软工实践寒假作业(2/2)
| 这个作业属于哪个课程 | 2021春软件工程实践|W班 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业(2/2) |
| 这个作业的目标 | 1.阅读《构建之法》,提出5-10个问题 2.设计一个程序,能够满足一些词频统计的需求 |
| 其他参考文献 | 《构建之法》 |
part1:阅读《构建之法》并提问
问题一
2.3 个人开发流程
工程师在“需求分析”和“测试”这两方面明显地要花更多时间(多60%以上);但是在具体编码上,工程师比学生要少花1/3的时间
显然,从学生到职业程序员,并不是更加没完没了地写程序————花在写代码上的时间反而少了许多
我认为这个结论是有问题的。文章对比的是学生和程序员在PSP表中的百分比数据,而非绝对时长,不能说工程师在“需求分析”和“测试”中花的时间多,或者说在编码上花的时间少。只能说明学生花在编码上的时间占比更高,学生花了相对比例更多的时间在编码上,而这也是情有可原的:以我的经历而言,学生时代初期大多时间花在具体某个算法,或者某个函数上,当需要编写较为大型的项目,需要把各种算法、函数、类集合在一起实现某种功能时,不是说把这些算法、函数、类写完堆一起就完事了,而是要花很多经历编写各个部分之间的接口、调用、异常之类相对繁琐的事情上。而职业程序员对这些应该是有丰富的经验,所以他们花在编码上的时间相对更少一些。
问题二
4.5 结对编程
在结对编程模式下,一对程序员肩并肩、平等地、互补地进行开发工作。
驾驶员:控制键盘输入。领航员:起到领航、提醒的作用。
驾驶员和领航员不断轮换角色,领航员要控制时间。
只有水平上的差异,没有级别上的差异。
这一小节让我感到十分新奇,也是第一次接触这种思想。现实生活中类似的搭档关系,如飞机驾驶员和副驾驶,战场上的狙击手和观察员,这些搭档一般不会互相轮换角色,但是结对编程中的两个人却可以不断轮换角色。但是我认为这样一对组合还是会有大体分工的,一个人更多的作为驾驶员,而另一个人更多的作为领航员。
而我想到的问题是,如果结对编程的两个人,在水平上有高低之分,那么是高水平的人更多作为驾驶员,还是低水平的更多作为驾驶员。换句话说,驾驶员和领航员哪一个需要更高的水平?
思考之后我认为,由于驾驶员控制键盘输出,会被此分心,而领航员全程专注于项目,需要更高水平来进行指导、检查、纠错等。
问题三
5.2 软件团队的模式
软件团队又各种形式,适用于不同的人员和需求。
包括 主治医师模式、明星模式、社区模式、业余剧团模式、秘密团队、特供团队、交响乐团模式、爵士乐模式、功能团队模式、官僚模式
这一节介绍了各种形式的软件开发模式,而这些模式是基于不同的人员和需求锁形成,而我想知道面对一些外部因素,哪一种开发模式更加稳定。比如当团队中突然有人员变动发生,哪一种开发模式能平稳过渡。或者是开发需求突然有重大变化,哪一种开发模式能迅速转型。
深入了解了各个开发模式的区别后,我对自己的问题有了一些看法。主治医师模式和明星模式基本不用担心非核心人物的人员变动,因为主导权掌握在“主治医师”和“明星”手中,只要核心不变,整个团队就能平稳过渡。而爵士乐模式面对突然改变的需求,能迅速转型,因为这种模式对变化的内容能给予有创意的回应。
问题四
6.1 敏捷的流程简介
产品订单上的任务被进一步细化了,被分解为以小时为单位。
冲刺期间,团队通过每日例会来进行面对面的交流,团队成员大多站着开会,所以又称为每日立会。
每日立会强迫每个人向同伴报告进度,迫使大家把问题摆在明面上。
同时团队要启动每日构建,让大家每天都能看到一个逐渐完善的版本。
敏捷流程能加强团队交流,但过于频繁的交流(每日立会),甚至是强迫交流,会不会使得开发人员的思维变得混乱?而这种每日立会是否有一些形式主义?在大型团队中进行每日立会,需要所有人都参与吗?如果所有人都必须参与的话,必然会浪费一些人的时间,因为不是所有人都能在同一时间完成手头上的工作,从而参加会议,而工作被打断是一件非常令人恼火的事情。是否可以拆分每日立会,让工作有依赖关系的成员进行高质量的单独小会。
这些问题不是我所能解答的,而是需要通过大量的工作经验才能摸索出一套独特的方法。
问题五
12 用户体验
以qq和微信为例,写一些我对于用户体验方面的疑惑。很多人说qq太繁重,什么个性主题、气泡、背景、字体、qq秀乱七八糟的,还集合了很多花里胡哨的功能,不像微信一样简洁。但事实上qq通过简单设置,同样能变得轻便简洁,但是qq能变得简单,微信却不能因人而异的变得更加有趣。而关键这一点,就在于设置。
在用户体验上,是应该给用户一个开关,还是说直接对功能进行阉割或是强制给予呢?大部分人会倾向于选择一个开关,但是再以小米手机系统为例,小米最新系统MIUI12,推出了一种新式下拉菜单,但同时也保留了旧的模式,用户可以通过一个开关来选择新旧模式。但问题出在MIUI系统中有很多新功能都被加了一个开关,导致整个系统处处都是开关,看上去选择是变得更多了,但实际上却变得更加臃肿,如果一个人换了手机,可能就需要很长时间才能调整好每一个开关,回到原先的设置。
所以说在软件更新中,是应该强制推出新功能让用户适应,即创造用户体验,还是应该保守一些,制作一个开关,让用户选择,或者干脆阉割新功能,以不变应万变?
