python爬虫 - js逆向之woff字体反爬破解
前言
本篇博文的主题就是处理字体反爬的,其实这种网上已经很多了,那为什么我还要写呢?因为无聊啊,最近是真没啥事,并且我看了下,还是有点难度的,然后这个字体反爬系列会出两到三篇博文,针对市面上主流的字体反爬,一一讲清楚
不多bb,先看目标站
aHR0cDo{防查找,删除我,包括花括号}vL3d3dy5kaWFucGluZy5jb20vbW{防查找,删除我,包括花括号}VtYmVyLzc5Mzk5NTky{防查找,删除我,包括花括号}L3Jldmlld3M=
分析
打开网站,如下:
发现,地址在源码里不显示

再看下面的文字,网页源码里面也没有正常显示

这种就很秀了啊,对于没搞过字体反爬的朋友来说,估计就迷糊了,不用怕,跟着我的思路来
先看地址栏,点下那个标签,看右边的css样式(对这个不理解的,看看html前端基础吧,最多一周就懂了),或者看看我的之前的博文,https://www.cnblogs.com/Eeyhan/category/1339041.html

在看下面的内容:

这种啥意思呢,首先哈,看到这种源码里面看不到的,那一定是在css样式里,用的@font-face自定义的字体,所以,上面圈出来的两个css就很重要了,点进去看看,点这个

进去之后,格式化一下,然后就看到如下:
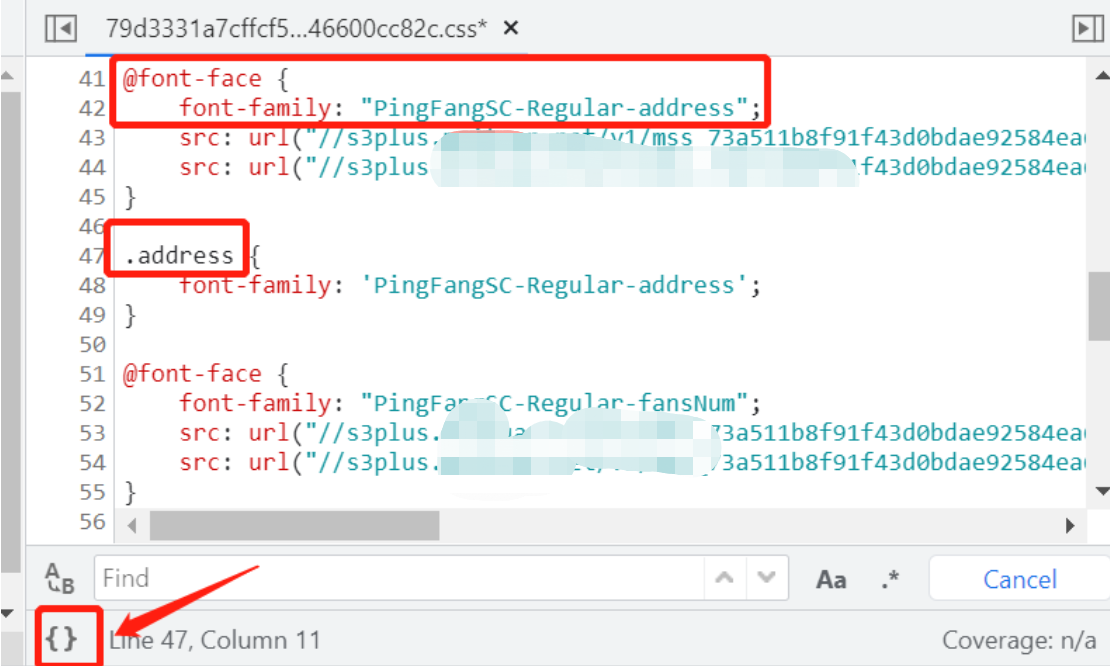
果然有个@font-face,就看这个后面的url引入了啥样式的字体文件,往后面拉下滚动条,果然看到一个woff的字体文件
补充一下,字体文件格式有哪几种呢?常见的有woff,svg,ttf,其他的就不细说了,好的,先把这个字体下载下来,复制链接浏览器打开直接下载,不用补齐http协议直接下载:

这个字体先放着,目前这个是地址相关的,再看内容的字体文件,同样的方式点击那个css,进入里面把链接复制出来下载:
因为我之前分析的时候已经下载过了,所以,文件名会有个(1)。
好的,这两个字体文件,梳理一下,f76的是地址的,924的是内容的,这种文件怎么打开呢?用这个地址:点我 ,(百度的在线字体编辑器网址已经打不开了,另外找的一个)在线打开:
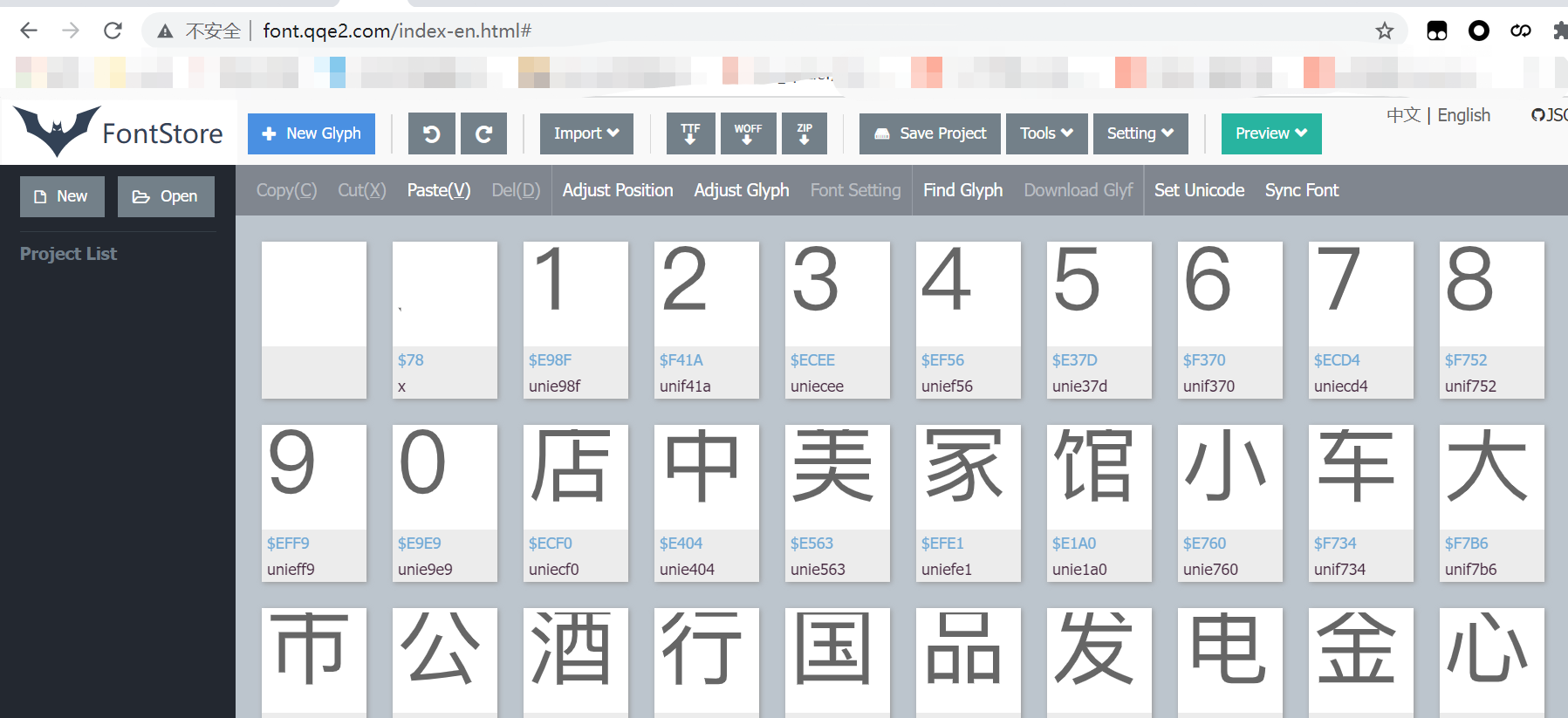
当然你也可以用fontcreator软件打开:
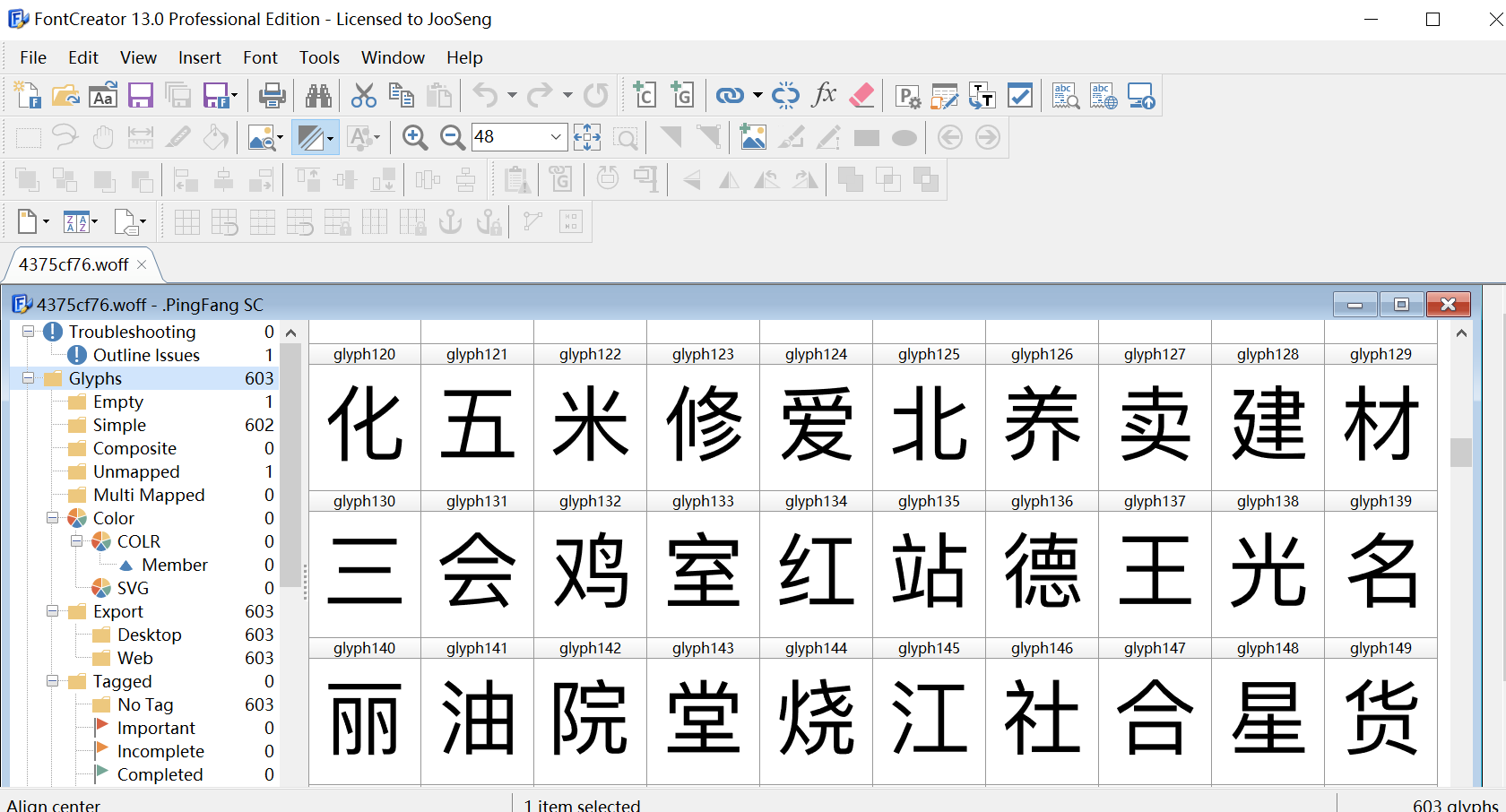
果然哈,这里面就是定义好的字体了,而可以看到,这种有编码,有实际字体的,只要找到映射关系,就可以把我们要的内容给映射出来了,那么,我们怎么去找映射关系呢?
