06--JS06--逆向02:重现JS代码、加密逻辑、逆向经验
JS逆向02:重现JS代码、加密逻辑、逆向经验
一、JS逆向方案二:重现JS
# 重现JS代码
根据JS代码的逻辑,用python代码,一步步 将JS代码逻辑还原
改换成我们自己的代码,实现JS代码同样的功能
# 缺点:
在加解密上,仅限于通用的加密、解密,可以使用python重现逻辑
但若是网站自定义一套逻辑,想要python重现 非常困难!!! 就只能方案一扣JS代码了
# 优点:
读懂JS的逻辑,自己重现 逻辑清晰,也易于调整
# 实际:
通常就是 方案一/二相结合,扣一部分、自己重现一部分
二、一切从MD5开始
在进行js逆向的时候,总会遇见一些人类无法直接能理解的东西出现。此时你看到的大多数,是被加密过的密文。
MD5(Message Digest 信息摘要) 是一个非常常见的hash算法
又称摘要算法,就是将任意复杂数据data,计算出能代表其特征的,固定长度的散列值(hash值、摘要digest)
所以md5,依然是国内非常多的互联网公司,选择的密码摘要算法
- 特点:
-
反向困难
这玩意不可逆,只能加密,无法加密。 故摘要算法,本质就不是一个加密逻辑
-
正向迅速
相同的内容,可以快速计算出一样的hash值(摘要)
-
输入敏感
不同的内容(哪怕是一丢丢不一样) ,计算出来的结果差别非常大
-
抗碰撞性
不同的输入,不会产生相同的散列值
-
用途:
在数学上,摘要 计算的逻辑就是hash
hash(数据) => 数字 (又称散列值、hash值)
-
密码
-
一致性检测 ===> 文件校验
- md5的python实现:
from hashlib import md5
obj = md5()
# 添加被hash的内容 字节形式
obj.update("alex".encode("utf-8"))
# obj.update("wusir".encode('utf-8')) # 可以添加多个被加密的内容
# 计算hash值 返回的是字节形式
bs = obj.digest()
print(bs)
# 计算hash值 返回的是字节转化为 32位的16进制数字(0-9 a-f) 表示的字符串
bs = obj.hexdigest() # hex n.16进制 digest n.摘要
print(bs)
- 撞库
把密文丢到网页里,发现有些网站可以直接解密。但其实不然,这里并不是直接解密MD5,而是"撞库"
就是它网站里存储了大量的MD5的值,而需要进行查询的时候,只需要一条select语句就可以查询到了
如何避免撞库: md5在进行计算时,加盐。 加盐之后, 就很难撞库了
from hashlib import md5
salt = "我是盐.把我加进去就没人能破解了"
obj = md5(salt.encode("utf-8")) # 加盐 盐尽可能复杂
obj.update("alex".encode("utf-8"))
bs = obj.hexdigest()
print(bs)
-
扩展:sha256
不论是sha1、sha256、md5都属于摘要算法。都是在计算hash值,只是散列的程度不同而已
该算法特性:只是散列,不是加密。而且由于是不可逆的,所以不存在解密的逻辑
from hashlib import sha1, sha256
sha = sha256(b'salt')
sha.update(b'alex')
print(sha.hexdigest())
三、URLEncode、Base64、字节的16进制
3.1 URLEncode
在访问一个url的时候,总能看到这样的一种url
https://www.sogou.com/web?query=%E5%90%83%E9%A5%AD%E7%9D%A1%E8%A7%89%E6%89%93%E8%B1%86%E8%B1%86&_asf=www.sogou.com
此时会发现, 在浏览器上明明是能看到中文的. 但是一旦复制出来. 或者在抓包工具里看到的. 都是这种%. 那么这个%是什么鬼? 也是加密么?
非也,其实在访问一个url的时候,浏览器会自动的进行urlencode操作,会对请求的url进行编码
这种编码规则被称为百分号编码,是专门为url(统一资源定位符)准备的一套编码规则.
