OO第一单元作业总结
OO第一单元表达式求导作业总结
一、基于度量的程序结构分析
首先解释若干参数:
ev(G)基本复杂度,是用来衡量程序非结构化程度的,非结构成分降低了程序的质量,增加了代码的维护难度,使程序难于理解。因此,基本复杂度高意味着非结构化程度高,难以模块化和维护。实际上,消除了一个错误有时会引起其他的错误。
Iv(G)模块设计复杂度,是用来衡量模块判定结构,即模块和其他模块的调用关系。软件模块设计复杂度高意味模块耦合度高,这将导致模块难于隔离、维护和复用。模块设计复杂度是从模块流程图中移去那些不包含调用子模块的判定和循环结构后得出的圈复杂度,因此模块设计复杂度不能大于圈复杂度,通常是远小于圈复杂度。
v(G)圈复杂度,是用来衡量一个模块判定结构的复杂程度,数量上表现为独立路径的条数,即合理的预防错误所需测试的最少路径条数,圈复杂度大说明程序代码可能质量低且难于测试和维护,经验表明,程序的可能错误和高的圈复杂度有着很大关系。
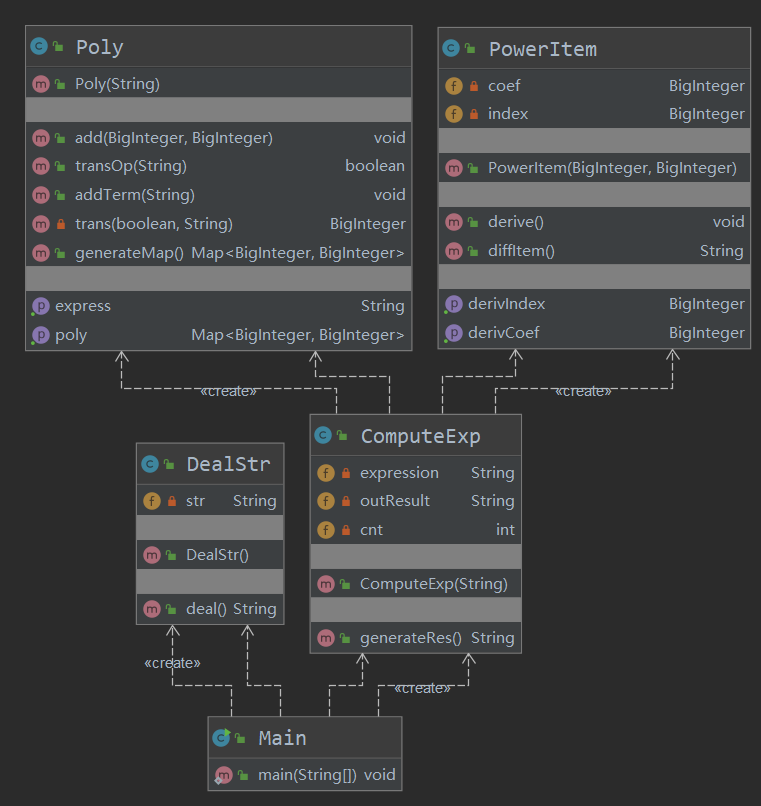
第一次作业————多项式求导
纵观三次作业需求,第一次作业可以说十分简单,因此我的代码结构也十分简单。
UML类图:
代码度量分析
| method | ev(G) | iv(G) | v(G) |
|---|---|---|---|
| ComputeExp.ComputeExp(String) | 1.0 | 1.0 | 1.0 |
| ComputeExp.generateRes() | 1.0 | 4.0 | 6.0 |
| DealStr.deal() | 1.0 | 1.0 | 1.0 |
| DealStr.DealStr() | 1.0 | 1.0 | 1.0 |
| Main.main(String[]) | 1.0 | 1.0 | 1.0 |
| Poly.add(BigInteger,BigInteger) | 1.0 | 2.0 | 2.0 |
| Poly.addTerm(String) | 1.0 | 6.0 | 6.0 |
| Poly.generateMap() | 1.0 | 2.0 | 2.0 |
| Poly.getExpress() | 1.0 | 1.0 | 1.0 |
| Poly.getPoly() | 1.0 | 1.0 | 1.0 |
| Poly.Poly(String) | 1.0 | 1.0 | 1.0 |
| Poly.trans(boolean,String) | 1.0 | 2.0 | 2.0 |
| Poly.transOp(String) | 2.0 | 1.0 | 2.0 |
| PowerItem.derive() | 1.0 | 2.0 | 2.0 |
| PowerItem.diffItem() | 1.0 | 13.0 | 15.0 |
| PowerItem.getDerivCoef() | 1.0 | 1.0 | 1.0 |
| PowerItem.getDerivIndex() | 1.0 | 1.0 | 1.0 |
| PowerItem.PowerItem(BigInteger,BigInteger) | 1.0 | 1.0 | 1.0 |
| Total | 19.0 | 42.0 | 47.0 |
| Average | 1.0555555555555556 | 2.3333333333333335 | 2.611111111111111 |
可见,只有简单的几个类,Poly类用于解析字符串,ComputeExp用于计算和化简,PowerItem为幂函数项的存取与与解析类,DealStr为字符串预处理类。代码复杂度方面也仅有一个方法的耦合度较高,应该来说较好地完成了设计。
