05--Redis高级:持久化、主从复制、哨兵、集群、redis做缓存
1 redis持久化
# 持久化
redis的所有数据保存在内存中,对数据更新将异步的保存到硬盘上
# 实现方式
# 1.快照 (全量复制):某时某刻数据的一个完整备份
-mysql的 Dump
-redis的 RDB
# 2.写日志 (日志回放):任何操作记录日志,要恢复数据,只要把日志重新走一遍即可
-mysql的 Binlog
-Redis的 AOF
1.1 RDB配置
# 触发机制:主要三种方式
1.save命令 :客户端执行save命令--> redis服务端--> 同步创建RDB二进制文件,如果老的RDB存在,会替换老的
2.bgsave命令:客户端执行save命令--> redis服务端--> 异步创建RDB二进制文件,如果老的RDB存在,会替换老的
3.自动触发(配置文件) :save三条,只要符合一条 就会更新RDB # 内部采用bgsave
# save与 bgsave命令区别:
save:在当前进程执行生成RDB文件,当数据量特别大的时候,有可能导致redis阻塞
bgsave:以后台进程形式执行生成RDB文件,是异步操作 不会影响当前redis客户端访问 # 手动备份时 常用
# 最佳配置
save 900 1 # 如果900s中改变了1条数据,自动生成rdb
save 300 10 # 如果300s中改变了10条数据,自动生成rdb
save 60 10000 # 如果60s中改变了1w条数据,自动生成rdb
dbfilename dump-${port}.rdb # rdb文件的名字 以端口号作为文件名 默认为dump.rdb
dir /bigdiskpath # 快照(rdb文件) 保存路径放到一个大硬盘位置目录
stop-writes-on-bgsave-error yes # 如果bgsave出现错误,是否停止写入 默认为yes 出现错误停止
rdbcompression yes # 采用压缩格式 是
rdbchecksum yes # 是否对rdb文件进行校验 是
1.2 AOF配置
# AOF原理
客户端每写入一条命令,都记录一条日志,放到日志文件中,如果出现宕机,可以重新执行命令 将数据完全恢复
# AOF的三种策略 fsync调用模式
always (同步写回) : redis命令-> 写入命令刷新的缓冲区-> 每条命令fsync到硬盘(AOF文件)
everysec (每秒写回) : redis命令-> 写入命令刷新的缓冲区-> 每秒把缓冲区fsync到硬盘(AOF文件) # 默认
no (操作系统控制写回) : redis命令-> 写入命令刷新的缓冲区-> 由操作系统决定何时把缓冲区fsync到硬盘(AOF文件)
# 对比:
always : 数据不丢失 IO开销大 性能消耗高
everysec : 丢失1秒数据 性能适中 # 生产环境 常用
no : 数据丢失不可控 性能消耗低
# AOF重写
-前提:随着命令的逐步写入和并发量增大,AOF文件会越来越大,故通过AOF重写来解决该问题
-本质:本质就是把过期的、无用的、重复的、可以优化的命令,来优化AOF命令日志
-使用:
-在客户端主动输入命令:bgrewriteaof
-配置文件:
# AOF持久化配置最优方案
appendonly yes # 开启AOF持久化
appendfilename "appendonly.aof" # AOF文件保存的名字
appendfsync everysec # 采用第二种策略
dir ./data # AOF文件存放的路径
no-appendfsync-on-rewrite yes # 在AOF重写的时候,是否要不做AOF的append操作
# 因为AOF重写消耗性能和磁盘,与正常AOF写入磁盘有一定的冲突,这段期间的数据,允许丢失
2 主从复制
2.1 介绍与配置
# 产生背景
单个服务器库 易发生机器故障、容量瓶颈、QPS瓶颈(每秒查询率 每秒处理响应的查询次数)
# 主从复制 主库master 从库slave slave n. 奴隶,苦工
主库数据主动同步到从库
实现读写分离:主库写入数据,从库查询数据(不允许写)
# 原理
1.副本库通过slaveof 127.0.0.1 6379命令,连接主库,并发送SYNC(全量同步)给主库
2.主库收到SYNC,会立即触发BGSAVE,后台保存RDB,发送给副本库
3.副本库接收后会应用RDB快照
4.主库会陆续将中间产生的新的操作,保存并发送给副本库
5.到此,我们主复复制就正常工作了
6.再此以后,主库只要发生新的操作,都会以命令传播的形式自动发送给副本库
7.所有复制相关信息,从info信息中都可以查到.即使重启任何节点,主从关系依然都在
8.如果发生主从关系断开时,从库数据没有任何损坏,在下次重连之后,从库发送PSYNC(增量同步)给主库
9.主库只会将从库缺失部分的数据同步给从库应用,达到快速恢复主从的目的
# 强调
1.数据流向是单向的,只能由master流向slave
2.主库必须持久化 如果不开启 有可能主库重启操作,造成所有主从库数据丢失!
