洗礼灵魂,修炼python(57)--爬虫篇—知识补充—编码之对比不同python版本获取的数据
前面既然都提到编码了,那么把相关的编码问题补充完整吧
编码
之前我说过,使用python2爬取网页时,容易出现编码问题,下面就真的拿个例子来看看:
python2下:
# -*- coding:utf-8 -*-
import urllib
url = 'http://www.qq.com/'
response = urllib.urlopen(url)
html = response.read()
print html
结果:

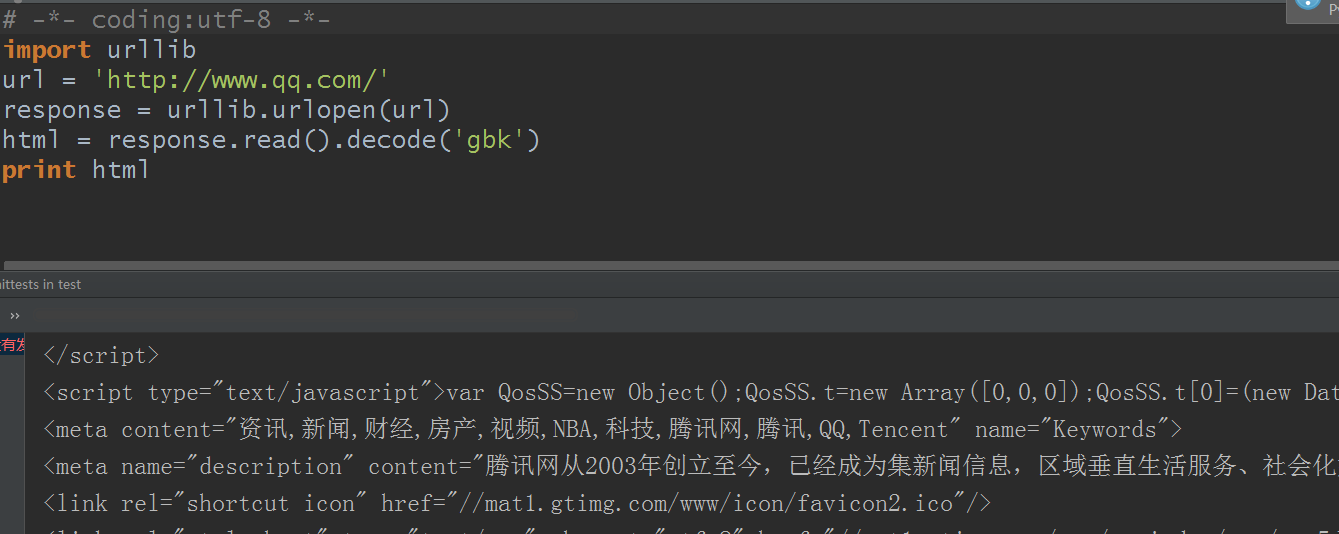
像那些就是编码问题不能显示的中文,先看看腾讯首页源代码是什么默认编码:

看到了吧?编码是gb2312。
有朋友说,我们使用的是utf-8啊,这就不统一了,改成相同的看看呢?
