python爬虫 - js逆向之猿人学第三题请求顺序验证+请求头验证
前言
继续猿人学的题
分析
打开网站:

直接翻页找接口

根据之前题的分析得知,肯定也是3和3?page=xx的是数据接口了,那么看下这个接口里的请求参数,发现就一个get请求,也没有请求参数,只有一个cookie
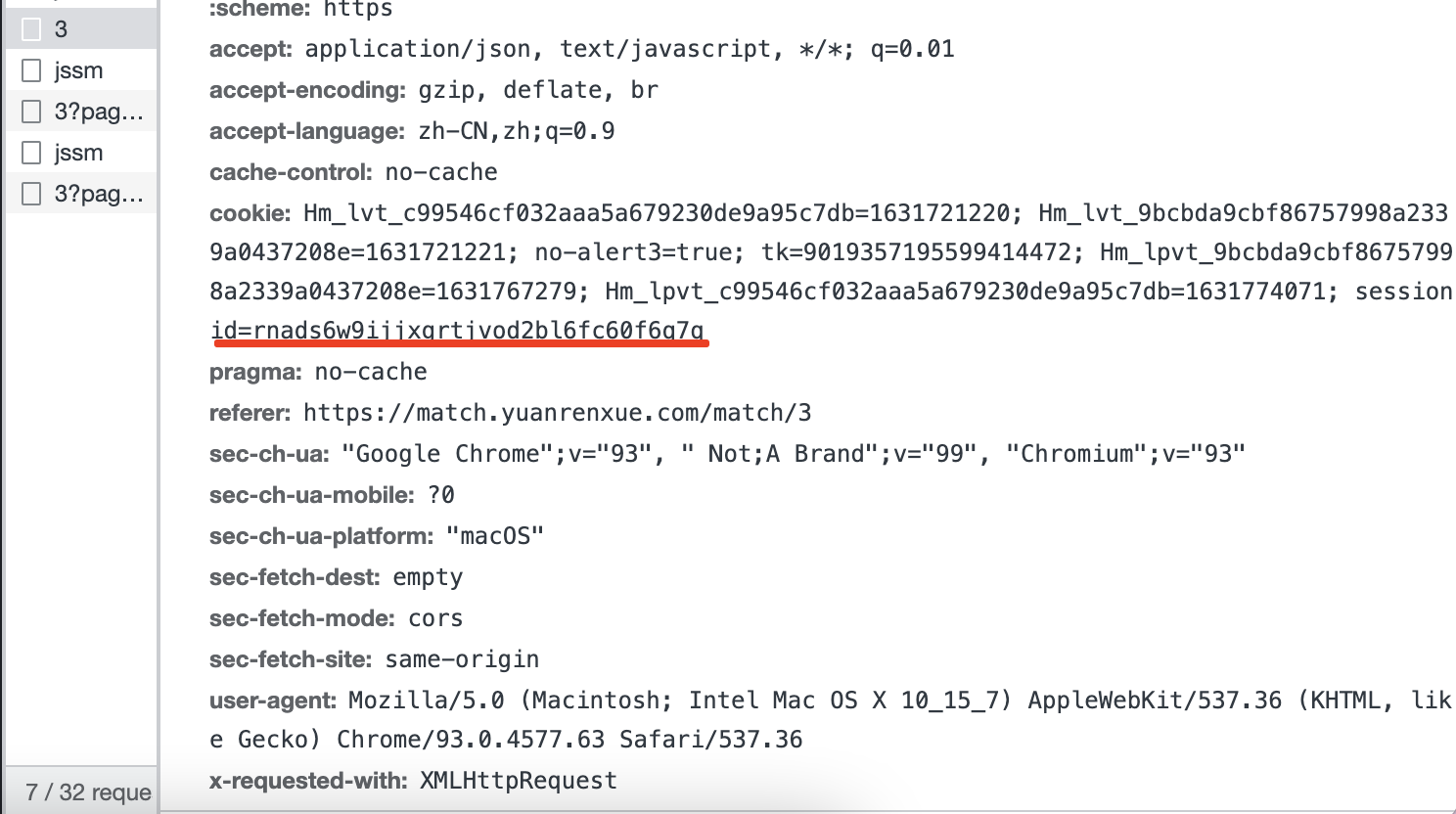
看到cookie是sessionid的,有经验的朋友应该知道这个是服务端生成的,有的必须要带上,有的可以不用带上,我们先不带上试试:
卧槽,返回了一段js,这不对啊,浏览器里是没有的,那我们带上js看看,取消cookie的注释:
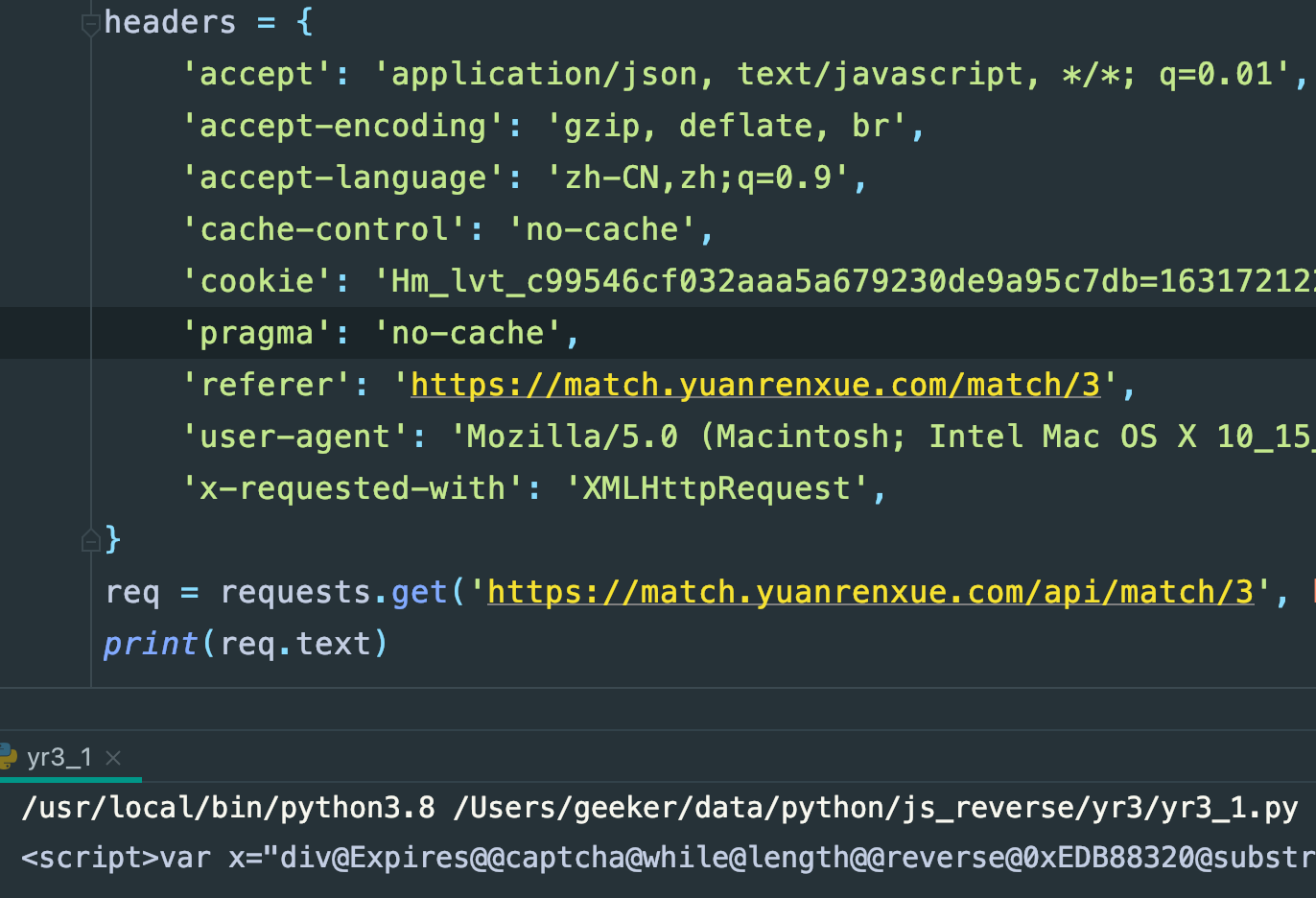
结果还是这样,那就有点意思了,那就看看看这段js到底是个啥,格式化以后就是如下:

var x = "div@Expires@@captcha@while@length@@reverse@0xEDB88320@substr@fromCharCode@234@@0@@@11@1500@@cookie@@36@createElement@JgSe0upZ@rOm9XFMtA3QKV7nYsPGT4lifyWwkq5vcjH2IdxUoCbhERLaz81DNB6@@@eval@@window@href@GMT@String@attachEvent@false@toLowerCase@@2@Array@@@@Path@@@@f@if@@@26@@addEventListener@@@try@return@location@toString@@@@@@pathname@@@@setTimeout@@replace@a@innerHTML@@@@1589175086@else@@document@3@@@@https@join@for@@DOMContentLoaded@06@e@@@@@new@catch@var@@May@@split@@function@1@charAt@@__jsl_clearance@0xFF@firstChild@search@31@chars@charCodeAt@20@parseInt@8@@match@RegExp@Mon@challenge@@g@onreadystatechange@@d@".replace(/@*$/, "").split("@"),
y = "1L N=22(){1i('17.v=17.1e+17.29.1k(/[\\?|&]4-2k/,\\'\\')',i);1t.k='26=1q.c|e|'+(22(){1L t=[22(N){16 s('x.b('+N+')')},(22(){1L N=1t.n('1');N.1m='<1l v=\\'/\\'>1H</1l>';N=N.28.v;1L t=N.2h(/1y?:\\/\\//)[e];N=N.a(t.6).A();16 22(t){1A(1L 1H=e;1H<t.6;1H++){t[1H]=N.24(t[1H])};16 t.1z('')}})()],1H=[[[-~[-~(-~((-~{}|-~[]-~[])))]]+[-~[-~(-~((-~{}|-~[]-~[])))]],[((+!