# 实现
一主一从、一主多从
# 如何实现:在从库中执行配置命令 或者 修改配置文件
方式一:在从库中执行
slaveof ip port # 配置要异步复制的 主节点ip 和端口
slaveof no one # 取消作为从库时,不会把之前的数据清除
方式二:配置文件 配在从库的配置文件中 # 常用
slaveof ip port
slave-read-only yes # 配置从节点只读 因为可读可写,数据会乱
# eg: 正常情况下 是两台机器 不是同一个机器两个进程(两个不同端口)
6380是从,6379是主
在6380上执行或配置 # 从库中 配置主库
# 方式一
slaveof 127.0.0.1 6379
# 方式二
slaveof 127.0.0.1 6379
slave-read-only yes
# 辅助配置(主从数据一致性配置)
min-slaves-to-write 1
min-slaves-max-lag 3
# 解读:
在从服务器的数量少于1个
或者三个从服务器的延迟(lag)值都大于或等于3秒时
主服务器将拒绝执行写命令
# 实际业务场景很少配置
实际生产中 并发量小的项目 基本都是单redis 偶尔会搭建redis主从复制
# 多个redis库 意味着部署多台机器 资源消耗严重
2.2 django缓存实现读写分离
# 第一步:settings中 配置多个redis
CACHES = {
"default": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": "redis://机器1的ip:6379/0",
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
}
},
"redis1": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": "redis://机器2的ip:6379/0",
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
}
}
}
# 第二步:使用
from django.core.cache import caches
caches['redis1'].set("name",'lqz') # 写
res=caches['default'].get('name') # 读
3 哨兵
3.1 介绍及配置
# 前提
1.主从复制存在的问题:
1.主从复制,主节点发生故障,需要做故障转移,可以手动转移:让其中一个slave变成master
2.主从复制,只能主写数据,所以写能力和存储能力有限
2.高可用 名词解释
通过设计减少系统不能提供服务的时间 俗讲:系统服务 能很长时间的 提供使用
# 哨兵 sentinel
sentinel是特殊的redis,可以管理多个Redis服务器,它提供了监控,提醒以及自动的故障转移的功能
# 作用
让redis的主从复制高可用 主要是解决了主从复制出现故障时需要人为干预的问题
# 主要功能
集群监控:多个sentinel负责监控Redis master和slave进程是否正常工作
消息通知:如果某个Redis实例有故障,那么哨兵负责发送消息作为报警通知给管理员
故障转移:如果master node挂掉了,会自动转移到slave node上
配置中心:如果故障转移发生了,通知client客户端新的master地址
# 安装配置
1.配置开启主从节点
2.配置开启sentinel监控主节点(sentinel是特殊的redis)
3.应该是多台机器
# 配置参数
sentinel monitor <master-name> <ip> <redis-port> <quorum>
# 配置sentinel去监听地址为ip:port的一个master
master-name # 主库名字 可以自定义
quorum # 指定一个数字,表明当有多少个sentinel认为一个master失效时,master才算真正失效
一般是 sentinel数量/2 + 1
monitor n.监控
sentinel auth-pass <master-name> <password>
# 设置连接master和slave时的密码
注意: sentinel不能分别为master和slave设置不同的密码
因此master和slave的密码应该设置相同
sentinel down-after-milliseconds <master-name> <milliseconds>
# 指定需要多少失效时间,master才会被这个sentinel主观地认为是不可用的。
单位是毫秒(ms),默认为30秒 30000ms
sentinel parallel-syncs <master-name> <numslaves>
# 指定在发生failover主备切换时,每次最多可以有多少个slave同时对新的master进行同步
通常将该值设为 1 表明故障切换时,每次只有一个slave来同步复制 处于了不能处理命令请求的状态
其他slave 依旧可以处理命令请求
数字越小,意味着完成failover所需的时间就越长
数字越大,意味着越多的slave因为replication复制状态而不可用
parallel n.平行
syncs v.同步