然而,还是如此:

有朋友想到了,解码啊,decode啊:
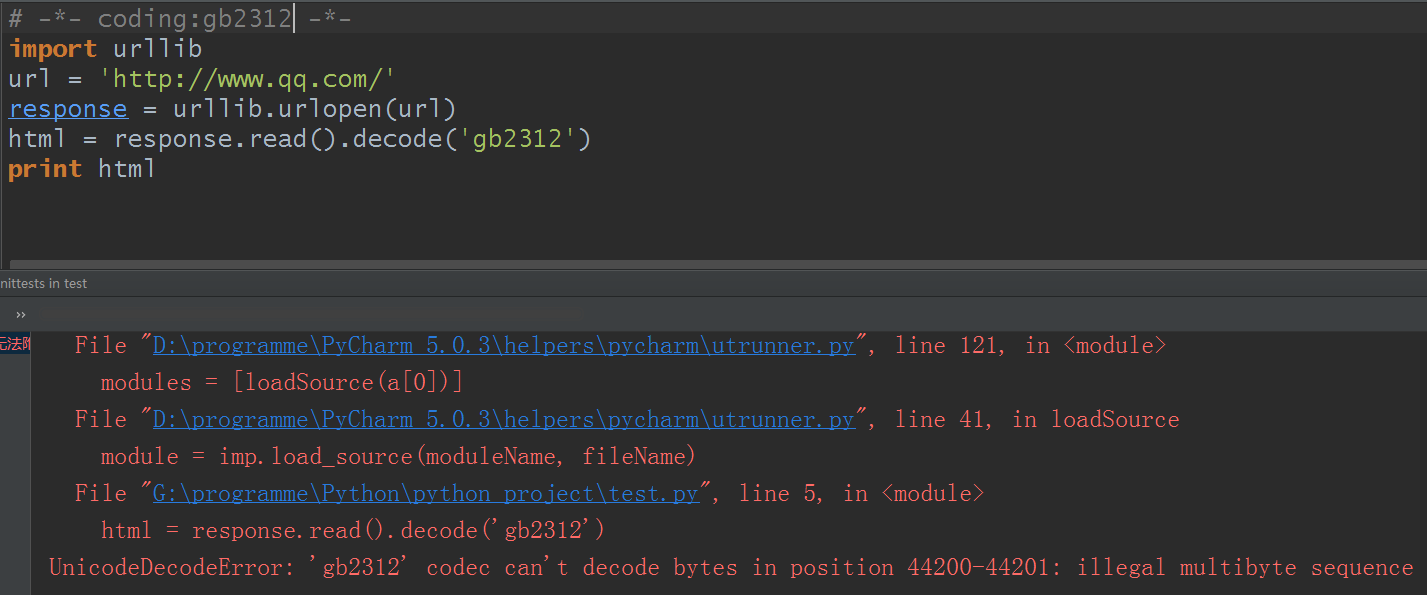
怎么回事啊?还报错了,提示gb2312不能解码bytes字节的字符,所以我们试了设置编码统一和解码都还是这样,那么既然腾讯首页有不能被gb2312解码的字符,我们可以使用一个奇怪的招:
加入参数:‘ignore’,可以忽略那些不符合统一编码的。这个单词的意思就是忽略
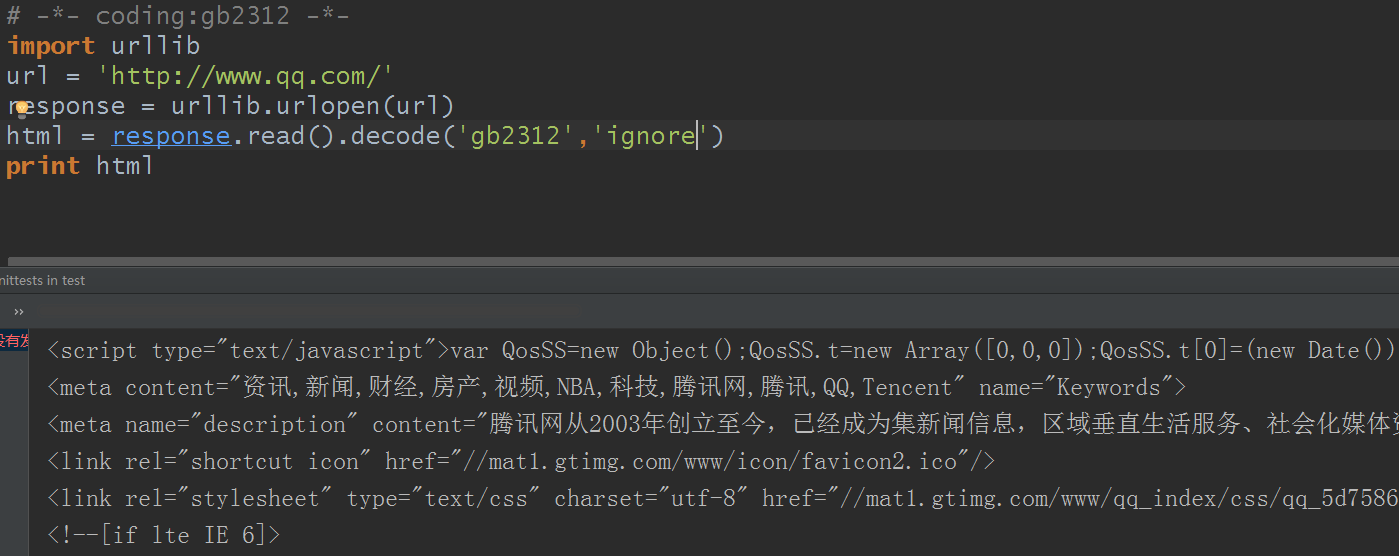
哎呀,可以了,好高兴对吧?