先看看规律哈,提前说下,这里直接是中文字,而不是网上有些老哥针对字体反爬讲解的数字,然后找到映射关系之后减2哈,所以还是要自己去找那套映射逻辑
怎么找?直接用一个字来看吧,就找这个【广】字
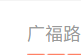
先看网页源码里这个广是啥编码,好的,,先放一放
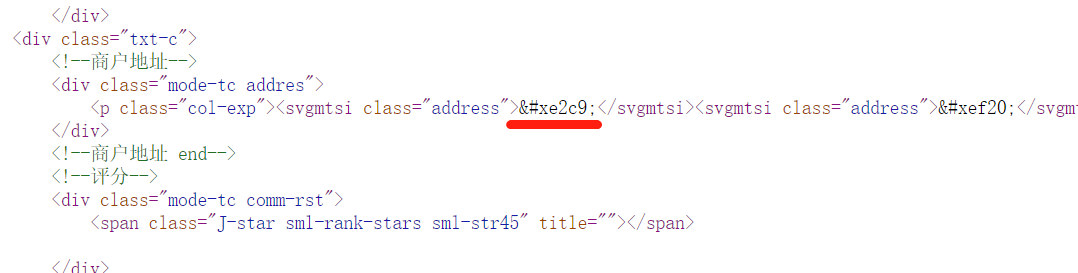
看这边woff字体里这个广是啥
在线网站看到的,还好,第一页就有,是unie2c9
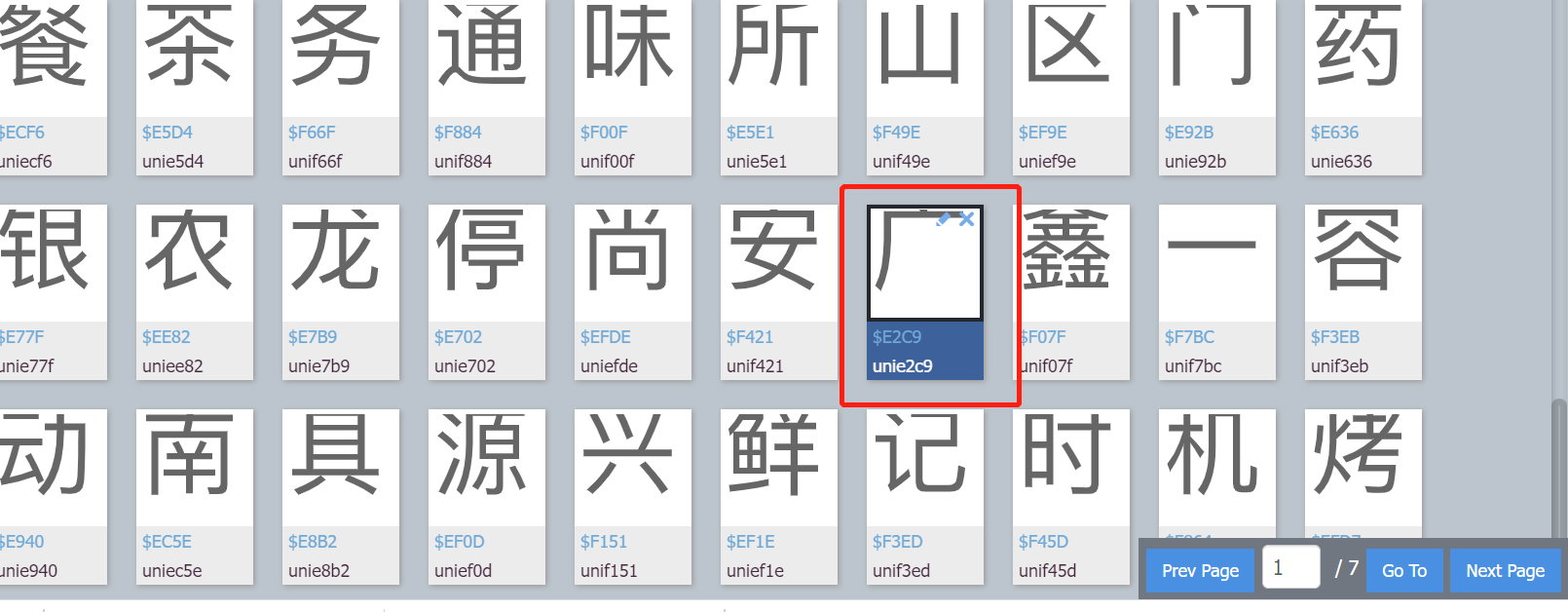
unie2c9跟,好像有点像,先不急,看下,fontCreator软件里是啥:

看着有点不一样哈,这不重要,接下来,我们用python的库看看,python里有一个大佬写好的字体映射文件库,fontTools(自己用pip安装,不多介绍了)

打印结果如下,然后它生成了一个font的xml文件,打开看看:

里面有两个关键的节点就是GlyphOrder和cmap,而这两个,刚才的代码里已经打印出来了,结果:

那行,我们找下这个【广】在哪,搜从在线字体文件编辑网里拿到的unie2c9,发现有两个:
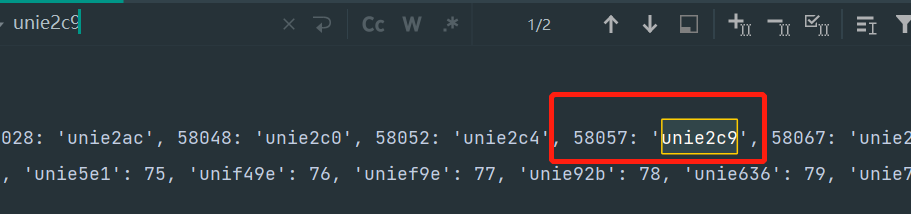

哪个才是呢?再搜下,字体文件拿到的glyph86,发现没有
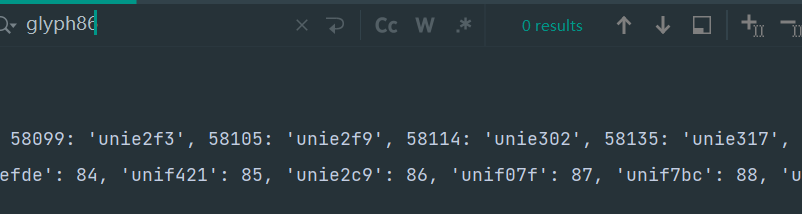
但是,目前感觉有点联系, --- unie2c9 --- 86
这种是啥呀,就不多说了,unie2c9前面的uni就是unicode编码的意思,姑且认定为【 = unie2c9】,那86啥,怎么映射出【广】字的,大胆猜测,这个86就是索引位置,在那个woff文件里数一下,看是不是第86个,先看这个,一行是10个,然后第一行是没有任何编码的,所以第一行只有9个,

