CTF-MISC总结
本文对CTF中常见的MISC题做出总结,并给出一些工具的安装与使用方法(见“十四”),后续根据做题中的所见所闻会不定期更新里面的内容,仅供参考。
目录
- 一、编码与加密
- 二、隐写术(Steganography)
- 三、压缩文件
- 四、swf游戏
- 五、取证分析(Forensic)
- 六、图片文件
- 七、视频文件
- 八、音频文件
- 九、流量分析
- 十、Microsoft Office
- 十一、注册表
- 十二、其它
- 十三、Linux常用指令
- 十四、Misc常用工具安装使用
- 十五、搜索引擎语法
- 【附】
一、编码与加密
(〇)密码学基础
1. Kerckhoffs原则
密码学上的柯克霍夫原则(Kerckhoffs's principle,也称为柯克霍夫假说、公理、或定律)系由奥古斯特·柯克霍夫在19世纪提出:即使密码系统的任何细节已为人悉知,只要密匙(key,又称密钥或秘钥)未泄漏,它也应是安全的。
(一)古典密码体制
1. 单表代换加密
(1)恺撒密码
恺撒密码(Caesar)是一种替换密码,明文中的所有字母都在字母表上向后(或向前)按照一个固定数目进行偏移后被替换成密文。例,当偏移量是3的时候,所有的字母A将被替换成D,B变成E,以此类推。
原文:A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
密文:D E F G H I J K L M N O P Q R S T U V W X Y Z A B C
恺撒密码还在现代的ROT13系统中被应用,但是和所有的利用字母表进行替换的加密技术一样,恺撒密码非常容易被破解,而且在实际应用中也无法保证通信安全。
根据偏移量的不同,还存在若干特定的恺撒密码名称:
- 偏移量为 10:Avocat (A→K)
- 偏移量为 13:ROT13
- 偏移量为 -5:Cassis (K 6)
- 偏移量为 -6:Cassette (K 7)
——ROT13
相当于偏移量为13的恺撒密码
ROT13(回转13位)是一种替换密码,是凯撒密码的一种变体,且是它自身的逆反,即:要还原成原文只要使用同一算法即可得,故同样的操作可用于加密与解密。该算法并没有提供真正密码学上的保全,故它不应该被用于需要保全的用途上。它常常被当作弱加密示例的典型。
应用ROT13到一段文字上仅仅只需要检查字母顺序并取代它在13位之后的对应字母,有需要超过时则重新绕回26英文字母开头即可。A换成N、B换成O、依此类推到M换成Z,然后串行反转:N换成A、O换成B、最后Z换成M。只有这些出现在英文字母里的字符受影响;数字、符号、空白字符以及所有其他字符都不变。替换后的字母大小写保持不变。
(2)仿射密码(Affine)
仿射密码是一种替换密码,是单表加密的一种。明文/密文的每个字母按如下表格对应一个数字作为 \(x\)。
| A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 |
-
加密函数: \(e(x)=ax+b(mod\enspace m)\),其中
-
\(a\) 和 \(m\) 互质
-
\(m\) 是字母的数目。
-
-
解密函数: \(d(x)=a^{-1}(x-b)(mod\enspace m)\),其中
- 是 \(a^{-1}\) 在 \(Z_m\) 群的乘法逆元。
当 \(a=1\) 时,仿射加密便为凯撒密码 ,\(b\) 便是恺撒密码中的偏移量。
举个例子
| 原始文件 | A | F | F | I | N | E | C | I | P | H | E | R |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| \(x\) | 0 | 5 | 5 | 8 | 13 | 4 | 2 | 8 | 15 | 7 | 4 | 17 |
| \(5x+8\) | 8 | 33 | 33 | 48 | 73 | 28 | 18 | 48 | 83 | 43 | 28 | 93 |
| \((5x+8)(mode\enspace 26)\) | 8 | 7 | 7 | 22 | 21 | 2 | 18 | 22 | 5 | 17 | 2 | 15 |
| 加密文件 | I | H | H | W | V | C | S | W | F | R | C | P |
\(a\) 为 \(5\),则经过计算 \(a\) 的乘法逆元 \(a^{-1}\) 为 \(21\)
| 加密文件 | I | H | H | W | V | C | S | W | F | R | C | P |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| \(y\) | 8 | 7 | 7 | 22 | 21 | 2 | 18 | 22 | 5 | 17 | 2 | 15 |
| \(21(y-8)\) | 0 | -21 | -21 | 294 | 273 | -126 | 210 | 294 | -63 | 189 | -126 | 147 |
| \((21(y-8))( mod\enspace 26)\) | 0 | 5 | 5 | 8 | 13 | 4 | 2 | 8 | 15 | 7 | 4 | 17 |
| 原文件 | A | F | F | I | N | E | C | I | P | H | E | R |
——乘法逆元及其计算
乘法逆元:如果 \(ax≡1 (mod\enspace b)\),且\(gcd(a,b)=1\)(\(a\) 与 \(b\) 互质),则称 \(a\) 关于模 \(b\) 的乘法逆元为 \(x\)。
在介绍乘法逆元的计算方法前先了解一下什么是欧几里得算法以及贝祖定理
-
欧几里得算法又称辗转相除法,常用于求两个数 \(m\) 和 \(n\) 的最大公约数 \(gcd(m,n)\),原理是用两个数 \(m\) 和 \(n\) 中较大的数 \(m\) 除以较小的数 \(n\),即 \(m\div n\),如果能整除,那么较小的那个数 \(n\),就是所求的最大公约数,否则 \(m\div n=q......r\) ,就用除数 \(n\) 和余数 \(r\) 作为新一轮的 \(m\) 和 \(n\) ,继续判断能否整除……依此类推,直到能够整除为止,这时作为除数的数就是所求的最大公约数。
【注】
- 被除数 \(\div\) 除数 \(=\) 商 …… 余数
- \(A\div B\) 读作“A除以B”或者“B除A”
举个例子:求1314和511的最大公约数
\[1314\div 511=2......292\\ 511\div 292=1......219\\ 292\div 219=1......73\\ 219\div 73=3 \]于是73就是1314和511的最大公约数,即 \(gcd(1314,511)=73\) 。
-
贝祖定理:如果 \(a\)、\(b\) 是整数,那么一定存在整数 \(x\)、\(y\) 使得 \(a\cdot x+b\cdot y=gcd(a,b)\),这个式子也被称为贝祖等式。
那么它们与乘法逆元有什么关系呢?我们由乘法逆元的定义可以知道 \(a\) 和它的逆元 \(x\) 满足 \(ax≡1 (mod\enspace b)\),即 \(a\cdot x+b\cdot (-z)=1\),这就与贝祖等式对应起来了(\(a\) 和 \(b\) 已知,且 \(gcd(a,b)=1\) ),于是根据贝祖定理,我们知道了,已知 \(a\) 和 \(b\),且 \(gcd(a,b)=1\),那么 \(a\) 关于 \(b\) 一定存在乘法逆元 \(x\),而求解 \(x\) 的方法就要用到扩展欧几里得算法——欧几里得算法的扩展。总结到一点,贝祖定理告诉我们乘法逆元存在,扩展欧几里得算法给我们提供了求解方法。下面着重讲解一下扩展欧几里得算法,以求30关于47的乘法逆元为例
即求整数 \(x\) 和 \(y\) 使得 \(30x+47y=1\)
用欧几里得算法把求30和47最大公约数的中间式子罗列出来并整理如下
接下来我们需要用上面的四个式子合并整理,凑出 \(30x+47y=1\)的形式。
不难看出,第n个式子的除数是第n-1个式子的余数,所以可以从最后一个式子开始用上一个式子带入,也就是用第n-1个式子代替第n个式子的除数(如用③式代替④式的4),别的不要动,也不要计算,带入一次后各个除数和余数的系数合并整理,进入下一次的替换,这就形成了递归,直到最后n == 1,就会出现出现形如 1 = 47x + 30y 。
具体操作如下
1=13+4*(-3)
1=13+[17*1+13*(-1)]*(-3) //用(3)式4=17*1+13*(-1)替换(4)式的除数4
1=17*(-3)+13*4 //整理
1= 17*(-3)+[30*1+17*(-1)]*4 //用(2)式13=30*1+17*(-1)替换除数13
1=30*4+17*(-7) //整理
1=30*4+[47*1+30*(-1)]*(-7) //用(1)式17=47*1+30*(-1)替换除数17
1=47*(-7)+30*11 //整理
最后我们可以知道30关于47的乘法逆元为11。
(3)移位密码
与凯撒密码类似,区别在于移位密码不仅会处理字母,还会处理数字和特殊字符,常用 ASCII 码表进行移位
(4)简单替换密码
简单替换密码(Simple Substitution Cipher)加密时,将每个明文字母替换为与之唯一对应且不同的字母。它与恺撒密码之间的区别是其密码字母表的字母不是简单的移位,而是完全是混乱的,这也使得其破解难度要高于凯撒密码。 比如:
明文字母 : abcdefghijklmnopqrstuvwxyz
密钥字母 : phqgiumeaylnofdxjkrcvstzwb
而解密时,我们一般是知道了每一个字母的对应规则,才可以正常解密。
Atbash Cipher
埃特巴什码(Atbash Cipher)是简单替换密码的特例,它使用字母表中的最后一个字母代表第一个字母,倒数第二个字母代表第二个字母,以此类推。在罗马字母表中,它是这样出现的:
明文:A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
密文:Z Y X W V U T S R Q P O N M L K J I H G F E D C B A
——攻击
- 频率分析法:在一个简单的替换密码中,明文中的每一个字母都被另一个字母替换,而且明文中相同的字母在转换为密文时总是被同一个字母所替换,而英语语言字母 \(e\) 和 \(n\) 使用频率很高,而字母$ x$ 和 \(z\) 使用频率很低。
- 语言特征分析法:比如,字母组合“io”在英语单词中经常出现,而“oi”组合却很少出现。历史上密码分析者还会通过对照在单词中不可能出现的字母组合清单,来排除掉这些字母组合。但是这种方法使用的前提是必须对消息的描述语言非常熟悉,然而实际情况并不总是这样。消息的描述语言可能是西班牙语、法语或者其他语言,这种差别对密码分析者来说是致命的打击。
2. 多表代换加密
(1)维吉尼亚密码
维吉尼亚密码是使用一系列凯撒密码组成密码字母表(如下图)的加密算法,属于多表密码的一种简单形式。如果仅使用维吉尼亚字母表的一列作为替换表,那维吉尼亚密码与凯撒轮换密码就没什么区别了,因此维吉尼亚密码表就设计成了多行,一行为一个字母加密,这一表格包括了26行字母表,每一行都由前一行向左偏移一位得到,具体使用哪一行字母表进行编译是基于密钥(关键字)进行的。
例如,假设明文为ATTACKATDAWN,选择某一关键词并重复直至与明文一样长度而得到密钥,如当关键词为LEMON时,密钥为LEMONLEMONLE,对于明文的第一个字母A,对应密钥的第一个字母L,于是使用表格中L行字母表进行加密,得到密文第一个字母L。类似地,明文第二个字母为T,在表格中使用对应的E行进行加密,得到密文第二个字母X。以此类推,可以得到:
明文:ATTACKATDAWN
密钥:LEMONLEMONLE
密文:LXFOPVEFRNHR

单表代换密码没有破坏统计规律,所以我们可以直接根据字母的频率分析进行破解。例如,对于一个字母来说,在一篇密文中,H出现的频率最高,那么H对应的明文可能是e、t、a等在前几位的字母。但对于维吉尼亚密码,可以被加密成不同的密文,因而简单的频率分析在这里并没有用。
(2)自动密钥密码(Autokey Cipher)
自动密钥密码(Autokey Cipher)也是多表替换密码,与维吉尼亚密码很像,但不同的是密钥的构成方式不同。 维吉尼亚密码密码的密钥是由关键字的重复构成的,而该密码的密钥是由关键字和明文本身构成,即前面是关键字,后面是明文,即密钥=关键字+明文。
在已知密钥的情况下可以用在线工具或者Python来解密
-
在线工具:自动密钥密码加密/解密
-
Python的pycipher内置了自动密钥密码的算法(使用前需要
pip install pycipher)from pycipher import Autokey Autokey('CULTURE').encipher('THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG') >>> 'VBPJOZGDIVEQVHYYAIICXCSNLFWWZVDPWVK' Autokey('CULTURE').decipher('VBPJOZGDIVEQVHYYAIICXCSNLFWWZVDPWVK') >>> 'THEQUICKBROWNFOXJUMPSOVERTHELAZYDOG'
暴破
在未知密钥的情况下可以用Breakautokey脚本暴破,这个脚本原理是依次搜索每个密钥长度,将最有可能的纯文本打印出来让我们辨认。(官方)
-
环境:脚本需要运行在
Python2环境下,且需要安装pycipher库(pip2 install pycipher) -
使用:将得到的密文赋给
breakautokey.py中的变量ctext;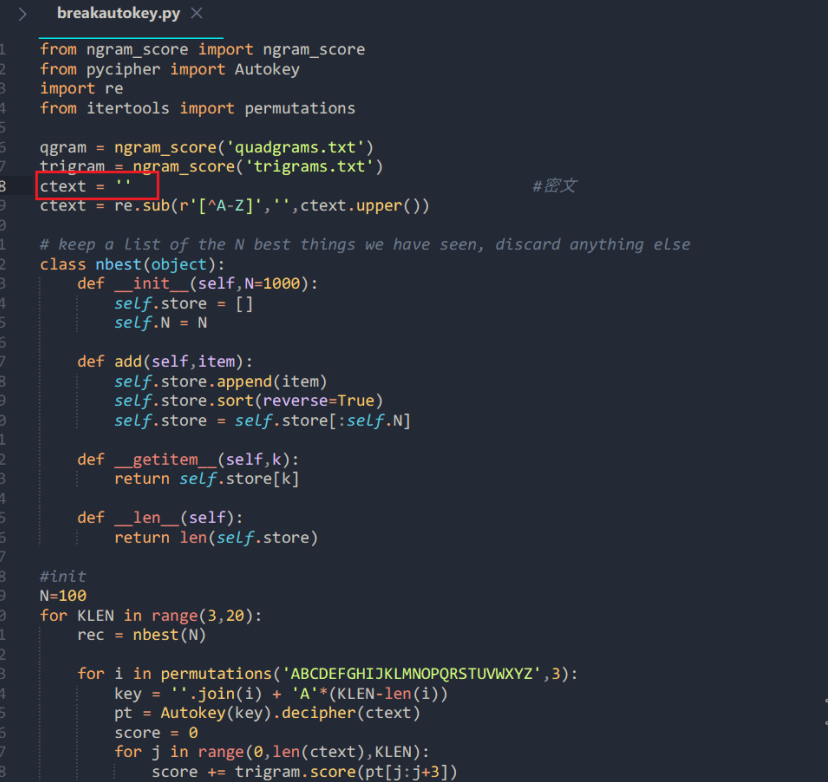
然后直接输入如下命令运行
python2 breakautokey.py
3. 移位加密
移位算法将明文消息中的字母重新排列,维持原为字母的本来面貌,只是调整了位置。
替换加密不同于移位加密,移位加密只是调整了明文中字母的位置,字母本身并没有改变。与之相反,替换加密保留了明文中字母的排列顺序,而更改了字母的本来面貌。如前所述,移位密码受限于有限的移位次数,因为可以移动的次数是有限的,所以大多数移位密码不用计算机,仅凭手算就可以破解。而替换密码理论上有很多种加密形式,其中的一些有很高复杂度
(1)栅栏密码(The rail fence cipher)
题目:BUUCTF-USB
所谓栅栏密码,就是将要加密的明文分为N个一组,再从每组的选出一个字母连起来,形成一段无规律的密文。
栅栏密码并非一种强的加密法,其加密原理限制了密钥的最高数量不可能超过明文字母数,而实际加密时密钥数目更少,因此有些密码分析员甚至能用手直接解出明文。
栅栏密码可以分为两类,第一种是N型栅栏密码,第二种是V型栅栏密码。
1. N型栅栏密码
例如使用密钥8(栅栏的栏数)加密一下明文1234567891234567891234567891234567891
1.......9.......8.......7.......6.......5..............................
.2.......1.......9.......8.......7.......6.............................
..3.......2.......1.......9.......8.......7............................
...4.......3.......2.......1.......9.......8...........................
....5.......4.......3.......2.......1.......9..........................
.....6.......5.......4.......3.......2.......1.........................
......7.......6.......5.......4.......3................................
.......8.......7.......6.......5.......4...............................
首先画出8栏表格,明文由上至下顺序写上,当到达最低部时,再回到第一栏重新开始,一直重复直至整篇明文写完为止。横向读取表格时即为密文:1987652198763219874321985432196543217654387654。
2. V型栅栏密码
使用密钥8(栅栏的栏数)加密一下明文Will invade Kentucky on October the eighth# signal is Frozen chicken'#
W.............n.............b.............#.............r.............#
.i...........e.t...........o.e...........h. ...........F.o...........'.
..l.........K...u.........t...r.........t...s.........'...z.........n..
...l....... .....c.......c..... .......h.....i....... .....e.......e...
.... .....e.......k.....O.......t.....g.......g.....s.......n.....k....
.....i...d.........y... .........h...i.........n...i......... ...c.....
......n.a........... .n...........e.e...........a. ...........c.i......
.......v.............o............. .............l.............h.......
在V型栅栏密码中,明文由上至下顺序写上,当到达最低部时,再回头向上,一直重复直至整篇明文写完为止。横向读取表格即为密文:Wnb#r#ietoehFo'lkutrts'znl cc hi ee ekOtggsnkidy hini cna neea civo lh。
——攻击
获取分组和密钥
- 密文长度短的直接暴力破解
- 如果知道某些明文,或者可以猜出一些明文,那么将更容易找到密钥。
4. 特殊代换加密
(1)摩斯密码
摩斯密码是一种通过电报传输消息的替换密码,代表了一种电码替换编码的方式,用一系列的点和划的组合代表不同的字母。
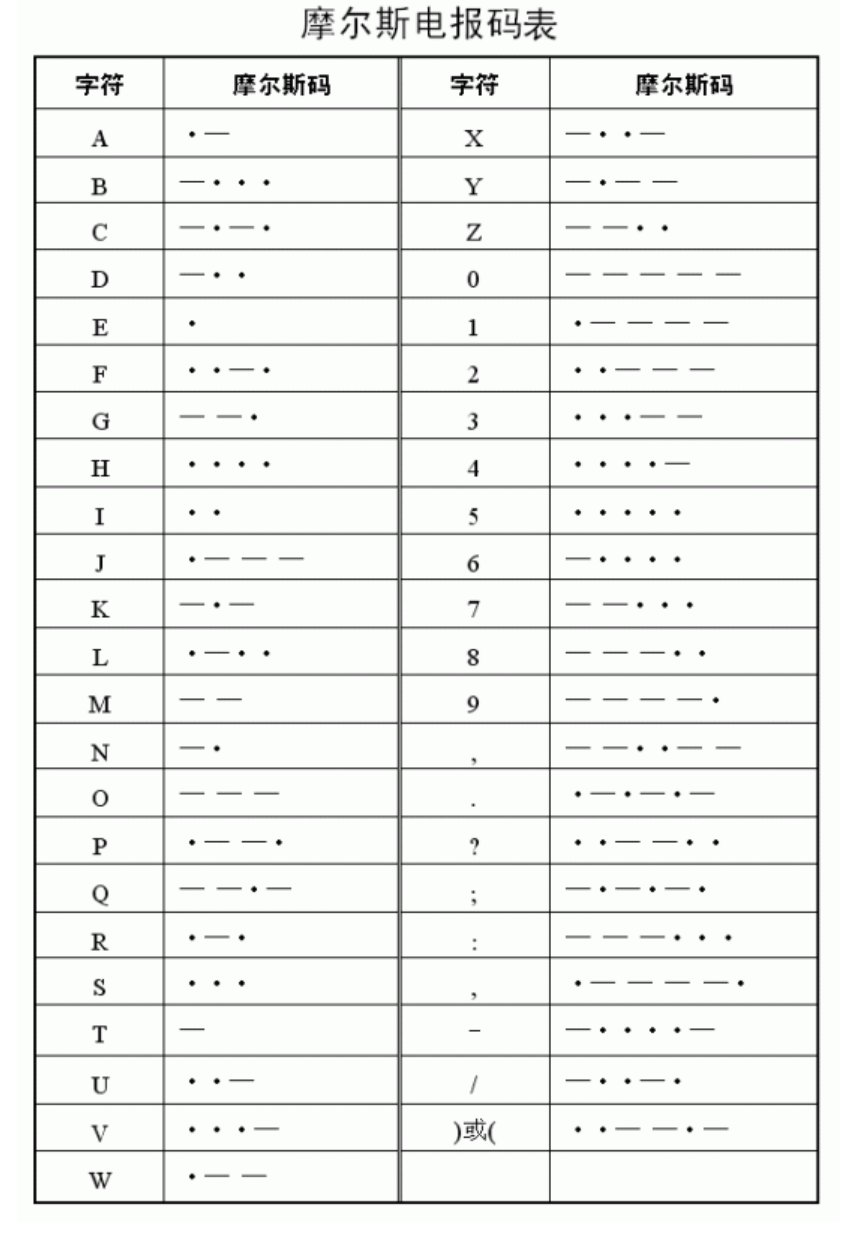
编码与解码脚本如下
# encoding: utf-8
a2mo_dict = {'a': '.-', 'b': '-...', 'c': '-.-.', 'd': '-..', 'e': '.',
'f': '..-.', 'g': '--.', 'h': '....', 'i': '..', 'j': '.---',
'k': '-.-', 'l': '.-..', 'm': '--', 'n': '-.', 'o': '---',
'p': '.--.', 'q': '--.-', 'r': '.-.', 's': '...', 't': '-',
'u': '..-', 'v': '...-', 'w': '.--', 'x': '-..-', 'y': '-.--', 'z': '--..',
'0': '-----', '1': '.----', '2': '..---', '3': '...--', '4': '....-',
'5': '.....', '6': '-....', '7': '--...', '8': '---..', '9': '----.'
}
mo2a_dict = dict(zip(a2mo_dict.values(), a2mo_dict.keys()))
def morse_encode():
"""
摩尔斯电码转换为字符串
"""
crypto_text = input("请输入摩尔斯电码:")
morse_key = crypto_text.strip().split(" ")
plain_text = [mo2a_dict[key] for key in morse_key]
plain_text = "".join(plain_text)
print("摩尔斯解码后的明文为:", plain_text)
def morse_decode():
"""
字符串编码成摩尔斯电码
"""
crypto_text = ""
plain_text = input("请输入要加密的明文:").strip().replace(" ", "")
for word in plain_text:
crypto_text += a2mo_dict[word] + " "
print("编码后的摩尔斯电码为:", crypto_text)
(2)猪圈密码
猪圈密码是一种以格子为基础的简单替代式密码。即使使用符号,也不会影响密码分析,亦可用在其它替代式的方法。
-
传统码表

-
变种1

-
变种2
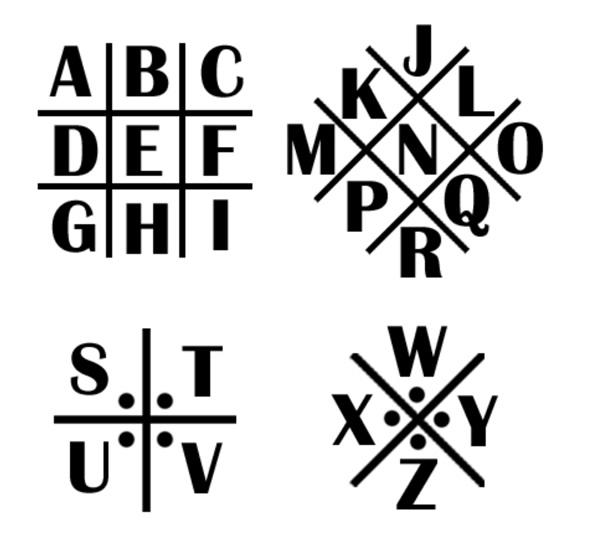
(3)培根密码
| 明文 | 密文 | 明文 | 密文 | 明文 | 密文 | 明文 | 密文 |
|---|---|---|---|---|---|---|---|
| A/a | aaaaa | H/h | aabbb | O/o | abbba | V/v | babab |
| B/b | aaaab | I/i | abaaa | P/p | abbbb | W/w | babba |
| C/c | aaaba | J/j | abaab | Q/q | baaaa | X/x | babbb |
| D/d | aaabb | K/k | ababa | R/r | baaab | Y/y | bbaaa |
| E/e | aabaa | L/l | ababb | S/s | baaba | Z/z | bbaab |
| F/f | aabab | M/m | abbaa | T/t | baabb | ||
| G/g | aabba | N/n | abbab | U/u | babaa |
培根密码主要有以下特点:
- 【传统】密文只有两种字符;【变体】密文可以划分成两种形式(如粗体细体、大写小写)
- 每一段的长度为 5
(5)棋盘密码/敲击密码
棋盘密码是利用波利比奥斯方阵(Polybius Square)进行加密的密码方式。
判别:只要出现数字是成双出现的数组串,而且有出现最大数字大于26的,那是棋盘密码的可能性就很大。

(二)代码混淆
1. AAEncode
将JavaScript代码转换成颜文字网络表情的编码
题目:
加密解密:
2. Brainfuck
Brainfuck是一种极小化的计算机语言,它是由Urban Müller在1993年创建的。由于fuck在英语中是脏话,这种语言有时被称为brainfuck或brainfuck,甚至被简称为BF。
brainfuck语言用> < + - . , [ ]八种符号来替换C语言的各种语法和命令。
3. Ook.?!
Ook.?!与Brainfuck类似,也是用替换法。
4. Vbscript.Encode加密(VBS加密)
用于对VBS脚本进行加密。
官方提供的加密工具sce10,算是比较正规的加密方式,用这种方法加密的代码,对于 VBScript,加密后在源文件的第一行会显示:<SCRIPT LANGUAGE="VBScript.Encode">。
判别:这种方法加密出来的代码有一个特点,一般以 #@~ 这几个字符开头,并且里面多次出现,并且不对中文字符编码
解密方式目前网络上有提供算法和程序的。有一个比较出名的软件名叫 scrdec18.exe ,只是使用稍有麻烦,是在命令行下使用的。
在线工具:asp在线解密工具|asp解密|VBScript.Encode|JScript.Encode 在线解密 (zhaoyuanma.com)
(三)现代编码
1. Base家族
python解码脚本编写:base64 --- Base16, Base32, Base64, Base85 数据编码 — Python 3.10.0 文档
统一填充符号是
’=’
(1)Base16
0123456789ABCDEF
使用16个ASCII可打印字符(数字0-9和字母A-F),对任意字节数据进行编码。
8比特数据按照4比特切分刚好是两组,所以Base16不可能用到填充符号“=”。
(2)Base32
在线Base32编码/解码工具链接:http://www.atoolbox.net/Tool.php?Id=931
ABCDEFGHIJKLMNOPQRSTUVWXYZ234567
| 值 | 符号 | 值 | 符号 | 值 | 符号 | 值 | 符号 | |||
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | A | 8 | I | 16 | Q | 24 | Y | |||
| 1 | B | 9 | J | 17 | R | 25 | Z | |||
| 2 | C | 10 | K | 18 | S | 26 | 2 | |||
| 3 | D | 11 | L | 19 | T | 27 | 3 | |||
| 4 | E | 12 | M | 20 | U | 28 | 4 | |||
| 5 | F | 13 | N | 21 | V | 29 | 5 | |||
| 6 | G | 14 | O | 22 | W | 30 | 6 | |||
| 7 | H | 15 | P | 23 | X | 31 | 7 | |||
| 填充 | = | |||||||||
Base32编码是使用32个可打印字符(字母A-Z和数字2-7)对任意字节数据进行编码的方案,编码后的字符串不用区分大小写并排除了容易混淆的字符,可以方便地由人类使用并由计算机处理。
码文最多可以有6个填充符
import base64
s = 'key' # 待编码的字符串
print(base64.b32encode(s.encode('ascii')).decode()) # 编码
m= 'NNSXS===' # 要解码的字符串
print(base64.b32decode(m).decode()) # 解码
(3)base64
原理:略
主要是变异base64解码,解码脚本如下
import base64
import string
str1 = "mTyqm7wjODkrNLcWl0eqO8K8gc1BPk1GNLgUpI==" #ma'wen文
string1 = "AaBbCcDdEeFfGgHhIiJjKkLlMmNnOoPpQqRrSsTtUuVvWwXxYyZz0987654321/+" #自定义码表
string2 = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/" #原码表
print (base64.b64decode(str1.translate(str.maketrans(string1,string2)))) #明文输出
(4)base85
$%()*+,-./0123456789:;?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[]^_`abcdefghijklmnopqrstuvwxyz{|}~
Base85 以 5 字符存储 4 字节二进制数据, 因此长度增加 25%。
Base85 可用于在 XML 文件中存储二进制数据, 相比 Base94 不带 !"#&'<=>\ 这 9 个字符, 无需转义。
(5)Base91
!"#$%&()*+,./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[]^_`abcdefghijklmnopqrstuvwxyz{|}~
用 91 个可打印字符表示 8 位二进制数据 (含无法显示 打印字符) 的编码方式。
相比 Base94不带 '-\这 3 个字符。
——BaseCrack工具
GitHub - mufeedvh/basecrack: Decode All Bases - Base Scheme Decoder
-
对来自用户输入的单个Base编码数据进行解码:
python basecrack.py -
对通过参数(-b/--base)传递的单个Base编码数据进行解码:
python basecrack.py -b SGVsbG8gV29ybGQh -
对通过文件(-f/--file)传递的多个Base编码数据进行解码:
python basecrack.py -f file.txt -
对任意模式的多重Base编码数据进行解码(-m/--magic):
先输入下面的命令
python basecrack.py --magic再粘贴密文
-
使用解码的Base数据生成字典文件并输出(-o/--output):
python basecrack.py -f file.txt -o output-wordlist.txt
2. Quoted-printable编码
Quoted-printable编码即为“可打印字符引用编码”、“使用可打印字符的编码”,我们收邮件,查看信件原始信息,经常会看到这种类型的编码。
在所有邮件处理的各式各样的编码中,很多编码的目的都是通过编码的手段使得七位字符的邮件协议体系可以传送八位的二进制文件、双字节语言等等。Quoted-Printable也是这样一些编码中的一个,它的目的同样是帮助非ASCII编码的信件传输通过SMTP。Quoted-Printable编码是字符对应的编码,每个末编码的二进制字符被编码成三个字符,即一个等号和一个十六进制的数字,如‘=AB’。 编码里面,有几个特定限定,一些可打印字符不用编码,当然如果你按照规范编码后,也一样可以显示的。
说白了就是一个等号加上某个字符的ASCII码形式即为此字符的Quoted-printable编码
在线解码:
3. PDU编码
在线解码:
发送短消息常用Text和PDU(Protocol Data Unit)模式。使用Text模式收发短信代码简单,实现起来十分容易,但最大的缺点是不能收发中文短信;而PDU模式不仅支持中文短信,也能发送英文短信。PDU模式收发短信可以使用3种编码:7-bit、8-bit和UCS2编码。7-bit编码用于发送普通的ASCII字符,8-bit编码通常用于发送数据消息,UCS2编码用于发送Unicode字符。一般的PDU编码由A B C D E F G H I J K L M十三项组成。
A:短信息中心地址长度,2位十六进制数(1字节)。
B:短信息中心号码类型,2位十六进制数。
C:短信息中心号码,B+C的长度将由A中的数据决定。
D:pduType,2位十六进制数。
E:Message Reference,2位十六进制数。
F:被叫号码长度,2位十六进制数。
G:被叫号码类型,2位十六进制数,取值同B。
H:被叫号码,长度由F中的数据决定。
I:协议标识,2位十六进制数。
J:数据编码方案,2位十六进制数。
K:有效期,2位十六进制数。
L:用户数据长度,2位十六进制数。
M:用户数据,其长度由L中的数据决定。J中设定采用UCS2编码,这里是中英文的Unicode字符。
4. 社会主义核心价值观编码
GitHub - sym233/core-values-encoder: Translating text to core values and back
在线解码器:CTF在线工具-在线核心价值观编码|核心价值观编码算法
5. 新约佛论禅
判别:以“新佛曰”开头
6. 与佛论禅
7. ATOM 128
在线工具:ATOM-128 / Fast Encryption (Encode or Decode) (persona-shield.com)
8. 汉字编码
题目:BUUCTF-从娃娃抓起
中文电码:标准中文电码(Chinese Commercial Code)查询 | ChaseDream
五笔编码:五笔输入法编码在线查询系统
9. DTMF拨号音编码
工具:DTMF2NUM.exe
就是老式翻盖机9键打字的声音。

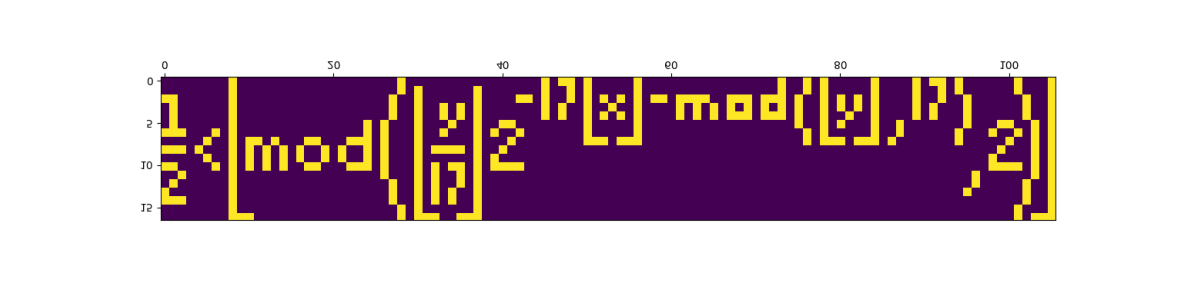
10. tupper公式(塔珀自指公式)
塔珀自指公式(Tupper’s Self-Referential Formula)来自于Jeff Tupper在2001年发表的一篇论文,涉及到一个函数 \(f( x , y )\),一个参数 \(k\),和一个图片 \(a\)。$f ( x , y ) $对 \(a\)中的每一个点 \(( x , y )\)进行判断,决定该点的颜色是0还是1,因此决定了\(a\)的图案。
如果给定不同的 \(k\),就会得到不同的图案。令人感到惊奇的是,有一个特别的\(k\)(如下),它会使得所得\(a\)竟然是公式本身。
k=960939379918958884971672962127852754715004339660129306651505519271702802395266424689642842174350718121267153782770623355993237280874144307891325963941337723487857735749823926629715517173716995165232890538221612403238855866184013235585136048828693337902491454229288667081096184496091705183454067827731551705405381627380967602565625016981482083418783163849115590225610003652351370343874461848378737238198224849863465033159410054974700593138339226497249461751545728366702369745461014655997933798537483143786841806593422227898388722980000748404719
下面就是塔珀公式
常数k是将公式的单色位图化成二进制后乘以17得来的。如果将k除以17(并化成二进制),最小一位代表图像左下角的像素;最小的17位构成了最左边的一列像素;第二小的17位构成了左数第二列像素;以此类推。
下面是根据\(k\)生成图片的Python脚本
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
def Tupper_self_referential_formula(k):
aa = np.zeros((17,106))
def f(x, y):
y += k
a1 = 2**-(-17*x - y%17)
a2 = (y // 17) // a1
return 1 if a2 % 2 > 0.5 else 0
for y in range(17):
for x in range(106):
aa[y, x] = f(x, y)
return aa[:,::-1]
k = 960939379918958884971672962127852754715004339660129306651505519271702802395266424689642842174350718121267153782770623355993237280874144307891325963941337723487857735749823926629715517173716995165232890538221612403238855866184013235585136048828693337902491454229288667081096184496091705183454067827731551705405381627380967602565625016981482083418783163849115590225610003652351370343874461848378737238198224849863465033159410054974700593138339226497249461751545728366702369745461014655997933798537483143786841806593422227898388722980000748404719 #输入你要提取的k
aa = Tupper_self_referential_formula(k)
plt.figure(figsize=(15,10))
plt.imshow(aa,origin='lower')
plt.savefig("tupper.png")
img = Image.open('tupper.png')
#翻转
dst1 = img.transpose(Image.FLIP_LEFT_RIGHT).rotate(180)
plt.imshow(dst1)
plt.show()
11. Codemoji
例题:
Codemoji是Mozilla推出的一款游戏,其中结合了表情符号的方法,旨在普及加密技术。关于Codemoji的官方介绍请参考https://codemoji.org/


区分另一种表情包编码:
12. 二维码
背景:条码是采用深浅模块图像单元承载信息的图形符号,诞生于上世纪50年代中期。最早发展成熟的条码技术是一维条码技术,一维条码中的“一维”是指条码信息只在一个方向上(垂直于条空的方向)存在,而与条空平行的竖向则不承载信息。一维条码技术是为了解决商品零售结算环节,产品编码信息快速获取问题而研发的,目前,应用最广泛的条码仍是超市等环节上采用的商品条码。随着条码技术的飞速发展,人们希望能够用条码标识更大量更多种类的信息,满足在物流、电子、单证、军事等领域自动化采集的需求。上世纪80年代中期,为了解决一维码信息容量不足等问题而研发的二维条码应运而生。二维码或称二维条码是能够在两个方向上承载信息的条码符号,作为一种衍生条码技术,从技术上可分为行排式和矩阵式两类。

汉信码:汉信码是我国唯一一个拥有完全自主知识产权的二维码,具有汉字表示能力强、可加密、效率高、抗畸变、抗污损、识读快速等特点。
工具:汉信码在线解码
PDF417:二维码PDF417是一种堆叠式二维条码。PDF(Portable Data File)意思是“便携数据文件”。组成条码的每一个条码字符由4个条和4个空共17个模块构成,故称为PDF417条码。 PDF417条码需要有417解码功能的条码阅读器才能识别。
工具:Pdf417在线解码
13. URL
(1)URL结构
统一资源定位符(Uniform Resource Locator,简称URL)是互联网上用来标识某一处资源的地址,完整的URL地址通用格式如下
协议://域名:端口号/资源位置?参数#锚点
以http://www.xxxxx.com:8080/news/index.asp?boardID=5&ID=24618&page=1#name为例
-
协议部分:支持多种协议(常用的有如下几种)
file 资源是本地计算机上的文件。格式
file:///,注意后边应是三个斜杠。ftp 通过 FTP访问资源。格式 :
FTP://http 通过 HTTP 访问该资源。 格式
HTTP://https 通过安全的 HTTPS 访问该资源。 格式
HTTPS://ed2k 通过 支持ed2k(专用下载链接)协议的P2P软件访问该资源。(代表软件:电驴) 格式
ed2k://thunder 通过 支持thunder(专用下载链接)协议的P2P软件访问该资源。(代表软件:迅雷) 格式
thunder://news 通过 NNTP 访问该资源。
-
文件名部分:本例中的文件名是
index.asp。文件名部分也不是一个URL必须的部分,如果省略该部分,则使用默认的文件名index.htm -
锚部分:从“#”开始到最后,都是锚部分。本例中的锚部分是“name”。
- 锚部分也不是一个URL必须的部分,其右面的字符被浏览器解读为位置标识符(一般情况下,锚链接会用到)
- 改变#不触发网页重载,浏览器只会滚动到相应位置,不会重新加载网页,但会改变浏览器的访问历史
-
参数部分:从“?”开始到“#”为止之间的部分为参数部分,又称搜索部分、查询部分,本例中的参数部分为
boardID=5&ID=24618&page=1。- 参数可以允许有多个参数,参数与参数之间用“&”作为分隔符。
- 很多资源,比如数据库服务、搜索引擎,都可以通过提问题或进行查询来缩小请求资源的范围。或者为了向应用程序提供它们所需要的输入参数,以便正确地与服务器进行交互。
(2)URL参数部分解析
① bing搜索引擎
-
q 参数: 这个应该没人不知道了吧。 q 就是 query(查询)的意思,后接你的搜索词。例如:search?q=测试
-
setlang 参数: 即:设置(set)必应界面语言(lang)。示例:设置界面为美国英语(代码:en-us)setlang=en-us
-
setmkt 参数: 即:设置(set)返回地区(mkt)示例:设置为为搜索返回的结果为美国英语网页(代码:en-us)setmkt=en-us
-
cvid 参数:cvid 表示 JavaScript 参数 ConversationId 。Bing 使用此键将你的搜索结果集合标识为对你的查询的回复。
-
FROM 参数:大名鼎鼎的 FROM 参数。代表搜索从何处发出,例如点击搜索框的搜索图标发起搜索就是 form=QBRE
-
qs 参数:qs 是您查询的 SuggestionType(查询类型)例如点击搜索下拉框建议就是 &qs=AS,直接发起搜索就是 &qs=ds,直接发起隐私搜索就是 &qs=n 等等。
-
sc 参数:sc参数显示你查询的 SuggestionCount 。意思是你从第几个下拉框搜索建议中点击的,从 0 开始。比如一共有8个建议,而你点击了第四个建议,那么就会发起:sc=8-3
-
