的接口的对象,输入流适配器和输出流适配器为流对象(如cin和cout)提供了迭代器的接口。
3. 迭代器函数
.begin()函数返回的是指向数组/容器第一个元素的指针,操作对象既可以是容器,也可以是普通数组;.end()函数返回指向数组/容器中最后一个元素之后一个位置的指针(注意不是最后一个元素),操作对象既可以是容器,也可以是普通数组;
(三)函数对象(function object)
函数对象:行为类似函数的对象,对它可以像调用函数一样调用。
-
函数对象是泛化的函数:任何普通的函数和任何重载了
()运算符的类的对象都可以作为函数对象使用。 -
使用STL的函数对象需要包含头文件
<functional>。STL提供了多个函数对象
-
用于算术运算的函数对象
-
一元函数对象(一个参数):
negate -
二元函数对象(两个参数):
plus、minus、multiplies、divides、modulus
-
-
用于关系运算、逻辑运算的函数对象(要求返回值为bool)
-
一元谓词(一个参数):
logical_not -
二元谓词(两个参数):
equal_to、not_equal_to、greater、less、greater_equal、less_equal、logical_and、logical_or
-
-
1. lambda表达式
有时没有必要为一个仅仅在局部范围使用的功能,定义一个全局函数,或者定义一个类来封装函数对象,lambda支持用简单的方式描述:给什么参数、完成什么任务,类似于函数。除了传递给函数的参数之外,还可以让函数体使用定义lambda表达式时所属作用域范围的其他变量(通过"捕获”语法)
lambda表达式相当于定义了一个匿名的内联函数,使用方法与函数调用的语法相同。
[捕获列表] (参数列表) ->返回类型{函数体}
-
捕获列表可捕获lambda所在函数的局部变量,在“函数体”中使用,有值捕获、引用捕获和隐式捕获3种捕获方式
注意使用的是定义lambda时,捕获列表中变量的当前值。
[]表示不捕获任何变量。[&]表示捕获外部作用域中所有变量,并作为引用在函数体中使用(按引用捕获)。[=]表示捕获外部作用域中所有变量,并作为副本在函数体中使用(按值捕获)。[=, &a]表示按值捕获外部作用域中所有变量,并按引用捕获a变量。[a]表示按值捕获a变量,同时不捕获其他变量。[this]捕获当前类中的 this 指针,让 lambda 表达式拥有和当前类成员函数同样的访问权限。如果已经使用了 & 或者 =,就默认添加此选项。捕获 this 的目的是可以在 lamda 中使用当前类的成员函数和成员变量。
int size = 10, base = 0; //局部变量 auto longer = [size](const string &s){return s.size()>size;} //值捕获 auto longer = [&size](const string &s){return s.size()>size;} //引用捕获 auto longer = [=](const string &s){return s.size()>base;} //隐式值捕获 auto longer = [&](const string &s){return s.size()>size;} //隐式引用捕获 -
参数列表、返回类型和函数体与普通函数一致。
- 无参数时可以省略参数列表
- 返回值得类型在可以类型推导时可省略,无法推导出返回值类型时需要显式给出返回值类型
-
可定义在函数内部,理解为未命名的内联函数。
2. 函数对象参数绑定
有时函数对象不能直接使用,或者通过这个函数对象的返回值需要进行进一步计算……函数对象参数绑定便支持将一种函数对象转换成我们所需要的另一种函数对象。
C++11标准通过bind参数绑定模板类实现函数对象参数绑定
template<class F,class...Args>
bind(F &&f, Args&&...args); //函数原型
auto newFunc=bind(Func, arg_list); //使用,绑定Func与arg_list获得新函数newFunc
-
newFunc是新的可以调用的函数对象 -
arg_list是一个逗号可以分隔的参数列表,对应了提供给Func的参数,当调用newFunc时,newFunc会调用Func,并传递给它arg_list中的参数通过
_n占位符明确newFun调用时的参数与arg_list中参数的映射关系,其中n是一个整数,表示newFunc中的第n个参数,_n放在不同的位置代表了不同的参数映射
(四)算法(algorithms)
STL算法本身是一种函数模版,通过迭代器获得输入数据,通过函数对象对数据进行处理,通过迭代器将结果输出
- STL内置的算法是通用的,独立于具体的数据类型、容器类型,可以广泛用于不同的对象和内置的数据类型。
- 使用STL的算法,需要包含头文件
<algorithm>。
STL算法包括不可变序列算法(不直接修改所操作的容器内容)、可变序列算法(会修改所操作的容器内容)、排序和搜索算法、数值算法。
1. transform算法
实现功能:顺序遍历first和last两个迭代器所指向的元素,将每个元素的值作为函数对象op的参数,op的返回值通过迭代器result顺序输出,每次操作完一个元素result迭代器指向的是下一个位置,遍历完后transform将该迭代器返回。
/*实现*/
template <class InputIterator, class OutputIterator, class UnaryFunction>
OutputIterator transform(InputIterator first, InputIterator last, OutputIterator result, UnaryFunction op) {
for (;first != last; ++first, ++result)
*result = op(*first);
return result;
}
举个例子:
/*连续输入4个整数后输出他们的相反数*/
#include<iostream>
#include<vector>
#include<iterator>
#include<algorithm>
#include<functional>
using namespace std;
int main() {
const int N = 4;
vector<int> s(N);
for (int i = 0; i < N; i++)
cin >> s[i];
transform(s.begin(), s.end(),
ostream_iterator<int>(cout, " "),
negate<int>() //计算相反数
);
return 0;
}
十三、流类库 & 输入输出
(〇)流类库头文件
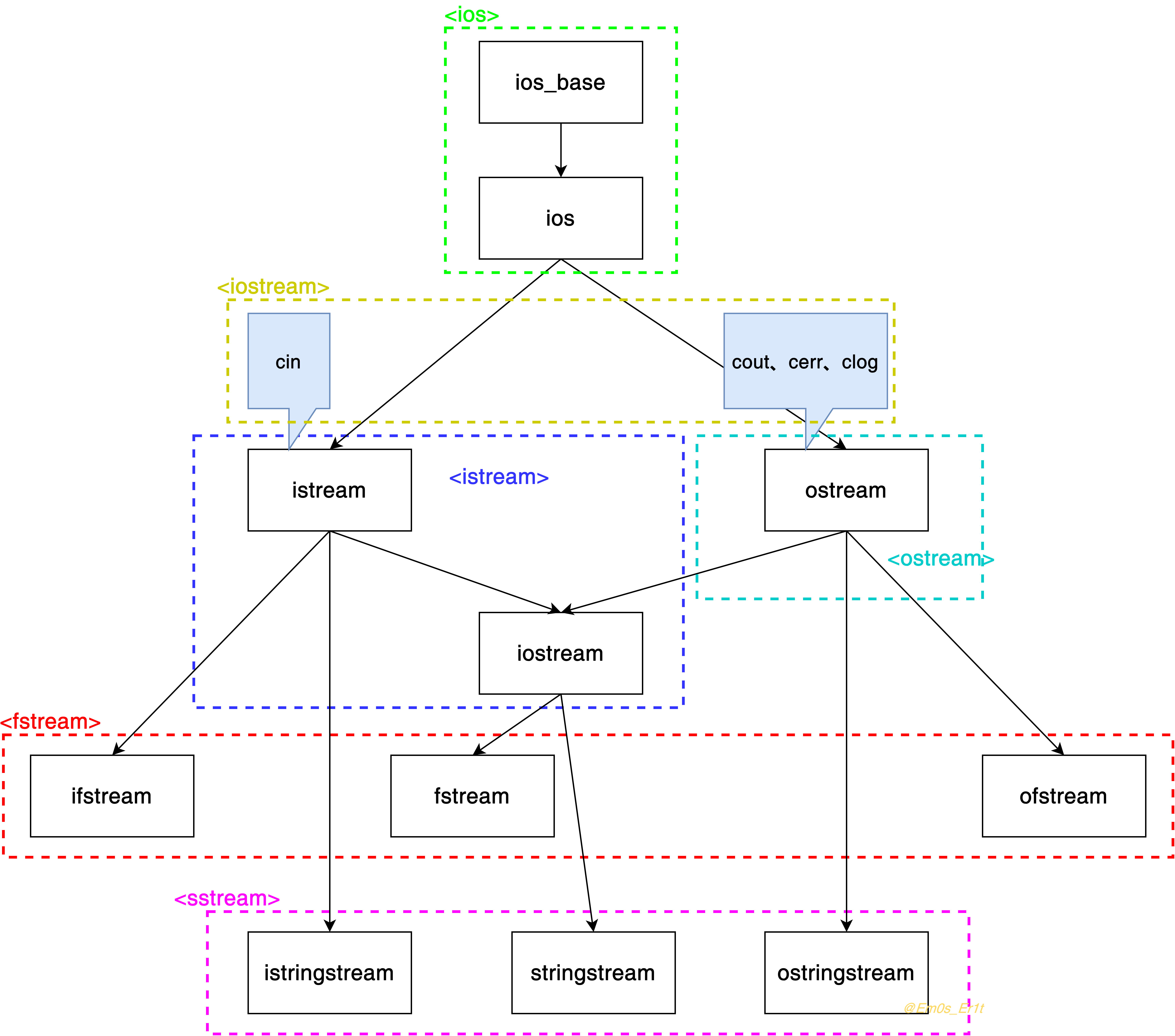
<iostream>头文件定义了cin、cout、 cerr 和clog对象,分别对应于标准输入流、标准输出流、非缓冲标准错误流和缓冲标准错误流,该头文件提供了格式化和无格式的I/O服务。
<fstream>头文件声明了对用户控制文件处理操作的服务。
<iomanip>头文件声明了对于执行格式化IO的服务 (即所谓的参数化流操作元,如setw和setprecision)。
(一)输出流
输出即从内存“写”到外部设备。
输出流类主要包括ostream、ofstream、ostringstream。
1. 文件输出流ofstream
文件输出流内置很多成员函数
(1)open & close
如果在构造函数中指定一个文件名以及打开模式,当构造这个对象时该文件是自动打开的(适用于打开一个文件),可以指定打开模式
ofstream myFile("filename");
ofstream myFile("filename", ios_base::out|ios_base::binary);
可以在调用默认构造函数之后使用open成员函数打开文件(适用于打开多个文件),也可以指定打开模式
ofstream myFile; //声明一个静态文件输出流对象,不关联到具体文件
myFile.open("filename_1"); //打开文件, 使流对象与文件建立联系
myFile.open("filename_2", ios_base::out|ios_base::binary); //以二进制的方式打开文件, 使流对象与文件建立联系
...
myFile.close() //关闭文件
(2)put & write——字符/内容输出
put函数支持把一个字符写到输出流
put函数不会受格式化参数的影响。
write函数支持把内存中的一块内容写到一个文件输出流
(3)seekp & tellp——控制文件写指针
2. 标准输出流ostream
ostream 类的无参构造函数和复制构造函数都是私有的,因此在程序中一般无法定义 ostream 类的对象
iostream 头文件中内置定义了3个标准输出流对象供我们使用,即cout、cerr、clog
-
cout 对应于标准输出流,用于向屏幕输出数据,也可以被重定向为向文件写入数据。
-
cerr 对应于标准错误输出流,用于向屏幕输出出错信息,不能被重定向。
cout 和 clog 都设有缓冲区,即它们在输出数据时,会先将要数据放到缓冲区,等缓冲区满或者手动换行(使用换行符 '\n' 或者 endl)时,才会将数据全部显示到屏幕上;而 cerr 则不设缓冲区,它会直接将数据输出到屏幕上。
-
clog 对应于标准错误输出流,用于向屏幕输出出错信息,不能被重定向。
3. 字符串输出流ostringstream
例
/*功能:数值输入,字符串输出*/
其它
(1)格式化输出
① 指定宽度输出
有2种方式可以用于指定输出域的宽度,这两种方式仅仅影响紧跟其后的域,该域输出完成后会恢复成默认值,默认采用右对齐方式输出
width成员函数setw操纵符(需要包含iomanip头文件)
#include<iostream>
#include<string>
#include<iomanip>
using namespace std;
struct Record {
double height;
string name;
double grade;
};
void main() {
Record r[] = { //定义一个结构体数组
1.74,"Alice",90,
1.83,"Bob",60,
1.68,"Ray",70,
};
/*记录1*/
cout << setw(10) << r[0].name << r[0].height << endl; //r[0].name是按照宽度为10输出,但r[0].height是没有格式化的输出
/*记录2*/
cout.width(10);
cout << r[1].name << r[1].height << endl; //r[1].name是按照宽度为10输出,但r[1].height是没有格式化的输出
/*记录3*/
cout << setw(10) << r[2].name << setw(10) << r[2].height << endl;
}
/*输出:
Alice1.74
Bob1.83
Ray 1.68
*/
② dec/hex/oct
控制符dec、hex和oct分别用于指示以十进制、十六进制和八进制格式显示整数。
#include<iostream>
using namespace std;
int main() {
int num{ 66 };
cout << "(十进制)" << num << " = ";
cout << hex;
cout << "(16进制)" << num << " = ";
cout << oct;
cout << "(8进制)" << num;
return 0;
}
/*输出:
(十进制)66 = (16进制)42 = (8进制)102
*/
③ setiosflags & resetiosflags
根据参数设置/消除输出格式。
- 定义:setiosflags定义在头文件iomanip中
- 影响:setiosflags的影响是持久的,直到用resetiosflags重新恢复默认值时为止。
- 参数:setiosflags的参数是该流的格式标志值,可用按位或运算符
|进行组合,可用参数如下-
ios_base::skipws在输入中跳过空白。 -
ios_base::left左对齐值,用填充字符填充右边。 -
ios_base::right右对齐值,用填充字符填充左边(默认对齐方式)。 -
ios_base::internal在规定的宽度内,指定前缀符号之后,数值之前,插入指定的填充字符。 -
ios_base::dec以十进制形式格式化数值(默认进制)。 -
ios_base::oct以八进制形式格式化数值。 -
ios_base::hex以十六进制形式格式化数值。 -
ios_base::showbase插入前缀符号以表明整数的数制。 -
ios_base::showpoint对浮点数值显示小数点和尾部的0。 -
ios_base:uppercase对于十六进制数值显示大写字母A到F,对于科学格式显示大写字 -
ios_base:showpos对于非负数显示正号( "+")。 -
ios_base::scientific以科学格式显示浮点数值。 -
ios_base::fixed以定点格式显示浮点数值(没有指数部分) -
ios_base::unitbuf在每次插入之后转储并清除缓冲区内容。
-
④ setprecision
定义:setprecision定义在头文件iomanip中
如果设置了ios_base::fixed或ios_base::scientific,则精度值表示小数点之后的位数,否则精度值表示有效数字位数
#include<fstream>
#include<iostream>
#include<iomanip>
#include<string>
using namespace std;
typedef struct Record {
double height;
string name;
double grade;
}Record;
int main() {
fstream txtout("test.txt"); //文本方式打开test.txt
Record ar[] = { //定义一个结构体数组
{1.74,"Alice",90},
{1.83,"Bob",60},
{1.68,"Ray",70},
{1.91,"David",80}
};
if (txtout) {
for (int i = 0; i < 4; i++) {
/*级联输出*/
txtout << setiosflags(ios_base::left) << setw(10) << ar[i].name //左对齐输出name
<< resetiosflags(ios_base::left) << setw(6) << ar[i].grade; //去掉左对齐后输出grade
txtout.width(8); //设置height的输出宽度
txtout << setprecision(2) << ar[i].height << endl; //保留小数点后面一位小数输出height
}
}
else
cout << "ERROR: Can't find the file." << endl;
txtout.close();
return 0;
}
/*输出:
Alice 90 1.7
Bob 60 1.8
Ray 70 1.7
David 80 1.9
*/
(2)put
输出流对象.put(ch)
-
参数:参数
ch可以是字符也可以是对应的ASCII值 -
功能:输出单个字符
ch; -
返回值:返回一个输出流类的引用对象
#include<iostream>
using namespace std;
int main() {
char ch = 's';
cout.put(69).put('m').put('0').put(ch);
return 0;
}
/*输出:
Em0s
*/
(二)输入流
输入即从外部设备“读”到内存。
输入流主要包括istream、ifstream、istringstream。
1. 文件输入流ifstream
文件输入流内置很多成员函数
(1)文件打开与关闭
如果在构造函数中指定一个文件名以及打开模式,当构造这个对象时该文件是自动打开的(适用于打开一个文件)
ifstream myFile("filename");
ifstream myFile("filename", ios_base::in|ios_base::binary);
可以在创建了一个空文件流对象之后使用open成员函数打开文件(适用于打开多个文件),也可以指定打开模式
ifstream myFile; //声明一个静态文件输出流对象,不关联到具体文件
myFile.open("filename_1"); //打开文件, 使流对象与文件建立联系
myFile.open("filename_2", ios_base::in|ios_base::binary); //以二进制的方式打开文件, 使流对象与文件建立联系
...
is_open函数可以判断是否成功打开该文件
在已经给一个文件流对象关联至一个文件的情况下如果想将其关联到另一个文件首先需要关闭已经关联的文件
myFile.close() //关闭文件
(2)>>
/*从test.txt文件中读取数据保存至数组中,读取完毕后输出数组元素*/
#include<iostream>
#include<fstream>
using namespace std;
int main() {
const int N = 10;
int arr[N] = {}, i = 0;
ifstream fin("test.txt");
/*读取*/
while (fin >> arr[i]) {
if (i >= N)
break;
i++;
}
/*输出*/
for (int i = 0; i < N; i++) {
cout << arr[i] << " ";
}
}
(3)read
read成员函数从一个文件读字节到一个指定的内存区域,由长度参数确定要读的字节数。当遇到文件结束或者在文本模式文件中遇到文件结束标记字符时结束读取。
(4)seekg & tellg
seekg函数用来设置文件输入流中读取数据位置的指针。
tellg函数返回当前文件读指针的位置。
2. 标准输入流istream
cin是C++编程语言中的标准输入流对象,即istream类的对象。cin主要用于从标准输入读取数据。
(1)>>
cin中重载了插入运算符以支持数据读取
功能:根据后面变量的类型读取数据。
原理:一开始,缓冲区为空,cin的成员函数会阻塞等待数据的到来,用户从键盘输入字符串,输入完毕后敲一下回车键代表本次输入结束,其实一次键盘输入并不是直接赋给变量,而是存放到输入缓冲区(按下回车之后字符串被送入到缓冲区中),之后cin的成员函数开始从输入缓冲区读取值,若缓冲区中第一个字符就是空格、tab或换行这些分隔符时,cin>>会将其视作无效字符忽略并清除,继续读取下一个字符,连续读取有效字符直至遇到空格、tab、换行这些分隔符后将已经读取的值赋给变量并在缓冲区中将其清空,但字符后面的分隔符是残留在缓冲区的,不做处理。
输入完毕后敲击的回车键
\r也会被转换为一个换行符\n存储在输入缓冲区中,比如我们在键盘上敲下了123456这个字符串,然后敲一下回车键\r将这个字符串送入了缓冲区中,那么此时缓冲区中的字节个数是7 ,而不是6。
应用:
-
接受一个字符串,字符串中不含“空格、“Tab”、“回车”
#include<iostream> using namespace std; void main() { char s[20]; cin >> s; // 输入: hello world cout << "s=" << s << endl; cout << "s:" << strlen(s) << endl; } /*输出: s=hello s:5 */ -
输入数字
(2)cin.ignore
-
原型:
cin.ignore(int n=1,char delim=EOF) -
功能:函数表示从输入流中提取字符,提取的字符被忽略不被使用。每抛弃一个字符,它都要计数并将其与
delim比较,如果计数值达到n(已经抛弃了n个字符)或者被抛弃的字符是delim,则cin.ignore()函数执行终止;否则,它继续等待。2个参数都有默认值,因此
cin.ignore()就等效于cin.ignore(1, EOF), 即跳过一个字符。 -
应用:该函数常用于跳过输入中的无用部分,以便提取有用的部分。
-
案例:
#include<iostream> using namespace std; int main() { int n; cin.ignore(5, 'A'); cin >> n; cout << n; return 0; }-
当输入
abcde34↙时会输出34,这是因为cin.ignore() 跳过了输入中的前 5 个字符,其余内容被当作整数输入 n 中。 -
当输入
abA34↙时会输出34,这是因为cin.ignore() 跳过了输入中的 'A' 及其前面的字符,其余内容被当作整数输入 n 中。
-
(3)cin.get
cin.get(字符变量名); //也可以写成`字符变量名=cin.get();`
cin.get(字符数组名, 接收字符数n);//有些类似getline。可以接收包含空格的多个字符,接收字符数为n-1,外加一个终止符`\0`
cin.get(); //没有参数主要是用于舍弃输入流中的不需要的字符, 或者舍弃回车, 弥补cin.get(字符数组名,接收字符数目)的不足.
