

拉勾网职位信息爬取
学习python网络爬虫有一段时间了,正好赶上休假闲来无事,记录一下爬取的过程。
一、开发工具
Pycharm 2017
Python 2.7.10
requests
pymongo
二、爬取目标
1、爬取与python相关的职位信息
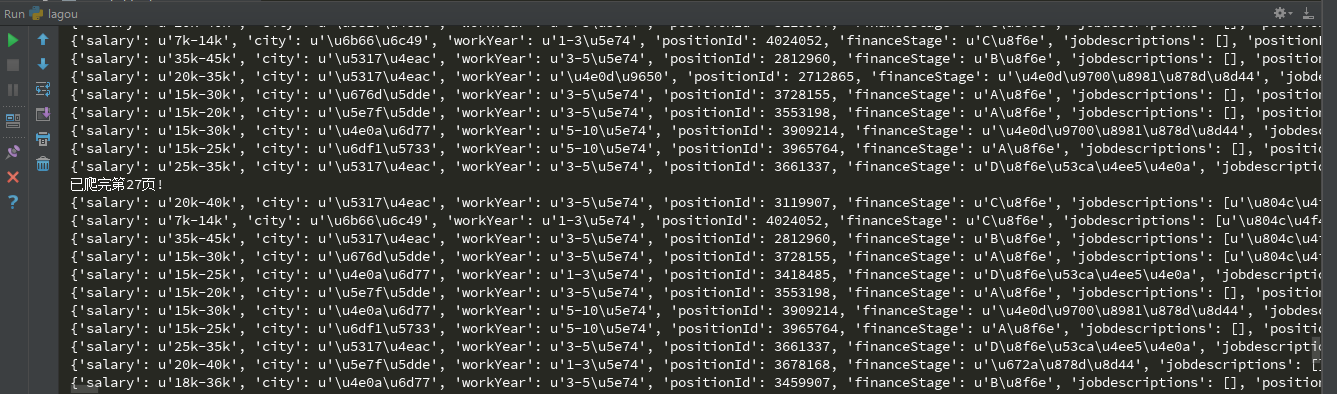
2、由于拉勾网只展示30页的搜索结果,每页15条职位信息,全部爬下来,最终将获取到450条信息
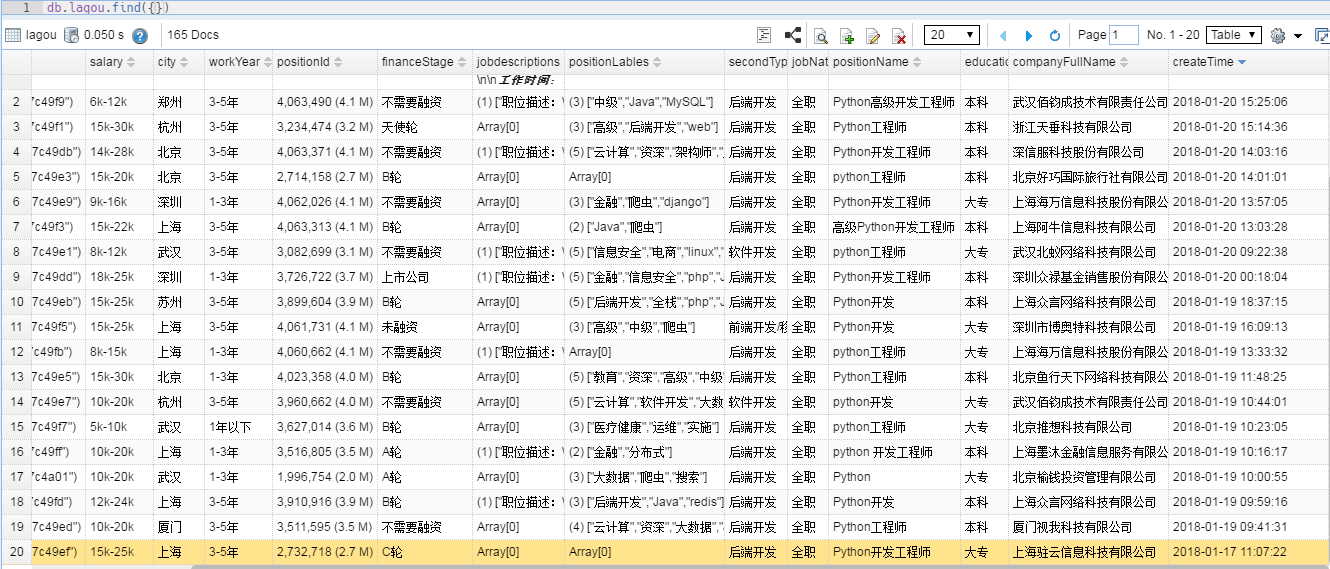
3、将结果存储在Mongodb中
三、结果展示
四、爬取过程
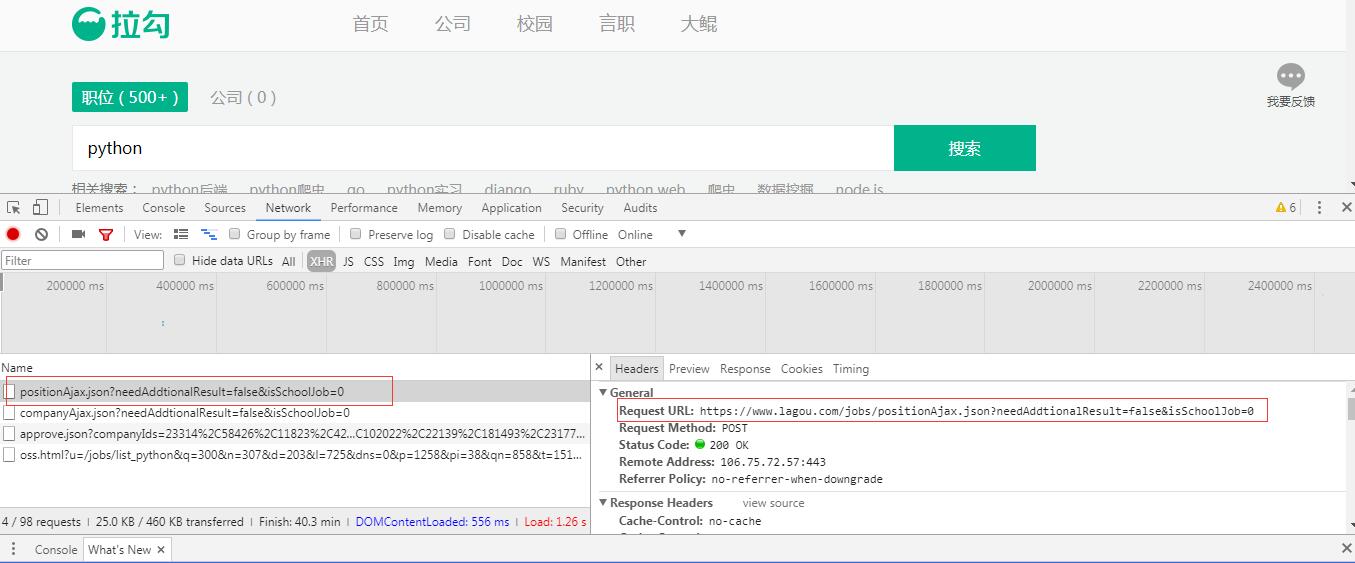
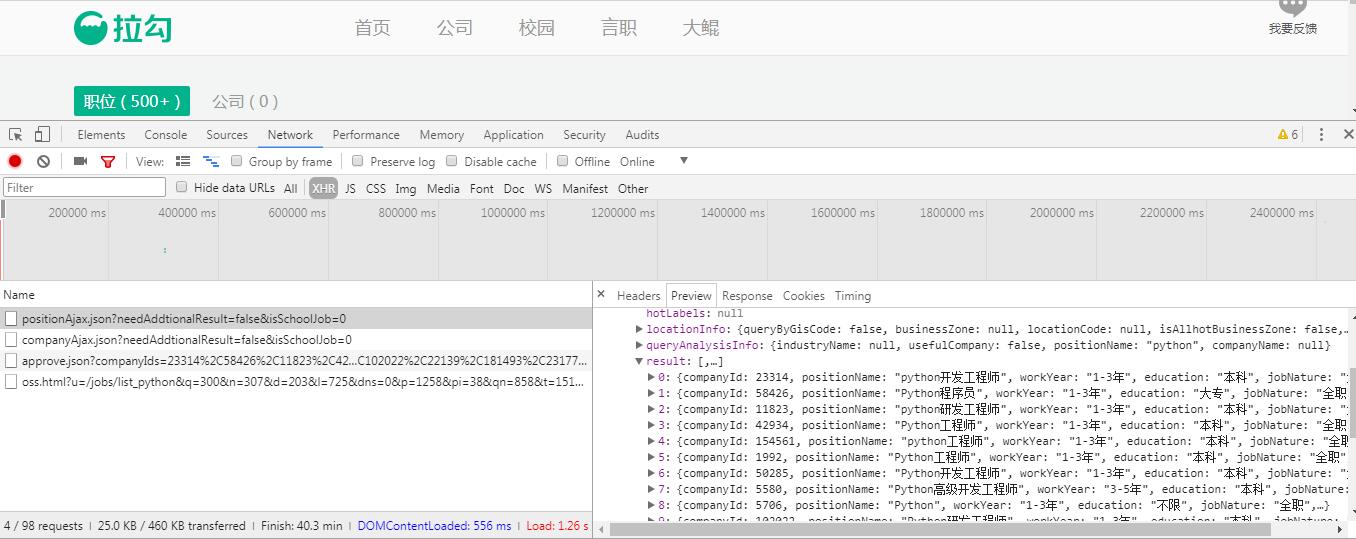
1、浏览器中打开拉勾网:https://www.lagou.com,搜索python,同时打开开发者工具进行抓包,找到能够返回数据的Request URL,通过一番查找,发现要找的url是https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false&isSchoolJob=0,它返回的是json格式的数据:
经过以上分析,可以写一下初始化的代码:设置请求的url和请求头,请求头在抓包时可以获取,通过程序去爬取网络,我们要做的一件重要的事情就是模拟浏览器,否则遇到具有反爬虫措施的网站,很难将数据爬下来。当然了,设置正确的请求头,只是应对反爬虫的一部分措施。
1 def __init__(self): 2 self.headers = {} 3 self.headers['User-Agent'] = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36' 4 self.headers['Host'] = 'www.lagou.com' 5 self.headers['Referer'] = 'https://www.lagou.com/jobs/list_python?px=default&city=%E5%85%A8%E5%9B%BD' 6 self.headers['X-Anit-Forge-Code'] = '0' 7 self.headers['X-Anit-Forge-Token'] = None 