

利用Python进行数据分析 第6章 数据加载、存储与文件格式(1)
学习时间:2019/10/20 周日下午17点开始。
学习目标:Page164-Page,共23页,目标3天学完,每天8页,预期1021学完。
实际反馈:第一天较为集中的学习7页,用时2.5小时。实际1025学完,耗时5天,2.5+5*1=7.5小时
- 输入输出通常可划分为几个大类:
读取文本文件和其他更高效的磁盘存储格式,加载数据库中的数据,利用Web API操作网络资源。
6.1 读写文本格式的数据
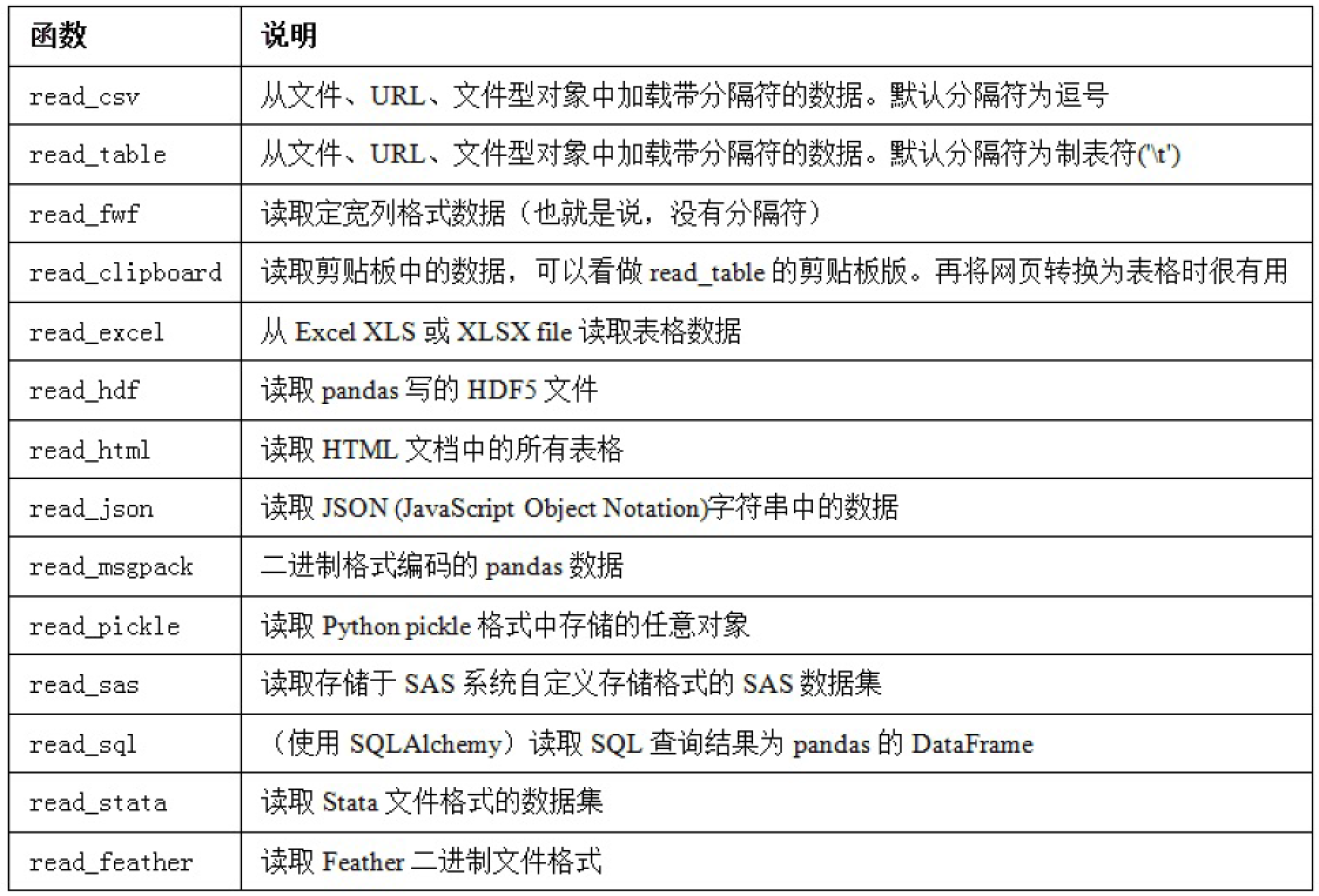
pandas提供了一些用于将表格型数据读取为DataFrame对象的函数,总结如下表。
其中,read_csv和read_table可能会在今后用的最多。
表6-1
Ps:简介这些函数在将文本数据转换为DataFrame时多用到的一些技术。这些函数的选项可划分为以下几个大类:
- 索引:将一个或多个列当做返回的DataFrame处理,以及是否从文件、用户获取列名。
- 类型推断和数据转换:包括用户定义值的转换、和自定义的缺失值标记列表等。
- 日期解析:包括组合功能,比如将分散在多个列中的日期时间信息组合成结果中的单个列。
- 迭代:支持对大文件进行逐块迭代。
- 不规整数据问题:跳过一些行、页脚、注释或其他一些不重要的东西(比如由成千上万个逗号隔离开的数值数据)。
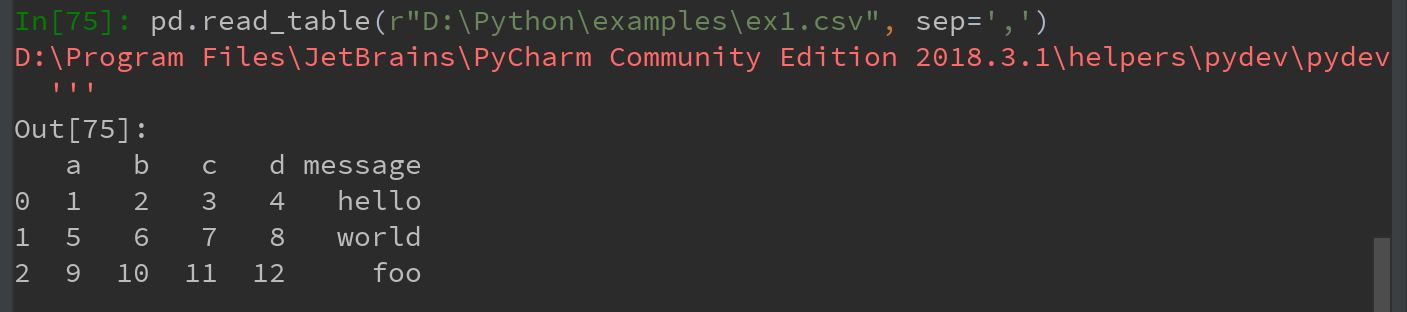
1)使用read_csv读取以逗号分隔的(CSV)文本文件:

