结对作业二
| 这个作业属于哪个课程 | 2021春软件工程实践W班 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 结对第二次作业——顶会热词统计的实现 |
| 结对学号 | 081700318 221801306 |
| 这个作业的目标 | 实现结对作业一中设计原型的部分功能 |
| 其他参考文献 | CSDN等相关技术性博客 |
云服务器访问链接
论文查询
(因为数据统计页面采用的是echart 所以会导致加载较久,推荐用firefox和chrome浏览器访问)
git仓库链接和代码规范链接
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| Estimate | 估计这个任务需要多少时间 | 5days | 7days |
| Development | 开发 | 1080 | 1320 |
| Understanding | 需求理解 | 30 | 30 |
| Analysis | 需求分析(包括学习新技术) | 60 | 90 |
| Coding Standard | 代码规范 | 30 | 20 |
| Discussing | 结对讨论交流 | 60 | 60 |
| Design | 具体设计 | 60 | 30 |
| Coding | 具体编码 | 720 | 1000 |
| Test | 测试 | 60 | 60 |
| Deploying | 部署到云服务器 | 60 | 30 |
| Reporting | 报告 | 70 | 50 |
| Size Measurement | 计算工作量 | 20 | 10 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 20 | 10 |
| Writing | 撰写报告 | 30 | 30 |
| 合计 | 1150 | 1370 |
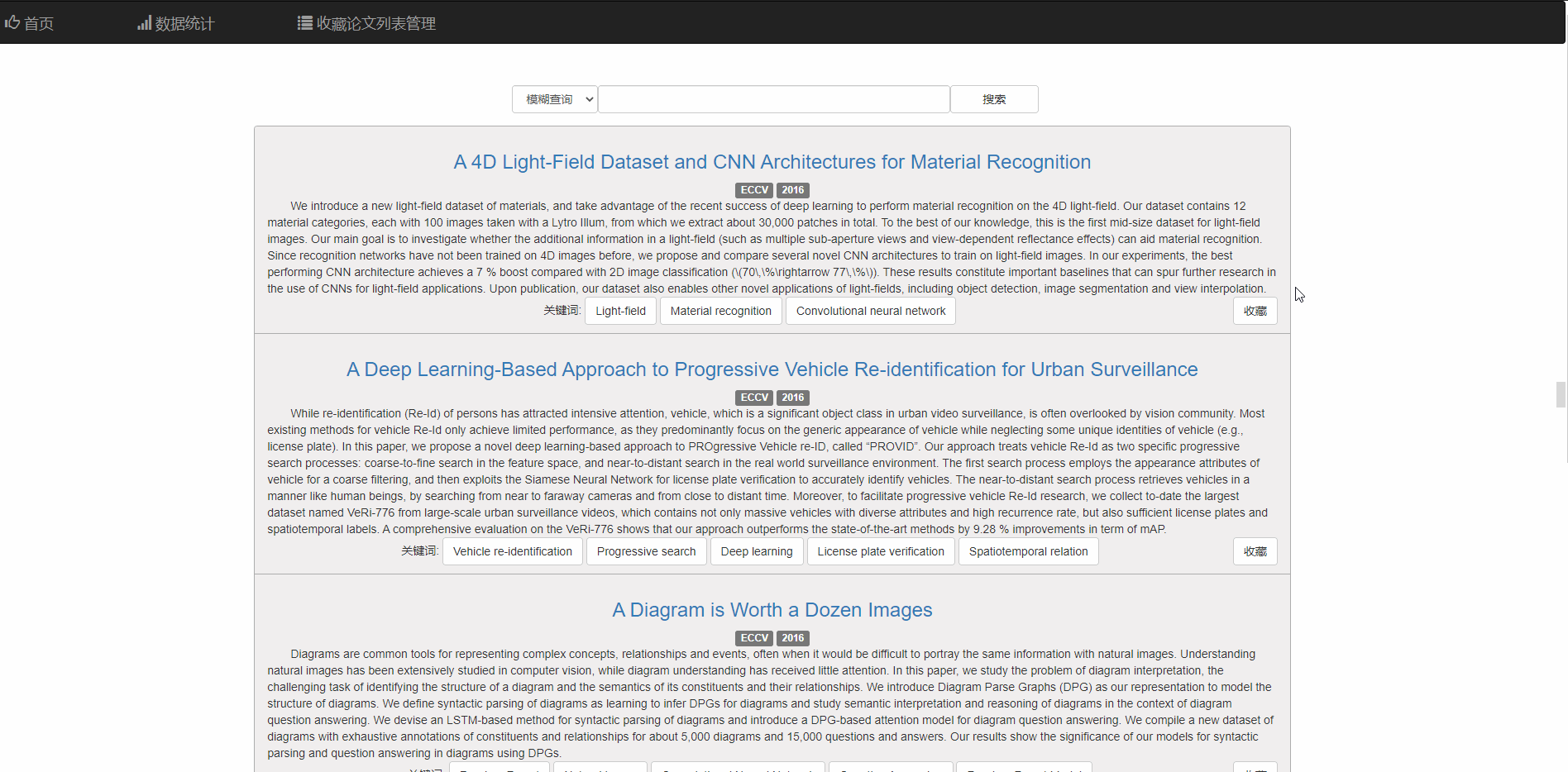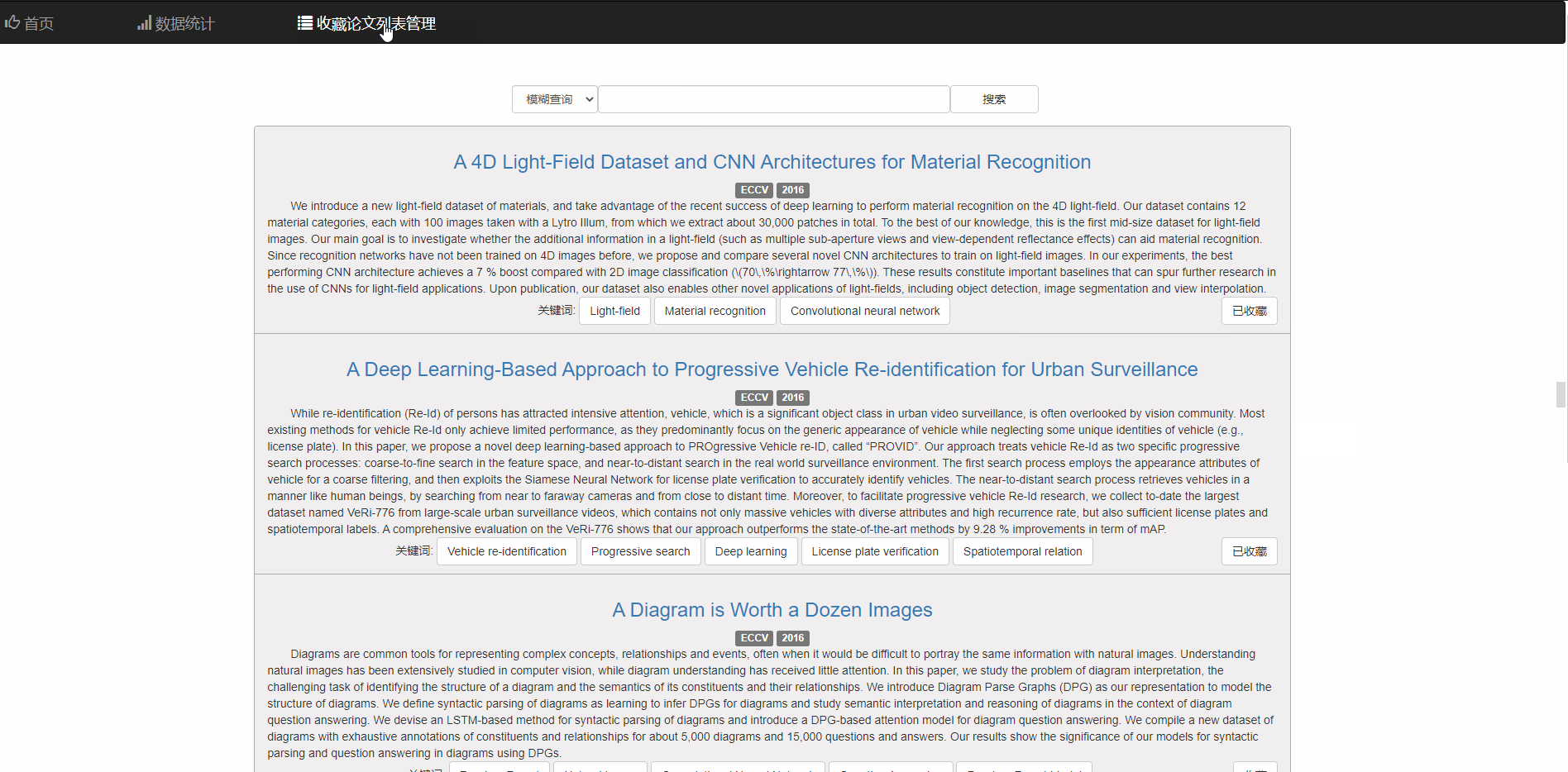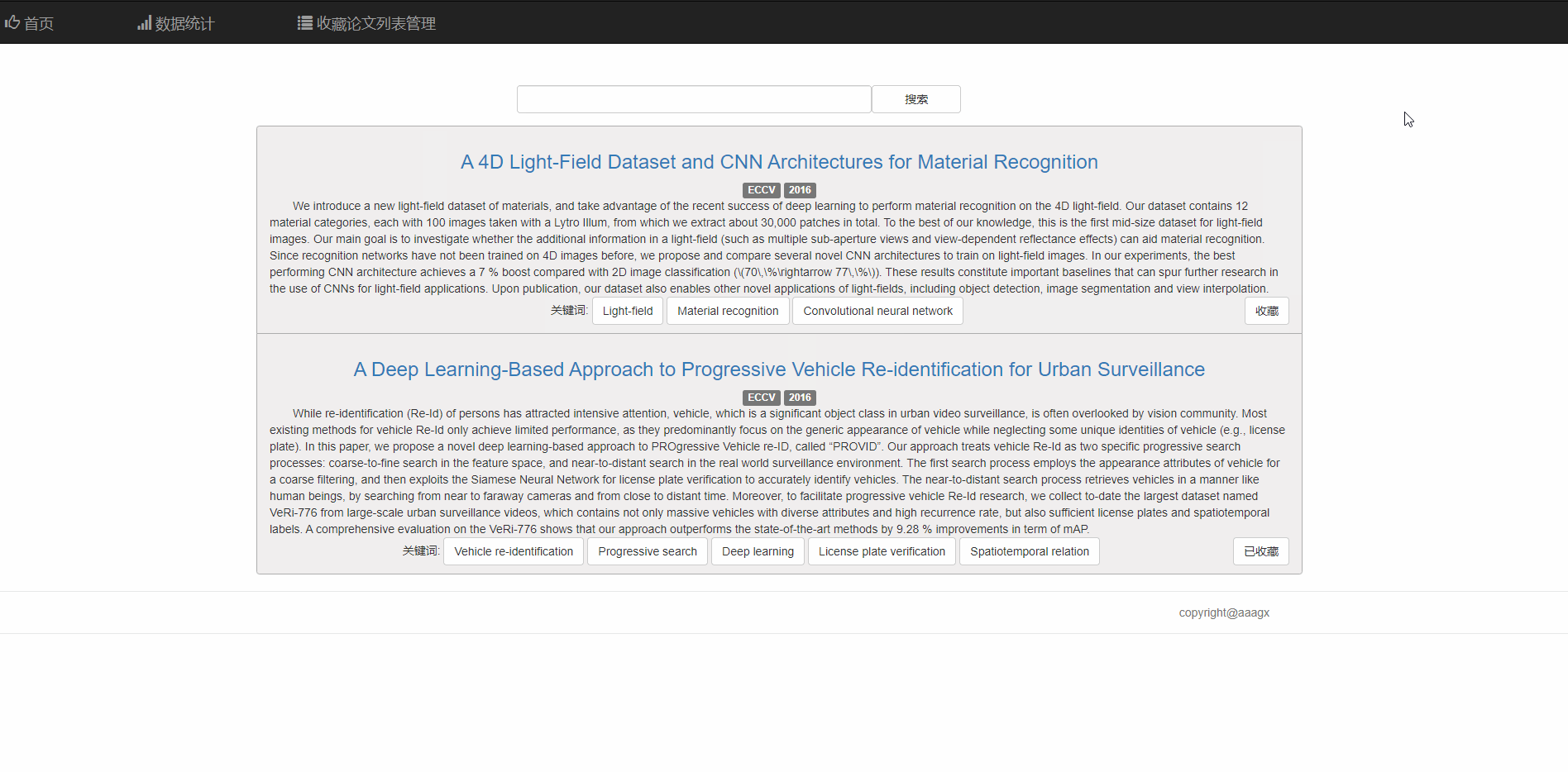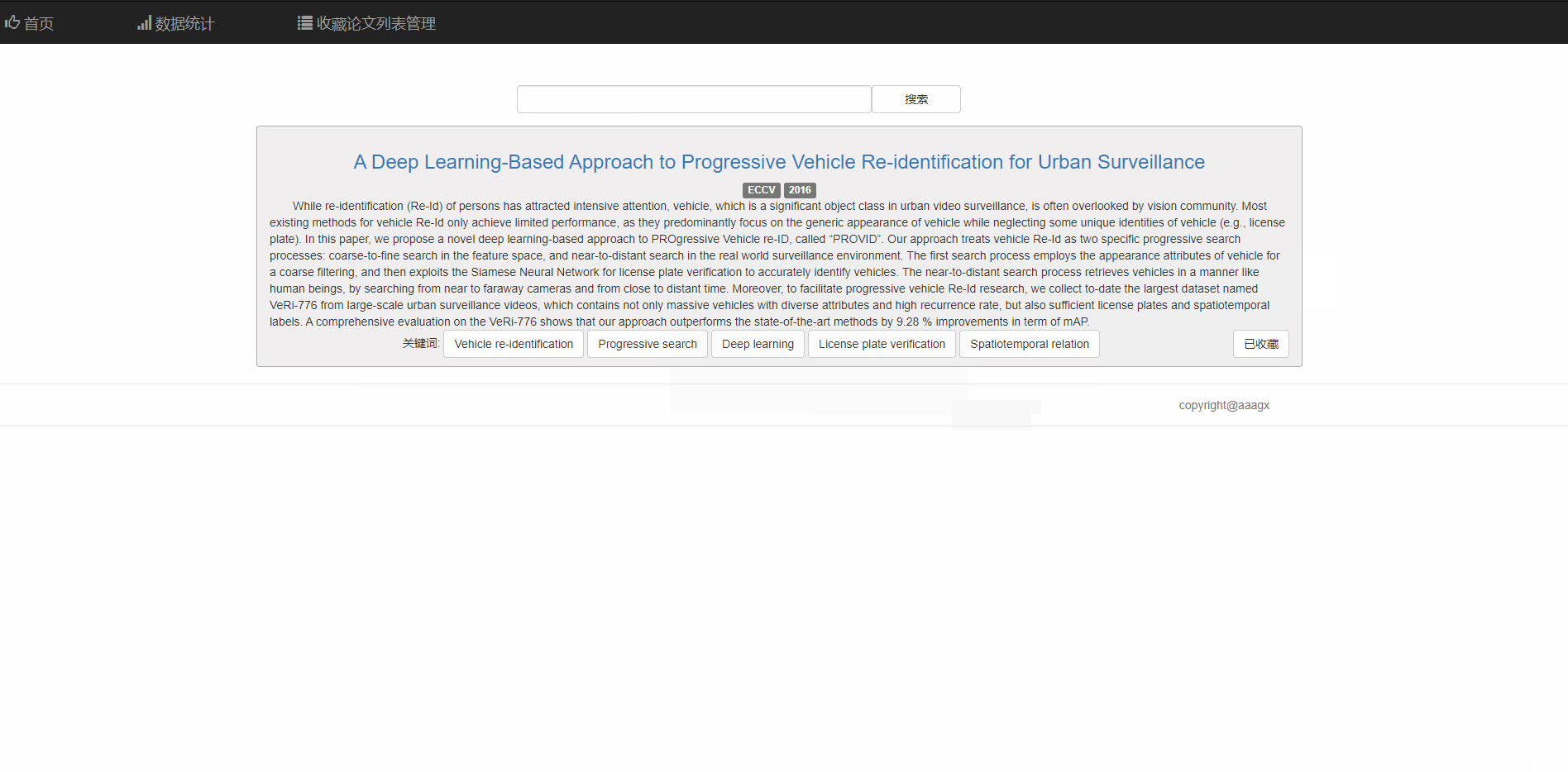
成品展示
首页部分
首页为论文查询入口,顶栏部分分为首页、数据统计、收藏论文列表

搜索功能
可以通过四种方式进行搜索,包括模糊查询、题目、关键词、文章内容

如根据关键词搜索Deep
