如何安装与设置Elasticsearch API
我的Elasticsearch系列文章,逐渐更新中,欢迎关注
0A.关于Elasticsearch及实例应用
00.Solr与ElasticSearch对比
01.ElasticSearch能做什么?
02.Elastic Stack功能介绍
03.如何安装与设置Elasticsearch API
04.如果通过elasticsearch的head插件建立索引_CRUD操作
05.Elasticsearch多个实例和head plugin使用介绍
如果想找更实操的操作手册,我推荐你看这篇从小白到大师成长_ElasticSearch入门教程_
从本文开始,我们将开始深入研究Elasticsearch API。在本文中,我们将主要侧重于Elasticsearch的安装,然后学习如何使用Elasticsearch提供的基本CRUD API。我们还将安装一个名为elasticsearch-head的第三方应用程序,以查看UI中的更改。
1.安装Elasticsearch
首先,让我们首先在系统中安装和配置Elasticsearch。在本教程中,我将Ubuntu 16.04用作具有8GB RAM的计算机上的操作系统。
1.1 Java安装
正如我们在之前的博客中所看到的那样,Elasticsearch是建立在名为Lucene的库之上的,而Lucene又是建立在Java之上的。因此,Java是安装Elasticsearch的先决条件。以下是在计算机中安装Java的步骤:
sudo add-apt-repository ppa:webupd8team/java -y sudo apt-get update sudo apt-get install oracle-java8-installer
1.2 Elasticsearch安装
让我们看看如何在此处将Elasticsearch作为服务安装。
-
在此处下载最新版本的Elasticsearch
-
输入
sudo dpkg -i elasticsearch-5.6.3.deb
完成上述安装后,键入
sudo service elasticsearch start
以启动服务。
这将在您的本地环境中作为服务安装并启动elasticsearch。
elasticsearch运行的默认端口是9200。要检查它是否正在运行,只需在终端中键入以下命令:
curl localhost:9200
上面的命令将导致如下所示的响应:
{ “name” : “9CCT_A1”, “cluster_name” : “elasticsearch”, “cluster_uuid” : “QqZcNgcdRDW8sWMaLNf-Jg”, “version” : { “number” : “5.6.3”, “build_hash” : “1a2f265”, “build_date” : “2017–10–06T20: 33: 39.012Z”, “build_snapshot” : false, “lucene_version” : “6.6.1” }, “tagline” : “YouKnow, forSearch” }
1.3配置文件
在Elasticsearch世界中最重要的事情之一就是正确配置它。我们应该熟悉Elasticsearch中两个重要的配置文件。这些是 :
1.3b elasticsearch.yml
此配置文件允许使用许多配置选项,例如更改elasticsearch的端口,定义集群中的节点,解决cors问题等。
该配置文件的位置在文件夹“ etc / elasticsearch”下。在这里,您可以看到elasticsearch.yml文件。
1.3b jvm.options.yml
yml文件中的配置包含在5.x之前版本的elasticsearch.yml中。此处的配置负责Java虚拟机内存管理。此配置文件的位置也位于
etc/elasticsearch
。我们将在以后的博客中详细介绍这一点。
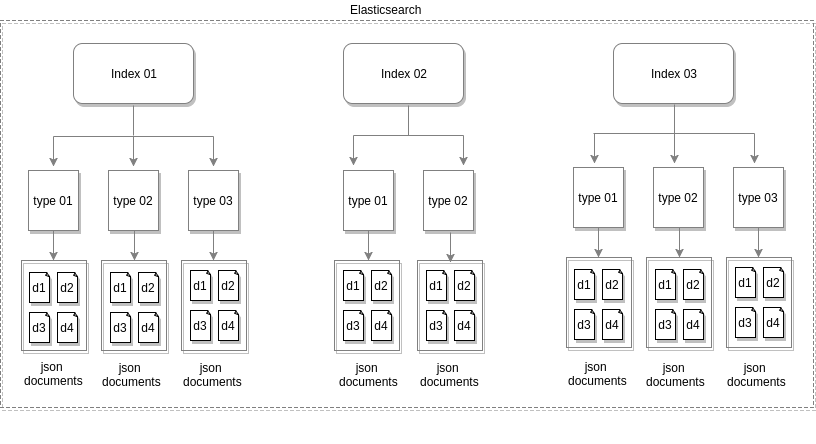
2. Elasticsearch中的索引,类型和文档
至此,我们已经成功在系统中安装了elasticsearch。现在让我们熟悉Elasticsearch中的基本数据存储模型。正如我们在之前的博客中提到的那样,Elasticsearch是一个NoSql数据库。
因此,在这里,代替SQL世界中的数据库,表,行是希拉基,最接近的希拉基类比是索引,类型和文档。这意味着,当文档(应为JSON格式)保存在Elasticsearch中时,其地址看起来像
index name:这类似于SQL world中的数据库名称。这是必不可少的信息。Elasticsearch可能包含许多索引,并且要存储的文档应提供失败的索引名称,这将导致错误,因为Elasticsearch无法确定文档属于哪个索引。此外,索引名称不支持大写和某些特殊字符。
type name:Elasticsearch中的类型类似于SQL世界中数据库下的表。因此,索引下可以有多个表。表格下可以有多个文档。如果我们没有给文档提供类型名称,elasticsearch仍将使用默认类型名称进行索引。
document ID:文档的唯一ID。可以由将文档放到Elasticsearch的用户提供,或者如果没有提供,Elasticsearch会自动生成一个唯一值。
注意:“索引名称+类型名称+文档ID”的组合对于elasticsearch中的每个文档都是唯一的
下图显示了具有多个索引的典型elasticsearch数据库的外观
