爬取百度翻译(可中英互译)
由于下学期报了一个Python的入门课程
所以寒假一直在自己摸索,毕竟到时候不能挂科,也是水水学分
最近心血来潮打算试试爬一下百度翻译
肝了一天终于搞出来了
话不多说,直接开搞(环境是Python 3.8 PyCharm Community Edition 2021.3.1)
基础步骤
百度翻译会识别到爬虫,所以得用headers隐藏一下
以chorme浏览器为例
在百度翻译页面点击鼠标右键,选择“检查”(或者直接F12)
显示以下界面
依次选Network-Fetch/XHR-Headers
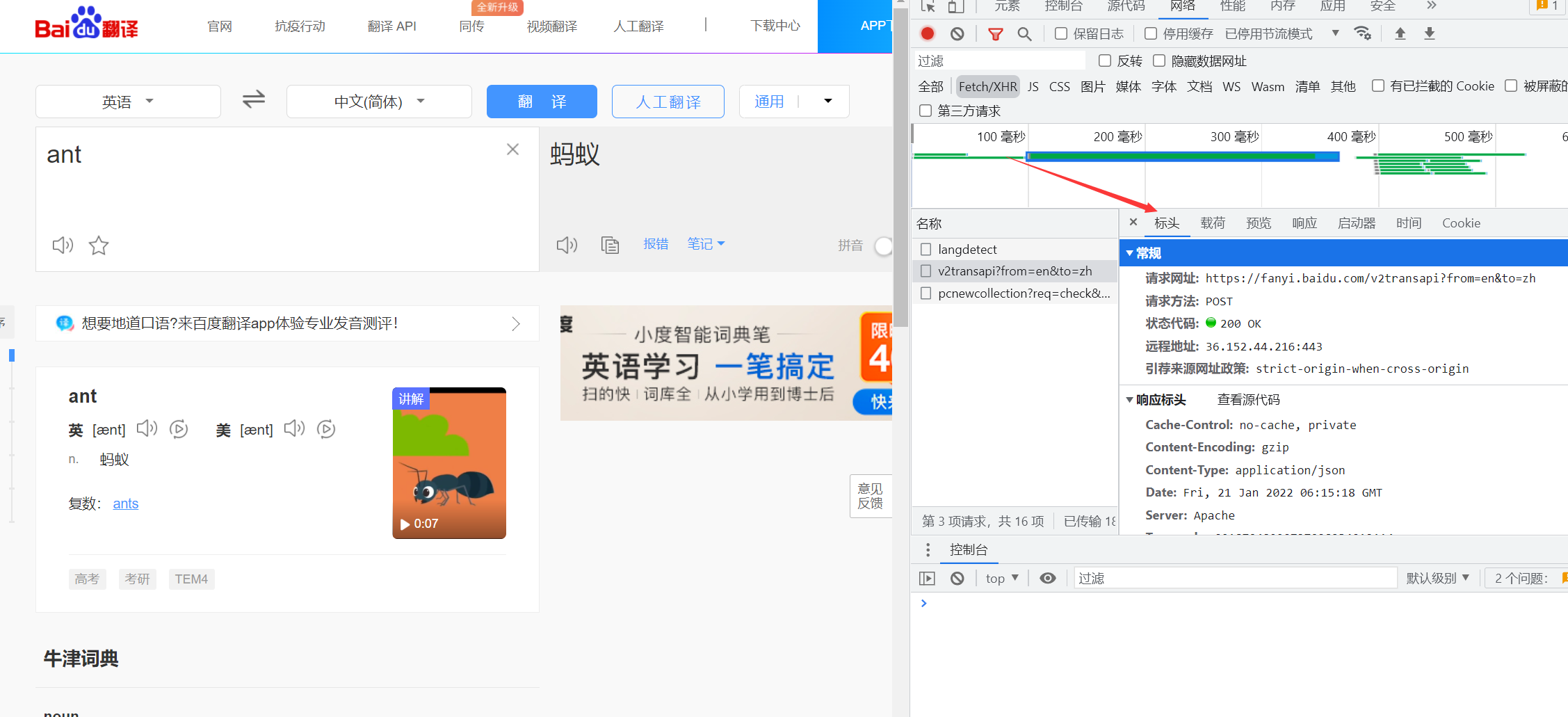
然后就能看到我们需要的标头
我们需要的是Cookie和User-Agent,用于表示是特定用户通过浏览器打开此网站
也就是伪装爬虫
然后我们复制到Pycharm当中即可
1 headers = {"User-Agent": Your User-Agent, "Cookie": Your Cookie} 2 # 后面填写你获取到的User-Agent和Cookie即可
提交表单
伪装好了之后,需要准备让爬虫向网站提交表单
但是我们提交之前需要看看我们要提交哪些数据
继续查看网站
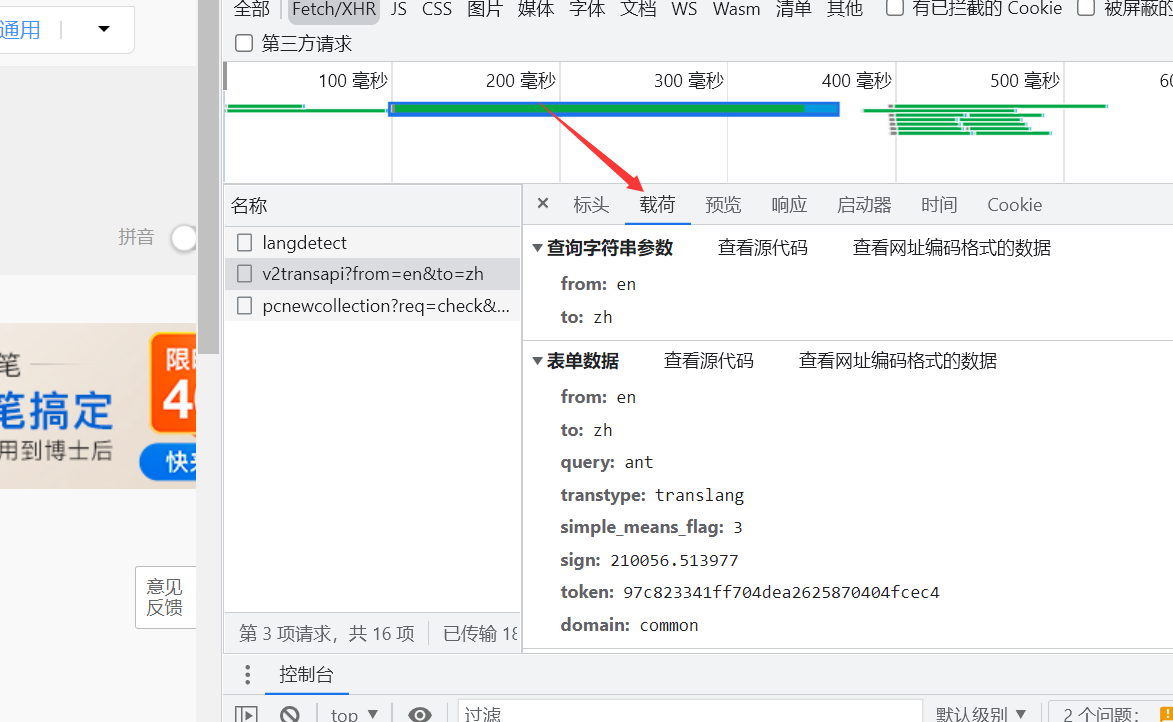
我们可以看到有一个表单数据
from: en to: zh # 从英文转中文 query: ant # 搜索ant单词 transtype: realtime # 可能是实时查询的意思? simple_means_flag: 3 sign: 210056.513977 token: 97c823341ff704dea2625870404fcec4 # 百度翻译用于识别的关键信息sign和token domain: common