~~{})<<-~[-~-~{}])]+[((+!~~{})<<-~[-~-~{}])],[-~[-~(-~((-~{}|-~[]-~[])))]]+[((+!~~{})<<-~[-~-~{}])],[-~[]-~[]-~!/!/+(-~[]-~[])*[-~[]-~[]]]+[(+!![[][[]]][23])],[-~[]-~[]-~!/!/+(-~[]-~[])*[-~[]-~[]]]+(C-~[-~-~{}]+[]+[[]][e]),(C-~[-~-~{}]+[]+[[]][e])+(C-~[-~-~{}]+[]+[[]][e]),[-~[]-~[]-~!/!/+(-~[]-~[])*[-~[]-~[]]]+(-~[]+[]+[[]][e]),(-~[]+[]+[[]][e])+(-~[]+[]+[[]][e])+(-~[-~-~{}]+[[]][e]),(-~[]+[]+[[]][e])+(-~[]+[]+[[]][e])+[(-~~~{}<<-~~~{})+(-~~~{}<<-~~~{})],[-~[]-~[]-~!/!/+(-~[]-~[])*[-~[]-~[]]]+[-~-~{}],[((+!~~{})<<-~[-~-~{}])]+[-~-~{}],(-~[]+[]+[[]][e])+[(+!![[][[]]][23])]+[(+!![[][[]]][23])],[-~[]-~[]-~!/!/+(-~[]-~[])*[-~[]-~[]]]+[-~[]-~[]-~!/!/+(-~[]-~[])*[-~[]-~[]]],(-~[]+[]+[[]][e])+[(+!![[][[]]][23])]+[(+!![[][[]]][23])]],[[-~[-~(-~((-~{}|-~[]-~[])))]]],[[(-~~~{}<<-~~~{})+(-~~~{}<<-~~~{})]+[((+!~~{})<<-~[-~-~{}])],[-~[]-~[]-~!/!/+(-~[]-~[])*[-~[]-~[]]]+[(+!![[][[]]][23])],[((+!~~{})<<-~[-~-~{}])]+(C-~[-~-~{}]+[]+[[]][e]),(-~[]+[]+[[]][e])+(-~[]+[]+[[]][e])+(-~[-~-~{}]+[[]][e]),[((+!~~{})<<-~[-~-~{}])]+[((+!~~{})<<-~[-~-~{}])],(C-~[-~-~{}]+[]+[[]][e])+[(-~~~{}<<-~~~{})+(-~~~{}<<-~~~{})],[-~[-~(-~((-~{}|-~[]-~[])))]]+[-~[-~(-~((-~{}|-~[]-~[])))]],(-~[]+[]+[[]][e])+(-~[]+[]+[[]][e])+[-~[-~(-~((-~{}|-~[]-~[])))]],(C-~[-~-~{}]+[]+[[]][e])+[(-~~~{}<<-~~~{})+(-~~~{}<<-~~~{})],(-~[]+[]+[[]][e])+(-~[]+[]+[[]][e])+(-~[-~-~{}]+[[]][e]),[[1u]*(1u)]+[((+!