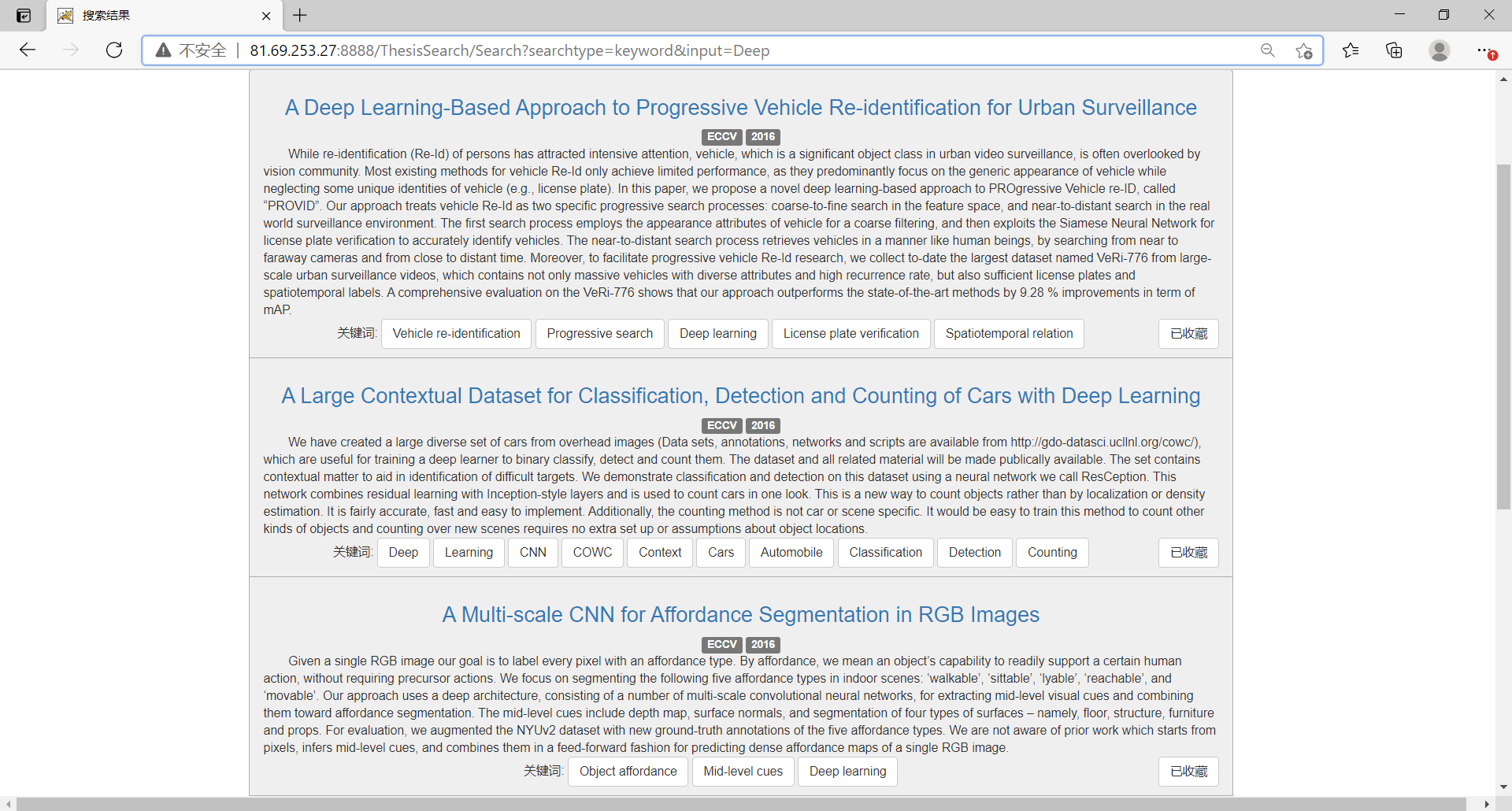
根据标题搜索UAV

可以分页显示论文列表
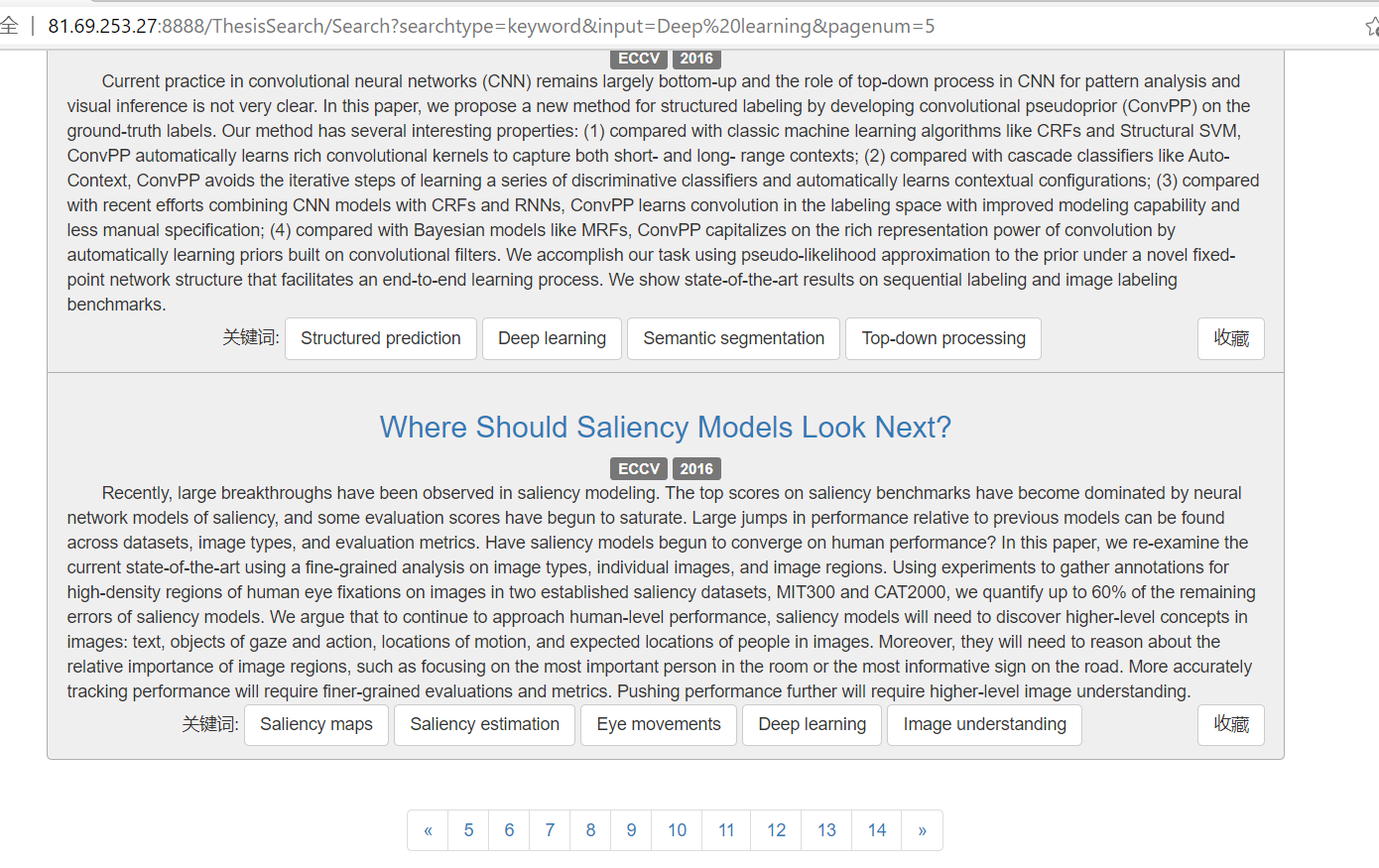
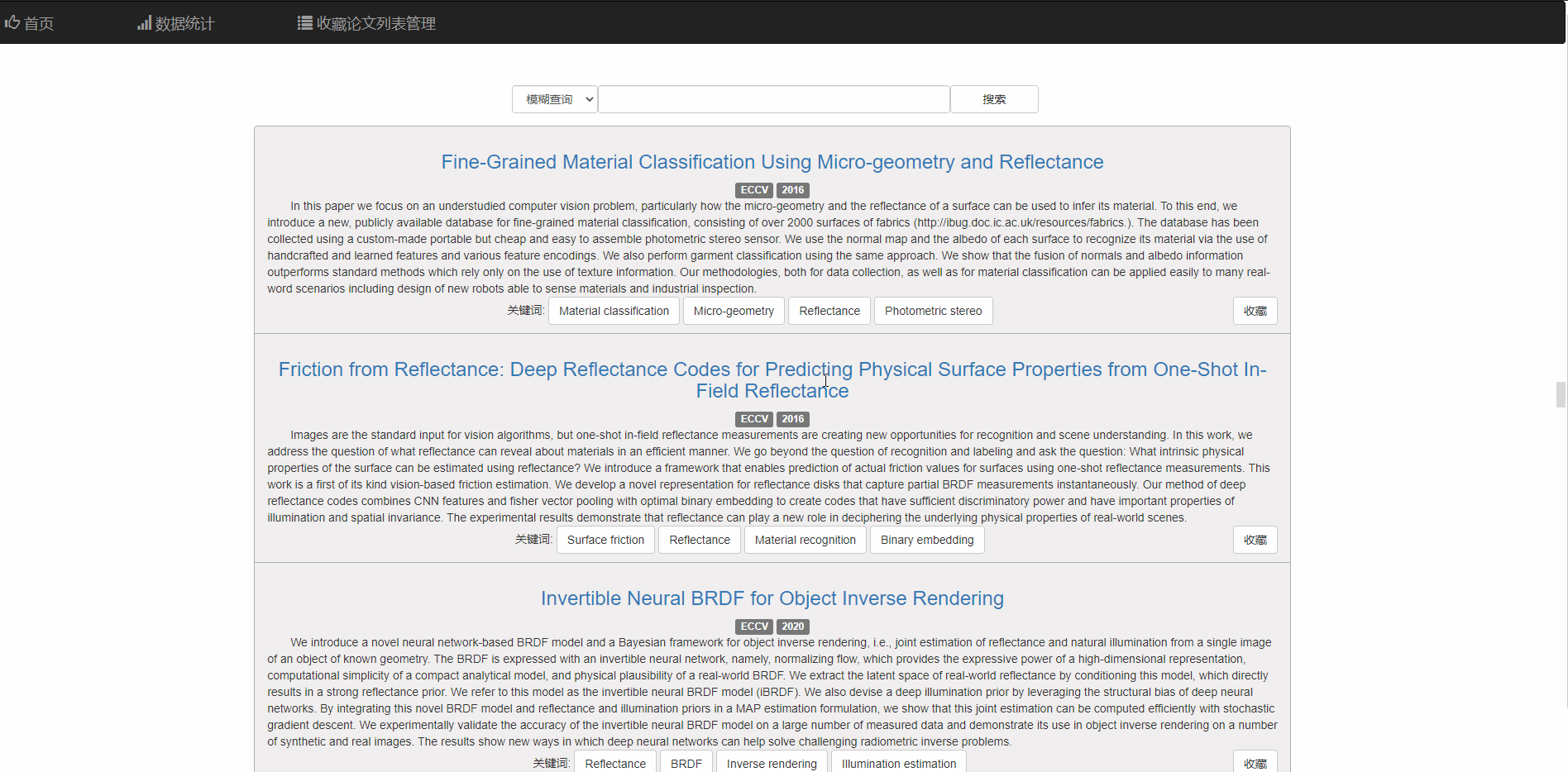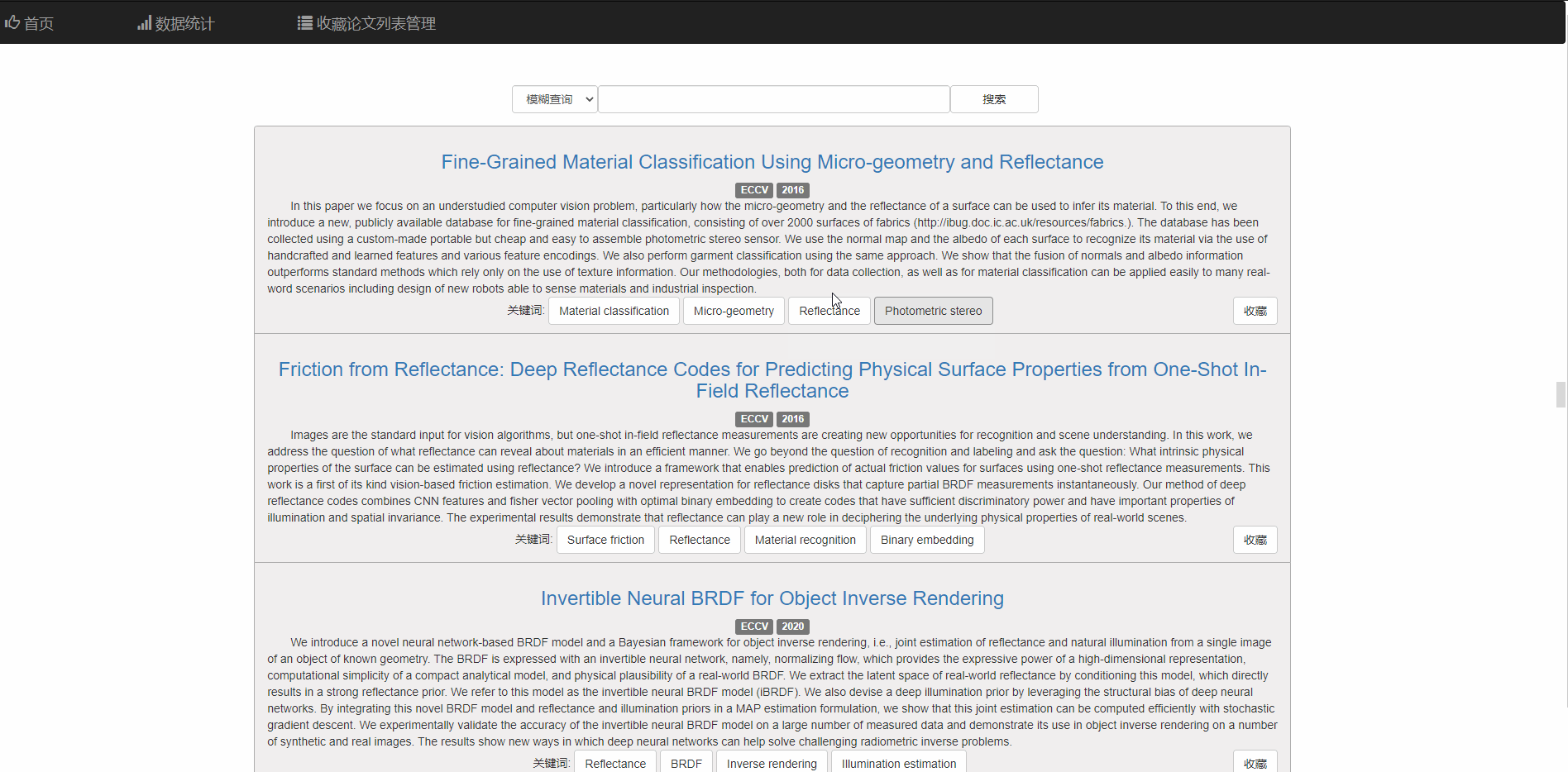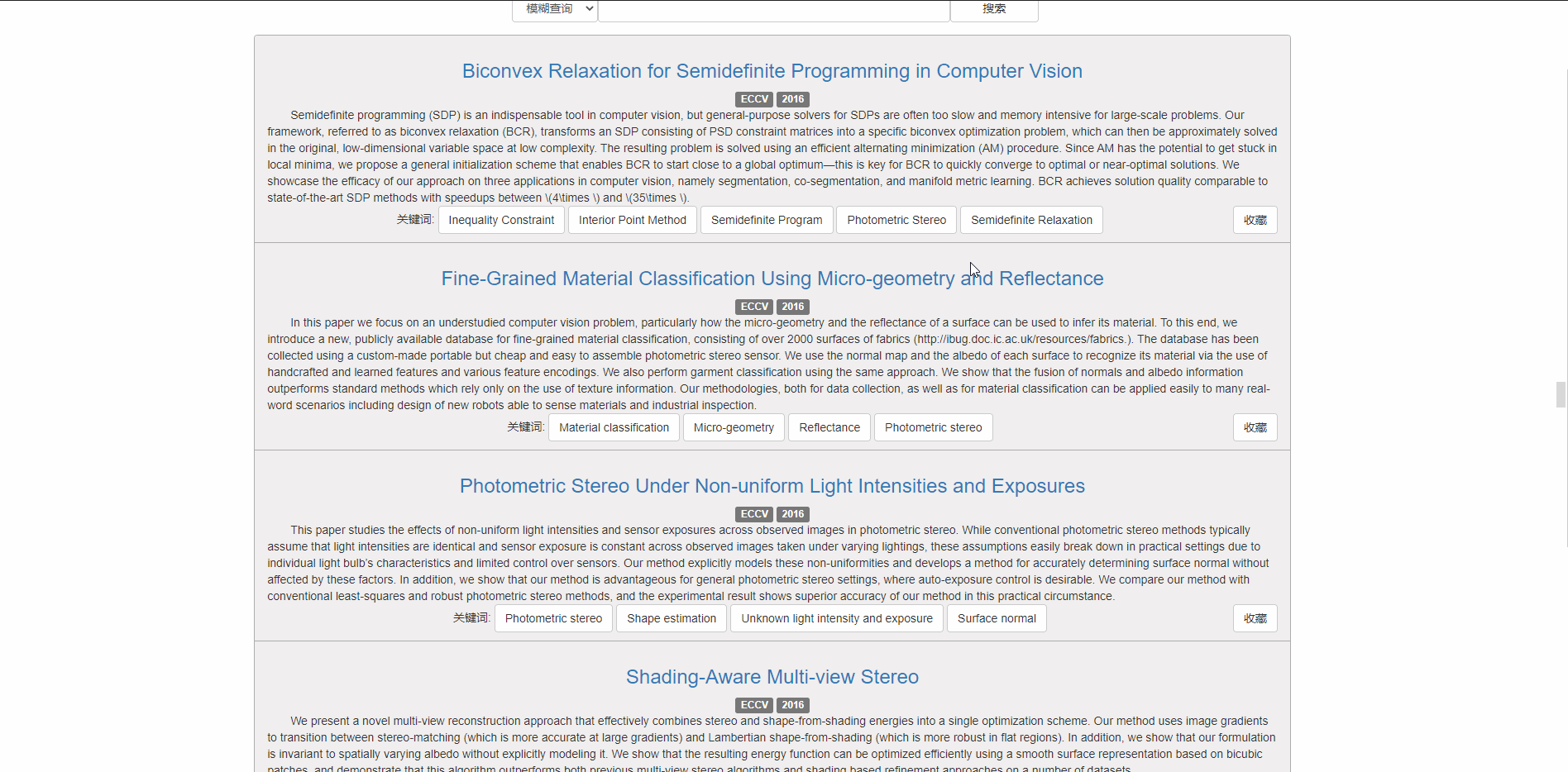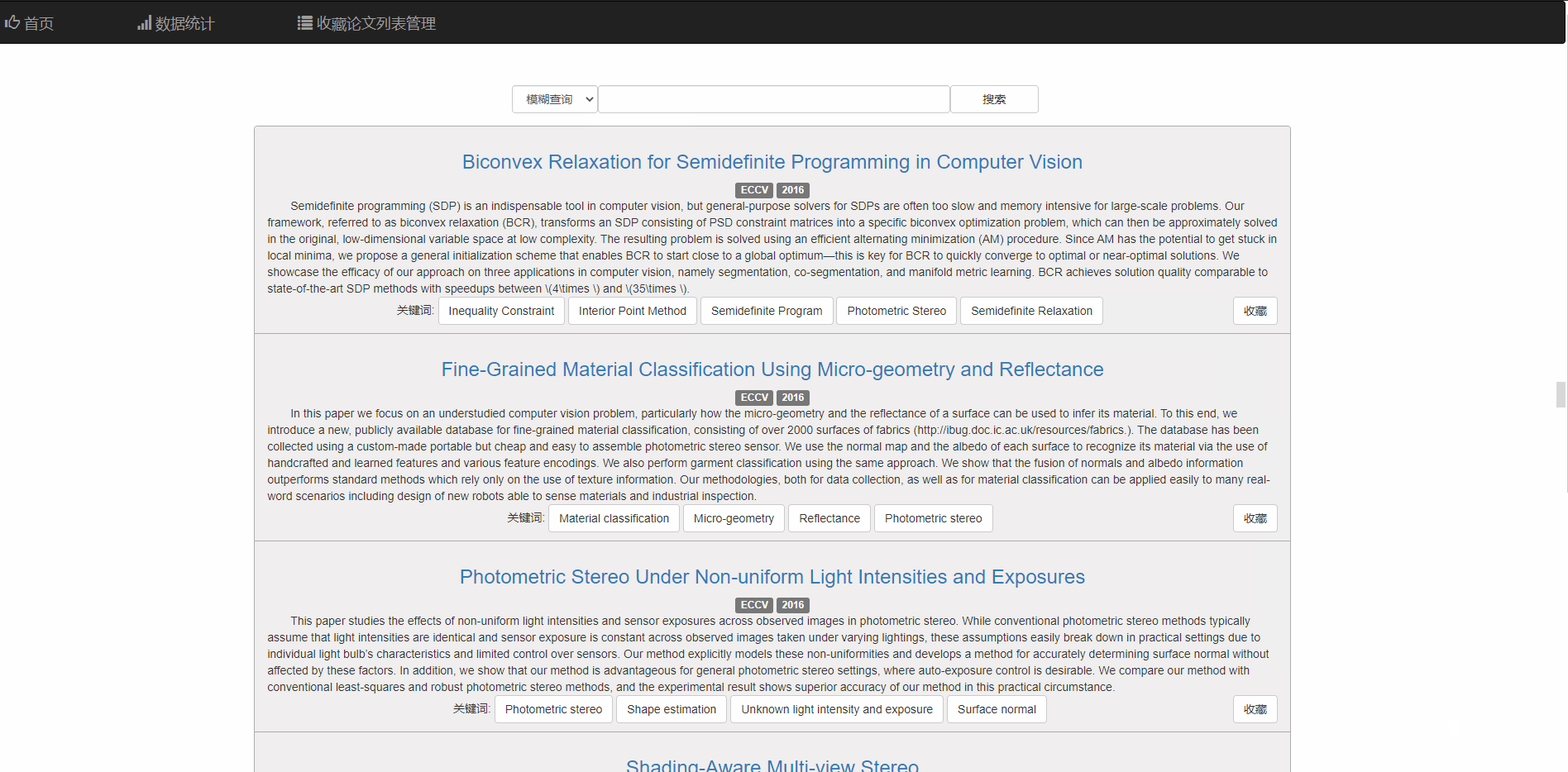
对于每篇论文,可点击标题到该论文的链接

也可以点击相关关键词查看相关论文 同时右下角的按钮支持收藏和取消收藏
数据统计部分
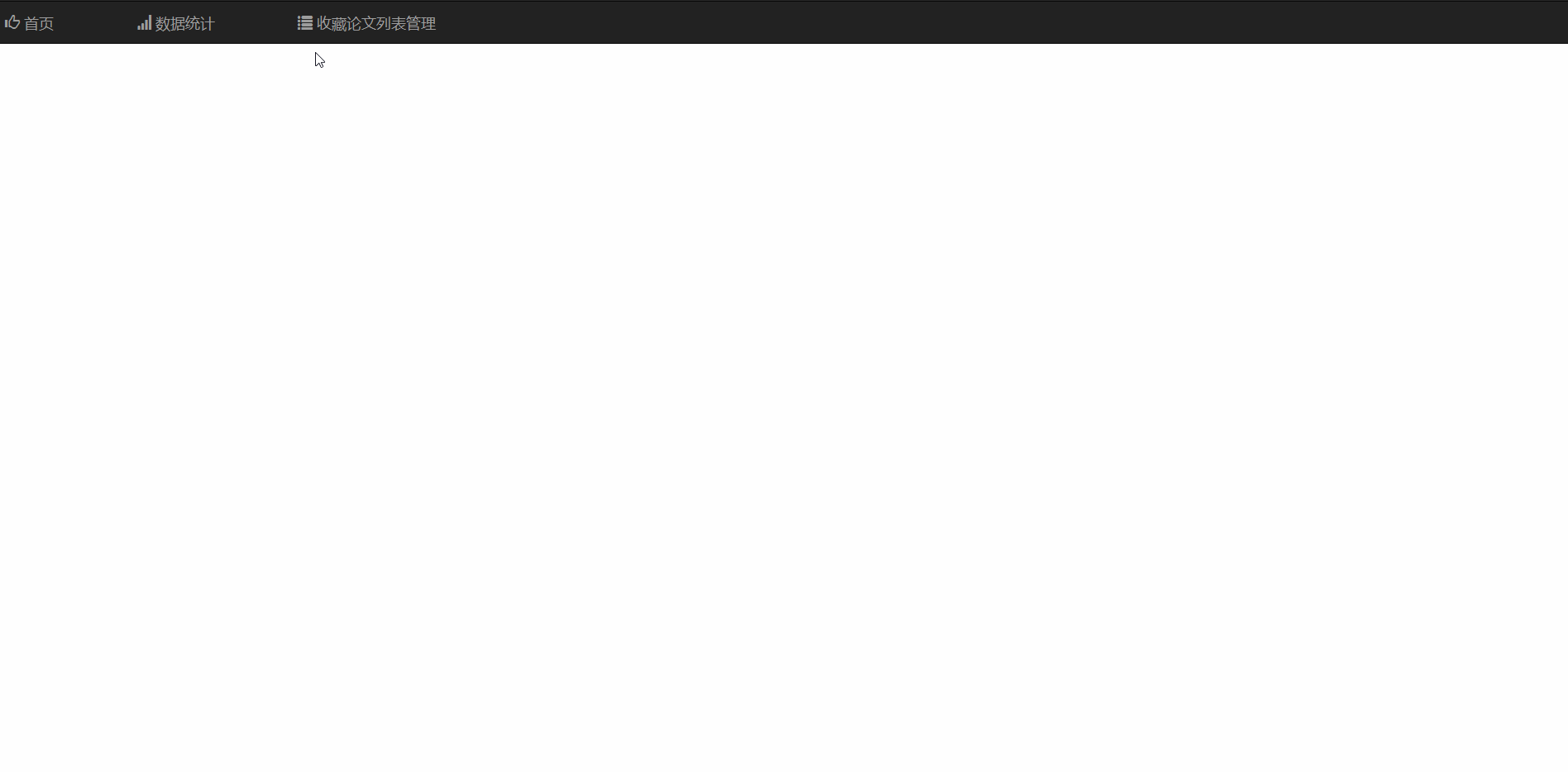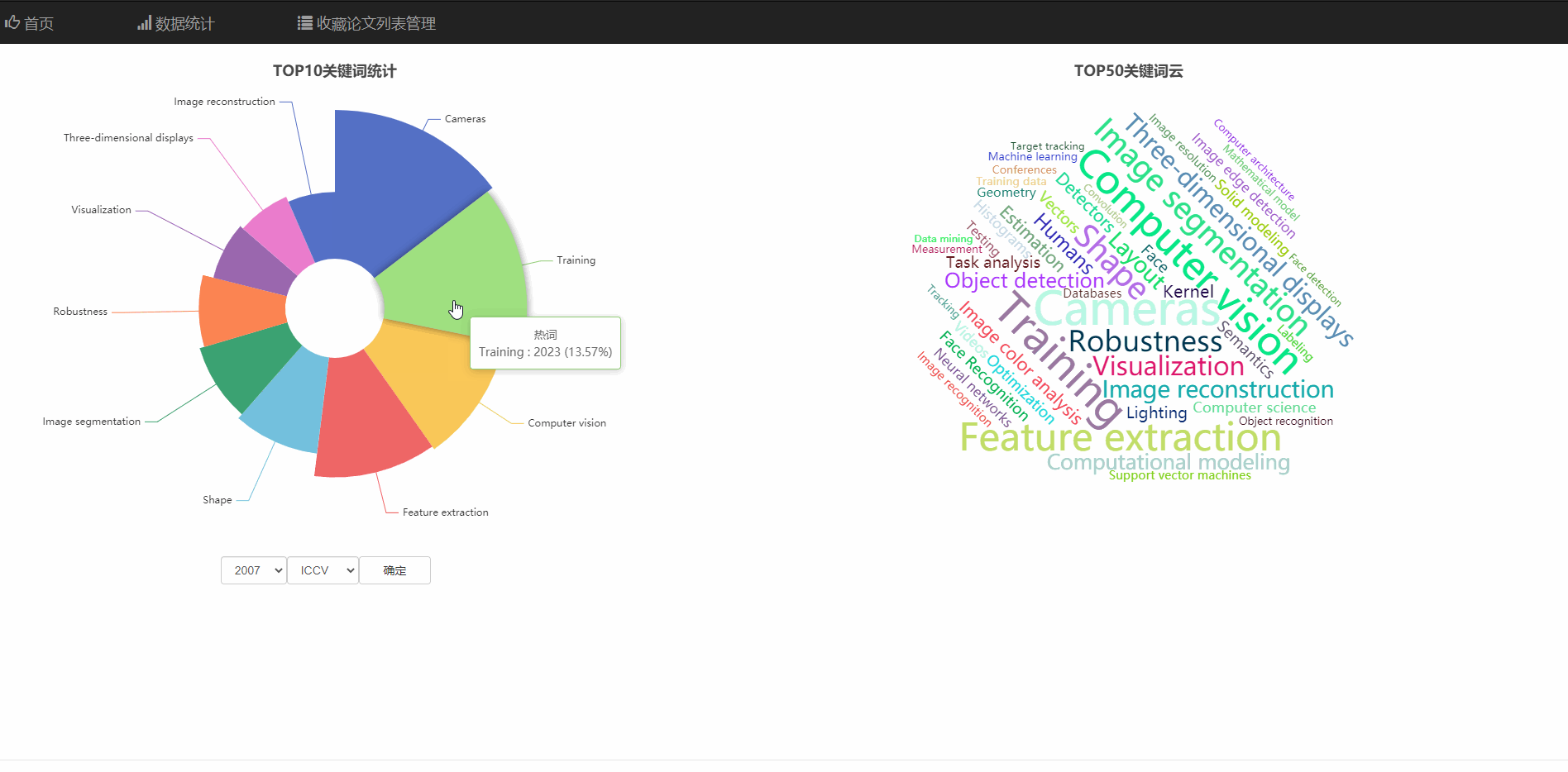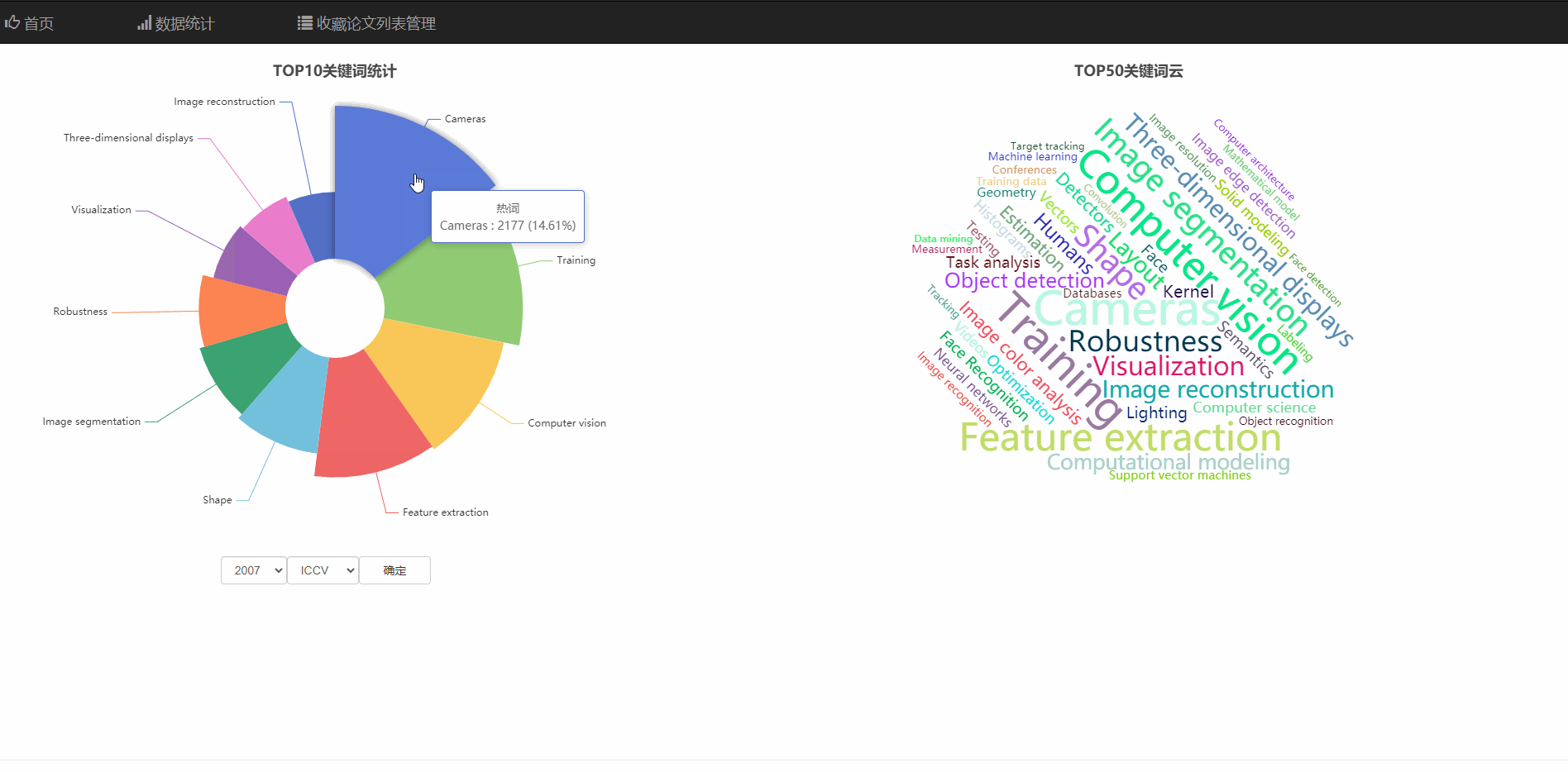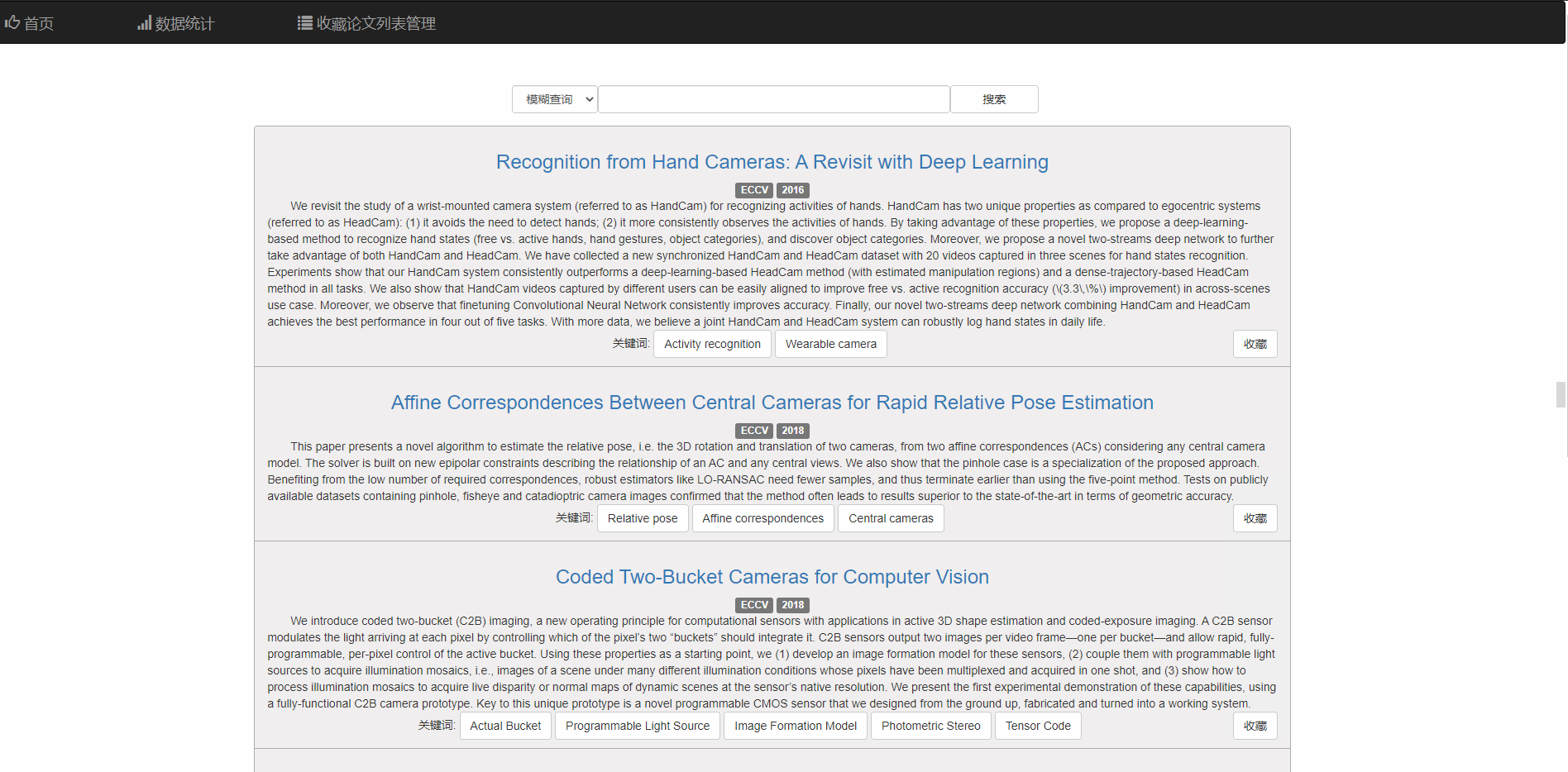
在数据统计页面中,可以查看热门领域的玫瑰统计图,和热词云图

可以查看不同年份、不同顶会的热门领域统计
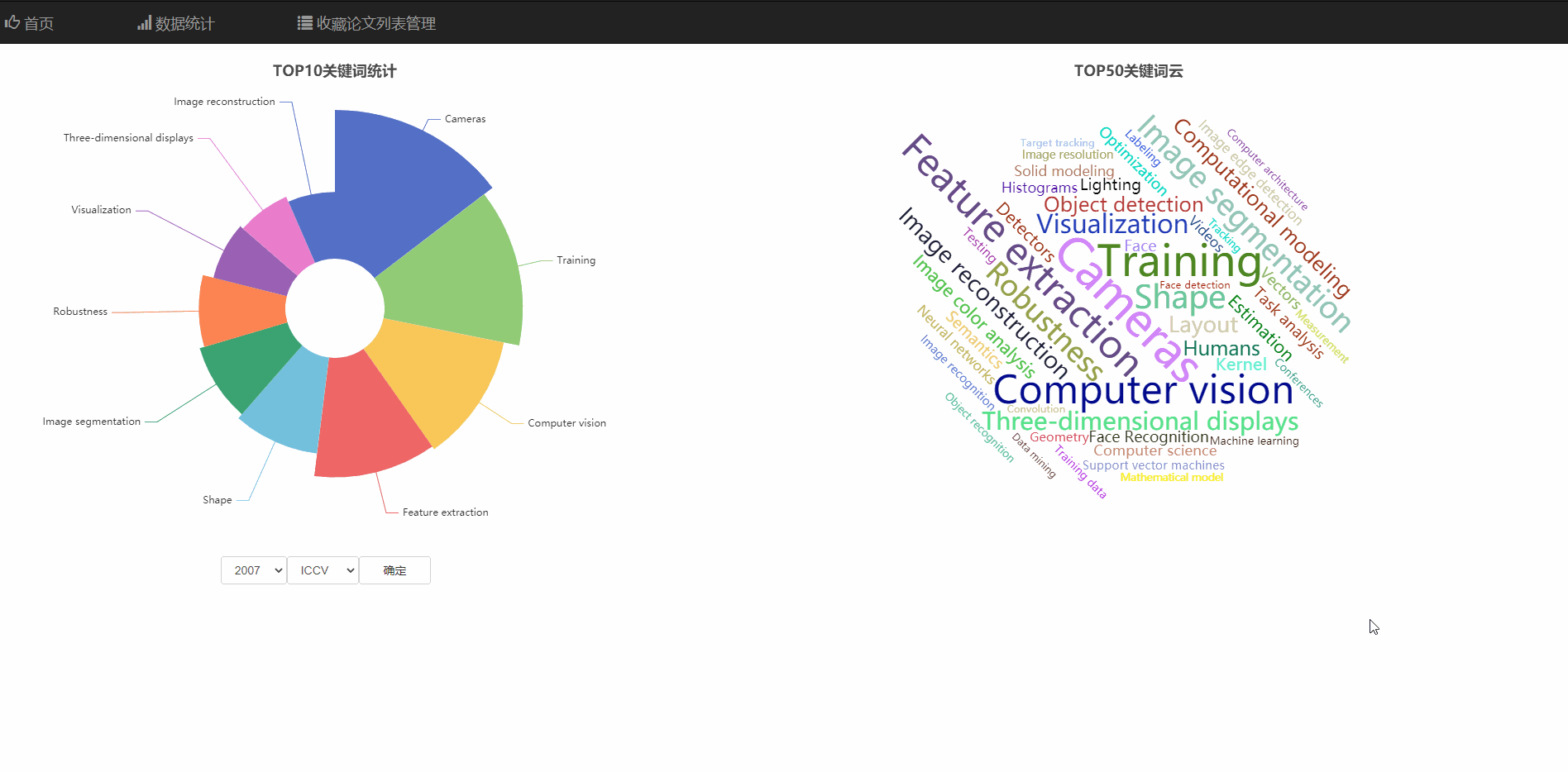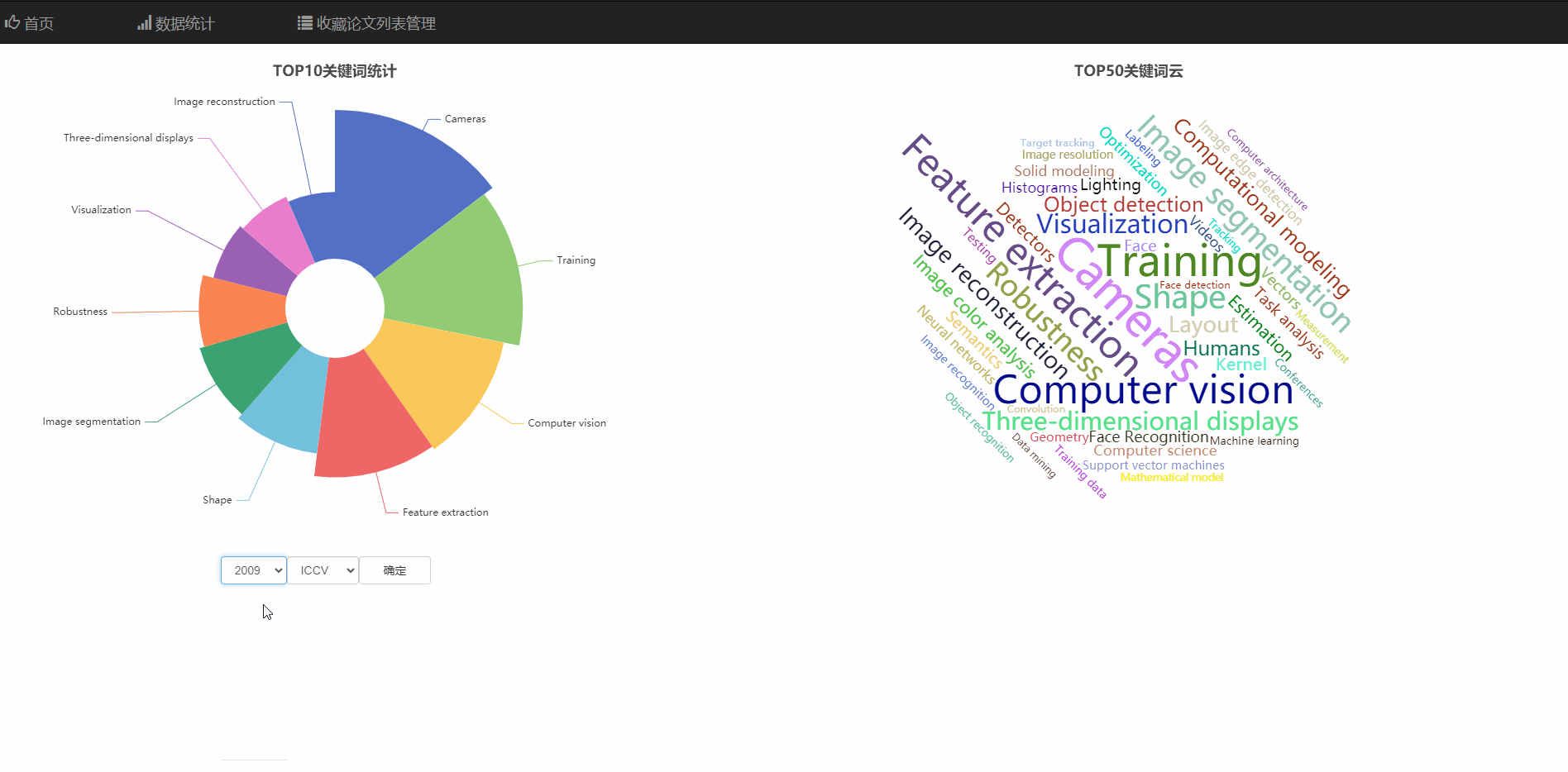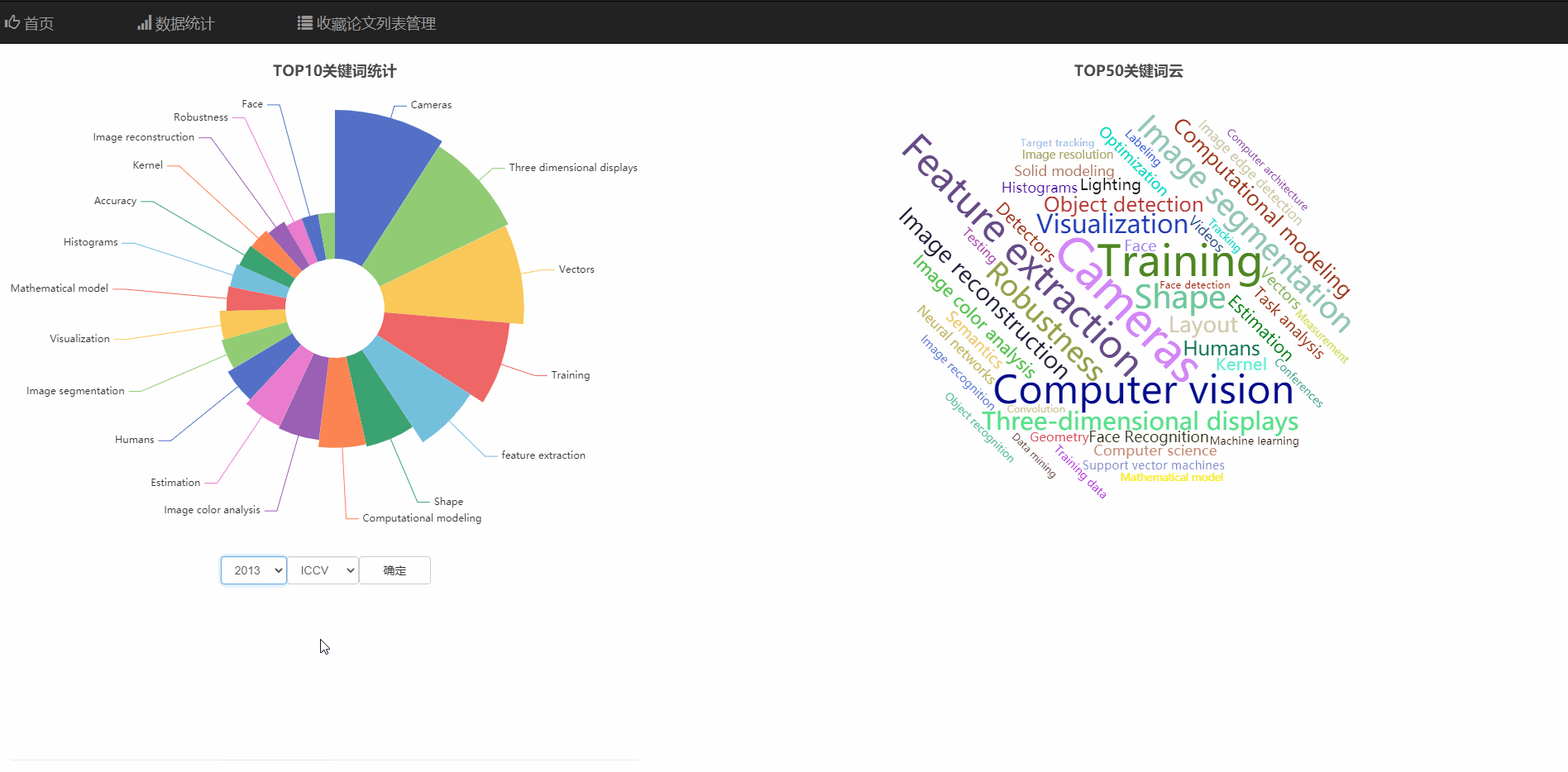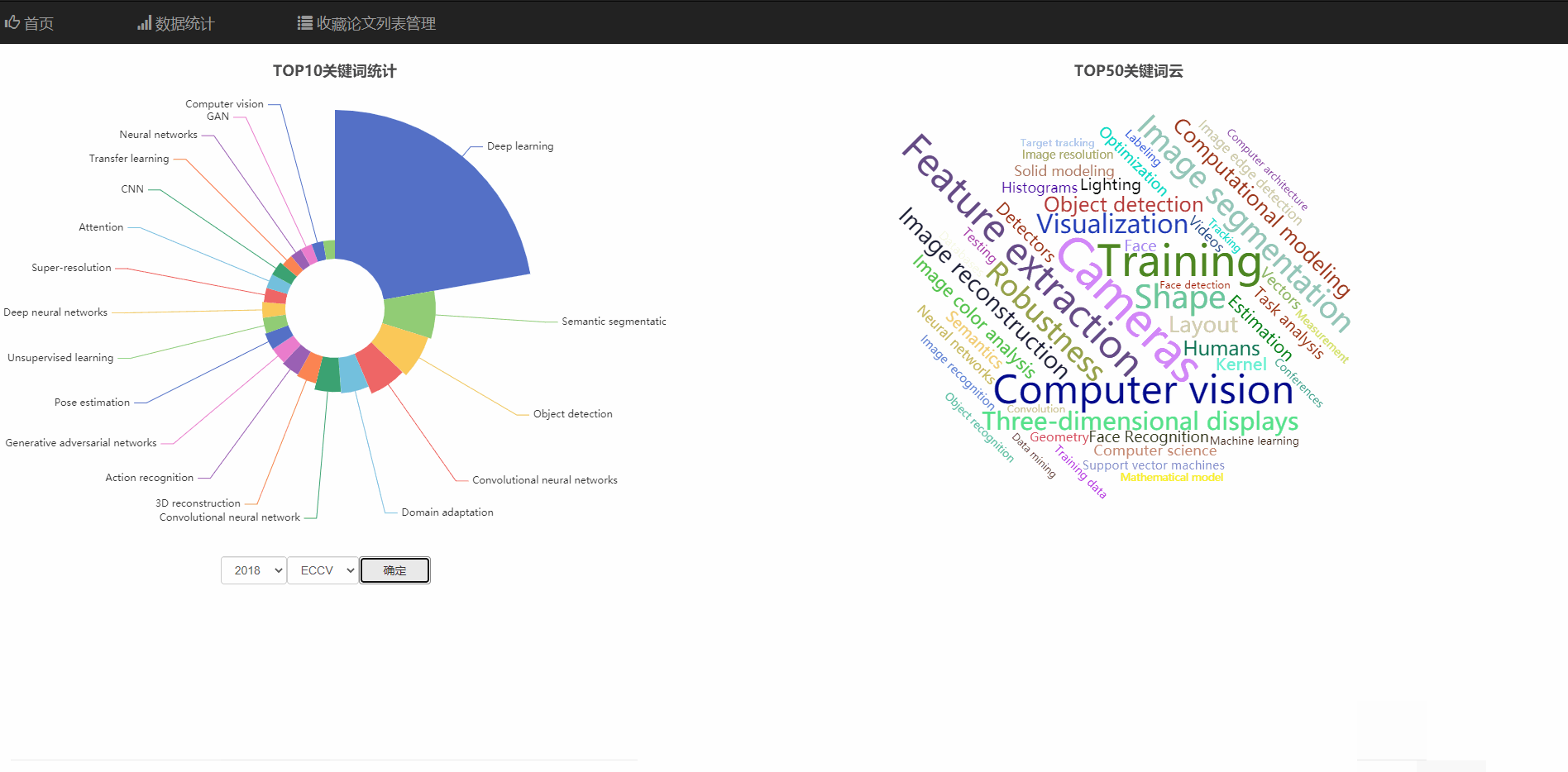
饼庄图是有大到小排序的可以看出热度的趋势
并且饼状图和词云支持通过直接点击图的部分跳转到对应关键词的搜索页
收藏列表部分
考虑到安全性的问题就没有给使用者提供直接移除数据库中论文的功能
而是通过为使用者维护一张收藏列表,使用者可以在搜索界面把中意的论文添加进收藏论文列表,并且再收藏论文列表中管理
在收藏论文列表中,可以查看已收藏的论文 并且可以模糊搜索已经收藏的论文,右下角的按钮同样支持取消收藏的功能。
结对讨论过程描述
讨论分工
关于热门领域统计的讨论
最后采用了玫瑰图来展现热门领域的统计
设计实现过程
这次作业是采用了servlet+jsp的方式实现开发的
前端的各种样式根据原型进行开发。
样式方面使用了bootstrap
一部分功能使用了js
与数据库的交互只使用了jdbc,没有使用框架。
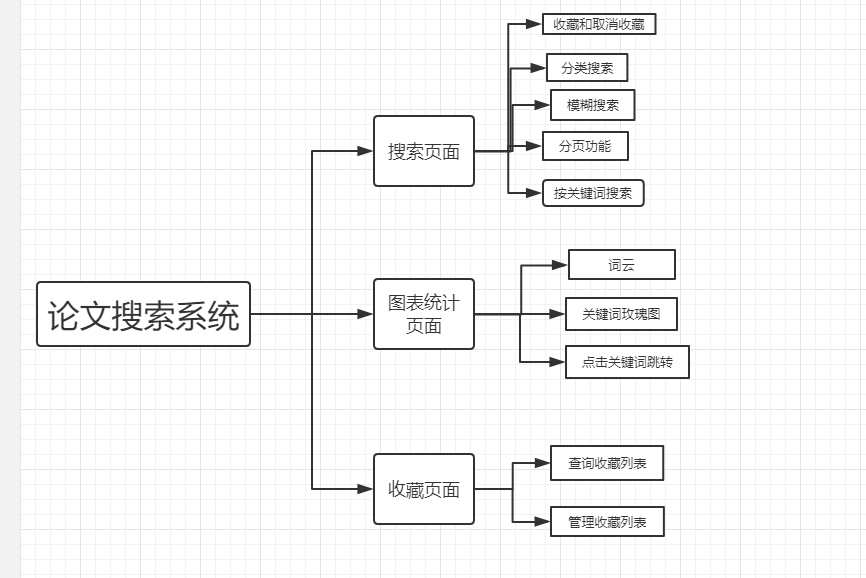
这次作业使用了jsp+servlet的方式,并没有实现前后端的分离,但采用了mvc的设计思想。
