elastic-job的分析
分布式定时任务
Overview
目前分布式架构在大数据量和高并发情况下有很好的表现,但由此带来的技术问题也显而易见。在集群情况下,定时任务存在于每个节点中,如果不对定时妥善任务管理,就会导致定时任务的重复执行造成数据不一致或者脏数据。又或者单机出现cpu或者内存瓶颈时候,在这种情况下,分布式定时任务应运而生。
技术方案
目前较为流行的分布式定时任务主要有quertz+DB,淘宝的TBSchedule、当当的elastic-job。
- quartz的集群方案是使用数据库来实现的数据的同步和任务的分配。当某个节点执行任务的时候,通过行锁锁住表,当执行完成之后,修改行中的标志位字段。对于失败的任务,可以又其他的任务继续执行。但是这只是一种串行策略,并不能提高执行效率。
- TBSchedule和elastic-job都采用看了分片的思想,通过zookepeer来完成节点的注册和信息的同步。当有节点宕机时候,zookepeer能够及时发现并且重新完成分片任务。两个框架的思想几乎是一样的,TBSchedule在稳定性方面有更大的优势。elastic-job在文档上更加全面,易开发。
一、elastic-job
elastic-job是当当的一个项目,包含Elastic-Job-Lite和Elastic-Job-Cloud两个子项目。 Elastic-Job-Cloud使用Mesos + Docker的解决方案,额外提供资源治理、应用分发以及进程隔离等服务,是一个全量级的解决方案。Elastic-Job-Lite定位为轻量级无中心化解决方案,使用jar包的形式提供分布式任务的协调服务。
1. quzrtz的介绍
elastic-job是基于quartz的二次开发,在quartz的基础之上,加入了选举和分片策略。要了解elastic-job首先要了解quartz。
quartz是由job、jobdetail和trigger、schedule组成。先给出一个比较简单的demo
public class MyJob implements Job {
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
TriggerKey triggerKey = jobExecutionContext.getTrigger().getKey();
System.out.println("堕落"+triggerKey.getGroup()+":"+triggerKey.getName());
System.out.println(jobExecutionContext.getJobDetail().hashCode());
}
}
SchedulerFactory schedulerFactory = new StdSchedulerFactory();
Scheduler scheduler = schedulerFactory.getScheduler();
//scheduler被停止后,除非重新实例化,否则不能重新启动
scheduler.start();
//绑定方法一,直接通过schedule绑定
JobDetail jobDetail1 = JobBuilder.newJob(MyJob.class).build();
Trigger trigger0 = TriggerBuilder.newTrigger().withSchedule(CronScheduleBuilder.cronSchedule("*/5 * * * * ?")).withIdentity("1","swc").startNow().build();
Trigger trigger1 = TriggerBuilder.newTrigger().withSchedule(CronScheduleBuilder.cronSchedule("*/10 * * * * ?")).withIdentity("1","swc").startNow().build();
scheduler.scheduleJob(jobDetail1,trigger1);
//scheduler.scheduleJob(jobDetail1,trigger0);
//绑定方法二,trigger通过名字来绑定job,这个时候,要指定Durability参数,指jobdetai在没有trigger的时候也不销毁。
JobDetailImpl jobDetail2 = (JobDetailImpl)JobBuilder.newJob(MyJob.class).withIdentity("2","swc").build();
Trigger trigger2 = TriggerBuilder.newTrigger().withSchedule(CronScheduleBuilder.cronSchedule("*/5 * * * * ?")).withIdentity("2","swc").forJob("2","swc").startNow().build();
Trigger trigger3 = TriggerBuilder.newTrigger().withSchedule(CronScheduleBuilder.cronSchedule("*/10 * * * * ?")).withIdentity("3","swc").forJob("2","swc").startNow().build();
jobDetail2.setDurability(true);//没有trigger绑定的job不销毁
scheduler.addJob(jobDetail2,false);
scheduler.scheduleJob(trigger2);
scheduler.scheduleJob(trigger3);
- Job 就是最基础的执行类,只有一个execute方法
- JobDetail 表示一个具体的可执行的调度程序, Job 是这个可执行程调度程序所要执行的内容,另外 JobDetail 还包含了这个任务调度的方案和策略(上下文信息)
- Trigger 是调度策略,和 JobDetail 绑定起来。一个 JobDetail 可以有多个 Trigger ,但是一个 Trigger 只能有一个 JobDetail
