《机器学习》第一次作业——第一至三章学习记录和心得
第一章 模式识别基本概念
-
模式识别:根据已有知识的表达,针对待识别模式,判别决策其所属的类别或者预测其对应的回归值,本质上是一种推理过程;从数学角度来看,它可以被看做一种函数映射。
由此可见,模式识别本质上是一种推理过程。
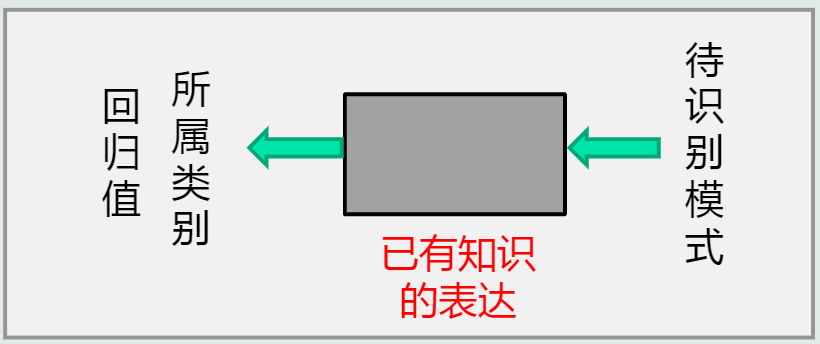
数学解释:
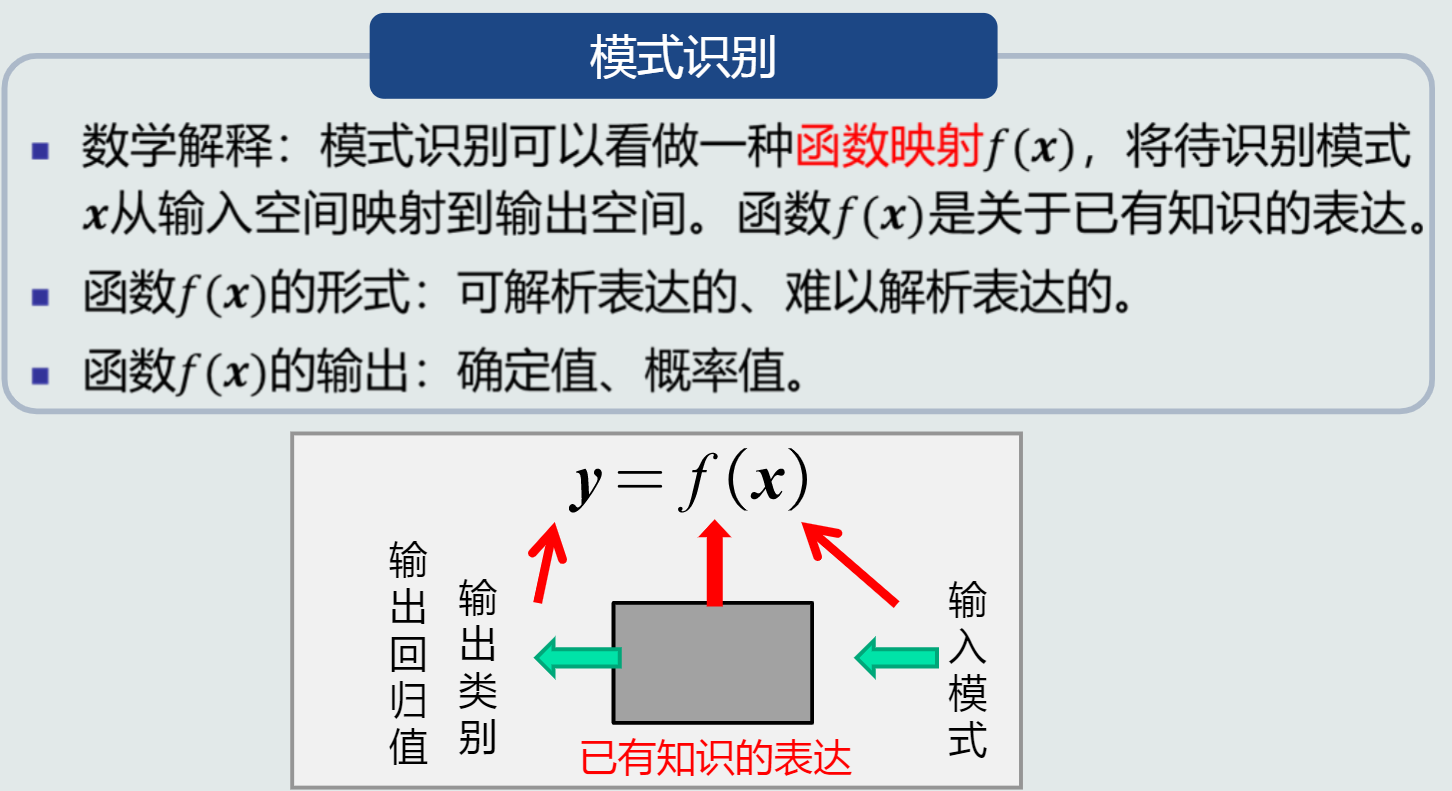
-
根据任务,模式识别可以划分为“分类”和“回归”两种形式:
- 分类:
- 输出量是离散的类别表达,即输出待识别模式所属的类别,分为二类或多类。
- 回归:
- 输出量是连续的信号表达(回归值)
- 输出量维度:单个或多个维度。
- 回归是分类的基础:离散的类别值是由回归值做判定决策得到的。
-
输入空间和输出空间
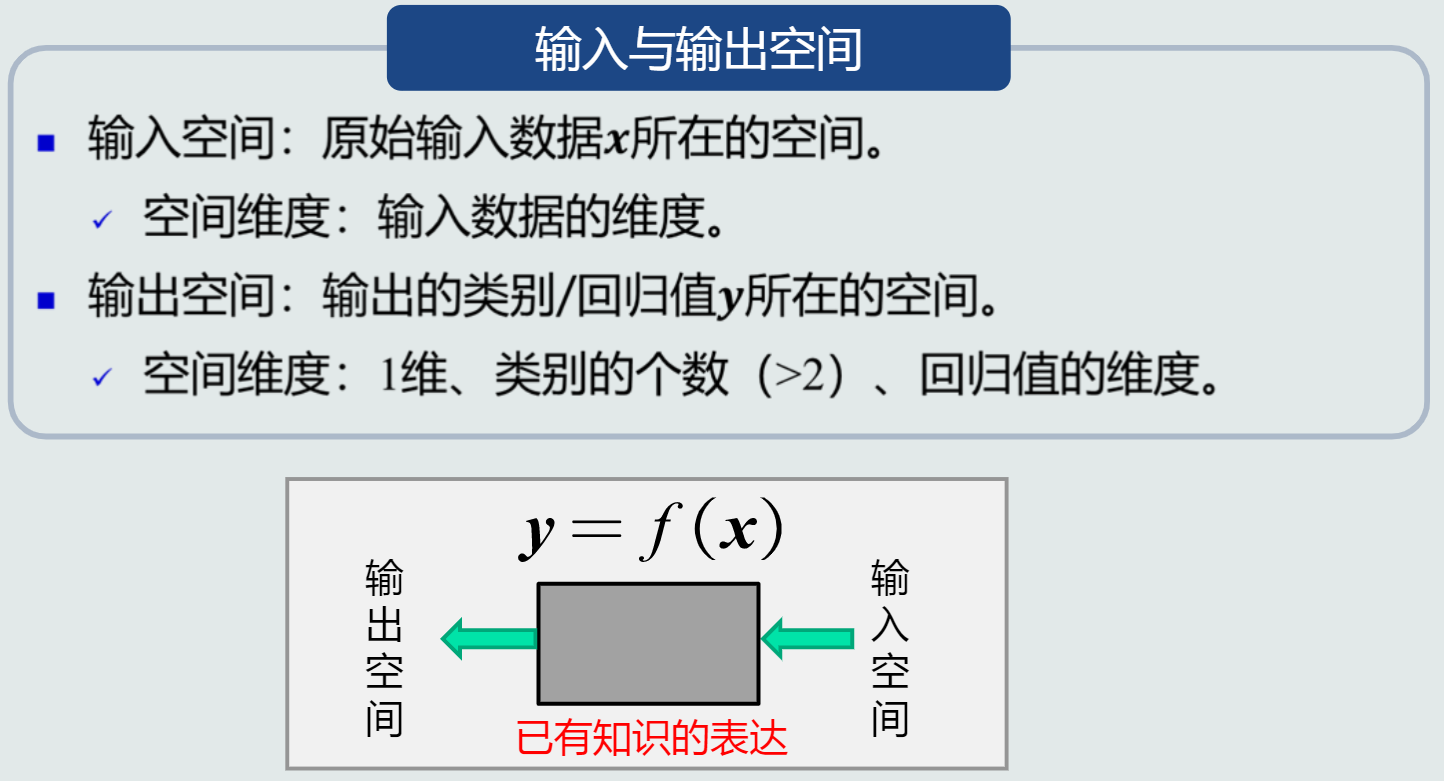
-
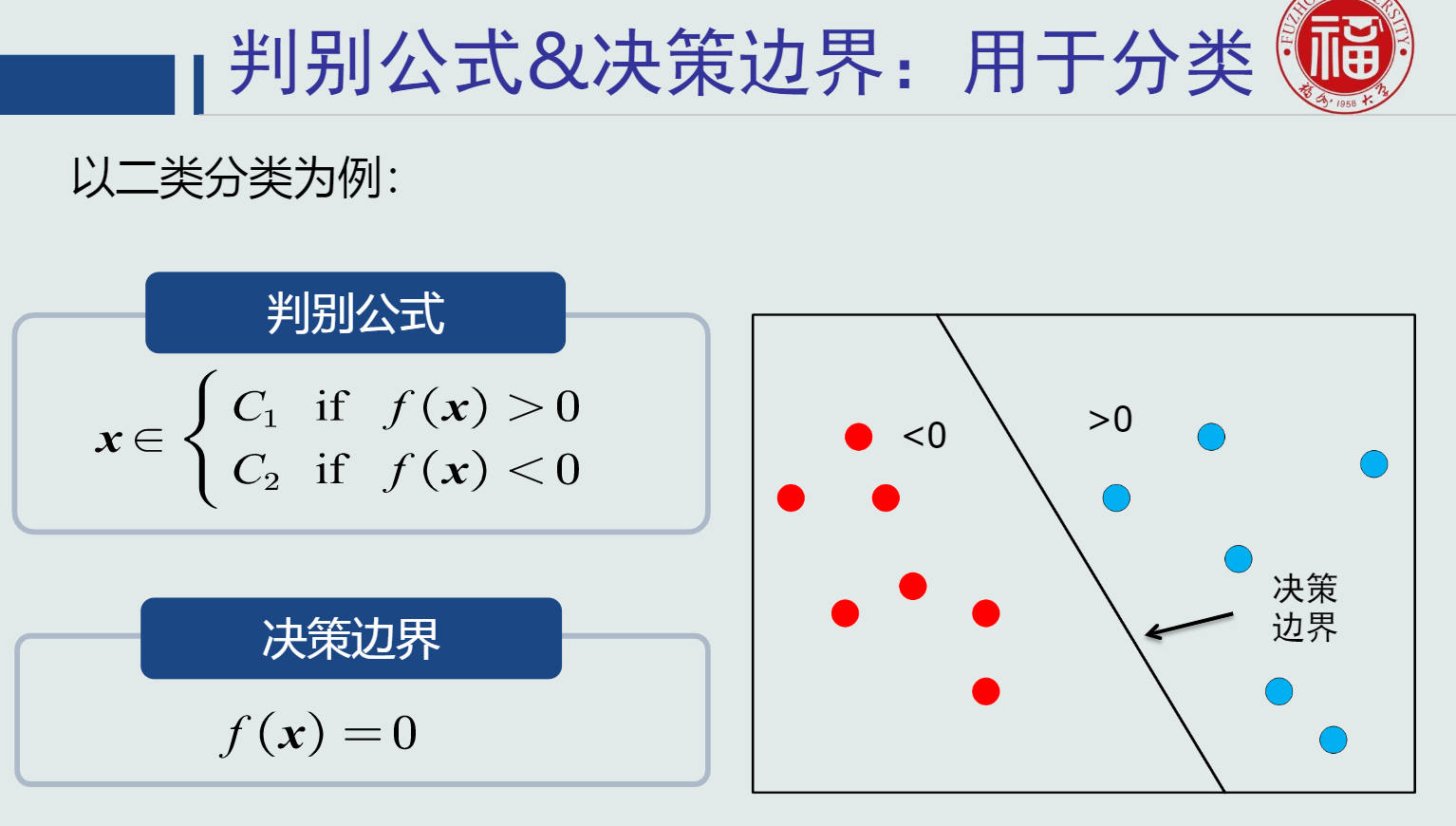
模型:关于已有知识的一种表达方式,即函数f(x)。模型可用于回归和分类。
- 回归:

- 分类:
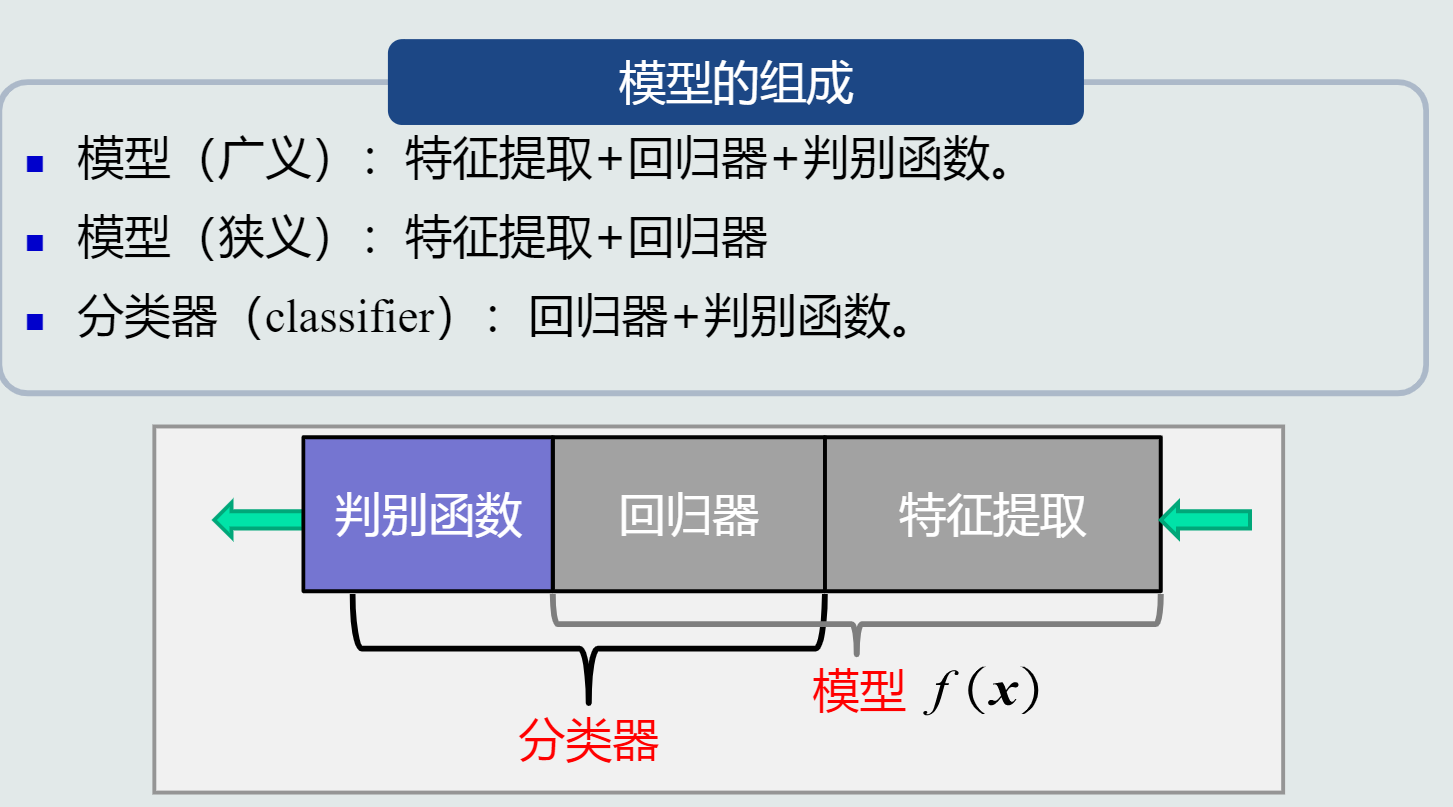
其中,判别函数使用一些特定的非线性函数来实现,通常记为函数g,通常判别函数固定,所以不把它归于模型的一部分。
判别器中,sign函数用来进行二类分类(判断回归值>0还是<0),max函数用来进行多类分类(取最大的回归值所在维度对应的类别)。
- 特征:可以用于区分不同类别模式的、可测量的量。例如:针对橙子和苹果两个类,形状or颜色?输入数据也可以看作原始特征表达。
-
特征特性:
- 特征具有辨别能力,提升不同类别之间的识别性能。(基于统计学规律,而非个例)
- 鲁棒性:针对不同的观测条件,仍能够有效表达类别之间的差异性。
-
特征向量:多个特征构成的列向量,可以表达为模长x方向。

