第一次个人编程作业
计算模块接口的设计与实现过程
- 解题思路:
1. 将导入的两个文本中一些无用的换行符、标签清除,然后分别进行分词。
2. 若文本长度小于500,使用余弦相似度算法。计算每个分词的词频,构成词频向量,然后通过下面公式计算出重复度
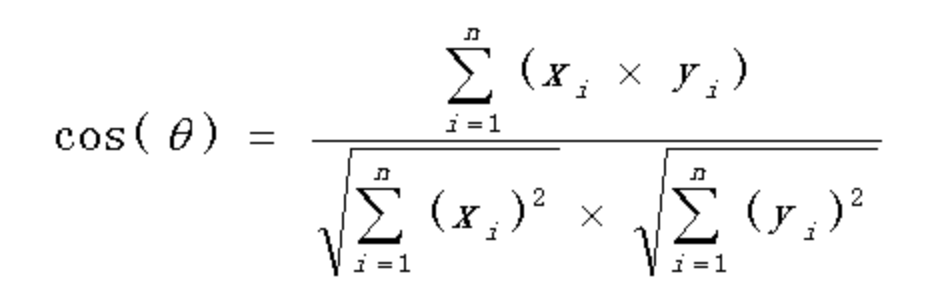
3. 若文本长度大于500,使用simHash算法。①将每个分词按照词频赋予不同权重。②通过hash函数计算各个特征向量的hash值,然后在hash值的基础上,给所有特征向量进行加权,即W = hash * weight。③将上述各个特征向量的加权结果累加,变成只有一个序列串。④将序列串降维成01串,就可以算出海明距离。⑤最后重复度 = 1 - 海明距离 / hash长度(我的是转换成64bit)
这两种算法原理感觉网上大佬们讲的够好了,就直接在下面贴出来。
- 心路历程:
看到题目的第一眼我是懵逼的,之前都只是负责项目页面的布局以及获取后端数据放到页面上,现在突然看到这么个论文查重有点不知所措。
本来是想用c++的,因为只有这个之前学过。。不过后面想想反正都不懂,干脆学个新语言来做好了。于是最后就决定用新学的java来写了。
然后就是java小白苦逼地配置环境,下载IDE等等等。。。。耗费大量时间。
百度了查了一会文本相似度算法,本来我一开始是用听说很香的余弦相似度算法来算两个文本的相似度的,但是后面导入长文本时我懵逼地发现这相似度结果很不对劲(都是0.99???后面我看了其他人用余弦相似度的写的代码,不会这么极端,就很奇怪),于是又去查了一下,发现余弦相似度对于短文本比较准确,对长文本就不怎么样了。于是我用了在查找途中看到的simHash算法,这个算法恰好和余弦相似度算法相反,长文本比较准确。所以最后我两个算法都用上了,然后根据文本的长度来判断该使用哪个算法。
- 主要函数:
1)BigInteger simHash(String str):负责simHash算法中的分词,并计算每个分词的权重最后返回加权累加。
