一、模块
1.模块介绍
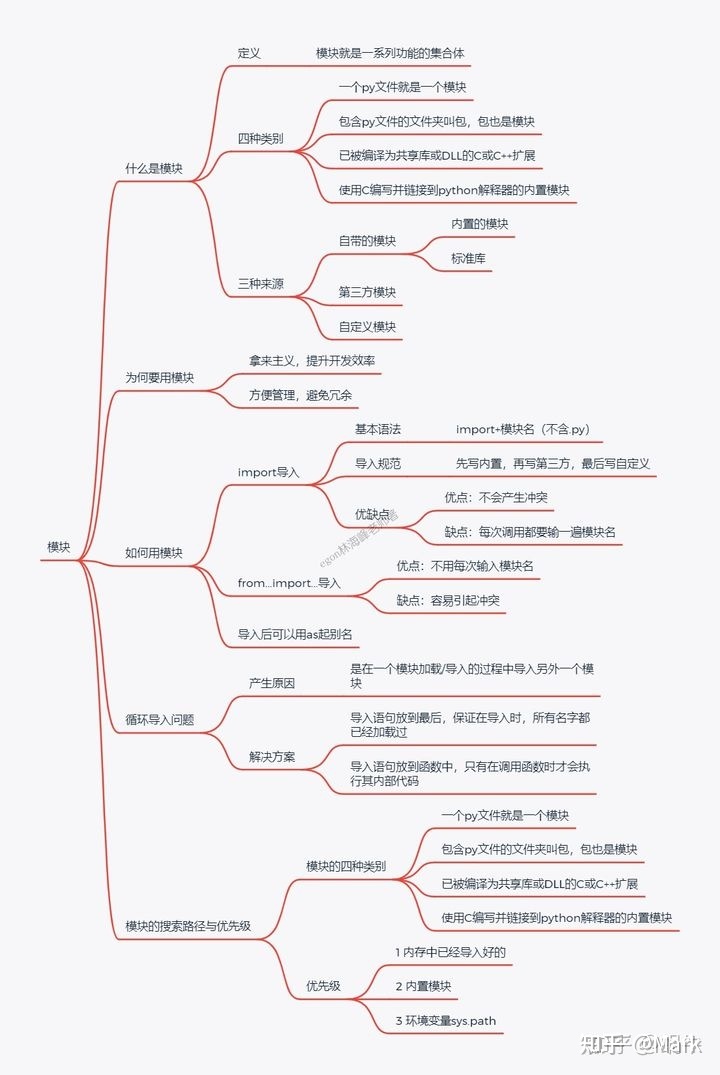
# 1.什么是模块?
模块就是一系列功能的集合体,分为三大类
# 2.模块的3种来源
1.内置的模块
2.第三方的模块
3.自定义的模块
一个python文件本身就一个模块,文件名m.py,模块名叫m
# 3.模块的四种类别
1.使用python编写的.py文件
2.已被编译为共享库或DLL的C或C++扩展
3.把一系列模块组织到一起的文件夹 # 注:文件夹下有一个__init__.py文件,该文件夹称之为包
4.使用C编写并链接到python解释器的内置模块
2.模块目的
# 1.内置与第三的模块拿来就用
无需定义,这种拿来主义,可以极大地提升自己的开发效率
# 2.自定义的模块
可以将程序的各部分功能提取出来放到一模块中为大家共享使用
好处是减少了代码冗余,程序组织结构更加清晰
3.模块使用
3.1 import语句
# 文件名:foo.py
x=1
def get():
print(x)
def change():
global x
x=0
class Foo:
def func(self):
print('from the func')
import foo
# 1.首次导入模块会发生3件事
1.执行foo.py
2.产生foo.py的名称空间,将foo.py运行过程中产生的名字都丢到foo的名称空间中
3.在当前文件中产生的有一个名字foo,该名字指向2中产生的名称空间
# 之后的导入,都是直接引用首次导入产生的foo.py名称空间,不会重复执行代码
import foo
import foo
# 2.引用:
print(foo.x)
print(foo.get)
# 强调1:模块名.名字,是指名道姓地问某一个模块要名字对应的值,不会与当前名称空间中的名字发生冲突
x=1111111111111
print(x)
print(foo.x)
# 强调2:无论是查看还是修改操作的都是模块本身,与调用位置无关
import foo
x=3333333333
foo.get() # 还是原模块下的 x
foo.change()
print(x) # 3333333
print(foo.x)
foo.get()