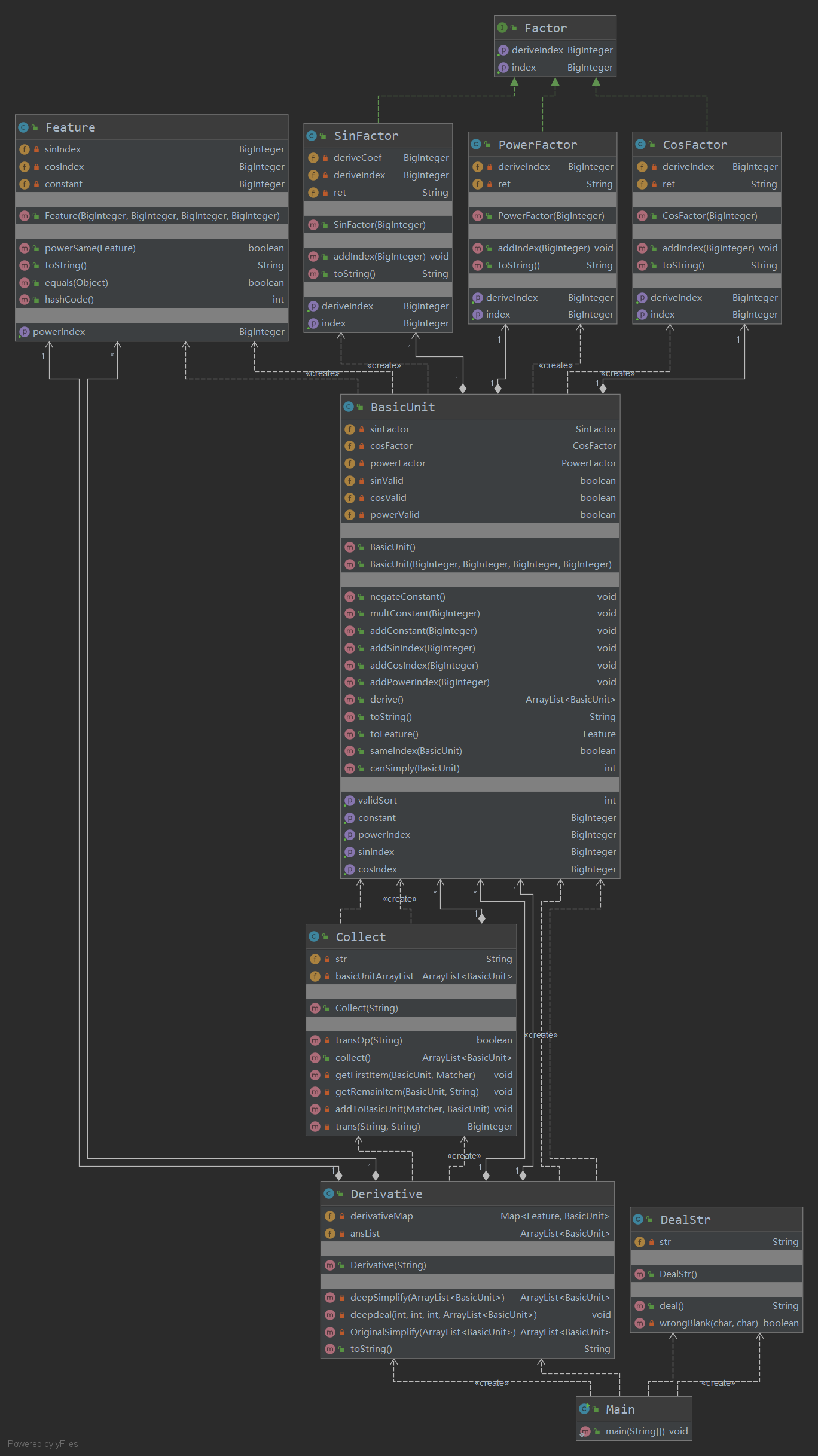
第二次作业
UML类图:
代码度量分析
| method | ev(G) | iv(G) | v(G) |
|---|---|---|---|
| BasicUnit.addConstant(BigInteger) | 1.0 | 1.0 | 1.0 |
| BasicUnit.addCosIndex(BigInteger) | 1.0 | 1.0 | 1.0 |
| BasicUnit.addPowerIndex(BigInteger) | 1.0 | 1.0 | 1.0 |
| BasicUnit.addSinIndex(BigInteger) | 1.0 | 1.0 | 1.0 |
| BasicUnit.BasicUnit() | 1.0 | 1.0 | 1.0 |
| BasicUnit.BasicUnit(BigInteger,BigInteger,BigInteger,BigInteger) | 1.0 | 2.0 | 5.0 |
| BasicUnit.canSimply(BasicUnit) | 5.0 | 5.0 | 7.0 |
| BasicUnit.derive() | 1.0 | 4.0 | 4.0 |
| BasicUnit.getConstant() | 1.0 | 1.0 | 1.0 |
| BasicUnit.getCosIndex() | 1.0 | 1.0 | 1.0 |
| BasicUnit.getPowerIndex() | 1.0 | 1.0 | 1.0 |
| BasicUnit.getSinIndex() | 1.0 | 1.0 | 1.0 |
| BasicUnit.getValidSort() | 1.0 | 1.0 | 1.0 |
| BasicUnit.multConstant(BigInteger) | 1.0 | 1.0 | 1.0 |
| BasicUnit.negateConstant() | 1.0 | 1.0 | 1.0 |
| BasicUnit.sameIndex(BasicUnit) | 1.0 | 3.0 | 3.0 |
| BasicUnit.toFeature() | 1.0 | 1.0 | 1.0 |
| BasicUnit.toString() | 1.0 | 9.0 | 17.0 |
| Collect.addToBasicUnit(Matcher,BasicUnit) | 1.0 | 12.0 | 12.0 |
| Collect.collect() | 1.0 | 5.0 | 5.0 |
| Collect.Collect(String) | 1.0 | 1.0 | 1.0 |
| Collect.getFirstItem(BasicUnit,Matcher) | 1.0 | 3.0 | 3.0 |
| Collect.getRemainItem(BasicUnit,String) | 1.0 | 2.0 | 2.0 |
| Collect.trans(String,String) | 1.0 | 2.0 | 2.0 |
| Collect.transOp(String) | 1.0 | 1.0 | 1.0 |
| DealStr.deal() | 1.0 | 6.0 | 7.0 |
| DealStr.DealStr() | 1.0 | 1.0 | 1.0 |
| DealStr.wrongBlank(char,char) | 1.0 | 1.0 | 15.0 |
| Derivative.deepdeal(int,int,int,ArrayList |
2.0 | 2.0 | 4.0 |
