python爬虫- js逆向解密之破解AES(CryptoJS)加密的反爬机制v2
前言
其实有关AES,之前发过一版的博客文章,python爬虫- js逆向解密之破解AES(CryptoJS)加密的反爬机制
而这次虽然也是AES,但是这次的变化有点大了。
这次的目标对象同样也是我的老朋友给我的,还是老规矩,地址我不会给出来的
打开网址,界面如下:

不要问我为什么码了这么多,主要涉及到了手机号哈,马赛克必须马死
开始分析
首先,看XHR,用结果搜,没搜到
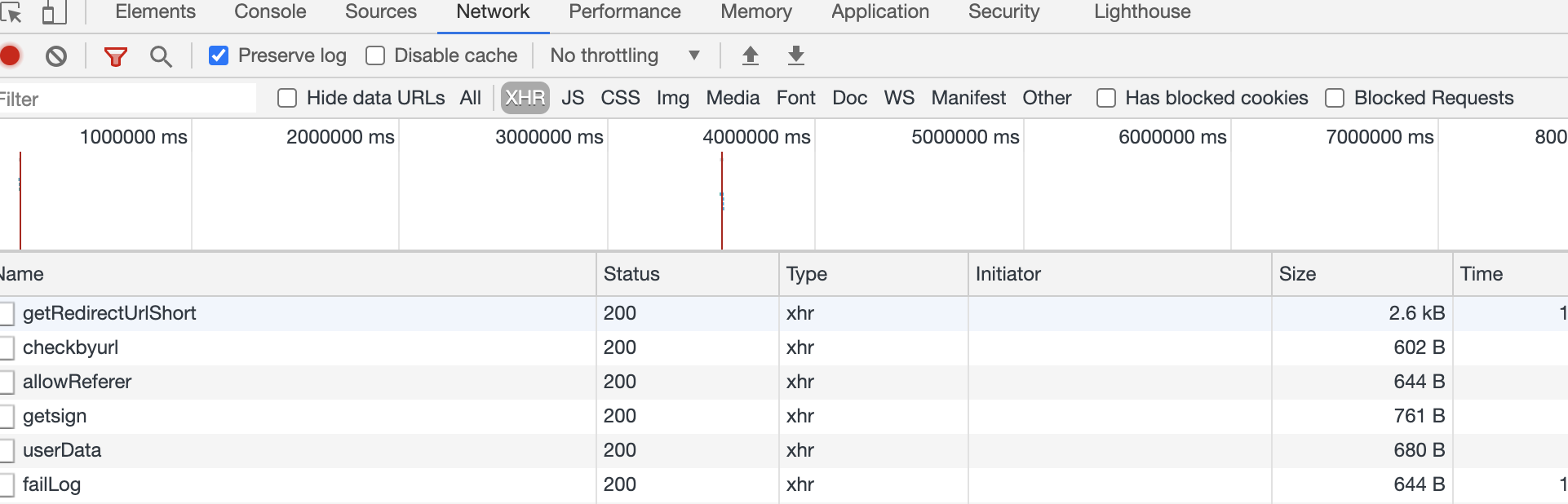
那行,接着看网站源码,用id为phonenum去整站搜索,然后找到以下几段代码块:


代码:
第一段:
key: "showEncryptPhone", value: function() { if (0 != $("#phonenum").length) { var e = getStoragePhone(); e ? ($("#phonenum").val(mobileEncrypt(e)), $("#phonenum").attr("disabled", "true")) : $("#changePhoneBtn").hide() } } } ------------ 第二段: $("#app").on("input propertychange", "#phonenum", function(e) { d("#phonenum"); var t = e.target.value; setStoragePhone(t) })
首先,可能稍微懂一点点js代码的,应该都能大概猜到,真正的代码其实是第一段,为啥呢,你看第二段,propertychange,这明显是监听修改的啊,再看第一个showEncryptPhone,这就是显示加密了的手机号,那一定是第一段代码了。
给第一段的每行代码

刷新页面,一步一步走,走到getStoragePhone()时,跳到里这个函数里:
当我鼠标放到window.msgTargetPhone时,已经有结果了
那么关键点就在getStoragePhone这个函数里了,重新打断点到这个函数上,之前的断点删除了,刷新看,结果立马就有了结果,那么,关键点就在window.msgTargetPhone上了,我用msgTargetPhone搜索,得到以下3个结果:


同样的,看名字,第三个肯定不是了,这不就是上面的那个被我们排除的函数一个原理吗?这第三个是监听是否改变值的,如果改变值就进入,而目标的整个页面里,手机号时是访问后就会自动出现的,并不是改变值出现的。而再看第一个,initUserMobileCache,看名字啊,初始化手机号,直觉告诉我就是这里了,先进这个函数看看咋回事
我正准备进入initUserMobileCache一顿分析时,我那朋友发来消息问我咋样了,我说,你可别急啊,我找到关键点了。
给这个函数打上断点:

刷新页面,一步一步往下走,直接走到下面这个函数,而且,这个e的参数看的太眼熟了,一看就是最开始的XHR请求得到的,这里我马死,就不展示了,这个s(e)走完之后就,手机号就出现了,那么,这么说,这个s(e)才是真正的关键点了

代码:
function s(e) {
var t = arguments.length > 1 && void 0 !== arguments[1] ? arguments[1] : g;
if (!e)
return "";
var n = p(e, t, {
iv: f
});
return n.toString(CryptoJS.enc.Utf8)
}
找到关键点
再回到上级看下,就是AESDecrypt这个函数跳转过去的,看到这个函数名AESDecrypt,那么不用多说了,用的就是AES加密了

接着我另开一个标签页,然后试试这个s函数能不能直接调用:

结果就报了个g没有定义,这个g,就烦了,不能搜了,为啥呢,这个太大众化了,根本不好搜索它在哪,不信你看:

你不会说这几百个一个一个看吧,那得整到啥时候去了,此时,应该怎么办呢,看源码,但是得有章法的看,看下面这一纵列的函数定义,这些都应该在一个函数作用域里,那就看上下文这个自执行函数【!function(e){】的作用域里有没有定义过【g】
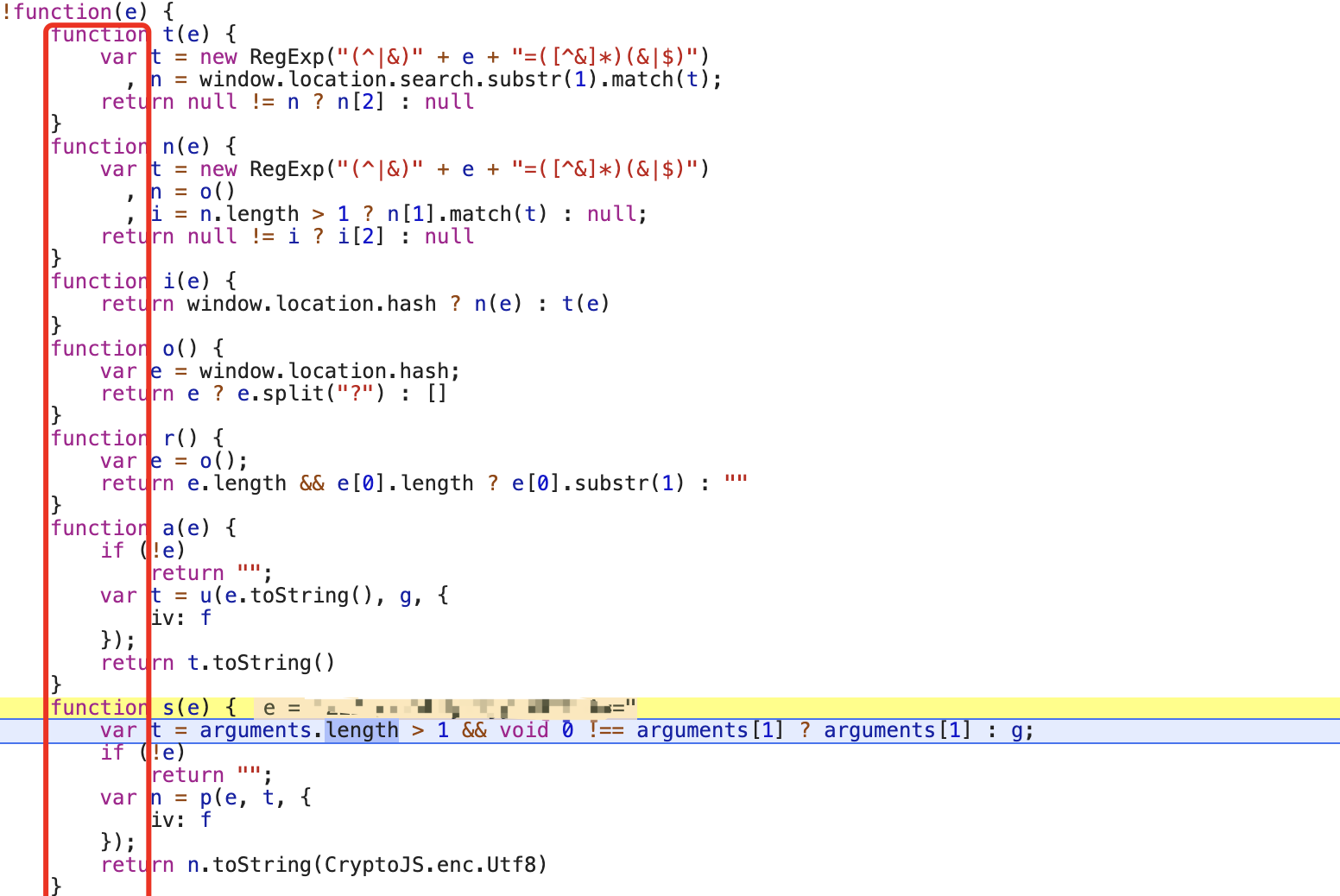
往下翻没几行就看到了下面这个,这里不就是定义了g吗,不止g,还有p也定义了
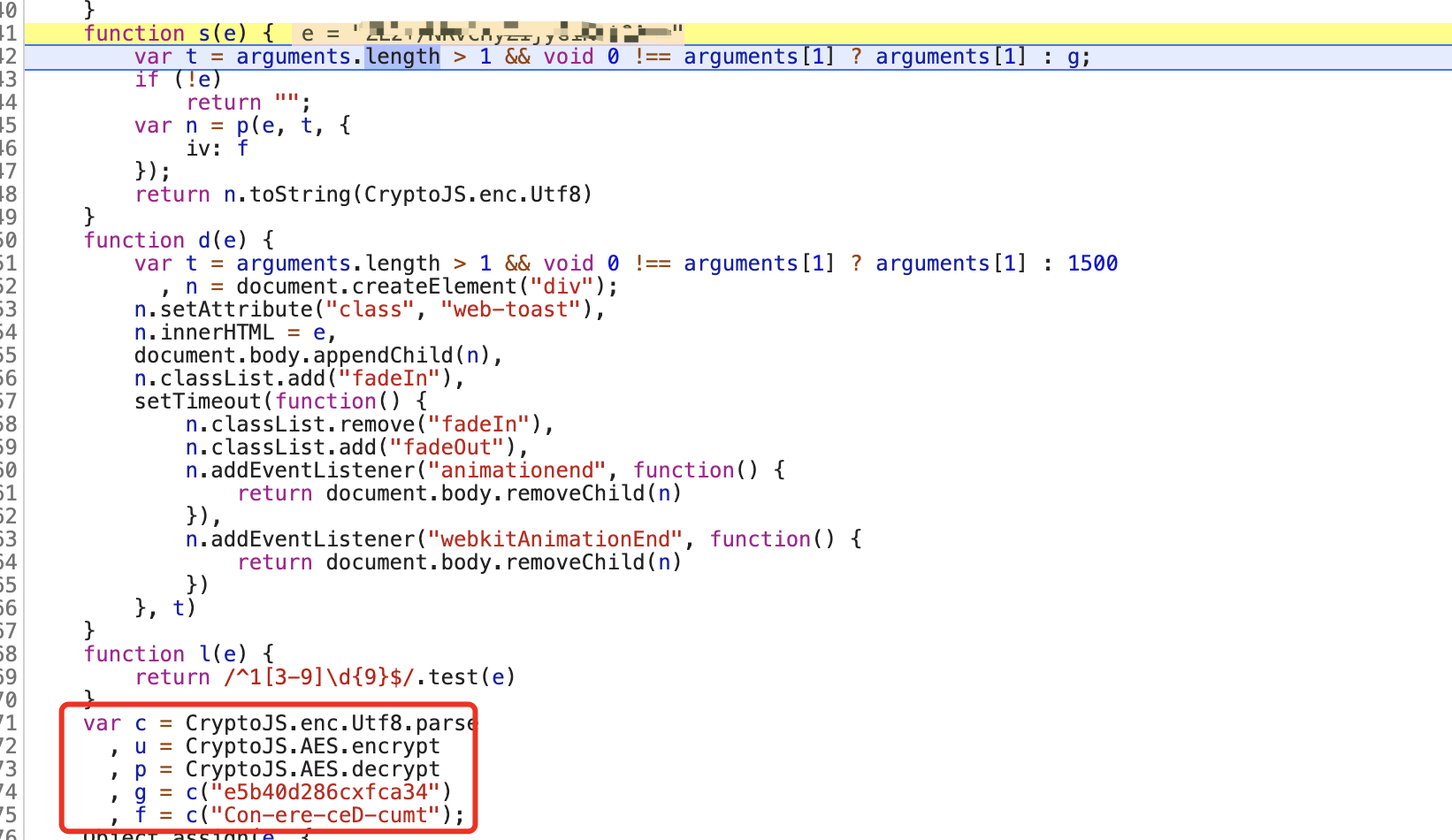
抠出核心代码
那么,我们就可以稍微改下s函数的源码:
function s(e) {
var t = arguments.length > 1 && void 0 !== arguments[1] ? arguments[1] : CryptoJS.enc.Utf8.parse('e5b40d286cxfca34');
if (!e)
return "";
var n = CryptoJS.AES.decrypt(e, t, {
iv: CryptoJS.enc.Utf8.parse('Con-ere-ceD-cumt')
});
return n.toString(CryptoJS.enc.Utf8)
}
去控制台看下呢,我顺便改了下函数名cryp:

没引入CrpytoJS,在控制台引入下:

var script = document.createElement('script');
script.src = "http://cdn.staticfile.org/crypto-js/3.1.9-1/crypto-js.min.js";
document.getElementsByTagName('head')[0].appendChild(script);
或者你也可以直接把crpyto的源码赋值下来然后在控制台然后回车

现在再看,果然成功了
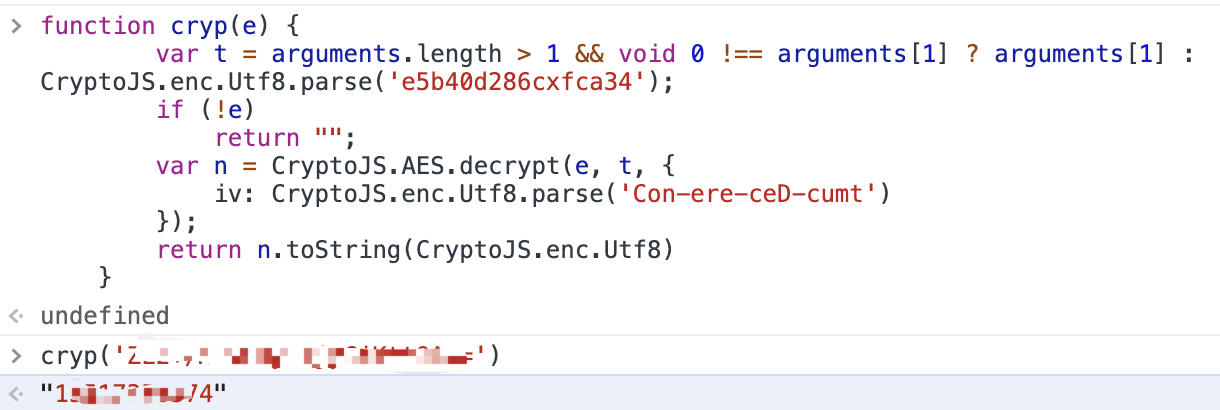
看来没毛病了,核心代码就是这个。
另外说下,我一开始是打算去扣cryptojs里的代码的,后面发现调用层级太多了,所以放弃了,直接引用整个crypto算了
用python实现
用crypto库实现
我之前的文章里,python爬虫- js逆向解密之破解AES(CryptoJS)加密的反爬机制 ,那套代码在这里没法用,所以,只能用下面的代码:
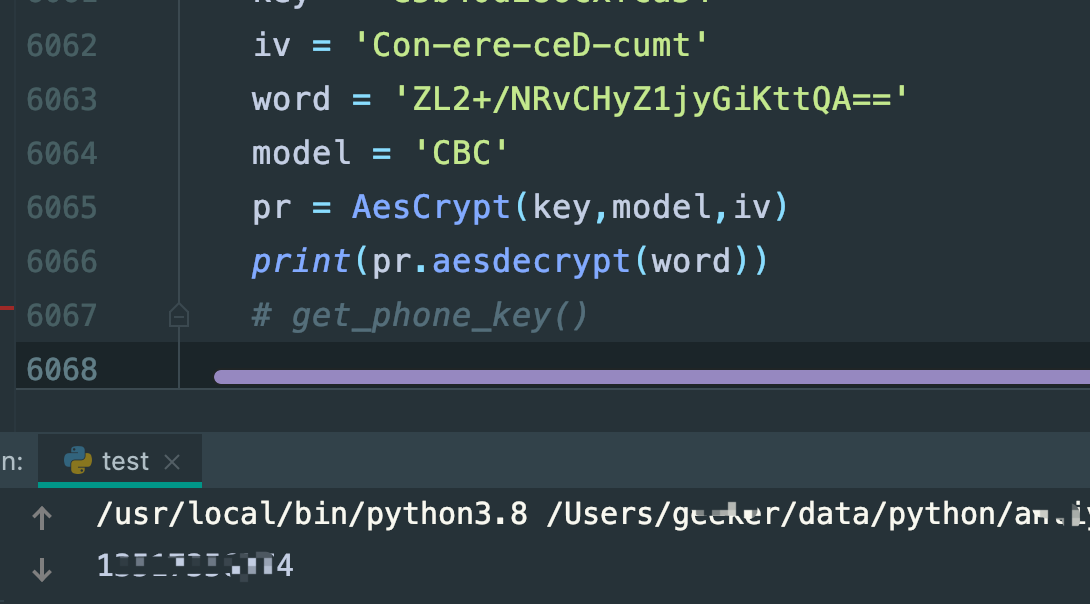
from Crypto.Cipher import AES
import base64
class AesCrypt():
def __init__(self, key, model, iv):
self.model = {'ECB': AES.MODE_ECB, 'CBC': AES.MODE_CBC}[model]
self.key = self.add_16(key)
self.iv = iv.encode()
if model == 'ECB':
self.aes = AES.new(self.key, self.model) # 创建aes对象
elif model == 'CBC':
self.aes = AES.new(self.key, self.model, self.iv) # 创建aes对象
def add_16(self, par):
# python3字符串是unicode编码,需要 encode才可以转换成字节型数据
par = par.encode('utf-8')
while len(par) % 16 != 0:
par += b'\x00'
return par
def aesdecrypt(self, text):
# CBC解密需要重新创建一个aes对象
if self.model == AES.MODE_CBC:
self.aes = AES.new(self.key, self.model, self.iv)
text = base64.decodebytes(text.encode('utf-8'))
self.decrypt_text = self.aes.decrypt(text)
return self.decrypt_text.decode('utf-8').strip('\0')
if __name__ == '__main__':
key = 'e5b40d286cxfca34'
iv = 'Con-ere-ceD-cumt'
word = 'xxxxxxx'
model = 'CBC'
pr = AesCrypt(key,model,iv)
print(pr.aesdecrypt(word))
执行,可行,结果能跟刚才控制台的结果对上:
用node.js实现
另外,不是说一定得python才能实现的,你也可以把crypto和这里抠出来的代码作为字符串,然后用execjs和js2py之类的库执行js,然后拿到结果,或者你还可以不用把crypto的源码拿出来,在你电脑上装上node.js,node里装上crypto,然后把js的环境设置到你本地的node环境也是可以的。
os.environ["NODE_PATH"] = "D:/xxzxx/node_modules"

