【JS逆向】之瑞数(通用版)
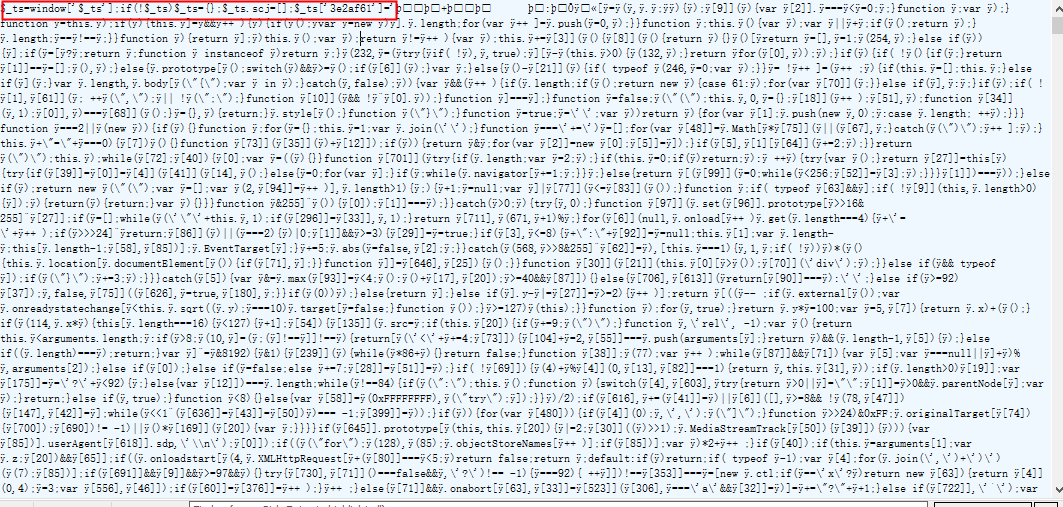
看网站反爬是否是瑞数可以从三个特征点观察,第一是返回页面状态码是202或者412,第二是会有个js文件(如下图所示),第三是该js文件开头是这种固定格式,3e2af61是对应瑞
数版本号。(该js文件非常重要,需要下载该文件)

核心代码:
# -*- coding: UTF-8 -*- import os import sys import codecs from spiders.building_penalty.govement_penalty_base_spider import govement_penalty_base_spider from utils.common_util import * from utils.ruishu_util import * import datetime from bs4 import BeautifulSoup from spiders.base_spiders.base_spider import * from urllib.parse import urlencode from config.proxy.config import * from utils.date_util import current_datetime class hub_building_panelty(govement_penalty_base_spider): name = "hub_building_panelty" is_not_change_proxy = True # 只用一个代理 is_proxy = True proxy_type = PROXY_TYPE_YR proxy_count = 50 custom_settings = { 'CONCURRENT_REQUESTS': 20, 'CONCURRENT_REQUESTS_PER_DOMAIN': 20, 'DOWNLOAD_TIMEOUT': 30, 'RETRY_TIMES': 30, 'HTTPERROR_ALLOWED_CODES': [302, 521, 504, 408, 500, 502, 503, 533, 404, 400, 412, 403, 417, 202, 478, 301], 'RETRY_HTTP_CODES': [504, 408, 500, 502, 503, 533, 407, 478, 301], # 400, 403 'COOKIES_ENABLED': False, 'REDIRECT_ENABLED': False, } def __init__(self, increment=None, *args, **kwargs): super(hub_building_panelty, self).__init__(*args, **kwargs) self.increment = increment self.headers = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9', 'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Host': 'zjt.hubei.gov.cn', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36', } path = os.path.abspath(os.path.dirname(sys.argv[0])) # 读取下载的js文件 with codecs.open(path + '/document/templates_ruishu_chongqing_chinatax.html', 'r', "utf-8") as f: self.templates = f.read() def start_requests(self): index_url = "https://zjt.hubei.gov.cn/zfxxgk/fdzdgknr/cfqz/xzcfjd/" yield scrapy.Request(url=index_url, method='GET', headers=self.headers, encoding="utf-8", dont_filter=True) def parse(self, response): resp_url = response.url resp_meta = copy.deepcopy(response.meta) try: if response.status == 202 or response.status == 412: # 找到正常状态码下两个cookie参数键名(特征部分字符相同) dict_data, url_key = get_ruishu_cookie("FSSBBIl1UgzbN7N80S", "FSSBBIl1UgzbN7N80T", response, self.request_http_pool, self.templates, 