一个url的完整组成:
scheme://host:port/dir/file?p1=v1&p2=v2#anchor
http ://www.baidu.com/tieba/index.html?name=alex&age=18#锚点 资源的某个位置
参数: key=value 的形式 # 服务器可以通过key拿value
此时,如果参数中出现一些特殊符号,比如'=' ,想给服务器传递 ‘a=b=c’ 这样的参数,必然会让整个URL产生歧义
故URLEncode:把url中的参数部分转化成字节,每个字节,再转化成2个16进制的数字,前面补%
- 场景:逆向中,requests会自动对url编码,主要是处理cookie,有可能需要手动处理;
数据形式是url编码时,需要进行解码
- urlencode编码
from urllib.parse import urlencode, quote,unquote, unquote_plus
# 单独编码字符串 quote unqquote 解码
wq = "米饭怎么吃"
print(quote(wq)) # %E7%B1%B3%E9%A5%AD%E6%80%8E%E4%B9%88%E5%90%83
print(quote(wq, encoding="gbk")) # %C3%D7%B7%B9%D4%F5%C3%B4%B3%D4
# 多个数据统一进行编码 urlencode
dic = {
"wq": "米饭怎么吃",
"new_wq": "想怎么吃就怎么吃"
}
print(urlencode(dic)) # wq=%E7%B1%B3%E9%A5%AD%E6%80%8E%E4%B9%88%E5%90%83&new_wq=%E6%83%B3%E6%80%8E%E4%B9%88%E5%90%83%E5%B0%B1%E6%80%8E%E4%B9%88%E5%90%83
print(urlencode(dic, encoding="utf-8")) # 也可以指定字符集
# 一个完整的url编码过程
base_url = "http://www.baidu.com/s?"
params = {
"wd": "大王"
}
url = base_url + urlencode(params)
print(url) # http://www.baidu.com/s?wd=%E5%A4%A7%E7%8E%8B
- 解码
s = "http://www.baidu.com/s?wd=%E5%A4%A7%E7%8E%8B"
print(unquote(s)) # http://www.baidu.com/s?wd=大王
print(unquote_plus(s)) # 解码 更强一点
3.2 Base64
-
背景
计算机对字符串加密的底层逻辑是 字符串的二进制形式数字,进行各做数学运算(位运算 取余等)
在Python中,二进制形式,通常是由 字节(bytes)类 表示的,形式:
b'16进制数字'通常被加密后的内容是字节,而密文是用来传输的(不传输谁加密啊)
但在http协议里,想要传输字节是很麻烦的一个事儿。
相对应的, 如果传递的是字符串,就好控制的多,此时base64就应运而生了。
-
Base64:将二进制字节 转化为 字符串的机制
26个大写字母 + 26个小写字母 + 10个数字 + 2个特殊符号( + / ),组成了一组类似64进制的计算逻辑
转化机制是将每三个 二进制字节,转化为4个字符
所以Base64解码时,也是按照4个字符为一组解码,故 Base64字符串长度,一定是4的倍数
import base64
### 方法:
b64encode(s) # 将字符串的字节形式(unicode) 编码成 base64的字节形式
b64decode(s) # 将Base64编码过的字节对象 或 字符串(ASCII 字符串) 解码成 字符串的字节形式
# url安全的Base64, 就是使用 - 和_ ,代替标准Base64 字母表中的 + 和 /
# 为了'/'避免在URL中引起歧义或冲突
urlsafe_b64encode(s) # 将字符串的字节形式(unicode) 编码成 url安全的base64 的字节形式