例1
#include<iostream>
using namespace std;
int main()
{
char ch;
int aeiou = 0, //统计输入的字符中元音字母个数
count = 0; //统计输入字符的总个数
while (ch = cin.get()) {
if (ch == '\n') break;
switch (ch) {
case 'a':case 'e':case 'i':case 'o':case 'u':
case 'A':case 'E':case 'I':case 'O':case 'U': aeiou += 1;
default: count += 1;
}
}
cout << "the sentence you input has " << count << " characters, with " << aeiou << " vowels in it." << endl;
return 0;
}
/*
输入:
Em0s_Er1t
输出:
the sentence you input has 9 characters, with 2 vowels in it.
*/
例2
#include <iostream>
using namespace std;
int main(){
char s1[20],s2[10];
cin.get(s1, 20);
cin.get(); //上面的cin语句执行时,用户键入回车后,`\r`残存在输入缓冲区,使得下面的cin读取此`\r`,所以需要cin.get()将这个回车符吃掉
cout << s1 << endl;
cin.get(s2, 10);
cout << s2 << endl;
}
/*
输入:12345678901234567890
输出:1234567890123456789
输出: //用户若输入的字符超过了19个,那么cin.get()吃掉的就是第20个字符,此处吃掉的是'0',而不是'\r',于是cin.get(s2,10)从缓冲区中读取的第一个字符是'\r',将其忽略。
*/
/*
输入:Em0s_Er1t
输出:Em0s_Er1t
输入:Em0s
输出:Em0s
*/
/*
输入:123456789012345678901234567890
输出:1234567890123456789 //用户输入的字符超过了19个,那么剩下的留在缓冲区里面,其中第20个字符紧接着被cin.get()吃掉,第21个及以后的字符随之被cin.get(s2,10)读取
输出:123456789
*/
(4)cin.getline
用
cin >> str这种写法在碰到行中的空格或制表符时就会停止,因此就不能保证 str 中读入的是整行
按行读取字符
//返回值就是函数所作用的对象的引用
istream & getline(char* buf, int bufSize); //从输入流中读取 bufSize-1 个字符到缓冲区 buf,或遇到\n为止(哪个条件先满足就按哪个执行)。函数会自动在 buf 中读入数据的结尾添加\0。
istream & getline(char* buf, int bufSize, char delim);//从输入流中读取 bufSize-1 个字符到缓冲区 buf,或遇到delim为止(哪个条件先满足就按哪个执行)。函数会自动在 buf 中读入数据的结尾添加\0。
3. 字符串输入流istringstream
istringstream用于从字符串读取数据
应用:将字符串转换为数值
#include<iostream>
#include<string>
#include<sstream>
using namespace std;
/*字符串转数值*/
template<class T>
T str2num(const string &s) {
istringstream is(s); //用s创建一个字符串输入流
T tmp;
is >> tmp; //从字符串输入流中读取数值
return tmp;
}
int main() {
string s;
cout << "Type an int:" << endl;
cin >> s;
cout << str2num<int>(s) << endl;
return 0;
}
其它
(1)get
get适用于各种输入流,不只局限于文件流、标准输入流等,其功能与提取运算符(>>)很相像,主要的不同点是get函数在读入数据时包括空白字符。
/*功能:控制台输入的转存到文件中*/
#include<iostream>
#include<fstream>
using namespace std;
int main() {
char ch;
ofstream txtout("test.txt");
while ((ch = cin.get()) != EOF)
txtout.put(ch);
return 0;
}
(2)getline
-
函数原型:getline函数有多种重载形式
//使用:输入流.getline(...) istream& getline (char* s, streamsize n); istream& getline (char* s, streamsize n, char delim); //is:表示一个输入流,例如 cin。 //str:string类型的引用,用来存储输入流中的流信息。 //delim:char类型的变量,所设置的截断字符;在不自定义设置的情况下,遇到’\n’,则终止输入 //使用:getline(输入流,...) istream& getline (istream& is, string& str, char delim); istream& getline (istream&& is, string& str, char delim); istream& getline (istream& is, string& str); istream& getline (istream&& is, string& str); -
功能:从输入流中读取
n个字符存入s/str,并且允许指定输入终止字符delim,读取完成后,从读取的内容中删除终止字符。
#include<string>
#include<iostream>
using namespace std;
int main() {
string name;
cout << "Type your name terminated by '\\t':" << endl;
getline(cin, name, '\t'); //输入完毕后点击Tab后回车即表示输入结束
cout << name << endl;
return 0;
}
(3)EOF终止符输入
-
文件流:到达文件末尾就读取结束了,无需额外加EOF终止符
-
标准流:
- Windows下控制台在我们输入完成之后,要确保光标位置在全新一行的开头,此时再点击 Crtl + z ,然后点击 Enter;
- Linux下控制台点击 Ctrl + d 代表输入结束;
(三)输入输出流
fstream类和stringstream类都继承了iostream,既可以是数据的源也可以是数据的目的。
1. fstream
fstream类支持磁盘文件的输入/输出
2. stringstream
stringstream类支持面向字符串的输入/输出
(四)条件状态
输入输出操作容易发生一些错误,IO类定义了一些函数以及标志以帮助我们访问和操纵流对象的状态。
/*在这里strm表示一种IO类型,比如istream*/
strm::badbit //用来指出流已经奔溃(100)
strm::failbit //用来指出一个IO操作失败(010)
strm::eofbit //指出流到达了文件结束(001)
strm::goodbit //指出流未发生错误(000)
每个状态都有对应的函数来获取
/*s表示一个流类对象,例如cin等*/
s.eof() //如果s的eofbit置位,则返回ture
s.bad() //若s的badbit置位,则返回ture
s.fail() //若s的failbit或badbit置位,则返回ture
s.good() //若s处于有效状态,则返回ture
s.rdstate() //返回流s的当前条件状态,返回类型为strm::iostate
还有一些函数用于操作这些状态
s.setstate(flags)//根据给定的flags标志位,将流s中对应的标志位置位,flags为strm::iostate类型。返回void
s.clear() //将流s中所有状态位复位,将流的状态设置为有效。返回void
s.clear(flags) //根据给定的flags标志位,将流s中对应条件状态位复位。flags类型为strm::iostate。返回void
(五)其它
1. 文件打开模式
| 模式标记 | 适用对象 | 作用 |
|---|---|---|
| ios::in | ifstream fstream | 打开文件用于读取数据。如果文件不存在,则打开出错。 |
| ios::out | ofstream fstream | 打开文件用于写入数据。如果文件不存在,则新建该文件;如果文件原来就存在,则打开时清除原来的内容。 |
| ios::app | ofstream fstream | 打开文件,用于在其尾部添加数据。如果文件不存在,则新建该文件。 |
| ios::ate | ifstream | 打开一个已有的文件,并将文件读指针指向文件末尾。如果文件不存在,则打开出错。 |
| ios:: trunc | ofstream | 打开文件时会清空内部存储的所有数据,单独使用时与 ios::out 相同。 |
| ios::binary | ifstream ofstream fstream | 以二进制方式打开文件。若不指定此模式,则以文本模式打开。 |
| ios::in | ios::out | fstream | 打开已存在的文件,既可读取其内容,也可向其写入数据。文件刚打开时,原有内容保持不变。如果文件不存在,则打开出错。 |
| ios::in | ios::out | ofstream | 打开已存在的文件,可以向其写入数据。文件刚打开时,原有内容保持不变。如果文件不存在,则打开出错。 |
| ios::in | ios::out | ios::trunc | fstream | 打开文件,既可读取其内容,也可向其写入数据。如果文件本来就存在,则打开时清除原来的内容;如果文件不存在,则新建该文件。 |
ios_base::ate 和 ios_base::app都会将文件指针指向文件尾,但二者的区别是ios_base::app只允许将数据添加到文件尾,而ios_base::ate仅仅将指针放到文件尾,后续操作取决于其他模式或者默认模式。
了解一下C语言文件打开模式与C++文件打开模式的对应关系
| c++模式 | c模式 | 含义 |
|---|---|---|
ios_base::in |
“r” | 以读模式打开文件。如果文件不存在,则打开出错。 |
ios_base::out |
“w” | 以写模式打开文件 ① 如果文件已存在,则清空文件,同 `ios_base::out |
| `ios_base::out | ios_base::app` | “a” |
| `ios_base::in | ios_base::out` | “r+” |
| `ios_base::in | ios_base::out | ios_base::trune` |
| `<其它模式> | ios_base::binary` | “b”+“其它模式” |
| `<其它模式> | ios_base::ate` | <其它模式所对应的C模式> |
2. 判断打开正常
ifstream fin;
fin.open("demo.txt");
/*方法1*/
if (fin.fail()) {} // open failed
/*方法2*/
if (!fin) {} // open failed
/*方法3*/
if (!fin.good()) {} // open failed
/*方法4(推荐)*/
if (!fin.is_open()) {} // open failed
十四、异常处理
C++中异常处理通过3步来实现——检查异常(使用try语句)、抛出异常(使用throw语句)、捕捉异常(使用catch语句)
(一)语法 & 执行流
try{
// 保护代码
}
catch(异常参数){
// catch 块
}
catch(异常参数){
// catch 块
}
catch(异常参数){
// catch 块
}
异常处理流程:
-
将可能抛出异常的程序段嵌在try块之中,通过正常的顺序执行到达try语句,然后执行try块内的保护段;
-
如果在保护段执行期间没有引起异常,那么跟在try块后的catch子句就不执行,程序从try块后的最后一个catch子句后面的语句继续执行;
-
若有异常则通过throw创建一个异常对象并抛掷,try块中后续的代码不执行;
如果在try块之外抛出异常,则程序直接终止
-
catch子句按其在try块后出现的顺序被检查。匹配的catch子句将捕获并处理异常(后面的catch不再执行)或继续抛掷异常,或部分处理然后继续抛掷;
-
如果匹配的处理器未找到,则库函数terminate将被自动调用,其默认是调用abort终止程序。
注意:
- try块和catch块之间不能有其它任何语句
例:
#include <iostream>
using namespace std;
double division(int a, int b) {
if (b == 0)
throw "Division by zero condition!";
return a / b;
}
int main()
{
int x = 50, y = 0;
double z = 0;
try {
cout << x << "/" << y << "=" << division(x, y) << endl; ///注:前面的"x/y"不会打印输出
}
catch (const char* msg) {
cerr << msg << endl;
}
return 0;
}
/*输出:
Division by zero condition!
*/
(二)异常声明
-
可以在函数的声明中列出这个函数可能抛掷的所有异常类型。如下
void fun() throw(A, B, C, D); //函数原型 -
若无异常接口声明,则此函数可以抛掷任何类型的异常。
-
不抛掷任何类型异常的函数声明如下,此时调用者无需做异常处理,且省去额外开销
/*写法1*/ void fun() throw(); /*写法2*/ void fun() noexcept; /*相关*/ noexcept(fun()) //noexcept运算符可以用于判断函数是否使用了noexcept说明,若是则返回true
慎用异常声明的情况
- 对于带类型参数的函数模板,要尽量避免使用exception specifications,因为不同类型对于相同行为的定义不同,抛出的异常也就不同,因而函数模板很难或不可能确定它具现化的函数实体所可能抛出的异常
- 使用回调(callback)函数时
- 系统可能抛出的异常
(三)异常处理中的构造与析构
找到一个匹配的catch异常处理后
- 初始化异常参数。
- 将从对应的try块开始到异常被抛掷处之间构造(且尚未析构)的所有自动对象进行析构,对于未被完全构造的对象,在抛掷异常时不会执行该对象的析构函数。
- 从最后一个catch处理之后开始恢复执行。
#include <iostream>
using namespace std;
class Sample1 {
public:
Sample1() { cout << "Constructor of Sample called." << endl; }
~Sample1() { cout << "Destructor of Sample called." << endl; }
};
class Sample2 {
public:
Sample2() { cout << "Constructor of Sample called." << endl; throw 1; }
~Sample2() { cout << "Destructor of Sample called." << endl; }
};
/*构造完毕后抛出异常*/
void f1() {
try {
Sample1 s;
throw 1;
}
catch (int) {
cout << "出现异常" << endl;
}
}
/*尚未构造完就抛出异常*/
void f2() {
try {
Sample2 s;
}
catch (int) {
cout << "出现异常" << endl;
}
}
int main()
{
f1();
cout << "-----------------" << endl;
f2();
return 0;
}
/*输出:
Constructor of Sample called.
Destructor of Sample called.
出现异常
-----------------
Constructor of Sample called.