-
特征空间

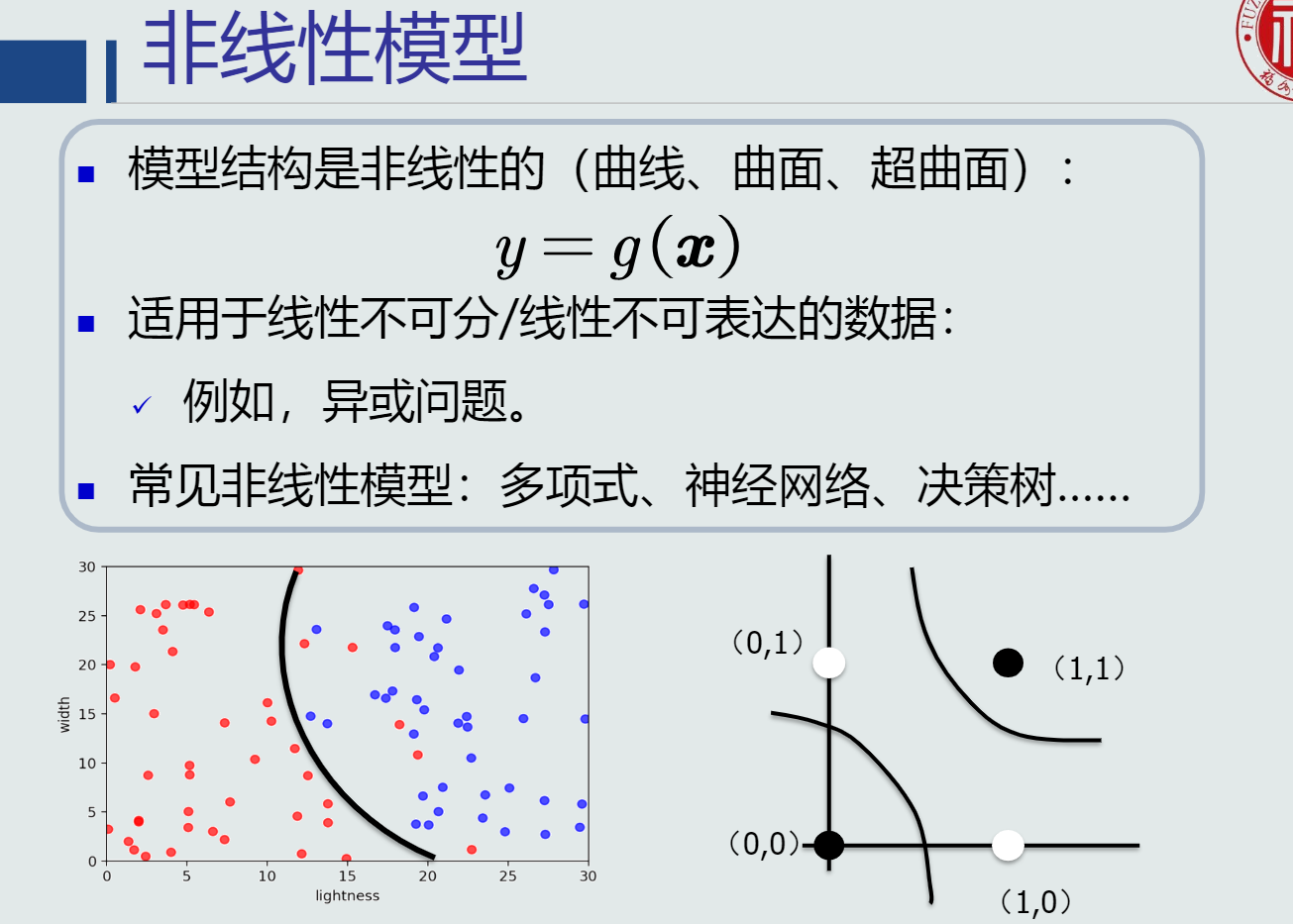
- 模型使用机器学习技术来得到,那么怎样进行机器学习?
(1)需要训练样本

(2)学习模型的参数和结构

其中模型有线性模型和非线性模型

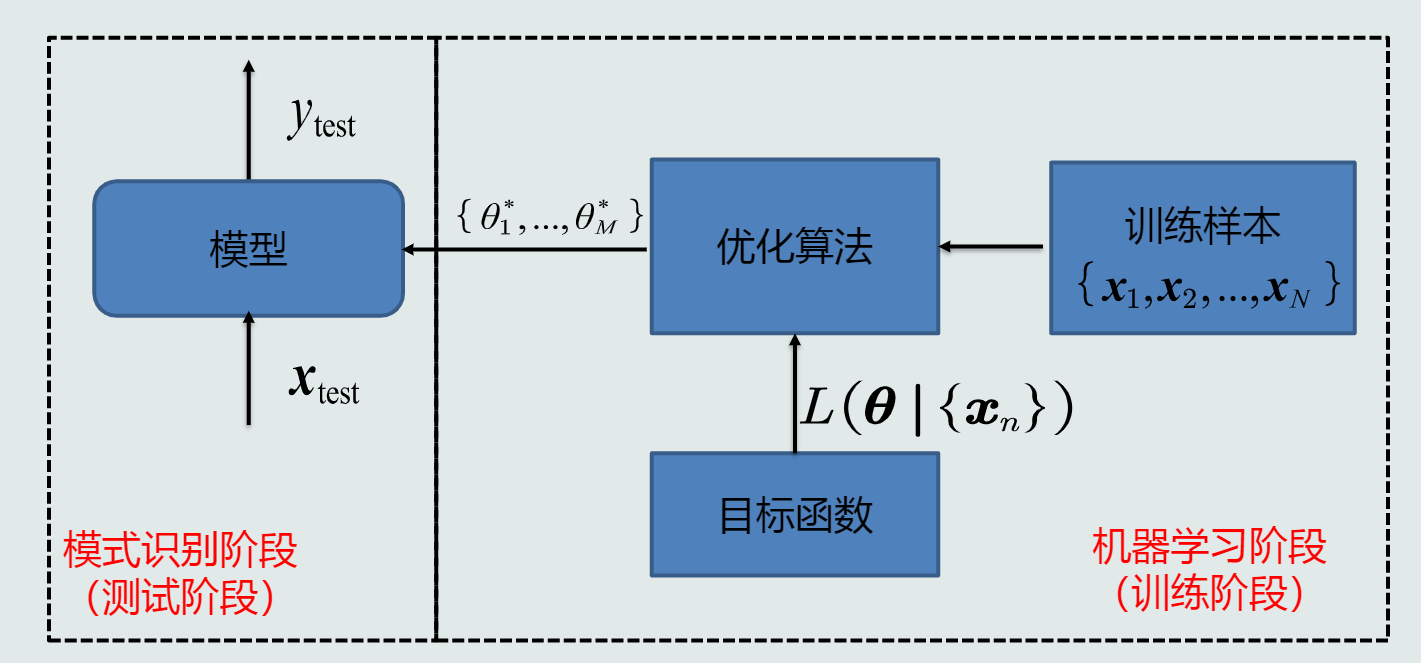
(3)利用训练样本,定义目标函数,使用优化算法来解出一组最优参数作为模式识别的模型
-
基于学习方式的分类
(1) 监督学习(有导师学习):输入数据中有导师信号,以概率函数、代数函数或人工神经网络为基函数模型,采用迭代计算方法,学习结果为函数。
(2) 无监督学习(无导师学习):输入数据中无导师信号,采用聚类方法,学习结果为类别。典型的无导师学习有发现学习、聚类、竞争学习等。
(3) 强化学习(增强学习):以环境反惯(奖/惩信号)作为输入,以统计和动态规划技术为指导的一种学习方法。 -
训练集和测试集

-
训练误差和测试误差

-
泛化能力:学习算法对新模式的决策能力。

泛化能力低会出现过拟合

提高泛化能力:正确选择模型;正则化。

-
评估方法:
(1)留出法
直接将数据集划分为两个互斥的集合,2/3-4/5。
划分原则:划分过程尽可能保持数据分布的一致性
方法缺陷:训练集过大,更接近整个数据集,但是由于测试集较小,导致评估结果缺乏稳定性;测试集大了,偏离整个数据集,与根据数据集训练出的模型差距较大,缺乏保真性。
(2)交叉验证法
将数据集划分为k个大小相似的互斥子集,每个子集轮流做测试集,其余做训练集,最终返回这k个训练结果的均值。
优点:更稳定,更具准确定;
缺单:时间复杂的较大 -
性能指标
准确度
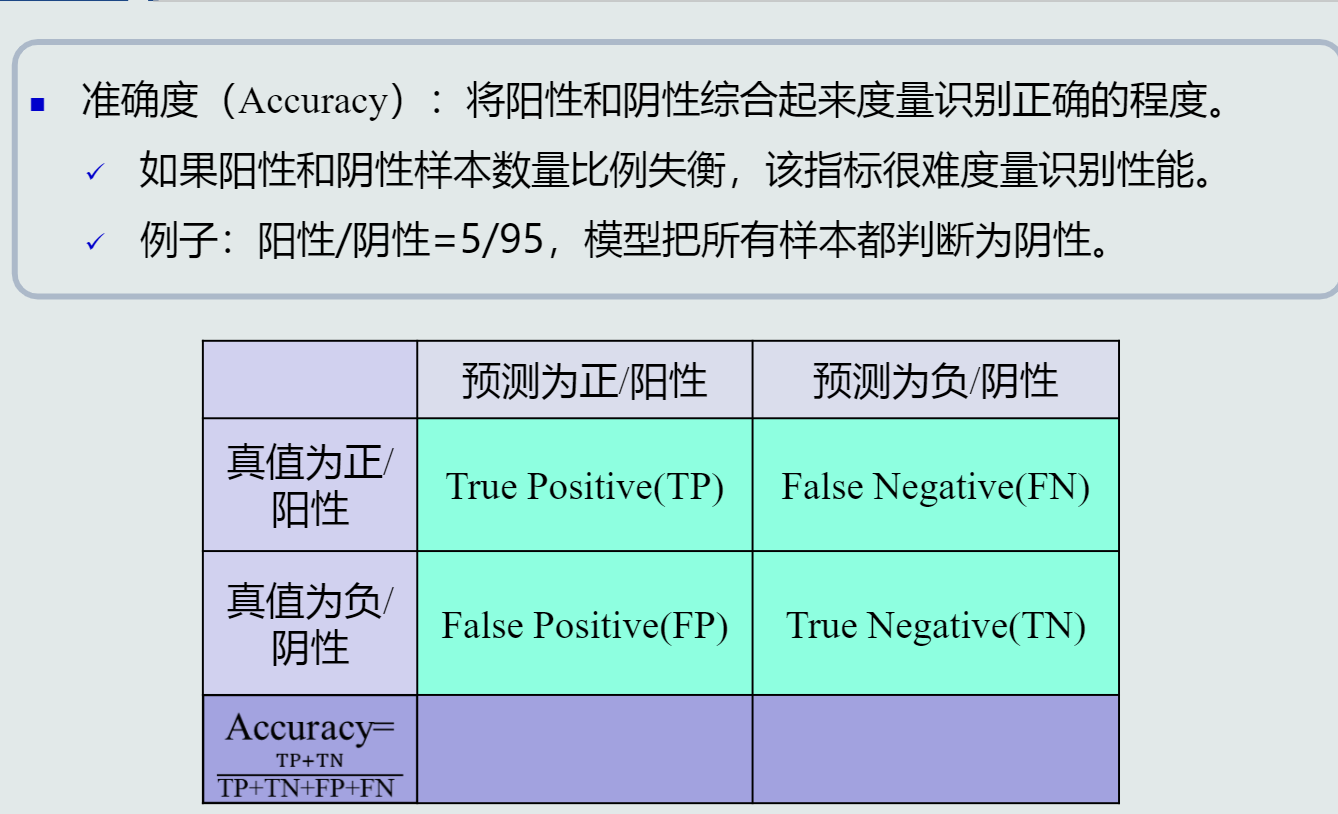
精度、召回率
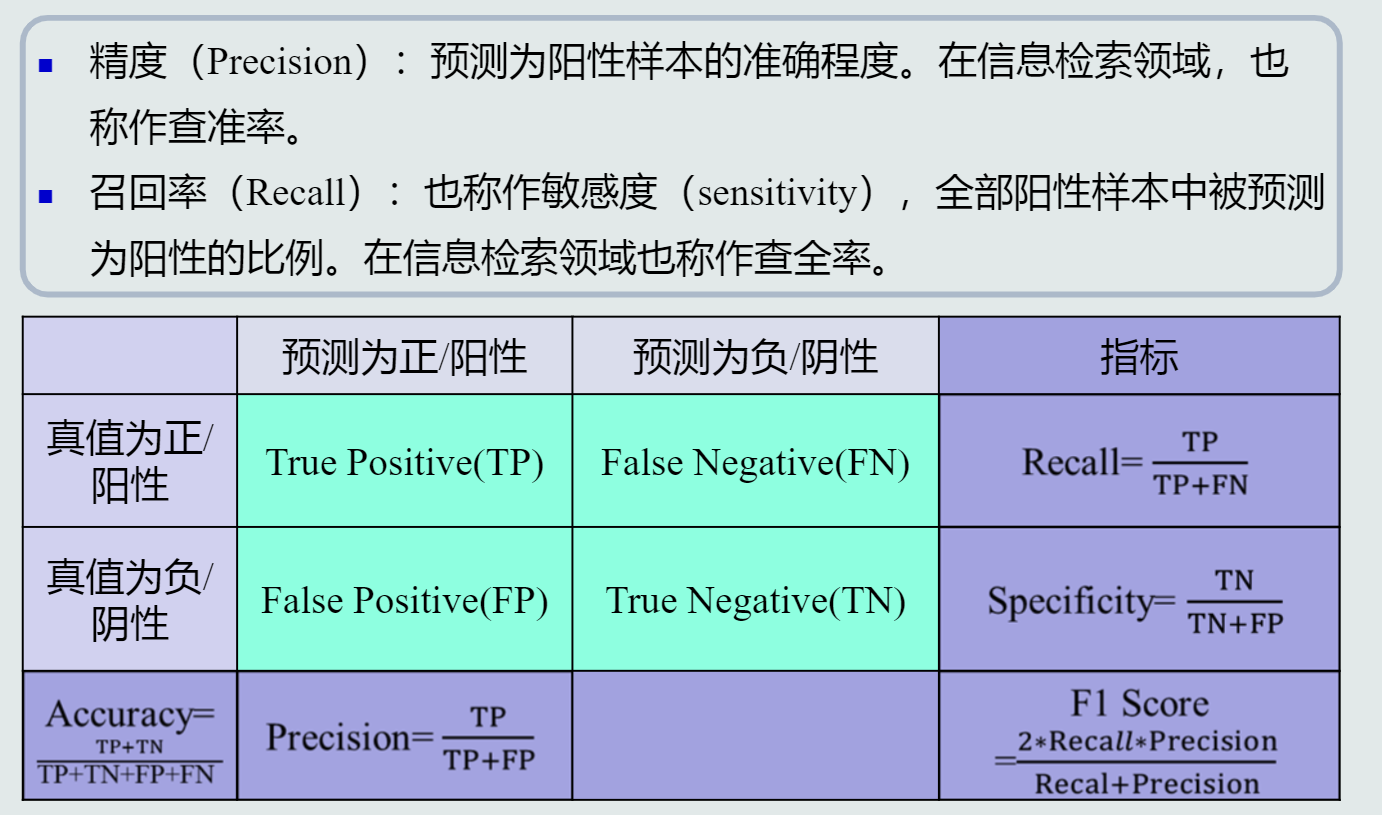