| Derivative.deepSimplify(ArrayList |
1.0 | 7.0 | 7.0 |
| Derivative.Derivative(String) | 3.0 | 4.0 | 5.0 |
| Derivative.OriginalSimplify(ArrayList |
4.0 | 7.0 | 7.0 |
| Derivative.toString() | 3.0 | 4.0 | 6.0 |
| Feature.equals(Object) | 3.0 | 4.0 | 6.0 |
| Feature.Feature(BigInteger,BigInteger,BigInteger,BigInteger) | 1.0 | 1.0 | 1.0 |
| Feature.getPowerIndex() | 1.0 | 1.0 | 1.0 |
| Feature.hashCode() | 1.0 | 1.0 | 1.0 |
| Feature.powerSame(Feature) | 1.0 | 1.0 | 1.0 |
| Feature.toString() | 1.0 | 1.0 | 1.0 |
| itempackage.CosFactor.addIndex(BigInteger) | 1.0 | 1.0 | 1.0 |
| itempackage.CosFactor.CosFactor(BigInteger) | 1.0 | 1.0 | 1.0 |
| itempackage.CosFactor.getDeriveIndex() | 2.0 | 1.0 | 2.0 |
| itempackage.CosFactor.getIndex() | 1.0 | 1.0 | 1.0 |
| itempackage.CosFactor.toString() | 1.0 | 2.0 | 2.0 |
| itempackage.PowerFactor.addIndex(BigInteger) | 1.0 | 1.0 | 1.0 |
| itempackage.PowerFactor.getDeriveIndex() | 2.0 | 1.0 | 2.0 |
| itempackage.PowerFactor.getIndex() | 1.0 | 1.0 | 1.0 |
| itempackage.PowerFactor.PowerFactor(BigInteger) | 1.0 | 1.0 | 1.0 |
| itempackage.PowerFactor.toString() | 1.0 | 3.0 | 3.0 |
| itempackage.SinFactor.addIndex(BigInteger) | 1.0 | 1.0 | 1.0 |
| itempackage.SinFactor.getDeriveIndex() | 2.0 | 1.0 | 2.0 |
| itempackage.SinFactor.getIndex() | 1.0 | 1.0 | 1.0 |
| itempackage.SinFactor.SinFactor(BigInteger) | 1.0 | 1.0 | 1.0 |
| itempackage.SinFactor.toString() | 1.0 | 2.0 | 2.0 |
| Main.main(String[]) | 1.0 | 1.0 | 1.0 |
| Total | 72.0 | 123.0 | 161.0 |
| Average | 1.309090909090909 | 2.2363636363636363 | 2.9272727272727272 |
