洗礼灵魂,修炼python(69)--爬虫篇—番外篇之feedparser模块
feedparser模块
1.简介
feedparser是一个Python的Feed解析库,可以处理RSS ,CDF,Atom 。使用它我们可从任何 RSS 或 Atom 订阅源得到标题、链接和文章的条目了。
RSS(Really Simple
Syndication,简易信息聚合):是一种描述和同步网站内容的格式你可以认为是一种定制个性化推送信息的服务。RSS 是用于分发 Web
站点上的内容的摘要的一种简单的 XML
格式它能够解决你漫无目的的浏览网页的问题。它的信息越是过剩,它的意义也越加彰显。网络中充斥着大量的信息垃圾,每天摄入了太多自己根本不关心的信息。让自己关注的信息主动来找自己,且这些信息都是用户自己所需要的,这就是RSS的意义
比如这个链接:http://feed.cnblogs.com/blog/sitehome/rss
打开得:

其实点个人博客主页的这里也可以:

不过点击去是个人的rss,里面全是个人的随笔或者文章:

2.方法/属性
feedparser是第三方库,需要pip或者easy_install安装,这些略过了
3.常用方法/属性解析
其他的方法都不用说了,基本上没用到,最常用的就是parse方法了
import feedparser
print(feedparser.parse('http://feed.cnblogs.com/blog/u/385429/rss'))
结果:
{'feed': {'title': '博客园_yangva', 'title_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '博客园_yangva'}, 'subtitle': '', 'subtitle_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': ''}, 'id': 'uuid:48bcc04f-645a-4725-a261-6d035a48dc1d;id=448', 'guidislink': True, 'link': 'uuid:48bcc04f-645a-4725-a261-6d035a48dc1d;id=448', 'updated': '2017-11-26T10:22:05Z', 'updated_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=26, tm_hour=10, tm_min=22, tm_sec=5, tm_wday=6, tm_yday=330, tm_isdst=0), 'authors': [{'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}], 'author_detail': {'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}, 'href': 'http://www.cnblogs.com/yangva/', 'author': 'yangva', 'generator_detail': {'name': 'feed.cnblogs.com'}, 'generator': 'feed.cnblogs.com'}, 'entries': [{'id': 'http://www.cnblogs.com/yangva/p/7811622.html', 'guidislink': True, 'link': 'http://www.cnblogs.com/yangva/p/7811622.html', 'title': '洗礼灵魂,修炼python(67)--爬虫篇—cookielib之爬取需要账户登录验证的网站 - yangva', 'title_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '洗礼灵魂,修炼python(67)--爬虫篇—cookielib之爬取需要账户登录验证的网站 - yangva'}, 'summary': '学完前面的教程,相信你已经能爬取大部分的网站信息了,但是当你爬的网站多了,你应该会发现一个新问题,有的网站需要登录账户才能看到更多的信息对吧?那么这种网站怎么爬取呢?这些登录数据就是今天要说的——cookie cookie 其实在前面在解析requests模块时也提到过的。 Cookie,指某些网站', 'summary_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '学完前面的教程,相信你已经能爬取大部分的网站信息了,但是当你爬的网站多了,你应该会发现一个新问题,有的网站需要登录账户才能看到更多的信息对吧?那么这种网站怎么爬取呢?这些登录数据就是今天要说的——cookie cookie 其实在前面在解析requests模块时也提到过的。 Cookie,指某些网站'}, 'published': '2017-11-23T10:19:00Z', 'published_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=23, tm_hour=10, tm_min=19, tm_sec=0, tm_wday=3, tm_yday=327, tm_isdst=0), 'updated': '2017-11-23T10:19:00Z', 'updated_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=23, tm_hour=10, tm_min=19, tm_sec=0, tm_wday=3, tm_yday=327, tm_isdst=0), 'authors': [{'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}], 'author_detail': {'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}, 'href': 'http://www.cnblogs.com/yangva/', 'author': 'yangva', 'links': [{'rel': 'alternate', 'href': 'http://www.cnblogs.com/yangva/p/7811622.html', 'type': 'text/html'}, {'rel': 'alternate', 'type': 'text/html', 'href': 'http://www.cnblogs.com/yangva/p/7811622.html'}], 'content': [{'type': 'text/html', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': "该文只有注册用户登录后才能阅读。