8 self.headers['X-Requested-With'] = 'XMLHttpRequest' 9 self.url = 'https://www.lagou.com/jobs/positionAjax.json?px=default&needAddtionalResult=false&isSchoolJob=0'
2、返回每一条数据中包含的信息比较,我们只获取想要的:薪资、城市、工作年限、职位、职位描述、学历、公司全称、发布时间等。
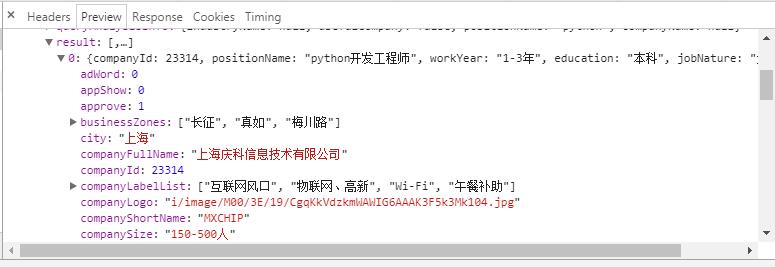
1 result = {} 2 result['positionName'] = position['positionName'] 3 result['createTime'] = position['createTime'] 4 result['secondType'] = position['secondType'] 5 result['city'] = position['city'] 6 result['workYear'] = position['workYear'] 7 result['education'] = position['education'] 8 result['companyFullName'] = position['companyFullName'] 9 result['financeStage'] = position['financeStage'] 10 result['jobNature'] = position['jobNature'] 11 result['salary'] = position['salary'] 12 result['jobdescriptions'] = Lagou.get_detail(position['positionId']) 13 result['positionLables'] = position['positionLables'] 14 result['positionId'] = position['positionId']
这里重点说明一下,职位信息是包含在详情页中的,通过观察发现,详情页名称是通过positionId.html方式命名的,所以要打开详情页获取职位信息就需要获取positionId,以上代码中:result['jobdescriptions'] = Lagou.get_detail(position['positionId'])可以看到。