那你说我还是习惯默认编码为utf-8,试试看:
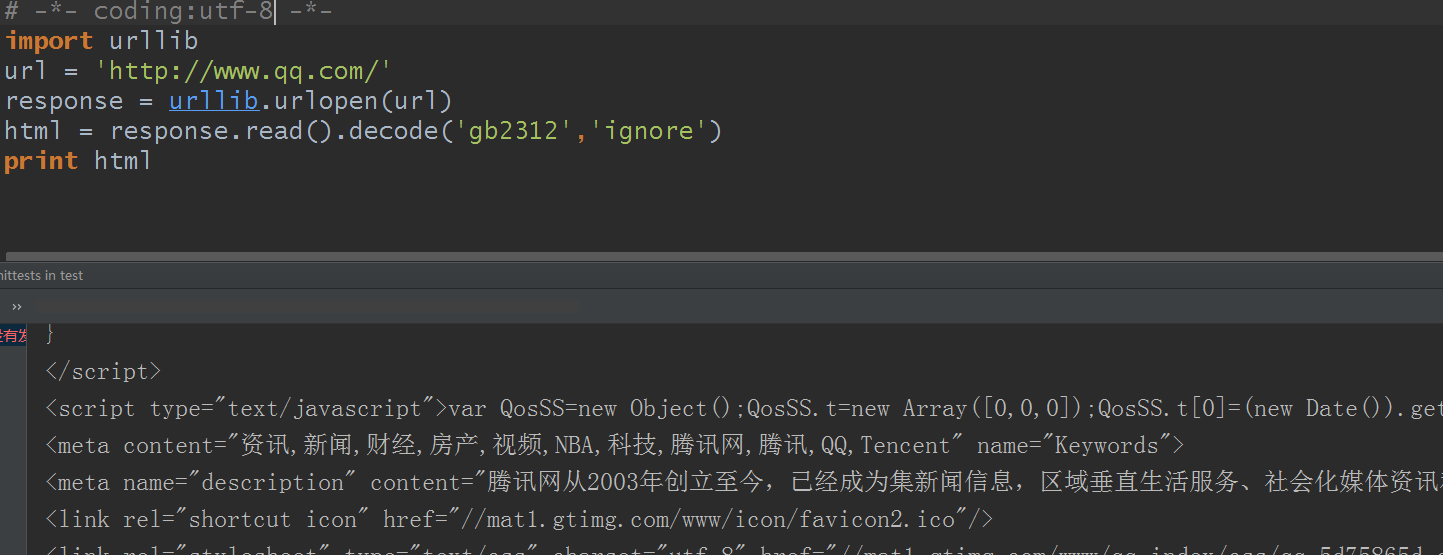
还是可以的对吧?
