第09篇-在Elasticsearch中构建自定义分析器
我的Elasticsearch系列文章,逐渐更新中,欢迎关注
0A.关于Elasticsearch及实例应用
00.Solr与ElasticSearch对比
01.ElasticSearch能做什么?
02.Elastic Stack功能介绍
03.如何安装与设置Elasticsearch API
04.如果通过elasticsearch的head插件建立索引_CRUD操作
05.Elasticsearch多个实例和head plugin使用介绍
06.当Elasticsearch进行文档索引时,它是怎样工作的?
10.Kibana科普-作为Elasticsearhc开发工具
11.Elasticsearch查询方法
15.使用Django进行ElasticSearch的简单方法
16.关于Elasticsearch的6件不太明显的事情
17.使用Python的初学者Elasticsearch教程
18.用ElasticSearch索引MongoDB,一个简单的自动完成索引项目
19.Kibana对Elasticsearch的实用介绍
20.不和谐如何索引数十亿条消息
21.使用Django进行ElasticSearch的简单方法
另外Elasticsearch入门,我强烈推荐ElasticSearch新手搭建手册和这篇优秀的REST API设计指南 给你,这两个指南都是非常想尽的入门手册。
介绍
在此阶段的上一篇博客中,我已经解释了有关常规分析器结构和组件的更多信息。我也解释了每个组件的功能。在此博客中,我们将通过构建自定义分析器,然后查询并查看差异来了解实现方面。
定制分析仪的外壳
因此,让我们考虑定制分析仪的情况。假设我们输入到Elasticsearch的文本包含以下内容
1. html标签
html标签在索引时可能会出现在我们的文本中,其实这在大多数情况下是不需要的。所以我们需要删除这些。
2.停止词
像the,and,or等这样的词,在搜索内容时意义不大,一般被称为停止词。
3.大写字母。
4.简写形式如
H2O、$、%
在某些情况下,像这样的简式应该用英文原词代替。
应用自定义分析器
在上面的示例文本中,下表列出了需要执行的操作以及自定义分析器的相应组件
Arun has 100 $ which accounts to 3 % of the total <h2> money </h2>
“ settings”中的层次结构如下所示:
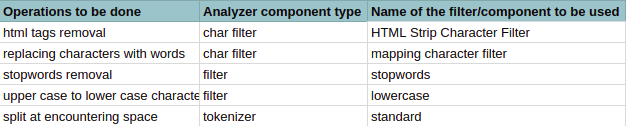
应用所有组件
现在应用上述所有组件创建一个自定义分析器,如下所示:
curl -XPUT localhost:9200/testindex_0204 -d '{ "settings": { "analysis": { "char_filter": { "subsitute": { "type": "mapping", "mappings": [ "$=> dollar", "%=> percentage" ] }, "html-strip": { "type": "html_strip" } }, "tokenizer": "standard", "filter": { "stopwords_removal": { "type": "stop", "stopwords": [ "has", "which", "to", "of", "the" ] } }, "analyzer": { "custom_analyzer_type_01": { "type": "custom", "char_filter": [ "subsitute", "html_strip" ], "tokenizer": "standard", "filter": [ "stopwords_removal", "lowercase" ] } } } }, "mappings": { "test_type": { "properties": { "text": { "type": "string", "analyzer": "custom_analyzer_type_01" } } } } }'
这将使用名为“ custom_analyzer_01” 的自定义分析器创建索引。
详细说明了此映射,下图说明了每个部分:
【图2】
使用自定义分析器生成令牌
使用分析器可以看到使用此分析器生成的令牌,如下所示:
curl -XGET "localhost:9200/testindex_0204/_analyze?analyzer=custom_analyzer_type_01&pretty=true" -d 'Arun has 100 $ which accounts to 3 % of the total <h2> money </h2>'
令牌列表如下:

在这里您可以进行一些观察:
令牌号3和6最初是$ 和%,但随后如本节中所指定的那样被替换为“ dollar”和“ percentage” char_filter 。
还有html标记<h2> ,</h2>也被html_strip 过滤器从令牌列表中删除
过滤器 "to","the","which","has"中提到的术语等stopwords 已从令牌列表中删除。
令牌编号1最初看起来应该像是“ Arun”,但已被应用的过滤器小写。
结论
在此博客中,我们看到了如何构建自定义分析器并将其应用于Elasticsearch中的字段。通过这个博客,我打算结束博客系列的第二阶段(索引,映射和分析)。从现在开始,此阶段是理解Elasticsearch的基础部分之一,我们可能会将此阶段的输入用于许多目的。从阶段03开始,我将向您介绍elasticsearch的查询DSL世界。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号