<a href='http://www.cnblogs.com/yangva/p/7811622.html' target='_blank'>阅读全文</a>。"}]}, {'id': 'http://www.cnblogs.com/yangva/p/7814108.html', 'guidislink': True, 'link': 'http://www.cnblogs.com/yangva/p/7814108.html', 'title': '洗礼灵魂,修炼python(66)--爬虫篇—BeauitifulSoup进阶之“我让你忘记那个负心汉,有我就够了” - yangva', 'title_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '洗礼灵魂,修炼python(66)--爬虫篇—BeauitifulSoup进阶之“我让你忘记那个负心汉,有我就够了” - yangva'}, 'summary': '该文被密码保护。', 'summary_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '该文被密码保护。'}, 'published': '2017-11-10T10:39:00Z', 'published_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=10, tm_hour=10, tm_min=39, tm_sec=0, tm_wday=4, tm_yday=314, tm_isdst=0), 'updated': '2017-11-10T10:39:00Z', 'updated_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=10, tm_hour=10, tm_min=39, tm_sec=0, tm_wday=4, tm_yday=314, tm_isdst=0), 'authors': [{'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}], 'author_detail': {'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}, 'href': 'http://www.cnblogs.com/yangva/', 'author': 'yangva', 'links': [{'rel': 'alternate', 'href': 'http://www.cnblogs.com/yangva/p/7814108.html', 'type': 'text/html'}, {'rel': 'alternate', 'type': 'text/html', 'href': 'http://www.cnblogs.com/yangva/p/7814108.html'}], 'content': [{'type': 'text/html', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '该文被密码保护。'}]}, {'id': 'http://www.cnblogs.com/yangva/p/7805300.html', 'guidislink': True, 'link': 'http://www.cnblogs.com/yangva/p/7805300.html', 'title': '洗礼灵魂,修炼python(65)--爬虫篇—BeautifulSoup:“忘掉正则表达式吧,我拉车养你” - yangva', 'title_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '洗礼灵魂,修炼python(65)--爬虫篇—BeautifulSoup:“忘掉正则表达式吧,我拉车养你” - yangva'}, 'summary': '该文被密码保护。', 'summary_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '该文被密码保护。'}, 'published': '2017-11-10T04:25:00Z', 'published_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=10, tm_hour=4, tm_min=25, tm_sec=0, tm_wday=4, tm_yday=314, tm_isdst=0), 'updated': '2017-11-10T04:25:00Z', 'updated_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=10, tm_hour=4, tm_min=25, tm_sec=0, tm_wday=4, tm_yday=314, tm_isdst=0), 'authors': [{'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}], 'author_detail': {'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}, 'href': 'http://www.cnblogs.com/yangva/', 'author': 'yangva', 'links': [{'rel': 'alternate', 'href': 'http://www.cnblogs.com/yangva/p/7805300.html', 'type': 'text/html'}, {'rel': 'alternate', 'type': 'text/html', 'href': 'http://www.cnblogs.com/yangva/p/7805300.html'}], 'content': [{'type': 'text/html', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '该文被密码保护。'