附加题
1994年,Intel 为奔腾 CPU 的浮点除法指令 FDIV 加入了一种新型的实现。这是 Sweeney-Robertson-Tocher(SRT)算法的一种高性能变体,依赖了一个共有 2048 项的硬件查找表。因为这种算法只会访问整个 128x16 尺寸查找表中的一个梯形子集,所以这 2048 项中只有略多于一半的项会被用到。由于一些意外,这 1066 项中有 5 项的值被错误地设置为 0(而不是正确的 2),因此可能导致运算结果的错误。但是,这些错误的索引只会在极少数情况下被访问到,以至于这个问题没有被 Intel 研发流程中的随机测试所发现。
1994年10月,美国弗吉尼亚州Lynchburg College数学系教授Thomas Nicely为研究孪生质数,发现用电脑处理长除法时一直出错。他用一个数字去除以824,633,702,441时,答案一直是错误的。他在 1994 年的 10 月 24 日(程序员节)向 Intel 提出了反馈,并于 10 月 30 日向其他的一些联系人发送了报告问题的电子邮件,很快这个问题被发到网络上,引起了全世界计算机从业者们的兴趣。
挪威工程师 Terje Mathisen成功复现了 Nicely 教授的例子。他用汇编语言写了一个简单的测试用例。德国的 Andreas Kaiser 找到了 20 多个特殊的数字,这些数字的倒数在奔腾 CPU 上的计算精度只达到了单精度。加州 Vitesse 半导体公司的 FPU(浮点单元)设计师 Tim Coe分析推断出了 Intel 的 FPU 设计师们是如何设计除法电路的。
美国麻省一家公司的老板 Cleve Moler总结了 bug 规律,即除数都略少于 3 乘以 2 的某个整数次幂。基于自己找到的规律,Moler 开始与 Coe、Mathisen、Peter Tang(来自美国阿贡国家实验室),以及 Intel 的几位软硬件工程师合作,尝试解决这个 FDIV 错误。他们开发出了一种巧妙的修复方法:当除数有效位的八个高位是 00011111、01001111、01111111、10101111 或 11011111 时,将除数和被除数都同乘以 15/16。这项优化技术被公布到了新闻组,可供全社会无偿自由使用。
于是,报道「该公司修复了 Intel 奔腾 CPU 浮点数 bug」的新闻,迅速登上了包括纽约时报在内的各大主流媒体。这家当时还名不见经传的小公司,由此正式出现在了公众视野之中。而这家公司就是出品 MATLAB 的 MathWorks。
来源:最难调试修复的 bug 是怎样的? - doodlewind的回答 - 知乎
Pentium FDIV bug - 百度百科
part2:WordCount编程
Github项目地址
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 5days | 4days |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 60 | 90 |
| • Design Spec | • 生成设计文档 | 30 | 15 |
| • Design Review | • 设计复审 | 30 | 15 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| • Design | • 具体设计 | 30 | 60 |
| • Coding | • 具体编码 | 300 | 600 |
| • Code Review | • 代码复审 | 60 | 20 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 120 | 180 |
| Reporting | 报告 | ||
| • Test Repor | • 测试报告 | 30 | 30 |
| • Size Measurement | • 计算工作量 | 10 | 10 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 20 | 20 |
| 合计 | 710 | 1060 |
解题思路描述
看到题目就想到用split 函数对字符串进行切割,后来改成了速度更快的Stringtokenizer ,然后使用Map 保存单词和词频,这是最基本的功能。之后就是对词频表进行排序。而字符、单词、行数统计可以通过对输入文件的字符串进行操作计算获得。
代码规范制定链接
设计与实现过程
代码包括WordCount 和Lib 两个类,其中WordCount 是主类,Lib 是工具类,其中包括9个方法。
WordCount 中的main 有一个run 方法,接收两个文件路径,然后依次调用Lib类中的各个函数,包括读取文件,构造词频表,分别计算字符、单词、行数,对词频表排序,构造输出信息,输出文件。
- 各个函数之间的关系
| 接收 | 返回 | |
|---|---|---|
| 读取文件 | 无 | 内容字符串 |
| 计算字符、行数 | 内容字符串 | int 类型的字符数和行数 |
| 构造词频表 | 内容字符串 | Map 类型词频表 |
| 计算单词 | Map 类型词频表 | int 类型单词数 |
| 对词频表排序 | Map 类型词频表 | 词频字符串 |
| 构造输出信息 | int 类型字符数、行数、单词数和词频字符串 | 输出字符串 |
| 单词判断 | 字符串 | boolean类型 |
| 输出文件 | 输出字符串 | 无 |
- 最终工具类Lib包含
/** 读取文件 ...*/
public static String getFile(String filename)
/** 字符统计 ...*/
public static int countCharacters(String content)
/** 单词统计 ...*/
public static int countWords(Map<String, Integer> map)
