python爬虫 - js逆向之svg字体反爬破解
前言
同样的,接上一篇 python爬虫 - js逆向之woff字体反爬破解 ,而且也是同一个站的数据,只是是不同的反爬
网址:
aHR0cDovL3{防查找,删除我,包括花括号}d3dy5kaWFuc{防查找,删除我,包括花括号}GluZy5jb20vcmV2aWV3L{防查找,删除我,包括花括号}zEwMDM1NDgxNjI=
分析
打开网站:

这个根据之前的经验,现在直接找css,找映射关系就行了,所以看右边的css,看到有很多东西,其中有两个比较重要:
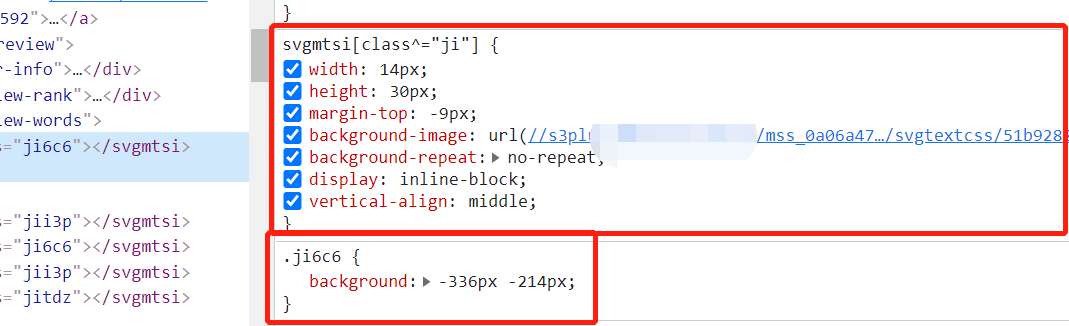
有没有想过,为啥给个ji6c6就能映射成【一】呢?为什么不是其他的,看到上面的background-image的url就很可疑了,打开这个url看看:
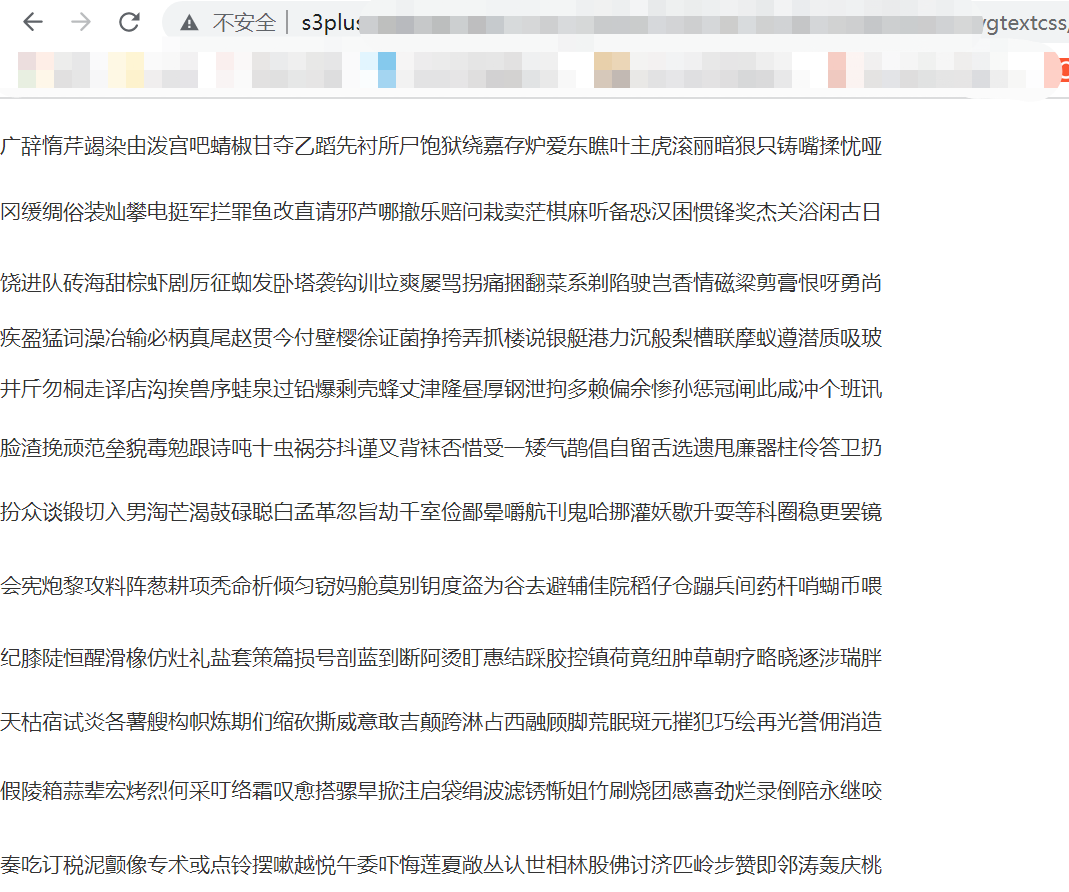
卧槽,这就是一堆字体啊,跟上一篇的woff字体有得一拼了,我猜哈,他就是通过这个的css来控制显示的:
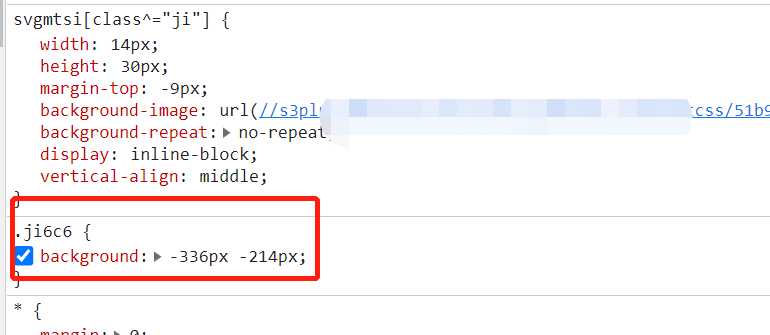
那行,我们随便改个数值看看:
改之前:
改之后,只改了宽度的px,

