python爬虫 - js逆向之猿人学第十三题cookie验证
前言
继续,不多说
分析
打开网站:
然后抓取接口:
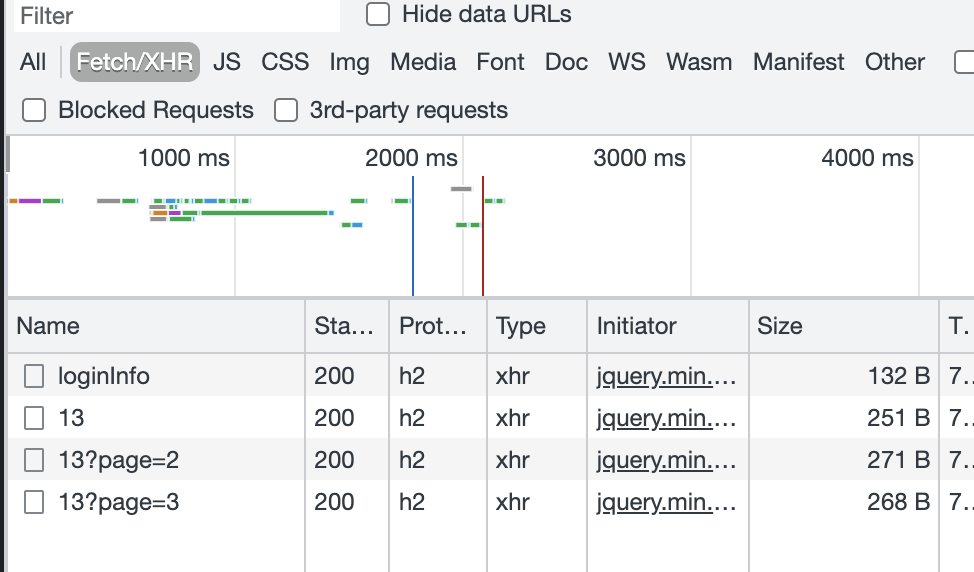
查看请求参数,发现没有什么特别的,就是多了个cookie
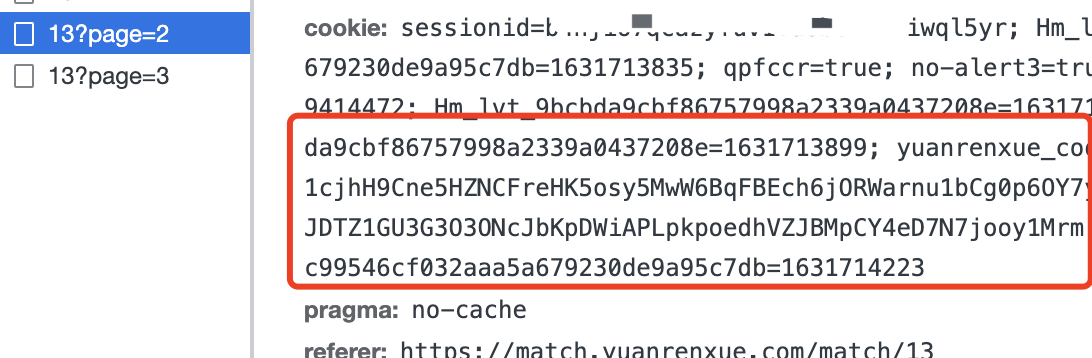
这个cookie咋来的?搜yuanrenxue_cookie搜不到:
那还是上抓包工具吧,抓包发现了这段js:
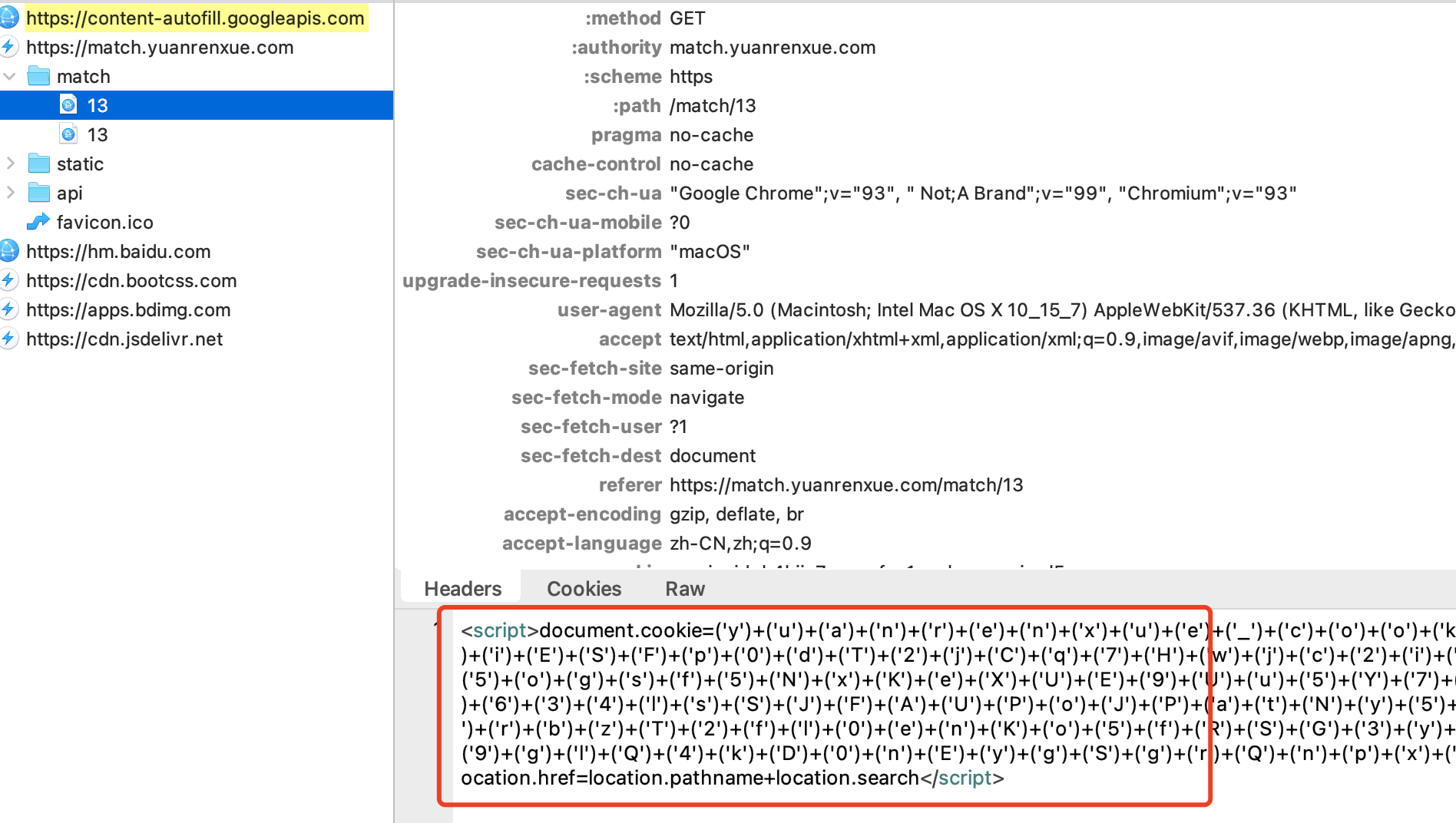
复制出来控制台执行:

这,不用多说了吧,前面复杂的都研究过了,拿到这个去请求就完了
python实现
import requests
import execjs
headers = {
'accept': 'application/json, text/javascript, */*; q=0.01',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'no-cache',
'pragma': 'no-cache',
'user-agent': 'yuanrenxue.project',
'x-requested-with': 'XMLHttpRequest',