sp 参数:sp 显示 SuggestionPosition,意思是你选择了搜索框下拉建议。比如你点击了第四个建议,就是 sp=4。如果没有选择建议,直接回车搜索,就会发起 &sp=-1
-
first 参数:first 参数表示从第几个结果开始显示。例如 first=100,就从第一百条结果(第十一页)开始显示。
-
pq 参数:pq 是 PartialQuery,意思是你上一个搜索词是什么。这个参数用来关联搜索词和相关搜索,也用来统计用户行为。
-
sk 参数:sk是 SkipValue ,因为你可能会跳过结果页面。
-
go 参数:从哪里发起搜索,例如点击搜索框的搜索图标发起搜索就是 &go=搜索,每个语言版本的 go 值不同。
-
tsc 参数:图像搜索参数,值为 ImageBasicHover。
-
ensearch 参数:代表主页是否出现信息流和新闻。例如 &ensearch=1 必应主页会出现信息流和新闻。
-
cc 参数:代表用户从必应哪个后缀的域名访问。例如用户访问 bing.ru 域名,就会跳转至 com 主域名并带参数 ?cc=ru
-
ref 参数:表示来源。目前仅仅发现 ref=go,意味着用户是从 go.microsoft.com/fwlink/?LinkID= 的失效链接上跳转而来。
-
linkid 参数:表示是从 go.microsoft.com/fwlink/?LinkID= 的那个失效链接上跳转而来。比如 ?ref=go&linkid=22 证明用户是从 go.microsoft.com/fwlink/?LinkID=22 这个失效链接跳转而来。
-
PC 参数:代表用户使用电脑版必应搜索。一般是 &PC=U531
-
scope 参数:用户从哪个范围进行搜索。网页版就是 ?scope=web,必应手机 APP 就是 ?scope=app
-
httpsmsn参数:代表是从 https 版本的 msn 网站上搜索跳转而来,为 httpsmsn=1
-
msnews参数:代表是从 msn 新闻网站上搜索跳转而来,为 msnews=1
-
ts参数:搜索发起时间。从 Windows 自带搜索中搜索,会携带此参数,为时间戳形式。
② 百度搜索引擎
(3)URL编码
工具:在线URL解码编码
URL 只能使用 ASCII 字符集来通过因特网进行发送,由于 URL 常常会包含 ASCII 集合之外的字符,所以必须转换为有效的 ASCII 格式。编码规则如下:
- URL 编码使用 "%" 其后跟随两位的十六进制数来替换非 ASCII 字符。
- URL 不能包含空格,且通常使用
+来替换空格。
14. 文本字符编码
参考:
① ASCII
② ANSI
英文用 128 个符号编码就够了,但是每个国家都有自己的语言,法语、日语、中文简体、中文繁体等等,在现有的 ASCII 码表中是无法表示出来的。对于中文简体电脑系统中,咱们国家标准总局发布了 GB2312 ,即扩展了 ASCII 码,最后出现了 GB2312、GBK 等,GB2312 是简体中文的码,GBK支持简体中文及繁体中文、兼容 GB2312 编码,BIG5 是支持繁体中文。GB2312 使用两个字节来存储一个汉字的,这样就可以存储较多的汉字了,要记住一点,GB2312、GBK 与 Unicode 和 UTF-8 是没有关联的,这是我国自己定义的标准。当然除了中文简体系统,还有日文系统 Shift_JIS ,韩文系统 EUC_KR,法文系统等等不同国家自己对于 ASCII 码的扩展,都是基于 ASCII 采用一个、两个或者三个字节的扩充,这里不详谈。然后我们就使用 ANSI 来对 GB2312,GBK,Shift_JIS,EUC_KR 等进行一个统称,即指不同国家对 ASCII 编码的扩展,成为 ANSI 。这样在中文简体电脑系统下 ANSI 默认指的是 GB2312,在繁体系统下默认是采用 BIG5 编码,在日文电脑系统中 ANSI 默认是 Shift_JIS 编码,韩文就是 EUC_KR。不同国家的不同 ANSI 编码是互补兼容的,相互独立的。
>GBK编码
由于ASCII编码不支持中文,因此,当中国人用到计算机时,就需要寻求一种编码方式来支持中文。于是,国人就定义了一套编码规则:当字符小于127位时,与ASCII的字符相同,但当两个大于127的字符连接在一起时,就代表一个汉字,第一个字节称为高字节(从0xA1\(\sim\)0xF7),第二个字节为低字节(从0xA1\(\sim\)0xFE),这样大约可以组合7000多个简体汉字。这个规则叫做GB2312。
但是由于中国汉字很多,有些字无法表示,于是重新定义了规则:不在要求低字节一定是127之后的编码,只要第一个字节是大于127,就固定表示这是一个汉字的开始,不管后面跟的是不是扩展字符集里的内容。这种扩展之后的编码方案称之为GBK标,包括了GB2312的所有内容,同时新增了近20000个新的汉字(包括繁体字)和符号。但是,中国有56个民族,所以,我们再次对编码规则进行了扩展,又加了近几千个少数民族的字符,于是再次扩展后得编码叫做GB18030。中国的程序员觉得这一系列编码的标准是非常的好,于是统统称他们叫做DBCS(Double Byte Charecter Set 双字节字符集)。
② Unicode字符集
因为世界国家很多,每个国家都定义一套自己的编码标准,结果相互之间谁也不懂谁的编码,就无法进行很好的沟通交流,所以及时的出现了一个组织ISO(国际标准化组织)决定定义一套编码方案来解决所有国家的编码问题,这个新的编码方案就叫做Unicode。注意Unicode不是一个新的编码规则,而是一套字符集(为每一个「字符」分配一个唯一的 ID(学名为码位 / 码点 / Code Point)),可以将Unicode理解为一本世界编码的字典。
ISO规定:每个字符必须使用2个字节,即用16位二进制来表示所有的字符,对于ASCII编码表里的字符,保持其编码不变,只是将长度扩展到了16位,其他国家的字符全部统一重新编码。由于传输ASCII表里的字符时,实际上可以只用一个字节就可以表示,所以,这种编码方案在传输数据比较浪费带宽,存储数据比较浪费硬盘。
>UTF-8编码
由于Unicode比较浪费网络带宽和硬盘,因此为了解决这个问题,就在Unicode的基础上,定义了一套编码规则(将「码位」转换为字节序列的规则(编码/解码 可以理解为 加密/解密 的过程)),这个新的编码规则就是UTF-8,采用1-4个字符进行传输和存储数据。
utf-8区分每个字符的开始是根据字符的高位字节来区分的,使用下面的模板进行转换
| Unicode符号范围(十六进制) | UTF-8编码方式(二进制) | UTF-8编码方式说明 |
|---|---|---|
| 0000 0000-0000 007F | 0xxxxxxx | 用1个字节表示的字符,第一个字节高位以0开头 |
| 0000 0080-0000 07FF | 110xxxxx 10xxxxxx | 用2个字节表示的字符,第一个字节的高位为以110开头,后面一个字节以10开头 |
| 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx | 用3个字节表示的字符,第一个字节以1110开头,后面俩字节以10开头 |
| 0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | 用4个字节表示的字符,第一个字节以“11110”开头,后面的三个字节以“10”开头 |
(四)对称加密算法
加盐加密后的密文通常以U2F开头,在线加密/解密,对称加密/非对称加密 (sojson.com)
(五)非对称加密算法
1. RSA¶
RSA算法是基于大数分解的非对称加密算法。
(1)原理
密钥生成
假设Alice想要通过不可靠的媒体接收Bob的私人讯息。她可以用以下的方式来产生一个公钥和一个私钥:
-
随意选择两个大的质数 \(p\) 和 \(q\),\(p\) 不等于 \(q\),计算 \(N=pq\);
-
根据欧拉函数,求得 \(r=\varphi (N)=\varphi (p)\times \varphi (q)=(p-1)(q-1)\)
欧拉函数¶
欧拉函数又称为 \(\varphi\) 函数(由高斯所命名)或是欧拉总计函数。对正整数n,欧拉函数 \(\varphi(n)\) 是小于等于 \(n\) 的正整数中与 \(n\) 互质的数的数目。
欧拉函数是积性函数,即是说若 \(m\),\(n\) 互质,则 \(\varphi (mn)=\varphi (m)\varphi (n)\)
-
选择一个小于 \(r\) 的整数 \(e\),使 \(e\) 与 \(r\) 互质。并求得 \(e\) 关于 \(r\) 的模反元素/逆元( \(ed\equiv 1{\pmod {r}}\) ),命名为 \(d\) 。(模反元素存在,当且仅当 \(e\) 与 \(r\) 互质)
-
将 \(p\) 和 \(q\) 的记录销毁。
\((N,e)\) 是公钥,\((N,d)\) 是私钥。Alice将她的公钥 \((N,e)\) 传给Bob,而将她的私钥 \((N,d)\) 藏起来。
加密
假设Bob想给Alice送讯息 \(m\),他知道Alice产生的 \(N\) 和 \(e\)。他使用起先与Alice约好的格式将 \(m\) 转换为一个小于 \(N\) 的非负整数 \(n\),比如他可以将每一个字转换为这个字的Unicode码,然后将这些数字连在一起组成一个数字。假如他的讯息非常长的话,他可以将这个讯息分为几段,然后将每一段转换为 \(n\)。用下面这个公式他可以将 \(n\) 加密为 \(c\)
计算 \(c\) 并不复杂。Bob算出 \(c\) 后就可以将它递移给Alice。
解密
Alice得到Bob的讯息 \(c\) 后就可以利用她的私钥 \(d\) 来解码。她可以用以下这个公式来将 \(c\) 转换为 \(n\):
得到 \(n\) 后,她可以将原来的讯息 \(m\) 重新复原。
(2)实现
扩展欧几里得算法
乘法逆元:如果 \(ax≡1 (mod\enspace b)\),且 \(gcd(a,b)=1\)(\(a\) 与 \(b\) 互质),则称 \(a\) 关于模 \(b\) 的乘法逆元为 \(x\)。
在介绍乘法逆元的计算方法前先了解一下什么是欧几里得算法以及贝祖定理
-
欧几里得算法又称辗转相除法,常用于求两个数 \(m\) 和 \(n\) 的最大公约数 \(gcd(m,n)\),原理是用两个数 \(m\) 和 \(n\) 中较大的数 \(m\) 除以较小的数 \(n\),即 \(m\div n\),如果能整除,那么较小的那个数 \(n\),就是所求的最大公约数,否则 \(m\div n=q......r\) ,就用除数 \(n\) 和余数 \(r\) 作为新一轮的 \(m\) 和 \(n\) ,继续判断能否整除……依此类推,直到能够整除为止,这时作为除数的数就是所求的最大公约数。
【注】
- 被除数 \(\div\) 除数 \(=\) 商 …… 余数
- \(A\div B\) 读作“A除以B”或者“B除A”
举个例子:求1314和511的最大公约数
\[1314\div 511=2......292\\ 511\div 292=1......219\\ 292\div 219=1......73\\ 219\div 73=3 \]于是73就是1314和511的最大公约数,即 \(gcd(1314,511)=73\) 。用代码实现如下
int gcd(int a, int b){ if(b == 0) return a; return gcd(b, a % b); } -
贝祖定理:如果 \(a\)、\(b\) 是整数,那么一定存在整数 \(x\)、\(y\) 使得 \(a\cdot x+b\cdot y=gcd(a,b)\),这个式子也被称为贝祖等式。
那么它们与乘法逆元有什么关系呢?我们由乘法逆元的定义可以知道 \(a\) 和它的逆元 \(x\) 满足 \(ax≡1 (mod\enspace b)\),即 \(a\cdot x+b\cdot (-z)=1\),这就与贝祖等式对应起来了(\(a\) 和 \(b\) 已知,且 \(gcd(a,b)=1\) ),于是根据贝祖定理,我们知道了,已知 \(a\) 和 \(b\),且 \(gcd(a,b)=1\),则一定存在整数 \(x\)、\(y\) 使得 \(a\cdot x+b\cdot y=1\) ,即 \(ax≡1 (mod\enspace b)\) —— \(a\) 关于 \(b\) 一定存在乘法逆元 \(x\),而求解 \(x\) 的方法就要用到扩展欧几里得算法——欧几里得算法的扩展。总结到一点,贝祖定理告诉我们乘法逆元存在,扩展欧几里得算法给我们提供了求解方法。
下面着重讲解一下扩展欧几里得算法,以求30关于47的乘法逆元为例
即求整数 \(x\) 和 \(y\) 使得 \(30x+47y=1\)
用欧几里得算法把求30和47最大公约数的中间式子罗列出来并整理如下
接下来我们需要用上面的4个式子合并整理,凑出 \(30x+47y=1\)的形式。
不难看出,第n个式子的除数是第n-1个式子的余数,所以可以从最后一个式子开始用上一个式子带入,也就是用第n-1个式子代替第n个式子的除数(如用③式代替④式的4),别的不要动,也不要计算,带入一次后各个除数和余数的系数合并整理,进入下一次的替换,这就形成了递归,直到最后n == 1,就会出现出现形如 1 = 47x + 30y 。
具体操作如下
1=13+4*(-3)
1=13+[17*1+13*(-1)]*(-3) //用(3)式4=17*1+13*(-1)替换(4)式的除数4
1=17*(-3)+13*4 //整理
1=17*(-3)+[30*1+17*(-1)]*4 //用(2)式13=30*1+17*(-1)替换(3)式除数13
1=30*4+17*(-7) //整理
1=30*4+[47*1+30*(-1)]*(-7) //用(1)式17=47*1+30*(-1)替换(2)式除数17
1=47*(-7)+30*11 //整理
最后我们可以知道30关于47的乘法逆元为11。
扩展欧几里得的递归算法只需要在欧几里得算法的基础上扩展即可
int exgcd(int a, int b, int &x, int &y){
if(b == 0){
x = 1;
y = 0;
return a;
}
int d = exgcd(b, a % b, y, x);
y -= (a / b) * x;
return d;
}
快速幂取模
首先 \(e\) 其实可以写成这样的形式
其中 \(x_i\) 都是 \(e\) 转化成二进制之后各位上的值,为0或1。
那么不难得出
而对于某一项 $ n ^{x_i* 2^ {i}}{\pmod {N}} $
如果
- \(x_i=0\):无效项
- \(x_i=1\):有效项
所以得出结论,表达式 \(n^{e}\) 是可以简化成所有有效项的乘积的,而某一项是否是有效项,就取决于对应的二进制位是否为1。又因为乘积取模可以在相乘之前先取模,即 \((x * y) \mod d = ((x \mod d) * (y \mod d)) \mod d;\)于是可以提取每个有效项的结果,取模后再乘起来。
/*计算(m^e)%N*/
int PowerMod(int m, int e, int N){
int ans = 1;
m = m % N;
while (e > 0){ //取出的e==0时也就代表取二进制位取完了,循环也就结束
if (e % 2 == 1) //根据二进制位是否是1决定要不要乘进去
ans = (ans * m) % N;
e = e / 2; //e就是x_i,存储每一个二进制位
m = (m * m) % N;//更新m的值,m就代表每一项
}
return ans;
}
素数生成算法
二、隐写术(Steganography)
(〇)文件元数据
无论什么格式的文件,它的元数据常常隐藏重要的信息
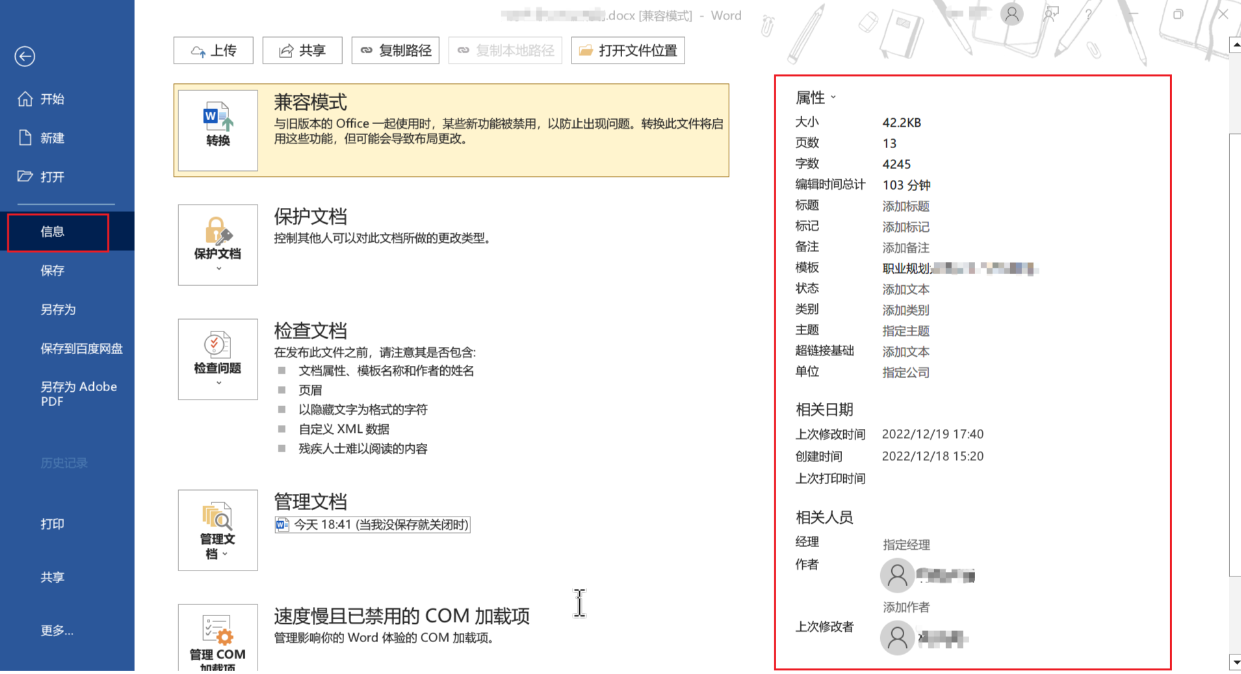
1. Word文件
对于一个Word文件,在信息标签页下可以看到关于这个文档的各种属性
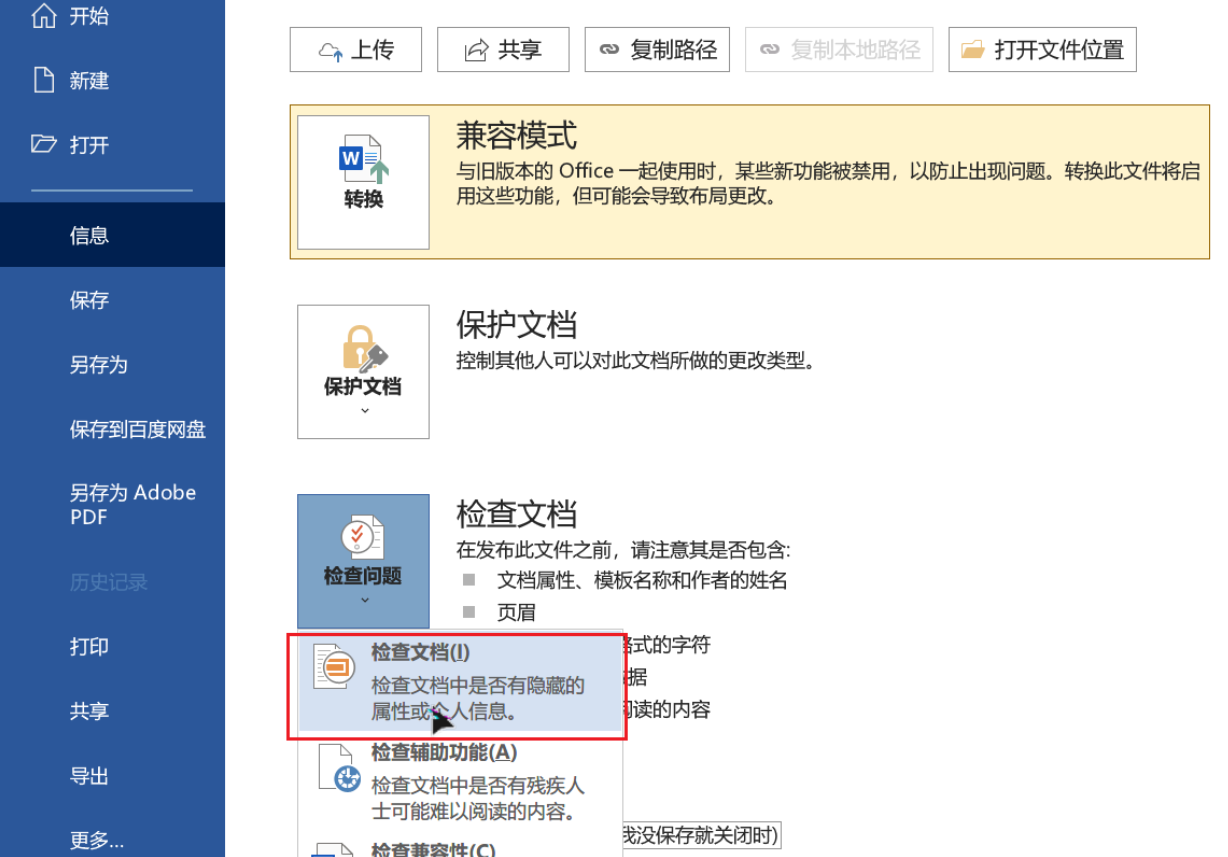
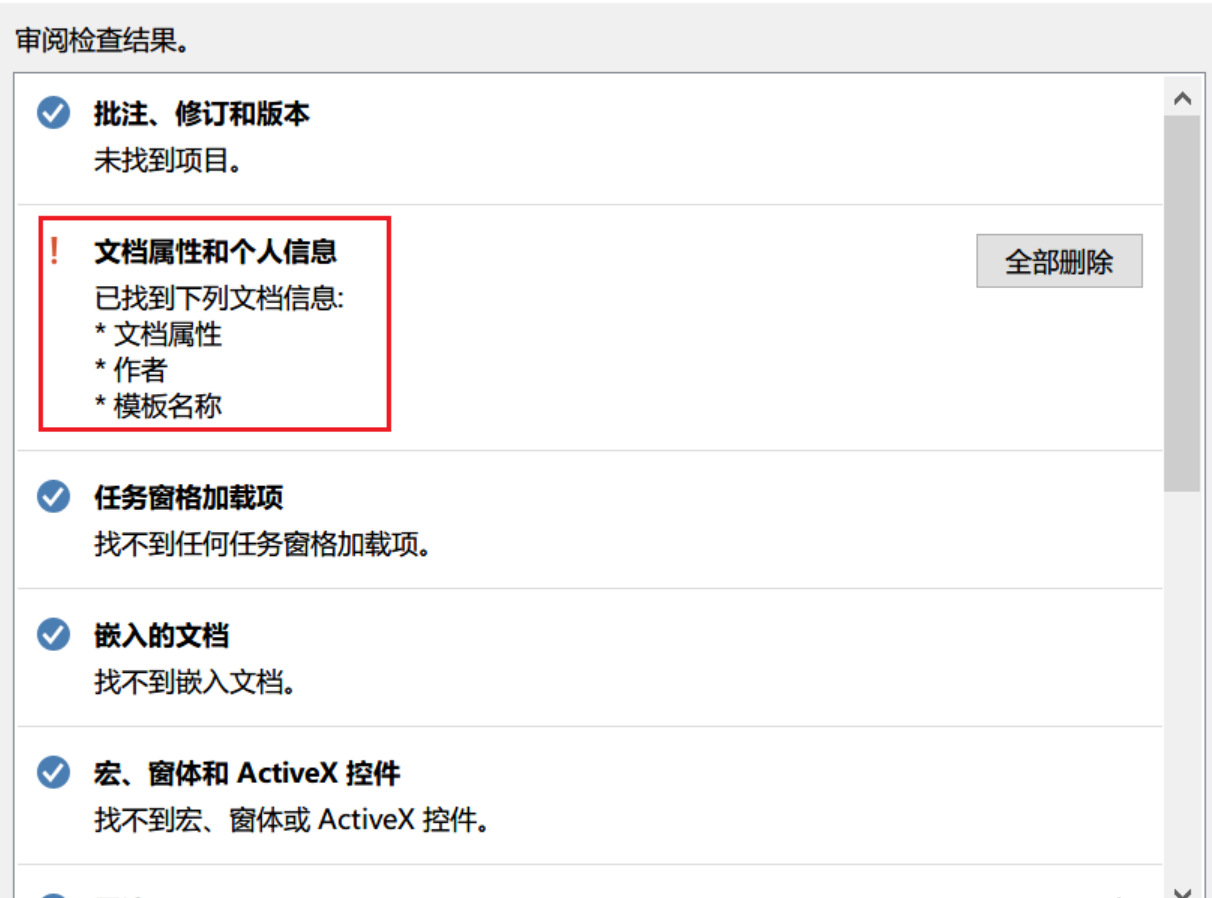
Word文件的元数据删除可以利用文档检查器(文件>信息>检查问题>检查文档)
可以在向外界发送文档前选择是否删除
2. 图像元数据
可交换图像文件格式(英语:Exchangeable image file format,官方简称Exif),是专门为数码相机的照片设定的,可以记录数码照片的属性信息和拍摄数据。Exif信息是可以被任意编辑的,因此只有参考的功能。在早期,摄影师需要随身携带笔记本来记录重要信息,如日期、快门速度、光圈等,这非常麻烦而且容易出错。如今,每台数码相机都支持Exif,能够将拍摄时的很多参数通过这种格式(Exif)记录到照片中,这些照片(或其他类型的文件)中的额外数据就叫元数据(metadata),它由一系列参数组成,如快门速度、光圈、白平衡、相机品牌和型号、镜头、焦距等等。Exif信息可能会造成隐私泄露(相机型号、位置等),在社会工程学中,Exif也是获取目标信息的一种手段。
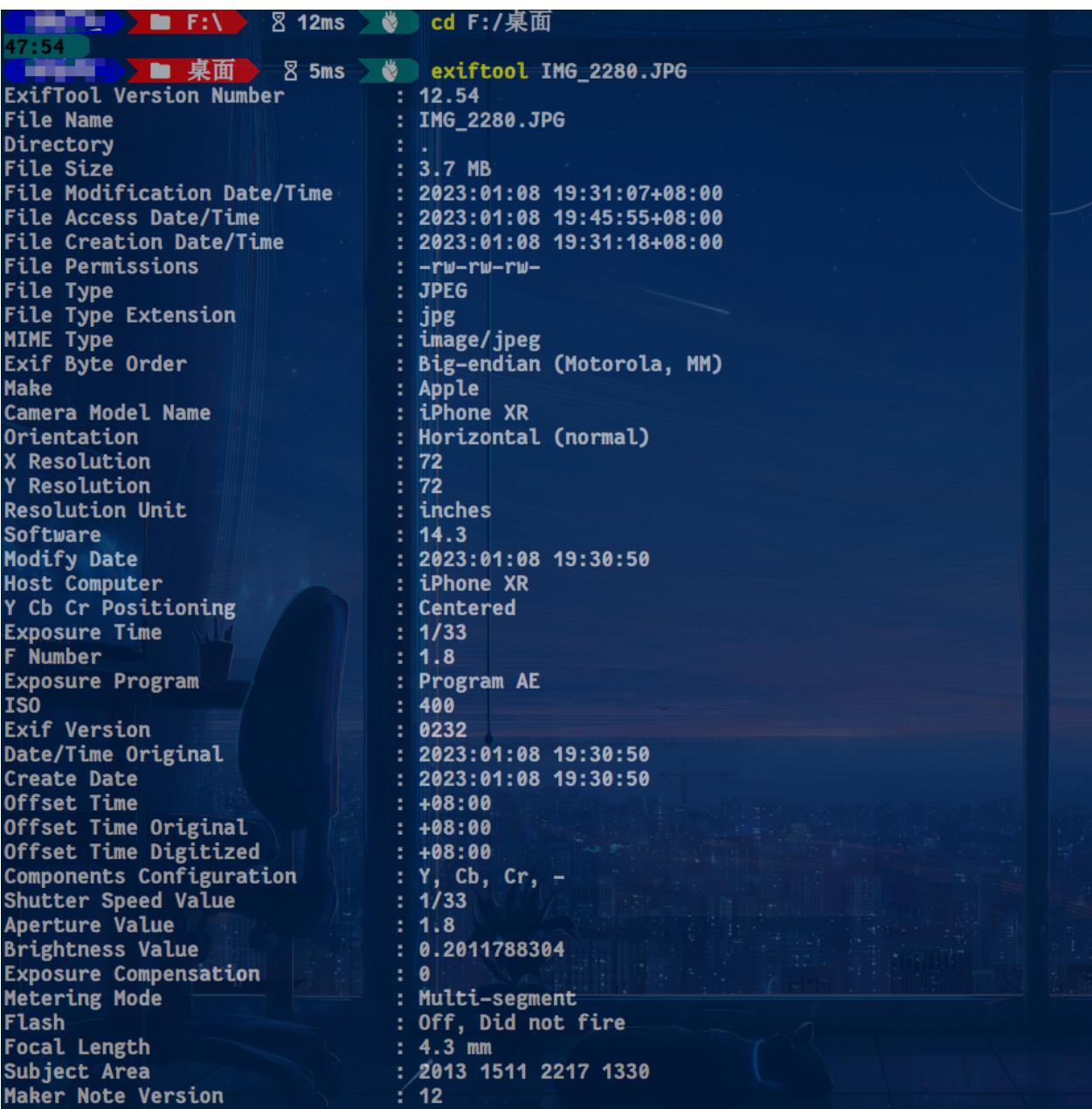
——exiftool安装
ExifTool由Phil Harvey开发,是一款免费、跨平台的开源软件,用于读写和处理图像(主要)、音视频和PDF等文件的元数据(metadata),借助这个工具可以看到图像文件的exif文件头
- Windows:下载ExifTool可执行文件(名为:exiftool-x.x.zip),解压得到exiftool(-k).exe,重命名为exiftool.exe,通过CMD命令行运行。
- Linux:下载ExifTool发行包(名为:Image-ExifTool-x.x.tar.gz),解压后运行./exiftool即可。或通过perl Makefile.PL && make install编译安装。
有时候需要对许多目标文件进行exif查询,此时想找出某一个关键的信息字段可以用下面的指令搜索关键字(前提:配置好grep和exiftool工具)
exiftool *|grep flag #搜索当前文件夹下所有文件的exif信息中的flag字符
(一)NTFS数据流隐写
NTFS是微软Windows NT内核的系列操作系统支持的、一个特别为网络和磁盘配额、文件加密等管理安全特性设计的磁盘格式。NTFS比FAT文件系统更稳定,更安全,功能也更为强大。
NTFS数据流文件,也叫Alternate data streams,简称ADS,是NTFS文件系统的一个特性之一,允许单独的数据流文件存在,同时也允许一个文件附着多个数据流,即除了主文件流之外还允许许多非主文件流寄生在主文件流之中,它使用资源派生的方式来维持与文件相关信息,并且这些寄生的数据流文件我们使用资源管理器是看不到的。
(二)base64隐写
参考:Base64隐写 (cltheorem.github.io)
题目:
Base64码表:ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=
Base64是一种用64个可打印字符来表示二进制数据的方法。
base64编码
-
1B=8bit,一个可打印字符对应6个比特,即一个单元,将目标字串变成二进制数据流,然后6个一单元划分对应成码表的索引,用base64码表中的字符替换。码文c和明文m的关系为 \(len(c)\times 6==len(m)\times 8\),即 \(len(c)\times 3==len(m)\times 4\),那么必须码文字符串的长度必须为4的倍数,明文字符串的长度必须为3的倍数。
-
对于明文字符串长度不足3的倍数的情况用每一个二进制位用\(0\ bit\)补足直到满足明文字符串长度为3的倍数。
不难看出,一个base64码文最多可以有2个‘=’,最少可以没有等号(此时明文长度刚好是3的倍数)。
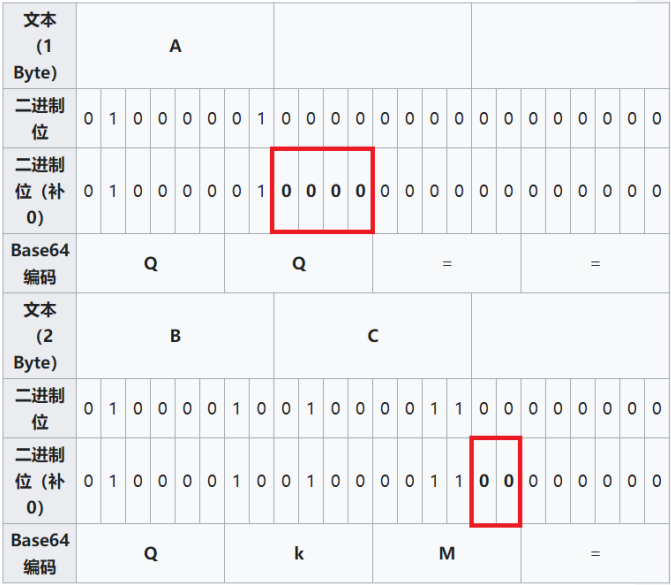
base64解码
-
把码文末端的
‘=’去除 -
在其二进制数据的末尾丢弃最小数目的二进制位使二进制位数为8的倍数,然后8位一组进行ASCII编码。
base64隐写原理
在base64解码中,去除等号之后将末尾一些二进制位丢弃使二进制位数为8的倍数,所以一些隐藏数据可以写在可以被丢弃的部分,这部分可以随意写成任意值而不用担心影响解码的结果,同时也说明了不同的base64码文可能生成相同的明文。
下面是提取脚本
import re
path = 'flag.txt' #your path
b64char = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
with open(path, 'r')as f:
cipher = [i.strip() for i in f.readlines()]
plaintext = ''
for i in cipher:
if i[-2] == '=': # There are 4-bit hidden info while end with two '='
bin_message = bin(b64char.index(i[-3]))[2:].zfill(4)
plaintext += bin_message[-4:]
elif i[-1] == '=': # There are 2-bit hidden info while end with one '='
bin_message = bin(b64char.index(i[-2]))[2:].zfill(2)
plaintext += bin_message[-2:]
plaintext = re.findall('.{8}', plaintext) # 8bits/group
plaintext = ''.join([chr(int(i,2)) for i in plaintext])
print(plaintext)
下面是隐写脚本
#!/usr/bin/env python
import base64
with open('./gitanjali.txt', 'r')as f:
data = [i.strip() for i in f.readlines()]
base64Data = [base64.b64encode(i) for i in data]
b64char = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
msg = 'Gitanjali' # 隐写内容,注意隐写内容不应超过最大隐写bit数
msg_bit = ''.join([bin(ord(i))[2:].zfill(8) for i in msg])
offset = 0
new_data = []
for i in base64Data:
if i[-2]=='=': # There are 4-bit hidden info while end with two '='
offset = int(msg_bit[:4],2)
i = i.replace(i[-3], b64char[b64char.index(i[-3])+offset])
msg_bit = msg_bit[4:]
elif i[-1]=='=': # There are 2-bit hidden info while end with one '='
offset = int(msg_bit[:2],2)
i = i.replace(i[-2], b64char[b64char.index(i[-2])+offset])
msg_bit = msg_bit[2:]
new_data.append(i+"\n")
with open('./encodeFile.txt', 'w')as f:
f.writelines(new_data)
(三)零宽字符隐写
参考:一个你所不知道的加密方式--零宽字符加密 - 知乎 (zhihu.com)
在线解码(需要多个网站都试试):
- Unicode Steganography with Zero-Width Characters (330k.github.io)
- 隐藏字符加密 - 一个工具箱 - 好用的在线工具都在这里! (atoolbox.net)
- Zero Width Lib (yuanfux.github.io)
辨别:把目标文本粘贴到vim中
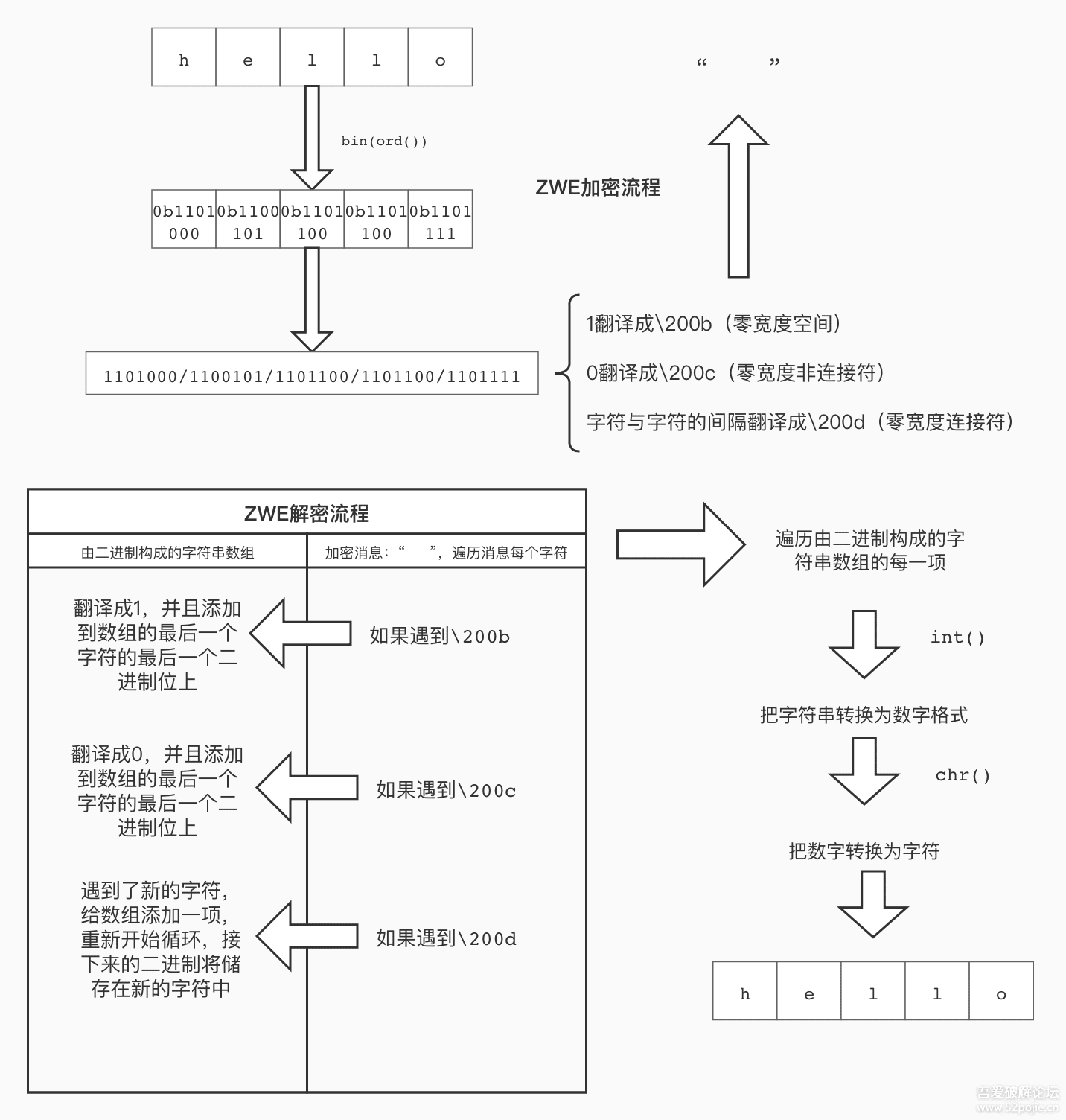
零宽字符是一种在浏览器中不打印的字符,大致相当于 display: none ,在许多文本应用中也不显示,比如邮箱、QQ、微信、文本编辑器等;
html中有三种零宽字符——零宽空格、零宽连字、零宽不连字
零宽字符在浏览器中对应的转义字符
零宽空格 --- ​
零宽不连字 --- ‌
零宽连字 --- ‍
零宽字符在Unicode中的编码为
\u200B \u200C \u200D
(五)PYC隐写
参考:pyc文件 - CTF Wiki (ctf-wiki.org)
例题:
基本原理是在 python 的字节码文件中,利用冗余空间,将完整的 payload 代码分散隐藏到这些零零碎碎的空间中。例如,从 Python 3.6开始,有一个较大的改变,就是不管 opcode 有没有参数,每一条指令的长度都两个字节,opcode 占一个字节,如果这个 opcode 是有参数的,那么另外一个字节就表示参数;如果这个 opcode 没有参数,那么另外一个字节就会被忽略掉,一般都为00。
Stegosaurus 是一款隐写工具,它允许我们在 Python 字节码文件 (pyc 或 pyo) 中嵌入任意 Payload。由于编码密度较低,因此我们嵌入 Payload 的过程既不会改变源代码的运行行为,也不会改变源文件的文件大小。 Payload 代码会被分散嵌入到字节码之中,所以类似 strings 这样的代码工具无法查找到实际的 Payload。 Python 的 dis 模块会返回源文件的字节码,然后我们就可以使用 Stegosaurus 来嵌入 Payload 了。
(六)可执行文件隐写
1. Hydan
Hydan是可以在32位ELF二进制文件里隐藏信息的工具,主要原理是利用了i386指令中的冗余信息,它利用二进制代码的逆向工程技术来判断在可执行文件中隐藏数据段的最佳位置。这个过程中还使用了一个x86反编译库:Mammon's Libdisasm。但可执行文件中可以用来隐藏数据的空间很小,一个JPEG图像文件中每17个字节中可以隐藏一个字节数据,而二进制文件(可执行文件)中每150字节的代码才可以隐藏一个字节。
(七)PDF隐写
1. wbStego
其实不只是PDF文件,wbStego算法支持把文件隐藏到 BMP、 TXT、 HTM 和 PDF 文件中,而CTF赛事中更常用于对BMP或者PDF文件隐写
原理:首先,wbStego会把待插入数据的每一个ASCII码转换为二进制形式;然后,把每一个二进制数字再替换为0x20或0x09,0x20代表0,0x09代表1;最后,按字节搜索PDF文件,在PDF文档的两个间接对象的字节之间,将这些十六进制数据嵌入到PDF文件中。所以用wbStego修改后的文件内容,会发现文件中已混入了很多由0x20和0x09组成的字节。
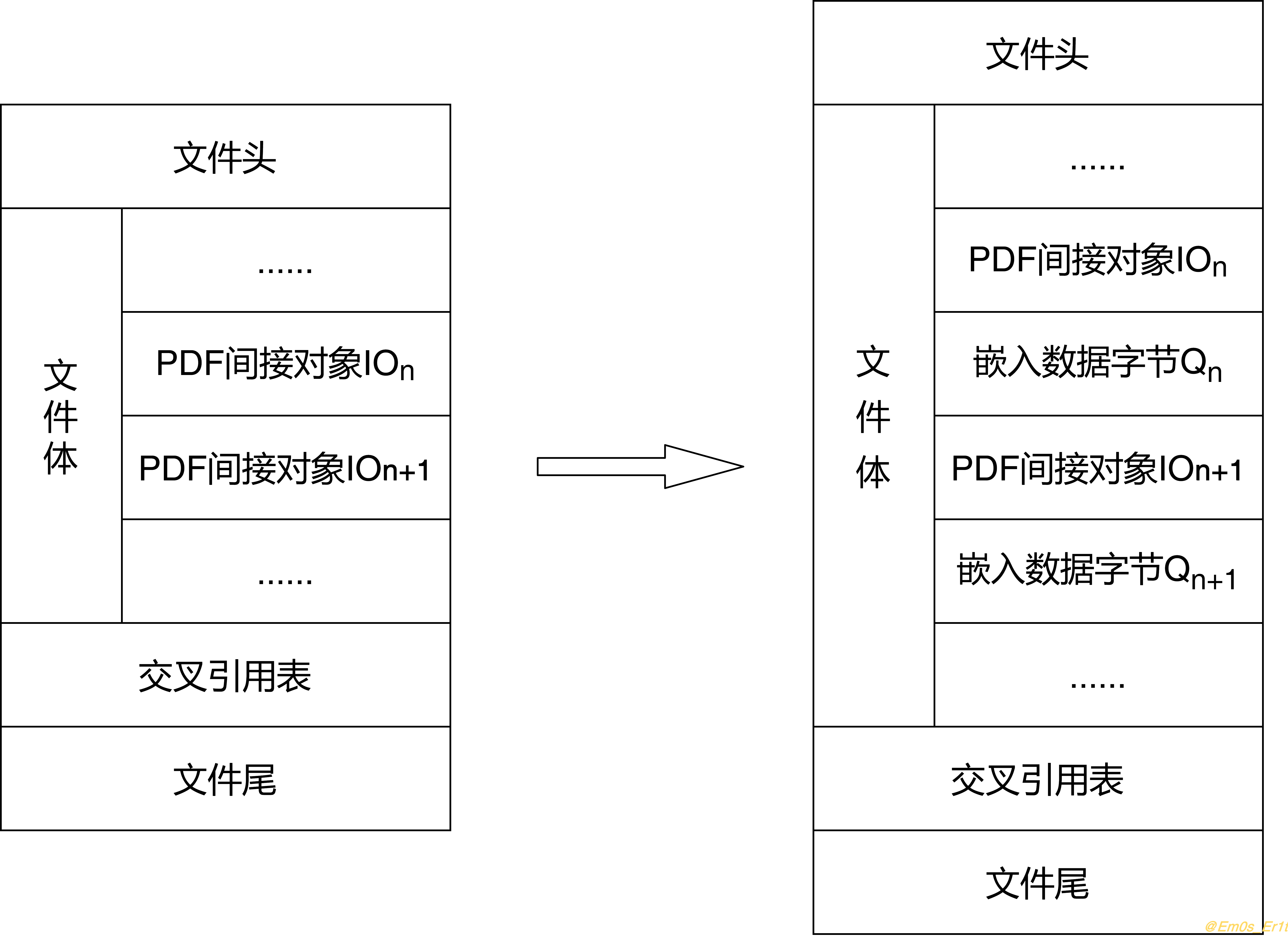
隐写与提取:wbStego4open
判断:文件中有很多由0x20和0x09组成长度为8B的字节块,且这些字节块位于两个间接对象之间(如下图,左边是隐写了数据的文件,右边是原始文件)。
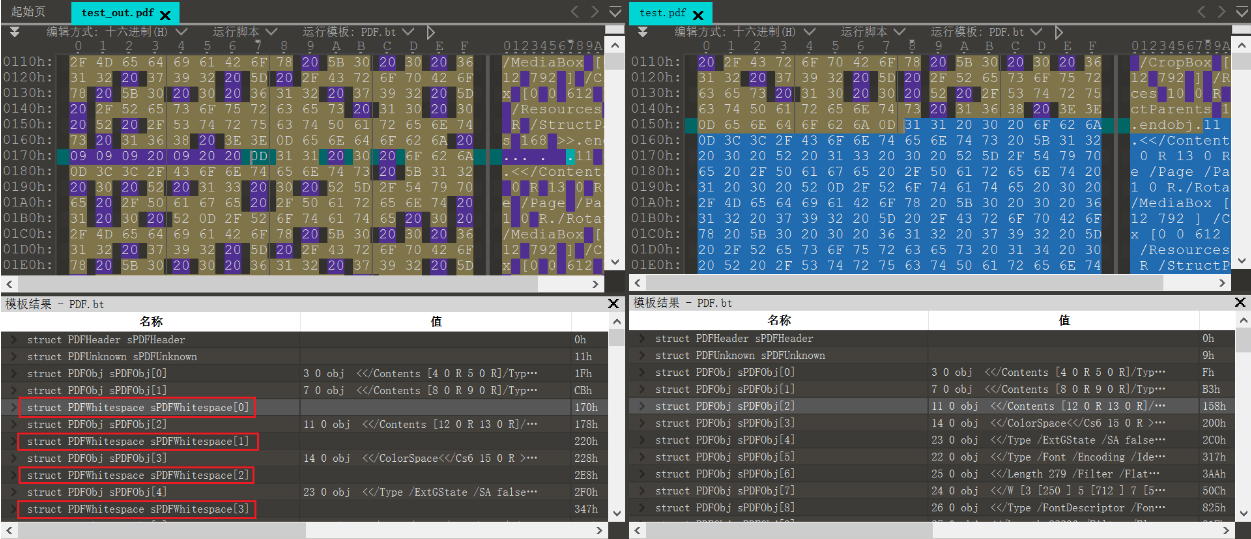
总的来说,如下图所示
(八)TTL隐写
原理:IP数据报的TTL(Time To Live)字段有8bit,可以表示0-255的范围,IP数据报每经过一个路由器,TTL字段就会减1,当TTL减为0的时候,该报文就会被丢弃,但是在大多数情况下通常只需要经过很小的跳数就能完成报文的转发, 远远比上限255小得多,所以我们可以用TTL值的前两位来进行传输隐藏数据。

(九)HTML文件隐写
HTML即超文本标识语言,它是用来构造超文本文件的工具语言。超文本文件是一种纯文本文件,由标记和数据两部分组成,数据即是文件中包含的能够在浏览器上显示出来的文字、图片和动画等多媒体次料;标记是用于控制数据显示格式和效果的、由浏览器解析执行的命令;属性则提供了有关 HTML 元素的更多的信息,且总是以名称/值对的形式出现,比如:
name="value"。
总结有如下几种隐写方法:
-
在网页结束标记
</HTML>后每行的行尾插入空格或Tab键隐藏信息,例如插入一个空格代表隐藏0,插入一个Tab代表隐藏1。原理:浏览器在解析HTML程序时会忽略掉行尾或HTML结束标记后的空白符号,不会影响浏览器的显示结果。
-
修改标记名称的大小写来隐藏信息。如用大写标记名称
<HTML>代表1,以小写的标记名称<html>代表0。这样,一个标记名称可隐藏1bit信息,具有较好的隐蔽性和抗攻击性,但隐藏容量较小。 -
修改属性值字符串的大小写来隐藏信息。如用属性字母的大写代表隐藏1,小写代表隐藏0。
原理:标记属性名称对大小写不敏感
-
用属性值的单引号、双引号或者不使用引号隐藏信息,如用双引号代表1,单引号代表0。
原理:属性值用单引号和用双引号括起来是等价的
-
用具有两种等价格式的单标记来隐藏信息。如标记
<BR>价于<BR/>,可用<BR>代表隐藏1,<BR/>代表隐藏0,类似的标记还有<HR>等价于<HR/>,<IMG>等价于<IMG/>等。这样的一个标记可隐藏1bit信息。 -
在符号“>”的左边插入空格来隐藏信息。如,用“>”左边有空格代表1,无空格代表0。
原理:符号“>”左边的一个或多个空格会被浏览器忽略
-
调整标记名称和标记属性之间的空格或标记属性之间的空格数来隐藏信息。如,用多个空格代表1,1个空格代表0。因此一个HTML标记有n个属性,则一个标记能隐藏n个bit的信息。
原理:属性之间的多个空格会被当成一个空格对待
-
利用标记中属性赋值号“=”左右添加空格来隐藏信息。以左右都无空格表示00,左无右有空格表示01,左有右无空格表示10,左右均有空格表示11,则一个属性赋值可隐藏2bit信息。
-
利用属性左引号后添加空格和右引号前添加空格来隐藏信息。以空格代表1,无空格代表0。则,一结属性值引号可隐藏2bit信息。
-
利用有些标记的结束标记可以省略来隐藏信息。如:
<P>(抱页标记)、<L1>(清单项目标记)、<TD>(表格单元格标记)、<DT>(定义条目标记)、<DD>(定义内容标记)、<Form>、<Input>等。则一结这样的标记可隐藏1bit信息。
(十)其它
1. 词频统计+隐写
例题:
题型:出题人会提供给我们大段的文章,重要信息隐藏在该文章的字母频率中
import re
path=r''
with open(path,'r') as file:
line = file.readlines()
file.seek(0,0)
result = {}
for i in range(97,123):
count = 0
for j in line:
find_line = re.findall(chr(i),j)
count += len(find_line)
result[chr(i)] = count
res = sorted(result.items(),key=lambda item:item[1],reverse=True)
num = 1
for x in res:
print('{0}: '.format(num),x)
num += 1
三、压缩文件
(一)ZIP文件
ZIP是一种相当简单的分别压缩每个文件的存档格式。分别压缩文件允许不必读取另外的数据而检索独立的文件;理论上,这种格式允许对不同的文件使用不同的算法,ZIP文件是一种压缩文件,可进行加密,也可不加密。
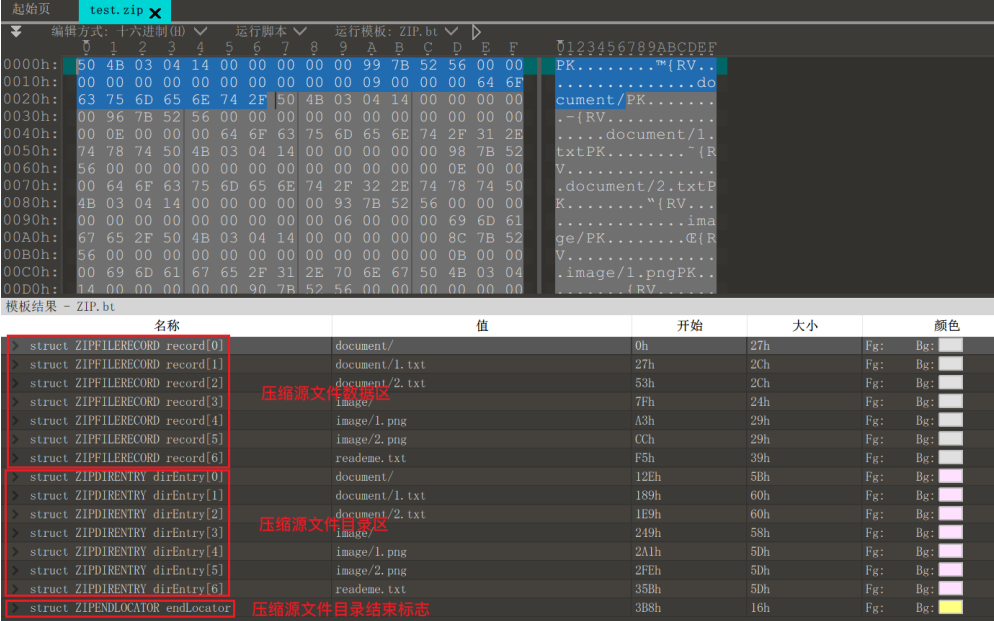
1. ZIP文件结构
一个 ZIP 文件由三个部分组成:
test
├─ reademe.txt
│
├─ document
│ └─1.txt
│ └─2.txt
└─ image
└─1.png
└─2.png
(1)压缩源文件数据区
在这个数据区中每一个压缩的源文件/目录对应一条记录,记录的格式如下:
① 文件头结构
| 组成 | 长度 |
| 文件头标记 | 4B(0x04034b50) |
| 解压文件所需pkware版本 | 2B |
| 全局方式位标记(第二个16进制位表示有无加密) | 2B |
| 压缩方式 | 2B |
| 最后修改文件时间 | 2B |
| 最后修改文件日期 | 2B |
| CRC-32校验 | 4B |
| 压缩后尺寸 | 4B |
| 未压缩尺寸 | 4B |
| 文件名长度 | 2B |
| 扩展记录长度 | 2B |
| 文件名 | (不定长度) |
| 扩展字段 | (不定长度) |
略
③ 数据描述符
这个数据描述符只在全局方式位标记的第3位设为1时才存在(见后详解),紧接在压缩数据的最后一个字节后。这个数据描述符只用在不能对输出的 ZIP 文件进行检索时使用。例如:在一个不能检索的驱动器(如:磁带机上)上的 ZIP 文件中。如果是磁盘上的ZIP文件一般没有这个数据描述符。
| 组成 | 长度 |
| CRC-32校验 | 4B |
| 压缩后尺寸 | 4B |
| 未压缩尺寸 | 4B |
在这个数据区中每一条记录对应在压缩源文件数据区中的一条数据
| 组成 | 长度 |
| 目录中文件文件头标记 | 4B(0x02014b50) |
| 压缩使用的pkware 版本 | 2B |
| 解压文件所需 pkware 版本 | 2B |
| 全局方式位标记(第二个16进制位表示有无加密,伪加密的关键) | 2B |
| 压缩方式 | 2B |
| 最后修改文件时间 | 2B |
| 最后修改文件日期 | 2B |
| CRC-32校验 | 4B |
| 压缩后尺寸 | 4B |
| 未压缩尺寸 | 4B |
| 文件名长度 | 2B |
| 扩展字段长度 | 2B |
| 文件注释长度 | 2B |
| 磁盘开始号 | 2B |
| 内部文件属性 | 2B |
| 外部文件属性 | 4B |
| 局部头部偏移量 | 4B |
| 文件名 | (不定长度) |
| 扩展字段 | (不定长度) |
| 文件注释 | (不定长度) |
| 组成 | 长度 |
| 目录结束标记 | 4B(0x02014b50) |
| 当前磁盘编号 | 2B |
| 目录区开始磁盘编号 | 2B |
| 本磁盘上纪录总数 | 2B |
| 目录区中纪录总数 | 2B |
| 目录区尺寸大小 | 4B |
| 目录区对第一张磁盘的偏移量 | 4B |
| ZIP文件注释长度 | 2B |
| ZIP 文件注释 | (不定长度) |
2. 破解加密后的ZIP文件
(1)密码破解
通常需要利用工具——Ziperello和ARCHPR
-
Ziperello在不知道密码位数的情况下暴力破解1~6位(超出6位消耗事件更长),但只可以暴破ZIP文件
-
ARCHPR更适用于在知道密码格式的情况下的掩码暴破,适用于ZIP和RAR。
下面是几种破解类型:
- 暴破:顾名思义,逐个尝试选定集合中可以组成的所有密码,直到遇到正确密码
- 字典:字典攻击的效率比破稍高,因为字典中存储了常用的密码,因此就避免了暴破时把时间浪费在脸滚键盘类的密码上
- 掩码攻击:如果已知密码的某几位,如已知6位密码的第3位是a,那么可以构造
??a???进行掩码攻击,掩码攻击的原理相当于构造了第3位为a的字典,因此掩码攻击的效率也比暴破高出不少
(2)CRC暴破(CRC碰撞)
即文件内容暴破
Misc中的有一类题目是我们需要知道加密后的压缩文件中的内容,但是压缩文件的密码我们不知道,直接暴破密码也不是很现实,但是当文件的大小比较小,或者字符数量较少,这个时候就可以构造一个和源文件等长的字符串,然后再对其进行CRC校验,比较校验码是否相同以此来暴破出压缩文件内部文件的内容。
例题:
下面这个脚本仅适用于字符小于等于4的情况
#这个脚本仅适用于字符小于等于4的情况
import zipfile
import string
import binascii
def CrackCrc(crc): #CRC暴破
with open('flag.txt','a') as f:
dic = string.ascii_letters + string.digits + '+/='
#dic = string.printable #根据情况自行设置字符表
for i in dic: #根据内部文件的大小设置不同的循环次数,大小为4就设置4层嵌套循环
for j in dic:
for k in dic:
for h in dic:
s = i + j + k + h
if crc == (binascii.crc32(s.encode())):
f.write(s)
return
def CrackZip(): #获取压缩文件的CRC校验码
for i in range(0,68):
path = 'E:\\CTF_project\\BUUCTF\\MISC\\zip\\'+'out'+str(i)+'.zip'
crc = zipfile.ZipFile(path,'r').getinfo('data.txt').CRC #获取压缩包内data.txt文件的CRC字段值
CrackCrc(crc)
if __name__=='__main__':
CrackZip()
print("CRC32碰撞完成")
另外有一个脚本可以破解更多位,源自GitHub - theonlypwner/crc32: CRC32 tools: reverse, undo/rewind, and calculate hashes,使用方法如下:
python crc32.py reverse <你的crc32密文,加上0x>
(3)已知明文攻击
介绍:这种攻击是基于 Biham 和 Kocher 在 94 年发表的论文《A Known Plaintext Attack on the PKZIP Stream Cipher》实现的。简单地来讲,就是当我们知道一个加密压缩包内某个文件的内容的时候,我们就可以利用明文攻击迅速有效找出 keys(可以理解为 password 的内部表示形式),从而破解这个压缩包,虽然password 不一定能成功还原,不过解压文件有 keys 就够了。比如压缩包里有一个常见的 license 文件,或者是某个常用的 dll 库,或者是带有固定头部的文件(比如 xml、exe、png 等容易推导出原始内容的文件),那么就可以运用这种攻击。当然,前提是压缩包要用 ZipCrypto 加密。
原理:我们为zip压缩文件所设定的密码用于初始化3个32bit的key,所以可能的key的组合是\(2^{96}\),这是个天文数字,如果用暴力穷举的方式是不太可能的,除非你的密码比较短或者有个厉害的字典。压缩软件用这3个key加密所有包中的文件,也就是说,所有文件加密的key是一样的,如果我们能够找到这个key,就能解开所有的文件。如果我们找到加密压缩包中的任意一个文件,这个文件和压缩包里的文件是一样的,我们把这个文件用同样的压缩软件同样的压缩方式进行无密码的压缩(每个压缩软件都压缩一遍,比较两者的CRC32来判断用的哪个压缩软件),得到的文件就是我们的已知明文。用这个无密码的压缩包和有密码的压缩包进行比较,分析两个包中相同的那个文件,抽取出两个文件的不同点,就是那3个key了,如此就能得到key。两个相同文件在压缩包中的字节数应该相差12个byte,就是那3个key了。虽然我们还是无法通过这个key还原出密码,但是我们已经可以用这个key解开所有的文件,所以已经满足我们的要求了,毕竟对我们而言,得到解压后的文件比得到密码本身更重要。(详见ZIP 明文攻击原理)
注意点 && 特征:
-
已知明文攻击需要我们拥有加密压缩包中的一个文件,两个文件必须完全一致。
——如何知道已知的某个文件是否就是加密压缩包中的该文件
-
初步判断可以通过比对文件大小、文件名称;
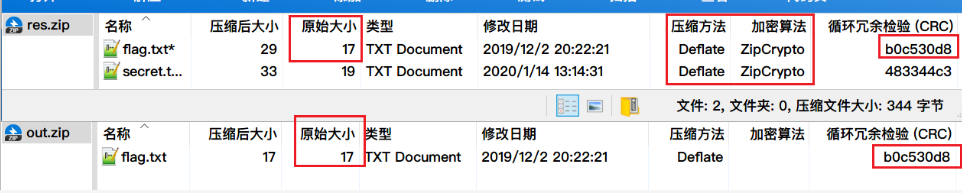
-
进一步判断需要对其采用与加密的压缩包同样的压缩方式(压缩方法、加密算法一致)压缩之后再比对CRC32的值。(如下图中res.zip是加密压缩包,out.zip是已知文件的压缩包,通过下图的比对可以推断两个flag.txt是完全一致的)
-
-
如果文件在加密前经过了压缩,加密算法的输入不再是我们所知道的明文而是压缩后的数据,明文攻击会失败(在压缩包里查看文件的属性可以看到压缩方式,如“ZipCrypto Deflate”就是加密压缩,“ZipCrypto Store”就是加密储存)。这就多了找出明文压缩后的数据这样一个额外步骤。(参考:ZIP 明文攻击原理)
相关题型:
-
最常见的玩法是给一个 文件 A 和一个压缩文件 B.zip,然后查看 B.zip 发现里面也有 A,和一个含有flag的文件 C,于是可以借助明文 A 破解压缩包 B 进而解出 C 得到 flag。(例题:[ACTF新生赛2020]明文攻击)
-
比较高级一点的,可能会利用某些文件头之类的来当做明文,如压缩包里有一个常见的 license 文件,或者是某个常用的 dll 库,或者是带有固定头部的文件(比如 xml、exe、png 等容易推导出原始内容的文件)
如XML 文件开头很可能是
<?xml version="1.0"
工具:ARCHPR和pkcrack
① 用ARCHPR进行已知明文攻击
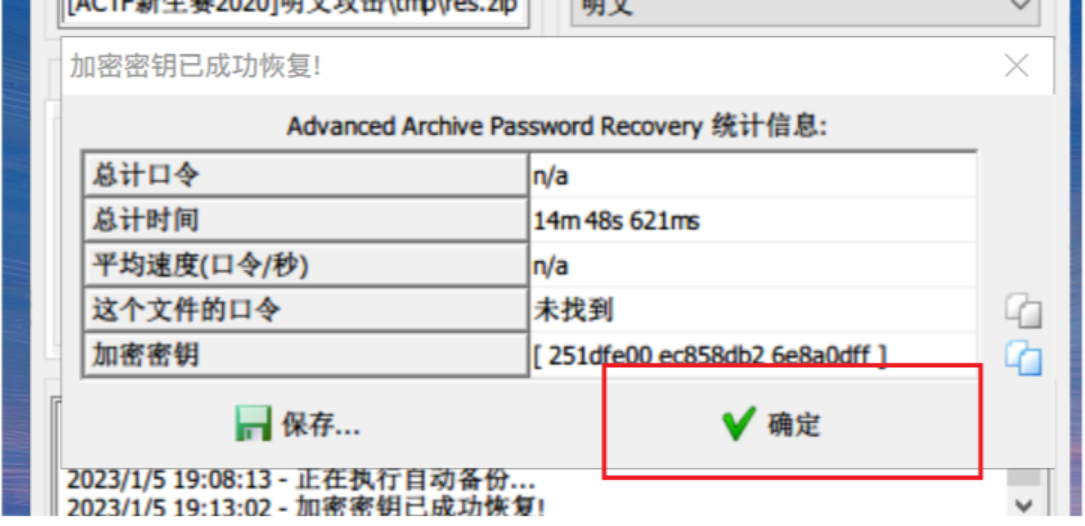
关于ARCHPR如何进行明文攻击如图所示,导入加密的ZIP文件并进行两处设置后点击开始
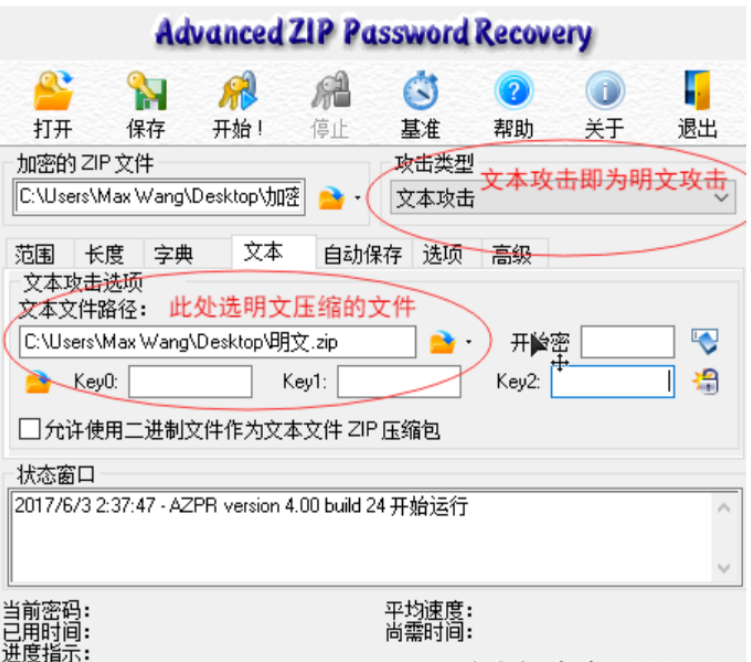
一开始会显示“搜索密钥”,等待一段时间后,当提示正在“尝试找回口令”便可以停止了,没必要一直等到它找回口令,因为我们的目的是破解出文件。

点击停止之后弹出提示框提示成功恢复加密密钥,此时点击确认会提示选择保存输出文件,保存后解压即可得到目标文件。
② pkcrack安装与使用
个人建议在linux下编译,然后在windows下运行
具体细节如下:
git clone https://github.com/keyunluo/pkcrack
mkdir pkcrack/build
cd pkcrack/build
cmake ..