再改个高度的px看看,我估计随便输入的值哈,所以肯定是对不齐的
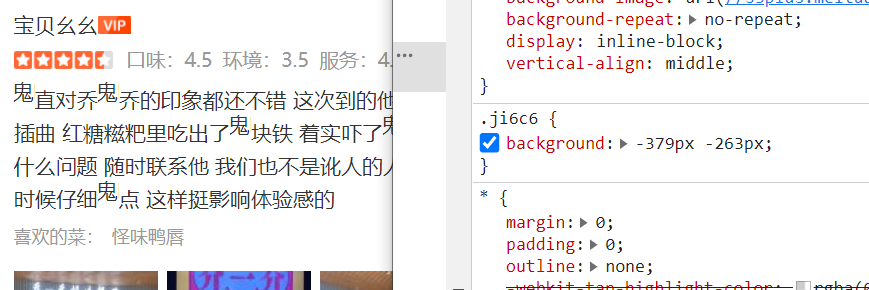
那么,再看下svg源码的文字,

对得上,所以宽度跟高度改来改去,现在能够确定的是,最开始的-336px和-214px,这个负值跟svg的值是相反的,svg是正数,css是负数,这个不重要哈,同时,我们也可以确认下:
用截图工具大概取个值,
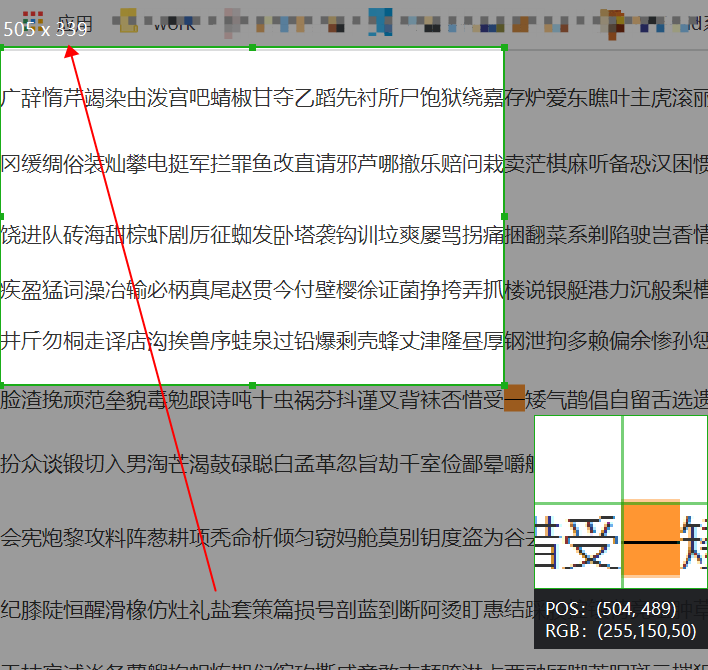
而源码里的是这样的:

感觉有点不一样,不过至少,宽度339px和336px能够约等于上,但是高度对不上,很奇怪了。
没事,再看看哈,把高度的值改为0px看看,改完成这样了

有老哥要问了,改为0px干嘛,现在不是要找高度的规律吗,对啊,要找规律就要看看第一排的px是多少啊,上面的0px显然不对,那么说明第一排的纵坐标的不是从0px,那稍微调下,调成一个与其他内容规整排列的
没过一会儿,就调出一个规整排列的,结果是-13px

再看第二排是多少:57px

第三排:104px

第四排:141px

第五排:175px
第六排:214px
第七排:257px
。。。。
结果发现这些值并没有很大的关联,插值并不是一致的
看来这条路不通,换,再回过头看css:

圈出来的就非常关键了,width为14px,大胆猜测,应该就是一个字体的宽度,高度的话,应该就似乎height加上margin-top的值,极为39px
那行,一个字体占比就是宽度为14,高度39,用这个值再次验证一下,再回过头看这个【一】,

再看,这里数起来,麻烦,直接用python操作了:




ok,又对上了,再随机找个吧,一次两次,万一还是巧合可以,随机再找一个还能对上,那就一定是了:
就找个【是】

140/14=10
1723/39=44.1794...≈ 45
45排有点多,看源码,源码里的y,1723大于上一排的1707,小于这一排的1746,那说明就是这一排了

然后直接说,也刚好是第10个数,ok了。而且这里还看出一个规律,【是】的高度是1723px,在svg源码里:

1746>1723>1707,所以闭着眼睛也知道一定在这一行,那么这里还可以有一个方法,用常用的那几个算法就能很快就能定位在哪一排,然后定位是哪一个字就行了,卧槽,感觉很简单啊
规律找出来了,剩下的就是代码调试了
调试
为了方便调试,就不每操作一次实际请求一次,因为这个平台的风控挺强的,所以直接查看源码,然后把内容保存到本地吧:
流程就是,读取源码,然后先把内容用xpath提取出来,把那些class属性找出来,然后请求拿到css,再通过css内容找到设置的宽度高度,同时把css里的svg的url请求一下,保存到本地,接着通过给定的宽度高度,取svg的原内容找就行了
所有需要i请求的,我都暂时保存在本地了,svg:
同时直接复制css里的内容,手动放到content2.html文件里了,给了一个style标签

python实现
在执行的时候发现,当是42,23673px时,会报错:
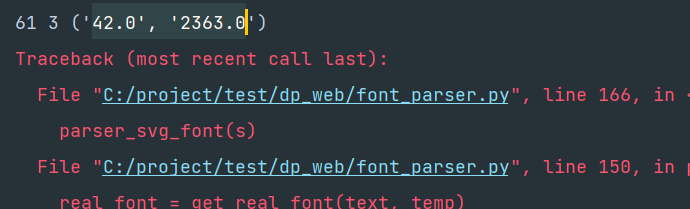
主要是没有那么多的纵向,那看来我们之前用height除以39还是有问题,不能涵盖完整的情况
后面经过我的测试,发现以下规律:
1.高度除以39,结果如果不超过svg总排数的,减去一个通用值(假设为2),即为真实纵向位置
2.高度除以39,结果如果超过svg总排数的,如果值小于【总排数加通用值(假设为2)】,先减去一个通用值(假设为2)之后,如果这个值结果带有小数,再四舍五入,如果结果没有超过总排数,不用四舍五入,直接取整,即为真实纵向位置
3.高度除以39,结果如果超过svg总排数的,如果值大于【总排数加通用值(假设为2)】,直接按最后一排的数作为真实纵向位置
也可能这套规律并不通用,至少目前来看没有问题
我过了2天,再次打开这个网址,然后看到变了,源码变得如下:

然后svg源码也变了:
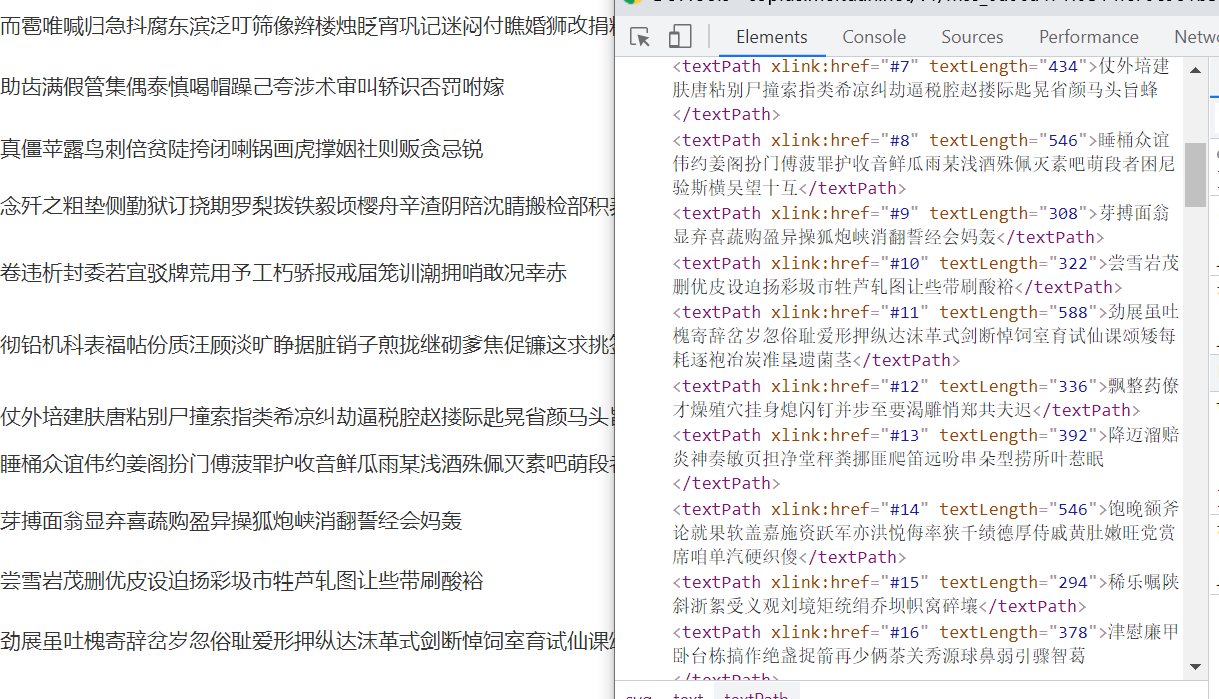
那这种,就没法用二分法了,所i有,上面想到的思路,并不通用,那咋办呢?这有点难为人了哈
但是,仔细发现,上面发现的规律还是可以通用的
只是二分法不通用了,来,继续看【一】,此时是【-126px -2737px】
126/14=9
2737/39=70.179.....
先找到70行,然后减2,得68,找第九个:

看是不是第9个,没毛病:

看来,在svg的总排数以前的,都可以这么算,现在找一个纵向相对比较大的:
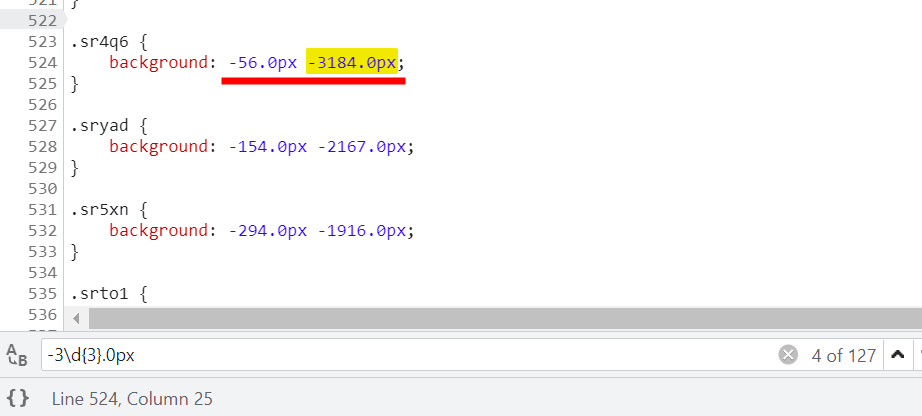
56/14=4
3184/39=81.641
此时,81.641<80+2,那就直接减2得79,然后小数位四舍五入,得80,找80行第4个:


就看是不是真的是这个【粉】字了,拿到刚才得class名【sr4q6】,到网页里覆盖即可:

果然变成了【粉】字

再来确认上面的规律的第三种情况,找个总值大于80+2的试试,发现,此时的css里没有,那就姑且这么认定了,直接写代码吧
同时更新下css和svg,以及html源码
此时,纵向的发现没毛病了,但是发现横向的又出现问题了,比如 -462.0px -1470.0px
462/14= 33
1470/39 = 37.69
按上面的逻辑,应该是33,35,但是一找发现报错:

看来横向也不能直接一昧的除14啊,看看这个本来应该是啥字:

把【sr7u9】换上去看看,变成了【谁】字
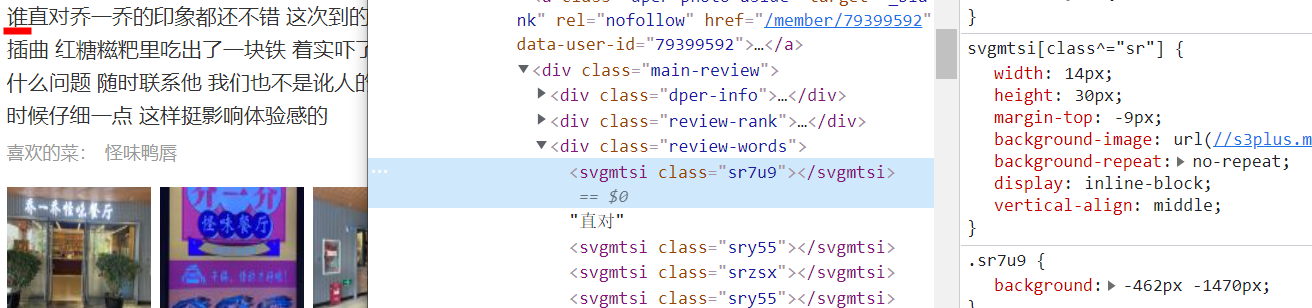
看看svg里【谁】:


卧槽,越来越迷糊了,这到底咋回事,接着再看,看横向坐标都大于等于400的看看:
找到这么多:
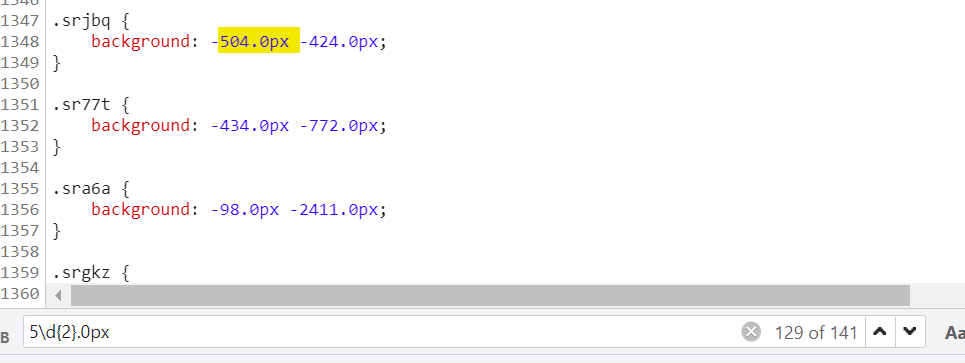
一个一个看,不信找不到规律:
看【srjbq】,-504.0px -424.0px
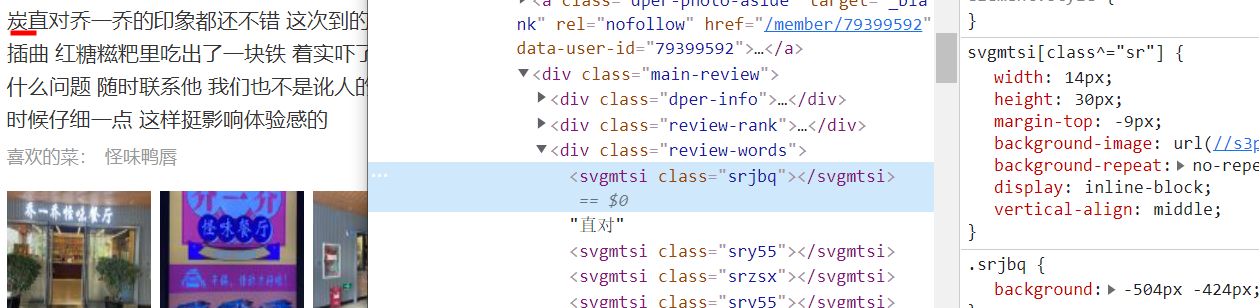
本来是
36 10.89
但这里取得是36 11
sr4qu -504.0px -2841.0px
算出是36,72.84 ==> 36,70
实际是36,71
sr5lf {
background: -518.0px -1324.0px
算出37 33.98 ==>33 31
实际37,33
.srwcf {
background: -532.0px -662.0px
算出 38 16.97 ==> 38 14
实际 38 17
.srqrx {
background: -546.0px -2841.0px
算出 39 72.84
实际 39 71
.srauc {
background: -546.0px -14.0px