往下数,数到第8行倒数第四个,也就是87,但是第一行只有9个,那就是86了
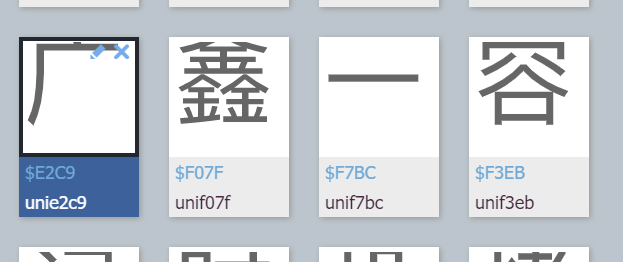
哈哈哈,刚好对上,那现在就说得通了,那我们先拿到源码,然后去找映射关系,找到索引位置,再从索引位置里找到真实的文字内容就行了。
但有个很繁琐的,这些实际的文字内容,我们要一个一个的手写映射关系(哭了),没法啊,找好之后,写成一个json,然后load吧
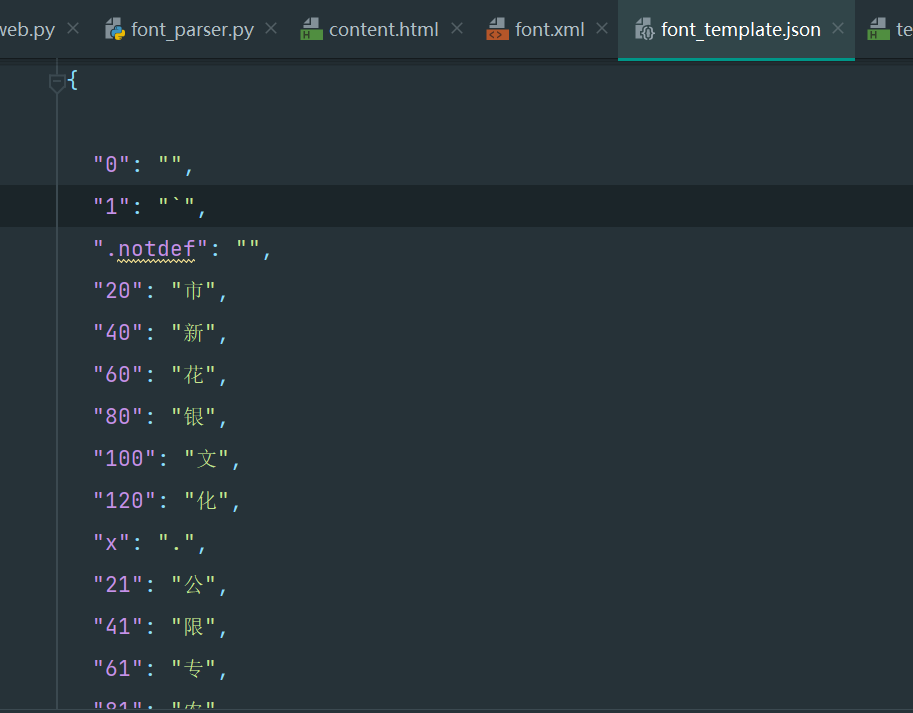
调试
先把刚才打开网页源码,直接copy到本地保存成html文件测试吧,免得一改什么就请求下,因为这个站的风控还挺强的
废话不多说,直接处理保存在本地的html,然后我只打印了地址信息
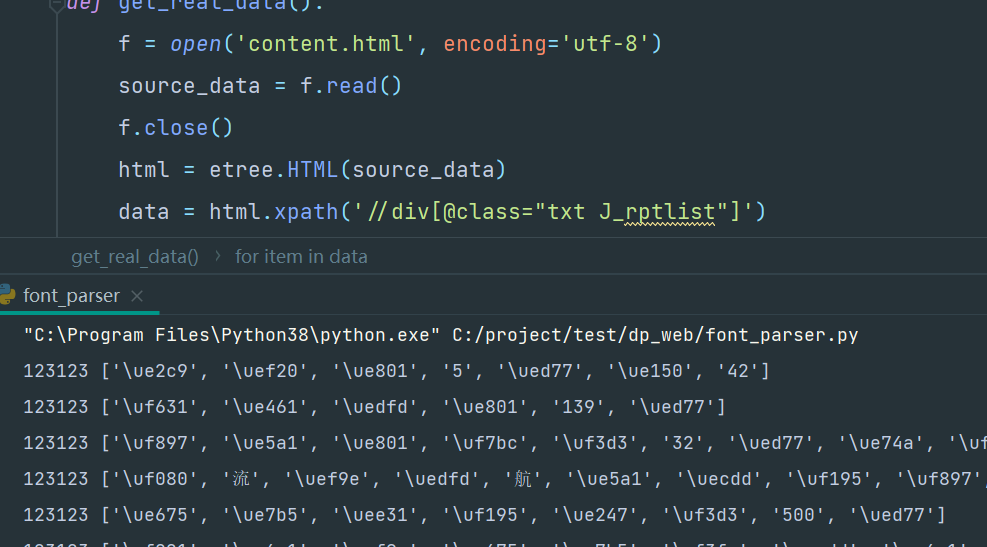
感觉跟在源码里看到的&#开头的有点不一样,好像给处理成了【\u】,先看看能不能处理吧:
复制一个['\ue2c9', '\uef20', '\ue801', '5', '\ued77', '\ue150', '42'],拿来处理下,
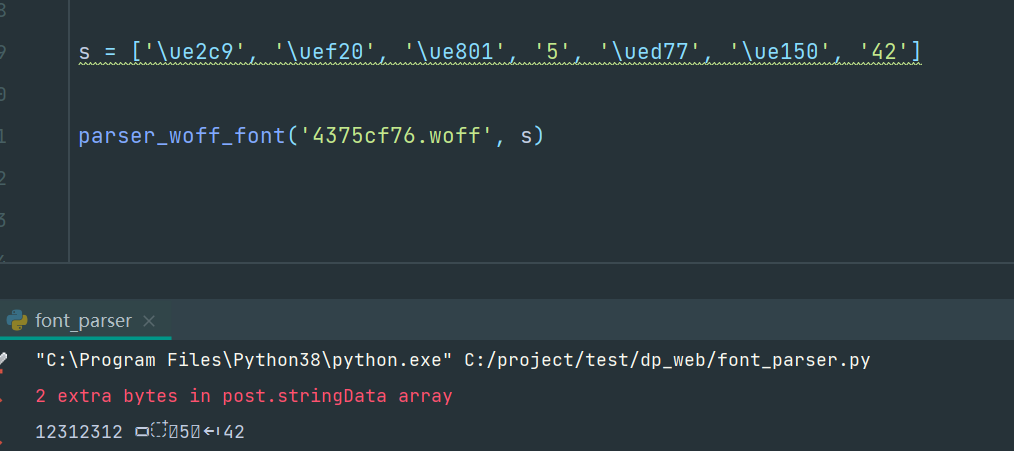
卧槽,这咋回事,打断点一看,这个参数并不是我们预期的,
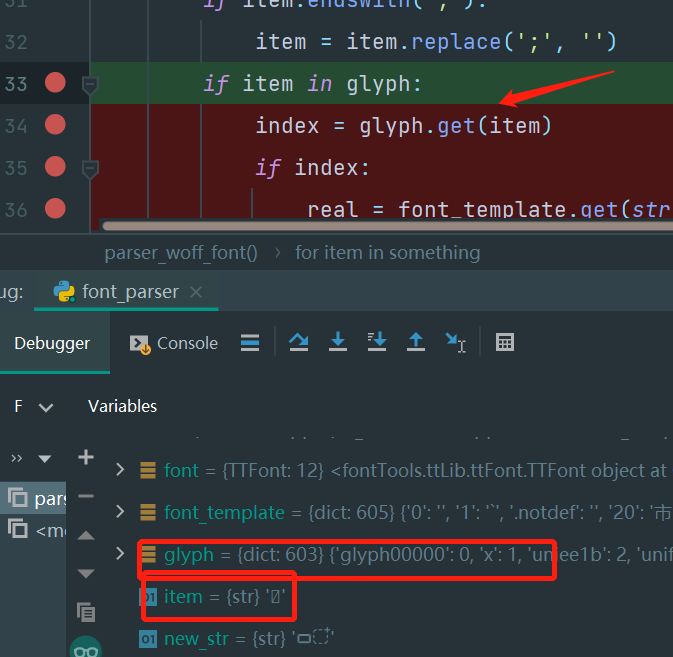
那多半就是那个被转义成【\u】的问题了,那我们直接在读取内容的时候,直接就替换一下:
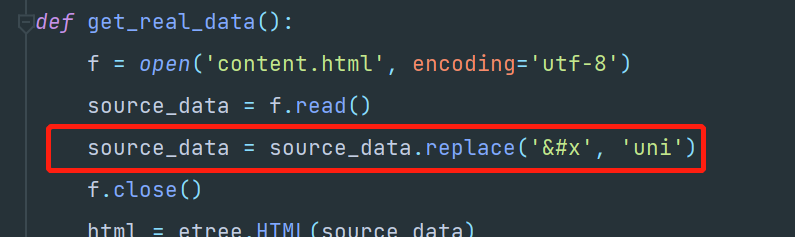
执行下:
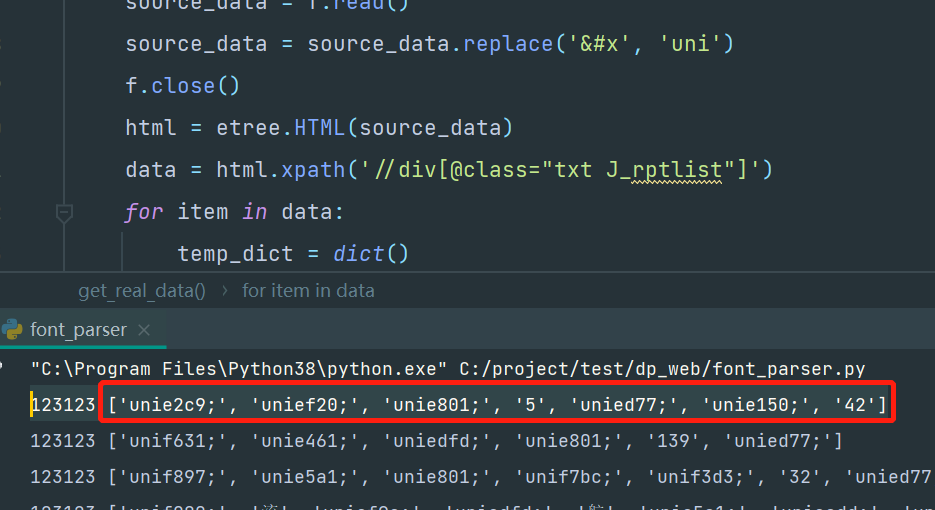
然后同样的,拿第一个来处理:
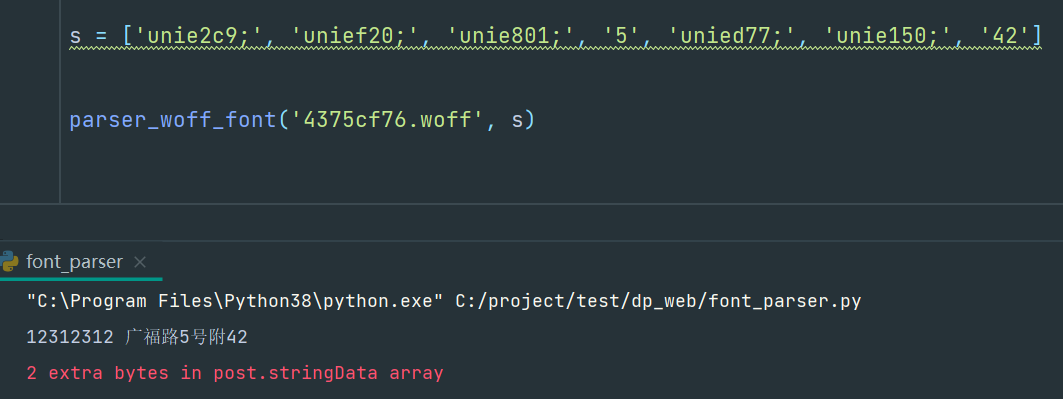
完美,跟原网站的数据对上