/** 行数统计 ...*/
public static int countLines(String content)
/** 构造词频表 ...*/
public static Map<String, Integer> countFrequency(String content)
/** 对词频表排序 ...*/
public static String sortFrequency(Map<String, Integer> map, int num)
/** 构造输出文件的信息 ...*/
public static String answerBuilder(int chars, int words, int lines, String frequency)
/** 单词判断 ...*/
public static boolean IsWord(String word)
/** 输出文件 ...*/
public static void outputInfo(String output, String answerBuilder)
- 由于题目主要是词频统计,所以一开始就使用replaceAll 替换字符串中所有非英文数字的字符,使用Stringtokenizer 来分割读入的文件内容,采用HashMap 来记录词频,通过将HashMap 中的包含映射关系的视图entrySet 转换为List ,然后重写比较器对词频进行排序,这一段作为核心功能,从头到尾没有变过,之后为了功能拆分,将词频排序放在按字典顺序输出功能部分,下文会提到。
Map<String, Integer> map = new HashMap<>();
content=content.replaceAll("[^A-Za-z0-9]", " ");
StringTokenizer st = new StringTokenizer(content, " ");
while (st.hasMoreTokens()) {
String word = st.nextToken();
//将单词全部转为小写
word = word.toLowerCase();
//根据作业要求,判断截取字符串是否为单词
if (IsWord(word)) {
if (map.get(word) != null) {
int value = map.get(word);
value++;
map.put(word, value);
} else {
map.put(word, 1);
}
}
}
return map;
其后的工作主要是编写输入输出、字符数、单词数、行数和按字典顺序输出功能。
- 输入输出
开始使用FileReader 和BufferedReader 按行输入,但是发现这种方法不会记录换行符,导致字符数、行数统计出现问题,之后使用BufferedInputStream 和FileInputStream 输入,能获得所有字符,通过StringBuilder 的append 和toString 两个函数构造最后的文件内容字符串。以下代码段不包含try/catch部分。
byte[] buffer = new byte[1024];
//创建BufferedInputStream 对象
BufferedInputStream bi = new BufferedInputStream(new FileInputStream(filename));
int bytesRead;
//从文件中按字节读取内容,到文件尾部时read方法将返回-1
while ((bytesRead = bi.read(buffer)) != -1) {
//将读取的字节转为字符串对象
String temp = new String(buffer, 0, bytesRead);
content.append(temp);
}
return content.toString();
-
字符统计
开始使用按字符读取文件的方式计算字符,之后改写了输入方式,直接对获得的文件内容使用String 中的方法Length 获得字符数量。 -
单词统计
开始使用Stringtokenizer 分割字符串后,逐个判断计数,之后直接对词频表计算所有Value的和。
for (Integer value : map.values()) {
words += value;
}
- 行数统计
开始使用逐行输入计算行数,但是这个方法不会跳过空行,之后改写了输入方式,通过Stringtokenizer 对换行符切割,然后判断有效行进行计数。
StringTokenizer st = new StringTokenizer(content, "\n\r");
while (st.hasMoreTokens()){
String line = st.nextToken();
if(!line.trim().equals("")){
lines++;
}
}
- 按字典顺序输出
首先是词频排序,这个功能是最早写在获取词频表中的,之后划分到这一块,上文有提到过。
//将HashMap 中的包含映射关系的视图entrySet 转换为List ,然后重写比较器
List<Map.Entry<String, Integer>> list = new ArrayList<>(map.entrySet());
//idea自动转化成lambda表达式
list.sort((o1, o2) -> o2.getValue().compareTo(o1.getValue()));
之后按Value 大小,记录同Value 值的Key 成为同词频单词表,对该表按字典顺序排序后,记录Key 和Value ,获得前10个记录后,退出函数。
这一段代码显得有些复杂,但我暂时也想不出更好的优化方法了。
StringBuilder result = new StringBuilder();
//同词频单词表
List<String> sameFrequency = new ArrayList<>();
//输出统计