出现异常
*/
(四)标准库中的异常处理
十五、预处理
(一)#include
在一个程序中,允许使用任意数量的#include命令行,它可以放置在任意位置(如程序文件的中间)
#include <filename>
#include "filename"
两种形式的区别是,处理器在哪里查找被包含文件。
#include <filename>用于包含标准函数库的头文件,如果文件名放在尖括号中,预处理程序在预先指定的目录中查找指定的文件,这通常与系统实现的方式有关。#include "filename"通常用于包含程序员定义的头文件。如果文件名包含在引号中,则预处理程序首先在被编译文件所在的目录中查找该文件,查找失败后再在预先指定的目录中查找该文件(与系统实现方式有关)。
1. <typeinfo>
(1)查询数据类型名
参数data可以是数据类型也可以是数据,该函数以C风格的字符串指针形式返回data的类型名。
typeid(data).name();
2. <climits>
头文件climits (在老式实现中为limits.h)定义了表示各种变量限制的符号名称。例如,INT__MAX为int的最大取值,CHAR_BIT为字节的位数。
| 常用类型最大值的符号常量 | 表示 |
|---|---|
| CHAR_MAX | char 的最大值 |
| SHRT_MAX | short 的最大值 |
| INT_MAX | int 的最大值 |
| LONG_MAX | long 的最大值 |
| LLONG_MAX | long long 的最大值 |
| 常用类型最小值的符号常量 | 表示 |
|---|---|
| CHAR_MIN | char 的最小值 |
| SHRT_MIN | short 的最小值 |
| INT_MIN | int 的最小值 |
| LONG_MIN | long 的最小值 |
| LLONG_MIN | long long 的最小值 |
| 带符号与无符号的符号常量 | 表示 |
|---|---|
| SCHAR_MAX | singed char 的最大值 |
| SCHAR_MIN | signed char 的最小值 |
| UCHAR_MAX | unsigned char 的最大值 |
| USHRT_MAX | unsigned short 的最大值 |
| UINT_MAX | unsigned int 的最大值 |
| ULONG_MAX | unsigned 的最大值 |
| ULLONG_MAX | unsigned long 的最大值 |
3. <cmath>
(1)fabs
用于查找给定数字的绝对值,它接受一个数字并返回绝对值。
(二)#define & #undef
#define常用于创建符号常量和宏,符号常量或者宏的作用域从其定义处开始,一直到用指令#undef撤消定义,或者达到文件尾。一旦被撤消定义,就可以用#define重新定义该名称。
下面着重讲#define的功能
1. 创建符号常量
符号常量:用符号表示的常量
#define 预处理指令创建符号常量的一般形式是
#define macro-name replacement-text
当这一行代码出现在一个文件中时,在该文件中后续出现的所有宏都将会在程序编译之前被替换为 replacement-text
2. 参数宏
与符号常量一样,宏标识符在程序编译前就用替换文本替换。宏可以包含参数,也可以不包含参数。无参数的宏的处理方式与符号常量相同。对于有参数的宏,先用替换文本取代参数,然后在程序中展开宏,即用替换文本去替换程序中的宏标识符和参数列表。
注意:
-
编译器不会对宏参数进行数据类型检查,宏仅用于文本替换。
-
有副作用的表达式不能传递给宏
-
对每个宏参数最好用括号括起来以保证正确的替换顺序
#define PI 3.14 #define AREA_1(r) (PI*(r)*(r)) #define AREA_2(r) (PI*r*r) #include<iostream> int main() { std::cout << AREA_1(3) << std::endl; //输出28.26(3.14*3*3) std::cout << AREA_2(1+2) << std::endl; //输出7.14(3.14*1+2*1+2) }
(三)条件编译
有几个指令可以用来有选择地对部分程序源代码进行编译,这个过程被称为条件编译。
每个#if结构都以#endif结束。
指令#ifdef和#ifndef分别是#if defined (名字)与#if !defined(名字)的简写。
多重条件预处理程序结构可用#elif (相当于if结构中的else if)与#else(相当于if结构中的else)指令。
常见的条件编译实例
判断是否已经定义了NULL,如果没有则定义符号常量NULL为0
#ifdef NULL
#define NULL 0
#endif
将代码注释掉
#if 0
不进行编译的代码
#endif
(四)#error
(五)#pragma
#pragma comment:将一个注释记录放置到对象文件或可执行文件中。
#pragma pack:用来改变编译器的字节对齐方式。
#pragma code_seg:它能够设置程序中的函数在obj文件中所在的代码段。如果未指定参数,函数将放置在默认代码段.text中
#pragma once:保证所在文件只会被包含一次,它是基于磁盘文件的,而#ifndef则是基于宏的。
(六)#line
(七)预定义符号常量
| 宏 | 描述 |
|---|---|
__LINE__ |
这会在程序编译时包含当前行号。 |
__FILE__ |
这会在程序编译时包含当前文件名。 |
__DATE__ |
这会包含一个形式为 month/day/year 的字符串,它表示把源文件转换为目标代码的日期。 |
__TIME__ |
这会包含一个形式为 hour:minute:second 的字符串,它表示程序被编译的时间。 |
#include <iostream>
using namespace std;
int main()
{
cout << "Value of __LINE__ : " << __LINE__ << endl;
cout << "Value of __FILE__ : " << __FILE__ << endl;
cout << "Value of __DATE__ : " << __DATE__ << endl;
cout << "Value of __TIME__ : " << __TIME__ << endl;
return 0;
}
/*输出:
Value of __LINE__ : 6
Value of __FILE__ : e:\c_work\c++\c++\test.cpp
Value of __DATE__ : Mar 11 2023
Value of __TIME__ : 01:49:59
*/
(八)# 和 ## 运算符
#是字符串化的意思,出现在宏定义中的#是把跟在后面的参数转换成一个字符串。
当用作字符串化操作时,# 的主要作用是将宏参数不经扩展地转换成字符串常量。
- 宏定义参数的左右两边的空格会被忽略,参数的各个 Token 之间的多个空格会被转换成一个空格。
- 宏定义参数中含有需要特殊含义字符如"或\时,它们前面会自动被加上转义字符 \。
##是连接符号,把参数连在一起,将多个 Token 连接成一个 Token。要点:
- 它不能是宏定义中的第一个或最后一个 Token。
- 前后的空格可有可无。
十六、其它
(一)类型别名
对已有类型起别名可以增强程序的可读性,使程序更加简洁
参考:
1. typedef
typedef可以将一个标识符声明成某个数据类型的别名,然后将这个标识符当数据类型来使用
typedef 已有类型名 新类型名表;
- typedef的官方定义:任何声明变量的语句前面加上typedef之后,原来是变量的都变成一种类型。不管这个声明中的标识符号出现在中间还是最后。
- 新类型表中可以有多个标识符,他们之间以逗号分隔,所以typedef可以为一个已有数据类型声明多个别名
举例如下,下面的变量声明加上typedef之后变量都被定义成了一种类型
typedef int x; // 定义了一个名为x的int类型
typedef struct { char c; } s; // 定义名为s的struct类型
typedef int *p; // 定义了一个名为p的指针类型, 它指向int (中文描述指针好累)
typedef int A[]; // 定义一个名为A的ints数组的类型
typedef int f(); // 定义一个名为f, 参数为空, 返回值为int的函数类型
typedef int g(int); // 定义一个名为g, 含一个int参数, 返回值为int行的函数类型
那么
typedef int P();
typedef int Q();
class X {
static P(Q); // 等价于`static int Q()`, Q在此作用域中不再是一个类型
static Q(P); // 等价于`static int Q(int ())`, 定义了一个名为Q的function
};
于是,下次阅读代码遇到typedef取别名就阅读其后跟随的定义,那么如何理解复杂的定义?
分析复杂定义——『右左法则』
定义中出现的一些符号的阅读方法如下:
*:表明在这个符号右边的变量是一个指针,且是指向...的指针(去掉*变量看还剩什么就代表指向什么)[]:表明在这个符号左边变量是一个数组,且每个元素是...的数组(去掉变量[]看还剩什么就代表每个元素是什么类型)():(函数...返回...,function ... return...)
[]和()的优先级比*更高
我们阅读复杂定义要遵循右左法则,即从变量名看起,先往右,再往左,碰到圆括号就调转阅读的方向;括号内分析完就跳出括号,还是先右后左的顺序。如此循环,直到分析完整个定义。
下面是一些案例
① void * (* (*fp1) (int)) [10];
找到变量名fp1,往右看是圆括号,调转方向往左看到*号,说明fp1是一个指针;跳出内层圆括号,往右看是参数列表,说明fp1是一个函数指针,接着往左看是*号,说明指向的函数返回值是指针;再跳出外层圆括号,往右看是[]运算符,说明函数返回的是一个数组指针,往左看是void *,说明数组包含的类型是void *。 简言之,fp1是一个指向函数的指针,该函数接受一个整型参数并返回一个指向含有10个void指针数组的指针。
② float (* (*fp2) (int, int, float)) (int);
找到变量名fp2,往右看是圆括号,调转方向往左看到*号,说明fp2是一个指针;跳出内层圆括号,往右看是参数列表,说明fp2是一个函数指针,接着往左看是*号,说明指向的函数返回值是指针;再跳出外层圆括号,往右看还是参数列表,说明返回的指针是一个函数指针,该函数有一个int类型的参数,返回值类型是float。简言之,fp2是一个指向函数的指针,该函数接受三个参数(int, int和float),且返回一个指向函数的指针,该函数接受一个整型参数并返回一个float。
③ typedef double (* (* (*fp3) ()) [10]) ();
如果创建许多复杂的定义,可以使用
typedef。这一条显示typedef是如何缩短复杂的定义的。
跟前面一样,先找到变量名fp3(这里fp3其实是新类型名),往右看是圆括号,调转方向往左是*,说明fp3是一个指针;跳出圆括号,往右看是空参数列表,说明fp3是一个函数指针,接着往左是*号,说明该函数的返回值是一个指针;跳出第二层圆括号,往右是[]运算符,说明函数的返回值是一个数组指针,接着往左是*号,说明数组中包含的是指针;跳出第三层圆括号,往右是参数列表,说明数组中包含的是函数指针,这些函数没有参数,返回值类型是double。简言之,fp3是一个指向函数的指针,该函数无参数,且返回一个含有10个指向函数指针的数组的指针,这些函数不接受参数且返回double值。
④ int (* (*fp4()) [10]) ();
这里fp4不是变量定义,而是一个函数声明。
找到变量名fp4,往右是一个无参参数列表,说明fp4是一个函数,接着往左是*号,说明函数返回值是一个指针;跳出里层圆括号,往右是[]运算符,说明fp4的函数返回值是一个指向数组的指针,往左是*号,说明数组中包含的元素是指针;跳出外层圆括号,往右是一个无参参数列表,说明数组中包含的元素是函数指针,这些函数没有参数,返回值的类型是int。简言之,fp4是一个返回指针的函数,该指针指向含有10个函数指针的数组,这些函数不接受参数且返回整型值。
⑤ 指针数组与数组指针
来源:https://www.nowcoder.com/questionTerminal/5e55c5b7eef5483eba6387551a2f3211
typedef char T[10];
T *a;
上述定义中a的类型与下面选项中完全相同的是?
A. char a[10] ;
B. char (*a)[10] ;
C. char * a ;
D. char *a[10] ;
选B。T *a说明a是指向T类型的指针,T代表一个数组类型,于是a是指向一个数组的数组指针。
char (*a)[10]:a是一个指针,指向char[10]数组char *a[10]:a是一个数组,每个数组类型是char*,所以是一个指针数组
⑥ int &* p 与 int *& p
int & *p:p是一个指针,指向一个int引用,不能建立指向引用的指针,此定义有误
int * &p:p是一个引用,所引类型是int指针,可以定义指向指针变量的引用
2. using
using 新类型名 = 已有类型名;
-
using只能为一个已有数据类型声明一个别名,typedef可以一次为一个已有数据类型声明多个别名
typedef double Area, Volume; using Area = double; using Volume = double; -
using还可用于给模板起别名,但typedef不能
template<typename T> using arr12 = std::array<T,12>; std::array<double, 12> al; std::array<std::string, 12> a2; //可将它们替换为如下声明 arr12<double> al; arr12<std::string> a2;
(二)断言
1. assert
assert是运行期断言,它用来发现运行期间的错误,不能提前到编译期发现错误,也不具有强制性,对性能有影响,发行版本中assert通常会被关掉(需要包含头文件<cassert>)
assert(布尔常量表达式);
//参数:
// - 布尔常量表达式:为 true 时继续向下执行,为 false 时终止程序
2. static_assert(静态断言)
static_assert是编译期间的断言,叫静态断言,用来发现编译期间的错误,以及用编译器来强制保证一些契约。
- static_assert可以用在全局作用域中,命名空间中,类作用域中,函数作用域中,几乎可以不受限制的使用。
- 编译器在遇到一个static_assert语句时,通常立刻将其第一个参数作为常量表达式进行演算,但如果该常量表达式依赖于某些模板参数,则延迟到模板实例化时再进行演算,这就让检查模板参数成为了可能。
- 性能方面,由于是static_assert编译期间断言,不生成目标代码,因此static_assert不会造成任何运行期性能损失。
static_assert(布尔常量表达式, 消息);
参数:
-
布尔常量表达式:bool 类型的常量表达式,
必须是常量表达式!!!不能是变量
-
消息:当布尔常量表达式为 false 时显示的字符串字面量,不能容纳动态信息
#include <cassert>
#include <cstring>
using namespace std;
template <typename T, typename U> int bit_copy(T& a, U& b){
//assert(sizeof(b) == sizeof(a));
static_assert(sizeof(b) == sizeof(a), "template parameter size no equal!");
memcpy(&a,&b,sizeof(b));
};
int main()
{
int aaa = 0x2468;
double bbb;
bit_copy(aaa, bbb);
getchar();
return 0;
}


-
头文件( .h ):放置各种声明,用于被cpp文件包含。
-
模块文件(.cpp):放置一些函数定义,也称为功能模块。
-
主程序文件(.cpp):包含main()的文件,程序入口,调用模块文件实现的方法。
-
头文件(.hpp):包含类模板(定义+声明)
当代码中含有类模板时,通常将类模板的定义与声明都放在hpp文件中而不是分开放置,并在主程序文件中包含
(四)extern "C"——C++和C的混合编程
extern 是 C 和 C++ 的一个关键字,但对于 extern "C",应该将其看做一个整体,和 extern 毫无关系。
extern "C" 可以修饰一句或一段 C++ 代码,它的功能是让编译器以处理 C 语言代码的方式来处理修饰的 C++ 代码。
例:
//myfun.h
void display();
//myfun.c
#include <stdio.h>
#include "myfun.h"
void display(){
printf("C++:http://c.biancheng/net/cplus/");
}
//main.cpp
#include <iostream>
#include "myfun.h"
using namespace std;
int main(){
display();
return 0;
}
-
当修饰一句C++代码时,头文件需修改如下
//myfun.h #ifdef __cplusplus extern "C" void display(); #else void display(); #endif -
当修饰一段C++代码时,头文件需修改如下
#ifdef __cplusplus extern "C" { #endif ... void display(); ... #ifdef __cplusplus } #endif
十七、思考
(〇)注意点
-
常函数成员中不能更新对象的非静态数据成员(如果有此类操作则编译器编译时报错),但可以更新静态数据成员;不能调用非静态成员函数,但可以调用静态成员函数。(可以理解为静态成员不严格属于类成员)
-
赋值兼容规则的前提也是公有派生类
-
区分虚函数与虚继承
- 虚函数用于实现动态多态性
- 虚继承用于解决菱形继承产生的同名问题
-
类的非静态成员变量不能作为成员函数的默认实参,但静态成员可以作为类成员函数的默认实参
编译器对默认实参的解释和翻译是在编译链接期,而非运行时。因此,默认实参要么是一个常量,要么有一个在编译期就能够确定的地址,比如静态变量。而this指针及其成员的地址在编译期还不确定,所以不行。
-
this指针不是对象本身的一部分
-
通过常对象只能调用它的常成员函数或者静态成员函数;常成员函数可以访问常数据成员,也可访问普通数据成员。
静态成员函数只能访问或修改静态数据成员,不用担心静态成员函数会修改常对象的数据成员。
-
基类的构造函数、析构函数、静态成员函数、赋值运算符重载函数、友元函数不能被派生类继承
-
类模板与函数模板都支持默认的模板参数,但需要从右往左给出
-
全局变量作用于整个工程,静态全局变量仅作用于定义它的文件
-
动态内存分配数组如果有括号,则括号内不能有任何东西。
-
如果只是声明一个空类,不做任何事情的话,编译器会自动生成一个默认构造函数、一个默认拷贝构造函数、一个默认赋值操作符、一个默认析构函数,这些函数只有在第一次被调用时,才会被编译器创建。所有这些函数都是inline和public的。
-
一个类的友元函数可以访问该类的所有成员,友元函数不是该类的成员函数。
-
把数组作为参数时,一般不指定数组第一维的大小,即使指定也会被忽略
-
C++语言中规定空结构体和空类所占内存大小为1,而C语言中空类和空结构体占用的大小是0。
-
一个类至多只能有一个默认构造函数
-
不能实例化抽象类的对象,但可以有抽象类的指针和引用
-
友元破坏了类的封装性和继承性
-
C++中,结构体和类的唯一区别在于,结构体和类具有不同的默认访问控制属性
-
字符串的长度不包括
\0 -
右值引用也必须立即进行初始化操作,且只能使用右值进行初始化。那么给一个函数的右值引用形参传左值也自然是不允许的
-
为了获得目标类型,编译器会不择手段,综合使用内置转换规则和用户自定义的规则, 进行多级类型转换。
-
一定要区分无参构造初始化与函数声明
Class c(); //函数声明 Class c; //定义一个对象c -
函数模板的实例化是由编译器完成的
-
虚函数不能是静态成员函数、构造函数、内联函数、友元函数
-
如果利用自动类型推导方式调用函数模板,不会发生隐式类型转换
-
不存在为了调用普通函数选择放弃调用可以匹配的模板函数而进行隐式类型转换。类型转换是无可匹配的情况下进行的
-
不能重载的运算符:成员访问运算符(
.)、成员指针访问运算符(.*与->*)、域运算符(::)、条件运算符(?:)、长度运算符(sizeof)、预处理符号(#) -
\[单目运算符>算术运算符>移位运算符>关系运算符>\&\&>||>条件运算符>赋值运算符 \]
-
virtual、static只能出现在函数原型声明中,不能出现在实现中
-
抽象类只能作为基类来使用,但抽象类本身可以是别的类的派生类,也可以是基类进而派生出其它类
-
C++11支持静态常量数据成员(const或constexpr修饰)类内初始化
-
派生类中调用基类同名的非私有成员的虚函数仍要用
基类名::限定,当然这样的调用就不算是多态性了 -
cout支持重定向,cerr和clog不支持重定向
-
C/C++语言规定,else连接到在同一层中最接近它而又没有其他else语句与之相匹配的if语句。
-
如果基类没有默认构造函数(如基类自己定义了带形参的构造函数,编译器不为其生成默认构造函数),派生类应该自定义带形参的构造函数。
-
先构造的后析构,后构造的先析构
-
构造函数中调用虚函数,虚函数表现为该类中虚函数的行为
-
复制运算符、条件选择运算符结合性从右到左
-
初始化数组时不可以在不给定数组长度的同时不指定元素
int a[] = {} //错误,不可以在不给定数组长度的同时不指定元素
-
对得到的随机数取模、加上偏移就得到了特定范围的随机数,如想要输出 \([min, max]\)范围内的随机数就是
rand()%(max-min+1)+min -
由于同名覆盖原则,单继承不会出现二义性问题。
-
派生类中用virtual声明了虚函数,则基类中对应函数不会自动被解析成虚函数
-
找到一个匹配的catch异常处理后
- 初始化异常参数。
- 将从对应的try块开始到异常被抛掷处之间构造(且尚未析构)的所有自动对象进行析构,对于未被完全构造的对象,在抛掷异常时不会执行该对象的析构函数。
- 从最后一个catch处理之后开始恢复执行。
-
常数据成员只能通过初始化列表来获得初值
-
对于普通成员函数及其const重载版本的常成员函数,普通对象优先匹配调用普通成员函数(常成员函数也可调用),常对象只能调用常成员函数。
-
转换构造函数调用往往会创建临时对象,对此临时对象要析构
-
动态申请数组,释放内存空间要用
delete[] -
A的ASCII码是65(十进制)
(一)函数中返回值类型的问题
返回值:函数返回值时会产生一个临时变量作为函数返回值的副本。
返回引用:当函数返回一个引用(不仅仅是对象引用)时,则返回一个指向返回值的隐式指针,此时可以作为左值。
按对象值返回:此时返回的其实是一个临时对象,通常作为右值而不让其作为左值,因为临时对象作为左值是没有意义的。
按对象的引用返回:
-
避免复制构造函数的调用,减小开销;
-
切记不能返回局部变量的引用(局部变量在函数执行完毕后便被销毁)
-
此时不会生成临时对象,可以作为左值,所以这种设定适用于需要对返回的对象进行修改时
若不希望被修改则可以再加个const变成常引用返回。
(二)函数中形参类型的问题
对象形参:会触发复制构造函数的调用,增加开销,不建议这样传
对象引用形参:
- 不会触发复制构造函数调用,提高效率
- 由于是双向传递,若不希望传入实参的被修改可以加const作为常引用传入,这样可以保护实参。
(三)只读 vs 常量
只读不一定代表不可修改,如常引用引一个变量时可以根据变量间接修改,但不能直接通过引用修改
#include <iostream>
using namespace std;
int main() {
int a = 10;
/*1. 不能通过常引用的别名更改所指向的内存空间的值,但可以用变量更改*/
const int &b1 = a;
//b1 = 100; //错误
a = 100;
cout << b1 << endl;
/*非常引用既能通过别名,也能通过变量修改内存空间的值*/
int &b2 = a;
a = 1000;
cout << b2 << endl;
b2 = 10000;
cout << b2 << endl;
return 0;
}
(四) 重载(overload) vs 重写(override) vs 重定义/隐藏
https://www.nowcoder.com/questionTerminal/4fff9573339149ccaa4911c9e7f6e6be
函数重载(overload)
函数重载是指在一个类中声明多个名称相同但参数列表不同的函数,这些的参数可能个数或顺序,类型不同,但是不能靠返回类型来判断。特征是:
- 相同的范围(在同一个作用域中);
- 函数名字相同;
- 参数不同;
- virtual 关键字可有可无(注:函数重载与有无virtual修饰无关);
- 返回值可以不同;
函数重写(也称为覆盖 override)
函数重写是指子类重新定义基类的虚函数。特征是:
- 不在同一个作用域(分别位于派生类与基类);
- 函数名字相同;
- 参数相同;
- 基类函数必须有 virtual 关键字,不能有 static 。
- 返回值相同,否则报错;
- 重写函数的访问修饰符可以不同;
重定义(也称隐藏)
- 不在同一个作用域(分别位于派生类与基类) ;
- 函数名字相同;
- 返回值可以不同;
- 参数无所谓是否相同;
- 参数不同,不论有无 virtual 关键字,基类的函数将被隐藏(注意别与重载以及覆盖混淆);
- 参数相同,基类函数没有 virtual关键字,基类的函数被隐藏(注意别与覆盖混淆);
总结:
- 同一作用域下(同一类中、同一块中)的同名函数考虑函数重载问题
- 不同作用域下(基类与派生类)的同名函数看有无virtual,
- 如果有则考虑是否能成功重写:重写不仅仅要求名称一致,还要求参数签名一致
- 如果没有则考虑隐藏:隐藏只要求名称一致
十八、工具
我们有时需要验证构造函数的调用情况,但一些编译器(如VS2017)会将一些构造函数的调用优化掉,于是我们可以用MinGW的g++指定其去除优化,将源代码编译链接成可执行文件。
只需要在其bin目录下输入如下指令就可以将test.cpp编译链接成test.exe
g++ test.cpp -o test.exe -fno-elide-constructors
——习题
(一)选择 & 判断
下列表达式中,不合法的是()
已知:double d = 3.2; int n = 3;
A. d<<2;
B. d/n
C. !d && (n-3)
D. (d-0.2)|n
AD。所有的位运算都不能直接操作浮点数
下列不正确的重载函数是()。
A. int print(int x);和void print(float x);
B. int disp(int x);和char *disp(int y);
C. int show(int x, char* s);和int show(char* s, int x);
D. int view(int x, int y);和int view(int x);
B。函数返回值不能作为函数重载的条件
以下有关C语言的说法中,错误的是()。
A. 内存泄露一般是指程序申请了一块内存,使用完后,没有及时将这块内存释放,从而导致程序占用大量内存。
B. 可以通过malloc(size_t)函数调用申请超过该机器物理内存大小的内存块。
C. 无法通过内存释放函数free(void*)直接将某块已经使用完的物理内存直接还给操作系统。
D. 可以通过内存分配函数malloc(size_t)直接申请物理内存。
D。内存泄漏也称作“存储渗漏”,用动态存储分配函数动态开辟的空间,在使用完毕后未释放,结果导致一直占据该内存单元,直到程序结束,(其实说白了就是该内存空间使用完毕之后未回收)即所谓内存泄漏。 free释放的内存不一定直接还给操作系统,可能要到进程结束才释放。 malloc不能直接申请物理内存,它申请的是虚拟内存
对两个字符 a 和 b 进行初始化,
char a[]="ABCDEF";
char b[]={'A','B','C','D','E','F'};
则以下叙述正确的是()
A. a数组比b数组长度长
B. a与b用sizeof取长度值相同
C. a与b数组完全相同
D. a和b中都存放字符串
A。a 是一个 C 风格的字符串,字符串以
\0结尾,所以sizeof(a)是获取数组的大小(包含\0)为 7,b 是一个普通的字符数组,所以sizeof(b)结果为 6。strlen()是获取字符串的长度,它是以\0作为结束标志,所以strlen(a)结果为 6(不包含\0),b 中没有\0,所以strlen(b)结果不确定。
引用与指针有什么区别?【多选】
A. 指针是一个实体,而引用仅是个别名
B. 指针没有 const,引用有 const;
C. 引用不能为空,指针可以为空;
D. “sizeof 引用”得到的是所指向的变量(对象)的大小,而“sizeof 指针”得到的是指针本身(所指向的变量或对象的地址)的大小;
E. 从内存分配上看:程序为引用变量分配内存区域,而指针不需要分配内存区域
F. 指针和引用的自增(++)运算,意义一样
A、C、D
下列说明语句中正确的是()
A. int a, &ra=a, &&ref=ra;
B. int &refa[10];
C. int a, &ra=a, &*refp=&ra;
D. int *pi, *&pref=pi;
D
程序进行编译时,不为形式参数分配存储空间。请问这句话的说法是正确的吗?
