洗礼灵魂,修炼python(65)--爬虫篇—BeautifulSoup:“忘掉正则表达式吧,我拉车养你”
前面解析了正则表达式,其实内容还挺多的对吧?确实挺适用的,不仅是python,其他语言或者web前端后端基本都要掌握正则表达式知识,但是你说,这么多,要完全的掌握,灵活运用的话,得搞多久啊?并且如果一次匹配稍有差池,一步错,步步错,并且很多朋友相信其实还不太熟练正则表达式,咋办呢?有没有什么可以替代正则表达式呢?哎,有的,那就是——BeautifulSoup。
BeautifulSoup
1.简介
官方文档的解释是:
“Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。”
通俗的说就是,BeautifulSoup模块是第三方模块(所以你需要事先用pip或者easy_install或者在pypi社区下载压缩包安装),它一样可以抓取html标签的代码,而且比正则表达式更适用简单
要说一下的是,Beautiful Soup3目前已经停止开发,推荐使用Beautiful Soup4,不过它已经被移植到bs4了,也就是说导入时我们需要 import bs4 。另外据说 BS4 对Python3的支持不够好,如果你是在要在python3中使用,可以考虑下载 BS3 版本。
注意,安装时,命令是:easy_install beautifulsoup4/pip install beautifulsoup4,使用的是小写
这里有篇beautifulsoup的官方文档,如果你觉得我的博文不适合你可以看看官方的:传送门
2.从例子中学习知识点:
好的,这里用我之前写的一个非常简单的html标签测试:
<html>
<head>
<title>这是第二节课</title>
<meta charset='utf-8'> <!--meta是单标签-->
<meta name='keywords' content='hello world,oh yeah'>
</head>
<!--<body bgcolor='green'>-->
<body link='red' vinlk='green' alink='blue'>
<h1>这是一个标题</h1>
<!--超链接必须加上http://不然无法跳转-->
<a href='http://www.baidu.com'>百度</a>
<a href='http://www.163.com'>网易</a>
<a href='http://www.qq.com'>腾讯</a>
<a href='http://www.sina.com'>新浪</a>