Ps:Win环境下,文件路径的书写格式以下 3 种均正确:
df = pd.read_csv(r"D:\Python\examples\ex1.csv")
df1 = pd.read_csv("D:/Python/examples/ex1.csv")
df2 = pd.read_csv("D:\\Python\\examples\\ex1.csv")
2)还可使用read_table读取CSV文件,并指定分隔符:
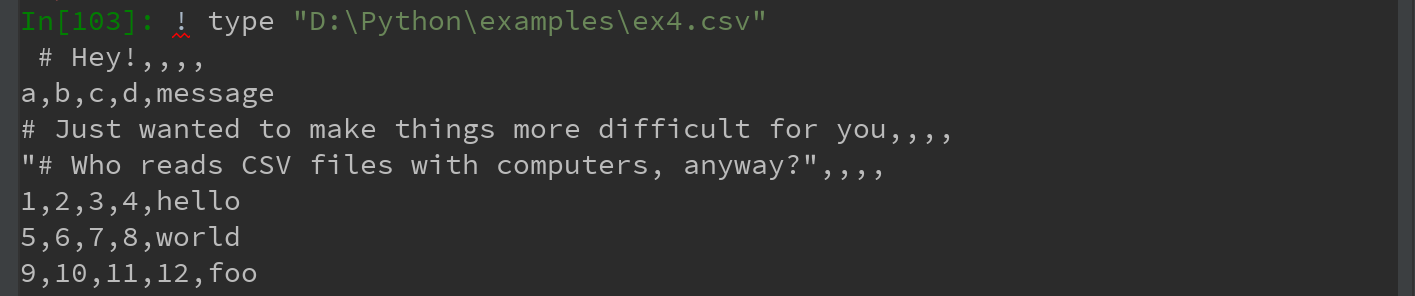
3)并非所有文件都有标题,如下图所示。读入该类文件有如下两种方法:
Ps1:win系统下,用cmd通过Type命令查看文件文本内容方法:
1 - 按下快捷键:WIN+R,调出运行窗口,输入:CMD;
2 - CMD的TYPE指令,语法:type 驱动器:\文件夹\文件名
3 - 示例:type D:\Python\examples\ex2.csv
Ps2:win系统下,IPython中通过type查看文件文本内容方法:
! type "D:\Python\examples\ex4.csv" ——绝对路径
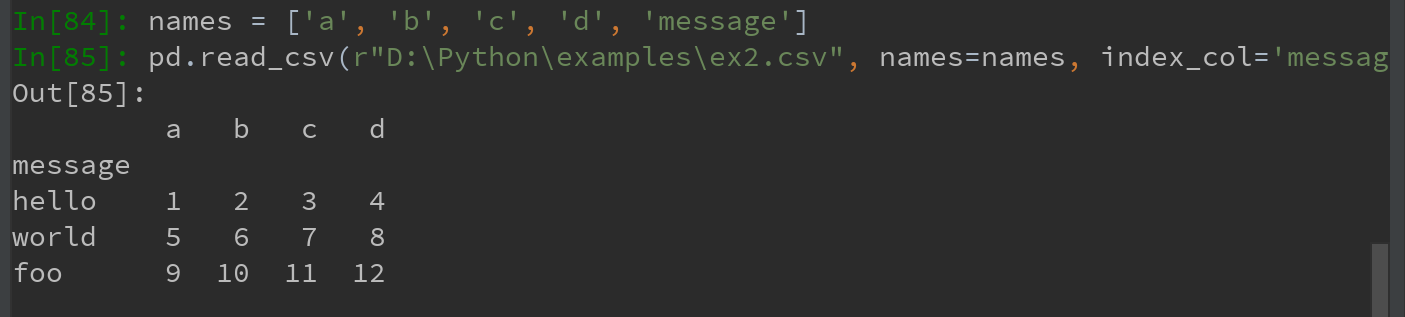
方法一:可以让pandas为其分配默认的列名;

