python爬虫 - js逆向之猿人学第十七题http2.0
前言
继续干17题,就是个http2.0协议,有关这个协议的,我之前就出过相关的文章:python爬虫 - 爬虫之针对http2.0的某网站爬取
代码
所以,就不多比比了,直接上代码:
import httpx
headers = {
"authority": "match.yuanrenxue.com",
'cookie': 'sessionid=换成你的sessionid',
"sec-ch-ua-mobile": "?0",
"user-agent": "yuanrenxue.project",
"referer": "https://match.yuanrenxue.com/match/17",
'x-requested-with': 'XMLHttpRequest'
}
def get_page(page=1):
url = f"https://match.yuanrenxue.com/api/match/17?page={page}"
with httpx.Client(headers=headers, http2=True) as client:
response = client.get(url)
result = response.json()
print(2312312, response)
data = result.get('data')
print(12312312, data)
return [d.get('value') for d in data]
def get_data():
end = 0
for i in range(1, 6):
temp_list = get_page(i)
some = sum(temp_list)
end += some
print('end', end)
get_data()
执行结果:
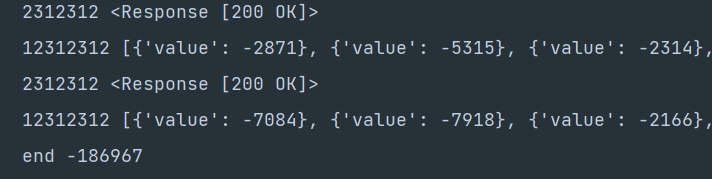
提交:
完毕
结语
知道http2.0的就很简单,不知道的就会怀疑人生

 浙公网安备 33010602011771号
浙公网安备 33010602011771号