urlsafe_b64decode(s) # 将url安全的Base64编码过的 字节对象 或 字符串(ASCII 字符串) 解码成 字符串的字节形式
### 案例:
# 把字节转化成b64
bs = "我要吃饭".encode("utf-8") # b'\xe6\x88\x91\xe8\xa6\x81\xe5\x90\x83\xe9\xa5\xad'
print(base64.b64encode(bs)) # b'5oiR6KaB5ZCD6aWt'
print(base64.b64encode(bs).decode()) # decode不需要指定字符集编码,因为base64的字符 全在ASCII中
# 把b64字符串转化成字节
s = "5oiR6KaB5ZCD6aWt"
print(base64.b64decode(s).decode("utf-8")) # 此时decode需要指定字符集编码,因为还原的数据 不一定全在ASCII中
# 实际中,一般就这两组Base64 尝试
注意:
b64处理后的字符串长度, 一定是4的倍数。如果在网页上,看到有些密文的b64长度,不是4的倍数,会报错
eg:
import base64
s = "ztKwrsTj0b0"
bb = base64.b64decode(s)
print(bb)
# 此时运行出现以下问题
Traceback (most recent call last):
File "D:/PycharmProjects/rrrr.py", line 33, in <module>
bb = base64.b64decode(s)
File "D:\Python38\lib\base64.py", line 87, in b64decode
return binascii.a2b_base64(s)
binascii.Error: Incorrect padding
-
解决思路
base64长度要求,字符串长度必须是4的倍数, 用 = 填充一下即可,= 填充的个数最多三个
import base64
s = "ztKwrsTj0b0"
s += ("=" * (4 - len(s) % 4))
print("填充后", s)
bb = base64.b64decode(s).decode("gbk")
print(bb)
3.3 二进制字节--16进制表示
import binascii
v1 = "4E2918885FD98109869D14E0231A0BF4" # 16进制表示的二进制数据 字符串
"""
a2b_hex的原理:
bs = bytearray() # []
for i in range(0, len(v1), 2):
item_hex = v1[i:i + 2]
item_int = int(item_hex, base=16)
bs.append(item_int)
v3 = bytes(bs)
print(v3) # b'N)\x18\x88_\xd9\x81\t\x86\x9d\x14\xe0#\x1a\x0b\xf4'
"""
v3 = binascii.a2b_hex(v1)
print(v3) # b'N)\x18\x88_\xd9\x81\t\x86\x9d\x14\xe0#\x1a\x0b\xf4'
### 二进制(字节) <---> 16进制表示该字节
# binascii.b2a_hex(data) # b to a 字节到16进制的转化
# binascii.hexlify(data)
返回二进制 data 的十六进制表示
data的每个字节都转换为相应的2位十六进制表示,因此返回的字节对象是data长度的两倍
# binascii.a2b_hex(hexstr)
# binascii.unhexlify(hexstr)
返回十六进制字符串hexstr表示的二进制数据
该函数是b2a_hex()的逆函数。 hexstr必须包含偶数个十六进制数字(可以是大写或小写)
四、对称加密
所谓对称加密,就是加密和解密用的是同一个秘钥
就好比:我要给你邮寄一个箱子,上面怼上锁,提前我把钥匙给了你一把、我一把。
那么我在邮寄之前,就可以把箱子锁上,然后快递到你那里,你用相同的钥匙,就可以打开这个箱子
条件: 加密和解密用的是同一个秘钥。那么两边就必须同时拥有钥匙,才可以