# 3.可以以逗号为分隔符在一行导入多个模块
# 建议如下所示导入多个模块
import time
import foo
import m
# 不建议在一行同时导入多个模块
import time,foo,m
# 4.导入模块的规范
按照下面顺序导入,方便查看
1. python内置模块
2. 第三方模块
3. 程序员自定义模块
import time
import sys
import 第三方1
import 第三方2
import 自定义模块1
import 自定义模块2
import 自定义模块3
# 5.import .. as ...
import foo as f # f=foo
f.get()
在模块名比较复杂的时候,使用as
import abcdefgadfadfas
abcdefgadfadfas.f1
abcdefgadfadfas.f2
abcdefgadfadfas.f3
import abcdefgadfadfas as mmm
mmm.f1
mmm.f2
mmm.f3
# 6.模块是第一类对象,可以赋值、有属性和方法
import foo
# 7.自定义模块的命名应该采用纯小写+下划线的风格,尽量不使用驼峰体
# 8.可以在函数内导入模块 属于局部的作用域
def func():
import foo
3.2 from-import 语句
# impot导入模块在使用时必须加前缀 "模块."
优点:肯定不会与当前名称空间中的名字冲突
缺点:加前缀显得麻烦
# from ... import ...导入也发生了三件事
1.产一个模块的名称空间
2.运行foo.py将运行过程中产生的名字都丢到模块的名称空间去
3.在当前名称空间拿到一个名字,该名字是模块名称空间中的某一个内存地址
from foo import x # x=模块foo中值0的内存地址
# from-impot导入模块在使用时不用加前缀
优点:代码更精简
缺点:容易与当前名称空间混淆
from foo import x # x=模块foo中值1的内存地址
x=1111
# 一行导入多个名字(不推荐)
from foo import x,get,change
# 导入所有名字 (*)
from socket import *
其实现原理是:
模块中自带变量:__all__ = ['变量名'] # 该列表中所有的元素必须是字符串类型
*就是去找该__all__ 的值 , 故可以通过该修改该变量,来实现修改导入* 的变量名
# as语法,为导入模块起别名
from foo import get as g # 这是为导入的变量名get,起别名 g
import foo as f # 为foo模块名,起别名 f
3.3 循环导入问题
# 循环导入问题
指的是在一个模块加载/导入的过程中导入另外一个模块
而在另外一个模块中又返回来导入第一个模块中的名字
由于第一个模块尚未加载完毕,所以引用失败、抛出异常
究其根源就是在python中,同一个模块只会在第一次导入时执行其内部代码,
再次导入该模块时,即便是该模块尚未完全加载完毕也不会去重复执行内部代码。
# 案例
# m1.py
print('正在导入m1')
from m2 import y
x='m1'
# m2.py
print('正在导入m2')
from m1 import x
y='m2'
# run.py
import m1
# 测试一
# 1.执行run.py会抛出异常
正在导入m1
正在导入m2
Traceback (most recent call last):
File "/Users/linhaifeng/PycharmProjects/pro01/1 aaaa练习目录/aa.py", line 1, in <module>
import m1
File "/Users/linhaifeng/PycharmProjects/pro01/1 aaaa练习目录/m1.py", line 2, in <module>
from m2 import y
File "/Users/linhaifeng/PycharmProjects/pro01/1 aaaa练习目录/m2.py", line 2, in <module>
from m1 import x
ImportError: cannot import name 'x'
# 2.分析
先执行run.py--->执行import m1,开始导入m1并运行其内部代码
--->打印内容"正在导入m1"
--->执行from m2 import y 开始导入m2并运行其内部代码
--->打印内容“正在导入m2”
--->执行from m1 import x,由于m1已经被导入过了,所以不会重新导入
所以直接去m1中拿x,然而x此时并没有存在于m1中,所以报错
# 测试二
# 1.执行文件不等于导入文件,比如执行m1.py不等于导入了m1
# 直接执行m1.py抛出异常
正在导入m1
正在导入m2
正在导入m1
Traceback (most recent call last):