2)public static String RemoveLebel(String str):负责将文本转化的字符里面的回车符、文本标签等清除,如果不清除相似度会很奇怪。
ps:因为余弦相似度算法知道原理后就是数学计算而已,所以感觉函数实现没什么好说的。
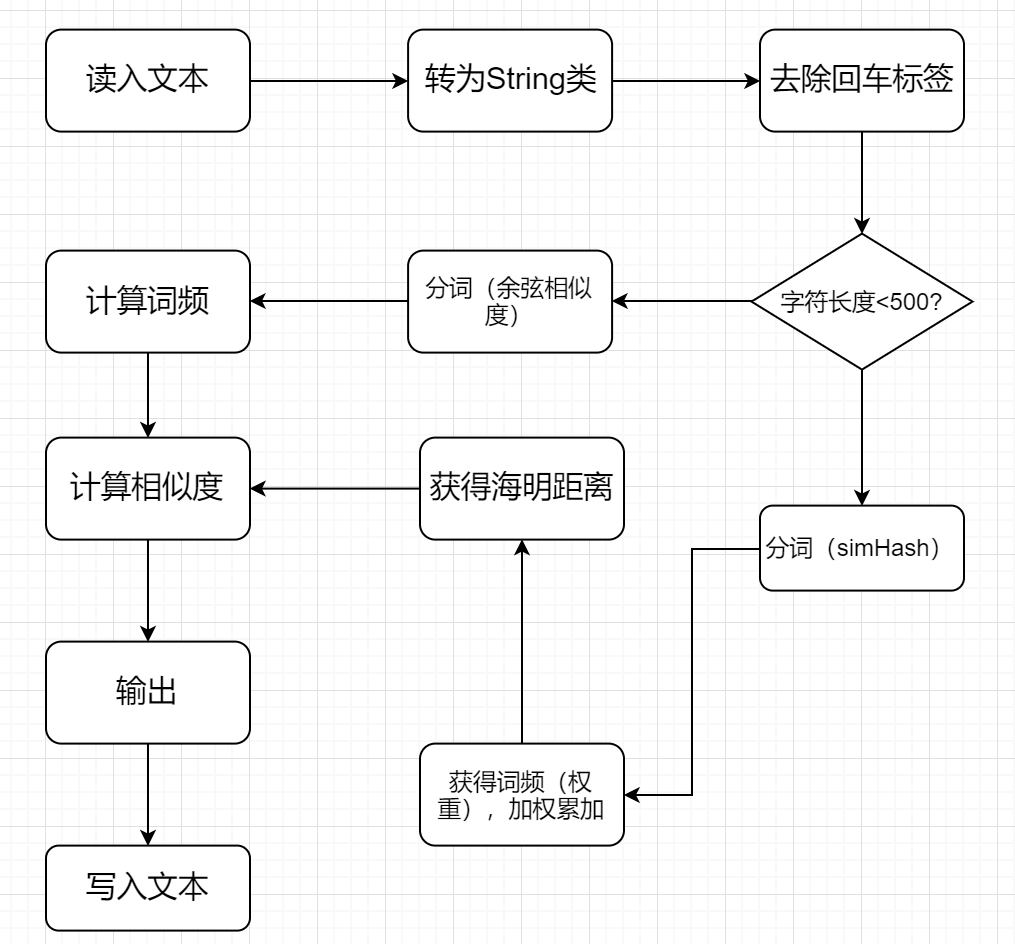
- 实现流程图:
计算模块接口部分的性能改进
-
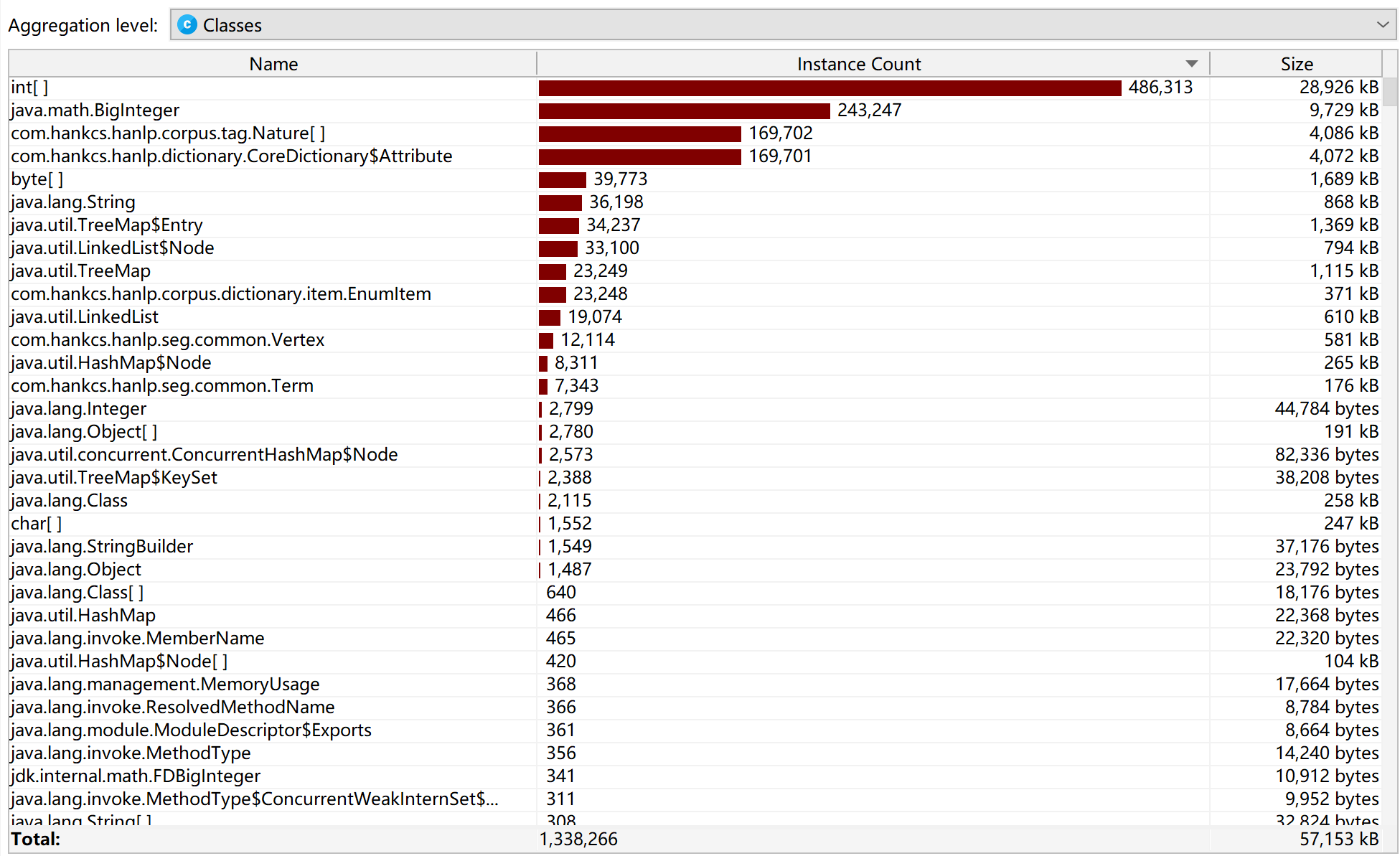
类的内存消耗:
-
CPU Load:
-
堆内存情况:

可以看出,simHash消耗内存最大。
至于改进。。。实在想不出,无能为力。
计算模块部分单元测试展示
- 测试代码:
class TestCase {
@Test
public void testSimHash() {
File f = new File("tests");
String[] files = f.list();
int cnt = 1;
for(String file: files) {
if(!file.equals("orig.txt") && !file.equals("short_orig.txt") && !file.equals("short_orig_other.txt")) {
System.out.println("simHash开始处理:" + file);
MainProcess.Process("tests/orig.txt", "tests/" + file, "ans/ans" + cnt + ".txt");
cnt++;
}
}
}
@Test
public void testCos() {
System.out.println("cos开始处理:" + "tests/short_orig_other.txt");
MainProcess.Process("tests/short_orig.txt", "tests/short_orig_other.txt", "ans/short_ans.txt");