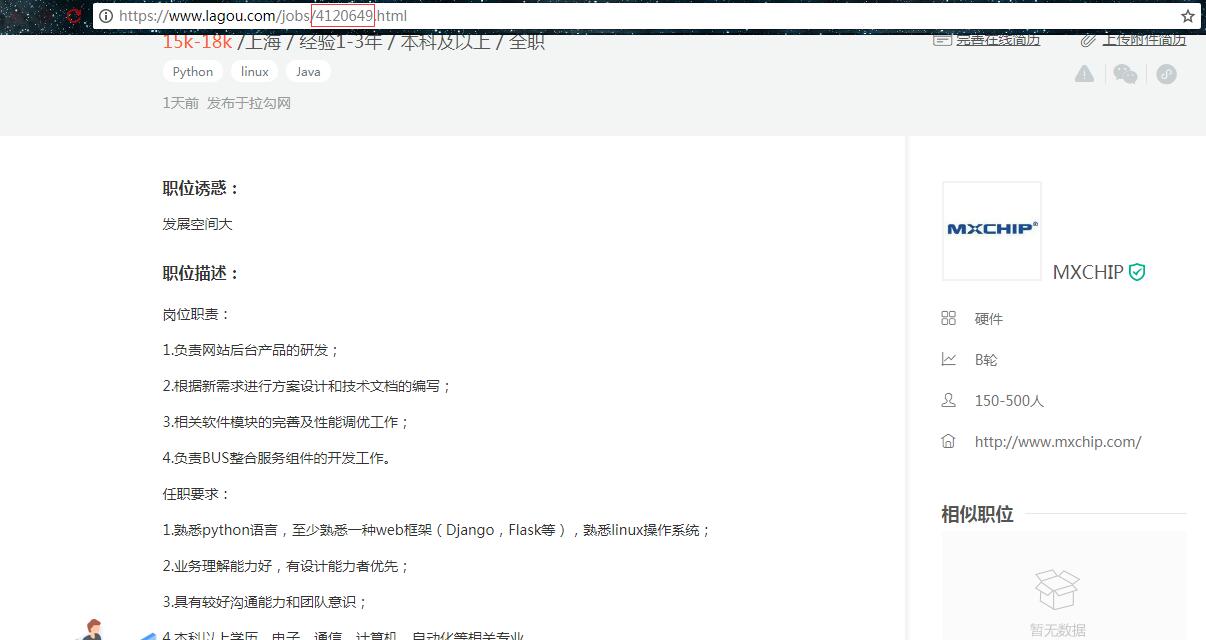
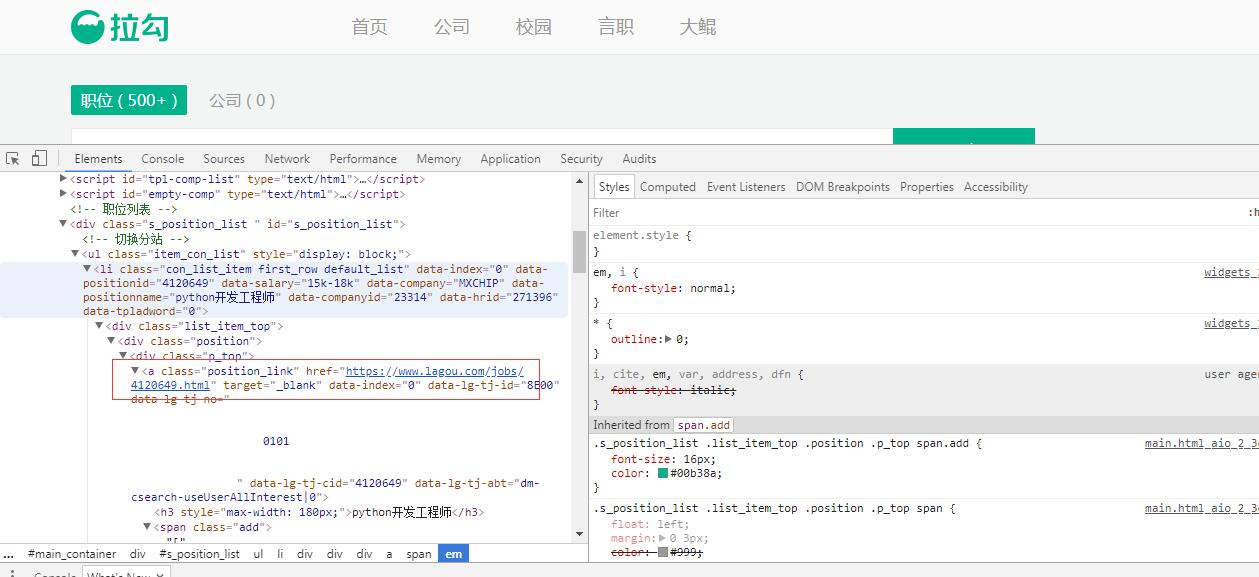
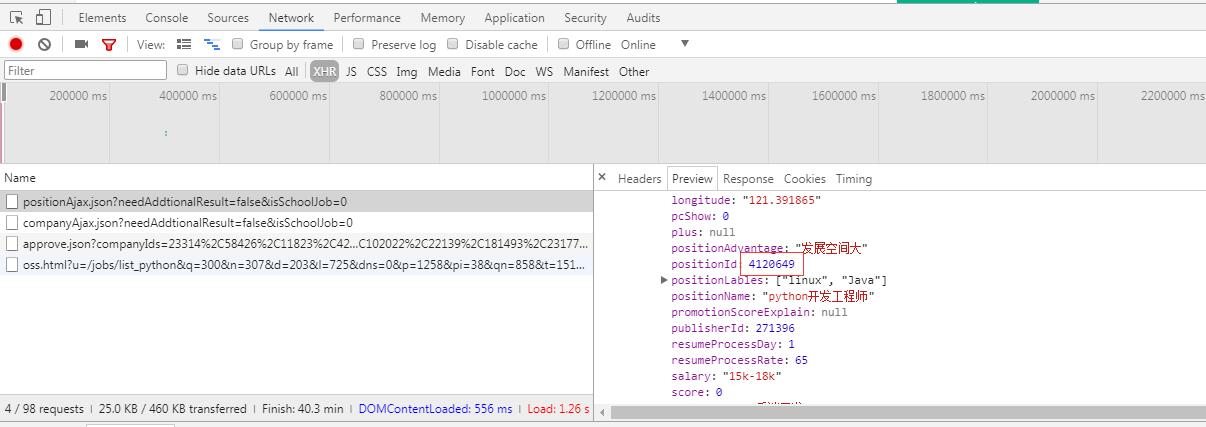
获取列表页和详情页的代码如下:
1 def get_data(self,page): 2 while 1: 3 try: 4 form_data = { 5 'first' : 'true', 6 'pn' : page, 7 'kd' : 'python' 8 } 9 result = requests.post(self.url,data=form_data,headers=self.headers) 10 return result.json()['content']['positionResult']['result'] 11 except: 12 time.sleep(1) 13 14 def get_detail(self,positionId): 15 url = 'https://www.lagou.com/jobs/%s.html' % positionId 16 text = requests.get(url,headers=self.headers).text 17 jobdescriptions = re.findall(r'<h3 class="description">(.*?)</div>',text,re.S) 18 jobdescriptions = [re.sub(r'</?h3>|</?div>|</?p>|</?br>|^\s+|</?li>','',j) for j in jobdescriptions] 19 return jobdescriptions
mongodb的部分单独写了一个模块在主代码中调用:
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 4 import pymongo 5 6 class MongodbOPT: 7 def __init__(self, host, port, db, passwd, collection): 8 self.host = host 9 self.port = str(port) 10 self.db = db 11 self.passwd = passwd 12 self.collection = collection 13 14 def getClient(self): 15 """返回MongoDB客户端对象""" 16 conn = 'mongodb://' + self.db + ':' + self.passwd + '@' + self.host + ':' + self.port + '/' + self.db 17 return pymongo.MongoClient(conn) 18 19 def getDB(self): 20 """返回MongoDB的一个数据库""" 21 client = self.getClient() 22 db = client['%s' % (self.db)] 23 return db 24 25 def insertData(self, bsonData): 26 """插入数据(单条或多条)""" 27 if self.db: 28 db = self.getDB() 29 collections = self.collection 30 if isinstance(bsonData, list): 31 result = db.get_collection(collections).insert_many(bsonData) 32 return result.inserted_ids 33 return db.get_collection(collections).insert_one(bsonData).inserted_id 34 else: 35 return None 36 37 def findAll(self, **kwargs): 38 if self.db: 39 collections = self.collection 40 db = self.getDB() 41 def findAllDataQuery(self, dataLimit=0, dataSkip=0, dataQuery=None, dataSortQuery=None,dataProjection=None): 42 return db.get_collection(collections).find(filter=dataQuery, projection=dataProjection, skip=dataSkip, 43 limit=dataLimit, sort=dataSortQuery) 44 return findAllDataQuery(self, **kwargs) 45 46 def updateData(self, oldData=None, **kwargs): 47 if self.db: 48 collections = self.collection 49 db = self.getDB() 50 def updateOne(self, oneOldData=None, oneUpdate=None, oneUpsert=False): # 单个更新 51 result = db.get_collection(collections).update_one(filter=oneOldData, update=oneUpdate, 52 upsert=oneUpsert) 53 return result.matched_count 54 def updateMany(self, manyOldData, manyUpdate=None, manUpsert=False): # 全部更新 55 result = db.get_collection(collections).update_many(filter=manyOldData, update=manyUpdate, 56 upsert=manUpsert) 57 return result.matched_count 58 if oldData: 59 oneup = kwargs.get("oneUpdate", "") 60 manyup = kwargs.get("manyUpdate", "") 61 if oneup: 62 return updateOne(self, oldData, **kwargs) 63 elif manyup: 64 return updateMany(self, oldData, **kwargs)
完整的代码放在github中了,有需要请移步:https://github.com/Eivll0m/PythonSpider/tree/master/lagou


