洗礼灵魂,修炼python(87)-- 知识拾遗篇 —— 线程(1)
线程(上)
1.线程含义:一段指令集,也就是一个执行某个程序的代码。不管你执行的是什么,代码量少与多,都会重新翻译为一段指令集。可以理解为轻量级进程
比如,ipconfig,或者, python XX.py(执行某个py程序),这些都是指令集和,也就是各自都是一个线程。
2.线程的特性:
-
线程之间可以相互通信,数据共享
-
线程并不等同于进程
-
线程有一定局限性
-
线程的速度由CPU和GIL决定。
GIL,GIL全称Global Interpreter Lock,全局解释锁,此处暂且不谈,再下面该出现的地方会做仔细的讲解。
3.python中的线程由内置模块Threading整合
例1:简答的线程应用:
我们先看看这段代码
#!usr/bin/env python
#-*- coding:utf-8 -*-
# author:yangva
import threading,time
begin = time.time()
def func1():
time.sleep(2)
print(func1.__name__)
def func2():
time.sleep(2)
print(func2.__name__)
func1()
func2()
end = time.time()
print(end-begin)
结果:
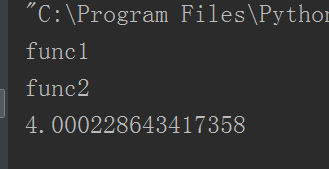
用时差不多4s对吧。好的,当我们使用线程来修改这段代码
#!usr/bin/env python
#-*- coding:utf-8 -*-
# author:yangva
import threading,time
begin = time.time()
def func1():
time.sleep(2)
print(func1.__name__)
def func2():
time.sleep(2)
print(func2.__name__)
'''创建线程对象,target参数为函数名,args可以为列表或元组,列表/元组
内的参数即为函数的参数,这里两个函数本就没有参数,所以设定为空,'''
t1 = threading.Thread(target=func1,args=[])
t2 = threading.Thread(target=func2,args=[])
#开始进程
t1.start()
t2.start()
end = time.time()
print(end-begin)
运行结果:
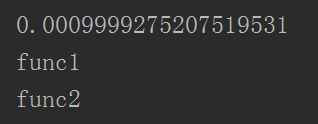
卧槽?啥情况?咋成了0s。这里要注意了,这里的是时间先出来,函数的打印语句后出来,那么就表示整个程序里的两个线程是同时进行的,并且没有等线程运行结束就运行到下面的打印用时语句了。注意这里的几个字“没有等线程运行结束”。所以这里就有问题对吧?没关系的,线程给我们准备了一个方法——join,join方法的用意就是等线程运行结束再执行后面的代码,那么我们加上join再看
#!usr/bin/env python
#-*- coding:utf-8 -*-
# author:yangva
import threading,time
begin = time.time()
def func1():
time.sleep(2)
print(func1.__name__)
def func2():
time.sleep(2)
print(func2.__name__)
'''创建线程对象,target参数为函数名,args可以为列表或元组,列表/元组
内的参数即为函数的参数,这里两个函数本就没有参数,所以设定为空,'''
t1 = threading.Thread(target=func1,args=[])
t2 = threading.Thread(target=func2,args=[])
#开始进程
t1.start()
t2.start()
#等待线程运行结束
t1.join()
t2.join()
end = time.time()
print(end-begin)
看看结果呢?

正常了对吧?时间最后出现,并且和没使用线程时节省了整整一倍对吧,那么按照常理我们都会认为这两个线程是同时运行的对吧?那么真的是这样吗?
因为都知道一个常识,一个CPU只能同时处理一件事(这里暂且设定这个CPU是单核),而这整个程序其实就是一个主线程,此处的主线程包括了有两个线程。这整个下来,程序运行的每个步骤是这样的:
第一步:先运行func1,因为线程t1在前面。
第二步:运行到睡眠语句时,因为睡眠语句时不占CPU,所以立马切换到func2
第三部:运行func2
第四步:运行到睡眠语句,立马又切换到func1的打印语句
第五部:func1整个运行完,立马切换到func2的打印语句,结束整个程序

