Day50--HTML--01
今日内容
一、什么是前端
"""
任何与用户直接打交道的操作界面都可以称之为前端 比如电脑界面、手机界面、平板界面
什么是后端
后端类似于幕后操作者(功能实现的逻辑代码),不直接与用户打交道
"""
二、为什么学前端
"""
全栈开发,前后端都会
但是前端不会学的很详细,只要求做到能够看得懂基本的前端代码以及能够搭建一些简单的页面即可
先打下前端的基础,为后续可能需要拓展做准备
"""
三、前端学习历程
# 一、基本语法
HTML:网页的骨架、内容,没有任何的样式
CSS:网页的外观、样式(给骨架添加各种样式,变得好看)
JS:控制网页实现动态效果
# 二、前端框架
Bootstrap、jQuery、Vue 等
提前给你封装好了很多操作,你只需要按照固定的语法句式即可
四、web服务本质及Http协议
软件开发架构
cs 客户端 服务端
bs 浏览器 服务端
ps:bs模式本质也是cs
1.网页访问过程
浏览器窗口输入网址回车发生了几件事:
"""
1. 浏览器朝服务端输入网址请求(eg:请求百度首页)
2. 服务端接受请求
3. 服务端返回相应的响应(eg:返回一个百度首页)
4. 浏览器接受响应,根据特定的规则渲染页面展示给用户看
"""
浏览器可以充当很多服务端的客户端
百度 腾讯视频 优酷视频
如何做到浏览器能够跟多个不同的服务端之间进行数据交互?
1.浏览器很牛逼 能够自动识别不同服务端做不同处理
2.制定一个统一的标准。(如果你想要让你写的服务端能够跟浏览器之间做正常的数据交互,那么你就必须遵循这个标准)
2.HTTP协议(必须记住)
"""
HTTP 超文本传输协议 用来规定服务端和浏览者之间的数据交互格式
该协议你可以不遵循,但是你写的服务端就不能被浏览器正常访问,你就自己跟自己玩,你自己写客户端,用户想要使用,就下载你专门的app即可
"""
四大特性
1. 基于TCP/IP的协议
作用于应用层之上的协议
2. 被动响应
基于请求,才响应;不请求,则不会响应
3. 短连接
请求响应后,就断开链接
延伸出:长链接(双方建立链接后,就不会断开) eg:聊天室(websocket)
4. 无状态
对于事务处理没有记忆功能,不会保存用户的信息
延伸出:可以记住用户状态的技术 eg:cookie、session、token
请求数据格式
请求首行 (包含标识HTTP协议版本、当前请求方式)
请求头 (一大堆K,V键值对)
# 空行 (一定要有一个空行:/r/n)
请求体 (并不是所有请求方式都有请求体,eg:get 无;post 有 存放的是post请求提交的敏感数据)
响应数据格式
响应首行 (包含标识HTTP协议版本、响应状态码)
响应头 (一大堆K,V键值对)
# 空行 (一定要有一个空行:/r/n)
响应体 (返回给浏览器展示给用户看的数据)
请求方式
1. get请求
超服务端要数据
eg:输入网址获取对应的内容
2. post请求
超服务端提交数据
eg:用户登录,输入用户名和密码之后,提交到服务端后端做身份校验
响应状态码
用一串简单的数字来表示一些复杂的状态或描述性信息
eg:
1xx >>> 服务端已经成功接受到了你的数据正在处理,你可以继续提交额外的数据
2xx >>> 服务端成功响应了你想要的数据 (200 OK 请求成功)
3xx >>> 重定向(自动跳转到其他链接请求的页面 eg:当你在访问一个需要登录之后才能看的页面,你会发现会自动跳转到登录页面)
4xx >>> 请求错误
404: 请求资源不存在
403: 当前请求不合法或者不符合访问资源的条件
5xx >>> 服务器内部错误(500 服务器出错)
URL
统一资源定位符 (俗称:网址)
3.HTML简介
超文本标记语言
HTML就是书写网页的一套标准,我们浏览器看到的所有网站页面,内部其实都是HTML代码。
注释: 注释是代码之母
<!-- 单行注释-->
<!--
多行注释1
多行注释2
多行注释3
-->
由于HTML代码非常的杂乱无章并且很多,所以我们我们习惯于用注释来划定区域方便后续的查找
eg:
<!-- 导航条开始-->
导航条所有的html代码
<!-- 导航条结束-->
ps:文件的后缀名其实给用户看的,只不过对应不同的文件后缀名有不同的软件来处理并添加很多功能
注意:
1. HTML代码是没有格式的,可以全部写在一行都没有问题,只不过我们习惯后了缩进来表示代码
2. 两种打开HTML文件的方式:
1.找到文件所在的位置右键选择浏览器打开;
2.在pycharm内部,集成了自动调用浏览器的功能,直接点击即可(前提是你的电脑上安装了对应的浏览器) 直接全部使用谷歌浏览器
3. 在pycharm中 书写HTML代码的时候,你只需要写标签名,然后tab就能自动补全