File "/Users/linhaifeng/PycharmProjects/pro01/1 aaaa练习目录/m1.py", line 2, in <module>
from m2 import y
File "/Users/linhaifeng/PycharmProjects/pro01/1 aaaa练习目录/m2.py", line 2, in <module>
from m1 import x
File "/Users/linhaifeng/PycharmProjects/pro01/1 aaaa练习目录/m1.py", line 2, in <module>
from m2 import y
ImportError: cannot import name 'y'
# 2.分析
执行m1.py,打印“正在导入m1”,执行from m2 import y ,导入m2进而执行m2.py内部代码
--->打印"正在导入m2",执行from m1 import x,
此时m1是第一次被导入,执行m1.py并不等于导入了m1,于是开始导入m1并执行其内部代码
--->打印"正在导入m1",执行from m2 import y,由于m2已经被导入过了,
所以无需继续导入而直接问m2要y,然而y此时并没有存在于m2中所以报错
# 解决循环导入问题:
注意:
循环导入问题大多数情况是因为程序设计失误导致,
解决方案也只是在烂设计之上的无奈之举,
在我们的程序中应该尽量避免出现循环/嵌套导入,
如果多个模块确实都需要共享某些数据,
可以将共享的数据集中存放到某一个地方,然后进行导入。
# 方案一:导入语句放到最后,保证在导入时,所有名字都已经加载过
# 文件:m1.py
print('正在导入m1')
x='m1'
from m2 import y
# 文件:m2.py
print('正在导入m2')
y='m2'
from m1 import x
# 文件:run.py内容如下,执行该文件,可以正常使用
import m1
print(m1.x)
print(m1.y)
# 方案二:导入语句放到函数中,只有在调用函数时才会执行其内部代码
# 文件:m1.py
print('正在导入m1')
def f1():
from m2 import y
print(x,y)
x = 'm1'
# 文件:m2.py
print('正在导入m2')
def f2():
from m1 import x
print(x,y)
y = 'm2'
# 文件:run.py内容如下,执行该文件,可以正常使用
import m1
m1.f1()
ps:
实际开发难免会遇到循环导入的问题,
若只是某个函数内需要使用导入模块,就放在函数体内。
利用定义函数时,不执行函数体代码的特性来解决。
3.4 模块的查找优先级
# 查找的优先级:
1.先从内存中查找
a.若是已经导入过的模块,会被加载到内存中,就会被直接引用;
b.查找内置模块 # 内置模块会提前直接加载内存中
# 查看已经加载到内存的模块:
import sys
print(sys.modules)
2.再从硬盘的文件中查找
按照sys.path中定义的路径,依次查找
sys.path
# sys.path也被称为模块的搜索路径,它是一个列表类型,存放了一系列的文件夹。
其中第一个文件夹是当前执行文件所在的文件夹。
故:若被导入的模块和执行文件在同一文件夹中,则可以被正常导入。
# 若被导入的模块与执行文件在不同路径下的情况下:
将被导入的模块,添加到系统路径中(sys.path)
import sys
sys.path.append(r'/pythoner/projects/') # 也可以使用sys.path.insert() 但基本使用append
import foo # 无论foo.py在何处,我们都可以导入它了
3.5 区分py文件的两种用途
# 一个python文件有两种用途
1.被当成主程序/脚本运行
2.被当做模块导入
# 二者的区别是什么?
为了区别同一个文件的不同用途,每个py文件都内置了__name__变量
该变量在py文件被当做主程序/脚本执行时,赋值为“__main__”;
在py文件被当做模块导入时,赋值为模块名
# eg:根据文件使用场景,执行不同的逻辑
if __name__ == '__main__':
foo.py 被当做脚本执行时运行的代码
else:
foo.py 被当做模块导入时运行的代码
3.5 编写模块的规范
# 通常只在类unix环境有效,作用是可以使用脚本名来执行,而无需直接调用解释器
#!/usr/bin/env python
"The module is used to..." # 模块的文档描述
import sys # 导入模块
# 定义全局变量,如果非必须,则最好使用局部变量,
这样可以提高代码的易维护性,并且可以节省内存提高性能
x=1
class Foo: # 定义类,并写好类的注释
'Class Foo is used to...'