接着再处理内容的,这个内容原理一样,只是把woff文件替换下即可
打印下内容的:
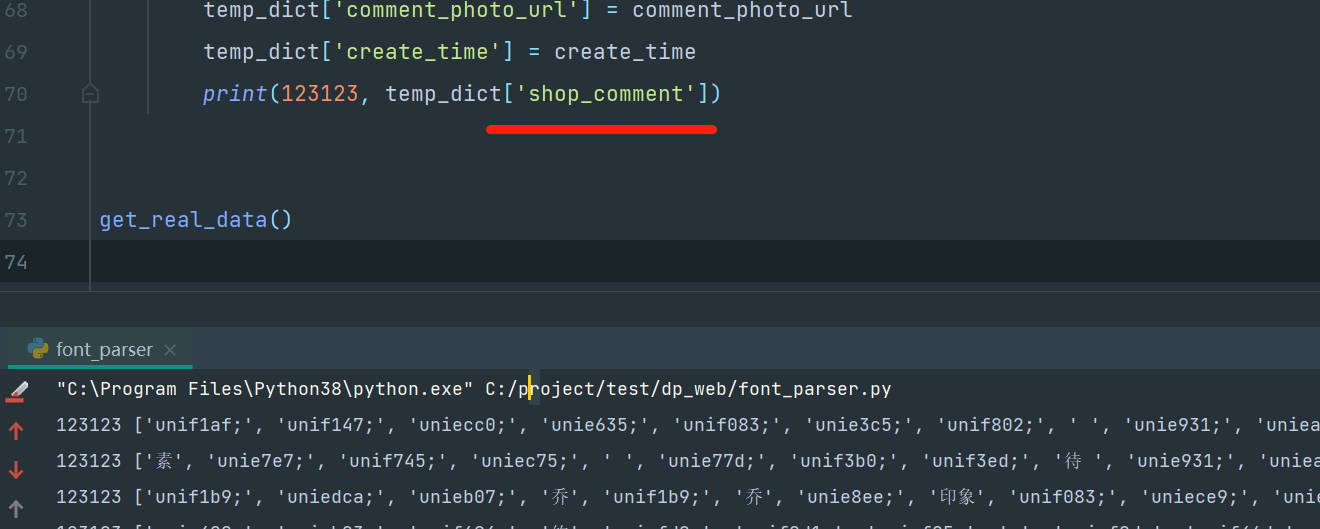
选第一个,然后执行:

对比原网站:

然后,有朋友要问了,那后面的emoji怎么没有搞出来,看看源码哈:
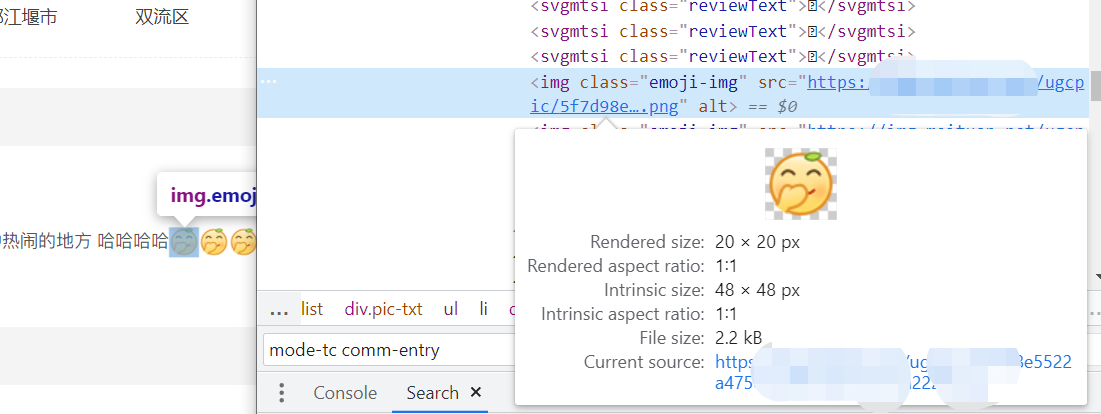
这个emoji,是个图片资源,你要处理肯定是可以的,拼接一下就可以了
python实现
提一句,那两个字体文件经过我的发现,是会不定期变的,所以你需要去请求源码,用正则匹配指定位置,然后请求css文件,再去把woff文件url匹配出来,单独请求,下载下来,接着完成后续的工作即可
最后用python完整实现,完整的代码就不贴出来了,后续的都是一些常规且简单的操作了,再一个就是,我根本就没写完整的代码(哈哈哈哈哈),只贴出部分:
from fontTools.ttLib import TTFont
import re
import requests
from lxml import etree
import json
def parser_woff_font(font='4375cf76.woff', something=None):
font = TTFont(font)
glyph = font.getReverseGlyphMap()
f = open('font_template.json', encoding='utf-8')
font_template = json.load(f)
f.close()
new_str = ''
for item in something:
if not item:
continue
if item.endswith(';'):
item = item.replace(';', '')
if item in glyph:
index = glyph.get(item)
if index:
real = font_template.get(str(index))
if real:
new_str += real
else:
new_str += item
print(12312312, new_str)
return new_str
def get_real_data():
f = open('content.html', encoding='utf-8')
source_data = f.read()
source_data = source_data.replace('&#x', 'uni')
f.close()
html = etree.HTML(source_data)
data = html.xpath('//div[@class="txt J_rptlist"]')
for item in data:
temp_dict = dict()
shop_name = item.xpath('./div[1]/h6//text()')
shop_addr = item.xpath('.//div[@class="mode-tc addres"]/p//text()')
shop_score = item.xpath('.//div[@class="mode-tc comm-rst"]/span/@class')
shop_comment = item.xpath('.//div[@class="mode-tc comm-entry"]//text()')
comment_photo_url = item.xpath('.//div[@class="mode-tc comm-photo"]/a/@href')
comment_photo_url = ''.join(comment_photo_url) if comment_photo_url else ''
create_time = item.xpath('.//div[@class="mode-tc info"]/span[1]/text()')
create_time = ''.join(create_time) if create_time else ''
if create_time:
create_time = create_time.replace('发表于', '')
temp_dict['shop_name'] = shop_name
temp_dict['shop_addr'] = shop_addr
temp_dict['shop_score'] = shop_score
temp_dict['shop_comment'] = shop_comment
temp_dict['comment_photo_url'] = comment_photo_url
temp_dict['create_time'] = create_time
print(123123, temp_dict['shop_comment'])
# get_real_data()
s = ['unif1af;', 'unif147;', 'uniecc0;', 'unie635;', 'unif083;', 'unie3c5;', 'unif802;', ' ', 'unie931;', 'uniea55;', 'unif534;', 'unied79;', 'unie1bd;', ' ', 'unie1e4;', 'unie7b0;', 'unie65d;', 'unif534;', 'unie3c5;', 'unie66f;', 'unif52d;', ' ', 'unif765;', 'unif49d;', 'unieb19;', 'unie2de;', 'unie66f;', '闹', 'unie8ee;', 'unie3a4;', 'unif759;', ' ', 'unif195;', 'unif195;', 'unif195;', 'unif195;']
parser_woff_font('2f66e924.woff', s)
那个映射的font_template.json文件,点我
说明一下,这个json映射关系是只针对这一个站,并不通用网上所有的字体反爬哈,而且,这个站的映射,说不定以后还会改变,所以,你懂我意思吧

 浙公网安备 33010602011771号
浙公网安备 33010602011771号