</body>
</html>
上面的head,title,meta cahrset,h1,a等等的就是Tag标签,那么我们怎么把数据拿到呢?
前提我们要创建一个BeautifulSoup对象:
import bs4
test=bs4.BeautifulSoup(html)
这里补充一下,你也可以在创建一个BeautifulSoup对象的同时打开本地文件,比如:
test1=bs4.BeautifulSoup(open(test.html))
不过,打开了一个文件,记得最后手动关闭
完整代码:
# -*- coding:utf-8 -*-
import bs4
html='''
<html>
<head>
<title>这是第二节课</title>
<meta charset='utf-8'> <!--meta是单标签-->
<meta name='keywords' content='hello world,oh yeah'>
</head>
<!--<body bgcolor='green'>-->
<body link='red' vinlk='green' alink='blue'>
<h1>这是一个标题</h1>
<!--超链接必须加上http://不然无法跳转-->
<a href='http://www.baidu.com'>百度</a>
<a href='http://www.163.com'>网易</a>
<a href='http://www.qq.com'>腾讯</a>
<a href='http://www.sina.com'>新浪</a>
</body>
</html>
'''
test=bs4.BeautifulSoup(html)
print test.title
结果测试:
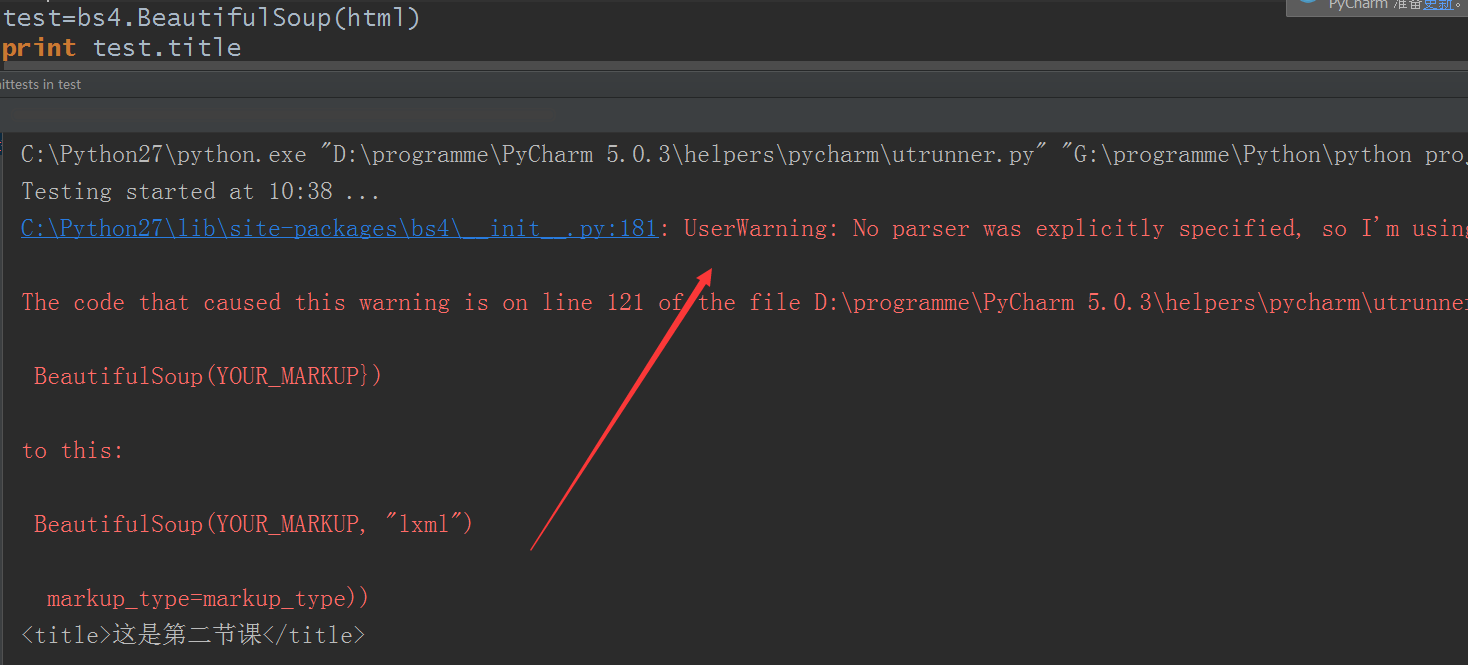
妥妥的就把title标签以及标签里的数据单独取出来了,但是出现一些东西,大概意思是没有给解析器吧,所以有一个警告,并不是报错,由于我是用的pycharm,可能不会默认使用解析器(解析器问题见下面),所以,加上python自带的解析器就没问题了
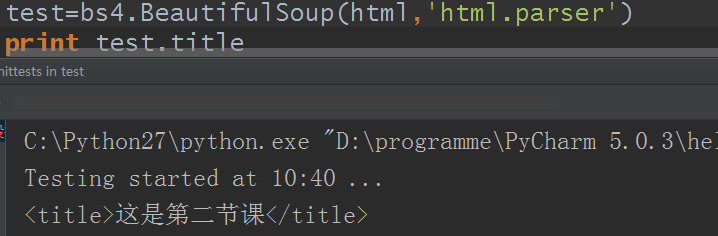
好的,通过用Tag标签就可以轻松的取出html标签里我们想要取的数据,这里来看,是不是觉得比正则表达式简单多了?但有一点是,它默认查找的是在所有内容中的第一个符合要求的标签(可以修改),和正则里的search和match方法类同对吧?
那这对象到底是什么类型呢?