}]}, {'id': 'http://www.cnblogs.com/yangva/p/7797316.html', 'guidislink': True, 'link': 'http://www.cnblogs.com/yangva/p/7797316.html', 'title': '洗礼灵魂,修炼python(64)--爬虫篇—re模块/正则表达式(2) - yangva', 'title_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '洗礼灵魂,修炼python(64)--爬虫篇—re模块/正则表达式(2) - yangva'}, 'summary': '该文被密码保护。', 'summary_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '该文被密码保护。'}, 'published': '2017-11-09T07:14:00Z', 'published_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=9, tm_hour=7, tm_min=14, tm_sec=0, tm_wday=3, tm_yday=313, tm_isdst=0), 'updated': '2017-11-09T07:14:00Z', 'updated_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=9, tm_hour=7, tm_min=14, tm_sec=0, tm_wday=3, tm_yday=313, tm_isdst=0), 'authors': [{'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}], 'author_detail': {'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}, 'href': 'http://www.cnblogs.com/yangva/', 'author': 'yangva', 'links': [{'rel': 'alternate', 'href': 'http://www.cnblogs.com/yangva/p/7797316.html', 'type': 'text/html'}, {'rel': 'alternate', 'type': 'text/html', 'href': 'http://www.cnblogs.com/yangva/p/7797316.html'}], 'content': [{'type': 'text/html', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '该文被密码保护。'}]}, {'id': 'http://www.cnblogs.com/yangva/p/7792055.html', 'guidislink': True, 'link': 'http://www.cnblogs.com/yangva/p/7792055.html', 'title': '洗礼灵魂,修炼python(63)--爬虫篇—re模块/正则表达式(1) - yangva', 'title_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '洗礼灵魂,修炼python(63)--爬虫篇—re模块/正则表达式(1) - yangva'}, 'summary': '该文被密码保护。', 'summary_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '该文被密码保护。'}, 'published': '2017-11-06T14:31:00Z', 'published_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=6, tm_hour=14, tm_min=31, tm_sec=0, tm_wday=0, tm_yday=310, tm_isdst=0), 'updated': '2017-11-06T14:31:00Z', 'updated_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=6, tm_hour=14, tm_min=31, tm_sec=0, tm_wday=0, tm_yday=310, tm_isdst=0), 'authors': [{'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}], 'author_detail': {'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}, 'href': 'http://www.cnblogs.com/yangva/', 'author': 'yangva', 'links': [{'rel': 'alternate', 'href': 'http://www.cnblogs.com/yangva/p/7792055.html', 'type': 'text/html'}, {'rel': 'alternate', 'type': 'text/html', 'href': 'http://www.cnblogs.com/yangva/p/7792055.html'}], 'content': [{'type': 'text/html', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '该文被密码保护。'