07--JS07--逆向03:字体反爬、JS反调试破解
JS逆向03:字体反爬、JS反调试破解
jsvmp : 代码虚拟化保护方案
ast : 抽象语法树
1.字体文件、字体反爬
### 1 字体文件 .ttf .woff 或 .eot
在计算机内存中,文字就是一堆二进制(unicode),要以文字图形的样子,展示给用户看
就要指定 它们之间的对应关系,就是字体文件
书法字体、火星文字体,不同的字体文件,对同样的文字unicode,显示出来的文字图形不一样
文字unicode <== 字体文件 ==> 显示的文字图形(按照字体文件的规则,对应显示)
eg: 帅(101011二进制) <--- 微软雅黑字体 ---> 帅(汉字的图形)
# 文字图形样子的核心:取决于 文字的unicode 和 字体文件
# windows中的font-creator软件,可以打开查看字体文件 (只有windows)
### 2 字体反爬原理
unicode的字节范围比较大(包含世界所有文字)
网站自定义了一套字体规则,把文字unicode中 用不上的unicode码,重新进行编排,对应上文字图形
而且有可能 编排对应后的文字图形,也做过一些微处理
例如:人字,细节处多一个小点,或者 一部分很长之类的
并在网页中显示时,不是直接显示 正常的现成文字图形
而是混杂着,重新编排的一些 特定unicode码 和 正常文字图形
所以正常爬取时,爬到这些特定的文字unicode码,并按照自己的现有字体文件 加载的话,就是乱的
### 3 解决字体反爬的实现步骤:
1.从网站中,获取字体文件
2.从字体文件中,获取所有的文字unicode码
3.先将文字unicode码,照着字体文件里面的样子,把所有对应的文字图形,画到同一张图片上去
4.再用人工智能-图片识别文字【AI_OCR】,去识别这个图片 # 识别没有百分之百的准确率
就知道了网页中 所有该文字unicode码,对应的正确文字是什么
# 3、4步是 对字体文件进行解析 # unicode ---> 正确的文字 (难)
5.在获取到页面源代码后
把unicode码的文字,进行正确文字的替换 # 后续就可以正常处理了
### 4 第三方图片识别文字 ---> 也可以用于识别 验证码
1.ddddocr # python的第三方库 免费
2.Tesseract-OCR # python的第三方库 免费
3.火山(字节) # 第三方 收费
4.百度AI(比上面这几个都好一些)
2.案例
2.1 获取字体文件
### 1 从网站中,获取到字体文件
import requests
from lxml import etree
from urllib.parse import urljoin
import re
# 1.先加载 index.html
url = "http://bikongge.com/chapter_1/font_1/index.html"
resp = requests.get(url)
resp.encoding = 'utf-8'
# print(resp.text)
# 2.从index.html中,获取style.css的url
tree = etree.HTML(resp.text)
href = tree.xpath("//link/@href")[0]
href = urljoin(url, href)
# print(href)
# 3.从style.css中,获取字体文件的url
font_resp = requests.get(href)
font_url_re = re.compile(r'src: url\("(?P<font_url>.*?)"\);', re.S)
font_url = font_url_re.search(font_resp.text).group("font_url")
# print(font_url)
# url拼接 这个url应该和谁拼接,是相对应style.css的,和style.css的url拼接
font_url = urljoin(href, font_url)
print(font_url)
# 4.下载字体文件
font_resp = requests.get(font_url)
with open("font.woff", mode="wb") as f:
f.write(font_resp.content)
# 对比查看:
s = "\ue0df" # 文字unicode码
print(s) # 直接打印(默认unicode编码打印):一个奇怪的乱字
# 但实际是 windows软件font-creator打开看
'\ue0df' => 店 (字体文件)
2.2 获取文字unicode码
# 2 从字体文件中,获取所有的文字unicode码 需要font-tools库
# pip install fontTools
# TTFont('字体文件')的方法
.getGlyphOrder() # 获取所有文字的unicode码 有顺序 推荐使用
.getGlyphNames() # 获取所有文字的unicode码 无顺序
from fontTools.ttLib import ttFont
ttf = ttFont.TTFont("font.woff")
uni_list = ttf.getGlyphOrder()[2:] # 推荐使用, 有顺序 ['unie467', 'uniee7e'...]