A. 正确
B. 错误
A。编译其实只是一个扫描过程,进行词法语法检查,代码优化而已,并没有分配内存空间。形参变量只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只在函数内部有效。函数调用结束返回主调用函数后则不能再使用该形参变量。
循环语句while(int i=0 ) i--;的循环次数是()
A. 0
B. 1
C. 5
D. 无限次
A。这个代码就相当于
int i=0;whie(i);i--;而while(0)本身就是不能执行的
下列的模板声明中,其中几个是正确的()
1)template
2)template<T1,T2>
3)template<class T1,T2>
4)template<class T1,class T2>
5)template<typename T1,T2>
6)template<typename T1,typename T2>
7)template<class T1,typename T2>
8)<typename T1,class T2>
A. 2
B. 3
C. 4
D. 5
B。4、6、7正确。函数模板的格式如下:
Template <class 形参名, class 形参名, ......> 返回类型函数名(参数列表){函数体}其中,class可以用typename关键字代替。
在下列表达式选项中,正确的是()
A. ++(a++)
B. a++b
C. a+++b
D. a++++b
C。A错误,因为a++操作通过临时量返回其值,该值是一个常量,因此不能被修改(不是左值),而后缀++需要对左值进行操作,所以会引起编译错误。C显然正确,至于是看作(a++)+b还是a+(++b),个人倾向于前者。因为在计算表达式时,应保证整个运算式的结合性一致。当遇到结合性不一致的情况时,一般会以圆括号包裹处理。这里+运算符为左结合性,前缀++为右结合性,后缀++为左结合性(C++中后缀运算符和单目运算符不仅优先级不同,结合性也不同,前缀++是单目运算符),所以从保持结合性一致出发,个人认为此处应看作(a++)+b。如果需要作为第二种表示,则需要添加圆括号。
下列程序的运行结果是B0,横线处缺失的程序代码为()
#include <iostream>
using namespace std;
class B0 {
public:
virtual void display() {
cout << "B0" << endl;
}
};
class B1: public B0 {
public:
void display() {
cout << "B1" << endl;
}
};
class D1: public B1 {
public:
void display() {
cout << "D1" << endl;
}
};
void fun(______) {
ptr.display();
}
int main() {
D1 d1;
fun(d1);
}
A. B0 &ptr
B. D1 &ptr
C. D1 ptr
D. B0 ptr
D。类 B0、B1、D1 均包含虚函数,传引用和传指针依然指向原来的对象 d1,因此会触发正常虚函数调用。但是传值会触发拷贝构造函数,如果参数为 B0 ptr,则 ptr 指向的是 B0 对象,调用 ptr.display(); 程序输出 B0。
在C++中,根据( )识别类层次中不同类定义的虚函数版本。
A. 参数个数
B. 参数类型
C. 函数名
D. this指针类型
D。
若给定条件表达式(M)?(a++):(a--),则其中表达式 M( )
A. 和(M==0)等价
B. 和(M==1)等价
C. 和(M!=0)等价
D. 和(M!=1)等价
B
下列关于类中的静态成员的说法错误的是()
A. 虽然静态成员不属于类的某个对象,但是我们仍然可以使用类的对象、引用或者指针来访问静态成员
B. 成员函数不用通过作用域运算符就能直接使用静态成员
C. 静态数据成员不是由类的构造函数初始化的
D. 静态成员不可以作为默认实参
D。类的非静态成员变量不能作为成员函数的默认实参,但静态成员可以作为类成员函数的默认实参
编译器对默认实参的解释和翻译是在编译链接期,而非运行时。因此,默认实参要么是一个常量,要么有一个在编译期就能够确定的地址,比如静态变量。而this指针及其成员的地址在编译期还不确定,所以不行。
在上下文及头文件均正常的情况下,下列代码的输出是?(注:print已经声明过)
main(){
char str[] = "Geneius";
print (str);
}
print(char *s){
if(*s){
print(++s);
printf("%c", *s);
}
}
A. suiene
B. neius
C. run-time error
D. suieneG
A。
有如下程序
#include<iostream>
using namespace std;
class Point {
public:
Point() { cout << "C"; }
~Point() { cout << "D"; }
};
int main() {
Point *ptr;
Point A, B;
Point *ptr_point = new Point[3];
return 0;
}
执行这个程序输出结果是()
A. CCCCCDDDDD
B. CCCCCDD
C. CCCDDDDD
D. CCCCDDDD
B。若最后再加上
delete[] ptr_point,则再会调用三次析构来析构Point数组的三个元素,此时选择A
有如下程序
#include<iostream>
using namespace std;
class Point {
public:
static int num;
Point() { num++; }
~Point() { num--; }
};
int Point::num = 0;
int main() {
Point *ptr;
Point A, B;
Point *ptr_point = new Point[3];
ptr = ptr_point;
delete[] ptr;
cout << Point::num << endl;
}
执行这个程序的输出结果是()
A. 2
B. 3
C. 4
D. 5
A
在一个类的对象空间里已经包含了静态成员的空间
A. 正确
B. 错误
B。静态成员为所有类共享,不包含在单个类对象空间里
unsigned char *p1;
unsigned long *p2;
p1 = (unsigned char *)0x801000;
p2 = (unsigned long *)0x810000;
请问p1+5= _____?p2+5= _____?
A. 801005 810005
B. 801005 810020
C. 801005 810014
D. 801010 810014
C。+5代表移动5个单位量,单位量取决于所指向内存空间的类型
(unsigned char *)0x801000即0x801000所代表的内存空间被认为是一个unsigned char
(unsigned long *)0x810000即0x810000所代表的内存空间被认为是一个unsigned long
p1+5=p1+5*1=p1+5*sizeof(unsigned char)=p1+5*1=0x801000+0x5=0x801005 p2+5=p2+5*1=p2+5*sizeof(unsigned long)=p1+5*4=0x810000+20=0x810000+0x14=0x810014
以下C++代码的输出结果是()
int i=1;
int main(){
int i=i;
}
A. main()里的i是个未定义值
B. main()里的i值为1
C. 编译器不允许这种写法
D. main()里的i值为0
A。main函数内出现了i,于是全局变量i不可见,此时i未定义就用来初始化。
以下代码的输出结果是()
#include<iostream>
using namespace std;
int main() {
int arr[] = { 1,3,5,7 };
int* ptr = arr;
printf("%d,%d\n", *++ptr, *ptr);
ptr = arr;
printf("%d,%d\n", *ptr++, *ptr);
ptr = arr;
printf("%d,%d\n", *ptr, *++ptr);
ptr = arr;
printf("%d,%d\n", *ptr, *ptr++);
return 0;
}
3,3 1,3 3,3 3,1
静态外部变量只在本文件内可用。请问这句话的说法是正确的吗?
A. 正确
B. 错误
A。全局变量作用于整个工程,静态全局变量仅作用于定义它的文件全局变量作用于整个工程,静态全局变量仅作用于定义它的文件
下面哪一句会出错?
char* s="AAA"; //1
printf("%s",s); //2
s[0]='B'; //3
printf("%s",s); //4
A. 第1句
B. 第2句
C. 第3句
D. 第4句
C。s指向常量区,是不可以修改常量区数值的,如果1句为
char s[]="AAA";则可以编译成功
下列语句中错误的是()
A. int *p = new int(10);
B. int *p = new int[10];
C. int *p = new int;
D. int *p = new int[40](0);
D。动态内存分配数组如果有括号,则括号内不能有任何东西。C++11的列表初始化可以用于初始化动态分配的数组,如
int *p = new int[10]{ 1,2,3,4,5,6,7,8,9,0 };
下面关于stl的数据结构的哪些说法正确
A. std::map 底层是由rb-tree实现
B. std::set 底层是由hashtable实现
C. std::unordered_map 底层是由rb-tree实现
D. std::multiset 用rb-tree的 insert_equal 来实现 insert
AD。来源
下列代码的输出为()
#include<stdio.h>
class CParent {
public: virtual void Intro(){
printf( "I'm a Parent, " );
Hobby();
}
virtual void Hobby(){
printf( "I like football!" );
}
};
class CChild : public CParent {
public: virtual void Intro(){
printf( "I'm a Child, " );
Hobby();
}
virtual void Hobby(){
printf( "I like basketball!\n" );
}
};
int main( void ){
CChild *pChild = new CChild();
CParent *pParent = (CParent *) pChild;
pParent->Intro();
return(0);
}
A. I'm a Parent, I like football!
B. I'm a Parent, I like basketball!
C. I'm a Child, I like basketball!
D. I'm a Child, I like football!
C。来源
CParent *pParent = (CParent *) pChild;是上行转换,即把子类的引用或指针转换为基类表示。这个是安全的。 所以上面的语句的作用是把pChild指针转换为基类指针并赋值给pParent,但是它指向的内容是没变的(所以虚指针不变),所以最终结果是pChild指针和pParent指针都指向了child类。 而且由于基类的方法都已经声明为了虚函数,所以最后pParent->Intro();根据虚函数表就是调用了child类里面的方法。
阅读如下程序,该程序的执行结果为()
#include "stdio.h"
class A
{
public:
virtual void Test()
{
printf("A test\n");
}
};
class B: public A
{
public:
void func()
{
Test();
}
virtual void Test()
{
printf("B test\n");
}
};
class C: public B
{
public:
virtual void Test()
{
printf("C test\n");
}
};
int main()
{
C c;
((B *)(&c))->func();
((B)c).func();
}
A. C test B test
B. B test B test
C. B test C test
D. A test C test
A。来源
C c;声明了一个C类的对象c。
((B *)(&c))->func();用B类的指针指向C类对象,此时func()是B类中的,由于Test()声明为虚函数,所以根据实际对象找到虚函数表,得到C中的虚函数输出"C test".
((B)c).func();将c转化为B 类,此时c不再是C类,而就是一个B类的对象。
下列有关静态成员函数的描述中,正确的是:
A. 静态数据成员(非const类型)可以在类体内初始化
B. 静态数据成员不可以被类对象调用
C. 静态数据成员不受private控制符作用
D. 静态数据成员可以直接用类名调用
D。静态数据成员受private控制符作用
派生类对象可以访问基类成员中的()?
A. 公有继承的私有成员
B. 私有继承的公有成员
C. 公有继承的保护成员
D. 以上都错
D。
- 派生类内部,派生类对象可以访问基类中的公有和保护成员;
- 派生类外部,派生类对象只能访问基类公有继承的公有成员。
以数组名作函数参数时,实参数组与形参数组都不必定义长度,因此实参与形参的结合方式是地址结合,与数组长度无关。请问这句话的说法是正确的吗?
A. 正确
B. 错误
B。来源
对于C++,struct T {},sizeof(struct T)的值为()
A. 4
B. 1
C. 0
D. 编译或运行期错误
B。
请选择下列程序的执行结果()
#include<iostream>
using namespace std;
class A{
public:
void f(){
cout<<"A::f()";
}
};
class B: public A{
public:
void f(){
cout<<"B::f()";
};
};
int main(){
B b;
b.f();
}
A. A::f();B::f() 都不可能
B. A::f();B::f() 都有可能
C. A::f()
D. B::f()
D。通过派生类对象调用同名成员,此时在未加任何特殊标识的情况下默认访问派生类中的那个成员,而基类中的同名成员会被隐藏。
在C++中,为了让某个类只能通过new来创建(即如果直接创建对象,编译器将报错),应该()
A. 将构造函数设为私有
B. 将析构函数设为私有
C. 将构造函数和析构函数均设为私有
D. 没有办法能做到
B. http://blog.csdn.net/hxz_qlh/article/details/13135433
编译器在为类对象分配栈空间时,会先检查类的析构函数的访问性,其实不光是析构函数,只要是非静态的函数,编译器都会进行检查。如果类的析构函数是私有的,则编译器不会在栈空间上为类对象分配内存。 因此, 将析构函数设为私有,类对象就无法建立在栈(静态)上了,只能在堆上(动态new)分配类对象 。
对拷贝构造函数的描述正确的是
A. 该函数名同类名,也是一种构造函数,该函数返回自身引用
B. 该函数只有一个参数,必须是对某个对象的引用
C. 每个类都必须有一个拷贝初始化构造函数,如果类中没有说明拷贝构造函数,则编译器系统会自动生成一个缺省拷贝构造函数,作为该类的保护成员
D. 拷贝初始化构造函数的作用是将一个已知对象的数据成员值拷贝给正在创建的另一个同类的对象
D。拷贝构造函数的参数可以是一个或多个,但左起第一个必须是自身类型的引用对象,其它参数必须设置默认值,B错;
以下变量均为int类型,则其值不为7的表达式是:
A. (x=y=6, x+y, x+1)
B. (y=6, y+1, x=y, x+1)
C. (x=6, x++, y=6, x+y)
D. (x=y=6, x+y, y+1)
C。对于C项而言,逗号表达式的执行顺序是从左向右依次执行。x=6,将6赋值给x;x++表达式的值是7,x的值变成7;y=6,将6赋值给y;x+y=7+6=13。故C项表达式的值是13。
当x=3,y=1,z=0时,表达式x<=y<=z的结果为:
A. 1
B. 0
C. 3
D. 其他都不对
A。<=为关系运算符且它的结合性是从左到右,故上式等价于 (x<=y)<=z。又因为x=3 y=1,所以x<=y的结果为0(代表假),然后0<=z的结果为1(代表真)。
类B是类A的公有派生类,类A和类B中都定义了虚函数func(),p是一个指向类A对象的指针,则p->A::func()将()?