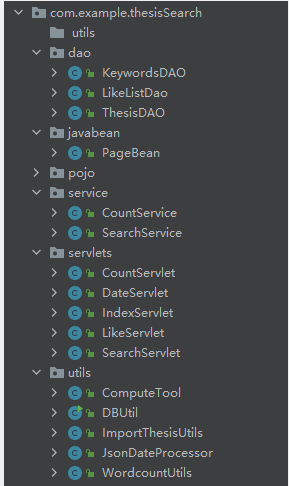
servlet只用来控制跳转和传参。
dao层则和数据交互 里面封装了jdbc的代码。
pojo则是一些数据模型类。
utils中是各种工具 包括创建数据库连接之类的。
service层则是封装了业务逻辑的类。
至于前端的显示则由jsp来负责。
处理一个请求的具体流程就是servlet调用service处理完业务逻辑 将结果转发给jsp呈现给用户。
还有一部分功能是由js调用ajax实现的。
代码说明
数据库设计
首先先介绍一下数据库设计,三张表分别对应三个功能
CREATE TABLE `Thesis` (
`title` varchar(255) CHARACTER
`thesisyear` int(20) NOT NULL,
`keyword` varchar(400) CHARACTER
`publishdate` varchar(255) CHARACTER
`link` varchar(255) CHARACTER NOT NULL,
`meeting` varchar(20) CHARACTER NOT NULL,
`abstract` varchar(4000) CHARACTER
`id` int(255) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`id`)
)
首先是用来存论文数据的表,搜索功能的实现就是在这个表中查找,值得一提的是keyword,直接通过一条字符串将所有keyword存在表中,虽然导致重复的存取,但搜索某一篇论文的时候不用再关联到另一个表一个一个取出keyword,让另一个表只负责关键词的统计和数量的计算,牺牲了一部分空间减少了执行查找语句的数量。作为主键的id是自增的,不用特别设计。
然后就可以根据这个表直接构建出对应的模型类
public class Thesis {
private String title;
private String date;
...}
然后是用于统计关键词的表keywords,表中ThesisID为外键,同样重复存取了meeting和ThesisYear帮助统计,不需要关联到Thesis表中执行统计。这种设计主要是考虑到这次数据库中的数据不算多,重复存取的开销不算大,如果是很大的数据就考虑用别的方法了
CREATE TABLE `Keywords` (
`keyword` varchar(255)
`ThesisID` int(255) NOT NULL,
`Thesisyear` int(20) NOT NULL,