方法二:利用pandas为其自定义列名:

Ps:如果希望将message列做成DataFrame的索引。可明确表示要将该列放到索引 4 的位置上,也可通过index_col参数指定“message”:
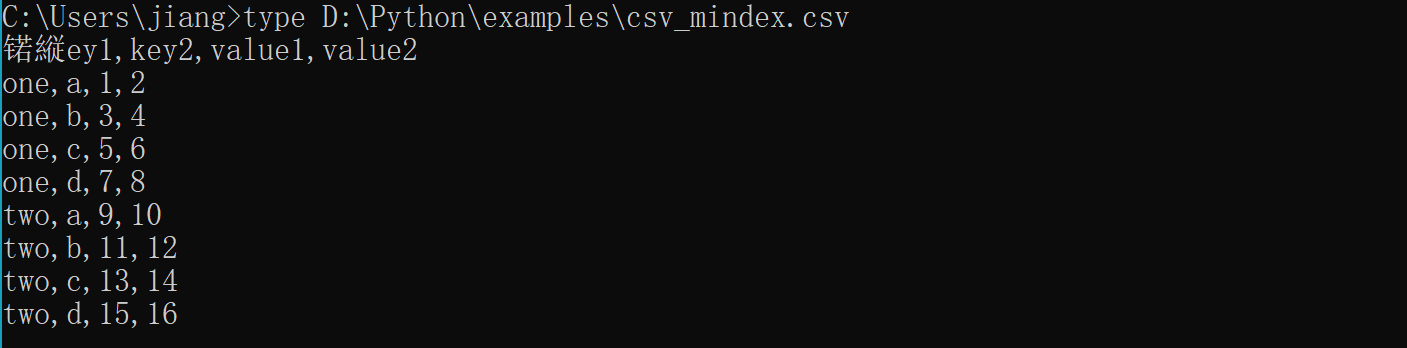
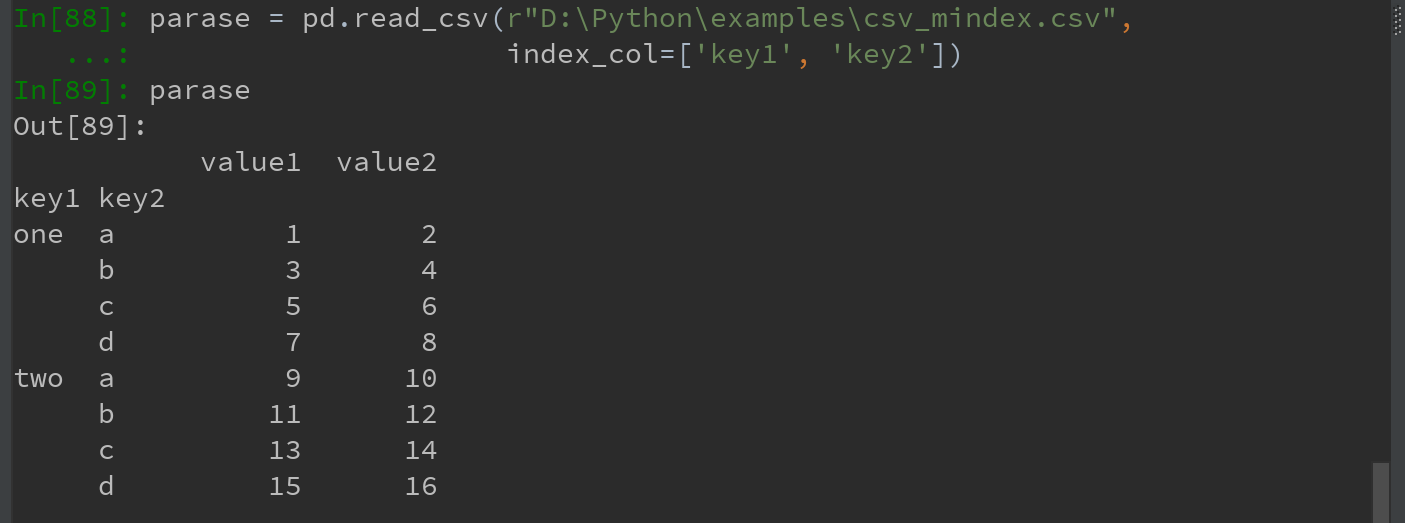
4)将多个列做成一个层次化索引,只需传入列编号或列名组成的列表即可:
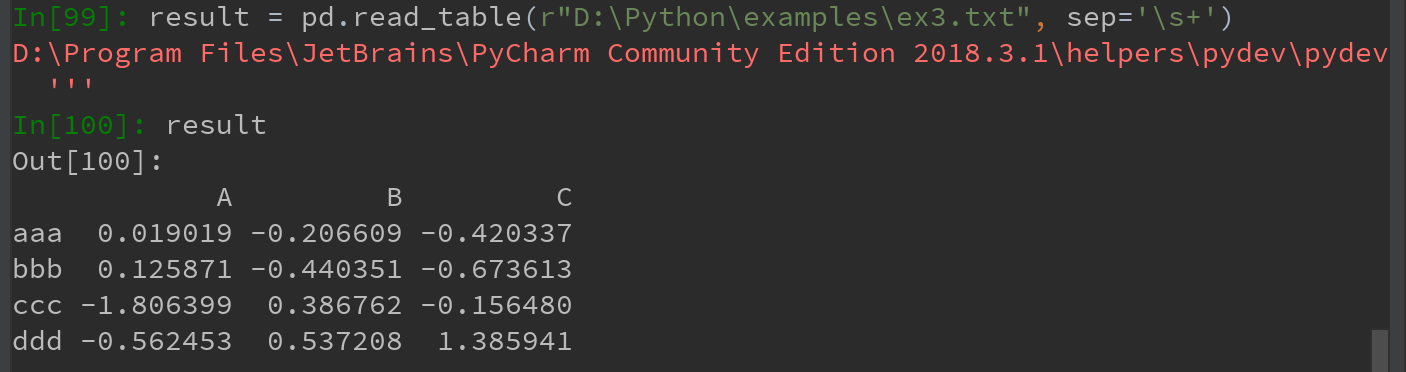
5)有的情况下,有些表格可能不是用固定的分隔符去分隔字段的(比如,空白符或其他模式)
如,读取下面的文本文件:

虽然可手动对数据进行规整,但是较为繁琐。该情况下,可传递一个正则表达式作为read_table的分隔符。可用正则表达式:\s+
(\s匹配任何空白字符,包括空格、制表符、换页符等等, 等价于[ \f\n\r\t\v];“\s+”则表示匹配任意多个上面的字符)
解析器函数还有许多参数可以帮助处理各种各样的异形文件格式(如表6-2中所示)。简单示例,可用skiprows跳过文件的第一行、第三行和第四行:

6)处理缺失值
缺失值处理,时文件解析任务中的一个重要组成部分。缺失数据经常没有(空字符串),或用某个标记值表示。
默认情况下,pandas会用一组经常出现的标记值进行识别,比如NA或NULL。
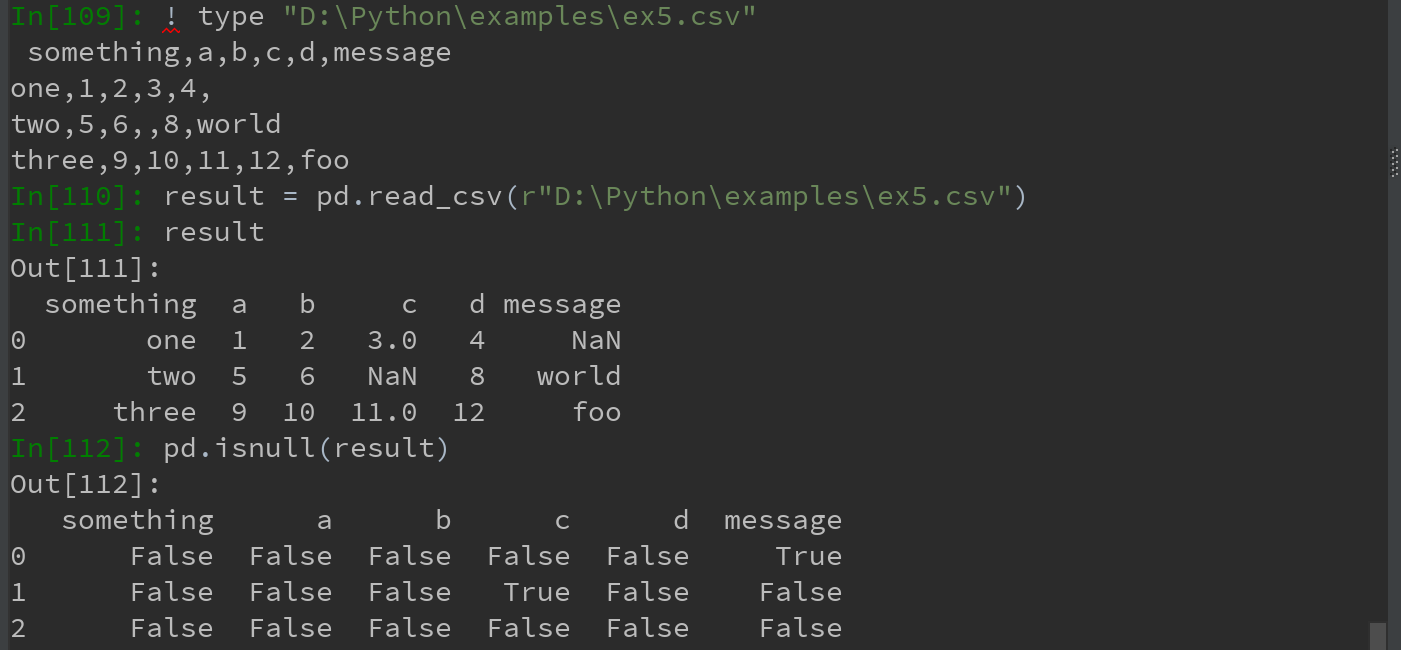
na_values可以用一个列表或集合的字符串表示缺失值(???尝试多种方式,似乎并无作用)

