洗礼灵魂,修炼python(70)--爬虫篇—补充知识:json模块
在前面的某一篇中,说完了pickle,但我相信好多朋友都不懂到底有什么用,那么到了爬虫篇,它就大有用处了,而和pickle很相似的就是JSON模块
JSON
1.简介
1)JSON(JavaScript Object Notation) ,js对象标记,是一种轻量级的数据交换格式。它易于阅读和编写,同时也易于机器解析和生成。它基于JavaScript Programming Language, Standard ECMA-262 3rd Edition - December 1999的一个子集,所以有另一个说法,JSON 语法是 JavaScript 对象表示语法的子集。
JSON采用完全独立于语言的文本格式,但是也使用了类似于C语言家族的习惯(包括C, C++, C#, Java, JavaScript, Perl, Python等),它通用于几乎所有的编程语言以及Web开发
2)JSON建构于两种结构:“名称/值”对的集合(A collection of name/value pairs)(是不是有点类似字典啊?),不同的语言中,它被理解为对象(object),纪录(record),结构(struct),字典(dictionary),哈希表(hash table),有键列表(keyed list),或者关联数组 (associative array),所以使得一种数据格式在同样基于这些结构的不同编程语言之间能够实现数据交换
- 数字(整数或浮点数)
- 字符串(在双引号中)
- 逻辑值(true 或 false)
- 数组(在方括号中)
- 对象(在花括号中)
- null
2.方法/属性
json从Python2.6开始加入了JSON模块,所以它已经是内置模块,不用安装

其实方法/属性并不多对吧?
3.常用方法/属性解析
最常用的就这几个:
dump(obj, fp, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, encoding='utf-8', default=None, sort_keys=False, **kw):对文件的序列化
dumps(obj, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, encoding='utf-8', default=None, sort_keys=False, **kw):对对象的序列化
load(fp, encoding=None, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw):对文件的反序列化
loads(s, encoding=None, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw):对对象的反序列化
以上的是官方文档里的,参数太多了对吧,其实基本很少用,你知道pickle的dump/dumps和load/loads怎么用就行了,效果是一样的。
json的序列化和反序列化的过程就是对对象的数据来回转化,这种就叫序列化与反序列化,或者叫编码与解码,相互关系:
序列化(dump/dumps):(这里只是针对python而言,当然可以序列化和反序列化为其他对象)

反序列化(load/loads):

例1:使用dumps和loads
#-*- coding:utf-8 -*-
import json
test={'username':'yang','password':'test','from':'中国'}
temp=json.dumps(test)
print(temp)
cont=json.loads(temp)
print(cont)
结果:
python3下:
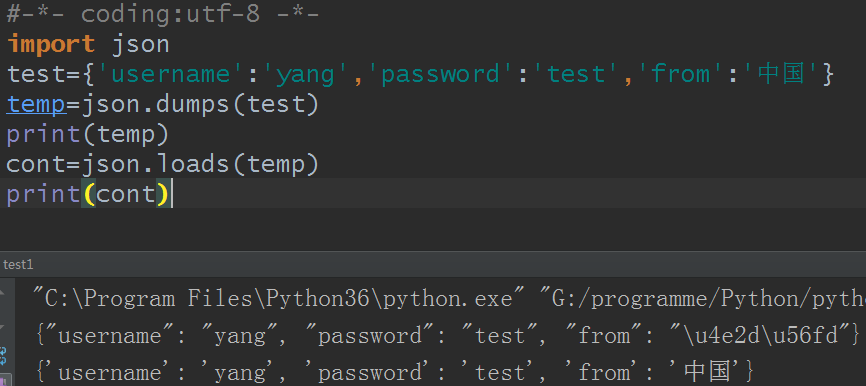
python2下,因为python2下默认是用ASCII码,所以中文显示不正常,这里就可以用dumps的ensure_ascii参数解决:

但是只是dumps转为字符串时可以正常显示,当loads转为原对象还是这样,因为默认编码ASCII,单个输出是没问题的:
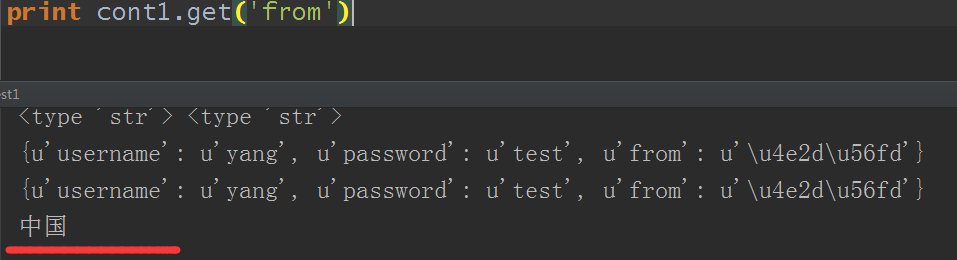
所以一般在不能显示中文时我都直接使用的是python3,这个问题前面也说过了,不再多说
例2:使用dump和load
#-*- coding:utf-8 -*-
import json
f=open('test.txt','w')
test={'username':'yang','password':'test','from':'中国'}
json.dump(test,f)
f.close()
f=open('test.txt','r')
cont=json.load(f)
print(cont)
f.close()
先打开test.txt文件看看:

再看运行结果:
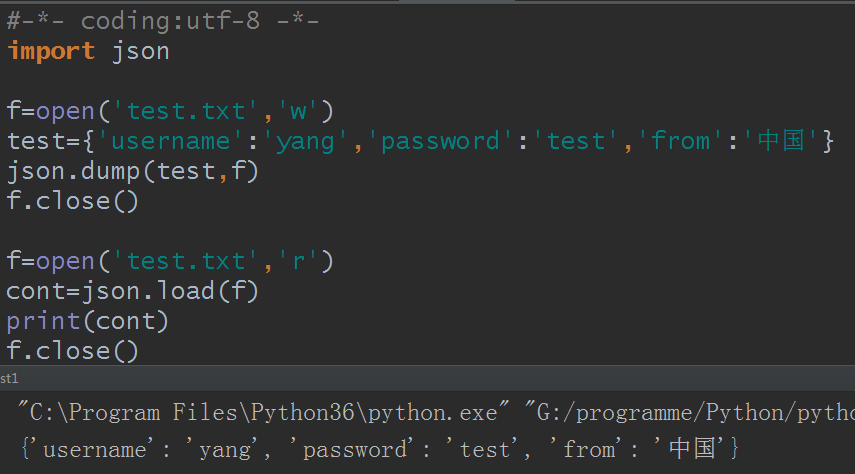
有没有发现其实和pickle模块很相似,那么就用这个例子,改成用pickle看看:
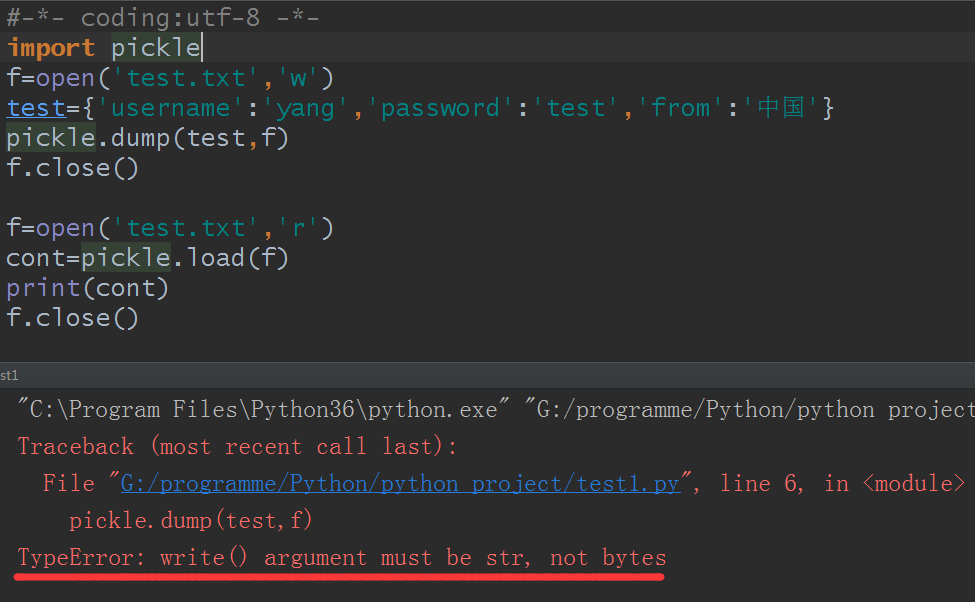
发现报错了,问题出在哪呢?出在打开方式,pickle打开必须是一个二进制方式,使用'wb'和‘rb’后成功运行
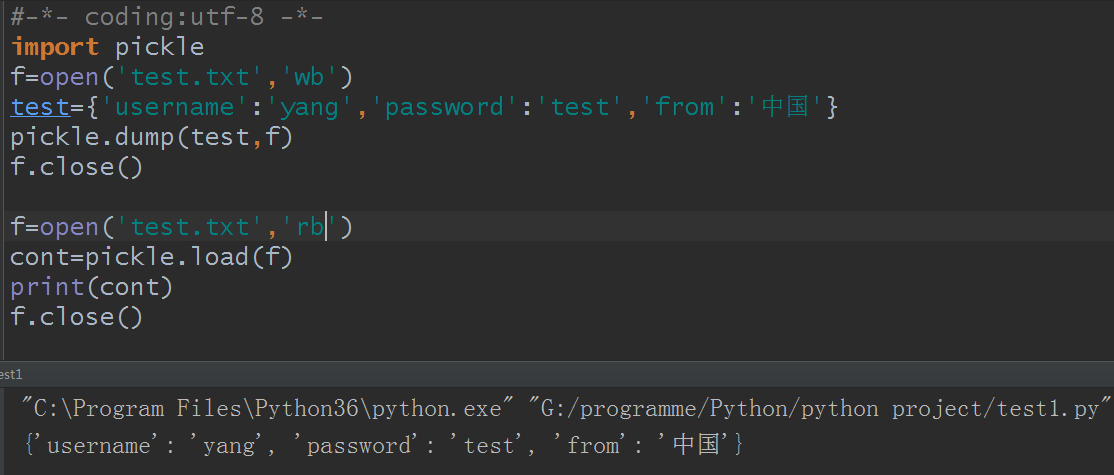
再看test.txt文件成了什么:

成了一堆乱码对吧
到底json和pickle有什么异同和区别呢?
4.json与pickle模块的异同点
相同点:
- json和pickle模块,两个都是用于序列化的模块
- 两个模块都提供了dumps,dump,loads,load 4个功能
不同点:
- json用于不同语言之间数据交换,多种语言通用,而pickle只在于python,是python特有
- JSON只能处理基本数据类型,并且json只能是字符串格式;pickle能处理所有Python的数据类型(包括类,自定义函数,模块,包等python的一切)
- pickle写入和读取文件时,用的是 ‘b'模式,而json不用加‘b’
- pickle反序列化后的对象与原对象是等值的副本对象,类似与deepcopy,而json是原对象
- json传输速度较慢,pickle较快,对大型数据的转换就能很明显的体现出来
5.json与爬虫有什么关系
在后期爬虫实战篇里绝对会遇到的,当网站使用js动态传输数据时,要爬取那些动态的数据,就知道它的用处了
补充一点:如果你觉得json模块序列化和反序列化麻烦,可以用第三方库dmjson来编码解码
Demjson 是 python 的第三方模块库,可用于编码和解码 JSON 数据,包含了 JSONLint 的格式化及校验功能。
Github 地址:https://github.com/dmeranda/demjson
官方地址:http://deron.meranda.us/python/demjson/
其主要的方法:
encode 将 Python 对象编码成 JSON 字符串
decode将已编码的JSON字符串解码为Python对象

 浙公网安备 33010602011771号
浙公网安备 33010602011771号