'common', spider_name=self.name) resp_meta['Cookie'] = dict_data['Cookie'] json_headers = copy.deepcopy(self.headers) json_headers['Cookie'] = dict_data['Cookie'] json_headers['Referer'] = resp_url yield scrapy.Request(url=resp_url, method='GET', headers=json_headers, encoding="utf-8", dont_filter=True, callback=self.parse, meta=resp_meta) else: if "parse_list" in str(resp_meta) and "parse_detail" not in str(resp_meta): list_headers = copy.deepcopy(self.headers) if "Cookie" in resp_meta: list_headers['Cookie'] = resp_meta['Cookie'] list_headers['Referer'] = resp_meta['resp_url'] yield scrapy.Request(url=resp_meta['resp_url'], method='GET', headers=list_headers, encoding="utf-8", dont_filter=True, callback=self.parse_list, meta=resp_meta) elif "parse_detail" in str(resp_meta): detail_headers = copy.deepcopy(self.headers) if "Cookie" in resp_meta: detail_headers['Cookie'] = resp_meta['Cookie'] detail_headers['Referer'] = resp_meta['resp_url'] yield scrapy.Request(url=resp_meta['resp_url'], method='GET', headers=detail_headers, encoding="utf-8", dont_filter=True, callback=self.parse_detail, meta=resp_meta) else: page_number = re.findall(r'createPageHTML\((.*?),',response.text)[0] search_number = 2 if self.increment else int(page_number) for index in range(0,search_number): list_headers = copy.deepcopy(self.headers) if "Cookie" in resp_meta: list_headers['Cookie'] = resp_meta['Cookie'] if index >= 1: send_url = "https://zjt.hubei.gov.cn/zfxxgk/fdzdgknr/cfqz/xzcfjd/index_{}.shtml".format(index) list_headers['Referer'] = "https://zjt.hubei.gov.cn/zfxxgk/fdzdgknr/cfqz/xzcfjd/index_{}.shtml".format(index + 1) yield scrapy.Request(url=send_url, method='GET', headers=list_headers,meta=resp_meta, encoding="utf-8", dont_filter=True, callback=self.parse_list) else: list_headers['Referer'] = 'https://zjt.hubei.gov.cn/zfxxgk/fdzdgknr/cfqz/xzcfjd/index_1.shtml' yield scrapy.Request(url=resp_url, method='GET', headers=list_headers,meta=resp_meta, encoding="utf-8", dont_filter=True, callback=self.parse_list) except: traceback.print_exc() self.logger.info(f"parse error url: {resp_url}") def parse_list(self, response): resp_url = response.url