# 将uni字符串,转化为 python的unicode格式 \u:unicode码
uni_ok_list = []
for uni in uni_list:
uni = uni.replace("uni", "\\u") # 不能直接 \u,会被直接识别为unicode,再加个\ 防止转义
uni_ok_list.append(uni)
print(uni_ok_list)
print(len(uni_ok_list)) # 601
2.3 根据字体文件画图
# 3 按照字体文件,把文字unicode码的文字图形,画出来
# 安装 pip install pillow
from PIL import Image
from PIL import ImageFont
from PIL import ImageDraw
# 1.创建画布 参数:模式-RGB彩色、大小、颜色
img = Image.new(mode="RGB", size=(2000, 1000), color=(255, 255, 255))
# 2.准备一只可以在图上画画的笔
img_draw = ImageDraw.Draw(img)
# 3.准备好画图的字体 画的字体、字体每个字的像素大小
img_font = ImageFont.truetype("font.woff", size=50)
# 4.准备开始画图,需要画图规划 不能全在一行,需要换行
# 例如:一行40个字 (50*40=2000,画布宽2000,正好够)
# 换行逻辑:
# 根据所有文字unicode码列表的索引号, 若 索引 % 40 == 0,(取余) 就该换行了
# 行号: 索引 // 40 # 整除,向下取整 从第0行开始
# 目的是为了计算,每行画笔的高度 y ---> (索引 // 40) * 每行的高度
# 指定每行字符的个数
line_length = 40
# 指定每行的高度 像素
line_height = 60
# 把一行需要画的字符,放进一个列表
char_line = []
for i in range(len(uni_ok_list)):
uni = uni_ok_list[i]
# 把 '\\uxxxx' 修改成unicode码,需要 用编码的转换 来进行调整 先编码成字节,再按照unicode解码
uni = uni.encode().decode("unicode-escape")
if i % line_length == 0 and i != 0: # 遍历到需要换行的字符了
# 1.先把上一行的字符,同时画到画布上
char_line_s = "".join(char_line)
# 画笔写字(.text)的参数:画的坐标(x,y)、文本内容、fill(填充颜色 数字或单词)、参照的字体
img_draw.text((0, (i // line_length - 1) * line_height), text=char_line_s, fill=1, font=img_font)
# 2.本次遍历到字符 需要换行,直接覆盖上一次的行列表
char_line = [uni]
else:
# 正常需画在同一行的字符,追加行列表
char_line.append(uni)
# 再画,最后不足一整行的字符
if char_line:
char_line_s = "".join(char_line)
img_draw.text((0, (len(uni_ok_list) // line_length) * line_height), text=char_line_s, fill='red', font=img_font)
# 完成上述操作,你只是在内存中画了一张图
# 保存到硬盘上
img.save("tu.jpg")
2.4 图片识别文字
# 4 接下来就是识别上面这张图,获取到所有文字 ---> 百度AI
pip install baidu-aip
# 该库 还需要其他库
pip install chardet
from aip import AipOcr
"""刚才创建的那个应用里. 有下面这三个东西"""
APP_ID = '27643903'
API_KEY = 'atSZosOQ1xOQmBOmGSgLnbNA'
SECRET_KEY = 'znj959V9ZN0zlGVhZexABFT4ek57Kom2'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
f = open("tu.jpg", mode="rb")
r = client.basicGeneral(f.read())
# 所有文字
result_list = []
for item in r['words_result']:
result_list.extend(item['words'])