- Scheduler 代表一个调度容器,一个调度容器中可以注册多个 JobDetail 和 Trigger。当 Trigger 与 JobDetail 组合,就可以被 Scheduler 容器调度了
public void start() throws SchedulerException {
if (shuttingDown|| closed) {
throw new SchedulerException(
"The Scheduler cannot be restarted after shutdown() has been called.");
}
notifySchedulerListenersStarting();
if (initialStart == null) {
initialStart = new Date();
this.resources.getJobStore().schedulerStarted();
startPlugins();
} else {
resources.getJobStore().schedulerResumed();
}
//schedThread这个线程在schedule初始化的时候会创建
//false 唤醒sigLock对象的所有等待队列的线程
//true,发出让主循环暂停的信号,以便线程在下一个可处理的时刻暂停
schedThread.togglePause(false);
notifySchedulerListenersStarted();
}
public Date scheduleJob(JobDetail jobDetail,Trigger trigger) throws SchedulerException {
//把相应的job和trig放到jobstore中,默认使用的RAMJobStore,底层使用hashmap或者treemap来实现。
resources.getJobStore().storeJobAndTrigger(jobDetail, trig);
notifySchedulerListenersJobAdded(jobDetail);
notifySchedulerThread(trigger.getNextFireTime().getTime());
notifySchedulerListenersSchduled(trigger);
return ft;
}
- schedule 初始化会生成 QuartzSchedulerThread ,并且启动。 QuartzSchedulerThread 的run中有一个大循环,用于控制整个 schedule 的运行,也用于去计时执行任务。
- 线程池默认有一个 simpThreadPool ,会在 QuartzSchedulerThread.run() 方法中被调用,通过 JobRunShell 后续就是去执行 job 中 execuse 方法。
2. Elastic-Job-Lite的使用
- 可以通过节点的水平扩展和任务的细化增减弹性伸缩任务处理能力。
- 需要将一个任务拆解程多个子任务,保证子任务之间没有任何耦合,如果有共享数据需要加锁。
- 分布式协调,可以支持自我故障的检测和修复,支持失效转移和任务重触发。
- 节点需要先注册到zookepeer,然后通过选举得到主节点,主节点根据节点数量和分片策略,同步信息到各个节点。其实就是在quartz的基础之上增加了分片策略和注册选举内容。
2.1 选举过程
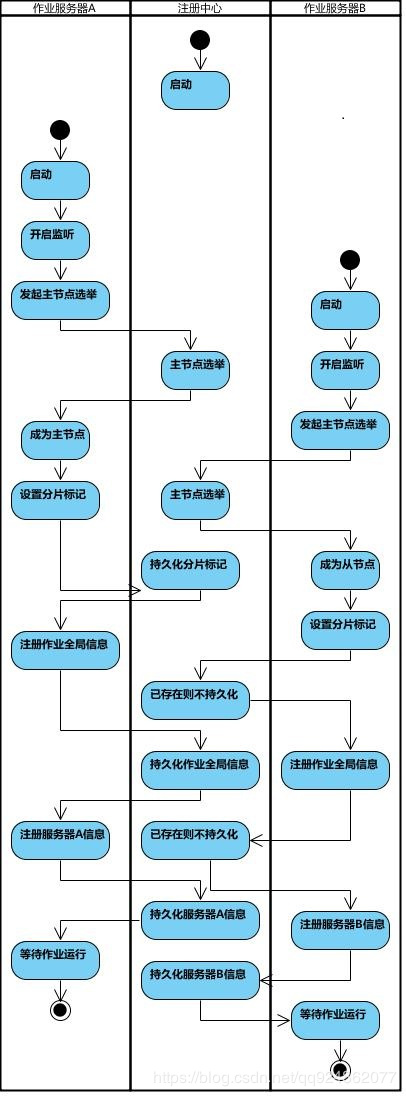
以下给出一个简单的demo:
@Bean(initMethod = "init")
public ZookeeperRegistryCenter regCenter(@Value("${regCenter.serverList}") final String serverList, @Value("${regCenter.namespace}") final String namespace) {
//zookepeer的ip和域名
return new ZookeeperRegistryCenter(new ZookeeperConfiguration(serverList, namespace));
}
@Resource
private ZookeeperRegistryCenter regCenter;
@Bean(initMethod = "init")
public JobScheduler simpleScheduler(final MyJoB job, //job
@Value("${simpleChannelCountJob.cron}") final String cron, //定时策略
@Value("${simpleChannelCountJob.shardingTotalCount}") final int shardingTotalCount,//分片数量
@Value("${simpleChannelCountJob.shardingItemParameters}") final String shardingItemParameters) {//分片策略0=abc
return new SpringJobScheduler(channelCountJob, regCenter,
getLiteJobConfiguration(channelCountJob.getClass(), cron, shardingTotalCount, shardingItemParameters));
}
private LiteJobConfiguration getLiteJobConfiguration(final Class<? extends SimpleJob> jobClass, final String cron, final int shardingTotalCount, final String shardingItemParameters) {
return LiteJobConfiguration.newBuilder(new SimpleJobConfiguration(JobCoreConfiguration.newBuilder(
jobClass.getName(), cron, shardingTotalCount).shardingItemParameters(shardingItemParameters).build(), jobClass.getCanonicalName())).overwrite(true).build();