不过有朋友说,你这看着有点麻烦了,我不想加那么多的参数,只想一个参数就搞定,可以的,把它解码为gbk:
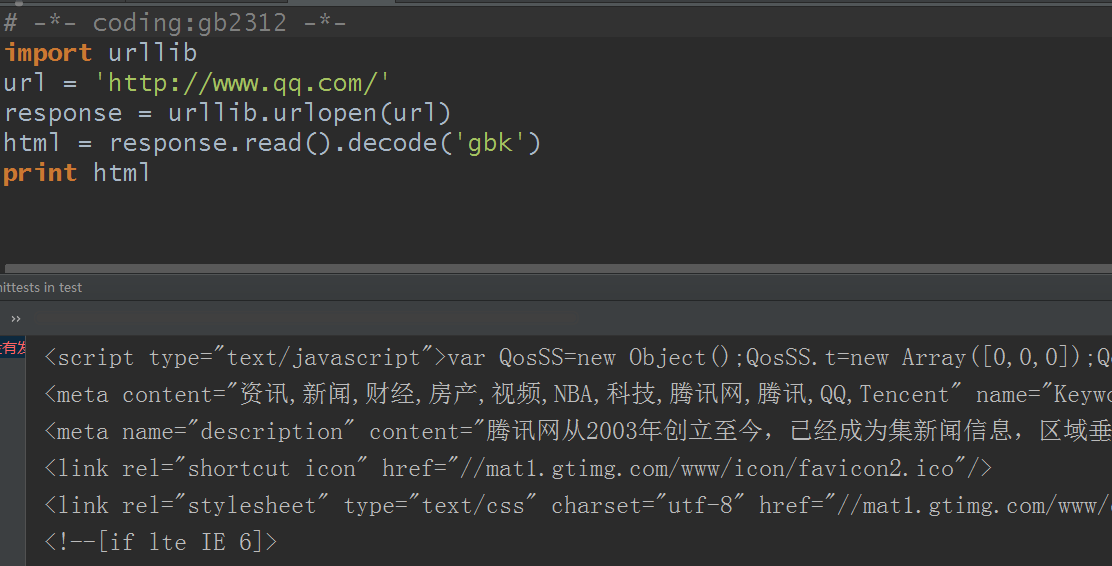
改为coding:utf-8也是没问题的:
我想你会有个疑问,刚才看到的腾讯首页源码不是gb2312吗?怎么却是gbk啊?(什么是gbk在前面也说过的,可以有繁体和简体的中文编码)。
其实这里也可以说个规律,在国内的BAT,网易,新浪和搜狐等等大公司的源代码基本都是gbk,就像刚才报错提示的,有bytes的字符集无法被gb2312解码,所以则报错了,识别不了,这些bytes字符集就是非gb2312的字符集。所以使用gbk就能解码。
腾讯首页整个源代码是拿到了,那么我想从中获取这一段文字呢?

我想通过程序就可以直接的获取到这一段文字呢?又怎么样搞呢?
发现我们需要截取的是下面个html标签<meta content>,而上面还有同样的html标签。像这种情况在以后的爬取中是经常遇到的,这种怎么搞呢?