这就是我们要提交的数据
但是我们提交表单的是动态的,所以要重新写一下data
也就是
data = { "from": "en", "to": "zh", "query": custom_input, "transtype": "translang", "simple_means_flag": "3", "token": '97c823341ff704dea2625870404fcec4' }
获取响应并处理结果
我们考虑到提交了数据之后,咱们需要接收网页的反馈
所以继续看看返回来的翻译在哪
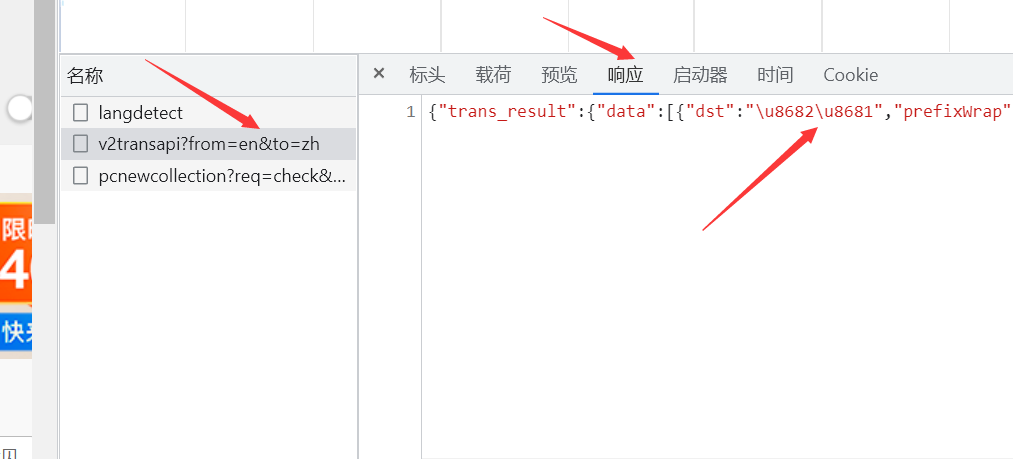
我们会发现,我们想要的和现实的似乎有些差别
结果是有了,但是不是中文,是Unicode
办法总是有的
response = requests.post(url='https://fanyi.baidu.com/v2transapi', headers=headers, timeout=1, data=data) response.encoding = 'utf-8' print(response.status_code) # 获取状态码 print(re.search("[\\u4e00-\\u9fa5]+", response.content.decode('unicode_escape'), flags=re.S)[0]) # 正则表达式查找汉字
这样打印出来的就是中文了~
挺意外的
差不多就可以提交了!