}]}, {'id': 'http://www.cnblogs.com/yangva/p/7794251.html', 'guidislink': True, 'link': 'http://www.cnblogs.com/yangva/p/7794251.html', 'title': '洗礼灵魂,修炼python(62)--爬虫篇—模仿游戏 - yangva', 'title_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '洗礼灵魂,修炼python(62)--爬虫篇—模仿游戏 - yangva'}, 'summary': '该文被密码保护。', 'summary_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '该文被密码保护。'}, 'published': '2017-11-06T09:34:00Z', 'published_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=6, tm_hour=9, tm_min=34, tm_sec=0, tm_wday=0, tm_yday=310, tm_isdst=0), 'updated': '2017-11-06T09:34:00Z', 'updated_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=6, tm_hour=9, tm_min=34, tm_sec=0, tm_wday=0, tm_yday=310, tm_isdst=0), 'authors': [{'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}], 'author_detail': {'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}, 'href': 'http://www.cnblogs.com/yangva/', 'author': 'yangva', 'links': [{'rel': 'alternate', 'href': 'http://www.cnblogs.com/yangva/p/7794251.html', 'type': 'text/html'}, {'rel': 'alternate', 'type': 'text/html', 'href': 'http://www.cnblogs.com/yangva/p/7794251.html'}], 'content': [{'type': 'text/html', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '该文被密码保护。'}]}, {'id': 'http://www.cnblogs.com/yangva/p/7767445.html', 'guidislink': True, 'link': 'http://www.cnblogs.com/yangva/p/7767445.html', 'title': '洗礼灵魂,修炼python(61)--爬虫篇—【转载】requests模块 - yangva', 'title_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '洗礼灵魂,修炼python(61)--爬虫篇—【转载】requests模块 - yangva'}, 'summary': '该文被密码保护。', 'summary_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '该文被密码保护。'}, 'published': '2017-11-06T02:22:00Z', 'published_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=6, tm_hour=2, tm_min=22, tm_sec=0, tm_wday=0, tm_yday=310, tm_isdst=0), 'updated': '2017-11-06T02:22:00Z', 'updated_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=6, tm_hour=2, tm_min=22, tm_sec=0, tm_wday=0, tm_yday=310, tm_isdst=0), 'authors': [{'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}], 'author_detail': {'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}, 'href': 'http://www.cnblogs.com/yangva/', 'author': 'yangva', 'links': [{'rel': 'alternate', 'href': 'http://www.cnblogs.com/yangva/p/7767445.html', 'type': 'text/html'}, {'rel': 'alternate', 'type': 'text/html', 'href': 'http://www.cnblogs.com/yangva/p/7767445.html'}], 'content': [{'type': 'text/html', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '该文被密码保护。'}]}, {'id': 'http://www.cnblogs.com/yangva/p/7786802.html', 'guidislink': True, 'link': 'http://www.cnblogs.com/yangva/p/7786802.html', 'title': '洗礼灵魂,修炼python(60)--爬虫篇—httplib2模块 - yangva', 'title_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '洗礼灵魂,修炼python(60)--爬虫篇—httplib2模块 - yangva'}, 'summary': '该文被密码保护。', 'summary_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '该文被密码保护。'