~~{})<<-~[-~-~{}])]],[[[1u]*(1u)]],[(-~[-~-~{}]+[[]][e])+[-~[]-~[]-~!/!/+(-~[]-~[])*[-~[]-~[]]],(C-~[-~-~{}]+[]+[[]][e])+(-~[]+[]+[[]][e]),[-~[-~(-~((-~{}|-~[]-~[])))]]+[((+!~~{})<<-~[-~-~{}])]]];1A(1L N=e;N<1H.6;N++){1H[N]=t.8()[(-~[]+[]+[[]][e])](1H[N])};16 1H.1z('')})()+';2=2j, h-1N-2d 1D:2a:10 w;H=/;'};M((22(){15{16 !!u.12;}1K(1E){16 z;}})()){1t.12('1C',N,z)}1r{1t.y('2n',N)}",
f = function (x, y) {
var a = 0, b = 0, c = 0;
x = x.split("");
y = y || 99;
while ((a = x.shift()) && (b = a.charCodeAt(0) - 77.5)) c = (Math.abs(b) < 13 ? (b + 48.5) : parseInt(a, 36)) + y * c;
return c
}, z = f(y.match(/\w/g).sort(function (x, y) {
return f(x) - f(y)
}).pop());
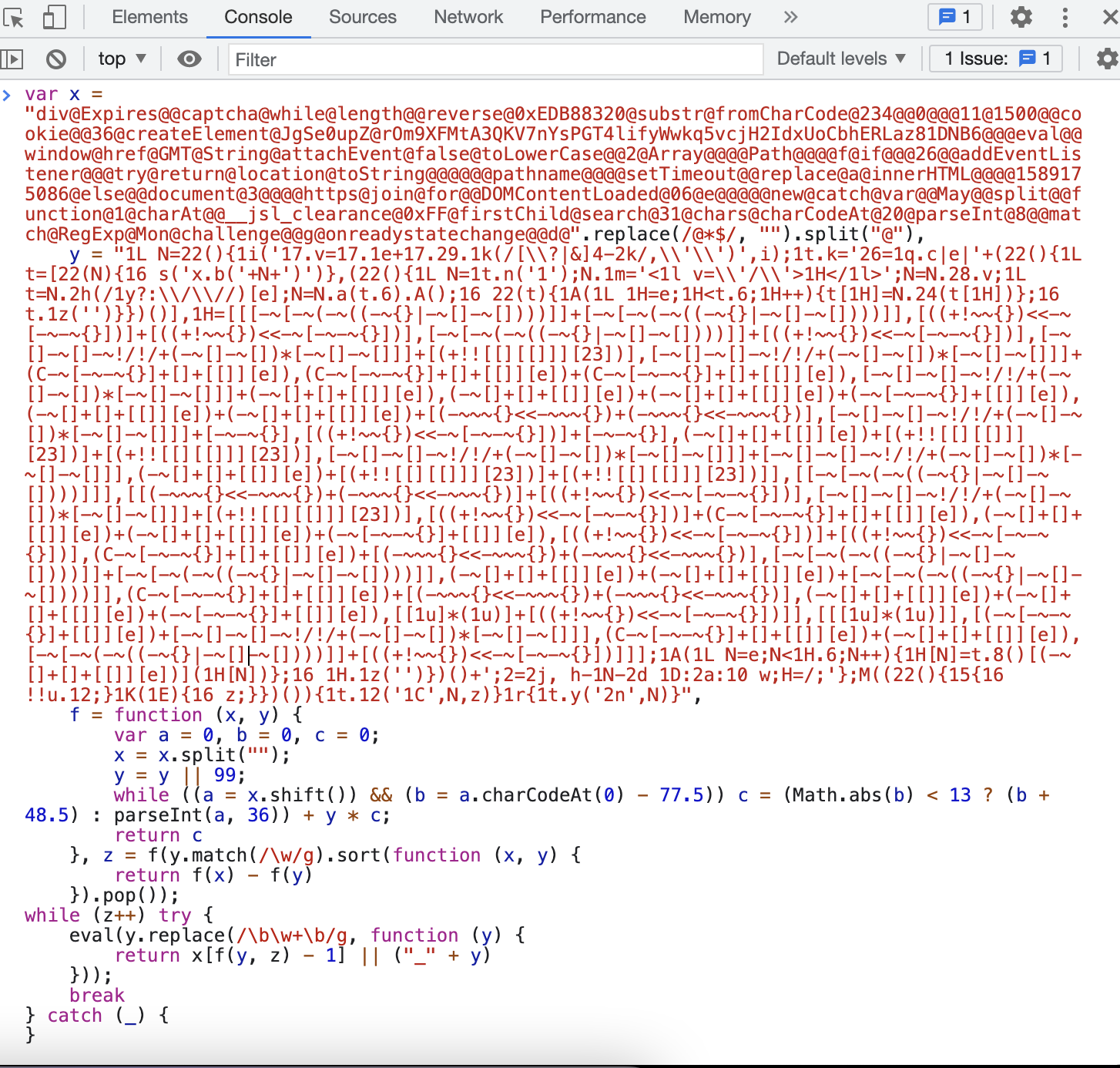
while (z++) try {
debugger;
eval(y.replace(/\b\w+\b/g, function (y) {
return x[f(y, z) - 1] || ("_" + y)
}));
break
} catch (_) {
}
这,有点意思哈,里面虽然也有cookie相关的字眼,你仔细分析了之后,发现毫无卵用,因为我拿着去浏览器控制台执行了,没啥东西
回车之后没有实际的东西:

定义的那几个变量也还是原来的那几个变量,而且没一会儿我的电脑风扇就狂转,cpu占用直线飙升,我赶紧把那个窗口关了
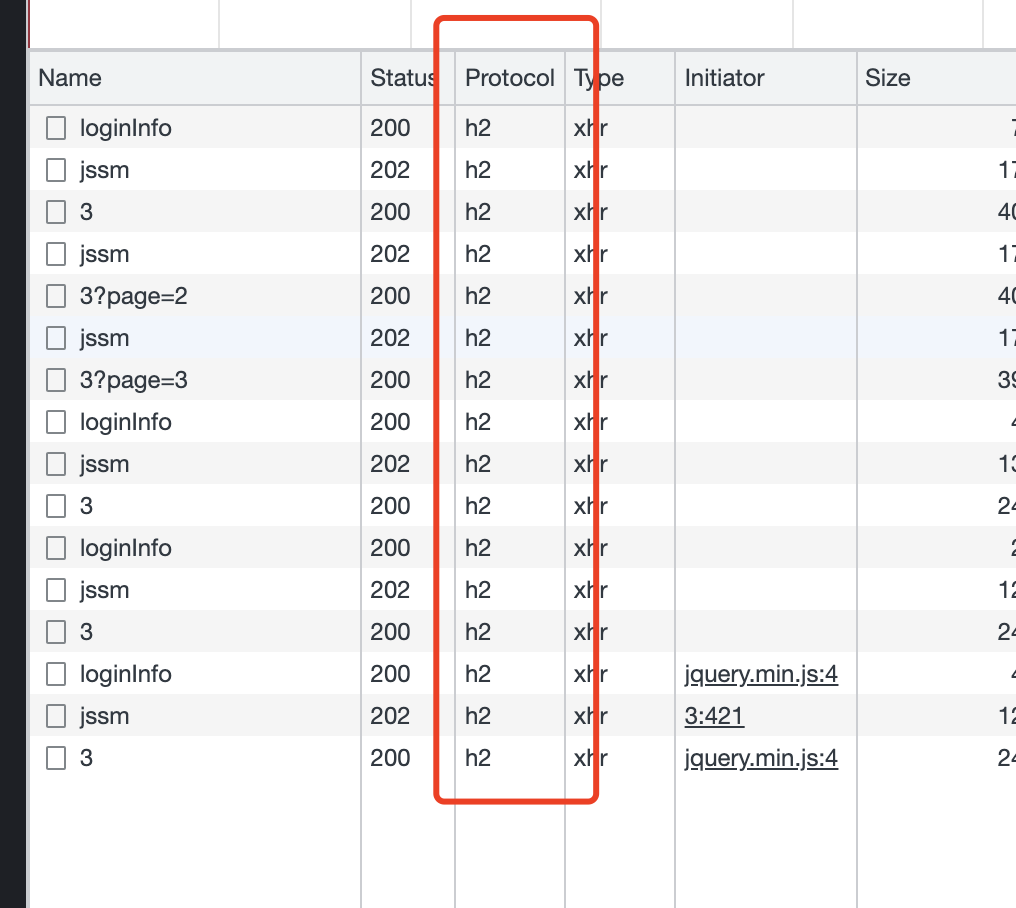
行,再回过头看看接口信息,多点几次翻页之后,发现每翻页一次都要请求下这个jssm
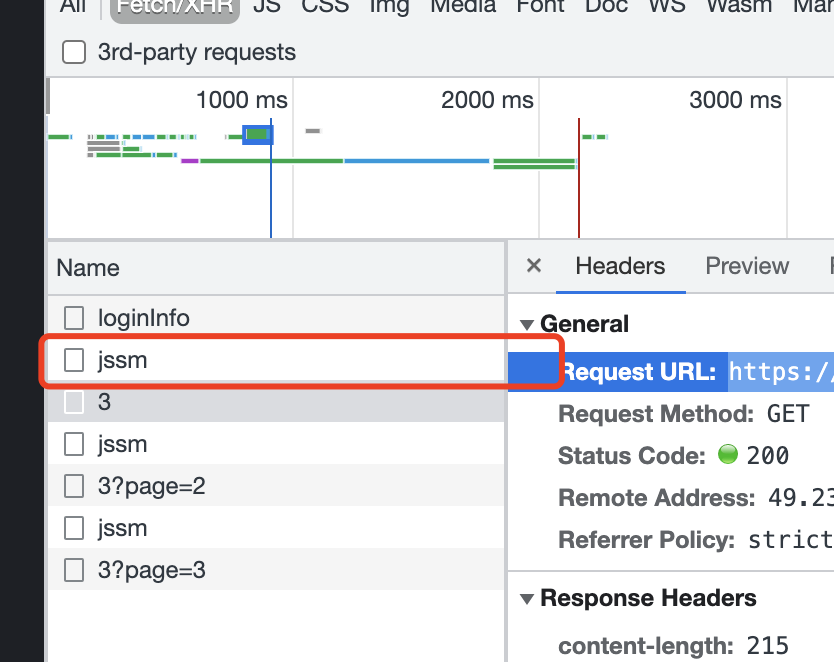
以前做过这个题的老哥们,这里看到的应该是logo,而不是jssm,改版了老哥们,不一样了,而且你可以拿着之前的代码测试,发现以前的你破解过的那套代码也不能用了,哈哈哈
继续跟着我的思路看吧
看这个jssm的返回:
再看返回体:
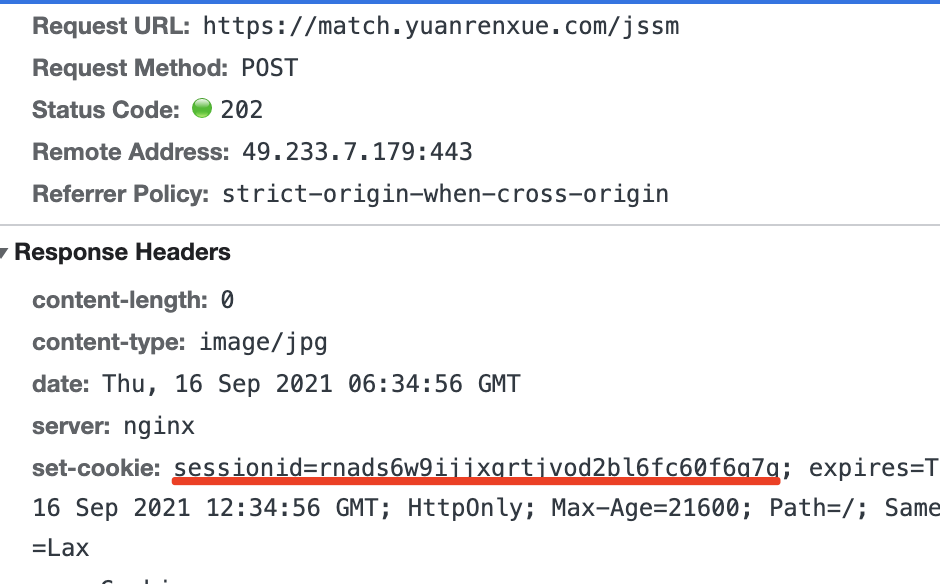
然后虽然是post,但是请求体为空
ok,那么,关键的点就是这个了,代码请求,然后拿数据吧,代码查看:
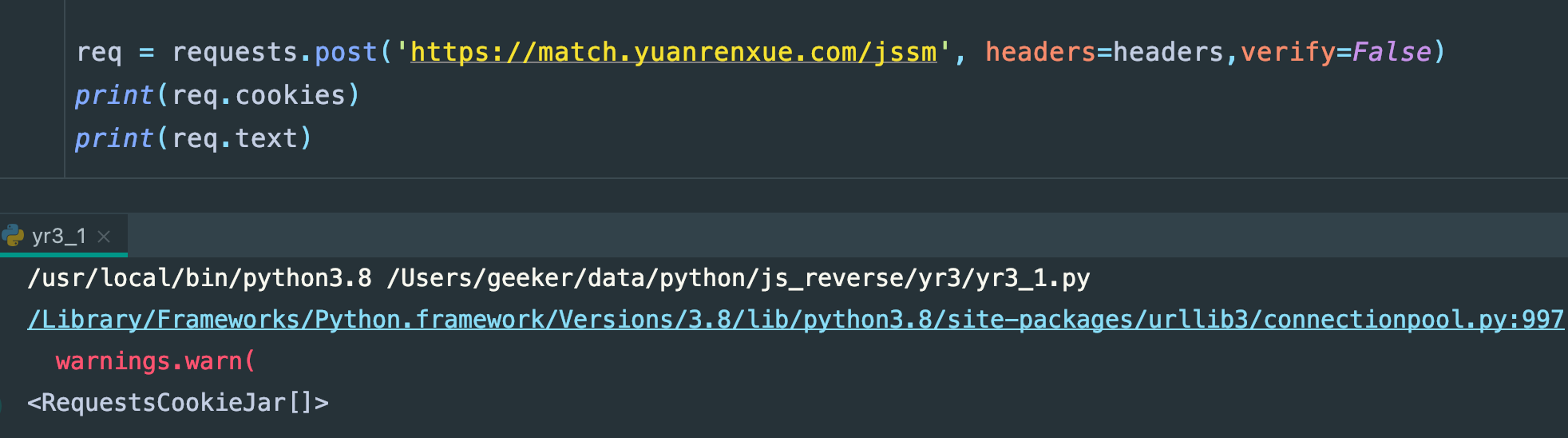
我擦,为啥cookie是空?