我想的方法是,尽量的匹配到我们需要截取的数据:
先调试一下简单的一段:

为什么取出来的字符是这样的,没办法python默认是ASCII啊,不识别中文,同样的代码使用python3看看:

确实取到了对不对,好的,调试好后,先做开始的尝试看看。
当我们只是通过这个【<meta content="】作为标记的话,取出来会有多个
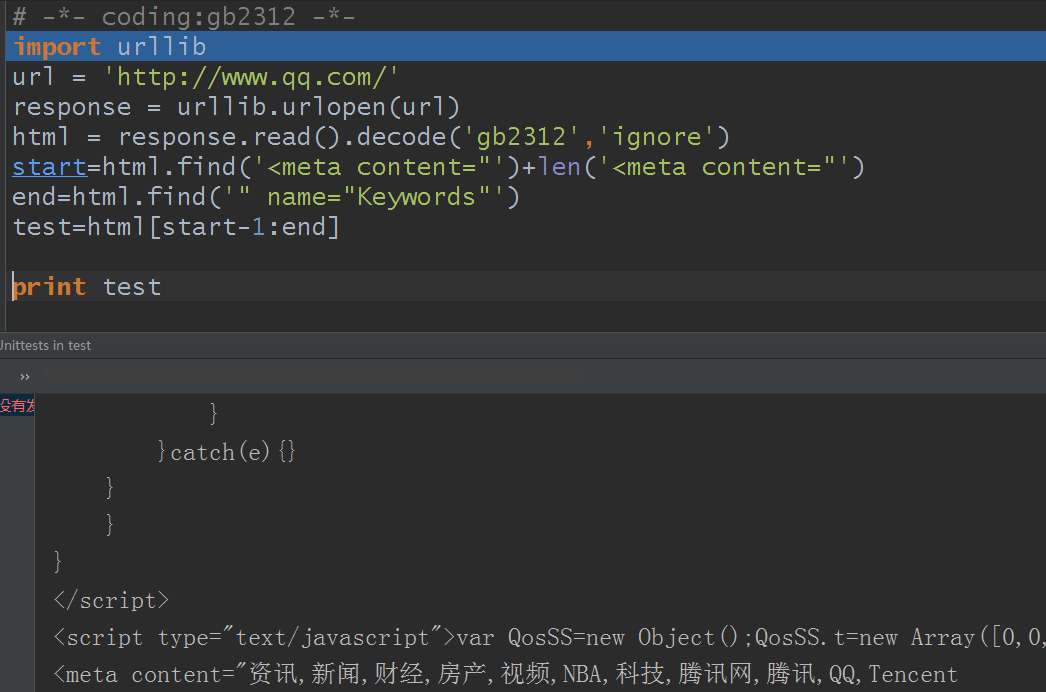
我们打开腾讯网页分析下网页源代码:

发现确实存在两个这样的标签,所以直接从前面的标签就开始截取了,所以并没有达到我们的效果,那你说,我再截取一次就是啊:
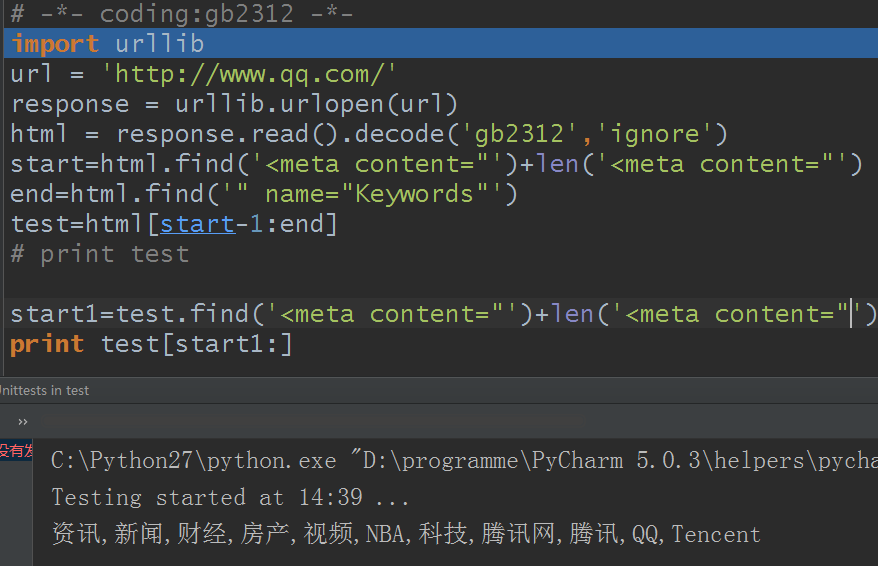
发现确实截取出来了,方法是可以,不过要这么复杂吗?我们只是为了截取一小段数据,那以后截取很多数据怎么办?还是这样吗?肯定费时啊
所以还是按照刚才的想法截取,把目标调试为【<meta content="资】
但发现了一些问题: 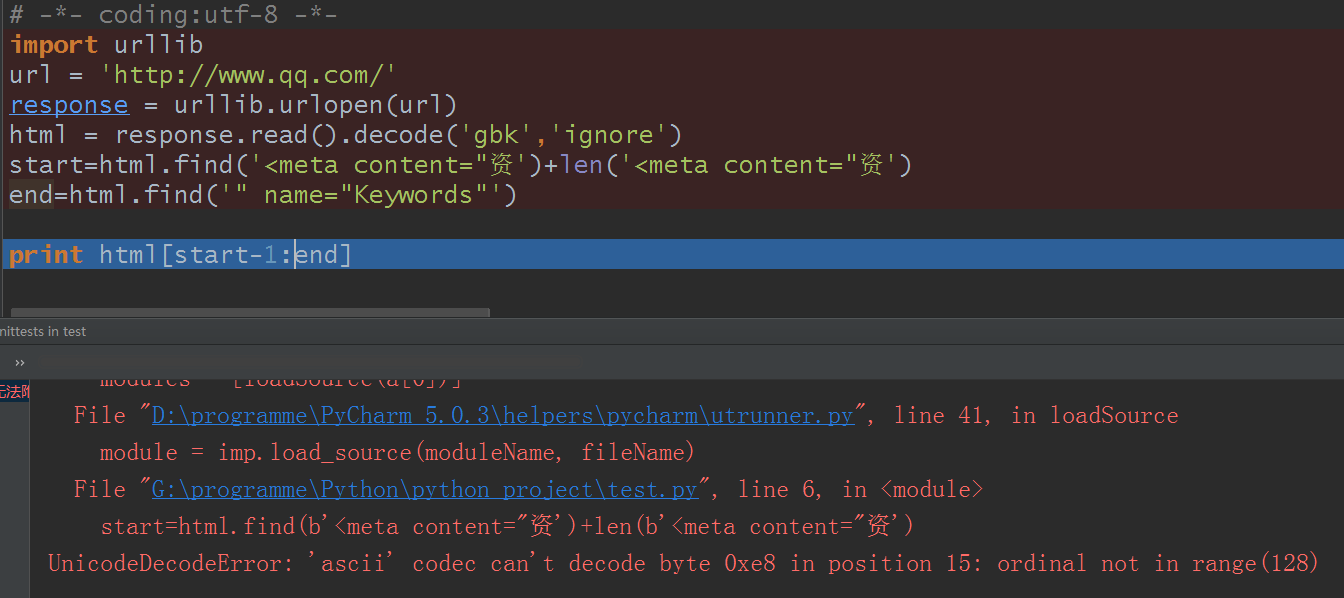
因为出现了中文‘资’,所以开始报错了,这个就麻烦了对吧?去掉就不行啊,那我用刚才的奇招,我的默认编码不对,换成相同的编码,并加入‘ignore’呢?