A. 调用类B中函数func()
B. 即调用类A中函数,也调用类B中的函数
C. 调用类A中函数func()
D. 根据p所指的对象类型而确定调用类A中或类B中的函数func()
设int a=1, b=2, c=3, d=4;,则以下条件表达式的值为()
a < b ? a : c < d ? c : d;
A. 1
B. 2
C. 3
D. 4
A。三目运算符从右到左组合,计算顺序显然也是从左到右。先算
c<d?c:d得a<b?a:4;再算a<b?a:4。得a=1
下面程序的输出结果是()
#include <iostream>
using namespace std;
int main()
{
char str1[] = "hello world";
char str2[] = "hello world";
const char str3[] = "hello world";
const char str4[] = "hello world";
const char* pstring1 = "hello world";
const char* pstring2 = "hello world";
cout << boolalpha << ( str1==str2 ) << ',' ;
cout << boolalpha << ( str3==str4 ) << ',' ;
cout << boolalpha << ( pstring1==pstring2 ) <<endl;
return 0;
}
A. false,false,true
B. false,false,false
C. true,true,true
D. false,true,true
A。来源
#include<iostream> using namespace std; int main(void) { char str1[] = "hello world"; //存放在栈中的数组 char str2[] = "hello world"; //存放在栈中的数组 const char str3[] = "hello world"; //存放在栈中的字符串常量 const char str4[] = "hello world"; //存放在栈中的字符串常量 const char* pstring1 = "hello world"; //本身在栈中,指向常量的指针 const char* pstring2 = "hello world"; //本身在栈中,指向常量的指针 //显然二者所指向的地址一致 int x = (int)pstring1; int y = (int)pstring2; //为了方便打印出指针所指向的地址 cout << boolalpha << ( str1==str2 ) << endl; //比较字串首地址 flase cout << boolalpha << ( str3==str4 ) << endl; //比较字串首地址 flase cout << boolalpha << ( pstring1==pstring2 ) <<endl; //比较指针所指地址 true cout << "str1=" << &str1 << ","; cout << "str2=" << &str2 << endl; cout << "str3=" << &str3 << ","; cout << "str4=" << &str4 << endl; cout << "pstring1=" << &pstring1 << ","; cout << "pstring2=" << &pstring2 << endl; //输出指针本身地址 cout<<hex; cout << "pstring1=" << x << ","; cout<<hex; cout << "pstring2=" << y << endl; //16进制输出指针所指地址 return 0; }
关于抽象类说法以下哪些是正确的?
A. 抽象类中可以不存在任何抽象方法
B. 抽象类可以为final的
C. 抽象类可以被抽象类所继承
D. 如果一个非抽象类从抽象类中派生,不一定要通过覆盖来实现继承的抽象成员
AC。A之所以对,是因为可以定义个抽象类a,a中有个抽象方法,然后定义个b,继承a,b没有实现a中的抽象方法,但是b也没有定义自己的抽象方法,b仍然是抽象类。
(C++部分)64位Linux系统里,下面几个sizeof的运行结果是()
int intValue = 1024;
char str[] = "Vipshop";
const char* ch = str;
a=sizeof(intValue) ;
b=sizeof(str);
c=sizeof(ch);
A. a=1,b=1,c=1
B. a=4,b=4,c=4
C. a=4,b=8,c=4
D. a=4,b=8,c=8
D。64位系统指针占8个字节
假定T是一个C++类,下列语句执行之后,内存里创建了()个T对象。
T b(5);
T c[6];
T &d = b;
T e=b;
T *p = new T (4);
A. 5
B. 8
C. 9
D. 12
C。程序的作用是统计x的二进制表示中0的个数
#include<iostream> using namespace std; /*输出x的二进制表示*/ void dec2Bin(unsigned int n) { unsigned int tmp; for (int i = 1; i <= 32; ++i) { tmp = n >> (32-i); cout << (tmp & 1); } cout << endl; } int fun(unsigned int x) { int n = 0; while (x + 1){ dec2Bin(x); n++; x = x | (x + 1); } return n; } int main() { cout << "The result is " << fun(2014) << endl;; return 0; }
在32位机器上,有如下代码,其输出结果为?
void func0(){
char array[] = "abcdefg";
printf("%d ", sizeof(array));
const char *p = "abcdefg";
printf("%d ", sizeof(p));
}
void func1(char p[10])
{
printf("%d ", sizeof(p));
}
void func2(char (&p)[10])
{
printf("%d ", sizeof(p));
}
int main()
{
char p[10] = "hello";
func0();
func1(p);
func2(p);
printf("%d ", sizeof(char[2]));
printf("%d ", sizeof(char &));
return 0;
}
A. 8 4 4 10 2 1
B. 4 4 4 10 4 1
C. 8 4 4 10 2 4
D. 8 4 4 4 2 1
E. 8 4 4 10 4 4
A。sizeof求数组时,大小等于数组元素个数*每个元素的大小(其中,计算字符串数组是需要计算结束符'\0',这是与strlen的区别,strlen不计算最后的'\0'),但是当数组是函数的形参时会将会降为指针,在32位系统中无论什么指针类型都是占4个字节 所以: 第1个printf输出:8 第2个printf输出:4 第3个printf输出:4 对于第4个,p是 int[10]的引用,所以 第4个printf输出:10 第5个printf输出:2 第6个printf输出:1
ClassA *pclassa=new ClassA[5];
delete pclassa;
c++语言中,类ClassA的构造函数和析构函数的执行次数分别为()
A. 5,1
B. 1,1
C. 5,5
D. 1,5
A。
A Class A *pclassa=newClassA[5];new了五个对象,所以构造5次,然后Pclass指向这五个对象delete pclassa;析构一次如果是
delete[] pclassa,这样就析构5次
定义宏
#define DECLARE(name, type) type name##_##type##_type
则DECLARE(val, int)替换结果为()
A. int val_int_type
B. int val_int_int
C. int name_int_int
D. int name_int_name
A。
##是一种分隔连接方式,它的作用是先分隔,然后进行强制连接,name和第一个_之间被分隔了,所以预处理器会把name##_##type##_type解释成4段:name、_、type以及_type,name和type会被替换,而_type作为一个整体不会被替换
已知int i=0, j=1, k=2;,则逻辑表达式++i || --j && ++k 的值为( )
A. 0
B. 1
C. 2
D. 3
B。应该按这样组合
(++i) || ((--j) && (++k)),由于逻辑运算符确保按从左到右的顺序计算操作数,因此++i先计算,如果++i非0,则右边的不用再计算,否则计算--j和++k(二者都确定了操作数,计算顺序可颠倒),再计算二者结果的逻辑与(由于要先得到--j和++k的结果,所以计算顺序靠后)。
有以下程序,程序运行的结果是DDDDD,请为横线处选择合适的程序( )
#include <iostream>
using namespace std;
class D{
int d;
public:
D(int x=1):d(x){}
~D(){cout<<"D";}};
int main(){
D d[]={_____________};
D* p=new D[2];
delete[]p;
return 0;
}
A. 3,3,3
B. D(3), D(3), D(3)
C. 3,3,3,3
D. D(3,3),D(3,3)
AB。A项调用转换构造函数
有定义int a=8, b=5, c;,执行语句c=a/b+0.4;后,c的值为( )
A. 1.4
B. 1
C. 2.0
D. 2
B
有如下代码:
struct A1
{
virtual ~A1() {}
};
struct A2
{
virtual ~A2() {}
};
struct B1 : A1, A2 {};
int main()
{
B1 d;
A1* pb1 = &d;
A2* pb2 = dynamic_cast<A2*>(pb1); //L1
A2* pb22 = static_cast<A2*>(pb1); //L2
return 0;
}
A. L1语句编译失败,L2语句编译通过
B. L1语句编译通过,L2语句编译失败
C. L1,L2都编译失败
D. L1,L2都编译通过
B。
static_cast关键字(编译时类型检查)直接检查表达式括号里面的类型。pb1是A1*类型,不能转A2*,L2编译失败;
dynamic_cast关键字(运行时类型检查)检查表达式指针指向的对象类型。pb1指向B1类对象,可以转A2,故L1编译时能通过。
在C++程序中,对象之间的相互通信通过( )
A. 继承实现
B. 调用成员函数实现
C. 封装实现
D. 函数重载实现
B。
下列程序的打印结果是?
char p1[15] = "abcd", *p2 = "ABCD", str[50] = "xyz";
strcpy(str + 2, strcat(p1 + 2, p2 + 1));
printf("%s", str);
A. xyabcAB
B. abcABz
C. ABabcz
D. xycdBCD
E. 运行出错
D。
strcat(p1+2,p2+1);返回以p1+2为首的字符串,即"cdBCD"。strcpy(str+2,strcat(p1+2,p2+1));将"cdBCD"copy到str+2位置上,并覆盖后面的内容,此时str为"xycdBCD"
有以下类定义
#include <iostream>
using namespace std;
class shape {
public:
virtual int area()=0;
};
class rectangle:public shape {
public:
int a, b;
void setLength (int x, int y) {a=x;b=y;}
int area() {return a*b;}
};
若有语句定义rectangle r; r.setLength(3,5); 则编译时无语法错误的语句是( )
A. shape *s1=&r;
B. shape &s2=r;
C. shape s3=r;
D. shape s4[3];
AB。不能实例化抽象类的对象,但可以有抽象类的指针和引用
class A {
public:
A();
~A();
Data* data;
};
class AX : public A {
public:
AX();
~AX();
AXData* ax_data;
};
以下不会造成内存泄漏的写法有()
A. AX* p = new AX(); delete p;
B. A* p = new AX(); delete p;
C. std::shared_ptr<AX> p{new AX()};
D. std::shared_ptr<A> p{new AX()};
下列关于shared_ptr说法正确的是:
A. shared_ptr 不能作为容器的元素
B. shared_ptr 是100%线程安全的
C. 容器可以作为share_ptr 管理的对象
D. 使用shared_ptr 一定可以避免内存泄漏
有以下程序
#include <iostream>
#include <vector>
using namespace std;
int main() {
vector<int> A(10);
int count=0,n;
cout<<"请输入n的值:";
cin>>n;
A.__________(n);
for(int i=2;i<=n;i++)
if(i%3==0&&i%5==0) A[count++]=i;
for(i=0;i<count;i++)
cout<<A[i]<<" ";
cout<<endl;
}
当键盘输入20,程序的运行结果是15,请为横线处选择合适的程序( )
A. size
B. reserve
C. resize
D. length
BC。
c++的一个类中声明一个static成员变量,下面描述正确的是()
A. static是加了访问控制的全局变量,不被继承
B. 类和子类对象,static变量占有一份内存
C. 子类继承父类static变量
D. static 变量在创建对象时分配内存空间
AB。静态成员不能被继承,派生类只是通过继承拥有了对其的访问权限
当一个类对象的生命周期结束后,关于调用析构函数的描述正确的是:()
A. 如果派生类没有定义析构函数,则只调用基类的析构函数
B. 如果基类没有定义析构函数,则只调用派生类的析构函数
C. 先调用派生类的析构函数,后调用基类的析构函数
D. 先调用基类的析构函数,后调用派生类的析构函数
C。构造函数与析构函数执行顺序:
- 调用虚基类构造函数
- 按照基类被继承时声明的顺序(从左向右)调用基类构造函数
- 按照初始化列表中的对象成员和基本类型成员在类中声明的顺序对其进行初始化,对象成员初始化是自动调用对象所属类的构造函数完成的。
- 执行派生类的构造函数体中的内容。
- 析构函数调用执行(次序与构造函数相反)。
下列一段 C++ 代码的输出结果是()
#include <iostream>
class Base{
public:
int Bar(char x){
return (int)(x);
}
virtual int Bar(int x){
return (2 * x);
}
};
class Derived : public Base{
public:
int Bar(char x){
return (int)(-x);
}
int Bar(int x){
return (x / 2);
}
};
int main(void){
Derived Obj;
Base *pObj = &Obj;
printf("%d,", pObj->Bar((char)(100)));
printf("%d,", pObj->Bar(100));
}
A. 100,-100
B. 100,50
C. 200,-100
D. 200,50
B。
下列哪两个是等同的
int b;
const int *a = &b; // 1
const * int a = &b; // 2
const int* const a = &b; // 3
int const* const a = &b; // 4
A. 1,4
B. 1,2
C. 3,4
D. 2,3
C。
1:不能通过a修改b的内容
2:
*不能位于类型前面3:不能改变a的指向,不能通过a修改b的内容
4:不能改变a的指向,不能通过a修改b的内容
在c++中的结构体是否可以有构造函数?
A. 不可以,结构类型不支持成员函数
B. 可以有
C. 不可以,只有类允许有构造函数
B
C++中空类编译器不会产生以下哪个成员函数?
A. 析构函数
B. 拷贝构造函数
C. 私有构造函数
D. 赋值函数
C
下列函数中,不能声明为虚函数的是()?
A. 构造函数
B. 析构函数
C. 私有成员函数
D. 公有成员函数
A
数组a的定义为:int a[3][4]; 下面哪个不能表示 a[1][1] ?
A. *(&a[0][0]+5)
B. *(*(a+1)+1)
C. *(&a[1]+1)
D. *(a[1]+1)
C
下面代码的输出是什么?
class A {
public:
A() {}
~A() { cout<<"~A"<<endl; }
};
class B:public A{
public:
B(A &a):_a(a) { }
~B() {
cout<<"~B"<<endl;
}
private:
A _a;
};
int main(void) {
A a; //很简单,定义a的时候调用了一次构造函数
B b(a);
}
A. ~B
B. ~B ~A
C. ~B ~A ~A
D. ~B ~A ~A ~A
D。
\[构造:虚基类构造函数\rightarrow 基类构造函数\rightarrow 对象成员构造函数\rightarrow 派生类构造函数\\析构:派生类析构函数\rightarrow 对象成员析构函数\rightarrow 基类析构函数\rightarrow 虚基类析构函数 \]
字符串只能存放在字符型数组中。请问这句话的说法是正确的吗?
A. 正确
B. 错误
B。还能放在常量区
在32位环境下,以下代码输出的是()
#include<stdio.h>
class A {
public:
A(){ printf("A");}
~A(){ printf("~A");}
};
class B : public A {
public:
B(){ printf("B");}
~B(){ printf("~B");}
};
int main() {
A *c = new B[2];
delete[] c;
return 0;
}
A. ABAB~A~A
B. ABAB~B~A~B~A
C. ABAB~B~A
D. ABAB~A~B~A~B
A。
以下代码是否完全正确,执行可能得到的结果是____。
class A{
int i;
};
class B{
A *p;
public:
B(){p=new A;}
~B(){delete p;}
};
void sayHello(B b){
}
int main(){
B b;
sayHello(b);
}
A. 程序正常运行
B. 程序编译错误
C. 程序崩溃
D. 程序死循环
C。深复制与浅复制问题
对C++中重载(overload)和重写(override)描述正确的有()
A. 重载是指在同一个类或名字空间中存在多个函数,它们的函数名相同,而函数签名不同
B. 重写是指在子类中实现一个虚函数,该虚函数与其父类中的一个虚函数拥有同样的函数签名
C. 虚函数不可以重载
D. 构造函数可以重载,析构函数可以重写
ABD
下列哪一个循环会导致死循环?()
A. for(int k=0;k<0;k++)
B. for(int k=10;k>0;k--)
C. for(int k=0;k<10;k--)
D. 没有答案
D。A 选项,循环一次不会执行。k = 0,判断 k < 0,不满足直接结束循环。
B 选项,当 k 不断减小到 0 时,条件不满足结束循环。
C 选项,k 为 int,不断递减后,最小值可为 -2147483648,再递减其值会溢出变为2147483647,结束循环。
关于类模板,描述错误的是( )?
A. 一个普通基类不能派生类模板
B. 类模板可以从普通类派生,也可以从类模板派生
C. 根据建立对象时的实际数据类型,编译器把类模板实例化为模板类
D. 函数的类模板参数需生成模板类并通过构造函数实例化
A。模板类是类模板的实例化
- 类模板可以继承:模板类、普通类、类模板;
- 普通类可以继承:模板类、普通类;
以下不正确的定义语句是( )。
A. double x[5] = {2.0, 4.0, 6.0, 8.0, 10.0};
B. char c2[] = {'\x10', '\xa', '\8'};
C. char c1[] = {'1','2','3','4','5'};
D. int y[5+3]={0, 1, 3, 5, 7, 9};
B。\xhh,表示1到3位八进制数所代表的任意字符。 \ddd,表示1到2位十六进制所代表的任意字符
C++当中,没有参数的两个函数是不能重载的,上述说法是否正确?