print(len(result_list)) # 注意:调整识别后的文字数量 是否与 unicode码字数量 一致
2.5 解析替换
### 5 替换--反向
# 5.1 把unicde对应的word,进行映射 ---> 字典
# zip() 有水桶效应(以短的一方,为边界)
# 故:uni_ok_list和result_list必须长度保持一致.
dic = dict(zip(uni_ok_list, result_list))
# 结果:{"\\uxxxx": 天}
# 5.2 获取页面源代码,并把字典中'\\u' ,按照页面的形式,换成 '&#X'
# 5.3 再页面源码的'&#X',替换成 识别后的文字
url = "http://bikongge.com/chapter_1/font_1/index.html"
resp = requests.get(url)
resp.encoding = 'utf-8'
page_source = resp.text
for k in dic:
# k: \\uxxxxx
# v: 天
v = dic[k]
kk = k.replace("\\u", "&#x") + ";"
# 字符串不可变. 需要重新赋值
page_source = page_source.replace(kk, v)
print(page_source)
3.JS反调试破解
-
常见的反调试技术
-
禁用调试快捷键:禁用鼠标右键、禁用快捷键F12,无法打开调试控制台
-
检测调试器工具:通过检测调试器工具的存在,判断是否处于调试环境
-
检测浏览状态:通过检测浏览器状态的变化(例如:浏览器窗口的大小),判断是否处于调试环境
-
定时检测:定时检测调试器状态,若检测到调试器存在,则执行相应的反调试代码(debugger)
-
模糊代码:对关键代码进行混淆或加密,使得难以分析和理解
-
-
破解本质:
- 1.绕过调试检测
- 2.不让它执行反调试函数 (基本都是将相应的反调试函数置空)
在网站执行它这些反调试函数之前,先执行我们自定义的JS代码,改变它的反调试函数代码,让其反调试不起作用。
-
破解手段:
-
1.根据其反调试代码函数,进行相应函数的Hook,详见JS02-高级:3.11 JS Hook
-
2.通过油猴插件,写JS脚本进行破解 两者本质一致
-
3.1 简单无限反调试
- 通过debugger断点定时递归,实现无限反调试
function Debugging(){
debugger;
setInterval(Debugging, 1000);
};
Debugging();
- 定时清空控制台,干扰console.log调试
function startClearConsole(){
// 每个一秒钟,清除控制台内容
setInterval(function(){
consolo.clear();
}, 1000);
};
startClearConsole();
3.2 反调试综合案例
- 案例网站:https://www.aqistudy.cn/
- 禁用F12、禁用鼠标右键、检测开启调试器、无限debugger、无限清除控制台、代码运行时间差检测、窗口尺寸差检测
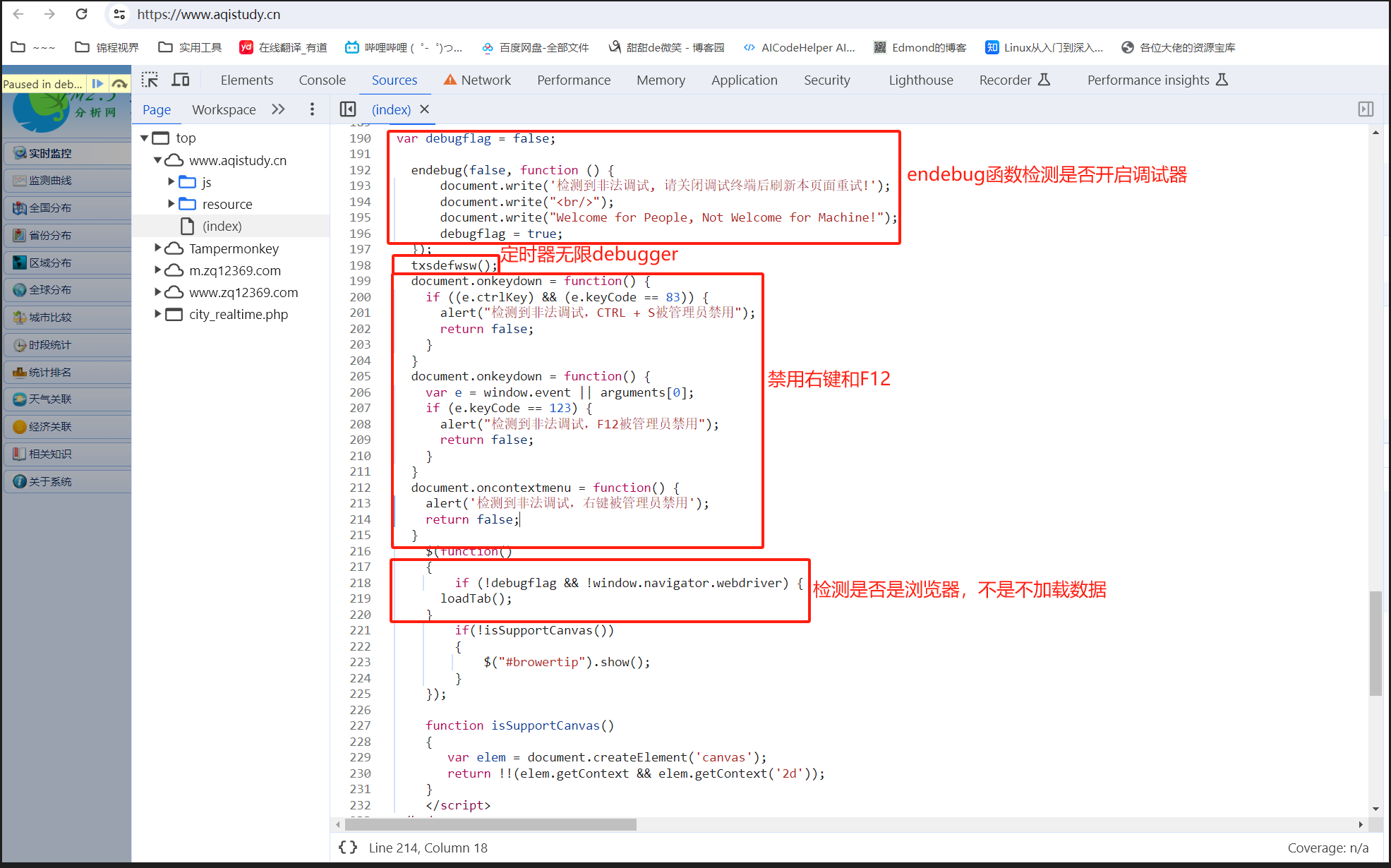
- 写油猴破解脚本
// 前提:安装油猴插件、编写脚本、开启脚本
// ==UserScript==
// @name 反调试脚本
// @namespace https://www.aqistudy.cn/