failover n.故障切换 失效备援
sentinel failover-timeout <master-name> <milliseconds>
# 指定故障转移failover 重试时间间隔,默认值为 180000ms 3min
failover-timeout 该选项会影响:
1.同一个sentinel对同一个master两次failover之间的间隔时间。
2.当一个slave从一个错误的master那里同步数据开始计算时间。直到slave被纠正为向正确的master那里同步数据时。
3.取消一个正在进行的failover所需要的时间
4.当进行failover时,配置所有slaves指向新的master所需的最大时间。
不过,即使过了这个超时,slaves依然会被正确配置为指向master,但是就不按parallel-syncs所配置的规则来了。
3.2 哨兵案例
# eg:
##### 1 搭一个一主两从
# 创建三个redis配置文件
# 第一个是主配置文件
daemonize yes
pidfile /var/run/redis.pid
port 6379
dir "/opt/soft/redis/data"
logfile “6379.log”
# 第二个是从配置文件
daemonize yes
pidfile /var/run/redis2.pid
port 6378
dir "/opt/soft/redis/data2"
logfile “6378.log”
slaveof 127.0.0.1 6379
slave-read-only yes
# 第三个是从配置文件
daemonize yes
pidfile /var/run/redis3.pid
port 6377
dir "/opt/soft/redis/data3"
logfile “6377.log”
slaveof 127.0.0.1 6379
slave-read-only yes
# 把三个redis服务都启动起来
redis-server redis_6379.conf
redis-server redis_6378.conf
redis-server redis_6377.conf
##### 2 搭建哨兵
# 哨兵服务器就是sentinel.conf这个文件 也类似于一个redis服务器
# 创建三个哨兵配置文件
sentinel_26379.conf sentinel_26378.conf sentinel_26377.conf
# 前提:
当前路径下创建 data1 data2 data3 3个文件夹
需要修改 端口(port)、文件地址日志文件名字(logfile)、工作文件地址(dir)
# 配置文件内容如下
port 26379
daemonize yes
dir ./data3
protected-mode no
bind 0.0.0.0
logfile "redis_sentinel3.log"
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
# 启动三个哨兵
redis-sentinel sentinel_26379.conf
redis-sentinel sentinel_26378.conf
redis-sentinel sentinel_26377.conf
# 登陆哨兵
redis-cli -p 26377
# 输入 info 可以查看当前master 地址
# 查看哨兵的配置文件被修改了,自动生成的
# 主动停掉主redis 6379,哨兵会自动选择一个从库作为主库
redis-cli -p 6379
shutdown
# 等待原来的主库启动,该主库会变成从库
3.3 客户端(python)连接
import redis
from redis.sentinel import Sentinel
# 连接哨兵服务器(主机名也可以用域名)
# 10.0.0.101:26379
sentinel = Sentinel([('10.0.0.101', 26379),
('10.0.0.101', 26378),
('10.0.0.101', 26377)],
socket_timeout=5)
print(sentinel)
# 获取主服务器地址 根据主库名字
master = sentinel.discover_master('mymaster')
print(master)
# 获取从服务器地址
slave = sentinel.discover_slaves('mymaster')
print(slave)
##### 读写分离
# 获取主服务器进行写入
master = sentinel.master_for('mymaster', socket_timeout=0.5)
w_ret = master.set('foo', 'bar')
# 获取从服务器进行查询
slave = sentinel.slave_for('mymaster', socket_timeout=0.5)
r_ret = slave.get('foo')
print(r_ret)
4 集群
4.1 介绍
# 产生背景
1 并发量:单机redis qps为10w/s,但是我们可能需要百万级别的并发量
2 数据量:机器内存16g--256g,如果存500g数据呢?