}
真正需要了解的类
public final class ShardingContext {
/**
* 作业名称.
*/
private final String jobName;
/**
* 作业任务ID.
*/
private final String taskId;
/**
* 分片总数.
*/
private final int shardingTotalCount;
/**
* 作业自定义参数.
* 可以配置多个相同的作业, 但是用不同的参数作为不同的调度实例.
*/
private final String jobParameter;
/**
* 分配于本作业实例的分片项.
*/
private final int shardingItem;//上诉分片策略中的0
/**
* 分配于本作业实例的分片参数.
*/
private final String shardingParameter;//上诉分片策略中的abc
public ShardingContext(final ShardingContexts shardingContexts, final int shardingItem) {
jobName = shardingContexts.getJobName();
taskId = shardingContexts.getTaskId();
shardingTotalCount = shardingContexts.getShardingTotalCount();
jobParameter = shardingContexts.getJobParameter();
this.shardingItem = shardingItem;
shardingParameter = shardingContexts.getShardingItemParameters().get(shardingItem);
}
}
public class MyJoB implements SimpleJob {
@Override
public void execute(final ShardingContext shardingContext) {
//ShardingContext存储了分片信息和当前节点的上下文信息,根据分片信息去处理
}
}
}
2.2 elastic-job 的选举
任务初始化
//节点首先注册到
private JobScheduler(final CoordinatorRegistryCenter regCenter, final LiteJobConfiguration liteJobConfig, final JobEventBus jobEventBus, final ElasticJobListener... elasticJobListeners) {
JobRegistry.getInstance().addJobInstance(liteJobConfig.getJobName(), new JobInstance());
this.liteJobConfig = liteJobConfig;
this.regCenter = regCenter;
List<ElasticJobListener> elasticJobListenerList = Arrays.asList(elasticJobListeners);
setGuaranteeServiceForElasticJobListeners(regCenter, elasticJobListenerList);
schedulerFacade = new SchedulerFacade(regCenter, liteJobConfig.getJobName(), elasticJobListenerList);
jobFacade = new LiteJobFacade(regCenter, liteJobConfig.getJobName(), Arrays.asList(elasticJobListeners), jobEventBus);
}
任务注册
/**
* 初始化作业.在conifg中配置的时候会调用init方法
*/
public void init() {
LiteJobConfiguration liteJobConfigFromRegCenter = schedulerFacade.updateJobConfiguration(liteJobConfig);
JobRegistry.getInstance().setCurrentShardingTotalCount(liteJobConfigFromRegCenter.getJobName(), liteJobConfigFromRegCenter.getTypeConfig().getCoreConfig().getShardingTotalCount());
JobScheduleController jobScheduleController = new JobScheduleController(
createScheduler(), createJobDetail(liteJobConfigFromRegCenter.getTypeConfig().getJobClass()), liteJobConfigFromRegCenter.getJobName());
//注册任务,将任务名称作为节点名称添加到zk中
JobRegistry.getInstance().registerJob(liteJobConfigFromRegCenter.getJobName(), jobScheduleController, regCenter);
//添加任务信息并参与选举
schedulerFacade.registerStartUpInfo(!liteJobConfigFromRegCenter.isDisabled());
//启动作业
jobScheduleController.scheduleJob(liteJobConfigFromRegCenter.getTypeConfig().getCoreConfig().getCron());
}
节点选举,先到先得原则
/**
* 注册作业启动信息.