字典的各列可以使用不同的NA标记值:
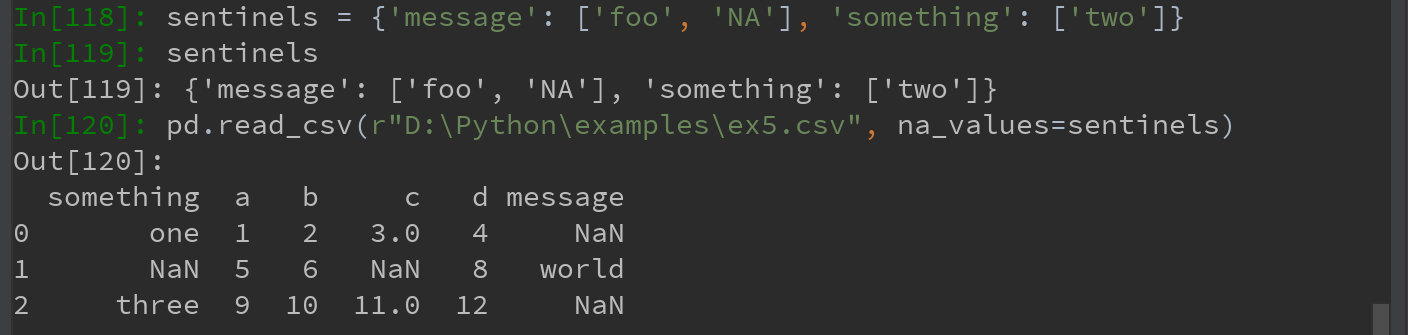
表6-2 pandas.read_csv / pandas.read_table函数的常用参数选项


6.1.1 逐块读取文本文件
当在处理很大的文件时,或找出大文件中的参数集以便于后续处理时,可能只想读取文件的一小部分,或者逐块对文件进行迭代。
在看大文件前,可先设置pandas显示更加紧凑:
![]()
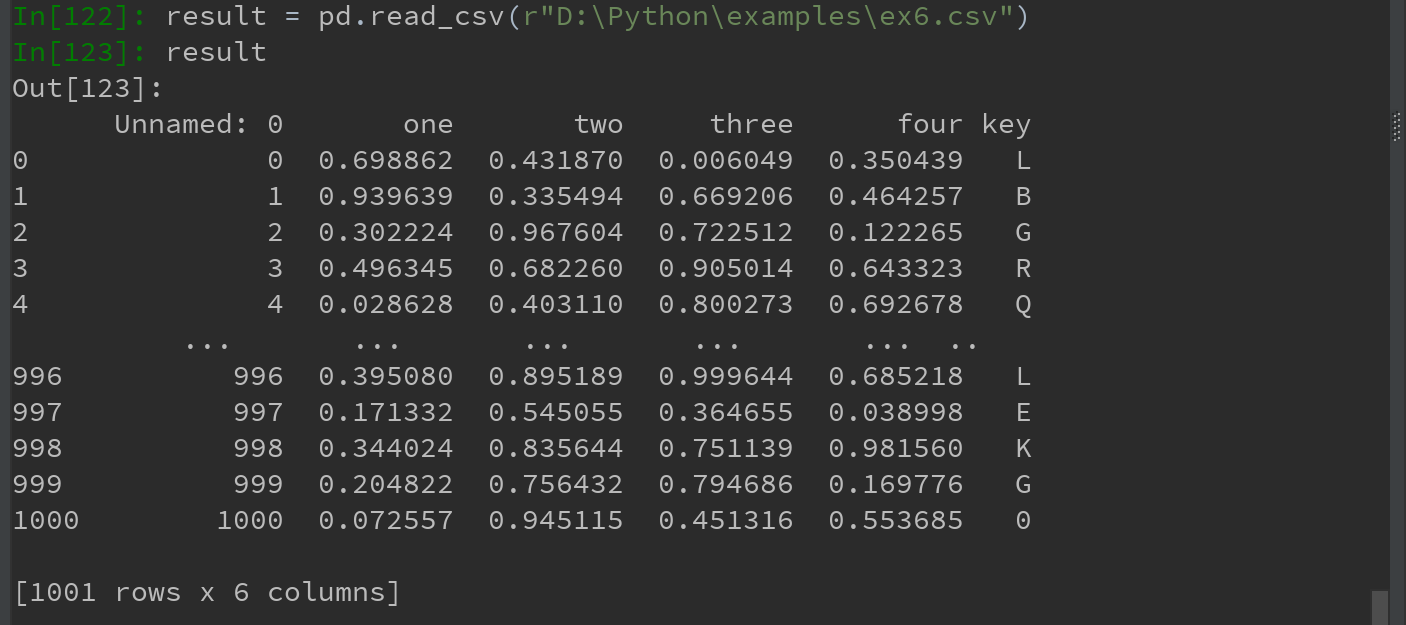
1)如果只想读取几行,通过nrows进行指定即可:

2)可通过指定chunksize(行数),进行逐块读取文件 ???有问题不懂
read_csv所返回的这个TextParser对象使你可以根据chunksize对文件进行逐块迭代。
如,对ex6.csv进行迭代处理,将值计数聚合到“key”列中:

???????
6.1.2 将数据写出到文本格式
1)利用DataFrame的to_csv方法,将数据写到一个以逗号分隔的文件中
先读取一个csv文件:


Ps:还可使用其他分隔符:

注:因此处直接写出到sys.stdout,故仅仅是打印出文本结果
缺失值在输出结果中会被表示为空字符串。如果希望将其表示为别的标记值:

注:因此处直接写出到sys.stdout,故仅仅是打印出文本结果
禁用行和列的标签:

自定义输出列,并按指定顺序排列:

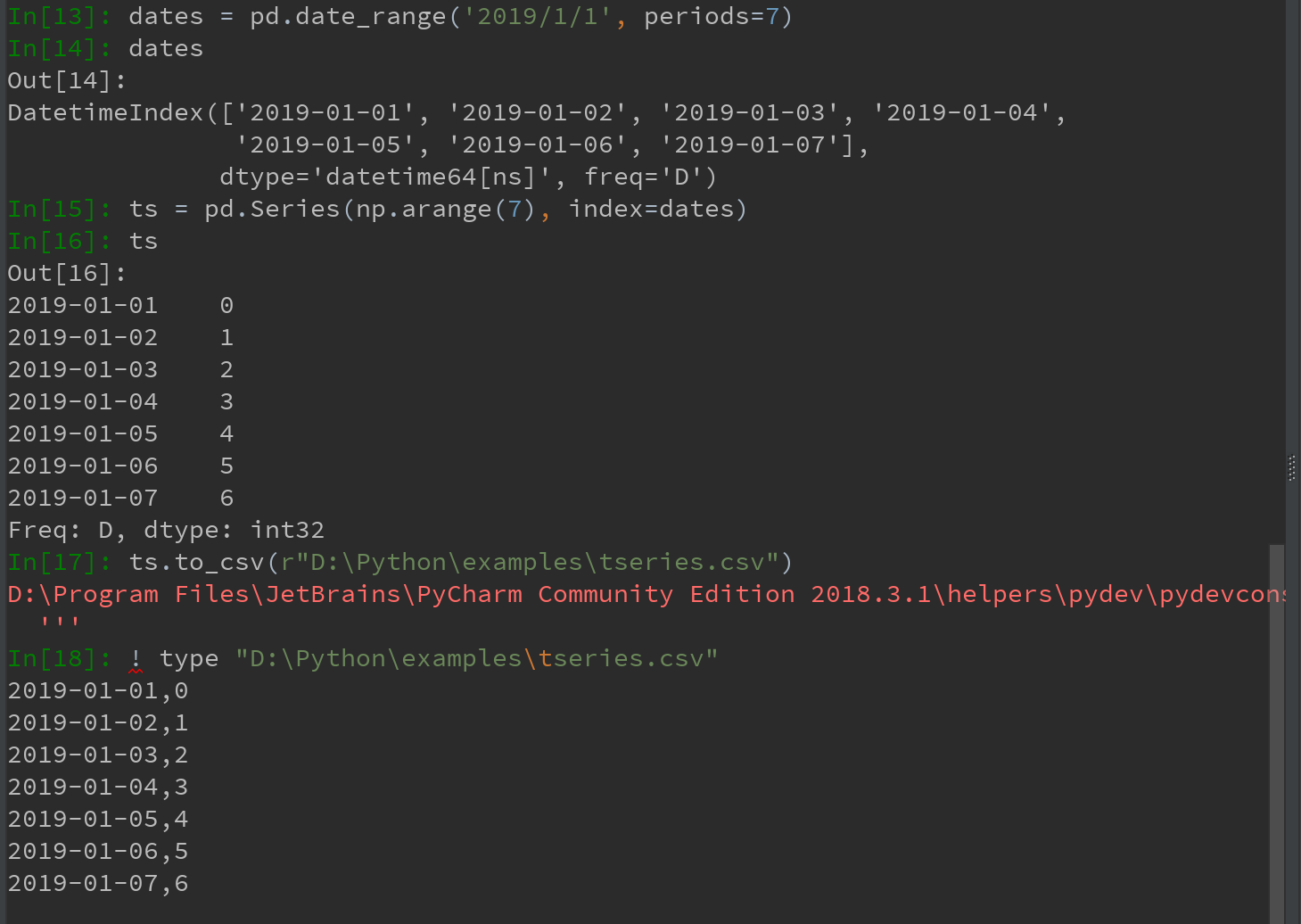
2)Series用to_csv方法
6.1.3 处理分隔符格式
大部分存储在磁盘上的表格型数据都能用pandas.read_table进行加载。但对于含有畸形行的文件,则该方法可能无法处理。介绍其他方法如下:

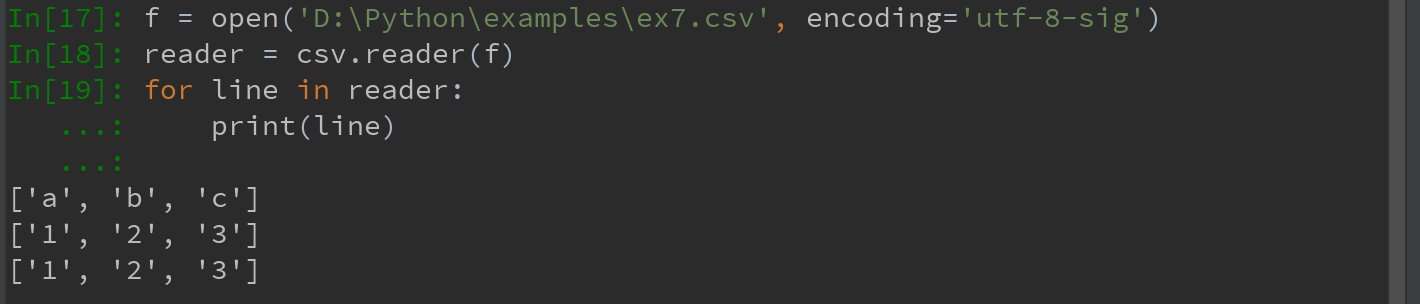
1)对于任何单字符分隔文件,可以直接用python内置的csv模块,将任意已打开的文件或文件型的对象传给csv.reader。

对这个reader进行迭代将会为每行产生一个元组(并移除所有的引号):
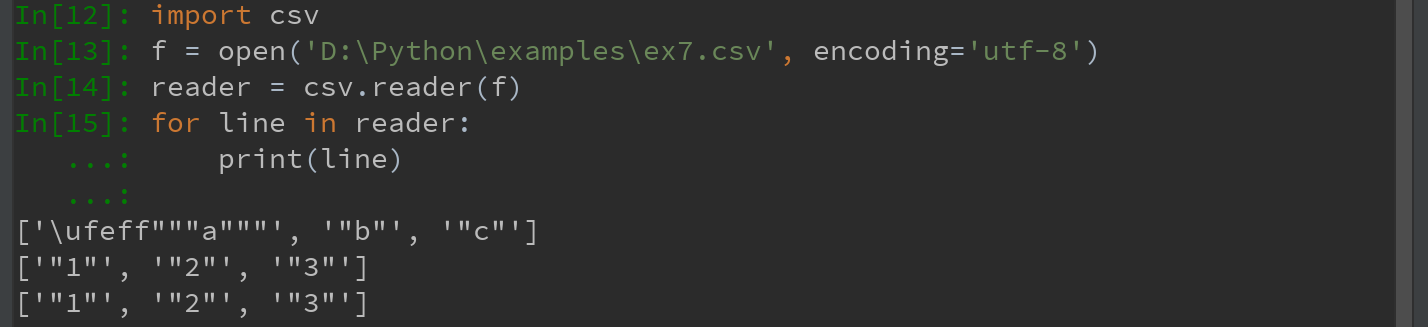
注意:open()函数使用时,一定要加上encoding='utf-8',否则会进行报错:UnicodeDecodeError
!!!延申:read_csv时开头出现 \ufeff ,且引号并未完全去除,不符合预期。
首行出现的“\ufeff”叫BOM("ByteOrder Mark")用来声明该文件的编码信息。
“utf-8”是以字节为编码单元,它的字节顺序在所有系统中都是一样的,没有字节序问题,因此它不需要BOM,所以当用"utf-8"编码方式读取带有BOM的文件时,它会把BOM当做是文件内容来处理, 也就会发生类似上边的错误.
"uft-8-sig"中sig全拼为 signature 也就是"带有签名的utf-8",因此"utf-8-sig"读取带有BOM的"utf-8文件时"会把BOM单独处理,与文本内容隔离开,也是我们期望的结果.
————————————————
参考文献:
https://blog.csdn.net/wozaizhe56/article/details/82048645
https://blog.csdn.net/vernice/article/details/46873169
2)创建数据列的字典,使得数据格式合乎要求。
第一步,读取文件到一个多行的列表中:

第二步,将这些行分为标题行和数据行:
![]()
第三步,用字典构造式和zip(*values),后者将行转置为列,创建数据列的字典:

注意:上述为标准方法,值得学习模板;
收集参数 *value的含义,可参考该链接复习:https://www.cnblogs.com/ElonJiang/p/11440695.html
函数zip可用于“缝合”任意数量的序列,可参考链接复习:https://www.cnblogs.com/ElonJiang/p/11355846.html
3)CSV文件的形式很多,只需定义 csv.Dialect的一个子类即可定义出新格式(如专门的分隔符、字符串引用约定、行结束符等):
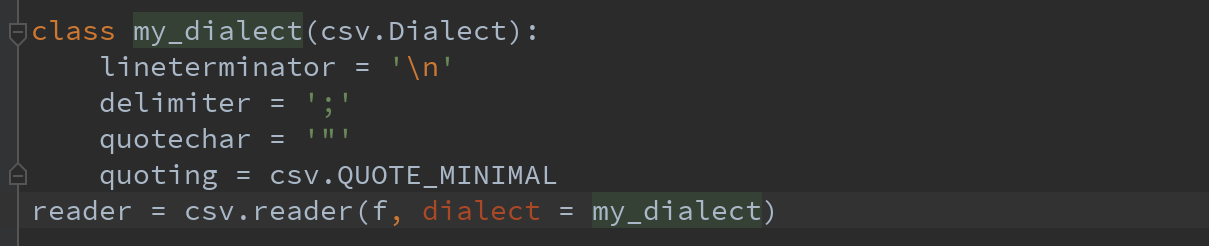
Ps:各个CSV语支的参数也可用关键字的形式提供给csv.reader,而无需定义子类:


6.1.4 JSON数据
JSON(JavaScript Object Notation的简称),已经成为通过HTTP请求在Web浏览器和其他应用程序之间发送数据的标准格式之一。比表格型文本格式(如CSV)灵活的多。
JSON非常接近于有效的Python代码。
基本类型有:对象(字典)、数组(列表)、字符串、布尔值以及null。对象中所有键都必须是字符串。
使用Python标准库中的 json模块 读写JSON数据,通过json.loads可将JSON字符串转换成Python形式。
1)一个JSON数据例子
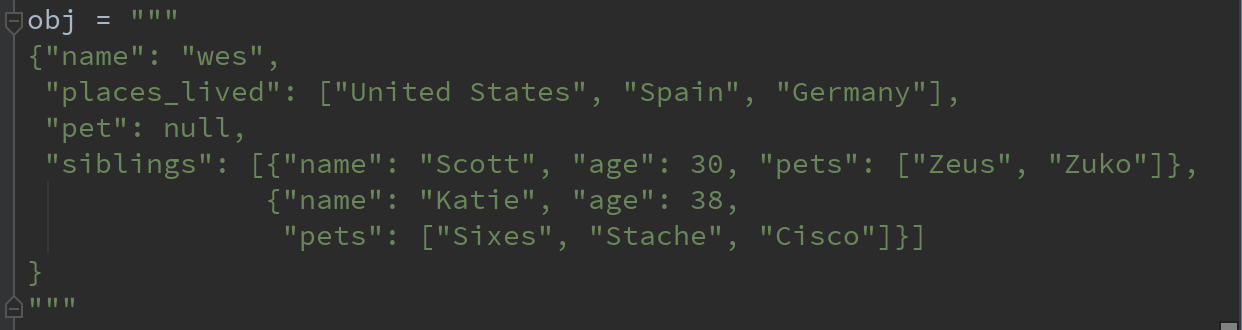
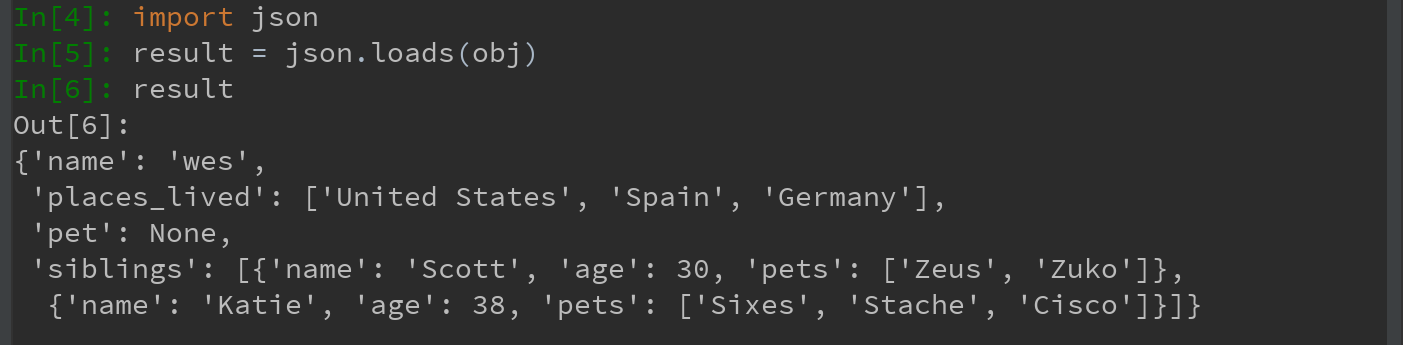
2)将该JSON数据用 json.loads将其转换成Python形式
Ps:json.dumps则是将Python对象转换成JSON格式

3)将JSON对象转换为DateFrame或Series或其他便于分析的数据结构
方法一(最简单):向Dateframe构造器传入一个字典的列表(就是原先的JSON对象),并选取数据字段的子集

方法二:用pandas.read_json自动将特别格式的JSON数据集转换为Series或DataFrame

data = pd.read_json(r"D:\Python\examples\example.json", encoding='utf-8') --报错!!!???
Ps:此处一直报错,ValueError: Unexpected character found when decoding array value (1),尝试添加encoding=‘utf-8' 无结果
6.1.5 XML和HTML:Web信息收集
Python有许多可读写常见HTML和XML格式数据的库,包括lxml、Beautiful Soup和html5lib。其中,lxml的速度比较快,但是其他库处理有误的HTML或XML文件更好。
pandas一个内置功能,read_html,它可使用lxml和Beautiful Soup子集将HTML文件中的表格解析为DataFrame对象。
需安装read_html用到的库lxml
示例暂无!!!
6.1.6 利用lxml.objectify解析XML
