Python爬虫之app逆向 frida javascript api手册
frida
什么是frida不用多说了,前面我有篇文章 对app的反爬测试之apk逆向分析-frida绕过ssl pinning检测 已经介绍过了, 不过里面用到的js脚本,貌似挺屌的是吧,那么做开发的肯定知道,想一直用同一套js脚本hook各种app肯定是不行的,那么我们做开发的,肯定想自己写hook脚本,然后读了别人的脚本,发现看不太懂啊,很多方法啥意思都不知道,其实,那些hookj脚本是javascript语法,有点不同的是,里面调用了很多frida 的api,所以就不太容易看懂脚本啥意思,那么我们要想自己写脚本,肯定要学会那些api的使用了
javascript api
以下内容转自看雪大佬 安全鸟一起飞 的frida手册指南
原文地址:
Frida官方手册 - JavaScript API(篇一)
Frida官方手册 - JavaScript API(篇二)
Frida官方手册 - JavaScript API(篇三)
篇一
JavaScript API
目录
- Global
- console
- rpc
- Frida
- Process
- Module
- ModuleMap
- Memory
- MemoryAccessMonitor
- Thread
- Int64
- UInt64
- NativePointer
- NativeFunction
- NativeCallback
- SystemFunction
- Socket
- SocketListener
- SocketConnection
- IOStream
- InputStream
- OutputStream
- UnixInputStream
- UnixOutputStream
- Win32InputStream
- Win32OutputStream
- File
- SqliteDatabase
- SqliteStatement
- Interceptor
- Stalker
- ApiResolver
- DebugSymbol
- Instruction
- ObjC
- Java
- WeakRef
- X86Writer
- X86Relocator
- X86_enum_types
- ArmWriter
- ArmRelocation
- ThumbWriter
- ThumbRelocator
- ARM_enum_types
- Arm64Writer
- Arm64Relocator
- AArch64_enum_types
- MipsWriter
- MipsRelocator
- Mips_enum_types
Global
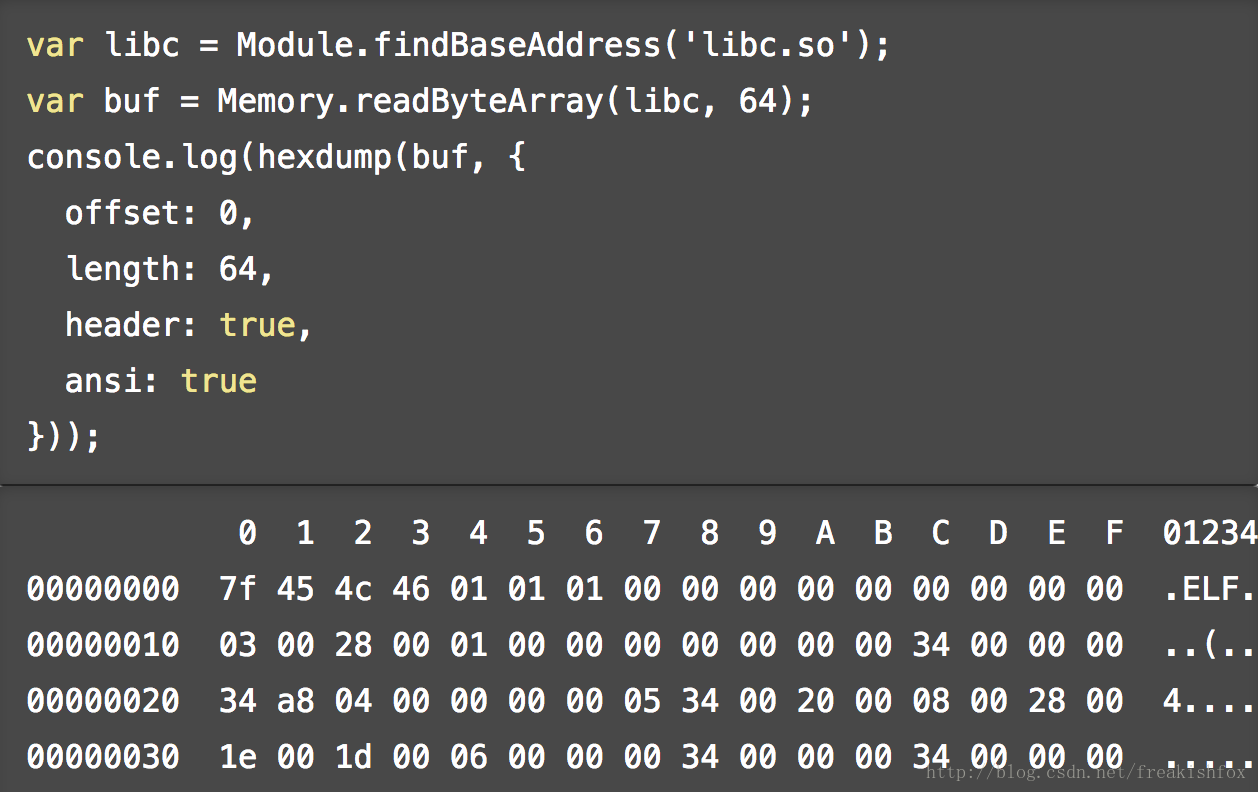
- hexdump(target[, options]): 把一个 ArrayBuffer 或者 NativePointer 的target变量,附加一些 options 属性,按照指定格式进行输出,比如:
- int64(v): new Int64(v) 的缩写格式
- uint64(v): new UInt64(v) 的缩写格式
- ptr(s): new NativePointer(s) 的缩写格式
- NULL ptr(“0”) 的缩写格式
- recv([type, ]callback): 注册一个回调,当下次有消息到来的时候会收到回调消息,可选参数 type 相当于一个过滤器,表示只接收这种类型的消息。需要注意的一点是, 这个消息回调是一次性的, 收到一个消息之后,如果需要继续接收消息,那就需要重新调用一个 recv
- send(message[, data]): 从目标进程中往主控端发 message(必须是可以序列换成Json的),如果你还有二进制数据需要附带发送(比如使用 Memory.readByteArray 拷贝的内存数据),就把这个附加数据填入 data 参数,但是有个要求,就是 data 参数必须是一个 ArrayBuffer 或者是一个整形数组(数值是 0-255)

- setTimeout(fn, delay): 在延迟 delay 毫秒之后,调用 fn,这个调用会返回一个ID,这个ID可以传递给 clearTimeout 用来进行调用取消。
- clearTimeout(id): 取消通过 setTimeout 发起的延迟调用
- setInterval(fn, delay): 每隔 delay 毫秒调用一次 fn,返回一个ID,这个ID可以传给 clearInterval 进行调用取消。
- clearInterval(id): 取消通过 setInterval 发起的调用
console
- console.log(line), console.warn(line), console.error(line): 向标准输入输出界面写入 line 字符串。 比如:使用 Frida-Python 的时候就输出到 stdout 或者 stderr,使用 frida-qml 的时候则输出到 qDebug,如果输出的是一个ArrayBuffer,会以默认参数自动调用 hexdump 进行格式化输出。
rpc
- rpc.exports: 可以在你的程序中导出一些 RPC-Style API函数,Key指定导出的名称,Value指定导出的函数,函数可以直接返回一个值,也可以是异步方式以 Promise 的方式返回,举个例子:

- 对于Python主控端可以使用下面这样的脚本使用导出的函数:

- 在上面这个例子里面,我们使用 script.on(‘message’, on_message) 来监控任何来自目标进程的消息,消息监控可以来自 script 和 session 两个方面,比如,如果你想要监控目标进程的退出,可以使用下面这个语句 session.on(‘detached’, my_function)
Frida
- Frida.version: 包含当前Frida的版本信息
Process
- Process.arch: CPU架构信息,取值范围:ia32、x64、arm、arm64
- Process.platform: 平台信息,取值范围:windows、darwin、linux、qnx
- Process.pageSize: 虚拟内存页面大小,主要用来辅助增加脚本可移植性
- Process.pointerSize: 指针占用的内存大小,主要用来辅助增加脚本可移植性
- Process.codeSigningPolicy: 取值范围是 optional 或者 required,后者表示Frida会尽力避免修改内存中的代码,并且不会执行未签名的代码。默认值是 optional,除非是在 Gadget 模式下通过配置文件来使用 required,通过这个属性可以确定 Interceptor API 是否有限制,确定代码修改或者执行未签名代码是否安全。(译者注:这个目前没有实验清楚,可以参考原文)
- Process.isDebuggerAttached(): 确定当前是否有调试器附加
- Process.getCurrentThreadId(): 获取当前线程ID
- Process.enumerateThreads(callbacks): 枚举所有线程,每次枚举到一个线程就执行回调类callbacks:
Process.enumerateThreadSync(): enumerateThreads()的同步版本,返回线程对象数组- onMatch: function(thread): 当枚举到一个线程的时候,就调用这个函数,其中thread参数包含 :
- id,线程ID
- state,线程状态,取之范围是 running, stopped, waiting, uninterruptible, halted
- context, 包含 pc, sp,分别代表 EIP/RIP/PC 和 ESP/RSP/SP,分别对应于 ia32/x64/arm平台,其他的寄存器也都有,比如 eax, rax, r0, x0 等。
- 函数可以直接返回 stop 来停止枚举。
- onComplete: function(): 当所有的线程枚举都完成的时候调用。
- onMatch: function(thread): 当枚举到一个线程的时候,就调用这个函数,其中thread参数包含 :
- Process.findModuleByAddress(address), Process.getModuleByAddress(address), Process.findModuleByName(name), Process.getModuleByName(name): 根据地址或者名称来查找模块,如果找不到这样的模块,find开头的函数返回 null,get开头的函数会抛出异常。
- Process.enumerateModules(callbacks): 枚举已经加载的模块,枚举到模块之后调用回调对象:
Process.enumerateModulesSync(): enumerateModules() 函数的同步版本,返回模块对象数组- onMatch: function(module): 枚举到一个模块的时候调用,module对象包含如下字段:
- name, 模块名
- base, 基地址
- size,模块大小
- path,模块路径
- 函数可以返回 stop 来停止枚举 。
- onComplete: function(): 当所有的模块枚举完成的时候调用。
- onMatch: function(module): 枚举到一个模块的时候调用,module对象包含如下字段:
- Process.findRangeByAddress(address), Process.getRangeByAddress(address): 返回一个内存块对象, 如果在这个address找不到内存块对象,那么 findRangeByAddress() 返回 null 而 getRangeByAddress 则抛出异常。
- Process.numerateRanges(protection | specifier, callbacks): 枚举指定 protection 类型的内存块,以指定形式的字符串给出:rwx,而 rw- 表示最少是可读可写,也可以用分类符,里面包含 protection 这个Key,取值就是前面提到的rwx,还有一个 coalesce 这个Key,表示是否要把位置相邻并且属性相同的内存块合并给出结果,枚举过程中回调 callbacks 对象:
Process.enumerateRangesSync(protection | specifier): enumerateRanges()函数的同步版本,返回内存块数组- onMatch: function(range): 每次枚举到一个内存块都回调回来,其中Range对象包含如下属性:
- base:基地址
- size:内存块大小
- protection:保护属性
- file:(如果有的话)内存映射文件:
4.1 path,文件路径
4.2 offset,文件内偏移 - 如果要停止枚举过程,直接返回 stop 即可
- onComplete: function(): 所有内存块枚举完成之后会回调
- onMatch: function(range): 每次枚举到一个内存块都回调回来,其中Range对象包含如下属性:
- Process.enumerateMallocRanges(callbacks): 用于枚举在系统堆上申请的内存块
- Process.enumerateMallocRangesSync(protection): Process.enumerateMallocRanges() 的同步版本
- Process.setExceptionHandler(callback): 在进程内安装一个异常处理函数(Native Exception),回调函数会在目标进程本身的异常处理函数之前调用 ,回调函数只有一个参数 details,包含以下几个属性:
- type,取值为下列之一:
- abort
- access-violation
- guard-page
- illegal-instruction
- stack-overflow
- arithmetic
- breakpoint
- single-step
- system
- address,异常发生的地址,NativePointer
- memory,如果这个对象不为空,则会包含下面这些属性:
- operation: 引发一场的操作类型,取值范围是 read, write 或者 execute
- address: 操作发生异常的地址,NativePointer
- context,包含 pc 和 sp 的NativePointer,分别代表指令指针和堆栈指针
- nativeContext,基于操作系统定义的异常上下文信息的NativePointer,在 context 里面的信息不够用的时候,可以考虑用这个指针,但是一般不建议使用(译者注:估计是考虑到可移植性或者稳定性)
- 捕获到异常之后,怎么使用就看你自己了,比如可以把异常信息写到日志里面,然后发送个信息给主控端,然后同步等待主控端的响应之后处理,或者直接修改异常信息里面包含的寄存器的值,尝试恢复掉异常,继续执行。如果你处理了异常信息,那么这个异常回调里面你要返回 true,Frida会把异常交给进程异常处理函数处理,如果到最后都没人去处理这个异常,就直接结束目标进程。
- type,取值为下列之一:
Module
- Module.emuerateImports(name, callbacks): 枚举模块 name 的导入表,枚举到一个导入项的时候回调callbacks, callbacks包含下面2个回调:
Module.eumerateImportsSync(name): enumerateImports()的同步版本- onMatch: function(imp): 枚举到一个导入项到时候会被调用,imp包含如下的字段:
- type,导入项的类型, 取值范围是 function或者variable
- name,导入项的名称
- module,模块名称
- address,导入项的绝对地址
- 以上所有的属性字段,只有 name 字段是一定会有,剩余的其他字段不能保证都有,底层会尽量保证每个字段都能给出数据,但是不能保证一定能拿到数据,onMatch函数可以返回字符串 stop 表示要停止枚举。
- onComplete: function(): 当所有的导入表项都枚举完成的时候会回调