还没完,找到刚才那个异步加载获得加密字段的xhr,发现这个平台的参数提交用的是payload类型:
没有键值对,也不是json,也不是类json,很强,这种的,我之前的文章里也说过,Python爬虫处理奇葩的请求参数payload,而这里的又完全不同的一种,不过方法是一样的,直接以字符串形式提交即可,看到了吗啊,里面的data的值直接就是一个字符串型即可
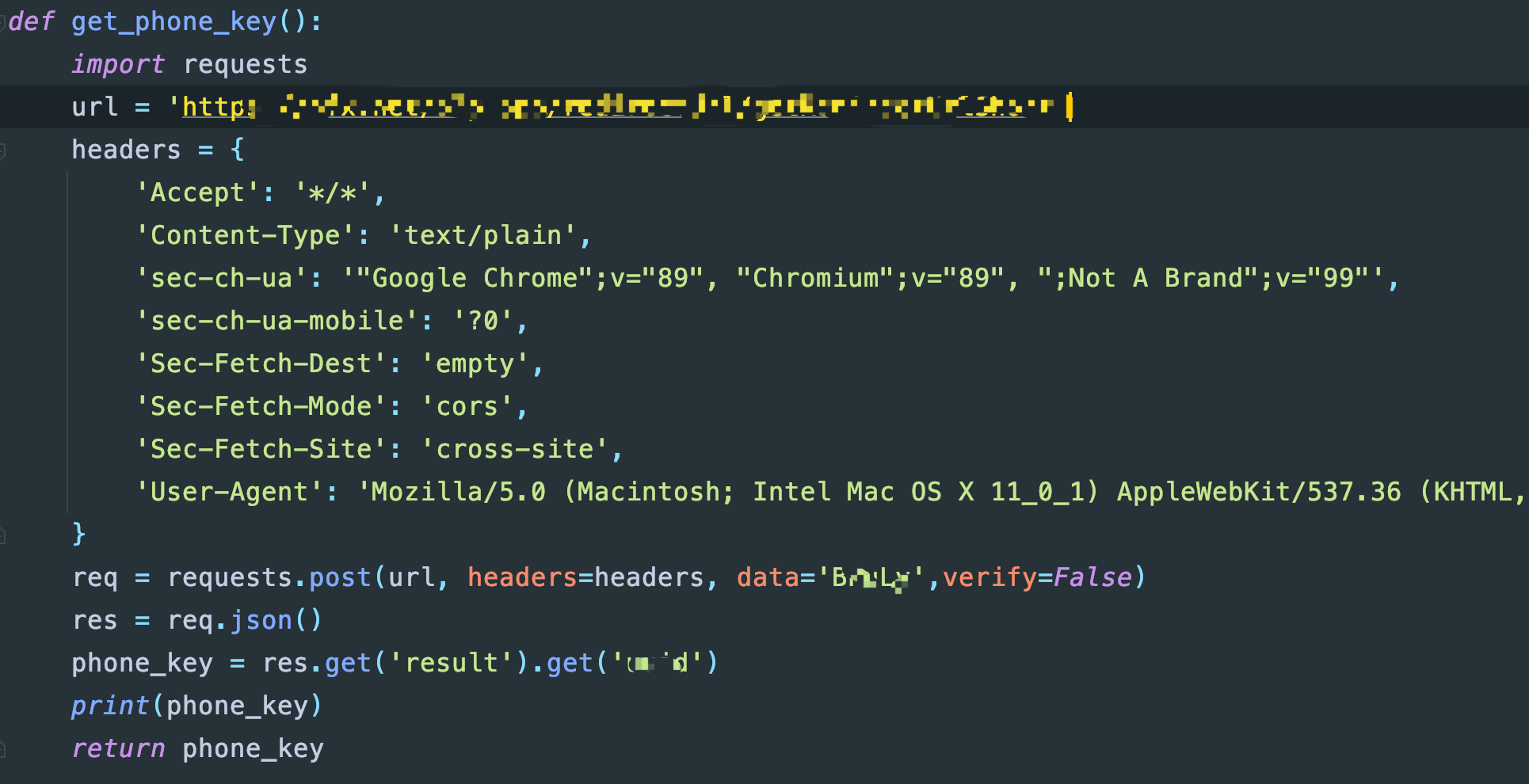
好,将两个对接上即可,完整的代码我就不给了,相信都走到这里了,各位朋友应该可以处理了。本次破解完毕
此时我将代码和结果甩给我那朋友,他发来三个字:【卧槽,稳】。我这个哥们儿一看到有新奇玩意儿就发给我让我搞,我其实挺感谢他的,能通过他一直保持学习是挺好的,而他也是技术出生,他做安全开发的,有很多东西我们都会交流,工作内容也有交集
结语
最近这几篇都是针对js的处理,也越来越觉得js是爬虫的大头,另外最近在某群里,有个老哥说他们公司招爬虫工程师,然后收到的简历上写的基本都是说会xpath处理,没有其他更多的技术呈现,那确实啊,很多人真的对爬虫的理解就是拿到数据,然后用正则或者bs4或者xpath就一顿操作,永远都写不完的表达式,不可能写一辈子的,想想你靠写xpath之类的,工资能提升吗?永远不可能的,还是要多学多用啊,涉及到的都要去了解,才能知道怎么逆向或者说怎么解析数据。就像我说的我这个朋友,他会时不时的给我一些网站让我去分析,为什么,是因为我之前很丧的时候就跟他说不想做开发了,他没有多说啥,而是时不时的给我点东西,让我找到点信心或者说乐趣,我才可以做到现在。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号