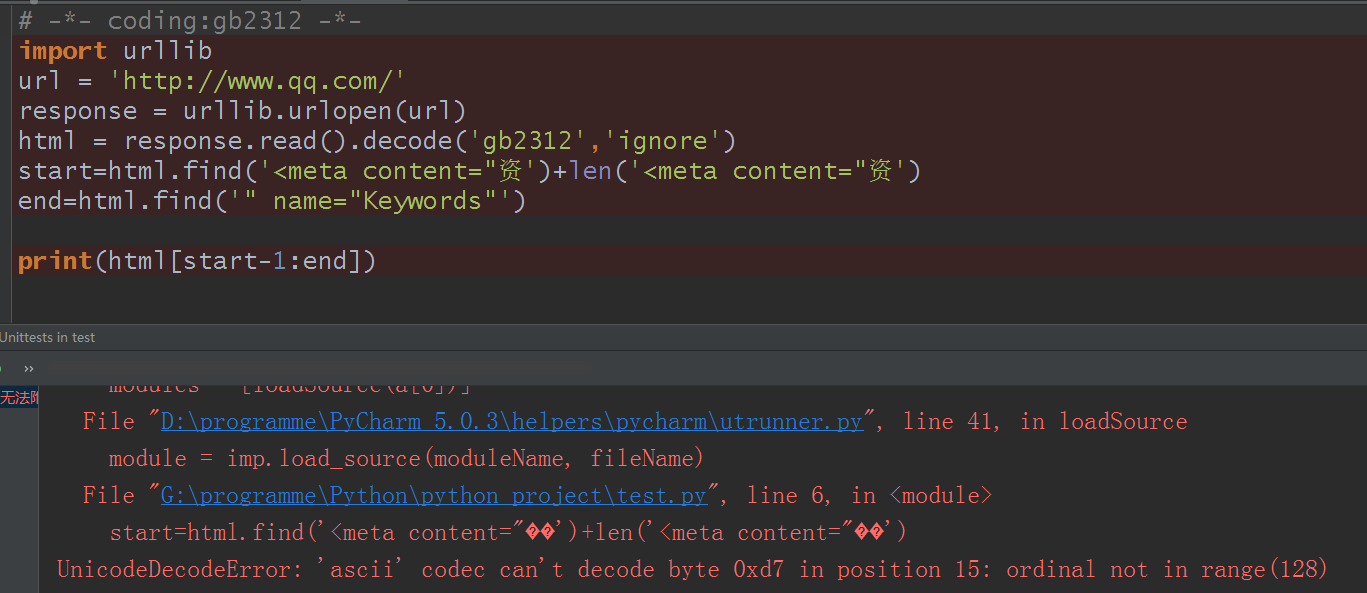
还是不行,还是提示ASCII不能解码byte
我们知道字,在字符前面加入b就可以转为bytes字符集。

既然你说不能解码byte的,我转成byte的看看:
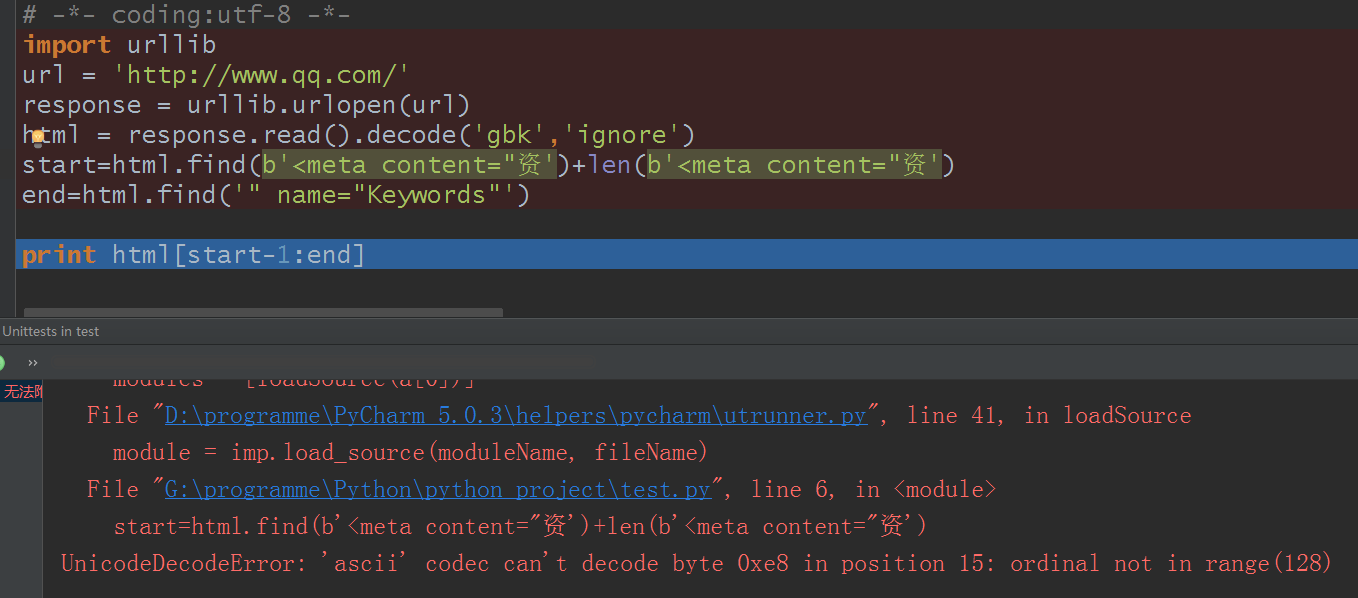
为什么报错,这是初学者很容易犯的错,你已经decode('gbk')了对不对(或者gb2312在这里都一样),那么此时编码就是Unicode了,然后因为你给了默认编码gb2312,这编码不就不统一了对吧?