- onMatch: function(imp): 枚举到一个导入项到时候会被调用,imp包含如下的字段:
- Module.emuerateExports(name, callbacks): 枚举指定模块 name 的导出表项,结果用 callbacks 进行回调:
Module.enumerateExportsSync(): Module.enumerateExports()的同步版本- onMatch: function(exp): 其中 exp 代表枚举到的一个导出项,包含如下几个字段:
- type,导出项类型,取值范围是 function或者variable
- name,导出项名称
- address,导出项的绝对地址,NativePointer
- 函数返回 stop 的时候表示停止枚举过程
- onComplete: function(): 枚举完成回调
- onMatch: function(exp): 其中 exp 代表枚举到的一个导出项,包含如下几个字段:
- Module.enumerateSymbols(name, callbacks): 枚举指定模块中包含的符号,枚举结果通过回调进行通知:

- onMatch: function(sym): 其中 sym 包含下面几个字段:
- isGlobal,布尔值,表示符号是否全局可见
- type,符号的类型,取值是下面其中一种:
- unknown
- undefined
- absolute
- section
- prebound-undefined
- indirect
- section,如果这个字段不为空的话,那这个字段包含下面几个属性:
- id,小节序号,段名,节名
- protection,保护属性类型, rwx这样的属性
- name,符号名称
- address,符号的绝对地址,NativePointer
- 这个函数返回 stop 的时候,表示要结束枚举过程
- Module.enumerateSymbolsSync(name): Module.enumerateSymbols() 的同步版本
- onMatch: function(sym): 其中 sym 包含下面几个字段:
- Module.enumerateRanges(name, protection, callbacks): 功能基本等同于 Process.enumerateRanges(),只不过多了一个模块名限定了枚举的范围
- Module.enumerateRangesSync(name, protection): Module.enumerateRanges() 的同步版本
- Module.findBaseAddress(name): 获取指定模块的基地址
- Module.findExportByName(module | null, exp): 返回模块module 内的导出项的绝对地址,如果模块名不确定,第一个参数传入 null,这种情况下会增大查找开销,尽量不要使用。
ModuleMap
- new ModuleMap([filter]): 可以理解为内存模块快照,主要目的是可以作为一个模块速查表,比如你可以用这个快照来快速定位一个具体的地址是属于哪个模块。创建ModuleMap的时候,就是对目标进程当前加载的模块的信息作一个快照,后续想要更新这个快照信息的时候,可以使用 update 进行更新。 这个 filter 参数是可选的,主要是用来过滤你关心的模块,可以用来缩小快照的范围(注意:filter是过滤函数,不是字符串参数),为了让模块进入这个快照里,过滤函数的返回值要设置为true,反之设为false,如果后续内存中的模块加载信息更新了, 还会继续调用这个filter函数。
- has(address): 检查 address 这个地址是不是包含在ModuleMap里面,返回bool值
- find(address), get(address): 返回 address 地址所指向的模块对象详细信息,如果不存在 find 返回null,get 直接会抛出异常,具体的返回的对象的详细信息,可以参考 Process.enumerateModules()
- findName(address), getName(address), findPath(address), getPath(address): 功能跟 find(), get() 类似,但是只返回 name 或者 path 字段,可以省点开销
- update(): 更新ModuleMap信息,如果有模块加载或者卸载,最好调用一次,免得使用旧数据。
Memory
- Memory.scan(address, size, pattern, callbacks): 在 address 开始的地址,size 大小的内存范围内以 pattern 这个模式进行匹配查找,查找到一个内存块就回调callbacks,各个参数详细如下:
Memory.scanSync(address, size, pattern): 内存扫描 scan() 的同步版本- pattern 比如使用13 37 ?? ff来匹配0x13开头,然后跟着0x37,然后是任意字节内容,接着是0xff这样的内存块
- callbacks 是扫描函数回调对象:
- onMatch: function(address, size): 扫描到一个内存块,起始地址是address,大小size的内存块,返回 stop 表示停止扫描
- onError: function(reason): 扫描内存的时候出现内存访问异常的时候回调
- onComplete: function(): 内存扫描完毕的时候调用
- Memory.alloc(size): 在目标进程中的堆上申请size大小的内存,并且会按照Process.pageSize对齐,返回一个NativePointer,并且申请的内存如果在JavaScript里面没有对这个内存的使用的时候会自动释放的。也就是说,如果你不想要这个内存被释放,你需要自己保存一份对这个内存块的引用。
- Memory.copy(dust, src, n): 就像是memcpy
- Memory.dup(address, size): 等价于 Memory.alloc()和Memory.copy()的组合。
- Memory.protect(address, size, protection): 更新address开始,size大小的内存块的保护属性,protection 的取值参考 Process.enumerateRanges(),比如:Memory.protect(ptr(“0x123”, 4096, ‘rw-‘));
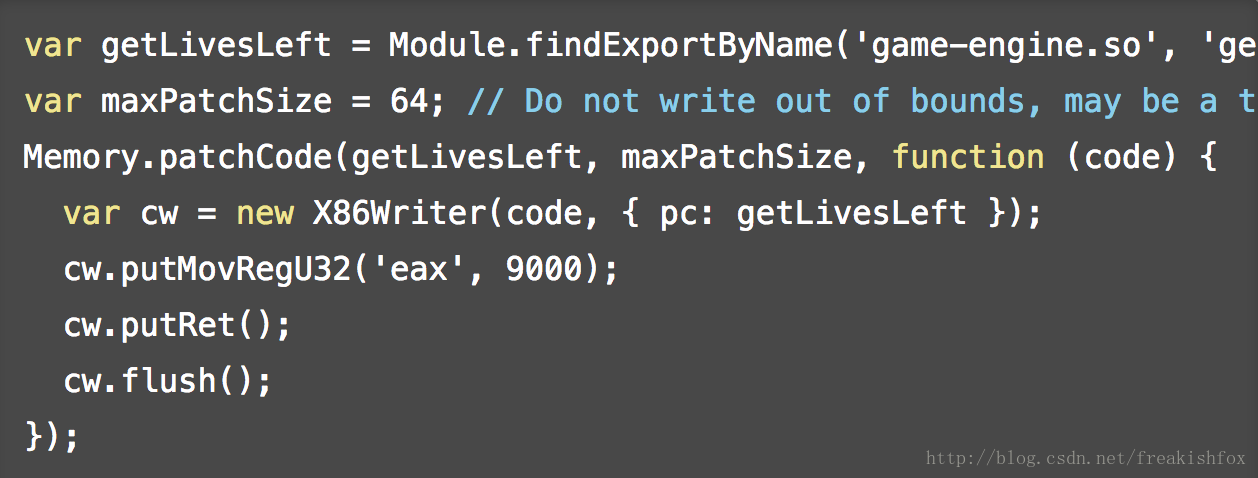
- Memory.patchCode(address, size, apply): apply是一个回调函数,这个函数是用来在 address 开始的地址和 size 大小的地方开始Patch的时候调用,回调参数是一个NativePointer的可写指针,需要在apply回调函数里面要完成patch代码的写入,注意,这个可写的指针地址不一定和上面的address是同一个地址,因为在有的系统上是不允许直接写入代码段的,需要先写入到一个临时的地方,然后在影射到响应代码段上,(比如 iOS上, 会引发进程丢失 CS_VALID 状态),比如:
- 下面是接着是一些数据类型读写:
- Memory.readPointer(address)
- Memory.writePointer(address, ptr)
- Memory.readS8, Memory.readU8
- …
MemoryAccessMonitor

-
MemoryAccessMonitor.enable(ranges, callbacks): 监控一个或多个内存块的访问,在触发到内存访问的时候发出通知。ranges 要么是一个单独的内存块,要么是一个内存块数组,每个内存块包含如下属性:
- base: 触发内存访问的NativePointer地址
- size: 被触发访问的内存块的大小
- callbacks: 回调对象结构:
- onAccess: function(details): 发生访问的时候同步调用这个函数,details对象包含如下属性:
- operation: 触发内存访问的操作类型,取值范围是 read, write 或者 execute
- from: 触发内存访问的指令地址,NativePointer
- address: 被访问的内存地址
- rangeIndex: 被访问的内存块的索引,就是调用MemoryAccessMonitor.enable()的时候指定的内存块序号
- pageIndex: 在被监控内存块范围内的页面序号
- pagesCompleted: 到目前为止已经发生过内存访问的页面的个数(已经发生过内存访问的页面将不再进行监控)
- pagesTotal: 初始指定的需要监控的内存页面总数
-
MemoryAccessMonitor.disable(): 停止监控页面访问操作
Thread
- Thread.backtrace([context, backtracer]): 抓取当前线程的调用堆栈,并以 NativePointer 指针数组的形式返回。
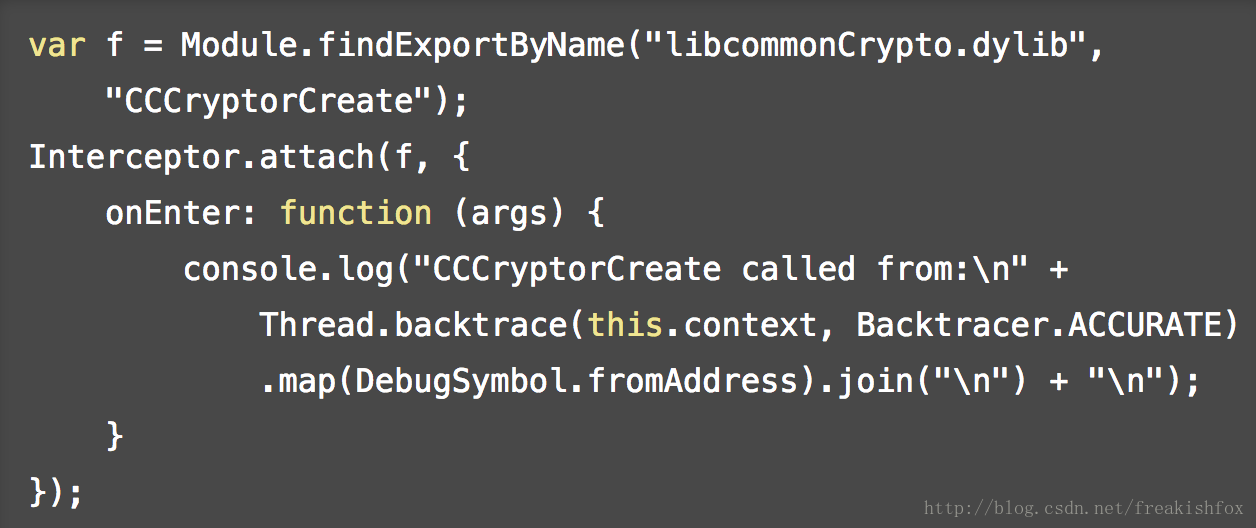
Thread.sleep(delay): 线程暂停 delay 秒执行- 如果你是在 Interceptor.onEnter或者Interceptor.onLeave 中调用这个函数的话,那就必须要把 this.context 作为参数传入,这样就能拿到更佳精准的堆栈调用信息,如果省略这个参数不传,那就意味着从当前堆栈的位置开始抓取,这样的抓取效果可能不会很好,因为有不少V8引擎的栈帧的干扰。
- 第二个可选参数 backtracer,表示使用哪种类型的堆栈抓取算法,目前的取值范围是 Backtracer.FUZZY 和 Backtracer.ACCURATE,目前后者是默认模式。精确抓取模式下,如果如果程序是调试器友好(比如是标准编译器编译的结果,没有什么反调试技巧)或者有符号表的支持,抓取效果是最好的,而模糊抓取模式下,抓取器会在堆栈上尝试抓取,并且会猜测里面包含的返回地址,也就是说中间可能包含一些错误的信息,但是这种模式基本能在任何二进制程序里面工作:
篇二
JavaScript API
Int64
- new Int64(v): 以v为参数,创建一个Int64对象,v可以是一个数值,也可以是一个字符串形式的数值表示,也可以使用 Int64(v) 这种简单的方式。
- add(rhs), sub(rhs), and(rhs), or(rhs), xor(rhs): Int64相关的加减乘除。
- shr(n), shl(n): Int64相关的左移、右移操作
- compare(rhs): Int64的比较操作,有点类似 String.localCompare()
- toNumber(): 把Int64转换成一个实数
- toString([radix = 10]): 按照一定的数值进制把Int64转成字符串,默认是十进制
UInt64
- 可以直接参考Int64
NativePointer
- 可以直接参考Int64
NativeFunction
- new NativeFunction(address, returnType, argTypes[, abi]): 在address(使用NativePointer的格式)地址上创建一个NativeFunction对象来进行函数调用,returnType 指定函数返回类型,argTypes 指定函数的参数类型,如果不是系统默认类型,也可以选择性的指定 abi 参数,对于可变类型的函数,在固定参数之后使用 “…” 来表示。
-
类和结构体
- 在函数调用的过程中,类和结构体是按值传递的,传递的方式是使用一个数组来分别指定类和结构体的各个字段,理论上为了和需要的数组对应起来,这个数组是可以支持无限嵌套的,结构体和类构造完成之后,使用NativePointer的形式返回的,因此也可以传递给Interceptor.attach() 调用。
- 需要注意的点是, 传递的数组一定要和需要的参数结构体严格吻合,比如一个函数的参数是一个3个整形的结构体,那参数传递的时候一定要是 [‘int’, ‘int’, ‘int’],对于一个拥有虚函数的类来说,调用的时候,第一个参数一定是虚表指针。
-
Supported Types
- void
- pointer
- int
- uint
- long
- ulong
- char
- uchar
- float
- double
- int8
- uint8
- int16
- uint16
- int32
- uint32
- int64
- uint64
-
Supported ABIs
- default
- Windows 32-bit:
- sysv
- stdcall
- thiscall
- fastcall
- mscdecl
- Windows 64-bit:
- win64
- UNIX x86:
- sysv
- unix64
- UNIX ARM:
- sysv
- vfp
NativeCallback
- new NativeCallback(func, returnType, argTypes[, abi]): 使用JavaScript函数 func 来创建一个Native函数,其中returnType和argTypes分别指定函数的返回类型和参数类型数组。如果不想使用系统默认的 abi 类型,则可以指定 abi 这个参数。关于argTypes和abi类型,可以查看NativeFunction来了解详细信息,这个对象的返回类型也是NativePointer类型,因此可以作为 Interceptor.replace 的参数使用。
SystemFunction
- new SystemFunction(address, returnType, argTypes[, abi]): 功能基本和NativeFunction一致,但是使用这个对象可以获取到调用线程的last error状态,返回值是对平台相关的数值的一层封装,为value对象,比如是对这两个值的封装, errno(UNIX) 或者 lastError(Windows)。
Socket
SocketListener
SocketConnection
IOStream
InputStream
OutputStream
UnixInputStream