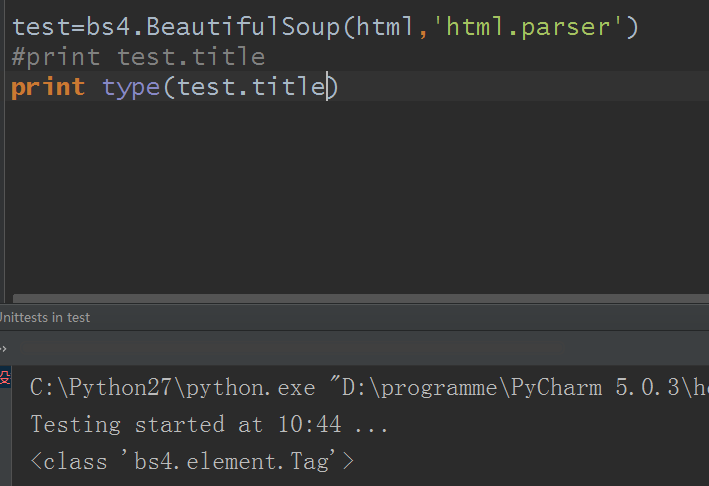
Tag
通俗点说,Tag就是HTML中的一个个标签。Tag有两个重要的属性:name,attrs
name:
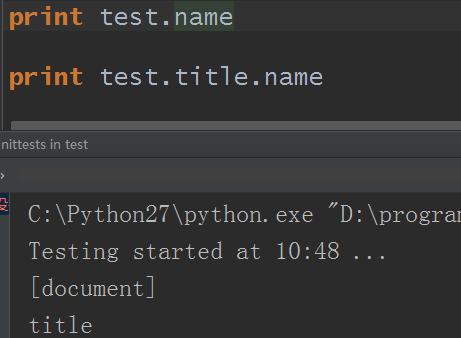
创建出来的test对象本身的name即为[document],对于其他内部标签,输出的值便为标签本身的名称
attrs:
前面的html标签里是这样的:
<body link='red' vinlk='green' alink='blue'>
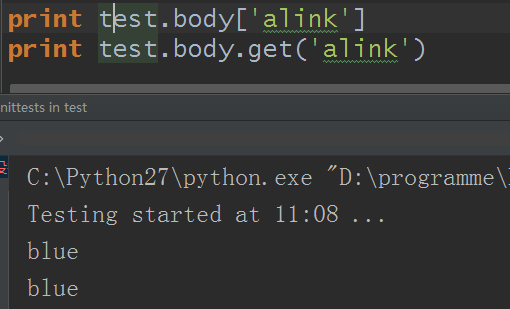
看出来了吧?attrs就是打印body的属性,结果得到一个字典,而且我们还可以通过键得到值,还可以使用字典方法get,也可以修改键值:
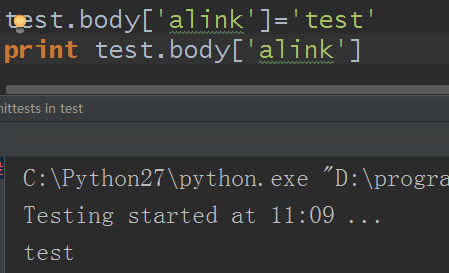
既然都是字典,相关的字典方法也都可以使用,自己发现了,这里略过
那有朋友说了,既然我们已经可以利用标签得到想要的数据,那么我们只要数据,而不要标签呢?
利用string方法
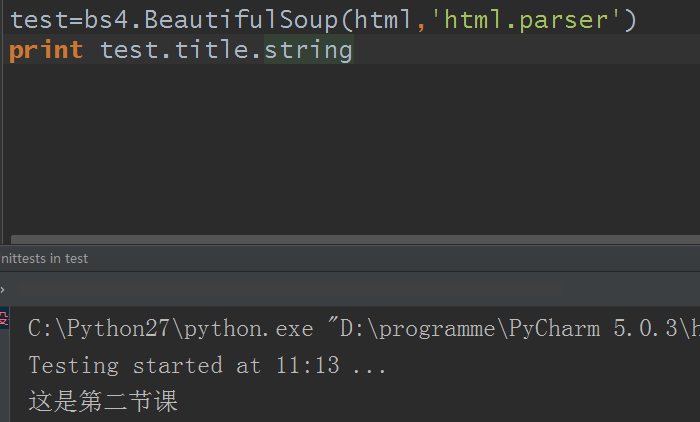
这样是不是很完美的又很轻易的把html标签里的数据轻松取出来来了呢?