并且,如果decode之后再次decode是会报错的,encode再次encode也同样(前面提过的)
好的,找到原因了,是不是有点跃跃欲试了,不再decode,直接默认编码和源代码的一样就是啊,对吧?试试看:
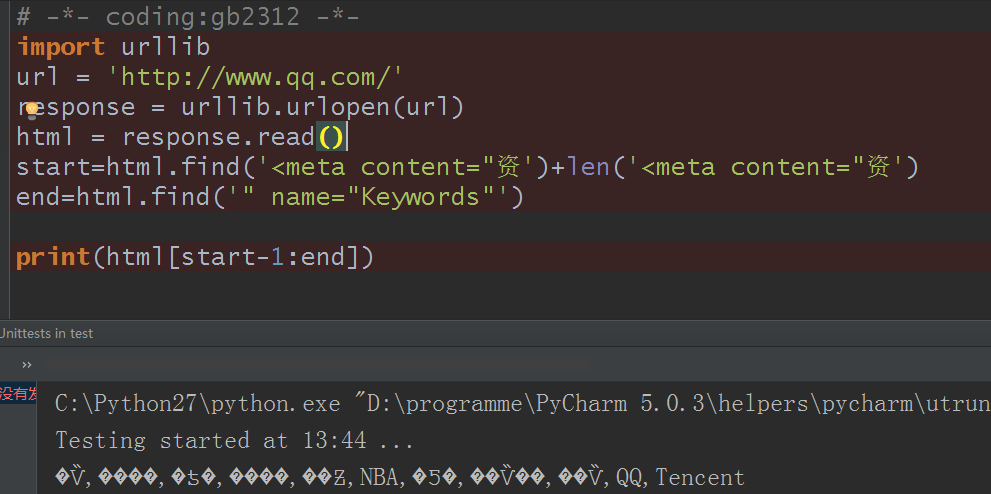
这……,这是啥呀?和我们预期的不一样对不对,英文是显示了,但是中文乱码了,那么还是编码问题,所以,搞半天啊,还是编码问题。
对于以上各种问题,好烦是不是,这时你如果还记得前面做的简单测试话,你应该一拍脑门的说,干嘛不用python3啊,好的,使用python3看看,(因为在python3中,urllib已经是一个包,这里稍微不同,其他主代码是相同的),并且python3默认编码是Unicode,所以必须要decode,不然又会出现不统一编码的问题,之前调试的时候就知道了有其他字符,所以不管了,直接上‘ignore' :

所以在这方面,python3比python2好很多。
总结:
当你遇到报错为:UnicodeDecodeError: 'ascii' codec can't decode byte 0xce in position 0: ordinal not in range(128)
或者出现'\xe6\x88\x91\xe7\x88\xb1\xe9\xb1\xbcC\xe5\xb7\xa5\xe4\xbd\x9c\xe5\xae\xa4时
不要悲伤,不要心急!
烦躁的心情须要镇静
相信吧,想要的结果将会来临
心儿永远向往着编程
现在却常是烦闷
一切都是瞬息
异常都将会过去
而那过去了的
就会成为亲切的怀恋
使用python3
一切问题都不是问题
(改自:普希金—《假如生活欺骗了你》,纯属此时场景借鉴,绝无他意)
免责声明
本博文只是为了分享技术和共同学习为目的,并不出于商业目的和用途,也不希望用于商业用途,特此声明。如果内容中测试的贵站站长有异议,请联系我立即删除



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】