UnixOutputStream
Win32InputStream
Win32OutputStream
File
SqliteDatabase
SqliteStatement
Interceptor
- Interceptor.attach(target, callbacks): 在target指定的位置进行函数调用拦截,target是一个NativePointer参数,用来指定你想要拦截的函数的地址,有一点需要注意,在32位ARM机型上,ARM函数地址末位一定是0(2字节对齐),Thumb函数地址末位一定1(单字节对齐),如果使用的函数地址是用Frida API获取的话, 那么API内部会自动处理这个细节(比如:Module.findExportByName())。其中callbacks参数是一个对象,大致结构如下:
事实上Frida可以在代码的任意位置进行拦截,但是这样一来 callbacks 回调的时候,因为回调位置有可能不在函数的开头,这样onEnter这样的回调参数Frida只能尽量的保证(比如拦截的位置前面的代码没有修改过传入的参数),不能像在函数头那样可以确保正确。- onEnter: function(args): 被拦截函数调用之前回调,其中原始函数的参数使用args数组(NativePointer对象数组)来表示,可以在这里修改函数的调用参数。
- onLeave: function(retval): 被拦截函数调用之后回调,其中retval表示原始函数的返回值,retval是从NativePointer继承来的,是对原始返回值的一个封装,你可以使用retval.replace(1337)调用来修改返回值的内容。需要注意的一点是,retval对象只在 onLeave函数作用域范围内有效,因此如果你要保存这个对象以备后续使用的话,一定要使用深拷贝来保存对象,比如:ptr(retval.toString())。
- 拦截器的attach调用返回一个监听对象,后续取消拦截的时候,可以作为 Interceptor.detach() 的参数使用。
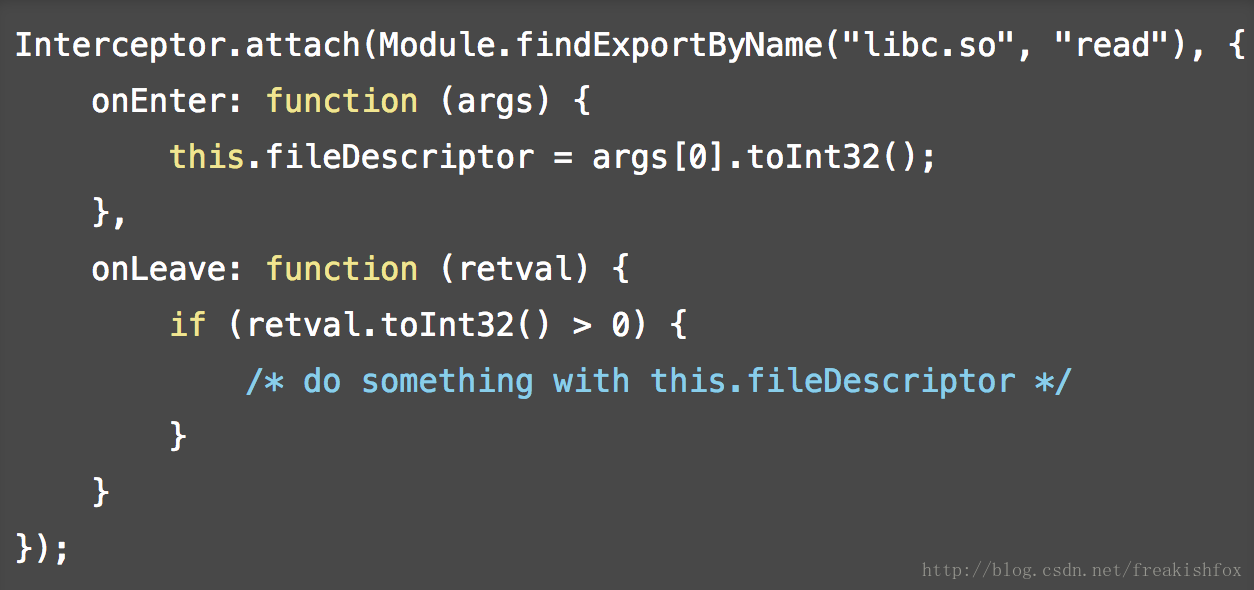
- 还有一个比较方便的地方,那就是在回调函数里面,包含了一个隐藏的 this 的线程tls对象,方便在回调函数中存储变量,比如可以在 onEnter 中保存值,然后在 onLeave 中使用,看一个例子:
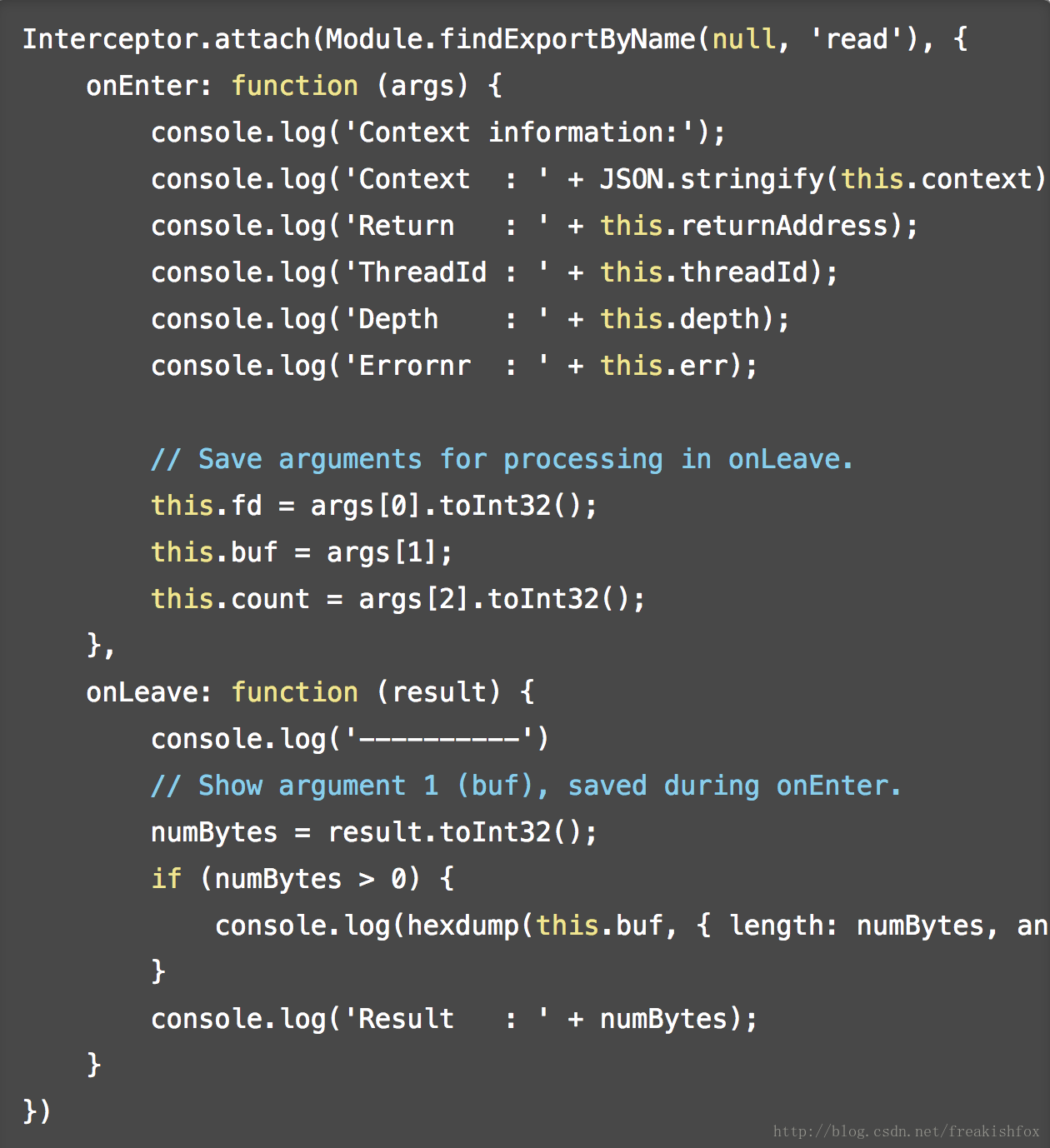
- 另外,this 对象还包含了一些额外的比较有用的属性:
Interceptor.detachAll(): 取消之前所有的拦截调用- returnAddress: 返回NativePointer类型的 address 对象
- context: 包含 pc,sp,以及相关寄存器比如 eax, ebx等,可以在回调函数中直接修改
- errno: (UNIX)当前线程的错误值
- lastError: (Windows) 当前线程的错误值
- threadId: 操作系统线程Id
- depth: 函数调用层次深度
- 看个例子:

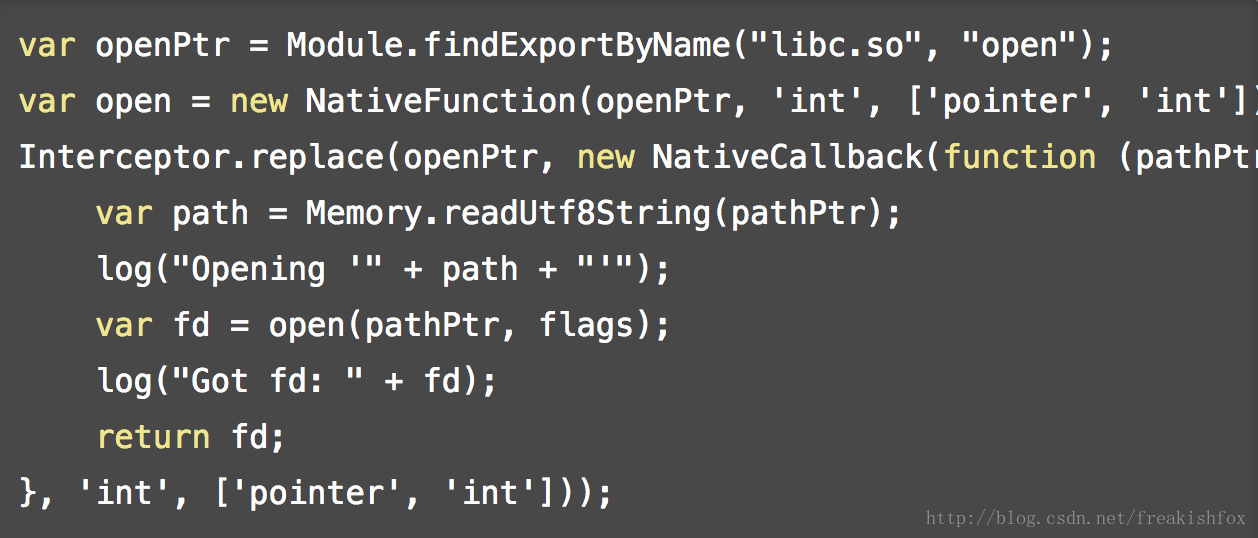
- Interceptor.replace(target, replacement): 函数实现代码替换,这种情况主要是你想要完全替换掉一个原有函数的实现的时候来使用,注意replacement参数使用JavaScript形式的一个NativeCallback来实现,后续如果想要取消这个替换效果,可以使用 Interceptor.revert调用来实现,如果你还想在你自己的替换函数里面继续调用原始的函数,可以使用以 target 为参数的NativeFunction对象来调用,来看一个例子:
- Interceptor.revert(target): 还原函数的原始实现逻辑,即取消前面的 Interceptor.replace调用
- Interceptor.flush(): 确保之前的内存修改操作都执行完毕,并切已经在内存中发生作用,只要少数几种情况需要这个调用,比如你刚执行了 attach() 或者 replace() 调用,然后接着想要使用NativeFunction对象对函数进行调用,这种情况就需要调用flush。正常情况下,缓存的调用操作会在当前线程即将离开JavaScript运行时环境或者调用send()的时候自动进行flush操作,也包括那些底层会调用 send() 操作的函数,比如 RPC 函数,或者任何的 console API
Stalker
- Stalker.follow([threadId, options]): 开始监视线程ID为 threadId(如果是本线程,可以省略)的线程事件,举个例子:


- Stalker.unfollow([threadId]): 停止监控线程事件,如果是当前线程,则可以省略 threadId 参数
- Stalker.parse(events[, options]): 按照指定格式介些 GumEvent二进制数据块,按照options的要求格式化输出,举个例子:

- Stalker.garbageCollect(): 在调用Stalker.unfollow()之后,在一个合适的时候,释放对应的内存,可以避免多线程竞态条件下的内存释放问题。
- Stalker.addCallProbe(address, callback): 当address地址处的函数被调用的时候,调用callback对象(对象类型和Interceptor.attach.onEnter一致),返回一个Id,可以给后面的Stalker.removeCallProbe使用
- Stalker.removeCallProbe(): 移除前面的 addCallProbe 调用效果。
- Stalker.trustThreshold: 指定一个整型x,表示可以确保一段代码在执行x次之后,代码才可以认为是可靠的稳定的, -1表示不信任,0表示持续信任,N表示执行N次之后才是可靠的,稳定的,默认值是1。
- Stalker.queueCapacity: 指定事件队列的长度,默认长度是16384
- Stalker.queueDrainInterval: 事件队列查询派发时间间隔,默认是250ms,也就是说1秒钟事件队列会轮询4次
ApiResolver
- new ApiResolver(type): 创建指定类型type的API查找器,可以根据函数名称快速定位到函数地址,根据当前进程环境不同,可用的ApiResolver类型也不同,到目前为止,可用的类型有:
- Module: 枚举当前进程中已经加载的动态链接库的导入导出函数名称。
- objc: 定位已经加载进来的Object-C类方法,在macOS和iOS进程中可用,可以使用 Objc.available 来进行运行时判断,或者在 try-catch 块中使用 new ApiResolver(‘objc’) 来尝试创建。
- 解析器在创建的时候,会加载最小的数据,后续使用懒加载的方式来持续加载剩余的数据,因此最好是一次相关的批量调用使用同一个resolver对象,然后下次的相关操作,重新创建一个resolver对象,避免使用上个resolver的老数据。