由于没有做很深入的优化,因此结构还是相对清晰而简单的,BasicUnit为基本求导单元,这是我认为最核心的部分,其中存储了三个函数类的实例,提供了求导方法。Collect类提供解析字符串的方法,Derivative提供求导连接及化简的方法。Feature本来是我准备化简用的能够提供BasicUnit每一项的特征的类,是完全冗余的,后来化简并没有顺利进行。从分析中看到两个方法写的难以维护(高ev(G)),其中用了面向过程的且并不优雅的代码架构,if嵌套深,条件多,主要是优化设计不全面,不充分造成。若干类的iv(G)和v(G)值较高,主要是由于不优雅地将情况用if-else列出,但其实让我避免了部分bug,后来在第三次代码中这些方法大部分被重写优化结构。
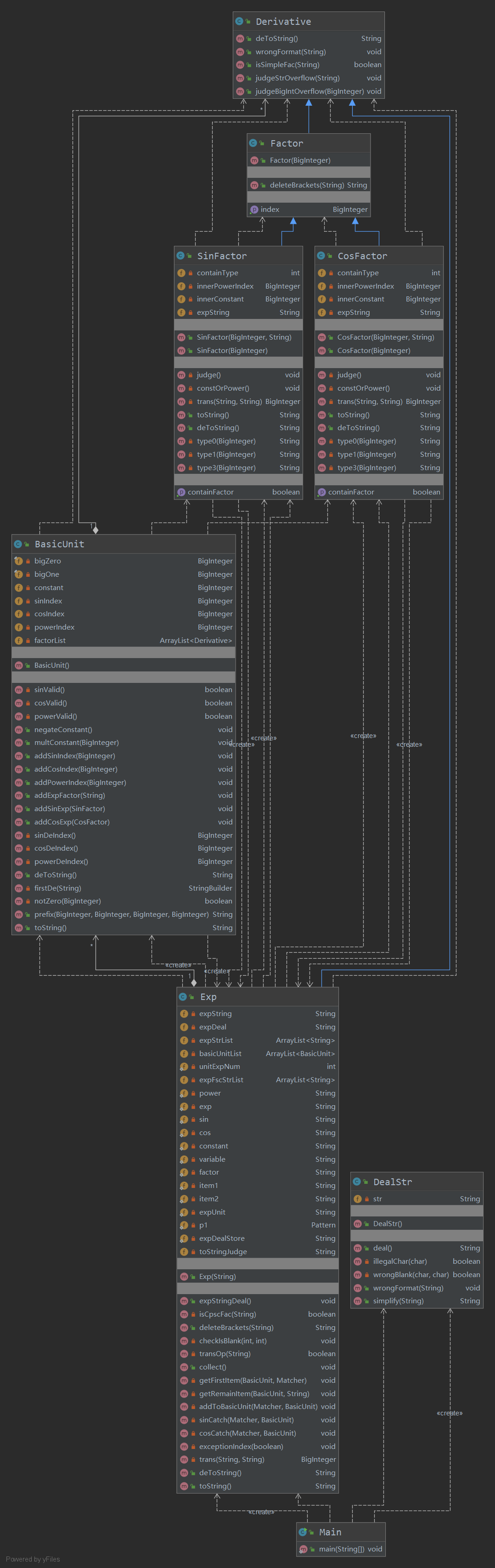
第三次作业
UML类图:
代码度量分析
| method | ev(G) | iv(G) | v(G) |
|---|---|---|---|
| BasicUnit.addCosExp(CosFactor) | 1.0 | 1.0 | 1.0 |
| BasicUnit.addCosIndex(BigInteger) | 1.0 | 1.0 | 1.0 |
| BasicUnit.addExpFactor(String) | 1.0 | 1.0 | 1.0 |
| BasicUnit.addPowerIndex(BigInteger) | 1.0 | 1.0 | 1.0 |
| BasicUnit.addSinExp(SinFactor) | 1.0 | 1.0 | 1.0 |
| BasicUnit.addSinIndex(BigInteger) | 1.0 | 1.0 | 1.0 |
| BasicUnit.BasicUnit() | 1.0 | 1.0 | 1.0 |
| BasicUnit.cosDeIndex() | 1.0 | 1.0 | 1.0 |
| BasicUnit.cosValid() | 1.0 | 1.0 | 1.0 |
| BasicUnit.deToString() | 10.0 | 11.0 | 15.0 |
| BasicUnit.firstDe(String) | 1.0 | 7.0 | 7.0 |
| BasicUnit.multConstant(BigInteger) | 1.0 | 1.0 | 1.0 |
| BasicUnit.negateConstant() | 1.0 | 1.0 | 1.0 |
| BasicUnit.notZero(BigInteger) | 1.0 | 1.0 | 1.0 |
| BasicUnit.powerDeIndex() | 1.0 | 1.0 | 1.0 |
| BasicUnit.powerValid() | 1.0 | 1.0 | 1.0 |
| BasicUnit.prefix(BigInteger,BigInteger,BigInteger,BigInteger) | 1.0 | 8.0 | 8.0 |
| BasicUnit.sinDeIndex() | 1.0 | 1.0 | 1.0 |
| BasicUnit.sinValid() | 1.0 | 1.0 | 1.0 |
| BasicUnit.toString() | 5.0 | 5.0 | 6.0 |
| CosFactor.constOrPower() | 1.0 | 4.0 | 4.0 |
| CosFactor.CosFactor(BigInteger) | 1.0 | 1.0 | 1.0 |
| CosFactor.CosFactor(BigInteger,String) | 1.0 | 1.0 | 1.0 |