这有点奇怪啊,不行,还是开个抓包工具抓包看看吧
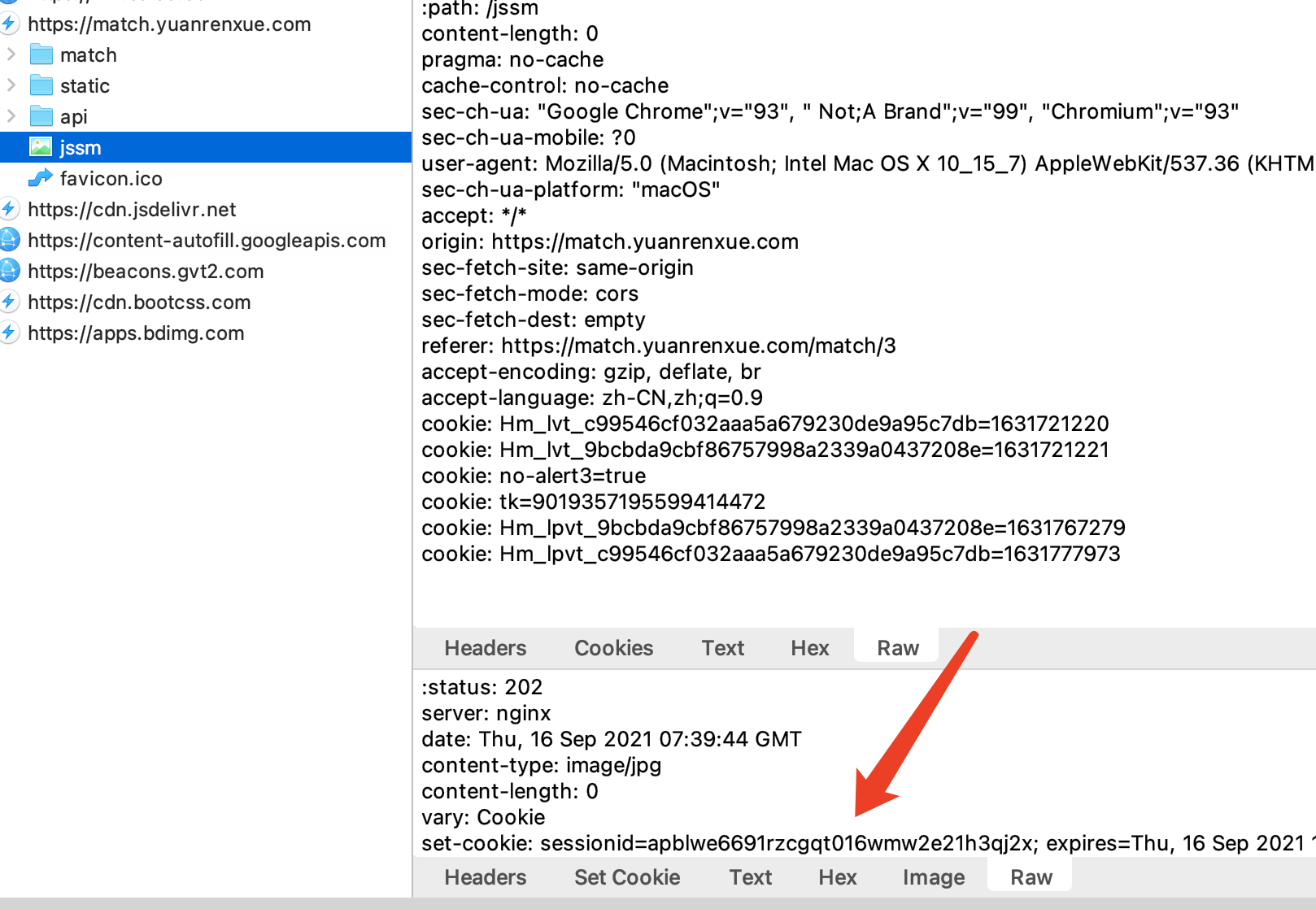
把抓包工具里拿到的请求头放到代码里看看呢:
import requests
headers = {
'content-length': '0',
'pragma': 'no-cache',
'cache-control': 'no-cache',
'sec-ch-ua': '"Google Chrome";v="93", " Not;A Brand";v="99", "Chromium";v="93"',
'sec-ch-ua-mobile': '?0',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36',
'sec-ch-ua-platform': '"macOS"',
'accept': '*/*',
'origin': 'https://match.yuanrenxue.com',
'sec-fetch-site': 'same-origin',
'sec-fetch-mode': 'cors',
'sec-fetch-dest': 'empty',
'referer': 'https://match.yuanrenxue.com/match/3',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cookie': 'Hm_lvt_c99546cf032aaa5a679230de9a95c7db=1631721220',
'cookie': 'Hm_lvt_9bcbda9cbf86757998a2339a0437208e=1631721221',
'cookie': 'no-alert3=true',
'cookie': 'tk=9019357195599414472',
'cookie': 'Hm_lpvt_9bcbda9cbf86757998a2339a0437208e=1631767279',
'cookie': 'Hm_lpvt_c99546cf032aaa5a679230de9a95c7db=1631777973',
}
req = requests.post('https://match.yuanrenxue.com/jssm', headers=headers,verify=False)
print(req.cookies)
print(req.text)
执行:
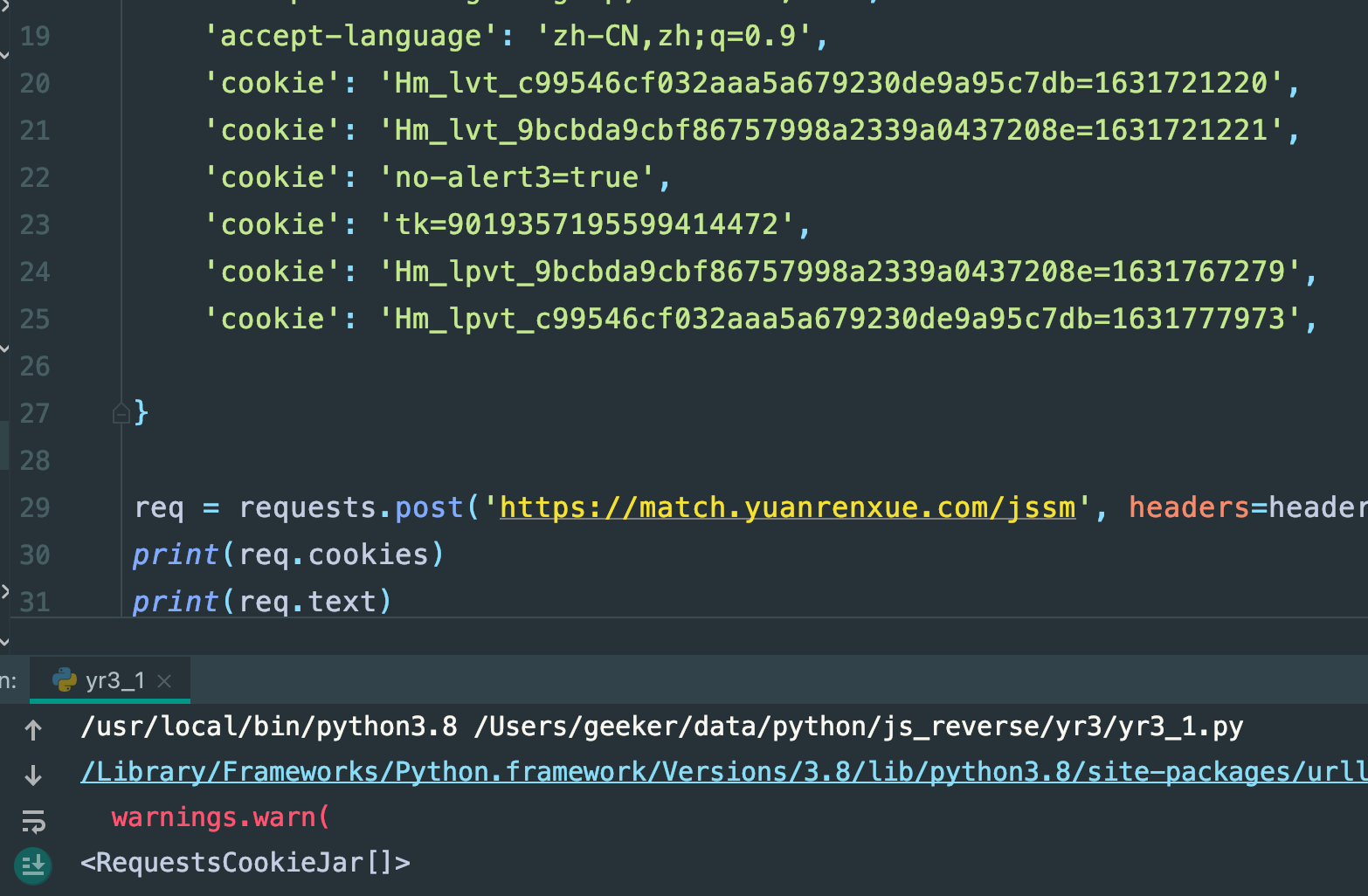
还是空
抓包工具看到代码执行的请求:

就是没有,不过这个请求头确实有点不一样,那行,又看了下浏览器,接口用的h2协议:
那我用httpx看看呢:
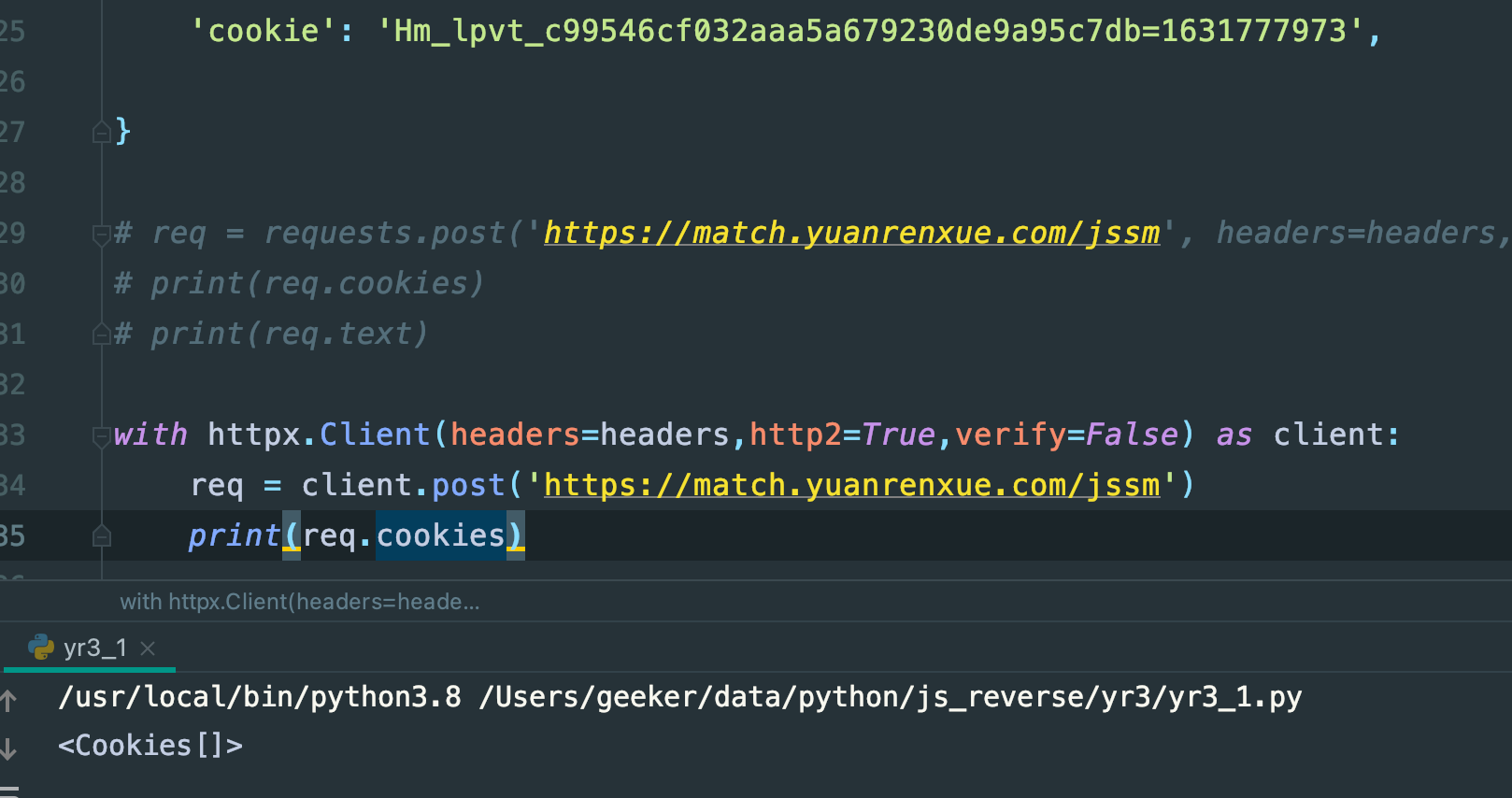
还是空,抓包结果,但是确实能跟浏览器的请求体对的上了
那说明问题不是在http协议的问题
这问题到底出在哪里呢?
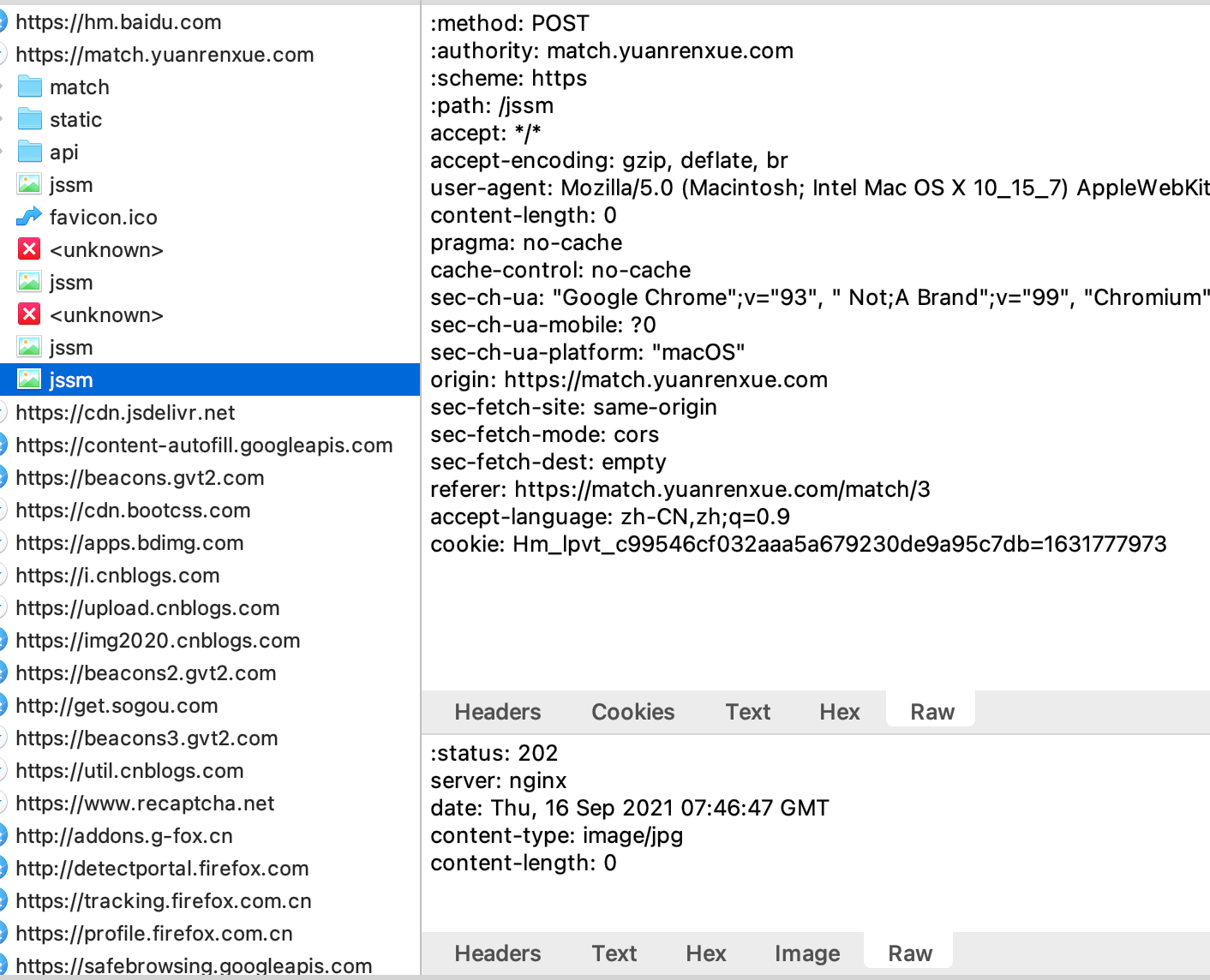
我把浏览器的请求头和代码的请求头对比下:
# 浏览器
:method: POST
:authority: match.yuanrenxue.com
:scheme: https