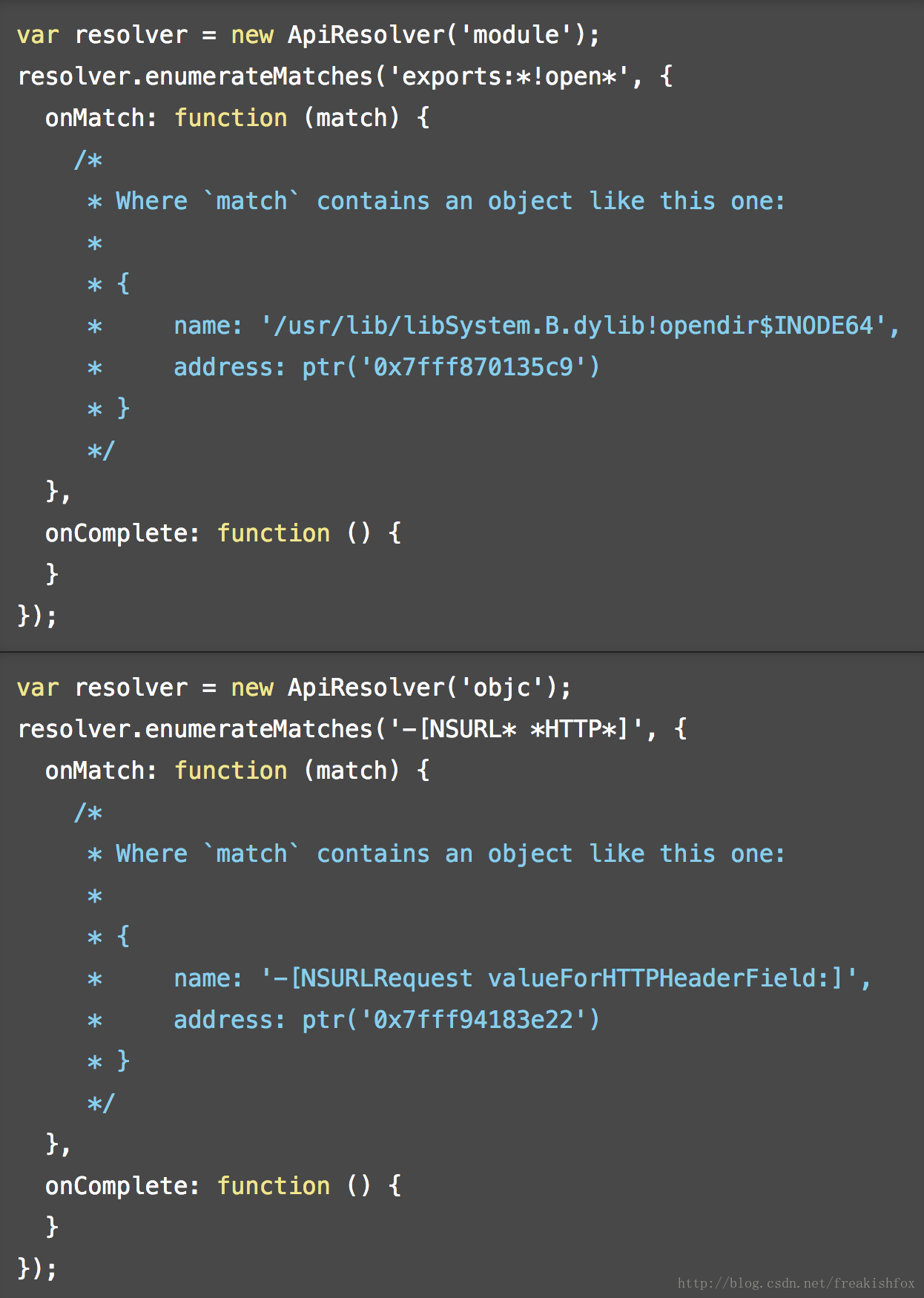
- enumerateMatches(query, callbacks): 执行函数查找过程,按照参数query来查找,查找结果调用callbacks来回调通知:
enumerateMatchesSync(query): enumerateMatches()的同步版本,直接返回所有结果的数组形式- onMatch: function(match): 每次枚举到一个函数,调用一次,回调参数match包含name和address两个属性。
- onComplete: function(): 整个枚举过程完成之后调用。
- 举个例子:
DebugSymbol
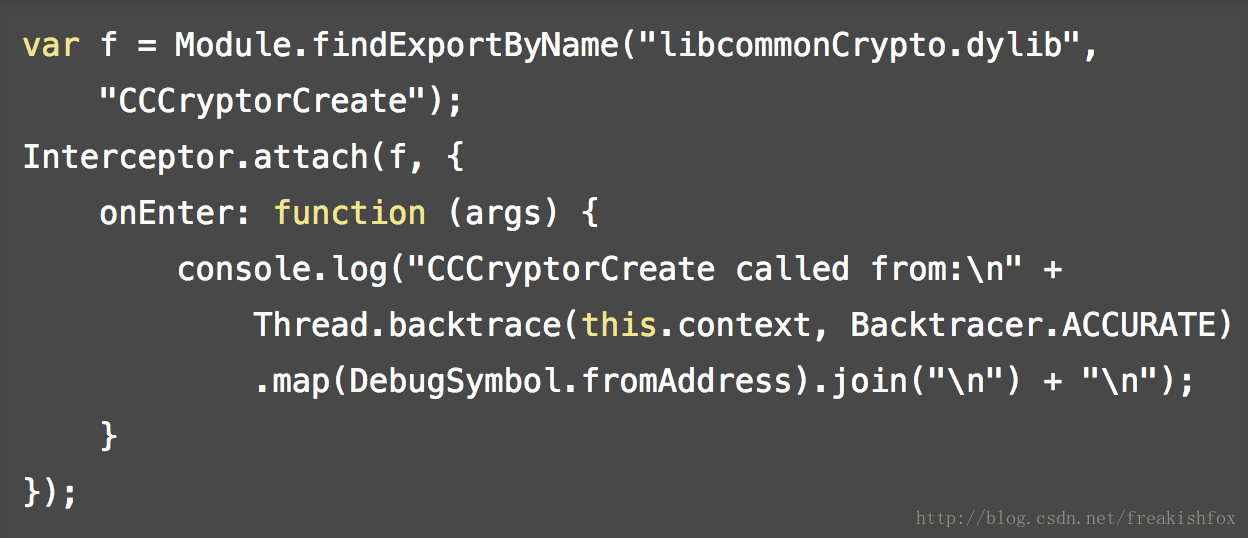
- DebugSymbol.fromAddress(address), DebugSymbol.fromName(name): 在指定地址或者指定名称查找符号信息,返回的符号信息对象包含下面的属性:
DebugSymbol.getFunctionByName(name), DebugSymbol.findFunctionsNamed(name), DebugSymbol.findFunctionsMatching(glob): 这三个函数,都是根据符号信息来查找函数,结果返回 NativePointer 对象。- address: 当前符号的地址,NativePointer
- name: 当前符号的名称,字符串形式
- moduleName: 符号所在的模块名称
- fileName: 符号所在的文件名
- lineNumber: 符号所在的文件内的行号
- 为了方便使用,也可以在这个对象上直接使用 toString() ,输出信息的时候比较有用,比如和 Thread.backtrace 配合使用,举个例子来看:
Instruction
- Instruction.parse(target): 在 target 指定的地址处解析指令,其中target是一个NativePointer。注意,在32位ARM上,ARM函数地址需要是2字节对齐的,Thumb函数地址是1字节对齐的,如果你是使用Frida本身的函数来获取的target地址,Frida会自动处理掉这个细节,parse函数返回的对象包含如下属性:
- address: 当前指令的EIP,NativePointer类型
- next: 下条指令的地址,可以继续使用parse函数
- size: 当前指令大小
- mnemonic: 指令助记符
- opStr: 字符串格式显示操作数
- operands: 操作数数组,每个操作数对象包含type和value两个属性,根据平台不同,有可能还包含一些额外属性
- regsRead: 这条指令显式进行读取的寄存器数组
- regsWritten: 这条指令显式的写入的寄存器数组
- groups: 该条指令所属的指令分组
- toString(): 把指令格式化成一条人比较容易读懂的字符串形式
- 关于operands和groups的细节,请参考CapStone文档
ObjC
Java
- Java.available: 布尔型取值,表示当前进程中是否存在完整可用的Java虚拟机环境,Dalvik或者Art,建议在使用Java方法之前,使用这个变量来确保环境正常。
- Java.enumerateLoadedClasses(callbacks): 枚举当前进程中已经加载的类,每次枚举到加载的类回调callbacks:
Java.enumerateLoadedClassesSync(): 同步枚举所有已经加载的类- onMatch: function(className): 枚举到一个类,以类名称进行回调,这个类名称后续可以作为 Java.use() 的参数来获取该类的一个引用对象。
- onComplete: function(): 所有的类枚举完毕之后调用
- Java.use(fn): 把当前线程附加到Java VM环境中去,并且执行Java函数fn(如果已经在Java函数的回调中,则不需要再附加到VM),举个例子:
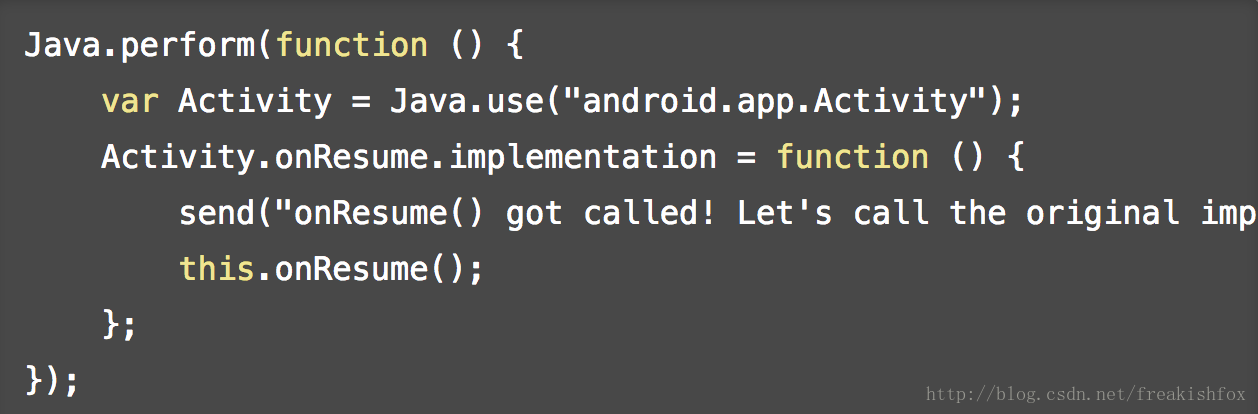
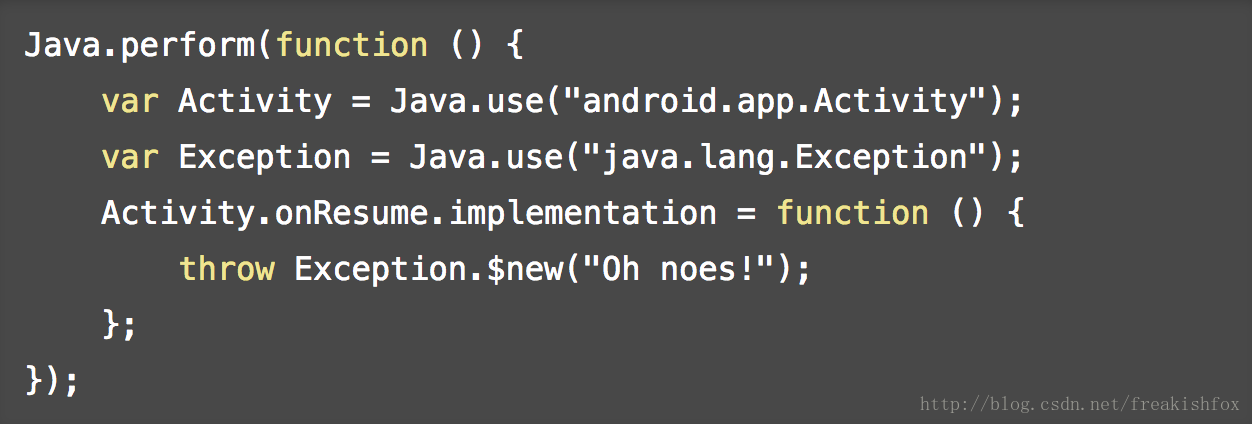
- Java.use(className): 对指定的类名动态的获取这个类的JavaScript引用,后续可以使用$new()来调用类的构造函数进行类对象的创建,后续可以主动调用 $dispose() 来调用类的析构函数来进行对象清理(或者等待Java的垃圾回收,再或者是JavaScript脚本卸载的时候),静态和非静态成员函数在JavaScript脚本里面也都是可见的, 你可以替换Java类中的方法,甚至可以在里面抛出异常,比如:
- Java.scheduleOnMainThread(fn): 在虚拟机主线程上执行函数fn
- Java.choose(className, callbacks): 在Java的内存堆上扫描指定类名称的Java对象,每次扫描到一个对象,则回调callbacks:
Java.cast(handle, klass): 使用对象句柄handle按照klass(Java.use方法返回)的类型创建一个对象的JavaScript引用,这个对象引用包含一个class属性来获取当前对象的类,也包含一个$className属性来获取类名称字符串,比如:- onMatch: function(instance): 每次扫描到一个实例对象,调用一次,函数返回stop结束扫描的过程
- onComplete: function(): 当所有的对象都扫描完毕之后进行回调

篇三
JavaScript API
WeakRef
- WeakRef.bind(value, fn): 监控value对象,当被监控的对象即将被垃圾回收或者脚本即将被卸载的时候,调用回调函数fn,bind返回一个唯一ID,后续可以使用这个ID进行 WeakRef.unbind()调用来取消前面的监控。这个API还是很有用处的,比如你想要在JavaScript的某个对象销毁的时候跟着销毁一些本地资源,这种情况下,这个机制就比较有用了。
- WeakRef.unbind(id): 停止上述的对象监控,并且会立即调用一次f n
x86Writer
- new X86Writer(codeAddress[, {pc: ptr(‘0x1234’)}]): 创建一个x86机器码生成器,并且在codeAddress指向的内存进行写入,codeAddress是NativePointer类型,第二个参数是可选参数,用来指定程序的初始EIP。在iOS系统上,使用Memory.patchCode()的时候,指定初始EIP是必须的,因为内存写入是先写入到一个临时的位置,然后再映射到指定位置的内存
- reset(codeAddress[, { pc: ptr(‘0x1234’) }]): 取消codeAddress位置的上次的代码写入
- dispose(): 立即进行X86相关的内存修改清理
- flush(): 代码中标签引用的解析,操作缓存立即应用到内存中去。在实际的应用中,当生成一段代码片段的时候,就应该调用一次这个函数。多个相关联的函数片段在一起使用的时候,也应该调用一次,尤其是要在一起协同运行的几个函数片段。