*
* @param enabled 作业是否启用
*/
public void registerStartUpInfo(final boolean enabled) {
listenerManager.startAllListeners();
//选举主节点
leaderService.electLeader();
//服务器信息持久化到zk上
serverService.persistOnline(enabled);
//将实例信息添加到zk的instances节点中
instanceService.persistOnline();
//重新分片
shardingService.setReshardingFlag();
monitorService.listen();
if (!reconcileService.isRunning()) {
reconcileService.startAsync();
}
}
/**
* 选举主节点.
*/
public void electLeader() {
log.debug("Elect a new leader now.");
//进行节点选举,如果选举成功在zk的leader/election/instance路径中填写服务器信息。
jobNodeStorage.executeInLeader(LeaderNode.LATCH, new LeaderElectionExecutionCallback());
log.debug("Leader election completed.");
}
/**
* 持久化作业服务器上线信息.
* @param enabled 作业是否启用
*/
public void persistOnline(final boolean enabled) {
if (!JobRegistry.getInstance().isShutdown(jobName)) {
jobNodeStorage.fillJobNode(serverNode.getServerNode(JobRegistry.getInstance().getJobInstance(jobName).getIp()), enabled ? "" : ServerStatus.DISABLED.name());
}
}
2.3 elastic-job 的分片
新的Job实例加入集群
现有的Job实例下线(如果下线的是leader节点,那么先选举然后触发分片算法的执行)
主节点选举
以上三种情况会让zookeeper上leader节点的sharding节点上多出来一个necessary的临时节点,主节点每次执行Job前,都会去看一下这个节点,如果有则执行分片算法。
/**
* 如果需要分片且当前节点为主节点, 则作业分片.
*
* <p>
* 如果当前无可用节点则不分片.
* </p>
*/
public void shardingIfNecessary() {
List<JobInstance> availableJobInstances = instanceService.getAvailableJobInstances();
if (!isNeedSharding() || availableJobInstances.isEmpty()) {
return;
}
if (!leaderService.isLeaderUntilBlock()) {
blockUntilShardingCompleted();
return;
}
waitingOtherJobCompleted();
LiteJobConfiguration liteJobConfig = configService.load(false);
//获取分片总数
int shardingTotalCount = liteJobConfig.getTypeConfig().getCoreConfig().getShardingTotalCount();
log.debug("Job '{}' sharding begin.", jobName);
jobNodeStorage.fillEphemeralJobNode(ShardingNode.PROCESSING, "");
//重新在zk写入服务器信息
resetShardingInfo(shardingTotalCount);
//获取分片策略
JobShardingStrategy jobShardingStrategy = JobShardingStrategyFactory.getStrategy(liteJobConfig.getJobShardingStrategyClass());
//执行分片1、执行策略,返回实例和分片的对应关系2、构建回调函数
jobNodeStorage.executeInTransaction(new PersistShardingInfoTransactionExecutionCallback(jobShardingStrategy.sharding(availableJobInstances, jobName, shardingTotalCount)));
log.debug("Job '{}' sharding complete.", jobName);
}
/**
* 分片结束之后.
*
* @param callback 执行操作的回调
*/
public void executeInTransaction(final TransactionExecutionCallback callback) {
try {
CuratorTransactionFinal curatorTransactionFinal = getClient().inTransaction().check().forPath("/").and();
callback.execute(curatorTransactionFinal);
curatorTransactionFinal.commit();
//CHECKSTYLE:OFF
} catch (final Exception ex) {
//CHECKSTYLE:ON
RegExceptionHandler.handleException(ex);
}
}
分片结束之后,会将信息同步给各个从节点服务器,从服务器通过监听,获取到服务器和分片的信息

 浙公网安备 33010602011771号
浙公网安备 33010602011771号