| CosFactor.deToString() | 4.0 | 4.0 | 4.0 |
| CosFactor.isContainFactor() | 1.0 | 1.0 | 1.0 |
| CosFactor.judge() | 1.0 | 12.0 | 14.0 |
| CosFactor.toString() | 3.0 | 3.0 | 3.0 |
| CosFactor.trans(String,String) | 1.0 | 2.0 | 2.0 |
| CosFactor.type0(BigInteger) | 4.0 | 3.0 | 4.0 |
| CosFactor.type1(BigInteger) | 3.0 | 3.0 | 3.0 |
| CosFactor.type3(BigInteger) | 4.0 | 4.0 | 4.0 |
| DealStr.deal() | 3.0 | 7.0 | 8.0 |
| DealStr.DealStr() | 1.0 | 1.0 | 1.0 |
| DealStr.illegalChar(char) | 3.0 | 1.0 | 15.0 |
| DealStr.simplify(String) | 2.0 | 4.0 | 5.0 |
| DealStr.wrongBlank(char,char) | 1.0 | 1.0 | 15.0 |
| DealStr.wrongFormat(String) | 1.0 | 1.0 | 1.0 |
| DealStrTest.deal() | 1.0 | 3.0 | 3.0 |
| Derivative.deToString() | 1.0 | 1.0 | 1.0 |
| Derivative.isSimpleFac(String) | 9.0 | 11.0 | 13.0 |
| Derivative.judgeBigIntOverflow(BigInteger) | 1.0 | 2.0 | 2.0 |
| Derivative.judgeStrOverflow(String) | 1.0 | 2.0 | 2.0 |
| Derivative.wrongFormat(String) | 1.0 | 1.0 | 1.0 |
| Exp.addToBasicUnit(Matcher,BasicUnit) | 1.0 | 10.0 | 10.0 |
| Exp.checkIsBlank(int,int) | 1.0 | 2.0 | 2.0 |
| Exp.collect() | 1.0 | 6.0 | 7.0 |
| Exp.cosCatch(Matcher,BasicUnit) | 1.0 | 4.0 | 4.0 |
| Exp.deleteBrackets(String) | 1.0 | 3.0 | 3.0 |
| Exp.deToString() | 3.0 | 8.0 | 8.0 |
| Exp.exceptionIndex(boolean) | 1.0 | 2.0 | 2.0 |
| Exp.Exp(String) | 1.0 | 2.0 | 2.0 |
| Exp.expStringDeal() | 1.0 | 12.0 | 14.0 |
| Exp.getFirstItem(BasicUnit,Matcher) | 1.0 | 3.0 | 3.0 |
| Exp.getRemainItem(BasicUnit,String) | 1.0 | 2.0 | 2.0 |
| Exp.isCpscFac(String) | 1.0 | 2.0 | 2.0 |
| Exp.sinCatch(Matcher,BasicUnit) | 1.0 | 4.0 | 4.0 |
| Exp.toString() | 2.0 | 2.0 | 2.0 |