- base: 输出结果的第一个字节码的内存位置,NativePointer类型
- code: 输出结果的下一个字节码的内存位置,NativePointer类型
- pc: 输出结果的指令指针的内存位置,NativePointer类型
- offset: 当前的偏移(JavaScript数值)
- putLabel(id): 在当前位置插入一个标签,标签用字符串id表示
- putCallAddressWithArguments(fund, args): 准备好一个调用C函数的上下文环境,其中args表示被调用函数的参数数组(JavaScript数组),数组里面可以是字符串形式指定的寄存器,可以是一个数值,也可以是一个指向立即数的NativePointer
- putCallAddressWithAlignedArguments(func, args): 跟上面一个函数差不多,但是参数数组是16字节对齐的
- putCallRegWithArguments(reg, args): 准备好一个调用C函数的上下文环境,其中args表示被调用函数的参数数组(JavaScript数组),数组里面可以是字符串形式指定的寄存器,可以是一个数值,也可以是一个指向立即数的NativePointer
- putCallRegWithAlignedArguments(reg, args): 参数数组16字节对齐
- putCallRegOffsetPtrWithArguments(reg, offset, args): 准备好一个调用C函数的上下文环境,其中args表示被调用函数的参数数组(JavaScript数组),数组里面可以是字符串形式指定的寄存器,可以是一个数值,也可以是一个指向立即数的NativePointer
- putCallAddress(address): 写入一个Call指令
- putCallReg(reg): 写入一个Call指令
- putCallRegOffsetPtr(reg, offset): 写入一个Call指令
- putCallIndirect(addr): 写入一个Call指令
- putCallNearLabel(labelId): 在前面定义的Label处创建一个Call 指令
- putLeave(): 创建一个 LEAVE 指令
- putRet(): 创建一个 RET 指令
- putRetImm(immValue): 创建一个RET指令
- putJmpShortLabel(labelId): 创建一个JMP指令,跳转到labelId标志的位置
- putJmpNearLabel(labelId): 创建一个JMP指令,跳转到labelId标志的位置
- putJmpReg(reg): 创建一个JMP指令
- putJmpRegPtr(reg): 创建一个JMP指令
- putJmpRegOffsetPtr(reg, offset): 创建一个JMP指令
- putJmpNearPtr(address): 创建一个JMP指令
- putJccShort(labelId, target, hint): 创建一个JCC指令
- putJccNear(labelId, target, hint): 在labelId处创建一个JCC指令
- putAddRegImm(reg, immValue)
- putAddRegReg
- putAddRegNearPtr(dstReg, srcAddress)
- putSubRegImm(reg, immValue)
- putSubRegReg(dstReg, srcReg)
- putSubRegNearPtr(dstReg, srcAddress)
- putIncReg(reg)
- putDecReg(reg)
- putIncRegPtr(target, reg)
- putDecRegPtr(target, reg)
- putLockXaddRegPtrReg(dstReg, srcReg)
- putLockIncImm32Ptr(target)
- putLockDecImm32Ptr(target)
- putAddRegReg(dstReg, srcReg)
- putAddRegU32(reg, immValue)
- putShlRegU8(reg, immValue)
- putShrRegU8(reg, immValue)
- putXorRegReg(dstReg, srcReg)
- putMovRegReg(dstReg, srcReg)
- putMovRegU32(dstReg, immValue)
- putMovRegU64(dstReg, immValue)
- putMovRegAddress(dstReg, immValue)
- putMovRegPtrU32(dstReg, immValue)
- putMovRegOffsetPtrU32(dstReg, dstOffset, immValue)
- putMovRegPtrReg(dstReg, srcReg)
- putMovRegOffsetPtrReg(dstReg, dstOffset, srcReg)
- putMovRegRegPtr(dstReg, srcReg)
- putMovRegRegOffsetPtr(dstReg, srcReg, srcOffset)
- putMovRegBaseIndexScaleOffsetPtr(dstReg, baseReg, indexReg, scale, offset)
- putMovRegNearPtr(dstReg, srcAddress)
- putMovNearPtrReg(dstAddress, srcReg)
- putMovFsU32PtrReg(fsOffset, srcReg)
- putMovRegFsU32Ptr(dstReg, fsOffset)
- putMovGsU32PtrReg(fsOffset, srcReg)
- putMovqXmm0EspOffsetPtr(offset)
- putMovqEaxOffsetPtrXmm0(offset)
- putMovdquXmm0EspOffsetPtr(offset)
- putMovdquEaxOffsetPtr(offset)
- putLeaRegRegOffset(dstReg, srcReg, srcOffset)
- putXchgRegRegPtr(leftReg, rightReg)
- putPushU32(immValue)
- putPushNearPtr(address)
- putPushReg(reg)
- putPopReg(reg)
- putPushImmPtr(immPtr)
- putPushax()
- putPopax()
- putPushfx()
- putPopfx()
- putTestRegReg(regA, regB)
- putTestRegU32(reg, immValue)
- putCmpRegI32(reg, immValue)
- putCmpRegOffsetPtrReg(regA, offset, regB)
- putCmpImmPtrImmU32(immPtr, immValue)