HTML文档结构
<!DOCTYPE html> 标签
<html>
<head> </head> :head标签不是给用户看的,而是定义一些配置主要给浏览器看的
<body> </body> :body标签 写什么浏览器就渲染什么,用户就能看到什么
</html>
ps: <!DOCTYPE html> 标签
<!DOCTYPE> 声明必须是 HTML 文档的第一行,位于 <html> 标签之前。
<!DOCTYPE> 声明不是 HTML 标签;它是指示 web 浏览器关于页面使用哪个 HTML 版本进行编写的指令。
标签具有的两个重要属性
1.id值
定义标签的唯一ID,HTML文档树中唯一
2.class
为html元素定义一个或多个类名(classname)(CSS样式类名) (该值有点类似于面向对象里面的继承,一个标签可以继承多个class值)
3.style
规定元素的行内样式(CSS样式)
ps: 标签既可以有默认的属性,也可以自定义属性
<p id="d1" class="c1" usename="jason" password="123"></p>
标签的分类1
1. 双标签 (有开始和结尾的双标签)
eg:<div>和</div> 第一个标签是开始,第二个标签是结束。结束标签会有斜线
2. 单标签(自闭和 标签)
eg:<br/>
head内的常用标签
1. <title>Title </title> :网页标题
2. <style> h1 {color: greenyellow;} </style> :内部用来书写css代码
3.<link rel="stylesheet" href="mycss.css"> :引入外部的css文件或网站图标
4.<script> alert(123) </script> : 内部用来书写js代码
<script src="myjs.js"> </script> : 或引用外部的js代码文件
5.<Meta> 标签介绍:(了解)
元素可提供有关页面的元信息(mata-information),针对搜索引擎和更新频度的描述和关键词。
标签位于文档的头部,不包含任何内容。
提供的信息是用户不可见的。
meta标签的组成:meta标签共有两个属性,它们分别是http-equiv属性和name 属性,不同的属性又有不同的参数值,这些不同的参数值就实现了不同的网页功能。
1.http-equiv属性:相当于http的文件头作用,它可以向浏览器传回一些有用的信息,以帮助正确地显示网页内容,与之对应的属性值为content,content中的内容其实就是各个参数的变量值。
<!--指定文档的编码类型(需要知道)-->
<meta http-equiv="content-Type" charset=UTF8">
<!--2秒后跳转到对应的网址,注意引号(了解)-->
<meta http-equiv="refresh" content="2;URL=https://www.oldboyedu.com">
<!--告诉IE以最高级模式渲染文档(了解)-->
<meta http-equiv="x-ua-compatible" content="IE=edge">
2.name属性: 主要用于描述网页,与之对应的属性值为content,content中的内容主要是便于搜索引擎机器人查找信息和分类信息用的。
就是给你html加上各种关键词信息,方便搜索引擎(百度等)搜索到 (这叫SEO搜索引擎优化)
<meta name="keywords" content="meta总结,html meta,meta属性,meta跳转">
网页的描述信息,会在搜索页面的右下角简介中展示
<meta name="description" content="老男孩教育Python学院">
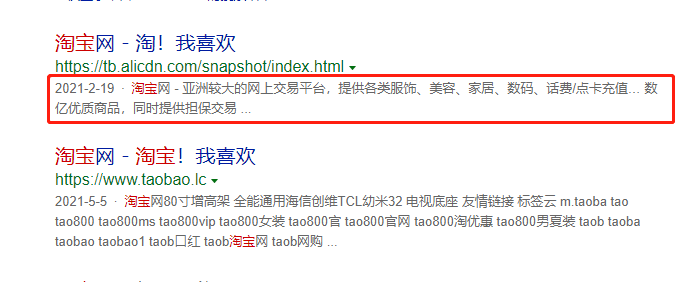
<!--例:淘宝的页面中-->
<meta name="keyword" content="淘宝,掏宝,网上购物,C2C,在线交易,交易市场,网上交易,交易市场,网上买,网上卖,购物网站,团购,网上贸易,安全购物,电子商务,放心买,供应,买卖信息,网店,一口价,拍卖,网上开店,网络购物,打折,免费开店,网购,频道,店铺">
<meta name="description" content="淘宝网 - 亚洲较大的网上交易平台,提供各类服饰、美容、家居、数码、话费/点卡充值… 数亿优质商品,同时提供担保交易(先收货后付款)等安全交易保障服务,并由商家提供退货承诺、破损补寄等消费者保障服务,让你安心享受网上购物乐趣!">
body内的常用标签
基本标签