3 CRUD操作-命令行
现在,我们对Elasticsearch中的数据混乱有了一个基本的想法。在本节中,让我们使用命令行界面在Elasticsearch中执行一些基本的CRUD操作。
3.1创建索引
从上一节中我们知道,要将文档存储在Elasticsearch中,我们需要指定索引名称。因此,重要的是在存储任何此类文档之前创建索引。让我们
test_index_01
从终端创建一个名为“ ” 的索引,如下所示:
curl -XPUT localhost:9200/test_name_01
上面的命令将产生如下所示的响应:
{ “acknowledged”: true, “shards_acknowledged”: true, “index”: ”test_index_01" }
3.2建立文件
现在我们已经创建了索引,我们可以将文档索引到elasticsearch。
在这种情况下,我们将为文档ID等于1的文档建立索引(存储)。可以按照以下步骤进行操作:
curl -XPUT localhost:9200/test_index_01/test_type_01/1 -d ‘{ “name”: ”ArunMohan”, “age”: 32 }’
在上述请求中,以下是我们传递给elasticsearch的数据的分割信息
indexname: test_index_01 type_name: test_type_01 documentid: 1 document : { “name”: “ArunMohan”, “age”: 32 }
以上请求将导致如下响应:
{ _index: test_index_01, _type: test_type_01, _id: 1, _version: 1, result: created, _shards: { total: 2, successful: 1, failed: 0 }, created: true }
在响应中,我们再次可以看到索引名称(“ _index”),类型名称(“ _type”),文档ID(“ _ id”)。还将操作状态作为“已创建”值。“ created”的值是true,表示文档索引成功。
3.3阅读文件
可以使用带有索引名称,类型名称和其中指定的文档ID的GET请求从elasticsearch中检索文档。这充当该文档的准确地址(前提是所传递的所有三个信息都是准确的),Elasticsearch将为我们获取该文档。让我们看看如何检索刚刚索引的文档。
curl -XGET localhost:9200/test_index_01/test_type_01/1
上面的请求将返回如下响应:
{ _index: test_index_01, _type: test_type_01, _id: 1, _version: 1, found: true, _source: { name: ArunMohan, age: 32 } }
在以上响应中,我们可以看到文档位于响应的“ _source”对象下。元数据包括其他信息和检索状态为“已找到”。
3.4更新文件
如果需要更新已经建立索引的文档的字段怎么办?Elasticsearch为我们提供了此操作的更新API。在我们的示例中,假设我要使用新值31更新年龄字段。对此的请求如下所示:
curl -XPOST localhost:9200/test_index_01/test_type_01/1/_update -d '{"doc":{"age":31}}'
您可能已经注意到,我在请求中仅给出了必填字段和该字段的新值({“ age”:31})。在名为“ doc”的对象下也是如此。该请求还包含有关要更新的文档的所有信息(索引名称,类型名称和文档ID),以便Elasticsearch可以找到该文档并对该特定字段进行更改(这不是它的确切工作方式,而是目前,我们正在深潜)。现在,如果文档中不存在这样的字段,Elasticsearch将在文档中创建一个这样的字段。
对于以上请求,我们将获得以下响应:
{ "_index": "test_index_01", "_type": "test_type_01", "_id": "1", "_version": 2, "result": "updated", "_shards": { "total": 2, "successful": 1, "failed": 0 } }
在以上响应的结果字段中,我们可以看到状态为“已更新”,表明更新成功。
3.5删除文件
删除类似于前面提到的内容。只需提供索引名称,类型名称和要删除的文档以及请求的文档ID,即可将其删除,如下所示:
curl -XDELETE localhost:9200/test_index_01/test_type_01/1
这将使我们得到如下响应:
{ "found": true, "_index": "test_index_01", "_type": "test_type_01", "_id": "1", "_version": 3, "result": "deleted", "_shards": { "total": 2, "successful": 1, "failed": 0 } }
结论
在本文中,我们已经看到了Elasticsearch的安装,然后是其上的基本CRUD操作。在本系列的下一个博客中,我们将看到如何在同一系统上使用多个elasticsearch实例。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号