make
安装完之后发现在bin目录下不只是生成了elf文件,还生成了exe文件。
使用如下:
pkcrack --help 查看手册
用法:pkcrack -c <crypted_file> -p <plaintext_file> [other_options]
-c:压缩包中需要破解的文件
-C:包含需要破解文件的压缩包
-P:包含已知文件的压缩包
-p:压缩包中的已知文件
-d:结果输出的文件
例:pkcrack -c "answer/key.txt" -p readme.txt -C Desktop.zip -P readme.zip
注意,使用pkcrack时,要先将已知的文件压缩为zip文件,其作为-P的参数
举个🌰:有加密压缩包Desktop.zip,含有readme.txt和flag.txt,其中的readme.txt已知。
首先我们要将readme.txt压缩为readme.zip,然后输入如下命令
pkcrack -c "flag.txt" -C Desktop.zip -p readme.txt -P readme.zip
(4)ZIP伪加密
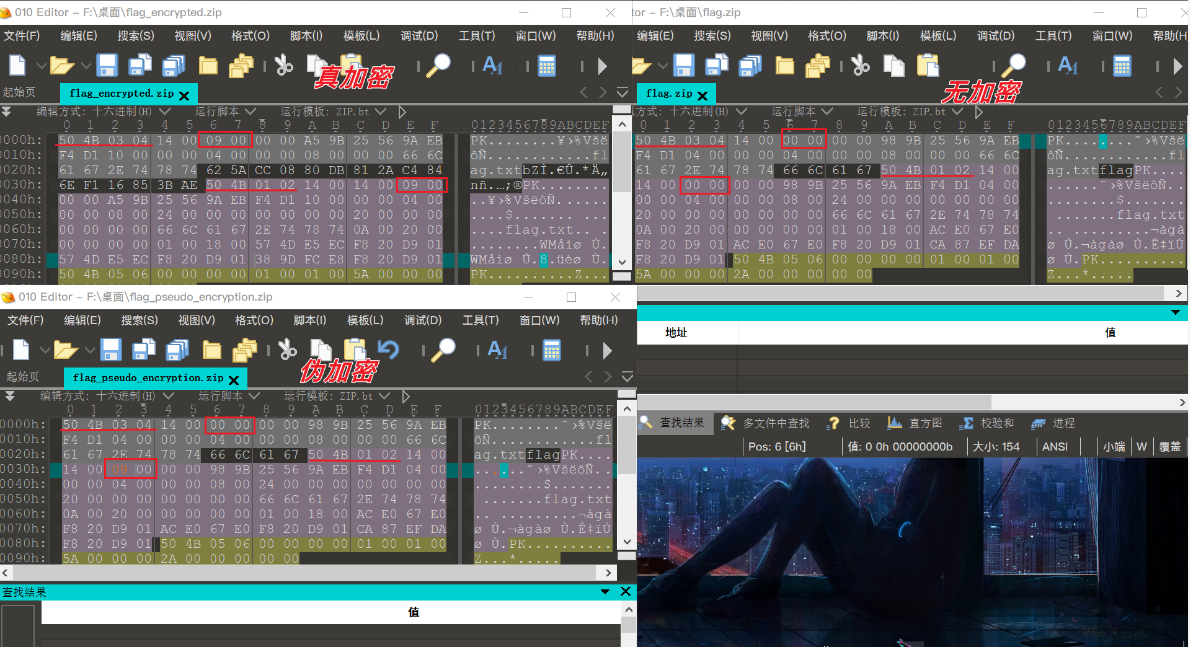
——如何识别真加密、伪加密、无加密
无加密
- 压缩源文件数据区的全局加密通常为
00 00(50 4B 03 04两个字节之后);- 压缩源文件目录区的全局方式位标记通常为
00 00(50 4B 01 02四个字节之后)。伪加密:
- 压缩源文件数据区的全局加密为
00 00;- 压缩源文件目录区的全局方式位标记为
09 00。(不一定是9,也可能被篡改成其他奇数)真加密:
- 压缩源文件数据区的全局加密通常为
09 00;- 压缩源文件目录区的全局方式位标记通常为
09 00。
伪加密是在未加密的zip文件基础上修改了它的压缩源文件目录区里的全局方式位标记的比特值,使得压缩软件打开它的时候识别为加密文件,提示输入密码, 而在这个时候,不管你用什么软件对其进行密码破解,都无法打开它。
破解方法:
-
使用ZipCenOp.jar(需要java环境)
在cmd中使用
java -jar ZipCenOp.jar r xxx.zip成功后压缩包可以直接打开 -
使用winRAR
进入工具,压缩修复文件,修复完后压缩包就可以打开了
上述两种方法很多情况都可以用,但是有时不行,第三种方法可以应对各种zip伪加密
-
修改文件头的加密标志位
加密标志位所在全局方式位字段在上述zip文件结构阐述中已经标识出来,它的四个(16进制)数字中只有第二个数字对其有影响,其它的不管为何值,都不影响它的加密属性。
- 第二个数字为奇数时 \(\rightarrow\) 会显示加密
- 第二个数字为偶数时 \(\rightarrow\) 显示未加密
(二)RAR文件
参考:
RAR文件格式主要有RAR-4和RAR-5两种,在使用WinRAR创建RAR文件时可以选择采用什么版本会生成对应格式的RAR文件
1. RAR4文件结构
RAR文件由可变长度的块组成。这些块的顺序可以变化,但是第一个块必须是标记块,然后是压缩文件头块
通用字段结构如下表:
| 名称 | 大小 | 描述 |
|---|---|---|
| HEAD_CRC | 2 | 整个块或者对块某个部分的CRC |
| HEAD_TYPE | 1 | 当前块的类型,不同的块对应不同的HEAD_TYPE,如下标记块:0x72压缩文件头:0x73 文件头:0x74注释头:0x75旧风格的用户身份信息:0x76子块:0x77恢复纪录:0x78用户身份信息:0x79子块:0x7a结尾块:0x7b |
| HEAD_FLAGS | 2 | 快标志 |
| HEAD_SIZE | 2 | 当前块的大小 |
| ADD_SIZE | 4 | 添加块的大小(可选,只有在块标记的第一位被置1的话时存在) |
现在的RAR-4.x 文件主要由标记块,压缩文件头块,文件头块,结尾块组成,其它块常出现在旧版本的rar文件中
(1)标记块(签名)
标记块也称为Magic number,大小固定是7 个字节,且是一个固定的字节序列 52 61 72 21 1A 07 00。
RAR 5.0的标记块和RAR4.x的不一样,RAR 5.0签名由8个字节组成
0000h: 52 61 72 21 1A 07 01 00 Rar!....
| 字段 | 值 | 长度(B) | 说明 |
|---|---|---|---|
| HEAD_CRC | 0x6152 | 2 | 固定 |
| HEAD_TYPE | 0x72 | 1 | 固定 |
| HEAD_FLAGS | 0x1A21 | 2 | 固定 |
| HEAD_SIZE | 0x0007 | 2 | 块大小 = 0x0007,即7个字节 |
(2)压缩文件头(MAIN_HEAD)
| 字段名称 | 长度(B) | 说明 |
|---|---|---|
| HEAD_CRC | 2 | HEAD_TYPE到RESERVED2的CRC |
| HEAD_TYPE | 1 | 0x73 |
| HEAD_FLAGS | 2 | 位标记: 0x0001 - MHD_VOLUME: 卷属性(压缩文件卷)0x0002 - MHD_COMMENT: 压缩文件注释存在,RAR 3.x使用单独的注释块,不设置这个标记。 0x0004 - MHD_LOCK: 压缩文件锁定属性0x0008 - MHD_SOLID: 固实属性(固实压缩文件)0x0010 - MHD_NEWNUMBERING: 新的卷命名法则(‘volname.partN.rar’) 0x0020 - MHD_AV: 用户身份信息存在,RAR 3.x使用单独的用户身份信息块,不设置这个标记。0x0040 - MHD_PROTECT: 恢复记录存在 0x0080 - HD_PASSWORD: 块头被加密 0x0100 - MHD_FIRSTVOLUME: 第一卷(只有RAR3.0及以后版本设置) 0x0200 - MHD_ENCRYPTVER: HEAD_FLAGS中的其他位保留用于内部使用。 |
| HEAD_SIZE | 2 | 压缩文件头总大小(包括压缩文件注释) |
| RESERVED1 | 2 | 保留 |
| RESERVED2 | 4 | 保留 |
对于压缩文件头里的位标记,如果它的第9位(从左到右)被置1,块头被加密,也就是通常所说的加密文件名,打开这样加密的RAR文件时,需要先输入密码才能看到压缩包内的文件列表。
(3)文件头(FILE_HEAD)
| 字段名称 | 长度(B) | 说明 |
|---|---|---|
| HEAD_CRC | 2 | 从HEAD_TYPE到FILEATTR的CRC |
| HEAD_TYPE | 1 | 0x74 |
| HEAD_FLAGS | 2 | 位标记: 0x0001 - LHD_SPLIT_BEFORE: 文件从上一卷继续0x0002 - LHD_SPLIT_AFTER: 文件从后一卷继续0x0004 - LHD_PASSWORD: 文件使用密码加密0x0008 - LHD_COMMENT: 文件注释存在,RAR 3.x使用独立的注释块,不设置这个标记。 0x0010 - LHD_SOLID: 前一文件信息被使用(固实标记) (对于RAR 2.0 和以后版本) 7 6 5 位(对于RAR 2.0和以后版本) 0 0 0 - 字典大小 64KB 0 0 1 - 字典大小 128KB 0 1 0 - 字典大小 256KB 0 1 1 - 字典大小 512KB 1 0 0 - 字典大小 1024KB 1 0 1 - 字典大小 2048KB 1 1 0 - 字典大小 4096KB 1 1 1 - 文件作为字典 0x0100 - LHD_LARGE: HIGH_PACK_SIZE和HIGH_UNP_SIZE结构存在。这些结构仅用在非常大(大于2GB)的文档,对于小文件这些结构不存在。0x0200 - LHD_UNICODE: FILE_NAME是用0隔开的包含普通的和Unicode编码的文件名。所以NAME_SIZE字段的值等于普通文件名的长度加Unicode编码文件名的长度再加1。如果此标记存在,但是FILE_NAME不包含0字节,它意味文件名使用UTF-8编码。0x0400 - LHD_SALT: 文件头在文件名后包含附加的8byte,它对于增加加密的安全性是必需的。(所谓的’Salt’)。0x0800 - LHD_VERSION: 版本标记。它是旧文件版本,版本号作为’;n’附加到文件名后。0x1000 - LHD_EXTTIME: 扩展时间区域存在。0x2000 - LHD_EXTFLAGS 0x8000 - 此位总被设置,所以完整的块的大小是HEAD_SIZE + PACK_SIZE(如果0x100位被设置,再加上HIGH_PACK_SIZE) |
| HEAD_SIZE | 2 | 文件头的全部大小(包含文件名和注释) |
| PACK_SIZE | 4 | 已压缩文件大小 |
| UNP_SIZE | 4 | 未压缩文件大小 |
| HOST_OS | 1 | 保存压缩文件使用的操作系统0x00 - MS DOS0x01 - OS/20x02 - Win320x03 - Unix0x04 - Mac OS0x05 - BeOS |
| FILE_CRC | 4 | 文件CRC |
| FTIME | 4 | MS DOS标准格式的日期和时间 |
| UNP_VER | 1 | 解压文件所需要最低RAR版本,版本编码方法:10 * 主版本 + 副版本。 |
| METHOD | 1 | 压缩方式:0x30 - 存储0x31 - 最快压缩0x32 - 较快压缩0x33 - 标准压缩0x34 - 较好压缩0x35 - 最好压缩 |
| NAME_SIZE | 2 | 文件名大小 |
| ATTR | 4 | 文件属性 |
| HIGH_PACK_SIZE | 4 | 可选值,已压缩文件大小64位值的高4字节。只HEAD_FLAGS中的0x100位被设置才存在。 |
| HIGH_UNP_SIZE | 4 | 可选值,未压缩文件大小64位值的高4字节。只有HEAD_FLAGS中的0x100位被设置才存在。 |
| FILE_NAME | NAME_SIZE | 文件名 - NAME_SIZE字节大小字符串 |
| SALT | 8 | 可选值,如果(HEAD_FLAGS & 0x400)!= 0,则存在 |
| EXT_TIME | 可变大小 | 可选值,扩展时间区域,如果(HEAD_FLAGS & 0x1000)!= 0,则存在 |
(4)结尾块(ENDARC_HEAD )
与标记块类似的是,结尾块也是一个固定字节串的块,依次是C4 3D 7B 00 40 07 00。
| 字段名称 | 长度(B) | 值 | 说明 |
|---|---|---|---|
| HEAD_CRC | 2 | 0x3DC4 | 从HEAD_TYPE 到HEAD_SIZE 的CRC校验值 |
| HEAD_TYPE | 1 | 0x7b | 0x7B |
| HEAD_FLAGS | 2 | 0x4000 | 位标记 |
| HEAD_SIZE | 2 | 0x0007 | 结尾块大小 |
2. 破解加密后的RAR文件
(1)密码破解
ARCHPR工具支持多种破解RAR文件密码的方式。
——常见问题
Q:RAR文件导入ARCHPR后提示非档案文件,但确实是RAR文件没错
A:ARCHPR只能破解RAR-4.x的,RAR-5.0的会显示不是档案文件
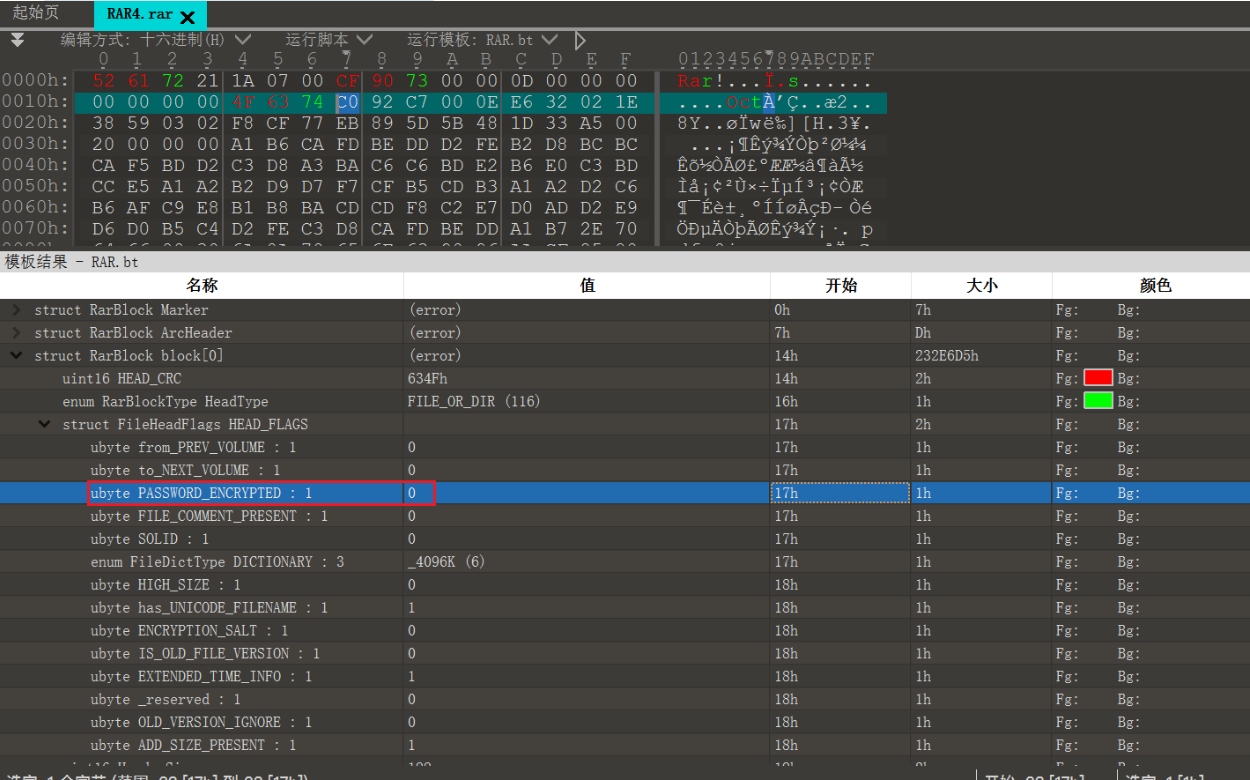
(2)RAR伪加密
RAR 文件的伪加密在文件头中的位标记字段上,用 010 Editor 可以很清楚的看见这一位,修改这一位可以造成伪加密。
(三)GZIP文件
GZIP最早由Jean-loup Gailly和Mark Adler创建,用于UNIX系统的文件压缩。我们在Linux中经常会用到后缀为.gz的文件,它们就是GZIP格式的。现今已经成为Internet 上使用非常普遍的一种数据压缩格式,或者说一种文件格式。——百度百科
(四)BR文件
BR文件是使用Brotli(一种开源数据压缩算法)压缩的文件。 它包含网页资产,例如 .CSS,XML文件, .SVG和 .JS 文件,以Brotli压缩数据格式压缩。 Web浏览器(例如Chrome和Firefox)使用BR文件来提高页面加载速度。
四、swf游戏
(一).swf文件
swf(shock wave flash)是Macromedia(现已被ADOBE公司收购)公司的动画设计软件Flash的专用格式,被广泛应用于网页设计、动画制作等领域,swf文件通常也被称为Flash文件。swf普及程度很高,现在超过99%的网络使用者都可以读取swf档案。这个档案格式由FutureWave创建,后来伴随着一个主要的目标受到Macromedia支援:创作小档案以播放动画。计划理念是可以在任何操作系统和浏览器中进行,并让网络较慢的人也能顺利浏览。swf 可以用Adobe Flash Player打开,浏览器必须安装Adobe Flash Player。
五、取证分析(Forensic)
关于取证:
-
活取证:抓取文件的metadata、创建是时间线、命令历史、分析日志文件、哈希摘要、转存内存信息,使用未受感染的干净程序进行取证,U盘、网络、存储设备收集到的数据。
在活取证中,可以使用内存dump工具,将被入侵的机器的内存保存下来,
- Windows环境下常用的工具是Dumpit。DumpIt 是一款绿色免安装的 windows 内存镜像取证工具。利用它我们可以轻松地将一个系统的完整内存镜像下来,并用于后续的调查取证工作,下载之后放到虚拟机中,双击之后输入y即可获取当前的状态的内存文件,
- Linux环境下常用的工具是lime(Linux Mem Extractor),从intel硬件或虚拟机上抓取内存,
-
死取证:系统关机后制作硬盘镜像、分析镜像。
(一)Windows取证基础
1. .evtx日志取证
windows 日志取证主要包括三方面:Windorw 系统日志(由 windows 系统记录的日志),应用程序独自维护的日志,防火墙或入侵检测系统维护的日志。其中 Windows 操作系统维护三个相互独立的日志文件分别为:系统日志、应用程序日志和安全日志。日志文件位置:C:\Windows\System32\winevt\Logs\ 。登陆事件、策略更改、账户登陆、系统事件的成功失败,还有任何成功的入侵都将在安全日志中留下痕迹。
通过对Windows事件日志的取证分析,取证人员可以对操纵系统、应用程序、服务、设备等操作行为记录,通过关键的时间点进行回溯。
下表为Vista/Win7/Win8/Win10/Server2008/Server 2012及之后的版本
| 类型 | 事件类型 | 描述 | 文件名 |
|---|---|---|---|
| Windows日志 | 系统 | 包含系统进程,设备磁盘活动等。事件记录了设备驱动无法正常启动或停止,硬件失败,重复IP地址,系统进程的启动,停止及暂停等行为。 | System.evtx |
| 安全 | 包含安全性相关的事件,如用户权限变更,登录及注销,文件及文件夹访问,打印等信息。 | Security.evtx | |
| 应用程序 | 包含操作系统安装的应用程序软件相关的事件。事件包括了错误、警告及任何应用程序需要报告的信息,应用程序开发人员可以决定记录哪些信息。 | Application.evtx | |
| 应用程序及服务日志 | Microsoft | Microsoft文件夹下包含了200多个微软内置的事件日志分类,只有部分类型默认启用记录功能,如远程桌面客户端连接、无线网络、有线网路、设备安装等相关日志。 | 详见日志存储目录对应文件 |
| Microsoft Office Alerts | 微软Office应用程序(包括Word/Excel/PowerPoint等)的各种警告信息,其中包含用户对文档操作过程中出现的各种行为,记录有文件名、路径等信息。 | OAerts.evtx | |
| Windows PowerShell | Windows自带的PowerShell应用的日志信息。 | Windows PowerShell.evtx | |
| Internet Explorer | IE浏览器应用程序的日志信息,默认未启用,需要通过组策略进行配置。 | Internet Explorer.evtx |
evtx文件是微软从 Windows NT 6.0(Windows Vista 和 Server 2008) 开始采用的一种全新的日志文件格式。在此之前的格式是 evt 。evtx由Windows事件查看器创建,包含Windows记录的事件列表,以专有的二进制XML格式保存。
.evtx文件可以在Windows事件查看器中打开,通过点击、筛选、查找等多种方式查看事件日志。
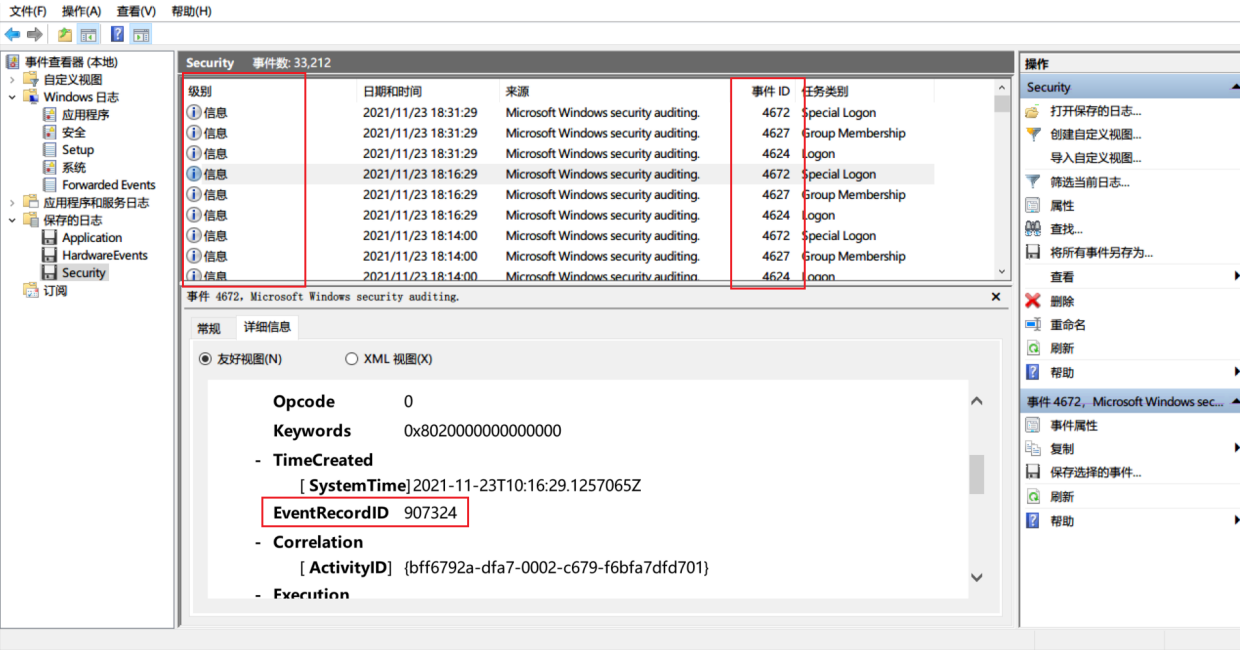
【注意】:
Windows操作系统默认没有提供删除特定日志记录的功能,仅提供了删除所有日志的操作功能。也就意味着日志记录ID(EventRecordID)应该是连续的,默认的排序方式应该是从大到小往下排列。
默认情况下,当一个evtx文件的记录满了,日志服务会覆盖最开始的记录,从头开始写入新的记录。
5 种事件类型(级别)分为:
- 信息(Information):信息事件指应用程序、驱动程序或服务的成功操作的事件。
- 警告(Warning):警告事件指不是直接的、主要的,但是会导致将来问题发生的问题。例如,当磁盘空间不足或未找到打印机时,都会记录一个“警告”事件。
- 错误(Error):错误事件指用户应该知道的重要的问题。错误事件通常指功能和数据的丢失。例如,如果一个服务不能作为系统引导被加载,那么它会产生一个错误事件。
- 成功审核(Success audit):成功的审核安全访问尝试,主要是指安全性日志,这里记录着用户登录/注销、对象访问、特权使用、账户管理、策略更改、详细跟踪、目录服务访问、账户登录等事件,例如所有的成功登录系统都会被记录为“ 成功审核”事件。
- 失败审核(Failure audit):失败的审核安全登录尝试,例如用户试图访问网络驱动器失败,则该尝试会被作为失败审核事件记录下来。
Windows 用 Event ID来标识事件的不同含义,以Security.evtx为例,一些常见的Event ID 如下
| 事件ID | 描述 |
|---|---|
| 4608 | Windows 启动 |
| 4609 | Windows 关机 |
| 4616 | 系统时间发生更改 |
| 4624 | 用户成功登录到计算机 |
| 4625 | 登录失败。使用未知用户名或密码错误的已知用户名尝试登录。 |
| 4634 | 用户注销完成 |
| 4647 | 用户启动了注销过程 |
| 4648 | 用户在以其他用户身份登录时,使用显式凭据成功登录到计算机 |
| 4703 | 令牌权限调整 |
| 4704 | 分配了用户权限 |
| 4720 | 已创建用户账户 |
| 4725 | 账户被禁用 |
| 4768 | 请求Kerberos身份验证票证(TGT) |
| 4769 | 请求Kerberos服务票证 |
| 4770 | 已续订Kerberos服务票证 |
| 4779 | 用户在未注销的情况下断开了终端服务器会话 |
(1)evtx文件结构
——file header
File Header(文件头)文件头长度为4KB(4096bytes),一个evtx只有一个文件头,其结构如下:
| 偏移 | 长度(Bytes) | 值 | 描述 |
|---|---|---|---|
| 0x00 | 8 | "ElfFile\x00" | 标志位/签名 |
| 0x08 | 8 | 第一个区块编号(存在时间最久的区块编号) | |
| 0x10 | 8 | 当前区块编号(块的编号从0开始) | |
| 0x18 | 8 | 下一条事件记录的ID | |
| 0x20 | 4 | 128 | 文件头有效部分的大小 |
| 0x24 | 2 | 1 | 次要版本 |
| 0x26 | 2 | 3 | 主要版本 |
| 0x28 | 2 | 4096 | 文件头的大小 |
| 0x2A | 2 | 区块的数量 | |
| 0x2C | 76 | 未知 (空值) | |
| 0x78 | 4 | 文件标志 | |
| 0x7C | 4 | 文件头前 120 bytes 的CRC32校验和 | |
| 0x80 | 3968 | 未知 (空值) |
——Chunk
每个块的大小是 65536 bytes(64KB),可以有多个块,主要由三部分组成:
- chunk header 块头
- array of event records 事件记录组
- unused space 未使用的空间
chunk头长度为512bytes,其结构如下:
| 偏移 | 长度(Bytes) | 值 | 描述 |
|---|---|---|---|
| 0x00 | 8 | "ElfChnk\x00" | 标志位/签名 |
| 0x08 | 8 | 基于日志编号的第一条日志记录的ID | |
| 0x10 | 8 | 基于日志编号的最后一条日志记录的ID | |
| 0x18 | 8 | 基于文件编号的第一条日志记录的ID | |
| 0x20 | 8 | 基于文件编号的最后一条日志记录的ID | |
| 0x28 | 4 | 128 | chunk头大小 |
| 0x2C | 4 | 最后一条日志记录的偏移量(相对于块头的起始偏移量) | |
| 0x30 | 4 | 下一条日志记录的偏移量(相对于块头的起始偏移量) | |
| 0x34 | 4 | 事件记录数据的 CRC32 校验和 | |
| 0x38 | 64 | Unknown (空值) | |
| 0x78 | 4 | Unknown (flags?) | |
| 0x7C | 4 | 块头CRC32校验和(块头前120个字节和128至512字节的数据的CRC32校验和) |
(2).evtx日志隐藏
参考:闲聊Windows系统日志_Make-CSDN博客_windows系统日志
2. 注册表取证
注册表有5个根键(HKEY):
- HKEY_CLASSES_ROOT:启动应用程序所需的全部信息,如扩展名,应用程序与文档之间的关系,驱动程序名,DDE和OLE信息,类ID编号和应用程序与文档的图标等。
- HKEY_CURRENT_USER:当前登录用户的配置信息,如环境变量,个人程序以及桌面设置等。
- HKEY_LOCAL_MACHINE:本地计算机的系统信息,如硬件和操作系统信息,安全数据和计算机专用的各类软件设置信息。
- HKEY_USERS:计算机的所有用户使用的配置数据,这些数据只有在用户登录系统时才能访问。
- HKEY_CURRENT_CONFIG:当前硬件的配置信息,其中的信息是从HKEY_LOCAL_MACHINE中映射出来的。
(1)关于启动项
HKLM\SOFTWARE\Microsoft\Windows\CurrentVevsion\Run
HKLM\SOFTWARE\Microsoft\Windows\CurrentVevsion\RunOnce
HKLM\SOFTWARE\Microsoft\Windows\CurrentVevsion\RunOnceEx
HKLM\SOFTWARE\Microsoft\Windows\CurrentVevsion\RunServices
HKLM\SOFTWARE\Microsoft\WindowsNT\CurrentVevsion\Winlogon\Userinit
HKLM\SOFTWARE\Microsoft\WindowsNT\CurrentVevsion\Winlogon\Shell
Userinit.exe 运行登录脚本、建立网络连接和启动shell。很多木马程序和流氓软件选择它作为启动项
Autoruns工具:查看系统启动项的工具
(2)关于用户与系统信息项
HKLM\SOFTWARE\Microsoft\WindowsNT\CurrentVevsion\RegisteredOwner
HKLM\SOFTWARE\Microsoft\WindowsNT\CurrentVevsion\Registeredorganizaion
HKLM\SOFTWARE\Microsoft\WindowsNT\CurrentVevsion\ProductID
HKLM\SAM\SAM\Domains\Account\Users\Names
HKLM\SOFTWARE\Microsoft\WindowsNT\CurrentVevsion\Winlogon
HKLM\SOFTWARE\Microsoft\WindowsNT\CurrentVevsion\ProfileList
3. 系统进程
此类进程在系统中都会有固定的存放位置,假如在此存放位置之外发现此类程序,则有可能是病毒。据百度百科记载大多数此类文件都会存放在 C:\Windows\System32 不过根据自己亲自实验发现,在win 10 中每个此类文件的存放位置都会有四个,win 中自带有数字签名,此时只需要查看数字签名是否正常。而且据网上流传通过右键查看程序的版本信息是否存在也可以判断程序是否正常。并且大部分程序都会有自己固定的注册表信息,如果发现此时某程序对应的注册表信息不正确也极有可能是中毒情况。
(1)与其他应用程序相关进程
iexplore.exe是IE 浏览器进程,这不是纯粹的系统程序,但是如果终止它,可能会导致不可知的问题。
中毒: 浏览器被劫持,任务管理器中多出进程:IEXPL0RE.EXE,注意,这里是数字“0”,不是字母“O”,或任务管理器查看有多个 iexplore.exe。
wmplayer.exe是Windows Media Player播放器的一部分,用于播放音频、视频文件。
spoolsv.exe是Print Spooler的进程,管理所有本地和网络打印队列及控制所有打印工作。如果此服务被停用,本地计算机上的打印将不可用。
中毒: 多个相似名称进程,CPU 占用率高,文件位置不正确。
ctfmon.exe是有关输入法的一个可执行程序。它可以选择用户文字输入程序,和微软Office 语言条。这不是纯粹的系统程序,但是如果终止它,可能会导致不可知的问题。它监视活动窗口,并为语音识别、书写识别、键盘、翻译和其他中文可选用户输入方法技术提供文本输入服务支持。
中毒: 此进程占用资源太多
internat.exe是多语言输入程序
中毒:出现提示缺少 exe 文件问题的大部分原因是因该文件被木马病毒破坏导致系统程序找不到此文件,出现错误提示框,或程序无法运行,解决此问题只需找到专业的 exe 文件下载网站,下载该文件后,找到适合程序的文件版本,复制到相应目录。
conime.exe是输入法编辑器相关程序。允许用户使用标准键盘就能输入复杂的字符与符号。
wuauclt.exe是Windows自动升级管理程序。该进程会不断在线检测更新。删除该进程将使计算机无法得到最新更新信息。
中毒:该病毒自动修改原先的 wuauclt.exe 为 wuauclt1.exe ,并建立新的 wuauclt.exe 。建议关闭 wuauclt.exe 进程,删除 wuauclt.exe 进程,然后把 wuauclt1.exe 更改为 wuauclt.exe 。
alg.exe用于处理微软 Windows 网络连接共享和网络连接防火墙。
中毒: 系统文件 ALG.EXE 出错,极有可能是盗号木马、流氓软件等恶意程序所导致,其感染相关文件并加载起来,一旦杀毒软件删除被感染的文件,就会导致相关组件缺失,游戏等常用软件运行不起来,通常会伴随下几种情况:
- 桌面图标无法删除
- 网络游戏打不开
- 电脑无故蓝屏
- 电脑没声音
- 桌面无法显示
- 主页被修改为网址导航
(2)图形化相关进程
csrss.exe是微软客户端、服务端运行时子系统,windows 的核心进程之一。管理 Windows 图形相关任务,对系统的正常运行非常重要。csrss是Client/Server Runtime Server Subsystem 的简称,即客户/服务器运行子系统,用以控制Windows图形相关子系统,必须一直运行。
explorer.exe是 Windows 文件资源管理器,它用于管理 Windows 图形界面,包括桌面和文件管理,删除该程序会导致 Windows 图形界面无法使用。
中毒: 查看文件位置是否正常,查看版本信息和数字签名值。
dwm.exe是桌面窗口管理器,跟桌面相关。 它建立在WPF核心图形层组件基础之上。 它的出现几乎改变了 Vista 中应用程序的屏幕象素显示方式。启用 DWM 后,提供的视觉效果有毛玻璃框架、3D窗口变换动画、窗口翻转和高分辨率支持 。其中最明显的特征有:任务栏窗口的实时缩略图;Alt+Tab 和 Win+Tab 组合键所看到的效果。
(3)登陆相关进程
smss.exe是一个会话管理子系统,负责启动用户会话。这个进程是通过系统进程初始化的并且对许多活动的,包括已经正在运行的 Windows 登录程序 (winlogon.exe) ,Win32子系统(csrss.exe)线程和设定的系统变量作出反映。
中毒: 查看文件位置是否正常,查看版本信息和数字签名值。
winlogon.exe是Windows 用户登陆程序,用于管理用户登录和退出。
中毒: 正常的winlogon系统进程,其用户名为 “SYSTEM” 程序名为小写 winlogon.exe 。而伪装成该进程的木马程序其用户名为当前系统用户名,且程序名为大写的 WINLOGON.exe。
lsass.exe用于本地安全和登陆策略,随着系统启动而自动启动。它提供本地的安全授权服务,并且它会为使用 winlogon 服务的授权用户生成一个进程。这个进程是通过使用授权的包,如果授权是成功的,lsass 就会产生用户的进入令牌,令牌被使用启动初始的 shell 。其他的由用户初始化的进程会继承这个令牌的。
中毒: 如果你的启动菜单(开始-运行-输入“msconfig”)里有个lsass.exe启动项,那就说明你中了LSASS.EXE木马病毒,中毒后,在进程里可以见到有两个相同的进程,分别是lsass.exe和LSASS.EXE,同时在windows下生成LSASS.EXE和exert.exe两个可执行文件,且在后台运行,LSASS.EXE管理exe类执行文件,exert.exe管理程序退出,还会在D盘根目录下产生和 autorun.inf两个文件,同时侵入注册表破坏系统文件关联。
——Windows 登录过程
SMSS.exe 会话管理进程是内核创建的第一个用户态进程,它启动后会创建 Windows 子系统服务进程 CSRSS 和 WinLogon 进程。WinLogon 会创建登录桌面以及服务系统管理进程 Servises ,在用户登录前,系统使用特殊帐户(NT AUTHORITY\SYSTEM (帐户域\帐户权限))先行登录处理 Servises。然后它会创建数个 svchost.exe子进程,而每个svchost.exe进程都会启动并运行一些基本的windows服务 。因为 CSRSS 和WinLogon 对系统来说缺一不可,因此 SMSS 创建这两个进程遇到问题时便采取紧急措施,不会正常启动。
Explorer 进程是由 UserInit 创建的,UserInit 是由 WinLogon 进程创建的,在 Windows 去启动过程中,用户输入用户名和密码后,负责登陆的系统进程 WinLogon 将用户名和密码发送给负责安全认证的另一个系统进程 Lsass。Lsass 调用验证模块对用户名和密码进行验证,如果通过,则创建一个访问令牌对象。 WinLogon 去启动 HKLM\SOFTWARE\Microsoft\WindowsNT\CurrentVevsion\Winlogon 的 Userinit 表键下指定的程序(默认为 userinit.exe) 。UseInit 进程执行登陆和初始化脚本,然后启动 Shell 表键中定义的 Shell 程序(默认即 Explorer.exe)。
所有这些过程都会被记录进系统内置的"安全"类型日志,可以通过事件查看器浏览。
(4)其他重要进程
svchost.exe是Windows 服务主进程,是通过动态链接库 (DLL) 运行的服务的通用进程名。许多服务通过注入到该程序中启动,所以会有多个该文件的进程。svchost 进程只作为服务宿主,它本身并不能实现任何功能,即它只能提供条件让其他服务在这里被启动。svchost通过系统服务在注册表中设置的参数找到某个服务的动态链接库。
中毒: 查看文件位置是否正常,查看版本信息和数字签名值。
rundll32.exe用于在内存中运行DLL文件,它们会在应用程序中被使用。这个程序对你系统的正常运行是非常重要的。
中毒: 查看文件位置是否正常,查看版本信息和数字签名值。
taskmgr.exe是任务管理器。它显示系统中正在运行的进程。这不是纯粹的系统程序,但是如果终止它,可能会导致不可知的问题。
中毒: 多个相似名称进程,CPU 占用率高,文件位置不正确。
services.exe用于管理启动和停止服务。该进程也会处理在计算机启动和关机时运行的服务。
中毒: 多个相似名称进程,CPU 占用率高,文件位置不正确。
conhost.exe是命令行程序的宿主进程。win7 之前的宿主程序是由 csrss.exe 来完成的,所有命令行进程都使用 session 唯一的 csrss.exe 进程。而到了 win7 则改成每个命令行进程都有一个独立的 conhost 作为宿主了。
mdm.exe是 Windows进程除错程序。用于使用可视化脚本工具对Internet Explorer除错。
中毒:木马病毒程序的惯用伎俩:伪装成与原进程相似的文件名;将原进程名改为其他进程,然后将病毒程序改为原进程进程名;而且中病毒时一般 cpu 的占用率会升高。
(二)内存取证
计算机的操作系统和应用使用主内存(RAM)来执行不同的任务。这种易失性内存包含大量关于运行应用、网络连接、内核模块、打开的文件以及几乎所有其他的内容信息,但这些信息每次计算机重启的时候都会被清除。
内存取证(Memory forensics)是一种从内存中找到和抽取这些有价值的信息的方式。
1.基础知识了解
.vmem文件表示虚拟内存文件,与pagefile.sys相同
.raw文件是内存取证工具Dumpit提取内存生成的内存转储文件
profile是特定操作系统版本以及硬件体系结构(x86,x64,ARM)中VTypes,共用体,对象类型的集合。除了这些组件以外,profile还包括元数据(操作系统的名称),内核版本以及编译号,系统调用信息,索引以及系统调用的名称,常量值(全局变量),在某些操作系统中能够在硬编码的地址处找到的全局变量 系统映射(关键全局变量和函数的地址,仅限Linux和Mac)
每个profile都有个一个唯一的名称,通常是由操作系统的名称,版本,服务包,系统结构等信息组成。
例如Win7SP1x64是64位的Windows 7 SP1系统配置文件的名称
2. Volatility环境配置
Volatility:是一款开源的,基于Python开发的内存取证工具集,能够对导出的内存镜像进行分析,通过获取内核数据结构,使用插件获取内存的详细情况以及系统的运行状态。Volatility支持对32位或64位Wnidows、Linux、Mac、Android操作系统的RAM数据进行提取与分析。
linux下运行 Volatility 命令的主要入口点是 vol.py 脚本,windows下是一个exe文件。
-
windows中可以直接下载已经编译好的可执行文件,放入环境变量中命令行使用
-
linux下也有对应的可执行文件,同时也可以下载源码自己手动配置。(如果需要用到一些插件,建议手动配置)
下面介绍如何在linux下源码配置并关联扩展插件。(Volatility 已经用 Python 3 重写了,但是本教程使用的是用 Python 2 写的原始的 Volatility 包)
-
下载源码并安装
git clone https://github.com/volatilityfoundation/volatility.git python setup.py build python setup.py install -
python2环境下配置第三方库
在进行安装时,部分模块可能会报错,这就需要到https://pypi.org/project/搜索相应版本的模块的源码,进行手动安装。
每次安装完一个库就在python2环境里import测试一下是否安装成功
-
Distorm3:反编译库
pip2 install distorm3 -
Yara:恶意软件分类工具
这里有个坑,安装yara需要手动安装yara-1.7.7· PyPI,直接pip安装会报错
cd yara-python python setup.py build sudo python setup.py install -
PyCrypto:加密工具集
pip2 install pycrypto -
PIL:图片处理库
pip2 install Pillow -
OpenPyxl:读写excel文件
pip2 install openpyxl -
ujson:JSON解析
pip2 install ujson
-
-
测试是否安装成功
python vol.py --info -
配置mimikatz扩展插件(如果只用本体的功能可以忽略这一步)
下载插件
wget https://github.com/volatilityfoundation/community/raw/master/FrancescoPicasso/mimikatz.py cp mimikatz.py ./volatility-master/volatility/plugins/安装construct模块
sudo pip2 uninstall construct sudo pip2 install construct==2.5.5-reupload单独执行一下mimikatz.py文件检查有没有报错
python mimikatz.py
3. Volatility使用
其实使用volatility主要是使用它的内置插件来获取种种信息。
Volatility命令的通用格式如下
#linux
python2 vol.py -f <memory-dump-file-taken-by-Lime> --profile=<name-of-our-custom-profile> <plugin-name>
#windows
volatility -f <memory-dump-file-taken-by-Lime> --profile=<name-of-our-custom-profile> <plugin-name>
#<plugin-name>可以放在profile的前面
使用下面的命令可以看volatility所支持的所有插件,不带前缀的是windows的插件,带linux前缀的是linux的插件,带mac前缀的是mac的插件
python vol.py --info
# 查看那些针对Linux设计的插件
python vol.py --info | grep -i linux_
一般在使用前看看目标内存转储文件的架构
#windows
volatility -f 内存转储文件 imageinfo
#linux
python vol.py -f 内存转储文件 imageinfo
Windows内存转储文件取证分析
对于Windows内存转储文件,插件使用及对应的说明如下。
| 插件名称 | 功能 |
|---|---|
| amcache | 查看AmCache应用程序痕迹信息 |
| apihooks | 检测内核及进程的内存空间中的API hook |
| atoms | 列出会话及窗口站atom表 |
| atomscan | Atom表的池扫描(Pool scanner) |
| auditpol | 列出注册表HKLMSECURITYPolicyPolAdtEv的审计策略信息 |
| bigpools | 使用BigPagePoolScanner转储大分页池(big page pools) |
| bioskbd | 从实时模式内存中读取键盘缓冲数据(早期电脑可以读取出BIOS开机密码) |
| cachedump | 获取内存中缓存的域帐号的密码哈希 |
| callbacks | 打印全系统通知例程 |
| clipboard | 提取Windows剪贴板中的内容 |
| cmdline | 显示进程命令行参数 |
| cmdscan | 提取执行的命令行历史记录(扫描_COMMAND_HISTORY信息) |
| connections | 打印系统打开的网络连接(仅支持Windows XP 和2003) |
| connscan | 打印TCP连接信息 |
| consoles | 提取执行的命令行历史记录(扫描_CONSOLE_INFORMATION信息) |
| crashinfo | 提取崩溃转储信息 |
| deskscan | tagDESKTOP池扫描(Poolscaner) |
| devicetree | 显示设备树信息 |
| dlldump | 从进程地址空间转储动态链接库 |
| dlllist | 打印每个进程加载的动态链接库列表 |
| driverirp | IRP hook驱动检测 |
| drivermodule | 关联驱动对象至内核模块 |
| driverscan | 驱动对象池扫描 |
| dumpcerts | 提取RAS私钥及SSL公钥 |
| dumpfiles | 提取内存中映射或缓存的文件 |
| dumpregistry | 转储内存中注册表信息至磁盘 |
| editbox | 查看Edit编辑控件信息 (Listbox正在实验中) |
| envars | 显示进程的环境变量 |
| eventhooks | 打印Windows事件hook详细信息 |
| evtlogs | 提取Windows事件日志(仅支持XP/2003) |
| filescan | 提取文件对象(file objects)池信息 |
| gahti | 转储用户句柄(handle)类型信息 |
| gditimers | 打印已安装的GDI计时器(timers)及回调(callbacks) |
| gdt | 显示全局描述符表(Global Deor Table) |
| getservicesids | 获取注册表中的服务名称并返回SID信息 |
| getsids | 打印每个进程的SID信息 |
| handles | 打印每个进程打开的句柄的列表 |
| hashdump | 转储内存中的Windows帐户密码哈希(LM/NTLM) |
| hibinfo | 转储休眠文件信息 |
| hivedump | 打印注册表配置单元信息 |
| hivelist | 打印注册表配置单元列表 |
| hivescan | 注册表配置单元池扫描 |
| hpakextract | 从HPAK文件(Fast Dump格式)提取物理内存数据 |
| hpakinfo | 查看HPAK文件属性及相关信息 |
| idt | 显示中断描述符表(Interrupt Deor Table) |
| iehistory | 重建IE缓存及访问历史记录 |
| imagecopy | 将物理地址空间导出原生DD镜像文件 |
| imageinfo | 查看/识别镜像信息 |
| impscan | 扫描对导入函数的调用 |
| joblinks | 打印进程任务链接信息 |
| kdbgscan | 搜索和转储潜在KDBG值 |
| kpcrscan | 搜索和转储潜在KPCR值 |
| ldrmodules | 检测未链接的动态链接DLL |
| lsadump | 从注册表中提取LSA密钥信息(已解密) |
| machoinfo | 转储Mach-O 文件格式信息 |
| malfind | 查找隐藏的和插入的代码 |
| mbrparser | 扫描并解析潜在的主引导记录(MBR) |
| memdump | 转储进程的可寻址内存 |
| memmap | 打印内存映射 |
| messagehooks | 桌面和窗口消息钩子的线程列表 |
| mftparser | 扫描并解析潜在的MFT条目 |
| moddump | 转储内核驱动程序到可执行文件的示例 |
| modscan | 内核模块池扫描 |
| modules | 打印加载模块的列表 |
| multiscan | 批量扫描各种对象 |
| mutantscan | 对互斥对象池扫描 |
| notepad | 查看记事本当前显示的文本 |
| objtypescan | 扫描窗口对象类型对象 |
| patcher | 基于页面扫描的补丁程序内存 |
| poolpeek | 可配置的池扫描器插件 |
| printkey | 打印注册表项及其子项和值 |
| privs | 显示进程权限 |
| procdump | 进程转储到一个可执行文件示例 |
| pslist | 按照EPROCESS列表打印所有正在运行的进程 |