# 解决
搭建多台机器 采用 集群
# 理解:
分布式:不同的业务模块或者同一个业务模块分拆多个子业务,部署在不同的服务器上,解决高并发的问题
集群:同一个业务部署在多台机器上,提高系统可用性
分布式:多个人在一起作不同的事
集群:多个人在一起作同样的事
分布式集群:每一个环节不同的事 都可以配置多个人
# Redis Cluser 集群是3.0以后加的
3.0-5.0之间,采用ruby脚本实现 需要额外安装ruby
5.0以后,内置了命令搭建
# 注意
1.搭建集群 需要搭建主从复制 # 若没有搭建主从,某个节点故障,那么该节点的数据可能直接丢失了
2.不同节点 应当部署不同机器上
也可实现 三台机器 搭建6个节点 但每个机器上的从节点,应当复制另外机器的主节点
# 若每个机器上的从节点 复制本机的主节点,那么本机挂掉,依旧会丢失数据 备份数据库就没有起作用
3.Redis Cluster至少需要三个主节点才能工作
# eg: 集群 6个节点
3个主节点 --对应--> redis的16384个hash槽
3个从节点 作为主节点的备份
4.2 数据分布(分布式数据库)
# 了解 分布式数据库
是由一组数据组成的,这组数据分布在计算机网络的不同计算机上
网络中的每个节点具有独立处理的能力,可以执行局部应用
同时,每个节点也能通过网络通信子系统执行全局应用
# 对比传统数据库-分库分表的区别:
最大的区别,便体现在分布式事务上
单机数据库的事务是在一个节点上完成的,分布式数据库需要多个节点协调完成
# 个人理解:
就是把单一整体服务器拆分给多个数据库服务器节点进行处理,每一个节点都可以处理和存储数据,对外是整体暴露的
# 数据分布(分区)的原因
假设全量的数据非常大,500g,单机已经无法满足,我们需要进行分区存储,分到若干个子集中
# 数据分区方式 数据库都有这两种数据分区
1.顺序分区
原理:100个数据分到3个节点上 1--33第一个节点;34--66第二个节点;67--100第三个节点
# 很多关系型数据库使用此种方式
2.哈希分区
原理:hash分区方式之一:节点取余 ,假设3台机器, hash(key)%3,落到不同节点上
# 方式对比
顺序分布: 数据分散度易倾斜,建值业务相关,可顺序访问,支持批量操作
# 分散度倾斜指的是
比如 按照用户id存储数据 id前一百在一个分区 可能id先建立的用户比后面更活跃
可能会导致 某个分区读写次数 比其他分区 高很多
# eg: BigTable,HBase
哈希分布: 数据分散度高,建值分布于业务无关,无法顺序访问,支持批量操作
# eg: 一致性哈希memcache,redis cluster,其他缓存产品
# 哈希分区的方法 详见:https://www.liuqingzheng.top/db/Redis%E7%B3%BB%E5%88%97/08-Redis%E7%B3%BB%E5%88%97%E4%B9%8B-Redis-Cluster/
1.节点取余分区
2.一致性哈希分区
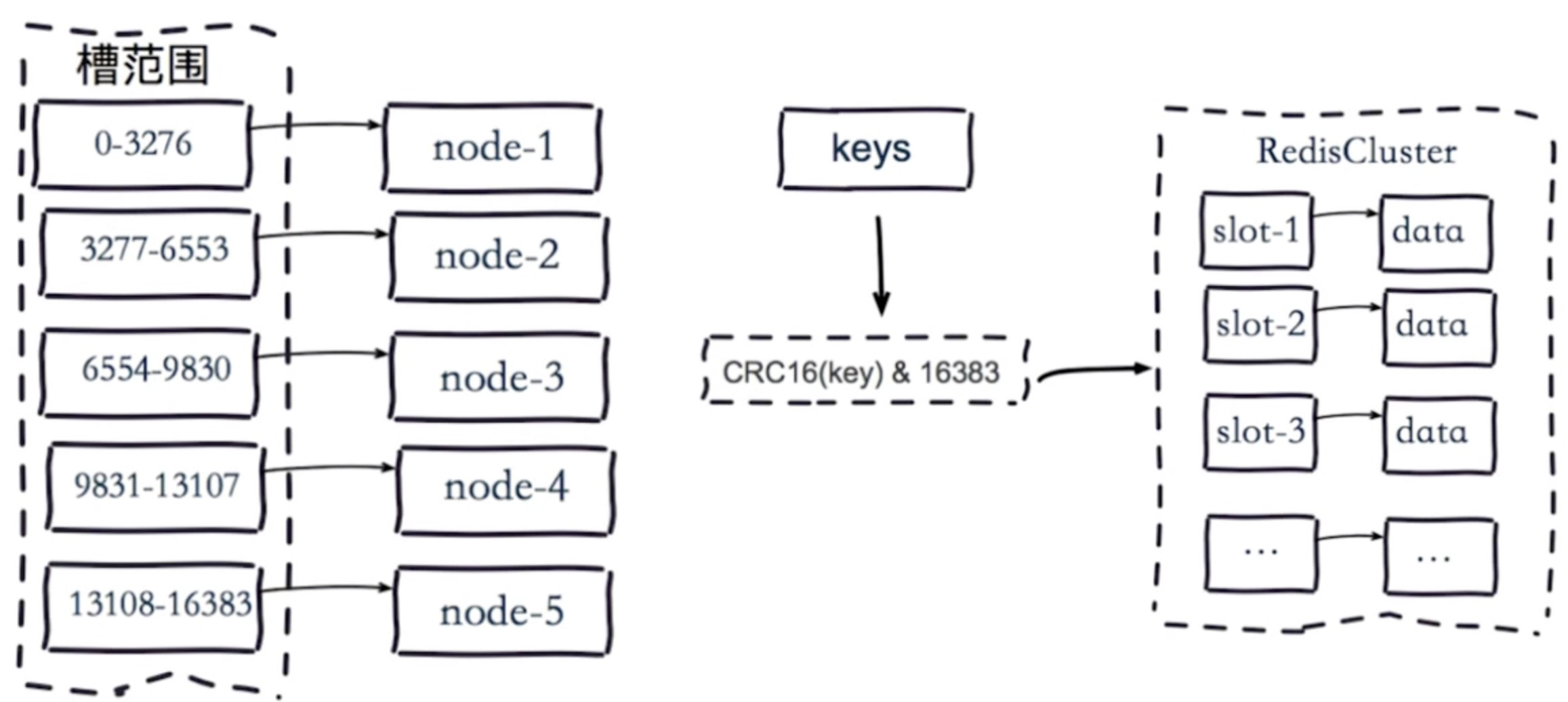
3.虚拟槽分区
预设虚拟槽: 每个槽映射一个数据子集,一般比节点数大
良好的哈希函数 # eg: CRC16
服务端管理 节点、槽、数据 # eg: redis cluster(槽的范围0–16383)
# 原理: 节点数自定义控制 redis有16384个hash槽 # hash槽 很专业的词
把16384个槽平均分配到5个节点,每个节点都会记录是不是负责这部分槽
客户端会把数据发送给任意一个节点,通过CRC16对数据的key进行哈希得到数据值 再对16383进行取余
计算出当前key属于哪个节点,属于哪部分槽
如果是负责该槽,则进行保存
如果槽不在负责范围内,则返回正确的节点结果,让客户端找对应的节点去存
# redis cluster是共享消息的模式,每个节点都知道哪个节点负责哪些槽
4.3 集群搭建
