python爬虫 - js逆向之猿人学第十二题base64加密
前言
继续分析,为什么一下从第二题跳到了十二题,我也不知道为啥他这个平台的难度不循序渐进,把这么一个非常简答的题放在了后面,既然简单,那就快速解决了
分析
打开界面:
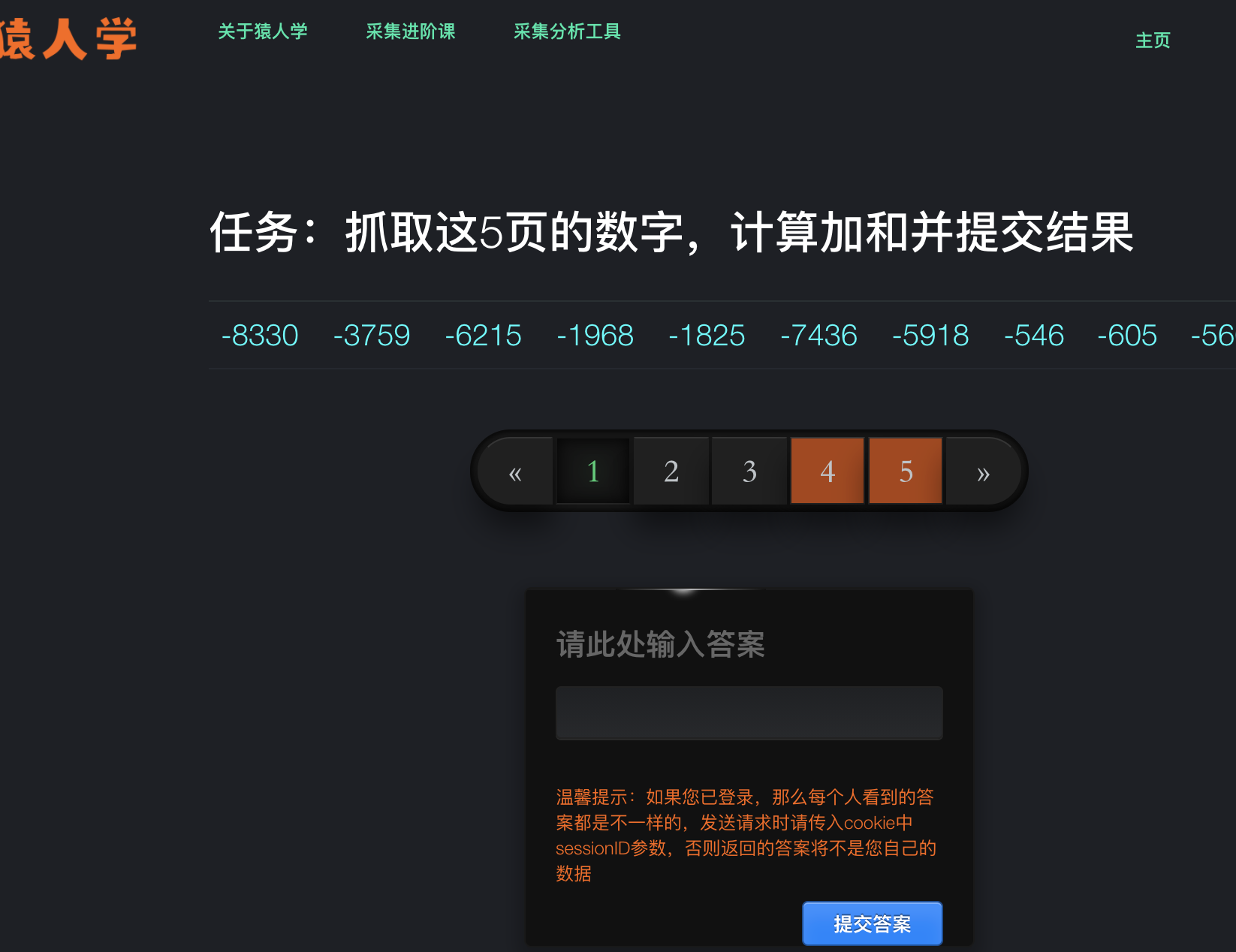
翻页,找接口:
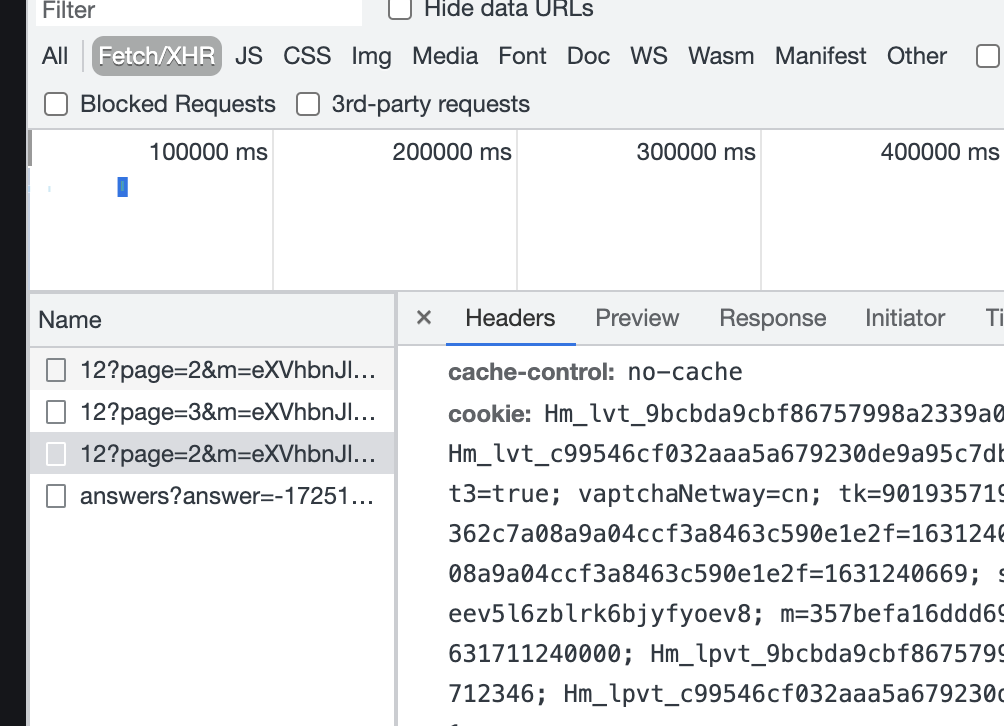
看参数:
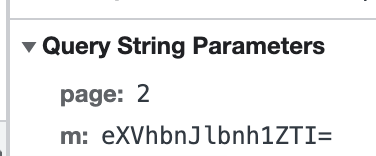
也是m,不多说,看到最后有【=】,先猜一波是不是base64,拿着去解码:

发现就是yuanrenxue+页码,然后base64加密,行,果然干脆,简单
python实现
不多说,直接代码:
import requests import base64 from urllib.parse import quote headers = { 'accept': 'application/json, text/javascript, */*; q=0.01', 'accept-encoding': 'gzip, deflate, br', 'accept-language': 'zh-CN,zh;q=0.9', 'cache-control': 'no-cache', 'pragma': 'no-cache', 'user-agent': 'yuanrenxue.project', 'x-requested-with': 