算出 39 0.35
实际 39 1
.srkfy {
background: -532.0px -741.0px
算出 38 19
实际 38 19
.sr7k0 {
background: -504.0px -772.0px
算出 36 19.79
实际 36 20
当我在找规律的时候,我无意间又打开一个标签:
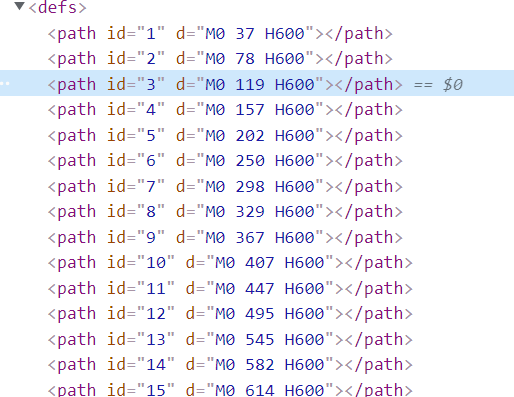
哎~,这他妈,看属性d的中间个数,嘿嘿,看来还是可以用二分法查找,ok,不再傻逼的找规律了,直接用算法,二分查找,或者冒泡的都可以,我这里就不耽误时间了,已经花了好几天时间分析了,不能再拖了,我就写个了最容易想的冒泡排序,也不考虑运行时间了,搞爬虫的,不用太纠结这些东西。
ok,代码:
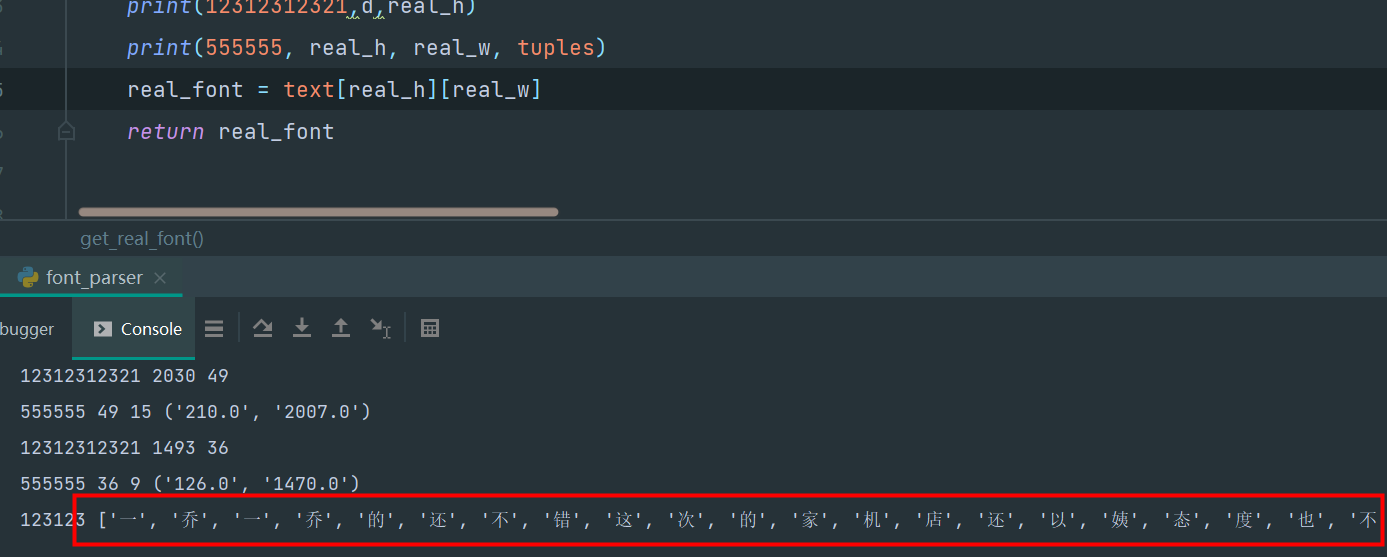
至少现在没报错了,而且对了下都对上了,
还是这个靠谱点,上面总结的规律还是不能完美覆盖问题,就以上这样才是最好的,
行,现在就差最后一个问题,就是文字的顺序,看如下哈,没有做svg的,文字就在外层,有做文字加密的未加密的并列,那这个顺寻就有点不好操作了