resp_meta = copy.deepcopy(response.meta) try: if response.status != 200: yield scrapy.Request(url=resp_url, method='GET', headers=self.headers, encoding="utf-8", dont_filter=True, meta={**resp_meta, 'parse_list': 'parse_list', 'resp_url': resp_url}, callback=self.parse) else: resp_soup = BeautifulSoup(response.text, 'html5lib') detail_list = resp_soup.select('ul.info-list li') for detail in detail_list: if "href" in str(detail): detail_url = response.urljoin(detail.select_one('a')['href']) detail_headers = copy.deepcopy(self.headers) if "Cookie" in resp_meta: detail_headers['Cookie'] = resp_meta['Cookie'] detail_headers['Referer'] = resp_url publish_time = detail.select_one('span').text title = detail.select_one('a')['title'] yield scrapy.Request(url=detail_url, method='GET', headers=detail_headers,meta={**resp_meta,'title':title,'publish_time':publish_time}, encoding="utf-8", dont_filter=True, callback=self.parse_detail) except: traceback.print_exc() self.logger.info(f"parse error url: {resp_url}") def parse_detail(self, response): resp_body = response.text resp_url = response.url resp_meta = copy.deepcopy(response.meta) try: if response.status != 200: yield scrapy.Request(url=resp_url, method='GET', headers=self.headers, encoding="utf-8", dont_filter=True, meta={**resp_meta, 'parse_detail': 'parse_detail', 'resp_url': resp_url}, callback=self.parse) else: resp_soup = BeautifulSoup(resp_body, 'html5lib') info = dict() info["PublishTime"] = resp_meta['publish_time'] info["Title"] = resp_meta['title'] if resp_soup.select('span.xl_sj_icon2'): info["MessageSource"] = resp_soup.select_one('span.xl_sj_icon2').text.replace('\n','').split(':')[-1].strip() info["Content"] = str(resp_soup.select_one('div#detailCon')) info["ResponseBodyHtml"] = resp_body info["SourceUrl"] = resp_url info["Website"] = '湖北省住房和城乡建设厅' info["KeyNo"] = md5encode(info["Title"] + "|" + info["Website"] + "|" + info["Content"]) yield info except: traceback.print_exc() self.logger.info(f"parse error url: {resp_url}")
注意点:和加速乐一样需要看网站是否绑定IP
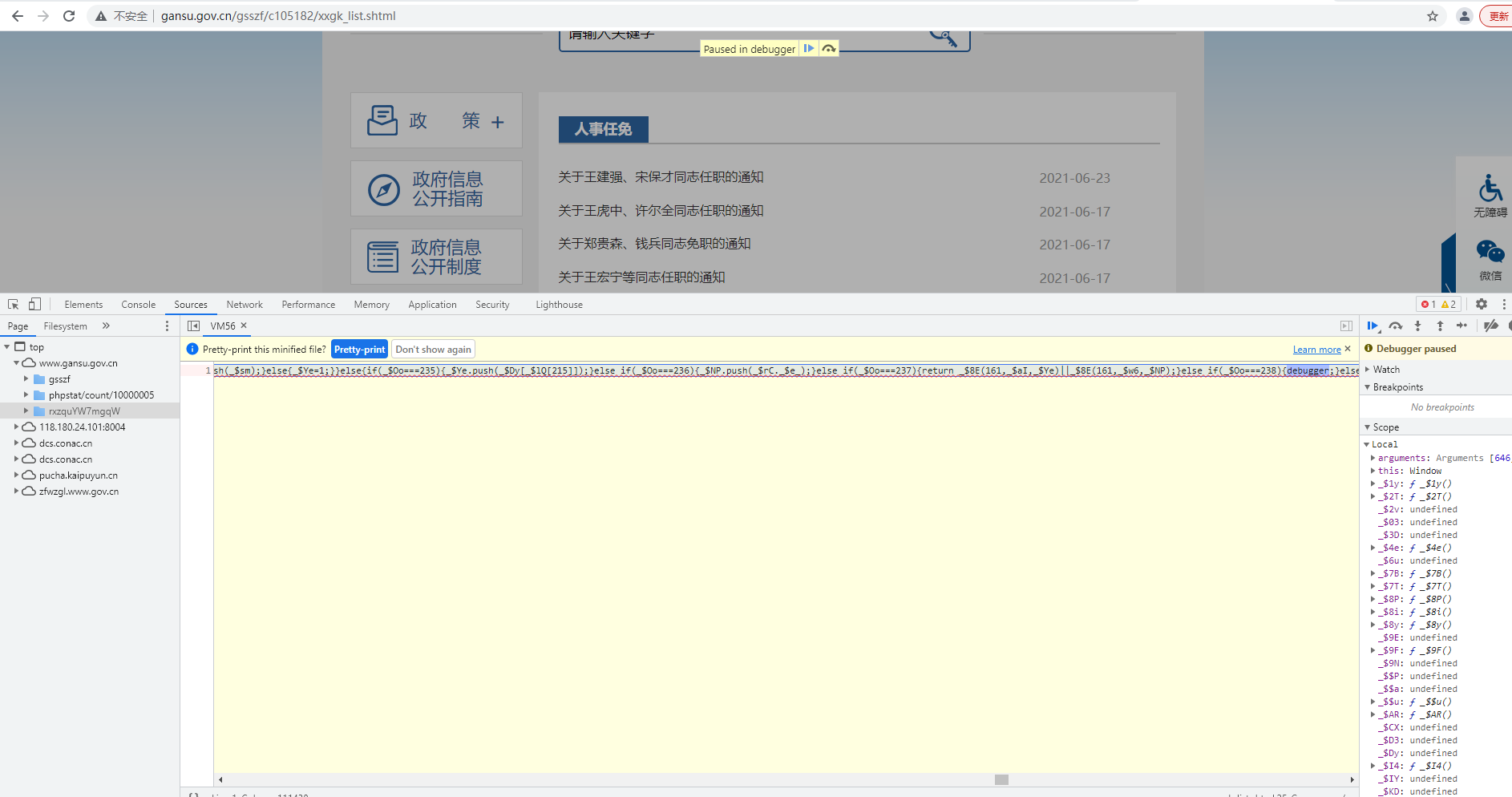
过debugger:
F12后发现:
点击格式化:

再进入下一步:

最后点击Activate breakpoints:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号