那这种又是什么类型 呢?
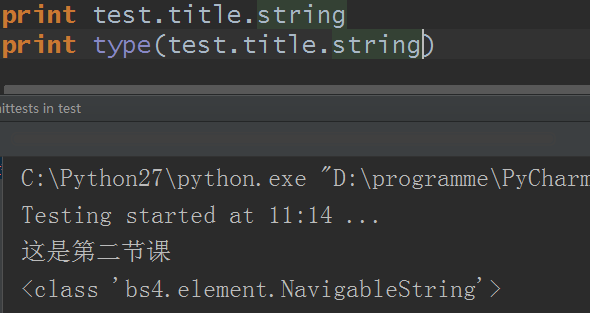
NavigableString
好的,它就是BeautifulSoup的NavigableString对象
NavigableString
翻译过来叫可以遍历的字符串,其实我们之前学习的字符串本来就可遍历对不对,所以它就是一个字符串,所以支持字符串相关的所有属性和方法,你可以随意处理,和前面得到的字典一样,这里就直接略过了
那有朋友说,假如html标签里恰好只是一个注释符呢?比如像这样:<h1><!--this is the test--></h1>,这种能不能得到数据,并且又是什么类型呢?
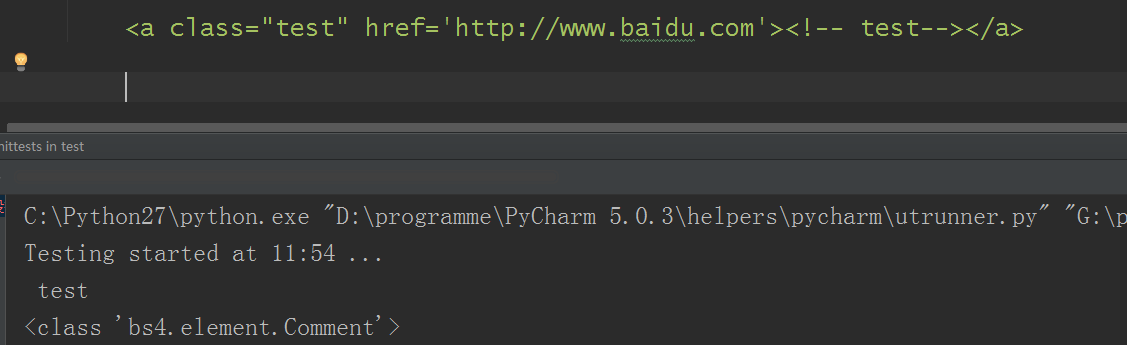
能得到数据对不对,并且默认把注释符省略了,那这个Comment对象又是什么呢?
Comment
Comment对象是一个特殊类型的NavigableString对象,其实输出的内容并不包括注释符号。
那假如我们在开发中,并不需要得到是注释符的数据呢?很简单啊,用if条件判断啊,看是否是Comment对象,是的话就pass咯。
这四个对象每个都有自己的方法和属性,你可以理解为如同是urllib.urlopen创建的对象
说了这么多,BeautifulSoup模块还没解析呢,是的,上面说到的,你如果学会了,那么获取html标签数据已经没问题了对吧?那么你说,我就是还想知道BeautifulSoup模块还有哪些功能对吧?好的,接着看:
3.BeautifulSoup模块方法/属性
注意看,我在python2上装了个BeautifulSoup和beautifulsoup,方法有点差别。按理说前者也可以使用的,不过既然有新版,那么我就用bs4来解析了。
要补充的是,bs4需要一个解析网页代码的工具,有lxml,有html5lib,html.parser(python自带)。所以还需要安装其中一个,那他们有什么区别呢?