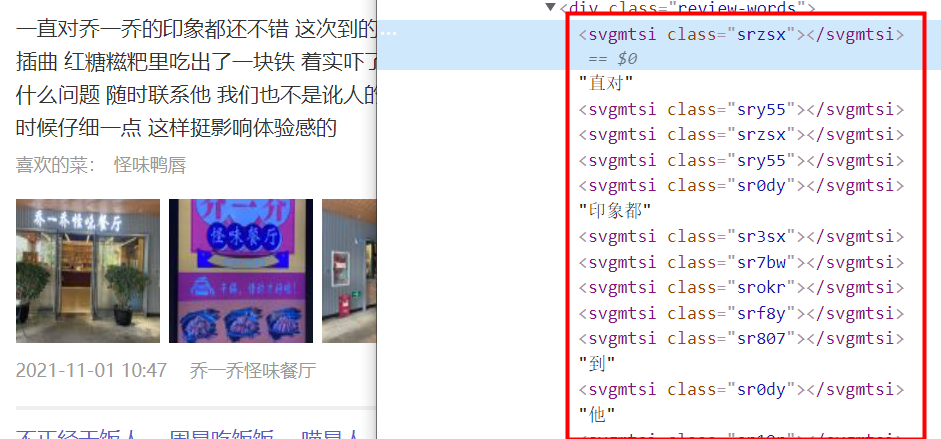
再看当我直接用xpath的text时,是如下,所以,这个顺序还真不好处理
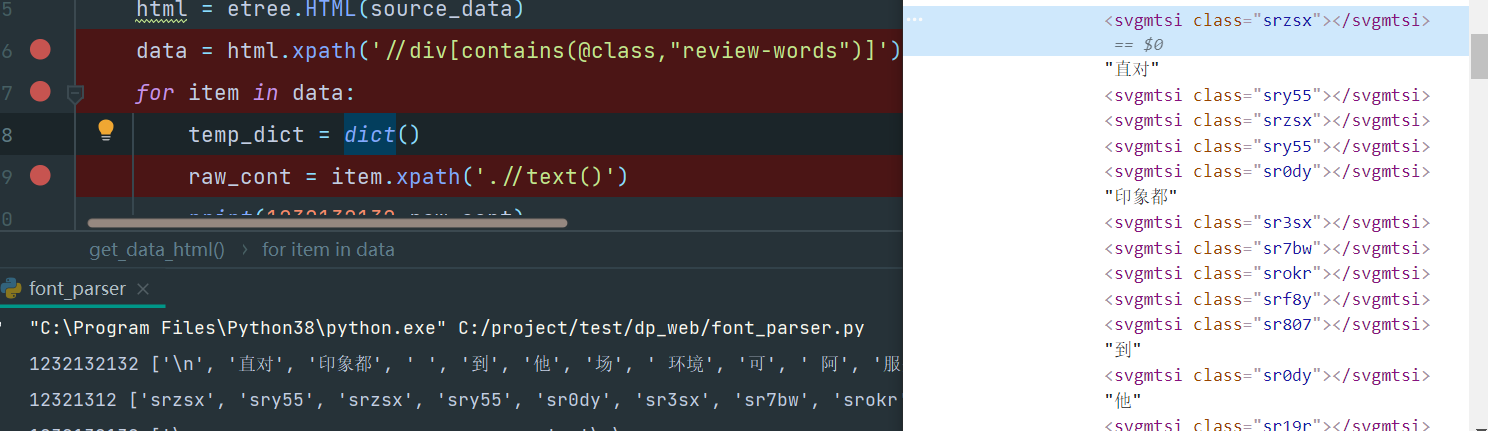
咋办,直接字符串替换吧
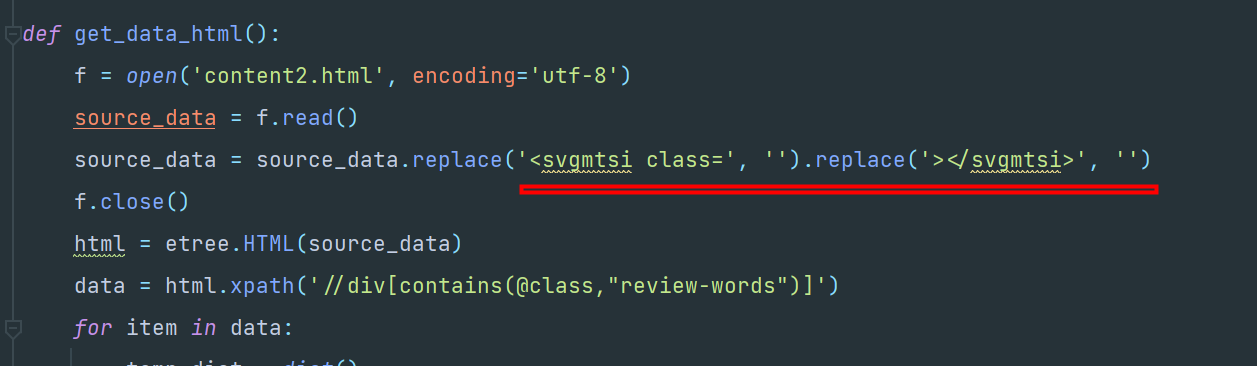
执行:
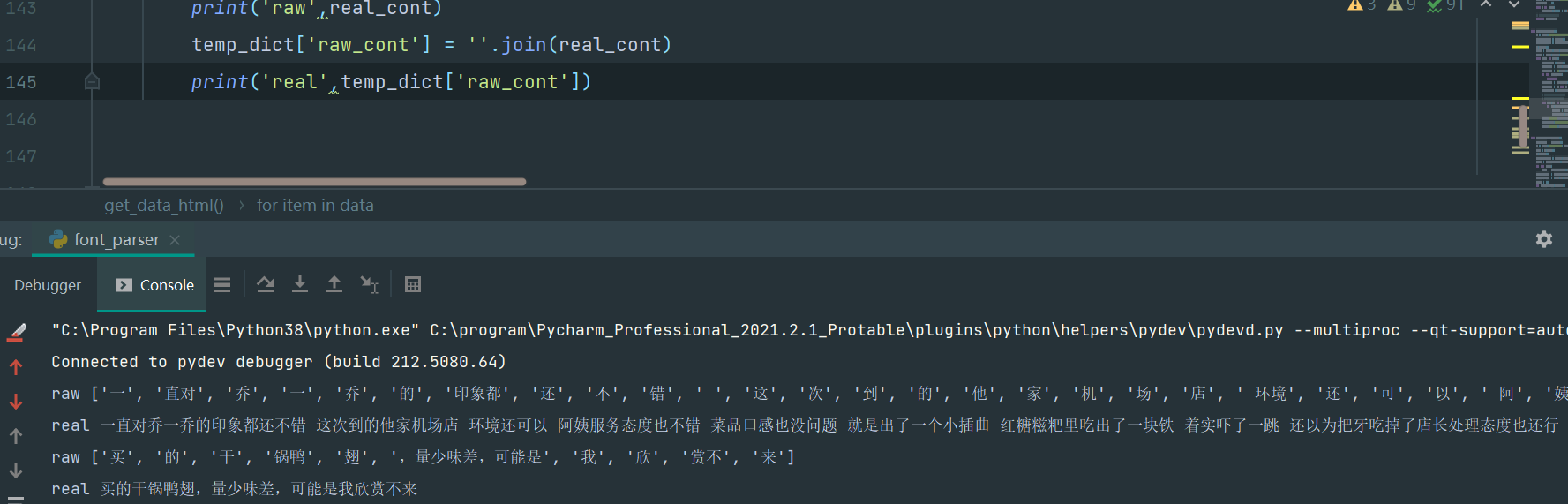
看第一条:
一直对乔一乔的印象都还不错 这次到的他家机场店 环境还可以 阿姨服务态度也不错 菜品口感也没问题 就是出了一个小插曲 红糖糍粑里吃出了一块铁 着实吓了一跳 还以为把牙吃掉了店长处理态度也还行 给菜品打了个8折 说事后牙有什么问题 随时联系他 我们也不是讹人的人 小问题也不去麻烦商家了 温馨提示一下估计这个铁的问题应该还存在 进货的时候仔细一点 这样挺影响体验感的
原文内容,完美对上,emoji图的问题暂不考虑,就是一个静态资源,想拼凑一下就是很简单的问题