A. 正确
B. 错误
B。const重载
class { public: /*这两个函数构成重载*/ void func(); void func() const; }
如果c为字符型变量,判断c是否为空格(假设已知空格ASCII码为32)不能使用()
A. if(c==32)
B. if(c=='32')
C. if(c=='\40')
D. if(c==' ')
B
在C++里,同一个模板的声明和定义是不能在不同文件中分别放置的,否则会报编译错误。为了解决这个问题,可以采取以下办法有()
A. 模板的声明和定义都放在一个.h文件中。
B. 模板的声明和定义可以分别放在.h和.cpp文件中,在使用的地方,引用定义該模板的cpp文件。
C. 使用export使模板的声明实现分离。
D. 以上说法都不对
ABC
class A {
int a;
short b;
int c;
char d;
};
class B {
double a;
short b;
int c;
char d;
};
在32位机器上用gcc编译以上代码,求sizeof(A),sizeof(B)分别是()
A. 12 16
B. 12 12
C. 16 24
D. 16 20
C
类 CBase 的定义如下: 在构造函数 CDerive 的下列定义中,正确的是()
class CBase
{
int x;
public:
CBase(int n){x=n;}
};
class CDerive:public CBase
{
CBase y;
int zpublic:
CDerive(int a,int b,int c);
};
A. CDerive::CDerive(int a,int b,int c):x(a),y(b),z(c){}
B. CDerive::CDerive(int a,int b,int c):CBase(a),y(b),z(c){}
C. CDerive::CDerive(int a,int b,int c):CBase(a),CDerive(b),z(c){}
D. CDerive::CDerive(int a,int b,int c):x(a),CBase(b),z(c){}
B
A 选项由于 x 在 基类 CBase 类中是私有的,所以派生类 CDerive 中无法直接访问。
B 选项正确。
C 选项调用了构造函数 CDerive(b),而 CDerive 类中没有一个参数的构造函数。
D 选项问题同 A 选项。
外部变量可以供其所在的程序文件中的任何函数使用()
A. 正确
B. 错误
B。
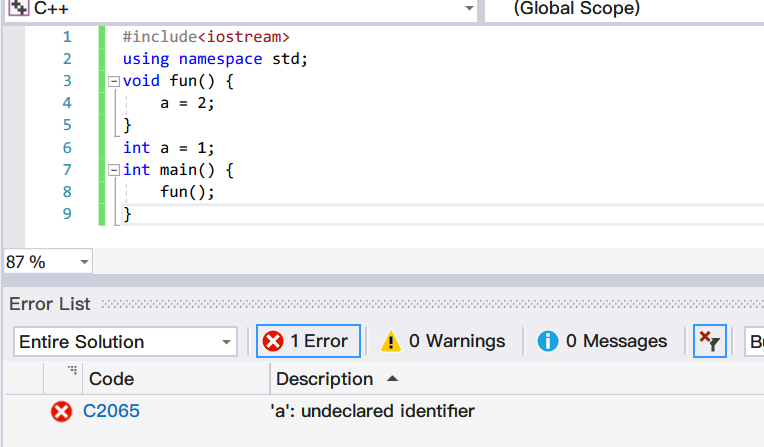
以下描述中正确的是( )
A. 由于do-while循环中循环体语句只能是一条可执行语句,所以循环体内不能使用复合语句
B. do-while循环由do开始,用while结束,在while(表达式)后面不能写分号
C. 在do-while循环体中,不一定要有能使while后面表达式的值变为零("假")的操作
D. do-while循环中,根据情况可以省略while
C。有break就可以
以下函数用法正确的个数是:
void test1(){
unsigned char array[MAX_CHAR+1],i;
for(i = 0;i <= MAX_CHAR;i++){
array[i] = i;
}
}
char*test2(){
char p[] = "hello world";
return p;
}
char *p = test2();
void test3(){
char str[10];
str++;
*str = '0';
}
A. 0
B. 1
C. 2
D. 3
A
第一个问题:重点不在于CHAR_MAX的取值是多少,而是在于i的取值范围是多少。一般char的取值范围是-128到127,而u char 则是
0~255,所以i的取值范围是0~255.所以当CHAR_MAX常量大于255时,执行i++后,i不能表示256以上的数字,所以导致无限循环。第二个问题:重点在于函数中p的身份,他是一个指针,还是数组名;如果是指针p,则p指向存放字符串常量的地址,返回p则是返回字符串常量地址值,调用函数结束字符串常量不会消失(是常量)。所以返回常量的地址不会出错。如果是数组p,则函数会将字符串常量的字符逐个复制到p数组里面,返回p则是返回数组p,但是调用函数结束后p被销毁,里面的元素不存在了。例子中p是数组名,所以会出错,p所指的地址是随机值。若是把char p[]="hello";改成char *p="hello";就可以了。
第三个问题:重点在于str++;这实际的语句就是str=str+1;而str是数组名,数组名是常量,所以不能给常量赋值。(可以执行str+1,但是不能str=.)
下面说明不正确的是()
A. char a[10]="china";
B. char a[10],*p=a;p="china";
C. char *a;a="china";
D. char a[10],*p;p=a="china";
D
以下程序的输出是:
#include <iostream>
using namespace std;
template <typename T>
void print(T t){
cout<<"The value is "<<t<<endl;
}
template <>
void print<char *>(char* c){
cout<<"The string is " << c <<endl;
}
int main() {
char str[] = "TrendMicro[char]";
unsigned char ustr[] = "TrendMicro[unsigned char]";
print(str);
print(ustr);
return 0;
}
A. The value is TrendMicro[char] The string is TrendMicro[unsigned char]
B. The value is TrendMicro[char] The value is TrendMicro[unsigned char]
C. The string is TrendMicro[char] The string is TrendMicro[unsigned char]
D. The string is TrendMicro[char] The value is TrendMicro[unsigned char]
D。模板函数和普通函数都符合条件时,优先执行普通函数
char *c[] = { "ENTER", "NEW", "POINT", "FIRST" };
char **cp[] = { c+3, c+2, c+1, c };
char ***cpp = cp;
int main(void)
{
printf("%s", **++cpp);
printf("%s", *--*++cpp+3);
printf("%s", *cpp[-2]+3);
printf("%s\n", cpp[-1][-1]+1);
return 0;
}
A. POINTERSTEW
B. FERSTEPOINW
C. NEWPOINTW
D. POINTFIREST
A
函数fun的声明为int fun(int *p[4]),以下哪个变量可以作为fun的合法参数()
A. int a[4][4];
B. int **a;
C. int **a[4]
D. int (*a)[4];
B。https://www.nowcoder.com/questionTerminal/e2ac8bddb9e5434a92511320221c8513
以下关于C++的描述中哪一个是正确的:
A. 任何指针都必须指向一个实例
B. 子类指针不可以指向父类实例
C. 任何引用都必须指向一个实例
D. 引用所指向的实例不可能无效
C。
下面代码的执行结果是什么:
char ccString1[]="Is Page Fault??";
char ccString2[]="No Page Fault??";
strcpy(ccString1,"No");
if(strcmp(ccString1,ccString2)==0)
cout<<ccString2;
else
cout<<ccString1;
A. No
B. No Page Fault??
C. Is Page Fault??
D. 其他三项都错
A。 执行strcpy(ccString1,"No"); ,ccString1变为"No\0Page Fault??",会将字符串的结束符'\0'放入,所以比较时返回false,执行cout << ccString1; 输出时遇到结束符'\0'就结束,只输出“NO”。
一维字符数组的输入:char str[21] ;cin >> str;说法是否正确?
A. 正确
B. 错误
正确
char是有符号还是无符号类型()
A. 有符号
B. 无符号
C. 取决于具体实现
C。C标准规定为 Implementation Defined(由实作环境决定)。
arm-linux-gcc 规定 char 为 unsigned char
vc 编译器、x86上的 gcc 规定 char 为 signed char
缺省情况下,编译器默认数据为signed类型,但是char类型除外。
以下哪些做法是不正确或者应该极力避免的:( )
A. 构造函数声明为虚函数
B. 派生关系中的基类析构函数声明为虚函数
C. 构造函数中调用虚函数
D. 析构函数中调用虚函数
ACD
下面关于C++lambda 表达式说法正确的有
A. [ capture ] ( params ) -> ret { body } 这是一个完整的 lambda 表达式形式
B. capture 值为[a,&b]表示 a变量以值的方式呗捕获,b以引用的方式被捕获
C. capture为[=]表示不捕获外部的任何变量
D. lambda 表达式是属于C++14的新特性
B。来源
以下程序
int main(){
char str[][10] = {"China", "Beijing"}, *p = (char*)str;
printf("%s\n", p + 10);
}
程序运行后的输出结果是()
A. China
B. Bejing
C. ng
D. ing
B
关于虚函数,以下说法正确的是?
A. 虚函数不能定义为private
B. 虚函数不可以被子类覆盖
C. 子类不能调用父类private的虚函数
D. 虚函数的重载性和它声明的权限有关
C。1.虚函数的重载与参数的个数或者返回者类型相关。
2.而虚函数声明的权限决定了能否被继承的子类进行重写,强调的是多态。
3.C++中 虚函数可以为private,并且可以被子类覆盖
若要定义一个只允许本源文件中所有函数使用的全局变量,则该变量需要使用的存储类型是()
A. extern
B. register
C. auto
D. static
D
A,外部变量,可供所以源文件使用
B,寄存器变量,放在寄存器而非内存中,效率更高,一般是临时变量
C,自动变量,所有未加 static 关键字的都默认是 auto 变量,也就是我们普通的变量
D,静态变量,在内存中只存在一个,可供当前源文件的所有函数使用
#include <stdio.h>
void g1(int *a, int n, int i){
while (2 * i <= n){
int j = 2 * i;
int v = a[j - 1];
if (j < n && v < a[j]){
v = a[j];
j += 1;
}
if (a[i - 1] < v){
int tmp = a[i - 1];
a[i - 1] = v;
a[j - 1] = tmp;
i = j;
} else{
break;
}
}
}
int g2(int *a, int n, int m){
int i;
for (i = n / 2; i > 0; --i)
g1(a, n, i);
for (i = 0; i < n && a[i] != m; ++i);
int j = 0;
for (++i; i > 0; i /= 2)
++j;
return j;
}
int main(int argc, char* argv[]){
int a[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16};
int n = sizeof(a) / sizeof(a[0]);
printf("%d", g2(a, n, 8));
return 0;
}
A. 3
B. 4
C. 5
D. 7
B。来源
多态类中的虚函数表建立在()
A. 编译阶段
B. 运行阶段
C. 构造函数被调用时进行初始化的
D. 类声明时
虚表是在编译时创建的,虚指针是在运行时才初始化的
以下变量分配在BSS段的是()
char s1[100];
int s2 = 0;
static int s3 = 0;
int main() {
char s4[100];
}
A. s1
B. s2
C. s3
D. s4
A。
- BSS段:通常是指用来存放程序中未初始化的全局变量的一块内存区域;
- 数据段:通常是指用来存放程序中 已初始化的全局变量 的一块内存区域,static意味着在数据段中存放变量;
- 代码段:通常是指用来存放 程序执行代码 的一块内存区域;
- 堆:存放进程运行中被动态分配的内存段,它的大小并不固定,可动态扩张或缩减,这一块在程序运行前就已经确定了;
- 栈:栈又称堆栈, 存放程序的 局部变量 (不包括static声明的变量)。除此以外,在函数被调用时,栈用来传递参数和返回值。
写出表达式b!=3&&5/a>a+b的结果,设a=3,b=4。
A. ture
B. false
C. 1
D. 2
B
#include<iostream>
using namespace std;
void main() {
int a = 1, b = 2;
cout << (a = a + 1, b + a, b + 3) << '\t';
cout << a, b + a, b + 3;
}
程序输出为___________
5 2
下面程序的输出结果是
char *p1 = "123", *p2 = "ABC", str[50]= "xyz";
strcpy(str + 2, strcat(p1, p2));
cout << str;
A. xyz123ABC
B. z123ABC
C. xy123ABC
D. 出错
D
1.在 C++ 代码中,char * p1 = "123";会编译报错。
2.即使在 C 代码中,char * p1 = "123";编译通过,由于 p1,p2 都是常量,所以通过 strcat(p1,p2) 会报错。
如下代码段,哪种描述是正确的()
#include <iostream>
using namespace std;
class A{ /*...*/ };
void f(const A** p) { /*...*/};
void g(const A* const *P) { /*...*/ };
void k(const A *&P) { /*...*/ };
int main() {
const A *ca = new A();
A *a = new A();
A **p = &a;
k(ca); //[1]
f(p); //[2]
g(p); //[3]
return 0;
}
A. 全部正确
B. 2错,1,3正确
C. 1,2错,3正确
D. 1正确,2,3,错
B。来源
下面这个程序执行后会有什么错误或者效果:
#define MAX 255
int main(){
unsigned char A[MAX], i;
for (i = 0; i <= MAX; i++)
A[i] = i;
}
A. 数组越界
B. 死循环
C. 栈溢出
D. 内存泄露
AB。
数组下标范围是0~MAX-1,当循环到i = MAX时,A[i] = A[MAX],此时数组发生了越界
i的类型是unsigned char,即i的取值范围是0~255,所以当i = 255时,i + 1 = 255 + 1后会导致i = 0,因此for (i = 0; i <= MAX; i++)会一直循环下去
下面C++程序的输出是_________。
void f(char * x)
{
x++;
*x='a';
}
int main()
{
char str [sizeof("hello")];
strcpy(str, "hello");
f(str);
cout<<str;
return 0;
}
A. hello
B. hallo
C. allo
D. 以上都不是
B。指针虽然传进去了,里面的值相应的会发生改变,但是这里的指针相当于函数的值传递,所以不改变原指针的指向。要想改变指针的指向,得用指针的指针。
可以重写私有的虚方法。()
A. T
B. F
A
对于以下C++程序代码输出是_____。
#include <iostream>
using namespace std;
int main(void)
{
const int a = 10;
int * p = (int *)(&a);
*p = 20;
cout<<"a = "<<a<<", *p = "<<*p<<endl;
return 0;
}
A. 编译阶段报错运行阶段报错
B. a = 10, *p = 10
C. a = 20, *p = 20
D. a = 10, *p = 20
E. a = 20, *p = 10
D。const变量在编译期会被编译期编译成一张常量表,所有读取常量的操作都会从这个常量表里直接读取(其实是在编译时编译器用表里面的对应值替换,这就是所谓的常量折叠),但当const变量是一个局部变量时,如果对const变量使用取地址
&操作赋给某个指针值或者使用extern声明,此时会在栈上被分配内存空间,并且通过指针的操作都是对栈上的空间进行操作,对常量表的内容不会有任何影响。
enum string{
x1,
x2,
x3 = 10,
x4,
x5,
} x;
函数外部访问x等于什么?
A. 5
B. 12
C. 0
D. 随机值
C。枚举变量是全局变量的情况下, 枚举值的缺省值是0,不是枚举的第一个值。
函数调用exec((vl,v2),(v3,v4),v5,v6);中,实参的个数是:
A. 3
B. 4
C. 5
D. 6
B。函数原型exec((vl,v2),(v3,v4),v5,v6); 用括号括起来的两个形参组成是一个逗号运算符组成的表达式 C语言中逗号运算符返回最后一个参数作为表达式的值 所以(vl,v2)和(v3,v4)是两个逗号表达式,相当于两个实参 所以一共4个实参
#include <iostream>
using namespace std;
class MD {
protected:
float miles;
public:
void setDist(float d) { miles = d; }
virtual float getDist() { return miles; }
float square() { return getDist()*getDist(); }
};
class FeetDist : public MD {
protected:
float feet;
public:
void setDist(float);
float getDist() { return feet; }
float getMiles() { return miles; }
};
void FeetDist::setDist(float ft) {
feet = ft;
MD::setDist(feet / 2);
}
int main() {
FeetDist feet;
feet.setDist(8);
cout << feet.getDist() << "," << feet.getMiles() << "," << feet.square() << endl;
return 0;
}
A. 8,4,16
B. 8,4,64
C. 8,8,64
D. 其他几项都不对
B。当子类和父类成员函数的返回值参数相同,函数名相同,有virtual关键字,则由对象的类型决定调用哪个函数。因为虚函数的存在,这道题的getDist()调用的是子类的的成员函数。
下列格式控制符,既可以用于输入,又可以用于输出的是()
A. setbase
B. setfill
C. setprecision
D. setw
A。来源
if ((ch - d) > 2) if (ch > d) ch = ch + 2;
else ch = d + 2;
以上语句中else与第_________个if语句嵌套(从左往右分为第一、第二)
A. 1
B. 2
B。C/C++语言规定,else连接到在同一层中最接近它而又没有其他else语句与之相匹配的if语句。
关于异常处理,哪些说法是错误的 。
A.在 C++程序中,由 throw 表达式抛出异常,而该表达式应直接或间接地被包含在 try 块中。
B.当抛出异常后,寻找匹配的 catch 子句有固定的过程:逆着程序函数的调用链返回,称为栈展开(Stack Unwinding)。
C.当某条语句抛出异常时,跟在其后的语句将被跳过,但析构函数仍然执行, 所以应该在析构函数中释放资源。
D.catch 子句实际是一个特殊的函数。
D。
以下程序输出结果是_____。
#include <iostream>
using namespace std;
class A{
public:
A ():m_iVal(0){test();}
virtual void func() { std::cout<<m_iVal<<' ';}
void test(){func();}
public:
int m_iVal;
};
class B : public A{
public:
B(){test();}
virtual void func(){
++m_iVal;
std::cout << m_iVal << ' ';
}
};
int main(int argc ,char* argv[]){
A*p = new B;
p->test();
return 0;
}
A. 1 0
B. 0 1
C. 0 1 2
D. 2 1 0
E. 不可预期
F. 以上都不对
C。调用顺序:
A()→test()→A::func()→B()→test()→B::func()→test()→B::func()构造函数中调用虚函数,虚函数表现为该类中虚函数的行为,即在父类构造函数中调用虚函数,虚函数的表现就是父类定义的函数的表现。原因如下:
假设构造函数中调用虚函数,表现为普通的虚函数调用行为,即虚函数会表现为相应的子类函数行为,并且假设子类存在一个成员变量int a;子类定义的虚函数的新的行为会操作a变量,在子类初始化时根据构造函数调用顺序会首先调用父类构造函数,那么虚函数回去操作a,而因为a是子类成员变量,这时a尚未初始化,这是一种危险的行为,作为一种明智的选择应该禁止这种行为。所以虚函数会被解释到基类而不是子类。
(二)简答题
1.《C++Primer》(第五版)P.716 练习18.27
struct Base1 {
void print(int) const;
protected:
int ival;
double dval;
char cval;
private:
int *id;
};
struct Base2 {
void print(double) const;
protected:
double fval;
private:
double dval;
};
struct Derived : public Base1 {
void print(std::string) const;
protected:
std::string sval;
double dval;
};
struct MI : public Derived, public Base2 {
void print(std::vector<double>);
protected:
int *ival;
std::vector<double> dvec;
};
1.已知如上所示的继承体系,下面对print的调用为什么是错误的?适当修改MI,令其对print的调用可以编译通过并正确执行。MI mi; mi.print(42);
① 没有匹配的print调用
② 当注释void print(std;:vector)时又会出现二义性;故为该函数定义一个新版本。
2.已知如上所示的继承体系,同时假定为MI添加了一个名为foo的函数:
int ival;
double dval;
void MI::foo(double cval)
{
int dval;
//练习中的问题发生在此处
}
(a) 列出在MI::foo中可见的所有名字。
(b) 是否存在某个可见的名字是继承自多个基类的?