常见的对称加密: AES、DES、3DES。 这里讨论AES、DES
4.1 AES
# 安装 Crypto
pip install pycrypto # windows可能装不上
pip install pycryptodome
# 效果一样,但可能在文件中,模块名是小写 crypto
# 需要手动修改 python目录\Lib\site-packages文件夹中,重新命名为 Crypto
# AES加密
from Crypto.Cipher import AES
from Crypto.Util.Padding import pad
"""
参数:key 秘钥的长度(字节)
16: *AES-128* 常见
24: *AES-192*
32: *AES-256*
参数:MODE 加密模式 常见:ECB、CBC 99.99%
ECB:不需要指定IV(偏移量)
CBC: 需要指定IV(偏移量)
以下内容来自互联网:
ECB:是一种基础的加密方式,密文被分割成分组长度相等的块(不足补齐),然后单独一个个加密,一个个输出组成密文。
CBC:是一种循环模式,前一个分组的密文和当前分组的明文异或或操作后再加密,这样做的目的是增强破解难度。
CFB/OFB:实际上是一种反馈模式,目的也是增强破解的难度。
FCB和CBC的加密结果是不一样的,两者的模式不同,而且CBC会在第一个密码块运算时加入一个初始化向量。
"""
# 1.先创建加密器 参数为 秘钥key(字节)、mode加密模式、IV偏移量
aes = AES.new(key=b"alexissbalexissb", mode=AES.MODE_CBC, IV=b"0102030405060708")
aes = AES.new(key="alexissbalexissb".encode(), mode=AES.MODE_CBC, IV=b"0102030405060708")
# 2.需要加密的数据,必须是16的倍数,且字节形式
# 填充规则: 缺少数据量的个数 * chr(缺少数据量个数)、或使用pad函数填充
data = "我吃饭了"
data_bs = data.encode("utf-8")
pad_len = 16 - len(data_bs) % 16
data_bs += (pad_len * chr(pad_len)).encode("utf-8")
# 或pad函数填充
data_bs = pad(data_bs, 16) # 参数:被填充的数据、填充多少位的倍数
# 3.encrypt() 加密 返回是字节形式,且不能被处理成utf-8
bs = aes.encrypt(data_bs)
print(bs)
# 4.常规操作:网站会将加密的数据,处理成Base64字符串,方便进行传输
import base64
ss = base64.b64encode(bs).decode()
print(ss) # "9noPO0fcQizMbPkXcVOTDg=="
AES解密
from Crypto.Cipher import AES
from Crypto.Util.Padding import unpad
import base64
# 1.通常得到的数据 是加密后,且转化为base64的字符串
s = "9noPO0fcQizMbPkXcVOTDg=="
bs = base64.b64decode(s) # b'\xf6z\x0f;G\xdcB,\xccl\xf9\x17qS\x93\x0e'
# 2.创建加密器
aes = AES.new(b"alexissbalexissb", mode=AES.MODE_CBC, IV=b"0102030405060708")
# 3.decrypt() 解密 返回是字节形式
result = aes.decrypt(bs) # 若加密前用pad()填充了,解密后的字节可能有填充的字符 需要去填充
# 4.unpad() 去填充
result = unpad(result, 16) # 参数:去填充的数据、填充多少位的倍数
print(result.decode("utf-8"))
4.1.1 常用AES加密封装
-
AES加密(utf-8字节处理)