| Exp.trans(String,String) | 1.0 | 2.0 | 2.0 |
| Exp.transOp(String) | 1.0 | 1.0 | 1.0 |
| ExpTest.expStringDeal() | 1.0 | 1.0 | 1.0 |
| Factor.deleteBrackets(String) | 1.0 | 3.0 | 3.0 |
| Factor.Factor(BigInteger) | 1.0 | 1.0 | 1.0 |
| Factor.getIndex() | 1.0 | 1.0 | 1.0 |
| Main.main(String[]) | 1.0 | 1.0 | 1.0 |
| SinFactor.constOrPower() | 1.0 | 4.0 | 4.0 |
| SinFactor.deToString() | 4.0 | 4.0 | 4.0 |
| SinFactor.isContainFactor() | 1.0 | 1.0 | 1.0 |
| SinFactor.judge() | 1.0 | 12.0 | 14.0 |
| SinFactor.SinFactor(BigInteger) | 1.0 | 1.0 | 1.0 |
| SinFactor.SinFactor(BigInteger,String) | 1.0 | 1.0 | 1.0 |
| SinFactor.toString() | 3.0 | 3.0 | 3.0 |
| SinFactor.trans(String,String) | 1.0 | 2.0 | 2.0 |
| SinFactor.type0(BigInteger) | 4.0 | 3.0 | 4.0 |
| SinFactor.type1(BigInteger) | 3.0 | 3.0 | 3.0 |
| SinFactor.type3(BigInteger) | 3.0 | 3.0 | 3.0 |
| SinFactorTest.i() | 1.0 | 1.0 | 1.0 |
| Total | 130.0 | 230.0 | 276.0 |
| Average | 1.7105263157894737 | 3.026315789473684 | 3.6315789473684212 |
第三次作业中出现了一些复杂度相当高,代码也很难维护的方法,这也是我debug时间较长的部分。原因应当是一开始各个“接口”功能没有定义清晰等原因导致。同时也是因为让一部分优化输出的情况直接被列出来,这是不好的习惯,应该在后续作业注意。
下面详述我的思路(摘自笔者讨论区帖子内容)
我没有构建典型的表达式树。大体上分三个层次获取表达式的结构,每一层有toString方法和求导方法。
-
表达式层(由基本单元构成,toString方法支持表达式因子层次输出)
-
基本单元层(是表达式层里面通过加减运算符连接的各个单元,即用乘号连接的若干项)
-
函数因子层(三角函数等)
意图是:最终效果为对整体字符串直接构造为表达式层,调用其求导方法返回结果。
表达式层的求导结果都直接由构成它的若干基本单元的表达结果直接相加,基本单元层求导结果是其若干个相乘项对每一项遍历求导再相连,因子的求导则分为表达式求导,函数求导等,表达式因子的求导直接调用表达式层对应类的求导方法即可,函数求导则像之前一样由诸如正弦函数类、余弦函数类来完成。