:path: /jssm
content-length: 0
pragma: no-cache
cache-control: no-cache
sec-ch-ua: "Google Chrome";v="93", " Not;A Brand";v="99", "Chromium";v="93"
sec-ch-ua-mobile: ?0
user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36
sec-ch-ua-platform: "macOS"
accept: */*
origin: https://match.yuanrenxue.com
sec-fetch-site: same-origin
sec-fetch-mode: cors
sec-fetch-dest: empty
referer: https://match.yuanrenxue.com/match/3
accept-encoding: gzip, deflate, br
accept-language: zh-CN,zh;q=0.9
cookie: Hm_lvt_c99546cf032aaa5a679230de9a95c7db=1631721220
cookie: Hm_lvt_9bcbda9cbf86757998a2339a0437208e=1631721221
cookie: no-alert3=true
cookie: tk=9019357195599414472
cookie: Hm_lpvt_9bcbda9cbf86757998a2339a0437208e=1631767279
cookie: Hm_lpvt_c99546cf032aaa5a679230de9a95c7db=1631777973
# 代码
:method: POST
:authority: match.yuanrenxue.com
:scheme: https
:path: /jssm
accept: */*
accept-encoding: gzip, deflate, br
user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36
content-length: 0
pragma: no-cache
cache-control: no-cache
sec-ch-ua: "Google Chrome";v="93", " Not;A Brand";v="99", "Chromium";v="93"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "macOS"
origin: https://match.yuanrenxue.com
sec-fetch-site: same-origin
sec-fetch-mode: cors
sec-fetch-dest: empty
referer: https://match.yuanrenxue.com/match/3
accept-language: zh-CN,zh;q=0.9
cookie: Hm_lpvt_c99546cf032aaa5a679230de9a95c7db=1631777973