然后我兴冲冲的去提交数据
百度翻译给了我一个大嘴巴深刻的教训
请输入要选择的翻译模式 [1]英译中 [2]中译英 1 请输入要翻译的英文 apple 200 未知错误 进程已结束,退出代码0
这是咋回事?apple的翻译应该是苹果而不是未知错误啊
然后我发现,前面的data漏了一个sign
sign是不同的单词算出来的不一样的,但是相对于单词是固定的
幸好网上巨佬多,找到了sign的算法
https://blog.csdn.net/qq_38534107/article/details/90440403?utm_source=app&app_version=5.0.0&code=app_1562916241&uLinkId=usr1mkqgl919blen
有兴趣可以看看sign算法的获取
最后把sign贴上去,就成功了!
消除警告
但是会出现一个Warning
请输入要选择的翻译模式 [1]英译中 [2]中译英 1 请输入要翻译的英文 apple 200 苹果 F:/Python/New/main.py:40: DeprecationWarning: invalid escape sequence '\/' print(re.search("[\\u4e00-\\u9fa5]+", response.content.decode('unicode_escape'), flags=re.S)[0]) 进程已结束,退出代码0
翻译结果底下出现一个警告,不好看
于是想办法,加入了这个
import warnings warnings.filterwarnings("ignore", category=Warning) # 关闭弃用报错
就没有错误了~
至此,英译中功能就做的差不多了
中译英是基本一样的,但是返回的东西很多,可以通过这个语句来筛选
print(re.findall(pattern='[a-zA-Z]+', string=response.content.decode('unicode_escape'), flags=re.S)[4])
差不多就是这样咯~
全部代码:
main.py
import requests from sign import sign import re import warnings warnings.filterwarnings("ignore", category=Warning) # 关闭弃用报错 headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/66.0.3359.139 Safari/537.36", "Cookie": 'BIDUPSID=248487DDE4F4874C768DD664800AFB01; ' 'PSTM=1624632627; ' '__yjs_duid' '=1_9e9a49b48ccf294be969148528d703281624677345512; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; ' 'REALTIME_TRANS_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; APPGUIDE_10_0_2=1; ' 'BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BAIDUID=39C416629357EBAB497629178C0541C1:FG=1; ' 'BDUSS' '=m9DMm1RUFZTTFBCNmdZUUFhY3lpeUR4Y3NNRW5SdThvb3FpTnZDNWdXNWRyeEJpSVFBQUFBJCQAAAAAAAAAAAEAAACSX1uneHp5MjAwMzIAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAF0i6WFdIulhZ; BDUSS_BFESS=m9DMm1RUFZTTFBCNmdZUUFhY3lpeUR4Y3NNRW5SdThvb3FpTnZDNWdXNWRyeEJpSVFBQUFBJCQAAAAAAAAAAAEAAACSX1uneHp5MjAwMzIAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAF0i6WFdIulhZ; H_PS_PSSID=35410_35105_31254_35774_34584_35490_35693_35796_35324_26350_35744; BAIDUID_BFESS=39C416629357EBAB497629178C0541C1:FG=1; BCLID=11903837222192425398; BDSFRCVID=meFOJeC627p69AjHgenlU9pUEeQF9_oTH6aoc1Pmnv6SwQ5bF3wEEG0PEM8g0Kub1VDqogKKQgOTHRCF_2uxOjjg8UtVJeC6EG0Ptf8g0f5; H_BDCLCKID_SF=tbFqoKI5JK03J-Fk-R6BMtCbMfQyetJyaR0tXJvvWJ5TMCoJ0-c25-InbPvwblL8-NT42-ovyJ6_ShPC-tnc3M4nKxC82Mb8Qa743qbX3l02Vhvae-t2ynLIQMFLQ-RMW23I0h7mWUoTsxA45J7cM4IseboJLfT-0bc4KKJxbnLWeIJIjjC5DTOXjH8OtTnfb5kXWnbEatD_Hn7zeUDWeM4pbt-qJqTzLNQLWqnjBpRBSDTx3fo1j4tUXxTnBT5KaKTvaCTw5l7KHq32yqKKQlKkQN3TWxuO5bRi5Roy-q3FDn3oypQJXp0n04bly5jtMgOBBJ0yQ4b4OR5JjxonDh83bG7MJPKtfJut_I05JID-bnPk5PQ_b-40Mq0X5-RLfKj-Kq7F5l8-hC3xj6rNMxksbfTQL6cjQmT-blLXXb7xOKQphP-a0-uH5Gjg-h_tKeFeLh5N3KJmsqC9bT3v5tjL34OD2-biWa6M2MbdLqOP_IoG2Mn8M4bb3qOpBtQmJeTxoUJ25DnJhbLGe4bK-TrLjHKftxK; BCLID_BFESS=11903837222192425398; BDSFRCVID_BFESS=meFOJeC627p69AjHgenlU9pUEeQF9_oTH6aoc1Pmnv6SwQ5bF3wEEG0PEM8g0Kub1VDqogKKQgOTHRCF_2uxOjjg8UtVJeC6EG0Ptf8g0f5; H_BDCLCKID_SF_BFESS=tbFqoKI5JK03J-Fk-R6BMtCbMfQyetJyaR0tXJvvWJ5TMCoJ0-c25-InbPvwblL8-NT42-ovyJ6_ShPC-tnc3M4nKxC82Mb8Qa743qbX3l02Vhvae-t2ynLIQMFLQ-RMW23I0h7mWUoTsxA45J7cM4IseboJLfT-0bc4KKJxbnLWeIJIjjC5DTOXjH8OtTnfb5kXWnbEatD_Hn7zeUDWeM4pbt-qJqTzLNQLWqnjBpRBSDTx3fo1j4tUXxTnBT5KaKTvaCTw5l7KHq32yqKKQlKkQN3TWxuO5bRi5Roy-q3FDn3oypQJXp0n04bly5jtMgOBBJ0yQ4b4OR5JjxonDh83bG7MJPKtfJut_I05JID-bnPk5PQ_b-40Mq0X5-RLfKj-Kq7F5l8-hC3xj6rNMxksbfTQL6cjQmT-blLXXb7xOKQphP-a0-uH5Gjg-h_tKeFeLh5N3KJmsqC9bT3v5tjL34OD2-biWa6M2MbdLqOP_IoG2Mn8M4bb3qOpBtQmJeTxoUJ25DnJhbLGe4bK-TrLjHKftxK; delPer=0; PSINO=3; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1641456854,1642661186,1642662678,1642687449; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1642688201; BA_HECTOR=248g858580ak84a0u91guirq80q; ab_sr=1.0.1_MjM4OGFjMTZiZjUyMmYxMmU5NDhjY2FkZDkzNzRkMzZkZGUxN2RmMmY1NzEwYzg5ZDlmYTk2YTIzZmM0ODBlMzJlYzAwNDMxNjllNjk3OGMxZDJmMzI1NjNiNjlhNjExNTEzYmNkZTFlZWNjYzI4ZGVmZTA4NDk3ODBjYThlYzM='} if __name__ == '__main__': print("请输入要选择的翻译模式") choose = int(input("[1]英译中\n[2]中译英\n")) while choose != 1 and choose != 2: print("错误!请重新输入") choose = int(input("[1]英译中\n[2]中译英\n")) data = {} if choose == 1: custom_input = input('请输入要翻译的英文\n') data = { "from": "en", "to": "zh", "query": custom_input, "transtype": "translang", "simple_means_flag": "3", "token": '97c823341ff704dea2625870404fcec4', "sign": sign(custom_input) } response = requests.post(url='https://fanyi.baidu.com/v2transapi', headers=headers, timeout=1, data=data) response.encoding = 'utf-8'print(re.search("[\\u4e00-\\u9fa5]+", response.content.decode('unicode_escape'), flags=re.S)[0]) elif choose == 2: custom_input = input('请输入要翻译成英文的中文\n') data = { "from": "zh", "to": "en", "query": custom_input, "transtype": "translang", "simple_means_flag": "3", "token": '97c823341ff704dea2625870404fcec4', "sign": sign(custom_input) } response = requests.post(url='https://fanyi.baidu.com/v2transapi', headers=headers, timeout=1, data=data) response.encoding = 'utf-8' print(re.findall(pattern='[a-zA-Z]+', string=response.content.decode('unicode_escape'), flags=re.S)[4])
sign.py