`meeting` varchar(20) NOT NULL,
KEY `id` (`ThesisID`),
CONSTRAINT `id` FOREIGN KEY (`ThesisID`) REFERENCES `Thesis` (`id`) ON DELETE CASCADE ON UPDATE CASCADE
)
最后就是LikeList了,包含了descripson和作为外键的ID,原本一开始还想添加笔记功能和多用户功能,但由于时间和水平有限没有实现。实际上用上了只有论文id项目,但是还是保留了一定的拓展性,为日后添加功能留了空间。
CREATE TABLE `LikeList` (
`descripsion` varchar(255),
`ThesisID` int(255) ,
'UserID' int(255) ,
CONSTRAINT `ThesisID` FOREIGN KEY (`ThesisID`) REFERENCES `Thesis` (`id`) ON DELETE CASCADE ON UPDATE CASCADE
)
与数据库交互(dao)
首先创建一个jdbc的工具类 ,DButil,设置数据库地址和账户, 通过这个工具类快速获得数据库连接和关闭数据库连接。
public class DBUtil {
static String ip ;
static int port;
static String database;
static String encoding ;
static String loginName;
static String password ;
public static Connection getConnection() throws SQLException ;//获取连接
public static void close(ResultSet rs, Statement stmt, Connection conn);//关闭连接
}
然后所有数据库接口都按照和哪个表交互来设计
然后类中只封装着和数据库交互的代码,不包含任何业务逻辑,所有方法大概都是遵从如下流程设计
public void deleteBymeeting(String meeting)
{
Connection ThesisConnection = null;
try {
ThesisConnection = DBUtil.getConnection();//获取链接
Statement ThesisStatement = ThesisConnection.createStatement();