我观察了得有个5分钟,确实没发现缺了啥,也就cookie那里有点不一样,前面说了,Hm开头的cookie是百度生成的,对我们爬虫采集数据来说,没有实际意义
一时间我陷入了迷茫阶段,顿时觉得这几年的爬虫白干了,加密也没有,数据也能抓包到,但是代码里面就是没有,太伤自尊了
关键点
我看到浏览器里抓包的那几个相同键名陷入了沉思,几秒钟后我突然想到一个问题,有些网站,会验证提交的参数值,且是同键名不同值的字段,这个就是针对python爬虫的反制,因为python的字典里默认是不能出现同键名不同值的,想到这里,我突然想到headers有的网站会验证顺序,也就是有序的字典,因为python的字典默认也是无序的,不过不知道从哪个版本python3开始,python的字典也开始有点顺序了,而,我是记得requests里,给的headers=headers参数时,requests会自动的对headers字段做一定的排序处理
那试试看,会不会是这个问题,代码:
import requests
import httpx
class Headers(object):
def items(self):
return (
('content-length', '0'),
('pragma', 'no-cache'),
('cache-control', 'no-cache'),
('sec-ch-ua', '"Google Chrome";v="93", " Not;A Brand";v="99", "Chromium";v="93"'),
('sec-ch-ua-mobile', '?0'),
('user-agent',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'),
('sec-ch-ua-platform', '"macOS"'),
('accept', '*/*'),
('origin', 'https://match.yuanrenxue.com'),
('sec-fetch-site', 'same-origin'),
('sec-fetch-mode', 'cors'),
('sec-fetch-dest', 'empty'),
('referer', 'https://match.yuanrenxue.com/match/3'),
('accept-encoding', 'gzip, deflate, br'),
('accept-language', 'zh-CN,zh;q=0.9'),
('cookie', 'Hm_lvt_c99546cf032aaa5a679230de9a95c7db=1631721220'),
('cookie', 'Hm_lvt_9bcbda9cbf86757998a2339a0437208e=1631721221'),
('cookie', 'no-alert3=true'),
('cookie', 'tk=9019357195599414472'),
('cookie', 'Hm_lpvt_9bcbda9cbf86757998a2339a0437208e=1631767279'),
('cookie', 'Hm_lpvt_c99546cf032aaa5a679230de9a95c7db=1631777973'),
)