}, 'published': '2017-11-05T09:57:00Z', 'published_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=5, tm_hour=9, tm_min=57, tm_sec=0, tm_wday=6, tm_yday=309, tm_isdst=0), 'updated': '2017-11-05T09:57:00Z', 'updated_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=5, tm_hour=9, tm_min=57, tm_sec=0, tm_wday=6, tm_yday=309, tm_isdst=0), 'authors': [{'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}], 'author_detail': {'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}, 'href': 'http://www.cnblogs.com/yangva/', 'author': 'yangva', 'links': [{'rel': 'alternate', 'href': 'http://www.cnblogs.com/yangva/p/7786802.html', 'type': 'text/html'}, {'rel': 'alternate', 'type': 'text/html', 'href': 'http://www.cnblogs.com/yangva/p/7786802.html'}], 'content': [{'type': 'text/html', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '该文被密码保护。'}]}, {'id': 'http://www.cnblogs.com/yangva/p/7783392.html', 'guidislink': True, 'link': 'http://www.cnblogs.com/yangva/p/7783392.html', 'title': '洗礼灵魂,修炼python(59)--爬虫篇—httplib模块 - yangva', 'title_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '洗礼灵魂,修炼python(59)--爬虫篇—httplib模块 - yangva'}, 'summary': '该文被密码保护。', 'summary_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '该文被密码保护。'}, 'published': '2017-11-05T02:39:00Z', 'published_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=5, tm_hour=2, tm_min=39, tm_sec=0, tm_wday=6, tm_yday=309, tm_isdst=0), 'updated': '2017-11-05T02:39:00Z', 'updated_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=5, tm_hour=2, tm_min=39, tm_sec=0, tm_wday=6, tm_yday=309, tm_isdst=0), 'authors': [{'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}], 'author_detail': {'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}, 'href': 'http://www.cnblogs.com/yangva/', 'author': 'yangva', 'links': [{'rel': 'alternate', 'href': 'http://www.cnblogs.com/yangva/p/7783392.html', 'type': 'text/html'}, {'rel': 'alternate', 'type': 'text/html', 'href': 'http://www.cnblogs.com/yangva/p/7783392.html'}], 'content': [{'type': 'text/html', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '该文被密码保护。'}]}, {'id': 'http://www.cnblogs.com/yangva/p/7782359.html', 'guidislink': True, 'link': 'http://www.cnblogs.com/yangva/p/7782359.html', 'title': '洗礼灵魂,修炼python(58)--爬虫篇—【转载】urllib3模块 - yangva', 'title_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '洗礼灵魂,修炼python(58)--爬虫篇—【转载】urllib3模块 - yangva'}, 'summary': '该文被密码保护。', 'summary_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '该文被密码保护。'