String sql = "delete from Thesis where meeting = '?'";//生成语句
PreparedStatement Ptmt = ThesisConnection.prepareStatement(sql);//预编译
Ptmt.setString(1, meeting);//插入值 防止sql注入
Ptmt.execute(sql);//执行
DBUtil.close(null,ThesisStatement,ThesisConnection);
} catch (SQLException throwables) {
throwables.printStackTrace();
}
//如有结果 在此处返回结果
}
执行业务逻辑(service)
所有的业务逻辑都被包含到service中,servlet和dao都不会去处理业务逻辑。
分页功能
由于是在搜索结果中分页,所以这部分方法就实现在SearchService中
首先实现一个pagebean模型类
public class PageBean {
private int PageNum;//当前所处页数
private int PageSize;//一页中含有几条记录
private int TotalRecord;//所有记录数
private int TotalPage;//所有页数
private String SearchType;//搜索类型
private String Input;//搜索的输入
private List<Thesis> list;//搜索到的论文结构
}
包含所有展示一个分页所需要的东西,之后这个东西会传递给jsp页面,jsp根据pagebean就可以显示对应的页面和生成页面跳转所需要的连接。
然后在service类中实现如下方法。
static public PageBean search(String type, String input,ThesisDAO SearchThesisDAO,int PageNum)
{
int TotalResultNum;
int SearchStart;
int SearchLength;
PageBean SearchResult=null;
//初始化
TotalResultNum=SearchThesisDAO.getNum(input,type);
//从数据库中获取一共有几条结果
SearchStart=(PageNum-1)*pagesize;
//通过当前所在页数计算出接下来数据库要从第几条结果开始取