from Crypto.Cipher import AES from Crypto.Util.Padding import pad def aes_encrypt(data_string): """ 返回的是 aes加密后的二进制数据 是字节形式,且不能被处理成utf-8 """ key_string = "fd6b639dbcff0c2a1b03b389ec763c4b" # utf8编码的(字节)字符串 key = key_string.encode('utf-8') # 编码成字节(二进制数据) iv_string = "77b07a672d57d64c" iv = iv_string.encode('utf-8') data = data_string.encode("utf-8") aes = AES.new( key=key, mode=AES.MODE_CBC, iv=iv ) raw = pad(data, 16) return aes.encrypt(raw) data = "|878975262|d000035rirv|1631615607|mg3c3b04ba|1.3.5|ktjwlm89_to920weqpg|433070" result = aes_encrypt(data) print(result) -
AES加密(十六进制字节处理)
from Crypto.Cipher import AES from Crypto.Util.Padding import pad import binascii def aes_encrypt(data_string): """ 返回的是 16进制表示的二进制数据 大写字符串 """ key_string = "4E2918885FD98109869D14E0231A0BF4" # 16进制表示的字节 字符串 key = binascii.a2b_hex(key_string) # 编码成字节(二进制数据) iv_string = "16B17E519DDD0CE5B79D7A63A4DD801C" iv = binascii.a2b_hex(iv_string) aes = AES.new( key=key, mode=AES.MODE_CBC, iv=iv ) raw = pad(data_string.encode('utf-8'), 16) aes_bytes = aes.encrypt(raw) return binascii.b2a_hex(aes_bytes).decode().upper() data = "|878975262|d000035rirv|1631615607|mg3c3b04ba|1.3.5|ktjwlm89_to920weqpg|4330701|https://w.yangshipin.cn/|mozilla/5.0 (macintosh; ||Mozilla|Netscape|MacIntel|" result = aes_encrypt(data) print(result)
4.2 DES
# DES加密解密 基本和 AES一样
from Crypto.Cipher import DES
from Crypto.Util.Padding import pad, unpad
# key: 8个字节
des = DES.new(b"alexissb", mode=DES.MODE_CBC, IV=b"01020304")
data = "我要吃饭".encode("utf-8")
# 需要加密的数据,也必须是8的倍数
# 填充规则: 缺少数据量的个数 * chr(缺少数据量个数)
pad_len = 8 - len(data) % 8
data += (pad_len * chr(pad_len)).encode("utf-8")
# 或pad函数填充
data_bs = pad(data_bs, 8) # 参数:被填充的数据、填充多少位的倍数
# 加密
bs = des.encrypt(data)
print(bs)
# 解密
des = DES.new(key=b'alexissb', mode=DES.MODE_CBC, IV=b"01020304")
data = b'6HX\xfa\xb2R\xa8\r\xa3\xed\xbd\x00\xdb}\xb0\xb9'