// @version 0.1
// @description try to take over the world!
// @author You
// @match https://www.aqistudy.cn/
// @match http://www.aqistudy.cn/
// @match https://www.aqistudy.cn/*
// @match *://*/*
// @icon https://www.google.com/s2/favicons?domain=aqistudy.cn
// @run-at document-start
// @grant unsafeWindow
// ==/UserScript==
// 注意:@run-at 脚本运行时刻
document-end 脚本在DOMContentLoaded事件发生时或之后被注入 ***
document-idle 脚本在DOMContentLoaded事件发生后被注入. 默认值
document-start 脚本在最早的时刻被注入
document-body 当body元素存在时脚本被注入
// 注意:@grant 油猴权限获取
none 脚本直接运行在前端页面中,但无法与油猴脚本交互,无法使用油猴更强的一些功能
脚本的window,就前端的window
unsafeWindow 脚本默认运行在一个沙盒环境中,使用unsafeWindow代替前端的window,与前端交互
且能使用油猴其他功能 ***
GM_* 函数 油猴一些特定的功能,需要单独授权
(function() {
'use strict';
// 设置全局变量debugflag为false,表示未检测到调试工具
unsafeWindow.debugflag = false;
// 取消检测调试工具的函数,将其设置为空函数
unsafeWindow.endebug = function(){};
// 关闭无限debugger函数的调用,将其设置为空函数
unsafeWindow.txsdefwsw = function(){};
// 取消禁止鼠标右键,将document.oncontextmenu设置为空函数
document.oncontextmenu = function(){};
// 取消禁止F12,将document.onkeydown设置为空函数
document.onkeydown = function(){};
// 取消代码运行时间差的debugger
var fnc_ = unsafeWindow.Function.prototype.constructor;
unsafeWindow.Function.prototype.constructor = function(){
if(arguments[0]==='debugger'){
return function(){}; // 返回空函数对象
} else {
return fnc_.apply(this, arguments);
}
}
// 禁用定时器
unsafeWindow.setInterval = function(){};
console.log(3333333333333333)
})();
// 目前:
先打开F12,这些脚本代码能有效果 不断点反调试了
但若是直接右键和F12,还是不能打开开发者工具

 浙公网安备 33010602011771号
浙公网安备 33010602011771号