pass
def test(): # 定义函数,并写好函数的注释
'Function test is used to…'
pass
if __name__ == '__main__': # 主程序
test() #在 被当做脚本执行时,执行此处的代码
二、包
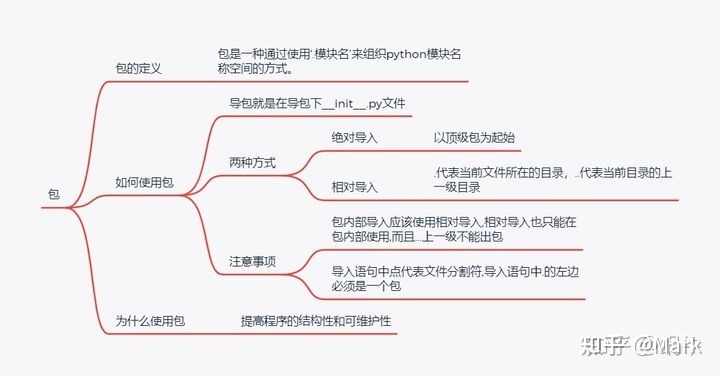
2.1 包的介绍
# 1.什么是包?
包就是一个包含有__init__.py文件的文件夹。
包的本质是模块的一种形式,是用来被当做模块导入的。
pool/ # 顶级包
├── __init__.py
├── futures # 子包
│ ├── __init__.py
│ ├── process.py
│ └── thread.py
└── versions.py # 子模块
# 2.为何要有包?
随着模块数目的增多,把所有模块不加区分地放到一起也是极不合理的,
于是Python为我们提供了一种把模块组织到一起的方法,即创建一个包。
# 强调
1.在python3中,即使包下没有__init__.py文件,import 包仍然不会报错,
而在python2中,包下一定要有该文件,否则import 包报错
2.创建包的目的不是为了运行,而是被导入使用,
记住,包只是模块的一种形式而已,包的本质就是一种模块
2.2 包的使用
# 1.首次导入包时,发生的事:
1.产生一个名称空间
2.运行包下的__init__.py文件,将运行过程中产生的名字都丢到1的名称空间中
也就是说导入包时只是导入__init__.py文件,并不会导入包下所有的子模块与子包
3.在当前执行文件的名称空间中拿到一个名字mmm,mmm指向1的名称空间
import mmm
print(mmm.x)
# 2.包的使用
环境变量是以执行文件为准的,所有被导入的模块
或者说后续的其他文件引用的sys.path都是参照 执行文件的sys.path
# 强调
1.关于包相关的导入语句也分为import和from ... import ...两种,
但是无论哪种,无论在什么位置,在导入时都必须遵循一个原则:
凡是在导入时带点的,点的左边都必须是包,否则非法。
可以带有一连串的点,如import 顶级包.子包.子模块,但都必须遵循这个原则。
但对于导入后,在使用时就没有这种限制了,点的左边可以是包,模块,函数,类 (它们都可以用点的方式调用自己的属性)。
# eg1:
from a.b.c.d.e.f import xxx
import a.b.c.d.e.f # 其中a、b、c、d、e 都必须是包
# eg2:
from foo.bbb.m4 import f4 # foo包内.子包bbb.模块m4.函数f1
import foo.bbb.m4.f4 # 语法错误,因为m4不是包,是一个模块 =====》点的左侧都必须是包
2.包A和包B下有同名模块也不会冲突,如A.a与B.a来自俩个命名空间
3.import导入文件时,产生名称空间中的名字来源于文件,
import 包,产生的名称空间的名字同样来源于文件,即包下的__init__.py,
# 导入包本质就是在导入该文件。
# 故:为了导入包后,能使用到包中的其他模块,就必须在__init__文件中,导入其他模块!
# 3.绝对导入与相对导入
# 3.1 绝对导入
注意: 模块导入的依据是执行文件的系统路径 sys.path,被导入的模块在该sys.path里,才能被导入
# eg:foo包的__init__文件,导入其他的模块 m1、m2、m3 以及子包bbb下的m4 模块
# 绝对导入,以顶级包的文件夹作为起始来进行导入
from foo.m1 import f1
from foo.m2 import f2
from foo.m3 import f3
from foo.bbb.m4 import f4
# 3.2 相对导入
相对导入:仅限于包内使用,不能跨出包 # 包内模块之间的导入,推荐使用相对导入
# '.':代表当前文件所在的目录
# '..':代表当前目录的上一级目录,依此类推
from .m1 import f1
from .m2 import f2
from .m3 import f3
from .bbb.m4 import f4
# 强调:
1.相对导入不能跨出包,所以相对导入仅限于包内模板彼此之间闹着玩
2.而绝对导入是没有任何限制的,所以绝对导入是一种通用的导入方式
2.3 绝对导入与相对导入
# 文件目录:
-script 文件夹 (在环境变量中)
-s1.py (add方法)
-s2.py
-package1 包
-__init__.py
-package_s1.py (test方法)
-package_s2.py (test_s2方法)
# 1.模块的使用
# 案例:在s2中 使用s1中的add
# 方式一:导入到方法
from s1 import add # 爆红,只是编辑器爆红
print(add(1,2))
# 方式二:导入到方法所在的文件
import s1
print(s1.add(1,2))
# 执行脚本(s2)所在路径,自动会加入到环境变量 所以可以直接导入s1
import sys
print(sys.path)
# 2.包的使用
# 包的__init__.py文件:
可将包内部本意提供给包外面的文件和方法,导入注册一下
不在这注册的,本意是只给包内部用,如果外部想用,使用完整路径导入使用
# 案例:在s2中 使用package1包下package_s1中的test
# 2.1 通过包的__init__.py 文件导入
# 前提:在package1包的__init__.py中:
# from .package_s1 import test
import package1
package1.test() # 就可以直接使用 包里面的package_s1下的test()
# 2.2 使用完整路径导入使用
from package1.package_s1 import test
test()
# 3 相对导入和绝对导入
# 案例:在package_s2中,使用package_s1下的test函数
# 1 相对导入
from . import package_s1
def test_s2():
package_s1.test()
# 2 绝对导入 (从环境变量的文件夹开始查找)
import package_s1 # 报错,因为package1包不在环境变量中
# 2.1 要么把package1加入到环境变量
sys.path.append('package_s1的文件路径')
# 2.2 从环境变量路径开始导入(script文件夹是在环境变量中)
from package1 import package_s1
def test_s2():
package_s1.test()
# 注意:包内部尽量用相对导入,因为若文件移动位置,绝对导入需要调整导入语句
# 4 相对导入的坑 *****
使用相对导入的py文件,不能作为脚本运行
# 案例:s2文件 使用s1的add方法
from . import s1 # 使用相对导入,且s2以脚本运行,报错
# 原因:
因为执行脚本时,当前脚本的'__name__'变为'__main__',
模块导入变成:'__main__.s1';异常:'__main__' is not a package。
import s1 # 使用绝对导入,不报错
print(s1.add(3,4))
# 注意:
1 导入模块的路径,需要从环境变量下(sys.path)开始导入
2 执行脚本所在路径,自动加入到环境变量
3 使用相对导入的py文件,不能作为脚本运行
三、软件开发的目录规范
1.目录规范1:
ATM ====》项目文件夹
|--bin ====》存放可执行文件,一般是启动文件
| |--start.py (或run.py)
|
|--conf ====》存放配置文件
| |--setting.py
|
|--core ====》存放业务核心逻辑相关代码
| |--core.py
|
|--api ====》存放接口文件,接口主要用于为业务逻辑提供数据操作
| |--api.py
|
|--db ====》存放操作数据库相关文件,主要用于与数据库交互
| |--db_handle.py
|
|--lib ====》存放程序中常用的自定义模块,常用的库,共享的库
| |--common.py
|
|--log ====》存放项目日志文件
| |--user.log
|
|--setup.py ====》管理项目软件安装、部署、打包的脚本。
|--readme ====》项目说明文件
|--requirements.txt ====》存放软件依赖的外部python包列表
# 注意导入问题很重要:
1.start.py 作为整个项目的执行文件时,其他文件夹下的文件都是作为模块来使用。
2.start.py 要想导入core文件夹下的src.py
===》只能使用绝对导入,并且需要将其添加到系统路径sys.path中,才能导入。
3.为了方便项目中其他文件之间方便导入文件,一般是将项目 整个文件夹,添加到系统变量中。
这个时候其他文件之间的导入,都是以项目文件夹做为起始位置去导入了。
4.注意start.py 作为启动文件,不应该被其他文件导入。(规范)
为什么?