# Redis Cluster架构 cluster n.集群 slot n.槽
开启节点、节点握手(meet相互通信)、节点指派hash槽、主从复制(高可用)
# 实现形式
通过客户端 发送命令的形式创建
# 集群节点配置
cluster-enabled yes # 是否开启cluster
cluster-node-timeout 15000 # 故障转移超时时间 默认 15s 自动带有哨兵功能
cluster-config-file nodes-7000.conf # 指定cluster节点的配置文件名字
自动生成配置文件内容 人为不可修改
cluster-require-full-coverage yes # 是否 cluster运行必须覆盖全部槽 slot
# redis cluster需要16384个slot都正常的时候才能对外提供服务 # 一般 需要设置成no
若 某段槽 对应的主从节点 都挂掉后,那么整个cluster也不能工作
# 命令参数 replicas n.副本 reshard v. 重新切分
redis-cli --cluster help # 查看集群命令 参数
create host1:port1 ... hostN:portN # 指定集群的节点 创建集群
--cluster-replicas <arg> # 指定每个主节点的从节点个数
reshard host:port # 集群的任意一节点进行迁移槽时,重新分slots
--cluster-from <arg> # 需要从哪些源节点上迁移slot,传递的是节点的node id,
可从多个源节点完成迁移,以逗号隔开
也可 all,源节点为集群的所有节点
不传递该参数的话,则会在迁移过程中提示用户输入
--cluster-to <arg> # slot需要迁移的目的节点的node id,目的节点只能填写一个
不传递该参数的话,则会在迁移过程中提示用户输入
--cluster-slots <arg> # 需要迁移的slot数量
不传递该参数的话,则会在迁移过程中提示用户输入
add-node new_host:new_port host:port # 添加节点,把新节点加入到指定的集群 默认:添加为主节点
--cluster-slave # 添加新节点作为从节点 默认:随机一个主节点
--cluster-master-id <arg> # 给新节点指定主节点
del-node host:port node_id # 删除给定的一个节点,成功后关闭该节点服务
# eg: 集群 6个节点
3个主节点 --对应--> redis的16384个hash槽
3个从节点 作为主节点的备份
# 1.配置6个节点服务器的配置文件
cd redis/conf
vim redis-7000.conf
# 写入
port 7000
daemonize yes
dir "/opt/soft/redis/data/"
logfile "7000.log"
dbfilename "dump-7000.rdb"
cluster-enabled yes
cluster-config-file nodes-7000.conf
cluster-require-full-coverage no
# 快速生成其他配置
sed 's/7000/7001/g' redis-7000.conf > redis-7001.conf
sed 's/7000/7002/g' redis-7000.conf > redis-7002.conf
sed 's/7000/7003/g' redis-7000.conf > redis-7003.conf
sed 's/7000/7004/g' redis-7000.conf > redis-7004.conf
sed 's/7000/7005/g' redis-7000.conf > redis-7005.conf
