洗礼灵魂,修炼python(64)--爬虫篇—re模块/正则表达式(2)
前面学习了元家军以及其他的字符匹配方法,那得会用啊对吧?本篇博文就简单的解析怎么运用
正则表达式使用
前面说了正则表达式的知识点,本篇博文就是针对常用的正则表达式进行举例解析。相信你知道要用正则表达式的话,得导入re模块
1.re模块方法/属性

2.re模块常用方法/属性(正则表达式举例使用)
re模块的匹配数据的相关方法一般就这四个:search,match,findall,compile
search(string[, pos[, endpos]])
1.简介

官方文档说的很直白,像我等屌丝都能读懂啥意思:扫描并查找字符串里的的pattern值,如果匹配到则返回一个match对象,即一个匹配对象,否则没找到的的话则返回None。
- 第一个参数是模式,也就是我们需要匹配的字符
- 第二个参数是被用来匹配的字符串
- 第三个是以什么为标准来匹配。它的值一般为三个:
re.X:忽略空格和注释
re.I:忽略大小写的区别
re.S:匹配任意字符,包括新行
2.说再多不如来一个例子:

什么意思呢?为什么报错?因为正则表达式,匹配的都是字符串对不对,不可以是其他任何数据类型,所以报错。
正确匹配之后,返回了一个match对象对不对?有朋友说,反正电脑上都装了两个版本的python,以上是在python2.7.13环境下的,试试另一个版本呢?
python3.6.1(上面是python2.7.13)
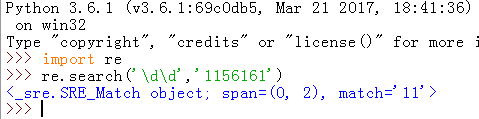
哎?WTF?咋回事,怎么不同版本匹配到的结果不一样啊?这是BUG还是什么?
好的,我可以负责任的告诉你,这不是BUG,这就是不同版本之间的区别,并且从python3.4还是python3.5开始(实在想不起了,但就是这俩版本之中其中一个版本),search方法才会智能的返回匹配到的字符所在起始位置(其实就是索引值)参数以及pattern参数的值或者None,而在之前,都只是返回一个匹配对象或None。
那怎么操作才能显示匹配的结果呢?
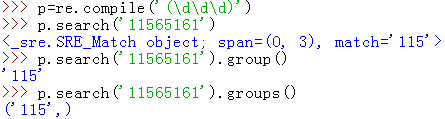
用group(),groups(),以及span()
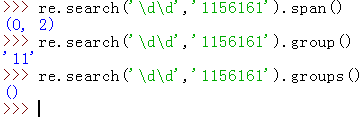
span():表示返回匹配字符串所在的起始位置,及索引值。上面的例子里匹配两个数字字符,则是0到2
group():表示获得一个或多个分组截获的字符串
- 指定多个参数时将以元组形式返回
- group1可以使用编号也可以使用别名
- 编号0代表整个匹配的子串,即group()==group(0)(group()等价于group(0))
- 没有截获字符串的组返回None
- 截获了多次的组返回最后一次截获的子串
groups():表示以元组形式返回全部分组截获的字符串,即groups()==group()==group(0)==(group(1),group(2),group(3),……)
但是这里为什么会返回一个空元组呢?因为给的pattern就只是一个参数,\d\d是被当作一个参数的。
当这么写groups()就可以匹配到一个元素的元组

那么匹配多个参数呢?

看到这里,我相信你也顺便的理解了前面说的groups()==group()==group(0)==(group(1),group(2),group(3),……)是什么意思了
并且在python3中,这几个方法也同样:

所以,不同的版本,使用相同的方法会有不同的结果
如果string中存在多个pattern子串,默认只返回第一个:

match
1.简介

意思是:尝试在字符串的起始处应用该pattern模式,如果匹配成功返回一个match对象,否则返回None
2.例
match和search基本没啥区别:

findall
1.简介

直译过来就是:搜索被匹配的string,以列表形式返回全部能匹配的子串。既然返回对象是一个列表,那么不存在group,groups,span等方法
2.例
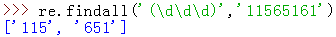
就这么简单
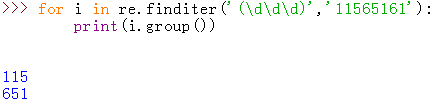
finditer
1.简介

搜索被匹配的string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器
2.例

或者可以这样:
compile
1.简介

这个方法是Pattern类对象的方法,用于将字符串形式的正则表达式编译为Pattern对象。换句话就是通过pattern值编译为pattern对象,再利用pattern对象的方法进行匹配
- 第一个参数是pattern模式
- 第二个参数flag是匹配模式,可以在regex字符串中指定模式,比如re.compile('pattern', re.I | re.M)与re.compile('(?im)pattern')是等价的
2.例
所以相信你也看来了,其实compile与search,match没什么区别,就是把之前一个步骤或者一行代码能搞定的拆分成了两个步骤或者两行代码
好的,看到那么多次的flags参数,这到底是干嘛的,上面也只是说可以等于多少,那么这里详细说明一下,它可以叫做修饰符,也可以叫做可选标志,前面只说了常用的三个值,下面是详细的:
-
re.IGNORECASE:忽略大小写,简写为 re.I
-
re.MULTILINE:多行模式,改变^和$的行为,简写为 re.M
-
re.DOTALL:点任意匹配模式,让'.'可以匹配包括'\n'在内的任意字符,简写为re.S
-
re.LOCALE:使预定字符类 \w \W \b \B \s \S 取决于当前区域设定, 简写为 re.L
-
re.ASCII:使 \w \W \b \B \s \S 只匹配 ASCII 字符,而不是 Unicode 字符,简写为 re.A
- re.UNICODE:使\w \W \b \B \s \S取决于Unicode定义的字符属性,简写为re.U
-
re.VERBOSE:详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。主要是为了让正则表达式更易读,简写为re.X
-
re.DEBUG:显示调试信息编译的表达式
以上的并不是都会用到,最常用的就是re.I,re.S,re.X
re.I
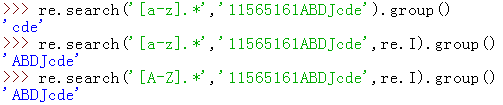
注意加与不加re.I参数的区别
re.S

注意加与不加re.S参数的区别
re.X
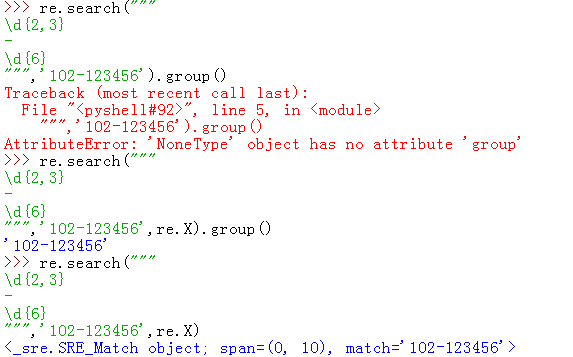
所以你看到了,使用re.X就可以把pattern值定时跨越多行了
这里要补充一句,不是每次匹配非得要在其后加入group()或者groups(),我加参数只是为了方便展示结果的
其他就很少用了,自己下去研究了
然后re模块还有其他的方法,大多是少用的或者是和字符串方法一样的,所以直接略过
作业:
1.匹配11位手机号
2.匹配身份证号(包括最后带‘X’的)
3.匹配ip地址,如:192.168.1.1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号