result = unpad(result, 16) # 参数:去填充的数据、填充多少位的倍数
result = des.decrypt(data)
print(result.decode("utf-8"))
五、非对称加密
非对称加密,加密和解密的秘钥不是同一个秘钥。
需要两把钥匙:一个公钥(公开的秘钥, 对数据进行加密)、一个私钥(私密的秘钥, 对数据进行解密)
公钥发送给客户端 (发送端),发送端用公钥对数据进行加密,再发送给接收端,接收端使用私钥来对数据解密。
由于私钥只存放在接受端这边,所以即使数据被截获了,也是无法进行解密的
# 非对称加密的逻辑:
1.先在服务器端. 生成一组秘钥 公钥/私钥
2.把公钥放出去,发送给客户端
3.客户端在拿到公钥之后. 可以使用公钥对数据进行加密
4.把数据传输给服务器
5.服务器使用私钥,对数据进行解密
常见的非对称加密算法: RSA、DSA等等。介绍一个:RSA加密,也是最常见的一种加密方案
5.1 RSA加密解密
5.1.1 创建公钥和私钥
from Crypto.PublicKey import RSA
# 1.创建 生成秘钥的对象
rsakey = RSA.generate(1024)
# 参数: bits 是生成RSA秘钥key的长度,只支持 1024 2048 3072
# 最低1024 推荐2048
# 2.秘钥写入文件,保存
# 公钥
with open("rsa.public.pem", mode="wb") as f:
f.write(rsakey.publickey().export_key())
# 私钥
with open("rsa.private.pem", mode="wb") as f:
f.write(rsakey.export_key())
# 了解
# rsakey.publickey() 生成公钥
# .export_key(format=) 导出秘钥
# 参数format 指定导出秘钥的格式,有三种 'PRM'、'DER'、'OpenSSH'
PEM 文本编码 默认格式 # 其实就是 DER格式 经过Base64编码后,再解码的文本格式
DER 二进制字节编码
OpenSSH 用于 运维 OpenSSH连接 的格式 # 与上两种生成的 有一点差异
5.1.2 加密
from Crypto.PublicKey import RSA
from Crypto.Cipher import PKCS1_v1_5
import base64
# 加密
data = "我要吃饭了"
with open("rsa.public.pem", mode="r") as f:
pk = f.read()
# 1.导入加密公钥
rsa_pk = RSA.import_key(pk)
# .importKey() 将秘钥,由pem格式(就是有什么begin和end标识的)的字符串 或 字节的形式,组装成 RSA key的对象
# 2.创建加密器
rsa = PKCS1_v1_5.new(key=rsa_pk) # 参数 key,不再是字节,而是需要RSA key的对象
# 3.用加密器 加密
result = rsa.encrypt(data.encode("utf-8")) # 参数:传入的数据,和 返回的加密结果,依旧都是字节形式
# 4.将加密后的数据,处理成base64 方便传输
b64_result = base64.b64encode(result).decode()
print(b64_result) # 每次加密后的密文,是不一样的
5.1.3 解密
from Crypto.PublicKey import RSA
from Crypto.Cipher import PKCS1_v1_5
from Crypto import Random
import base64
# 随机
gen_random = Random.new
data = "e/spTGg3roda+iqLK4e2bckNMSgXSNosOVLtWN+ArgaIDgYONPIU9i0rIeTj0ywwXnTIPU734EIoKRFQsLmPpJK4Htte+QlcgRFbuj/hCW1uWiB3mCbyU3ZHKo/Y9UjYMuMfk+H6m8OWHtr+tWjiinMNURQpxbsTiT/1cfifWo4="