- putCmpRegReg(regA, regB)
- putClc()
- putStc()
- putCld()
- putStd()
- putCpuid()
- putLfence()
- putRdtsc()
- putPause()
- putNop()
- putBreakpoint()
- putPadding(n)
- putNopPadding(n)
- putU8(value)
- putS8(value)
- putBytes(data) 从ArrayBuffer中拷贝原始数据
X86Relocator
- new X86Relocator(inputCode, output): 创建一个代码重定位器,用以进行代码从一个位置拷贝到另一个位置的时候进行代码重定位处理,源地址是 inputCode的NativePointer,output表示结果地址,可以用X86Writer对象来指向目的内存地址
- reset(inputCode, output): 回收上述的X86Relocator对象
- dispose(): 内存清理
- input: 最后一次读取的指令, 一开始是null,每次调用readOne()会自动改变这个属性
- eob: 表示当前是否抵达了块结尾,比如是否遇到了下列任何一个指令:CALL, JMP, BL, RET
- eoi: 表示input代表的属性是否结束,比如可能当前遇到了下列的指令:JMP, B, RET,这些指令之后可能没有有效的指令了
- readOne(): 把一条指令读入relocator的内部缓存,返回目前已经读入缓存的总字节数,可以持续调用readOne函数来缓存指令,或者立即调用writeOne()或者skipOne(),也可以一直缓存到指定的点,然后一次性调用writeAll()。如果已经到了eoi,则函数返回0, 此时eoi属性也是true
- peekNextWriteInsn(): peek一条指令出来,以备写入或者略过
- peekNextWriteSource(): 在指定地址peek一条指令出来,以备写入或者略过
- skipOne(): 忽略下一条即将写入的指令
- skipOneNoLabel(): 忽略下一条即将写入的指令,如果遇到内部使用的Label则不忽略,这个函数是对skipOne的优化,可以让重定位范围覆盖的更全面
- writeOne(): 写入下条缓存指令
- writeOneNoLabel()
- writeAll(): 写入所有缓存的指令
x86枚举类型
- 寄存器:xar, xcx, xdx, xbx, tsp, xbp, xsi, xdi, sax, ecx, edx, ebx, esp, ebx, esi, edi, rax, rcx, rdx, rbx, rsp, rbp, rsi, rdi, r8, r9, r10, r11, r12, r13, r14, r15, r8d, r9d, r10d, r11d, r12d, r13d, r14d, r15d, xip, eip, rip
- 跳转指令:jo, jno, jb, jae, je, jne, jbe, ja, js, jns, jp, jnp, jl, jge, jle, jg, jcxz, jecxz, jrcxz
- 分支提示:no-hint, likely, unlikely
- 指针类型:byte, sword, qword
ArmWriter(参考X86Writer)
- new ArmWriter(codeAddress[, {pc: ptr(‘0x1234’)}])
- reset(codeAddress[, {pc: ptr(‘0x1234’)}])
- dispose()
- flush()
- base
- code
- pc
- offset
- skip(nBytes)
- putBImm(target)
- putLdrRegAddress(reg, address)
- putLdrRegU32(reg, val)
- putAddRegRegImm(dstReg, srcReg, immVal)
- putLdrRegRegImm(dstReg, srcReg, immVal)
- putNop()
- putBreakpoint()
- putInstruction(insn)
- putBytes(data)
ArmRelocator(参考X86Relocator)
ThumbRelocator(参考X86Relocator)
Arm enum types
- 寄存器:r0~r15, sp, lr, sb, sl, fp, ip, pc
- 条件码:eq, ne, hs, lo, mi, pl, vs, vc, hi, ls, ge, lt, gt, le, al
Arm64Writer(参考X86Writer)
Arm64Relocator(参考X86Relocator)
AArch64 enum types
- 寄存器:x0 x1 x2 x3 x4 x5 x6 x7 x8 x9 x10 x11 x12 x13 x14 x15 x16 x17 x18 x19 x20 x21 x22 x23 x24 x25 x26 x27 x28 x29 x30 w0 w1 w2 w3 w4 w5 w6 w7 w8 w9 w10 w11 w12 w13 w14 w15 w16 w17 w18 w19 w20 w21 w22 w23 w24 w25 w26 w27 w28 w29 w30 sp lr fp wsp wzr xzr nzcv ip0 ip1 s0 s1 s2 s3 s4 s5 s6 s7 s8 s9 s10 s11 s12 s13 s14 s15 s16 s17 s18 s19 s20 s21 s22 s23 s24 s25 s26 s27 s28 s29 s30 s31 d0 d1 d2 d3 d4 d5 d6 d7 d8 d9 d10 d11 d12 d13 d14 d15 d16 d17 d18 d19 d20 d21 d22 d23 d24 d25 d26 d27 d28 d29 d30 d31 q0 q1 q2 q3 q4 q5 q6 q7 q8 q9 q10 q11 q12 q13 q14 q15 q16 q17 q18 q19 q20 q21 q22 q23 q24 q25 q26 q27 q28 q29 q30 q31
- 条件码:eq ne hs lo mi pl vs vc hi ls ge lt gt le al nv
- 索引模式:post-adjust signed-offset pre-adjust
MipsWriter(参考X86Writer)
MipsRelocator(参考X86Relocator)
MIPS enum types
- 寄存器:v0 v1 a0 a1 a2 a3 t0 t1 t2 t3 t4 t5 t6 t7 s0 s1 s2 s3 s4 s5 s6 s7 t8 t9 k0 k1 gp sp fp s8 ra hi lo zero at 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31

 浙公网安备 33010602011771号
浙公网安备 33010602011771号