int outputCount = 0;
for (int i = 0; i < list.size() && outputCount < num; i++) {
//如果当前字符词频与下一个不一样,则对当前所有同词频单词排序
if ((i == list.size() - 1) || !list.get(i).getValue().equals(list.get(i + 1).getValue())) {
//将当前单词加入同词频单词表
sameFrequency.add(list.get(i).getKey());
//对同词频单词表排序
sameFrequency.sort(String::compareTo);
//按字典顺序记录同词频单词
for (String s : sameFrequency) {
String temp = s + ": " + list.get(i).getValue();
result.append(temp);
outputCount++;
if (outputCount != num) {
result.append("\n");
} else
break;
}
sameFrequency.clear();
} else sameFrequency.add(list.get(i).getKey());
}
return result.toString();
性能改进
1.使用Stringtokenizer 代替了split ,加快了分割字符的速度。
使用split

使用Stringtokenizer

2.使用StringBuilder 代替了String 的字符串拼接,加快了字符串拼接速度
使用String 拼接

使用StringBuilder
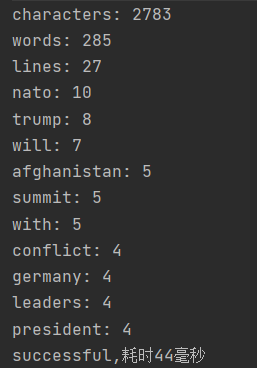
3.使用BufferedInputStream 和FileInputStream 输入,代替了BufferedReader 和FileReader ,用字节流读取代替了字符流读取,加快了读取速度。
开始时分别用按字符读取和按行读取计算字符数和行数,优化了输入函数了,调整了各个函数,使得一次读取就能进行字符和行数的读取。
使用字符流

使用字节流

在大文件读取上速度能加快近一倍
单元测试
- 统计字符测试
for (int i = 0; i < 128; i++) {
char ch = 'i';
sb.append(ch);
}
assertEquals(128, Lib.countCharacters(sb.toString()));
- 统计单词测试
String s = "abcd,abcd\nabcd abcd\r abcd(abcd) abcd+abcd-abcd abcd";
assertEquals(10, Lib.countWords(Lib.countFrequency(s)));
- 统计行数测试
String s = " \n \r \r\n a\na\ra\n\ra \na \ra \n\r a a \n a a \r a a \n\r";
assertEquals(9, Lib.countLines(s));
- 判断单词测试
String[] trueWords = {"abcd", "abcdef", "abcd123"};
String[] falseWords = {"a", "abc", "a1", "ab123", "123ab", "123456"};
for (String word : trueWords) {
assertTrue(Lib.IsWord(word));
}
for (String word : falseWords) {
assertFalse(Lib.IsWord(word));
}
- 统计词频测试
//构造一个包含字母、数字的字符串
String str = "abc abcd abcd abcd123 abcd123 123ab 123456 Lakers Champion GOGO gogo where amazing happens nice\n";
StringBuilder sb = new StringBuilder();
for (int i = 0; i < 1000; i++) {
sb.append(str);
}
String test = "..."
assertEquals(test, Lib.sortFrequency(Lib.countFrequency(sb.toString()), 10));
- 输入输出测试
String s = "abcd,abcd\nabcd abcd\r abcd(abcd) abcd+abcd-abcd abcd";
String path = "test.txt";
Lib.outputInfo(path, s);
assertEquals(s, Lib.getFile(path));
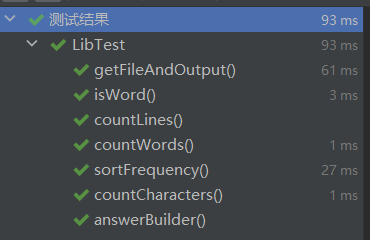
测试结果
覆盖率

其中WordCount 是主函数,单元测试的是Lib类中的各个功能
没有覆盖到的代码主要是catch模块。
异常处理说明
代码较为简单,除了IO异常,并无其他异常
心路历程与收获
了解了如何使用GitHub进行版本控制,不会再出现更新代码后发现bug,回不去的情况了,但是使用的时候还不够熟练,commit的时间点还是有问题,经常会有无效的commit出现,或者写着写着忘记commit,导致多个新增功能或者是多个不同的修改同时commit,这样代码复查起来就更麻烦了。
简单的进行了一些单元测试,只是最基本的测试,但也了解了单元测试的意义,希望在以后的项目中能利用到单元测试的更多功能。
了解了更多关于封装函数的知识,这次项目中的函数封装做的并不好,感觉还有很多提升空间,也希望之后的项目中能更好的封装。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号