|
解析器 |
使用方法 |
优势 |
劣势 |
|
Python标准库 |
BeautifulSoup(markup, “html.parser”) |
Python的内置标准库 执行速度适中 文档容错能力强 |
Python 2.7.3 or 3.2.2)前 的版本中文档容错能力差 |
|
lxml HTML 解析器 |
BeautifulSoup(markup, “lxml”) |
速度快 文档容错能力强 |
需要安装C语言库 |
|
lxml XML 解析器 |
BeautifulSoup(markup, [“lxml”, “xml”])BeautifulSoup(markup, “xml”) |
速度快 唯一支持XML的解析器 |
需要安装C语言库 |
|
html5lib 解析器 |
BeautifulSoup(markup, “html5lib”) |
最好的容错性 以浏览器的方式解析文档,解析方式与浏览器相同 生成HTML5格式的文档 |
速度慢 不依赖外部扩展 |
如果我们不安装解析器,则 Python 会使用 Python默认的解析器,lxml 解析器速度快,功能强大,推荐安装
4.常用方法/属性
假设我们需要获取到百度首页源代码的某一部分的内容:
html='''
<div class="qrcodeCon">
<div id="qrcode">
<div class="qrcode-item qrcode-item-1">
<div class="qrcode-img"></div>
<div class="qrcode-text">
<p><b>手机百度</b></p>
</div>
</div>
</div>
</div>
<div id="ftCon">
<div class="ftCon-Wrapper"><div id="ftConw"><p id="lh"><a id="setf" href="//www.baidu.com/cache/sethelp/help.html" onmousedown="return ns_c({'fm':'behs','tab':'favorites','pos':0})" target="_blank">把百度设为主页</a><a onmousedown="return ns_c({'fm':'behs','tab':'tj_about'})" href="http://home.baidu.com">关于百度</a><a onmousedown="return ns_c({'fm':'behs','tab':'tj_about_en'})" href="http://ir.baidu.com">About Baidu</a><a onmousedown="return ns_c({'fm':'behs','tab':'tj_tuiguang'})" href="http://e.baidu.com/?refer=888">百度推广</a></p><p id="cp">©2017 Baidu <a href="http://www.baidu.com/duty/" onmousedown="return ns_c({'fm':'behs','tab':'tj_duty'})">使用百度前必读</a> <a href="http://jianyi.baidu.com/" class="cp-feedback" onmousedown="return ns_c({'fm':'behs','tab':'tj_homefb'})">意见反馈</a> 京ICP证030173号 <i class="c-icon-icrlogo"></i> <a id="jgwab" target="_blank" href="http://www.beian.gov.cn/portal/registerSystemInfo?recordcode=11000002000001">京公网安备11000002000001号</a> <i class="c-icon-jgwablogo"></i></p></div></div></div>
<div id="wrapper_wrapper">
</div>
</div>
<div class="c-tips-container" id="c-tips-container"></div>
<script>
window.__async_strategy=2;
//window.__switch_add_mask=false;
</script>
<script>
'''
好的,我们先看看生成的BeautifulSoup对象有什么方法属性:

和刚才的bs4模块方法对比好多啊,对了,这个BeautifulSoup对象里的方法才是本篇博文的重点
prettify():作格式化输出待处理文本对象(你可以理解为类同前面的print urllib.urlopen('test.html').read())

5.Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:
BeautifulSoup
Tag
NavigableString
Comment
(以上四个对象相关特性上面已经解析,略过)
那么还有的功能呢?不急,本篇暂且到此,下一篇继续

 浙公网安备 33010602011771号
浙公网安备 33010602011771号