}, 'published': '2017-11-04T03:31:00Z', 'published_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=4, tm_hour=3, tm_min=31, tm_sec=0, tm_wday=5, tm_yday=308, tm_isdst=0), 'updated': '2017-11-04T03:31:00Z', 'updated_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=4, tm_hour=3, tm_min=31, tm_sec=0, tm_wday=5, tm_yday=308, tm_isdst=0), 'authors': [{'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}], 'author_detail': {'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}, 'href': 'http://www.cnblogs.com/yangva/', 'author': 'yangva', 'links': [{'rel': 'alternate', 'href': 'http://www.cnblogs.com/yangva/p/7782359.html', 'type': 'text/html'}, {'rel': 'alternate', 'type': 'text/html', 'href': 'http://www.cnblogs.com/yangva/p/7782359.html'}], 'content': [{'type': 'text/html', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '该文被密码保护。'}]}], 'bozo': 0, 'headers': {'Cache-Control': 'private', 'Content-Type': 'application/xml', 'Content-Encoding': 'gzip', 'Vary': 'Accept-Encoding', 'Server': 'Microsoft-IIS/7.5', 'Set-Cookie': 'ASP.NET_SessionId=vqicjsq5n41af0lenvppfqim; path=/; HttpOnly', 'X-AspNetMvc-Version': '4.0', 'X-AspNet-Version': '4.0.30319', 'X-Powered-By': 'ASP.NET', 'X-UA-Compatible': 'IE=edge', 'Date': 'Sun, 26 Nov 2017 12:00:58 GMT', 'Connection': 'close', 'Content-Length': '2333'}, 'href': 'http://feed.cnblogs.com/blog/u/385429/rss', 'status': 200, 'encoding': 'utf-8', 'version': 'atom10', 'namespaces': {'': 'http://www.w3.org/2005/Atom'}}
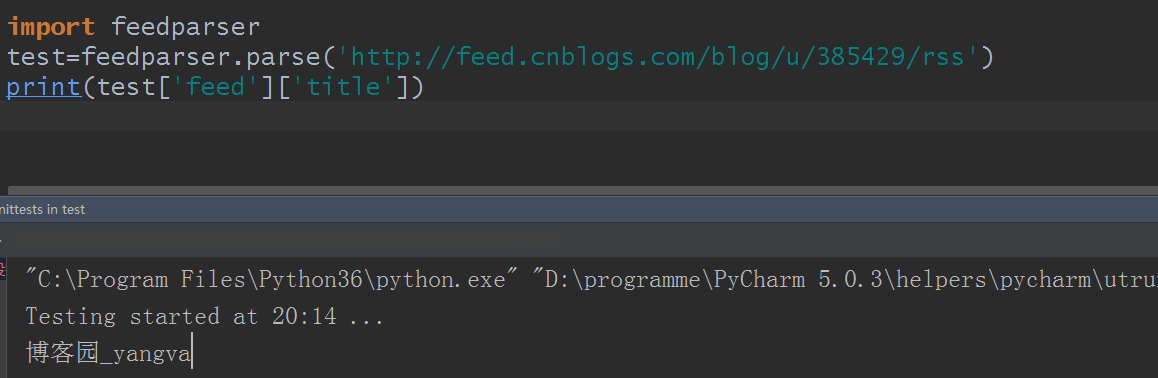
这样就把一些数据拿到了,标题,摘要,url地址全有了,相信你学到这里了,这些参数你基本上能看懂了
每个 RSS 和 Atom 订阅源都包含一个标题(.feed.title)
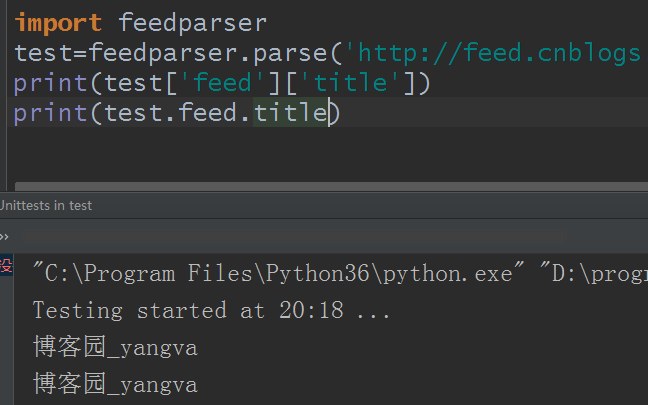
也可以通过属性访问:
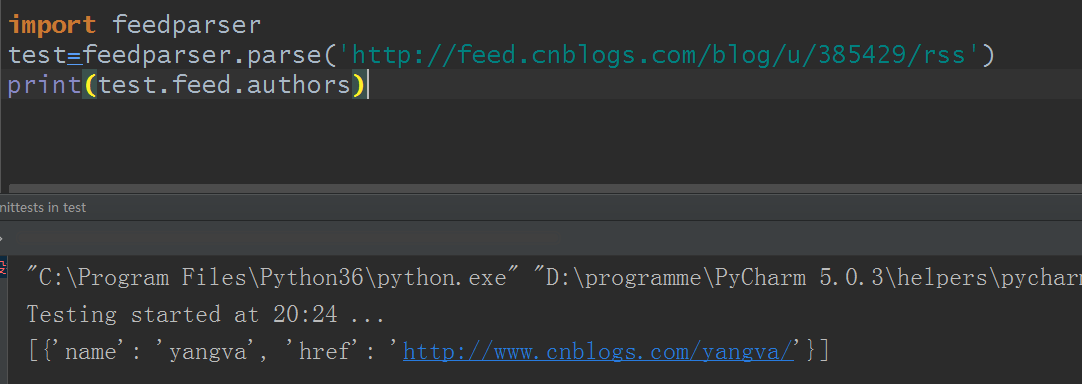
还有authors作者以及主页等
还有一组文章条目(.entries)

每个文章条目都有一段摘要(.entries[i].summary)

或者是包含了条目中实际文本的描述性标签(.entries[i].description)

还有很多很多,只要对象feedparser.parse(url)里面有的,基本都可以访问,根据实际情况来就行
综合使用
- 可以刷博客访问量
- 爬取别人的博客文章(我之前那些被爬虫爬取的博客文章不出意外就是用的rss爬的)
- ……
有朋友肯定想,我不用webbrowser和feedparser也可以爬取啊,是的,不过有了feedparser就多了一种办法啊,并且还不止干这些,你还可以结合上一篇的webbrowser模块一起使用:
import webbrowser,time,os,feedparser
browser_path = r'C:\Users\Administrator\AppData\Local\Google\Chrome\Application\chrome.exe'
test = feedparser.parse('http://feed.cnblogs.com/blog/sitehome/rss')
blog_urls = [entry.id for entry in test.entries] #这是根据parse对象匹配出来的,根据实际情况匹配就行
count = 0
for url in blog_urls: #个人建议,已经有for循环用来迭代url了,不需要在用while,不然嵌套太多层,不利于优化
webbrowser.register('chrome',None,webbrowser.BackgroundBrowser(browser_path))
webbrowser.get('chrome').open_new_tab(url)
count += 1
time.sleep(3)
if not count%5: #注意这里的if not,很巧妙,可以实现每打开五个标签就关闭,再次重新打开,直到for循环结束
os.system('taskkill /F /IM chrome.exe')
同样的,不方便展示效果,自己复制代码下去测试体验吧,还是那句话,没必要去刷博客访问量,没意思。
另外同样的,不要一直去测试运行代码,别把博客园服务器搞崩了,这样就太不好了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号