F-score

混淆矩阵

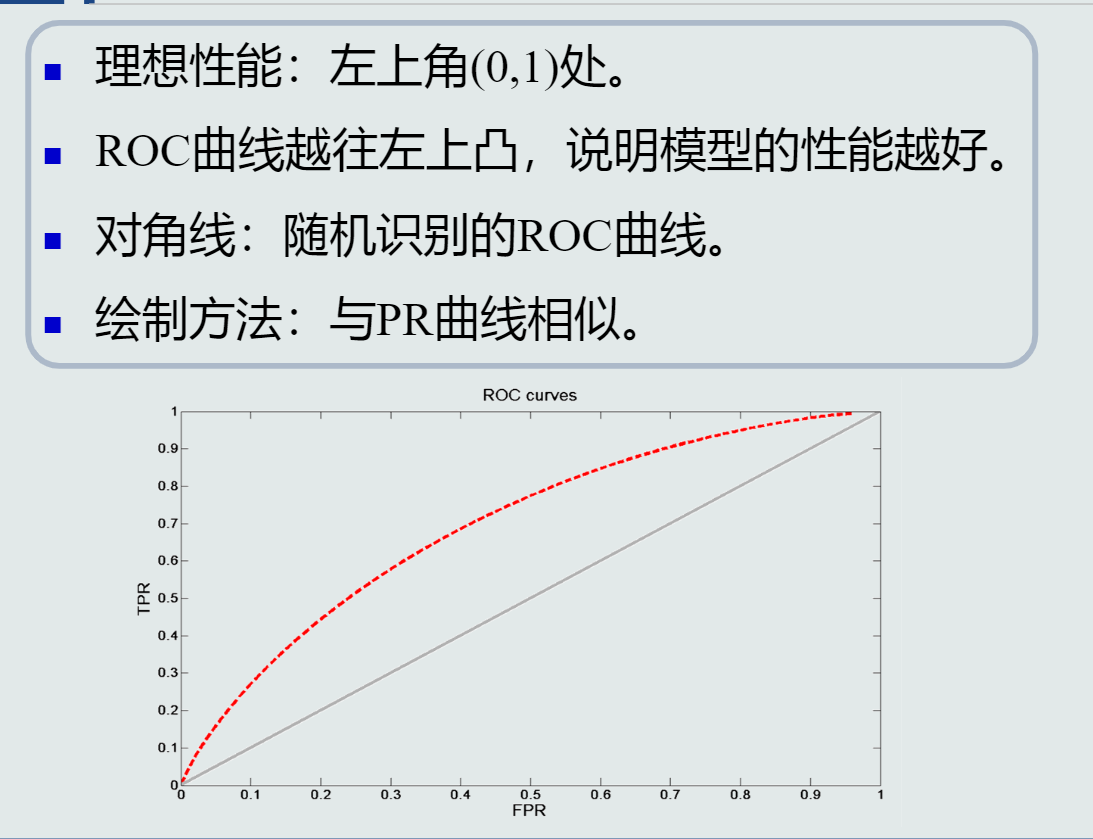
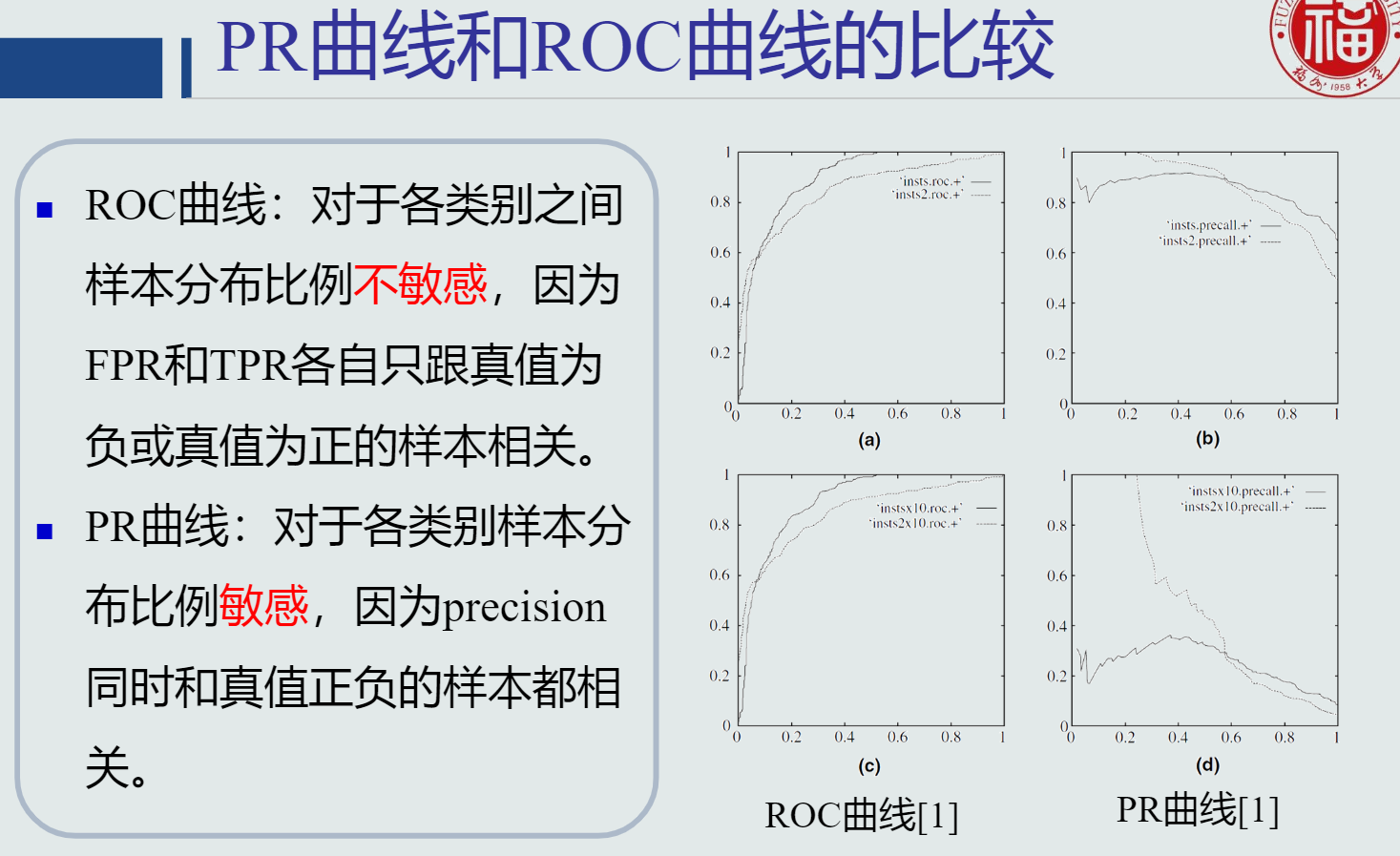
PR曲线

ROC曲线

第二章 基于距离的分类器
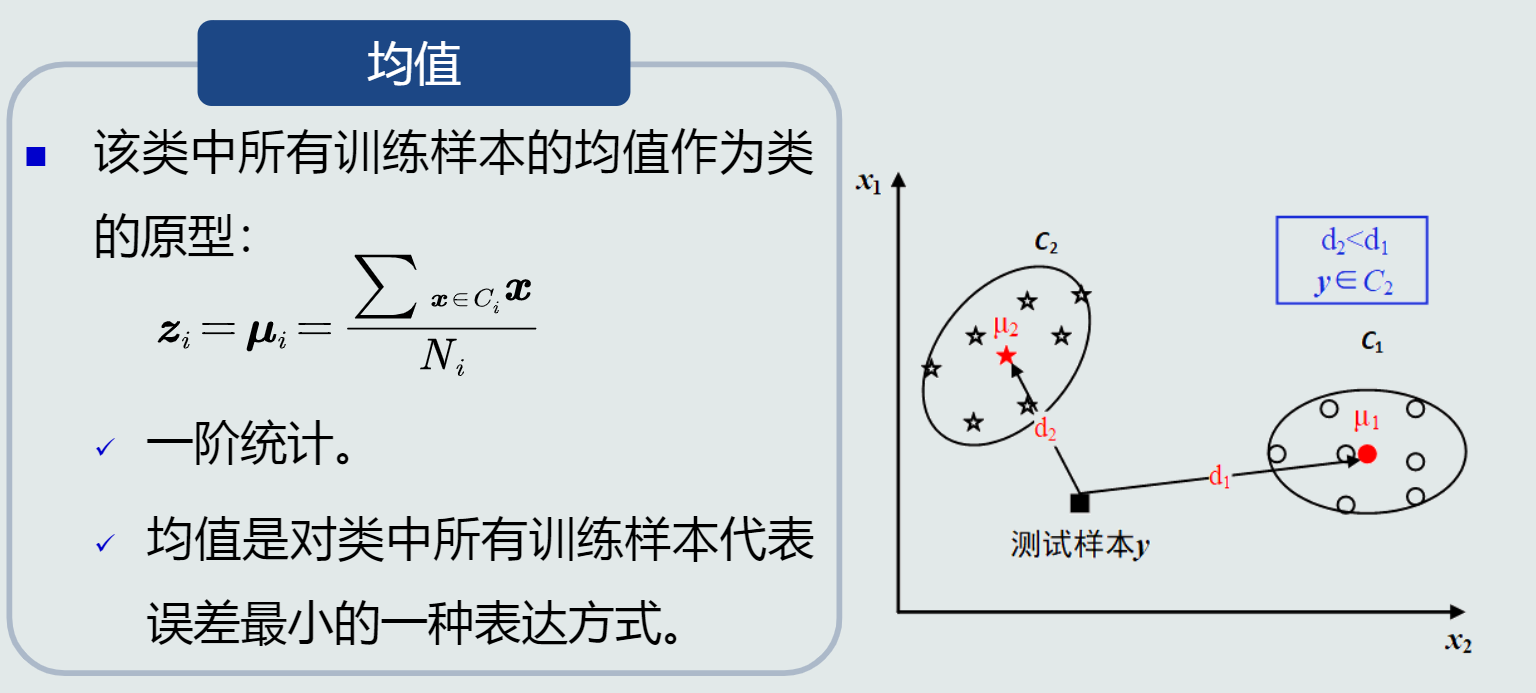
- MED分类器:把测试样本到每个类之间的距离作为决策模型,将测试样本判定为与其最近的类。
类的原型:
(1)将均值作为类的原型
(2)选取最近邻作为类的原型
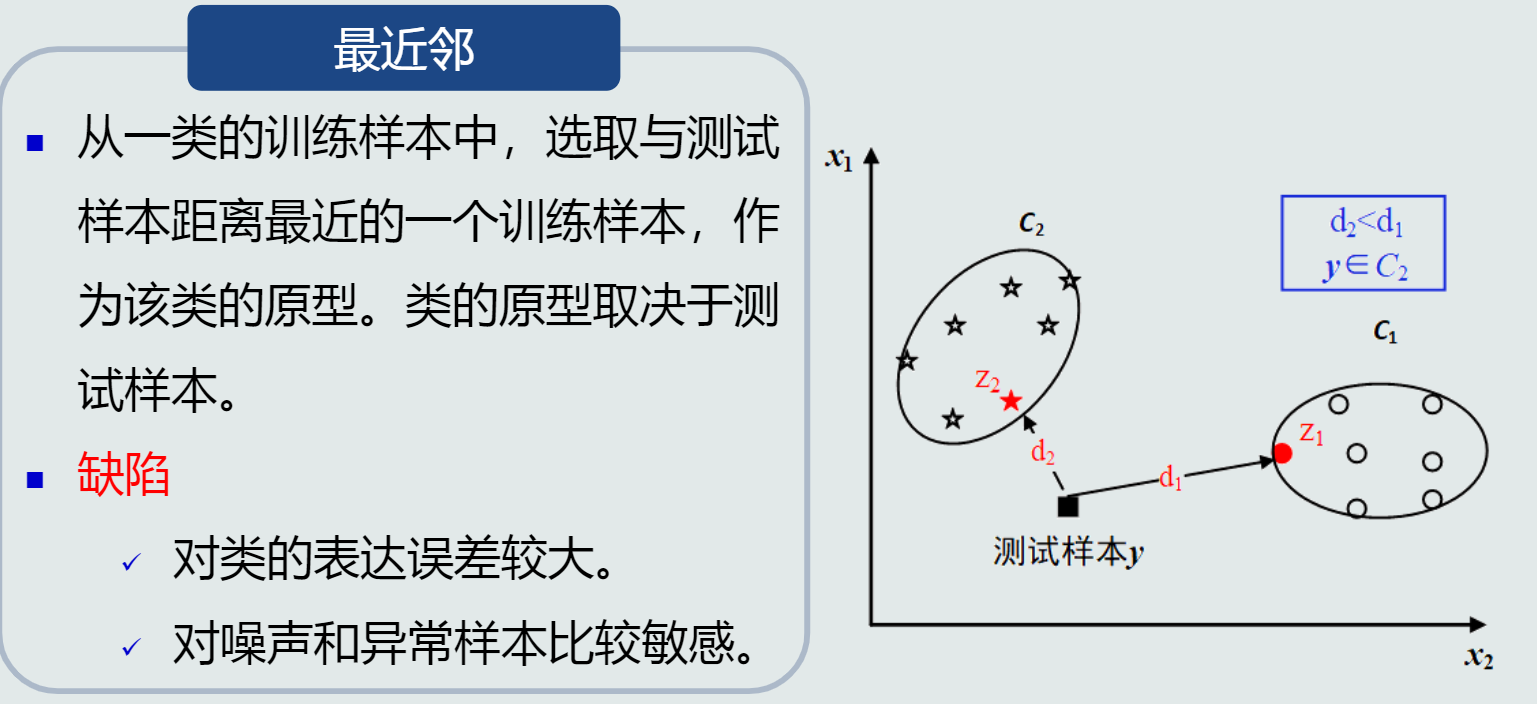
-
距离度量的三种方式