SearchLength=PageNum*pagesize<TotalResultNum?5:TotalResultNum-(PageNum-1)*pagesize;
//通过当前所在页数和总页数和总共接过数计算出接下来数据库要取到第几条结果
SearchResult=new
PageBean(PageNum,pagesize,TotalResultNum,SearchThesisDAO.getLimit(SearchStart,SearchLength,input,type),type,input);
//构建一个pagebean并且传出
//getLimit(SearchStart,SearchLength,input,type) 取得从SearchStart开始 Searchend结束的论文条目 也就是当前页所拥有的搜索结果
return SearchResult;
}
传入参数和转发请求(servlet)
servlet大概就包含两种
处理需要跳转请求
public void doGet(HttpServletRequest request, HttpServletResponse response) throws IOException {
String type = (String) request.getParameter("searchtype");//获取参数
String input =(String) request.getParameter("input");
PageBean SearchResults=null;//执行封装好的业务逻辑并取得结果
SearchResults = SearchService.search(type, input, SearchThesisDAO, Integer.parseInt(request.getParameter("pagenum")));
//设置参数
request.setAttribute("result",SearchResults);
request.setAttribute("searchtype",type);
//转发请求给jsp 让jsp显示
try {
request.getRequestDispatcher("/WEB-INF/views/SearchResult.jsp").forward(request,response);
} catch (ServletException e) {
e.printStackTrace();
}
}