# 解密
with open("rsa.private.pem", mode="r") as f:
prikey = f.read()
# 1.导入解密私钥
rsa_pk = RSA.import_key(prikey)
# 2.创建解密器
rsa = PKCS1_v1_5.new(rsa_pk)
# 3.用解密器 解密
result = rsa.decrypt(base64.b64decode(data), setinel=gen_random) # 参数:传入的数据,和 返回的解密结果,依旧都是字节形式
# 参数:
1.解密的数据,一般是base64格式,需base64解码
2.setinel 指定 随机的 ,一般默认填 None
print(result.decode("utf-8"))
5.2 对称与非对称 总结
# 总结:对于逆向而言
1.服务返回的数据是密文,若涉及到 数据解密操作,一般都是 对称加密 AES、DES
2.非对称加密 RSA,一般都是使用 加密操作,模拟浏览器发送请求,服务器自己再解密,做一些判断性的操作
若是 服务器返回的数据,是经过RSA加密的
网站需要展示数据,就必须RSA解密,服务器就必须把解密的私钥 发送给 网站
那么私钥也会暴露在公共环境中,非对称加密 就没有意义了,还不如 对称加密
3.前端 采用对称加密 一般是 crypto-js 模块
前端 采用非对称加密 一般是 JSEncrypt 模块
六、逆向经验
6.1 webpack、vit打包
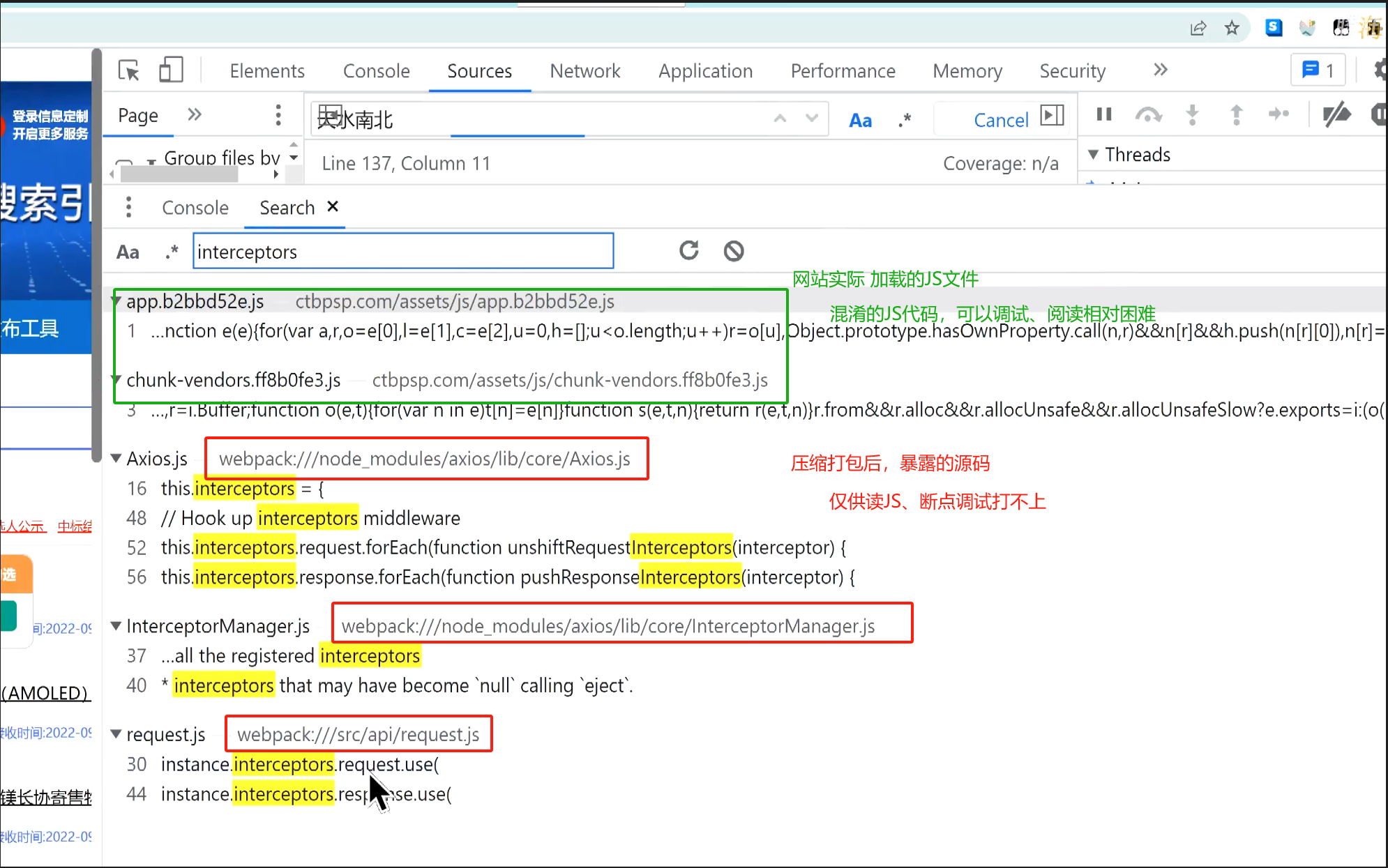
在浏览器中搜索时,发现有些JS文件是以webpack开头的,这些是网站程序员的失误
webpack、vit是前端项目 压缩、打包的工具。这些路径的文件,是真实的前端资源源码,并且在文件里,有些行灰色,不能打断点
故常用来自己 参照该文件 读JS、但断点调试还是需要用上面 网站实际加载的JS文件
eg: https://ctbpsp.com/#/ 注意:用chrome 浏览器右上角 > 更多工具 > 开发者工具 打开
6.2 AES、DES秘钥
在网站中,发现给的秘钥key长度特别长,尝试方法1:直接截取对应长度
6.3 固定网站动态JS文件
# 前景:
例如:问财 https://www.iwencai.com/unifiedwap/result?w=20220903%E6%B6%A8%E5%81%9C&querytype=stock
chameleon.min.1720410.js
chameleon.min.1720411.js
chameleon.min.1720412.js
若动态JS文件每次加载,只是一些小的变动,例如某个变量值变化(时间戳之类的)
且每次JS文件名(例:上面),都会变化
会导致在动态JS文件上,打上断点后,下一次就加载运行其他JS文件了,就断不住
那么爬虫调试时,可以将 动态JS文件,固定成静态的JS文件
# 固定网站动态js文件的技巧
就是用第三方抓包工具,用本地JS文件 替换网站加载的 动态JS文件
跟利用第三方抓包工具,解决 网站禁用F12调试 的方法 本质一样
# 步骤:
1.先将第一次的 JS文件,复制保存到本地,chameleon.min.js
2.打开Charles,找到动态JS文件,右键--->Map Local---> 编辑替换
http://s.this.cn
/js
/chameleon
chameleon.min.1720410.js
3.编辑替换规则
Map From
Path:/js/chameleon/chameleon.min.*.js
Map To
Local Path: 选择 第一步中复制到本地的 chameleon.min.js
4.此时 在浏览器调试,依旧断点不上 (因为虽然替换了动态JS文件的内容,但JS文件名依旧在变化)
5.但可以在需要打断点的地方,手动在 本地的JS文件中 写上debugger
6.后续就可以 在F12中,继续打断点,再 Ctrl+Shift+r 刷新 调试了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号