--因为start.py 作为执行文件时,其系统路径 sys.path 的第一个元素是 start.py的父级bin文件夹。
而现在需要导入的模块 core,并不在bin文件下,且系统路径并没有包含core的文件路径,故添加系统路径,再绝对导入。
# eg:start.py 导入core下core
import sys
import os
# __file__ ==> 当前文件的绝对路径 (....ATM/bin/start.py)
# os.path.dirname(__file__) # os.path.dirname(路径)==》获取该路径的文件夹路径 (....ATM/bin)
BASE_DIR = os.path.dirname(os.path.dirname(__file__)) (....ATM)
sys.path.append(BASE_DIR)
from core import core
2.目录规范2(常用):
# 正是为了规避处理系统环境变量的问题,所以把程序的执行文件(启动文件)直接放在项目文件下
ATM ====》项目文件夹
|--conf ====》存放配置文件
| |--setting.py
|
|--core ====》存放业务核心逻辑相关代码
| |--core.py
|
|--api ====》存放接口文件,接口主要用于为业务逻辑提供数据操作
| |--api.py
|
|--db ====》存放操作数据库相关文件,主要用于与数据库交互
| |--db_handle.py
|
|--lib ====》存放程序中常用的自定义模块,常用的库,共享的库
| |--common.py
|
|--log ====》存放项目日志文件
| |--user.log
|
|--start.py (或run.py) ====》程序的启动文件
|--setup.py ====》管理项目软件安装、部署、打包的脚本。
|--readme ====》项目说明文件
|--requirements.txt ====》存放软件依赖的外部python包列表
# eg:start.py 导入core下core
这时start.py 的sys.path 直接包含 ATM 项目文件夹
导入就可以直接以ATM文件夹作为起始位置去导入。
from core import core
# readme的内容:目的是能简要描述该项目的信息,让读者快速了解这个项目
1.软件定位,软件的基本功能;
2.运行代码的方法: 安装环境、启动命令等;
3.简要的使用说明;
4.代码目录结构说明,更详细点可以说明软件的基本原理;
5.常见问题说明
四、函数的类型提示
# 类型提示 Type hinting(最低 Python 版本为 3.5)
# 函数参数 给定一些自定义的类型提示 '变量:提示信息' '-> 函数返回的类型 提示信息'
def register(name:str='egon',age:int=18,hobbbies:tuple=(1,2))->int:
print(name)
print(age)
print(hobbbies)
return 111
register(1,'aaa',[1,])
res=register('egon',18,('play','music'))
def register(name:"必须传入名字傻叉",age:1111111,hobbbies:"必须传入爱好元组")->"返回的是整型":
print(name)
print(age)
print(hobbbies)
return 111
register(1,'aaa',[1,])
res=register('egon',18,('play','music'))
res=register('egon',19,(1,2,3))
# 查看函数的类型提示信息
print(register.__annotations__)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号