所以你看似是同时,其实并不是同时运行,只是谁没有占用CPU就会立马把运行权利放开给其他线程运行,这样交叉运行下来就完成了整个程序的运行。就这么简单,没什么难度对吧?
此时我设定的函数是不带参数,当然你可以试试带参数,效果也是一样的
再说明一下join的特性,join的字面意思就是加入某个组织,线程里的join意思就是加入队列。
就好比去票站排队买票一样,前面的人完了才到你,票站开设一天为排好队的人售票,那么这里的票站就是一个主线程,队伍中的每个人各自都是一个线程,不过这个买票站不止有一个窗口,当前面的正在买票的人耗费很多时间时,那么后面排队的人如果看到其他的窗口人少就会重新排到新的队伍中以此来节省排队时间,尽快买到票,直到票站里的工作人员下班结束售票(整个进程结束)。我这么说的话,相信很多人就懂了吧?生活常识对吧?
而这里的两个线程(或者你可以给三个、四个以上)结合起来就叫多线程(并不是真正意义上的,看后面可得),此时的两个线程并不是同时进行,也不是串行(即一个一个来),而是并发的
例2:对比python2和python3中线程的不同
先看python3下的:
不使用线程:
#!usr/bin/env python
#-*- coding:utf-8 -*-
# author:yangva
import threading,time
begin = time.time()
def func(n):
res = 0
for i in range(n):
res += i
print('结果为:',res)
func(10000000)
func(20000000)
end = time.time()
print(end-begin)
运行结果:
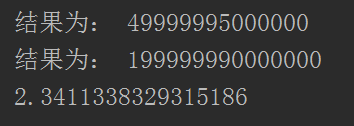
使用线程:
#!usr/bin/env python
#-*- coding:utf-8 -*-
# author:yangva
import threading,time
begin = time.time()
def func(n):
res = 0
for i in range(n):
res += i
print('结果为:',res)
t1 = threading.Thread(target=func,args=(10000000,))
t2 = threading.Thread(target=func,args=(20000000,))
#开始进程
t1.start()
t2.start()
#等待线程运行结束
t1.join()
t2.join()
end = time.time()
print(end-begin)
运行结果:
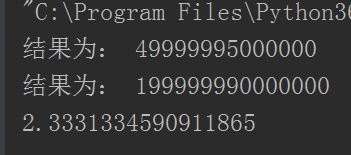
差距竟然很小了对吧?和前面使用sleep的结果完全不一样了。
再看python2下:
不使用线程:
代码和前面的一样,不浪费时间了,运行结果:

使用线程:
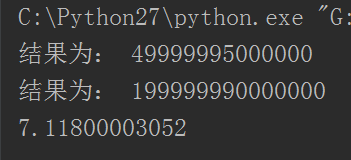
发现居然还比不使用线程还慢,卧槽,那我还搞毛的线程啊。不急着说这个
从python2和python3的对比下,相信你已经知道了,python3优化的很不错了,基本能和不使用线程锁耗时间一样。并且同样的代码,不使用线程下的版本2和版本3的对比都感觉时间缩短了,这就是python3的优化。
那么这种为何不能和前面的sleep运行的结果成倍的减少呢?在版本2里反而还不减反增。这一种就是计算密集型线程。而前面的例子使用time模块的就是IO密集型线程
IO密集型:IO占用的操作,前面的time.sleep的操作和文件IO占用的则为IO密集型
计算密集型:通过计算的类型
好的,开始说说这个使用线程为何还是没有很明显节省资源了,前面我提到的,一个CPU只能同时处理一件事(这里暂且设定这个CPU是单核),关键就在于CPU是单核,但相信大家对自己的电脑都很了解,比如我的电脑是四核的,还有的朋友的CPU可能是双核,但再怎么也不可能是单核对吧?单核CPU的时代已经过去了。
但是这里它就是一个BUG,究其根源也就是前面提到的GIL,全局解释锁
4.全局解释锁GIL
1)含义:
GIL,全局解释锁,由解释器决定有无。常规里我们使用的是Cpython,python调用的底层指令就是借助C语言来实现的,即在C语言基础上的python,还有Jpython等等的,而只有Cpython才有这个GIL,而这个GIL并不是Python的特性,也就是这个问题并不是python自身的问题,而是这个C下的解释器问题。
在Cpython下的运行流程就是这样的