'cookie': 'sessionid=换成你的sessionid'
}
def get_cookie():
url = 'https://match.yuanrenxue.com/match/13'
req = requests.get(url, headers=headers)
res = req.content.decode('utf-8')
cont = res.replace('<script>document.cookie=','').replace(';location.href=location.pathname+location.search</script>','')
req.close()
cookie = execjs.eval(cont)
return cookie
def fetch(page,cc):
url = f'https://match.yuanrenxue.com/api/match/13?page={page}'
cookie = {
'cookie': f'sessionid=换成你的sessionid; {cc}'
}
headers.update(cookie)
req = requests.get(url, headers=headers)
res = req.json()
data = res.get('data')
data = [temp.get('value') for temp in data]
print('temp', data)
return data
def get_answer():
cookie = get_cookie()
sum_number = 0
for i in range(1, 6):
cont = fetch(i,cookie)
sum_number += sum(cont)
print('答案:', sum_number)
get_answer()
说明下,为哈这里获取的cookie需要我们自己拼接而不用requests自带的session对象,因为返回的是js源码,requests默认支持重定向,然后带上代理,但是涉及到js代码的,由于并不是识别js代码,所以,没法,得手动处理,唉,前面那么复杂都搞出来了,这里手动处理下无非也就多写几行代码的事
执行:
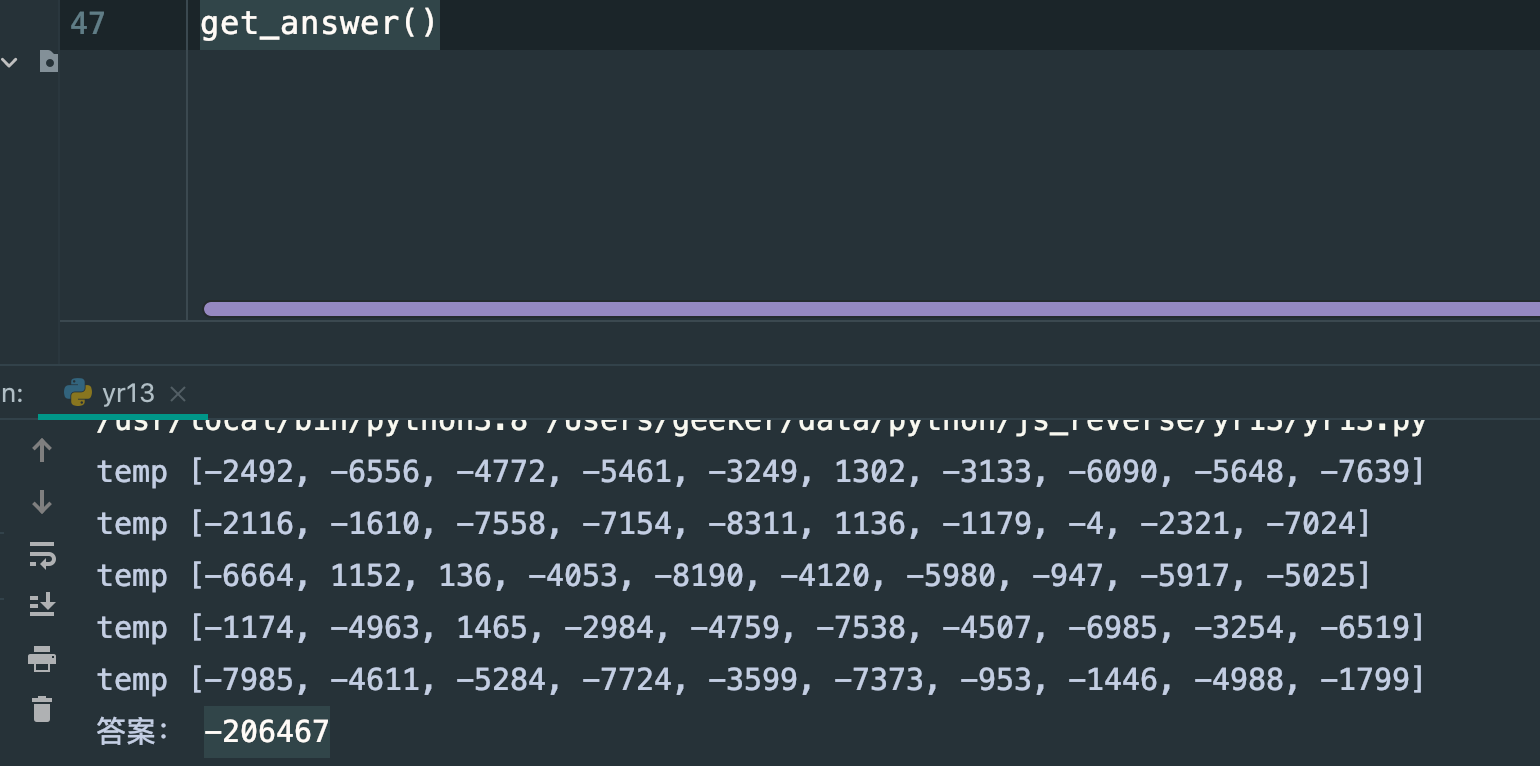
答案放上去:

over
结语
这没必要多说啥了,第二题都挺过来了,这道题那不是小case

 浙公网安备 33010602011771号
浙公网安备 33010602011771号