| psscan | 进程对象池扫描 |
| pstree | 以树型方式打印进程列表 |
| psxview | 查找带有隐藏进程的所有进程列表 |
| qemuinfo | 转储Qemu 信息 |
| raw2dmp | 将物理内存原生数据转换为windbg崩溃转储格式 |
| screenshot | 基于GDI Windows的虚拟屏幕截图保存 |
| servicediff | Windows服务列表(ala Plugx) |
| sessions | _MM_SESSION_SPACE的详细信息列表(用户登录会话) |
| shellbags | 打印Shellbags信息 |
| shimcache | 解析应用程序兼容性Shim缓存注册表项 |
| shutdowntime | 从内存中的注册表信息获取机器关机时间 |
| sockets | 打印已打开套接字列表 |
| sockscan | TCP套接字对象池扫描 |
| ssdt | 显示SSDT条目 |
| strings | 物理到虚拟地址的偏移匹配(需要一些时间,带详细信息) |
| svcscan | Windows服务列表扫描 |
| symlinkscan | 符号链接对象池扫描 |
| thrdscan | 线程对象池扫描 |
| threads | 调查_ETHREAD 和_KTHREADs |
| timeliner | 创建内存中的各种痕迹信息的时间线 |
| timers | 打印内核计时器及关联模块的DPC |
| truecryptmaster | 恢复TrueCrypt 7.1a主密钥 |
| truecryptpassphrase | 查找并提取TrueCrypt密码 |
| truecryptsummary | TrueCrypt摘要信息 |
| unloadedmodules | 打印卸载的模块信息列表 |
| userassist | 打印注册表中UserAssist相关信息 |
| userhandles | 转储用户句柄表 |
| vaddump | 转储VAD数据为文件 |
| vadinfo | 转储VAD信息 |
| vadtree | 以树形方式显示VAD树信息 |
| vadwalk | 显示遍历VAD树 |
| vboxinfo | 转储Virtualbox信息(虚拟机) |
| verinfo | 打印PE镜像中的版本信息 |
| vmwareinfo | 转储VMware VMSS/VMSN 信息 |
| volshell | 内存镜像中的shell |
| windows | 打印桌面窗口(详细信息) |
| wintree | Z顺序打印桌面窗口树 |
| wndscan | 池扫描窗口站 |
| yarascan | 以Yara签名扫描进程或内核内存 |
| 功能 | 命令行及参数 |
|---|---|
| 查看进程列表 | Vol.exe -f Win7_SP1_x86.vmem –profile=Win7SP1x86 pslist |
| 查看进程列表(树形) | Vol.exe -f Win7_SP1_x86.vmem –profile=Win7SP1x86 pstree |
| 查看进程列表(psx视图) | Vol.exe -f Win7_SP1_x86.vmem –profile=Win7SP1x86 psxview |
| 查看网络通讯连接 | Vol.exe -f Win7_SP1_x86.vmem –profile=Win7SP1x86 netscan |
| 查看加载的动态链接库 | Vol.exe -f Win7_SP1_x86.vmem –profile=Win7SP1x86 dlllist |
| 查看SSDT表 | Vol.exe -f Win7_SP1_x86.vmem –profile=Win7SP1x86 ssdt |
| 查看UserAssist痕迹 | Vol.exe -f Win7_SP1_x86.vmem –profile=Win7SP1x86 userassist |
| 查看ShimCache痕迹 | Vol.exe -f Win7_SP1_x86.vmem –profile=Win7SP1x86 shimcache |
| 查看ShellBags | Vol.exe -f Win7_SP1_x86.vmem –profile=Win7SP1x86 shellbags |
| 查看服务列表 | Vol.exe -f Win7_SP1_x86.vmem –profile=Win7SP1x86 svcscan |
| 查看Windows帐户hash | Vol.exe -f Win7_SP1_x86.vmem –profile=Win7SP1x86 hashdump |
| 查看最后关机时间 | Vol.exe -f Win7_SP1_x86.vmem –profile=Win7SP1x86 shutdowntime |
| 查看IE历史记录 | Vol.exe -f Win7_SP1_x86.vmem –profile=Win7SP1x86 iehistory |
| 提取注册表数据 | Vol.exe -f Win7_SP1_x86.vmem –profile=Win7SP1x86 dumpregistry |
| 解析MFT记录 | Vol.exe -f Win7_SP1_x86.vmem –profile=Win7SP1x86 mftparser |
| 导出MFT记录,恢复文件 | Vol.exe -f Win7_SP1_x86.vmem –profile=Win7SP1x86 mftparser –output-file=mftverbose.txt -D mftoutput |
| 获取TrueCrypt密钥信息 | Vol.exe -f Win7_SP1_x86.vmem –profile=Win7SP1x86 truecryptmaster |
| 获取TrueCrypt密码信息 | Vol.exe -f Win7_SP1_x86.vmem –profile=Win7SP1x86 truecryptpassphras |
Linux内存转储文件取证分析
直接参考
CTF常用命令总结
使用imageinfo插件来猜测dump文件的profile值
volatility -f xxx imageinfo
指定profile值,使用pslist去列举系统进程
volatility -f xxx --profile=xxx pslist
查看控制台输入的历史命令
volatility cmdscan -f xxx --profile=xxx
查看IE历史信息
volatility iehistory -f xxx --profile=xxx
查看截图
volatility -f xxx --profile=xxx screenshot --dump-dir=./
配合管道指令和搜索指令扫描特定类型的文件
volatility -f xxx --profile=xxx filescan | grep 'flag|ctf'
volatility -f xxx --profile=xxx filescan | grep "doc|docx|rtf|txt"
volatility -f xxx --profile=xxx filescan | grep "jpg|jpeg|png|tif|gif|bmp"
#查看桌面文件
volatility -f Cookie.raw --profile=xxx filescan | grep "Desktop"
导出某个进程的内存数据
volatility -f xxx --profile=xxx memdump -p [PID] -D [输出目录]
获取系统密码(2种方法)
-
使用
hashdump将hash值提取打印出来volatility -f xxx --profile=xxx hashdump打印出的字符串含义满足如下关系(最后末尾的项是NT-HASH,是我们要破解的HASH值)
用户名:RID:LM-HASH值:NT-HASH值把要破解的用户名所在行复制粘贴作为Single Hash,load到ophcrack然后crack
-
用mimikatz扩展插件直接获取明文密码
python vol.py -f xxx --profile=xxx mimikatz
查看缓存在内存的注册表
PS:注册表是Microsoft Windows中的一个重要的数据库,用于存储系统和应用程序的设置信息。
volatility -f xxx --profile=xxx hivelist
恢复被删除的文件,mftoutput.txt 里面包含内存里面的文件(文件路径,文件内容)
volatility -f xxx --profile=xxx mftparser>mftoutput.txt
导出注册表资源
volatility -f xxx --profile=xxx dumpregistry --dump-dir=C:\Users\18267\Desktop\2
提取filescan的文件
volatility -f xxx --profile=xxx dumpfiles -Q 0x...... --dump-dir=./
//-Q指定了文件物理位置的开始,另一个参数制定了保存的位置。
| 命令 | 功能 |
|---|---|
| cmdscan | 列出历史cmd命令 |
| filescan | 扫描文件,可配合grep使用 |
| pslist/psscan | 列出进程列表 |
| svcscan | 扫描windows服务列表 |
| memdump | 从内存dump进程的内存 |
| dumpfiles | 从内存dump文件 |
4. Magnet AXIOM环境配置与使用
国外的一款图形化取证工具,功能类似于取证大师,内置volatility
使用:打开Magnet AXIOM Process;点击新建案件;在证据来源标签页下选择源计算机、加载或获取、证据源,然后加载要分析的转储文件。切换到分析证据,选中要分析的源然后点击分析证据
分析过程中CPU占用比较大,时间也比较久
5. ophcrack配置与使用
Ophcrack是一款利用彩虹表来破解 Windows密码的工具。其次是两篇有关Ophcrack的技术文章:杜莉翻译的“安全高手的利器认识彩虹哈希表破解工具”
- 下载便携版免安装ophcrack download | SourceForge.net
- 下载彩虹表Ophcrack (sourceforge.io)(只能下XP free small、XP free small、Vista free)
- 建立一个tables文件夹,把下载的彩虹表解压到该文件夹下,在ophcrack中点击Table,选中你下载的彩虹表对应的table,然后点击install,弹出文件夹选择框后选择解压出的彩虹表文件夹,可以看到标识变成绿色。
点开load
Single Hash主要用于对单个Hash的破解,PWDUMP file是对获取的Pwdump文件进行破解,Encrypted SAM是对加密的sam文件进行破解
(三)磁盘取证
文件系统是一种用于向用户提供底层数据访问的机制。它将设备中的空间划分为特定大小的块(或者称为簇),一般每块512字节。数据存储在这些块中,大小被修正为占用整数个块。由文件系统软件来负责将这些块组织为文件和目录,并记录哪些块被分配给了哪个文件,以及哪些块没有被使用。不过,文件系统并不一定只在特定存储设备上出现。它是数据的组织者和提供者,至于它的底层,可以是磁盘,也可以是其它动态生成数据的设备(比如网络设备)。——维基百科
DOS / Microsoft Windows对几类文件系统(FAT12/FAT16 、FAT32/VFAT、FAT64/exFAT、NTFS)的支持情况如下
| Windows | FAT12/FAT16 | FAT32/VFAT | FAT64/exFAT | NTFS |
|---|---|---|---|---|
| Windows 3.x或更早 (MS-DOS 6.22) (PC-DOS 7.0) | 可读/可写 | 不支持 | 不支持 | 不支持 |
| Windows 95 | 可读/可写 | 不支持 | 不支持 | 不支持 |
| Windows 95(OSR2以后) Windows 98(含SE) ME | 可读/可写 | 可读/可写 | 不支持 | 不支持 |
| Windows NT 4.0 及以前 | 可读/可写 | 不支持 | 不支持 | 可读/可写 |
| 2000 Windows XP Windows Vista Server 2003 Server 2008 (R2) Windows 7 Windows 8 Server 2012 (R2) Windows 8.1Windows 10 | 可读/可写 | 可读/可写 | 可读/可写 | 可读/可写 |
| Windows CE | 可读/可写 | 可读/可写 | 可读/可写 | 不支持 |
1. NTFS磁盘文件系统取证
磁盘文件系统是一种设计用来利用数据存储设备来保存计算机文件的文件系统,最常用的数据存储设备是磁盘驱动器,可以直接或者间接地连接到计算机上。例如:FAT、exFAT、NTFS、HFS、HFS+、ext2、ext3、ext4、ODS-5、btrfs、XFS、UFS、ZFS。——维基百科
NTFS 包含若干用于定义和组织文件系统的文件(内含对磁盘的管理数据)。
| 区段编号 | 元文件名 | 作用 |
|---|---|---|
| 0 | $MFT | 描述卷上的所有文件,包括文件名、时间戳、流名称和数据流所在的簇的编号列表、索引、安全标识符,以及文件属性(如“只读”、“压缩”、“加密”等)。 |
| 1 | $MFTMirr(MFT镜像) | $MFT 的最开始的几个关键项的副本,通常是 4 项(4KB) |
|
| 2 | $LogFile(日志文件) | 包含文件系统更改的事务日志,以保护元数据的稳定性。 |
| 3 | $Volume(卷文件) | 包含卷的相关信息,如卷对象标识符、卷标、文件系统版本,以及卷标志(加载、需要扫描、需要调整 $LogFile 大小、在 NT4 上加载、正在更新卷串行号、需要升级结构)。卷串行号储存在 $Boot 文件中。 |
|
| 4 | $AttrDef(属性定义表) |
使用的 NTFS 属性的表,包含名称、编号和描述。 |
| 5 | $Root(根目录) |
根目录。 |
| 6 | $Bitmap(位图文件) |
一个位图,用于指示卷上的指定簇正在被使用或空闲。 |
| 7 | $Boot(引导文件) | 卷引导记录,该文件位于卷的第一个簇,其中包含引导代码(用于定位并启动 NTLDR/BOOTMGR)、一个 BIOS 参数区块(其中包含卷串行号),以及 $MFT 和 $MFTMirr 所在的簇编号。 |
|
| 8 | $BadClus(坏簇文件) |
包含所有标记为“有坏扇区”的簇的一个文件。该文件用于为 chksdk(磁盘扫描)工具简化簇的管理,用于放置新发现的坏扇区,以及标识未被引用的簇。 |
| 9 | $Secure(安全文件) |
访问控制列表(ACL)数据库,统一将 ACL 存储于该数据库中而非每个文件存储各自的 ACL 以减少总体代价。包含两个索引:SII——可能是安全ID索引,以及 SDH——安全描述符哈希,用于索引包含实际 ACL 列表的称为 SDS 的流的位置。 |
| 10 | $UpCase(大写文件) |
一个 Unicode 大写字母表,用于确保在 Win32 和 DOS 命名空间下大小写不敏感。 |
| 11 | $Extend(扩展元数据文件) | 一个文件系统目录,包含若干不定的可选扩展,如 \(Quota、\)\(ObjId\)、\(Reparse、\)$UsnJrnl $等。 |
|
| 12 ... 23 | 保留。 | |
| 通常是 24 | $Extend\$Quota(配额管理文件) |
包含关于磁盘限额的信息。 |
| 通常是 25 | $Extend\$ObjId(对象ID文件) |
包含用于分布链接跟踪的信息。 |
| 通常是 26 | $Extend\$Reparse |
包含对卷上所有重解析点(如符号链接)的反引用。 |
| 27 ... | *file.ext* |
常规文件项的开始位置。 |
(1)$MFT文件
MFT以文件记录来实现对文件的管理,每个文件记录都对应着不同的文件,大小固定为1KB,也就是占用两个扇区,而不管簇的大小是多少。如果一个文件有很多属性或是分散成很多碎片,就很可能需要多个文件记录。这时,存放其文件记录位置的第一个记录就称作“基本文件记录”。
文件记录在MFT中物理上是连续的,从0开始依次按顺序编号。
前16个文件记录总是元文件的记录,并且这16个文件记录的顺序是固定的(按照上表中的顺序)
$MFT可以看作是一个结构体数组,结构体元素(即文件记录)的结构组成如下
struct 文件记录{
文件记录头;
属性1;
属性2;
属性3;
……
}
——文件记录头
文件记录头是固定长度的
| 字节偏移 | 字段长度(字节) | 字段名和含义 |
| 0x00 | 4 | MFT标志,一定为字符串“FILE” |
| 0x04 | 2 | 更新序列号(Update Sequence Number)的偏移 |
| 0x06 | 2 | 更新序列号的大小与数组,包括第一个字节 |
| 0x08 | 8 | 日志文件序列号($LogFile Sequence Number,LSN),每次记录被修改都将导致其被修改 |
| 0x10 | 2 | 序列号(Sequence Number),记录主文件表记录被重复使用的次数。 |
| 0x12 | 2 | 硬连接数(Hard Link Count),即有多少目录指向该文件。只出现在基本文件记录中 |
| 0x14 | 2 | 第一个属性的偏移地址 |
| 0x16 | 2 | 标志(Flag),00H表示文件被删除,01H表示文件正在使用,02H表示目录被删除,03H表示目录正在使用 |
| 0x18 | 4 | 文件记录的实际长度也即文件记录在磁盘上实际占用的字节空间。 |
| 0x1C | 4 | 给文件记录的分配长度,一般为“00 04 00 00”,也就是1KB的长度 |
| 0x20 | 8 | 基本文件记录中的文件索引号,基本文件记录在此的值总为0。如果不为0,则是一个主文件表的文件索引号,指向所属的基本文件记录中的文件记录号。在基本文件记录中包含有扩展文件记录的信息,存储在“属性列表ATTRIBUTE_LIST”属性中。 |
| 0x28 | 2 | 下一属性ID,当增加新的属性时,将该值分配给新属性,然后该值增加,如果MFT记录重新使用,则将它置0,第一个实例总是0 |
| 0x2A | 2 | 边界,Windows XP中为偏移0x30处 |
| 0x2C | 4 | 文件记录参考号(从0开始编号),Windows XP中使用,Windows 2000中无此参数 |
| 0x30 | 2 | 更新序列号,这两个字节同时会出现在该文件记录第一个扇区最后两个字节处及该文件记录第二个扇区最后两个字节处, |
| 0x32 | 4 | 更新数组 |
——属性列表
对于属性列表中的每个属性而言
每个文件记录中都有多个属性,它们相对独立,有各自的类型和名称。属性头前4个字节区分属性的种类,主要有以下几种属性
| 属性类型(Little-Endian) | 属性类型名 | 属性描述 |
| 10 00 00 00 | $STANDARD_INFORMATION | 标准信息:包括一些基本文件属性,如只读、系统、存档;时间属性,如文件的创建时间和最后修改时间;有多少目录指向该文件(即其硬连接数(hard link count)) |
| 20 00 00 00 | $ATTRIBUTE_LIST | 属性列表:当一个文件需要多个文件记录时,用来描述文件的属性列表 |
| 30 00 00 00 | $FILE_NAME | 文件名:用Unicode字符表示的文件名,由于MS-DOS不能识别长文件名,所以NTFS系统会自动生成一个8.3文件名 |
| 40 00 00 00 | $VOLUME_VERSION | 在早期的NTFS v1.2中为卷版本 |
| 40 00 00 00 | $OBJECT_ID | 对象ID:一个具有64字节的标识符,其中最低的16字节对卷来说是唯一的(链接跟踪服务为外壳快捷方式,即OLE链接源文件赋予对象ID;NTFS提供的API是直接通过这些对象的ID而不是文件名来打开文件的) |
| 50 00 00 00 | $SECURITY_DESCRIPTOR | 安全描述符:这是为向后兼容而保留的,主要用于保护文件以防止没有授权的访问,但Windows 2000/XP中已将安全描述符存放在$Secure元数据中,以便于共享(早期的NTFS将其与文件目录一起存放,不便于共享) |
| 60 00 00 00 | $VOLUME_NAME | 卷名(卷标识):该属性仅存在于$Volume元文件中 |
| 70 00 00 00 | $VOLUME_INFORMATION | 卷信息:该属性仅存在于$Volume元文件中 |
| 80 00 00 00 | $DATA | 文件数据:该属性为文件的数据内容 |
| 90 00 00 00 | $INDEX_ROOT | 索引根 |
| A0 00 00 00 | $INDEX_ALLOCATION | 索引分配 |
| B0 00 00 00 | $BITMAP | 位图 |
| C0 00 00 00 | $SYMBOLIC_LINK | 在早期的NTFS v1.2中为符号链接 |
| C0 00 00 00 | $REPARSE_POINT | 重解析点 |
| D0 00 00 00 | $EA_INFORMATION | 扩充属性信息 |
| E0 00 00 00 | $EA | 扩充属性 |
| F0 00 00 00 | $PROPERTY_SET | 早期的NTFS v1.2中才有 |
| 00 10 00 00 | $LOGGED_UTILITY_STREAM | EFS加密属性:该属性主要用于存储实现EFS加密的有关加密信息,如合法用户列表、解码密钥等 |
(2)工具
- NTFS Log Tracker(导出为可视化的csv或者db文件)
- X-Ways Forensics(强大的综合性计算机取证工具)
2. 磁盘加密
BitLocker加密解密
题目:
在CTF中需要找BitLocker 恢复密钥来进行BitLocker解密,进而提取出磁盘里面的内容
Bitlocker可以对存储设备做硬件加密,防止设备丢失时,导致文件内容被别人破解查看
Bitlocker的解锁方式主要有三种:TPM、PIN、恢复密钥。
- TPM是在主板上的硬件芯片,可以存储各种证书密钥,不是所有电脑都有。
- PIN就是自己设置的一个解锁密码。
- 恢复密钥是一个最短48位的数字,可以被制作成密钥文件存储于U盘作为解密工具。
恢复密钥的获取方式(来自在 Windows 中查找 BitLocker 恢复密钥 (microsoft.com)):
-
在 Microsoft 帐户中: 在另一台设备上登录到 Microsoft 帐户以查找恢复密钥。 如果你有一台支持自动设备加密的现代设备,则恢复密钥最有可能在你的 Microsoft 帐户中。 有关详细信息,请参阅 Windows 中的设备加密。
或者直接登录此处就可以获取
-
在打印输出上: 在激活 BitLocker 时,可能打印了恢复密钥。 在存放与你的计算机相关的重要文件的位置查找。
-
在 U 盘上: 将 U 盘插入锁定的电脑,然后按照说明进行操作。 如果你已在 U 盘上将密钥另存为文本文件,则使用另一台计算机阅读此文本文件。
-
在 Azure Active Directory 帐户中: 如果设备曾使用工作或学校电子邮件帐户登录到组织,则恢复密钥可能存储在与Azure AD关联的组织帐户。 你或许可以直接访问它,也可能需要联系系统管理员来访问恢复密钥。
-
由系统管理员持有: 如果设备已连接到域, (工作或学校设备) ,请向系统管理员请求恢复密钥。
这种类型的题目通常结合内存取证,从内存中dump出恢复密钥,解密磁盘,挂载并取出加密磁盘中的flag
——如何解密磁盘文件:
- 用工具把磁盘挂载到Windows系统内之后会提示输入PIN码和恢复密钥
- 挂载到Linux系统可以参考How To Mount BitLocker-Encrypted Windows Partitions On Linux - Linux Uprising Blog
3. 磁盘挂载
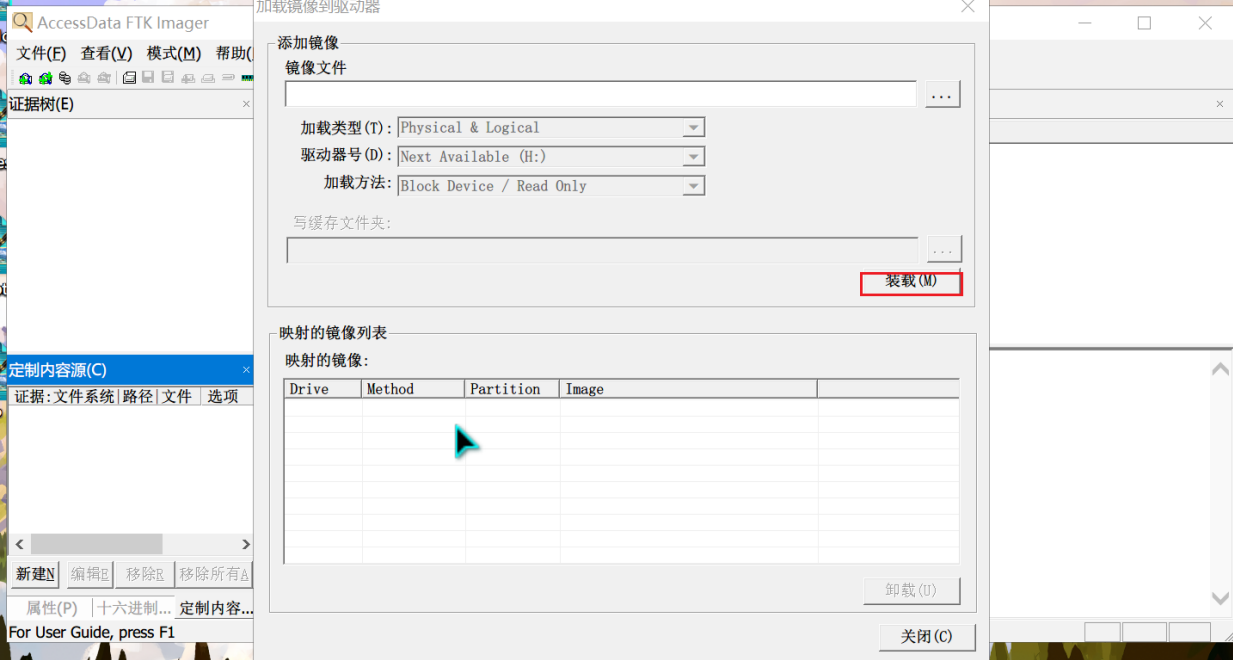
【方法一】FTK Imager挂载
FTK Imager工具 “可写”模式下挂载系统镜像为本地驱动器
【方法二】Linux的mount指令
Linux 系统中“一切皆文件”,所有文件都放置在以根目录为树根的树形目录结构中。在 linux 看来,任何硬件设备也都是文件,它们各有自己的一套文件系统(文件目录结构)。Linux中的根目录以外的文件要想被访问,需要将其“关联”到根目录下的某个目录来实现,这种关联操作就是“挂载”,这个目录就是”挂载点”,解除次关联关系的过程称之为“卸载”。不是根目录下任何一个目录都可以作为挂载点,由于挂载操作会使得原有目录中文件被隐藏,因此根目录以及系统原有目录都不要作为挂载点,会造成系统异常甚至崩溃,挂载点最好是新建的空目录。
-
device:指明要挂载的设备;
-
设备文件:例如/dev/sda5
-
卷标:
-L ‘LABEL’, 例如 -L 'MYDATA' -
UUID:
-U ‘UUID’,例如 -U '0c50523c-43f1-45e7-85c0-a126711d406e' -
伪文件系统名称:proc, sysfs, devtmpfs, configfs
-
-
dir:挂载点,事先存在;建议使用空目录,进程正在使用中的设备无法被卸载;
-
系统类型:指定欲挂载的文件系统类型。Linux 常见的支持类型有 EXT2、EXT3、EXT4、iso9660(光盘格式)、vfat、reiserfs 等。如果不指定具体类型,挂载时 Linux 会自动检测。
-
options:
options 描述 rw/ro 是否对挂载的文件系统拥有读写权限,rw 为默认值,表示拥有读写权限;ro 表示只读权限。 async/sync 此文件系统是否使用同步写入(sync)或异步(async)的内存机制,默认为异步 async。 dev/nodev 是否允许从该文件系统的 block 文件中提取数据,为了保证数据安装,默认是 nodev。 auto/noauto 是否允许此文件系统被以 mount -a 的方式进行自动挂载,默认是 auto。 suid/nosuidsuid/nosuid 设定文件系统是否拥有 SetUID 和 SetGID 权限,默认是拥有。 exec/noexec 设定在文件系统中是否允许执行可执行文件,默认是允许。 user/nouser 设定此文件系统是否允许让普通用户使用 mount 执行实现挂载,默认是不允许(nouser),仅有 root 可以。 defaults 定义默认值,相当于 rw、suid、dev、exec、auto、nouser、async 这 7 个选项。 remount 重新挂载已挂载的文件系统,一般用于指定修改特殊权限。 -
其它选项
选项 描述 -r readonly,只读挂载; -w read and write, 读写挂载; -n 不更新/etc/mtab; -a 自动挂载所有支持自动挂载的设备;(定义在了/etc/fstab文件中,且挂载选项中有“自动挂载”功能) -B, --bind 绑定目录到另一个目录上;
【方法三】OSFMount / DiskGenius
(四)ISO镜像光盘取证
1. ISO 9960文件结构
先理清一下ISO文件的结构(n和m是数目)
参考:
ISO文件有很多数据类型,关于ISO文件的数据类型表可以参照附录部分
(1)系统区域(System Area)
前32 KB(\(0 \sim 7FFFH\))是ISO 9660 文件的系统区域,可用于任意数据。通常用于存储启动信息,以防 ISO 9660 文件系统不是存储在光学介质上,而是存储在类似硬盘的设备上,例如在 U 盘上。因此需要在该位置查找主启动记录(MBR,用于 BIOS)、GUID 分区表(GPT,用于 EFI)或 Apple 分区图 (APM)。
(2)卷描述符(Volume Descriptors)
先总结一下特点:
- 每个卷描述符都是2KB(800H个字节)大小
- 卷描述符以一个卷描述符类型码起始,类型码不同,作用也不同。
- 符合 ISO 9660 标准的光盘必须至少包含一个描述文件系统的主卷描述符和一个卷描述符集终止符,该终止符是标记描述符集末尾的卷描述符。
准备挂载 CD 时,您的第一个操作将是读取卷描述符(具体来说,您将查找主卷描述符)。
卷描述符有很多种,基本格式如下:
| 偏移 | 长度(字节) | 字段名称 | 数据类型 | 描述 |
|---|---|---|---|---|
| 0 | 1 | 类型 | int8 | 卷描述符类型代码(见下文)。 |
| 1 | 5 | 标识符 | strA | 始终为"CD001"。 |
| 6 | 1 | 版本 | int8 | 卷描述符版本(0x01)。 |
| 7 | 2041 | 数据 | - | 取决于卷描述符类型。 |
可以看出每个卷描述符因此是一个扇区(2 KB)长。
卷描述符类型码不同数值所代表的含义如下
| 数值 | 描述 |
|---|---|
| 0 | 引导记录 |
| 1 | 主卷描述符 |
| 2 | 补充卷描述符 |
| 3 | 卷分区描述符 |
| 4-254 | (保留) |
| 255 | 卷描述符集终结符 |
下面一 一介绍几种几种常见的卷描述符。
引导记录卷描述符(The Boot Record)
第一种类型的卷描述符是"引导记录"。
描述符格式如下:
| 偏移 | 长度(字节) | 字段名称 | 数据类型 | 描述 |
|---|---|---|---|---|
| 0 | 1 | 类型 | int8 | 0表示启动记录。 |
| 1 | 5 | 标识符 | strA | 始终为"CD001"。 |
| 6 | 1 | 版本 | int8 | 卷描述符版本(0x01)。 |
| 7 | 32 | 引导系统标识符 | strA | 可以作用于系统并从引导记录引导系统的系统的 ID。 |
| 39 | 32 | 启动标识符 | strA | 标识在此描述符的其余部分中定义的引导系统。 |
| 71 | 1977 | 引导系统使用 | - | 自定义 - 由引导系统使用。 |
最常见的引导系统使用规范是El Torito。它将字节 71 到 74 记录为 El Torito Boot Catalog 的块地址的小端 32 位数字。此目录列出了可用的启动映像,这些映像用作启动系统的起点。
主卷描述符(The Primary Volume Descriptor)
这是一个冗长的描述符,但它包含一些非常有用的信息。
| 偏移 | 长度(字节) | 字段名称 | 数据类型 | 描述 |
|---|---|---|---|---|
| 0 | 1 | Type Code(类型代码) | int8 | 始终为主卷描述符0x01。 |
| 1 | 5 | Standard Identifier(标准标识符) | strA | 始终为"CD001"。 |
| 6 | 1 | Version(版本) | int8 | 总是0x01。 |
| 7 | 1 | Unused(闲置字段) | - | 总是0x00。 |
| 8 | 32 | System Identifier(系统标识符) | strA | 可以作用于扇区\(0x00\sim 0x0F\)的系统的名称。 |
| 40 | 32 | Volume Identifier(卷标识符) | strD | 标识此卷。 |
| 72 | 8 | Unused Field(未使用的字段) | - | 都是零。 |
| 80 | 8 | Volume Space Size(卷空间大小) | int32_LSB-MSB | 记录卷的逻辑块数。 |
| 88 | 32 | Unused Field(未使用的字段) | - | 都是零。 |
| 120 | 4 | Volume Set Size(卷集大小) | int16_LSB-MSB | 此逻辑卷中集的大小(磁盘数)。 |
| 124 | 4 | Volume Sequence Number(卷序列号) | int16_LSB-MSB | 卷集中此磁盘的编号。 |
| 128 | 4 | Logical Block Size | int16_LSB-MSB | 逻辑块的大小(以字节为单位)。注意:这意味着 CD 上的逻辑块可能不是 2 KB! |
| 132 | 8 | Path Table Size | int32_LSB-MSB | 路径表的大小(以字节为单位)。 |
| 140 | 4 | Location of Type-L Path Table | int32_LSB | 路径表的 LBA 位置。指向的路径表仅包含小端值。 |
| 144 | 4 | Location of the Optional Type-L Path Table | int32_LSB | 可选路径表的 LBA 位置。指向的路径表仅包含小端值。零表示不存在可选路径表。 |
| 148 | 4 | Location of Type-M Path Table | int32_MSB | 路径表的 LBA 位置。指向的路径表仅包含大端值。 |
| 152 | 4 | Location of Optional Type-M Path Table | int32_MSB | 可选路径表的 LBA 位置。指向的路径表仅包含大端值。零表示不存在可选路径表。 |
| 156 | 34 | Directory entry for the root directory(根目录的目录条目) | - | 请注意,这不是 LBA 地址,而是实际的目录记录,其中包含单字节目录标识符(0x00),因此固定的 34 字节大小。 |
| 190 | 128 | Volume Set Identifier(卷集标识符) | strD | 此卷所属的卷集的标识符。 |
| 318 | 128 | Publisher Identifier(发布者标识符) | strA | 卷发布者。对于扩展的发布者信息,第一个字节应0x5F,后跟根目录中文件的文件名。如果未指定,则应0x20所有字节。 |
| 446 | 128 | Data Preparer Identifier(数据准备器标识符) | strA | 为此卷准备数据的人员的标识符。对于扩展的准备信息,第一个字节应0x5F,后跟根目录中文件的文件名。如果未指定,则应0x20所有字节。 |
| 574 | 128 | Application Identifier(应用程序标识符) | strA | 标识数据如何记录在此卷上。对于扩展信息,第一个字节应0x5F,后跟根目录中文件的文件名。如果未指定,则应0x20所有字节。 |
| 702 | 37 | Copyright File Identifier(版权文件标识符) | strD | 根目录中包含此卷集版权信息的文件的文件名。如果未指定,则应0x20所有字节。 |
| 739 | 37 | Abstract File Identifier(抽象文件标识符) | strD | 根目录中包含此卷集抽象信息的文件的文件名。如果未指定,则应0x20所有字节。 |
| 776 | 37 | Bibliographic File Identifier(书目文件标识符) | strD | 根目录中包含此卷集的书目信息的文件的文件名。如果未指定,则应0x20所有字节。 |
| 813 | 17 | Volume Creation Date and Time(卷创建日期和时间) | dec-datetime | 创建卷的日期和时间。 |
| 830 | 17 | Volume Modification Date and Time(卷修改日期和时间) | dec-datetime | 修改卷的日期和时间。 |
| 847 | 17 | Volume Expiration Date and Time(卷到期日期和时间) | dec-datetime | 在此日期和时间之后,此卷被视为已过时。如果未指定,则该卷永远不会被视为已过时。 |
| 864 | 17 | Volume Effective Date and Time(批量生效日期和时间) | dec-datetime | 在该字段指定的日期之后可以使用该卷。如果未指定,则可以立即使用该卷。 |
| 881 | 1 | File Structure Version(文件结构版本) | int8 | 目录记录和路径表版本(始终0x01)。 |
| 882 | 1 | Unused(闲置字段) | - | 总是0x00。 |
| 883 | 512 | Application Used | - | ISO 9660 未定义的内容。 |
| 1395 | 653 | Reserved(保留字段) | - | 由 ISO 保留。 |
卷描述符集终结符(Volume Descriptor Set Terminator)
卷描述符集终结符当前未定义其卷描述符的\(7\sim 2047\)字节内容 。这意味着其只有类型代码 (255)、标准标识符 ('CD001') 和描述符版本 号(0x01)。
| 偏移 | 长度(字节) | 字段名称 | 数据类型 | 描述 |
|---|---|---|---|---|
| 0 | 1 | 类型 | int8 | 255 表示卷描述符集终止符。 |
| 1 | 5 | 标识符 | strA | 始终为"CD001"。 |
| 6 | 1 | 版本 | int8 | 卷描述符版本(0x01)。 |
(3)路径表(The Path Table)
路径表汇总了相关目录层次结构的目录结构。对于映像中的每个目录,路径表提供目录标识符、记录目录的范围的位置、与目录关联的任何扩展属性的长度以及其父目录路径表条目的索引。
路径表的位置可以在主卷描述符中找到。有两种表类型 - L 路径表(与 x86 相关)和 M 路径表。这两个表之间的唯一区别是 L 表中的多字节值是 LSB 优先的,而 M 表中的值是 MSB 优先的。
路径表条目的结构如下:
| 偏移 | 大小 | 描述 |
|---|---|---|
| 0 | 1 | 目录标识符的长度 |
| 1 | 1 | 扩展属性记录长度 |
| 2 | 4 | 范围位置 (LBA)。这是不同的格式,具体取决于这是L表还是M表(请参阅上面的说明)。 |
| 6 | 2 | 父目录的目录编号(路径表中的索引)。这是将表限制为 65536 条记录的字段。 |
| 8 | (可变) | 以 d 类字符表示的目录标识符(名称)。 |
| (可变) | 1 | 填充字段 - 如果"目录标识符的长度"字段为奇数,则包含零,否则不存在。这意味着每个表条目将始终以偶数字节号开头。 |
路径表按目录级别的升序排列,并在每个目录级别中按字母顺序排序。
(4)目录表(Directories)
在从 ISO 9660 CD 读取时的某个时刻,您将需要一个目录记录来查找文件,即使您最初通常使用路径表来查找目录也是如此。与路径表不同,每个目录表只有一个版本,多字节码采用双字节序格式。每个目录都将以 2 个特殊条目开头:一个空字符串,描述 "." 条目,字符串 "\1" 描述".."条目。目录记录的布局如下:
| 偏移 | 大小 | 描述 |
|---|---|---|
| 0 | 1 | 目录记录的长度。 |
| 1 | 1 | 扩展属性记录长度。 |
| 2 | 8 | 双端格式的范围位置 (LBA)。 |
| 10 | 8 | 双端格式的数据长度(范围大小)。 |
| 18 | 7 | 日期和时间(见下文)。 |
| 25 | 1 | 文件标识(见下文)。 |
| 26 | 1 | 以交错模式记录的文件的文件大小,否则为零。 |
| 27 | 1 | 以交错模式记录的文件的交错间隙大小,否则为零。 |
| 28 | 4 | 卷序列号 - 记录此扩展数据的卷,采用 16 位双端格式。 |
| 32 | 1 | 文件标识符(文件名)的长度。这将以";"字符结尾,后跟 ASCII 编码的小数("1")中的文件 ID 号。 |
| 33 | (变量) | 文件标识符。 |
| (变量) | 1 | 填充字段 - 如果文件标识符的长度为偶数,则为零,否则,此字段不存在。这意味着目录条目将始终从偶数字节号开始。 |
| (变量) | (变量) | 系统使用 - 最大记录大小为 255 的剩余字节可用于 ISO 9660 的扩展。最常见的是系统使用共享协议(SUSP)及其应用程序Rock Ridge交换协议(RRIP)。 |
即使目录跨越多个扇区,也不允许目录条目跨越扇区边界(与路径表不同)。如果没有足够的空间来记录扇区末尾的整个目录条目,则该扇区将进行零填充,并使用下一个连续扇区。
上述一些字段需要解释。
日期/时间字段(Date/Time)
目录表的日期/时间格式与主卷描述符中使用的格式不同。目录表的日期/时间格式为:
| 偏移 | 大小(字节) | 描述 |
|---|---|---|
| 0 | 1 | 自1900年以来的年数 |
| 1 | 1 | 月 |
| 2 | 1 | 日 |
| 3 | 1 | 时(\(0 \sim 23\)) |
| 4 | 1 | 分( \(0 \sim 59\) ) |
| 5 | 1 | 秒( \(0 \sim 59\) ) |
| 6 | 1 | 从 GMT 偏移 15 分钟,从 -48(西)到 +52(东)。 |
这与包含 ASCII 编码十进制值的 PVD 形成鲜明对比,但这种格式可能为了节省大量条目的磁盘空间。
文件标识字段(File Flags)
另一个需要解释的字段是"文件标志"字段。这由一个位标志表示,如下所示:
| 位 | 描述 |
|---|---|
| 0 | 如果设置,则不需要让用户知道此文件的存在,即"隐藏"标志。 |
| 1 | 如果已设置,则此记录描述一个目录(换句话说,它是一个子目录范围)。 |
| 2 | 如果设置,则此文件是"关联文件"。 |
| 3 | 如果设置,扩展属性记录将包含有关此文件格式的信息。 |
| 4 | 如果已设置,则在扩展属性记录中设置所有者和组权限。 |
| 5 & 6 | (保留) |
| 7 | 如果设置,则这不是此文件的最终目录记录(对于跨越多个扩展数据块的文件,例如长度超过 4GB 的文件。 |
六、图片文件
常见的图片存储格式有bmp,jpg,png,tif,gif,pcx,tga,exif,fpx, svg,psd,cdr,pcd,dxf,ufo,eps,ai,raw,WMF,webp,avif,apng 等。
有的出题人会将图片以base64编码的形式呈现
(一).gif
1. 分帧工具
gif在线分帧Split GIF image in frames (ezgif.com)
linux下的convert命令可以实现分帧。(墙推)
convert cipher.gif flag.png
windows下可以试试GifSplitter ,但帧数多时会很慢。
2. 题型
有时候会将一个含有flag的图片的像素点信息放到每一帧图片中,[2021CISCN线上赛]running_pixel
(二).png
参考:
根据图像的颜色类型划分,PNG 总计支持五类图像。
| PNG image type | Colour type |
|---|---|
| 灰度 | 0 |
| 真彩色 | 2 |
| 索引颜色 | 3 |
| 有透明通道的灰度 | 4 |
| 有透明通道的真彩色 | 6 |
针对这五种类型,其实都支持透明度配置,只是各有区分罢了。灰度(0)、真彩色(2)、索引颜色(3) 通过 tRNS 数据块来维护透明度设置。其中灰度(0)、真彩色(2)支持由配置一个统一的透明度(2字节),无法为每个像素单独配置透明度;索引颜色(3)支持为每个索引颜色设置透明度,但每个索引颜色的透明度设置最大只有 8 bits 的选择空间。对于有透明通道的真彩色(6)、灰度(4),它们不能拥有 tRNS 数据块,因为它们本身的就有透明通道来记录每个像素点的透明度。
PNG图像格式文件由文件署名(89 50 4E 47 0D 0A 1A 0A)和数据块(chunk)组成,下面重点讲数据块
数据块分两个大类,一种是称为关键数据块(critical chunk),就是必须要有的块;另一种叫做辅助数据块(ancillary chunks)。每一个数据块都分为下面4个字段
| 名称 | 字节数 | 说明 |
|---|---|---|
| Length(长度) | 4字节 | 指定数据块中数据域的长度,其长度不超过(231−1)(231−1)字节 |
| Chunk Type Code(数据块类型码) | 4字节 | 数据块类型码由ASCII字母(A-Z和a-z)组成 |