(c) 将Base1的dval成员与Derived 的dval 成员求和后赋给dval的局部实例。
(d) 将MI::dvec的最后一个元素的值赋给Base2::fval。
(e) 将从Base1继承的cval赋给从Derived继承的sval的第一个字符。
(a)MI::foo中可见的所有名字有:ival,dval, cval, sval, fval, dvec和print
(b)Dval和print
(c)dval = Base1::dval + Derived::dval;
(d)fval = dvec.back()。
(e)sval[0] = cval。
2.《C++Primer》(第五版)P.719 练习18.28
已知存在如下的继承体系,在 VMI 类的内部哪些继承而来的成员无须前缀限定符就能直接访问?哪些必须有限定符才能访问?说明你的原因。
struct Base {
void bar(int);
protected:
int ival;
};
struct Derived1 : virtual public Base {
void bar(char);
void foo(char);
protected:
char cval;
};
struct Derived2 : virtual public Base {
void foo(int);
protected:
int ival;
char cval;
};
class VMI : public Derived1, public Derived2 { };
无需限定符的成员:
- Derived1::bar(bar不仅是Base的成员,也是Derived1的成员,派生类的bar比共享虚机类的bar优先级更高);
- Derived2::ival(派生类Derived2的ival比共享虚机类的ival优先级更高);
需要限定符的成员:
- foo(Derived1和Derived2都存在该成员);
- cval(Derived1和Derived2都存在该成员);
- 其他需要限定符的原因为会被覆盖。
3.《C++Primer》(第五版)P.721 练习18.29
class Class { ... };
class Base : public Class { ... };
class D1 : virtual public Base { ... };
class D2 : virtual public Base { ... };
class MI : public D1, public D2 { ... };
class Final : public MI, public Class { ... };
(a) 当作用于一个Final对象时,构造函数和析构函数的执行次序分别是什么?
(b) 在一个Final对象中有几个Base部分?几个Class部分?
(c) 下面的哪些赋值运算符将造成编译错误?
Base *pb; Class *pc; MI *pmi; D2 *pd2;
(a) pb = new Class;
(b) pc = new Final;
(c) pmi = pb;
(d) pd2 = pmi;
(a)构造函数执行次序Class、Base、D1、D2、MI、Class、Final,析构函数执行次数与上述相反;
(b)一个Base两个Class;
(c)(a)编译错误,(b)编译错误,Class是Final的一个二义基类(c)编译错误,(d)正确。
(三)读程题
#include<iostream>
#include<string>
using namespace std;
class Sample {
string tips;
public:
Sample(string t) :tips(t) { cout << "Constructor of " << tips << " called." << endl; }
~Sample() { cout << "Destructor of " << tips << " called." << endl; }
};
Sample g1("v_Global_1");
static Sample g2("v_Global_2");
void f() {
static Sample v_sl("v_StaticLocal");
Sample v_l("v_Local_f");
}
int main() {
Sample v_lm("v_Local_main");
cout << "--------------<before f>---------------" << endl;
f();
cout << "--------------<after f>---------------" << endl;
return 0;
}
/*输出:
Constructor of v_Global_1 called.
Constructor of v_Global_2 called.
Constructor of v_Local_main called.
--------------<before f>---------------
Constructor of v_StaticLocal called.
Constructor of v_Local_f called.
Destructor of v_Local_f called. //离开作用域自动调用析构函数
--------------<after f>---------------
Destructor of v_Local_main called.
Destructor of v_StaticLocal called.
Destructor of v_Global_2 called. //全局对象最后析构
Destructor of v_Global_1 called.
*/
#include<iostream>
using namespace std;
class Base {
int x;
public:
virtual void set(int b) { x = b; }
int get() { return x; }
};
class Derived :public Base {
int y;
public:
void set(int d) { y = d; }
int get() { return y; }
};
int main() {
Base B_obj;
Derived D_obj;
Base *p = &B_obj;
p->set(100);
cout << "B_obj x=" << p->get() << endl;
p = &D_obj;
p->set(200);
p->Base::set(300);
cout << "B_obj x=" << p->Base::get() << endl;
p->set(p->get() + 200);
cout << "D_obj y=" << p->get() << endl;
return 0;
}
/*输出:
B_obj x=100
B_obj x=300
D_obj y=300
*/
#include<iostream>
#include<string>
using namespace std;
class A {
int x, y;
public:
A(int newx, int newy) :x(newx), y(newy) { cout << "1" << endl; }
A(const A &a) { cout << "2" << endl; }
~A() { cout << "3" << endl; }
};
A f() {
return A(1, 2);
}
int main(){
f();
return 0;
}
/*输出:
1
2
3
3
*/
#include<iostream>
#include<string>
using namespace std;
void main() {
int d1 = 5, d2 = 7.5, d3 = 20.0;
float a = 4.0, b = 1.5;
int t1 = d1 + d2 / b * a;
cout << t1 << endl;
}
/*输出:
23
*/
#include<iostream>
using namespace std;
class AA {
public:
AA(int i, int j) {
A = i;
B = j;
cout << "Constructing(" << A << "," << B << ").\n";
}
~AA() { cout << "Destructed(" << A << "," << B << ").\n"; }
void print() { cout << A << "," << B << endl; }
private:
int A, B;
};
void main() {
AA *al, *a2;
AA a3(3, 4), a4(7, 8);
al = new AA(1, 2);
a2 = new AA(5, 6);
al->print();
a3.print();
a2->print();
a4.print();
delete al;
delete a2;
}
/*输出:
Constructing(3,4).
Constructing(7,8).
Constructing(1,2).
Constructing(5,6).
1,2
3,4
5,6
7,8
Destructed(1,2).
Destructed(5,6).
Destructed(7,8).
Destructed(3,4).
*/
#include<iostream>
using namespace std;
class value {
private:
int a;
public:
value(int i = 1) { a = i; }
void list() { cout << a << " "; }
};
value data1[4];
value data2[4] = { 10, 20, 30 };
void main() {
for (int i = 0; i < 4; i++) {
data1[i].list();
data2[i].list();
cout << endl;
}
}
/*输出:
1 10
1 20
1 30
1 1
*/
#include <iostream>
using namespace std;
static int n3 = 0;
void function(char s[]) { s[n3++] += 2; }
void main()
{
char str[10] = "abcd";
cout << str << endl;
int n1 = 1, n2 = strlen(str);
cout << n2 << endl;
while (n1++ <= n2)
function(str);
cout << n1 << endl;
cout << n3 << endl;
cout << str << endl;
}
/*输出:
abcd
4
6 //这里是6,不是5
4
cdef
*/
#include<iostream>
#include<vector>
using namespace std;
void main() {
char s1[20];
cin >> s1; // 输入: hello world
cout << "s1=" << s1 << endl;
cout << "s1:" << strlen(s1) << endl;
char s2[] = "Hello C\0++";
cout << "s2:" << strlen(s2) << endl;
}
/*输出:
hello world
s1=hello
s1:5
s2:7
*/
#include<iostream>
using namespace std;
int main()
{
int a = 4, b = 3, c = 0;
for (int k = 0; k < 4; k++)
{
switch (--a > 0)
{
case 1:
{
switch (--b)
{
case 2:cout << "&"; break;
case 1:cout << "@"; break;
}
}
case 0:
{
switch (c++)
{
case 0:cout << "#";
case 1:cout << "*";
case 2:cout << "%";
}
}
break;
}
cout << "!" << endl;
}
return 0;
}
/*输出:
&#*%!
@*%!
%!
!
*/
#include<iostream>
using namespace std;
int fun(int i);
void main()
{
int i = 1;
switch (i){
default: i++; break;
case 0: i++; fun(i);
case 1: i++; fun(i);
case 2: i++; fun(i);
}
cout << i << '\n';
}
int fun(int i)
{
static int k = 10;
i++; k++;
cout << k << '\n';
return k;
}
/*输出:
11
12
3
*/
#include<iostream>
#include<string>
using namespace std;
void main()
{
int a, b = 5;
cin >> a;
switch (a > 0)
{
case 1:
switch (b < 10) {
case 0: cout << "*" << endl;
case 1: cout << "#" << endl;
}
default: cout << "!\n";
case 0:
switch (b > 0) {
case 0: cout << "ok1\n";
case 1: cout << "ok2\n";
}
}
}
/*
输入:1
输出:#
!
ok2
*/
/*
输入:0
输出:ok2
*/
#include <iostream>
#include <string>
using namespace std;
char s(char *w, int y)
{
char t, *s1, *s2;
s1 = w;
s2 = w + y + 5;
while (s1 > s2)
{
t = *s1++; *s1 = *s2--; *s2 = t;
return *s1;
}
return *s1 + 2;
}
void main(void)
{
char p[] = "123";
cout << s(p, strlen(p));
}
/*输出:
3
*/
#include<iostream>
#include<string>
#include<iomanip>
using namespace std;
void fun(int *a, int *b)
{
int *c;
c = a; a = b; b = c;
}
int main()
{
int x = 7, y = 19;
int *p = &x, *q = &y;
cout << *p << " " << *q << endl;
fun(p, q);
cout << *p << " " << *q << endl;
return 0;
}
/*输出:
7 19
7 19
*/
#include <iostream>
using namespace std;
class A
{
public:
int n;
A() { cout << "A"; }
};
class B :public A
{
public:
B() { cout << "B"; }
};
class C :public B
{
A a;
public:
C() :a(), B() { cout << "C"; }
};
void main(void)
{
C c;
}
/*输出:
ABAC
*/
#include <iostream>
using namespace std;
class Base
{
protected:
int *p;
public:
Base(int a = 0)
{
p = new int(a);
}
~Base()
{
delete p;
}
virtual void print()
{
cout << "p->" << *p << endl;
}
};
class Derived :public Base
{
static int y;
public:
Derived(int b = 0)
{
*p = b; y++;
}
void print()
{
cout << *p << ',' << y << endl;
}
};
int Derived::y = 100;
void main(void)
{
Derived d(50);
Base *pb = &d;
pb->print();
Derived d1(20);
d1.print();
}
/*输出:
50,101
20,102
*/
#include <iostream>
using namespace std;
class B
{
int a, b;
public:
B(int aa = 0, int bb = 0) { a = aa; b = bb; }
void operator ++();
void operator ++(int);
void show() { cout << a << '\t' << b; }
};
void B:: operator ++()
{
a += 2;
b += 5;
}
void B:: operator ++(int)
{
a += 5;
b += 2;
}
void main(void)
{
B x(3, 5);
x++;
x.show();
}
/*输出:
8 7
*/
#include <iostream>
using namespace std;
class A
{
public:
A(int n) { num = n; }
int compare(A a)
{
if (this->num == a.num)return 1;
else return 0;
}
private:
int num;
};
void main(void)
{
A aa(5);
A bb(10);
A cc(5);
cout << aa.compare(bb) << '\t';
cout << cc.compare(aa) << endl;
}
/*输出:
0 1
*/
#include<iostream>
#include<string>
#include<iomanip>
using namespace std;
class Base {
public:
virtual void set(int b) {
x = b;
}
int get() {
return x;
}
private:
int x;
};
class Derived :public Base {
public:
void set(int d) {
y = d;
}
int get() {
return y;
}
private:
int y;
};
int main()
{
Base B_obj;
Derived D_obj;
Base *p = &B_obj;
p->set(100);
cout << "B_obj x=" << p->get() << endl;
p = &D_obj;
p->set(200);
p->Base::set(300);
cout << "B_obj x=" << p->Base::get() << endl;
p->set(p->get() + 200);
cout << "D_obj x=" << p->get() << endl;
}
/*输出:
B_obj x=100
B_obj x=300
D_obj x=300
*/
#include <iostream>
using namespace std;
int f(int x) { cout << "f1 ="; return x; }
int f(char a, char b = 0)
{
cout << "f2 ="; return (a > b ? 1 : -1);
}
double f(double &x)
{
cout << "f3 ="; x += sizeof(x); return 0;
}
int main()
{
short a = 0;
char c = 'A';
double y;
y = f(0);
cout << y << endl;
y = f(a);
cout << y << endl;
y = f(c);
cout << y << endl;
y = f(a, c);
cout << y << endl;
f(y);
cout << y << endl;
return 0;
}
/*输出:
f1 =0
f1 =0
f2 =1
f2 =-1
f3 =7
*/
#include <iostream>
using namespace std;
char gid = 'A';
class Number
{
private:
int i;
char id;
public:
Number(int x = 0)
{
i = x;
id = gid++;
cout << "Constructor Number:" << id << i << endl;
}
Number(const Number &x)
{
i = x.i;
id = gid++;
cout << "Copy Number:" << id << i << endl;
}
~Number() { cout << "Destructor Number:" << id << i << endl; }
Number operator+(const Number &x);
};
Number Number::operator+(const Number &x)
{
Number result(i + x.i);
return result;
}
int main()
{
Number x(1), y;
y = x + 2;
return 0;
}
/*输出:
Constructor Number:A1
Constructor Number:B0
Constructor Number:C2
Constructor Number:D3
Copy Number:E3
Destructor Number:D3
Destructor Number:E3
Destructor Number:C2
Destructor Number:E3
Destructor Number:A1
*/
#include<iostream>
using namespace std;
void main(void)
{
int a[4][4] = { 1,2,3,4,2,2,5,6,3,5,2,7,4,6,4,7 };
int i, j, flag = 0, sum = 0;
for (j = 0; j < 4; j++)
for (i = 0; i <= j; i++) {
if (a[j][i] == a[i][j])
{
sum += a[i][j];
continue;
}
flag = 1;
}
if (flag)cout << "No!" << endl;
else cout << "All Right!" << endl;
cout << "sum=" << sum << endl;
}
/*输出:
No!
sum=32
*/
#include<iostream>
#include<string>
#include<iomanip>
using namespace std;
class Base{
public:
virtual void func1() { cout << "Base::func1" << endl; }
void func2() { cout << "Base::func2" << endl; }
};
class Derived:public Base{
public:
void func1() { cout << "Derived::func1" << endl; }
virtual void func2() { cout << "Derived::func2" << endl; }
};
void main() {
Derived d;
Base *p = &d;
p->func1(); //多态
p->func2(); //不是多态
}
/*输出:
Derived::func1
Base::func2
*/
#include <iostream>
using namespace std;
class Sample1 {
public:
Sample1() { cout << "Constructor of Sample called." << endl; }
~Sample1() { cout << "Destructor of Sample called." << endl; }
};
class Sample2 {
public:
Sample2() { cout << "Constructor of Sample called." << endl; throw 1; }
~Sample2() { cout << "Destructor of Sample called." << endl; }
};
void f1() {
try {
Sample1 s;
throw 1;
}
catch (int) {
cout << "出现异常" << endl;
}
}
void f2() {
try {
Sample2 s;
}
catch (int) {
cout << "出现异常" << endl;
}
}
int main()
{
f1();
cout << "-----------------" << endl;
f2();
return 0;
}
/*输出:
Constructor of Sample called.
Destructor of Sample called.
出现异常
-----------------
Constructor of Sample called.