可以看出servlet只做出了简单的四件事,获取参数,执行逻辑,设置参数,转发请求。具体的逻辑都包含在service类中了,显得比较简洁,大部分功能都是按照这样设计的。
处理需要数据的请求
在不需要跳转至jsp时,一些servlet还需要有将结果打包成json字符串发送。来处理前端的一些对于数据的请求
public void doGet(HttpServletRequest request, HttpServletResponse response) {
response.setContentType("application/json;charset=utf-8");// 指定返回的格式为JSON格式
response.setCharacterEncoding("UTF-8");
response.setHeader("Access-Control-Allow-Origin", "*");//跨域
//获取参数
....
//调用业务逻辑
...
//返回json字符串
try {
out = response.getWriter();
JSONArray Jarray = (JSONArray) JSON.toJSON(list);
out.write(Jarray.toJSONString());
} catch (IOException e) {
e.printStackTrace();
}
}
显示页面(JSP JS)
Jsp可以从request对象中直接获取servlet传来的对象,非常方便,并且直接用在页面的显示之中,省去处理json的步骤
例:显示搜索结果
<%PageBean Pb=(PageBean) request.getAttribute("result");
List<Thesis> result=Pb.getList();
if(result.size()!=0)
{
for(Thesis i:result)
{%>
<li class="list-group-item thesis-item">
<h3><a href="<%=i.getLink()%>"><%=i.getTitle()%></a></h3>//显示标题
<span class="label label-default"><%=i.getMeeting()%></span>//显示会议
<span class="label label-default"><%=i.getYear()%></span>//显示年份
<div class='thesis-content'><%=i.getAbstractContent()%>
</div>
</li>
<%}