| Chunk Data(数据块实际内容 | 可变长度 | 存储按照Chunk Type Code指定的数据 |
| CRC(循环冗余检测) | 4字节 | 对Chunk Type Code域和Chunk Data域中的数据进行计算并存储值,用来检测是否有错误的循环冗余码 |
1. 关键数据块
有4个数据块属于关键数据块
-
文件头数据块IHDR(header chunk):它包含有PNG文件中存储的图像数据的基本信息,并要作为第一个数据块出现在PNG数据流中,而且一个PNG数据流中只能有一个文件头数据块。下面给出IHDR的Chunk Data部分组成结构
Chunk Data内的域名称 字节数 说明 Width 4 字节 图像宽度,以像素为单位 Height 4 字节 图像高度,以像素为单位 Bit depth 1 字节 图像深度:索引彩色图像:1,2,4或8 ;灰度图像:1,2,4,8或16 ;真彩色图像:8或16 ColorType 1 字节 颜色类型:0:灰度图像, 1,2,4,8或16;2:真彩色图像,8或16;3:索引彩色图像,1,2,4或84:带α通道数据的灰度图像,8或16;6:带α通道数据的真彩色图像,8或16 Compression method 1 字节 压缩方法(LZ77派生算法) Filter method 1 字节 滤波器方法 Interlace method 1 字节 隔行扫描方法:0。
非隔行扫描:1。此时数据是按照行(ScanLine)来存储的,为了区分第一行,PNG规定在每一行的前面加上0以示区分 -
调色板数据块PLTE(palette chunk):它包含有与索引彩色图像(indexed-color image)相关的彩色变换数据,它仅与索引彩色图像有关,而且要放在图像数据块(image data chunk)之前。真彩色的PNG数据流也可以有调色板数据块,目的是便于非真彩色显示程序用它来量化图像数据,从而显示该图像。
颜色
字节
意义
Red
1 字节
0 = 黑色, 255 = 红
Green
1 字节
0 = 黑色, 255 = 绿色
Blue
1 字节
0 = 黑色, 255 = 蓝色
-
图像数据块IDAT(image data chunk):它存储实际的数据,在数据流中可包含多个连续顺序的图像数据块。IDAT存放着图像真正的数据信息,因此,如果能够了解IDAT的结构,我们就可以很方便的生成PNG图像。
因此,调色板的长度应该是3的倍数,否则,这将是一个非法的调色板。
对于索引图像,调色板信息是必须的,调色板的颜色索引从0开始编号,然后是1、2……,调色板的颜色数不能超过色深(即IHDR中的Bit depth)中规定的颜色数,如图像色深为4的时候,调色板中的颜色数不可以超过\(2^4=16\),否则,这将导致PNG图像不合法。
真彩色图像和带\(\alpha\)通道数据的真彩色图像也可以有调色板数据块,目的是便于非真彩色显示程序用它来量化图像数据,从而显示该图像。
-
图像结束数据IEND(image trailer chunk):它用来标记PNG文件或者数据流已经结束,并且必须要放在文件的尾部。
如果我们仔细观察PNG文件,我们会发现,文件的结尾12个字符看起来总应该是这样的:
00 00 00 00 49 45 4E 44 AE 42 60 82不难明白,由于数据块结构的定义,IEND数据块的长度总是0(00 00 00 00,除非人为加入信息),数据标识总是IEND(49 45 4E 44),因此,CRC码也总是
AE 42 60 82。同时在IEND块后面添加任何的字符都对文件的打开造成不了影响,那我们就可以在这里藏一些数据(除了ios系统会直接提示),一些入门MISC题经常会把一些信息隐写在后面。最后,除了表示数据块开始的IHDR必须放在最前面, 表示PNG文件结束的IEND数据块放在最后面之外,其他数据块的存放顺序没有限制。
2. 辅助数据块
PNG文件格式规范制定的10个辅助数据块是:
- 背景颜色数据块bKGD(background color)。
- 基色和白色度数据块cHRM(primary chromaticities and white point)。所谓白色度是指当R=G=B=最大值时在显示器上产生的白色度。
- 图像γ数据块gAMA(image gamma)。
- 图像直方图数据块hIST(image histogram)。
- 物理像素尺寸数据块pHYs(physical pixel dimensions)。
- 样本有效位数据块sBIT(significant bits)。
- 文本信息数据块tEXt(textual data)。
- 图像最后修改时间数据块tIME (image last-modification time)。
- 图像透明数据块tRNS (transparency)。
- 压缩文本数据块zTXt (compressed textual data)。
——数据块小结
关键数据块、辅助数据块和专用公共数据块(special-purpose public chunks)综合下表中:
| 数据块符号 | 数据块名称 | 多数据块 | 可选否 | 位置限制 |
|---|---|---|---|---|
| IHDR | 文件头数据块 | 否 | 否 | 第一块 |
| cHRM | 基色和白色点数据块 | 否 | 是 | 在PLTE和IDAT之前 |
| gAMA | 图像γ数据块 | 否 | 是 | 在PLTE和IDAT之前 |
| sBIT | 样本有效位数据块 | 否 | 是 | 在PLTE和IDAT之前 |
| PLTE | 调色板数据块 | 否 | 是 | 在IDAT之前 |
| bKGD | 背景颜色数据块 | 否 | 是 | 在PLTE之后IDAT之前 |
| hIST | 图像直方图数据块 | 否 | 是 | 在PLTE之后IDAT之前 |
| tRNS | 图像透明数据块 | 否 | 是 | 在PLTE之后IDAT之前 |
| oFFs | (专用公共数据块) | 否 | 是 | 在IDAT之前 |
| pHYs | 物理像素尺寸数据块 | 否 | 是 | 在IDAT之前 |
| sCAL | (专用公共数据块) | 否 | 是 | 在IDAT之前 |
| IDAT | 图像数据块 | 是 | 否 | 与其他IDAT连续 |
| tIME | 图像最后修改时间数据块 | 否 | 是 | 无限制 |
| tEXt | 文本信息数据块 | 是 | 是 | 无限制 |
| zTXt | 压缩文本数据块 | 是 | 是 | 无限制 |
| fRAc | (专用公共数据块) | 是 | 是 | 无限制 |
| gIFg | (专用公共数据块) | 是 | 是 | 无限制 |
| gIFt | (专用公共数据块) | 是 | 是 | 无限制 |
| gIFx | (专用公共数据块) | 是 | 是 | 无限制 |
| IEND | 图像结束数据 | 否 | 否 | 最后一个数据块 |
tEXt和zTXt数据块中的标准关键字:
| 关键字 | 说明 |
|---|---|
| Title | 图像名称或者标题 |
| Author | 图像作者名 |
| Description | 图像说明 |
| Copyright | 版权声明 |
| CreationTime | 原图创作时间 |
| Software | 创作图像使用的软件 |
| Disclaimer | 弃权 |
| Warning | 图像内容警告 |
| Source | 创作图像使用的设备 |
| Comment | 各种注释 |
3. PNG文件分析技巧
在010 Editor中打开目标PNG文件,点击视图>输出窗口>显示或隐藏全部输出窗口可以打开输出窗口
当PNG经过人为修改导致文件结构解析错误会反馈到该窗口,如显示某个块的CRC校验错误,便可以判断这个块一定被人为修改过;同时该窗口会显示正确的CRC值,帮助我们利用此值覆盖明显错误的CRC值;此外还可以利用原先的zhi暴破被修改字段的正确值(如图片宽高),进而修复PNG文件
例题:
(三).jpg/.jpeg
1. 文件结构
JPEG文件一般有两种文件扩展名:.jpg和.jpeg,这两种扩展名的实质是相同的,我们可以把.jpg的文件改名为.jpeg,而对文件本身不会有任何影响。严格来讲,JPEG的文件扩展名应该为.jpeg,由于DOS时代的8.3文件名命名原则,就使用了.jpg的扩展名,这种情况类似于.htm和.html的区别。
其实JPEG是压缩标准,JPEG/JFIF和JPEG/Exif才是文件格式标准,本标题下重点讲述JPEG/JFIF格式
JPEG文件分为多个段,段的通用结构如下

SOI (0xFFD8)和 EOI (0xFFD9) 作为JPEG文件的起止标志,不参照上图的数据划分。
每个段的对应标识如下
| 段类型名 | 段标识 | 描述 |
|---|---|---|
| SOI | 0xFFD8 | Start Of Image(文件开始) |
| SOF0 | 0xFFC0 | Start Of Frame 0(帧开始) |
| SOF2 | 0xFFC2 | Start of Frame 2 |
| DHT | 0xFFC4 | Define Huffman Table(s)(霍夫曼表) |
| DQT | 0xFFDB | Define Quantization Table(s)(定义量化表) |
| DRI | 0xFFDD | Define Restart Interval |
| SOS | 0xFFDA | Start of Scan(扫描行开始) |
| RST0~RST7 | 0xFFD0 ~ 0xFFD7 | Restart |
| APP0~APP15 | 0xFFE0 ~ 0xFFEF | Application-sepcific(定义交换格式和图像识别信息) |
| COM | 0xFFFE | Comment(注释) |
| EOI | 0xFFD9 | End of Image(文件结束) |
下面对JPEG/JFIF文件的常见段做详细说明
(1)SOI & APP0——JPEG/JFIF文件的固定头
JPEG/JFIF文件的固定头
0000h: FF D8 FF E0 00 10 4A 46 49 46 ÿØÿà..JFIF
其中
-
SOI:FFD8
-
APP0:
---------------------------------------------------------------------- 名称 字节数 值 说明 ---------------------------------------------------------------------- 段标识 1 FF 段类型 1 E0 段长度 2 0010 如果有RGB缩略图就=16+3n (以下为段内容) 交换格式 5 4A46494600 “JFIF”的ASCII码 主版本号 1 次版本号 1 密度单位 1 0=无单位;1=点数/英寸;2=点数/厘米 X像素密度 2 水平方向的密度 Y像素密度 2 垂直方向的密度 缩略图X像素 1 缩略图水平像素数目 缩略图Y像素 1 缩略图垂直像素数目 (如果“缩略图X像素”和“缩略图Y像素”的值均>0,那么才有下面的数据) RGB缩略图 3×n n=缩略图像素总数=缩略图X像素×缩略图Y像素
(2)SOF0
--------------------------------------------------------------------------
名称 字节数 值 说明
--------------------------------------------------------------------------
段标识 1 FF
段类型 1 C0
段长度 2 其值=8+组件数量×3
(以下为段内容)
样本精度 1 8 每个样本位数(大多数软件不支持12和16)
图片高度 2
图片宽度 2
组件数量 1 1=灰度图,3=YCbCr/YIQ 彩色图,4=CMYK 彩色图
(以下每个组件占用3字节)
组件 ID 1 1=Y, 2=Cb, 3=Cr, 4=I, 5=Q
采样系数 1 0-3位:垂直采样系数
4-7位:水平采样系数
量化表号 1
---------------------------------------------------------------------------
(3)DHT
--------------------------------------------------------------------------
名称 字节数 值 说明
--------------------------------------------------------------------------
段标识 1 FF
段类型 1 C4
段长度 2 其值=19+n(当只有一个HT表时)
(以下为段内容)
HT信息 1 0-3位:HT号
4位: HT类型, 0=DC表,1=AC表
5-7位:必须=0
HT位表 16 这16个数的和应该≤256
HT值表 n n=表头16个数的和
--------------------------------------------------------------------------
2. JPEG压缩原理简述
本标题下内容参考《基于DCT变换的JPEG图像压缩原理》一文和视频“JPEG 有损压缩 离散余弦变换 DCT 一条视频讲清楚”,此外有自己的个人理解,仅供参考,主要是为理解JPEG一些基于DCT的隐写原理服务。
JPEG图像格式使用离散余弦变换(Discrete Cosine Transform,DCT)函数来压缩图像,而这个图像压缩方法的核心是:通过识别每个8×8像素块中相邻像素中的重复像素来减少显示图像所需的位数,并使用近似估算法降低其冗余度。因此,我们可以把DCT看作一个用于执行压缩的近似计算方法。因为丢失了部分数据,所以DCT是一种有损压缩技术,但一般不会影响图像的视觉效果。
JPEG压缩过程主要分为9个步骤:颜色空间转换、采样、分块、离散余弦变换(DCT)、(Zigzag)Z字形扫描排序、量化、DC系数的DCPM编码、AC系数的游程长度编码、熵编码、压缩。
下面对颜色空间转换、采样、分块、离散余弦变换(DCT)、Z字形扫描排序、量化做详细说明
(1)颜色空间转换
——颜色空间(色域)
颜色空间是一种针对不同应用而采用某接受的方式对彩色加以说明的彩色模型,说白了就是如何用数字表示一种颜色,下面是几种常见的表示方法。
- RGB 用于扫描仪和显示设备、计算机系统(将颜色的亮度、色度、饱和度融为一体)
- R(red):红色
- G(green):绿色
- B(blue):蓝色
- CMY 用于打印机、印刷出版业
- C(cyan):青色
- M(magenta):品红
- Y(yellow):黄色
- HSV/HSI/HSB/HSL 广泛用于图像处理和计算机视觉
[hue,saturation,value/intensity/brightness/luminance(or lightness)],即色度、饱和度、亮度- YUV/YCbCr 用于视频和电视。JEPG采用的是YCbCr颜色空间
- Y:指颜色的明视度、亮度、灰度值;
- U/Cb:指色调;
- V/Cr:指饱和度。
大多数计算机系统采用的是RGB颜色空间,而JEPG采用的是YCbCr颜色空间,因而需要进行RGB到YCbCr的转换。对每个像素值按如下计算方法便可实现这种转换。
-
RGB $\rightarrow $ YCbCr:
\[Y = 0.299R+0.587G+0.114B\\Cb = -0.1687R-0.3313G+0.5B+128\\Cr = 0.5R=0.418G-0.0813B+128 \]一般来说,C值(包括Cb、Cr)应该是一个有符号的数字,但这里通过加上128,使其变为8位的无符号整数,从而方便数据的存储和计算。
-
YCbCr $\rightarrow $ RGB:
\[R = Y+1.402(Cr-128)\\G = Y-0.34414(Cb-128)-0.71414(Cr-128)\\B = Y+1.772(Cb-128) \]
(2)采样
在转换完颜色空间之后,需要对每个像素的YCbCr三个分量按一定比例进行色度抽样,由于人眼对亮度的敏感程度要高于对色彩的敏感程度,我们减少一些色彩像素并不会造成太大影响,因而Y分量比Cb和Cr分量重要的多,基于此,我们通常对Y分量进行全采样,对Cb和Cr分量部分提取,使几个相邻像素共享一个Cb和Cr分量,从而大大减少了数据量
在JPEG中主要采用411和422的采样方式,也就是对于 \(2\times 2=4\) 个像素,本应总共需要4个Y、4个Cb、4个Cr,总共需要4+4+4=12字节,422采样意思为每4个像素单元有4个Y,2个Cb,2个Cr,此时只需要4+2+2=8字节,411则是6字节。
(3)分块
由于DCT变换是以 \(8\times 8=64\) 个像素组成的像素块(64分块)为单位的,因此针对一副数字图像,在进行DCT之前需要进行分块。由于图像的YCbCr三个分量是交替出现的,首先需要将依次分量分开存入3张表中;然后依次从左到右,从上到下,读取 \(8\times 8=64\) 的子块,存放到64长度的表中作为 \(8\times 8\) 的数据矩阵,然后才能进行DCT变换。
(4)离散余弦变换DCT
输入就是上述的 \(8\times 8\) 的数据矩阵,记作A,经过公式计算(公式略),输出一个新的 \(8\times 8\) 的矩阵B,矩阵B便是DCT系数矩阵,它有如下特征:
-
这个矩阵并非像初始矩阵A一样直接用于显示,而是将A的能量(低频部分)集中在左上角,其余高频分布于右下角。
一幅图像有一些主要的色彩和一些相对不重要的细节变化,而DCT变换实现的就是将这个像素块的主要颜色数据部分提取出来放在矩阵左上角,而细节数据则放在右下角。低频部分的改变是会产生较大变动的,但将细节部分的数据(高频部分)丢弃不会使图片产生较大的变动,有损压缩往往会去除掉这部分数据
-
最左上角
B[0][0]是所有像素的一个均值,叫做直流分量DC或直流系数,不难理解,通常相邻的 \(8\times 8\) 图象块的DC分量很接近;矩阵B的其余元素为交流分量AC或交流系数。所以DCT系数包括直流系数(DCT系数矩阵的最左上角那个第一个系数)和交流系数(DCT系数矩阵中除了直流系数之外的其它系数)
(5)Z字形扫描排序
我们知道DCT变换后将 \(8\times 8\) 的矩阵变成了另外一种元素更小的 \(8\times 8\) 的矩阵。在计算机中数组的存放一般按照行方式存储,但是如果这样的话,每一行的结尾点和下一行的开始点(或者说元素点之间的相邻性)不密切,因此在JPEG中采用以下的顺序扫描存储

这种扫描顺序一般将其称之为Zigzag扫描排序,这样保证了数列里的相邻点在图片上也是相邻的
(6)量化
量化表是控制 JPEG 压缩比的关键,JPEG系统分别规定了亮度分量和色度分量的量化表(该表中色度分量相应的量化步长比亮度分量大),还可以根据输出图片的质量来自定义量化表,通常自定义量化表与标准量化表呈比例关系,表中数字越大则质量越低,压缩率越高
量化就是将DCT系数矩阵各个系数除以量化表对应值(量化步长),结果取整。量化后得到新的DCT系数矩阵,经过量化后的DCT系数矩阵,高频部分往往会含有大量连续的0。
可以看出,量化过程是有损的,在解码时,反量化会乘回量化表的相应值,由于存在取整,低频段会有所损失,高频段的0字段则会被舍弃,最终导致图像质量降低。
(四).bmp
参考:
BMP是Window操作系统中的标准图像文件格式,图像相同的条件下,位图图像文件通常比使用其它压缩算法的图像文件大很多,存储结构的格式可以在WINGDI.h文件中找到定义。
BMP文件的结构组成如下:
| 组成结构 | 含义 |
|---|---|
| 位图文件头(bitmap-file header) | 包含BMP图像文件的类型、显示内容等信息 |
| 位图信息头(bitmap-information header) | 包含有BMP图像的宽、高、压缩方法,以及定义颜色等信息; |
| 彩色表/调色板(color table) | 这个部分是可选的,有些位图需要调色板,有些位图,比如真彩色图(24位的BMP)就不需要调色板; |
| 位图数据(bitmap-data) | 这部分的内容根据BMP位图使用的位数不同而不同,在24位图中直接使用RGB,而其他的小于24位的使用调色板中颜色索引值。 |
1. 位图文件头(bitmap-file header)
typedef struct tagBITMAPFILEHEADER {
WORD bfType; //图像类型,根据不同的操作系统而不同,在Windows中,此字段的值总为‘BM’
DWORD bfSize; //图像文件的大小
WORD bfReserved1; //保留字段,始终为0
WORD bfReserved2; //保留字段,始终为0
DWORD bfOffBits; //BMP图像数据的地址
} BITMAPFILEHEADER, FAR *LPBITMAPFILEHEADER, *PBITMAPFILEHEADER;
| 偏移量 | 大小(B) | 说明 |
|---|---|---|
| 0000h | 2 | 用于标识BMP和DIB文件的魔数,一般为0x42 0x4D,即ASCII的BM。 |
| 0002h | 4 | BMP文件的大小(单位为字节) |
| 0006h | 2 | 保留(实际值因创建程序而异) |
| 0008h | 2 | 保留(实际值因创建程序而异) |
| 000Ah | 4 | 位图数据(像素数组)的地址偏移,也就是起始地址。 |
2. 位图信息头(bitmap-information header)
typedef struct tagBITMAPINFOHEADER{
DWORD biSize; //本结构的大小,根据不同的操作系统而不同,在Windows中,此字段的值总为28h字节=40字节
LONG biWidth; //BMP图像的宽度,单位像素
LONG biHeight; //BMP图像的高度
WORD biPlanes; //色彩平面数
WORD biBitCount; //BMP图像的色深,即一个像素用多少位表示,常见有1、4、8、16、24和32,分别对应单色、16色、256色、16位高彩色、24位真彩色和32位增强型真彩色
DWORD biCompression; //压缩方式,0表示不压缩,1表示RLE8压缩,2表示RLE4压缩,3表示每个像素值由指定的掩码决定
DWORD biSizeImage; //BMP图像数据大小,必须是4的倍数,图像数据大小不是4的倍数时用0填充补足
LONG biXPelsPerMeter;//水平分辨率,单位像素/m
LONG biYPelsPerMeter;//垂直分辨率,单位像素/m
DWORD biClrUsed; //BMP图像使用的颜色,0表示使用全部颜色,对于256色位图来说,此值为100h=256
DWORD biClrImportant; //重要的颜色数,此值为0时所有颜色都重要,对于使用调色板的BMP图像来说,当显卡不能够显示所有颜色时,此值将辅助驱动程序显示颜色
} BITMAPINFOHEADER, FAR *LPBITMAPINFOHEADER, *PBITMAPINFOHEADER;
通过修改biBitCount字段可以实现给图片升维降维
| 偏移量 | 大小(字节) | 说明 |
|---|---|---|
| 0Eh | 4 | 该头结构的大小(40字节) |
| 12h | 4 | 位图宽度,单位为像素(有符号整数,以像素为单位) |
| 16h | 4 | 位图高度,单位为像素(有符号整数,以像素为单位)。这个值还有一个用处,指明图像是正向的位图还是倒向的位图,该值是正数说明图像是倒向的即图像存储是由下到上;该值是负数说明图像是倒向的即图像存储是由上到下。大多数BMP位图是倒向的位图,所以此值是正值。 |
| 1Ah | 2 | 色彩平面数;只有1为有效值 |
| 1Ch | 2 | 每个像素所占位数,即图像的色深。典型值为1、4、8、16、24和32 |
| 1Eh | 4 | 所使用的压缩方法,可取值见下表。 |
| 22h | 4 | 图像大小。指原始位图数据的大小(详见后文),与文件大小不是同一个概念。 |
| 26h | 4 | 图像的横向分辨率,单位为像素每米(有符号整数) |
| 2Ah | 4 | 图像的纵向分辨率,单位为像素每米(有符号整数) |
| 2Eh | 4 | 调色板的颜色数,为0时表示颜色数为默认的\(2^{色深}\)个 |
| 32h | 4 | 重要颜色数,为0时表示所有颜色都是重要的;通常不使用本项 |
其中biCompression字段的取值如下
| 值 | 标识 | 压缩方法 | 备注 |
|---|---|---|---|
| 0 | BI_RGB | 无 | 最常见 |
| 1 | BI_RLE8 | RLE 8位/像素 | 只能用于格式为8位/像素的位图 |
| 2 | BI_RLE4 | RLE 4位/像素 | 只能用于格式为4位/像素的位图 |
| 3 | BI_BITFIELDS | 位字段或者霍夫曼1D压缩(BITMAPCOREHEADER2) | 像素格式由位掩码指定,或位图经过霍夫曼1D压缩(BITMAPCOREHEADER2) |
| 4 | BI_JPEG | JPEG或RLE-24压缩(BITMAPCOREHEADER2) | 位图包含JPEG图像或经过RLE-24压缩(BITMAPCOREHEADER2) |
| 5 | BI_PNG | PNG | 位图包含PNG图像 |
| 6 | BI_ALPHABITFIELDS | 位字段 | 针对Windows CE .NET 4.0及之后版本 |
3. 彩色表/调色板(color table)
这部分定义了图像中所用的颜色。如上所述,位图图像一个像素接着一个像素储存,每个像素使用一个或者多个字节的值表示,所以调色板的目的就是要告诉应用程序这些值所对应的实际颜色。
典型的位图文件使用RGB彩色模型。在这种模型中,每种颜色都是由不同强度(从0到最大强度)的红色(R)、绿色(G)和蓝色(B)组成的,也就是说,每种颜色都可以使用红色、绿色和蓝色的值所定义。
在位图文件的实现中,调色板可以包含很多条目,条目个数就是图像中所使用的颜色的个数。每个条目都是如下的结构,而调色板是该结构的结构体数组。
typedef struct tagRGBQUAD {
BYTE rgbBlue; //1B。蓝色值
BYTE rgbGreen; //1B。绿色值
BYTE rgbRed; //1B。红色值
BYTE rgbReserved; //1B。保留,总为0
}RGBQUAD;
每个条目用来描述一种颜色,包含4个字节,其中三个表示蓝色、绿色和红色,第四个字节没有使用(大多数应用程序将它设为0);对于每个字节,数值0表示该颜色分量在当前的颜色中没有使用,而数值255表示这种颜色分量使用最大的强度。
4. 位图数据(bitmap-data)
位图中像素的比特是以行为单位对齐存储的,每一行的大小都向上取整为4字节(32位DWORD)的倍数。
存储一行像素所需的字节数可以按下面公式计算
如果图像的高度大于1,多个经过填充实现对齐的行就形成了像素数组。
位图数据有以下几种呈现形式
-
如果图像是单色、16色和256色,则紧跟着调色板的是位图数据,位图数据是指向调色板的索引序号。此时位图数据可以根据需要选择压缩与不压缩,如果选择压缩,则根据BMP图像是16色或256色,采用RLE4或RLE8压缩算法压缩。
-
如果位图是16位、24位和32位色,则图像文件中不保留调色板,即不存在调色板,图像的颜色直接在位图数据中给出。
-
16位图像使用2字节保存颜色值,常见有两种格式:5位红5位绿5位蓝和5位红6位绿5位蓝,即555格式和565格式。555格式只使用了15 位,最后一位保留,设为0。
-
24位图像使用3字节保存颜色值,每一个字节代表一种颜色,按红、绿、蓝排列。
-
32位图像使用4字节保存颜色值,每一个字节代表一种颜色,除了原来的红、绿、蓝,还有Alpha通道,即透明色。如果放到
-
——RLE压缩
游程编码(run-length encoding,缩写RLE),又称行程长度编码或变动长度编码法,是一种与资料性质无关的无损数据压缩技术,基于“使用变动长度的码来取代连续重复出现的原始资料”来实现压缩。
RLE4压缩规则如下:
- 若\(第1个字节\ne0\),第一个字节代表后面一个字节的颜色索引的重复次数
- 若\(第1个字节=0\),第二个字节代表后面有几个有效颜色索引
- 一个颜色索引占\(4\ bit\)(一个字节2个颜色索引)
RLE8的压缩规则可以参考上面的RLE4,惟一的区别是RLE8使用1个字节存放颜色索引,而RLE4使用4位存放颜色索引。
下面举个栗子:
假设有如下16色位图数据,共20字节,数据使用了RLE4压缩
05 00 04 05 00 08 09 05 04 00 04 05 08 09 04 08 07 01 00 00
解压过程如下:
-
首先读取05,因为05不等于0,05表示后面数据重复的次数,接着读取00,00表示有两个颜色索引,每个索引占4位,第一个像素在高4位,第二个像素在低4位,即在一个字节中低像素在高位,高像素在低位。05 00解压后等于00 00 0。(5个索引)
-
读取04,按照上面的操作解析,04是后面数据重复的次数,05是两个颜色索引,第3个颜色索引为5,第4个颜色索引为0。04 05解压后等于05 05。(4个索引)
-
读取00,再读取08,08表示后面有效的颜色索引数。00 08解压后等于09 05 04 00。
-
读取04,按照上面的操作解析,04是后面数据重复的次数,05是两个颜色索引。04 05解压后等于05 05。
-
读取08,按照上面的操作解析,08是后面数据重复的次数,09是两个颜色索引。08 09解压后等于09 09 09 09。
-
读取04,按照上面的操作解析,04是后面数据重复的次数,08是两个颜色索引。04 08解压后等于08 08。
-
读取07,按照上面的操作解析,07是后面数据重复的次数,01是两个颜色索引。07 01解压后等于01 01 01 0。
-
读取00,再读取下一个字节00,00表示后面有效的颜色索引数,0表示无,即解压完一行数据。
综合上面的操作,解压后的数据为:
00 00 00 50 50 90 50 40 00 50 50 90 90 90 90 80 80 10 10 10
当数据比较多而且重复的时候,使用RLE压缩效果相对比较理想。
(五)绘图
1. 二维码绘制
01串作为输入,二维码图片输出
from PIL import Image
data= "1111111000100001101111111100000101110010110100000110111010100000000010111011011101001000000001011101101110101110110100101110110000010101011011010000011111111010101010101111111000000001011101110000000011010011000001010011101101111010101001000011100000000000101000000001001001101000100111001111011100111100001110111110001100101000110011100001010100011010001111010110000010100010110000011011101100100001110011100100001011111110100000000110101001000111101111111011100001101011011100000100001100110001111010111010001101001111100001011101011000111010011100101110100100111011011000110000010110001101000110001111111011010110111011011"
width = 25 #width和height取决于data的长度,若data长度为25*25=625,那么width=height=25
height = 25
im = Image.new("RGB", (width, height)) # 创建图片
for i in range(0, width):
line = data[width*i:width*(i+1)] # 获取一行
for j in range(0, height):
if line[j] == '0':
im.putpixel((i, j), (255, 255, 255)) # rgb转化为像素
else:
im.putpixel((i, j), (0, 0, 0)) # rgb转化为像素
im.save("out_CQR.png")
(六)图片拼接
(七)图像隐写
参考:
1. 宽高修改
如果图片原本是800(宽) \(\times\) 600(高),然后图片的高度从600变成500,这样下面800 \(\times\) 100区域的信息就无法从图片中显示出来,我们可见的只有上方800 \(\times\) 500的区域,这样就达成了图片隐写的目的。同理可知图片的宽度也可以进行类似的修改以达到隐藏信息的目的。
(1).png宽高隐写
PNG文件中的文件头数据块IHDR(header chunk)中定义了图片的高度和宽度,可以通过修改高度值或宽度值对部分关键信息进行隐藏。
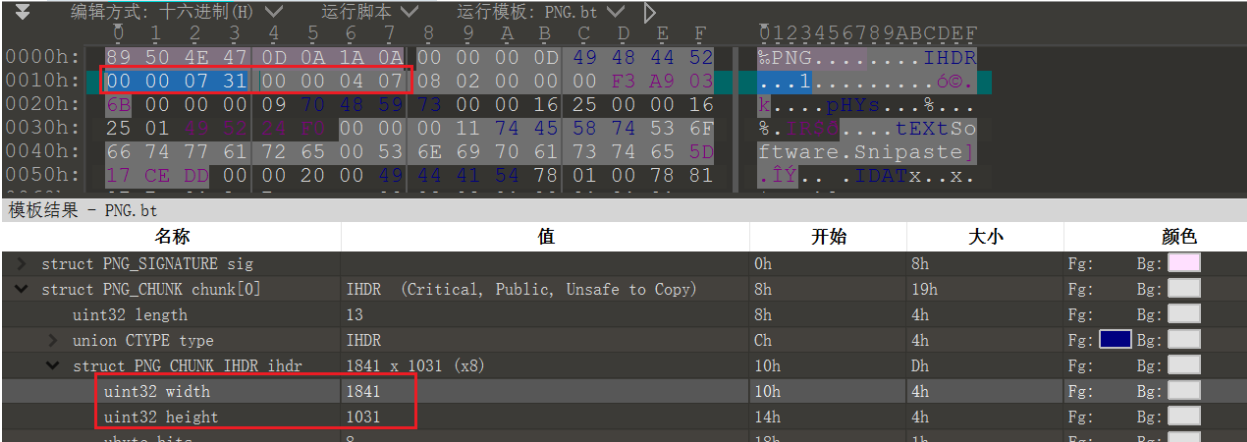
- 原理:png图片的宽和高信息在png的IHDR数据块内,通过修改图片的宽和高数据使图片仅显示一部分,另一部分不显示
- 特征:010 Editor中打开后会在输出窗口(
视图>输出窗口>显示或隐藏全部输出窗口)反馈CRC校验值错误的报错提示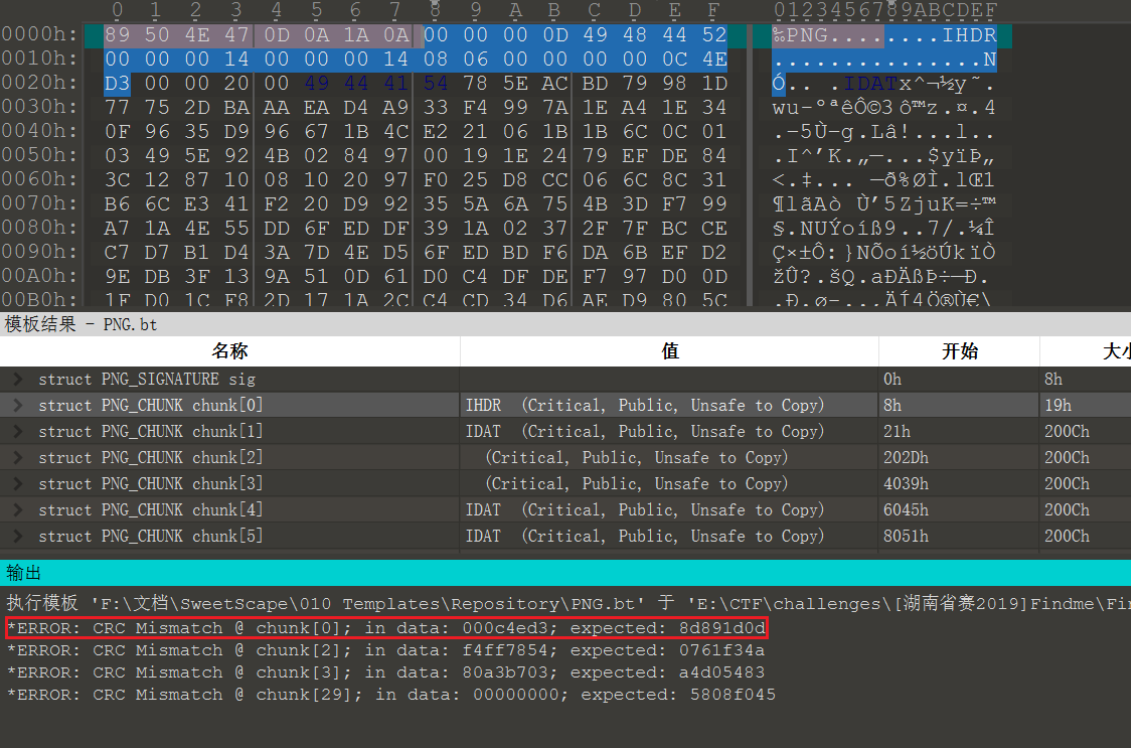
- 破解:不能任意修改宽高,但可以通过CRC值来暴破获取正确的宽值或者高值(如下)
import zlib
import struct
filename='' #图片路径
crc_str= '' #图片的CRC值(16进制字符串,如'0xc4ed3')
# 同时暴破宽度和高度
with open(filename, 'rb') as f:
all_b = f.read()
data = bytearray(all_b[12:29])
n = 4095
for w in range(n):
width = bytearray(struct.pack('>i', w))
for h in range(n):
height = bytearray(struct.pack('>i', h))
for x in range(4):
data[x+4] = width[x]
data[x+8] = height[x]
crc32result = zlib.crc32(data)
#替换成图片的crc
if crc32result == int(crc_str,16):
print("宽为:", end = '')
print(width, end = ' ')
print(int.from_bytes(width, byteorder='big'))
print("高为:", end = '')
print(height, end = ' ')
print(int.from_bytes(height, byteorder='big'))
(2).jpg宽高隐写
SOF0段的X_image和Y_image分别记录图片的宽和高,直接修改,不用担心校验错误。
(3).bmp宽高隐写
2. IDAT隐写(.png)
例题:[SCTF2014]misc400b
——知识储备
图像数据块 IDAT(image data chunk)是PNG文件中很重要的一种数据块
- 它用于储存图像实际的像素数据
- 在图像数据流中可包含很多个连续顺序的IDAT块,若写入一个多余的IDAT也不会明显影响肉眼对图片的观察。
- 数据采用 LZ77 算法的派生算法进行压缩,可以用 zlib 对数据进行解压缩
zlib是一种用于压缩的函数库,最初用于libpng,所以在PNG图片中能识别出很多zlib数据块。使用Python自带的zlib库可以方便的对数据块进行压缩和解压缩操作。
判别:值得注意的是,通常IDAT 块只有当上一个块充满时,才会继续一个新的块。一旦出现不符合这个规律的情况(有一块IDAT还没填满但紧跟其后的是一个新的块),那么就是人为添加了数据块。此外文件结构中可能会存在size=0的IDAT块,这说明相应的块是无法用肉眼看到的,也即隐藏的内容。
- 可以利用PNGcheck软件输入
pngcheck -v test.jpg对图片的文件结构进行检测。 - 或者直接用010 Editor打开文件,观察IDAT的大小(如下图可以发现最后两个IDAT大小很可疑)
破解:010 editor打开文件,提取可疑IDAT中的数据部分(即需要剔除IDAT的长度、数据块类型、末尾的 CRC 校验值),然后扔进zlib解压脚本里解压获得原始数据。
#zlib解压脚本
#运行在python2环境下
import zlib
import binascii
IDAT = ".........".decode('hex') #填入dump出的IDAT的数据部分,例如按上图就是"789C...7667"
result = binascii.hexlify(zlib.decompress(IDAT))
print (result.decode('hex'))
print (len(result.decode('hex')))
3. LSB隐写
原理:LSB全称Least Significant Bit,即最低有效位。PNG文件中的图像像数一般是由RGB三原色(红绿蓝)组成,每一种颜色占用8位,取值范围为0x00~0xFF,即有256种颜色,一共包含了256的3次方的颜色,即16777216种颜色,人类的眼睛可以区分约1000万种不同的颜色,这意味着人类的眼睛无法区分余下的颜色约有6777216种,LSB隐写就是修改RGB颜色分量的最低二进制位(LSB),而人类的眼睛不会注意到这前后的变化,每个像素可以携带3比特的信息(RGB分量各一个),提取过程便是将这些像素的各个分量的最低位合并起来便是隐藏信息。
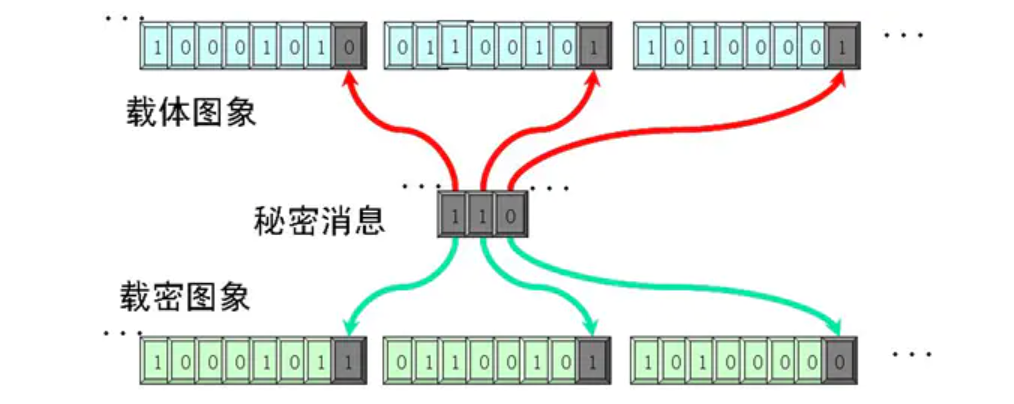
判别:
参考:png文件隐写——不负责任的总结:
-
LSB-Steganography工具实现的不加密隐写可以用Stegsolve查看,这种算法的特点就是LSB位前面很多0
关于Stegsolve的使用参考“十四”
-
cloacked-pixel工具实现的加密隐写(带密钥)可以用Stegsolve查看,这种算法的特点是开头有个数字,根据观察,这个数字应该是有用的数据的长度,然后才是很多个0,接着是相应长度的数据。
cloacked-pixel使用方法:
lsb.py hide <img_file> <payload_file> <password> #隐写 lsb.py extract <stego_file> <out_file> <password> #提取 lsb.py analyse <stego_file> #分析检测
提取工具:
- 对于不加密的LSB隐写:在Stegsolve中extract
- 对于带密码的LSB隐写:cloacked-pixel
4. JSteg隐写(.jpeg)
原理:JSteg算法其实是LSB替换思想在DCT域的实现。JSteg隐写算法嵌入过程的关键步骤就是将原始图像的AC系数的最低位(LSB)替换为要隐藏的秘密信息。一般图像的压缩和处理过程中为了保持图像的可视性,都保留了图像的中低频部分,而低频部分的改变有可能引起图像较大的变动,为了将隐藏的信息与载体图像的视觉重要部分绑定,JSteg将隐藏信息嵌入在载体的中频部分数据的LSB(最底层)里,在隐写之后人眼无法分辨隐写图与原图的差别,达到既不引起视觉变化,又不会被轻易破坏的目的,提取秘密消息时,只需将载密图像中不等于0、1的量化DCT系数的LSB取出即可。流程如下:
-
选择载体图像,并且将载体图像划分为连续的8×8的子块。
-
对每个子块使用DCT变换之后,用相应的量化表量化,得到对应的8×8量化DCT子块。
一定要注意,JSteg是针对量化后DCT系数的LSB修改的,不是DCT变换后量化前的DCT系数
-
将需要隐藏的信息编码为二进制数据流,对DCT子块系数进行Z字形扫描,并且使用秘密信息的二进制流替换非0和非1的AC系数的最低比特位。
——为什么不使用值为0和$\pm$1的AC系数?
- DCT系数中“0”的比例最大(一般可达到60%以上,取决于图像质量和压缩因子),压缩编码是利用大量出现连零实现的,如果改变DCT系数中“0”的话,不能很好的实现压缩。
- DCT系数中的“1”若变成“0”,由于接受端无法区分未使用的“0”和嵌入消息后得到的“0”,从而无法实现秘密信息的提取。
-
进行熵编码等,产生JPEG隐密图像。
检测原理:Jsteg算法容易造成DCT系数中值对现象出现,利用 \(\chi^2\) 检验可以很容易地检测出秘密信息的存在性。
① 值对现象
设(2i, 2i+1)是一值对,采用JSteg嵌入信息会使得DCT系数值等于 \(2i\) 的DCT系数个数与DCT系数值等于 \(2i+1\) 的像素个数越来越接近。
② \(\chi^2\) 检验
\(\chi^2\) 检验攻击思想是通过比较载密图像的理论频率分布和观测到的载体的样本分布,判断待测载体是否载密。
我们可以对JPEG图像的量化后的DCT系数绘制频数分布直方图,理论上原始图像的直方图(如下图)会有以下特征:
- 对称性:以0为中心达到最大值,两侧分布近似对称
- 单侧单调性:以0值为中心达到最大值,两侧单调下降
- 梯度下降性:小值样点较多,大值样点较少,分布曲线在两侧下降梯度逐渐减小
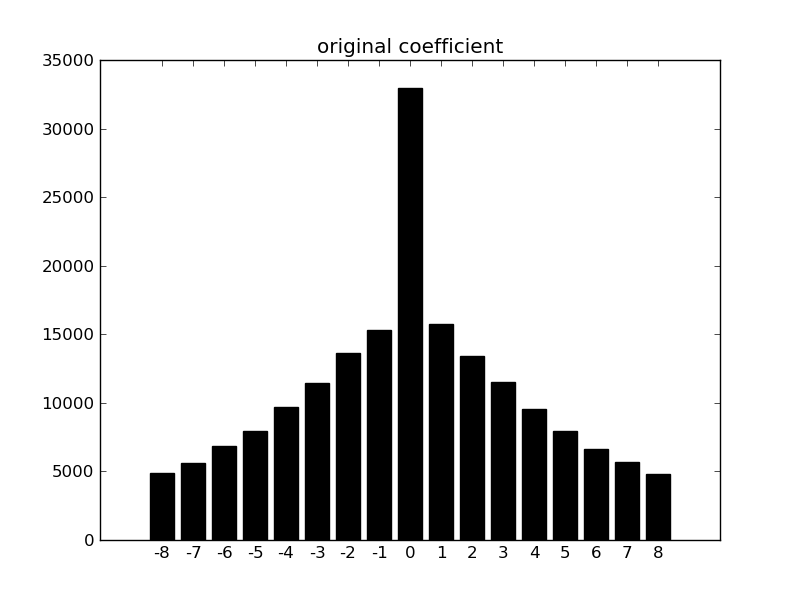
但采用JSteg隐写修改了DCT系数的LSB之后,随着嵌入的数据增多这种特性很容易被破坏,容易产生值对现象如下图,2和3,-2和-3都为值对),这种缺陷可以作为这种隐写的判定特征。
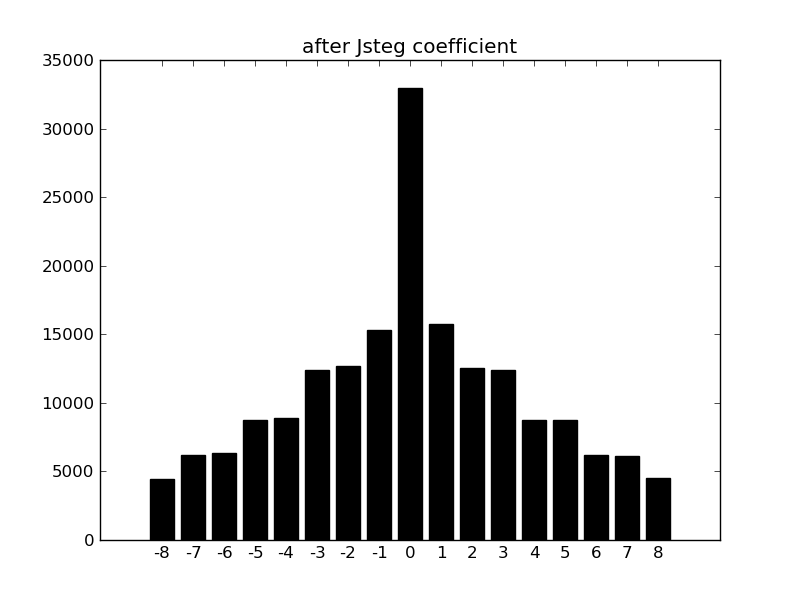
但是,当嵌入的数据很少时,值对现象不明显,该方法检测效果不够理想。
5. F5隐写(.jpeg)
背景:在F5之前还有F3与F4,从JSteg到F3,再到F4,接着是F5,后者都是对前者缺陷的改进。F3算法解决了JSteg值对现象的问题维持了原始图像直方图特性,但使得偶系数数目变多(显著特征就是新增很多0);F4进一步改进,除0之外的偶系数分布正常,但依旧新增很多0系数。此外,JSteg、F3、F4都会更改很多系数DCT系数来完成隐写,这也是一大缺陷。
原理:F5隐写采用的是基于汉明码的矩阵编码隐写,且采用绝对值减1的嵌入方法不会产生值对现象,可以有效抵抗 \(\chi^2\) 检验攻击。矩阵编码是将图像的像素每 \(n\) 个分为一组,最多只修改其中 \(d_{max}\) 的个像素,就可以嵌入 \(k\) 位比特的秘密信息,从而提高嵌入效率,一般用有序元组 \((d_{max},n,k)\) 来表示这种编码方式。F5 算法实现矩阵编码时,取 \(d_{max}=1\) ,矩阵编码方式为 \((1,n,k)\),码字长度为 \(n=2^k-1\),表示对于最多只需改变一个LSB位,用 \(n\) 个LSB 来表示 \(k\) 比特的信息,\(k\) 的具体值是需要根据图像可嵌入容量和待嵌入数据的长度来确定的,确定了 \(k\) 的值之后进而可以确定 \(n\) 的具体值( \(n=2^k-1\))。例如我们可以用 3 个 LSB 位 a1、a2、a3 嵌入两个比特 x1、 x2,能做到最多改变一个 LSB 位来表示这2个比特,在嵌入时会遇到以下 4 种情况:
- x1 = a1⊕a3,x2 = a2⊕a3 ——不作任何改变;
- x1≠a1⊕a3, x2 = a2⊕a3 ——改变 a1 的值;
- x1 = a1⊕a3,x2 ≠ a2⊕a3 ——改变 a2 的值;
- x1 ≠ a1⊕a3,x2 ≠ a2⊕a3——改变a3的值。
4 种情况中,我们均只需要在3个DCT系数中修改一个就可以表示2个字符,这样的好处是大大增加了嵌入效率,且可以有效地抵制 RS 统计分析,但对于同样要嵌入2个比特信息,正常只需要2个DCT系数,而在这里则需要3个,此外,F5会产生收缩现象。
检测原理:F5算法虽然保持了某些直方图特性,但是在嵌入过程中会产生很多的值为0的DCT系数,会产生收缩现象,另外,图像中各块经过再次量化压缩,会造成块间的不连续性,从而降低块间的相关性。因此,F5隐写仍然会引起图像的一些统计特性发生改变。
——收缩现象
我们知道量化后的DCT系数有正有负,那么F5是如何修改又是如何处理符号的?
