
反爬虫之防盗链
防盗链(起始url溯源):发起请求URL的上一个URL是否符合要求(跟Referer相关)
(1)对比Json数据中的视频链接(无效)和有效视频链接,可以发现有效视频链接是再Json链接基础上进行了加工。
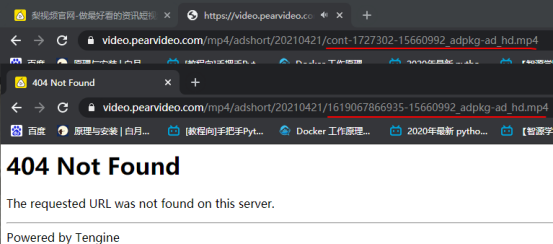
(2)对比原始页面链接和有效视频链接,可以发现video_id的联系

(3)拼接好url,会发现请求到的内容如下

''' 1、拿到contID 2、拿到videoStatus返回的json -> srcURL 3、scrURL里面的内容进行修改 4、下载视频 ''' import requests url = 'https://www.pearvideo.com/video_1727302'#起始页面url contId = url.split('_')[1] videoStatus = 'https://www.pearvideo.com/videoStatus.jsp?contId={}&mrd=0.24372510157125427'.format(contId) #Json数据接口 headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.128 Safari/537.36', #防盗链:主要监测请求的上一个页面是否符合要求 'Referer':url } response = requests.get(videoStatus,headers=headers) dic = response.json() srcUrl = dic['videoInfo']['videos']['srcUrl'] systemTime = dic['systemTime'] #https://video.pearvideo.com/mp4/adshort/20210421/cont-1727302-15660992_adpkg-ad_hd.mp4 目标 #https://video.pearvideo.com/mp4/adshort/20210421/1619070081837-15660992_adpkg-ad_hd.mp4 Json videoUrl = srcUrl.replace(systemTime,"cont-" + contId) print("视频:",videoUrl)
'''
1、拿到contID
2、拿到videoStatus返回的json -> srcURL
3、scrURL里面的内容进行修改
4、下载视频
'''
import requests
url = 'https://www.pearvideo.com/video_1727302'#起始页面url
contId = url.split('_')[1]
videoStatus = 'https://www.pearvideo.com/videoStatus.jsp?contId={}&mrd=0.24372510157125427'.format(contId) #Json数据接口
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.128 Safari/537.36',
#防盗链:主要监测请求的上一个页面是否符合要求
'Referer':url
}
response = requests.get(videoStatus,headers=headers)
dic = response.json()
srcUrl = dic['videoInfo']['videos']['srcUrl']
systemTime = dic['systemTime']
#https://video.pearvideo.com/mp4/adshort/20210421/cont-1727302-15660992_adpkg-ad_hd.mp4 目标
#https://video.pearvideo.com/mp4/adshort/20210421/1619070081837-15660992_adpkg-ad_hd.mp4 Json
videoUrl = srcUrl.replace(systemTime,"cont-" + contId)
print("视频:",videoUrl)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号