# 2.启动6个节点
redis-server ./conf/redis-7000.conf
redis-server ./conf/redis-7001.conf
redis-server ./conf/redis-7002.conf
redis-server ./conf/redis-7003.conf
redis-server ./conf/redis-7004.conf
redis-server ./conf/redis-7005.conf
# 3.节点meet,节点指派槽,主从配置 3.0--5.0版本需原生操作 或 安装ruby脚本(跟下面搭建一样)
# 4.创建集群 指定每个主节点的 从库数量为1个 故:6个节点 分成 三对主从
redis-cli --cluster create --cluster-replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005
>>> yes
# 5.查看集群节点和槽信息
客户端 连接任意节点
redis-cli -p 7000 CLUSTER NODES # 集群节点信息
redis-cli -p 7000 cluster slots # 查看槽的信息
4.4 集群伸缩
# 伸缩原理
加入节点、删除节点 槽和数据需要在节点之间的移动
4.4.1 集群扩容
# 作用:为它迁移槽和数据实现扩容 作为从节点负责故障转移
# 1 准备新节点 一主一从 两个
-集群模式
-配置和其他节点统一
-启动后是孤儿节点
sed 's/7000/7006/g' redis-7000.conf > redis-7006.conf
sed 's/7000/7007/g' redis-7000.conf > redis-7007.conf
redis-server conf/redis-7006.conf
redis-server conf/redis-7007.conf
# 查看新节点 孤立状态re
redis-cli -p 7006 cluster nodes
# 2 加入集群和配置主从
-添加到集群
-新的两个节点 建立主从关系
# 添加到集群
### 方式一:连接7000主节点 执行meet通信
redis-cli -p 7000 cluster meet 127.0.0.1 7006
redis-cli -p 7000 cluster meet 127.0.0.1 7007
### 方式二:命令行形式 添加新节点到集群中
redis-cli --cluster add-node 127.0.0.1:7006 127.0.0.1:7000
redis-cli --cluster add-node 127.0.0.1:7007 127.0.0.1:7000
# 把7007做为7006的从 replicate v.复制
redis-cli -p 7007 cluster replicate 7006的id
# 查看
redis-cli -p 7000 cluster nodes # 已经添加到集群中
# 3 迁移槽和数据
-槽迁移计划
-迁移数据
redis-cli --cluster reshard 127.0.0.1:7000
>>> 打印当前集群状态
命令交互:
希望迁移多少个槽 : 4096
希望那个id是接收的 : 7006的id # 接受槽的节点id
传入source id : all # 槽的来源 从哪些节点迁移出来 all表示每个节点平均分一点
是否执行迁移计划 : yes # 真正开始迁移数据
# 也可以直接将参数 写在命令中
redis-cli --cluster reshard 127.0.0.1:7000 --cluster-from all --cluster-to 7006的id --cluster-slots 4096