F5规定修改规则是把要修改的DCT系数的绝对值减 1,保持符号不变得到新的DCT系数,如要修改DCT系数值为-3的LSB,根据F5算法就会改成-2,如果是3就会改成2,我们不难看出这种修改会使DCT系数向0靠拢,体现在直方图上便是嵌入消息后,直方图向中间收缩,使得中间越来越“高”,这便是收缩现象。
检测工具:使用stegdetect工具可以检测
6. JPHide(.jpeg)
参考:
原理:Jphide是一种基于控制表的JPEG图像隐写算法,通过控制表确定嵌入位置和消息嵌入方式,该算法抗统计检测能力较强。它使用 Blowfish 算法加密信息,利用控制表确定信息的隐藏位置及嵌密的方式,同时结合 Blowfish 生成的随机序列控制具体位置的嵌入。
——Blowfish
Blowfish是一种对称加密算法
提取:JPHS内置JPHIDE和JPSEEK,具体用法见“十四”。
- JPHide程序主要是实现将信息文件加密隐藏到JPEG图像功能
- JPSeek程序主要实现从用JPHide程序加密隐藏得到的JPEG图像探测提取信息文件
7. outguess隐写(.jpeg)
原理:OutGuess隐写算法是在JSteg算法的基础上发展而来的,通过在JSteg算法的基础上加上了纠正过程,使得一阶直方图不发生任何改变,从而能较好的抵抗 \(\chi^2\) 检验攻击。其思想就是在第一次嵌入时将信息隐藏在随机选定的DCT系数的LSB中,第二次嵌入时对第一次嵌入进行修正,使得载密图像直方图与载体图像直方图保持一致。OutGuess隐写中的修正步骤使得隐秘图像的DCT系数直方图与原始图像的DCT系数直方图保持一致,使得一系列基于原始直方图估计的隐写分析(如 \(\chi^2\) 检验攻击)将都不能用于检测OutGuess隐写。
检测原理:OutGuess隐写对量化后的DCT系数所做的调整将增大JPEG图像中的分块效应。
——分块效应
由于JPEG压缩过程中要量化各个分块的DCT系数,在不同64分块之间会有一定的不连续性,即分块效应。在压缩比较高时,人眼甚至可以分辨出各小块之间的界限。
提取:outguess
检测工具:使用stegdetect工具可以检测
8. 盲水印
盲水印是一种肉眼不可见的水印方式,可以保持图片美观的同时,保护资源版权。
- 提取:
- ImageIN:GUI交互(建议只得到一张图的情况下使用)
- BlindWaterMark:命令行python脚本(CTF题中可能会给两张一样的图,这个时候用此工具更好)
9. 追加插入
原理:计算机中图片处理程序识别图片的过程是,从图片头开始,以图片头声明的格式所定义的编码格式对数据流进行读取,一直到图片的结束符,当图片处理程序识别到图片的结束符后,不再继续向下识别,如果结束符后面还有数据便会被忽略
(1)在JPG文件“FF D9”后隐藏数据
一个完整的 JPG 文件由 FF D8 开头,FF D9结尾,图片浏览器会忽略 FF D9 以后的内容,因此可以在 JPG 文件中加入其他文件。这种方法多用于在一张图片中隐藏一个压缩包。
(2)在PNG文件“00 00 00 00 49 45 4E 44 AE 42 60 82”后隐藏数据
PNG文件有一个图像结束数据IEND(image trailer chunk),用来标记PNG文件或者数据流已经结束,并且必须要放在文件的尾部,且其值固定如下
00 00 00 00 49 45 4E 44 AE 42 60 82
这是因为由于数据块结构的定义,IEND数据块的长度总是0(00 00 00 00,除非人为加入信息),数据标识总是IEND(49 45 4E 44),因此,CRC码也总是AE 42 60 82。同时在IEND块后面添加任何的字符都对文件的打开造成不了影响,那我们就可以在这里藏一些数据(除了ios系统会直接提示),一些MISC题经常会把信息隐写在后面。
10. 前置插入
任何可以插入批注内容的文件都可能被插人数据,而丝毫不影响视觉效果。例如,HTML文件和JPEG文件都很容易用来嵌入数据。
(1)JPEG文件插入批注
相比于png文件,由于JPEG文件没有对图像数据的校验位,所以在JPEG文件中添加信息简单了很多。
JPEG文件首部有许多数据区域可以用来隐藏信息,我们最多可以在JPEG文件中插入65533个字节的批注信息,而这些内容在浏览图像的时候都是看不到的。
破解:借助jpeg图片格式分析工具JPEGsnoop就能发现其中的痕迹
11. 时间轴隐写(.gif)
例题:buu-蜘蛛侠呀
原理:利用多帧之间的时间间隔不同,如采用两种不同时长的帧间间隔分别代表1和0来隐藏数据。
判别:若得到一个播放不连贯的gif文件可以猜测是时间轴隐写。
破解:linux的identify可以用于提取gif各帧间的间隔(如下)。
identify -format "%T" test.gif
七、视频文件
(一).mp4
题目:
详细参考:
MP4文件由一系列的box对象组成,所有的数据都包含在这些box中,除此以外,文件中再无其它数据。此外。
所有的Mp4文件中,首先有且仅有一个File Type 类型的Box。Box由包含了size(Box大小)和type(Box 类型)的Box Header开始。Header允许紧凑或扩展的size(32位或64位)和紧凑和扩展的type(32位或者完整的通用唯一标识符,即UUID)。
大多数标准的Box使用的都是32位size和32位type,只有包含了媒体数据的Box需要使用64位size。这里的size,指的是包括Header在内的整个Box占用的大小。在size指定的空间中,除了Box header占用的空间外,其它空间由真实的数据(BoxData)数据占据。这些数据,可能包括其它子Box、也可能是媒体数据。
我们可以利用该信息对MP4文件进行分析。需要注意的是,数据存储使用大端字节序。
下表中列出了所有必选或可选的Box类型,✅代表Box必选。
| ftyp |
|
|
|
|
| ✅ | file type and compatibility |
| pdin |
|
|
|
|
|
| progressive download information |
| moov |
|
|
|
|
| ✅ | container for all the metadata |
|
| mvhd |
|
|
|
| ✅ | movie header, overall declarations |
|
| trak |
|
|
|
| ✅ | container for an individual track or stream |
|
|
| tkhd |
|
|
| ✅ | track header, overall information about the track |
|
|
| tref |
|
|
|
| track reference container |
|
|
| edts |
|
|
|
| edit list container |
|
|
|
| elst |
|
|
| an edit list |
|
|
| mdia |
|
|
| ✅ | container for the media information in a track |
|
|
|
| mdhd |
|
| ✅ | media header, overall information about the media |
|
|
|
| hdlr |
|
| ✅ | handler, declares the media (handler) type |
|
|
|
| minf |
|
| ✅ | media information container |
|
|
|
|
| vmhd |
|
| video media header, overall information (video track only) |
|
|
|
|
| smhd |
|
| sound media header, overall information (sound track only) |
|
|
|
|
| hmhd |
|
| hint media header, overall information (hint track only) |
|
|
|
|
| nmhd |
|
| Null media header, overall information (some tracks only) |
|
|
|
|
| dinf |
| ✅ | data information box, container |
|
|
|
|
|
| dref | ✅ | data reference box, declares source(s) of media data in track |
|
|
|
|
| stbl |
| ✅ | sample table box, container for the time/space map |
|
|
|
|
|
| stsd | ✅ | sample descriptions (codec types, initialization etc.) |
|
|
|
|
|
| stts | ✅ | (decoding) time-to-sample |
|
|
|
|
|
| ctts |
| (composition) time to sample |
|
|
|
|
|
| stsc | ✅ | sample-to-chunk, partial data-offset information |
|
|
|
|
|
| stsz |
| sample sizes (framing) |
|
|
|
|
|
| stz2 |
| compact sample sizes (framing) |
|
|
|
|
|
| stco | ✅ | chunk offset, partial data-offset information |
|
|
|
|
|
| co64 |
| 64-bit chunk offset |
|
|
|
|
|
| stss |
| sync sample table (random access points) |
|
|
|
|
|
| stsh |
| shadow sync sample table |
|
|
|
|
|
| padb |
| sample padding bits |
|
|
|
|
|
| stdp |
| sample degradation priority |
|
|
|
|
|
| sdtp |
| independent and disposable samples |
|
|
|
|
|
| sbgp |
| sample-to-group |
|
|
|
|
|
| sgpd |
| sample group description |
|
|
|
|
|
| subs |
| sub-sample information |
|
| mvex |
|
|
|
|
| movie extends box |
|
|
| mehd |
|
|
|
| movie extends header box |
|
|
| trex |
|
|
| ✅ | track extends defaults |
|
| ipmc |
|
|
|
|
| IPMP Control Box |
| moof |
|
|
|
|
|
| movie fragment |
|
| mfhd |
|
|
|
| ✅ | movie fragment header |
|
| traf |
|
|
|
|
| track fragment |
|
|
| tfhd |
|
|
| ✅ | track fragment header |
|
|
| trun |
|
|
|
| track fragment run |
|
|
| sdtp |
|
|
|
| independent and disposable samples |
|
|
| sbgp |
|
|
|
| sample-to-group |
|
|
| subs |
|
|
|
| sub-sample information |
| mfra |
|
|
|
|
|
| movie fragment random access |
|
| tfra |
|
|
|
|
| track fragment random access |
|
| mfro |
|
|
|
| ✅ | movie fragment random access offset |
| mdat |
|
|
|
|
|
| media data container |
| free |
|
|
|
|
|
| free space |
| skip |
|
|
|
|
|
| free space |
|
| udta |
|
|
|
|
| user-data |
|
|
| cprt |
|
|
|
| copyright etc. |
| meta |
|
|
|
|
|
| metadata |
|
| hdlr |
|
|
|
| ✅ | handler, declares the metadata (handler) type |
|
| dinf |
|
|
|
|
| data information box, container |
|
|
| dref |
|
|
|
| data reference box, declares source(s) of metadata items |
|
| ipmc |
|
|
|
|
| IPMP Control Box |
|
| iloc |
|
|
|
|
| item location |
|
| ipro |
|
|
|
|
| item protection |
|
|
| sinf |
|
|
|
| protection scheme information box |
|
|
|
| frma |
|
|
| original format box |
|
|
|
| imif |
|
|
| IPMP Information box |
|
|
|
| schm |
|
|
| scheme type box |
|
|
|
| schi |
|
|
| scheme information box |
|
| iinf |
|
|
|
|
| item information |
|
| xml |
|
|
|
|
| XML container |
|
| bxml |
|
|
|
|
| binary XML container |
|
| pitm |
|
|
|
|
| primary item reference |
|
| fiin |
|
|
|
|
| file delivery item information |
|
|
| paen |
|
|
|
| partition entry |
|
|
|
| fpar |
|
|
| file partition |
|
|
|
| fecr |
|
|
| FEC reservoir |
|
|
| segr |
|
|
|
| file delivery session group |
|
|
| gitn |
|
|
|
| group id to name |
|
|
| tsel |
|
|
|
| track selection |
| meco |
|
|
|
|
|
| additional metadata container |
|
| mere |
|
|
|
|
| metabox relation |
-
ftyp box:作为最常见的Box,其出现在文件的开始位置,描述的文件的版本、兼容协议等,ISO_IEC_14496-12_2015版本规范规定,Mp4格式文件中必须有且只有一个’ftyp’类型的Box。为了与早期没有
ftype类型的版本兼容。当文件中,包含FTYP类型的Box,且该Box包含Major_brand='mp41', minor_version=0,以及单独指定兼容性compatible_brands=‘mp41’,则该文件需要按照有FTYP Box的方式读取。
ftyp box的语法定义如下:class FileTypeBox extends Box('ftyp') { unsigned int(32) major_brand; // 一个品牌的标志符 unsigned int(32) minor_version; // 是主要品牌的次要版本的信息,为一个整数 unsigned int(32) compatible_brands[]; // 兼容的品牌列表 }一个典型的FileTypeBox的结构数据如下
00 00 00 20代表box长度为32个字节(包括自己在内)ftyp代表是File Type Box;
isom代表是品牌标识符,不同的mp4文件可能不一样,此视频文件的品牌标识符是isom;
isom后面的
00 00 02 00是商标版本号isomiso2avc1mp41都是一些其兼容版本的列表
0000h: 00 00 00 20 66 74 79 70 69 73 6F 6D 00 00 02 00 ... ftypisom.... 0010h: 69 73 6F 6D 69 73 6F 32 61 76 63 31 6D 70 34 31 isomiso2avc1mp41 -
moov box:这个box在MP4文件中必须有但是只存在一个,里面不包含具体媒体数据,但包含本文件中所有媒体数据的宏观描述信息,该 Box 一般在文件的头部或尾部,方便定位。moov box下有mvhd和trak box。
- mvhd:记录了创建时间、修改时间、时间度量标尺、可播放时长等信息。
- trak:里面一系列
子box描述了每个媒体轨道的具体信息。
-
moof box:这个box是视频分片的描述信息。并不是MP4文件必须的部分,但在我们常见的可在线播放的MP4格式文件中(例如Silverlight Smooth Streaming中的ismv文件)确是重中之重。
-
mdat box:实际媒体数据。我们最终解码播放的数据都在这里面。
-
mfra box:一般在文件末尾,媒体的索引文件,可通过查询直接定位所需时间点的媒体数据。
八、音频文件
(一)音频隐写
1. DeepSound隐写
DeepSound 是一种隐写术工具和音频转换器,可将秘密数据隐藏到音频文件中。该应用程序还使您能够直接从音频文件或音频 CD 曲目中提取秘密文件。 DeepSound 可用作 wave、flac、wma、ape 和音频 CD 的版权标记软件。DeepSound 还支持使用 AES-256(高级加密标准)加密机密文件以提高数据保护。 该应用程序还包含一个易于使用的音频转换器模块,可以将多种音频格式(FLAC、MP3、WMA、WAV、APE)编码为其他格式(FLAC、MP3、WAV、APE)。
官方:DeepSound 2.0 Free Download (soft112.com)
Deepsound的密码可通过john爆破
2. MP3stego隐写
MP3stego是命令行工具(也有图形界面的)
decode -X -P <your password> <your encoded filename>
3. SilentEye隐写
官方:SilentEye
4. Steghide隐写
Steghide不仅仅可以将信息隐藏到图片,还可以隐藏到音频文件中
安装与使用见“十四”
5. 频谱(spectrum)隐写
例题:
音频中的频谱隐写是将字符串隐藏在频谱中,此类音频通常会有一个较明显的特征,听起来是一段杂音或者比较刺耳。
分析工具:Audacity/Sonic Visualiser
提取:AU中打开切换到频谱图可以看到隐藏信息(有时需要拉伸一下才看得清内容,实在看不清可以换Sonic Visualiser)
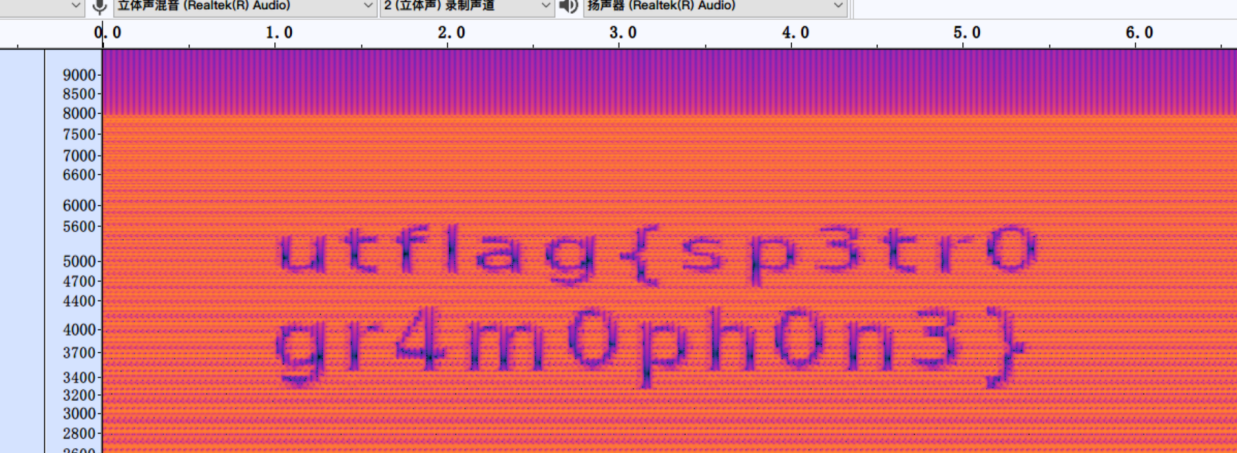
6. 其它
(1)SSTV——用音频传输图片
例题:
慢扫描电视(Slow-scan television 简称SSTV)是业余无线电爱好者的一种主要图片传输方法,慢扫描电视通过无线电传输和接收单色或彩色静态图片。
解码工具可以采用linux下的QSSTV,使用如下命令安装
sudo apt-get install qsstv
启动qsstv,设置一下输入qsstv>Options>Configration>Sound>Sound Input>from file
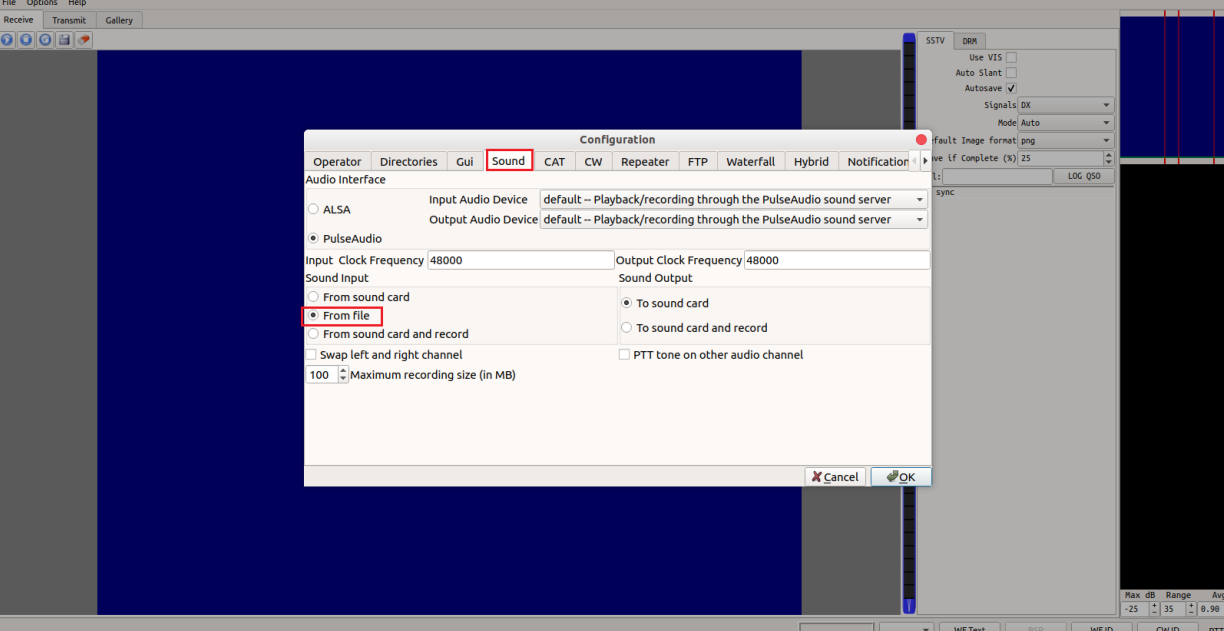
点击选择文件便可解码得到图像
九、流量分析
(一)网络协议包流量
1. Wireshark抓包工具的使用
本标题下侧重于实战技巧方面的总结
(1)过滤器使用
Wireshark所支持的过滤关系如下
| English写法 | Alias写法 | C-like写法 | 描述 | 举例 |
|---|---|---|---|---|
| eq | any_eq | == | Equal (any if more than one) | ip.src == 10.0.0.5 |
| ne | all_ne | != | Not equal (all if more than one) | ip.src != 10.0.0.5 |
| all_eq | === | Equal (all if more than one) | ip.src === 10.0.0.5 |
|
| any_ne | !== | Not equal (any if more than one) | ip.src !== 10.0.0.5 |
|
| gt | > | Greater than | frame.len > 10 |
|
| lt | < | Less than | frame.len < 128 |
|
| ge | >= | Greater than or equal to | frame.len ge 0x100 |
|
| le | <= | Less than or equal to | frame.len <= 0x20 |
|
| contains | Protocol, field or slice contains a value | sip.To contains "a1762" |
||
| matches | ~ | Protocol or text field matches a Perl-compatible regular expression | `http.host matches "acme\.(org |
可以将多个过滤表达式按照如下逻辑关系串接在一起构成复合过滤表达式
| English写法 | C-like写法 | 描述 | 举例 |
|---|---|---|---|
| and | && | Logical AND | ip.src==10.0.0.5 and tcp.flags.fin |
| or | || | Logical OR | ip.src==10.0.0.5 or ip.src==192.1.1.1 |
| xor | ^^ | Logical XOR | tr.dst[0:3] == 0.6.29 xor tr.src[0:3] == 0.6.29 |
| not | ! | Logical NOT | not llc |
| […] | Subsequence | ||
| in | Set Membership | http.request.method in |
下面列出一些常用的过滤表达式
① 追踪流
tcp.stream eq <编号>
用于显示某条TCP连接从建立(三报文握手)到释放(四报文挥手)这个过程中双方生成的所有数据包(比如tcp.stream eq 0筛选出第一个TCP流)
但有时会有很多TCP连接,这些TCP连接是为不同的应用层服务的,所以更常见的应用是选中某个应用层协议记录然后右键追踪对应的TCP流进行分析
② 内容筛选
用如下命令筛选内容包含username的http数据包
http contains "username"
我们在找flag时可以尝试flag、FLAG、ctf等关键字。
(2)tshark——导出数据部分
tshark是wireshark网络分析工具下的一个命令行工具,可以通过命令提取自己想要的数据。wireshark的安装目录下有该工具。
下面是一些选项及其解释,详见官网
捕获接口:
-i: -i <interface> 指定捕获接口,默认是第一个非本地循环接口;
-f: -f <capture filter> 设置抓包过滤表达式,遵循libpcap过滤语法,这个实在抓包的过程中过滤,如果是分析本地文件则用不到。
-s: -s <snaplen> 设置快照长度,用来读取完整的数据包,因为网络中传输有65535的限制,值0代表快照长度65535,默认也是这个值;
-p: 以非混合模式工作,即只关心和本机有关的流量。
-B: -B <buffer size> 设置缓冲区的大小,只对windows生效,默认是2M;
-y: -y<link type> 设置抓包的数据链路层协议,不设置则默认为-L找到的第一个协议,局域网一般是EN10MB等;
-D: 打印接口的列表并退出;
-L 列出本机支持的数据链路层协议,供-y参数使用。
捕获停止选项:
-c: -c <packet count> 捕获n个包之后结束,默认捕获无限个;
-a: -a <autostop cond.> ... duration:NUM,在num秒之后停止捕获;
filesize:NUM,在numKB之后停止捕获;
files:NUM,在捕获num个文件之后停止捕获;
捕获输出选项:
-b <ringbuffer opt.> ... ring buffer的文件名由-w参数决定,-b参数采用test:value的形式书写;
duration:NUM - 在NUM秒之后切换到下一个文件;
filesize:NUM - 在NUM KB之后切换到下一个文件;
files:NUM - 形成环形缓冲,在NUM文件达到之后;
RPCAP选项:
remote packet capture protocol,远程抓包协议进行抓包;
-A: -A <user>:<password>,使用RPCAP密码进行认证;
输入文件:
-r: -r <infile> 设置读取本地文件
处理选项:
-2: 执行两次分析
-R: -R <read filter>,包的读取过滤器,可以在wireshark的filter语法上查看;在wireshark的视图->过滤器视图,在这一栏点击表达式,就会列出来对所有协议的支持。
-Y: -Y <display filter>,使用读取过滤器的语法,在单次分析中可以代替-R选项;
-n: 禁止所有地址名字解析(默认为允许所有)
-N: 启用某一层的地址名字解析。“m”代表MAC层,“n”代表网络层,“t”代表传输层,“C”代表当前异步DNS查找。如果-n和-N参数同时存在,-n将被忽略。如果-n和-N参数都不写,则默认打开所有地址名字解析。
-d: 将指定的数据按有关协议解包输出,如要将tcp 8888端口的流量按http解包,应该写为“-d tcp.port==8888,http”;tshark -d. 可以列出所有支持的有效选择器。
输出选项:
-w: -w <outfile| > 设置raw数据的输出文件。这个参数不设置,tshark将会把解码结果输出到stdout,“-w -”表示把raw输出到stdout。如果要把解码结果输出到文件,使用重定向“>”而不要-w参数。
-F: -F <output file type>,设置输出的文件格式,默认是.pcapng,使用tshark -F可列出所有支持的输出文件类型。
-V: 增加细节输出;
-O: -O <protocols>,只显示此选项指定的协议的详细信息。
-P: 即使将解码结果写入文件中,也打印包的概要信息;
-S: -S <separator> 行分割符
-x: 设置在解码输出结果中,每个packet后面以HEX dump的方式显示具体数据。
-T: -T ek|fields|json|jsonraw|pdml|ps|psml|tabs|text,设置解码结果输出的格式,包括text,ps,psml和pdml,默认为text
-e: 如果-T fields选项指定,-e用来指定输出哪些字段;
-E: -E <fieldsoption>=<value>如果-T fields选项指定,使用-E来设置一些属性,比如
header=y|n
separator=/t|/s|<char>
occurrence=f|l|a
aggregator=,|/s|<char>
-t: -t a|ad|d|dd|e|r|u|ud 设置解码结果的时间格式。“ad”表示带日期的绝对时间,“a”表示不带日期的绝对时间,“r”表示从第一个包到现在的相对时间,“d”表示两个相邻包之间的增量时间(delta)。
-u: s|hms 格式化输出秒;
-l: 在输出每个包之后flush标准输出
-q: 结合-z选项进行使用,来进行统计分析;
-X: <key>:<value> 扩展项,lua_script、read_format,具体参见 man pages;
-z:统计选项,具体的参考文档;tshark -z help,可以列出,-z选项支持的统计方式。
其他选项:
-h: 显示命令行帮助;
-v: 显示tshark 的版本信息;
常用指令:
-
提取流量包test.pcap中的数据部分并另存为data.txt文件
tshark -r test.pcap -T fields -e data > data.txt
(3)对象导出
① HTTP对象
有时需要我们重点分析用HTTP传输的文件,此时需要我们将文件提取出来分析
-
【方法一】直接从Wireshark中提取
选中要提取文件的数据包,wrieshark都会标明文件的类型。所以我们也就能够区分出这是一个什么类型的文件。
选中一个记录导出分组字节流可以将文件提取出来
或者
文件>导出对象>HTTP罗列出所有传输的文件,选中保存所需要分析的文件即可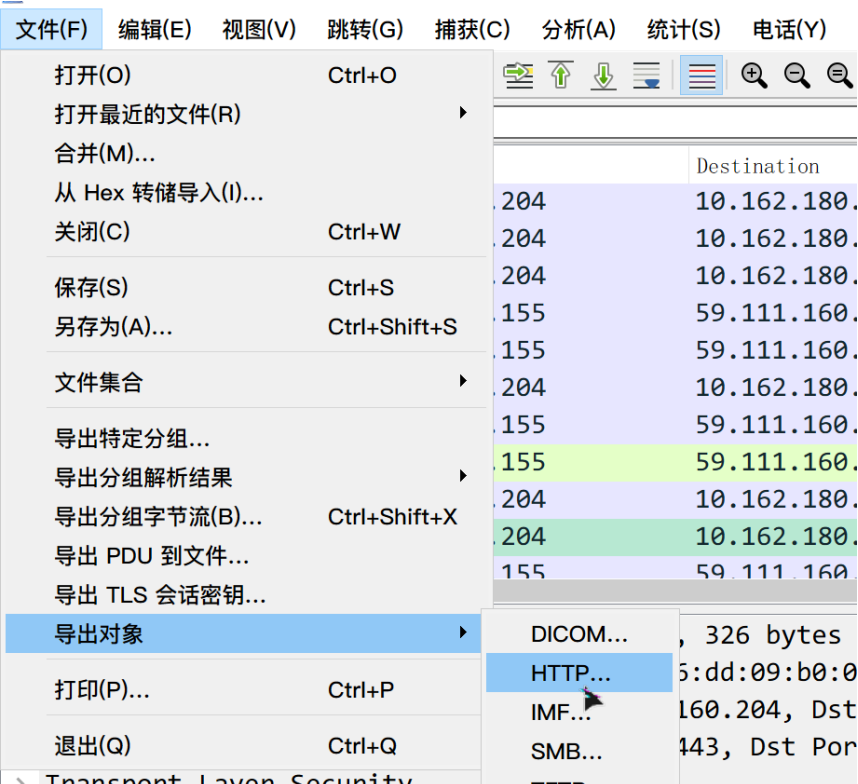
-
【方法二】使用binwalk等工具进行文件分离
binwalk -e <文件名>
② IMF对象
当流量包中含有许多SMTP记录时,可以导出IMF对象获取所传输的邮件内容
例题:
>关于IMF
IMF(Internet Message Format):因特网消息格式。因特网消息格式是指文本消息在因特网上传输的格式。若SMTP等价于邮件信封,则IMF等价于信封中的信件,它包含发起者、接收者、主题和日期。实际上,IMF消息通常被称为“SMTP消息”。
点击文件>导出对象>IMF
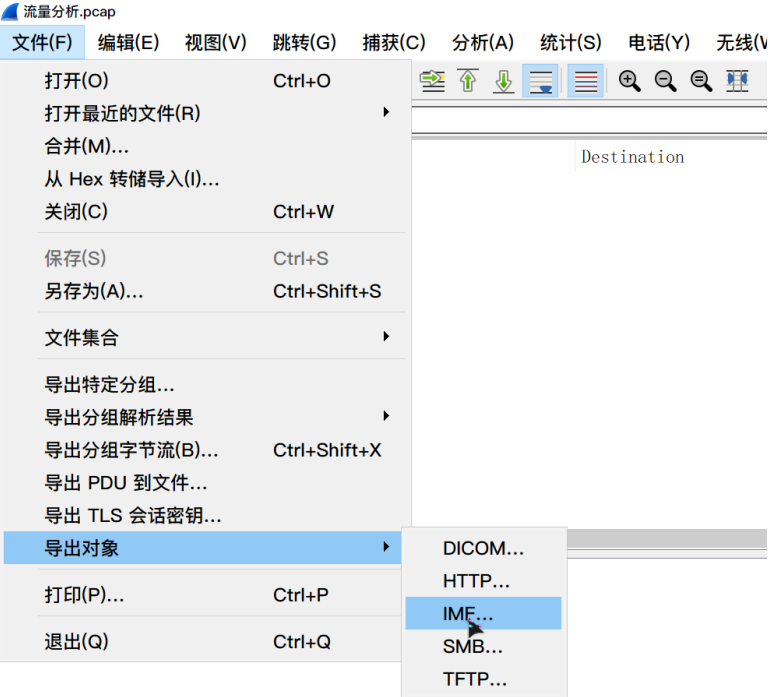
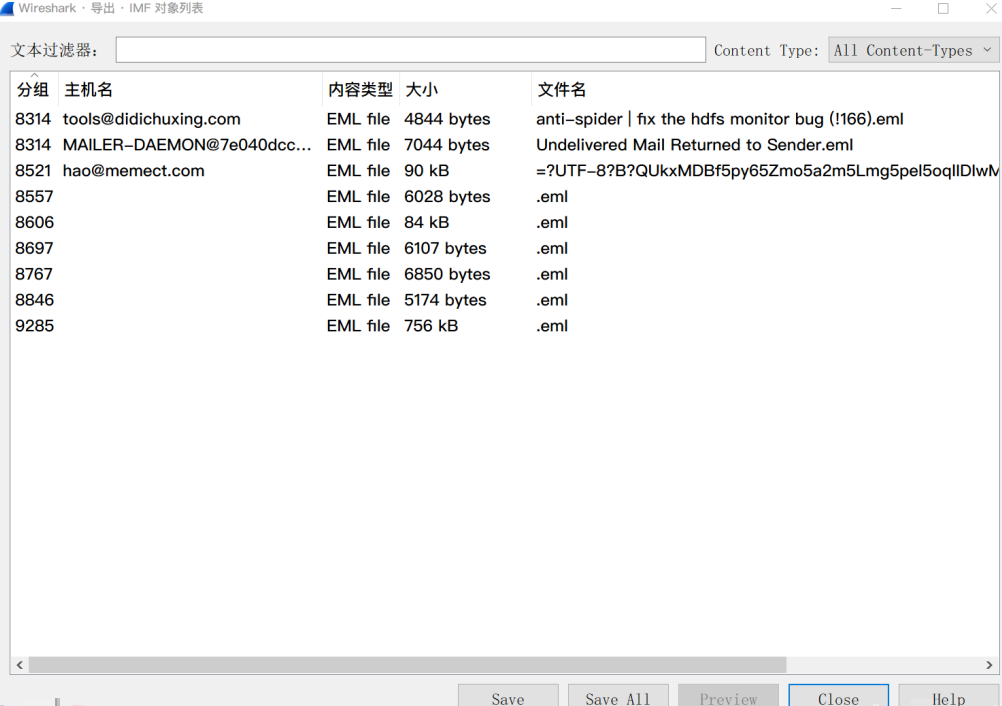
导出之后得到的文件以.eml为扩展名,可以通过邮件查看器(如Windows自带的Mail)或者文本编辑器打开这些邮件查看里面的内容(如下是用邮件查看器打开一个eml文件),使用邮件查看器时建议在离线状态下查看。
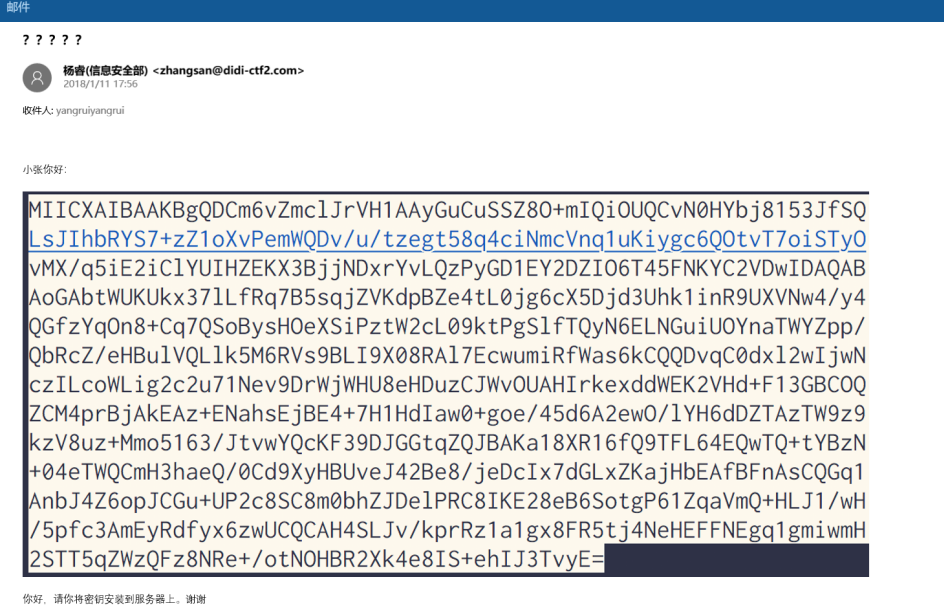
(4)了解流量包中所涉及到的协议
打开一个流量包,难免呈现出来协议乱序的流量记录,直接翻看容易遗漏一些记录。可以点击Protocol使之按照协议排序,同协议的记录会被放在一起呈现,这样有助于我们第一时间了解这个流量包内涉及了哪些协议。
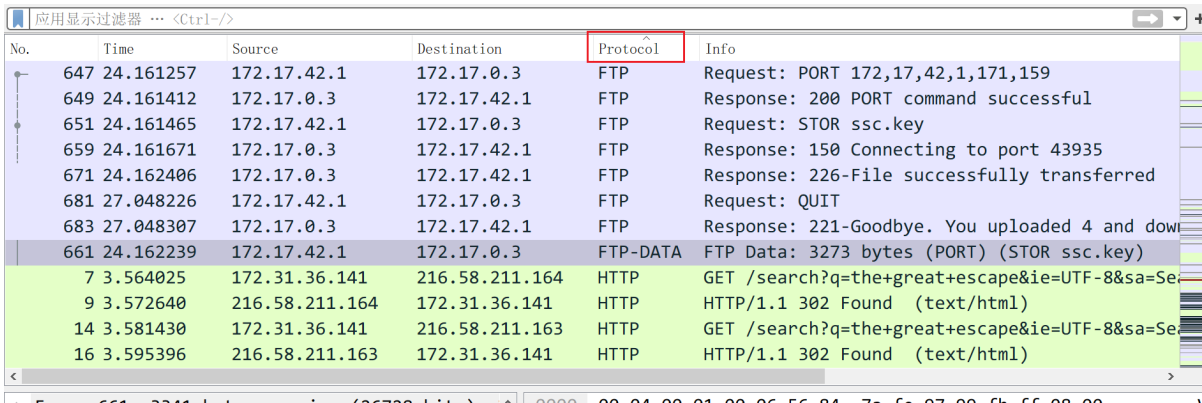
(5)统计功能
① 统计流量包中的IP地址出现频数
例题:
我们有时得到一个异常流量包,需要获取黑客攻击用到的IP地址,通常是通信最频繁的外网IP,此时可以利用Wireshark统计IP出现的频率(统计>IPv4 Statistics>All Address)
(6)FTP流量分析
在进行文件传输时,FTP 的客户和服务器之间要建立两个并行的TCP连接 ——“控制连接”和“数据连接”。FTP客户所发出的传送请求,通过控制连接发送给服务器端的控制进程,但控制连接并不用来传送文件。实际用于传输文件的是“数据连接”。
我们在用Wireshark分析FTP流量包时要注意Protocol为ftp的记录对应的是控制连接,Protocol为ftp-data对应的是数据连接
① 控制连接流量分析
Wireshark中对应Protocol为FTP的记录都属于是控制连接,注意!!其中并不含所传输的数据,只含有控制指令
在Wireshark中可以通过ftp.request.command过滤查看客户端发出的FTP命令(命令含义详见《FTP协议(指令集)》)
下面的例子中可以看到用户名和密码,然后是SYST查明服务器上操作系统的类型、PASV选用被动模式、LIST让服务器发送文件列表,以及RETR下载命令,并从FTP服务器上面下载了Fl-g.zip和sqlmap.zip,后来在同一个服务器上传(STOR)了profile文件。
选中一个记录右键点击追踪TCP流可以看到整个控制连接中客户与服务器的通信过程
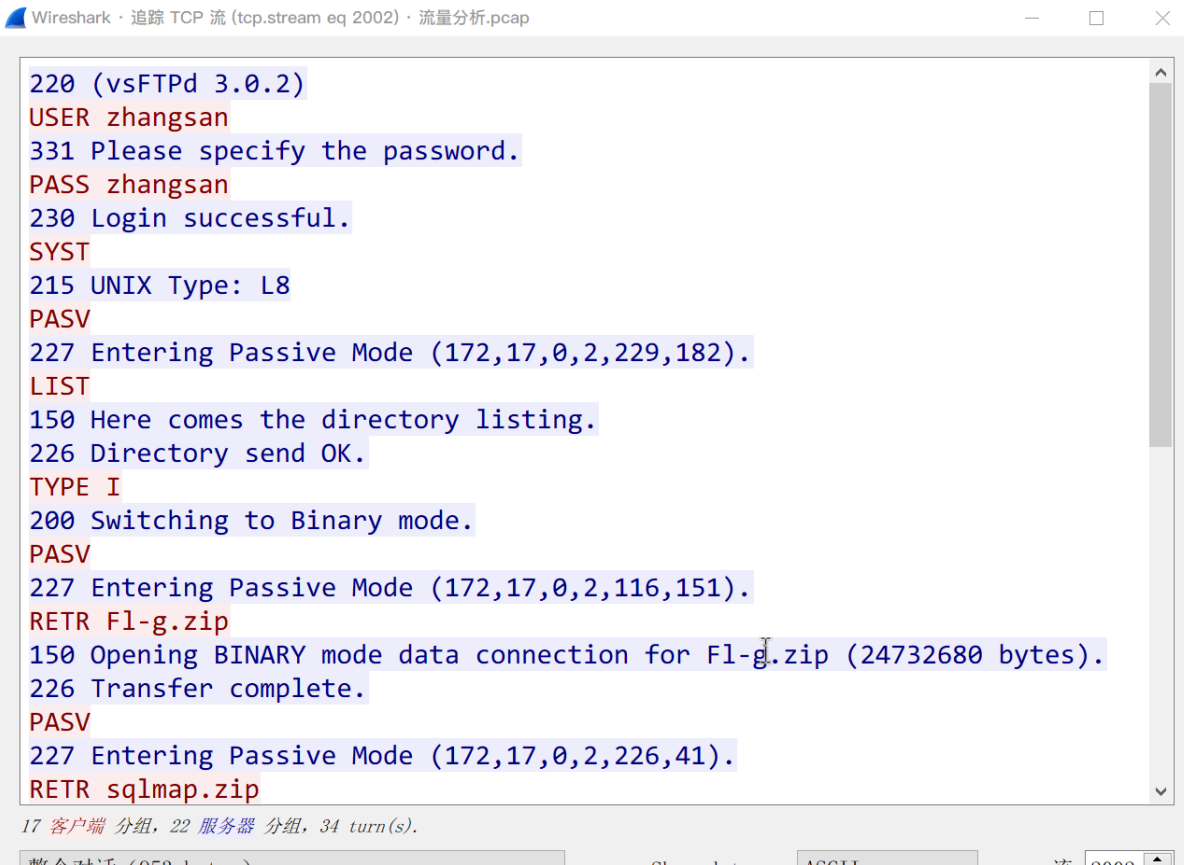
或者直接过滤ftp也是一目了然
② 数据连接流量分析
Wireshark对应Protocol为FTP-DATA的记录都属于是数据连接,含有所传输的数据
过滤ftp-data可以看到所有数据连接传输的数据,同时可以看到所传输的文件名
选中一个记录右键点击追踪TCP流可以看到该记录对应的数据连接所传输的数据内容(下面的例子可以看出来传输的是一个压缩包)
我们无法使用Wireshark中的导出对象功能一下子导出这些数据,但是,我们可以追踪每个数据连接逐个导出。
将底部的“Show data as”更改为“原始数据”后窗口显示十六进制字符,而不是ASCII字符,然后使用窗口底部的“另存为”按钮将其保存为原始二进制文件便可以成功导出
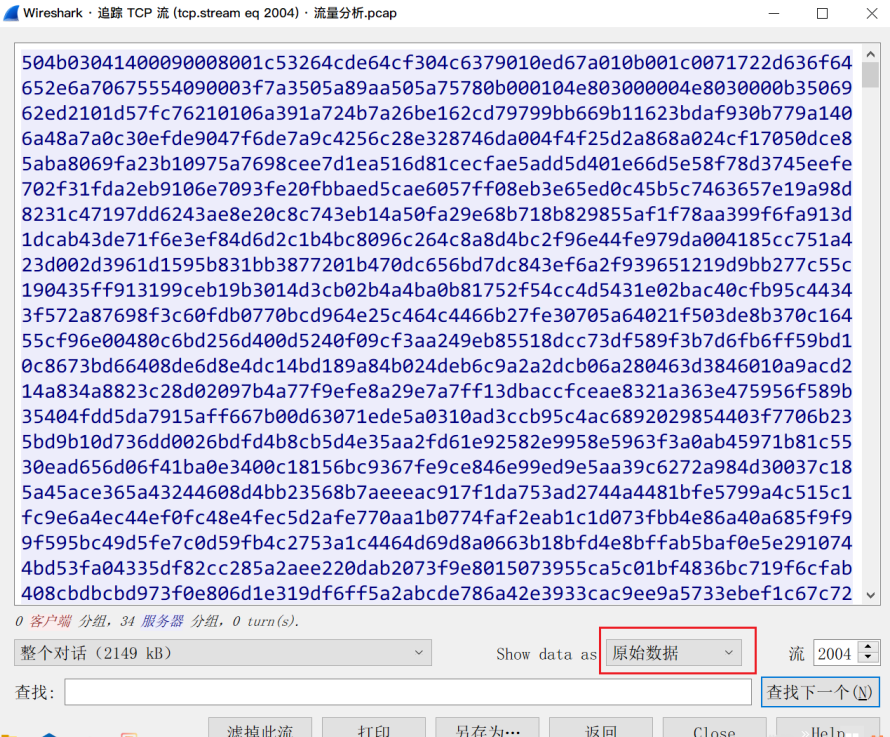
(7)VoIP流量分析
例题:
基于IP的语音传输(VoIP)是一种语音通话技术,经由IP协议来达成语音通话与多媒体会议,也就是经由互联网来进行通讯,在IP电话的通信中至少需要两种应用协议。
- 一种是信令协议,它使我们能够在互联网上找到被叫用户,如
SIP、H.323 - 另一种是话音分组的传送协议,它使我们用来进行电话通信的话音数据能够以时延敏感属性在互联网中传送。如
RTP - 此外,还有一种协议是为了提高服务质量,如
RSVP和RTCP
VoIP使用RTP协议对语音数据进行传输,语音载荷封装在RTP包里面。要对传输中的语音进行截获和还原,需要通过Wireshark对RTP包进行分析和解码。
点击电话>VoIP通话
选中一个记录播放
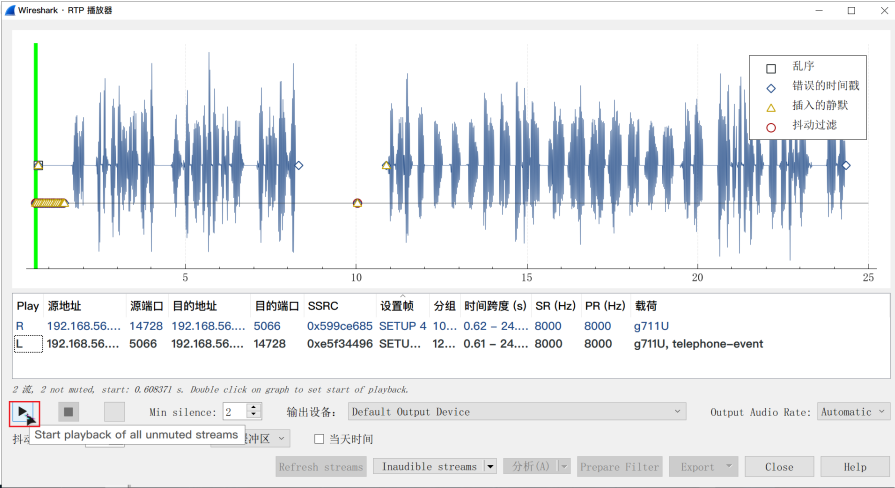
(7)TLS流量分析
例题:
CTF中常出现的是通过指定服务端的私钥以及通讯的内容,对报文进行解密。
这就需要我们获取私钥,得到私钥后将其包裹上-----BEGIN PRIVATE KEY-----和-----END PRIVATE KEY-----并另存为key.txt,在Wireshark中依次点击编辑>首选项>Protocols>TLS>Edit添加这个私钥文件然后就可以解密了。
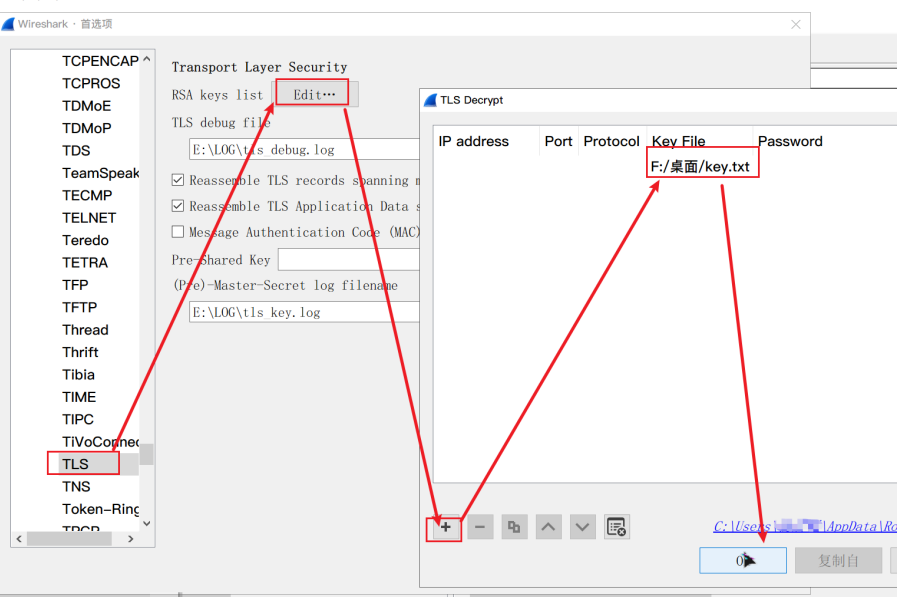
(二)USB流量包分析
USB流量指的是USB设备接口的流量,攻击者能够通过监听usb接口流量获取键盘敲击键、鼠标移动与点击、存储设备的铭文传输通信、USB无线网卡网络传输内容等等。在CTF中,USB流量分析主要以键盘流量和鼠标流量为主。
USB流量的捕获可以使用wireshark自带的工具usbpcap来进行,安装wirshark时勾选上安装usbpcap即可。
USB协议的数据部分在Leftover Capture Data域之中,在Linux/Windows(Windows的在wireshark目录下)下可以用tshark工具可以将 leftover capture data单独提取出来,命令如下:
tshark -r test.pcapng -T fields -e usb.capdata > usbdata.txt
#从test.pcapng中提取出数据段放入usbdata.txt
1. 鼠标流量
鼠标流量包的数据长度为4个字节。
-
第一个字节代表按键。当取0x00时,代表没有按键;当为0x01时,代表按左键;当为0x02时,代表当前按键为右键。
-
第二个字节可以看成是一个signed byte类型,其最高位为符号位,当这个值为正时,代表鼠标水平右移多少像素,为负时,代表水平左移多少像素。
-
第三个字节与第二字节类似,代表垂直上下移动的偏移。
可以用USB鼠标流量包取证工具UsbMiceDataHacker 绘制鼠标移动以及拖动轨迹。
2. 键盘流量
例题:
键盘数据包的数据长度为8个字节,击键信息集中在第3个字节(HID Usage ID),第3个字节对应的具体键位可以查阅Hut1_12v2.pdf第53页。
BYTE1 -|
|--bit0: Left Control 是否按下,按下为1
|--bit1: Left Shift 是否按下,按下为1
|--bit2: Left Alt 是否按下,按下为1
|--bit3: Left GUI 是否按下,按下为1
|--bit4: Right Control是否按下,按下为1
|--bit5: Right Shift 是否按下,按下为1
|--bit6: Right Alt 是否按下,按下为1
|--bit7: Right GUI 是否按下,按下为1
BYTE2 -- 暂不清楚,有的地方说是保留位
BYTE3~BYTE8 -- 这六个为普通按键
例如:键盘发送 02 00 0e 00 00 00 00 00,查阅可知0e对应 k,则表示同时按下了Left Shift + k,即大写K。
若击键记录过多可以直接用UsbKeyboardDataHacker提取用户的击键信息,linux下运行脚本
python UsbKeyboardDataHacker.py test.pcapng
十、Microsoft Office
office文件格式根据版本可以分为Office2007之前的版本和Office2007之后的版本。
-
Office 2007之前的版本为OLE复合格式,如doc、dot、xls、xlt、pot、ppt;
Office 2007 之前的版本可以看作二进制文件,可以用OffVis工具解析其文档结构。其中十六进制文件头为 D0 CF 11 E0 A1 B1 1A E1,这是固定的 OLESS 文档格式文件头。
-
Office 2007之后的版本为OpenXML格式,如docx、docm、dotx、xlsx、xlsm、xltx、potx
Office 2007 之后的版本本质上是一个压缩包。由于文档中包含 ooxml 文件,因此不能用 offvis 进行解析,按下 offvis 的 Parser 按钮确实无法解析文件,这类文档可以通过解析出 .xml 和 .rels 来获取内容和逻辑关系。
(一)Word
1. .docx
word doxc文件本质:docx格式的文件本质上是一个ZIP文件:docx 格式文件的主要内容是保存为XML格式的,但文件并非直接保存于磁盘。它是保存在一个ZIP文件中,然后取扩展名为docx。

docx文件结构
-
_rels文件夹:存放了所有指定的rels文件
-
docProps文件夹:存放了docx文档的主要属性信息
-
word文件夹:存放了docx文档的具体内容
document.xml:记录Word文档的正文内容footer*.xml:记录Word文档的页脚header*.xml:记录Word文档的页眉comments.xml:记录Word文档的批注footnotes.xml:记录Word文档的脚注endnotes.xml:记录Word文档的尾注
-
[Content_Types].xml:包含包中所有部件的内容类型的列表,每个部分及其类型必须列在[Content_Types] .xml中,它把各个xml文件组合成一个整体。
2. .doc
(二)破解加密后的Office文档
有两种工具可以用于破解此类加密
1. John the Ripper——Linux
(1)安装
安装John the Ripper(若用的是Kali,则无需安装,直接下一步下载Office2John)
sudo apt-get install -y john
接着额外下载Office2John.py文件,因为我们需要Office2John.py用于获取文件哈希值(这个哈希值在破解文件密码时需要用到),采用如上命令安装John the Ripper是不包含Office2John.py的。
(2)使用
先用office2john.py提取已加密的test.docx的哈希值并另存为hash
python office2john.py test.docx > hash
然后准备一个字典zidian.txt用john破解
john --wordlist=zidian.txt hash
用如下指令将密码显示出来
john --show hash
2. Accent OFFIC Password Recovery——Windows
官网:AccentOPR
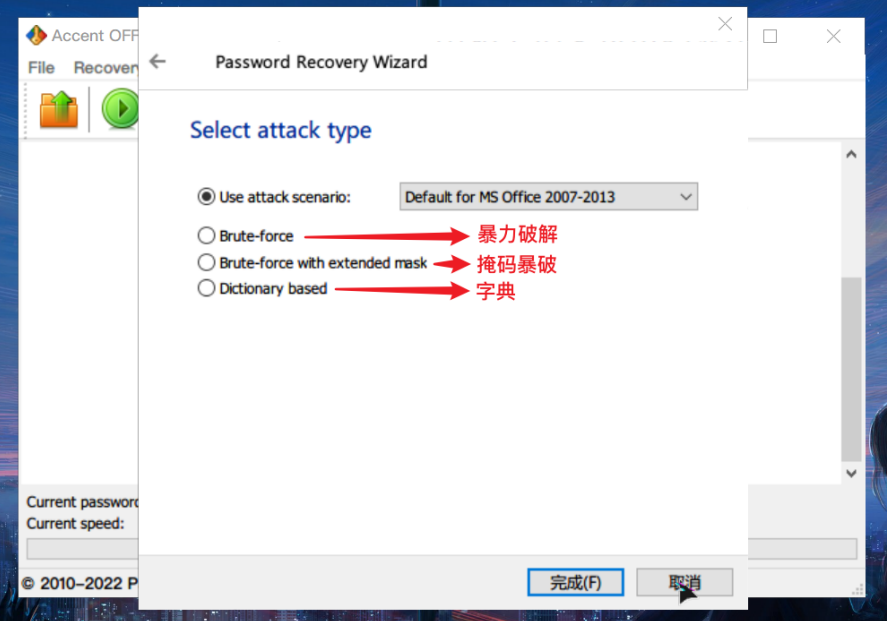
(三)Office文档隐写
1. Word隐写
(1)Word中隐藏字段
下面介绍几种隐藏方法
原理1: 用Word自带的隐藏字段功能,在Word中选中要隐藏的字段,右击选择“字体”选项,在效果一栏中有隐藏选项,选中后即可隐藏。默认情况下隐藏文字是不会被打印出来的。
破解1:针对这种方法如果想知道是否有隐藏文本,可以用下面两种方法
-
在文件选项中单击“文件” \(\rightarrow\) “更多”\(\rightarrow\) “选项”\(\rightarrow\) “显示”,在
始终在屏幕上显示这些格式标记标签下选择隐藏文字复选框,即可查看,打印选项标签勾选打印隐藏文字即可打印。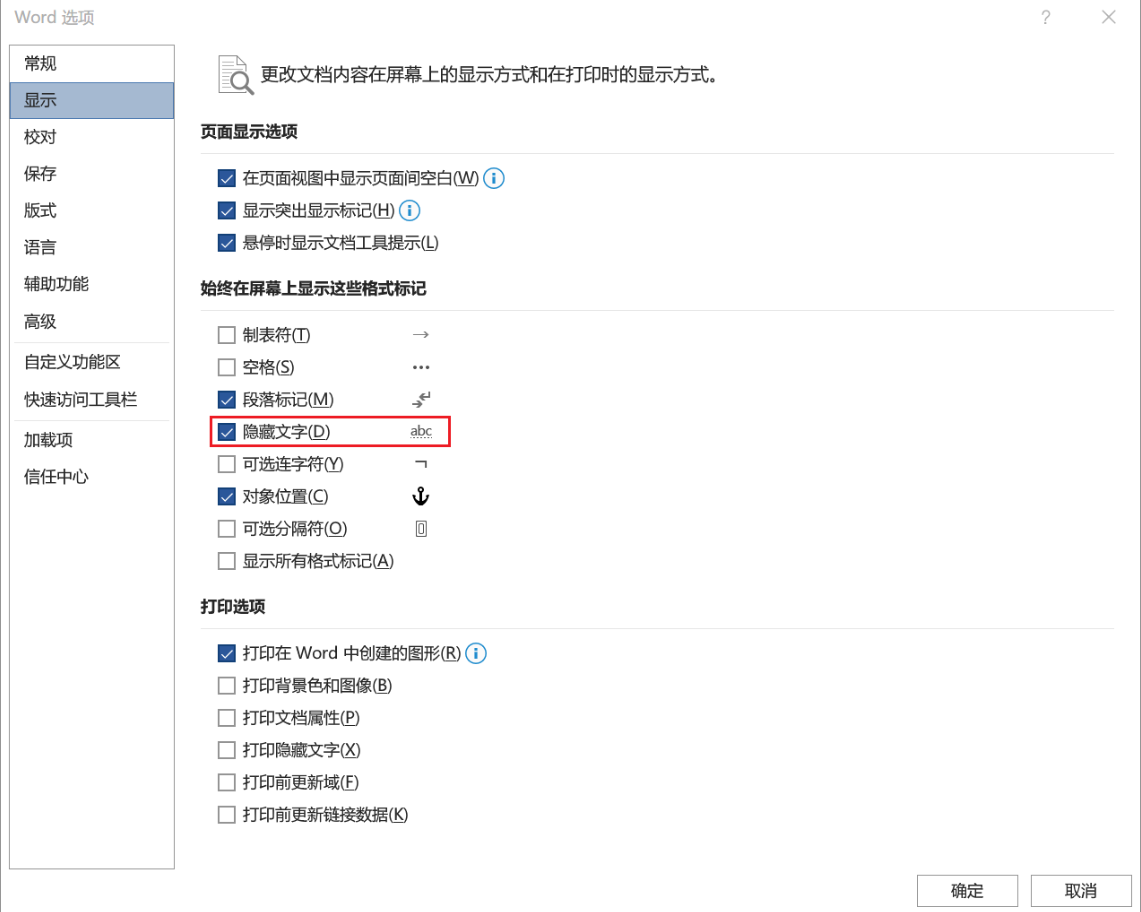
如果我们想要复制隐藏的文字,则需要在字体使之取消隐藏才能复制
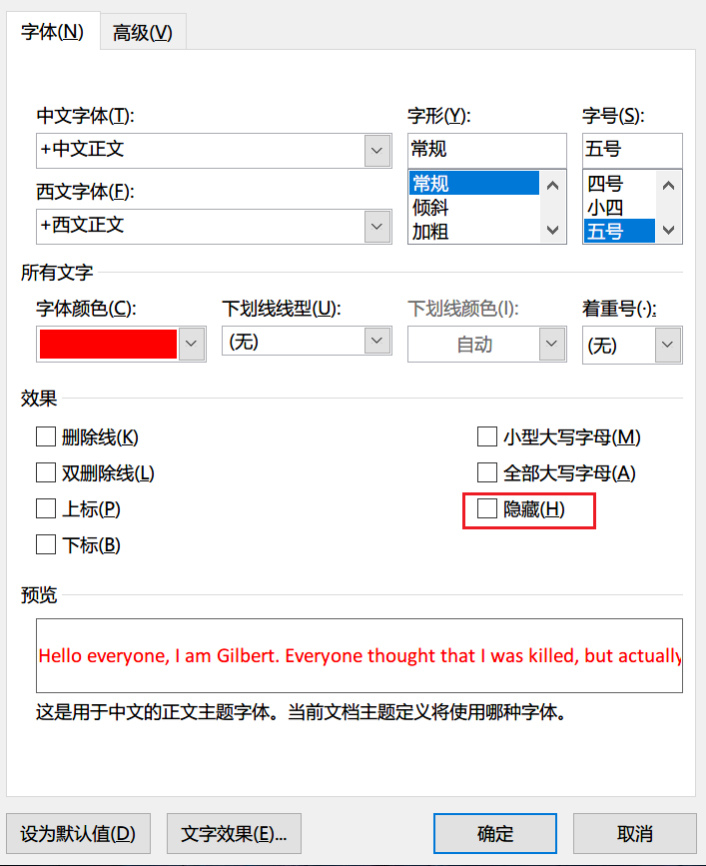
-
或者使用Word自带的文档检查器,在保存文件后选择“文件”\(\rightarrow\) “信息” \(\rightarrow\) “检查”\(\rightarrow\) “检查问题”\(\rightarrow\)“检查文档”,查看是否有隐藏文字。文档检查器是检查文档中隐藏的各种元数据的一个好方法,它除了可以识别隐藏文字,还可以识别作者、批注和其他可识别个人的信息。
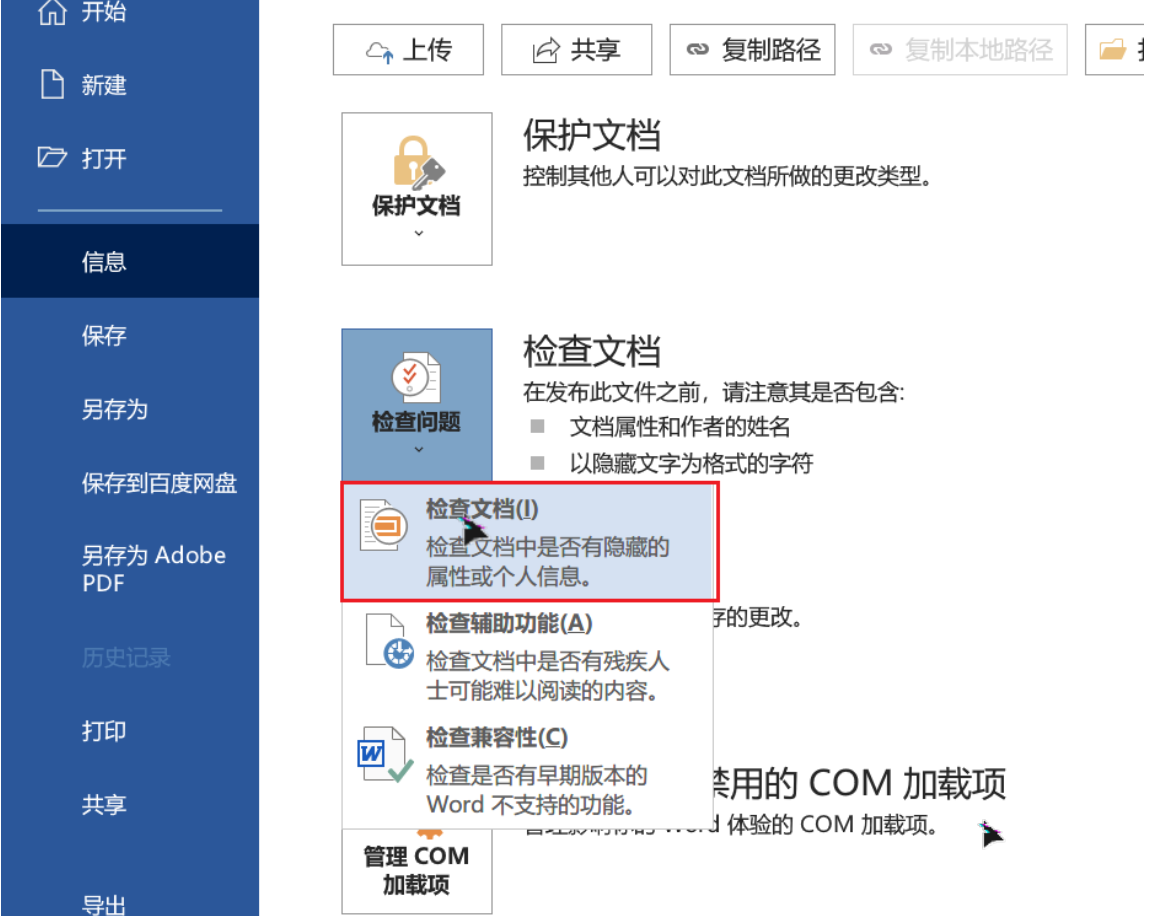
原理2:另一种隐藏方法的原理是白色背景下的白字无法被看出有隐藏的文字,这种方法隐藏的文字无法用上述的破解方法破解。
破解2:
- 全选改字体颜色为别的颜色
- 搜索字符串,例如flag等
原理3:利用段落间的行间距
破解3:逐行选中打开段落窗口观察行间距,如大间距代表1,小间距代表0
例题:
(2)Word中隐藏图片
原理:word中插入的图片分为嵌入式和非嵌入式,区别在嵌入式会跟着文本的位置产生移动,即有回车后,图片下移。但非嵌入的不会跟着文本走,即有回车后,图片保持原位置不动。
破解:word改后缀名为zip然后解压
2. Excel隐写
(1)原理
用excel工作表的单元格来隐藏数值
例题:
选中要隐藏的数据区域,鼠标右键,点击“设置单元格格式”;
在弹出的对话框里,我们选中“数字”,然后再点击“自定义”,在类型的输入框里输入三个分号(“;;;”或者“;;;”);
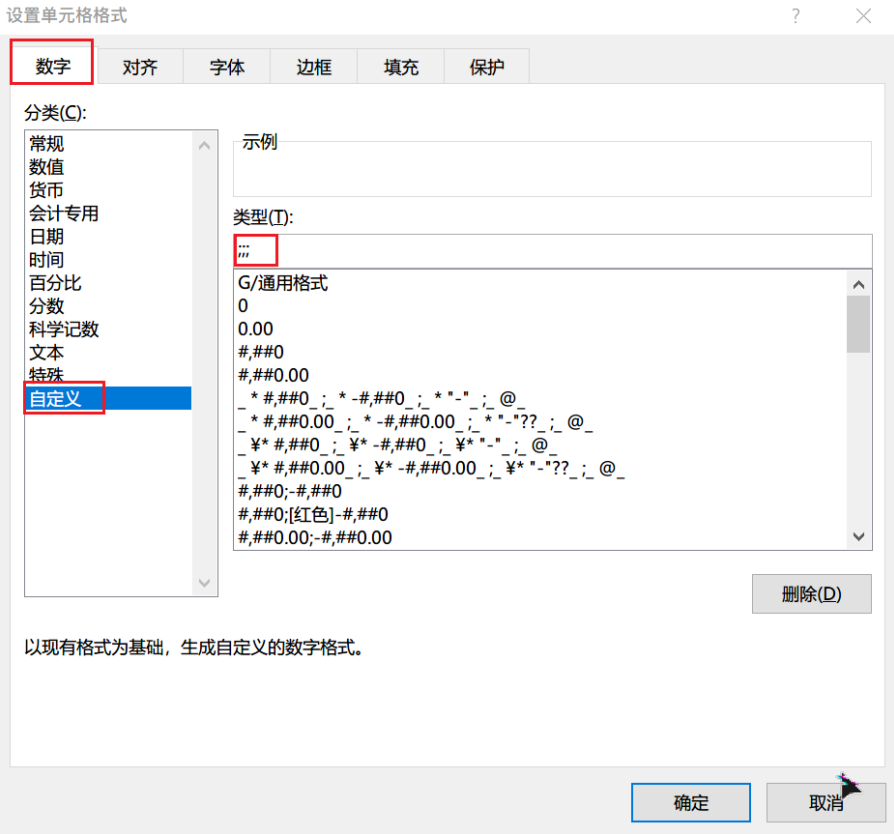
点击确定后,我们发现表中的数据进行了隐藏,只有点击那个单元格才会在excel的输入框内显示出来;
(2)破解
只要将自定义的类型填入“G/通用格式”即可(如下图)
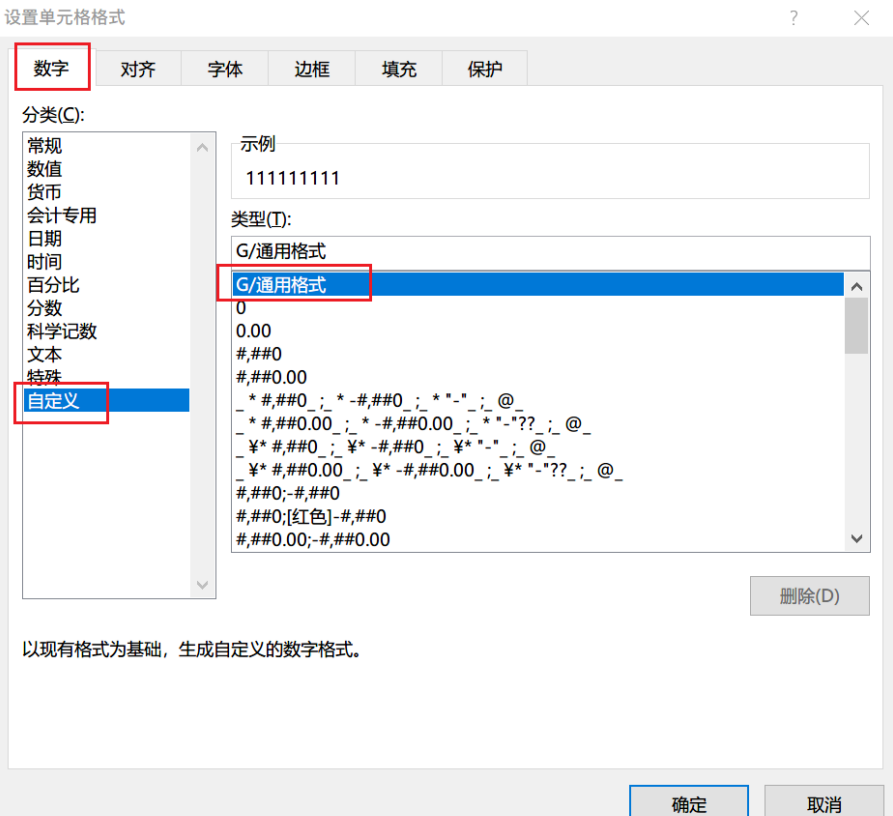
十一、注册表
十二、其它
(一)从lsass里抓本地登录密码
参考:
lsass包含所有安全服务提供者或SSP,它们是管理不同类型身份验证的数据包。出于实际原因,用户输入的凭据通常保存在这些SSP中,这样用户就不必在几秒或几分钟后再次输入它们。
这就是为什么mimikatz模块提取位于这些不同ssp中的信息,就是因为试图找到一些身份验证机密,并将它们显示给攻击者。因此,如果一个权限帐户连接到其中一台受感染的主机,则Mimikatz模块允许你快速提取它的凭证,从而利用这个帐户的权限来攻击更多的目标。
但是今天,大多数杀毒软件已经可以检测到Mimikatz的存在或执行,并能阻止它
(二)二维码提取
普通二维码:CQR工具
PDF417码:在线工具Read Barcode Online (aspose.app)
(三)文件类型识别
1. 直接根据文件头识别
这种情况通常是文件头已知,那么直接根据文件头(魔法字节)查表即可,有时无法根据文件头辨识的文件就用file命令或者binwalk工具(binwalk <文件路径>)。
例题:
下面是参照表
| Mime Type(Content-Type) | 文件扩展名 | 签名 |
|---|---|---|
| video/3gpp | 3gp |
|
| video/mp4 | mp4 |
|
| video/3gpp2 | 3g2 |
|
| video/x-m4v | m4v |
|
| audio/mp4 | m4a |
|
| image/x-icon | ico |
|
| application/x-futuresplash | spl |
|
| video/mpeg | mpg |
|
| video/x-ms-vob | vob |
|
| application/vnd.lotus-1-2-3 | 123 |
|
| application/vnd.quark.quarkxpress | qxd |
|
| application/x-font-ttf | ttf |
|
| application/x-msmoney | mny |
|
| application/x-msaccess | mdb |
|
| video/x-fli | fli |
|
| image/x-rgb | rgb |
|
| application/xml-dtd | dtd |
|
| image/x-pcx | pcx |
|
| application/msword | doc dot |
|
| application/vnd.ms-works | wks wps |
|
| application/vnd.nitf | ntf |
|
| application/vnd.lotus-notes | nsf |
|
| application/x-freearc | arc |
|
| video/webm | webm |
|
| video/x-matroska | mkv |
|
| application/x-msdownload | msi com dll exe |
|
| audio/silk | sil |
|
| application/postscript | eps |
|
| application/pdf | |
|
| application/vnd.fdf | fdf |
|
| application/mac-binhex40 | hqx |
|
| text/plain | log |
|
| application/vnd.rn-realmedia | rm |
|
| application/vnd.rn-realmedia-vbr | rmvb |
|
| audio/x-pn-realaudio | ra ram |
|
| audio/basic | au |
|
| application/vnd.epson.msf | msf |
|
| application/vnd.ms-pki.seccat | cat |
|
| video/x-ms-asf | asf asx |
|
| audio/x-ms-wma | wma |
|
| video/x-ms-wmv | wmv |
|
| application/x-mswrite | wri |
|
| application/x-7z-compressed | 7z |
|
| image/vnd.adobe.photoshop | psd |
|
| application/xml | xml |
|
| application/vnd.framemaker | fm |
|
| application/vnd.mif | mif |
|
| application/gpx+xml | gpx |
|
| application/winhlp | hlp |
|
| image/vnd.dwg | dwg |
|
| application/vnd.lotus-organizer | org |
|
| text/x-vcard | vcf |
|
| application/octet-stream | bin dms mar |
|
| image/bmp | bmp |
|
| application/x-mobipocket-ebook | prc |
|
| application/x-bzip2 | bz2 |
|
| application/x-iso9660-image | iso |
|
| application/mac-compactpro | cpt |
|
| application/x-shockwave-flash | swf |
|
| application/x-cdlink | vcd |
|
| image/vnd.ms-modi | mdi |
|
| video/x-flv | flv |
|
| audio/x-aiff | aiff |
|
| message/rfc822 | eml |
|
| image/gif | gif |
|
| image/tiff | tif tiff |
|
| audio/mpeg | mp3 |
|
| application/vnd.ms-cab-compressed | cab |
|
| application/vnd.ms-htmlhelp | chm |
|
| application/java-archive | jar |
|
| application/x-ms-shortcut | lnk |
|
| application/x-tgif | obj |
|
| application/vnd.palm | pdb |
|
| application/vnd.tcpdump.pcap | dmp cap |
|
| application/vnd.smaf | mmf |
|
| audio/midi | mid midi rmi |
|
| application/vnd.rim.cod | cod |
|
| audio/ogg | oga ogg |
|
| video/ogg | ogv |
|
| application/ogg | ogx |
|
| image/x-portable-graymap | pgm |
|
| application/zip | zip |
|
| application/vnd.openxmlformats-officedocument.wordprocessingml.document | docx |
|
| application/vnd.openxmlformats-officedocument.presentationml.presentation | pptx |
|
| application/vnd.openxmlformats-officedocument.spreadsheetml.sheet | xlsx |
|
| application/vnd.google-earth.kmz | kmz |
|
| application/vnd.kde.kword | kwd |
|
| application/vnd.oasis.opendocument.text | odt |
|
| application/vnd.oasis.opendocument.presentation | odp |
|
| application/vnd.oasis.opendocument.text-template | ott |
|
| application/vnd.sun.xml.calc | sxc |
|
| application/vnd.sun.xml.draw | sxd |
|
| application/vnd.sun.xml.impress | sxi |
|
| application/vnd.sun.xml.writer | sxw |
|
| application/x-msmetafile | wmz wmf |
|
| application/x-xpinstall | xpi |
|
| application/vnd.ms-xpsdocument | xps |
|
| application/epub+zip | epub |
|
| image/x-cmx | cmx |
|
| video/x-msvideo | avi |
|
| audio/x-wav | wav |
|
| image/webp | webp |
|
| application/x-rar-compressed | rar |
|
| application/x-stuffit | sit |
|
| application/vnd.yamaha.smaf-phrase | spf |
|
| application/vnd.lotus-wordpro | lwp |
|
| application/pls+xml | pls |
|
| audio/x-caf | caf |
|
| application/x-csh | csh |
|
| application/pkcs10 | p10 |
|
| audio/x-flac | flac |
|
| application/pkix-attr-cert | ac |
|
| application/x-apple-diskimage | dmg |
|
| application/vnd.xara | xar |
|
| application/rtf | rtf |
|
| image/png | png |