出现异常
*/
#include <iostream>
using namespace std;
int x[3][3] = { {1,2, 3}, {4,5,6},{7,8,9} };
int *p[3] = { x[0], x[1], x[2] };
void main() {
for (int i = 0; i < 3; i++)
cout << *p[i] << " " << *(p[i] + 2) << endl;
}
/*输出:
1 3
4 6
7 9
*/
(四)程序填空
#include <iostream>
using namespace std;
int f(char *s1, char *s2)
{
char *p = s1, *q = s2;
while (①___________)
{
q++;
p++;
}
return (②___________);
}
void main(void)
{
char s1[100], s2[100];
cin.getline(s1, 100);
cin.getline(s2, 100);
cout << f(s1, s2);
}
①
*p != '\0' && *p == *q判断当前两个字符是否相等的同时也需要判断是否达到字符串的末尾,这里判断结尾只判断其中一个字符串或者两个字符串都判断两种方法都可以,因为如果是q先达到末尾,则&&的第二个条件肯定不满足②
*p == *q
若一头小母牛从出生第四个年头开始每年生一头母牛,按此规律,第 n 年时总共会有多少头母牛。采用递推算法。
#include<iostream>
using namespace std;
void main() {
int n, i;
long a = 0, b = 0, c = 0, d = 1, temp; //a是3岁及以上母牛数,b是2岁,c是1岁,d是0岁
cout << "请输入年数n: ";
cin >> n;
cout << endl;
for (i = 1; i < n; i++) {
①___________; //第n年时,3岁及以上母牛数
②___________; //第n年时,2岁母牛数
③___________; //第n年时,1岁母牛数
④___________; //第n年时,新生牛数
}
cout << "第n年总共有" << ⑤___________ << "头母牛。" << endl;
}
① a+=b ② b=c ③ c=d ④ d=a ⑤a+b+c+d
template<typename T>class List;
template<typename T>class Node {
T info; //数据域
Node<T> *link; //指针域
public:
Node(); //生成头结点的构造函数
Node(const T & data); //生成一般结点的构造函数
friend class List<T>;
//省略其他成员函数定义
};
template<typename T>class List {
Node<T> *head, *tail; //链表头指针和尾指针
public:
List(); //构造函数,生成头结点(空链表)
List(List<T> &); //拷贝构造函数
~List(); //析构函数
//其它成员函数略
};
template<typename T>List<T>::List(List<T> & ls) { //拷贝构造函数
Node<T>* TempP = ls.head->link, *P1;
head = tail = ①__________;//动态建立链表的头结点
while (TempP != NULL) {
P1 = new Node<T>(②__________);//复制一个链表结点
P1->link = tail->link;//向后生成链表
③___________;
tail = P1;
④___________;//准备复制ls的下一个结点
}
}
①
new Node<T>()②
TempP->info③
tail->link=P1④
TempP=TempP->link
以下程序定义了一个链表类 List,其元素为整型数据结点。链表可以通过流运算符从当前目录中的文件“ListA.txt”中读取数据,再向控制台输出。本程序的执行流程是,创建链表对象并通过文件设置链表初值,然后向链表中添加一些数据。请按以上说明和要求将下面程序补充完整,并调试运行。
//此处添加代码
class List;
ostream& operator<<(ostream &os, List &a);
istream& operator>>(istream &, List &);
class Node
{
public:
int info; //数据域
Node *link; //指针域
Node(const int data = 0) { info = data; link = NULL; }
};
class List
{
Node *head, *tail;
public:
List(); ~List();
void Empty(); //清空整个链表
List &operator+=(const Node &a); //在当前表的最后添加一个元素
friend ostream& operator<<(ostream &, List &); //用于直接输出链表对象
friend istream& operator>>(istream &, List &); //用于从文件输入链表对象
};
List::List()
{
//此处添加代码
}
List::~List()
{
Empty();
delete head;
}
void List::Empty()
{
//此处添加代码
}
List& List::operator+=(const Node &a)
{
//此处添加代码
}
ostream& operator<<(ostream &os, List &a)
{
//此处添加代码
}
istream& operator>>(istream &fs, List &a)
{
//此处添加代码
}
int main()
{
List list; //创建链表
fstream file;
file.open("ListA.txt", ios::in);
if (!file)
{
cout << "Can not open input file!\n" << endl;
return 0;
}
file >> list;
file.close();
file.clear();
cout << list;
for (int i = 0; i < 3; i++) //向链表中添加 3 个结点
{
Node node(i);
list += node;
}
cout << "当前链表内容:" << endl;
cout << list;
return 0;
}
/*
【题目】以下程序定义了一个链表类 List,其元素为整型数据结点。链表可以通过
流运算符从当前目录中的文件“ListA.txt”中读取数据,再向控制台输出。
【说明】本程序的执行流程是,创建链表对象并通过文件设置链表初值,然后向链
表中添加一些数据。请按以上说明和要求将下面程序补充完整,并调试运行。*/
#include<iostream>
#include<fstream>
using namespace std;
class List;
ostream& operator<<(ostream &os, List &a);
istream& operator>>(istream &, List &);
class Node
{
public:
int info; //数据域
Node *link; //指针域
Node(const int data = 0) { info = data; link = NULL; }
};
class List
{
Node *head, *tail;
public:
List(); ~List();
void Empty(); //清空整个链表
List &operator+=(const Node &a); //在当前表的最后添加一个元素
friend ostream& operator<<(ostream &, List &); //用于直接输出链表对象
friend istream& operator>>(istream &, List &); //用于从文件输入链表对象
};
List::List()
{
head = nullptr;
tail = nullptr;
ifstream fin("ListA.txt");
if (!fin)
cerr << "can't open the file" << endl;
Node *node = new Node(), *tmp;
tail = node;
while (fin >> node->info) {
tmp = head;
head = node;
head->link = tmp;
node = new Node();
}
delete node;
}
List::~List()
{
Empty();
delete head;
}
void List::Empty()
{
if (head == tail && head == nullptr)
return;
Node *p, *q;
for (p = head, q = head->link; p != tail; p = q, q = q->link) {
delete p;
}
delete p;
head = tail = nullptr;
}
List& List::operator+=(const Node &a)
{
tail->link = new Node(a);
tail = tail->link;
tail->link = nullptr;
return *this;
}
ostream& operator<<(ostream &os, List &a)
{
for (Node *p = a.head; p != nullptr; p = p->link)
os << p->info << " ";
return os;
}
istream& operator>>(istream &fs, List &a)
{
a.head = nullptr;
a.tail = nullptr;
Node *node = new Node(), *tmp;
a.tail = node;
while (fs >> node->info) {
tmp = a.head;
a.head = node;
a.head->link = tmp;
node = new Node();
}
delete node;
return fs;
}
int main()
{
List list; //创建链表
fstream file;
file.open("ListA.txt", ios::in);
if (!file){
cout << "Can not open input file!\n" << endl;
return 0;
}
file >> list;
file.close();
file.clear();
cout << list << endl;
for (int i = 0; i < 3; i++) //向链表中添加 3 个结点
{
Node node(i);
list += node;
}
cout << "当前链表内容:" << endl;
cout << list << endl;;
return 0;
}
下列程序为线性表插入一个新元素,请加插入元素的算法补全
#include<iostream>
using namespace std;
template <typename T, int size>class seqlist {
T slist[size]; //存放顺序表的数组
int Maxsize; //最大可容纳项数
int last; //已存表项的最后位置
public:
seqlist() { last = -1; Maxsize = size; } //初始化为空表
bool Insert(const T & x, int i); //x插入到列表中第i个位置处(下标)
T Get(int i) { return i<0 || i>last ? NULL : slist[i]; } //取第i个元素之值
//其他成员函数略
};
template <typename T, int size> bool seqlist<T, size>::Insert(const T & x, int i) {
...//此处添加代码
}
int main() {
seqlist <int, 100> seqlisti; //顺序表对象seqlisti的元素为整型
int i, j, k, a[10] = { 2,3,5,11,13,17,19,23,29 };
for (j = 0; j < 9; j++) seqlisti.Insert(a[j], j); //把素数写入
for (i = 0; i < 9; i++) cout << seqlisti.Get(i) << ' '; //打印出素数表
cout << endl;
seqlisti.Insert(7, 3);
for (i = 0; i < 10; i++) cout << seqlisti.Get(i) << ' '; //打印出添加素数7后的素数表
cout << endl;
return 0;
}
补全如下:
template <typename T, int size> bool seqlist<T, size>::Insert(const T & x, int i) { int j; if (i<0 || i>last + 1 || last == Maxsize - 1) return false; //插入位置不合理,不能插入(稳健性) else { last++; for (j = last; j > i; j--) slist[j] = slist[j - 1];//从表最后位置向前依次后移,空出指定位置 slist[i] = x; return true; } }
以下是一个链表类模板的应用程序,链表的节点为结构体,包含一个数据域和一个指 针域,其中数据域的类型参数化。链表类的数据成员为指向节点的指针。各函数成员功能 参见注释行。该链表为空链表的标志是头指针和尾指针同指向一个头节点(链表有效数据 从该节点的下一个节点开始)。请完成程序空缺部分。
template<typename T>struct Node {
T info; //数据域
Node<T> *link; //指针域
};
template<typename T>class List {
Node<T> *head, *tail; //头指针和尾指针
public:
List(); //生成头结点(空链表) ~List();
void MakeEmpty(); //清空链表,只余头结点
Node<T>* Find(T data); //搜索值为 data 的结点,返回结点地址
void PrintList(); //打印链表的数据域
void InsertRear(Node<T>* p); //在链尾添加结点,可用来正向生成链表
Node<T>*CreatNode(T data); //创建一个值为 data 的孤立结点
T DeleteNode(Node<T>* p); //删除指定结点,返回该节点值
};
template<typename T>List<T>::List() { //建立空链表,仅创建头节点
head = tail = new Node<T>;
head->link = NULL;
}
template<typename T>
List<T>::~List() {
①______________; //先清空链表
delete head; //释放头结点
}
template<typename T>void List<T>::MakeEmpty() {
Node<T> *tempP;
while (head->link != NULL) {
tempP = head->link;
head->link = ②______________; //把头结点后的第一个节点从链中脱离
delete tempP; //删除(释放)脱离下来的结点
}
tail = head; //表头指针与表尾指针均指向表头结点,表示空链
}
template<typename T>Node<T>* List<T>::Find(T data) {
Node<T> *tempP = head->link;
while (③______________ && ④______________)
//数未找到同时链表未搜完则继续搜索
tempP = tempP->link;
return tempP; //搜索成功返回该结点地址,不成功返回 NULL
}
template<typename T>void List<T>::PrintList() {
Node<T>* tempP = head->link;
while (tempP != NULL) {
cout << tempP->info << '\t';
tempP = tempP->link;
}
cout << endl;
}
template<typename T>void List<T>::InsertRear(Node<T> *p) {
p->link = tail->link;
⑤______________; //p 节点连到链尾
tail = p;
}
template<typename T>Node<T>* List<T>::CreatNode(T data) { //创建值为 data 的孤立结点
Node<T>*tempP = ⑥______________; //建立 1 个结点
tempP->info = data;
⑦______________; //指针域不能悬浮
return tempP;
}
template<typename T> T List<T>::DeleteNode(Node<T>* p) {
T temp;
temp = p->info; //保存 p 节点值
Node<T>* tempP = head;
//用 tempP 找 p 节点的前节点:
while (tempP->link != NULL && ⑧______________) tempP = tempP->link;
//未找到就继续向后找。
if (tempP->link == tail) tail = ⑨______________; //p 节点是尾节点,修改尾指针
tempP->link = p->link; //将 p 节点从链表中脱离
delete p; //释放 p 节点空间
return temp;
}
int main() {
Node<int> * P1;
List<int> list1;
int i, j, m;
cout << "请输入 9 个整数:" << endl;
for (i = 0; i < 9; i++) {
cin >> m; //输入节点数据
P1 = ⑩______________; //创建孤立节点
list1.InsertRear(P1); //正向生成 list1
}
list1.PrintList();
cout << "请输入一个要求删除的整数" << endl;
cin >> j;
P1 = ⑪______________; //搜索值为 j 的节点
if (P1 != NULL) {
list1.DeleteNode(P1); //删除该节点
list1.PrintList();
}
else cout << "无该数据节点" << endl;
return 0;
}
① MakeEmpty()
② tempP->link
③ tempP->info!=data //③④ 可以互换
④ tempP!=NULL
⑤ tail->link=p
⑥ new Node
⑦ tempP->link=NULL
⑧ tempP->link!=p
⑨ tempP
⑩ list1.CreatNode(m)
⑪ list1.Find(j)
(五)编程题
注意:
- 返回值、分号不能漏;
- 输入输出看清楚往哪里输入输出;
判断某一年是否是闰年
/*
闰年:
(1)四年一闰百年不闰:即如果year能够被4整除,但是不能被100整除,则year是闰年。
(2)每四百年再一闰:如果year能够被400整除,则year是闰年。
*/
bool ifleapyear(int year) {
return (year % 4 == 0) && (year % 100 != 0) || (year % 400 == 0);
}
在不使用中间变量的情况下交换两个变量的数值
template<class T>
void myswap(T &a,T &b) {
a = a + b;
b = a - b;
a = a - b;
}
计算一个数的阶乘
long factorial(long n) {
if (n == 0)
return 1;
else
return n * factorial(n - 1);
}
字符串逆置(非递归)
void inverse(char str[]){
char tmp;
int i, j = strlen(str);
for (i = 0; i < (j / 2); i++){
tmp = str[i];
str[i] = str[j - i - 1];
str[j - i - 1] = tmp;
}
}
判断一个正整数是否是同构数,正整数范围[1, 10000],例如:376 * 376 = 14376,376出现在平方数中,376是同构数。
bool judge_isomorph(int num) {
if (num < 1 || num>10000)
return false;
string s = to_string(num * num);
return s.find(to_string(num)) != -1;
}
/*测试:376*376=14376,376是同构数*/
用递归求数组元素最小值的下标
/*方案一*/
template<class T>
int get_min_index(T* arr, int start, int len) {
if (start < len - 1) {
int min_index = get_min_index(arr, start + 1, len);
if (arr[min_index] < arr[start])
return min_index;
else
return start;
}
else return start;
}
//主调:get_min_index(arr, 0, sizeof(arr) / sizeof(arr[0]));
判断一个数是否是素数(试除法)
/*
一个数,如果有因子的话,那么在它的平方根数以内就应该有,否则就没有因子。
所以必定有一个因子不大于m的平方根。故判断m是否为素数,只要试除到m的平方根就可以了,不必一直到m-1。
*/
bool ifprime(int num) {
for (int i = 2; i <= sqrt(num); i++)
if (num%i == 0) {
return false;
}
return true;
}
判断一个数是否是素数(筛选法)
/*
1. 留下某个最先遇到的素数,将其所有的倍数从该数集中去掉,最后,数集中就全是素数了。
(如从2开始的某个连续整数集合,留下2,除去所有2的倍数,留下3,除去所有3的倍数,留下5,再除去所有5的倍数,如此等等。)
2. 接下来,要判断一个数是否为素数,可以该数为下标,访问素数集合。如果是,则为素数,否则不是素数。
*/
#include<iostream>
#include<vector>
using namespace std;
void main() {
/*生成素数判别序列*/
const int N = 100000;
vector<int> if_index_prime(N, 1);
if_index_prime[0] = 0; if_index_prime[1] = 0; //去掉0和1,这两个肯定不是素数
for (int i = 2; i < N; i++) {
if (if_index_prime[i]) {
for (int j = 2; i*j < N; j++)
if_index_prime[j*i] = 0;
}
}
/*待判别的数作为下标索引判别*/
int num = 111;
if (if_index_prime[num])
cout << num << " is a prime number" << endl;
else
cout << num << " is not a prime number" << endl;
}
验证哥德巴赫猜想:任何一个充分大的偶数都可以表示为两个素数之和。 例如:4=2+2,6=3+3,8=3+5,……,50=3+47 此题要求将 [START, END] 之间的所有偶数用两个素数之和表示。
#include<iostream>
#include<cmath>
using namespace std;
bool ifprime(int num) {
for (int i = 2; i <= sqrt(num); i++)
if (num%i == 0) {
return false;
}
return true;
}
void main() {
/*验证[START, END]范围内的偶数是否满足哥德巴赫猜想*/
const int START = 4, END = 50;
for (int n = START; n <= END; n+=2) {
for (int i = 2; i <= n / 2; i++)
if (ifprime(i) && ifprime(n-i))
cout << n << '=' << i << '+' << n - i << endl;
}
}
selfString类实现(不能使用标准模板库)
(1)两个数据成员:char* dataStr(存储英文句子),int length(英文句子长度);
(2)至少实现两个成员函数:构造函数(从文件中读取一段英文句子),析构函数;
(3)用友元函数实现求两个英文句子的最长公共单词(单词以空格区分,如hello world这个英文句子有两个单词hello和world)。
#define _CRT_SECURE_NO_WARNINGS
#include<iostream>
#include<fstream>
using namespace std;
class selfString {
char *dataStr;
int length;
static const int MAXSIZE = 1000;//设置当前类可以存储的最大字符串长度(类的静态常量是整数类型或枚举类型,可以直接在类定义中
public:
selfString(const char *fname,int len) {
length = len;
dataStr = new char[length + 1];
fstream fin(fname);
if (!fin) {
cerr << "can't open the file." << endl;
exit(0);
}
fin.getline(dataStr, length + 1);
//cerr << dataStr << endl;
fin.close();
}
~selfString() {
delete[] dataStr;
}
friend void getlongestword(const selfString &ss1, const selfString &ss2) {
char* str1 = new char[ss1.length + 1]();
char* str2 = new char[ss2.length + 1]();
strcpy(str1, ss1.dataStr);
strcpy(str2, ss2.dataStr);
/*单词分割*/
int k1 = 0;
char* s1[MAXSIZE] = {0};
s1[0] = strtok(str1, " ");
while (s1[++k1] = strtok(NULL, " "));
//cout << k1 << endl;
int k2 = 0;
char* s2[MAXSIZE] = {0};
s2[0] = strtok(str2, " ");
while (s2[++k2] = strtok(NULL, " "));
//cout << k2 << endl;
/*穷举法查找*/
char *tmp = nullptr;
int maxlength = 0;
for (int i = 0; i < k1; i++) {
for (int j = 0; j < k2; j++) {
if (strcmp(s1[i], s2[j]) == 0 && maxlength < strlen(s2[j])) {
tmp=s1[i];
maxlength = strlen(s2[j]);
}
}
}
cout << tmp <<" "<<maxlength<< endl;
delete[] str1;
delete[] str2;
}
};
int main() {
selfString s1("test1.txt",40), s2("test2.txt",40);
getlongestword(s1, s2);
return 0;
}
求一个数的所有因数
#include<iostream>
#include<vector>
using namespace std;
void getfactor(vector<int> &vfac, int n) {
int k = 0;
for (int i = 1; i <= n / 2; i++) {
if (n%i == 0) {
vfac.push_back(i);
}
}
vfac.push_back(n); //n是n的因数
}
void main() {
vector<int> v;
getfactor(v, 36);
for (auto i : v)
cout << i << " ";
}
输出1000以内的完数(“完数”是指一个数恰好等于它的所有不同因子之和),格式是:完数=因子1+因子2+...+因子n,例如6=1+2+3
#include<iostream>
#include<vector>
#include<cmath>
using namespace std;
void get_perfectnumber_1(int n) {
vector<int> v; // 用来保存完数的因子
int a;
for (int i = 1; i < n; i++) {
a = 1;
v.push_back(1);
for (int j = 2; j <= sqrt(i); j++) {
if (i%j == 0) {
if (j*j == i) {
a += j;
v.push_back(j);
}
else {
a += (j + i / j);
v.push_back(j);
v.push_back(i / j);
}
}
}
if (a == i) { // 如果是完数则按格式输出
cout << a << "=";
for (auto i = v.begin(); (i + 1) != v.end(); i++)
cout << *i << "+";
auto j = v.end();
j--;
cout << *j << endl;
}
v.clear();
}
}
void get_perfectnumber_2(int n) {
int sum = 0, half;
vector<int> numbers; // 用来保存完数的因子
for (int i = 1; i < n; ++i) {
sum = 0;
numbers.clear();
half = i / 2; // 初始化准备,每次因子只需要检测一半,后一半不可能取到
for (int j = 1; j <= half; ++j) { // 需要包括half本身
if (i % j == 0) {
sum += j;
numbers.push_back(j);
}
}
if (sum == i) { // 如果是完数则按格式输出
cout << i << "=" << numbers[0];
for (size_t j = 1; j < numbers.size(); ++j)
cout << "+" << numbers[j];
cout << endl;
}
}
}
int main() {
const int N = 100000;
/*输出N以内的完数*/
get_perfectnumber_1(N);
cout << endl;
get_perfectnumber_2(N);
return 0;
}
/*输出:
1=1
6=1+2+3
28=1+2+14+4+7
496=1+2+248+4+124+8+62+16+31
8128=1+2+4064+4+2032+8+1016+16+508+32+254+64+127
6=1+2+3
28=1+2+4+7+14
496=1+2+4+8+16+31+62+124+248
8128=1+2+4+8+16+32+64+127+254+508+1016+2032+4064
*/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号