由于有这个GIL,所以在同一时刻只能有一个线程进入解释器。
龟数在开发Cpython时,就已经有这个GIL了,当他开发时,由于有可能会有一些数据操作风险,比如同时又两个线程拿一个数据,那么操作后就会有不可预估的后患了,而龟数当时为了避免这个问题,而当时也正是CPU单核时期,所以直接就加了这个GIL,防止同一时刻多个线程去操作同一个数据。
那么到了多核CPU时代,这个解决办法在现在来看就是一个BUG了。
总之,python到目前为止,没有真正意义上的多线程,不能同时有多个线程操作一个数据,并且这个GIL也已经去不掉了,很早就有人为了取消GIL而奋斗着,但是还是失败了,反正Cpython下,就是有这么个问题,在python3中只是相对的优化了,也没有根本的解决GIL。并且只在计算密集型里体现的很明显
那么有朋友觉得,卧槽,好XX坑啊,那我XX还学个啥玩意儿啊,崩溃中,哈哈哈
没法啊,就是这么个现状,但是多线程既然开不了,可以开多进程和协程啊。而且在以后还是有很多替代方案的。
总结:
根据需求选择方案。
如果是IO密集型:使用线程
如果是计算密集型:使用多进程/C语言指令/协程
5.setDaemon特性
好的,来点实际的
#!usr/bin/env python
#-*- coding:utf-8 -*-
# author:yangva
import threading,time
begin = time.time()
def music(name):
for i in range(2):
print('I listenning the music %s,%s'%(name,time.ctime()))
time.sleep(2)
print('end listenning %s'%time.ctime())
def movie(name):
for i in range(2):
print('I am watching the movie %s,%s'%(name,time.ctime()))
time.sleep(3)
print('end wachting %s'%time.ctime())
t1 = threading.Thread(target=music,args = ('晴天-周杰伦',) )
t2 = threading.Thread(target=movie,args=('霸王别姬',))
t1.start()
t2.start()
t1.join()
t2.join()
end = time.time()
print(end - begin)
查看运行结果:
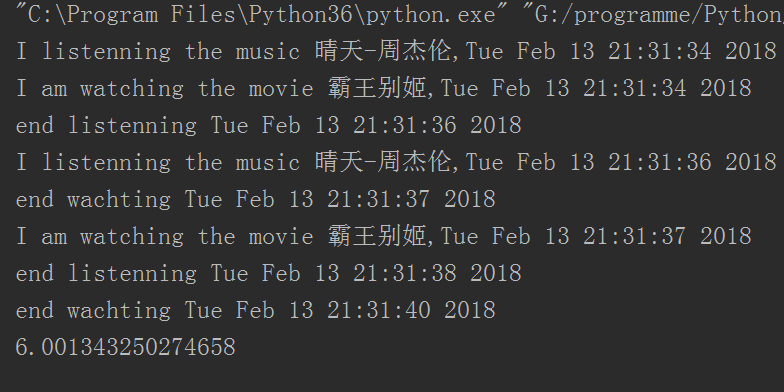
因为这是IO密集型的,所以可以有多线程的效果。
那么在很多的开发中,还有另一种写法
#!usr/bin/env python
#-*- coding:utf-8 -*-
# author:yangva
import threading,time
begin = time.time()
def music(name):
for i in range(2):
print('I listenning the music %s,%s'%(name,time.ctime()))
time.sleep(2)
print('end listenning %s'%time.ctime())
def movie(name):
for i in range(2):
print('I am watching the movie %s,%s'%(name,time.ctime()))
time.sleep(3)
print('end wachting %s'%time.ctime())
threads = []
t1 = threading.Thread(target=music,args = ('晴天-周杰伦',) )
t2 = threading.Thread(target=movie,args=('霸王别姬',))
threads.append(t1)
threads.append(t2)
for i in threads:
i.start()
i.join()
end = time.time()
print(end - begin)
而这种写法的运行结果:

咋回事,10s,注意了,这是很多人容易犯的错
首先要说下,join是等程序执行完再往下走,所以join带有阻塞功能,当你把i.join()放到for循环里面, 那么听音乐的线程必须结束后再执行看电影的线程,也就是整个程序变成串行了对吧?
所以正确的写法是这样:
#!usr/bin/env python
#-*- coding:utf-8 -*-
# author:yangva
import threading,time
begin = time.time()
def music(name):
for i in range(2):
print('I listenning the music %s,%s'%(name,time.ctime()))
time.sleep(2)
print('end listenning %s'%time.ctime())
def movie(name):
for i in range(2):
print('I am watching the movie %s,%s'%(name,time.ctime()))
time.sleep(3)
print('end wachting %s'%time.ctime())
threads = []
t1 = threading.Thread(target=music,args = ('晴天-周杰伦',) )
t2 = threading.Thread(target=movie,args=('霸王别姬',))
threads.append(t1)
threads.append(t2)
for i in threads:
i.start()
i.join()
end = time.time()
print(end - begin)
运行结果:

结果和前面的写法一样了对吧?说下,for循环下的i,我们可以知道i一定是for结束后的最后的值,不信的话可以试试这个简单的:
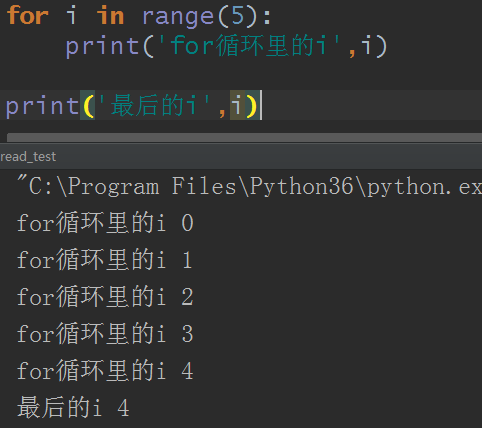
那么说回上面的问题,当i.join()时,此时的i一定是t2对不对?那么整个程序就在t2阻塞住了,直到t2执行完了才执行打印总用时语句,既然执行t2,因为执行t2要6秒,而t1要4秒,那么可以确定,在t2执行完时,t1绝对执行完了的。或者换个说法,for循环开始,t1和t2谁先开始不一定,因为线程都是抢着执行,但一定是t1先结束,然后再是t2结束,再结束整个程序。所以说,只有把i.join()放在for循环外,才真的达到了多线程的效果。
好的,再说一个有趣的东西,不多说,直接看
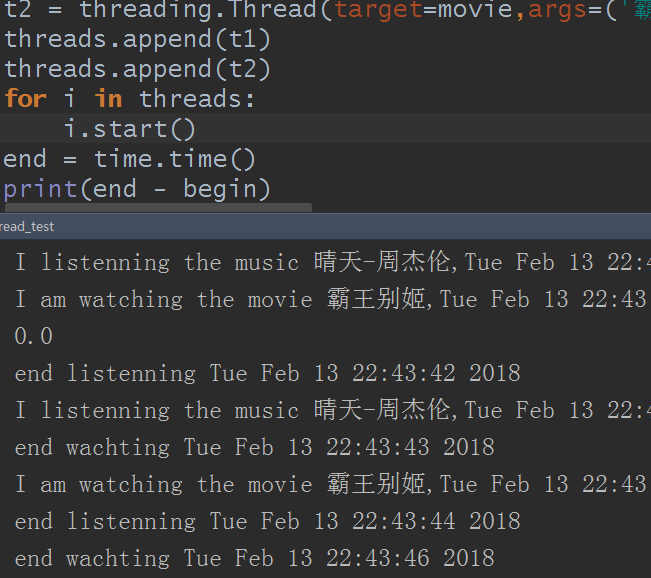
未截到图的区域和上面的一样,不浪费时间了。看到了吗?最后打印的时间居然在第三排,如果你们自己测试了的话,就知道这打印时间语句和上面两个是同时出现的,咋回事,因为这是主线程啊,主线程和两个子线程同时运行的,所以这样,那么我们加一个东西
加了一个setDaemon(True),这个方法的意思是设置守护进程,并且要注意,这个必须在设置的线程start()方法之前