在这里有一个浪费了我自己许多时间的规范问题,如我的设计中,假如把某一层次toString方法和求导方法返回的字符串分为两种格式,可加格式(如+sin(x)*sin(sin(x)),带符号,不要求可乘)和可乘因子格式(如(-2*sin(x)*sin(sin(x))),可以作为因子直接相乘),表达式层求导要求基本单元层求导结果是可加的(以便直接连在一起),而基本单元层的导函数字符串生成过程要求因子返回的导函数是可乘的因子形式。表达式的toString方法设计为可以直接在编程时如果把各个层次的对其他层次的要求明确出来,可以避免像这次递归调用的构建中我出现的“递归修改”的问题。
该思路遇到的问题主要有如何解析表达式,如何存储,如何化简等。我的设计的劣势就在于跨括号的化简比较困难,如(x+(x+(x+1)))。优势在于每一个层次相对完整,其他层次只有构造、获取表达式、获取求导表达式三个访问方式;另外求导的时候可以清晰地预料到每一个层次的求导结果的形式一定程度上便于编程和debug。
二、关于bug的分析
本单元三次作业中,第一、二次作业强测与互测均未出现bug,第三次作业由于低级的失误在强测中挂了四个点。具体来说,我的程序除了在每个类的求导方法内部处理乘积项含0的消去化简,还在得到结果表达式之后进行了直接处理,其中一个处理是想当然地把所有"**1"字符串替换为空,而这在幂次为10-19次的时候会有非常明显的bug,如"sin(x)**12*x"会输出为"sin(x)2*x"。在测试中,我着重测试了各种内部化简可能出现的问题,但是巧合的是所有的数据均没有最后输出结果有10-19次幂的,测试时,幂次要么为10以内,要么是20以上。如果随机生成数据是很有可能覆盖到我这个bug的,而我的测试强度显然不够,这一点在下面讨论。
三、测试策略
- 进行测试:在前两次作业中,我未使用脚本程序,而是手动输入比对。在第三次作业中我采用了与python自动比对求导结果的脚本,只需要提供按行排列好的测试数据即可。
- 数据来源:一方面来自于我在架构时考虑到的可能出现的问题,主要是针对自己的问题,也会构造一些我的程序可以很好的处理但其他的程序不一定能很好地处理的测试数据,另一方面来自于我在debug时能够测出自己bug的程序。从第三次作业效果来看,可能这样自己手动完全针对性生成是不够的,今后的作用考虑引入随机数据生成。
四、应用对象创建模式来重构
第一次作业,我先是几乎完全延续着面向过程的思路完成了程序。为了第二次作业做准备,我进行了重构和代码结构的简化,但实际上并没有为第二次作业留出很好的扩展接口。第二次作业我仍然进行了重构。但由于我第二次作业架构模型已经是分层次构造,因此到第三次作业主要进行了代码修改和易读性的优化(还是重写了一些功能代码)。在这三次作业中。第一次作业由于需求和实现十分简单,我并没有使用工厂模式,第二次作业我使用了简单工厂模式,经研究发现,简单工厂模式相较于抽象工厂模式已经能够很好地适应第一单元的任务,因此采用了简单工厂模式。
五、对比和心得体会
对比:
- 纵向对比(自我对比):从第一次作业到第三次作业,我感觉到自己对需求的解读能力有了一定的提升,第三单元已经能够较好的对自己的层次化模型采用先整体把握,再局部思考。尤其是第三次作业能够清晰地意识到定义好各个模块规范的重要性。
- 横向对比(与优秀代码对比):能明显感觉到自己还有很多不足。代码不够清晰,不够具有逻辑感。技巧也不够丰富。
心得体会:
还是要不断学习新的方法,优化性能和优化代码结构的道路很难有止境,唯有不断地学习。
我个人认为自己的模型与二叉树模型各有优劣,因此模型这个问题无法一概而论,一定程度上依赖每个人的实现方法,我认为我的模型契合我自己的思维,并且完整地实现了功能,就是可以接受的。
较深刻的体会有两点,一个是建模一定要层次清晰,分层建模法是一个重要地认识需求的方法,另一个是在各个模块,各个层次的对接中常常会有不适配的bug,这要求我们从一开始就定义清晰每个模块的外部功能接口。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号