>>> yes
# 查看集群信息
redis-cli -p 7000 cluster nodes
redis-cli -p 7000 cluster slots
向集群某主节点 添加一个新从节点
# 其他:如果想给7000 某个主节点 再加一个从节点 怎么弄?
# 方式一: 手动
启动起7000,meet一下7008 再让7008复制7000
redis-cli -p 7000 cluster meet 127.0.0.1 7008
redis-cli -p 7008 cluster replicate 7000的id
# 方式二: cluster 命令
redis-cli --cluster add-node 127.0.0.1:7008 127.0.0.1:7000 --cluster-slave --cluster-master-id 7000的id
4.4.2 集群缩容
# 步骤
1.当前节点 迁移槽 到其他节点 # 只能迁移到主节点身上
2.从集群中 下线 当前节点
# 下线迁槽 (把7006的1366个槽迁移到7000上)
redis-cli --cluster reshard --cluster-from 7006的id --cluster-to 7000的id --cluster-slots 1366 127.0.0.1:7000
>>> yes
redis-cli --cluster reshard --cluster-from 7006的id --cluster-to 7001的id --cluster-slots 1366 127.0.0.1:7000
>>> yes
redis-cli --cluster reshard --cluster-from 7006的id --cluster-to 7002的id --cluster-slots 1365 127.0.0.1:7000
>>> yes
# 忘记节点,关闭节点
关闭顺序:先下从,再下主,因为先下主会触发故障转移
redis-cli --cluster del-node 127.0.0.1:7000 要下线的7007id
redis-cli --cluster del-node 127.0.0.1:7000 要下线的7006id
redis-cli --cluster del-node 127.0.0.1:7000 c2d0ed9ff7b08086d233c43ba8c3da22c5604853
# 故障转移
关掉其中一个主,另一个从立马变成主顶上
重启停止的主,发现变成了从
4.5 客户端连接
##### 命令行连接
redis-cli -c -p 7000 # -c表示集群模式 若不加-c 设值或取值时,该节点没有对应的槽,不能操作,但会返回正确的节点位置
set hello world # ok
cluster keyslot php # 查看某个key 所在的槽 9244
set php sb # 不命中 会自动跳转到7001上操作 不加-c,只会返回错误,不会去执行7001上保存
##### python连接 需要安装 redis-py-cluster
# pip3 install redis-py-cluster
from rediscluster import RedisCluster
startup_nodes = [{"host":"127.0.0.1", "port": "7000"},{"host":"127.0.0.1", "port": "7001"},{"host":"127.0.0.1", "port": "7002"}]
# rc = RedisCluster(startup_nodes=startup_nodes,decode_responses=True)
rc = RedisCluster(startup_nodes=startup_nodes)
rc.set("foo", "bar")
print(rc.get("foo"))
5 redis做缓存
https://www.liuqingzheng.top/db/Redis系列/09-Redis系列之-缓存的使用和优化/
5.1 缓存使用场景
1 降低后端负载:对高消耗的sql,join结果集/分组统计的结果做缓存
2 加速请求响应:利用redis优化io响应时间
3 大量写合并为批量写:如计数器先redis累加再批量写入db
5.2 缓存更新
# 缓存更新策略 前两种自带 第三种程序主动更新
# 1.内存溢出淘汰策略
即:超过maxmemory-policy(最大内存),新的数据放不进去了 此时需要淘汰一些数据
# LRU/LFU/FIFO算法剔除
LRU : Least Recently Used # 最长时间 没有被使用的 # 保证热点数据 常用
LFU : Least Frequently Used # 一定时间段内 使用次数最少的
FIFO : First In First Out # 先进先出
# 1.1 如何保证redis中数据是最热(最新)的: 配置LRU的剔除算法
-配置文件中:
maxmemory-policy: volatile-lru
volatile-lru # 对有过期时间的key采用LRU淘汰算法 volatile n.易丢失的
allkeys-lru # 对全部key采用LRU淘汰算法