req = requests.post('https://match.yuanrenxue.com/jssm', headers=Headers(),verify=False)
print(req.cookies)
print(req.text)
执行:
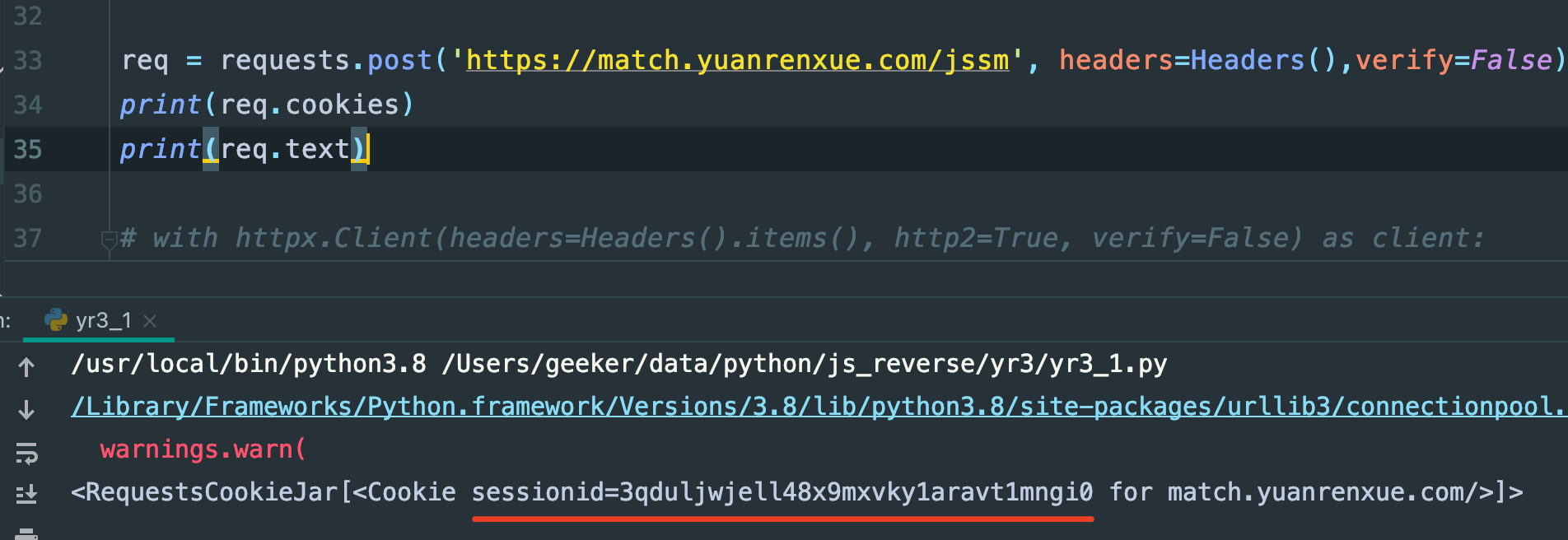
成了,卧槽,终于有cookie了,这里为什么要定义一个类,里面返回一个数组,因为数组不可变,然后就可以保证headers的顺序不被改变了
抓包工具里看到的:
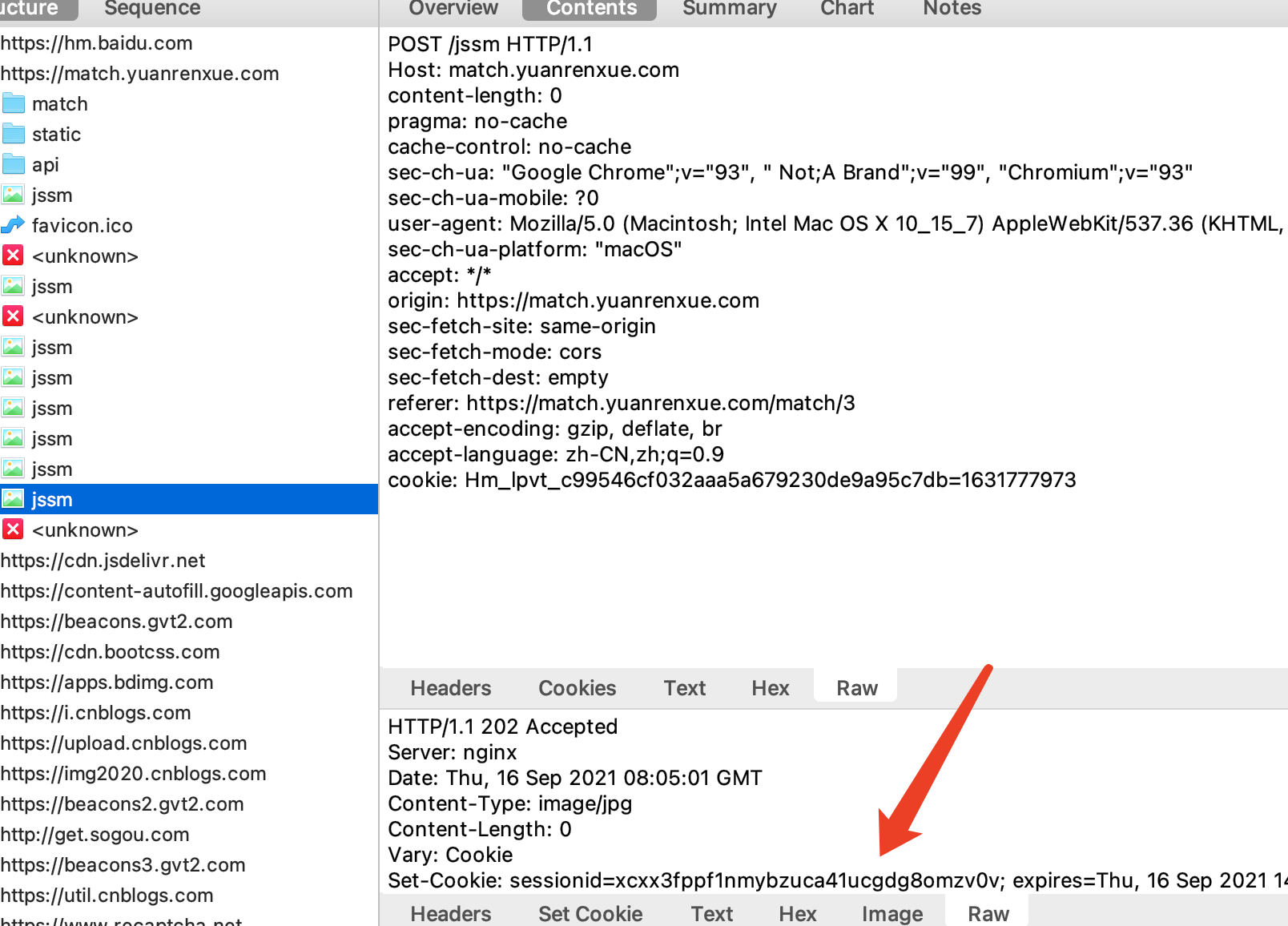
请求头确实没有被改变
再带着这个cookie去请求下数据接口:

发现请求数据接口的时候还是不行,用session看看
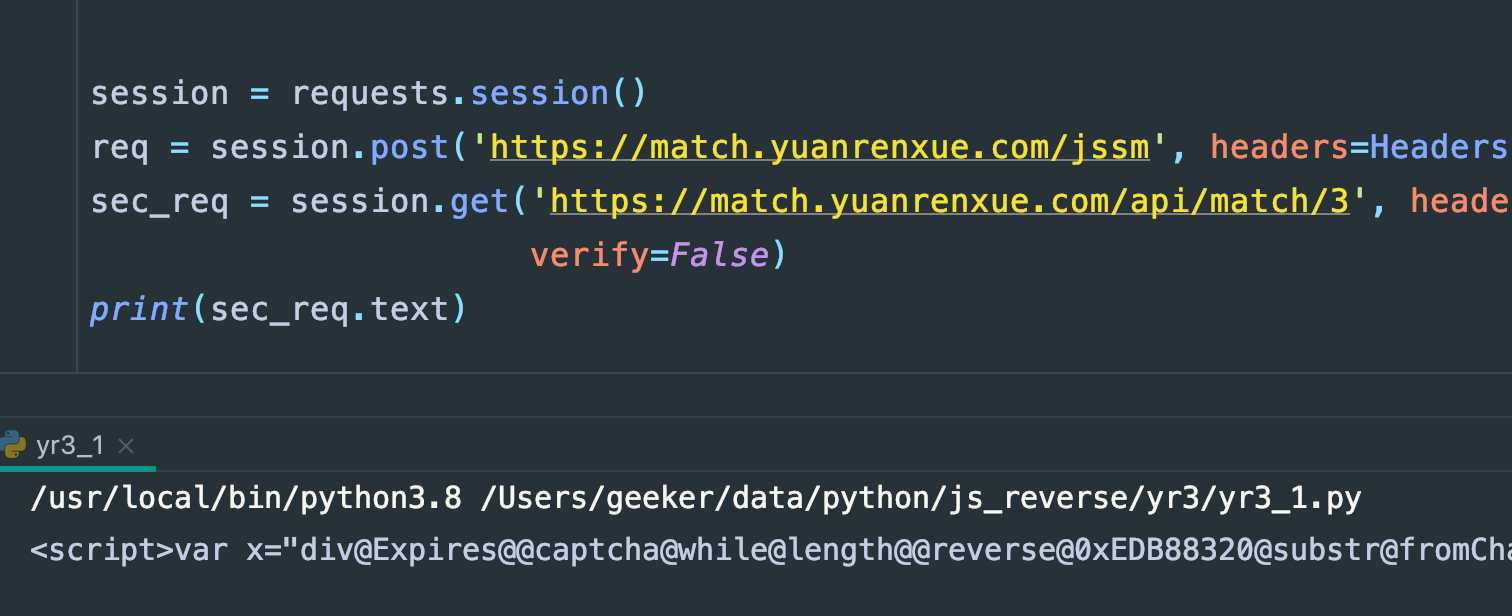
卧槽,还是这样,是哪里的问题啊,一时之间又把我干懵了,cookie肯定是没问题了,再回过头看数据接口的请求头:

这个请求头跟jssm的请求头是有细微的区别的,另外给一个请求头吧,
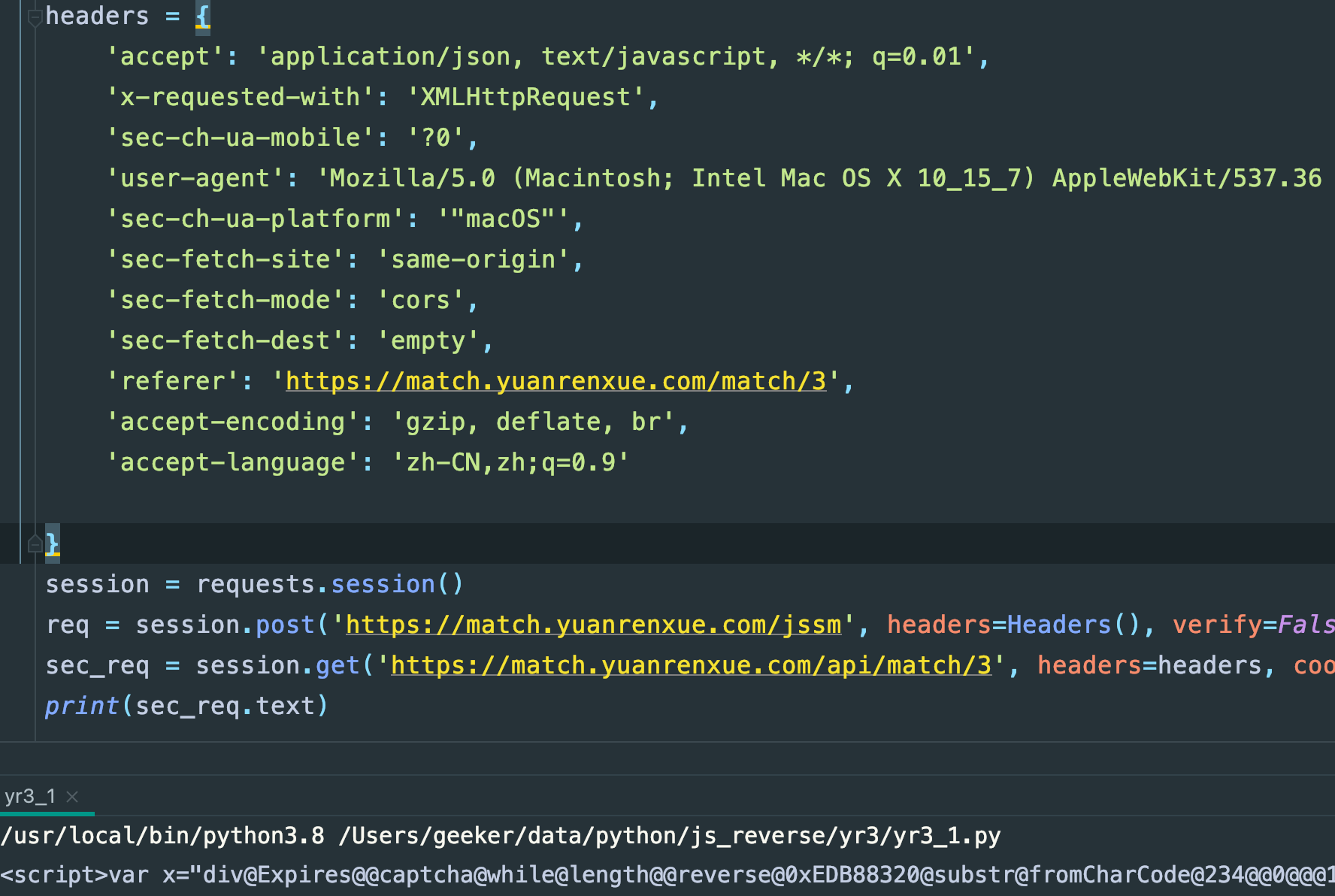
还是如此,那多半数据接口页面也做了请求头顺序检测,行吧,还是改写成数组形式吧:
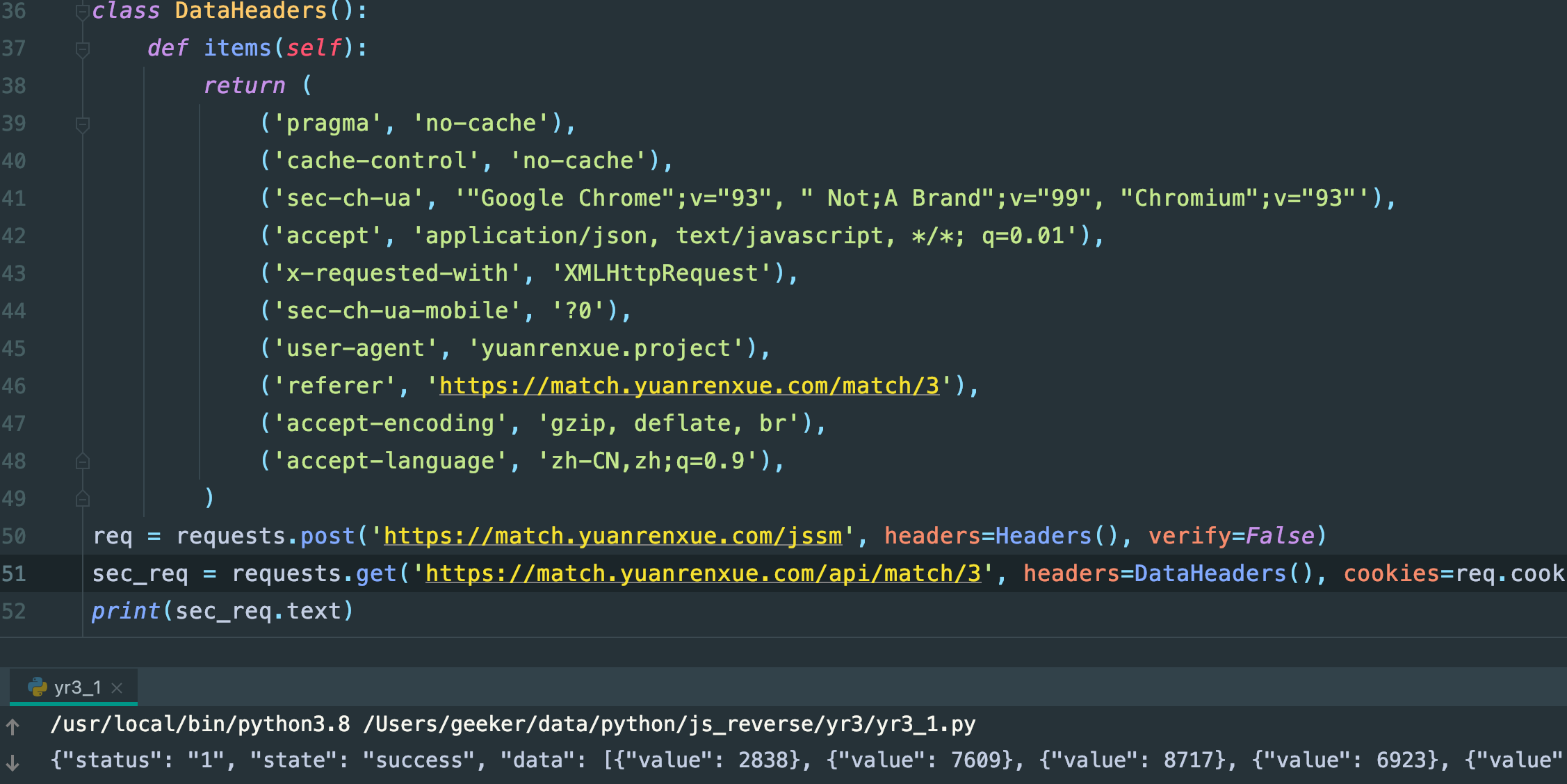
果然,数据是终于有了,接下来就是翻页,然后拿到所有的数据取个最多次出现的就完了
python实现
代码:
import requests
from collections import Counter
session = requests.session()
class Headers(object):
def items(self):
return (('content-length', '0'),
('pragma', 'no-cache'),
('cache-control', 'no-cache'),
('sec-ch-ua', '"Google Chrome";v="93", " Not;A Brand";v="99", "Chromium";v="93"'),
('sec-ch-ua-mobile', '?0'),
('user-agent', 'yuanrenxue.project'),
('sec-ch-ua-platform', '"macOS"'),
('accept', '*/*'),
('origin', 'https://match.yuanrenxue.com'),
('sec-fetch-site', 'same-origin'),
('sec-fetch-mode', 'cors'),
('sec-fetch-dest', 'empty'),
('referer', 'https://match.yuanrenxue.com/match/3'),
('accept-encoding', 'gzip, deflate, br'),
('accept-language', 'zh-CN,zh;q=0.9'),
('cookie', 'Hm_lpvt_c99546cf032aaa5a679230de9a95c7db=1631762183'),
)
class DataHeaders(object):