但是预见图表时碰到了困难,因为图表的各种参数是在js中实现的,直接将js写在jsp中显得很臃肿,因此这部分改为传统的通过ajax对servlet发出请求获取json数据,并且设置图表的参数
function genData(count) {
var legendData = [];
var seriesData = [];
$.ajax({
url: "Count?count="+count,
dataType: "json", //数据格式
type: "get", //请求方式
async: false, //是否异步请求
success: function (data) {
//如果请求成功,返回数据。
$.each(data, function (i, item) {
legendData.push(item.keyword);
seriesData.push({
name: item.keyword,
value: item.nums,
url:
"Search?searchtype=title&input=" +
item.keyword,
});
});
},
});
return {
legendData: legendData,
seriesData: seriesData,
};
总的来说,这次的代码没有用到很复杂的方法和算法,主要还是在做crud,因此这里主要就贴一些规范设计和我打代码的时候分层思想。
心路历程和收获
林逸晖:第一次设计一个完整的系统,发现不是那么容易的事情。熟练了对于servlet和jsp的使用。因为是第一次做,所以整了个前后端没有分离的系统,希望能在之后软件工程实践中能学习前后端分离的项目形式。
程文健:对于两人结对编程还是不熟悉,尽管中间插入了一次软件工程小组实践,学习了一下如何使用Git进行多人协作,但毕竟已经是结对后期了,所以整个过程中还是一一种野路子的方法进行的。有时候感觉GitHub挺麻烦的,还是直接qq传文件或者直接复制比较容易,导致一些commit可能有点问题,希望这一块以后能在实践中加强。虽然我负责的部分不多,但对前后端的处理有了一定的理解,之后的软工实践继续努力。
评价结对队友
TO 林逸晖:程文健对负责的任务做得还行,能发现一些细节上的问题,编码过程中也提出了有用的意见,在整个项目中还是起到了重要的作用。
TO 程文健:林逸晖实在是太强了我的哥!他的整体把控能力很好,整个项目做下来有条不紊,感觉我只是个腿部挂件。他真的……为什么这么……我真的……我不会形容,他真的太强了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号