'XMLHttpRequest', 'cookie': 'sessionid=换成你的sessionid' } def fetch(page): m = base64.b64encode(f'yuanrenxue{page}'.encode('utf-8')).decode() url = f'https://match.yuanrenxue.com/api/match/12?page={page}&m={quote(m)}' req = requests.get(url, headers=headers) res = req.json() data = res.get('data') data = [temp.get('value') for temp in data] print('temp', data) return data def get_answer(): sum_number = 0 for i in range(1, 6): cont = fetch(i) sum_number += sum(cont) print('答案:', sum_number) get_answer()
执行:
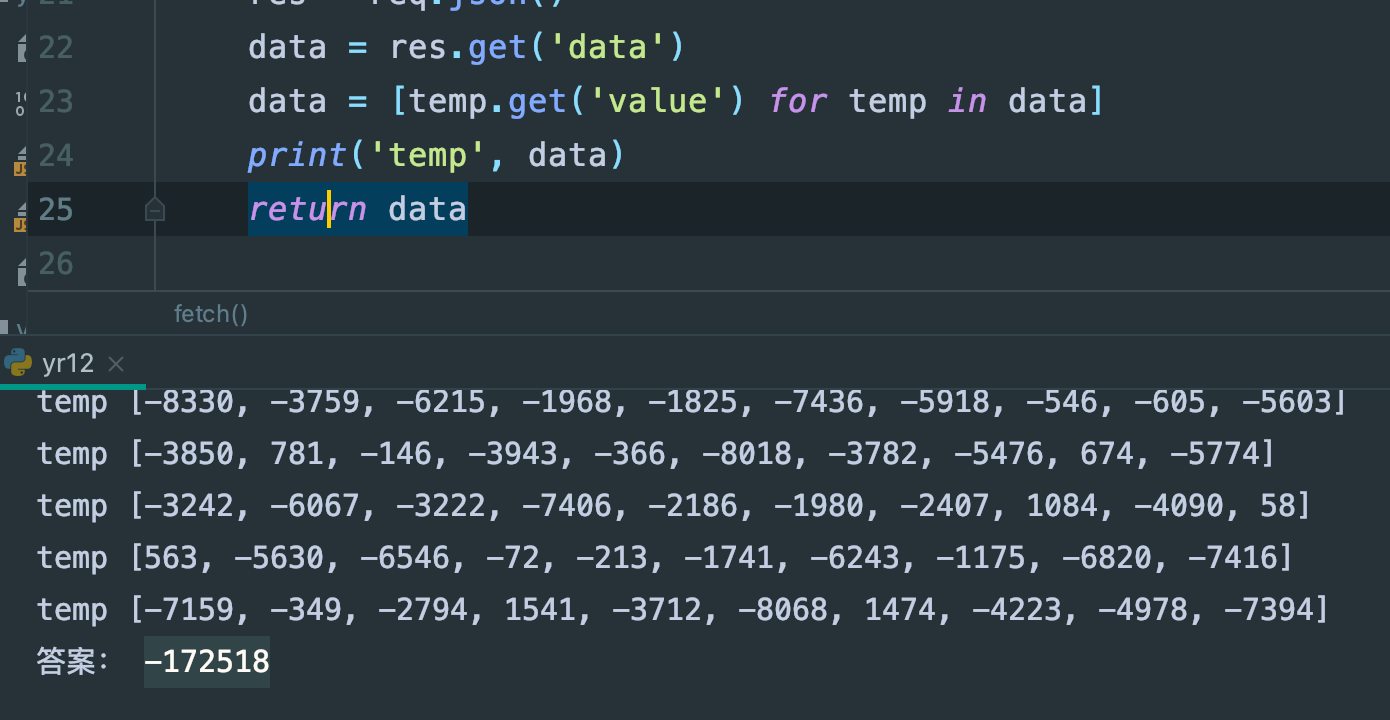
填入答案:
结语
这个就真的是入门级的了,写出来呢,主要还是为了完整性而已,免得以后的朋友看到,会问为啥没有第12题

 浙公网安备 33010602011771号
浙公网安备 33010602011771号