}
}
- 测试结果:
cos开始处理:tests/short_orig_other.txt
查重结果为:0.81
simHash开始处理:orig_0.8_add.txt
查重结果为:0.88
simHash开始处理:orig_0.8_del.txt
查重结果为:0.92
simHash开始处理:orig_0.8_dis_1.txt
查重结果为:0.89
simHash开始处理:orig_0.8_dis_10.txt
查重结果为:0.89
simHash开始处理:orig_0.8_dis_15.txt
查重结果为:0.89
simHash开始处理:orig_0.8_dis_3.txt
查重结果为:0.89
simHash开始处理:orig_0.8_dis_7.txt
查重结果为:0.86
simHash开始处理:orig_0.8_mix.txt
查重结果为:0.88
simHash开始处理:orig_0.8_rep.txt
查重结果为:0.80
- 测试覆盖率:
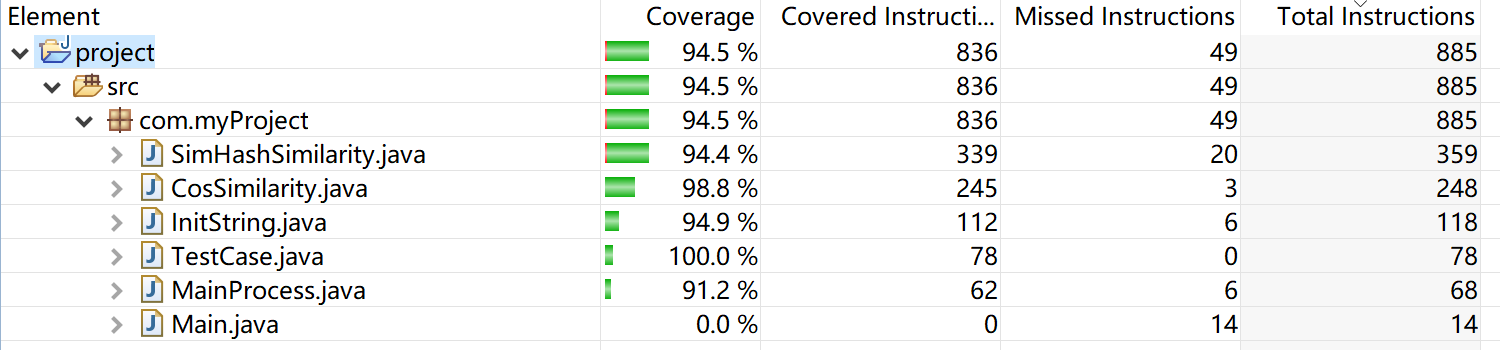
计算模块部分异常处理说明
只设计了一个空文本的异常
File Content = new File("tests/" + file);
if(Content.length() == 3) { //UTF-8空文本字节为3
try{
throw new MyException("这是空文本!");
} catch(MyException e) {
e.printStackTrace();
}
}
public class MyException extends Exception{
public MyException() {
super();
}
public MyException(String message) {
super(message);
}
}
测试结果:

P2P表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| Estimate | 估计这个任务需要多少时间 | 60 | 60 |
| Development | 开发 | 900 | 920 |
| Analysis | 需求分析 (包括学习新技术) | 180 | 200 |
| Design Spec | 生成设计文档 | 60 | 80 |
| Design Review | 设计复审 | 20 | 20 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 15 |
| Design | 具体设计 | 30 | 40 |
| Coding | 具体编码 | 360 | 420 |
| Code Review | 代码复审 | 10 | 15 |
| Test | 测试(自我测试,修改代码,提交修改) | 20 | 30 |
| Reporting | 报告 | 60 | 60 |
| Test Repor | 测试报告 | 30 | 30 |
| Size Measurement | 计算工作量 | 10 | 20 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 10 | 20 |
| 合计 | 1800 | 1960 |
总结
这次作业可谓是收益匪浅。从寻找算法,安装Java IDE,配置环境,学习Java语法,编程实现算法到如何导入jar包,使用Jprofiler查看性能,用Junit进行单元测试。我一遍遍的百度查找,或者问旁边的大佬。Java方面的知识以极为迅猛的速度增加。
虽然说这很让人疲倦和难受。。主要是对我这种有点死脑筋的人来说,如果一件事找不出解决方法,就会一直去寻找直到找到,在没找到的途中会近乎无视其他事情,这种事很糟糕,希望后面能有所改善。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号