|
| application/applixware | aw |
|
| application/java-vm | class |
|
| application/vnd.ms-powerpoint | pps ppt |
|
| application/vnd.ms-excel | xla xls |
|
| audio/adpcm | adp |
|
| application/vnd.lotus-approach | apr |
|
| application/x-mspublisher | pub |
|
| application/vnd.visio | vsd |
|
| application/x-xz | xz |
|
| application/vnd.wordperfect | wpd |
|
| image/jpeg | jpe jpeg jpg |
|
| audio/x-aac | aac |
|
2.先还原文件再根据文件头判别文件类型
有的时候我们得到的文件是经过修改后的,需要我们逆操作还原,修改形式可以如下
-
原始文件整体与某字节异或
例题:
十三、Linux常用指令
(〇)其它
1. 以root管理员身份进入终端
输入sudo su
emos@emos-virtual-machine sudo su
[sudo] password for emos:
root@emos-virtual-machine:/home/emos/Documents#
2. 关机指令
halt:立刻关机poweroff:立刻关机shutdown -h now:立刻关机(root用户使用)shutdown -h 10:10分钟后自动关机
(一)cat
cat命令用于连接文件并打印到标准输出设备上。
1. 创建文件
使用cat命令我们可以轻松创建一个新的文件。
(注:输入完毕后,按 Ctrl + d 结束输入并保存)
root@emos-virtual-machine:/home/emos/Documents# cat >test2.txt
hello
world
@Em0s_Er1t
root@emos-virtual-machine:/home/emos/Documents# cat test2.txt
hello
world
@Em0s_Er1t
2. 显示文件内容
cat最常用的应用就是显示某个文件的内容,此外在单个文件查看的基础上再命令后面增加想要查看的文件即可显示多个文件内容。
root@emos-virtual-machine:/home/emos/Documents# cat test.txt
flag{Em0s_Er1t}
root@emos-virtual-machine:/home/emos/Documents# cat test.txt test2.txt
flag{Em0s_Er1t}
hello
world
@Em0s_Er1t
还可以按照行相反的顺序(从下往上)显示文件内容,但用的是tac命令(即cat的逆置)
root@emos-virtual-machine:/home/emos/Documents# tac test2.txt
@Em0s_Er1t
world
hello
用-n选项可以显示行号
root@emos-virtual-machine:/home/emos/Documents# cat -n test2.txt
1 hello
2 world
3 @Em0s_Er1t
3. 文件拷贝
cat命令还可以把一个文件的内容拷贝到另外一个文件,执行方式类似于创建新文件,不过这次的内容是指定文件的内容。
root@emos-virtual-machine:/home/emos/Documents# cat test.txt
flag{Em0s_Er1t}
root@emos-virtual-machine:/home/emos/Documents# cat test.txt>test1.txt
root@emos-virtual-machine:/home/emos/Documents# cat test1.txt
flag{Em0s_Er1t}
此外还可以将多个文件内容拷贝到一个文件中
4. 文件拼接
cat 命令可以将一个文件的内容添加到另一个文件的末尾。
root@emos-virtual-machine:/home/emos/Documents# cat test1.txt>>test.txt
root@emos-virtual-machine:/home/emos/Documents# cat test.txt
flag{Em0s_Er1t}
flag{Em0s_Er1t}
5. 文件内容追加
cat命令允许用户输入新文本,并将其追加到某个指定的现有文件中,下面是把输入的"hello world"追加到test.txt文件的末尾。
(注:输入完毕后,按 Ctrl + d 结束输入并保存)
root@emos-virtual-machine:/home/emos/Documents# cat >>test.txt
hello world
root@emos-virtual-machine:/home/emos/Documents# cat test.txt
flag{Em0s_Er1t}
flag{Em0s_Er1t}
hello world
十四、Misc常用工具安装使用
相关:
(一)字符匹配
1. grep——linux
Grep 是一个可以从文件或流中查找字符串的一个命令行工具, 它可以通过使用正则表达式来更灵活的查找一个字符串。
[root@www ~]# grep [-acinv] [--color=auto] '要搜寻的字符串' filename
| 选项 | 功能 |
|---|---|
| -r | 递归搜索目标字符串 |
| -b | 在每一行前面加上其所在的块号,根据上下文定位磁盘块时可能会用到 |
| -c | 显示匹配到的行的数目,而不是显示行的内容 |
| -h | 不显示文件名 |
| -i | 比较字符时忽略大小写的区别 |
| -l(小写的字母L) | 只列出匹配行所在文件的文件名(每个文件名只列一次),文件名之间用换行符分隔 |
| -n | 在每一行前面加上它在文件中的相对行号 |
| -s | 无声操作,即只显示报错信息,用于检查退出状态 |
| -v | 反向查找,只显示不匹配的行 |
| -w | 把表达式作为词来查找,就好像它被<和>夹着那样。只适用于grep(并非所有版本的grep都支持这一功能,譬如,SCO UNIX就不支持) |
常用指令:
-
查找当前文件夹下所有文件是否有flag字符串,忽略大小写(
-i),递归搜索(-r),每一行前面加行号(-n)grep -rni "flag" *
2. strings——linux
strings 命令在对象文件或二进制文件中查找可打印的字符串。字符串是 4 个或更多可打印字符的任意序列,以换行符或空字符结束。 strings 命令对识别随机对象文件很有用。
(二)文件分离工具
binwalk:可快速分辨文件是否由多个文件合并而成,并将文件进行分离。如果分离成功会在目标文件的目录。
分析文件:
binwalk filename分离文件:
binwalk -e filename
formost命令:formost filename -o 输出的目录名
dd:当文件自动分离出错或者因为其他原因无法自动分离时使用
(三)图片分析工具
1. montage
linux下的工具,实现图形的拼接
2. Stegsolve
Analyse下有5个功能选项
- File Format:查看文件结构信息
- Data Extract:数据提取
- Steregram Solve:立体试图,可以左右控制偏移
- Frame Browser:帧浏览器,常用于gif等动图逐帧查看
- Image Combiner:拼图,用于多个图片拼接
重点了解一下Data Extract功能
① Data Extract
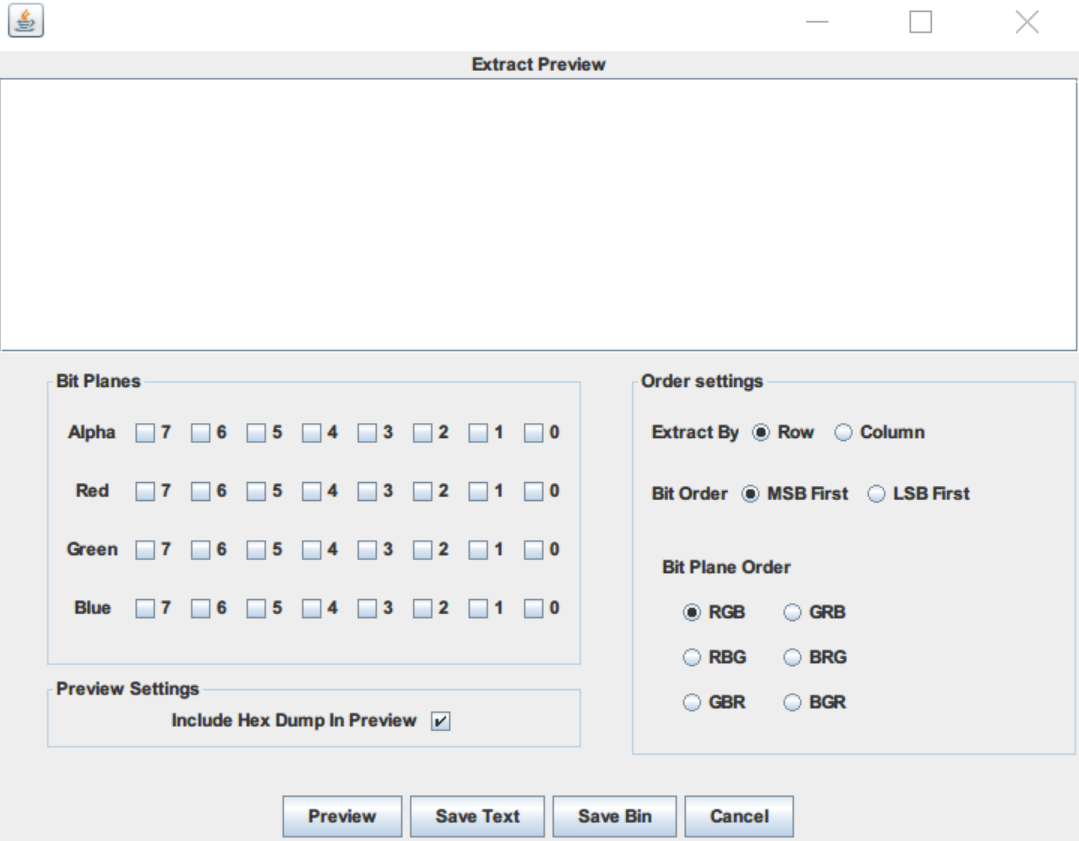
-
Bit Planes:我们可以选择性显示
RGBA各分量平面的值——知识储备
RGB代表红绿蓝,它们的值代表的实际上是亮度,如R的数字越大,则代表红色亮度越高;R的数字越小,则代表红色亮度越低,G,B同理。可以理解为一个图片的一个像素的颜色是由三个颜色分量叠加起来的。
R、G、B的亮度都有256个级别,即从 \(0\sim 255\)。从数字0到255的逐渐增高,我们人眼观察到的就是对应颜色的亮度越来越大。然而 \(2^8=256\),所以用8个二进制位,即一个字节就可以用来表示R/G/B的亮度数据,因而会看见上图的 \(7\sim 0\) 一共8个通道
A即Alpha,代表透明度,该通道用256级灰度来记录图像中的透明度信息,定义透明、不透明和半透明区域,alpha的值为0就是全透明,alpha 的值为 255 则表示不透明
-
Extra By:分为row(行)和column(纵),每个像素用R,G,B三个分量表示,那么一张图片就像一个矩阵,矩阵的每个单位就是(\(0\sim 255\),\(0\sim 255\),\(0\sim 255\))也就会有是纵排列和行排列了,一般事先访问行再访问列
-
Bit Order(位顺序):MSB是一串数据的最高位,LSB是一串数据的最低位。
-
Bit Plane Order(位平面的顺序): 整个图像分解为8个位平面,从LSB(最低有效位0)到MSB(最高有效位7)随着从位平面0 到位平面7,位平面图像的特征逐渐变得复杂,细节不断增加,一般图片是24位,也就是可以分配给RGB各8bit用于表示其亮度,大家可以想像成三明治,比如BGR就是B为三明治第一层,G为第二层,R为第三层。
(四)隐写检测工具
1. stegdetect
stegdetect 用来检测jpg类型的图片是否隐藏着其他文件或内容。它可以检测到通过JSteg、JPHide、OutGuess、Invisible Secrets、F5、appendX和Camouflage等这些隐写工具隐藏的信息。
安装:
推荐在linux环境下,下载stegdetect 源码包之后进入其目录,执行下面指令
linux32 ./configure linux32 make
使用stegdetect时会有一些参数,下面简单罗列一下:
-
q ——仅显示可能包含隐藏内容的图像
-
n ——启用检查JPEG文件头功能,以降低误报率。如果启用,所有带有批注区域的文件将被视为没有被嵌入信息。如果JPEG文件的JFIF标识符中的版本号不是1.1,则禁用OutGuess检测。
-
s ——修改检测算法的敏感度,该值的默认值为1。检测结果的匹配度与检测算法的敏感度成正比,算法敏感度的值越大,检测出的可疑文件包含敏感信息的可能性越大。
-
d ——打印带行号的调试信息。
-
t ——设置要检测哪些隐写工具(默认检测jopi),可设置的选项如下:
-
j ——检测图像中的信息是否是用jsteg嵌入的。
-
o ——检测图像中的信息是否是用outguess嵌入的。
-
p ——检测图像中的信息是否是用jphide嵌入的。
-
i ——检测图像中的信息是否是用invisible secrets嵌入的。
常用指令
stegdetect.exe -tjopi -s 10.0 hide.jpg
(五)隐写工具
1.JPHS(JPHideandSeek)【JPEG】
JPHS程序用于实现JPHide隐写与信息提取,它包括2个命令行程序——JPHIDE和JPSEEK
- JPHide程序主要是实现将信息文件加密隐藏到JPEG图像功能,
- JPSeek程序主要实现从用JPHide程序加密隐藏得到的JPEG图像探测提取信息文件
JPHS在Windows下可以使用拥有图形化操作界面的Jphswin,集成了JPHIDE和JPSEEK的功能,下面演示如何使用Jphswin将文件隐写入jpeg图片中并提取。
(1)隐写
我们现在要将flag.txt隐写写入示例图片test.JPG
选择“Open jpeg”打开示例图片,如果你选择的不是JPEG格式的图片,程序会自动退出
选择“Hide”选项之后在两次文本框输入相同的口令,这里以输入flag作为口令为例。
点击OK后会弹出文件选择框让你选择想要写入的文件
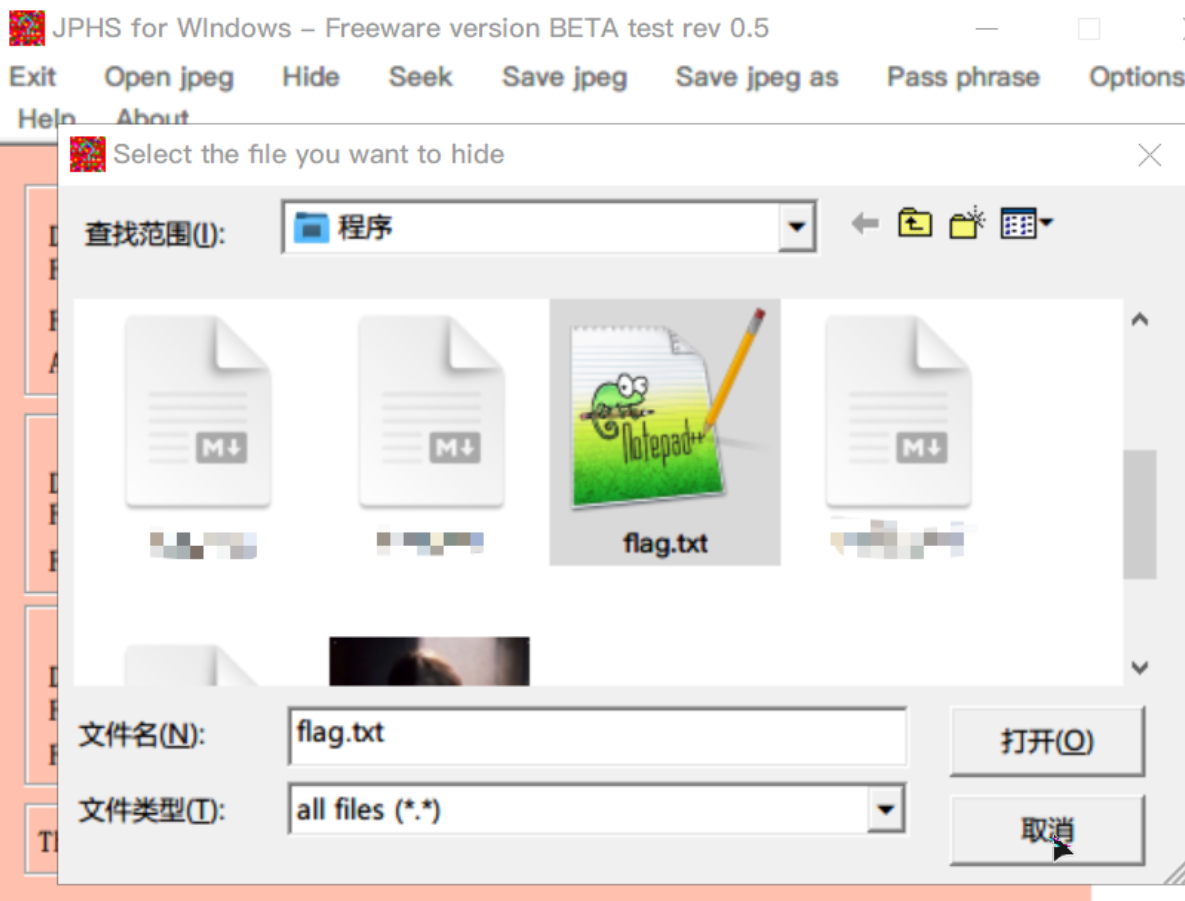
接着就可以点击“Save jpeg as”选项将图片另存为jpeg格式并输入文件的名称为新的图像文件,如重命名成test_flag.JPG,于是这个文件内便隐藏了flag.txt
(2)提取
接下来演示如何从test_flag.JPG中提取flag.txt,当然我们此时已经掌握了之前隐写用到的口令。
一样的打开图片文件test_flag.JPG,这次点击Seek选项,输入之前的口令点击OK
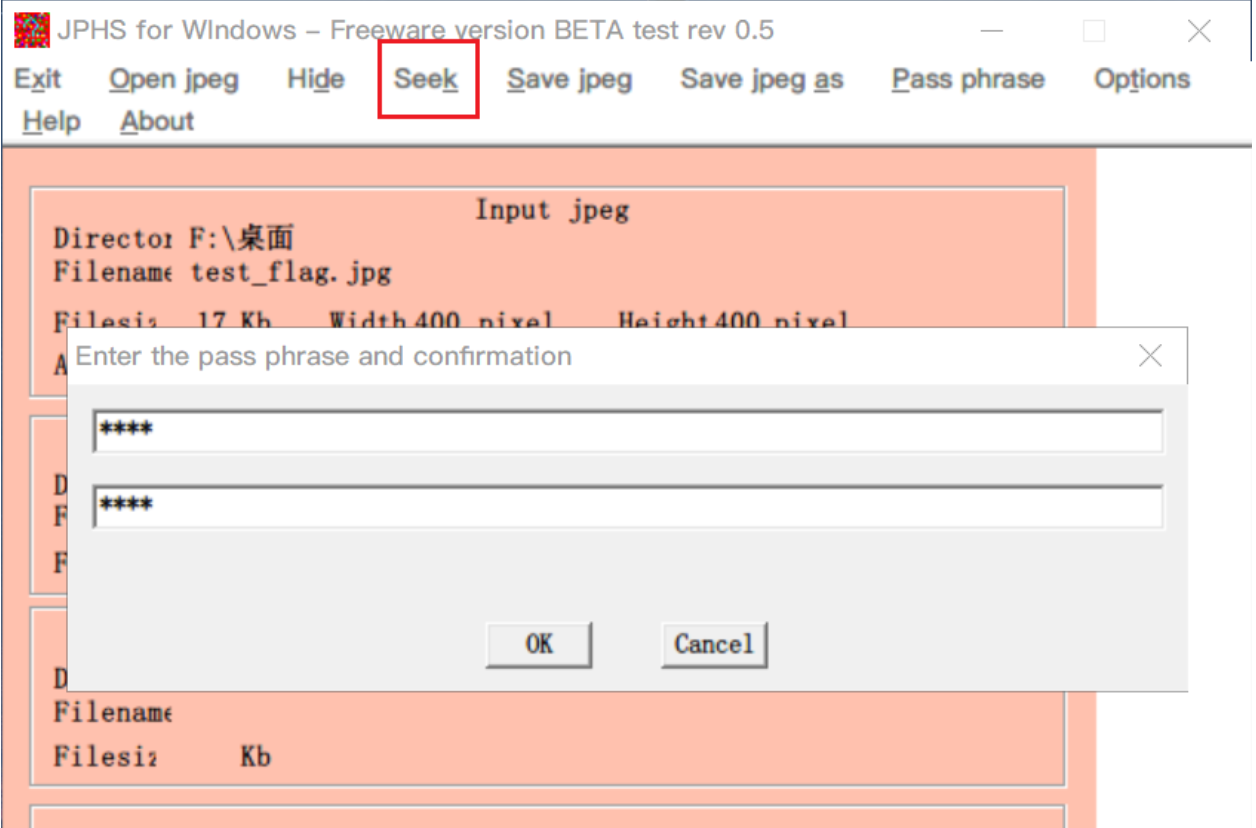
点击OK后会弹出文件选择框让你选择输出路径与输出文件名,我这里设置成out.txt
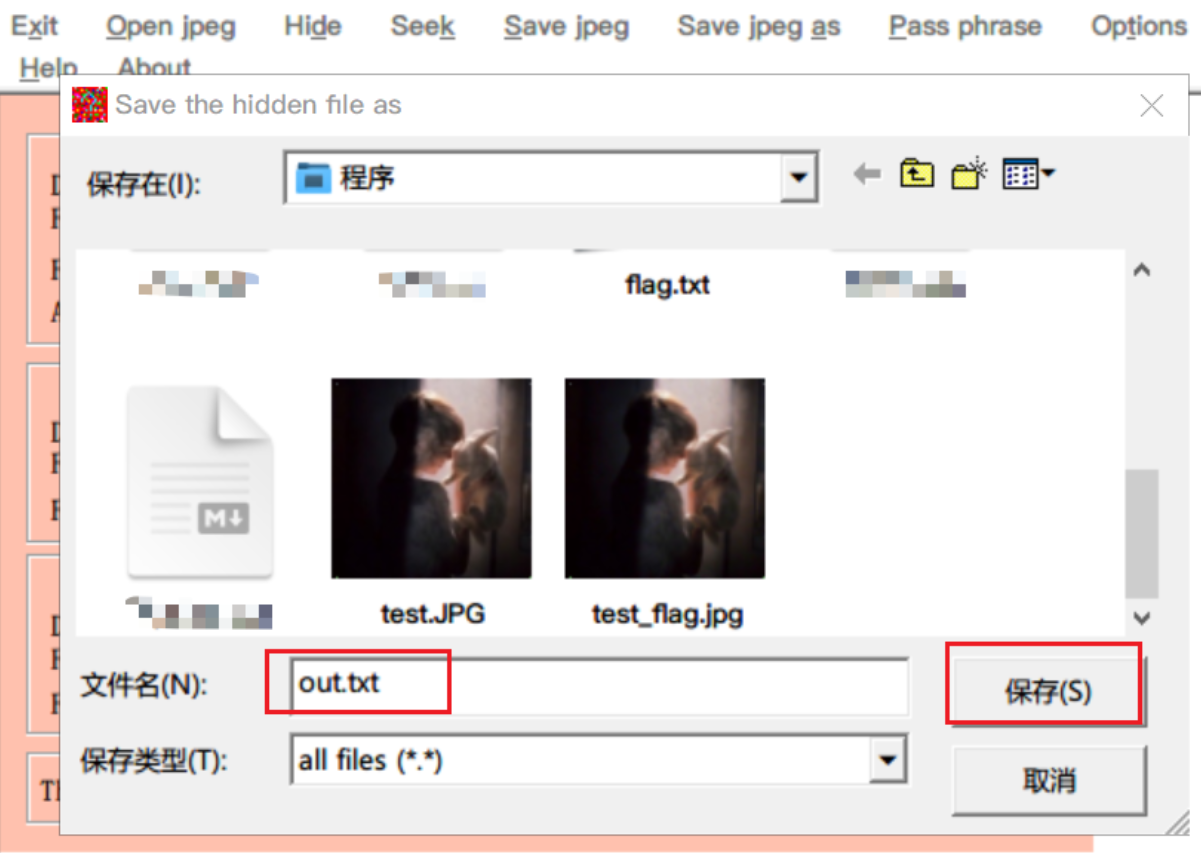
打开out.txt,可以看到提取成功。
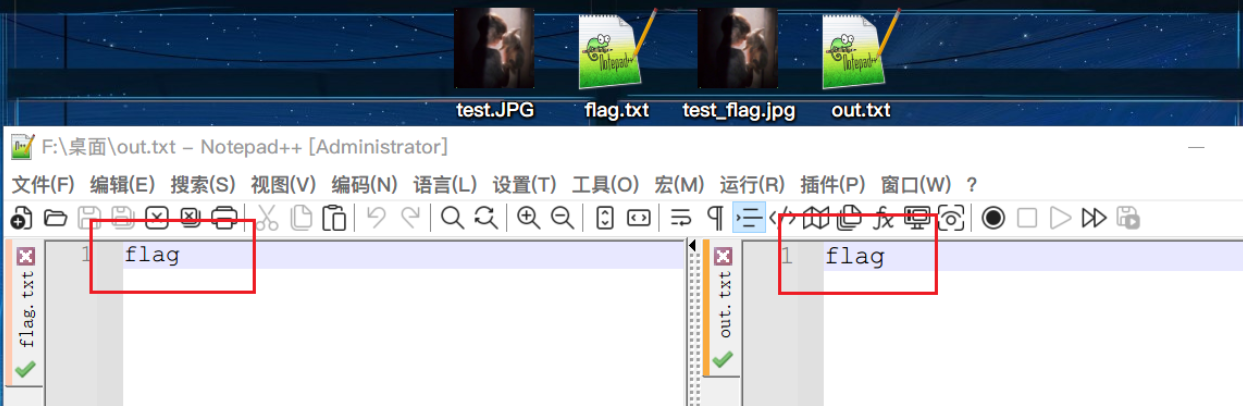
如果输入的错误的密码,它可能也会输出文件,但是会弹窗显示密码错误
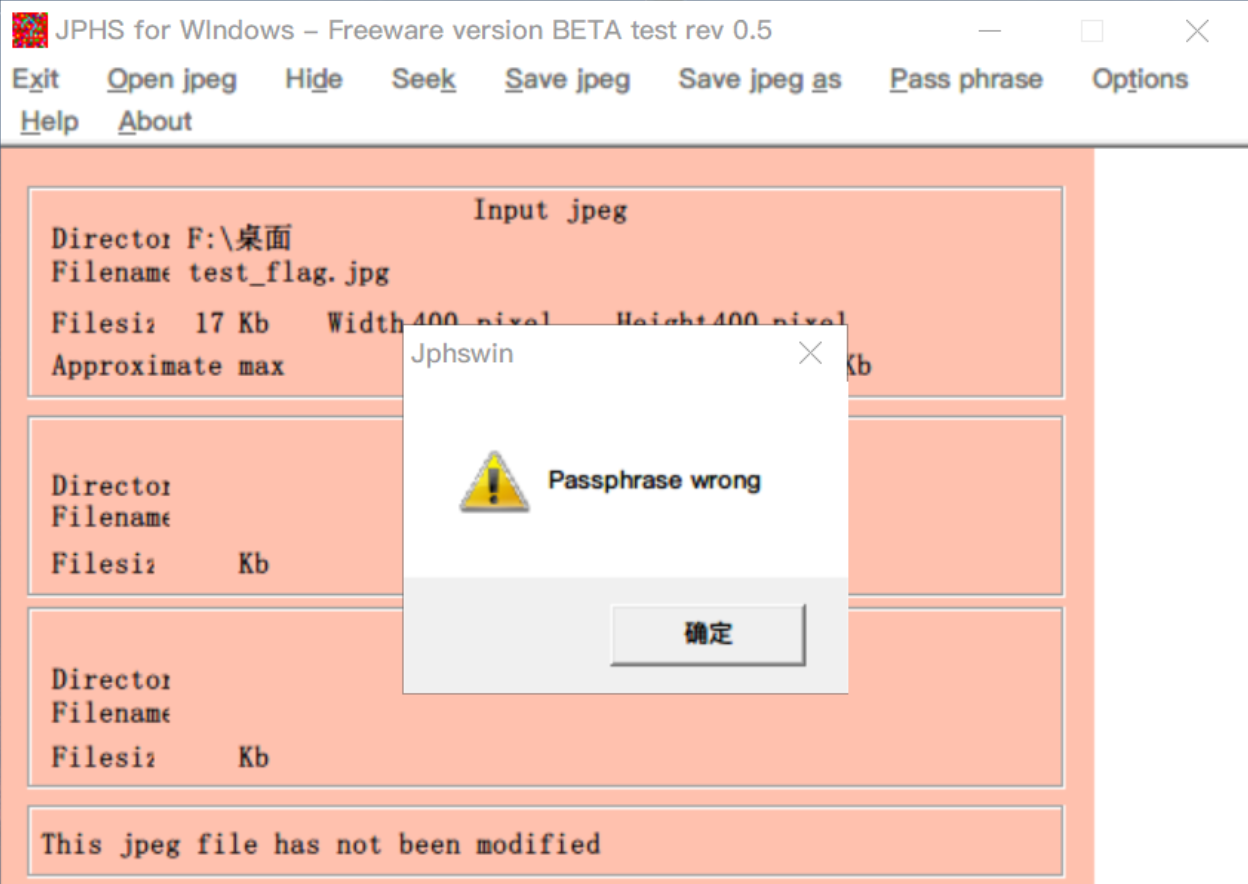
2. wbStego4open【BMP、 TXT、 HTM 、PDF 】
官方:wbStego4open
wbStego4open是一个隐写开源工具, 支持 Windows 和Linux 平台。可以用 wbStego4open 可以把文件隐藏到 BMP、 TXT、 HTM 和 PDF 文件中, 且不会被看出破绽。
点击Flowchart-Mode可以将界面调成流程图模式
还可以用它来创建版权标识文件并嵌入到文件中将其隐藏。
(1)隐写
点击Continue进入模式选择
Encode对应隐写写入数据Decode对应提取数据
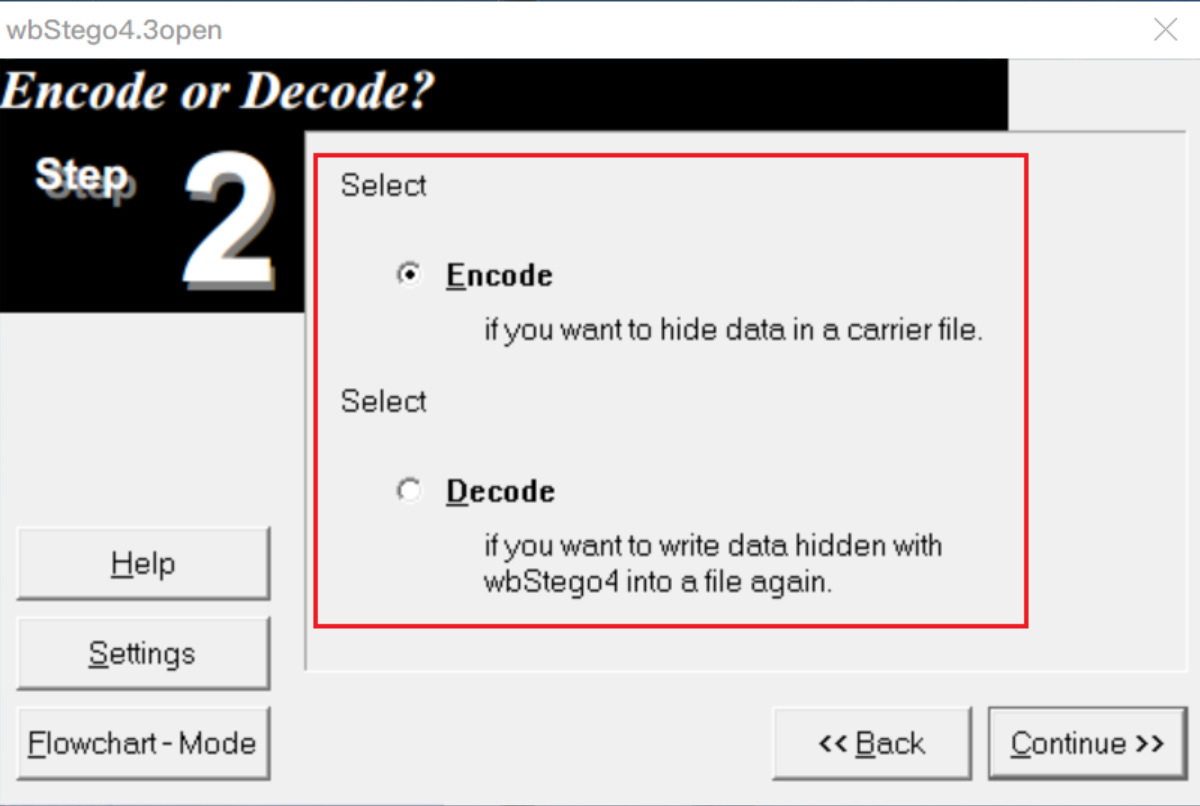
点击 Encode>Continue,会让你选择待隐藏的目标数据文件
接下来我们要把flag.txt写入test.pdf,于是选择flag.txt的路径即可
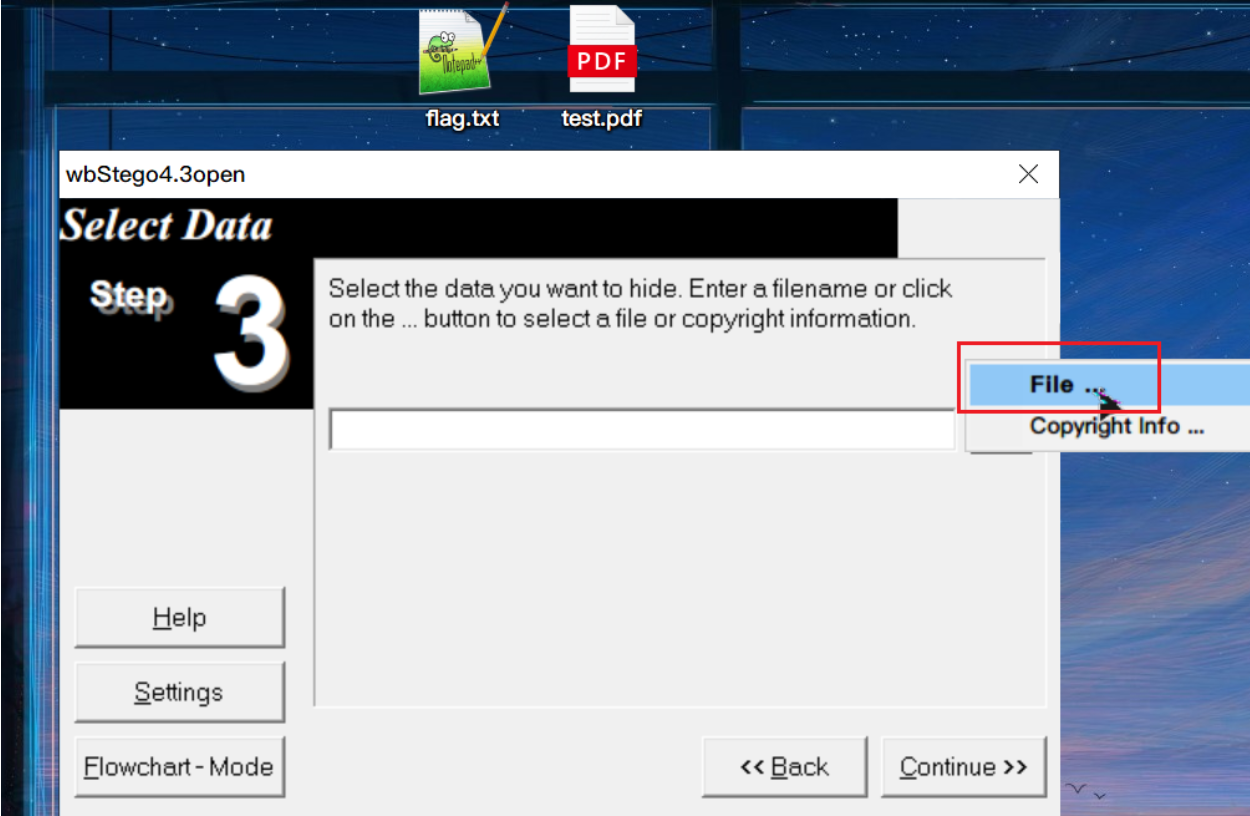
接着是载体文件,就是要写入的目标文件,这里选择test.pdf的路径,然后还要对应选择文件类型,接着Continue。
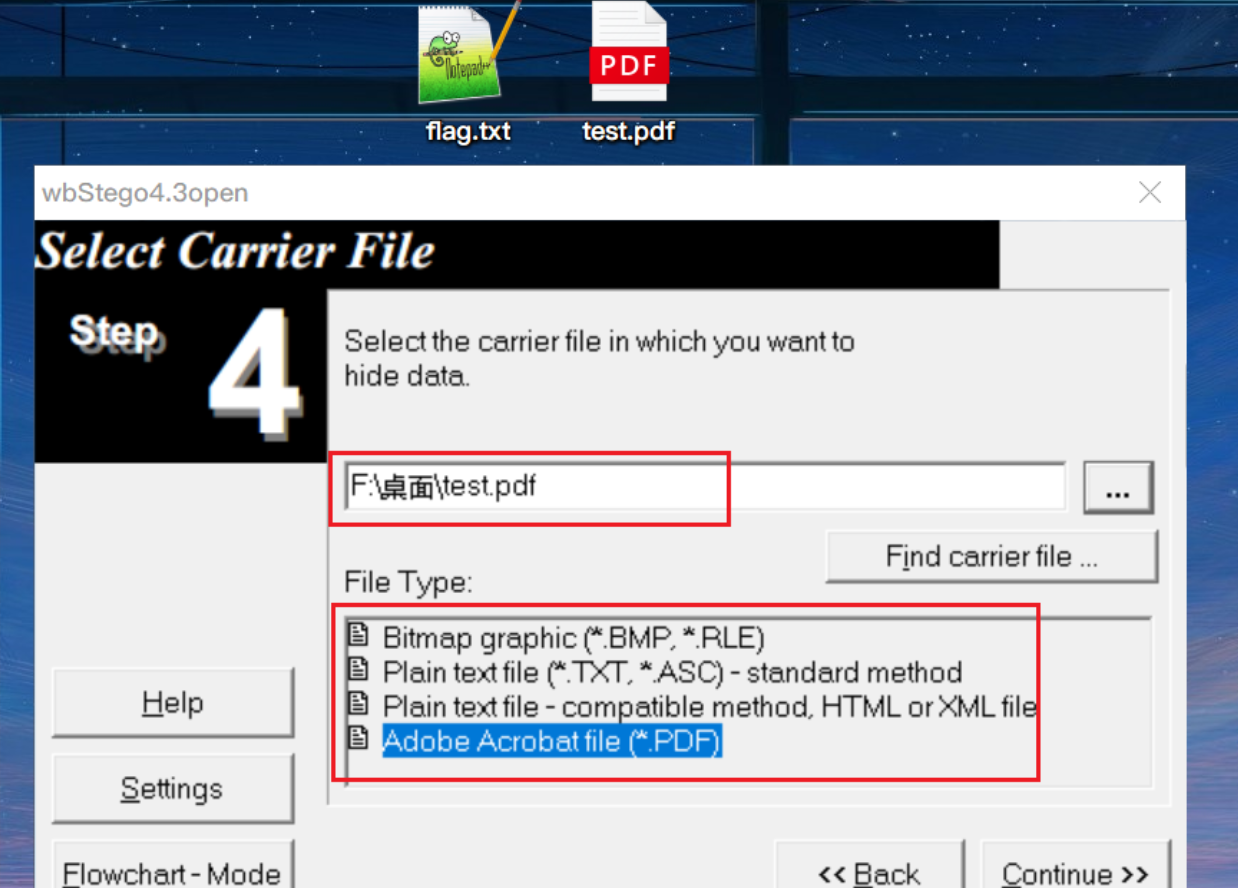
下一步可以点击Cryptography settings选择加密算法与输入口令(两次输入口令要一致)。当然如果不想设置口令可以直接Continue
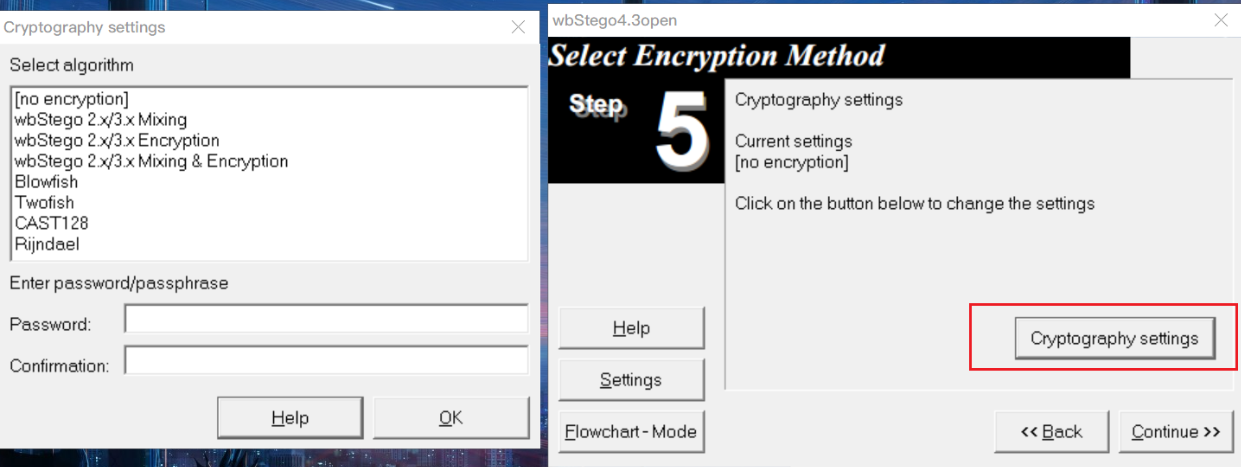
然后选择文件输出路径以及文件名
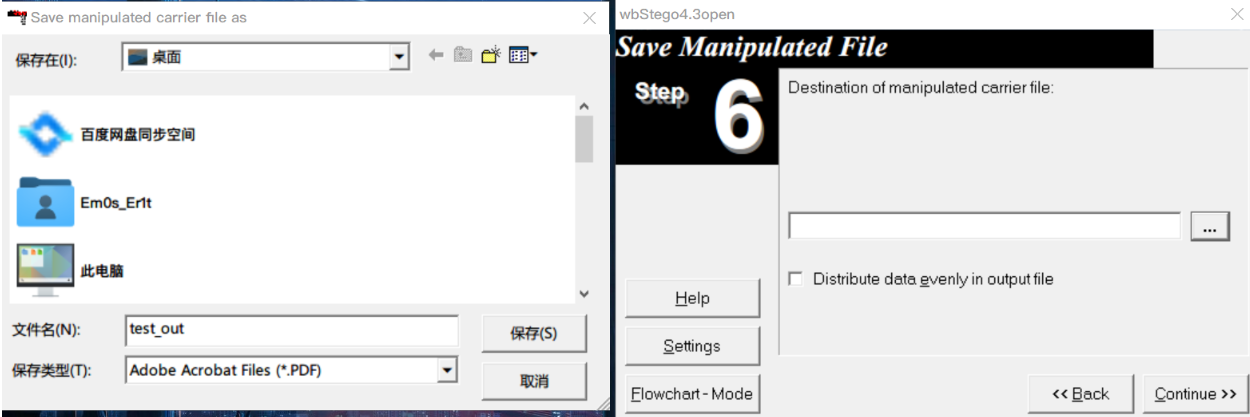
至此隐写成功
比较原始文件和输出文件可以发现,输出文件出现很多由0x20和0x09聚集成的长度为8B的字节块,这可以作为一种wbStego4open隐写的特征
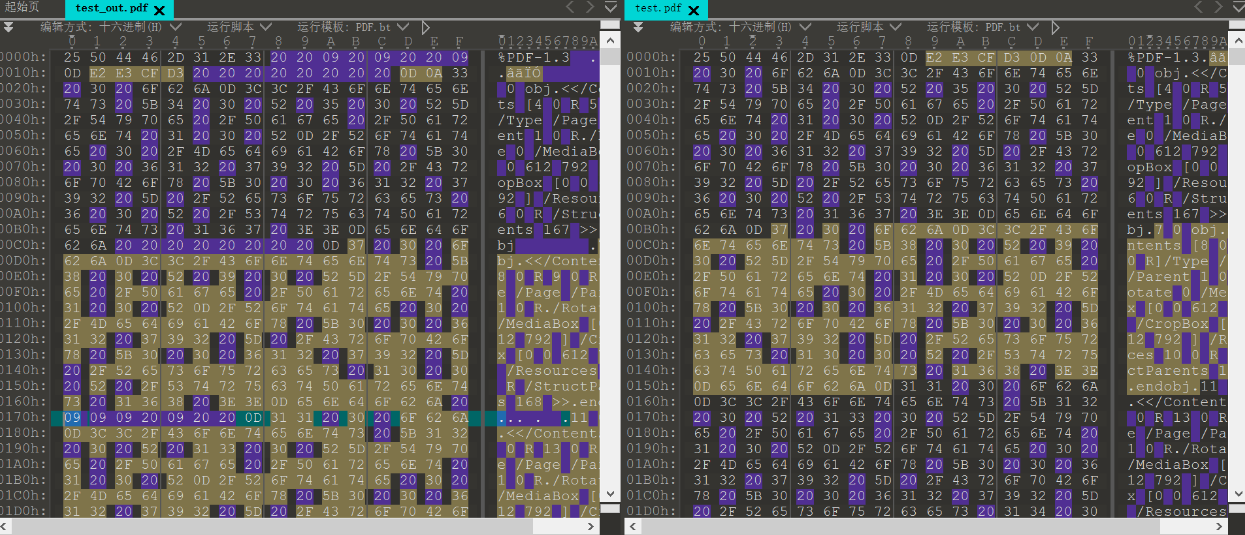
此外观察这些字节块的位置可以发现这些字节块的分布都是位于PDF文件的两个间接对象之间(在010 Editor中打开可以发现这些字节块对应PDFWhitespace sPDFWhitespace,在原始文件中并没有这种结构)
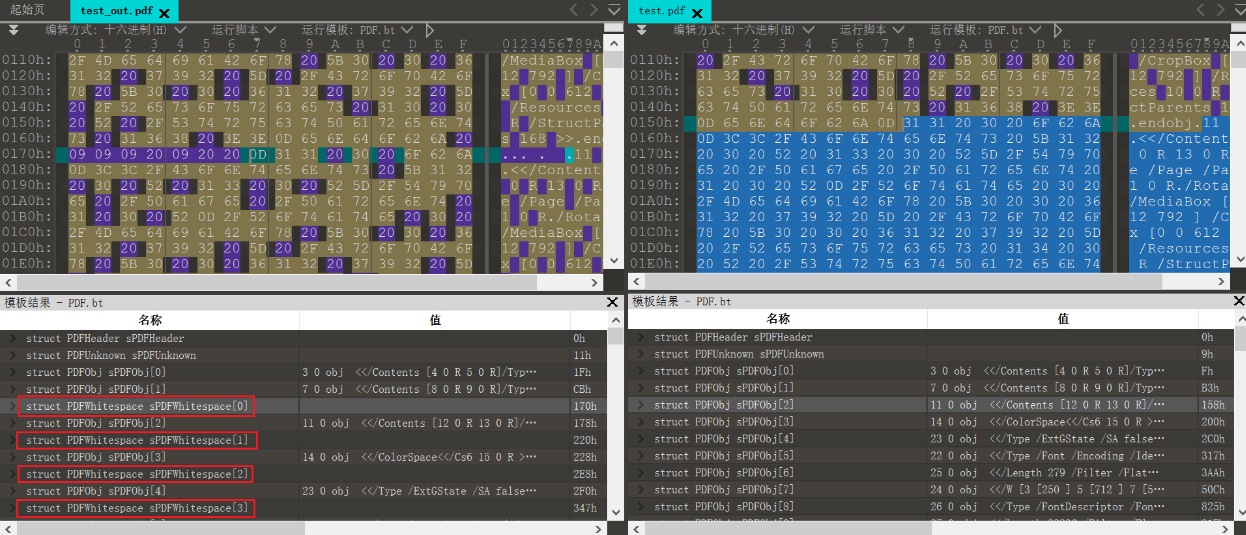
(2)提取
现在要从test_out.pdf中提取出flag.txt,选择Decode然后Continue
选择载体文件
接着有口令要输入口令,没有口令直接Continue(无需设定解密模式,因为程序会自动检查用的是什么加密算法)
选择隐写数据的输出路径和文件名
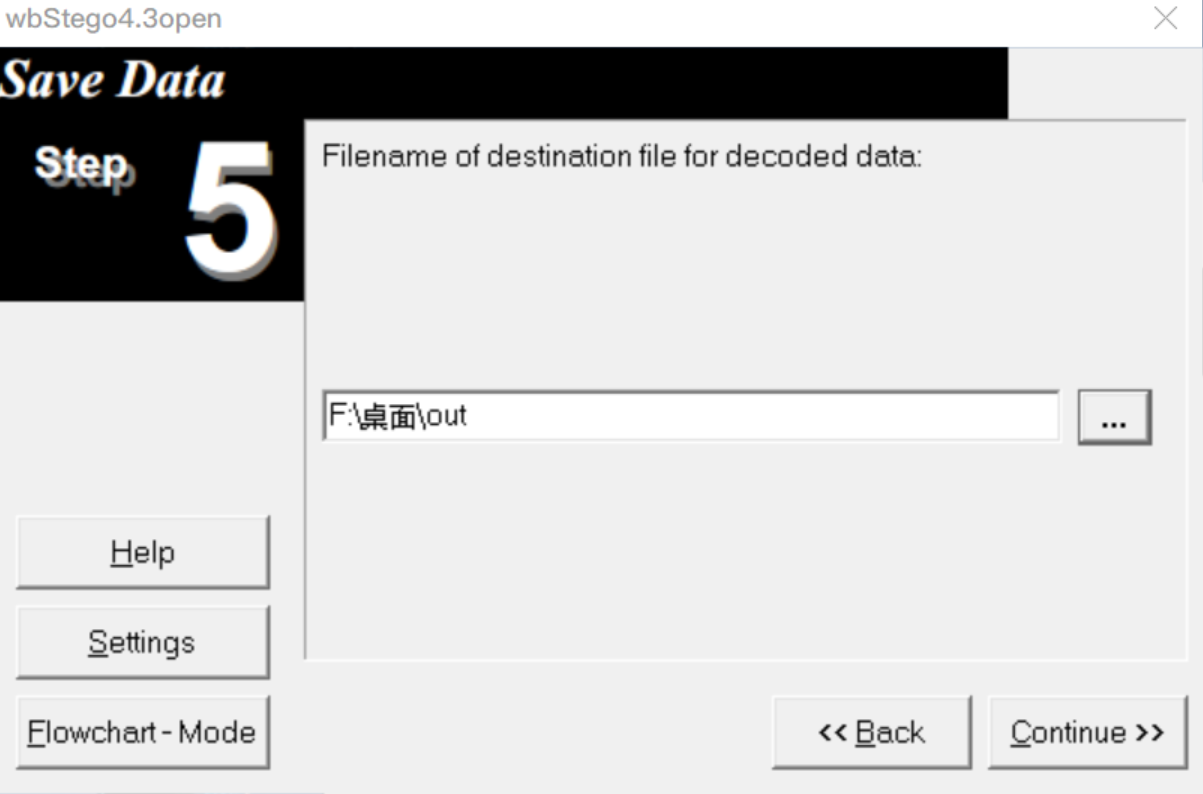
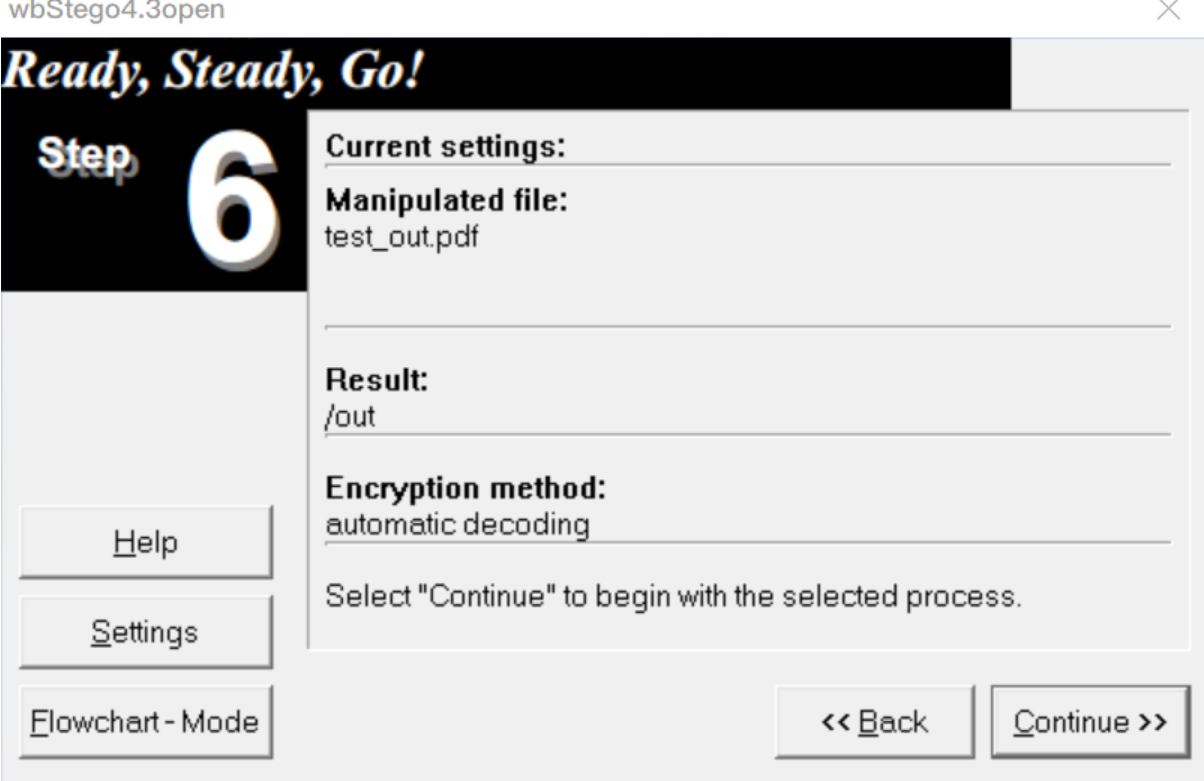
接着提取出隐写数据输出到该路径下
3. Hydan
需要在linux环境下安装,推荐用ubuntu 32位来安装
./hydan tar message.txt > tar.steg
4. F5-steganography【BMP、GIF、JPEG】
下载并解压之后在解压目录下打开命令行使用,解压目录有几个关键文件用途如下:
- Embed.java:用于将信息嵌入图像文件的主程序;
- Extract.java:用于将隐藏信息从图像文件载体中提取的主程序;
- bin.noise:该文件含有需要隐藏的信息;
- e:将指定信息(bin.noise)嵌入指定图像文件(lopez.bmp)的演示程序脚本;
- e.bat:将指定信息(bin.noise)嵌入指定图像文件(lopez.bmp)的批处理演示程序;
- d:将隐藏信息从图像文件(lopez.jpg)中提取到指定文件(output.txt)的演示程序脚本;
- d.bat:将隐藏信息从图像文件(lopez.jpg)中提取到指定文件(output.txt)的批处理演示程序。
接下来演示工具的具体使用方法,使用前需要配置java环境,配置过程略
(1)隐写
java Embed <载体文件路径> <输出文件路径和名> -c "" -e <待嵌入数据文件路径> -p <口令>
将测试文件复制到F5-steganography目录下,现在要实现将flag.txt写入载体文件test.jpg
命令行输入如下指令之后生成载密文件test_out.jpg(密码可以自行设定或者不设定)
java Embed test.jpg test_out.jpg -c "" -e flag.txt -p Em0s_Er1t
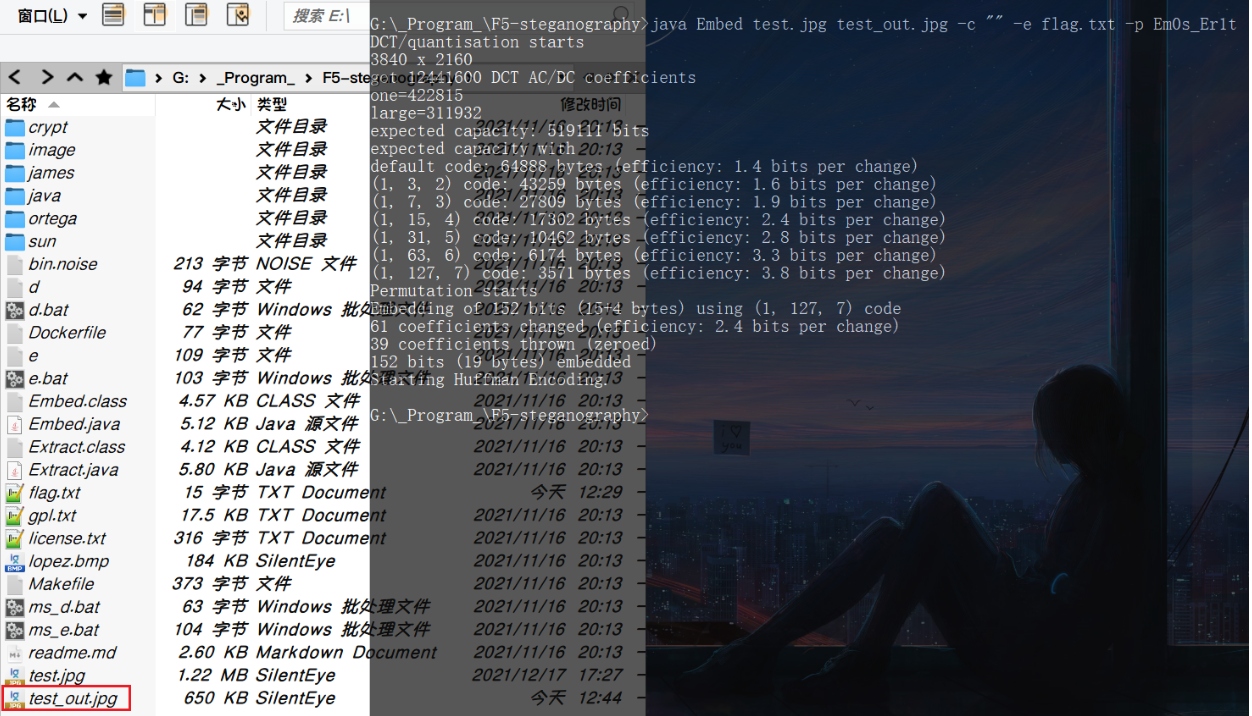
(2)提取
java Extract <载体文件路径> -p <口令>
命令行输入如下指令,即可实现从test_out.jpg提取出隐写信息。
java Extract test_out.jpg -p Em0s_Er1t
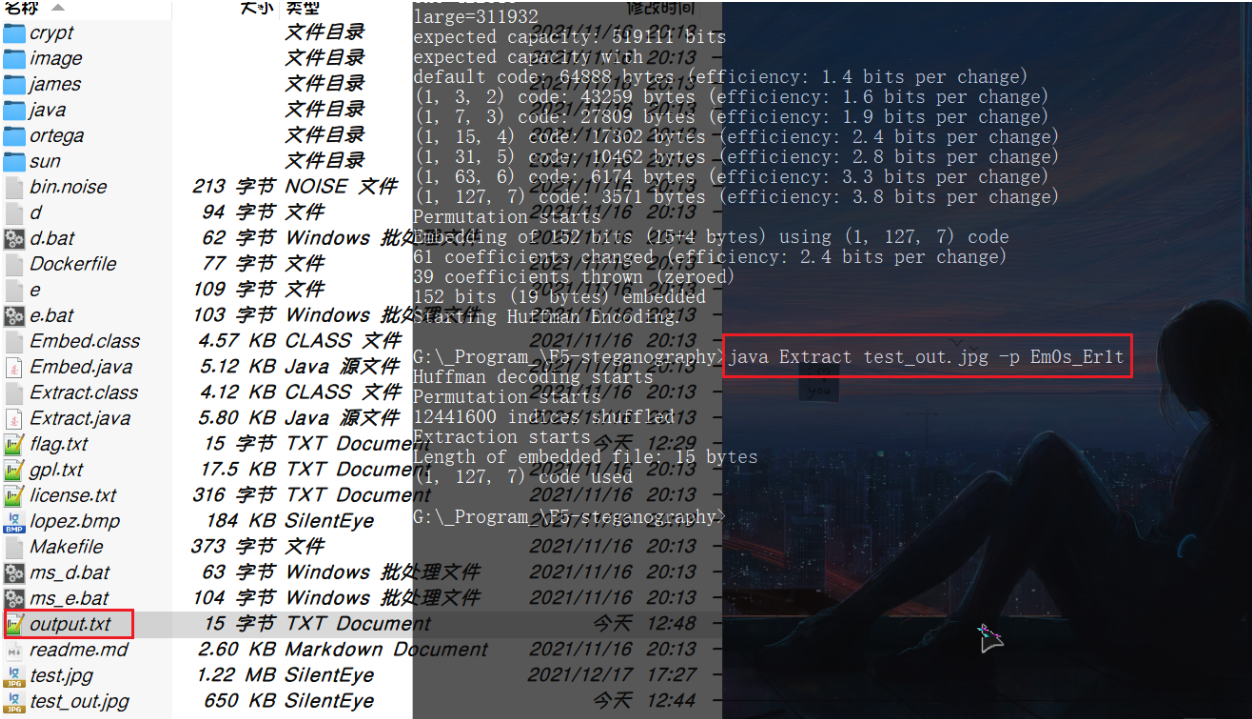
5. outguess【JPEG】
官方:outguess
(1)隐写
outguess -k "my secret key" -d hidden.txt in.jpg out.jpg
隐写之后,in.jpg会覆盖out.jpg,hidden.txt中的内容是要隐藏的东西
(2)提取
outguess -k "my secret key" -r out.jpg hidden.txt
提取之后,解密内容放在hidden.txt中
6. steghide【JPEG、BMP、WAV 】
官方:steghide
(1)安装
steghide是linux下工具,安装采用如下命令
sudo apt-get install steghide
(2)隐写
steghide embed -cf <载体文件> -ef <待隐藏文件>
接着会提示输入密码,不输入则为空密码
(3)提取
steghide extract -sf <携带隐藏信息的文件>

7. Stegosaurus【PYC、PYO】
Stegosaurus 是一款隐写工具,它允许我们在 Python 字节码文件(pyc 或 pyo)中嵌入任意 Payload。由于编码密度较低,因此我们嵌入 Payload 的过程既不会改变源代码的运行行为,也不会改变源文件的文件大小。 Payload 代码会被分散嵌入到字节码之中,所以类似 strings 这样的代码工具无法查找到实际的 Payload。 Python 的 dis 模块会返回源文件的字节码,然后我们就可以使用 Stegosaurus 来嵌入 Payload 了。
- 提示:Stegosaurus 仅支持对 Python3.6 及其以下版本的字节码文件隐写
- 运行环境:linux下Python3.6及以上
(1)隐写
显示可隐藏多少数据
python3 -m stegosaurus example.py -r
支持ASCII码信息和shellcode信息的隐藏
#ASCII
python3 -m stegosaurus example.py -s -p "Em0s_Er1t"
#shellcode
python3 -m stegosaurus example.py -s -p "\xeb\x2a\x5e\x89\x76"
(2)提取
python3 -m stegosaurus <含隐藏信息的字节码文件> -x
(六)拼图工具
1. montage + gaps
montage用于将多个图片合并为一个图像,该图像是乱序的,而再经过gaps处理后,图像便实现了有序整合
(1)安装
先根据不同的linux系统环境选择相对应的命令安装montage
#Debian
apt-get install graphicsmagick-imagemagick-compat
#Ubuntu
apt-get install graphicsmagick-imagemagick-compat
#Alpine
apk add imagemagick6
#Arch Linux
pacman -S imagemagick6
#Kali Linux
apt-get install graphicsmagick-imagemagick-compat
#Raspbian
apt-get install graphicsmagick-imagemagick-compat
#Docker
docker run cmd.cat/montage montage
然后安装gaps:
先使用git下载 https://github.com/nemanja-m/gaps.git
git clone https://github.com/nemanja-m/gaps.git
cd gaps
紧接着在Python3环境下安装依赖库——numpy,opencv-python,matplotlib,pytest,pillow
先尝试输入pip3 install -r requirements.txt安装,若安装成功就接着输入sudo python setup.py install安装即可
若报错就需要一个个安装上面提到的库,嫌安装得慢就换别的下载源(如下)
阿里云:http://mirrors.aliyun.com/pypi/simple/
中国科技大学:https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple/
豆瓣:http://pypi.doubanio.com/simple/
清华大学:https://pypi.tuna.tsinghua.edu.cn/simple/
sudo pip3 install <包名称> -i <下载源>
——相关问题与解决方案
在安装
opencv-python时,如果出现一直卡在Building wheel for opencv-python不动的情况,可以尝试升级pip工具包,即输入如下指令,然后再install即可。sudo pip3 install --upgrade pip setuptools wheel
输入如下命令查询版本号(后续要使用)
pip3 list
用查询到的版本号修改gaps文件夹下的requirements.txt文件中的版本号后输入如下命令进行安装即可
sudo python3 setup.py install
(2)使用
montage
montage的作用是将多个图片拼接成一个图片
montage *.jpg -tile <横向的子图片数量>x<纵向的子图片数量> -resize <输出图片的宽度(像素)>x<输出图片的高度(像素)> -geometry <子图片宽度(像素)>x<子图片高度>+0+0 <输出的图片名称> #+0+0代表子图片之间没有间隙
举个例子,若当前路径下有120张图片,且每张的分辨率(以像素为单位)都是200x100,要使拼起来的图片(令其名为out.jpg)横向有10张图片,纵向有12张图片,分辨率为4000x2400,那么需要输入的命令如下:
montage *.jpg -tile 10x12 -resize 4000x2400 -geometry +0+0 out.jpg
gaps
gaps的作用是还原拼图
gaps --image=<乱序图片的路径> --generations=<遗传算法的代数量> --population=<拼图块的数量> --size=<拼图块的像素尺寸>
#--size通常设置成拼图块的宽度(横向)像素值
#--generations通常设置成拼图块的个数
那么,将上例中的拼图排序可以用下面的指令
gaps --image=out.jpg --generations=120 --population=120 --size=200
十五、搜索引擎语法
https://blog.csdn.net/u014565127/article/details/53868443
https://blog.csdn.net/u014565127/article/details/53842885
【附】
ISO数据类型参照表
基本数据类型
| 数据类型 | 描述 |
|---|---|
| int8 | 无符号 8 位整数。 |
| sint8 | 有符号 8 位整数。 |
| int16_LSB | 小端编码的无符号 16 位整数。 |
| int16_MSB | 大端编码无符号 16 位整数。 |
| int16_LSB-MSB | 小端后跟大端编码无符号 16 位整数。 |
| sint16_LSB | 小端编码的有符号 16 位整数。 |
| sint16_MSB | 大端编码的有符号 16 位整数。 |
| sint16_LSB-MSB | 小端后跟大端编码的有符号 16 位整数。 |
| int32_LSB | 小端编码的无符号 32 位整数。 |
| int32_MSB | 大端编码无符号 32 位整数。 |
| int32_LSB-MSB | 小端后跟大端编码无符号 32 位整数。 |
| sint32_LSB | 小端编码的有符号 32 位整数。 |
| sint32_MSB | 大端编码有符号 32 位整数。 |
| sint32_LSB-MSB | 小端后跟大端编码的有符号 32 位整数。 |
字符串使用 ASCII 编码进行编码。文件结构规范不纳入所有字符。它定义了两组字符:a类 字符集和d 类字符集。
-
a-characters:
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z 0 1 2 3 4 5 6 7 8 9 _ ! " % & ' ( ) * + , - . / : ; < = > ? -
d-characters:
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z 0 1 2 3 4 5 6 7 8 9 _
| 数据类型 | 描述 |
|---|---|
| strA | 仅包含 ASCII a 字符的字符串,向右填充空格。 |
| strD | 仅包含 ASCII d 字符的字符串,向右填充空格。 |
请注意,并非所有 CD 都严格遵守 ISO 9660 中指定的字符集。