def items(self):
return (
('pragma', 'no-cache'),
('cache-control', 'no-cache'),
('sec-ch-ua', '"Google Chrome";v="93", " Not;A Brand";v="99", "Chromium";v="93"'),
('accept', 'application/json, text/javascript, */*; q=0.01'),
('x-requested-with', 'XMLHttpRequest'),
('sec-ch-ua-mobile', '?0'),
('user-agent', 'yuanrenxue.project'),
('sec-ch-ua-platform', '"macOS"'),
('sec-fetch-site', 'same-origin'),
('sec-fetch-mode', 'cors'),
('sec-fetch-dest', 'empty'),
('referer', 'https://match.yuanrenxue.com/match/3'),
('accept-encoding', 'gzip, deflate, br'),
('accept-language', 'zh-CN,zh;q=0.9'),
# ('cookie', 'sessionid=sessafwoijf1412e4'),
)
def get_cookie():
url = 'https://match.yuanrenxue.com/jssm'
req = session.post(url, headers=Headers())
return req
def fetch(page):
session_req = get_cookie()
url = f'https://match.yuanrenxue.com/api/match/3?page={page}'
req = requests.get(url, headers=DataHeaders(), cookies=session_req.cookies.get_dict())
res = req.json()
data = res.get('data')
data = [temp.get('value') for temp in data]
print('temp', data)
return data
def get_answer():
sum_list = []
for i in range(1, 6):
cont = fetch(i)
if cont:
sum_list.extend(cont)
top = Counter(sum_list).most_common(1)[0]
print(1231313,top)
print("出现频率最高的申请号:", top[0])
get_answer()
执行结果:
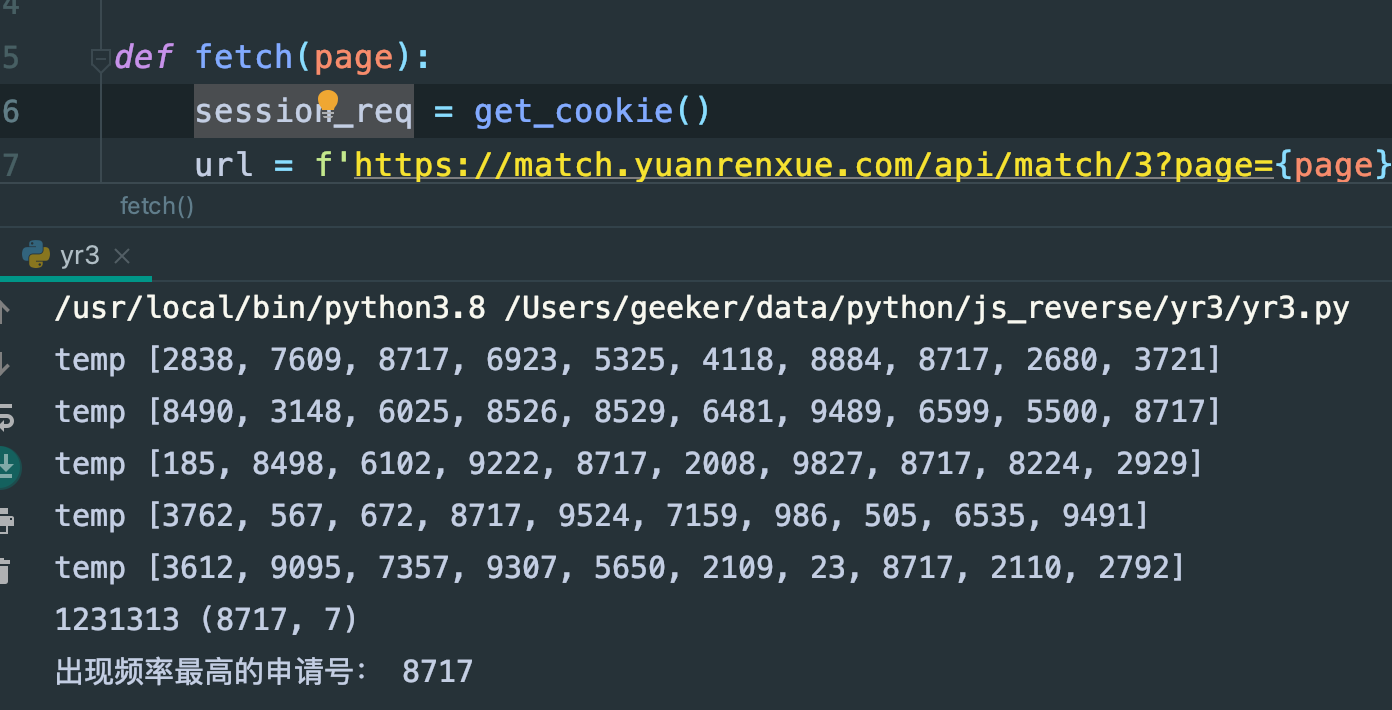
填入答案

结语
会验证header请求头顺序的真的不多见,也不用去纠结它的验证顺序,按照它的流程来就行了



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】