部分python代码
content2.html和css.txt,svg.html,自行下载

def get_real_height(text, raw_height):
# 这个函数已经弃用,得到的结果不精准
length = len(text)
temp_h = raw_height / 39
if temp_h > length + 2: # 大于总排数+2
height = length
elif temp_h > length: # 大于总排数,小于总排数+2
height = length - 2
height = int(round(height, 0)) # 四舍五入
else: # 小于总排数
height = raw_height // 39
return height
def get_real_font(text, text_index, tuples=None):
if not tuples:
tuples = ('336.0', '214.0')
width, height = tuples
width = int(float(width))
height = int(float(height))
real_w = int(width / 14)
d, real_h = get_real_height_v2(text_index, height)
# print(12312312321, d, real_h)
# print(555555, real_h, real_w, tuples)
real_font = text[real_h][real_w]
return real_font
def get_css():
f = open('css.txt', encoding='utf-8')
source_data = f.read()
f.close()
cont = re.findall(r'\.(\w+) \{.*?background: -(.*?)px -(.*?)px;', source_data, re.S | re.M)
css_dict = {}
for c in cont:
css_dict[c[0]] = c[1:]
# print(css_dict)
return css_dict
def get_data_html():
css_dict = get_css()
f = open('svg.html', encoding='utf-8')
svg = f.read()
f.close()
html_source = etree.HTML(svg)
text = html_source.xpath('//text[position()>1]/text()')
if not text:
text = html_source.xpath('//textpath/text()')
text_index = html_source.xpath('//defs/path/@d')
text_index = [int(te.split(' ')[1]) for te in text_index]
f = open('content2.html', encoding='utf-8')
source_data = f.read()
source_data = source_data.replace('<svgmtsi class=', '').replace('></svgmtsi>', '')
f.close()
html_source2 = etree.HTML(source_data)
data = html_source2.xpath('//div[contains(@class,"review-words")]')
for item in data:
temp_dict = dict()
raw_cont = item.xpath('.//text()')
raw_cont = ''.join(raw_cont).strip() if raw_cont else ''
if not raw_cont:
continue
raw_cont = raw_cont.split('"')
raw_cont = [t for t in raw_cont if t]
real_cont = raw_cont[:]
# print(real_cont)
# print(raw_cont)
for ind, ra in enumerate(raw_cont):
if ra.startswith('sr'):
real_c = parser_svg_font(ra, css_dict, text, text_index)
real_cont[ind] = real_c
print('raw', real_cont)
temp_dict['raw_cont'] = ''.join(real_cont)
print('real', temp_dict['raw_cont'])
def parser_svg_font(s, css_dict, text, text_index):
cont = []
if isinstance(s, list):
cont = []
for i in s:
temp = css_dict.get(i)
real_font = get_real_font(text, text_index, temp)
# print(real_font)
cont.append(real_font)
elif isinstance(s, str):
temp = css_dict.get(s)
cont = get_real_font(text, text_index, temp)
# print(123123, cont)
return cont
def get_real_height_v2(data_list, target):
"""
:param data_list: 传入的有序列表
:param target: 传入要查找的目标值
"""
# data_list默认已排好序
if target in data_list:
return data_list.index(target)
for index, d in enumerate(data_list):
if d > target:
if index == 0:
return d, index
else:
if data_list[index - 1] < target:
return d, index
get_data_html()
然后有没有可优化的地步,那肯定有的,那个处理svg部分的映射关系,和横向坐标除以14,然后判断svg的classa是否是sr开头的,计算映射真实文字的函数,等等,很多都可以优化的,具体细节就不去抠了,核心的逻辑能实现,剩下的就是完善优化了。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】