还有其他内存溢出淘汰的参数 自行百度
# 1.2 LFU配置
-Redis4.0之后为maxmemory_policy淘汰策略添加了两个LFU模式
volatile-lfu # 对有过期时间的key采用LFU淘汰算法
allkeys-lfu # 对全部key采用LFU淘汰算法
-配置文件中:
maxmemory-policy: volatile-lfu
lfu-log-factor 10 # 默认为10 实际采用默认就可以
lfu-decay-time 1 # 默认为1
# counter并不是一个简单的线性计数器,而是用基于概率的对数计数器来实现
lfu-log-factor # counter的概率因子 数值越大 增长越慢
lfu-decay-time # counter的衰减因子 默认为1 也就是N分钟内没有访问,counter就要减N
# 2.超时剔除: eg: 设置过期时间(expire)
# 3.主动更新: 开发控制生命周期
即:常说的redis和mysql的双写一致性问题 就是保障redis和mysql数据同步
# 方案: 使用3和4
1.先更新数据库,再更新缓存 # 一般不用
# 缺点:
主要是怕两个并发的写操作导致脏数据
2.先删缓存,再更新数据库 # 也不是很好
# 缺点:
删完缓存,在存数据的过程中,新的请求又来了,又导致新的旧缓存 (且不是最新数据)
3.先更新数据库,再删缓存 # 推荐用
# 缺点:
在更新数据库时,此时的请求依旧是缓存的旧数据 但可理解
但只要再删掉缓存,数据就一致了
4.定时更新 # 对实时性要求不高
eg: 每隔12个小时,更新一下缓存(定时读取数据库,再写入缓存)
# 详见:
https://www.cnblogs.com/liuqingzheng/p/11080680.html
# 更新总结:
低一致性: 使用Redis自带的内存淘汰机制
高一致性: 主动更新, 并以超时剔除作为兜底方案
读操作:
缓存命中直接返回
缓存未命中则查询数据库, 并写入缓存, 设定超时时间
写操作:
先写数据库, 然后再删除缓存
要确保数据库与缓存操作的原子性
5.3 缓存粒度控制
# 缓存粒度:指的是缓存mysql表数据时,缓存全部字段属性还是部分字段属性
缓存全部属性
缓存部分重要属性
# 比较
1.通用性:全量属性更好
2.占用空间:部分属性更好
3.代码维护:表面上全量属性更好
# eg: 实际生产中 肯定是常用字段属性 不会全缓存
1.从mysql获取用户信息:select * from user where id=100
2.设置用户信息缓存:set user:100 select * from user where id=100
# 缓存粒度控制: "*" 还是 "某些字段"
8 redis实现布孔过滤器
9 python实现布隆过滤器
5.4 缓存穿透、缓存击穿、缓存雪崩
# 引言:
在生产环境中,会因为很多的原因造成 访问请求绕过了缓存,都需要访问数据库持久层
虽然对Redis缓存服务器不会造成影响,但是数据库的负载就会增大,使缓存的作用降低
# 实际生产:击穿和雪崩会有一丢丢可能遇见
# 缓存穿透(通常是恶意的)
# 描述:
缓存穿透是指缓存和数据库中都没有的数据
而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据
这时的用户很可能是攻击者,攻击会导致数据库压力过大
# 解决方案:
1.接口层校验
接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截 就不会访问到持久化层(mysql)
2.缓存空对象
从缓存和数据库中都取不到的数据,此时可以将key-value对写为key-null
同时设置缓存有效时间 设置短点,如30秒(设置太长会导致正常情况也没法使用)
这样可以防止攻击用户反复用同一个id暴力攻击
3.布隆过滤器拦截
在访问缓存层和存储层之前,将存在的所有key用布隆过滤器提前保存起来,做第一层拦截,
请求来了,先去布隆过滤器查,如果没有,表示非法,直接返回
# 缓存击穿
# 描述:
也叫作热点key问题, 就是一个被高并发访问, 并且缓存重建业务比较复杂的数据
缓存击穿是指缓存中没有 但数据库中有的热点数据 # 一般是缓存时间到期
这时由于并发用户特别多,同时读缓存没读到数据,
又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力
# 解决方案:
1.设置热点数据永远不过期。
2.分布式互斥锁
只允许一个线程重建缓存,其他线程等待重建缓存的线程执行完,重新从缓存获取数据即可
# 缓存雪崩
# 描述:
指在同一时间段大量的缓存key同时失效或者Redis服务宕机
而查询数据量巨大,导致大量请求到达数据库, 引起数据库压力过大甚至down机。
和缓存击穿不同的是
缓存击穿指并发查同一条数据
缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
# 解决方案:
1.缓存数据的过期时间 设置随机,防止同一时间大量数据过期现象发生。
2.如果缓存数据库是分布式集群部署,将热点数据均匀分布在不同搞得缓存数据库中。
3.设置热点数据永远不过期。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号