-
最小欧氏距离(MED)分类器
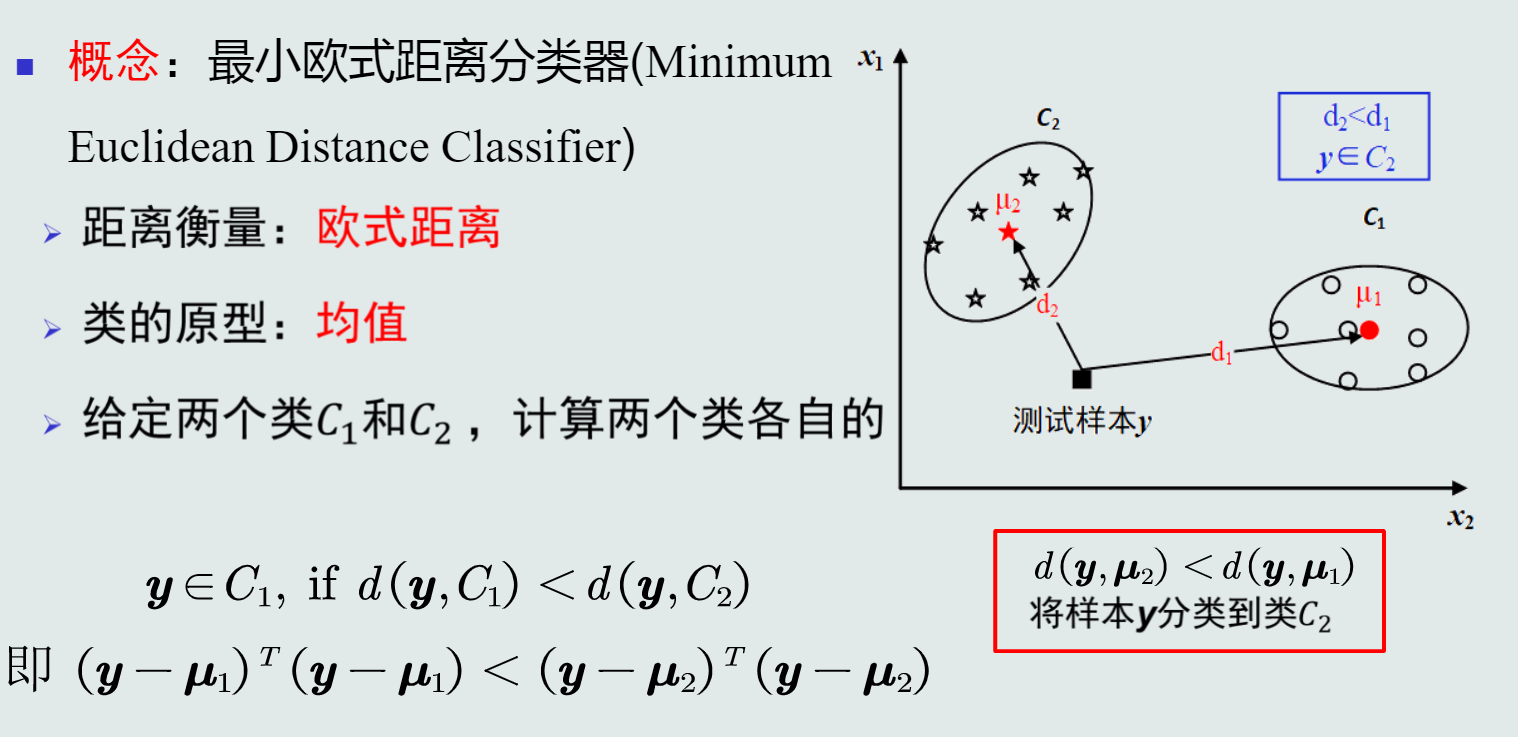
-
特征正交白化的目的

-
特征转换分为两步:去除特征间的相关性(解耦),再对特征进行尺度变换(白化),使得每维特征的方差相等。
解耦过程




白化过程
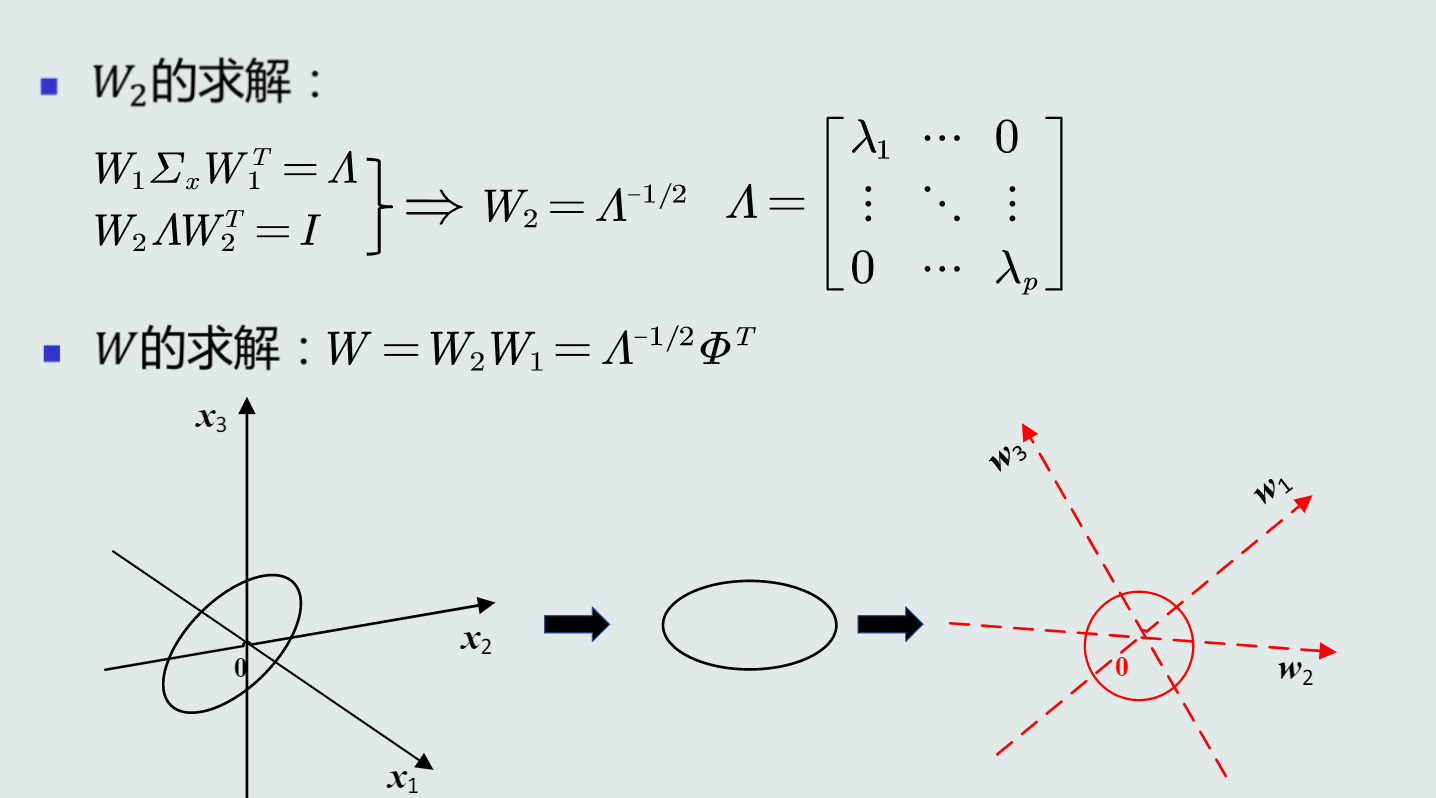

-
最小类内距离(MICD)分类器:基于马氏距离的分类器

-
MICD的决策边界

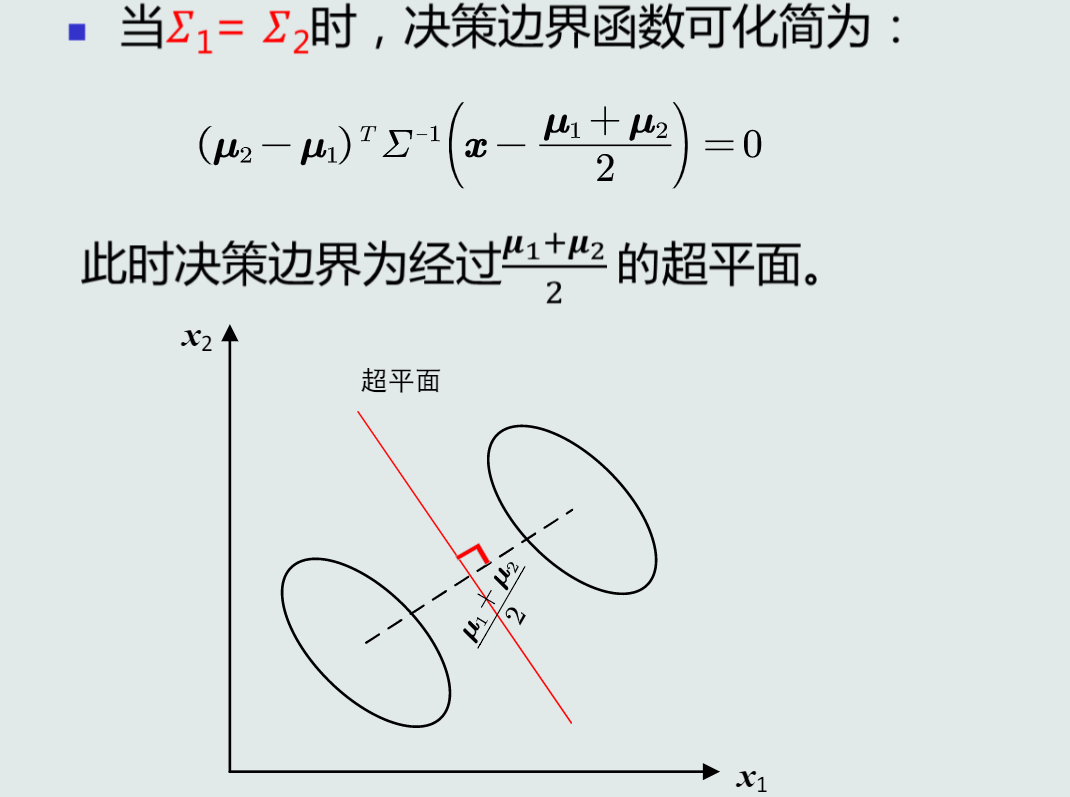
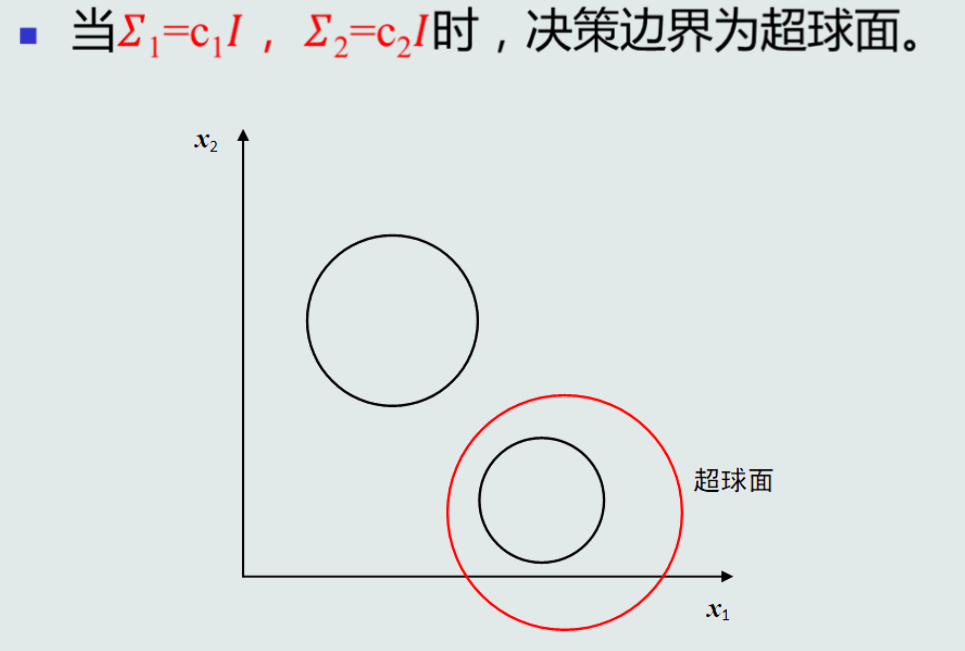
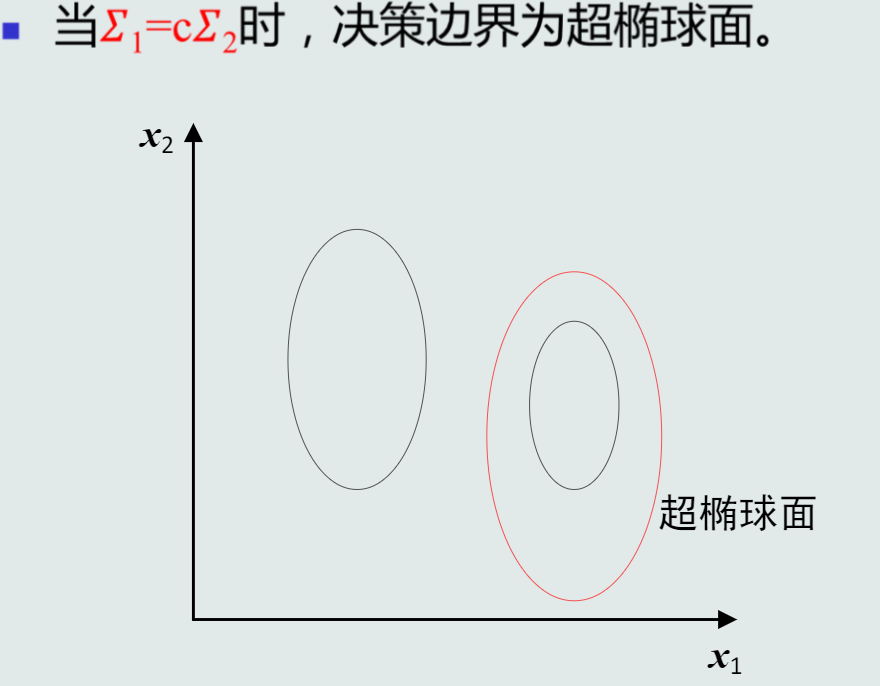
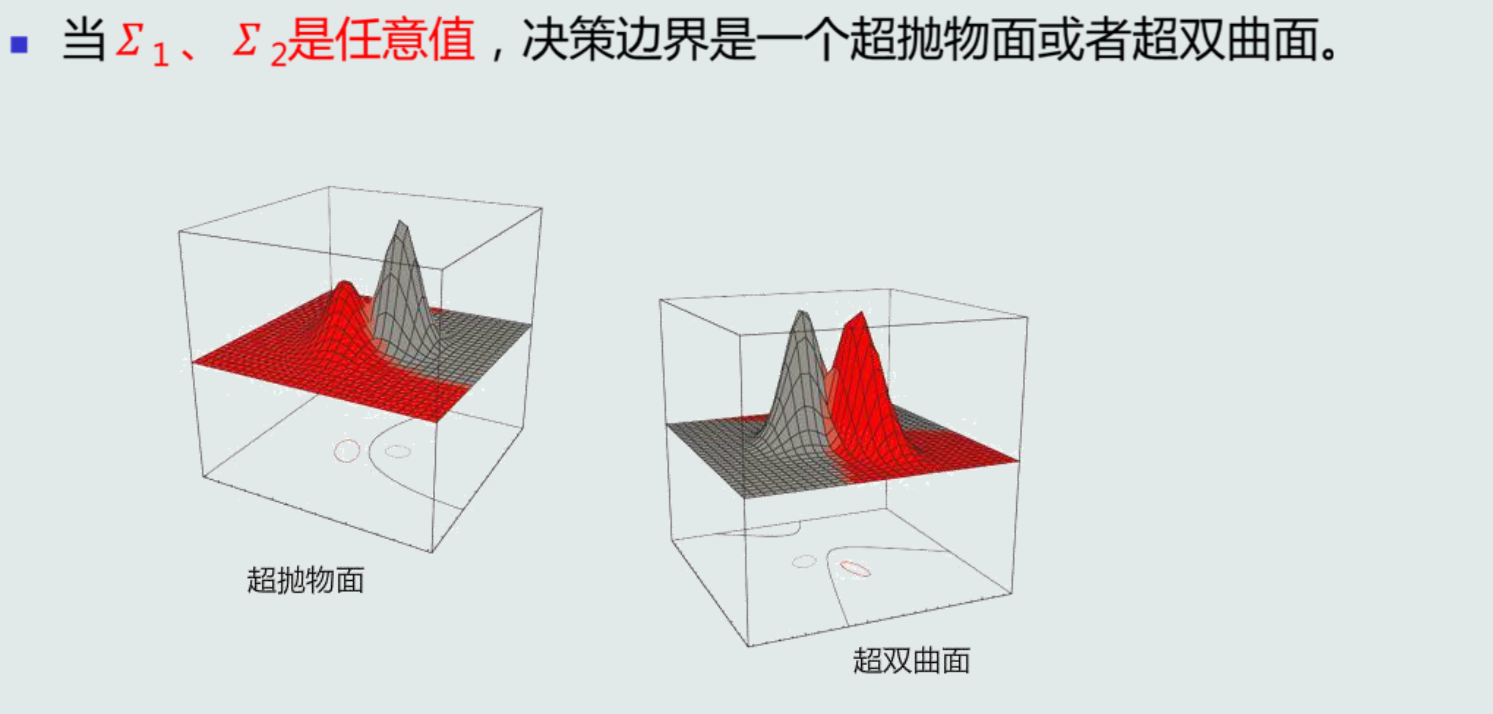
第三章 贝叶斯决策与学习
- 基于距离的决策存在的问题:
- 仅考虑每个类别各自观测到的训练样本的分布情况(例如:均值(MED分类器)、协方差(MICD分类器))
- 没有考虑类的分布等先验知识(例如:类别之间样本数量的比例,类别之间的相互关系)
- 概率的观点
- 随机性:每个样本是一次随机采样,样本个体具有随机性