<h1>标题标签 </h1> 1-6级标题
<b>加粗</b>
<i>斜体</i>
<u>下划线</u>
<s>删除线</s>
<p>段落标签</p>
<hr> 水平分割线
<br> 换行标签
标签的分类2
# 1.块级标签:独占一行
eg: h1~h6 p div
a.块级标签可以修改长度
b.块级标签内部可以嵌套任意的块级标签和行内标签
但p标签 虽然是块级标签,但是只能嵌套行内标签,不能嵌套块级标签 (HTML书写规范)
如果你套了,问题也不大 因为浏览器会自动帮你解开(浏览器是直接面向用户的,不会轻易的报错,哪有有报错用户也基本感觉不出来)
# 2.行内标签(内联标签):自身文本多大就占多大
eg:i u s b span
a.行内标签不可以修改长度 修改了也不会变化
b.行内标签不能嵌套块级标签,可以嵌套行内标签(但没什么意义)
特殊符号
>>> 空格
> >>> 大于号 '>'
< >>> 小于号 '<'
& >>> 连接符 '&'
¥ >>> 人民币符 '¥'
© >>> 版权'©' (英文Copyright(版权)的简写,代表作者版权所有声明)
® >>> 注册商标'®'
常用标签
div 属于块级标签
span 属于行内标签
上述的两个标签是在构造页面初期最常使用的,页面的布局一般先用div 和span 占位之后再去调整样式,尤其是div使用非常的频繁
div 你可以把它理解成 一块区域,也就意味着用div来提前规定所有的区域,之后往该区域内部填写内容即可
span 给普通的文本占位
img 标签
# 图片标签
<img src="" alt="" title='新垣结衣'>
属性:
src=''
1.图片的路径,可以是本地的也可以是网上的
2.URL 自动朝该url发送get请求获取数据
alt='这是我的前女友' : 当图片加载不出来的时候,给图片的描述信息
title='新垣结衣' : 当鼠标悬浮到图片上之后,自动展示的提示信息
height='800px' : 修改图片的高度 px像素单位
width='' : 修改图片的宽度
若只修改高度或者宽度,另一个会根据原图等比例调整;若都修改了,没有考虑比例性的问题,图片就会失真
a标签
# 超链接标签
所谓的超链接是指从一个网页指向一个目标的连接关系,这个目标可以是另一个网页,也可以是相同网页上的不同位置,还可以是一个图片,一个电子邮件地址,一个文件,甚至是一个应用程序。
<a href=""></a>
"""
当a标签制定的网址从来没有被点击过,那么a标签的字体颜色是蓝色,若点击过后 变成紫色 (浏览器给你记忆了)
"""
属性:
href
1. 放URL,用户点击就会跳转到该URL页面
2. 放其他标签的id值,点击即可跳转到对应的标签位置 格式:href='# id值'
target=
1. 默认a标签是在当前页面完成跳转 》》》 '_self'
2. 修改为新建窗口页面跳转 》》》 '_blank'
# a标签的锚点功能
""" eg: 点击一个文本标题,页面自动跳转到标题对应的内容区域(目录到正文内容) """
<a href="" id="d1">顶部</a>
<h1 id="d3">hello word!</h1>
<div style="height: 1000px; background-color: red"></div>
<a href="" id="d2">中间</a>
<div style="height: 1000px; background-color: greenyellow"></div>
<a href="#d3">回到h1</a>
<a href="#d2">回到中间</a>
列表标签
1.无序列表(较多)
<ul>
<li>第一项</li>
<li>第二项</li>
<li>第三项</li>
<li>第四项</li>
</ul>
# 虽然ul标签很丑,但是在页面布局的时候 只要是排版一致的几行数据基本上用都是 ul标签
type属性:
disc(实心圆点,默认值)
circle(空心圆圈)
square(实心方块)
none(无样式)
2.有序列表(了解)
<ol>
<li>111</li>
<li>222</li>
<li>333</li>
</ol>
type属性:
1 数字列表,默认值
A 大写字母
a 小写字母
Ⅰ大写罗马
ⅰ小写罗马
start="": 定义起始位
3.标题列表(了解)
<dl>
<dt>标题1</dt>
<dd>内容1</dd>
<dt>标题2</dt>
<dd>内容1</dd>
<dd>内容2</dd>
</dl>
总结
"""
学习前端就是死记硬背!!!
"""

 浙公网安备 33010602011771号
浙公网安备 33010602011771号