import js2py import requests import re def sign(word): session = requests.Session() headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36"} session.headers = headers response = session.get("http://fanyi.baidu.com/") gtk = re.findall(";window.gtk = ('.*?');", response.content.decode())[0] word = word context = js2py.EvalJs() js = r''' function a(r) { if (Array.isArray(r)) { for (var o = 0, t = Array(r.length); o < r.length; o++) t[o] = r[o]; return t } return Array.from(r) } function n(r, o) { for (var t = 0; t < o.length - 2; t += 3) { var a = o.charAt(t + 2); a = a >= "a" ? a.charCodeAt(0) - 87 : Number(a), a = "+" === o.charAt(t + 1) ? r >>> a : r << a, r = "+" === o.charAt(t) ? r + a & 4294967295 : r ^ a } return r } function e(r) { var o = r.match(/[\uD800-\uDBFF][\uDC00-\uDFFF]/g); if (null === o) { var t = r.length; t > 30 && (r = "" + r.substr(0, 10) + r.substr(Math.floor(t / 2) - 5, 10) + r.substr(-10, 10)) } else { for (var e = r.split(/[\uD800-\uDBFF][\uDC00-\uDFFF]/), C = 0, h = e.length, f = []; h > C; C++) "" !== e[C] && f.push.apply(f, a(e[C].split(""))), C !== h - 1 && f.push(o[C]); var g = f.length; g > 30 && (r = f.slice(0, 10).join("") + f.slice(Math.floor(g / 2) - 5, Math.floor(g / 2) + 5).join("") + f.slice(-10).join("")) } var u = void 0 , l = "" + String.fromCharCode(103) + String.fromCharCode(116) + String.fromCharCode(107); u = 'null !== i ? i : (i = window[l] || "") || ""'; for (var d = u.split("."), m = Number(d[0]) || 0, s = Number(d[1]) || 0, S = [], c = 0, v = 0; v < r.length; v++) { var A = r.charCodeAt(v); 128 > A ? S[c++] = A : (2048 > A ? S[c++] = A >> 6 | 192 : (55296 === (64512 & A) && v + 1 < r.length && 56320 === (64512 & r.charCodeAt(v + 1)) ? (A = 65536 + ((1023 & A) << 10) + (1023 & r.charCodeAt(++v)), S[c++] = A >> 18 | 240, S[c++] = A >> 12 & 63 | 128) : S[c++] = A >> 12 | 224, S[c++] = A >> 6 & 63 | 128), S[c++] = 63 & A | 128) } for (var p = m, F = "" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(97) + ("" + String.fromCharCode(94) + String.fromCharCode(43) + String.fromCharCode(54)), D = "" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(51) + ("" + String.fromCharCode(94) + String.fromCharCode(43) + String.fromCharCode(98)) + ("" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(102)), b = 0; b < S.length; b++) p += S[b], p = n(p, F); return p = n(p, D), p ^= s, 0 > p && (p = (2147483647 & p) + 2147483648), p %= 1e6, p.toString() + "." + (p ^ m) } ''' js = js.replace('\'null !== i ? i : (i = window[l] || "") || ""\'', gtk) # 执行js context.execute(js) # 调用函数得到sign sign = context.e(word) return sign
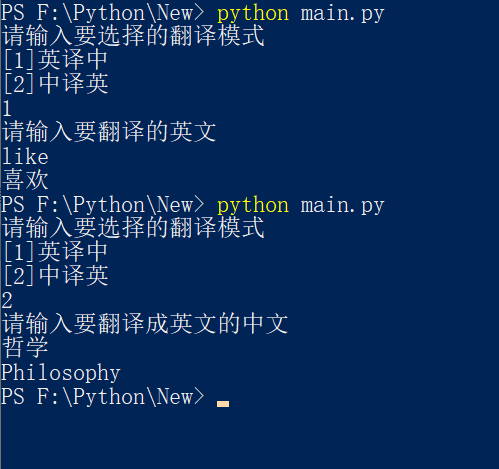
运行示例:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号