- 机器学习的任务:反复观测采样,找出数据蕴含的概率分布规律
- 推理决策:根据学习出来的概率分布规律来做决定
- 每维特征构成一个随机变量,其概率分布由两个元素组成
- 该特征的取值空间(离散或连续)
- 在该特征维度上,样本处于各个取值状态的可能性
- 后验概率:用于分类决策
- 从概率的观点,给定一个测试模式x,决策其属于哪个类别需要依赖条件概率:p(C|x)
- 输入模式x:随机变量(单维特征)或向量(高维特征)
- 类别输出C:随机变量,取值是所有类别标签
- 针对每个类别Ci,该条件概率可以写作:p(Ci|x)
- 该条件概率也称作后验概率,表达给定模式x属于类Ci可能性
- 决策方式:找到后验概率最大的那个类
- 如何得到后验概率——贝叶斯规则 Bayes rule
- 已知先验概率和观测概率,模式x属于类Ci后验概率的计算公式为:p(Ci|x)=p(x|Ci)p(Ci)p(x)
- 其中,p(Ci)为类Ci的先验概率,p(x|Ci)为观测似然概率,p(x)=∑jp(x|cj)p(cj)=∑jp(x,Cj)为所有类别样本x的边缘概率
- 加入先验后,相较于观测,后验概率产生了迁移
- MAP分类器
-
最大后验概率分类器:将测试样本决策分类给后验概率最大的那个类
-
判别公式:

-
决策边界
- 对于二类分类:p(x|C1)p(C1)−p(x|C2)p(C2)=0
- 单维空间:通常有两条决策边界;
- 高维空间:复杂的非线性边界
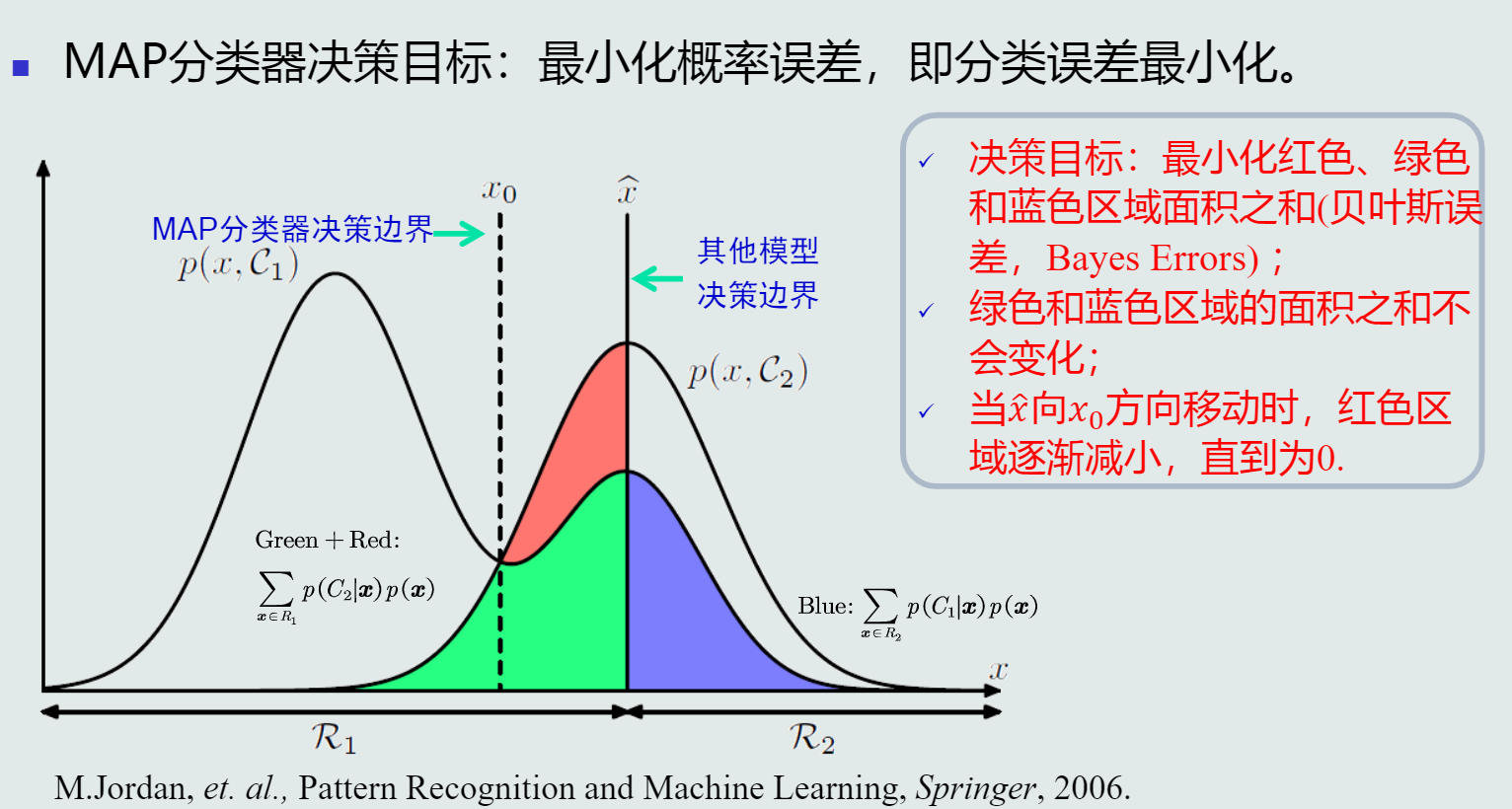
- MAP分类器决策误差
-
决策误差:可以用概率误差表达,等于未选择的类所对应的后验概率:p(error|x)={p(C2|x),ifdecidex∈C1p(C1|x),ifdecidex∈C2
-
给定所有测试样本(N为样本个数),分类决策产生的平均概率误差为:样本的概率误差的均值

-
MAP分类器决策目标:最小化概率误差,即分类误差最小化
- 先验和观测概率的表达方式
- 常数表达
- 参数化解析表达:高斯分布……
- 非参数化表达:直方图、核密度、蒙特卡洛……——很难用方程形式表达
- 观测概率
- 单维高斯分布
-
分布函数:p(x|Ck)=12π√σke−12(x−μkσk)2,k=1,2,...,K,其中:μk,σk分别代表k的均值和标准差,K代表类别个数
-
带入MAP分类器的判别公式:

-
得到决策边界:

-
当σi=σj=σ时,决策边界是线性的:

- 如果μi<μj,且P(Ci)<P(Cj),则δ<0,说明:在方差相同的情况下,MAP决策边界偏向先验可能性较小的类,即分类器决策偏向先验概率高的类
- 其他情况下,也能得到相同的结论
-
当σi≠σj时,决策边界有两条(非线性边界)

-
MAP分类器可以解决MICD分类器存在的问题

-
高维高斯分布
-
假设观测概率是多维高斯分布,概率密度函数为:p(x|Ci)=1(2π)p/2|∑i|1/2e−12(x−μi)T∑−1i(x−μi)
-
带入MAP分类器可以得到判别函数:
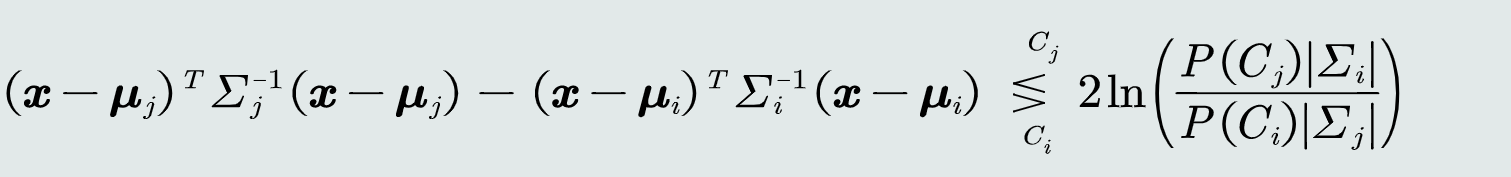
-
决策边界是一个超二次型,但始终是偏移MICD决策边界如下距离:
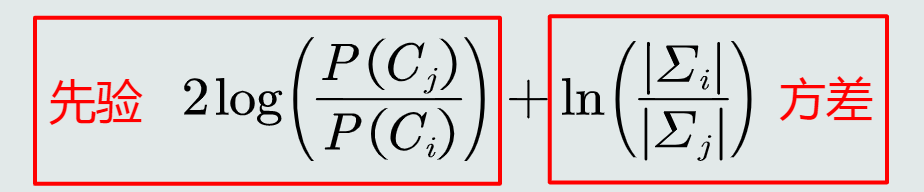
-
-
- 决策风险:贝叶斯决策不能排除出现错误判断的情况,由此会带来决策风险。且不同错误决策会产生程度完全不一样的风险
- 损失:表征当前决策动作相对于其他候选类别的风险程度
- 假设分类器把测试样本x决策为Ci类,这个决策动作记作αi
- 假设该测试样本x的真值是属于Cj类,决策动作αi对应的损失可以表达为:λ(αi|Cj),简写为λij
- 损失的评估:针对所有决策动作和候选类别,可以用一个矩阵来表示对应的损失值
- 决策风险的评估:给定一个测试样本x,分类器决策其属于Ci类的动作αi对应的决策风险可以定义为相对于所有候选类别的期望损失,记作R(αi|x)=∑jλijp(Cj|x)
- 贝叶斯分类器:在MAP分类器基础上,加入决策风险因素,得到贝叶斯分类器 Bayes classifier。给定一个测试样本x,贝叶斯分类器选择决策风险最小的类。
-
判别公式:

-
贝叶斯决策的期望损失
- 对于单个测试样本,贝叶斯决策损失就是决策风险R(αi|x)
- 对于所有测试样本(N为样本个数),贝叶斯决策的期望损失是所有样本的决策损失之和:R({x})=∑iR(αi|{x})=∑i∑kλik∑x∈RiP(Ck|x)
-
贝叶斯分类器的决策目标
- 决策目标:最小化期望损失
- 实现方式:对每个测试样本选择风险最小的类

- 朴素贝叶斯分类器
-
背景:如果特征是多维,学习特征之间的相关性会很困难
-
分类器公式:

-
对于决策边界附近的样本的处理方式
- 拒绝选项:在两个类别的决策边界附近,导致属于该类的决策有很大的不确定性。为了避免出现错误决策,分类器可以选择拒绝。
- 如何拒绝:
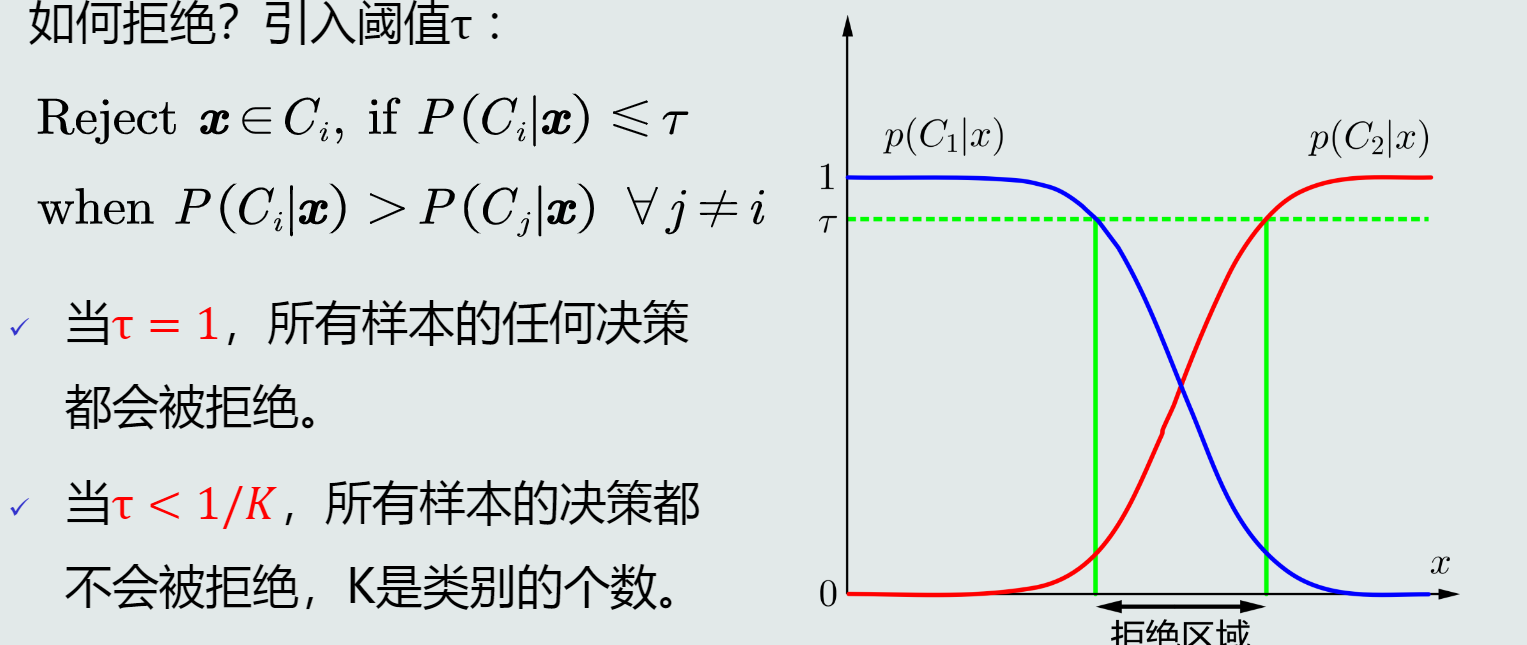
- 根据概率分布的表达形式,监督式学习方法有以下两种:
- 参数化方法:给定概率分布的解析表达,学习这些解析表达函数中的参数。该类方法也称为参数估计
- 非参数化方法:概率密度函数形式未知,基于概率密度估计技术,估计非参数化的概率密度表达。
- 参数估计方法
- 最大似然估计 Maximum Likelihood Estimation
- 贝叶斯估计 Bayesian Estimation
- 最大似然估计
-
定义:

-
先验概率估计
- 目标函数:给定所有类的N个训练样本,假设随机抽取其中一个样本属于C1类的概率为P,则选取到N1个属于C1类样本的概率为先验概率的似然函数(即目标函数):P(N1|N,P)=CN1NPN1(1−P)N−N1=N!N1!(N−N1)!PN1(1−p)N−N1
- 相关背景知识:Bernouli分布
- 先验概率估计:

-
观测概率估计:高斯分布(待学习参数:均值μ和协方差∑)
-
目标函数:

-
参数估计:



-
- 无偏估计
-
定义:如果一个参数的估计量的数学期望是该参数的真值,则该估计量称作无偏估计
-
含义:只要训练样本个数足够多,该估计值就是参数的真实值
-
相关背景知识:数学期望和方差/协方差

-
判断是否为无偏估计
-
高斯分布均值的最大似然估计
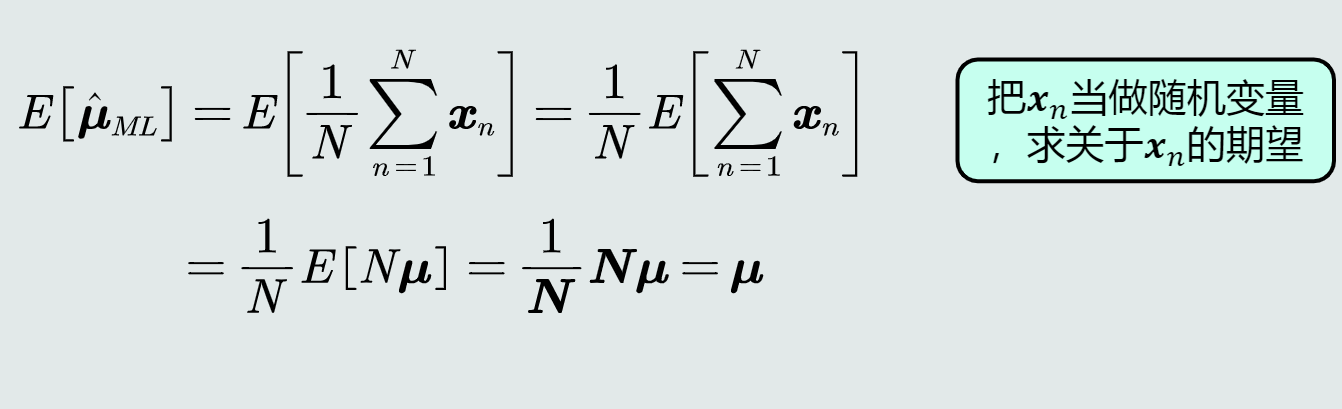
-
均值的最大似然估计是无偏估计
-
-
高斯分布协方差的最大似然估计
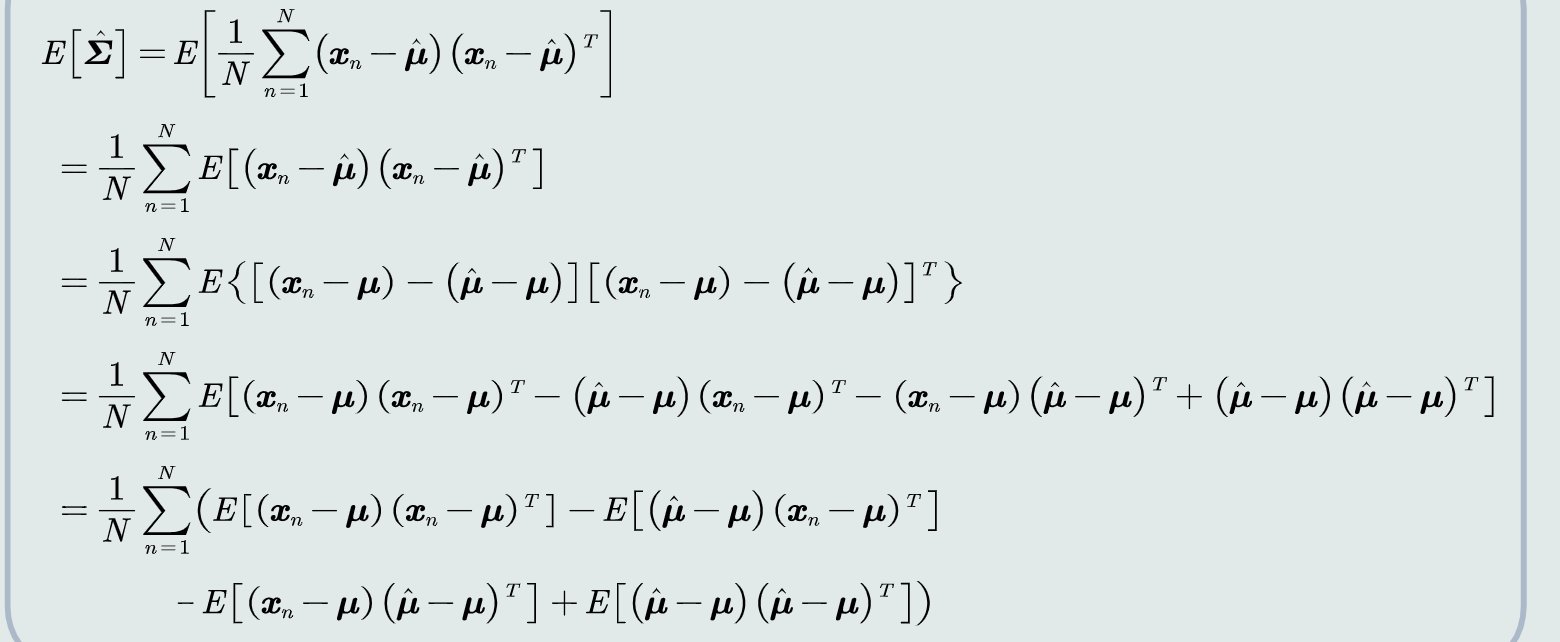

- 偏差多少:

- 偏差多少:
估计偏差是一个较小的数。当N足够大时,最大似然估计可以看做是一个较好的估计
- 修正:在实际计算中,可以通过将训练样本的协方差乘以N/(N-1)来进行修正

图估计更加平滑
-
贝叶斯估计

-
无参数估计

-
K近邻(KNN)估计

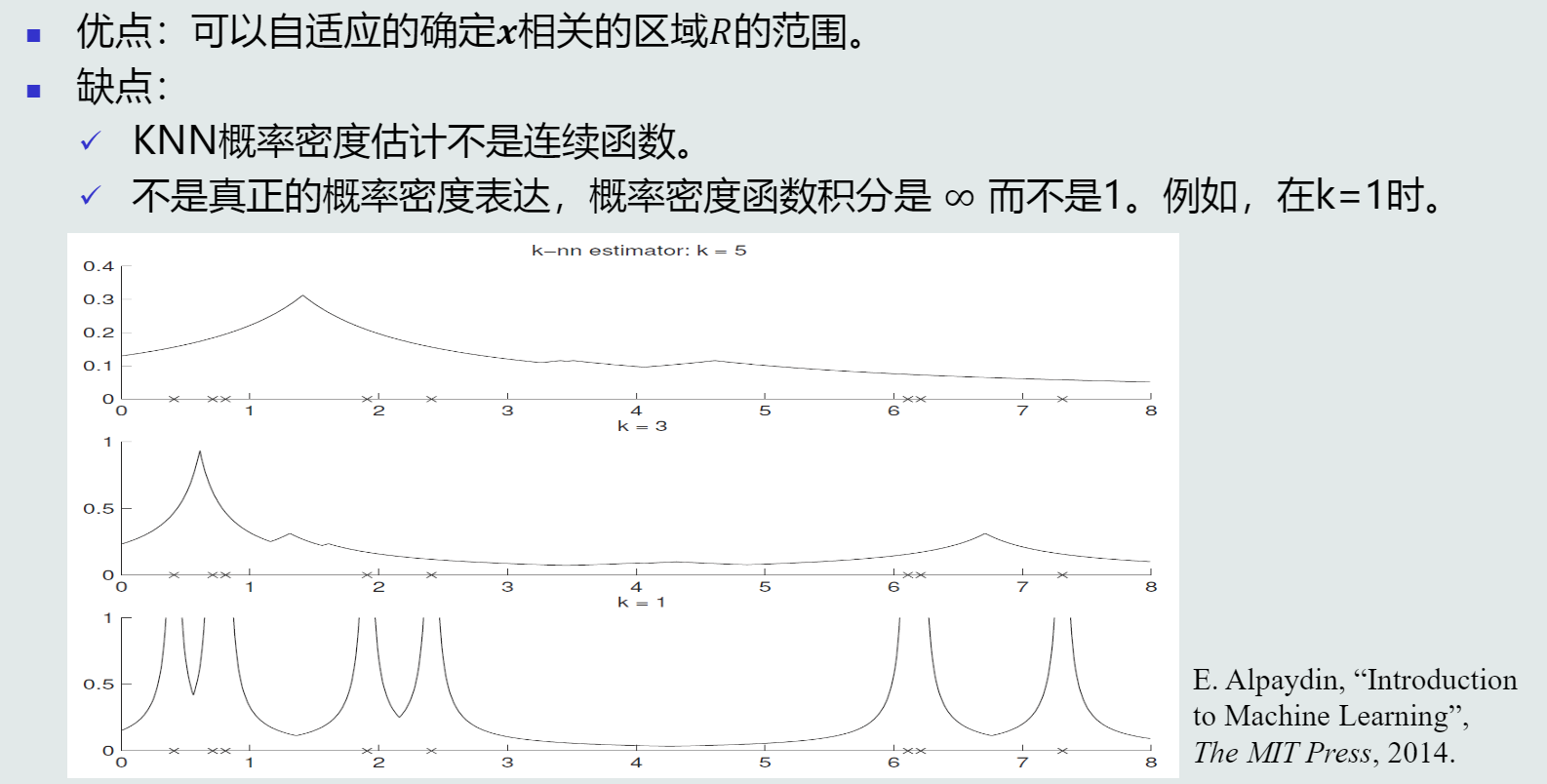
-
直方图估计


-
核密度估计





 浙公网安备 33010602011771号
浙公网安备 33010602011771号