咦?主线程运行后就直接结束了,这啥情况呢?那再设置在子线程上呢:
设置在t1(听音乐)上:
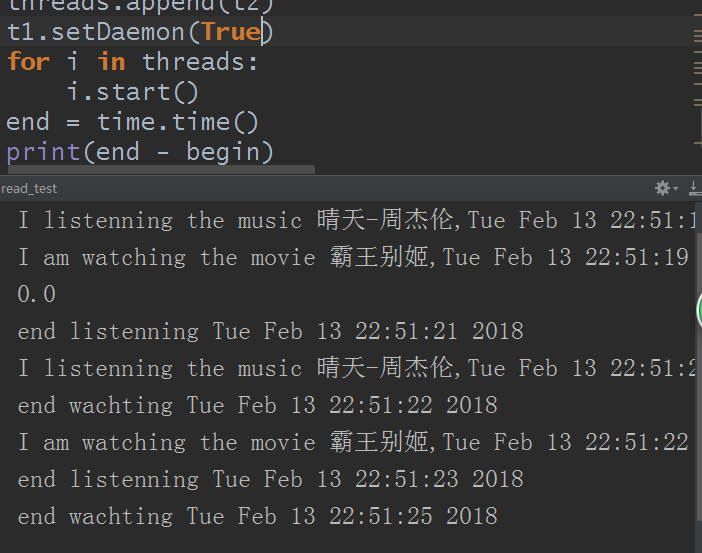
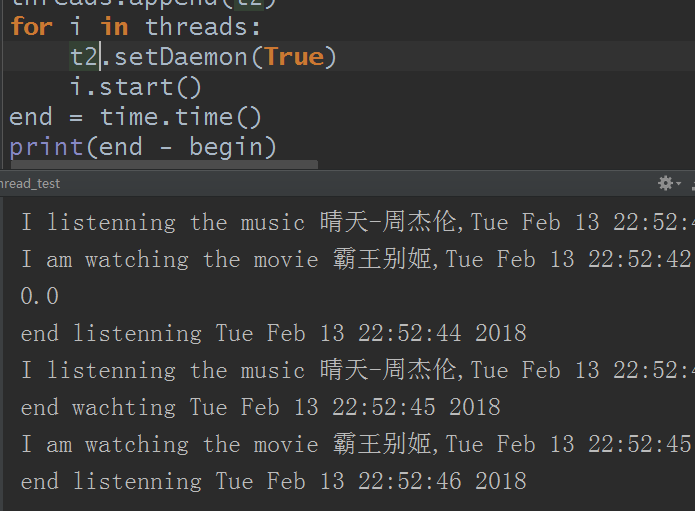
再设置在t2(看电影)上:
看出什么问题了吗?
好的,不废话,直接说作用吧,setDaemon是守护进程的意思,而这里我们用在线程上,也就是对线程的守护。设置谁做为守护线程(进程),那么当此线程结束后就不管被守护的线程(进程)结束与否,程序是否结束全在于其他线程运行结束与否,但被守护的线程也一直正常的在运行。所以上面的主线程设置守护线程后,因为等不到其他同级别的线程运行所以就直接结束了。而当设置t1作为守护线程时,程序就不管t1了,开始在意其他线程t2运行结束与否,但同时还是在运行自己,因为t2运行时间比t1久,所以t1和t2还是正常的运行了。而当设置t2作为守护线程时,当t1听完音乐结束,整个程序也结束了,而t2并没有正常的结束,不过一直存在的,就是这么个意思
6.通过自定义类设置线程
#!usr/bin/env python
#-*- coding:utf-8 -*-
# author:yangva
import threading,time
class mythread(threading.Thread):
def __init__(self,name):
super(mythread,self).__init__()
self.name = name
def run(self): #对继承threading的重写方法
print('%s is rurning'%self.name)
time.sleep(2)
t = mythread('yang')
t.start()
运行结果:

没啥特点对不对,其实就是写了一个类继承thread,然后运行而已。本质上以上的代码和下面这一段没区别:
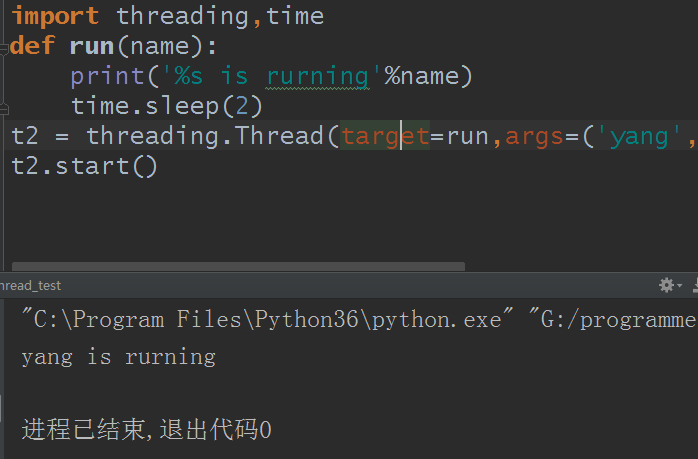
好的,本篇博文暂且到这里,还没完,下一篇的才是重头戏

 浙公网安备 33010602011771号
浙公网安备 33010602011771号